
Abstract
The present work presents hybrid machine learning paradigms built with nine widely used optimization algorithms in determining the compressive strength (CS) of ultrahigh performance concrete (UHPC). Nine hybrid artificial neural network (ANN) models were constructed using nine meta-heuristic algorithms such as Ant Lion Optimization (ALO), Grey Wolf Optimization (GWO),Slap Swarm Algorithm (SSA), Whale Optimization Algorithm (WOA), Dragonfly Algorithm (DA), Particle Swarm Optimization (PSO), Harish Hawk Optimization (HHO) Slime Mould Optimization (SMO), Gorilla Troops Optimization (GTO). A total number of 308 observations were acquired and modelled to estimate the CS of UHPC concrete produced with manufactured sand. The developed hybrid model of ANN and Gorilla Troop Optimization (i.e., ANN-GTO) achieved the most accurate prediction of the CS with R2 = 0.9629, VAF = 96.28, RMSE = 0.0518 in the model construction stage and R2 = 0.9578, VAF = 95.78, RMSE = 0.0540 in the testing phase. The outcomes of the sensitivity analysis show that the developed ANN-FF accurately captures the strength of the relationship between influential variables and the CS concrete. The assessment of results was investigated based on the Taylor diagram, accuracy matrix, and uncertainty analysis. Overall, the built ANN-GTO secured the first rank in terms of uncertainty analysis. According to the results, the built ANN-GTO can be a new option for assisting engineers in civil engineering projects.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The practical applications of concrete depend on its rheological, mechanical, and durability properties. Several factors that influence these properties, includes cementitious materials, chemical admixtures, aggregate type and grading, water-to-binder (w/b) ratio, fibres and other inclusions, curing conditions (temperature and relative humidity), etc. (Wang et al., 2015; Yoo & Banthia, 2016). The development of ultrahigh performance concrete (UHPC) aims to provide materials with high compressive strength, improved ductility and durability properties. Its mechanical properties are highly influenced by the mixture's ingredients and the curing conditions (Dingqiang et al., 2018; Yoo & Banthia, 2016). UHPC with extremely high compressive strength and a low w/b ratio is made using fine powders (quartz, silica fume, etc.), well-graded aggregates, and water-reducing admixtures of high range. These ingredients produce superior particle packing density and the lowest porosity whilst ensuring adequate flow and consolidation. The most practical method to considerably reduce emissions of greenhouse gases may involve the use of supplementary cementitious materials (SCMs).Industrial by-products like Fly Ash (FA), Silica Fume (SF) and Ground Granulated Blast Furnace Slag (GGBS) are cementitious and pozzolanic, making them a top choice amongst researchers as a potential substance to blend with cement in order to reduce carbon emissions. (Megat Johari et al., 2011; Nodehi & Mohamad Taghvaee, 2021).
UHPC is a composite made from SCMs containing cement, fine aggregate, superplasticizer, and a low water-to-cement material ratio (w/cm). According to some published research (Soliman & Tagnit-Hamou, 2016; Yang et al., 2017), SCMs have distinct effects on the properties of concrete, including cement hydration, the development of mechanical properties, and durability properties. In the recent years, several researchers have looked into the mechanical and durability properties of UHPC made with different SCM and different amounts of each SCM (Yu et al., 2014; Zhou et al., 2018).
Ultrafine particle size of SF, results in enhanced pozzolanic reactivity and denser particle packing, which helps in the development of UHPC (Rougeau & Borys, 2004; Siddique & Iqbal Khan, 2011). Owing to its pozzolanic nature, SF has mechanical and long-lasting properties that enhance concrete strength. Moreover, SF in UHPC decreases its fluidity. The utilization of GGBS, pulverized fly ash (PFA), metakaolin, RHA, and other materials along with SF in UHPC has been reported (Shi et al., 2015; Yazici et al., 2008; Yazıcı et al., 2010). It has been proven that GGBS, a by-product of blast furnace iron manufacturing, is a highly appropriate possible replacement for cement in UHPC (Yazıcı et al., 2010). It has been reported by many researchers that increasing the percentage of GGBS used as a replacement for cement can significantly reduce the price of concrete and create opportunities for more cost-effective, environmentally friendly concrete (Khatib & Hibbert, 2005; Siddique, 2014). The addition of SF, which contains a high concentration of responsive silica, combined with GGBS helps to accelerate the hydration process because it is known that the rate of hydration caused by GGBS is slow (Mohan et al., 2020). Moreover, it has been reported that GGBS when added to SF concrete the fluidity of SF concrete increases. The primary cause of UHPC's high functionality is that each component actively participates in the pozzolanic reaction (Prakash et al., 2022).
Artificial intelligence (AI)-based modelling has seen many research activities recently. Although artificial neural networks (ANNs) were a popular alternative for solving prediction problems. Since AI approaches have proven more effective than traditional modelling techniques, they have some limitations. There is a lack of insight into the relative value of the parameters in ANN. Neural networks are often criticised for the wide variety of training they need to function. As the information gained during model training is implicitly retained, it is challenging to interpret the total network structure logically. In addition, ANN has several inherent flaws such slow convergence, poor generalization, hitting minimum local, and over-fitting issues. Hence, to overcome the above limitations, gorilla troop optimization coupled with ANN were adopted by few authors (Wu et al., 2022) to predict concrete's mechanical and durability properties.Soft computing techniques have been widely utilised to estimate a variety of concrete parameters, including compressive strength (Kaveh & Khalegi, 1998; Velay-Lizancos et al., 2017) and splitting tensile (Behnood et al., 2015). This is because they are effective at processing knowledge, making predictions and forecasting.
Contrarily, ANNs and other Tradational machine learning (TML) algorithms are regarded as Blackbox models, which may produce unfavourable outcomes, especially for new datasets, despite their higher performance. However, their use is constrained by overfitting-related issues, considered the main drawbacks of TML approaches (Hossein et al., 2010; S et al., 2014). Thus, to overcome the limitations of TML models, modern researchers have turned to hybrid computational modelling as an effective alternative for estimating the desired result (Kaveh et al., 2021; Tien Bui et al., 2018). When meta-heuristic optimization algorithms (MOAs) and TML algorithms are combined, high-dimensional models are produced that balance the exploration and exploitation (E&E) phases during optimization, providing a successful method for addressing a challenging issue. Particle swarm optimization (PSO), artificial bee colonies (ABC), genetic algorithms (GA), Slap Swarm Algorithm (SSA), imperialist competitive algorithms (ICA), grey wolf optimizers (GWO), Harish Hawk Optimization (HHO), Whale Optimization Algorithm (WOA), Ant Lion Optimization (ALO), Dragonfly algorithm (DA), biogeography-based optimization (BBO) etc. are a few optimization algorithms (OAs) that have been widely used to solve numerous problems by optimizing the learning parameters of the TML algorithm (Golafshani et al., 2020; Koopialipoor et al., 2019). In a recent study, Ojha et al. (2017) showed that ANN-based MOA models, including as ANN-PSO (Roy et al., 2022), ANN-GA (Li et al., 2021), ANN-BBO (Fattahi & Bayatzadehfard, 2018), ANN-ICA, ANN-ABC (Koopialipoor et al., 2019), ANN-GWO (Raja & Shukla, 2021) and ANN-HHO (Nourani et al., 2021) are increasingly being used in complicated process modelling. However, a thorough review of the literature reveals that, with the exception of a few studies, the applicability of hybrid models for predicting the compressive strength of UHPC has not been investigated.
