
Abstract
This year, various researchers paid the attention towards the analysis of m-polar fuzzy attributes for knowledge-processing tasks. In this process, a problem addressed while dealing with acceptation, rejection and uncertain parts of m-polar fuzzy attributes. One of suitable example is classifying the potential researchers of the given field to upscale the university ranking is a major issue for the academic or research team as it is based on multi-valued parameters. This becomes more complex when several random, ghost or fake researchers exist in the university. These types of researchers used to have several papers in most of the research areas rather than a specialized field. Hence, it is difficult for any expert to characterize them based on their truth, false or indeterminant areas based on the given n-number of papers to upscale the university ranking. To solve this problem, two methods are proposed in this paper using the algebra of n-valued neutrosophic set and its Euclidean distance with an illustrative example.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
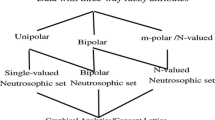
Dealing with multi-valued (Singh 2018b), m-polar (Singh 2018c) or n-valued attributes (Singh 2018e) is addressed as most crucial tasks for the Data Analytics researchers. It is indeed requirements for the researchers to analyze the n-valued attributes as it exists in various data sets (Kroonenberg 2008; Zenzo 1988). One of the most suitable and relevant example is QS rankingFootnote 1 or rating of any universityFootnote 2 used to be based on multi-valued parameters (Ascar and Yener 2009). The precise representation of these types of data sets and its analysis is indeed requirement for researchers to upscale his/her university ranking. The research paper, its indexing and citation are also used to be considered as one of the prominent parameters while declaration of QS ranking. In this process, the classification of authentic research papers and its citation from multiple indexing is another concern for the academic or research team. The reason is most of the researchers just focus on increasing the research document or citation count using some non-ethical ways. It becomes more hot spot for researchers when SCOPUS retracted several papers published by a top institute such as ISM Dhanbad,Footnote 3 Bose InstituteFootnote 4 and others institutes of India.Footnote 5 This issue created an alarm for the research communities to fix this issue at any cost and save the research from monkey, ghosts or random researchers who publish any papers in any fields without knowing the subject. The reason is document counts matter for the university ranking rather than expertise or particular research areas. The document count for the single author, multiple authors, Web of Science journal or conference papers used to be counted as one as discussed in Singh and Singh (2019). Due to that, the H-index (Batneck and Kokkelmans 2011; Senanayake et al. 2014) and citations can be manipulated by old researchers due to his/her honor, nearness of editor or a particular group, whereas the new scholars are unable to receive a citation. It can be observed when a Web of Science paper of old professor is unable to get a single citation, whereas a Google scholar paper of new scholar received more than ten citations. Hence, the citation of a paper is also vague while considering the intellectual measurement. Similarly, the citation of review or technical paper cannot be considered equally in case of intellectual measurement. The reason is that, receiving a citation for technical paper will take more time when compared to any review paper due to its less covering areas. At the same time, characterizing the citation due to its novelty, significance of results, forced citation, honor-based citation, journal to journal citation, conference to conference citation, within group citation, or editor citations is a difficult task. Sometimes, citation can be motivational or non-motivational as a paper cited due to its novelty or significance of results via which the author get motivated to start his/her research. The another citation used to receive attention due to its wrong methodology or disproval of the method. These type of citations cannot be considered equally while measuring the intellectualism of an author.
All of the above issues demolish the name of university, life of researchers as well as ethics of research which establishes to share the true knowledge rather than ranking, document count or manipulated citation. The day branding or count started playing a major role for the university ranking; each of the universities focuses on quantity of papers rather than quality of papers as addressed by several agencies, recently. In this case, characterizing the domain-based expert is a difficult task for the academic and research teams. One of the best example is the research paper published by a scholar from young university and old university such as MIT in the same journal cannot be considered at equal intellectual level. The type of effort done by the scholar of young university cannot be considered as equal to effort given by scholar of MIT while considering the intellectual measurements. However, the MIT fellow used to get first job when compared to the scholar of a young university which demotivates them. In this case, characterizing the potential scholars from these young universities is a major task for the research community to save their life or career. It is indeed requirement of the university because the potential researchers used to mentally harrased by ghost or manipulative researchers. These issues degrade the university ranking as well as life of students. To resolve this issue, a method is introduced in this paper to classify the expertise of any professor based on their published papers in n-number of journals or conferences using the mathematics of n-valued neutrosophic set and Euclidean distance (Fig. 1).

