
Abstract
Purpose of Review
We review recent methodological advancements in estimation of distance-dependent landscape effects on terrestrial species. These methods address key theoretical elements from landscape and metapopulation ecology that were ignored in previous approaches. Models that treat landscapes as circles within which all land features are equally important to a focal population ignore distant-dependent population processes, such as dispersal, resource selection, and social interactions. Realistic models that estimate variation in landscape-scale effects over space and time are necessary to understand the complex processes that influence population dynamics.
Recent Findings
The addition of kernel smoothers to generalized linear models has potential to increase the biological realism of landscape-species models. These models include estimation of parameters that dictate the relationship between distance and importance of landscape features to focal populations. There are examples of implementing these models in both maximum likelihood and Bayesian frameworks, as well as examples using model selection to determine appropriate smoothing kernel shape. One key limitation of these models is computational effort, although we provide some guidance for reducing model runtime.
Summary
Models allowing for inference on explicit ecological processes are critical to advancing knowledge of the basic landscape ecology of species and will benefit efforts to prioritize conservation and evaluate species recovery efforts. We describe how distance-dependent landscape-scale effect models can be used for these purposes in a variety of scenarios. We conclude by proposing a process-based, spatio-temporal framework for understanding the mechanisms behind the spatial scale at which landscapes influence species.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Understanding the spatial scale at which landscape features influence ecological processes (the scale of effect) has been a central part of ecology for decades [1,2,3,4,5,6]. Although the importance of landscape-level processes on local patterns is now widely recognized, challenges still remain that hinder inference about the scale of effect [7]. One challenge is that many of the early statistical methods that were employed to estimate the scale of effect ignored important sources of uncertainty as well as key theoretical elements from landscape ecology and metapopulation ecology, such as distance decay functions [8]. A second obstacle is that mechanisms governing the scale of effect are variable and complex [9], making it difficult to identify unifying themes [7, 10•].
The primary objective of this paper is to review recent methodological developments that address the statistical issue described above. In particular, we summarize recent advancements in estimating distance-dependent landscape effects, and we identify strengths and weaknesses of these approaches that warrant for further investigation. The distance-dependent approach assumes that the influence of a landscape feature on local population processes (e.g., local abundance) decreases continuously with increasing distance between the feature and local process. An important weakness that we focus on is that most efforts to understand the scale of effect have ignored temporal dynamics, which often are critical to understanding the mechanisms giving rise to observed patterns. We end by proposing a general framework for using spatio-temporal models to draw inferences on the scale of effect.
The Biological Relevance of Landscape Scale
Landscape ecology, as described by Forman [11], centers on the spatial relationship among land features and ecosystems, the movement of elements and species among them, and the dynamic nature of these processes. Landscape ecology is ingrained with concepts of geography [12], biogeography [13, 14], and phytosociology [15]. There are hundreds of metrics that could be used to measure the complexity of any given landscape [16]. These measurements adequately describe the landscape, yet they do not in themselves illuminate the ecological processes operating within those landscapes. To understand the relationships between populations (or communities or single organisms) and their surrounding landscape, a species-centric view is required [17,18,19,20,21].
The processes that govern genetic diversity, occupancy, and abundance are complex and often influenced by inter-patch dynamics [22]. Consider a scenario where we use several years of counts of breeding adults to monitor population growth of two resident birds (species A and B) that use similar resources and inhabit the same region. Population growth of species A is sensitive to chick survival, and population growth of species B is sensitive to adult survival. As the young of species A disperse from nests, their survival varies with the distribution and abundance of foraging cover (row crops). Adult survival of species B varies with the distribution and abundance of resources critical for nesting (native warm season grass) and overwinter forage (row crops). Resource selection and survival of both species are moderated by patch adjacency to predator habitat and degree of patch isolation. Dispersal of species A occurs over a larger area than the selection of nesting and overwinter forage of species B. Would we uncover these mechanisms or the scale of effect of these mechanisms if we used models with general measures of landscape complexity such as contagion, edge density, or patch diversity? Identifying these species-specific relationships and the degree to which these relationships decay with distance would require not only measuring appropriate landscape features at correct spatial scales but the collection of biological data at appropriate temporal scales. Moreover, although it would require much data, a dynamic model that explicitly models survival, reproduction, immigration, and emigration at the biologically appropriate scales would be ideal. Dynamic inter-patch processes such as foraging [23], nest site selection [24], mate finding [25], migration, or seeking refuge from predators [26] can induce landscape-scale effects. The mismatch in scale between our measurements and the dynamic nature of landscape processes has long been a concern in ecology [27] and necessitates a nuanced, biologically realistic approach to modeling landscape context.
