
Abstract
Dynamic games with multiple regimes frequently appear in economic literature. It is well known that, in regime-switching systems, novel effects emerge which do not appear in smooth problems. In this contribution, we explore in detail a differential game with regime switching and spillovers and study the behavior of optimal trajectories both in cooperative and non-cooperative differential game settings. We explicitly derive analytic solutions and point out cases where these solutions cannot be obtained via the application of maximum principle. We demonstrate that our approach that is based on an extension of the classical maximum principle agrees with the intuition given by the hybrid maximum principle while being more convenient for solving problems at hand.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
8.1 Introduction
Examples of non-smooth dynamics in Economics are numerous, but papers dealing with full formal complexity of dynamics are scarce, see Brito et al. [5], Brito et al. [6], for example. Recently, some interest emerged in regime-switching differential games, e.g., Dawid et al. [8], Gromov and Gromova [19], Long et al. [22], Bondarev, and Greiner [4]. In there, different types of switching conditions and different types of solutions are proposed. Note that a lot of economic phenomena naturally conform to switching dynamics: consider, e.g., a transition to new production technology, changing leadership in oligopolistic markets with imitation, resource extraction games, or advertising games.
On the theory side, there is an increasing number of papers dealing with switching systems or sliding dynamics, see Di Bernardo et al. [10] for an overview. However, this strand of literature does not consider optimal dynamics and is focused on a qualitative behavior of non-smooth dynamical systems in the vicinity of the switching manifold.
On the other hand, the optimal dynamics of switched systems is extensively studied in hybrid optimal control theory, where a number of important results were obtained, see, e.g., Boltyansky [2], Azhmyakov et al. [1], Shaikh and Caines [27] among many others. A particularly important result consists in the formulation of Hybrid Maximum Principle [27] that extends the classical maximum principle to the class of hybrid control systems, that is systems experiencing structural changes due to some exogenous or endogenous events. We refer the interested reader to Lunze and Lamnabhi-Lagarrigue [23] for a detailed account on hybrid systems and related fields.
While the hybrid maximum principle is capable of addressing a wide class of multi-modal control problems its application is pretty much restricted due to the rapidly increasing difficulty of obtaining an analytical solution as the model complexity increases. To overcome this difficulty, an approach based on the extension of the classical maximum principle was proposed in Gromov and Gromova [19]. This approach, albeit less general, allows one to solve a pretty wide range of multi-modal optimal control problems in a rather intuitive way.
In this paper, we continue this line of research and apply the previously described methodology to the analysis of a particular class of switched differential games that has been studied recently in Bondarev [3], Bondarev and Greiner [4]. The goal of this study is to provide a detailed analysis and thorough understanding of the consequences of non-smooth dynamics for economic models. We wish to note that after this paper was submitted for publication, the authors came across a recent preprint by Reddy et al. [24] and the paper [25] that consider similar problems, albeit from a somewhat different perspective.
We intentionally consider the simplest possible model with a single common state which has linear dynamics. It has been demonstrated (see Dockner and Nishimura [12], Wirl and Feichtinger [31]) that even this class of models can have surprisingly rich dynamics, including thresholds, history dependence and multiple equilibria.
We consider only two specific cases: the open-loop Nash equilibrium with two players and the social cooperation case. These two suffice to demonstrate the main qualitative findings, whereas the method itself is no way limited to these situations.
The contribution of this paper is twofold. First, we explicitly derive optimal trajectories both for the cooperative and non-cooperative cases for a regime-switching system through the application of a modified version of the classical maximum principle. This increases the tractability of results and makes explicit solution feasible. Second, we demonstrate that our results are in the agreement with the intuition given by the hybrid maximum principle while being more tractable and intuitive. We show in which cases the problem admits regular cases of finite-time switches and study the conditions for the emergence of new complicated types of dynamics such as the sliding motion along the switching manifold.
The paper is organized as follows: in Sect. 8.2, we describe the multi-modal differential game with spillovers that forms the subject of our study. In Sects. 8.3 and 8.4, a detailed analysis of optimal solutions both for the cooperative and the Nash equilibrium cases is presented in detail. Section 8.5 contains a discussion of possible extensions associated with more complex dynamic patterns that can occur in the considered game. Finally, Sect. 8.6 presents brief conclusions.
8.2 A Multi-modal Dynamic Game
As a starting point of our analysis, consider a differential game with two players and one state variable such that the objectives of players are interdependent (referred to simply as a game further on):
where x is the common state variable and \(u_{i}\) are the controls (strategies) of both players with the subscript \(-i\) denoting the complement to i: \(u_{-1}=u_2\) and so on. The objective (8.1) contains the cross-term \(c_{i}xu_{-i}\) which measures the indirect benefit of a given player from efforts of the other player. We interpret this in terms of advertising models, whereas the goodwill accumulation is affecting both agents. Furthermore, both the controls and the state are required to be (almost everywhere) differentiable. Note that the payoff functional (8.1) has a linear-quadratic form and hence enjoys a number of important properties. In particular, it is known that Hamilton–Jacobi–Bellman approach and Maximum Principle yield the same controls if they are restricted to linear-feedback forms, see Dockner et al. [11].
We additionally impose the following non-negativity constraints on controls and the state:
where U is the set of admissible controls and \(\mathbb {R}_+=[0,\infty )\). These are standard for economic applications, where controls \(u_{\{1,2\}}\) are interpreted as investments. Thus, by (8.2), we just require investments to be non-negative and the resulting stock to be bounded by zero.
This game has a bilinear-quadratic structure, similar to advertising and marketing models (see the seminal example by Deal et al. [9] and more recent [20] for a review) and includes a spillover effect modeled by the term \(c_{i}xu_{-i}\). This term is novel and rarely appears in economic applications. It can represent a positive or negative impact on the value of firm i by state and investments product of firm j, hence the term spillover effect. Such effects are typically present in advertising and goodwill models, where the value of advertising for one firm positively depends on advertising efforts of the other firm provided they have similar products.
