
Abstract
As machine learning (ML) techniques and sensor technology continue to gain importance, the data-driven perspective has become a relevant approach for improving the quality of maintenance for machines and processes in industrial environments. Our study provides an analytical literature review of existing industrial maintenance strategies showing first that, among all extant approaches to maintenance, each varying in terms of efficiency and complexity, predictive maintenance best fits the needs of a highly competitive industry setup. Predictive maintenance is an approach that allows maintenance actions to be based on changes in the monitored parameters of the assets by using a variety of techniques to study both live and historical information to learn prognostic data and make accurate predictions. Moreover, we argue that, in any industrial setup, the quality of maintenance improves when the applied data-driven techniques and methods (i) have economic justifications and (ii) take into consideration the conformity with the industry standards. Next, we consider ML to be a prediction methodology, and we show that multimodal ML methods enhance industrial maintenance with a critical component of intelligence: prediction. Based on the surveyed literature, we introduce taxonomies that cover relevant predictive models and their corresponding data-driven maintenance techniques. Moreover, we investigate the potential of multimodality for maintenance optimization, particularly the model-agnostic data fusion methods. We show the progress made in the literature toward the formalization of multimodal data fusion for industrial maintenance.
This work was partly supported by a grant from the German Federal Ministry for Economic Affairs and Energy (BMWi) for the Platona-M project under the grant number 01MT19005D.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Maintenance strategies
- Predictive maintenance
- Multimodal machine learning
- Predictive models
- Data fusion
- CRISP_DM
- Industrial Data Space
1 Introduction
A proper quality of maintenance is crucial in assuring both the desired quality of planning for the service/production/distribution chain and the desired quality of the commodities in any industry area. In the context of our research work, we investigate the optimization of maintenance quality. Among all the existing approaches to maintenance, varying in terms of efficiency and complexity, predictive maintenance seems to fit the needs of a highly competitive industry setup, as argued by [1]. Predictive maintenance evolved from condition-based maintenance, where decisions are based on evaluation of the machine status through inspections and measurements.
Predictive maintenance allows maintenance actions to be based on changes in the parameters of industrial assets, that are continuously monitored by sensors. Due to recent advances in sensor technology, data communication, and computing, the ability to collect significant volumes of heterogeneous, raw sensor data produced by industrial assets under observation is exponentially increasing. Therefore, historical information about normal and abnormal patterns and the related corrective actions employed during the lifetime of an industrial asset is becoming available. Consequently, the capability of forecasting failures based on aggregated live and historical data—i.e., the predictive maintenance approach—is currently a relevant research topic with applicability in all industrial fields and the research object of our analytical literature review. To deal with such high-dimensional problems, predictive maintenance approaches must continuously optimize themselves using a variety of techniques and prediction models that study both live and historical information. This information is further used for learning prognostics data and making accurate diagnostics and predictions, as presented by references [2,3,4]. Although the authors argue that the implementation of effective prognosis for maintenance has a variety of benefits, including increased system safety, improved operational reliability, reduced service times/repair failure times, and life cycle costs, the existing literature does not inform us about the optimal methodologies to be used in practice for the implementation of a particular maintenance scenario. Past works on predictive maintenance show that maintenance actions are performed by employing various prediction models and modeling techniques by applying different perspectives; i.e., (i) knowledge-based perspective with prediction models comprising expert systems and fuzzy logic; (ii) data-based perspective with ANNs, stochastic and statistical models, respectively; and (iii) hybrid prediction models encompassing a mixture of distinct methods for reaching the same end goal: a higher maintenance quality.
Among statistical prediction models, machine learning (ML) methods are considered the most suitable to deal with high dimensional and unstructured data, as argued by [5, 6]. Moreover, multimodality is increasingly used by ML methods for combining data from multiple, diverse modalities and sources to retrieve new insights from the combined knowledge. There are a lot of previous works on multimodality, as the topic dates back to the 90s. Maintenance scenarios that implement multimodal ML methods for predictive maintenance optimization purposes are defined by [2, 3, 6, 7].
However, to date, no standard or good practice recommendations for the fusion and integration of multimodal data have emerged. Our research reviews the model-agnostic data fusion techniques to find solutions for their optimal usage. We argue that understanding the capabilities and challenges of existing multimodal data fusion methods and techniques has the potential to deliver better data analysis tools across all domains, including in the maintenance quality and management field of research.
Furthermore, we envision the problem of maintenance’s quality as a complex topic with many complementary aspects: technical, economic, and the conformity with the mainstream industrial standards. The first aspect follows the classical optimization concerns relative to maintenance costs by considering aspects related to maintenance investment costs and resulting benefits. Traditional approaches consider maintenance only as a cost. However, maintenance activities have direct implications on production and quality and, therefore, should be treated as an investment, as argued by [8]. Moreover, choosing the appropriate timing for performing maintenance activities has economic justifications as explained by [9] in the description of the damage model. The damage model recommends the use of maintenance actions only when clear evidence of the machine or equipment status exists. It shows that, based on long-term historical data, it is possible to adapt the predictive maintenance interval to the industrial item life cycle by forecasting the item’s wear and its impact on the production chain. Reference [9] explains that the probability that an item will fail is high at the beginning of its operational life in its burn-in period. During the burn-in period, the failure probability of an item decreases continuously. During the item’s working period, the failure probability is low and remains constant; therefore, predicting the item’s failure during the working period is challenging. The probability of failure increases with the number of working hours, so that, in the wear period, the probability for an item to fail is again high. Therefore, as a good practice, [9] recommends performing maintenance actions during the wear period of an item’s life cycle.
