
Abstract
Ongoing market requirements and real-time demands have led to intense competiveness in the manufacturing industry. Hence competitors are bound to employ newer means of manufacturing systems that can handle the ongoing market conditions in a flexible and efficient manner. To tackle these problems manufacturing control systems have evolved to the distributed manufacturing control system by exploiting their control architectures. These distributed control architectures provide an efficient mechanism that gives reactive and dynamically optimized system performance. This paper studies the impact of design and control factors on the performance of flexible manufacturing system. The system is evaluated on the basis of makespan, average machine utilization and the average waiting time of parts at the queue. Discrete-event based simulation models are developed to conduct simulation experiments. The results obtained were subjected to multi-response optimization as per Grey based Taguchi methodology. The effect of control architecture was statistically significant on the performance of flexible manufacturing system.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The global competition and ever-changing market requirements have led to throat cut competition in industries. There is a need for highly customized products, products with high quality at lower costs, increased product diversity in smaller lots and short makespan times (MST). In the existing market scenario, competitors are bound to employ newer means of manufacturing systems that can handle the ongoing market conditions in a flexible and efficient manner. The technologies like computer integrated manufacturing (CIM), robotics and flexible manufacturing system (FMS) have been a center of attraction for researchers to successfully employ and attain the competitive edge over the others.
Flexibility enables a manufacturing system to respond to changes in volume, product-mix, variety and quality at low cost. The inherent flexibility in manufacturing system can be attributed to its components, capabilities, interconnections, mode of operation and control. Today, flexibility is an integrated element of the manufacturing systems, and hence, the emergence of FMS is one of the important keys to organizational success. FMS is designed to best suit the batch production requirements with moderate variations of product types in midvolumes. Browne et al. (1984) studied eight different flexibilities namely routing, machine, operation, production, expansion, process, product, and volume. Later on Sethi and Sethi (1990) added three more to this list namely material handling, program and market flexibility.
Practically, manufacturing systems operate in dynamic environments experiencing machine failure, order cancellation, etc. In the presence of such real-time events, it becomes very difficult to produce products on schedule. The problem of scheduling involves provision of resources to process different types of jobs. Each job consists of a sequence of operations performed by exactly one machine. The sequence in which jobs are sequenced significantly influences the system performance which is to be optimized (Pezzellaa et al. 2008). Thus, scheduling has to be an ongoing reactive process where there is continuous schedule revision and updates taking place to tackle various disturbances occurring at the shop floor. Such a problem which involves scheduling under dynamic environments is known as dynamic scheduling. The approach of dynamic scheduling is of great importance for scheduling parts in a dynamic environment like FMS. An effective scheduling process allows the firms to effectively utilize the resources to fulfill the objectives as per production plans (Girish and Jawahar 2009). Hence, the quality of solution for the scheduling problems is of great significance in the industry (Motaghedi-larijani et al. 2010). Several approaches have been proposed to solve the scheduling problem. One such approach is distributed scheduling (Cardin et al. 2017).
Recently, research is focused on finding better scheduling solutions in the least possible times. The scheduling approaches can be broadly categorized as traditional scheduling and distributed scheduling approaches. The conventional scheduling methods are basically centralized, i.e., central decision-making is involved for all the events taking place. These methods are essentially inflexible, less responsive to machine failure, operator absence, etc. (Shen and Norrie 1999). However, in distributed scheduling approaches; based on heterarchical control architectures, the decision-making is delegated to different decision-making entities. One of the distributed approaches, referred to as multi-agent based scheduling has exhibited several potential advantages of better flexibility, reactiveness and robustness than the traditional scheduling systems (Ouelhadj and Petrovic 2009). Hence, multi-agent based scheduling systems are considered as one of the most important methods for solving dynamic scheduling issues. In multi-agent systems, the decision-making entities are known as agents. These agents are made autonomous to take their decisions and work in cooperation and coordination with other agents to achieve their goals.