In this context, the motive for this study was the need to fill the informational gaps in the existing literature. It's worth noting that many new OAs have been implemented in the intervening years, including GWO (ZorarpacI & Özel, 2016), ABC(Karaboga & Basturk, 2007), ICA (Ojrulwkp et al., 2007), Slime mould algorithm (SMA) (Li et al., 2020), HHO (Heidari et al., 2019),Marine predators algorithm (MPA) (Faramarzi et al., 2020) and so on. However, a literature review suggests that very little research was done using ANNs with other hybrid ANNs such as (ANN-GTO (Gorilla troops optimization), ANN-SMO, ANN-WOA. ANN-SSA, ANN-ALO, ANN-HHO, ANN-PSO, ANN-DA, ANN-GWO) for predicting compressive strength of UHPC. The study's primary purpose is to examine the effectiveness of various optimization techniques on ANN models. Therefore, many ANN combinations are employed.
Artificial gorilla troop optimization (AGTO) is an advanced meta-heuristic technique used to solve optimization problems (Ginidi et al., 2021).A technique named gorilla troops optimization technique (GTOT) proposed by (Benyamin Abdollahzadeh et al.) is developed in this article for evaluating the compressive strength of UHPC. The literature reviewed the application of Gorilla Troops Optimization (GTO) confirms that no study has been conducted to predict the Compressive strength, Flexural Strength etc. for UHPC. Taylor (2001) invented a diagram in the form of a 2D graph in his study to give a statistical overview of how well patterns fit one another in terms of their correlation, RSME, and the ratio of their variance.The objective of the present research was to evaluate the Compressive Strength of ternary blended UHPC subjected to an elevated temperature ranging from 28℃ to 120℃ and varying the curing days. In this paper, a practically new model based on the ANN-GTO is proposed to predict Compressive Strength using the experimental data conducted in the lab (Prakash et al., 2022).
Methodology
Material properties
The cementitious materials employed were ordinary Portland cement (OPC) grade 53, SFand GGBS. Various laboratory studies (IS 4031:1996 (Part 1 to 15) n.d.) were used to assess the physical and chemical properties of cement. In this study, GGBS and SF were both used as pozzolanic materials. Both SF and GGBS sample satisfied the requirements of IS: 15,388 (IS:, 153882003) and IS 10289:1987 (IS:12,089–1987 1987) respectively. SF is provided by Elkem South Asia Pvt. Ltd and GGBS was obtained from L&T Ltd.,India. Ordinary riverbed sand with a fineness modulus of 2.60 was used as the fine aggregate. The water absorption rate and specific gravity were found to be 1.1% and 2.51, respectively.After sieve analysis, the sand sample conforms to zone III as per IS 383–2016 (IS383, 20162016). Locally available crushed Pakur stone of size 12.5 mm was used as coarse aggregate. The Water absorption and Specific gravity were obtained as 0.4% and 2.82, respectively. UHPC mixes are prepared by using Structuro 203 (FOSROC), a polycarboxylic ether-based superplasticizer that reduces water content (Should).The chemical admixture had a specific gravity of 1.077.
Mixture proportion
Initially, the ACI 211–1(ACI 211 1998) approach was used to design the UHPC mixtures. The preliminary mix proportions for UHPC with 1.2% superplasticizers by weight of the binder were calculated using a constant water-binder ratio (w/b) of 0.20 and a constant total binder content of 740 kg/m3. The initial estimate of the amount of trapped air in the mixture was 0.5%. The ratio of coarse and fine material is calculated using the absolute volume method. Table 1 illustrates the mix proportions for UHPC mixes.
Compressive strength test methods
For the uniaxial compressive strength test, concrete cube samples of 150 mm were cast. After normal water curing for 1, 3, 7, 28, and 56 days following Indian Standard Code IS: 516–1976, the tests were carried out (IS:516, 2004). The compressive strength of cube specimens were the average values of three specimens for each age. The specimens are molded and kept in a safe environment at room temperature for 24 h. One set of samples was taken out of the mold after 24 h and put in the oven for 48 h to undergo high temperature curing at 60 °C, 90 °C, and 120 °C. After 72 h, when they had reached thermal equilibrium, the compressive strength test was carried out.
Compressive strength test results
Compressive strength test results show that the compressive strength values of UHPC ranged between 83 and 153 MPa for all samples at 28 days. Due to the partial replacement of cement with GGBS and SF, all the mixes had lower cement content than the control mix.The early age of UHPC mixes with GGBS was less when compared to UHPC mixes with SF. According to Nevelle and Aitcin (Mehta & Aitcin, 1990; Neville, 2011) “the initial hydration of GGBS is slow as it depends upon the breakdown of the glass by the hydroxyl ions released during the hydration of Portland cement”. Due to the progressive release of alkalis by GGBS and with the formation of Ca(OH)2 with the Portland cement,the UHPC mixes with GGBS was observed to show a gain in strength in later ages.The compressive strength of GGBS and SF slightly decreased above their optimal replacement levels of 40% and 12%, respectively.
When compared to binary blended UHPC mixes with SF, the compressive strength of the ternary blended mixes with GGBS and SF was 17% higher. The highly reactive nature of SF particles further contributed to the acceleration of the hydration process by SF leading to an early age gain in strength for ternary mixes. The synergetic effect is also evident from the Scanning Electron Microscope(SEM) image present in Fig. 1. The SEM image clearly shows the formation of ettringite and calcium silicate hydrate (C–S–H) gel at 28 days.

Formation of C–S–H gel after ternary blended with GGBS &SF
The data set for the present study has been taken from the authors previous research (Prakash et al., 2022). In the present study a total of 308 test data points with nine input features and one output features have been employed in the final data set. For one set of temperature and curing variation a total of 22 data sets were used.
