
Abstract
Artificial neural network (ANN) method has been applied in the present work to predict the California bearing ratio (CBR), unconfined compressive strength (UCS), and resistance value (R) of expansive soil treated with recycled and activated composites of rice husk ash. Pavement foundations suffer from poor design and construction, poor material handling and utilization and management lapses. The evolutions of soft computing techniques have produced various algorithms developed to overcome certain lapses in performance. Three of such algorithms from ANN are Levenberg–Muarquardt Backpropagation (LMBP), Bayesian Programming (BP), and Conjugate Gradient (CG) algorithms. In this work, the expansive soil classified as A-7-6 group soil was treated with hydrated-lime activated rice husk ash (HARHA) in varying proportions between 0.1 and 12% by weight of soil at the rate of 0.1% to produce 121 datasets. These were used to predict the behavior of the soil’s strength parameters (CBR, UCS and R) utilizing the evolutionary hybrid algorithms of ANN. The predictor parameters were HARHA, liquid limit (wL), (plastic limit (wP), plasticity index (IP), optimum moisture content (wOMC), clay activity (AC), and (maximum dry density (δmax). A multiple linear regression (MLR) was also conducted on the datasets in addition to ANN to serve as a check and linear validation mechanism. MLR and ANN methods agreed in terms of performance and fit at the end of computing and iteration. However, the response validation on the predicted models showed a good correlation above 0.9 and a great performance index. Comparatively, the LMBP algorithm yielded an accurate estimation of the results in lesser iterations than the Bayesian and the CG algorithms, while the Bayesian technique produced the best result with the required number of iterations to minimize the error. And finally, the LMBP algorithm outclassed the other two algorithms in terms of the predicted models’ accuracy.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Design, construction, and performance evaluation in geotechnical engineering require the calculation of soil strength properties (Kisi and Uncuoglu 2005). The strength properties of both cemented and uncemented soils are key elements needed in soil classification, characterization, and identification according to appropriate design standards (Onyelowe et al. 2020a, 2020b). Fundamentally, foundation designs related to flexible pavement subgrade depend on certain primary strength properties, which include; (a) California bearing ratio (CBR), (b) unconfined compressive strength (UCS), and (c) resistance value (R). It is important to note that previous research designs have depended only on the CBR evaluation in their designs for the strength and reliability of pavement foundation (Van and Duc and Onyelowe 2018; Van et al. 2018). Sadly, while CBR is a good determinant property in highway foundation design, it does not deal with lateral failure determination. Therefore, the combination of CBR, UCS, and R-value gives a more dependable and reliable design and even time monitoring of the structures’ performance, tests through which CBR, UCS, and R are estimated are standardized by standard conditions (BS 1377—2, 31990; BS 19241990; BS 59302015). It is highly complicated and time-consuming to determine these properties in the laboratory due to repeated test runs to achieve accurate results with less human or equipment error (Kisi and Uncuoglu 2005). Similar complications are encountered during a stabilization procedure when an expansive soil requires strength improvement before utilization as a subgrade material (Kisi and Uncuoglu 2005; Van and Duc and Onyelowe, K.C. 2018; Van et al. 2018). The aim of this paper is the assessment of the effect of a hybrid binder; hydrated-lime activated rice husk ash on the strength properties of expansive soil and the development and training of an artificial neural network (ANN), first with the Levenberg–Muarquardt backpropagation algorithm (LMBP) and correlated with the performance of Bayesian and Conjugate Gradient (CG) algorithms to predict CBR, UCS and R performance with the addition of binder based on the specimen data from 121 tests. However, there have been researches previously and ongoing in soft computing employment in civil engineering design and operation. Ferentinou and Fakir (Ferentinou and Fakir 2017) employed Levenberg–Muarquardt backpropagation algorithm (LMBP) based ANN in the prediction of UCS of various rocks using four (4) predictor