A simulation experiment is conducted to study the effects of control architecture, sequencing flexibility, buffer capacity and scheduling rules on the performance of FMS. When operations on a part can be performed in any order without any precedence between operations, there exists sequencing flexibility. Sequencing flexibility is product specific instead of process specific. The issue of scheduling the parts in the presence of sequencing flexibility is complicated by physical constraints like processing of different parts at different machining stations with different priorities (Choi and James 2004). For this study, the performance of the FMS domain is evaluated based on control architecture along with sequencing flexibility, buffer capacity, and scheduling rules as the motivating factors. As the first step, FMS configuration and part data regarding processing requirements have been established. Four models of three control architecture types (CA), four levels of sequencing flexibility (SFL), four buffer capacity levels (BC) and four scheduling control rules are considered for the detailed study. The performance of the system is evaluated in terms of performance measures: makespan time (MST), average machine utilization (AMU) and the average waiting time at the queue (AWQ). Taguchi’s (L4) orthogonal array is used to design the simulation experiments. Grey relational analysis is conducted for the optimized system performance. The results obtained are statistically analyzed to establish the significance of the study. Hence, in this paper an attempt has been made to develop a distributed scheduling framework. This framework is used to investigate the effect of various design factors (control architectures, sequencing flexibility, and buffer capacity) and control factors (sequencing and dispatching rules) on the performance of FMS. Therefore, the objectives of the present study are as follows:
-
To study the effects of control architecture, sequencing flexibility, buffer capacity; and sequencing and dispatching rules on the performance of FMS.
-
To study the interaction among control architecture, sequencing flexibility, buffer capacity; and sequencing and dispatching rules in the selected FMS environment.
-
To optimize the performance measures of FMS.
This paper is organized as follows. Introduction is given in section one. This is followed by section two which deals with relevant literature in the area of research. Section three presents the problem formulation and assumptions. Section four discusses the operational logic for simulation model. Section five underlines Grey based Taguchi’s methodology for multiple performance characteristics optimization while section six presents simulation experiment results. Section seven encompasses the results analysis and discussions. The findings of the present work and conclusions are stated in section eight.
Literature Review
In view of ongoing industrialization and market requirements, it is becoming increasingly difficult to produce the required product at the right time and cost. The ever-changing market conditions, high variety of custom products, and uncertainties encountered during manufacturing activities have made the existing manufacturing control problems difficult to handle. Hence, there is a requirement of a control system architecture that exhibits flexibility as well as provide optimal performance (Gunasekaran and Ngai 2012).
Conventionally, the existing manufacturing control architectures; based on hierarchical control architectures, have the advantage of optimized system performance but are not flexible and responsive enough to meet the market requirements. However, the distributed manufacturing control; based on heterarchical control architectures, have a heterarchical relationship among the decisional entities or agents. These control architectures are endowed with responsiveness, flexibility, scalability, and fault-tolerance against perturbations (Leitão 2009). The agents in distributed control architectures cooperate and coordinatewith the other agents for the attainment of their objectives. Maione and Naso (2003) proposed a heterarchical manufacturing control application in a flexible assembly system. Leitão et al. (2012) presented an approach for dynamic task allocation and dynamic routing of pallets based on heterarchical control. Borangiu et al. (2014) considered a multi-agent based control problem to solve operation scheduling, product routing and resource allocation problems in an FMS cell. Rajabinasab and Mansour (2011) studied the heterarchical multi-agent scheduling for flexible job shop having stochastic events. Xiong and Fu (2018) developed a simulation model to exploit routing and process flexibilities with constraints and to provide good quality solutions.
