
Abstract
In this paper, a decentralized robust zero-sum optimal control method is proposed for modular robot manipulators (MRMs) based on the adaptive dynamic programming (ADP) approach. The dynamic model of MRMs is formulated via joint torque feedback (JTF) technique that is deployed for each joint module, in which the local dynamic information is used to design the model compensation controller. An uncertainty decomposition-based robust control is developed to compensate the model uncertainties, and then the robust optimal control problem of MRMs with uncertain environments can be transformed into a two-player zero-sum optimal control one. According to the ADP algorithm, the Hamilton-Jacobi-Isaacs (HJI) equation is solved by constructing action-critic neural networks (NNs) and then the approximate optimal control policy derivation is possible. Experiments are conducted to verify the effectiveness of the proposed method.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Modular robot manipulators have attracted wildly attentions in robotics community since they are possessed of better structural adaptability and flexibility than conventional robot manipulators. An MRM is composed by standardized robotic modules, which consist of actuators, speed reducers, sensors and communication units. These modules can be assembled to desired configurations via standard mechanical interfaces according to the requirements of various tasks. Benefitting from the advantages above, MRMs are often utilized in dangerous and complex environments. Correspondingly, appropriate control systems are required to guarantee the robustness and precision of MRMs with uncertain environments.
In order to seek out appropriate control for MRMs, joint torque feedback techniques have attached attentions of both robotic researchers and industrial manufacturers. JTF technique can not only eliminate the necessity of contact model in motion control of robot-environment interactive tasks, it also facilitates in suppressing the effect of uncertain contact force created between the end-effector and payloads [1,2,3]. However, the existed JTF-based motion/force control methods have not considered the issue of optimal implementation between the error performance of joint motion and the output torque of actuator. Indeed, an ideal controllers for MRMs should be possessed of the properties that ensure the robustness of the robotic systems, and simultaneously take into account the optimal realization of the composite of error performance and output power.
Adaptive dynamic programming methodology is considered as one of the key directions to address the optimal control problems in complex systems. Some investigations reported the latest research progress of ADP-based optimal control methods for robot manipulators systems [4,5,6]. These strategies both follow the premise that the dynamic models of the robotic systems are completely unknown, thus the application of these methods are limited to address the optimal control problems of specific classes of robotic systems without implementing dynamic compensation. Dong et al. address the optimal control problems of MRMs by combining the model-based compensation control with ADP-based learning control [7], and their researches are further expanded to deal with the optimal tracking control issues of MRMs with uncertain environments [8]. However, the existing methods consider the disturbance torques, which are introduced by environmental contacts, as a class of dynamic uncertainties, and ignoring the intractability of decomposing the effects of model uncertainties and environmental contact disturbance targetedly. Indeed, there is less discussion on ADP-based robust optimal control for robot manipulators with both dynamic decomposition and optimal compensation, especially, for MRMs with uncertain environmental contact.
In this paper, a novel decentralized robust zero-sum neuro-optimal control method is presented for MRMs with uncertain environments. First, the dynamic model of the MRM systems is formulated via JTF technique, and a model-based compensation controller is designed by effectively utilizing the local dynamic information of each joint module. Second, a decentralized robust controller is proposed to deal with the compensation control issue of model uncertainties. Then, the robust optimal control problem of uncertain environment-contacted MRMs is transformed into a two-player zero-sum optimal control one. The ADP algorithm is employed to solve the HJI equation, in which the cost function, optimal control policy and worst disturbance can be approximated by constructing one critic NN and two action NNs, and then the decentralized robust zero-sum neuro-optimal control is developed. Finally, experiments are performed to verify the effectiveness of the proposed method.
