
Abstract
Digital elevation model (DEM) is a critical data source for variety of applications such as road extraction, hydrological modeling, flood mapping, and many geospatial studies. The usage of high-resolution DEMs as inputs in many application areas improves the overall reliability and accuracy of the raw dataset. The goal of this study is to develop a machine learning model that increases the spatial resolution of DEM without additional information. In this paper, a GAN based model (D-SRGAN), inspired by single image super-resolution methods, is developed and evaluated to increase the resolution of DEMs. The experiment results show that D-SRGAN produces promising results while constructing 3 feet high-resolution DEMs from 50 feet low-resolution DEMs. It outperforms common statistical interpolation methods and neural network algorithms.This study shows that it is possible to use the power of artificial neural networks to increase the resolution of the DEMs. The study also demonstrates that approaches from single image super-resolution can be applied for DEM super-resolution.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Digital elevation models (DEMs) are visualization of terrain’s surface powered by elevation data. Over the years, DEMs have served as input in many research studies including stream network extraction [1], flood risk and hazard mapping [2], and extracting urban features [3]. Due to a variety of application areas, the generation of DEMs has been studied in many fields with different techniques including LiDAR [4]. LiDAR is an optical remote-sensing technique that measures the distance between sensor and object, and reflected energy from the object. LiDAR data have been used as the primary source of high-resolution and accurate DEMs. Despite wide usage of LiDAR data, DEMs still contain issues and systematic errors [5, 6]. The process of generating DEM consists of numerous steps including data collection, data reduction, interpolation, and etc. Each of these steps contains some level of uncertainties and accumulation of these uncertainties has a plausible effect in revealing the desired quality level of DEM [7, 8]. The resolution and accuracy of DEM have a significant effect on the outcome of these analyses.
The resolution of DEM refers to the dimensions of the land that has been covered by a single grid cell. For example, if the resolution of a DEM is 3 m, each grid cell in the DEM stores the elevation data for 3 m × 3 m area of land, and DEM resolution is very crucial for many applications. It is shown that the resolution and information content of DEM has a massive impact on the computed topographic indices [9]. Chaubey et al. [10] examined the effect of DEM resolution on the predictions from the SWAT (Soil and Water Assessment Tool) model and they found a clear link between DEM resolution and accuracy of predicted stream network and sub-basin classification in the SWAT model. Similarly, several studies demonstrated that using high-resolution DEMs as inputs construct more accurate flood maps compared to low-resolution DEMs [11, 12]. However, it should be noted that not all tasks require high-resolution DEMs to get better performance or solve the current problem according to some studies. For example, Zang and Montgomery [13] simulated geomorphic and hydrologic processes for two watersheds using 2–90 m DEMs and according to their results, 10 m DEMs provide substantial improvement over 30 or 90 m DEMs but 2–4 m DEMs provide only small improvements for the task. Claessens et al. [14] used four different DEMs resolutions [10, 25, 50 and 100 m] to analyze the effect of DEM resolution on determining the slope and catchment area of a region as well as the relative hazard for shallow land sliding. They claimed that there may not be “perfect” DEM resolution for shallow land sliding over a longer timeframe due to various failures in time and space. So, it should be highlighted that using higher resolution DEMs may not be applicable or optimal for some study areas.
Water resource management and hydrological modeling using physically based or data-driven (i.e. artificial neural networks) approaches [15,16,17] need high-resolution DEM for accurate hydrological predictions [18]. Besides advanced hydrological modeling, monitoring and geographic analysis such as watershed delineation [19, 20] and stage height measurements [21] benefit from DEMs. In some cases, it is not feasible to use high-resolution DEM due to the limitation of computing systems or model run time. Even in such cases, resampling high-resolution DEM to lower one gives a better result than the original coarse resolution DEM. Despite the importance of high-resolution DEM, many areas in the United States and the world do not have access to high-resolution DEMs due to technological limitations or the cost of the data collection process [22]. As an alternative, enhancing the resolution (super-resolution) of the existing datasets can be seen as the optimal approach to fill the gap. Super-resolution is a widely studied topic in computer vision in which aims to generate high-resolution images with the help of one or multiple low-resolution images. DEM, denoted by a matrix, is highly similar to images in terms of denotation. DEM could be considered as an image in super-resolution application, since its planer coordinates and height values can be seen as the pixel position and corresponding color values, respectively [23].