The dynamic constraint is given by
i.e., the stock of (advertising, technology, resource, capital) is changing due to the common investments/extractions of both players and depreciates over time. In this equation, coefficients \(b_{i}\) represent the efficiency of investments of the firm i.
It can be transformed into a multi-modal game, once we let efficiency coefficients \(b_{i}\) to vary across regimes, \(b^{+}_{i}\ne b^{-}_{i}\) with either time-dependent or state-dependent (autonomous) switching. For instance, the situation with \(b^{+}_{i}> b^{-}_{i}\) would refer to joint learning while both firms become more efficient after reaching the threshold, whereas the case \(b^{+}_{i}> b^{-}_{i},\;b^{+}_{-i}< b^{-}_{-i}\) refers to the changing leadership situation, while the firm which becomes the leader is more efficient in investments (learns more).
Let f(x, t) be a smooth map, \(f:\mathbb {R}_+\times \mathbb {R}_+\rightarrow \mathbb {R}\), such that the rank of Df is equal to 1 for all \((x,t)\in \mathbb {R}_+\times \mathbb {R}_+\). The level set \(f(x,t)=0\) is the switching manifold. Define
We limit ourselves to the two basic cases (using the terminology from [19] and [27]):
-
1.
Time-driven (controlled) switch: \(f(x(t),t)=t-\tau ^*\) with \(\tau ^{*}\) fixed
-
2.
State-driven (autonomous) switch: \(f(x(t),t)= x(t)-x^{*}\) with \(x^{*}\) fixed, but t left free.
In Long et al. [22], a somewhat similar problem is considered but with \(\tau \) being subject to decision of one of the players. Here, we mainly focus on the derivation of optimal solutions with the help of the standard Maximum Principle, whereas in the aforementioned paper an alternative piece-wise Nash solution concept is developed.
Many economic problems can be put into this simple framework. As examples, consider resource extraction problems with regime switches (e.g., Long et al. [22]), technological transitions where efficiency of investments change after initial transition time (e.g., Dawid et al. [8]), pollution control (e.g., Gonzalez [18]), and patent races (e.g., Fudenberg et al. [15]).
In the following, we will use \(\tau \) and \(x(\tau )\) to denote the switching time and the switching state. Furthermore, we put the asterisk \((*)\) to denote which component of the solution is fixed at the switching. That is to say, we use \(x^{*}(\tau )\) or simply \(x^*\) when referring to a state-driven switch and \(x(\tau ^{*})\), resp., \(\tau ^*\) when referring to a time-driven switch.
Whichever type of switching is considered, we assume that the system has a fixed initial mode, that is, \(0<\tau ^*\), resp., \(x(0)<x^*\) and thus refer to \(T^-=[0,\tau ^*)\), resp., \(T^-=\{t\in \mathbb {R}_+|x(t)<x^*\}\) as the first interval and consequently, \(T^+=\mathbb {R}_+\setminus T^-\) as the second interval (note that \(T^+\) can be empty).
In the following, we will use the minus and the plus superscripts to refer to the first, resp. the second interval. We make some remarks further on what changes in our results if the switching sequence is reversed. Finally, we assume that all parameters in the model are non-negative:
It is worth noting that the distinction between the two types of switches is of substantial rather than notational character. For instance, for the time-driven switch, the switching time \(\tau ^*\) is always eventually reached as the system evolves. In contrast to it, the switching state is not always reached as the following definition suggests.
Definition 8.1
The game (8.1)–(8.3) is said to be in the normal mode, if the switching threshold \(f(x(\tau ),\tau )\) is never reached by the optimal trajectory and no switching occurs. Otherwise, the game is said to be in the switching mode.
In other words, if the game is in the normal mode and under the fixed switching sequence condition, Definition 8.1 implies that \(T^-=[0,\infty )\) and the second interval is never reached.
We observe that under the assumption of fixed sequence, the only case when the game can be in the normal mode is when the switching condition is defined to be dependent on x and the equilibrium of the dynamics in the first interval is such that \(x^{-}_{eq}<x^{*}(\tau )\). This agrees with the assumption that both equilibria are regular (terminology follows Di Bernardo et al. [10]) in the case of a state-driven switch,Footnote 1 that is:
Assumption 8.1
If equilibria of the dynamic system (8.3) exist, they are regular:
with \(x^{\pm }_{eq}\) denoting the (potential) equilibria of the system below and above the threshold value \(x^{*}\).
By employing this assumption, we restrict the attention to the case of at most one switching event. Indeed, if the optimal trajectory contacts the switching manifold, the optimal jump in the co-state trajectory will immediately select the extension after the threshold lying on the stable manifold of the associated equilibrium (since this is, by construction of the model, of a saddle type). However, in more complex settings, multiple (or even infinite number of) switches are potentially possible. We will further discuss the relevance and importance of this assumption in Sect. 8.5.
Below, we explore the solution technique for this game in more details. We consider separately the social cooperative and the (open-loop) Nash equilibrium solutions to the differential game (8.1)–(8.4).
8.3 Cooperative Game
8.3.1 Second Interval
The solution for the cooperative game is obtained by solving the optimal control problem given by dynamic constraint (8.3) and an objective being the sum of individual ones:
The Hamiltonian is
The optimal controls are obtained from the first order optimality condition to be
Plugging (8.9) into (8.3) and introducing a new variable \(\lambda =e^{\rho t}\psi \) representing the current value of the adjoint \(\psi \) we get a system of two autonomous DEs:
Using vector-matrix notation and introducing some abbreviations the system (8.10) can be rewritten as
where \(z=\begin{bmatrix}x\\ \lambda \end{bmatrix}\), \(C=\begin{bmatrix}r &{} b \\ -c &{} \rho -r\end{bmatrix}\), and \(g=\begin{bmatrix} 0\\ - a \end{bmatrix}\). In (8.11), we also used the following short notation: \(a =a_1+a_2\), \(b =b_1^2+b_2^2\), \(c =c_1^2+c_2^2\), \(q=b_1c_2+b_2c_1\), and \(r=q-\delta \).