2 Dynamic Model Formulation
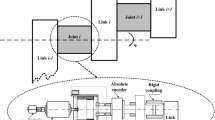
We consider the MRMs comprise n joint modules installed in series, and each integrated with a DC motor, a speed reducer, two encoders and a joint torque sensor. By referencing the modelling methods of JTF-based robot manipulators with multi-degree of freedom (DOF) [9, 10], we formulate the dynamic model of the MRM system as a synthesis of interconnected robotic joint subsystems, in which the ith joint subsystem dynamic model is represented as:
where the subscript “i” indicates the ith subsystem; \({{I}_{mi}}\) is the moment of inertia of actuator rotor about the rotation axis; \({{\gamma }_{i}}\) denotes the gear ratio; \({{q}_{i}},{{\dot{q}}_{i}}\) and \({{\ddot{q}}_{i}}\) are the joint angular position, velocity and acceleration respectively; \({{f}_{i}}\left( {{q}_{i}},{{{\dot{q}}}_{i}} \right) \) represents the joint lumped frictional torque; \({{z}_{i}}\left( {{q}_{i}},{{{\dot{q}}}_{i}},{{{\ddot{q}}}_{i}} \right) \) denotes the interconnected dynamic coupling (IDC) among the joint subsystems; \({{\tau }_{si}}\) represents the coupling torque at the torque sensor location; \({{d}_{i}}\left( {{q}_{i}} \right) \) is the disturbance torque and \({{\tau }_{i}}\) indicates the control torque.
(1) Joint friction
The friction term can be defined as a function with respect to joint angular position and velocity, which is given as:
where  indicates the parametric uncertainty of the friction; \({{f}_{bi}}\), \({{f}_{si}}\), \({{f}_{\tau i}}\) and \({{f}_{ci}}\) represent the ideal parameters of the friction model; \({{f}_{pi}}\left( {{q}_{i}},{{{\dot{q}}}_{i}} \right) \) denotes the position dependency of friction and the other friction modeling errors; \(\mathop {\mathrm {sgn}} \left( {\dot{q}} \right) \) is a classical sign function; \({{\hat{f}}_{bi}}\), \({{\hat{f}}_{si}}\), \({{\hat{f}}_{\tau i}}\) and \({{\hat{f}}_{ci}}\) are estimated parameters of the friction model and \(Y\left( {{{\dot{q}}}_{i}} \right) \) is defined as:
indicates the parametric uncertainty of the friction; \({{f}_{bi}}\), \({{f}_{si}}\), \({{f}_{\tau i}}\) and \({{f}_{ci}}\) represent the ideal parameters of the friction model; \({{f}_{pi}}\left( {{q}_{i}},{{{\dot{q}}}_{i}} \right) \) denotes the position dependency of friction and the other friction modeling errors; \(\mathop {\mathrm {sgn}} \left( {\dot{q}} \right) \) is a classical sign function; \({{\hat{f}}_{bi}}\), \({{\hat{f}}_{si}}\), \({{\hat{f}}_{\tau i}}\) and \({{\hat{f}}_{ci}}\) are estimated parameters of the friction model and \(Y\left( {{{\dot{q}}}_{i}} \right) \) is defined as:

(2) Interconnected dynamic coupling
The IDC term \({{z}_{i}}\left( {q},{{\dot{q}}},{{{\ddot{q}}}} \right) \), which is considered a complex nonlinear function, can be defined with respect to the positions, velocities and accelerations of the lower joint modules (from joint 1 to \(i-1\)), that is given as:
where \(D_{j}^{i}\) and \(\varTheta _{kj}^{i}\) are given as \(D_{j}^{i}=z_{mi}^{T}{{z}_{lj}}\) and \(\varTheta _{kj}^{i}=z_{mi}^{T}\left( {{z}_{lk}}\times {{z}_{lj}} \right) \) respectively, \({{z}_{mi}}\), \({{z}_{lj}}\) and \({{z}_{lk}}\) are the unity vectors along the axis of rotation of the ith robot, jth joint and kth joint respectively. Moreover, we have the relations \(\hat{D}_{j}^{i}=D_{j}^{i}-\tilde{D}_{j}^{i}\) and \(\hat{\varTheta }_{kj}^{i}=\varTheta _{kj}^{i}-\tilde{\varTheta }_{kj}^{i}\), where \(\tilde{D}_{j}^{i}\) and \(\tilde{\varTheta }_{kj}^{i}\) are the alignment errors.