The second aspect that we believe influences the quality of maintenance is conformity to industrial standards during the development life cycle of a maintenance product. Our review of the literature shows that ad-hoc maintenance model development and implementations that do not comply with existing mainstream standards are problematic. This situation leads to the absence of good practice recommendations or general solutions in the development of maintenance products. We briefly review two existing industrial standards for model development: Industrial Data Space [10] and Cross-Industry Standard Process for Data Mining (CRISP-DM) [11]. The CRISP-DM standard represents a guideline to follow in the process of prototyping a learning model for maintenance purposes. We shortly list the guideline steps: business understanding, data understanding, data preparation, data fusion, model prototyping, model evaluation, and deployment. On its turn, Industrial Data Space represents the solution to the actual problems raised by the huge volume of heterogeneous data that needs to be handled in a standardized way in the industrial setup. Among the expected benefits of any standard, we mention knowledge sharing and (re)use, which help build complex operational models.
The technical aspect of maintenance quality is related to the set of decisions concerning the appropriate techniques and methods that should be used for the development of an operational and highly qualitative maintenance model. Our literature survey focuses on analyzing the technical aspect, but further works are planned to consider its connections with the economic aspect. To our knowledge, none of the reviewed research works consider the conformity with industrial standards for model development and data management and security. One of the main issues with actual maintenance techniques and methods is precisely the absence of this holistic view in considering the problem of the maintenance quality, as directly influenced by all of the above three mentioned aspects; i.e., technical (data-driven oriented), economic (maintenance as a long-term investment), and conformity with industrial standards.
The rest of the paper is structured as follows: Sect. 2 describes the theoretical background of our paper, i.e., the maintenance taxonomy according to the terminology defined by both [12, 13] maintenance standards, and the multimodal ML methods, as in [14, 15]. The description of the review process and the selection of the literature are presented in Sect. 3. The findings and results of the investigated approaches are highlighted in Sect. 4. Section 5 discusses the identified problems and further research challenges for the reviewed topics. Finally, Sect. 6 concludes our review by outlining our approach and planned future works.
2 Theoretical Background
2.1 Classification of Maintenance Approaches
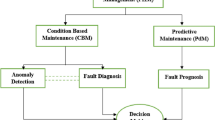
The European recognized maintenance standards: DIN EN 13306 - Maintenance Terminology [12] and DIN EN 31051 - Fundamentals of Maintenance [13], are defining maintenance-related terminology and concepts. According to the DIN EN 31051 standard, the maintenance concept is defined as: the combination of all technical and administrative actions as well as actions of management in the lifetime of a unit, in order to be in the fully functional state or to recover in this one so that this unit can fulfill his requirements. The main maintenance activities (i.e., service, inspection, repair, and improvement) are defined by the DIN EN 31051 standard. Their definitions, together with other relevant maintenance concepts defined by the DIN EN 31051 maintenance standard, are listed in Table 1. On the other hand, the DIN EN 13306 maintenance standard defines the existing maintenance strategies, i.e. corrective maintenance, preventive maintenance, condition-based maintenance, and predictive maintenance. They are discussed in the following subsections. Moreover, the definition of a further maintenance strategy, namely prescriptive maintenance—which is not yet standardized but is already used in practice—is discussed in the following subsection.
Corrective Maintenance.
According to the DIN EN 13306 standard, corrective maintenance is defined as: the maintenance carried out after fault recognition that is intended to put an item into a state in which it can perform a required function. A system that employs corrective maintenance should be aware of all its predefined sets of failures and damages. However, in the industrial operational context, new faults and their corresponding patterns may appear over time because of the item’s usage during working hours.
One main advantage of applying corrective maintenance techniques is that the wear limit of an item, i.e., the service time, is fully used. This implies that the effort for item inspection and for repairing or replacing the deteriorated item is significantly reduced compared with the case of preventive maintenance.
The main disadvantage is that corrective maintenance interventions are performed only after the occurrence of failures: it is the simplest approach to applying maintenance, and therefore it is still frequently adopted. However, it is the least effective, and the costs of interventions are substantial. The main challenge in applying corrective maintenance is that the item can fail at a time not previously known or decided and, consequently, can produce damages and additional costs of interventions that can be higher than the yield of the full usage of its wear margin.
Preventive Maintenance.
The DIN EN 13306 standard defines preventive maintenance as: the maintenance carried out at predetermined intervals or according to prescribed criteria and intended to reduce the probability of failure or the degradation of the functioning of an item. Consequently, preventive maintenance defines a set of actions carried out before failure, which is intended to prevent failures or the degradation of a machine.
One main challenge of preventive maintenance approaches in an operational context is that industrial scenarios for data analysis do not provide tracking of the past, abnormal behavior, or maintenance operations that were performed to correct or prevent a faulty behavior. The general assumption is that after several operational hours, the wear margin of an item is worn out. The employed approach is to change the item or overhaul part of it before the wear margin is used. Consequently, this approach leads to inefficient use of resources, as unnecessary corrective actions are often performed.
Condition-Based Maintenance.