The Threshold Landscape Model
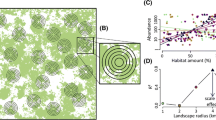
Studies that relate landscape context (e.g., landscape composition and complexity) to local population processes have typically defined the landscape as a circular region surrounding the focal site [28]. In studies considering multiple spatial scales, landscapes are concentric circles that expand until some large distance from the focal patch is reached [e.g., 29]. When an appropriate scale is chosen either through a priori model construction, arbitrarily, or through model selection, the assumption is that all land features within that circle are equally important to the focal patch. In other words, everything in the landscape matters to the local population up to a certain distance threshold (Fig. 1, middle panel). The threshold model is essentially a distance-dependent approach that assumes the effect of landscape features is uniform out to a prescribed distance. The benefit of the threshold model of landscapes is that it is easily translated to conservation prescriptions. For example, it allows managers to predict how populations will respond to variation in landscape cover types or landscape complexity and make management recommendations in a direct way, e.g., “x hectares of y land cover within d distance are needed to increase local populations by z amount”. Under the threshold model, any placement of the prescribed land cover within the defined landscape is acceptable, whether it be directly adjacent to the focal site or at the edge of the landscape.

The two approaches to estimating landscape-scale effects: the threshold method and the distance-dependent method. Both approaches attempt to answer the same question: what extent of the landscape should we consider? Specifically, the distance-dependent approach seeks to answer “how does the strength of landscape effects decrease with distance?”. For example, on the left, how much of the landscape surrounding the sampling point (red circle) matters to the population within the sampling point? Heuristically, we can consider this question in terms of “relative importance” (middle panel). The threshold approach assumes all land features within some buffer are equally important to the focal population. Land features outside of that buffer have no impact on the focal population. The distance-dependent approach assumes some decline in importance (e.g., a Gaussian function) with increasing distance to the focal population. The resulting landscapes between the two approaches can be markedly different (right panel). The colors of the distance weighted landscape represent relative importance, ranging from high (purple) to low (yellow)
Distance-Dependent Landscape Effects
A linchpin of landscape and spatial ecology is Tobler’s first law of geography: “everything is related to everything else, but near things are more related than distant things” [30]. Space is a critical component of resource selection, and resource selection is tied to fitness [31]. Is it likely that all areas within a species-specific landscape are equally available or important to the species? Dispersal is not a uniform process, but rather dispersal outcomes are best described using kernels that decay with distance [32, 33]. Foraging behavior is another distance-dependent process [34,35,36]. At the core of modern metapopulation theory lie distance-dependent extinction and immigration rates [37]. Any one of these processes could be the underlying mechanism of a particular landscape-scale effect and would violate the assumption of the landscape threshold model. Conservation prescriptions made via the landscape threshold model may have substantial negative consequences if the biological process underlying landscape population responses is distance-dependent. Miguet et al. [38••] found that accounting for a decline in landscape effect with increasing distance improved model performance slightly but had significant implications for landscape management. For example, if conservation funding is limited, the landscape threshold model would overestimate the size of the surrounding area needing landscape management [38••]. This could lead to conservation of areas that have no possible benefit to the focal population which would waste valuable resources. More direct comparisons of the landscape threshold model and distance-dependent model are needed, but a distance-dependent landscape model may describe many systems better than a threshold landscape model. Additionally, the distance-dependent approach can produce spatially explicit conservation prescriptions that the landscape threshold model cannot (e.g., conservation 3000 m away is 88% less influential than conservation 1000 m away [39••]).
Aue et al. [40] suggested that weighting landscape features by their distance to focal populations would improve our ability to make inferences about landscape-scale effects. Recent advancements in methods that consider landscape effects as distance-dependent processes have emerged in terrestrial ecology [40, 41••]. These approaches are similar to those used in aquatic ecology [42] and home range estimation [43], for example. The scale of effect typically defines a distinct area within which landscape features influence a population, community, or some other response metric of interest at a localized site [44] (Fig. 1, middle panel). The distance-dependent approach seeks to estimate an area relevant to local populations but also to describe a relationship between increasing distance and the importance of landscape features to the localized site (Fig. 1, middle panel). In reality, this translates to a landscape weighted by importance to the local population, where at some distance, the effect of that land feature on local processes is negligible (Fig. 1, right panel). This area where distance-weighted effects are substantially greater than zero is conceptually similar to the scale of effect described by the landscape threshold model (Fig. 1, right panel). In this review, we will refer to the output of distance-dependent models as “distance-dependent effects”.