These heterarchical control studies have resulted in better reactivity and robustness against disturbances. However, they lack certainty, and minimum system performance cannot be guaranteed (Jimenez et al. 2016). In such situation it is found that semi-heterarchical control architecture, combines the benefits of hierarchical and heterarchical control architectures. The decisional entity at the upper or global level (hierarchical position) can act as a coordinator, mediator or facilitator to the lower or local level (heterarchical) entities, depending upon their functionality. The global control manages the overall system performance while reactivity is maintained at the local level (Monostori et al. 2006). Chou et al. (2013) studied a flexible job shop scheduling problem based on semi-heterarchical control. Barbosa et al. (2015) investigated a semi-heterarchical based distributed control mechanism that exhibits emergent behavior in the evolutionary and reconfigurable systems. Wang et al. (2012) evaluated distributed control architecture based on semi-heterarchical architecture to handle dynamicity and disturbances. This approach exhibited the advantage of finding efficient routing paths quickly. Sallez et al. (2010) presented a semi-heterarchical control approach for dynamic allocation and routing processes in an FMS. Rey et al. (2014) used distributed approach semi-heterarchical architecture to solve a flexible assembly cell problem. Borangiu et al. (2014) presented a semi-heterarchical control approach for planning and control in an FMS environment. During operational mode, the control switched between centralized and decentralized controls. This switching enabled the control architecture to maintain global optimality in the absence of perturbation and robustness against disturbances in the case of perturbation occurrence. Pach et al. (2014) solved the problem of FMS by heterogeneous semi-heterarchical control.
Erol et al. (2012) studied a multi-agent based scheduling approach for simultaneous scheduling of machines and automated guided vehicles (AGVs). They developed a simulation model to test the proposed approach in real time. The results showed close performance to optimization results and outperformed the comparison criteria. Sallez et al. (2009) investigated the potential of the routing control problem approach based on semi-heterarchical control. Chen and Chen (2010) presented a multi-agent based multi-section FMS model. The authors developed semi-heterarchical architecture simulation model and studied the effect of dispatching rules on the system performance. Recently successful results have been achieved by using distributed approaches like multi-agent systems (MAS) to solve complex and dynamic flexible job shop scheduling problems including machine flexibility and product flexibility (Nouiri et al. 2018).
An FMS is defined as computer-controlled complex, integrated manufacturing system that consists of numerically controlled machine tools and connected by automated material handling system that can process mid volumes and mid variety of parts. The judicious use of the flexibility types and their levels are always provide maximum benefits from FMS (Ali and Wadhwa 2010; Ali and Murshid 2016; Teich and Claus 2017). There are mainly eight types of flexibilities namely machine flexibility, product flexibility, process flexibility, operation flexibility, routing flexibility, volume flexibility, expansion flexibility, and production flexibility (Browne et al. 1984). Further, routing flexibility has been identified as an important flexibility type as it maintains a better balance between machine loads and aids in preventing bottleneck (Sethi and Sethi 1990). The effect of routing flexibility and pallet flexibility was studied on the performance of FMS (Ali and Ahmad 2014). Joseph and Sridharan (2011a, b) also investigated the combined effect of routing and operations flexibilities to evaluate the performance of an FMS. To respond to business changes, He et al. (2014) studied machine flexibility and system layout flexibility. Since flexibility incorporation or expansion is capital intensive, the right type and level of flexibility are to be known before implementation.
Sequencing flexibility is the ability to make jobs by following different operations sequences. A new performance-based approach was proposed by the authors to quantify sequencing flexibility. With mean flow time as a performance measure, Chan (2004) explored the effects of operation flexibility (sequencing flexibility) and different scheduling rules on the performance of an FMS. A simulation-based conceptual study to get better insight into the concept of sequencing flexibility was conducted by Wadhwa et al. (2005). The proposed mechanism reduced the manufacturing lead time considerably. The simultaneous effects of routing flexibility and sequencing flexibility was also studied by Joseph and Sridharan (2011b), on the performance of an FMS. Likewise, with MST as a performance measure, the effect of routing flexibility and pallet flexibility together was explored by Ali (2012). These two flexibility types simultaneously influenced the system performance significantly. Ihsan and Omer (2003) developed a simulation model to study reactive scheduling problems in a dynamic and stochastic manufacturing environment.