The DIN EN 13306 standard defines condition-based maintenance as preventive maintenance, which includes a combination of condition monitoring and/or inspection and/or testing, analysis, and ensuring maintenance actions. Condition-based maintenance (CbM) aims to anticipate a maintenance operation, based on the evidence of degradation and deviations from a supposed asset’s normal behavior. The equipment is monitored with multiple sensors that are supposed to acquire relevant data about the equipment’s operation life. Additionally, contextual parameters like vibration, temperature, humidity, etc., may also provide important information. Key Process Indicators (KPIs) or health indicators are usually computed and analyzed to discover trends that lead to abnormal contexts and failure events. Consequently, CbM enables existing failures to be detected, diagnosed, and corrected before breakdowns or other serious consequences occur.
The challenge is how to use this asset health information for optimizing the accuracy of predicting the remaining asset lifetime, optimizing maintenance schedules, and maximizing the industrial efficiency.
Predictive Maintenance.
According to the DIN EN 13306 standard, predictive maintenance (PdM) is defined as: the condition-based maintenance carried out following a forecast derived from repeated analysis or known characteristics and evaluation of the significant parameters of the degradation of the item. PdM is a subclass of CbM. Consequently, PdM is performed based on an estimate of the asset’s health status, e.g., detection of Remaining Useful Life (RUL), saving costs, and improving the overall process efficiency. PdM uses a variety of approaches and ML methods to study both real-time data and historical data and to learn prognostic models that are expected to make accurate predictions about the status of a machine or equipment. The main challenge of predictive models is that they rely on the assumption that there are certain contexts in the equipment lifetime where the failure rate is increasing. In the industrial operational context, there are patterns in which the failure probability does not increase but remains constant during the equipment’s lifetime. Therefore, the equipment can fail at any time; this is the case with electrical and electronic components.
Prescriptive Maintenance.
Terminologically, neither the DIN EN 13306 nor the DIN EN 31051 maintenance standards mentions it, but its functionality can be consequently deduced and is seen as: a recommendation of one or more courses of action based on the outcomes of models for corrective and predictive maintenance. Existing prescriptive maintenance models are based on ad-hoc model development where ML methods and data fusion techniques are jointly used with fuzzy reasoning, simulation techniques, and evolutionary algorithms. The main challenge of prescriptive maintenance is the difficulty with building prescriptive, operative models in practice.
Tables 3, 4 and 5 introduced in Sect. 4 are constructed based on the reviewed literature on corrective, preventive, and predictive maintenance strategies. The tables present the surveyed literature, a structured review of the maintenance type and goals correlated with a specific statistical or data-driven operational method, and the corresponding results.
2.2 Multimodal ML Methods
Understanding the specific application context, or the business requirements is the first step for any learning model developed and deployed in an industrial environment. The main business requirements in the form of business goals must be identified, as they strongly influence all processes of model development. The basic steps of the model development life cycle for maintenance purposes are formalized by the CRISP-DM standard and explained in [11] i.e. (1) Business understanding, (2) Data acquisition and understanding, (3) Data preparation, (4) Data fusion, (5) Model development, (6) Model evaluation, and (7) Deployment.
In the context of the CRISP-DM data-driven development life cycle, our focus is the model development and the understanding of multimodal ML methods, in particular the model-agnostic multimodal data fusion.
Multimodality is defined by [14] as referring to the way something happens or is experienced: we read textual information, we see objects, we hear sounds, we feel textures and smell odors. All these perceptions represent modalities. A research problem, application, or data set is multimodal when it includes multiple such modalities.
To understand and to make sense of the world around us, A.I. techniques multimodal ML, must be able to interpret multimodal information and further to reason about it and make decisions. Multimodal ML is a multi-disciplinary field of research that builds models, that process and relate information from multiple modalities, as defined in [14]. The main idea is that data from different sensors provide different representations of the same phenomena. In MML literature, this is known as multimodal, multi-view, multi-representation, or multi-source learning, as described in [15]. The main multimodal ML methods were identified and defined in [14] i.e., representation, translation, alignment, fusion, and co-learning. Their definitions, according to references [14, 15], are listed in Table 2.
3 Research Methodology
3.1 Selection of Literature
A systematic search was employed to find journals and proceeding between 2016 and 2019 using the English language and the keywords: maintenance AND machine learning. We iteratively continued the search using the following keywords: predictive maintenance, multimodal machine learning, multimodal methods, multimodality, maintenance AND big data, maintenance AND Industry 4.0. A useful and predictive condition-based maintenance literature review using bibliometric indicators [16] helped us determine the most influential journals, articles, authors, and institutions in predictive condition-based maintenance, with the only drawback that the research reviews articles published up until December 2017, with the most cited papers dating back to the interval 2006–2009. We finally obtained a shorter literature list, which was further reduced by eliminating the duplicates when similar topics and approaches were found. Science Direct, Scopus, and Google Scholars were used, due to their wide collection of proceedings and journals. The conference and journal publications selected for our review belong to the non-empirical conceptual and mathematical fields of research. Consequently, they describe issues and perspectives related to maintenance strategies and their modeling techniques applied in an industrial setup. The overview of the reviewed maintenance literature is presented in Sect. 4, in Tables 3, 4 and 5.
3.2 Description of the Criteria Used for Analysis
Our survey focuses on: (i) the decision process in choosing a specific maintenance approach, i.e., maintenance goals, benefits, challenges, and obtained results; and (ii) the implementation of the maintenance approach, i.e., the employed prediction models and their corresponding modeling techniques. The selected literature was carefully examined to extract useful information based on the following criteria:
-
Prediction models: reveal a taxonomy of the most active prediction model types employed in a maintenance process, i.e., physical models, knowledge-based models, database models, and hybrid models.