Review Methodology
We searched for peer-reviewed journal article titles, abstracts, keywords, and subject headings published from January 2010 to April 2020 using the following Boolean search entered into the University of Georgia Library Multi-Search tool, a tool that utilizes many databases simultaneously, including Web of Science, ScienceDirect, and Wildlife and Ecology Studies Worldwide: “landscape AND (smoother OR kernel OR distance based OR distance-based OR distance-dependent OR distance dependent OR distance-decay OR distance decay) AND (response grain OR spatial extent OR spatial scale OR scale of effect OR characteristic scale OR spatial scaling) AND (ecology OR wildlife OR conservation) AND (occupancy OR abundance OR community)”. We then evaluated each manuscript returned from our search (n = 69) and retained those relevant to our review (i.e., manuscripts related to terrestrial species-landscape relationships; n = 47). To supplement our initial search, we also conducted ancillary searches of relevant terms using Google Scholar and Mendeley. Several manuscripts that we found used distance decay in their models, for example, to describe the decline in beetle species richness as distance from conservation practices increased [45], but did not estimate scale of effect per se, so these manuscripts were excluded from our review. Additionally, we evaluated manuscripts that cited Chandler and Hepinstall-Cymerman [41••] and Miguet et al. [38••] because these manuscripts were specifically dedicated toward developing distance-dependent approaches to estimating species-landscape interactions. In total, we focused on 9 manuscripts for this review that developed or applied the distance-dependent approach to estimating terrestrial species-landscape relationships [38••, 39••, 40, 41••, 42,43,44,45,46,47, 48••, 49, 50••].
The General Approach to Estimating Distance-Dependent Landscape Effects
Both Chandler and Hepinstall-Cymerman [41••] and Miguet et al. [38••] thoroughly describe the process of estimating distance-dependent landscape effects, so we will summarize the general approach briefly. The main assumption when estimating distance-dependent landscape effects is, of course, that if there is an influence of a landscape feature on local population processes, the strength of that effect decreases with distance from the focal point. Practically, there must be a way to estimate this relationship using data common to landscape-species studies (e.g., counts or presence/absence data). The manuscripts reviewed here all used kernel smoothing approaches. For determining landscape-scale effects, the smoothing parameters can be estimated [38••, 41••, 48••, 49] or determined via model selection [40, 50••]. Both approaches are structurally similar in that they apply a kernel to smooth a spatially explicit covariate (e.g., forest cover) around each sampling point to compute a distance-weighted covariate value. It is important to note that the spatial covariate must be discretized, for example, into concentric, non-overlapping rings [48••] or pixels [39••]. A distance matrix is then calculated between each sampling site and each discrete unit of the spatial covariate (e.g., a site x pixel matrix). A matrix of spatial covariate values associated with each discrete unit and sampling site (e.g., a site x pixel matrix) is also provided as data.
The maximum distance between sampling sites and points in the landscape considered in the model (dmax) is either defined by the availability of spatial covariates or defined by the investigator a priori as some distance that is predicted to encompass all landscape effects [e.g., 39••, 48••]. Spatial covariates should extend beyond the boundaries of the study area by dmax to avoid biased estimates introduced by boundary edge effects. If initial modeling indicates that distance-dependent landscape effects extend beyond this area, i.e., if there is non-negligible kernel weight at dmax, the investigator should increase dmax. During the estimation process for any one site, the vector of spatial covariate values associated with surrounding discrete units (e.g., rings or pixels) are weighted and summed according to the modeled kernel smoother.