Understanding the necessity of n-valued neutrosophic concept lattice
The neutrosophic set theory is depicted in Smarandache 1998, Smarandache (2013), Smarandache (2017) as an extension of intuitionistic fuzzy sets (Atanassov 1986) for multi-decision process (Chen 2015; Chen et al. 2016a, b; Liu and Chen 2017, 2018). In this case, discovering some of the interesting patterns is addressed as a major task for the several researchers (Chen et al. 2016a; Liu and Chen 2017, 2018; Wang and Chen 2018). The problem becomes more difficult when the indeterminacy exists in each component of m-polar fuzzy attributes such as rating of any movieFootnote 6 of any event or diagnoses of disease.Footnote 7 The precise measurement of these types of n-valued neutrosophic attributes is a mathematically expensive task as discussed by Singh (2017a, b, 2018a, b, c, d, e, f) and other authors as shown in Table 1. To resolve this issue, the current paper introduces n-valued neutrosophic context and its analysis using the properties of neutrosophic graph and multigranulation. One of the applications is also given to illustrate the proposed method for investigating the potential researchers from their given n-number of papers using the n-valued attributes such as keywords, title, abstract and proposed methodology. The level of granulation to decide that the claimed paper validates his/her expertise is defined by user or expert cognition to solve the particular problem (Wilke and Portmann 2016). However, the research paper is closed to the given research areas or not is computed using the Euclidean distance. The reason is metric of Euclidean distance provides a platform for the precise measurement of given papers distinctly from n-number of research areas. The paper is closed to the given research field iff its distance is near to the define threshold as per user or expert requirement.
The motivation of current study is to characterize the n-valued neutrosophic attributes based on its acceptation, rejection and uncertain parts for knowledge-processing tasks. The objective is to find some of the impressive or useful pattern in the given n-valued context for multi-decision process. To achieve this goal, the mathematical algebra of concept lattice theory and Lower Neighbors as introduced by Lindig (2000) is utilized in this paper. It is a well-known mathematical model for knowledge-processing tasks as developed by Wille (1982). One of the significant outputs of the proposed method is that it provides a flexible way to discover some of the closest patterns in the given n-valued neutrosophic context based on user-required distance.
Remaining part of the paper is composed as follows: Sect. 2 provides some basic definitions for graphical visualization of n-valued neutrosophic context. Section 3 contains two proposed method for building the n-valued neutrosophic concept lattice and its navigation at user-defined granulation for the computed distance. Section 4 illustrates the proposed method. Section 5 includes discussions followed by conclusions and references.
2 n-valued neutrosophic context and its graphical visualization
Definition 1
(Three-way fuzzy context) (Singh 2017a; Li et al. 2017): a three-way fuzzy context can be written as K = (X, Y, \({\tilde{R}}\)). The set X represents objects, the set Y represents three-way fuzzy attributes, and \({\tilde{R}}= \{ ((x,y), T_{{\tilde{R}}}(x,y), I_{{\tilde{R}}}(x,y), F_{{\tilde{R}}}(x,y): \forall x \in X, y \in Y \}\) as a corresponding three-way relationship among them. It means the \({\tilde{R}}\) can be characterized by a truth (\(T_{{\tilde{R}}}(x,y)\)), an indeterminacy (\(I_{{\tilde{R}}}(x,y)\)) and a falsity (\(F_{{\tilde{R}}}(x,y)\)) membership-values, independently in [0, 1]\(^3\). The truth (\(T_{{\tilde{R}}}(x,y)\)), indeterminacy (\(I_{{\tilde{R}}}(x,y)\)), and falsity (\(F_{{\tilde{R}}}(x,y)\)) membership-values are real standard or non-standard subsets of \( ]0^{-},1^{+}[\) defined as \(0^{-} \le T_{{\tilde{R}}}(x,y) + I_{{\tilde{R}}}(x,y)+ F_{{\tilde{R}}}(x,y) \le 3^{+}\). Here, \(1^{-}= 1-\epsilon \) represents 1 as the standard part, whereas the \(\epsilon \) represents as its non-standard part which can be characterized as real standard format (0, 1) or [0, 1] for defining the L-fuzzy context (Burusco and Fuentes-Gonzalez 1994) in three-way fuzzy space where truth, falsity and indeterminacy are represented, independently.
Example 1
Let us suppose, the university team wants to classify the expertise of a professor working in the Data Analytics \(y_1\) in CS dept (\(x_1\)), IT dept (\(x_2\)), and MBA dept (\(x_3\)) based on their given research papers. In this case, some of the papers may lie in Data Analytics field, some are the totally irrelevant, whereas some of them may be uncertain. This case can be written precisely using the neutrosophic context as shown in Table 2. The neutrosophic relation \(\frac{(0.6, 0.3, 0.1) }{\tilde{R_{(x_1, y_1)}}}\) represents that 60% papers of CS dept (\(x_1\)) professor lies truly on Data Analytics field (\(y_1\)), 30% papers are irrelevant from Data Analytics (\(y_1\)), whereas 10% of professors’ research papers are uncertain as per its title, keywords and methodology. In a similar way, other relationships shown in Table 2 can be interpreted.