-
Modelling techniques: represent the implementation pipeline (data analysis + algorithms) used. It is a relevant criterion which further helps us select the set of the most used ML algorithms to be critically reviewed.
-
Obtained results/performance metrics: extract the information concerning how the model was evaluated and give us a hint about how optimal the data analysis and learning algorithms were applied.
-
Maintenance goals: provide us with a taxonomy of topics showing the final decisions of the algorithm’s pipeline. Paired with the modeling techniques criterion, it gives useful information about the successful algorithm pipeline used for a certain maintenance goal.
The literature review we conduct is formalized by [17, 18] and starts with clarifying relevant maintenance terminology and definitions based on the accepted, European maintenance standards [12, 13]. Thereby, the surveyed works we consider are grouped by maintenance approach, and further on, they are grouped by prediction models and the modeling techniques used in the implementation of the maintenance strategies.
4 Research Findings
This section presents the reviewed results displayed in Tables 3, 4 and 5.
The surveyed works we consider are grouped by maintenance type, and further on, they are grouped by prediction modeling types and relevant modeling techniques used in the implementations.
4.1 Corrective Maintenance
Our survey shows that the fault recognition and diagnostic is generally seen as a process of pattern recognition, i.e., the process of mapping the information, i.e., the features obtained in the measurement space to the machine faults in the fault space, as described in [19,20,21,22].
Diagnosis is a necessary part of any maintenance system, as using prognostics only cannot provide, in practice, a sure prediction that covers all failures and faults. In case of an unsuccessful prognosis, a diagnosis is a complementary tool for providing maintenance decision support. The methods employed in order to deal with fault classification and diagnostics are diverse: from expert systems [24] to hidden Markov models (HMM)s as presented in [19], artificial neural networks (ANN)s as described in [20], a support vector machine (SVM) as in [21], and fuzzy algorithms enhanced with spectral clustering and Haar wavelet transform as described in [22].
4.2 Preventive Maintenance
The reviewed literature shows that a relevant class of preventive maintenance techniques are the prognostics through pattern recognition, classification, and machine health status identification.
Prognostics analyze data by automatically finding new insights in terms of behavioral patterns. The information extracted from the monitored data can help detect patterns that characterize the machine working conditions or anticipate and estimate critical events like fault detection as in [3] and Remaining Useful Life (RUL) estimation as in [5].
Prognostics are considered superior to diagnostics in the sense that they prevent faults and are employed for prediction problems with items like spare parts and human resources, saving unplanned maintenance costs. The reference [30] proposes a data mining maintenance approach for predicting material requirements in the automotive industry by measuring the similarity of customer order groups. Identifying behavioral patterns in data means classifying similar data in some data-groups that share the same characteristics, i.e., operational conditions, as described by references [25,26,27,28,29].
Within these classified groups, there are data-points that are far from the identified pattern (i.e., the outliers), or they may correspond to a distinctive property (i.e., the mean point or the group distribution). Such patterns may help to identify faults or any other type of abnormal behavior. Large groups of data are interpreted as normal behavior, while small groups of data or events that are far from the pattern usually represent anomalies.
4.3 Predictive Maintenance
The survey shows that the predictive maintenance process has the goal of providing an accurate estimate of the RUL, but also, it should assess the provided estimate, as argued in [31,32,33]. Time series analysis is used to anticipate anomalies and malfunctions in equipment and process maintenance procedures. Traditional approaches are moving at an average rate over a time window, ARMA/ARMAX, Kalman filter, and cumulative sum, as described in [6].
Recursive neuronal networks (RNNs) show relevant characteristics for time series forecasting, as their loops allow information to persist, as presented in [5]. Multi-sensor fusion ranges from multi-signal combinations, as argued in [5, 6], to a more complex integration of the conditional assessment, RUL estimations, and decision-making, as presented in [2] and [7].
Operational predictive approaches are based on a schema that implies frequent and sometimes unnecessary maintenance of the equipment and of the entire production process that leads to high maintenance time and costs. They use complex AI-based algorithms, and data fusion strategies—in an ad-hoc manner, usually after trial and error approaches—which imply the usage of consecutive fusion algorithms, as described by reference [27]. The uncertainty in prediction is always a challenge, and, to this time, the fuzzy logic is used to represent uncertainties in prediction, as argued by [4]. As a case of condition-based maintenance, reference [34] shows that techniques for condition monitoring and diagnostics are gaining acceptance in the industry sectors, as they also prove to be effective in the predictive maintenance and quality control areas. The authors apply a feature-based fusion technique implemented with the cascade correlation neuronal network to multiple sensor data collected from rotating imbalance vibration of a test rig. The results show that the multi-sensory data fusion outperforms the single sensor diagnostic. The reference [35] focuses on the capability of providing real-time maintenance by extracting knowledge from the monitored assets (with vibration sensors) on the production line. Using intelligent, data-driven monitoring algorithms (ADMM), data fusion strategies, and the proposed three-level (IoT, Fog with gateway nodes for sensors aggregation, and Decision) layered system model, the authors argue on the efficiency of cloud-oriented maintenance.