parameters at the input end. The results returned at 0.99 and 0.92 for training and test states, respectively, showing the validity of LMBP-based ANN in predicting geotechnical properties supporting ANN as alternative tool in soft computing geotechnics. Nawi et al. (Nawi et al. 2013) presented that the LMBP algorithms have noticeable drawbacks such as sticking in a local minimum and slow rate of convergence and proposed an improved form trained on Cuckoo search algorithm, which increased the convergence rate of the hybrid learning method. Kingston et al. (2016) utilized the Bayesian algorithm’s ability to compare models of varying complexity to select the most appropriate ANN structure as a tool in water resources engineering. However, the Bayesian method employs alternative methods to estimate competing models’ probabilities, which is called the Markov Chain Monte Carlo (MCMC), which simulates from the posterior weight distribution to approximate the outcome. The outcome although shows that the MCMC-based Bayesian ANN performed better in this paper than the conventional model selection methods. Hosseini et al. (Hosseini et al. 2018) employed the ANN LMBP algorithm to predict soil mechanical resistance and compared the results with the conventional multiple regression (MR) by making use of bulk density and volumetric soil water content as predictors. The results showed that the intelligent method of ANN performed well. Although Sariev, and Germano (Sariev and Germano 2019) stated in their work that the Bayesian-based ANN tends to overfit data under statistical and evolutionary models as its drawback, it was used with high performance in the probability of default estimation through regularization technique. Saldaña et al. (Saldaña et al. 2020), utilized the traditional LMBP-based ANN algorithm to predict UCS with p-wave velocity, density, and porosity as predictors. The unconfined compressive strength (UCS) of cement kiln dust (CKD) treated expansive clayey soil was predicted by Salahudeen et al. (Salahudeen et al. 2020) using LMBP-based ANN. The model performance was evaluated using mean square error (MSE), and the coefficient of determination, and the results showed satisfactory performance in the prediction model. Additionally, the particle swarm optimization-based ANN was used by Abdi et al. (Abdi et al. 2020) to predict UCS of sandstones, and the results showed a reliability with a correlation of 0.974, of the PSO-based ANN model to predict UCS and recommended its utilization as a feasible tool in soft computing geotechnics. Erzin and Turkoz (Erzin and Turkoz 2016) employed ANN also in their work to predict CBR values of sands and the results showed that the predicted model and those obtained from experiments matched greatly. The performance indices were also used, which showed high prediction performance. In a two-case study presented by Kisi and Uncuoglu (Kisi and Uncuoglu 2005), three backpropagation training algorithms; Levenberg–Marquardt (LM), Conjugate Gradient (CG) and Resilient Backpropagation (RBP) algorithms were employed to predict stream flow forecasting and lateral stress determination in cohesionless soils. The primary focus of this study (Kisi and Uncuoglu 2005) was the convergence velocities in training and performance in testing. The results in the two cases showed LMBP algorithm was faster and had better performance than the other algorithms due to its design to approach second-order training speed without passing through the computation of Hessian matrix, the RBP algorithm presented results with the best accuracy in the period of testing due to its ability to transfer functions in the hidden layers by squashing, which compresses range of infinite inputs into finite outputs. In the above-cited results, the algorithms currently being used in ANN programming have performed optimally with high and low points. Additionally, the literature review has revealed that ANN has been used successfully in predicting CBR and UCS but has not been employed in the triocombination of CBR, UCS, and R predictions for the purpose more sustainable pavement design, construction, and performance monitoring. The present work compares the performance of a different set of three algorithms and tries to propose the best approach under the present predictors being used and the type of soil being studied. The results of this research work promise to present a design, construction, and performance evaluation plan to follow in a smart environment for efficient earthwork delivery.