Developing mathematical models for manufacturing systems is a very complex problem. Hence, simulation studies have gained much appreciation among the researchers to evaluate the manufacturing systems at planning, designing and control levels (Wadhwa et al. 2009; Ali and Saifi 2011, etc.). The discrete-event simulation technique is widely accepted by the researchers to study FMS performance (Ali 2012; El-Khalil 2013). For the development of the computational model, mathematical modeling techniques are commonly used. The limitations related to mathematical modeling are the assumptions made, as they may not be practically feasible. Moreover, with the increase in problem size, the computational time also increases. The simulation models are the best, for different system performance metrics analysis of FMS and their behavior in particular conditions. Simulation modelling saves time, cost and resources efficiently (Yadav and Jayswal 2018).
The performance of FMS has been evaluated from the operational viewpoint (Aized et al. 2008; Baykasoglu and Ozbakır 2008; Agarwal et al. 2018; Katic and Agarwal 2018; Solke and Singh 2018) and control viewpoint (Chan et al. 2008; Ali and Wadhwa 2010). Wadhwa et al. (2008) considered planning and control strategies to evaluate the performance FMS. The authors studied the system performance in terms of MST, lead time and work-in-process. Further Ali and Wadhwa (2010) considered minimum number parts in the buffer queue (MINQ) and minimum waiting time of all the parts in the buffer queue (MWTQ) as the dispatching rules to evaluate the performance FMS. Singholi et al. (2013) also studied the combined effect of the machine and routing flexibilities by considering MINQ and MWTQ as control rules. The sequencing rules used to select the part from a queue in an FMS further complicate the decision making process.
It is evident that the existing scheduling approaches are incapable of meeting the current market challenges due to lack of reactivity and robustness. Many solutions have been proposed by the researchers like FMS and reconfigurable manufacturing system (RMS) etc. Of the proposed solutions, the philosophy of FMS has widely been accepted by the practitioners and research community. The inherent trait of flexibility empowers the FMS to handle the ongoing market disturbances. However, due to increased pressure to perform in shorter time windows and ever-increasing customization demands, the FMS scheduling has also suffered from performance deterioration. Moreover, by virtue of flexibility in FMS, many potential options are being evaluated before any decision is made. This severely limits the real-time decision making and its implementation leading to poor system responsiveness and robustness. However, with the distributed scheduling approach, the issue of degraded system performance can be tackled effectively. As distributed scheduling systems are based on multi-agent systems, the decision-making and implementation process is very quick. This makes the distributed scheduling system more flexible, reactive and robust; as compared to existing scheduling systems, to meet the present market requirements. Thus, a distributed scheduling framework for FMS is expected to overcome the existing limitations of the present FMS scheduling systems. Practically, at the shop floor, design and control decisions are of great importance; from the optimal system performance viewpoint. Moreover, from the literature, it is seen that there are few studies on the effect of design factors and control factors on the performance of FMS by considering distributed scheduling of parts. Hence, there is a need to study the combined effect of the above-mentioned decision factors on the performance of a FMS distributed scheduling of parts. Thus, the main contribution of this research work is to assist decision-makers with a methodology for determining the effect of design and control factors on the performance of the FMS.
Problem Description and Assumptions
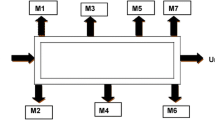
The FMS consists of six CNC machines; indexed as CM1, CM2, CM3, CM4, CM5, and CM6. The FMS layout is considered in the present study as it is the most frequent configuration studied by the researchers (Chan et al. 2008; Ali and Wadhwa 2010). All six CNC machines have dedicated input buffer. The capacity of the buffer is fixed. Six different part types; indexed as P1, P2, P3, P4, P5, and P6 are considered. The number of operations required for complete processing on a part type ranges from four to six. The processing times are taken as deterministic and are shown in Table 1. The typical configuration of FMS is shown in Fig. 1.

Layout of the flexible manufacturing system (FMS)
The following sub-sections describe the design and control factors studied in the present study.
Design Factor 1: Control Architectures
Conventional Hierarchical Control Architecture
The conventional hierarchical control architecture, Fig. 2a, involves a centralized decision-making process. The decision making entities lower in the hierarchy just implement the instructions obtained from the top centralized decision making entity. Moreover, many times this central decision-making entity gets overloaded due to frequent information exchange needed for the decision-making process. As a result, for any decision to be made delay is always present. This delay prevents the decision to be implemented in real time, and hence system performance deteriorates.