Note that the problem (8.11) constitutes a system of two linear ODEs. Thus, there is at most only one equilibrium in each interval and the resulting piece-wise system has at most two equilibria (or exactly two if the equilibria are regular), each one associated with the corresponding regime.
The equilibrium state of the system (8.11) is
Since \(x^C_{eq}\) must be non-negative,Footnote 2 we impose the following regularity assumption.
Assumption 8.2
The coefficients of the matrix C have to satisfy \(\det (C)<0\) or, equivalently,
The matrix C has two eigenvalues:
We will enumerate the eigenvalues in the way that \(\sigma _2>\sigma _1\). Assumption 8.2 implies, in particular, that \(\sigma _1\sigma _2<0\) and hence, the equilibrium point of (8.11) is a saddle.
To simplify further analysis, we rewrite C in terms of its eigenvalues. So, we get
The two-point boundary value problem associated with the optimal control problem (8.3), (8.7) consists in solving the system of DEs (8.11) while satisfying the following boundary conditions:
The conditions (8.13) allow us to determine the initial condition on the adjoint variable as stated below. We define \(\lambda ^{*+}=\lim _{t\rightarrow \tau +0}\lambda (t)\).
Proposition 8.1
The initial value \(\lambda ^{*+}\) guaranteeing the fulfilment of (8.13) is uniquely defined as
Proof
The solution of (8.11) is dominated by its largest positive eigenvalue \(\sigma _2\), which is larger than \(\rho \) due to Assumption 8.2. This implies that the initial conditions \((x^*(\tau ^*),\lambda (\tau ^*))\) must be chosen in the way that the solution’s component at \(e^{\sigma _2 t}\) is equal to 0. This is equivalent to saying that the initial condition must lie on the stable manifold of the saddle. As time elapses, the state and the adjoint variable will approach their equilibrium values (8.12).
Let \(v_{1,x}\) and \(v_{1,\lambda }\) be the respective components of the eigenvector corresponding to \(\sigma _1\). The linear subspace corresponding to \(v_1\) can be written as \(V_1=\left\{ (x^C_{eq}+\alpha v_{1,x}, \lambda ^C_{eq}+\alpha v_{1,\lambda })\mid \alpha \in \mathbb {R}\right\} \). Setting the first component to \(x^*\), we recover \(\alpha \) and the respective \(\lambda \)-component of the vector of initial conditions. \(\square \)
Now we can compute explicit expressions for the optimal solution x(t) and \(\lambda (t)\) to get
One can easily check that \(x(\tau )=x^*\) and \(\lim _{t\rightarrow \infty }x(t)=x^C_{eq}\). Furthermore, we observe that x(t) changes monotonously and the sign of \(\dot{x}(t)\) depends on whether x(t) is smaller or greater than \(x^C_{eq}\): if \(x(t)< x^C_{eq}\), then \(\dot{x}(t)\ge 0\) and vice versa. The optimal control is
We know that all the previous results stay valid only for the case that the optimal control (8.15) is non-negative. We have the following result.
Proposition 8.2
The optimal controls \(u^C_i\) are non-negative if the following condition holds:
Proof
To check if this is the case, we compute the derivative of \(u^C_i(t)\) w.r.t. time:
We see that the sign of the derivative is constant for all \(t\in T^+\) and is determined only by the parameters and the value of the switching state \(x^*\).
Depending on the sign of the derivative, the minimal value of the control is attained either at \(t=\tau \) or at \(t=\infty \). Thus, both of the following two expressions must be non-negative to ensure that the control falls in with the bounds:
This yields the required result. \(\square \)
Note that \(\sigma _1\sigma _2<0\), while, say, \(r-\sigma _2\) can be of either sign depending on parameters.
Finally, substituting (8.14) into the expression for the payoff function, integrating and performing some algebraic simplifications, we get
Note that the value function depends both on \(\tau ^*\) and \(x^*\). Relaxing one of the arguments, we recover either a state-dependent or time-dependent switch.
8.3.2 First Interval
8.3.2.1 Normal Mode
We start by considering the normal mode as introduced in Def. 8.1. The social cooperative game is given by the optimal control problem with joint maximization. Under given assumptions, there exists only one Skiba-threshold in a system (8.3):
Lemma 8.1
The indifference point (DNSS-point) \(x^{C}_{S}\) exists for cooperative game (8.1)–(8.3) and \(x^{C}_{S}<x^{*}(\tau )\).
Proof
Any bi-stable system without heteroclinic connections possesses such a point, see Wagener [30], Bondarev and Greiner [4]. The state–co-state system associated with (8.3) in cooperative case is given by (8.10) is linear in each interval and as such has a unique equilibrium. The overall piece-wise canonical system is thus bi-stable (it has two regular equilibria by Assumption 8.1) and it does not have heteroclinic connections since we assume fixed switching sequence and there is no unstable focus in between. By definition of the DNSS-point, it has to be \(x^{C}_{S}<x^{*}(\tau )\). \(\square \)
Denote the associated equilibrium of the first interval flow cooperative game by \(x^{C,-}_{eq}\), and assume \(0\le x^{C,-}_{eq}<x^{*}(\tau )\). We use the minus superscript to denote quantities associated with the first interval (so \(C^{-}\) denotes the equivalent of the matrix C for the first interval).
Proposition 8.3
Let \(x(0)<x^{*}(\tau )\) and Assumption 2 holds for matrix \(C^{-}\). Then:
-
If \(x(0)<x^{C}_{S}\), the cooperative game is in the normal mode and \(x^{C,-}_{eq}\) is realized as the long-run equilibrium of the cooperative game.
-
If \(x(0)>x^{C}_{S}\), the cooperative game is in the switching mode and \(x^{C,-}_{eq}\) realizes as the long-run equilibrium with a unique switching event at \(x^{*}(\tau )\).
-
Outcome is indeterminate only at \(x^{C,-}_{eq}=x^{C}_{S}\) which has zero measure.