2 Materials and methods
2.1 Materials preparation
Expansive clay soil was prepared. Tests were conducted on both untreated and treated soils to determine the datasets by observing the effects of stabilization on the predictor parameters presented in Appendix, Table 8, needed for evolutionary predictive modeling. The hydrated-lime activated rice husk ash (HARHA) is a hybrid geomaterial binder developed by blending rice husk ash with 5% by weight hydrated-lime (Ca(OH)2) and allowed for 24 h for activation reaction to complete. The hydrated lime served as the alkali activator. Rice husk is an agro-industrial waste derived from rice processing in rice mills and homes disposed of in landfills. Through controlled direct combustion proposed by Onyelowe et al. (Onyelowe et al. 2019), the rice husk mass was turned into ash to form rice husk ash (RHA). The HARHA was used in varying proportions between 0.1 and 12 in increments of 0.1 to treat the clayey soil. The response behavior with different properties were tested, observed, and recorded (see Table 8 in Appendix).
3 Methods
3.1 The algorithms of Artificial Neural Network (ANN)
7-10-3 artificial neural network training from matlab toolbox software was used in this work, which signifies the input parameters to the number of neurons and the number of outputs. This learning method has gone through a series of modifications and hybridization, in a bid to improve its performance, speed, global error, and convergence efficiency. In this work, three training algorithms were deployed: LMBP, Bayesian Programming (BP), and CG algorithms to present the algorithm with the best results fits astounding rate, reduced global error, and best performance index. However, the focus is to reduce the global error to a nearest minimum for better deployment and better outcomes. Generally, the global error is estimated with Eq. 1 (Kisi and Uncuoglu 2005);
where P = total number of training patterns, EP = error for training pattern, and (Kisi and Uncuoglu 2005);
N = total number of output nodes, Oi = network output at ith output node, ti = the target output at the ith output node. Generally, it is important to reduce this global error (see Eq. 1) in every evolutionary programming algorithm by adjusting the biases and weights.
3.2 Levenberg–Marquardt Bachpropagation (LMBP) Algorithm
This was designed to overcome the computation of Hessian matrix by approaching the second-order speed of training. As it is usual in feed-forward training network (FFTN) where the performance function has the form of a sum of squares, the Hessian matrix is usually estimated with Eq. 3 and this is usually an approximation (Kisi and Uncuoglu 2005);
where J is the Jacobian matrix. J contains the 1st derivative of the network errors with respect to biases and weights. And the gradient is usually estimated with (Kisi and Uncuoglu 2005);
where e is the vector of network errors. The iterations or trials used to obtain the best feet in LMBP algorithm usually reduce the performance function.
3.3 Bayesian programming (BP) algorithm
The Bayesian programming algorithm is a concept backed by Bayes’s theorem, which states that any prior notions pertaining to an uncertain parameter are updated and modified based on new data to produce a posterior probability of the unknown quantity (Quan et al. 2015; Zhan et al. 2012). Baye’s theorwm can be used based on ANN to compute the posterior distribution of the network weights (w) given a set of N target data y and assumed model structure (Quan et al. 2015; Zhan et al. 2012).
3.4 Conjugate gradient (CG) algorithm
The most negative of the gradients, the weight in the steepest descent direction of the model are adjusted with the basic backpropagation algorithm, which is why the performance function (PF) is reduced rapidly. Though this happens in an ANN model, it does not produce the fastest convergence. A search is performed along the conjugate directions in the deployment of CGA, and a higher rate of convergence in the steepest direction is produced in the model (Kisi and Uncuoglu 2005). This is the key factor being deployed in CGA models. Additionally, the step size is modified at each trial in CGA and the search along the CG direction determines the size of the step, which in turn minimizes the PF along the model line. This algorithm method resumes by searching along the direction of the steepest descent, the first iteration;
And to obtain the optimal distance to travel along the search direction, a line search is performed (Kisi and Uncuoglu 2005);
The fundamental procedure for determining the new search direction so that it is conjugated to the previous search direction is to combine the new steepest descent direction with the previous search direction (Kisi and Uncuoglu 2005);
The procedure of computing the constant \({\beta }_{k}\) differentiates the various versions of CGA. However, for the Fletcher–Reeves proposal, the procedure is (Kisi and Uncuoglu 2005);
Equation 8 is the ratio of the normal square of the current gradient to the normal square of the previous gradient (Kisi and Uncuoglu 2005). This was used in the study.