With recent developments in graphical processing units (GPU) and novel algorithms, deep learning techniques have become attractive to researchers in geoscience and hydrology domain [24] for their performance in learning features in different fields including super-resolution. Convolutional neural networks (CNNs), a deep neural network algorithm, based single-image super-resolution (SRCNN) demonstrated the effectiveness of CNNs in image enhancement [25]. Taking advantage of the similarity between DEM datasets and images, D-SRCNN is developed in this study to increase the resolution of DEMs with similar approaches in SRCNN [26]. Alongside the success of CNN, new deep neural network algorithms like generative adversarial networks (GANs) have been started to gain attention in super-resolution literature. GANs are the special types of structures that consists with opposing two neural networks working simultaneously to beat each other. SRGAN, one of the early successful examples of GANs in super-resolution, has achieved to increase the resolution of an image up to four times upscaling factor with high performance [27].
In this paper, the performance of GANs is explored to develop a deep neural network model, D-SRGAN, that aims to convert provided low-resolution DEMs into high-resolution ones without additional information. More specifically, the model is designed to increase the resolution of 50 feet DEMs to 3 feet DEMs and it is trained and tested with the data collected from Wake and Guilford counties in North Carolina via North Carolina Floodplain Mapping Program*.Footnote 1 The performance of D-SRGAN is compared with traditional interpolation methods such as bicubic and bilinear as well as the two neural networks [26, 28] to understand the effectiveness of the approach.
Main contributions of this paper are: (a) proposing a new generative adversarial network (D-SRGAN) based approach for increasing the resolution of 50-feet DEMs to the resolution of 3-feet DEMs, (b) showing that techniques used in the single image super-resolution can be used for DEM super-resolution as well as a result of the similarity between DEM and image data.
The paper is organized as follows: Sect. “Related Work” reviews the relevant research in image super-resolution and DEM super-resolution. Section 3 gives details about our network design and the general concept. Also, experimental data are provided in Sect. 3. Section 4 covers the detailed results of the proposed method and related discussion. The paper finalized with conclusions and possible future research paths.
Related Work
Super-resolution is a process of producing a high-resolution image from one or more low-resolution images and it is one of the active fields in computer science. Super-resolution can be classified into two groups: multi-frame super-resolution and single image super-resolution (SISR) [29, 30]. Multi frame super-resolution combines information from different low- resolution images to produce a higher resolution image by employing various techniques such as iterative back projection or probabilistic approaches [31,32,33]. Since our concept focuses on single image super-resolution, we will not provide further information about multi-frame super-resolution. Over the years, various approaches have been proposed on SISR. Interpolation-based methods such as linear, bicubic or Lanczos have been applied with the power of predefined mathematical formulation without the training phase. Despite the performance of these methods, they underperform at high- frequency regions due to the tendency of smoothness [30, 34]. Reconstruction-based methods take advantage of prior knowledge to generate high-resolution images. Various approaches have been used in reconstruction-based methods such as steering kernel regression (SKR) [35] or non-local means (NLMs) [36]. Alongside the success of preserving edges and suppressing artifacts, reconstruction-based methods are not successful in producing super-resolution images at large magnification factors [37, 38]. Learning or example-based methods aim to gather insight information from paired low and high-resolution images to understand missing details in low-resolution images. Numerous approaches have been proposed as learning or example-based methods such as neighbor embedding [39], sparse coding [40] and regression methods [41, 42]. One of the crucial elements for these methods is the training set. Quality of the training set can lead to capture redundant or erroneous features and reduce the effectiveness of the methods dramatically [29, 30, 38].
Despite the fact that the root of convolutional neural networks goes back [43, 44], CNNs are starting to reach its true potential with the help of recent developments on modern GPUs (graphic processing units). Several novel approaches have been used in different tasks such as image classification [45], face recognition [46], and super-resolution [47]. In the literature regarding SISR, Dong et al. [25] have proposed a method namely super-resolution convolutional neural network (SRCNN) to learn a mapping end to end between the low and high-resolution images. The method starts with bicubic interpolation of low-resolution image followed by overlapping patch extraction and representation as high-dimensional vector, then non-linearly maps the high- dimensional vector to another high-dimensional vector, finally it reconstructs the high-resolution image from these vectors. Fast Super-Resolution Convolutional Neural Network (FSR- CNN) has been developed by Dong et al. [47] to increase speed of current SRCNN. In the FSRCNN, deconvolutional layer has been chosen over bicubic interpolation and single mapping layer replaced with four mapping layers and an expanding layer. Kim et al. [48] constructed a network powered by 20 convolutional layers with a high learning rate and the result of that network is considerably better in comparison to the methods at that time. Deep-recursive convolutional network (DRCN) [49] is powered by deep recursive layers. Accuracy of the model can be increased with more iteration and it does not require introducing new parameters for additional convolutional layers. DRCN proposed two methods to enhance learning procedure, namely supervision of recursions and skip- connection. Shi et al. [50] introduced the first convolutional neural network (CNN) capable of real-time SR of 1080p videos on a single K2 GPU. The network consists of L layers. First L-1 layers, feature maps are extracted at low-resolution (LR) space. The final layer, sub-pixel convolutional layer, upscales LR feature maps to high-resolution (HR) output. The study demonstrated that working on the LR space dramatically reduces computational and memory-wise complexity. Lim et al. [51] developed a deep neural network with removing the batch normalization layers and all activation layer outside the residual block in SRResNet [27] and won NTIRE2017 Super-Resolution Challenge. Zhang et al. [52] proposed to use residual dense block (RDB) to extract abundant local features via dense convolutional layers. It performs the skip connections for ahead of each block.