Definition 2
(n-Valued neutrosophic context) (Singh 2018e; Voutsadakis 2002): an n-valued neutrosophic context provides a way to analyze the context based on several truth membership-values (\(T_{1}, T_{2},..., T_{p}\)), indeterminacy membership-values (\(I_{1}, I_{2},..., I_{r}\)), and falsity membership-values (\(F_{1}, F_{2},..., F_{s}\)) where \(p+r+s \ge n\). The author considers the particular case, where \(p=r=s=n\), i.e. (\(T_{1}, T_{2},..., T_{n}\)), n-types of indeterminacy membership-values (\(I_{1}, I_{2},..., I_{n}\)) and n-types of falsity membership-values (\(F_{1}, F_{2},..., F_{n}\)). It means the n-valued neutrosophic relation (\({\tilde{R}}\)) on the set X and Y can be represented as follows:
where \(0^{-} \le \sum ^{n}_{i=1} T_{{\tilde{R}}_i}(x,y)+\sum ^{n}_{j=1}I_{{\tilde{R}}_j}(x,y)+ \sum ^{n}_{k=1}F_{{\tilde{R}}_k}(x,y) \le n^{+}\), where \(n=i+j+k\). The detail about n-valued neutrosophic context can be studied in Broumi et al. (2015), Senanayake et al. (2014). One of the examples for better understanding is shown by Singh (2018e).
Example 2
Let us suppose, an n-number of professors are working in the field of Data Analytics (\(y_1\)) in the given departments (i.e. \(x_1, x_2, x_3\)). In this case, their expertise can be classified using the word Data Analytics in their title, abstract, keywords, methodology or other parts as shown in Table 3, where \(\left\{ x_{1}, x_{2}, x_{3} \right\} \) represents the Departments, \(y_1\) the research topic, i.e. Data Analytics and n-valued represents the number of professors (Table 4).
Definition 3
(n-Valued neutrosophic graph) (Broumi et al. 2015; Singh 2018e): let us suppose, G = (V, E) is a neutrosophic graph in which the vertices (V) can be characterized by n-valued truth-membership function \(T_{1,...,n}(v_{i})\), n-valued indeterminacy-membership function \(I_{1,...,n}(v_{i})\) and n-valued falsity-membership function \(F_{1,...,n} (v_{i})\) where \(\left\{ (T_{1,...,n}(v_{i}), I_{1,...,n}(v_{i}), F_{1,...,n}(v_{i})) \in [0,1]^n\right\} \) for all \(v_{i} \in V\). Similarly, the edges (E) can be defined as n-valued neutrosophic set: \(\left\{ (T_{1,...,n}(V \times V), I_{1,...,n}(V \times V), F_{1,...,n}(V \times V)) \in [0,1]^3\right\} \) for all \(V \times V \in E\) such that:
Example 3
Let us suppose, the expert wants to visualize the n-number of professors in the given university based on their research areas as shown in Table 5 for precise analysis. The graphical structure visualization of given context can be resolved using the mathematical algebra of n-valued neutrosophic graphs, where the departments can be considered as vertex n-valued neutrosophic graph \(\left\{ v_{1}, v_{2}, v_{3} \right\} \) and the corresponding n-valued relationship can be considered as edges (E). The compact representation of this context is shown in Fig. 2.
The n-valued neutrosophic graph is complete iff:
It is noted that
Definition 4
(Three-way fuzzy concepts) (Singh 2017a, b): let us suppose, any given an L-set A\(\in L^{\tiny {\textit{X}}}\) of objects an L-set A\(^{\uparrow }\in L^{\tiny {\textit{Y}}}\) of attributes can be defined using the UP operator (\(\uparrow \)) of Galois connection as given below:
Similarly, for any L-set of B\( \in L^{\tiny {\textit{Y}}}\) of attributes an L-set B\(^{\downarrow }\in L^{\tiny {\textit{X}}}\) of objects set can be defined using down operator (\(\downarrow \)) of Galois connection as follows:
A\(^{\uparrow } (y)\) is interpreted as the L-set of attribute y\(\in \textit{Y}\) shared by all objects from A. Similarly, B\(^{\downarrow } (x)\) is interpreted as the L-set of all objects x\(\in \textit{X}\) having the same attributes from B in common. This can be computed similarly for truth, indeterminacy and falsity membership-values for the given neutrosophic set of attributes. The pair (A, B) is called as formal neutrosophic concept iff \(\textit{B}^{\downarrow }\) = \((\textit{A}, (T_A, I_A, F_A))\) and \(\textit{A}^{\uparrow }\) = \((B, (T_B, I_B, F_B))\). The \(\downarrow \) is applied on three-way fuzzy attributes as follows:
It provides the covering objects set as follows:
The obtained object set has a maximal membership for the truth, indeterminacy and falsity membership-values while integrating the information from the given three-way fuzzy attributes. In a similar way, the UP arrow (\(\uparrow \)) can be applied on the obtained object sets which provide three-way fuzzy attributes having maximal membership-values while integrating the information from the constituted objects set for its truth, falsity and indeterminacy membership-values. The discovered pair of object and attribute sets will be called as three-way fuzzy concepts. In this paper, the author tries to extend it to n-valued neutrosophic attributes in the next section.
3 Proposed method
This section introduced two methods for analysis of n-valued neutrosophic contexts for knowledge-processing tasks.
3.1 The proposed method for generating the n-valued neutrosophic concepts
In this section, a method is proposed to generate the n-valued neutrosophic concepts based on their Lower Neighbors as given below:
Step 1 Let us suppose, a n-valued three-way fuzzy context K = (X, Y, \(\tilde{R_n}\)), where \(|X|=k\), \(|Y|=m\) and, \(\tilde{R_n}\) represents a mapping for their corresponding n-valued neutrosophic relationship among them as shown in Table 6.