In Fig. 1a–c, the global flowchart of the ANN training algorithm methods and execution is presented. The 121 input and output datasets were deployed to the computing platform to generate the predicted outputs and models of that operation. Several trials or iterations were carried out to achieve the best fit. The input data are consistently fed to the network and in each instance, the calculated output result is compared with the actual result to obtain the error function. By so doing, the network’s learnable parameters (weight and bias) are adjusted such as to decrease the network’s error until the desired output result is achieved (Rezaei et al. 2009).

4 Results and discussions
4.1 Architecture of the ANN Model
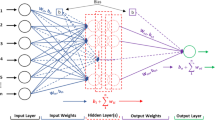
Figure 2 represents the working of the ANN model. Levenberg–Marquardt (LM backpropagation algorithm was used in model development. During the forward pass, weights are assigned to the variables according to the desired output values. Depending on the evaluation criteria, the weights are readjusted to minimize the errors (Rezaei et al. 2009; Shi and Zhu 2008).

Architecture of the ANN model
4.2 Pearson correlation analysis
According to previous studies, the current research employed Pearson correlation coefficients to measure the linear relationship between the input and output parameters (Fan, et al. 2002; Adler and Parmryd 2010; Benesty et al. 2008). The use of HARHA influenced the values of CBR, UCS, and R almost in a similar manner presented in Tables 1, 2, 3. The value of CBR depicted a strong positive linear relationship with the use of HARHA. In contrast, liquid limit, plastic limit, plastic index, and clay activity manifested a similar intensity of negative relation with CBR. The value of CBR seems to be unaffected relative to OMC. The maximum dry density greatly influenced the value of CBR, depicting a strong positive relationship. A similar type of trend was observed for the value of UCS and R values.
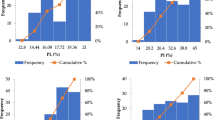
The distribution histograms were plotted for the input and output parameters, as shown in Fig. 3. A slight or no skewness was observed in both types of parameters used. The essential statistical functions have been listed in Table 3, depicting the satisfying values of skewness and kurtosis.

Distribution histogram for input (in blue) and output (in green) parameters
4.3 Statistical functions for input and output parameters of the model
The setting parameters and statistical functions of the ANN models are listed in Tables 4 and 5. 70% of the total data set was used for training the model, while 30% of the data was equally divided among testing and validation data sets. The analysis was carried out via the machine learning toolbox of MATLAB R2020b. The 10 number of hidden neurons were used based on the best model as per the evaluation criteria as shown in the setting of parameters for the ANN models presented in Table 4. The ANN was allowed to randomly pick the data points for training and validation data sets.
4.4 ANN model training and performance validation
Figure 4 manifests the training state of the ANN models. The gradient was reduced to 0.1666 after 20 iterations for the CBR model, whereas the minimum gradient for UCS, and R models was achieved in 15 and 14 iterations, respectively.

Training state of ANN model for (a) CBR, (b) UCS, (c) R
The validation of the models was carried out using a mean square error (MAE). The best performance for the validation of the CBR model was achieved in 14th iteration, and the error observed was 0.16405 as depicted in Fig. 5. Similarly, the best performance of the validation of UCS and R models was achieved at 9 and 8 epochs, respectively. The MAE observed at these epochs are 2.9159 and 0.00768, respectively.

Best performance validation for (a) CBR, (b) UCS, (c) R with corresponding epochs
The error histogram of the three models was drawn in Fig. 6, which reflects the strong correlation of the experimental and predicted results. Almost 95% of the data yields an error lesser than 1%.