(3) Joint torque and disturbance torque
The coupled joint torques \({{\tau }_{si}}\), which are measured by using the embedded torque sensors, can be represented as the following form:
where \({{\tau }_{sri}}\) indicates the joint torque that is obtained in free space and \({{\tau }_{sci}}\) denotes the torque produced by environmental contact in constrained space. Besides, the disturbance torque term \({{d}_{i}}\left( {{q}_{i}} \right) \) can be defined as:
where \({{d}_{is}}\left( {{q}_{i}} \right) \) represents the disturbance of torque sensor and \({{d}_{ic}}\left( {{q}_{i}} \right) \) indicates unmeasured environmental contact torque in joint space.
Assumption 1
The uncertainty term \({{\tilde{F}}_{i}}\) is bounded by \(\left| {{{\tilde{F}}}_{i}} \right| \le {{\rho }_{Fin}}\), the friction modeling error is bounded by \(\left| Y\left( {{{\dot{q}}}_{i}} \right) {{{\tilde{F}}}_{i}} \right| \le Y\left( {{{\dot{q}}}_{i}} \right) {{\rho }_{Fin}}\) and \({{f}_{pi}}\left( {{q}_{i}},{{{\dot{q}}}_{i}} \right) \) is bounded by \(\left| {{f}_{pi}}\left( {{q}_{i}},\!{{{\dot{q}}}_{i}} \right) \right| \!\le \! {{\rho }_{fpi}}\).
Assumption 2
The terms \({{U}_{zi}}\) and \({{V}_{zi}}\) are bounded by \(\left| {{U}_{zi}} \right| \le {{\rho }_{Ui}}, \left| {{V}_{zi}} \right| \le {{\rho }_{Vi}}\).
Assumption 3
The disturbance \({{d}_{is}}\left( {{q}_{i}} \right) \) is bounded by \(\left| {{d}_{is}}\left( {{q}_{i}} \right) \right| \le {{\rho }_{dsi}}\) and the unmeasured environmental contact torque \({{d}_{ic}}\left( {{q}_{i}} \right) \) is bounded by \(\left| {{d}_{ic}}\left( {{q}_{i}} \right) \right| \le {{\rho }_{dci}}\).
Then, define \({{B}_{i}}={{\left( {{I}_{mi}}{{\gamma }_{i}} \right) }^{-1}}\in {{R}^{+}}\) and the state vector \({{x}_{i}}={{\left[ \begin{matrix} {{x}_{i1}} &{} {{x}_{i2}} \\ \end{matrix} \right] }^{T}}={{\left[ \begin{matrix} {{q}_{i}} &{} {{{\dot{q}}}_{i}} \\ \end{matrix} \right] }^{T}}\in {{R}^{2\times 1}}\) and the control input \({{u}_{i}}={{\tau }_{i}}\in {{R}^{1\times 1}},i=1,2,\ldots n\), the state space of ith subsystem can be formulated as
where \({{\phi }_{i}}\left( {{x}_{i}} \right) \), \({{\upsilon }_{i}}\left( x \right) \) and \({{p}_{i}}\left( {{x}_{i}} \right) \) are represented as follows:
Next, a decentralized robust zero-sum optimal control method is presented for MRMs to ensure that both position and velocity of the closed-loop robotic systems are asymptotically stable.