Applied machine learning methods
Artificial neural network (ANN)
ANN are composed of many highly interconnected processing elements (neurons) working together (Adeli, 2001). Each node receives a signal from neurons attached to it and is fully connected through connection weights. The outputs of the nodes in each layer serve as the inputs for the nodes in the layer above them, whilst the nodes in succeeding layers get input from those in the layer before. The perceptron is the simplest type of ANN design. It was developed by (Rosenblatt, 1958) and comprises of one neuron with two inputs and one output (Kaveh & Khavaninzadeh, 2023). Perception is defined as a four-tuple entity (i.e., sensors that (i) receive inputs and (ii) multiply them by weights, (iii) a function collecting all the weighted data to produce a measurement on the impact of the observed phenomenon, and (iv) a constant threshold). 'Training' is the process by which the network learns, and it entails changing these weights to create a specific output. Figure 2 shows a schematic illustration of the perceptron structure.

Schematic diag ram of perceptron structure
Each neuron has an input link, which is represented by the vector xi = (x1, x2). Inputs and a bias are both added to the neuron. The weights for each input are represented by this equation: Wi = (w1, w2). The net input that approaches a neuron is computed using the weighted sum function. Equation 1 is used to determine the weighted sums of the input components (also known as the sum function).
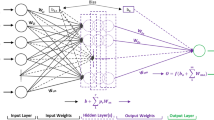
where vj is the weighted sum of the jth neuron for the input received from the preceding layer, with n neurons, wij is the weight between the jth neuron and the ith neuron in the preceding layer; xi is the output of the ith neuron in the preceding layer and b is a constant.The architecture of a two-hidden layer MLP with back propagation is schematically represented in Fig. 3.

Schematic representation of the architecture of a two-hidden layer MLP with back propagation
Ant lion optimization (ALO)
A new algorithm inspired by nature called Ant Lion Optimizer (ALO) was introduced by Mirjalili (2015). The ALO emulates how ant lions in the wild execute their hunting. An ant lion larva excavates a cone-shaped hole in the sand by marching in a circle and tossing sand with its enormous jaw. The larva hides underneath the cone's bottom after digging the trap and waits for insects to fall into the pit. Insects can readily fall to the bottom of the trap because the cone’s edge is sharp. The ant lion tries to capture its victim after realizing it is trapped. It is then dragged into the soil and eaten. Ant lions prepare the pit for the subsequent hunt by discarding the leftover prey outside the pit after eating it.
Grey wolf optimization (GWO)
A nature-inspired optimization system called GWO (Mirjalili et al., 2014) mimics the strict hierarchy of grey wolves, which are known for their predominantly hunting behaviour.GWO consists of a few males and females, with the α (alpha) group making essential decisions like hunting, being recognised as the best solution. The second level of wolves are the β (beta) wolves, who make decisions and obey the alpha wolves. The best candidates to replace a dead or elderly alpha wolf are the beta, which can be female and helps in flock adjustment. δ (Delta) wolves are the third level of wolves; they serve as scouts and sentinels are used in hunting. ω (omega), the last group of animals and considered the weakest level, is in charge of keeping an eye on the younger wolves. Three levels of grey wolf hunting were described by Muro et al. (2011): (a) locating, pursuing, and closing in on the target; (b) encircling the target; and (c) rushing the target. The GWO algorithm takes into account these two different social behaviours. The best solution for the mentioned algorithm's modelling step is α (alpha), followed by β (beta), δ (delta), and ω (omega) suitable solutions in the subsequent steps. Refer to the original work by Mirjalili et al. (Mirjalili et al., 2014) for thorough descriptions of GWO.
Slap swarm algorithm (SSA)
By modelling SSA after swarming, translucent water invertebrates known as salps, or salp chains, Mirjalili et al. (2017) proposed SSA. This algorithm is built on a leader–follower relationship, where the leader moves to the best food and the follower stays put. The SSA mathematical model is divided into three phases: the initial allocation of salps is at random; the next phase designates the salp closest to the food supply and with the lowest fitness value as the leader, with the other salps designated as followers. Finally, the position is updated in the third and final phase.The leader changes his stance on the ideal global resolution and considers better alternatives. Until the termination condition or the maximum number of iterations is achieved, the loops continue. The follower changes their position in the leader’s hierarchy.
Whale optimization algorithm (WOA)
A recently developed optimization algorithm called WOA imitates the hunting behaviour of humpback whales in their natural habitat (Kaveh & Ghazaan, 2017).The most incredible aspect of humpback whales, according to Watkins and Schevill (Watkins & Schevill, 1979), is their unique hunting approach, known as the bubble-net feeding technique. Humpback whales are the small fish seen near the surface. When numerous distinctive bubbles appear in a nine or circular-shaped pattern, the hunting procedure is completed. Based on the surface observations, the aforementioned behaviour was studied in 2011 and earlier. Using tag sensors, Goldbogen et al.(2013)carried out a distinct study.The two new bubble motion plans, upward spirals and double loops, were developed using the 300 bubble-net feeding episodes from nine individual tagged humpback whales. In particular, humpback whales create spiral-shaped bubbles all around their prey and then swim toward the top in the movement pattern described earlier. Three unique phases make up the innovative movement plan: coral loop, lobtail, and capture loop. Additional details and descriptions of behaviour may be found in the literature (Goldbogen et al., 2013; Mirjalili & Lewis, 2016). Bubble-net feeding is a technique used exclusively by humpback whales, hence this uniqueness must be emphasized.
Dragonfly algorithm (DA)
A new and intriguing meta-heuristic optimization algorithm inspired by nature called the Dragonfly Algorithm (DA) was developed by Mirjalili (2016). It is used to solve a variety of optimization problems. Dragonflies are small flying carnivores that consume a range of other small insects, including mosquitoes, bees, ants, and butterflies (Babayigit, 2018; Mirjalili, 2016).It is utilised to handle a variety of optimization challenges like tiny flying carnivorous insects known as dragonflies hunt and consume a range of tiny insects, including mosquitoes, bees, ants, and butterflies (Babayigit, 2018; Mirjalili, 2016).
DA is based on the dragonfly swarming activities that are dynamic (migratory) and static (feeding) in nature. The exploitation and exploration stages of DA are represented by the dynamic and static swarms respectively.In the exploitation phase, many dragonflies cause the swarms to travel across great distances in a single direction and divert predators. However, during the exploration phase, dragonflies form tiny groups and circle a constrained region in an effort to find food and entice soaring predators.