The uncertainty in prediction is always a challenge, and to this time, fuzzy logic is used to represent uncertainties in prediction, as argued by [4, 30, 36,37,38], which showed that the problem of scheduling under the constraint of the deadline for all production jobs could also be solved using predictive maintenance algorithms. The efficiency of the algorithms for predicting machine failures is further evaluated by using simulation tests. The results, i.e., the optimized job schedules, show a nearly 50% drop in the number of operations compared with the initial nominal schedule.
4.4 Multimodal ML Methods: Data Fusion
A relevant research challenge for the multimodal data fusion perspective is to identify patterns and common governance rules that can be used to apply the appropriate multimodal data fusion technique in an application-specific context or for a data set.
Reference [38] argues that data fusion is a multidisciplinary research area with ideas raised from many diverse research fields such as signal processing, information theory, statistical estimation and inference, and artificial intelligence.
Data fusion appeared in the literature as mathematical models for data manipulation. The diversity of the research fields is indeed reflected in the reviews of maintenance techniques in Tables 3, 4 and 5.
Multimodal data fusion represents the integration of information from multiple modalities, with the goal of (i) making a prediction, and (ii) retrieving new insights from the joined knowledge, as defined by [14].
There are many approaches to data fusion, as the topic dates back to the 90s. The model-agnostic technique of data fusion is discussed in [14, 39] and later described by [15], which also lays the ground for the formal multimodal data fusion theory. Multimodal data fusion has a direct economic impact on the implementation of maintenance techniques, that are based on the aggregation of data from heterogeneous sources into actionable decisions for maintenance purposes. Multimodal data fusion represents the core concept in MML, as argued in references [14, 15, 38, 39]. The model-agnostic data fusion types that are used in the operational environment are listed in Table 6.
Reference [15] lays the grounds for the multimodal data fusion theory by giving a solution to the research problem of determining the appropriate type of data fusion for a specific application context or a data set. In the authors’ view, the main challenge in multimodal data fusion research revolves around the dependency-problem, i.e., the arguments for choosing a specific type of data fusion. The assumption is that the optimal fusion type to be employed in an operational environment depends on the level of dependency we expect to see between the inputs in the modalities: (i) feature-based fusion assumes a dependency at the lowest level of features (or raw input unprocessed data), (ii) intermediate-fusion assumes a dependency at a more abstract, semantic level; and (iii) decision-based fusion assumes no dependency at all in the input, but only later at the level of decisions.
5 Discussion of Findings
Our literature review reveals that past works on industrial maintenance approaches show that maintenance actions are performed by employing various prediction models and modeling techniques.

Taxonomy of prediction models
However, the existent literature does not inform us to which extent the new A.I. technology, based on ML methods and techniques, is influencing and changing the maintenance strategies in the industrial environment.
We show in Fig. 1 that predictive maintenance models can be classified into four distinctive categories: physical models, knowledge-based models, data-driven models, and hybrid models.
Physical models use the laws of physics to describe the behavior of a failure, as presented in reference [2]. Knowledge-based models assess similarities among observed situations and a set of previously defined failures. These models can be sub-divided in expert system models that are able to answer complex queries as presented by reference [24] and fuzzy models as in reference [4]. Both model types employ a deductive, top-down approach that builds mathematical models and rule-based models, respectively, based on the domain experts’ knowledge of the analyzed system. The higher complexity of real systems represents the main challenge for these models.
Data-driven models are based on acquired data. These types of models can further be distinguished among stochastic models, statistical models and artificial neural networks (ANNs). Data-based models employ an inductive, bottom-up approach that empirically builds a learning model from historical or live data. Stochastic models provide event-based information with hidden Markov models and Kalman filters belonging to this category. Statistical models predict a future state by comparing the monitored results with a machine-health state without faults. Hybrid models use combinations of two or more modeling techniques as in [40,41,42].
Among data-driven models, the ML models represent a category of relevant prediction models for maintenance optimization. Some consider them to be statistical models. However, the ML methods are focusing on increasing the accuracy of their predictions, while the classical statistical community is more concerned with the understanding of their models and of the model’s parameters, i.e., model calibration and inference.
As displayed in Fig. 2, ML techniques for maintenance can be divided into two main categories depending on their type of employed ML approach: (i) a supervised approach, where information on the occurrence of failures is present in the dataset and (ii) an unsupervised approach, where the asset/process information is available but no maintenance-related data exists.
Classification is one of the most used ML methods that occurs in a wide range of maintenance scenarios. Classification models predict categorical (discrete and unordered) class labels. Maintenance classification techniques are applied when there is a need to distinguish between the faulty and non-faulty conditions of the system being monitored.

ML approaches and techniques for prediction models
Binary classification methods are used to predict the probability that an industrial asset fails within an established time period in the future. The testing datasets must contain positive and negative examples that indicate the failure and normal operating conditions, respectively. Consequently, the target variables are usually categorical in nature. The learning model identifies each new example as likely to fail or likely to work over the next period.
The business requirements, the analyzed available data, and the domain experts make estimations for the (i) minimum lead time required to replace components, deploy resources, and perform maintenance actions to avoid a problem that is likely to occur in the future or (ii) a minimum count of events that can be triggered before a critical problem occurs. Multi-class classification methods are used for making predictions in the following possible scenarios: (i) defining a plan maintenance schedule, i.e., estimation of the time intervals when an asset has the bigger probability of failing; (ii) monitoring the health status of an asset, i.e., estimation of the probability that an asset will fail due to a specific cause-/root problem; and (iii) prediction that an asset will fail due to a specific type of failure. In this case, a set of prescriptive maintenance actions can be considered for each of the previously identified set of failures. Multiple classifiers represent a type of ML method for classification, which can be used in the process of knowledge discovery to discern patterns of data degradation for an asset or a process. The benefits of multiple classifiers reside in allowing the planning of the maintenance schedules using a statistical cost minimization approach, as discussed in [1].