a Hierarchical control architecture; b heterarchical control architecture; c semi-heterarchical control architecture
Heterarchical Control Architecture
In heterarchical control architecture, Fig. 2b, the decision making process is decentralized to decisional entities lower in control architecture. Here decisions are taken by several lower decisional entities instead of one centralized decisional entity. Hence, the decision-making process is quick and can be applied in real time. The heterarchical control architecture enables a high local performance against disturbances.
Semi-Heterarchical Control Architectures
In semi-heterarchical control architectures, Fig. 2c decisional entity has a global view of the system in addition to the local view of the local decisional entities. Semi-heterarchical control architectures has the merits of hierarchical and the heterarchical control architectures respectively. The semi-heterarchical control architecture tends to provide better the response against the disturbances, maintaining the overall system performance as well the system reactivity, flexibility, modularity and robustness at the same time.
In this paper, for distributed control architectures machines are modeled as agents that can take their own decisions; cooperate and collaborate with other fellow machines in the existing layout to achieve their pre-defined goals. In case of any disturbance like machine failure, these machine agents in view of the current system state and available information take their decisions.
One conventional control architecture, namely hierarchical (Hi); and three distributed control architectures, namely heterarchical (He), semi-heterarchical I (SHe I) and semi-heterarchical II (SHe II) are considered in this study. These are shown in Fig. 2. The SHe I control architecture differs from SHe II based on the supervisory mechanism employed. In SHe I, the supervisory mechanism maintains system performance by re-routing the parts as and when required while in SHe II the supervisory mechanism manipulates the production rates of the parts being produced to balance the system performance.
Design Factor 2: Sequencing Flexibility
For the present FMS layout, sequencing flexibility has been evaluated in terms of sequencing flexibility measure. The sequencing flexibility takes into account the total number of operations required on a part and the precedence existing between these operations (Rachamadugu et al. 1993). When there is no option available for an operation then sequencing flexibility is zero. As the number of options for an operation increases, sequencing flexibility also increases. And sequencing flexibility is maximum; when no operation on a part has any precedence or any operation can be performed on a part in any sequence. The four levels of sequencing flexibility have been studied from SF = 0 to SF = 1. The part types with four to six operations are studied in this study. Rachamadugu et al. (1993), defines the measure of sequencing flexibility as:
where mi is the total number of required operations for part type i, Ti is the number of transitive arcs in the operations graph for part type i. The total number of precedence relationships between all operation pairs of a part type, both implicit and explicit, is given by the number of transitive arcs (Ti). Consider a part type with operations graph as shown in Fig. 3.

Operations graph
The Fig. 3 shows that there are four explicit precedence arcs (1, 2), (2, 4), (3, 4) and (3, 5); and one precedence implicit arc (1, 2, 4). So, the total number of transitive precedence relations (Ti) is equal to 5. Using Eq. 1, the calculated SFM value for the part type with operations graph shown in Fig. 3 is 0.5. From Eq. 1, it can be inferred that when SFM = 0; there exists no sequencing flexibility and when SFM = 1; there exists full sequencing flexibility. In this study, the operations graph for each part type is generated, and corresponding sequencing flexibility levels value are calculated using Eq. 1. To illustrate, the operations graphs for a part type with five total required number of operations have been presented at different sequencing flexibility in Fig. 4a–d. The part types and the corresponding sequencing flexibility levels for which the study has been conducted are tabulated in Table 2.

a Operation graph with SFM = 0. b Operation graph with SFM = 0.2. c Operation graph with SFM = 0.5. d Operation graph with SFM = 1.0
Design Factor 3: Buffer Capacity
The buffer capacity is modelled in terms of the capacity of each input dedicated buffer of a machine. In this study, four buffer capacity levels are studied based on the input buffer size. The buffer capacity level varies from 6 to 24 in steps of 6.