Step 2 The first n-valued neutrosophic concepts can be generated using the attributes which covers all the objects set with user-required level of acceptance.
Step 3 The maximal covering attributes for each object set can be discovered using the UP operator (\(\downarrow \)), i.e. \(A_{s_{i}}^{\uparrow }\) = \(B_{s_j}.\)
Step 4 The neutrosophic membership-value for the obtained set of attributes can be computed as follows:
where \(j\le n\) and \({\tilde{R}}\) represent the n-valued neutrosophic relationship between given object and attribute sets.
Step 5 The covering object set, i.e. \(A_{s_i}\), for the obtained attribute set can be discovered using down arrow (\(\downarrow \)), i.e \(B_{s_{j}}^{\downarrow }\) = \(A_{s_i}\).
Step 6 The neutrosophic membership-values can be computed as follows:
where \(i\le n\) and \({\tilde{R}}\) represent the n-valued neutrosophic relationship between given object and attribute sets.
Step 7 The obtained pair (\(A_{s_i}\), \(B_{s_j}\)) can be called as n-valued neutrosophic concepts.
Step 8 Find the Lower Neighbors for the first concept using the addition of their uncovered attributes, i.e.: \(y_k\) = \(Y-y_{j}\), where \(j\le m\) and \(k \le m\).
Step 9 Discovered the maximal n-valued neutrosophic concepts for each of the obtained Lower Neighbors using the Galois connection (\(\downarrow , \uparrow \)).
Step 10 Build the n-valued concept lattice based on their obtained Next Neighbor concepts. Table 7 summarizes the proposed algorithm established above.

An n-valued neutrosophic graph
Complexity The proposed method generates the concepts using their Lower Neighbors for the given n-valued neutrosophic context having m number of attributes and k number of objects. The Lower Neighbor is generated using maximal acceptance of complex fuzzy attributes which may take O(k.m) time complexity for the truth, indeterminacy and falsity membership-values, independently. It takes maximal O\((m^{2}. k.n )\) time complexity that will provide overall O\((|C|.m^{4}.k^{2}.n)\) time complexity, where C is Lower Neighbor. One of the significant advantages of using the Next Neighbor algorithm is that it builds the concept and edges among them simultaneously. It provides an adequate way for finding the next successor of the given concept based on top-down algorithm which helps in breadth first searching. It is also helpful in removing the non-maximal candidate while generating the Next Neighbor concepts. This reduces the time complexity of user or expert to find the adequate pattern for knowledge-processing tasks when compared to subset-based method shown in Singh (2018e).
3.2 The proposed method for closest n-valued neutrosophic attribute selection
This section introduces a method for the discovery of closest n-valued neutrosophic attributes and its object set based on Euclidean distance and its metric. This metric provided a tool to measure the distance via fixing two points on a line or considering any chosen point as the origin. In this way, it provides a way to compute the distance among two points in n-space too, where the distance among two points can be computed. At the same time, it gives a mathematical way to process the given context based on user defined multi-granulation (Qi and Wei 2018). Recently, Singh (2017b) its properties are utilized to discover some closest patterns in the single-valued neutrosophic attributes using Euclidean distance. This paper aimed at discovering the n-valued closest set of attributes for multi-decision process. To achieve this goal, the properties of granular computing discussed by Pedrycz and Chen (2015) are utilized in this paper. The objective is to refine or coarse the obtained pattern based on the user or expert requirement. The steps of the proposed method are given as below:
Step 1 Let us suppose, two n-valued neutrosophic attributes set as follows:
-
(1)
\(\left\{ B_{1}, (T_{B_1}, I_{B_1}, F_{B_1})\right\} \) and (2) \(\left\{ B_{2}, (T_{B_2}, I_{B_2}, F_{B_2})\right\} \).
Step 2 Select the attributes \(B_1\) and \(B_2\) to compute the Euclidean distance.
Step 3 Compute the Euclidean distance as follows:
- (1)
\(T_{E_{d}}(B_1, B_2)\) = \( \sqrt{(T_{B_1}-T_{B_2})^{2}}\).
- (2)
\(I_{E_{d}}(B_1, B_2)\) = \( \sqrt{(T_{B_1}-T_{B_2})^{2}}\).
- (3)
\(F_{E_{d}}(B_1, B_2)\) = \( \sqrt{(T_{B_1}-T_{B_2})^{2}}\).
Step 4 Similarly, compute for each n-valued neutrosophic components.
Step 5 The average n-valued neutrosophic Euclidean distance can be computed for each component as follows:
- (1)
\(T_{E_{AD}(B_{1}, B_{2})}\) = \(\frac{\sum T(E_d (B_1, B_2))}{ \max (|B_{1}|, |B_{2}|)}\).
- (2)
\(I_{E_{AD}(B_{1}, B_{2})}\) = \(\frac{\sum I(E_d (B_1, B_2))}{ \max (|B_{1}|, |B_{2}|)}\).
- (3)
\(F_{E_{AD}(B_{1}, B_{2})}\) = \(\frac{\sum F(E_d (B_1, B_2))}{ \max (|B_{1}|, |B_{2}|)}\),
where \(|B_1|\) and \(|B_2|\) represent the number of attributes in the set \(B_{1}\) and, \(B_{2}\), respectively.