Regressions are typically used to compute the RUL of an item, as presented in [36]. RUL is defined as the amount of time that an asset is operational before the next failure occurs. The operational historical data is needed because the RUL calculation is not possible without knowing how long the asset has survived before a failure. While classification methods are used to distinguish between faulty and healthy behaviors based on the historical data, they do not intuitively map to health factors that can be further used in maintenance-related decision making, unlike RUL regression methods.
Clustering is the process of grouping a set of data into multiple classes, subsets or clusters, where data within a cluster have high similarity. The reviewed ML literature recommends the following clustering methods: PCA + k-Means [37] and variants of Deep Learning using RNNs [36] and ANNs [5, 31]. They can be used for information clustering when there is no knowledge or understanding of the monitored system, as discussed in [5, 31, 36].
6 Conclusions
6.1 Research Contribution
Sections 4 and 5 represent our contribution to the actual research that intends to (i) formalize the usage of multimodal ML methods for maintenance goals, and (ii) optimize the quality of maintenance in operational environments.
Based on the surveyed literature, we construct taxonomies that cover the main predictive models and their modeling techniques relative to maintenance goals. We show that among all data-driven prediction models, the ML approaches are the most suitable to deal with big volumes of heterogeneous data. They are accepted in the field because prediction is considered easier than model inference, i.e., the ML models are performing tests to check how well a learning model that is trained on a data set, can accurately predict new data. This allows the ML methods to work with larger volumes of complex, heterogeneous, and unstructured data easily.
6.2 Implications for Research and Practice
Our review shows that ML and multimodality are receiving attention from both academia and practice as technical ways for implementing maintenance goals. However, the research is still in its early phase, as there are basic issues that are biasing the usage of multimodal ML methods in operational environments. As argued in reference [43], (i) there are no established, standard methods by which to identify feature dependencies in multiple sensors and modalities; (ii) the technology exists, but there are no standard methods by which to extract unbiased feature from raw data, and therefore, deep learning methods are preferred; (iii) multimodal data fusion best practices, i.e., data sets, fusion algorithms, success stories, training, and evaluation of results, should be recorded and shared; (iv) the absence of a clearly defined generic framework to standardize the usage of a data fusion pipeline, i.e., it is clear that in an operational environment, more than one data fusion technique should be applied; (v) there are no standard techniques for dealing with temporal and spatial (aka contextual) data alignment and synchronization; and (vi) there is a lack of research studies by which to analyze the performance of ML algorithms in a cloud environment.
Thus, we argue that the quality of maintenance in an industrial setup can be improved only when, in the development of a generalized architecture for predictive maintenance purposes, the following aspects are considered: (i) the technological aspect that recognizes the potential of multimodal ML methods for maintenance purposes; (ii) the business aspect that envisions a structured development of the implementation works, starting with the business model’s conceptualization and assuring its conformity with industry standards, such as Industrial Data Space and CRISP_DM; and (iii) the economic aspect that follows the classical optimization concerns relative to maintenance costs.
The approach we envision for the optimization of predictive, industrial maintenance investigates the ML technical perspective and, consequently, focuses on a variety of (multimodal) ML methods that study both live and historical information to learn prognostics data and perform accurate diagnostics and predictions.
6.3 Limitations and Future Works
For our research work, we are not considering the empirical research perspective, i.e., we are not discussing the maintenance strategies and their operationalization based on information obtained from interviews or from analyzing relevant case studies.
Future works are planned to analyze the usage of multimodal ML methods combined with semantic technologies in a cloud-oriented environment. The goal is to overcome the problem of sensor integration for efficient data analysis. We recognize that the actual trend for maintenance engineering is cloud maintenance. Within this context, the envisioned digital platform is seen as a management system of smart services, i.e., prediction-as-a-service and maintenance-as-a-service, with expected benefits in terms of technology, performance, and costs.