3 Decentralized Robust Zero-Sum Neuro-Optimal Control Based on ADP
Consider the MRM systems with the dynamic model formulation (1) and the state space description (7), if the contact disturbance \({{p}_{i}}\left( {{x}_{i}} \right) \) is viewed as a system control input, the robust optimal control problem can be transformed into a two-player zero-sum optimal control issue, in which the continuously differentiable infinite horizon local cost function can be defined as follows:
where
is a filtered error function with the initial filtered error \({{s}_{i0}}\left( {{e}_{i}} \right) ={{s}_{i}}\left( 0 \right) \); \({{e}_{i}}={{x}_{i1}}-{{x}_{id}}\) and \({{\dot{e}}_{i}}={{x}_{i2}}-{{\dot{x}}_{id}}\) indicate the position and velocity tracking error of the ith joint module respectively; \({{x}_{id}}\), \({{\dot{x}}_{id}}\) and \({{\ddot{x}}_{id}}\) represent the desired angular position, velocity and acceleration that are known and bounded reference states. \(Q_{i}^{T}={{Q}_{i}}\), \(R_{i}^{T}={{R}_{i}}\) denote the positive constant matrixes; \({{\alpha }_{ei}}\) and \({{\gamma }_{pi}}\) are determined positive constants.
According to (9), one can define the local Hamiltonian as:
where \(\nabla {{J}_{i}}\left( {{s}_{i}} \right) =\left( {\partial {{J}_{i}}\left( {{s}_{i}} \right) }/{\partial {{s}_{i}}} \right) \) denotes the partial derivative of \({{J}_{i}}\left( {{s}_{i}} \right) \) with regard of \({{s}_{i}}\). Define the utility function as
Then, one obtain that the optimal local cost function \(J_{i}^{*}\) satisfies:
According to (11) and (13), the local optimal control pair (\(u_{i}^{*},p_{i}^{*}\)) satisfies the following HJI equation:
On the basis of the principle of optimality, the local optimal control pair (\(u_{i}^{*},p_{i}^{*}\)) can be represented as follows:
Rewriting the optimal control law \(u_{i}^{*}\) of the ith subsystem as:
to deal with modeled dynamic term \({{\phi }_{i}}\), model uncertainty term \({{\upsilon }_{i}}\) and contact disturbance term \({{p}_{i}}\) respectively, then, the HJI equation can be modified as:
Therefore, the zero-sum optimal control problem has been transformed into the one of obtaining the decentralized control laws \({{u}_{i1}}\), \({{u}_{i2}}\) and \(u_{i3}^{*}\) respectively, and therefore, to realize the optimal compensation of model uncertainty and environmental contact disturbance of the MRM system.
First, we can design control law \({{u}_{i1}}\), that is given as:
Second, we consider that the MRM systems, which work in free space, is possessed of accurate joint torque sensing. Thus, substituting (18) into (17), one obtains:
Note that we have \(p_{i}^{*}=u_{i3}^{*}=0\) when the MRM system works in free space, therefore, combining the time derivative of (10) and the model-based compensation control (18), one obtains
Here, we introduce the decentralized robust control \({{u}_{i2}}\) to compensate the effects of model uncertainties. For the unmodeled friction in (2), we decomposed \({{\tilde{F}}_{i}}\) as the summation of constant part and variable part, which is given as:
where \({{\tilde{F}}_{ic}}\) indicates an unknown constant vector and \({{\tilde{F}}_{iv}}\) denotes an unknown variable vector that is bounded as:
in which \({{\rho }_{Fivn}}={{[\begin{matrix} {{\rho }_{Fiv1}} &{} {{\rho }_{Fiv2}} &{} {{\rho }_{Fiv3}} &{} {{\rho }_{Fiv4}} \\ \end{matrix}]}^{T}}\) is a determined constant vector. Then, one can design the robust control law \({{u}_{i2f}}\), which is given as:
where \({{u}_{i2fu}}\) is designed to compensate friction term \({{f}_{pi}}\left( {{x}_{i1}},{{x}_{i2}} \right) \); \({{u}_{i2fc}}\), \({{u}_{i2fv}}\) are used to compensate the effect of uncertainties \({{\tilde{F}}_{ic}}\) and \({{\tilde{F}}_{iv}}\) respectively:
where \({{\varepsilon }_{ifu}}\), \({{\varepsilon }_{ifc}}\) and \({{\varepsilon }_{ifvn}}\) are determined positive parameters. Moreover, we decomposed the terms of \({{U}_{zi}}\) and \({{V}_{zi}}\) as:
where \({{U}_{zic}}\) and \({{V}_{zic}}\) are with known up-bounds; \({{U}_{ziv}}\) and \({{V}_{ziv}}\) are bounded as:
where \({{\rho }_{Uiv}}\) and \({{\rho }_{Viv}}\) are constant up-bounds to be determined.