Step 6 It represents the neutrosophic Euclidean distance as (\(T_{12}, I_{12}, F_{12})_{ED}\) for the n-valued neutrosophic attributes \(B_1\) and \(B_2\).
Step 7 The closest set of attributes can be chosen based on defined level of neutrosophic granulation for the computed distance, i.e. \((\alpha , \beta , \gamma )\)-cut, where \(\alpha \) level is defined for truth, \(\beta \) level defined for indeterminacy and \(\gamma \) level is defined for falsity.
Step 8 The set of attributes or its corresponding objects can be decided as closest iff:
Step 9 The set of attributes having lowest distance is considered as closest which depends on the variation in neutrosophic granulation, i.e. \((\alpha , \beta , \gamma )\)-cut.
Step 10 It can be observed that the level of granulation varies from an expert to solve the particular problem. In case the expert wants to select 80% closest concepts without any indeterminacy then the \((\alpha , \beta , \gamma )\) = (0.8, 0.0, 0.2).
Complexity Let us suppose, the number of attributes in the given n-valued neutrosophic context is m (or number of objects is k). The proposed method computes neutrosophic distance based on truth, falsity, indeterminacy membership-values, independently. It may take maximum O(\(m *m *m \)) (or O(\(n *n *n\))) time complexity for each n-valued neutrosophic relations. Hence, the proposed method takes overall O(\(m^3.n\)). It is one of the significant advantages of the proposed method while considering the time constraints.
4 Illustrations
In this section, each of the proposed method is illustrated considering one of the n-valued neutrosophic contexts with their comparative study of the obtained results to validate the results.
4.1 n-Valued neutrosophic context and its application
At the moment, one of the applications of the n-valued neutrosophic context is shown in Singh (2018e) with illustration. At the same time, some other researchers have given an application of n-valued neutrosophic contexts to measure the rating or ranking of any university. It is used to based on different research fields and publications. In this case, a precise measurement of a potential professor and its output become one of the crucial tasks for the academic as well as research team. This problem arises due to following circumstances:
- 1.
The professor is recruited due to caste-based reservation,Footnote 8 by paying moneyFootnote 9 or some other resources by management in a country such as India.
- 2.
The professor undeserved the given post but recruited due to nearness/dearness/fake data/predatory journal publication to give less salary.Footnote 10
- 3.
The professor is forced to write other names without his/her contribution just to appease some one.Footnote 11
- 4.
The higher authority of university forces scholar or faculties to write his/her name to get the promotions, increments or other facility. In this case, the professors do not know who wrote his name and which paper came online. It can be identified easily when a professor got accidently more papers in a year, i.e. per week one paper without knowing the subject.
- 5.
The professors forced by management to publish the papers in predatory journalsFootnote 12 or cnferencesFootnote 13 without any facility, proper salary just to increase the document counts or ranking.Footnote 14
- 6.
The professor is monkey- or ghost-type researchers who have papers in several research fields without expertise.Footnote 15
- 7.
The professor is manipulative and try to publish their papers in a journal or conference where the Editor of Journal is either his/her supervisors or somehow related.Footnote 16
- 8.
The professor writes sometime rebuttal, review papers, and conference papers just to increase counts without any novelty.Footnote 17
- 9.
The professors or students are bound to write the research papers to get QS ranking without any research lab and any motivation, which create many issues.Footnote 18
- 10.
The paper is retractedFootnote 19 due to plagiarism.Footnote 20 It happened recently in ISM Dhanbad, Bose Institute and others as discussed in Sect. 1.
- 11.
The selection committee does not recruit the well-qualified candidate due to their own insecurity of job at some cases.
- 12.
Standardization of impact factor and indexing became a measurement of intellectuals rather than content of paper.Footnote 21
- 13.
The professor used to receive their name via paying money to scholars or scholars selling papers due to his poor condition in a country such as India.
Each of the above-mentioned issues are a cognisable offense which damages the name of university, career of scholars as well as students. The reason is research becomes document count, ranking, producing mountain of garbage, power, prestige or influencing someone. However, its motive is to share the true knowledge and ideas among the scholars to solve the particular problem of society. In this, it is indeed a requirement for the university to find some of potential researchers in the given field for job, promotions, increments and other multi-decision process. It became more difficult when n-numbers of professors claim the same. To deal with this issue, a current paper tried to resolve the problem using the mathematical algebra of n-valued neutrosophic contexts as shown in Sect. 3.1. One of the examples is illustrated with an example as given below:
Example 6
Let us suppose the university wants to find one of the suitable researchers in field of data analytics (\(y_1\)), quantum computing (\(y_2\)), and soft computing (\(y_3\)). In this regard, the university team finds three departments, i.e. information technology (IT), computer science (CS) and applied mathematics (AM) departments, i.e. \(\left\{ x_1, x_2, x_3\right\} \) which run these courses. It is well known that each department used to contain more than one professor in the given research field; among them characterizing one of the potential faculty is a rigorous task. In general, the academic or research team characterizes the expertise based on their acceptation, rejection and uncertain parts of published research papers by the given professor. Let us suppose, there are three professors who claim the same from each department by providing their ten best research papers in the given field.