Proof
If Assumption 8.2 holds, the \(x^{C,-}_{eq}\) is positive. We also assumed that \(x^{C,-}_{eq}<x^{*}(\tau )\) so it can be reached by the x(t) process without crossing the threshold. Now if \(x(0)<x^{C}_{S}\) holds, it means that by definition of the Skiba point it is optimal to converge to this value \(x^{C,-}_{eq}\). Once it is a saddle, no arcs entering the \(x>x(\tau )\) region can be part of the optimal trajectory converging to this (lower) equilibrium. Game is in the normal mode.
On the contrary, once \(x(0)>x^{C}_{S}\), it is optimal to converge to the equilibrium \(x^{C,+}_{eq}>x^{*}(\tau )\) and crossing occurs. It is the unique one since the equilibrium is a saddle (so there are no arcs re-entering the first region).
At last, once \(x(0)=x^{C}_{S}\) the dynamics is indeterminate, as is standard for this types of models (see discussion in Krugman [21]), but this is a non-generic point. \(\square \)
We further on assume away the indeterminacy by letting \(x^{C,-}_{eq}\ne x^{C}_{S}\).
8.3.2.2 State-Driven Switch
In the first interval, we optimize the objective function given by
Here, the optimal value of the objective function enters as the terminal cost for the respective optimization problem. Note that we put the superscripts − and \(+\) to distinguish between the parameters and variables that take different values in the first, resp., second phases.
There are two possible cases: when the switching state \(x^*\) is fixed and the switching time \(\tau \) is free and the opposite. The former corresponds to the state-driven switch, while the latter to the time-driven one.
We start be considering the state-driven switch. Here, the terminal time \(\tau \) is free and hence, we can use the result presented in the Appendix. According to (8.31), we evaluate \(H(t,x,\psi )\) at \(t=\tau \) and equate the resulting expression to \(-\frac{d}{d\tau }J^+(\tau )\), where \(J^+(\tau )\) is given in (8.16). Replacing \(\psi \) with \(e^{-\rho \tau }\lambda \), we get the following quadratic equation in \(\lambda \):
Solving (8.17), we get two candidates for the end-point values of the adjoint variable \(\lambda ^{*-}=\lim _{t\rightarrow \tau -0}\lambda (t)\). We require that \(\lambda ^{*-}(\tau )\) yields \(\dot{x}(\tau )>0\), which is equivalent to (cf. 8.10):
When \(\lambda ^{*-}\) is determined, the final step consists in solving the system (8.10) with conditions \(x(0)=x_0\), \(x(\tau )=x^*\) and \(\lambda _i(\tau )=\lambda _i^{*-}\). This allows us to determine \(\tau \), for instance, by integrating (8.10) backward in time with initial conditions \((x^*,\lambda _i^{*-})\) and determining \(\tau \) from \(x(\tau )=x_0\).
8.3.2.3 Time-Driven Switch
If the switching time \(\tau ^*\) is fixed, the endpoint condition on \(\lambda ^{*-}\) is uniquely determined by
which equals \(\lambda ^{*+}\) (see Proposition 8.1). Again, this agrees with the Hybrid Maximum Principle in that the adjoint variable is continuous at an autonomous switch.
Finally, the switching state is computed by solving the system (8.10) over the interval \([0,\tau ^*]\) with boundary conditions \(x(0)=x_0\), and \(\lambda _i(\tau ^*)=\lambda _i^{*-}\). The obtained solution is used to determine the switching state \(x(\tau ^*)\).
8.4 Nash Equilibrium Solution
8.4.1 Second Interval
We start by determining the Nash equilibrium solution to the differential game (8.1)–(8.5) in the second interval \(T^+\). In doing so, we will initially suppose that both the initial time and the state are fixed to \((\tau ^*,x^*)\). Relaxing respective terms, we will recover either the state- or the time-driven switch.
Since the presented below results can be of interest on their own, we first drop the \(+\) superscript indicating the value of the parameter \(b_i\) in the second interval and restore it later when making a connection to the first interval.
When determining the Nash equilibrium solution one has to solve simultaneously as many optimization problems as many players there are. That is to say, for \(i\in \{1,2\}\), we maximize \(J_i\) w.r.t. \(u_i\) while assuming that \(u_{-i}\) is chosen to satisfy \(u_{-i}=u^{NE}_{-i}\). Following the standard procedure, we write the individual Hamiltonian for each optimization problem:
The respective optimal controls are found to be \(u_i^{NE}=e^{\rho t} b_i \psi _i\). Plugging \(u^{NE}\) into (8.3), and going over to the current values of the adjoint states \(\lambda _i=e^{\rho t}\psi _i\), we recover a set of autonomous DEs corresponding to Hamiltonians (8.18):
The resulting system of differential equations for x and \(\lambda _i\) has the following form:

The matrix A is block-diagonal with the first eigenvalue \(\sigma _1=-\delta <0\). Thus, the character of the system’s behavior in long run is determined by the eigenvalues of the second block submatrix. The respective eigenvalues are \(\sigma _{\{2,3\}}= \delta +\rho \pm \sqrt{b_1 b_2 c_1 c_2}\).
Assumption 8.3
The coefficients of the matrix A satisfy
We have the following result.
Proposition 8.4
The system (8.20) has the following long-run solution
with \(x_{eq}\ge 0\) iff Assumption 8.3 holds. Furthermore, it holds that \(\lambda _i(t)=\lambda _{i,eq}\, \forall t\in T^+\).
Proof
The equilibrium solution to (8.20) is obtained as \(-A^{-1}f\). The non-negativity of the equilibrium state \(x_{eq}\) follows from Assumption 8.3.