For illustration, if we were to estimate the effects of forest density (forest) on the abundance (Ni,t) of an amphibian at ephemeral wetland sites (indexed by i) over 10 years (indexed by t) using a Gaussian smoothing kernel embedded in a generalized linear model, we may model abundance in year 1 as:
where λi, 1 is expected abundance at site i in year 1, β0 is the intercept of the linear model, and β1 is the coefficient of effect of distance-weighted forest density on year 1 abundance, s(foresti, 1, σ1). The value of forest density at site i in year 1 is the sum of distance-weighted forest values within surrounding areas j (e.g., each discretized ring):
where weights in year 1 w1 at each distance from site i to ring (or pixel) j is determined by a Gaussian kernel:
where d is the distance between site i and ring (or pixel) j. Note that when using rings to discretize the landscape, this equation also includes the area of each non-overlapping concentric ring [9]. The Gaussian kernel used here has one parameter, σ1, dictating its shape in year 1. In subsequent years, we could model N as random Poisson process, with expected abundance λi, t varying based on realized abundance in the previous year, some intrinsic growth rate γ0, and the effect of landscape-scale forest density on growth rate γ1, where each year we allow scale of effect σt to vary:
We allow the scale of effect to vary among years to reflect (phenomenologically) any shifts in population dynamics that drive the relationship between landscape-scale forest density and abundance (e.g., juvenile dispersal or predation). A temporal lag in the effect of landscape processes on local abundance could be included in the model as well. The parameters could be estimated within the model [39••, 41••] or determined via model selection [38••].
Model Considerations
Kernel Shape
The kernels typically have 1 or 2 parameters that dictate the shape of the relationship between increasing distance and the weight of a landscape feature (see Table 1 in Miguet et al. [38••]). Gaussian kernels were most commonly used to weight landscapes [39,40,••, 40, 41••, 48••]. Kovács et al. [50••] used a rotationally symmetric two-dimensional t distribution kernel. Miguet et al. [38••] describe several alternative kernels, including negative exponential and exponential power functions. Practically any function that decreases with distance could be used to weight landscape features, including a threshold model (Fig. 1) or a step function [49]. The selection of the kernel could be informed by biological processes [46]. For example, if it is expected that landscape effects decrease sharply with increasing distance, a negative exponential function or an exponential power function may be most appropriate. Yeiser et al. [39••], Aue et al. [40], Chandler and Hepinstall-Cymerman [41••], Moll et al. [48••], and Kovács et al. [50••] defined the shape of the kernel a priori, and Miguet et al. [38••] used model selection to determine the most appropriate kernel shape. Miguet et al. [38••] compared identically parameterized models with different weighting functions that defined the spatial smoothing kernel, including a threshold model, using Akaike’s information criterion (AIC [51]). If model selection indicates that any one model has substantial support, this would alleviate assumptions about the shape of the relationship between increasing distance and importance of landscape features. In general, functions that include more than one parameter (e.g., the exponential power family of functions) provide greater flexibility [38••]. However, adding parameters to the scale of effect may increase the difficulty of estimation.
Shape Parameter Estimation Vs Selecting a Shape Parameter Via Model Selection
The parameters controlling the shape of the weighting kernels have been estimated in both likelihood-based [40, 41••] and Bayesian frameworks [39••, 48••, 49] and selected via model selection in a likelihood-based framework [38••, 50••]. Estimation of kernel shape parameters is the same as estimating any other unknown parameter in likelihood-based or Bayesian frameworks [39,40,••, –40, 41••, 48••, 49]. For model selection, several candidate models with the same parameterization are considered; however, each has different values assigned to the shape parameters that dictate the relationship between land features and distance [38••, 50••]. The models are then ranked according to some information criterion (e.g., AIC [51]). Estimation can be difficult if there are small effect sizes or little spatial autocorrelation in landscape metrics [41••]. Making inference via model selection may also be difficult in these scenarios (e.g., many models would receive equal support). One drawback of using model selection to determine distance-based landscape effects is that it is difficult to understand the uncertainty around shape parameters. Selecting one characteristic scale of effect (i.e., the top model) would not carry any uncertainty. Averaging predictions over all candidate models is one way to incorporate uncertainty into the model selection approach. In general, we expect that the inference would be similar whether using an estimation approach or a model averaging approach. As with any model, fitting these models to data that is information poor would lead to very high uncertainty.
Limitations
There can be great computational effort associated with estimating distance-based landscape effects. Computational effort in this case can be increased in many ways (e.g., model complexity, Bayesian vs Frequentist approach), but directly relevant to the distance-dependent approach are the resolution of the discretized landscape (i.e., pixel size or ring width) and extent of the study area considered (dmax). As with any spatial analyses, there is a tradeoff between the resolution of the data and the geographic extent at which you can make inferences when computational resources are limiting. As mentioned in The General Approach to Estimating Distance-Dependent Landscape Effects section, initial analyses will determine if dmax is sufficiently large. Extending dmax and maintaining the same resolution of the discretized landscape could result in models that require excessive memory or processing time. High-performance computing via cloud services allows relief from typical limits of processing and memory limits on local machines. If high-performance computing services are not available, then a solution is to lower the resolution of the discretized covariate. This could lead to estimation and inference issues if response variables of interest vary at resolutions finer than that of the distance-weighted covariate (i.e., the modifiable aerial unit problem [52, 53]). Additionally, increasing dmax too far can lead to estimation issues as there is less variation among sampling points when distance-weighted landscapes substantially overlap [41••].