Control Factor 1: Sequencing Rules
In the manufacturing control problem, sequencing rules are of great importance for effective manufacturing control. Sequencing rule forms the basis for the selection of a part from a queue, to get processed at a machine. Sequencing decisions are made just before the processing of a part. The sequencing rules studied in this work are discussed below.
-
a.
Among all the parts in the buffer, the one that enters first is processed first (FCFS).
-
b.
Among all the parts in the buffer, the one that enters last is processed first (LCFS).
-
c.
Among all the parts in the buffer, the one that is having the shortest processing time is processed first (SPT).
-
d.
Among all the parts in the buffer, the one that is having the highest processing time is processed first (HPT).
Control Factor 2: Dispatching Rules
Dispatching rules are control decisions made to route a part to a machine from the buffer of the available potential machines; depending upon the routing flexibility level. These control decisions are made just after the completion of the processing of part at a machine. The dispatching rule studied in this work is discussed below.
-
a.
Minimum number of parts in the queue (MINQ): A part is routed to a queue at a machine with the minimum number of parts in its input buffer, among all the available queues of the machines; depending upon the routing flexibility level.
Moreover, some assumptions are considered as follows:
-
The processing times are known in advance and deterministic.
-
Machines can fail before, during or after an operation.
-
Machine failure and machine repair have been assumed as exponentially distributed.
-
Pre-emption is allowed, i.e., an operation on a part may get completed on one or more machines.
-
One operation at a time is allowed to be executed on one machine.
-
All the transfer time of parts within the system is assumed to be unity.
-
Due dates are not considered.
-
Order cancellations are not considered.
-
Rework is not allowed.
-
The availability of parts in the system is limited.
Performance Measures
The following performance measures are considered to evaluate the performance of FMS.
-
1.
Makespan Time (MST).
The time of completion for a batch of products is known as makespan time (MST). It is an important measure of system performance to implement FMS. Lower the MST value better is the system performance.
For MST:
Let
Set j = (1, 2,…, J) represents the number of parts in a system.
k = (1, 2,…, K) represents The operation of each job.
If PTjk is the processing time and CTjk is the completion time, then the MST is the time of completion of processing J number of parts in a batch. It is defined as:
where Cmax = maximum time of completion of all the k operations on j number of parts (MST).
-
2.
Average Machine Utilization (AMU)
The AMU is the average machines or resources utilization. It is the ratio of the time for which machines or resources are available for processing and not idle to total available time. A high value of resource utilization is always desired for better system performance. It can be computed as:
where
AMU = Average machine utilization
Si = Number of resources at station i
Ui = Utilization of station i
-
3.
Average waiting time in Queue (AWQ)
The AWQ is the average time spent by parts in the queue waiting to get processed at different machines. For a manufacturing system to perform well, a lower AWQ is desired. It can be expressed as
where
AWQ = Average waiting time in queue
Si = Number of resources at station i
Ti = Waiting time in queue of station i
Operational Logic for Simulation Model
Discrete event simulation based models have been developed in MATLAB general purpose programming environment in this paper. These models are used to evaluate the effect of various design factors and control factors on the performance of the FMS. The FMS models developed consists of various entities like parts, machines and their associated attributes. Various events are appropriately generated to capture the dynamics of the problem environment. The simulation model is developed in a modular way, as shown in Fig. 5. A multilevel verification has been done to validate the simulation model. In the present problem, the machine has been modeled as an agent in the distributed control architectures only, i.e., heterarchical and semi-heterarchical control. The simulation model consists of modules with each module having its specific task to perform. At the start, as the simulation model runs, the initialization module sets the simulation clock to zero. It also initializes the variables and statistics counter. After initialization, the control architecture module is called into the main program. This module defines the inter-relationships between different decision-making entities. And hence, it lays down the type of control architecture being exercised by the simulation model. There are three control architectures evaluated in this study, i.e., hierarchical, heterarchical and semi-heterarchical. Once a particular type of control architecture is defined, event function schedules various deterministic as well as non-deterministic events to take place. Various events like part processing, machine failure, part sequencing, part re-routing, etc., take place during the execution of the simulation model. Since all the operations are centered on parts being processed in the manufacturing system, part specific factors and rules are defined in the problem. These sequencing and dispatching rules and factors like sequencing flexibility function, etc., are called into the main program with the help of function files. After the occurrence of each event in the main program of the simulation model, the system state is advanced to the current state. The simulation clock and various statistical counters and variables are also updated accordingly. Each time as the simulation model runs, and command flow executes from top to bottom; the simulation termination condition is checked to stop or terminate the simulation code. If the simulation model termination condition is met, the program stops. Computation of various performance measures and statistics is done, and a report is generated. However, if the simulation termination condition is not met, the simulation model goes on running. The cycle of various events goes on repeating until the termination condition is met.