On the other hand, the same Assumption implies that at the equilibrium point the system (8.20) has two positive and one negative eigenvalues. This means that the initial values are to be located along the respective eigenvector \(v_1=[1,0,0]^\top \), which, in turn, implies that \(\lambda _i(\tau ^*)=\lambda _{i,eq}\). Since the r.h.s. of (8.19) do not depend on x, we have that \(\lambda _i(t)=\lambda _{i,eq}\, \forall t\in T^+\). \(\square \)
Solving the equation for x(t) with initial condition \(x(\tau ^{*})=x^{*}\), we get
At this point, we note that the system state changes monotonically (given (8.5)); furthermore, at the switching time \(\tau ^*\) the phase vector \(\dot{x}(\tau ^*)\) points toward the region \(x>x^*\) if \(x^*<x_{eq}\) (that is, Assumption 8.1 holds).
Finally, the value functions are computed to be
where we restored the \(+\) superscript. Note that the value functions depend on both \(\tau ^*\) and \(x^*\). Letting one of them be free, we recover a state-driven switch or a time-driven switch, respectively.
8.4.2 First Interval
In this subsection, we compute the optimal controls for the first interval in three cases (including the normal mode) and discuss the specific aspects of each case.
8.4.2.1 Normal Mode
We start by considering the conditions under which the normal mode is realized in the system. We assume that an equivalent of Assumption 8.3 holds for the first interval, i.e., the \(x^{-}_{eq}\) value is positive and the equilibrium is of the saddle type (1, 0, 0).
Recall first also that in piece-wise smooth system the so-called Skiba (DNSS) points (thresholds) may exist even if dynamics is linear in each of the intervals (see Skiba [28], Sethi [26], Caulkins et al. [7] for original definition and Bondarev and Greiner [4] for (pseudo) DNSS-points in piece-wise smooth systems).
Definition 8.2
The value \(x^{i}_{S}\) is called a (pseudo) DNSS-threshold for player i in a differential game given by a piece-wise smooth dynamical system if converging from this threshold to the \(x^{-}_{eq}\) or \(x^{+}_{eq}\) yields the same value for player i:
with \(J^{\pm }_{i}(x(0)=x^{i}_{S})\) being value functions of player i with initial condition set at the threshold while converging to \(x^{\pm }_{eq}\).
Let \(A^{-}\) be the system matrix for the dynamical system associated with the first intervalFootnote 3 analogous to A defined above.
Then we get the following:
Proposition 8.5
Let \(x(0)<x^{*}(\tau )\) and Assumption 8.3 holds for the matrix \(A^{-}\). Then:
-
1.
Once \(x(0)<\min \{x^{1}_{S},x^{2}_{S}\}\) the normal mode realizes with \(x^{-}_{eq}\) being the long-run equilibrium of the game
-
2.
Once \(x(0)>\max \{x^{1}_{S},x^{2}_{S}\}\) the switching mode realizes and the optimal trajectory reaches the switching manifold in finite time
-
3.
Once \(x(0)\in [x^{i}_{S},x^{-i}_{S}]\), the outcome is indeterminate
If Assumption 8.3 does not hold for the matrix \(A^{-}\), only the switching mode realizes as the outcome of the game.
Proof
If Assumption 8.3 holds, \(x^{-}_{eq}\) is positive. We also assumed that \(x^{-}_{eq}<x^{*}(\tau )\) so it can be reached by the x(t) process without crossing the threshold. Now if \(x(0)<\min \{x^{1}_{S},x^{2}_{S}\}\) holds, it means that by definition of the Skiba point it is optimal to converge to this value \(x^{-}_{eq}\). Once it is a saddle type (1, 0, 0), no arcs entering the \(x>x(\tau )\) region can be part of the optimal trajectory converging to this (lower) equilibrium. Game is in the normal mode.
On the contrary, once \(x(0)>\max \{x^{1}_{S},x^{2}_{S}\}\), it is optimal to converge to the equilibrium \(x_{eq}>x^{*}(\tau )\) and crossing occurs. It is a unique one, since the equilibrium is a saddle type (1, 0, 0) (so there are no arcs re-entering the first region).
At last, once \(x(0)\in [x^{i}_{S},x^{-i}_{S}]\) the dynamics is indeterminate, as is standard for this types of models (see discussion in Krugman [21]), provided \(x^{i}_{S}\ne x^{-i}_{S}\). \(\square \)
To avoid further complications, we will assume for the rest of this subsection that \(x(0)\notin [x^{i}_{S},x^{-i}_{S}]\).
This condition implies that there are exactly two branches of the optimal trajectory: once \(x(0)<\min \{x^{1}_{S},x^{2}_{S}\}\), the optimal trajectory cannot cross the indeterminacy region \([x^{i}_{S},x^{-i}_{S}]\) and since the switching manifold is located to the right of this region, the switching mode cannot realize as the optimal one. We thus consider only the normal mode, that is a game with the only one regular equilibrium which is the lower one. On the other hand, once \(x(0)>\max \{x^{1}_{S},x^{2}_{S}\}\), the lower equilibrium cannot be reached by the optimal trajectory since it is located to the left of the indeterminacy region and we could consider the switching trajectory only, whereas there is only one feasible equilibrium located to the right of the switching manifold, \(x^{+}_{eq}\). The fact that the optimal trajectory cannot cross the region \([x^{i}_{S},x^{-i}_{S}]\) follows from the definition of the Skiba-point: once the game starts to the left from this region, it is not profitable for both players to move to the upper equilibrium and vice versa. So we can observe that the existence of these (pseudo) Skiba-points actually simplifies the analysis by helping us to select the proper mode for the game.
8.4.2.2 State-Driven Switch
Similar to the cooperative case we assume that the switching state is fixed, i.e., \(x(\tau )=x^*\), while the switching instant is left free. This means, in particular, that the adjoint variables corresponding to the state x are not fixed at the final time and that the functions \(J_i^+\) should now be considered as functions of \(\tau \). In this case, we have to employ a slightly modified version of the Pontryagin’s maximum principle as described in Appendix.