Primary Knowledge Gap: What Governs the Scale of Effect?
Predicting the mechanisms of species’ scale of effect could improve the design of reserve networks, conservation corridors, enrollment of conservation parcels in working landscapes, and the design of regional-scale ecological research. Miguet et al. [9] hypothesized several mechanisms for species’ selection of spatial scale: local movements, dispersal movements, population density, space-time relationships, and numerous indirect effects. The sensitivity of a species’ dynamics to these processes can vary with time and space [e.g., 54], which suggests the potential for spatio-temporal variation in scale of effect in any given population. The potential complexity in the mechanisms that drive scale of effect is likely akin to the complexity that drives population dynamics. So far, there is little evidence for any unifying mechanisms governing scale of effect [9, 48].
Our understanding of the mechanisms behind distance-dependent landscape effects will be accelerated by study designs and models grounded in biologically relevant hypotheses. Suárez-Castro et al. [55] found that in landscape ecology, “interactions between species traits and landscape structure are usually ignored”. Ecologists interested in understanding landscape-scale effects should approach study design in context of the question: “why would there be landscape-scale effects?”. Two related questions should be considered: (1) which population processes (e.g., fecundity, dispersal) are governing population outcomes (e.g., abundance, site occupancy)? and (2) are there land features at biologically relevant scales that influence those population processes? Explicitly considering biological traits or processes that influence distance-dependent landscape effects would dictate land cover classification [56], the sampling design, the spatial extent of the study, the resolution (temporal and spatial) of data collected, and the type of modeling approach used. While there is not likely to be one consistent predictor of scale of effect across species and landscapes, we find it plausible that there could emerge a hierarchy of mechanisms consisting of those outlined in Miguet et al. [38••] that are consistent among taxa. For example, we would predict that movement capabilities, likely allometrically influenced, would be an intrinsic predictor of scale of effect, while factors like population density, landscape fragmentation, and local movement patterns moderate scale of effect across different geographies.
An additional complication is that many of the processes that could govern scale of effect may be occurring simultaneously. It is not uncommon for a study to uncover several spatial scales at which species respond to environmental change [10•]. In context of the distance-dependent view of landscape-scale effects, this means multiple relevant relationships between increasing distance from the focal point and importance of landscape features. Several processes, including resource distributions that vary over space and time influencing different vital rates and differing spatial scale at which these processes are occurring, can contribute to the species-specific nature of habitat and landscapes [21]. When estimating one distance-dependent relationship, are we essentially averaging across several distinct spatially explicit processes and producing one relationship that may not represent any relevant population-landscape relationship? A potential avenue for further model development is uncovering ways to estimate multi-dimensional scale selection within a single species and compare this to estimating multiple distant-dependent relationships.
Bridging the Knowledge Gap: A Proposed Spatio-Temporal Framework
Many studies of landscape-scale effects include estimation of abundance or occupancy, which are snapshots of populations that are dictated by births, deaths, emigration, and immigration. The scale of effect estimated from occupancy and abundance data is an emergent property that results from spatio-temporally explicit processes. Let us return to our example in the The Biological Relevance of Landscape Scale section of how dispersal and resource selection of young in species A influences breeding season abundances. The variation in the abundance estimates is reflecting processes that occurred during the previous breeding season. Even if breeding season abundance is sensitive to young survival during the previous year, there are other events occurring between two breeding seasons that can influence populations. As a result, inference on the mechanisms behind changing demography is muddled. In this case, we would learn more by measuring age-structured survival via mark-recapture methods and relating survival to landscape features [55, 56]. In the same way that a scale of effect estimator can be embedded in the linear model of abundance, it can be included in these generalized linear models. Estimating the influence of landscape structure on key vital rates in conjunction with estimating breeding population size would provide a broader understanding of the mechanisms driving the dynamics of this population. The costs of capturing and monitoring individuals increase substantially with scale, however, so integrating data sets that include broad-scale, information poor data (e.g., occupancy or abundance) with various local-scale, information rich data would provide an avenue for understanding the mechanisms of population dynamics across large geographic areas [57, 58].