Particle swarm optimization (PSO)
PSO was first developed in 1995 by Kennedy and Eberhart (2021) as a part of the swarm-based community, which was influenced by the schooling and flocking habits of birds and fish. In a multidimensional context, PSO's main objective is to identify globally optimal solutions. The random speeds and positions of objects are first implemented by PSO. In a multidimensional environment, each object then adjusts its location in accordance with its personal best position,speed and overall best position to select the appropriate state. Individual particles can only achieve one place, which is the ideal global status; nevertheless, they can only choose one position, which is the perfect personal position. The particle's position is changed in accordance with its optimum personal position and the orientation of its optimum global location. The differences between an object's best personal position and its best location worldwide are taken into account whilst modifying the objects' speeds. The particles converge around the optima through a combination of E&E. The acceleration coefficients C1 (cognitive coefficient) and C2 (social coefficient), with fixed values of 1 and 2, respectively, depend on the subject and show how confidently a given element is positioned in relation to its own and the world's circumstances. Previous studies can be used to learn the detailed working principles of PSO (Le et al., 2019), (Kaveh & Nasrollahi, 2014).
Harish hawk optimization (HHO)
Heidari et al. (2019) have developed a novel SI-based optimization method known as Harris Hawk Optimization (HHO),that relates the hunting habits of the Harris hawk with computerized mathematical systems. A group of Harris hawks attack their prey, usually rabbits, from a wide range of angles and use a variety of dynamic and clever strategies to adapt to their prey’s flight pattern, leaving the prey baffled and exhausted.The algorithm is divided into three steps. Birds serve as prospective answers to the selected difficulty during the exploratory phase, which is the first stage of waiting, searching, and discovering.The second stage involves the transition from exploration to exploitation, which depends on the availability and quality of the prey. The targeted prey is attacked by the environment and besieged from many sides throughout the exploitation phase, the third step. Depending on the energy level of the prey, as determined in the second stage, the besiegement’s severity will change (Kaveh et al., 2022).
Smile mould optimization (SMO)
SMA is a newly developed meta-heuristic OA (Li et al., 2020) that draws inspiration from nature and considers mathematical simulation modelling of slime mould propagation waves. when choosing the most effective route for connecting food. Slime mould is a type of eukaryotic organism found in nature. Because of their distinct traits and patterns, they utilise multiple food sources to build a venous network for communication. Slime mould has a maximum growth length of 900 cm2. If sufficient food exists in the environment. The bio-oscillator creates a spreading wave when a vein receives food, which improves the cytoplasmic flow into the vein and speeds up the flow of cytoplasm, thickening the vein. Given these favourable and unfavourable reactions, the slime might create the ideal path for a substantially stronger relationship to food. As a consequence, slime mold has been the subject of mathematical modelling and application in the fields of path networks and graph theory, which simulate the creation of positive and negative reactions through wave propagation. Based on the source of the food's quality, slime mould could also adjust their dynamic search patterns.Numerous challenges involving engineering optimization can be solved using this technique. The slime mould algorithm has two main levels: (a) acquiring food, after which the slime's behaviour is to acquire food based on its odour in the atmosphere (b) warping foodstuffs, after which the slime's behaviour is to undergo contraction of its venous configuration. Detailed information regarding the working principle of SMA can be found in the original work of Li et al. (2020).
Gorilla troops optimization (GTO)
Gorilla troop optimization (GTO) is based on the group behaviours of gorillas, where five strategies are simulated. These strategies include migration to a previously undiscovered territory, relocating to other gorillas, migrating toward a known site, pursuing the silverback, and competing for adult females. To illustrate the exploration and application of the optimization method, they are mimicked and demonstrated. During the exploration stage, three strategies are used: migration to an undiscovered area, moving near other gorillas and movement in the general direction of a predetermined place. In the exploitation stage, two strategies are used: “follow the silverback” and “competition for adult females.” (Ginidi et al., 2021).
Hybridization of regression models
The performance of MOAs can be improved by modifying the learning parameters (such as the weights and biases) for conventional machine learning (CML) algorithms. By enhancing the learning parameters of CML techniques, the combination of CML and MOA helps in the search for the precise global minimum and produces more accurate results (Bardhan et al., 2022; Golafshani et al., 2020). In this study, advanced MOAs (ALO, GWO, SSA, WOA, DA, PSO, HHO, SMO, and GTO) were employed to develop hybrid ANN models in order to maximize the learning parameters of ANN. The learning parameters of an ANN are the input weights, hidden biases, output weights, and output biases. Figure 4 shows the hybridation of regression models. Following is an overview of the methodological development of ANN-based hybrid models: Hyper-parameters (such the activation function and Nhn) are selected in the first step, and then weights and biases are produced at random. The second stage involves developing the ideal learning parameter values utilizing MOAs. Finally, the findings are validated for the new dataset using the generated hybrid ANN models using the altered weights and biases. Although each MOA uses the same hybrid model development procedure, the optimal learning parameters that come from this technique are different. In addition to the ANN's learning parameters, deterministic parameters such as the population size (Np), generation probability (GP), maximum number of iterations (itr), inertia weights (wmax and wmin), random parameters (r1, r2), acceleration coefficients of PSO (c1 and c2), lower bound (lb), upper bound (ub), and other MOA parameters are significant and thus, should be tuned appropriately during hybrid modelling.

Hybridation of regression models
Data processing and analysis
Descriptive analysis and correlation
In order to develop the nine machine learning models to predict the compressive strength of the UHPC, a total of 308 test data points with nine input features have been used as the final dataset. In the present study, nine SI algorithms have been used to construct hybrid ANN, namely GWO, WOA, SSA, GTO, ALO, DA, PSO, HHO and SMA. Table 2 shows the descriptive statistics for the input parameters (C, SF, GGBS, FA, CA, SP, W, T, Age) and the output parameters (f'c). Figure 5 illustrates the results of the statistical analysis performed after the descriptive analysis to determine the degree of correlation (DOC) using the Pearson correlation between the above mentioned parameters. Thus, the descriptive analysis confirms that a wide range of data points are available and can be used as input parameters to get the desired result. Following normalization, all of the data is divided into training (TR) and testing (TS) subsets. After the aforementioned descriptive analysis described that the collected database had a wide range of experimental data, a statistical analysis was conducted to measure the degree of correlation (DOC) using Pearson correlation between the parameters mentioned above.The Pearson correlation in Fig. 5 demonstrates that when all parameters were evaluated, the DOCs between f’c and parameters (SF, GGBS, SP, T, Age) were significantly higher compared to other parameters. On the other hand, it was revealed that there is a negative correlation between f’c and parameters (Cement, CA, FA).

Pearson’s correlation coefficient
In this study, the training subset was drawn from 70% of the total dataset at random, whilst the testing subset was drawn from the remaining 30%. It is important to note that the number of samples used in a prediction model is at the discretion of the researchers, even though there are no established standards or criteria in this regard. However, a model developed with a large dataset may be considered more reliable than one developed with a small dataset. Furthermore, a validated model using a large dataset is more reliable. Thus, in this study, the training and testing subsets of the hybrid ANN were developed and validated using around 206 and 102 data points, respectively.