To use the condition (8.31), we rewrite the Hamiltonians (8.18) replacing u with respective optimal controls \(u^{NE}\). Thus, we get
Finally, we write (8.31) while replacing \(\psi _i\) with \(e^{-\rho t}\lambda _i\). This results in the following set of equations:
Solving the system (8.25), (8.26) with respect to \(\lambda _i\), we obtain a number of candidates for the end-point values of the respective adjoint variables at \(t=\tau \): \(\lambda _i^{*-}=\lim _{t\rightarrow \tau -0}\lambda _i^-(t)\). Note that according to Bézout’s theorem [16], there cannot be more than four such candidates. Choosing an appropriate solution to (8.25), (8.26) is a separate problem that requires some extra analysis. One obvious test consists in checking the direction of the state phase vector at \(\tau \): it should hold that \(\dot{x}(\tau )>0\). This is equivalent to requiring that \((b^-_1)^2\lambda ^{*-}_1+(b^-_2)^2\lambda ^{*-}_2>\delta x^*\). We conjecture that there will be at most two feasible solutions out of four. A rigorous proof of this fact is yet to follow.
When \(\lambda _i^{*-}\) are determined, the final step consists in solving the system (8.20) with conditions \(x(0)=x_0\), \(x(\tau )=x^*\) and \(\lambda _i(\tau )=\lambda _i^{*-}\). This will allow us to determine \(\tau \), for instance, by integrating (8.20) backward in time with initial conditions \((x^*,\lambda _i^{*-})\) and determining \(\tau \) from \(x(\tau )=x_0\). If there are more than one feasible solution to (8.25)–(8.26), the optimal solution is obtained by comparing the values of the objective functions.
8.4.2.3 Time-Driven Switch
If \(\tau ^*\) is fixed, while the switching state \(x(\tau ^*)\) is unrestricted one can make use of the standard transversality condition from optimal control theory and compute the end-point values of adjoint variables as
Expressed in terms of current values of adjoint variables, this yields \(\lambda _i^{*-}=\lambda _{eq}\) (cf. (8.22)). This agrees with the Hybrid Maximum Principle in that the adjoint variables do not undergo a discontinuity at a time-driven, i.e., controllable switch.
Finally, the switching state is computed following the same procedure as in Sect. 8.3.2.3. We note that since the DEs for \(\lambda \) do not depend on x, the problem can be conveniently solved in two runs: first, the DEs for \(\lambda \) are solved backward in time to recover \(\lambda _i(0)\); next, the whole system (8.20) is solved forward to yield the required value of the state.
8.5 Extensions
It is of interest what would be the global dynamics of the system (8.3) for the state-driven switch in case Assumption 8.1 does not hold. In particular, since \(x^{*}\) is an arbitrary value, it could be the case that one of \(x^{+}_{eq}>x^{*}\) and \(x^{-}_{eq}<x^{*}\) do not hold or both do not hold. These are cases of virtual (again following terminology of Di Bernardo et al. [10]) equilibria. We discuss these two cases separately.
One virtual equilibrium. If only one of the equilibria is virtual the dynamics of both cooperative and non-cooperative cases becomes somewhat simple. In the case of the fixed switching sequence, we observe that:
Proposition 8.6
Once either \(x^{+}_{eq}>x^{*}\) or \(x^{-}_{eq}<x^{*}\) but not both, the equilibrium which remains regular is reached by the optimal trajectory in finite time.
Once \(x^{+}_{eq}>x^{*}\) but \(x^{-}_{eq}>x^{*}\) and \(x(0)<x^{*}\), there is a unique switching trajectory with a unique stitching event at some \(x^{*}(\tau )\) which reaches \(x^{+}_{eq}\).
Once \(x^{+}_{eq}<x^{*}\) but \(x^{-}_{eq}<x^{*}\) and \(x(0)>x^{*}\), there is a unique switching trajectory with a unique stitching event at some \(x^{*}(\tau )\) which reaches \(x^{-}_{eq}\).
Once \(x^{+}_{eq}>x^{*}\) but \(x^{-}_{eq}>x^{*}\) and \(x(0)>x^{*}\), there is a unique smooth trajectory in the second interval which reaches \(x^{+}_{eq}\).
Once \(x^{+}_{eq}<x^{*}\) but \(x^{-}_{eq}<x^{*}\) and \(x(0)<x^{*}\), there is a unique smooth trajectory in the second interval which reaches \(x^{-}_{eq}\).
Proof
It has been shown in numerous literature (see e.g. Feichtinger and Wirl [13]) that in (optimally controlled) systems with a threshold there exist optimal solution candidates crossing the threshold in finite time. Once we get only one (thus unique) regular equilibrium, it is reached by the optimal trajectory either by crossing the threshold or not. \(\square \)
Now the case of one virtual equilibrium is not exhausting the full list of global configurations. The other oneFootnote 4 is the case of two virtual equilibria.
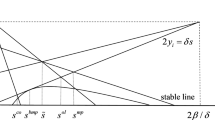
Two virtual equilibria. If both equilibria are virtual, that is, they are infeasible, there are no optimal control candidates leading to any equilibrium. This is the case where we have to apply the alternative solution concept to find a suitable solution. We thus may resort to the sliding mode control (see, e.g., Gamkrelidze [17] and further works). We abstain here from the formal proof of the optimality of such control (leaving this for future extension) and limit ourselves to the following observation:
Proposition 8.7
For a system (8.3) with a state-driven switch and once both \(x^{+}_{eq}<x^{*}\) and \(x^{-}_{eq}>x^{*}\), the only optimal control candidates are those leading to the sliding mode dynamics such that
Proof
If both equilibria of regular flows are virtual, there are no candidate trajectories crossing the threshold, Thus, the only sufficiently long trajectory is the one leading to the threshold \(x^{*}\) and this is the only optimal control candidate. \(\square \)
This type of dynamics will not come up from the maximum principle (as is noted already in Gamkrelidze [17]) and in general is obtained as a (linear) combination of controls, leading the trajectory of the state to the switching manifold. Once the trajectory reaches the switching manifold, it stays there the rest of the game, converging to the pseudoequilibrium (see Di Bernardo et al. [10]) which is defined as the equilibrium of the (in our case one-dimensional) sliding flow \(\dot{\lambda }_{S}:=conv\{\dot{\lambda }^{+},\dot{\lambda }^{-}\}|x=x^{*}\) while state remains fixed at the threshold value. There are several methods of defining this flow (see Filippov [14], Utkin [29]) which in general lead to equivalent results.