Alongside CNNs, new promising approaches have been explored in super-resolution applications such as generative adversarial networks (GAN). GANs can be considered as a framework that consists of two neural networks designed to defeat each other in a zero-sum game [53]. After it was proposed, numerous variations of GANs have been tested for various tasks such as image to image translation [54] or image editing [55]. SRGAN (super-resolution generative adversarial network) is one of the first implementation of GAN designed to achieve SISR. The generator of SRGAN starts with taking the power of deep residual blocks with skip-connections. At the end of the network, the resolution of the image is increased with two sub-pixel convolutional layers. SRGAN uses perceptual loss that consists of adversarial and content losses. Instead of using pixel-wise MSE (mean square error), the content loss is calculated from feature maps of VGG network (pretrained network by Oxford’s Visual Geometry Group) [27]. The design of ProGanSR has been influenced by curriculum learning, which proposes the direction of learning should be from small upscaling factors to large upscaling factors. ProGanSR uses the asymmetric pyramids structure to obtain efficiency. Each pyramid consists of Dense Compression Units followed by sub-pixel convolution layers to increase the resolution of input by two times [56]. Mahapatra et al. proposed local saliency maps, which define the importance of each pixel, to use in the GAN loss function over classical MSE [57]. Wang et al. [58] propose the ESRGAN which removes the batch normalization layers from the SRGAN and uses the residual-in-residual dense block (RRDB) instead of regular residual blocks in SRGAN in order to improve efficiency.
The literature on single DEM super-resolution, Xu et al. proposed a non-local algorithm that searches similar patches over the training set with a predefined equation, then increases the resolution of target DEM with weights calculated through the searching phase [23]. D-SRCNN is a CNN based method that aims to increase the resolution of given DEM with similar architecture in SRCNN and it performs better than the non-local based method [26]. Alongside D-SRCNN, Xu et al. [28] also proposed a CNN based model that is broadly derived from EDSR (enhanced deep super-resolution network) [51]. The network is pre-trained with natural images in order to obtain high-resolution gradient maps which will be fine-tuned with high-resolution DEMs in the next process. In addition to deep learning methods, traditional interpolation approaches such as bicubic, kriging, inverse distance weighting can be used for single DEM super-resolution. Nevertheless, these statistical models tend to produce more smooth terrains [59]. Also, it is possible to use additional data in order to increase the resolution of DEMs. Argudo et al. [59] proposes a fully convolutional neural network that accepts the low-resolution DEM and its high-resolution orthophoto to produce the high-resolution of DEM. Yu et al. [60] introduces a regularized framework that enables the combining of multiple data for corresponding DEM to reconstruct a higher resolution DEM. Despite the importance of DEM, the research on single DEM super-resolution is still limited. Recent methods in image super-resolution can be applied to DEM image enhancements with the help of the similarity between DEM and image data.
Methods
Generative adversarial networks (GANs) have been used by many researchers from various fields since they were first proposed by Ian Goodfellow et al. [53]. GANs consist of two adversarial components, namely generator and discriminator, which aim to compete in a minimax game. Generator aims to capture data distribution and produce realistic samples to convince discriminator as fabricated ones are real. On the other hand, discriminator intents to determine the source of incoming samples. The cost of each network is directly related to the success of the opposing component, and the general process can be expressed by the following formulation (Eq. 1) where discriminator and generator try to beat one another with value function V(G, D).
where \(D\left( x \right)\) is the discriminator's estimate of the probability that real data instance x is real, \(G\left( z \right)\) is the generator's output when given noise z, \(D\left( {G\left( z \right)} \right)\) is the discriminator's estimate of the probability that a fake instance is real, \(E_{x} -\) the expected value over all real data instances, \(E_{z}\) is the expected value over all random inputs to the generator.