Sensitivity
In the context of suggested models, sensitivity analysis (SA) is a technique used to learn how alterations to input parameters affect output results. This will help us determine which input parameters had an effect on the output. Here, the Cosine Amplitude Method (Biswas et al., 2021) is employed to determine the input-to-output mapping (CS) of a finite-response-plate (UHPC) system. The data pairings in this study are represented in a data array X, as follows in Eq. 2–4.
and variable xi in X, is a length vector of m as in Eq. 7.
The correlation between the strength of the relation (Rij) and datasets of xi and xj is provided by in Eq. 8.
Figure 6 presents a graphical representation of Rij, illuminating the connection between the input bias structure of UHPC and the parameters used to generate it. With a strength value of 0.87, age is the strongest predictor of CS of UHPC, followed by SF (0.81) and GGBS (0.72). The relative strengths of the parameters T and Cement are approximately 0.71 and 0.69. The strength values for CA and FA both seem to be 0.64, however SP's value is significantly lower as 0.22. All eight characteristics should be taken into account when forecasting output since they have significant influences on the interfacial bond strength.

Sensitivity analysis
Performance parameters
It is essential to evaluate the performance of machine learning (ML) models during the training and testing phases to ensure the model will perform satisfactorily on future, unseen data in terms of accuracy, robustness, and generalization capabilities. To evaluate how well machine learning models predicted the target, statistical indicators could be used. In this study, the performance parameters may be divided into error measuring parameters such as (RMSE, MAE, RSR, and WMAPE) and parameters for trend measurement as (R2, VAF, PI and WI) were used to evaluate the prediction accuracy of each individual model, using Eq. 5–12 respectively. The ideal values of these performance parameters are listed in Table 3.
where \(y\) and \(\widehat{y}\) are the actual and estimated output; n is the total number of observations; \({y}_{\mathrm{mean}}\) is the average of the actual values.
Results and discussion
In this part, we discuss the contributions made by the different forecasting models. The methodology section evaluates the UHPC using nine design parameters (SF, GGBS, C, SP, CA, FA, T and age). In preparation for this procedure, test were performed in the lab as mentioned in “Mixture Proportion”, “Compressive Strength Test Methods” and total 308 results were obtained for different combination of input parameter. The whole dataset is going to be tested and trained separately. After that, the dataset that was used for training was the one that was used to generate proposed models and the dataset that was used for testing was the one that was used to evaluate the generalization potential and robustness of the models that were developed. In order to validate the robustness of the models, the performance indicators are estimated and evaluated immediately. In the next subsections, a comparative analysis of the parametric configuration of the models that were used in the study is provided for the predictive capacity of the created models. This review focuses on the predictive ability of the models. Lastly, the most accurate forecasting model will be discussed.
Parametric configuration of hybrid models
The ANN model is optimally calibrated using nine optimizing algorithms, namely GWO, WOA, SSA, GTO, ALO, DA, PSO, HHO and SMA, once the experimental results have been collected. Due to the random nature of meta-heuristic algorithms, the collection of parametrical parameters, i.e.dynamic parameters, has a major influence on optimization modelling.Thus, during deployment, it is essential to change the dynamic parameters. Using the trial and error method, the optimal hidden layer for ANN simulation was found to be 10.In this study, deterministic parameters like population size, the number of search agents and number of iterations were accurately simulated. Hidden neurons were taken as 10 and 500 iterations were performed keeping the mean square error as a loss function.
Simulation and statistical details of different developed models
After developing the models, their performance will be discussed in the following subsection. Figure 7 shows the stack bar for the training and testing of the above prediction models. Tables 4 and 5 contain all relevant performance parameters for the above mentioned models. As indicated, all the developed models have succeeded in capturing the relationship to predict the fck of UHPC. It was observed that ANN-GTO outperformed other models in terms of prediction accuracy in training (R2 = 0.9629, VAF = 96.28, RMSE = 0.0518, and RSR = 0.1930) stages. Also, in the testing phase, the ANN-GTO model outperformed other models with R2 = 0.9578, VAF = 95.78, RMSE = 0.0540, and RSR = 0.2056. The ANN-GWO was the second-best performing model amongst others with R2 = 0.9466 in training and R2 = 0.9504 in testing. The ANN-DA and ANN-PSO were the least performing model amongst all the developed model in training (R2 = 0.8241, VAF = 82.35, RMSE = 0.1129 and RSR = 0.4202) and testing (R2 = 0.8076, VAF = 80.74, RMSE = 0.1106 and RSR = 0.4401), respectively. It was observed in the study that the use of meta-heuristic optimization on the conventional model improves the performance of the model significantly.

Stack bar plot
Accuracy matrix
Recently, a heat map-like graphical assessment known as an accuracy matrix has been introduced to better visualize the model's effectiveness and explain the values of performance indices (Kumar et al.). In this matrix, a number of statistical parameters are used to show the model's predictiveperformance on the training and testing datasets. The performance indicators determined in this study and their associated accuracy matrices are shown in Figs. 8 and 9. It compares the actual values of the performance parameters to the desired values for each and displays the result as a percentage. For example, in this work, we found that the MAE for the training subset of the hybrid ANN-GTO model was 0.0413, whilst the ideal value is 0. (see Table 3). In this way, we can conclude that the hybrid ANN-GTO achieved 96% ((1–0.041327) × 100%) accuracy concerning MAE. On the other hand, the values of R2 and PI were obtained as 0.9578 and 1.8581 in the testing phase respectively, for ANN-GTO (see Table 4), which shows that ANN-GTO attained 96% ((0.9578/1) × 100%) and 93% ((1.8581/2) × 100%) accuracy in terms of R2 and PI, respectively. The same method was used for all the remaining variables. It should be noted, however, that factors like VAF, which are calculated in percentage terms, must first be transformed into their decimal form before the process mentioned above can be carried out.

Accuracy matrix for training dataset

Accuracy matrix for testing dataset
Taylor diagram
Figures 10 and 11 illustrate how the performance of the hybrid ANN-GTO models on both the training and testing datasets can be analyzed using the Taylor diagram (2001). This graph is used to evaluate the accuracy with which the models can anticipate the desired result. Authors evaluate the models' relative merits using three statistical measures (RMSE, correlation coefficients and standard deviation ratios). The average root-mean-square-error (RMSE; the distance from the measured point) is used as a benchmark. The correlation coefficient and standard deviation are both set to 1 for the reference model. The graph demonstrates that all nine hybrid models had standard deviation and correlation coefficient values for the training phase that were quite close to one. A conclusion that can be drawn from the graph is that the ANN-DA model had the lowest correlation during training whilst the ANN-GTO model provided the best performance, followed by the ANN-GWO model. Out of all nine hybrid models of ANN, the ANN-GTO model had the best performance for the testing dataset. As a result, it is possible to draw the conclusion that the ANN-GTO model has the best overall performance because it produced satisfactory results for both datasets.