The academic or research team can characterize those research papers in particular field based on their acceptance, rejection and uncertain parts via matching of keywords, title, abstract, methodology from the given field as shown in Table 7. It provides a neutrosophic value to represent the expertise of a given professor for the particular field. Let us suppose, a professor from IT department having 60% papers truly belonging to Data Analytics, 30% papers are uncertain, whereas 20% papers are not in Data Analytics. This classification can be represented using the neutrosophic relation as shown in first entry of Table 8 which computation is shown in Table 7. Similarly, Tables 9 and 10 represent the CS and AM department expertise of given field. Table 11 represents the composed format of Tables 8, 9, and 10 in the form of n-valued neutrosophic context.
The goal is to find some of the impressive patterns from the context shown in Table 11 for multi-decision process. To achieve this goal, the proposed method shown in Sect. 3.1 can be utilized as follows:
Step 1 To illustrate the proposed method shown in Table 5 the n-valued neutrosophic context shown in Table 11 is considered.
Step 2 The first concept can be generated using the attributes which cover all the object set maximally. It can be discovered using UP arrow (\(\uparrow \)) of Galois connection as follows:
Step 3 The membership-values of covering attributes for its truth, indeterminacy and falsity-values can be computed as follows: \(T_{B_{s_j}}(y_{j})\) = \(\min _{j \in T_{B_{s_j}}} \mu ^{{\tilde{R}}}_{T}(x_i,y_j)\), \(I_{B_{s_j}}(y_{j})\) = \(\max _{j \in I_{B_{s_j}}} \mu ^{{\tilde{R}}}_{I}(x_i,y_j)\), \(F_{B_{s_j}}(y_{j})\) = \(\max _{j \in F_{B_{s_j}}} \mu ^{{\tilde{R}}}_{F}(x_i,y_j)\). It provides following neutrosophic attributes as an Intent:
Step 4 Similarly, apply the \(\downarrow \) on the obtained objects set as follows:
Step 5 The membership-values of covering objects for its truth, indeterminacy and falsity-values can be computed as follows: \(T_{A_{s_i}}(x_{i})\) = \(\min _{j \in T_{A_{s_i}}} \mu ^{{\tilde{R}}}_{T}(x_i,y_j)\), \(I_{A_{s_i}}(x_{i})\) = \(\max _{i \in I_{A_{s_i}}} \mu ^{{\tilde{R}}}_{I}(x_i,y_j)\), \(F_{A_{s_i}}(x_{i})\) = \(\max _{i \in F_{A_{s_i}}} \mu ^{{\tilde{R}}}_{F}(x_i,y_j)\). It provides the following neutrosophic attributes as an Intent:
Step 6 In this way, it provides a formal neutrosophic concept as follows:
Concept 1 Extent:
Intent:
Information This concept shows that professor number 3 of each department has maximal papers in the given departments, i.e. (0.9, 0.1, 0.0).
Step 7 Now add the uncovered attributes \(y_1\), \(y_2\), and \(y_3\) independently to the attributes of concept 1 and others recursively for generating its lower neighbors. It provides the following concepts:
Concept 2 Extent:
Intent:
Concept 3 Extent:
Intent:
Concept 4 Extent:
Intent:
Step 8 Similarly other concepts can be generated using Galois connection via adding the uncovered attributes \(y_k\) = \(Y-y_{j}\), where \(j\le m\) and \(k \le m\) on the concept numbers 2, 3 and 4.
Step 9 It provides the following maximal membership-values Lower Neighbor as concepts:
Concept 5 Extent:
Intent:
Concept 6 Extent:
Intent:
Concept 7 Extent:
Intent:
Concept 8 Extent:
Intent:
Information This concept shows that professor 3 from IT (\(x_1\)) and applied mathematics (\(x_3\)) have almost equal papers in data analytics (\(y_1\)), soft computing (\(y_2\)) as well as quantum computing (\(y_3\)) when compared to any other professors in the given university. Hence, these two professors can be considered as potential researchers in these two fields equally. Other professors have either 3 or 4 papers in these areas.
Step 10 The n-valued neutrosophic concepts are shown in Fig. 3. The knowledge extracted from above-mentioned concepts is shown in Table 12. It shows that the professor 3 from Applied Mathematics is an expert in the given field when compared to any researchers in the university, whereas the professor 3 from CS department stands at the second. The IT department contains professors 1 and 3 as experts of Data Analytics and Quantum computing, respectively. In this way, the management can pay more attention to professor 3 in terms of lab facility, increments, promotions or other research facility to increase the QS ranking of the given university. In case these professors does not get any liabilities automatic, the ranking of university is affected by random or ghost researchers which may spoil the name of university. In this way, the proposed method will be helpful for the university research team to maintain university ranking via utilizing the maximal effort of the potential researchers in the given university.