Then, by adopting the decomposition-based analysis of the uncertainties, we can design the robust control law \({{u}_{i2h}}\), which is formulated as:
where \({{u}_{i2hU}}\) is used to compensate the effect of the term \({{U}_{zi}}\), that is given as:
where \({{\varepsilon }_{iUs}}\) and \({{\varepsilon }_{iUB}}\) are positive parameters to be determined. Moreover, one can design the control law \({{u}_{i2hV}}\) to compensate the effect of the term \({{V}_{zi}}\):
where \({{\varepsilon }_{iVs}}\) and \({{\varepsilon }_{iVB}}\) are positive parameters to be determined. Then, by combining (23) with (29), one obtain the decentralized control law \({{u}_{i2}}\), which is given as follows:
Then, we introduce the critic NN, u-action NN and p-action NN to approximate the performance index function \({{J}_{i}}\left( {{s}_{i}} \right) \), the optimal control law \(u_{i3}^{*}\) and the worst contact disturbance \(p_{i}^{*}\) respectively.
By employing RBF NNs, the ideal critic NN is represented as:
where \({{w}_{ci}}\) is the unknown ideal NN weight, \({{\varepsilon }_{ci}}\) represent the finite approximation error of the critic NN, \({{\sigma }_{ci}}\left( {{s}_{i}} \right) \) indicates a standard activation function. Besides, the gradient of the approximated cost function is given as:
where \(\nabla {{\sigma }_{ci}}\left( {{s}_{i}} \right) ={\partial {{\sigma }_{ci}}\left( {{s}_{i}} \right) }/{\partial {{s}_{i}}}\;\) indicates the gradients of the activation function and \(\nabla {{\varepsilon }_{ci}}\) is the gradient error. Then, one can rewrite the Hamiltonian and obtain the following relation:
where \({{e}_{cHi}}\) denotes the approximation error of the critic NN:
Let \({{\hat{w}}_{ci}}\) be the estimated weight vector of \({{w}_{ci}}\), therefore, one obtains:
Then, one can define the approximate Hamilton function as:
Define the weight approximation error \({{\tilde{w}}_{ci}}={{w}_{ci}}-{{\hat{w}}_{ci}}\), then, one obtains:
Define the residual error function \({{E}_{ci}}=\frac{1}{2}e_{ci}^{2}\), which is minimized to adjust the weight vector of the critic NN, that is updated by
where \({{\alpha }_{ci}}>0\) is the learning rate of the critic NN, and \({{p}_{ci}}\text {=}\nabla {{\sigma }_{ci}}\left( {{s}_{i}} \right) {{\dot{s}}_{i}}\).