Evaluation of ANN model
The comparison of experimental results and predicted values is presented in Fig. 7 and Tables 6 and 7. The coefficient of determination (R2) for the three models is more significant than 0.95, representing the most robust agreement of the experimental results to the predicted one. The other functions such as mean absolute error (MAE) (Benesty 2009; Willmott and Matsuura 2005), relative squared error (RSE), root mean squared error (RMSE) (Willmott et al. 2009), relative root mean square error (RRMSE), performance indicator(ρ) (Iqbal 2020; Babanajad et al. 2017), and objective function OBF were also used for the model evaluation. The mathematical equations of the statistical evaluation functions are presented in Eq. 9–16.
where ei and mi are nth experimental and model TSR(%), respectively; \(\stackrel{-}{{e}_{i }}\) and \(\stackrel{-}{{m}_{i}}\) denotes the average values of experimental and model TSR(%), respectively;n is the number of samples in the data set. And the subscripts T and V represent the training and validation data, and n is the total number of sample points, All statistical error evaluation functions satisfied the performance of the three models. The proximal value of OBF to zero reflects that the models are not overfitted.

Experimental and predicted trends for (a) CBR, (b) UCS, (c) R with error analysis
4.5 Comparative analysis of employed algorithms
Three algorithms were compared in terms of iterations required for the best training and validation performance using mean squared error (MAE) as shown in Fig. 8. Levenberg–Marquardt algorithm required a lesser number of iterations, followed by conjugate gradient algorithm and Bayesian algorithm. The minimum error for the training data set achieved using the Bayesian algorithm was recorded after 366, 558, and 160 iterations for CBR, UCS, and R models, respectively. In contrast, the minimum MAE for the validation data set using the conjugate gradient algorithm was observed after 30, 12, and 9 iterations for the CBR, UCS, and R models, respectively. These observations were recorded as 14, 9, and 8 epochs for the three models, i.e., CBR, UCS, and R, respectively. The authors observed a similar pattern of the number of iterations during the models’ training states, as depicted in Fig. 9. The error analysis (see Fig. 10) illustrated that LMBP algorithms outclass the other two types of algorithms regarding a close agreement to the experimental values and this results agree with the findings of Alaneme et al., (2020; Alaneme et al. 2020). However, the Bayesian and conjugate gradient algorithms also yielded acceptable errors for the specific problem. The extent of error was smaller in the case of Bayesian algorithms relative to the conjugate gradient algorithm.

Comparison of best performance validation (1) CBR model (2) UCS model (3) R model using the Bayesian algorithm (a), (d), (g), conjugate gradient algorithm (b), (e), (h), and LMBP algorithm (c), (f), (i)

Comparison of training states of (1) CBR model (2) UCS model (3) R model using the Bayesian algorithm (a), (d), (g), conjugate gradient algorithm (b), (e), (h), and LMBP algorithm (c), (f), (i)

Comparison of errors of (1) CBR model (2) UCS model (3) R model using the Bayesian algorithm (a), (d), (g), conjugate gradient algorithm (b), (e), (h), and LMBP algorithm (c), (f), (i)
5 Conclusions
From the preceding comparative model prediction utilizing Levenberg–Muarquardt Backpropagation (LMBP), Bayesian and Conjugate Gradient (CG) algorithms of the evolutionary Artificial Neural Network (ANN) for the prediction of hydrated-lime activated rice husk ash (HARHA) modified expansive soil for sustainable earthwork in a smart environment, the following can be remarked;
-
The artificial neural network has a strong ability to predict the strength properties (CBR, UCS, and R) of the soil containing HARHA. The predicted results of the ANN models using the three different algorithms accurately followed the experimental trend with a very close agreement.
-
While comparing the effect of changing algorithms, it was concluded that the LMBP algorithm yields an accurate estimation of the results in comparatively lesser iterations compared to the Bayesian and the conjugate gradient algorithms; hence, showing a faster rate of computing.
-
The pattern, Bayesian > Conjugate gradient > LMBP, was observed for the required number of iterations to minimize the error.
-
Finally, the LMBP algorithm outclasses the other two algorithms in terms of the predicted models’ accuracy (Table 8).