Three-way n-valued neutrosophic concept lattice generated from Table 13
4.2 Euclidean distance measurement of n-valued neutrosophic attributes
In the previous section, it is observed that the number of concepts generated from the proposed method shown in Sect. 3.1 provides repeated concepts. It becomes irrelevant when an expert wants to analyze some of the closest or productive professor based on given acceptance value for the n-valued neutrosophic attributes. To fulfill this need, another method is proposed in Sect. 3.2 to find some of the closest n-valued neutrosophic attributes (or objects set) based on their Euclidean distance for truth, falsity and indeterminacy, independently. Recently, it is introduced for processing the single-valued neutrosophic attributes data sets by Singh (2017b).
To illustrate the proposed method shown in Sect. 3.2, the current paper utilizes the context shown in Tables 8, 9 and 10 to compute the Euclidean distance. The problem is to find some of the potential professors in the given research field having maximal papers in the given fields with minimum indeterminacy (i.e. minimum plagiarism, minimum randomness, minimum manipulative), and falsity (i.e. in different areas), i.e. (1, 0, 0) neutrosophic values. Table 13 represents the computed Euclidean distance for the neutrosophic values shown for each professor shown in Table 8. It shows that the professor 3 has the lowest Euclidean distance, i.e. (0.24, 0.14, 0.12), when compared to any other professor. Similarly, Table 14 shows the Euclidean distance of neutrosophic values for the professors shown in Tables 9 and 10. It shows the professor 3 of each department having lowest distance from the given subject and its expertise based on their research papers. It means the professor 3 is one of the potential experts in the given field based on the requirement commensurate with knowledge discovered in Table 12.
Table 15 represents the comparative analysis of the proposed methods with recently available approaches in n-valued neutrosophic sets (Fatimah et al. 2018; Senanayake et al. 2014) on various parameters. Table 15 represents the comparative analysis of the proposed method with recently, introduced method in Singh (2018e). It represents that each of the available methods focuses on precise representation of n-valued neutrosophic attributes without any mathematical analysis for knowledge-processing tasks. In this way, the proposed methods in this paper are distinct from following approaches:
It provides a mathematical way to visualize the n-valued neutrosophic attributes in the graph.
It provides a method for precise refinement of closed or similar attributes based on their Euclidean distance defined in N-valued space.
This significance differentiates the proposed methods from three-way n-valued neutrosophic concept lattice shown in Singh (2018e). One of the useful examples is given for the application of the proposed method which will be helpful for the university academic or research team to identify some potential researchers based on their n-number of published papers. In future, the author will try to incorporate the theory of fuzzy hypergraph for the adequate analysis of n-valued context as discussed by William-West and Singh (2018a).
5 Conclusions
This paper introduced a mathematical model to characterize the n-valued attributes based on its acceptation, rejection and uncertain parts, independently with its graphical visualization. At the same time, a method is proposed to discover some of the interesting patterns based on the computed Euclidean distance at user-defined granulation with an illustrative example. The analysis derived from the proposed method is also compared with recently available approaches as shown in Table 15. It shows that the proposed method provides a more significant way for the analysis of n-valued neutrosophic contexts within O\((|C|.m^{4}.k^{2}.n)\) and \(O (m^{3}. n)\) time complexity, where C represents Lower Neighbor, m number of attributes, and k represents number of objects in the given n-valued neutrosophic context. In near future, the author will focus on other applications of n-valued neutrosophic sets and introducing some of its metric.
Notes
References
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20(1):87–96
Akram M, Adeel A, Alcantud JCR (2019) Group decision-making methods based on Hesitant N-Soft Sets. Expert Syst Appl 115:95–105
Alkhazaleh S (2017) N-Valued refined neutrosophic soft set theory. J Intell Fuzzy Syst 32(6):4311–4318
Alkhazaleh S, Hazaymeh A (2018) N-valued refined neutrosophic soft sets and their applications in decision making problems and medical diagnosis. J Artif Intell Soft Comput Res 8(1):79–86
Ascar E, Yener B (2009) Unsupervised multiway data analysis: a literature survey. IEEE Trans Data Knowl Eng 21(1):6–20
Batneck C, Kokkelmans S (2011) Detecting h-index manipulation through self co-citation analysis. Scientometrics 87:85–98
Burusco A, Fuentes-Gonzalez R (1994) The study of the L-fuzzy concept lattice. Math Soft Comput 1(3):209–218
Broumi S, Deli I, Smarandache F (2015) N-valued interval neutrosophic sets and their application in medical diagnosis. Crit Rev Center Mathematics of Uncertainty, Creighton University, USA 10:46–69