Taylor diagram for the training stage

Taylor diagram for the testing stage
Uncertainty analysis
Uncertainty analysis is used to determine the predictive models' uncertainties, demonstrating the accuracy of trained models in predicting future outcomes.The error mean e and the standard deviation of the prediction error Se are determined as demonstrated in Eq. 12 and 13 respectively.
where ei denotes an individual error in prediction. When the mean error is positive, the trained model overestimated the data, and when it is negative, the trained model underestimated the data. Using the mean and standard deviation of an error, the Wilson score method without continuity correction can be used to determine a confidence interval around the predicted values of an error. Table 6 and Figs. 12 and 13 illustrate the results of the uncertainty analysis for the proposed model. The results show that, in comparison to other models, ANN-GTO obtains lower values of band width (0.1016 and 0.1057) for training and testing data.

Uncertainty analysis for the training stage

Uncertainty analysis for the testing stage
Conclusion
In this work, nine hybrid ANNs were used to estimate the CS of the concrete cast using manufactured sand. Specifically, nine widely used ML algorithms, namely GTO, GWO, WOA, SSA, ALO, DA, PWO, HHO and SMO were utilized to optimize the weights and biases of ANNs. For training and validation of the constructed ANNs, a total of 308 samples which consisting of nine distinct input variables, were acquired. The inputs were selected based on the influence on the strength using Pearson correlation and sensitivity analysis. As per the estimated results, the developed ANN-GTO was the best-fitted model in both TR (R2 = 0.9629, VAF = 96.28, RMSE = 0.0518, and RSR = 0.1930) TS (R2 = 0.9578, VAF = 95.78, RMSE = 0.0540, and RSR = 0.2056) phases. This result is suggestively better than the approaches, including the AN BBO, ANN-DE, ANN-GA, ANN-PSO, and ANN-SA models. According to the overall results, the suggested ANN-GTO model can be considered a capable alternative for estimating the CS of UHPC concrete. Similar results were concluded from the other studies like Taylor Diagram, accuracy matrix and uncertainty analysis of the parameters. The key advantages of the suggested ANN-GTO model are (a) optimized weight and biases generated through 15,000 solutions, which is a multiplication of population size and maximum iteration count; (b) faster convergence; and (c) higher generalization ability. Despite these advantages, the proposed ANN-GTO model's computational cost is very high. This is one of the limitations. Another constraint is the searching space configuration of the GTO algorithms' parameters, which confines the position of the particles because several runs must be performed to get the best results. Consequently, the future work should include (a) construction and validation of other hybrid models based on an extensive database (b) implementation of other hybrid ANNs for a comparative evaluation of results (c) implementation of recently developed MH algorithms; and (d) development and implementation of an improved version of the GTO algorithm to estimate the desired output at a low computation cost.
References
Adeli, H. (2001). Neural networks in civil engineering: 1989–2000. Comput Civ Infrastruct Eng, 16(2), 126–142. https://doi.org/10.1111/0885-9507.00219
Babayigit, B. (2018). Synthesis of concentric circular antenna arrays using dragonfly algorithm. International Journal of Electronics, 105(5), 784–793. https://doi.org/10.1080/00207217.2017.1407964
Bardhan, A., GuhaRay, A., Gupta, S., Pradhan, B., & Gokceoglu, C. (2022). A novel integrated approach of ELM and modified equilibrium optimizer for predicting soil compression index of subgrade layer of dedicated freight corridor. Transp Geotech, 32, 100678.
Behnood, A., Verian, K. P., & Modiri Gharehveran, M. (2015). Evaluation of the splitting tensile strength in plain and steel fiber-reinforced concrete based on the compressive strength. Construct Build Mater, 98, 519–529. https://doi.org/10.1016/j.conbuildmat.2015.08.124
Biswas, R., Bardhan, A., Samui, P., Rai, B., Nayak, S., & Armaghani, D. J. (2021). Efficient soft computing techniques for the prediction of compressive strength of geopolymer concrete. Comp Concrete, 28(2), 221–232. https://doi.org/10.12989/cac.2021.28.2.221
Dingqiang, F., Wenjing, T., Dandian, F., Jiahao, C., Rui, Y., & Kaiquan, Z. (2018). Development and applications of ultra-high performance concrete in bridge engineering. IOP Conf Ser Earth Environ Sci. https://doi.org/10.1088/1755-1315/189/2/022038
Dm, S., Bolouri, J., & Alavi, A. H. (2014). Engineering applications of arti fi cial intelligence an evolutionary computational approach for formulation of compression index of fi ne-grained soils. Eng Applicat Artif Intell, 33, 58–68. https://doi.org/10.1016/j.engappai.2014.03.012
Faramarzi, A., Heidarinejad, M., Mirjalili, S., & Gandomi, A. H. (2020). Marine predators algorithm: a nature-inspired metaheuristic. Exp Syst Applicat, 152, 113377. https://doi.org/10.1016/j.eswa.2020.113377
Fattahi, H., & Bayatzadehfard, Z. (2018). Forecasting surface settlement caused by shield tunneling using ANN-BBO model and ANFIS based on clustering methods. Journal of Engineering Geology, 12, 55.
Ginidi, A., Ghoneim, S. M., Elsayed, A., El-Sehiemy, R., Shaheen, A., & El-Fergany, A. (2021). Gorilla troops optimizer for electrically based single and double-diode models of solar photovoltaic systems. Sustain. https://doi.org/10.3390/su13169459
Golafshani, E. M., Behnood, A., & Arashpour, M. (2020). Predicting the compressive strength of normal and high-performance concretes using ANN and ANFIS hybridized with grey wolf optimizer. Construct Build Mater, 232, 117266.
Goldbogen, J. A., Friedlaender, A. S., Calambokidis, J., McKenna, M. F., Simon, M., & Nowacek, D. P. (2013). Integrative approaches to the study of baleen whale diving behavior, feeding performance, and foraging ecology. BioScience, 63(2), 90–100. https://doi.org/10.1525/bio.2013.63.2.5
Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., & Chen, H. (2019). Harris hawks optimization: algorithm and applications. Fut Generat Comp Syst, 97, 849–872. https://doi.org/10.1016/j.future.2019.02.028
Hossein, A., Amir, A. Æ., & Gandomi, H. (2010). Multi expression programming : a new approach to formulation of soil classification. Eng Comp. https://doi.org/10.1007/s00366-009-0140-7
IS:12089–1987 (1987) Specification for granulated slag for the manufacture of Portland slag cement. Bur Indian Stand New Delhi :1–14
IS:15388. (2003). Indian standard specification for silica fume. Bur Indian Stand New Delhi.