References
Abdi Y, Momeni E, Khabir RR (2020) A reliable PSO-based ANN approach for predicting unconfined compressive strength of sandstones. Open Construction Building Technol J 2020 14: 237–249. DOI: https://doi.org/10.2174/1874836802014010237
Adler J (2010) Parmryd J (2010) Quantifying colocalization by correlation: pearson correlation coeeficient is superior to the Mander, s overlap coefficient. Cytometry A 77(8):733–742
Alaneme GU, Onyelowe KC, Onyia ME, Bui Van D, Mbadike EM, Ezugwu CN, Dimonyeka MU, Attah IC, Ogbonna C, Abel C, Ikpa CC, Udousoro IM (2020) Modeling volume change properties of hydrated-lime activated rice husk ash (HARHA) modified soft soil for construction purposes by artificial neural network (ANN). Umudike J Eng Technol (UJET) 6(1):1–12. https://doi.org/https://doi.org/10.33922/j.ujet_v6i1_9
Babanajad SK, Gandomi AH, Alavi AH (2017) New prediction models for concrete ultimate strength under true-triaxial stress states: An evolutionary approach. Adv Eng Softw 2017(110):55–68
Benesty J et al. (2009) Pearson correlation coefficient, in Noise reduction in speech proceeding, 2009, Springer, p. 1–4
Benesty J, Chen J, Huang Y (2008) On the importance of the Pearson correlation coefficient in noise reduction. IEEE Trans Audio Speech Language Proc 16(4):757–765
BS 1377 - 2, 3, 1990. Methods of Testing Soils for Civil Engineering Purposes, British Standard Institute, London
BS 5930, (2015). Methods of Soil Description, British Standard Institute, London
BS 1924, (1990). Methods of Tests for Stabilized Soil, British Standard Institute, London
Erzin Y, Turkoz D (2016) Use of neural networks for the prediction of the CBR value of some Aegean sands. Neural Comput Applic 27:1415–1426. https://doi.org/10.1007/s00521-015-1943-7
Fan X et al. (2002). An evaluation model of supply chain performances using 5DBSC and LMBP neural network algorithm
Ferentinou M, Fakir M (2017) An ANN approach for the prediction of uniaxial compressive strength, of some sedimentary and Igneous Rocks in Eastern KwaZulu-Natal. Symp Int Soc Rock Mech Proc Eng 191(2017):1117–1125. https://doi.org/10.1016/j.proeng.2017.05.286
Hosseini M, Naeini SARM, Dehghani AA, Zeraatpisheh M (2018) Modeling of soil mechanical resistance using intelligentmethods. J Soil Sci Plant Nutr 18(4):939–951
Iqbal MF et al (2020) Prediction of mechanical properties of green concrete incorporating waste foundry sand based on gene expression programming. J Hazard Mater 2020(384):121322
Kingston GB, Maier HR, Lambert MF (2016) A Bayesian approach to artificial neural network model selection. Centre Appl Model Water Eng School Civ Environ Eng Univ Adelaide Bull 6(2016):1853–1859
Kisi O, Uncuoglu E (2005) Comparison of three back-propagation training algorithms for two case studies. Indian J Eng Materials Sci 12(2005):434–442
Nawi NM, Khan A, Rehman MZ, (2013) A new levenberg marquardt based back propagation algorithm trained with cuckoo search. In: The 4th international conference on electrical engineering and informatics (ICEEI 2013), Procedia Technology 11 (2013): p. 18 – 23. https://doi.org/https://doi.org/10.1016/j.protcy.2013.12.157
Onyelowe KC, Van Bui D, Ubachukwu O et al (2019) Recycling and reuse of solid wastes; a hub for ecofriendly, ecoefficient and sustainable soil, concrete, wastewater and pavement reengineering. Int J Low-Carbon Technol 14(3):440–451. https://doi.org/10.1093/Ijlct/Ctz028
Onyelowe KC, Onyia ME, Onukwugha ER, Nnadi OC, Onuoha IC, Jalal FE (2020) Polynomial relationship of compaction properties of silicate-based RHA modified expansive soil for pavement subgrade purposes Epitőanyag—J Silicate Based Composite Materials 72(6):223–228. https://doi.org/https://doi.org/10.14382/epitoanyag-jsbcm.2020.36