Chen SM (2015) A novel similarity measure between Atanassov’s intuitionistic fuzzy sets based on transformation techniques with applications to pattern recognition. Inform Sci 291:96–114
Chen SM, Cheng SH, Lan TC (2016a) Multicriteria decision making based on the TOPSIS method and similarity measures between intuitionistic fuzzy values. Inform Sci 367–368:279–295
Chen SM, Cheng SH, Chiou CH (2016b) Fuzzy multiattribute group decision making based on intuitionistic fuzzy sets and evidential reasoning methodology. Inform Fusion 27:215–227
Fatimah F, Rosadi D, Hakim RBF, Alcantud JCR (2018) N-soft sets and their decision making algorithms. Soft Comput 22(12):3829–3842
Formica A (2018) Similarity reasoning in formal concept analysis: from one-to many-valued contexts. Knowl Inform Syst. https://doi.org/10.1007/s10115-018-1252-4
Kroonenberg PM (2008) Applied multiway data analysis. Wiley, New York
Li JH, Huanga C, Qi J, Qian J, Liu W (2017) Three-way cognitive concept learning via multi-granularity. Inform Sci 378:244–263
Lindig C (2000) Fast concept analysis. In: Ganter B, Mineau GW (eds.) ICCS 2000, LNCS, vol 1867. Springer, Heidelberg, pp 152–161
Liu P, Chen SM (2017) Group decision making based on Heronian aggregation operators of intuitionistic fuzzy numbers. IEEE Trans Cybern 47(9):2514–2530
Liu P, Chen SM, Liu J (2017) Multiple attribute group decision making based on intuitionistic fuzzy interaction partitioned Bonferroni mean operators. Inform Sci 411:98–121
Liu P, Chen SM (2018) Multiattribute group decision making based on intuitionistic 2-tuple linguistic information. Inform Sci 430–431:599–619
Pedrycz W, Chen SM (2015) Granular computing and decision-making: interactive and iterative approaches. Springer, Heidelberg
Qi J, Wei L (2018) Wan Q (2018) Multi-level granularity in formal concept analysis. Granular Comput. https://doi.org/10.1007/s41066-018-0112-7
Singh PK (2017a) Three-way fuzzy concept lattice representation using neutrosophic set. Int J Mach Learn Cybern 8(1):69–79
Singh PK (2017b) Medical diagnoses using three-way fuzzy concept lattice and their Euclidean distance. Comput Appl Math 37(3):3282–3306. https://doi.org/10.1007/s40314-017-0513-2
Singh PK, Aswani Kumar C (2017c) Concept lattice reduction using different subset of attributes as information granules. Granular Comput 2(3):159–173. https://doi.org/10.1007/s41066-016-0036-z
Singh PK (2018a) Complex vague contexts analysis using Cartesian products and granulation. Granular Comput. https://doi.org/10.1007/s41066-018-0136-z
Singh PK (2018b) \(m\)-polar fuzzy graph representation of concept lattice. Eng Appl Artif Intell 67:52–62
Singh PK (2018c) Concept lattice visualization of data with \(m\)-polar fuzzy attribute. Granular Comput 2(3):159–173. https://doi.org/10.1007/s41066-017-0060-7
Singh PK (2018d) Object and attribute oriented m-polar fuzzy concept lattice using the projection operator. Granular Comput. https://doi.org/10.1007/s41066-018-0117-2
Singh PK (2018e) Three-way \(n\)-valued neutrosophic concept lattice at different granulation. Int J Mach Learn Cybern 9(11):1839–1855. https://doi.org/10.1007/s13042-018-0860-3
Singh PK (2018f) Interval-valued neutrosophic graph representation of concept lattice and its (\(\alpha, \beta, \gamma \))-decomposition. Arab J Sci Eng 43(2):723–740
Singh PK, Singh CK (2019) Bibliometric Study of Indian Institutes of Technology in Computer Science. In: Proceedings of Amity International Conference on Artificial Intelligence held at Dubai, Feb 4–6, 2019 (Accepted for Publication)
Smarandache F (1998) Neutrosophy. Neutrosophic probability set, and logic. ProQuest Information & Learning, Ann Arbor
Smarandache F (2013) \(n\)–Valued refined neutrosophic logic and its applications to physics. Infinite Study 4:143–146
Smarandache F (2017) Plithogeny, plithogenic set, logic, probability, and statistics, Pons Publishing House, Brussels
Senanayake U, Piraveenan M, Zomaya AY (2014) The p-index: ranking scientists using network dynamics. Procedia Comput Sci 29:465–477
Voutsadakis G (2002) Polyadic concept analysis. Order 19:295–304
Wang CY, Chen SM (2018) A new multiple attribute decision making method based on linear programming methodology and novel score function and novel accuracy function of interval-valued intuitionistic fuzzy values. Inform Sci 438:145–155
Wilke G, Portmann E (2016) Granular computing as a basis of humandata interaction: a cognitive cities use case. Granular Comput 1(3):181–197
Wille R (1982) Restructuring lattice theory: an approach based on hierarchies of concepts. In: Rival I (ed) Ordered sets. NATO Advanced Study Institutes Series (Series C — Mathematical and Physical Sciences), vol 83. Springer, Dordrecht, pp 445–470
William-West TO, Singh D (2018) Granular computing as a basis of human-data interaction: a cognitive cities use case. Granular Comput 3(1):75–92
Zenzo SD (1988) A many-valued logic for approximate reasoning. IBM J Res Dev 32(4):552–565
Acknowledgements
The author sincerely thanks the reviewers and Editor for their comments.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The author declares that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Singh, P.K. Multi-granular-based n-valued neutrosophic context analysis. Granul. Comput. 5, 287–301 (2020). https://doi.org/10.1007/s41066-019-00160-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41066-019-00160-y