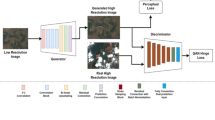
In our study, the goal is generating a high-resolution DEM from a low-resolution DEM. The low-resolution DEMs are accepted by the generator in order to produce high-resolution DEMs. Discriminator of the network takes fabricated or real high-resolution DEM as input and guesses the origin of input. There are two different losses in the system to regulate weights of the networks, content and adversarial, namely. The discriminator is only affected by the adversarial loss during the training phase. On the other hand, content loss of fabricated high-resolution DEMs is used in the manipulation of the generative network’s weights alongside the adversarial loss. The general structure of the GAN training process is represented in Fig. 1.

General structure of the GAN training process
As can be seen in Fig. 1, generator takes low-resolution DEMs and converts to high-resolution DEMs. The discriminator compares the generated and real high-resolution DEMs to predict whether they are real or fake. The adversarial loss is calculated based on the success of the discriminator and weights of the both discriminator and generator are updated. At the same time, the content loss is calculated according to pixel-wise difference between the generated and real high-resolution DEMs to feedback the generator.
Network Architectures
Our network design consists of two opposing components (i.e. generator, discriminator). The architecture of components is based on the SRGAN [27] and EDSR models [51]. The generator of our network takes the low-resolution DEMs as input and passes it to a convolution layer with 64 feature maps, then passes it to residual blocks. The generator has twenty residual blocks with duplicated design. Each residual block is created with two convolutional layers with 3 × 3 kernel and 64 feature maps. Between the two convolutional layers, ReLU [61] is used as an activation layer. Inside each residual block, there is a connection (skip connections) between incoming data from the predecessor component and the last phase of the current residual block which aims to gather low-level features in order to improve the performance of the generator [49, 62]. A similar link between input data and the output of the final residual block is also established. The next components of the generator are two upsampling blocks which are used to increase the resolution. Upsampling blocks are obtained with a convolutional layer with 256 feature maps followed by sub-pixel convolutional layers [50]. In the end, the output of the upsampling blocks is passed to a convolutional layer prior to getting out the generator. The visual representation of the generator is provided in Fig. 2.

Architecture of generator component
The discriminator of the network has nine convolutional layers with 3 × 3 filter kernels and increment in feature maps from 64 to 512 by a factor of two. Each convolutional layer is followed by Leaky RELU as an activation function with alpha is equal to 0.2. Strided convolutional layers are used to reduce the resolution of DEM while the number of features is doubling. In the last convolutional layer, there is an additional adaptive average pooling layer prior to dense layers. The outcome of the discriminator is produced with sigmoid function after the dense layers. The visual representation of the discriminator is provided in Fig. 3. In the Figs. 2 and 3, kernel size, feature map, and stride are denoted by k, n, and s respectively.

Architecture of discriminator component
Loss Functions
Under this section, we will review the loss functions applied in the neural networks. In the training phase, the adversarial loss is used by both discriminator and generator. In addition to adversarial loss, the generator is affected by content loss to converge fast and produce more accurate data points.
Adversarial Loss
Adversarial loss is an essential part of the GAN structure. In our design, it is the only element that is used by discriminator of the network as a loss function. The adversarial component is helping to enhance the discriminator while distinguishing the source of data as expected. In the training phase, mean absolute error, L1 Loss, is used as adversarial loss for both discriminator and generator. The formulation of adversarial loss for discriminator (Eq. 2) is provided below:
where \(y_{i} \;\) is the real high resolution DEMs, \(x_{i}\) low resolution DEMs,\(m\) total number of samples.
Adversarial loss is also used for the generator to create more realistic examples with aiming to fool the discriminator. Formulation of adversarial loss for generator (Eq. 3) calculated as follows:
where \(x_{i} \;{\text{is}}\;{\text{the}}\;{\text{low}}\;{\text{ resolution DEMs}}\), \(m\;{\text{is}}\;{\text{the}}\;{\text{total number of samples}}\).
Content Loss
Alongside adversarial loss, it is a common procedure to use a loss function to determine the difference between ground truth and fabricated data to capture the goodness of produced data and mean square error (MSE) is the widely used optimization value in various work [23, 26, 59]. It sounds reasonable to use MSE in order to understand the result of the ongoing process, since DEM contains the numerical value of earth surface elevations and MSE is used as a metric to understand the goodness of methods in the field.
where \(x_{i} \;{\text{is}}\;{\text{the}}\;{\text{generated high resolution DEMs}}\), \(y_{i} \;{\text{is}}\;{\text{the}}\;{\text{real high resolution DEMs}}\), \(m\;{\text{is}}\;{\text{the}}\;{\text{total number of samples}}{.}\).