Structure of the simulation model
Once the simulation model is executed, material flow as well as information flow takes place, as shown in Fig. 6. Initially, one part of each part type is created and sent the loading area for the model to run. At the loading station, parts wait for a signal to enter the manufacturing system. As the signal is received at the loading station a part is released into the manufacturing system. Once a part enters the manufacturing system, it is sent to a decision area to identify its part type. After a decision regarding the part identity is made, based on the part type attributes are assigned to the part. The part is routed to the respective machine depending upon its machining requirements, after attributes assignment. A decision is then made for the distributed control or type of control architecture for the decision-making process. If distributed control is present, the decision making is delegated and taken by the heterarchical decision making entities or machine agents. In the case of semi-heterarchical control, there is a regular flow of information from heterarchically modelled machine agents to the hierarchically modelled supervisor, as shown in Fig. 6.

Flow chart of the existing FMS layout for material and information flow
This information flow helps the supervisor in semi-heterarchical control to tune the system parameters for manufacturing system performance improvement. However, if the distributed control is not present, the decision-making process is not delegated, and the decision is taken by a hierarchical decision making entity. The part is then sent to a decision-making point where machine input buffer status is checked for available capacity. If the buffer capacity is less than its full capacity, the part is accommodated into the buffer and waits for its turn to get processed. However, if the machine input buffer is full, the system blocks. The part waits in the input buffer of each machine till the machine is available. Parts are processed on each machine depending upon its operational requirements; based on sequencing rule. However, during operation, a machine can fail leading to manufacturing system blockage. At this point, if decision-making is based on distributed control architecture, real-time corrective action is taken. However, if the distributed control is not present, the system waits for instructions to take action. After successful completion of an operation on a part at a machine, a part among the parts waiting in queue/buffer is engaged at the machine; based on sequencing rule. The processed part is then checked for its operation sequence. If all the operations on the part are completed, the part exits the manufacturing system and is moved to the store. The part while exiting the manufacturing system signals the loading area to launch a raw part of the same type into the manufacturing system. However, if the operation sequence is not completed, the part is routed to the respective potential machine based on the dispatching rule for further processing. In this way, consistent work in the process is maintained in the manufacturing system. This events’ cycle is repeated again and again till all the required number of parts are processed and completed.
Design for Experiments and Methodology
In the present study, four factors with four levels of each are studied. If simulation experiments are being conducted with four factors and each having its four levels, the number of experiments to be conducted comes out to be 44, i.e., 256 experiments. However, with Taguchi’s experimental design the number of experiments is reduced to 16 only. Taguchi’s design experiments give optimal factor levels with a reduced number of experiments to be performed.
Taguchi’s Design for Experiments
Taguchi’s design of experiments is a technique based on matrix experiments (Phadke 1989). In this technique, a set of experiments is performed by varying the levels of assumed factors. The effect of various factors is efficiently determined by matrix experiments based on special matrices known as orthogonal arrays. The rows in the orthogonal array indicates the number of experiments to be performed. The orthogonal arrays give the best combination between different factors and their levels that influence the system performance. Table 3 presents the Taguchi’s standard L16 (44) orthogonal array which is the basis of the present study’s experimental design. The combinations of different factor levels in matrix experiments and the present study are presented in Tables 4 and 5 respectively.