Then, we employ the action NNs to approximate \(u_{i3}^{*}\) and \(p_{i}^{*}\) respectively. The ideal u- and p-action NNs are given as follows:
where \({{w}_{ai}}\), \({{w}_{pi}}\) represent the ideal weight vectors, \({{\sigma }_{ai}}\), \({{\sigma }_{pi}}\) denote the activation functions and \({{\varepsilon }_{ai}}\), \({{\varepsilon }_{pi}}\) are the finite approximation errors of u- and p-action respectively. Let \({{\hat{w}}_{ai}}\) and \({{\hat{w}}_{pi}}\) be the estimation weight vectors of \({{w}_{ai}}\) and \({{w}_{pi}}\), then we have:
Since \(\left( {\partial {{{\hat{H}}}_{i}}\left( {{s}_{i}},{{{\hat{u}}}_{i}},{{{\hat{p}}}_{i}},{{{\hat{w}}}_{ci}} \right) }/{\partial {{{\hat{u}}}_{i}}}\; \right) =0\) and \(\left( {\partial {{{\hat{H}}}_{i}}\left( {{s}_{i}},{{{\hat{u}}}_{i}},{{{\hat{p}}}_{i}},{{{\hat{w}}}_{ci}} \right) }/{\partial {{{\hat{p}}}_{i}}}\; \right) =0\), so that \({{\hat{u}}_{i3}}\) and \({{\hat{p}}_{i}}\) can be further described as follows:
where the update laws for u- and p-action NN weights are given as:
where \({{\alpha }_{ai}}\) and \({{\alpha }_{pi}}\) are the positive learning rates of u- and p-action NNs.
Then, by combining (18), (32) with (43), the proposed decentralized robust zero-sum neuro-optimal control law \(u_{i}^{*}\) is given as:
Theorem 1
Consider an n-DOF modular robot manipulator, with the dynamic model of the ith joint subsystem formulated in (1); the model uncertainties existed in (2), (4) and the environmental contact disturbance given in (6). The closed-loop robotic system is asymptotically stable under the decentralized robust zero-sum neuro-optimal control law proposed by (46).
Proof
A Lyapunov function candidate is selected as:
where \({{\delta }_{si}}>0\) and \({{\delta }_{pi}}\ge {{\delta }_{\varOmega i}}>0\) are determined positive definite constants. Then, one obtains the time derivative of (47) that is given as:
Therefore, we know that \({{\dot{V}}_{g}}\left( t \right) \le 0\) when the following condition holds:
Besides, from (48), one obtains that if (49) is satisfied, then \({{\dot{V}}_{g}}\left( t \right) <0\) for any \({{s}_{i}}\ne 0\). Therefore, by the Lyapunov theory, the closed-loop robotic system is asymptotically stable under the proposed decentralized robust zero-sum neuro-optimal control (46). This completes the proof of the Theorem 1.
4 Experimental Results
In this section, the experimental results are presented based on the experimental platform as illustrated in [8], and the experimental results are collected to verify the effectiveness of the proposed control method. We consider the environmental contact as a kind of instantaneous collision between the MRM link and the collision object that may create instantaneous contact forces.

Error curves under the collision contact, (a) position errors, (b) velocity errors.

Control torque and weight adjustment curves, (a) control torque, (b) weight adjustment.
The parameter definition is represented as follows: The critic NN is chosen as 2-5-1 with 2 input neurons, 5 hidden neurons and 1 output neuron, and the weight vectors are selected as  for joint 1 and
for joint 1 and  for joint 2, with the initial values \({{\hat{w}}_{c1}}={{\hat{w}}_{c2}}=\left[ 0 \right] \). The NN structures and initial weight values of the and action NNs are selected as the same of the critic NNs. The other model parameters, uncertainty up-bound parameters and control parameters are given in Table 1.
for joint 2, with the initial values \({{\hat{w}}_{c1}}={{\hat{w}}_{c2}}=\left[ 0 \right] \). The NN structures and initial weight values of the and action NNs are selected as the same of the critic NNs. The other model parameters, uncertainty up-bound parameters and control parameters are given in Table 1.
Figure 1 illustrate the position and velocity error curves under the situation of instantaneous collision contact. In this figure, obvious position and velocity deviations are captured, which are due to the effect of collision force. Moreover, we also observe that the error values decreased to normal ranges with very short time periods, which may attribute to the performance of the proposed zero-sum neuro-optimal controller that realized the optimal compensation of unknown contact disturbance.