Onyelowe KC, Onyia M, Onukwugha ER, Bui Van D, Obimba-Wogu J, Ikpa C (2020) Mechanical properties of fly ash modified asphalt treated with crushed waste glasses as fillers for sustainable pavements. Epitőanyag–Journal of Silicate Based and Composite Materials 72(6):219–222. https://doi.org/https://doi.org/10.14382/epitoanyag-jsbcm.2020.35
Onyelowe KC, Alaneme GU, Onyia ME, Bui Van D, Diomonyeka MU, Nnadi E, Ogbonna C, Odum LO, Aju DE, Abel C, Udousoro IM, Onukwugha E (2021) Comparative modeling of strength properties of hydrated-lime activated rice-husk-ash (HARHA) modified soft soil for pavement construction purposes by artificial neural network (ANN) and fuzzy logic (FL). Jurnal Kejuruteraan 33(2)
Quan S, Sun P, Wu G, Hu J (2015) One bayesian network construction algorithm based on dimensionality reduction. In: 5th international conference on computer sciences and automation engineering (ICCSAE 2015), Atlantis Publishers, p. 222–229
Rezaei K, Guest B, Friedrich A, Fayazi F, Nakhaei M, Beitollahi A et al (2009) Feed forward neural network and interpolation function models to predict the soil and subsurface sediments distribution in Bam. Iran Acta Geophys 2009(57):271–293. https://doi.org/10.2478/s11600-008-0073-3
Salahudeen AB, Sadeeq JA, Badamasi A, Onyelowe KC (2020) Prediction of unconfined compressive strength of treated expansive clay using back-propagation artificial neural networks. Nigerian Journal of Engineering, Faculty of Engineering Ahmadu Bello University Samaru - Zaria, Nigeria. Vol. 27, No. 1, April 2020. ISSN: 0794 – 4756. Pp. 45 – 58
Saldaña M, Pérez-Rey JGI, Jeldres M, Toro N (2020) Applying statistical analysis and machine learning for modeling the UCS from P-Wave velocity, density and porosity on dry travertine. Appl Sci 10:4565. https://doi.org/10.3390/app10134565
Sariev E, Germano G (2019). Bayesian regularized artificial neural networks for the estimation of the probability of default. Quantitative Finance, 20: 2, 311–328, doi: https://doi.org/10.1080/14697688.2019.1633014
Shi BH, Zhu XF (2008) On improved algorithm of LMBP neural networks. Control Eng China 2008(2):016
Van B, Duc and Onyelowe, K.C. (2018) Adsorbed complex and laboratory geotechnics of Quarry Dust (QD) stabilized lateritic soils. Environ Technol Innovation 10:355–368. https://doi.org/10.1016/j.eti.2018.04.005
Van Bui D, Onyelowe KC, Van Nguyen M (2018) Capillary rise, suction (absorption) and the strength development of HBM treated with QD base Geopolymer. Int J Pavement Res Technol [in press]. https://doi.org/10.1016/j.ijprt.2018.04.003
Willmott CJ, Matsuura K (2005) Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim Res 30(1):79–82
Willmott CJ, Matsuura K, Robeson SM (2009) Ambiguities inherent in sums-of-squares-based error statisitics. Atmosp Environ 43(3):749–752
Zhan Z, Fu Y, Yang RJ et al. (2012) A Bayesian inference based model interpolation and extrapolation. SAE Int J Materials Manuf 5(2). Doi: https://doi.org/10.4271/2012-01-0223
Author information
Authors and Affiliations
Corresponding author
Appendix
Rights and permissions
About this article

Cite this article
Onyelowe, K.C., Iqbal, M., Jalal, F.E. et al. Application of 3-algorithm ANN programming to predict the strength performance of hydrated-lime activated rice husk ash treated soil. Multiscale and Multidiscip. Model. Exp. and Des. 4, 259–274 (2021). https://doi.org/10.1007/s41939-021-00093-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41939-021-00093-7