There are several additional processes that have lagging effects on populations. For example, occupancy often has less to do with current conditions than site and landscape conditions of the previous year. Estimating metapopulation dynamics using a spatio-temporal framework allows for understanding how time lags and spatial processes influence populations [59]. In general occupancy, abundance, or diversity at any given site is a result of interspecific and intraspecific interactions and spatio-temporal variation in vital rates. These processes inherently vary over space and time. In order for us to understand the landscape-scale consequences of habitat loss, resource fragmentation, or climate change on species of conservation concern, we need to house our models and hypotheses within a spatio-temporal framework. In this context, the inference of these models is greatly enhanced by estimating distance-dependent landscape effects.
Conclusions
It is increasingly clear that landscape-scale effects moderate the success of broad-scale conservation programs, and in light of limited funding, fleeting political capital, and the urgency of species decline across the globe, it is imperative that we use models that are defensible and based in biological realism. The emergence of distance-dependent methods when estimating scale of effect in terrestrial systems is a welcome advance that we believe can improve the application of landscape ecology to conservation problems. Landscape effects should be evaluated in a way that is driven by hypotheses around the mechanisms of species’ scale selection. This would accelerate the construction of a literature database that could be leveraged to make predictions about scale of effect that would influence conservation and management planning.
Trial and error will undoubtedly be an integral part of developing this method for use in terrestrial landscape ecology. There are many practical considerations to implementing these models, including ensuring the appropriate scale of data is used, managing computation time, selecting the most appropriate smoothing kernel, and finding effective ways of translating distance decay relationships into conservation prescriptions. The application of distance dependence to estimating landscape-scale effects is in its early stages, but the literature referenced herein should provide an initial set of caveats, considerations, and model structures for the practitioner to consider [38••, 39••, 40, 41••, 42,43,44,45,46,47, 48••, 49, 50••].
References
Papers of particular interest, published recently, have been highlighted as: • Of importance •• Of major importance
Forman RTT, Godron M. Patches and structural components for a landscape ecology. Bioscience. 1981;31:733–40.
Wiens JA. Spatial scaling in ecology. Funct Ecol. 1989;3:385–97.
Forman RTT. Some general principles of landscape and regional ecology. Landsc Ecol. 1995;10:133–42.
Turner MG. Landscape ecology: what is the state of the science? Annu Rev Ecol Evol Syst. 2005;36:319–44.
Wilson MC, Chen XY, Corlett RT, Didham RK, Ding P, Holt RD, et al. Habitat fragmentation and biodiversity conservation: key findings and future challenges. Landsc Ecol. 2016;31:219–27.
Levin SA. The problem of pattern and scale in ecology. Ecology. 1992;73:1943–67.
Jackson HB, Fahrig L. Are ecologists conducting research at the optimal scale? Glob Ecol Biogeogr. 2015;24:52–63.
Hanski I. Metapopulation ecology. New York: Oxford University Press; 1999.
Miguet P, Jackson H, Jackson N, Martin A, Fahrig L. What determines the spatial extent of landscape effects on species? Landsc Ecol. 2016;31:1177–94.
• Stuber EF, Fontaine JJ. How characteristic is the species characteristic selection scale? Glob Ecol Biogeogr. 2019;28:1839–54. Present evidence that there is variation within and among species regarding the spatial scale dictating population-landscape relationships, and they indicate that it is likely there are multiple spatial scales of selection for any one species.
Forman RTT. An ecology of the landscape. Bioscience. 1983;33:535.
Troll C. The geographic landscape and its investigation. In: Weins JA, Moss MR, Turner MG, Mladenoff DJ, editors. Foundation papers in landscape ecology. 2006. New York: Columbia University Press; 1950.
Lack D. Ecological features of the bird faunas of British small islands. J Anim Ecol. 1942;11:9–36.
MacArthur RH, Wilson EO. An equilibrium theory of insular zoogeography. Evolution (N Y). 1963;17:373–87.
Whittaker RH. Vegetation of the Great Smoky Mountains. Ecol Monogr. 1956;26:1–80.
Mcgarigal K, Cushman SA, Ene E. FRAGSTATS v4: spatial pattern analysis program for categorial and continuous maps. Amherst: Comput Softw Progr Prod by authors Univ Massachusetts; 2012.
Wiens JA. Population responses to patchy environments. Annu Rev Ecol Syst. 1976;7:81–120.
Carr LW, Fahrig L. Effect of road traffic on two amphibian species of differing vagility. Conserv Biol. 2001;15:1071–8.