References
Susto, G.A., Mcloone, S., Pampuri, S., Benghi, A., Schirru, A.: Machine learning for predictive maintenance: a multiple classifier approach. IEEE Trans. Ind. Informat. 11(3), 812–820 (2015). https://doi.org/10.1109/TII.2014.2349359
Liu, Z., Norbert, M., Nezih, M.: The role of Data Fusion in predictive maintenance using Digital Twin. AIP Conf. Proc. 1949(1), 020023 (2018). https://doi.org/10.1063/1.5031520
Manco, G., et al.: Fault detection and explanation through big data analysis on sensor streams. Expert Syst. Appl. 87, 141–156 (2018). https://doi.org/10.1016/j.eswa.2017.05.079
Niu, G., Li, H.: IETM centered intelligent maintenance system integrating fuzzy semantic inference and data fusion. Microelectron. Reliab. 75, 197–204 (2017). https://doi.org/10.1016/j.microrel.2017.03.015
Guo, L., Li, N., Jia, F., Lei, Y., Lin, J.: A recurrent neural network-based health indicator for remaining useful life prediction of bearings. Neurocomputing 240, 98–109 (2017). https://doi.org/10.1016/j.neucom.2017.02.045
Acorsi, R., Manzini, R., Pascarella, P., Patella, M., Sassi, S.: Data Mining and Machine Learning for Condition-based Maintenance. In: (eds.) Proceedings of the 2017 International Conference on Flexible Automation and Intelligent Manufacturing FAIM, 27–30 June 2017, Modena, Italy, pp. 1153-1161 (2017). https://doi.org/10.1016/j.promfg.2017.07.239
Safizadeh, M., Latifi, S.: Using multisensory data fusion for vibration fault diagnosis of rolling element bearings by accelerometer and load cell. Inf. Fusion 18(1), 1–8 (2014). https://doi.org/10.1016/j.inffus.2013.10.002
Schmidt, B., Sandberg, U., Wang, U.: Next generation condition based Predictive Maintenance. Methods 13306, 4–11 (2014)
Schenk, M.: Instandhaltung technischer Systeme. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-03949-2
Otto, B., et al.: Industrial Data Space – Digital soveregnity over data, In: Fraunhofer Gesellschaft zur Förderung der angewandten Forschung (2016)
Diez-Olivan, A., del Ser, J., Galar, D., Sierra, B.: Data fusion and machine learning for industrial prognosis: Trends and perspectives towards Industry 40. Information Fusion 50, 92–111 (2019). https://doi.org/10.1016/j.inffus.2018.10.005
DIN EN-13306. DIN Standards – Maintenance terminology, Beuth Publishing DIN (2018). https://dx.doi.org/10.31030/2641990
DIN EN-31051. DIN Standards – Fundamentals of maintenance, Beuth Publishing DIN (2019). https://dx.doi.org/10.31030/3048531
Baltrusaitis, T., Ahuja, C., Morency, L.: Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 41(2), 423–443 (2019). https://doi.org/10.1109/TPAMI.2018.2798607
Alpaydin, E.: Classifying multimodal data. In: Oviatt, S., Schuller, B., Cohen, P.R., Sonntag, D., Potamianos, G., Krüger, A. (eds.) The Handbook of Multimodal-Multisensor Interfaces, In Association for Computing Machinery and Morgan & Claypool, NY, pp. 49–69 (2018)
Noman, N.A., Nasr, E.S.A., AlShayea, A., Kaid, H.: Overview of predictive condition based maintenance research using bibliometric indicators. J. K. Saud Univ. Eng. Sci. 31(4), 355–367 (2019)
Oates, B.J.: Researching Information Systems and Computing. Sage Publications Ltd., Thousand Oaks (2006)
Peffers, K., Tuunanen, T., Rothenberger, M., Chatterjee, S.: A design science research methodology for information systems research. J. Manag. Inf. Syst. 24(3), 45–77 (2007). https://doi.org/10.2753/MIS0742-1222240302
Bunks, C., McCarthy, D., Al-Ani, T.: Condition-based Maintenance of machines using hidden Markov Models. Mech. Syst. Sign. Process. 14(4), 597–612 (2000). https://doi.org/10.1006/mssp.2000.1309
Deuszkiewick, P., Radkowski, S.: On-line condition monitoring of a power transmission unit of a rail vehicle. Mech. Syst. Sign. Process. 17(6), 1321–1334 (2003). https://doi.org/10.1006/mssp.2002.1578
Hao, Y., Sun, J., Yang, G., Bai, J.: The application of support vector machines to gas turbines performance diagnosis. Chinese J. Aeronaut. 18(1), 15–19 (2005). https://doi.org/10.1016/S1000-9361(11)60276-8
Baraldi, P., Zio, E., di Maio, F.: Unsupervised clustering for fault diagnostics in nuclear power plants components. Int. J. Comp. Intell. Syst. 6(4), 764–777 (2014). https://doi.org/10.1080/18756891.2013.804145
Merkt, O.: On the Use of Predictive Models for Improving the Quality of Industrial Maintenance: an Analytical Literature Review of Maintenance Strategies. In: Ganzha, M., Maciaszek, L., Paprzycki, M. (eds.) Proceedings of the 2019 Federated Conference on Computer Science and Information Systems FedCSIS, 1–4 September, pp. 693-704. Leipzig University, Leipzig, Germany (2019). https://dx.doi.org/10.15439/2019F101
Alexandru, A.: Using Expert Systems for Fault Detection and Diagnosis. Industrial Applications (1998)
Krishnakumari, A., Elayaperumal, A., Saravanan, M., Arvindan, C.: Fault diagnostics of spur gear using decision tree and fuzzy classifier. Int. J. Adv. Manuf. Technol. 89(9–12), 3487–3494 (2017). https://doi.org/10.1007/s00170-016-9307-8
Jaramillo, V.H., Ottewill, J.R., Dudek, R., Lepiarczyk, D., Pawlik, P.: Condition monitoring of distributed systems using two-stage Bayesian inference data fusion. Mech. Syst. Sign. Process. 87, 91–110 (2017). https://doi.org/10.1016/j.ymssp.2016.10.004