Figure 2(a) illustrate the control torque curves under the situation of instantaneous collision contact. From this figure, the reliable control torque outputs are obtained, in which the instant increase of control torques keep in safe limits. This is attribute the contribution of the proposed optimal control that realizes the optimization of tracking errors and output torques.
Figure 2(b) illustrate the variations of the estimated critic NN weights under the proposed method. From this figure, one obtain that the critic NN weights may converge in certain ranges for each isolated joint subsystem. With the critic NN weight estimations, the HJI equation and the optimal control law can be solved and derived respectively.
5 Conclusion
In this paper, we develop a decentralized robust zero-sum neuro-optimal control scheme for MRMs. Based on local dynamic information of each joint module and the JTF technique, a model-based compensation controller and an uncertainty decomposition-based robust controller are designed for controlling MRM systems. Based on ADP algorithm, the HJI equation is solved by constructing the action-critic NNs, and then the decentralized robust zero-sum neuro-optimal control is developed. Finally, experimental results are illustrated to verify the effectiveness and advantages of the proposed method.
References
Albu-Schaffer, A., Ott, C., Hirzinger, G.: A unified passivity-based control framework for position, torque, and impedance control of flexible joint robots. Int. J. Robot. Res. 26(1), 23–39 (2007)
Liu, G., Liu, Y., Goldenberg, A.A.: Design, analysis, and control of a spring-assisted modular and reconfigurable robot. IEEE/ASME Trans. Mech. 16(4), 695–706 (2011)
Lee, H., Kim, S., Chang, H., Kim, J.: Development of a compact optical torque sensor with decoupling axial-interference effects for pHRI. Mechatronics 52, 90–101 (2018)
He, W., Dong, Y.: Adaptive fuzzy neural network control for a constrained robot using impedance learning. IEEE Trans. Neural Netw. Learn. Syst. 29(4), 1174–1186 (2018)
Roveda, L., Pallucca, G., Pedrocchi, N., Braghin, F., Tosatti, L.M.: Iterative learning procedure with reinforcement for high-accuracy force tracking in robotized tasks. IEEE Trans. Ind. Electron. 14(4), 1753–1763 (2018)
Leottau, D., Ruiz-del-Solar, J., Babuska, R.: Decentralized reinforcement learning of robot behaviors. Artif. Intell. 256, 130–159 (2018)
Dong, B., Zhou, F., Liu, K., Li, Y.: Decentralized robust optimal control for modular robot manipulators via criticidentifier structure-based adaptive dynamic programming. Neural Comput. Appl. (2018). https://doi.org/10.1007/s00521-018-3714-8
Dong, B., Zhou, F., Liu, K., Li, Y.: Torque sensorless decentralized neuro-optimal control for modular and reconfigurable robots with uncertain environments. Neurocomputing 282, 60–73 (2018)
Imura, J., Yokokohji, Y., Yoshikawa, T., Sugie, T.: Robust control of robot manipulators based on joint torque sensor information. Int. J. Robot. Res. 13(5), 434–442 (1994)
Dong, B., Liu, K., Li, Y.: Decentralized control of harmonic drive based modular robot manipulator using only position measurements: theory and experimental verification. J. Intell. Robot. Syst. 88, 3–18 (2017)
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grant nos. 61374051, 61773075 and 61703055) and the Scientific Technological Development Plan Project in Jilin Province of China (Grant nos. 20170204067GX, 20160520013JH and 20160414033GH).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Dong, B. et al. (2019). Decentralized Robust Optimal Control for Modular Robot Manipulators Based on Zero-Sum Game with ADP. In: Lu, H., Tang, H., Wang, Z. (eds) Advances in Neural Networks – ISNN 2019. ISNN 2019. Lecture Notes in Computer Science(), vol 11555. Springer, Cham. https://doi.org/10.1007/978-3-030-22808-8_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-22808-8_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-22807-1
Online ISBN: 978-3-030-22808-8
eBook Packages: Computer ScienceComputer Science (R0)