Holland JD, Fahrig L, Cappuccino N. Body size affects the spatial scale of habitat–beetle interactions. Oikos. 2005;110:101–8.
Fahrig L, Baudry J, Brotons L, Burel FG, Crist TO, Fuller RJ, et al. Functional landscape heterogeneity and animal biodiversity in agricultural landscapes. Ecol Lett. 2011;14:101–12.
Betts MG, Fahrig L, Hadley AS, Halstead KE, Bowman J, Robinson WD, et al. A species-centered approach for uncovering generalities in organism responses to habitat loss and fragmentation. Ecography (Cop). 2014;37:517–27.
Gaillard JM, Festa-Bianchet M, Yoccoz NG. Population dynamics of large herbivores: variable recruitment with constant adult survival. Trends Ecol Evol. 1998;13:58–63.
Proffitt KM, Hebblewhite M, Peters W, Hupp N, Shamhart J. Linking landscape-scale differences in forage to ungulate nutritional ecology. Ecol Appl. 2016;26:2156–74.
Thogmartin WE. Landscape attributes and nest-site selection in wild turkeys. Auk. 1999;116:912–23.
Walter JA, Firebaugh AL, Tobin PC, Haynes KJ. Invasion in patchy landscapes is affected by dispersal mortality and mate-finding failure. Ecology. 2016;97:3389–401.
Thaker M, Vanak AT, Owen CR, Ogden MB, Niemann SM, Slotow R. Minimizing predation risk in a landscape of multiple predators: effects on the spatial distribution of African ungulates. Ecology. 2011;92:398–407.
Wiens JA. Scale problems in avian censusing. Stud Avian Biol. 1981;6:513–21.
Quinn JE, Brandle JR, Johnson RJ. The effects of land sparing and wildlife-friendly practices on grassland bird abundance within organic farmlands. Agric Ecosyst Environ. 2012.
Herrmann HL, Babbitt KJ, Baber MJ, Congalton RG. Effects of landscape characteristics on amphibian distribution in a forest-dominated landscape. Biol Conserv. 2005;123:139–49.
Tobler WR. A computer movie simulating urban growth in Detroit region. Econ Geogr. 1970;46:234–40.
Southwood TRE. Habitat, the templet for ecological strategies? J Anim Ecol. 1977;46:336–65.
Allen SH, Sargeant AB. Dispersal patterns of red foxes relative to population density. J Wildl Manag. 1993;57:526–33.
Verhulst S, Perrins CM, Riddington R. Natal dispersal of great tits in a patchy environment. Ecology. 1997;78:864–72.
Holtcamp WN, Grant WE, Vinson SB. Patch use under predation hazard: effect of the red imported fire ant on deer mouse foraging behavior. Ecology. 1997;78:308–17.
Kunkel KE, Pletscher DH, Boyd DK, Ream RR, Fairchild MW. Factors correlated with foraging behavior of wolves in and near glacier National Park, Montana. J Wildl Manage. 2004;68:167–78.
Brown JS, Laundre JW, Gurung M. The ecology of fear: optimal foraging, game theory, and trophic interactions. J Mammal. 1999;80:385–99.
Hanski I, Ovaskainen O. Metapopulation theory for fragmented landscapes. Theor Popul Biol. 2003;64:119–27.
•• Miguet P, Fahrig L, Lavigne C. How to quantify a distance-dependent landscape effect on a biological response. Methods Ecol Evol. 2017;8:1717–24. Describe the different methodologies and considerations of using a distance-dependent approach to estimating scale of effect, and they explore differences between the distance-dependent and threshold-based approach to landscape-scale effect estimation.
•• Yeiser JM, Morgan JJ, Baxley DL, Chandler RB, Martin JA. Private land conservation has landscape-scale benefits for wildlife in agroecosystems. J Appl Ecol. 2018;55:1930–9. Demonstrate how distance-dependent scale of effect estimation can be used in context of conserving species within fragmeneted landscapes.
Aue B, Ekschmitt K, Hotes S, Wolters V. Distance weighting avoids erroneous scale effects in species-habitat models. Methods Ecol Evol. 2012;3:102–11.
•• Chandler RB, Hepinstall-Cymerman J. Estimating the spatial scales of landscape effects on abundance. Landsc Ecol. 2016;31:1383–94. Demonstrate and assess the use of smoothing kernels to estimate landscape-scale effects on abundance
Walsh CJ, Webb JA. Spatial weighting of land use and temporal weighting of antecedent discharge improves prediction of stream condition. Landsc Ecol. 2014;29:1171–85.