Since the generator is affected by multiple loss functions, its loss function (Eq. 5) combination of content loss (Eq. 4) and adversarial loss (Eq. 3) and it is as follows:
where \(I_{{C_{Gen} }} - content loss of generator\), \(I_{{A_{Gen} }} - adversarial loss of generator\) ,\(\alpha - weight of adversarial loss\).
Data Processing
The dataset used in the experiment is collected from North Carolina Floodplain Mapping Program*.Footnote 2 It is a government program that allows the public to download different data types such as DEM for selected regions from North Carolina. The dataset covers a total area of 732 km2 from Wake and Guilford counties. As a training set, a total area of 590 km2 is used. The rest of the dataset, area of 142 km2, is accepted as a test set. Each of the used DEMs was collected at a spacing of approximately 2 points per square meter. In the experiment, 3 feet and 50 feet DEMs are used as high-resolution and low-resolution examples, respectively. The NC Program delivered each tile of high-resolution DEMs as 1600 × 1600 data points and the low-resolution DEMs as 100 × 100 data points. In the preprocessing phase, HR DEMs are split to 400 × 400 data points and LW DEMs are split to 25 × 25 data points. In addition to the fragmentation process, DEMs with missing values are discarded from the dataset prior to the experiment. The average, minimum and maximum elevation values in both datasets are pro›vided in Table 1. The distribution of elevation values is also provided for both datasets in Fig. 4. The network in our study is implemented with Pytorch framework.

Distribution of elevation data
Results and Discussions
The goal of our network is increasing the resolution of given DEM with 4 × upscaling factor. The generator is designed to take low-resolution DEMs (50 feet) with 25 × 25 cells as input and returns high-resolution DEMs (3 feet) with 400 × 400 cells as output. The discriminator of the network is accepting DEMs with 400 × 400 cells as input and guess the source of it whether generated by the generator or not. At the beginning of the training procedure, the Adam algorithm [63] is used as optimizer with learning rates 0.0001 for both discriminator and generator. The rest of the parameters are used with their default values in Pytorch implementation. The weight of the adversarial loss in the generator is set to the learning rate of the generator, and the weight changes with it. The learning rate of the generator is divided by two on 800th and 1600th epoch. Also, during the training procedure, discriminator is frozen as a favor to the generator time to time since its performance reaches almost the perfect level. Figure 5 showcases the visualization of fabricated HR DEM for different epochs with same input DEM.

Example outputs of generator during different training epochs
Based on the network, GAN based approach provides promising results. Since DEM contains the height value of the corresponding area, it is reasonable to use a metric that reflects quantitative measurements in order to understand the performance of the method. Also, it is common practice to use MSE to understand the effectiveness of proposed methods [23, 26, 59]. The result of GAN based model is compared with different methods to understand their effectiveness. From the classical methods, bicubic and bilinear interpolations are performed with the help of a well-known Python library scikit-image. Also, D-SRCNN [26] and DPGN [28] are two recent methods that aim to increase the resolution of DEMs with neural networks used to compare the results with our method. Both models use convolutional neural networks and ReLU as activation function similar to our model. D-SRGAN and DPGN use residual blocks and skip-connections to increase effectiveness. All networks use similar loss functions to find the content loss, but D-SRGAN includes the adversarial loss in its loss function. Table 2 shows mean squared errors of different methods on both training and test datasets for elevation data. According to the results, D-SRGAN outperform tested classical methods and D-SRCNN on both training and test datasets. As can be seen from the table, DPGN and D-SRGAN give the best results among the other methods in training and test sets, respectively. However, it should be noted that the average error between training and test sets are very close in D-SRGAN to respect other neural network methods. The error distribution of D-SRGAN is also provided in Fig. 6. The mean, median and standard deviation of error distribution in the testing dataset for D-SRGAN are 0.75, 0.64 and 0.50 m, respectively. The distribution of errors shows that most of the time D-SRGAN provides promising results with a limited number of outliers.

Error distribution of D-SRGAN on testing dataset
Figure 7 visualizes the example DEMs from the testing dataset which are generated with D-SRGAN, bicubic interpolation in order to show the strength and weaknesses of GAN based model. D-SRGAN is capable of regeneration of DEMs with 4 × higher resolution under the promising deviation. According to Fig. 6, %78 of all values fall within plus or minus one standard deviation from the mean which shows the stability of our model. As seen from the figure that D-SRGAN is struggling to capture finer details of DEMs. In image super-resolution, MSE based solutions have a tendency to miss high-frequency content and produce more smooth results in which similar effects can be found in GAN-based model [27]. However, D-SRGAN still outperforms other methods in similar conditions.