Liu, C., Li, Y., Zhou, G., Shen, W.: A sensor fusion and support vector machine-based approach for recognition of complex machining conditions. J. Intell. Manuf. 29(8), 1739–1752 (2018). https://doi.org/10.1007/s10845-016-1209-y
Diez, A., Khoa, N.L.D., Alamdari, M.M., Wang, Y., Chen, F., Runcie, P.: A clustering approach for structural health monitoring on bridges. J. Civil Struct. Health Monit. 6(3), 429–445 (2016)
Li, C., Sánchez, R.-V., Zurita, G., Cerrada, M., Cabrera, D.: Fault diagnosis for rotating machinery using vibration measurement deep statistical feature learning. Sensors 16(6), 895, 1–19 (2016)
Widmer, T., Klein, A., Wachter, P., Meyl, S.: Predicting Material Requirements in the Automotive Industry Using Data Mining. In: Abramowicz, W., Corchuelo, R. (eds.) BIS 2019. LNBIP, vol. 354, pp. 147–161. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-20482-2_13
Mosallam, A., Medjaher, K., Zerhouni, N.: Data-driven prognostic method based on Bayesian approaches for direct remaining useful life prediction. J. Intell. Manuf. 27(5), 1037–1048 (2016). https://doi.org/10.1007/s10845-014-0933-4
Alsina, E.F., Chica, M., Trawinski, K., Regattieri, A.: On the use of Machine Learning methods to predict component reliability from data-driven industrial case studies. Int. J. Adv. Manuf. Technol. 94(5–8), 2419–2433 (2018). https://doi.org/10.1007/s00170-017-1039-x
Cristaldi, L., Leone, G., Ottoboni, R., Subbiah, S., Turrin, S.: A comparative study on data-driven prognostic approaches using fleet knowledge. In: Arpaia, A., Catelani, M., Cristaldi, L. (eds.) Proceedings of the 2016 IEEE International Conference on Instrumentation and Measurement Technology (I2MTC), 23–26 May, 2016, Taipei, Taiwan, pp. 1-6 (2016). https://doi.org/10.1109/I2MTC.2016.7520371
Liu, Q. (C.), Wang, H.P. (B.): A case study on multisensory data fusion for imbalanced diagnosis of rotating machinery. AI EDAM 15(3), 203–2010 (2001)
Xenakis, A., Karageorgos, A., Lallas, E., Chis, A.E., Gonzalez-Velez, H.: Towards distributed IoT/cloud based fault detection and maintenance in industrial automation. In: Shakshuki, M.E., Yasar, A.-U.-H. (eds.) Proceedings of the 10th International Conference on Ambient Systems, Networks and Technologies (ANT 2019), April 29 - May 2, 2019, Leuven, Belgium, pp. 683–690 (2019). https://doi.org/10.1016/j.procs.2019.04.091
Sobaszek, Ł., Gola, A., Kozłowski, E.: Application of survival function in robust scheduling of production jobs. In: Ganzha, M., Maciaszek, L., Paprzycki, M. (eds.) Proceedings of the 2017 Federated Conference on Computer Science and Information systems FedCSIS, 3–6 September 2017, pp. 575-578. Czech Technical University in Prague, Prague (2017). http://dx.doi.org/10.15439/2017F276
Sobaszek, Ł., Gola, A., Kozłowski, E.: Job-shop scheduling with machine breakdown prediction under completion time constraint. In: Ganzha, M., Maciaszek, L., Paprzycki, M. (eds.) Proceedings of the 2018 Federated Conference on Computer Science and Information Systems FedCSIS, 9–12 September 2018, pp. 437-440. Adam Mickiewicz university Poznan, Poland (2018). http://dx.doi.org/10.15439/2018F83
Khaleghi, B., Karray, F., Khamis, A., Razavi, S.N.: Multisensor data fusion: a review of the state-of-the-art. Inf. Fusion 14, 28–44 (2013). https://doi.org/10.1016/j.inffus.2011.08.001
Bengio, Y., Courville, A., Vincent, P.: Representation learning: a review and new perspectives, Technical report. Univ. Montreal, 35(8), 1798–1828 (2013). https://doi.org/10.1109/TPAMI.2013.50
Baban, C.F., Baban, M., Suteu, M.D.: Using a fuzzy logic approach for the predictive maintenance of textile machines. J. Intell. Fuzzy Syst. 30(2), 999–1006 (2016). https://doi.org/10.3233/IFS-151822
Cui, W., Lu, Z., Li, C., Han, X.: A proactive approach to solve integrated production scheduling and maintenance planning problem in flow shops. Comput. Ind. Eng. 115, 342–353 (2018). https://doi.org/10.1016/j.cie.2017.11.020
Seidgar, H., Zandieh, M., Mahdavi, I.: An efficient metaheuristic algorithm for scheduling a two-stage assembly flow shop problem with preventive maintenance activities and reliability approach. Int. J. Ind. Syst. Eng. 26(1), 16–41 (2017). https://doi.org/10.1504/IJISE.2017.083180
Chou, C.-A., Jin, X., Müller, A., Ostadabbas, S.: MMDF 2018 Multimodal Data Fusion Workshop Report. Northeastern University, Boston (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Merkt, O. (2020). Predictive Models for Maintenance Optimization: An Analytical Literature Survey of Industrial Maintenance Strategies. In: Ziemba, E. (eds) Information Technology for Management: Current Research and Future Directions. AITM ISM 2019 2019. Lecture Notes in Business Information Processing, vol 380. Springer, Cham. https://doi.org/10.1007/978-3-030-43353-6_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-43353-6_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-43352-9
Online ISBN: 978-3-030-43353-6
eBook Packages: Computer ScienceComputer Science (R0)