Worton BJ. Kernel methods for estimating the utilization distribution in home-range studies. Ecology. 1989;70:164–8.
Brennan JM, Bender DJ, Contreras TA, Fahrig L. Focal patch landscape studies for wildlife management: optimizing sampling effort across scales. In: Liu J, Taylor WW, editors. Integr Landsc Ecol into Nat Resour Manag. Cambridge: Cambridge University Press; 2002. p. 68–91.
Boetzl FA, Krimmer E, Krauss J, Steffan-Dewenter I. Agri-environmental schemes promote ground-dwelling predators in adjacent oilseed rape fields: diversity, species traits and distance-decay functions. J Appl Ecol. 2019;56:10–20.
Heaton MJ, Gelfand AE. Kernel averaged predictors for spatio-temporal regression models. Spat Stat. 2012;2:15–32.
Heaton MJ, Gelfand AE. Spatial regression using kernel averaged predictors. J Agric Biol Environ Stat. 2011;16:233–52.
•• Moll RJ, Cepek JD, Lorch PD, Dennis PM, Robison T, Montgomery RA. At what spatial scale(s) do mammals respond to urbanization? Ecography (Cop). 2019;43:171–83. Use a distance-dependent approach to scale of effect estimaiton to understand landsacpe-scale effects of urbanization on mammal communities.
Frishkoff LO, Mahler DL, Fortin MJ. Integrating over uncertainty in spatial scale of response within multispecies occupancy models yields more accurate assessments of community composition. Ecography (Cop). 2019;42:2132–43.
•• Kovács G, Kaasik R, Lof ME, van der Werf W, Kaart T, Holland JM, et al. Effects of land use on infestation and parasitism rates of cabbage seed weevil in oilseed rape. Pest Manag Sci. 2019;75:658–66. Use distance-dependent methods to estimate the effects of surrounding landscape features on infestation rates of insects in agricultural landscapes.
Burnham KP, Anderson DR. Model selection and multimodel inference. New York: Springer-Verlag; 2002.
Openshaw S. Concepts and techniques in modern geography number 38 - the modifiable areal unit problem. Norwick: Geo Books; 1984.
Best NG, Ickstadt K, Wolpert RL. Spatial Poisson regression for health and exposure data measured at disparate resolutions. J Am Stat Assoc. 2000;95:1076–88.
Guo Q, Taper M, Schoenberger M, Brandle J. Spatial-temporal population dynamics across species range: from centre to margin. Oikos. 2005;108:47–57.
Suárez-Castro AF, Simmonds JS, Mitchell MGE, Martine M, Rhodes JR. The scale-dependent role of biological traits in landscape ecology: a review. Curr Landsc Ecol Reports. 2018;3:12–22.
Fahrig L, Baudry J, Brotons L, Burel FG, Crist TO, Fuller RJ, et al. Functional landscape heterogeneity and animal biodiversity in agricultural landscapes. Ecol Lett. 2011;14:101–112
Schaub M, Abadi F. Integrated population models: a novel analysis framework for deeper insights into population dynamics. J Ornithol. 2011;152:227–37.
Besbeas P, Freeman SN, Morgan BJT, Catchpole EA. Integrating mark-recapture-recovery and census data to estimate animal abundance and demographic parameters. Biometrics. 2002;58:540–7.
Howell PE, Muths E, Hossack BR, Sigafus BH, Chandler RB. Increasing connectivity between metapopulation ecology and landscape ecology. Ecology. 2018;99:1119–28.
Funding
John Yeiser, Richard Chandler, and James Martin received funding from the University of Georgia. James Martin received funding from McIntire-Stennis grant GEOZ0194-MS and Richard Chandler received funding from National Science Foundation grant DEB-1652223.
Author information
Authors and Affiliations
Contributions
J. Yeiser, R. Chandler, and J. Martin searched and reviewed literature and edited the manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Spatial Scale-Measurement, Influence, and Integration
Rights and permissions
About this article

Cite this article
Yeiser, J.M., Chandler, R.B. & Martin, J.A. Distance-Dependent Landscape Effects in Terrestrial Systems: a Review and a Proposed Spatio-Temporal Framework. Curr Landscape Ecol Rep 6, 1–8 (2021). https://doi.org/10.1007/s40823-020-00061-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40823-020-00061-w