Example SR results from D-SRGAN and bicubic
Alongside the investigation of D-SRGAN performance on the dataset for generating 3 feet DEMs from 50 feet DEMs, its effectiveness on different resolution DEMs is also examined. For this purpose, four different DEMs are created from 3 and 50 feet DEMs. Two of these DEMs were created from 3 feet DEM to 100 and 25 feet DEMs and the other two were created from 50 feet DEM to 100 and 25 feet DEMs using bicubic interpolation to present an assessment on D-SRGAN performance with different DEM resolutions. In the new experiment, the model’s blocks are updated to be consistent with the input–output pairs. To speed up the training phase, some weights of D-SRGAN model trained for 50 to 3 feet DEMs are transferred to new models. According to experiment results, D-SRGAN outperforms two classical interpolation methods on generating 3 feet DEMs from 25 and 100 feet DEMs as it does in the previous experiment. Tables 3 and 4 shows the performance comparison of proposed model and other methods as MSE in meters. Since the data for 25 and 100 feet DEMs are interpolated, and the goal is to get an insight for D-SRGAN performance on different DEM resolutions, results are only compared with classical methods. Based on the overall results, it can be concluded that D-SRGAN can provide promising results for different DEM resolutions.
In addition to previous results, slope analysis provides valuable insights regarding the performance of methods in different terrains. The slope is a common parameter that is used in various applications in environmental sciences via DEMs [64, 65]. For each elevation value of a DEM, the slope is calculated with the average maximum technique proposed by Burrough et al. [66] based on a 3 × 3 cells around the value cell. As the slope value changes from lower to greater, the terrain goes from flatter to steeper. Figure 8 shows the slope imagery of the test set for generating 3 feet DEMs from 50 feet DEMs as well as the error distribution over slope values which are normalized into [0, 1]. As seen below, D-SRGAN performs better results on flatter terrain than steeper terrain.

The slope analysis of D-SRGAN on test set
Conclusions
In this study, a generative adversarial network, D-SRGAN, is proposed. GAN based model aims to convert low-resolution DEMs into high-resolution ones without needing additional information. The experiment outcomes show that GAN based model produces promising results while constructing 3 feet high-resolution DEMs from 50 feet low-resolution DEMs. Despite the overall success, the models could not perform evenly over the terrains. They produce more realistic examples in flatter terrains than stepper terrains. As a future work, this problem can be overcome by using different metrics in the training phase of the generator such as slope. In addition to using different losses, working on variational autoencoders (VAEs) [67] to find better architecture to minimize the slope errors between flatter and steeper terrains can be studied. Also, investigating the effects of the generated high-resolution DEMs in different tasks with comparing the results with real high-resolution DEMs is a potential open question.
References
Tarboton DG. A new method for the determination of flow directions and upslope areas in grid digital elevation models. Water Resour Res. 1997;33(2):309–19.
Li J, Wong DWS. Effects of DEM sources on hydrologic applications. Comput Environ Urban Syst. 2010;34.3:251–61.
Priestnall G, Jaafar J, Duncan A. Extracting urban features from LiDAR digital surface models. Comput Environ Urban Syst. 2000;24(2):65–78.
Florinsky I. Digital terrain analysis in soil science and geology. Cambridge: Academic Press; 2016.
Fisher PF, Tate NJ. Causes and consequences of error in digital elevation models. ProgPhysGeogr. 2006;30(4):467–89.
Liu X. Airborne LiDAR for DEM generation: some critical issues. ProgPhysGeogr. 2008;32(1):31–49.
Woodrow K, Lindsay JB, Berg AA. Evaluating DEM conditioning techniques, elevation source data, and grid resolution for field-scale hydrological parameter extraction. J Hydrol. 2016;540:1022–9.
Heritage GL, et al. Influence of survey strategy and interpolation model on DEM quality. Geomorphology. 2009;112.3-4:334–44.
Sørensen R, Seibert J. Effects of DEM resolution on the calculation of topographical indices: TWI and its components. J Hydrol. 2007;347(1–2):79–89.
Chaubey I, et al. Effect of DEM data resolution on SWAT output uncertainty. Hydrol Process Int J. 2005;19(3):621–8.