IS:516. (2004). Method of tests for strength of concrete. Bur Indian Stand New Delhi.
IS 383:2016 (2016) Indian Standard Coarse and Fine aggregate for Concrete- Specification. Bur Indian Stand New Delhi, India (January):1–21
IS 4031:1996 (Part 1 to 15) (Ed.) (n.d.) Various laboratory tests of cement. Bureau of Indian Standards
James Kennedy and Russell Eberhart. (2021). Particle swarm optimisation. Stud Computat Intell, 927, 5–13. https://doi.org/10.1007/978-3-030-61111-8_2
Karaboga, D., & Basturk, B. (2007). A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm. J Global Optimizat, 39(3), 459–471. https://doi.org/10.1007/s10898-007-9149-x
Kaveh, A., & Ghazaan, M. I. (2017). Enhanced whale optimization algorithm for sizing optimization of skeletal structures. Mech Based Design Struct Mach, 45(3), 345–362. https://doi.org/10.1080/15397734.2016.1213639
Kaveh, A., & Khavaninzadeh, N. (2023). Efficient training of two ANNs using four meta-heuristic algorithms for predicting the FRP strength. Structures, 52(February), 256–272. https://doi.org/10.1016/j.istruc.2023.03.178
Kaveh, A., & Nasrollahi, A. (2014). A new probabilistic particle swarm optimization algorithm for size optimization of spatial truss structures. Int J Civil Eng, 12(1), 1–13.
Kaveh, A., Dadras Eslamlou, A., Javadi, S. M., & Geran Malek, N. (2021). Machine learning regression approaches for predicting the ultimate buckling load of variable-stiffness composite cylinders. Acta Mechanica, 232, 921–931.
Kaveh, A., Rahmani, P., & Eslamlou, A. D. (2022). An efficient hybrid approach based on Harris Hawks optimization and imperialist competitive algorithm for structural optimization. Eng Computat, 38(s2), 1555–1583. https://doi.org/10.1007/s00366-020-01258-7
Kaveh, A., & Khalegi, A. (1998). Prediction of strength for concrete specimens using artificial neural networks. Advances in Engineering Computational Technology, 165–171. https://www.webofscience.com/wos/WOSCC/full-record/000077305500020
Khatib, J. M., & Hibbert, J. J. (2005). Selected engineering properties of concrete incorporating slag and metakaolin. Construct Build Mater, 19(6), 460–472. https://doi.org/10.1016/j.conbuildmat.2004.07.017
Koopialipoor, M., Fallah, A., Armaghani, D. J., Azizi, A., & Mohamad, E. T. (2019). Three hybrid intelligent models in estimating flyrock distance resulting from blasting. Eng Comp, 35, 243–256.
Kumar, R., Rai, B., & Samui, P. A. (2023). comparative study of prediction of compressive strength of ultra-high performance concrete using soft computing technique. Struct Concrete. https://doi.org/10.1002/suco.202200850
Le, L. T., Nguyen, H., Dou, J., & Zhou, J. (2019). A comparative study of PSO-ANN, GA-ANN, ICA-ANN, and ABC-ANN in estimating the heating load of buildings’ energy efficiency for smart city planning. Applied Sciences. https://doi.org/10.3390/app9132630
Li, S., Chen, H., Wang, M., Heidari, A. A., & Mirjalili, S. (2020). Slime mould algorithm: a new method for stochastic optimization. Fut Generat Comp Syst, 111, 300–323. https://doi.org/10.1016/j.future.2020.03.055
Li, Y., Jia, M., Han, X., & Bai, X. S. (2021). Towards a comprehensive optimization of engine efficiency and emissions by coupling artificial neural network (ANN) with genetic algorithm (GA). Energy, 225, 120331. https://doi.org/10.1016/j.energy.2021.120331
Megat Johari, M. A., Brooks, J. J., Kabir, S., & Rivard, P. (2011). Influence of supplementary cementitious materials on engineering properties of high strength concrete. Construct Build Mater. https://doi.org/10.1016/j.conbuildmat.2010.12.013
Mehta, P. K., & Aitcin, P.-C. (1990). Effect of coarse aggregate characteristics on mechanical properties of high-strength concrete. ACI Materials Journal, 87(2), 103–107. https://doi.org/10.14359/1882
Mirjalili, S. (2015). The ant lion optimizer. Adv Eng Soft, 83, 80–98. https://doi.org/10.1016/j.advengsoft.2015.01.010
Mirjalili, S. (2016). Dragonfly algorithm: a new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neur Comp Applicat, 27(4), 1053–1073. https://doi.org/10.1007/s00521-015-1920-1
Mirjalili, S., & Lewis, A. (2016). The whale optimization algorithm. Advances in Engineering Software, 95, 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008
Mirjalili, S., Mohammad, S., & Lewis, A. (2014). Advances in engineering software grey wolf optimizer. Adv Eng Software, 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007
Mirjalili S, Gandomi AH, Zahra S, Saremi S (2017) Advances in Engineering Software Salp Swarm Algorithm : A bio-inspired optimizer for engineering design problems. 114:163–191. Doi: https://doi.org/10.1016/j.advengsoft.2017.07.002
Mohan, A., Karthika, S., Ajith, J., & dhal L, Tholkapiyan M,. (2020). Investigation on ultra high strength slurry infiltrated multiscale fibre reinforced concrete. Mater Today Proc, 22, 904–911. https://doi.org/10.1016/j.matpr.2019.11.102
Muro, C., Escobedo, R., Spector, L., & Coppinger, R. P. (2011). Wolf-pack ( Canis lupus ) hunting strategies emerge from simple rules in computational simulations. Behavioural Processes, 88(3), 192–197. https://doi.org/10.1016/j.beproc.2011.09.006
Neville, A. M. (2011). Properties of concrete. Journal of General Microbiology. https://doi.org/10.4135/9781412975704.n88
Nodehi, M., & Mohamad Taghvaee, V. (2021). Sustainable concrete for circular economy: a review on use of waste glass. Glas Struct Eng. https://doi.org/10.1007/s40940-021-00155-9
Nourani, B., Arvanaghi, H., & Salmasi, F. (2021). A novel approach for estimation of discharge coefficient in broad-crested weirs based on harris hawks optimization algorithm. Flow Measurem Instrument, 79(March), 101916. https://doi.org/10.1016/j.flowmeasinst.2021.101916
Ojha, V. K., & Abraham, A. (2016). Snášel V (2017) Metaheuristic design of feedforward neural networks: a review of two decades of research. Eng Applicat Artif Intell, 60, 97–116. https://doi.org/10.1016/j.engappai.2017.01.013
Ojrulwkp R, Iru QO, Qvsluhg E, Dujdul VW, Xfdv DUR, Shv GW, Rswlpl RI, Sureohpv D (2007) ,pshuldolvw &rpshwlwlyh $ojrulwkp $q $ojrulwkp iru 2swlpl]dwlrq ,qvsluhg e\ ,pshuldolvwlf &rpshwlwlrq. :4661–4667
Prakash, S., Kumar, S., Biswas, R., & Rai, B. (2022). Influence of silica fume and ground granulated blast furnace slag on the engineering properties of ultra-high-performance concrete. Innov Infrastruct Solut. https://doi.org/10.1007/s41062-021-00714-7
Raja, M. N. A., & Shukla, S. K. (2021). Predicting the settlement of geosynthetic-reinforced soil foundations using evolutionary artificial intelligence technique. Geotext Geomemb, 49(5), 1280–1293. https://doi.org/10.1016/j.geotexmem.2021.04.007
Rosenblatt, F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408. https://doi.org/10.1037/h0042519
Rougeau P, Borys B (2004) Ultra high performance concrete with ultrafine particles other than silica fume. In: Proceedings of the International Symposium on Ultra High Performance Concrete, Kassel, Germany. pp 213–226.