We also note that even in the case the pseudoequilibrium is repelling; it still can be reached from the outside of the switching manifold by the suitably designed sequence of controls. We stop our discussion of the sliding mode here since it is not easy to prove the optimality of such a candidate and this is an entirely different problem requiring much more complicated analysis left for further research.
The other question is whether the study undertaken here is applicable to a wider variety of problems besides those linear in the state. We claim that the core method is valid for many piecewise systems which allow for derivation of steady states. This, of course, includes a lot of non-linear problems. We do not claim however that any piece-wise system may be treated this way, since non-linear systems may exhibit rather rich additional dynamics. Checking the derivations above we observe that the explicit solution for the underlying canonical system is not actually necessary to derive the global dynamics. We still need to know where both equilibria are located (are they regular or virtual), which requires explicit derivation of those equilibria. The method for obtaining boundary conditions at the switching time is quite general and does not rely on the linear-quadratic structure of the problem. This has been taken only for the sake of simplicity of exposition and by no way limits the applicability of our results to a larger class of piece-wise smooth problems.
8.6 Conclusions
In this paper, we considered an example of a multi-modal differential game with two players and one state variable. It is demonstrated that this differential game can possess a rich variety of types of dynamics, including the normal mode (with smooth solution trajectory), the switching mode (with optimal trajectory consisting of two parts) and even the sliding mode, which requires some further analysis.
We applied a modified version of a standard Maximum Principle and obtained full analytic results for the switching trajectories including the conditions on adjoint states at the threshold. We studied both time-driven and state-driven switching conditions. In so doing, we explore the main difficulties arising in these two formulations (leading, in general, to different optimal control problems).
Moreover, we also find out that the game, although linear-quadratic in each of the intervals, is overall non-linear and as such possesses so-called indifference (DNSS) points for each of the players. It is remarkable that this effect arises solely because of the piece-wise structure of the state equation (8.3), leading to the multiplicity of equilibria in the overall game, both for cooperative and non-cooperative solutions. To see this, we observe that every sub-system (lower and upper ones) possesses a unique equilibrium despite the presence of the \(c_{i}xu_{-i}\) term in objective functionals. As such, the smooth system itself cannot exhibit Skiba-points (since the multiplicity of equilibria is a necessary condition for this, see Wagener [30]). However, the combined piece-wise smooth system has two equilibria and thus can exhibit Skiba-points even for linear-quadratic systems.
The main insight from our analysis so far is the following: The relevant method for obtaining an optimal solution depends on the global configuration of the respective dynamic system’s equilibria. While in the normal mode conventional optimal control methods can be used, in the case of switching additional boundary constraints on adjoint variables have to be taken into account. In the even more special case of sliding, conventional tools are inapplicable at all. Thus, the general algorithm to solve this kind of problems would be as follows: we have to define the configuration of equilibria of the game first and then select an appropriate solution technique. This issue is frequently neglected in economic applications of regime-switching systems, where usually only the switching mode is studied.
Notes
- 1.
Since in the case of a time-driven switch this notion does not bear any meaning.
- 2.
Also note that if Assumption 8.2 doesn’t hold, we have \(\text {trace}(C)=\rho >0\) and hence, the equilibrium is a source (either an unstable focus or an unstable node). This implies that there does not exist an initial state \((x_0,\lambda _0)\) such that the solution to (8.11) converges to the equilibrium.
- 3.
It may easily be derived by substituting for \(b^{-}_{1,2}\) in (8.20).
- 4.
We neglect the case of boundary equilibria as having zero measure in the space of parameters.
References
Azhmyakov, V., Attia, S., Gromov, D., & Raisch, J. (2007). Necessary optimality conditions for a class of hybrid optimal control problems. In A. Bemporad, A. Bicchi, & G. Buttazzo (Eds.), Hybrid systems: Computation and control. HSCC 2007 (Vol. 4416, pp. 637–640). Lecture notes in computer science. Springer.
Boltyansky, V. G. (2004). The maximum principle for variable structure systems. International Journal of Control, 77(17), 1445–1451.
Bondarev, A. (2018). Games without winners: Catching-up with asymmetric spillovers. WWZ working paper 2018/12, Wirtschaftswissenschaftliches Zentrum (WWZ), Universität Basel, Basel.
Bondarev, A., & Greiner, A. (2018). Catching-up and falling behind: Effects of learning in an R&D differential game with spillovers. Journal of Economic Dynamics and Control, 91, 134–156.
Brito, P. B., Costa, L. F., & Dixon, H. (2013). Non-smooth dynamics and multiple equilibria in a Cournot-Ramsey model with endogenous markups. Journal of Economic Dynamics and Control, 37(11), 2287–2306.
Brito, P. B., Costa, L. F., & Dixon, H. D. (2017). From sunspots to black holes: Singular dynamics in macroeconomic models. In K. Nishimura, A. Venditti, & N. C. Yannelis (Eds.), Sunspots and Non-linear dynamics: Essays in honor of Jean-Michel Grandmont (pp. 41–70). Cham: Springer International Publishing.
Caulkins, J. P., Feichtinger, G., Grass, D., Hartl, R. F., Kort, P. M., & Seidl, A. (2015). Skiba points in free end-time problems. Journal of Economic Dynamics and Control, 51, 404–419.
Dawid, H., Kopel, M., & Kort, P. (2013). R&D competition versus R&D cooperation in oligopolistic markets with evolving structure. International Journal of Industrial Organization, 31(5), 527–537.
Deal, K. R., Sethi, S. P., & Thompson, G. L. (1979). A bilinear-quadratic game in advertising. In P. T. Liu & J. G. Sutinen (Eds.), Control theory in mathematical economics (pp. 91–109). New York: Marcel Dekker.