Sanders BF. Evaluation of on-line DEMs for flood inundation modeling. Adv Water Resour. 2007;30(8):1831–1843. https://doi.org/10.1016/j.advwatres.2007.02.005.
Li Z, Mount J, Demir I. Evaluation of model parameters of HAND model for real-time flood inundation mapping: iowa case study. EarthArXiv. 2020.
Zhang W, Montgomery DR. Digital elevation model grid size, landscape representation, and hydrologic simulations. Water Resour Res. 1994;30(4):1019–28.
Claessens L, et al. DEM resolution effects on shallow landslide hazard and soil redistribution modelling. Earth Surface Process Landf. 2005;30(4):461–77.
Sit M, Demir I. Decentralized flood forecasting using deep neural networks. 2019; arXiv preprint http://arxiv.org/abs/1902.02308.
Xiang Z, Yan J, Demir I. A rainfall‐runoff model with LSTM‐based sequence‐to‐sequence learning. Water Resour Res. 2019;56(1):e2019WR025326. https://doi.org/10.1029/2019WR025326.
Xiang Z, Demir I. Distributed long-term hourly streamflow predictions using deep learning–A case study for State of Iowa. Environ ModelSoftw. 2020;131:104761. https://doi.org/10.1016/j.envsoft.2020.104761.
Vaze J, Teng J, Spencer G. Impact of DEM accuracy and resolution on topographic indices. Environ ModelSoftw. 2010;25(10):1086–98.
Sit M, Sermet Y, Demir I. Optimized watershed delineation library for server-side and client-side web applications. Open Geospat Data, Softw Stand. 2019;4(1):8.
Demir I, Szczepanek R. Optimization of river network representation data models for web-based systems. Earth Space Sci. 2017;4(6):336–47.
Sermet Y, et al. Crowdsourced approaches for stage measurements at ungauged locations using smartphones. Hydrol Sci J. 2019;65(5):1–10. https://doi.org/10.1080/02626667.2019.1659508.
Saksena S, Merwade V. Incorporating the effect of DEM resolution and accuracy for improved flood inundation mapping. J Hydrol. 2015;530:180–94.
Xu Z, et al. Nonlocal similarity based DEM super resolution. ISPRS J Photogramm Remote Sens. 2015;110:48–54.
Sit, M, et al. A comprehensive review of deep learning applications in hydrology and water resources. Water Sci Technol. 2020.
Dong C, et al. Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell. 2016;382:295–307.
Chen, Z, Wang X, Xu Z. Convolutional neural network based DEM Super resolution. Int Arch Photogramm Remote Sens Spatial Inf Sci. 2016;41:247–250. https://doi.org/10.5194/isprs-archives-XLI-B3-247-2016.
Ledig C, et al. Photo-realistic single image super-resolution using a generative adversarial network. CVPR. 2017;2(3):105–114. https://doi.org/10.1109/CVPR.2017.19.
Xu Z, et al. Deep gradient prior network for DEM super-resolution: transfer learning from image to DEM. ISPRS J Photogramm Remote Sens. 2019;150:80–90.
Nasrollahi K, Moeslund TB. Super-resolution: a comprehensive survey. Mach Vis Appl. 2014;25.6:1423–68.
Bevilacqua M. Algorithms for super-resolution of images and videos based on learning methods. Diss. 2014.
Farsiu S, et al. Fast and robust multiframe super resolution. IEEE Trans Image Process. 2004;1310:1327–44.
Irani M, Peleg S. Improving resolution by image registration. CVGIP Graph Models Image Process. 1991;533:231–9.
Jung C, et al. Position-patch based face hallucination using convex optimization. IEEE Signal Process Lett. 2011;18.6:367–70.
Yang, C-Y, Ma C, Yang M-H. Single-image super-resolution: A benchmark. In: European Conference on computer vision. Springer, Cham, 2014.
Takeda H, Farsiu S, Milanfar P. Kernel regression for image processing and reconstruction. IEEE Trans Image Process. 2007;16(2):349–66.
Protter M, et al. Generalizing the nonlocal-means to super-resolution reconstruction. IEEE Trans Image Process. 2008;18(1):36–51.
Lin Z, Shum H-Y. Fundamental limits of reconstruction-based superresolution algorithms under local translation. IEEE Trans Pattern Anal Mach Intell. 2004;26(1):83–97.
Li Y, et al. Single image super-resolution reconstruction based on genetic algorithm and regularization prior model. Inform Sci. 2016;372:196–207.