Roy, S. M., Pareek, C. M., Machavaram, R., & Mukherjee, C. K. (2022). Optimizing the aeration performance of a perforated pooled circular stepped cascade aerator using hybrid ANN-PSO technique. Inf Process Agric, 9(4), 533–546. https://doi.org/10.1016/j.inpa.2021.09.002
Shi, C., Wang, D., Wu, L., & Wu, Z. (2015). The hydration and microstructure of ultra high-strength concrete with cement-silica fume-slag binder. Cement Concrete Comp, 61, 44–52. https://doi.org/10.1016/j.cemconcomp.2015.04.013
Siddique, R. (2014). Utilization (recycling) of iron and steel industry by-product (GGBS) in concrete: Strength and durability properties. J Mater Cycles Waste Manag, 16(3), 460–467. https://doi.org/10.1007/s10163-013-0206-x
Siddique, R., & Iqbal Khan, M. (2011). Supplementary cementing materials, Engineering material-silica fume. https://doi.org/10.1007/978-3-642-17866-5
Soliman, N. A., & Tagnit-Hamou, A. (2016). Development of ultra-high-performance concrete using glass powder—towards ecofriendly concrete. Construct Build Mater, 125, 600–612. https://doi.org/10.1016/j.conbuildmat.2016.08.073
Taylor, K. E. (2001). Summarizing multiple aspects of model performance in a single diagram. J Geophys Res Atmos, 106(D7), 7183–7192.
Tien Bui, D., Nhu, V. H., & Hoang, N. D. (2018). Prediction of soil compression coefficient for urban housing project using novel integration machine learning approach of swarm intelligence and Multi-layer Perceptron Neural Network. Adv Eng Informatics, 38(April), 593–604. https://doi.org/10.1016/j.aei.2018.09.005
Velay-Lizancos, M., Perez-Ordoñez, J. L., Martinez-Lage, I., & Vazquez-Burgo, P. (2017). Analytical and genetic programming model of compressive strength of eco concretes by NDT according to curing temperature. Construct Build Mater, 144, 195–206. https://doi.org/10.1016/j.conbuildmat.2017.03.123
Wang, D., Shi, C., Wu, Z., Xiao, J., Huang, Z., & Fang, Z. (2015). A review on ultra high performance concrete: part II. hydration, microstructure and properties. Construct Build Mater, 96, 368–377.
Watkins, W. A., & Schevill, W. E. (1979). Aerial observation of feeding behavior in four baleen whales: eubalaena glacialis, balaenoptera borealis, megaptera novaeangliae, and balaenoptera physalus. Journal of Mammalogy, 60(1), 155–163. https://doi.org/10.2307/1379766
Wu, T., Wu, D., Jia, H., Zhang, N., Almotairi, K. H., Liu, Q., & Abualigah, L. (2022). A modified gorilla troops optimizer for global optimization problem. Applied Sciences. https://doi.org/10.3390/app121910144
Yang, J., Wang, Q., & Zhou, Y. (2017). Influence of curing time on the drying shrinkage of concretes with different binders and water-to-binder ratios. Advances in Materials Science and Engineering. https://doi.org/10.1155/2017/2695435
Yazici, H., Yiǧiter, H., Karabulut, A. Ş, & Baradan, B. (2008). Utilization of fly ash and ground granulated blast furnace slag as an alternative silica source in reactive powder concrete. Fuel. https://doi.org/10.1016/j.fuel.2008.03.005
Yazıcı, H., Yardımcı, M. Y., Yiğiter, H., Aydın, S., & Türkel, S. (2010). Mechanical properties of reactive powder concrete containing high volumes of ground granulated blast furnace slag. Cement Concrete Comp, 32(8), 639–648. https://doi.org/10.1016/j.cemconcomp.2010.07.005
Yoo, D. Y., & Banthia, N. (2016). Mechanical properties of ultra-high-performance fiber-reinforced concrete: a review. Cement Concrete Comp, 73, 267–280. https://doi.org/10.1016/j.cemconcomp.2016.08.001
Yu, R., Spiesz, P., & Brouwers, H. J. H. (2014). Mix design and properties assessment of ultra-high performance fibre reinforced concrete (UHPFRC). Cement Concrete Res. https://doi.org/10.1016/j.cemconres.2013.11.002
Zhou, M., Lu, W., Song, J., & Lee, G. C. (2018). Application of ultra-high performance concrete in bridge engineering. Construct Build Mater, 186, 1256–1267. https://doi.org/10.1016/j.conbuildmat.2018.08.036
ZorarpacI, E., & Özel, S. A. (2016). A hybrid approach of differential evolution and artificial bee colony for feature selection. Expert Syst Applicat, 62, 91–103. https://doi.org/10.1016/j.eswa.2016.06.004
Funding
The authors received no financial supports for this research, authorship and/or publication of this article.
Author information
Authors and Affiliations
Contributions
Shubhum Prakash: Methodology, Data curation, Investigation, Writing - original draft. Baboo Rai: Conceptualization, Visualization, Supervision, Writing - review & editing Sanjay Kumar: Writing - original draft, Supervision, Writing - review & editing
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no potential conflict of intrest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Prakash, S., Kumar, S. & Rai, B. A new technique based on the gorilla troop optimization coupled with artificial neural network for predicting the compressive strength of ultrahigh performance concrete. Asian J Civ Eng 25, 923–938 (2024). https://doi.org/10.1007/s42107-023-00822-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42107-023-00822-y