Di Bernardo, M., Budd, C., Champneys, A., Kowalczyk, P., Nordmark, A., Olivar, G., et al. (2008). Bifurcations in nonsmooth dynamical systems. SIAM Review, 50(4), 629–701.
Dockner, E., Jorgensen, S., Long, N., & Sorger, G. (2000). Differential games in economics and management sciences. Cambridge: Cambridge University Press.
Dockner, E. J., & Nishimura, K. (2005). Capital accumulation games with a non-concave production function. Journal of Economic Behavior & Organization, 57(4), 408–420. Multiple Equilibria, Thresholds and Policy Choices.
Feichtinger, G., & Wirl, F. (2000). Instabilities in concave, dynamic, economic optimization. Journal of Optimization Theory and Applications, 107(2), 275–286.
Filippov, A. F. (1988). Differential equations with discontinuous righthand sides. Dordrecht: Kluwer Academic.
Fudenberg, D., Gilbert, R., Stiglitz, J., & Tirole, J. (1983). Preemption, leapfrogging and competition in patent races. European Economic Review, 22(1), 3–31. Market Competition, Conflict and Collusion.
Fulton, W. (1989). Algebraic curves: An introduction to algebraic geometry. Addison-Wesley.
Gamkrelidze, R. V. (1986). Sliding modes in optimal control theory. Proceedings of Steklov Institute for Mathematics, 169, 180–193.
Gonzalez, F. (2018). Pollution control with time-varying model mistrust of the stock dynamics. Computational Economics, 51(3), 541–569.
Gromov, D., & Gromova, E. (2017). On a class of hybrid differential games. Dynamic Games and Applications, 7(2), 266–288.
He, X., Prasad, A., Sethi, S. P., & Gutierrez, G. J. (2007). A survey of Stackelberg differential game models in supply and marketing channels. Journal of Systems Science and Systems Engineering, 16(4), 385–413.
Krugman, P. (1991). History versus expectations. The Quarterly Journal of Economics, 106(2), 651–667.
Long, N. V., Prieur, F., Tidball, M., & Puzon, K. (2017). Piecewise closed-loop equilibria in differential games with regime switching strategies. Journal of Economic Dynamics and Control, 76, 264–284.
Lunze, J., & Lamnabhi-Lagarrigue, F. (Eds.). (2009). Handbook of hybrid systems control: Theory, tools, applications. Cambridge University Press.
Reddy, P. V., Schumacher, J. M., & Engwerda, J. (2019). Analysis of optimal control problems for hybrid systems with one state variable. Technical report.
Seidl, A. (2019). Zeno points in optimal control models with endogenous regime switching. Journal of Economic Dynamics and Control, 100, 353–368.
Sethi, S. P. (1977). Nearest feasible paths in optimal control problems: Theory, examples, and counterexamples. Journal of Optimization Theory and Applications, 23(4), 563–579.
Shaikh, M. S., & Caines, P. E. (2007). On the hybrid optimal control problem: Theory and algorithms. IEEE Transactions on Automatic Control, 52(9), 1587–1603.
Skiba, A. K. (1978). Optimal growth with a convex-concave production function. Econometrica, 46(3), 527–539.
Utkin, V. I. (1992). Sliding Modes in Control and Optimization. Berlin: Springer.
Wagener, F. O. O. (2003). Skiba points and heteroclinic bifurcations, with applications to the shallow lake system. Journal of Economic Dynamics and Control, 27(9), 1533–1561.
Wirl, F., & Feichtinger, G.(2005). History dependence in concave economies. Journal of Economic Behavior & Organization, 57(4), 390–407. Multiple Equilibria, Thresholds and Policy Choices.
Acknowledgements
The work of D. Gromov was supported by the Russian Science Foundation (project no. 17-11-01093).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix
Appendix
Consider the following optimal control problem:
where the final time T is assumed to be free. A particular feature of this problem statement is that the terminal payoff function depends on the final time, rather the final state. To accommodate the known results to this case, we reformulate the system and include an auxiliary variable \(\theta \) that evolves according to \(\dot{\theta }=1\) with initial condition \(\theta (0)=0\). Following [Pontryagin], we write the Hamiltonian function as
where \(H(t,x,\psi ,u)=\langle \psi ,f(x,u)\rangle +f_0(t,x,u)\) is the “original” Hamiltonian function. Following the standard procedure, we obtain the optimal control \(u^o\) by maximizing \(H(\theta ,x,\psi ,u)\), i.e., \(H^*(\theta ,x,\psi )=\max _u H(\theta ,x,\psi ,u)\) and write the differential equations for the adjoint variables as
While the end-point conditions on the adjoints \(\psi \) are determined according to the standard procedure, for \(\psi _\theta \), we have \(\psi _\theta (T)=\frac{d}{dt}\phi (t)\big |_{t=T}\). Finally, we recall that, for an optimal control problem with free final time, we have
along the optimal trajectory. Evaluating (8.30) at \(t=T\) and noting that \(\theta (T)=T\), we obtain
That is to say, in contrast to the case when the terminal payoff expressed in terms of x(T) defines the final values of the adjoint variables, the terminal payoff expressed in terms of the final time imposes an additional restriction on the value of the Hamiltonian function at \(t=T\).
Note that an alternative approach would be to use the jump condition from Boltyansky [2]. However, the above-described approach seems to be more appropriate as it is tailored to a particular class of multi-modal optimal control problems as contrasted to the general formulation proposed by Boltyansky.
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Bondarev, A., Gromov, D. (2021). On the Structure and Regularity of Optimal Solutions in a Differential Game with Regime Switching and Spillovers. In: Haunschmied, J.L., Kovacevic, R.M., Semmler, W., Veliov, V.M. (eds) Dynamic Economic Problems with Regime Switches. Dynamic Modeling and Econometrics in Economics and Finance, vol 25. Springer, Cham. https://doi.org/10.1007/978-3-030-54576-5_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-54576-5_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-54575-8
Online ISBN: 978-3-030-54576-5
eBook Packages: Economics and FinanceEconomics and Finance (R0)