Chang H, Yeung D-Y, Xiong Y. Super-resolution through neighbor embedding. Computer Vision and Pattern Recognition, 2004. In: CVPR 2004. Proceedings of the 2004 IEEE Computer Society Conference on. Vol. 1. IEEE, 2004.
Yang J, et al. Image super-resolution via sparse representation. IEEE Trans Image Process. 2010;19.11:2861–73.
Ni KS, Nguyen TQ. Image superresolution using support vector regression. IEEE Trans Image Process. 2007;16(6):1596–610.
Kim KI, Kwon Y. Single-image super-resolution using sparse regression and natural image prior. IEEE Trans Pattern Anal Mach Intell. 2010;6:1127–33.
Fukushima K. Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. BiolCybern. 1980;36(4):193–202.
LeCun, Y, et al. Object recognition with gradient-based learning. In: David AF, Joseph LM, Vito di Ges´u, Roberto Cipolla, editors. Shape, contour and grouping in computer vision. Berlin: Springer; 1999, p. 319–45. https://link-springer-com.proxy.lib.uiowa.edu/book/10.1007%2F3-540-46805-6#toc.
Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. In: Pereira F, Burges CJC, Bottou L, Weinberger KQ, editors. Advances in neural information processing systems. Curran Associates, Inc; 2012. p. 1097–1105. https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf.
Lawrence S, et al. Face recognition: a convolutional neural-network approach. IEEE Trans Neural Netw. 1997;8.1:98–113.
Dong C, Loy CC, Tang X. Accelerating the super-resolution convolutional neural network. In: European Conference on computer vision. Springer, Cham, 2016.
Kim J, Lee JK, Lee KM. Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on computer vision and pattern recognition. 2016.
Kim J, Lee JK, Lee KM. Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the IEEE Conference on computer vision and pattern recognition. 2016.
Shi, W, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
Lim B, et al. "nhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE Conference on computer vision and pattern recognition workshops. 2017.
Zhang Y, et al. "Residual dense network for image super-resolution. In: Proceedings of the IEEE Conference on computer vision and pattern recognition. 2018.
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial nets. In: Ghahramani Z, Welling M, Cortes C, Lawrence N, Weinberger KQ, editors. Advances in neural information processing systems. Curran Associates, Inc; 2014. p. 2672–2680. https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf.
Isola P, et al. Image-to-image translation with conditional adversarial networks. 2017; arXiv preprint.
Perarnau G, et al. Invertible conditional gans for image editing. 2016; arXiv preprint http://arxiv.org/abs/1611.06355.
Wang Y, et al. A fully progressive approach to single-image super-resolution. 2018; arXiv preprint http://arxiv.org/abs/1804.02900.
Mahapatra D. Retinal vasculature segmentation using local saliency maps and generative adversarial networks for image super resolution. 2017; arXiv preprint http://arxiv.org/abs/1710.04783
Wang X, et al. Esrgan: Enhanced super-resolution generative adversarial networks. In: Proceedings of the European Conference on Computer Vision (ECCV). 2018.
Argudo O, Chica A, Andujar C. Terrain super‐resolution through aerial imagery and fully convolutional networks. Comput Graphics Forum. 2018;37(2):101–110. https://doi.org/10.1111/cgf.13345.
Yue L, et al. "Fusion of multi-scale DEMs using a regularized super-resolution method. Int J GeographInfSci. 2015;29.12:2095–120.
Nair V, Hinton GE. "Rectified linear units improve restricted Boltzmann machines. In: ICML. 2010.
He K, et al. Identity mappings in deep residual networks. In: European Conference on computer vision. Springer, Cham, 2016.
Kingma DP, Ba J. Adam: A method for stochastic optimization. 2014; arXiv preprint http://arxiv.org/abs/1412.6980.
Tang J, Pilesjö P. Estimating slope from raster data: a test of eight different algorithms in flat, undulating and steep terrain. River Basin Manag. 2011;VI:143–154. https://doi.org/10.2495/RM110131.
Bolstad PV, Stowe T. An evaluation of DEM accuracy: elevation, slope, and aspect. PhotogrammEng Remote Sens. 1994;60(11):1327–32.
Burrough PA, et al. Principles of geographical information systems. Oxford: Oxford University Press; 2015.
Kingma DP, Welling W. Auto-encoding variational bayes. 2013. arXiv preprint http://arxiv.org/abs/1312.6114.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of Interest/Competing Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Demiray, B.Z., Sit, M. & Demir, I. D-SRGAN: DEM Super-Resolution with Generative Adversarial Networks. SN COMPUT. SCI. 2, 48 (2021). https://doi.org/10.1007/s42979-020-00442-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-020-00442-2