The S/N ratio can be expressed as the ratio of the mean to the standard deviation or signal to noise. Thus to minimize the sensitivity to noise, S/N ratio for MST can be expressed as:
Taguchi defined three categories of S/N ratios i.e., the smaller-the-best, the larger-the-best, and the nominal-the-best. For MST and AUQ, smaller-the-best and for AMU, larger-the-best is considered for the analysis.
In Taguchi’s matrix experiment design, highest value for the S/N ratio indicates the optimal setting. This is true only for the single performance characteristic optimization. However, for the optimization of multiple performance characteristics, Taguchi’s approach is inadequate. In multiple performance characteristics optimization, the S/N ratio evaluation of all the performance characteristics is needed. To solve this problem grey relational analysis (GRA) has been adopted. This technique converts a multi-characteristics performance optimization problem into a single characteristic performance problem.
Grey Relational Analysis (GRA)
Deng (1989) proposed the grey system theory is used to solve the complex interrelationship between various chosen performances measures. The major advantage of grey relational analysis is that it is based on the original data and calculations are simple. This single performance characteristic is known as grey relational grade, used to evaluate multiple performance characteristics. The grey relational analysis consists of three basic steps:
-
1.
Data pre-processing
-
2.
Calculate grey relational coefficients
-
3.
Calculate grey relational grade
In GRA data pre-processing is the first step. It involves the conversion of the original sequence into a comparable sequence. This is done by normalizing the data in the range between 0 and 1. This conversion is also known as the grey relational generation. The next step is the calculation of the grey relational coefficient from the normalized experimental data. In the next step, the grey relational grade is calculated by averaging the grey relational coefficients. The grey relational grade converts the complex multiple process responses into an optimized single grey relational grade. The optimum level of the process parameters is the level with the highest grey relational grade.
Simulation Experiment Results
In this study the effect of design factors namely control architectures (CA), sequencing flexibility (SF), buffer capacity (BC) and control factor namely part-sequencing rule (SR) is studied on the performance of FMS. It has been observed that 30 simulation replications are sufficient to filter out the stochastic effects in the results. Hence, each simulation run consists of 30 replications for each of the 16 simulation experiments. The simulation results are statistically analyzed. A multi-factor ANOVA is conducted to study the effect of the design and control factors on the performance of FMS. A 5% level of significance is considered for all the statistical treatment of the problem. The simulation results and their analysis are presented in the following sub-sections.
Matrix Experiment Results
The simulation experiment is carried out based on Taguchi’s L16 orthogonal array as tabulated in Table 3. A product-mix of 6 different parts with 100 parts of each type is considered. The framework of simulation experiments according to the L16 orthogonal array as shown in Table 5. The results obtained after performing simulation experiments for the system performance measures for machine failure and without machine failure modes are shown in Tables 6, 7 and 8.
The next step in Taguchi’s experimental framework involves data analysis by employing the analysis of means (ANOM) and the analysis of variance (ANOVA). To determine a system factor combination that gives us optimal system performance, ANOM is used whereas the relative significance of the system factors towards the system performance is determined by ANOVA.
Analysis of Means (ANOM) for Optimal System Factors Combination
The main objective to follow matrix design framework experiments is the identification of an optimal combination of system factors which gives the best system performance with the reduced number of simulation experiments. The effect of a system factor level that causes deviation from the overall mean is known as the main effect. The main effect of each factor is determined by ANOM. The main factor effects, calculated by using the Eq. 6 (Phadke 1989), are tabulated in Tables 9, 10 and 11 respectively.
where,
mij= main factor effect for the jth level of factor i
i = the factor (i.e., machine flexibility, sequencing flexibility, control rules, no. of parts)
j = the factor level (i.e., 1, 2, 3, or 4)
αijk= the S/N ratio of factor i with level j
l = occurrence of factor i with level j (i.e., 4)
S/N ratios are used to represent the optimum level of each factor by the maximum number of points in the main effect plots as shown in Figs. 7, 8, 9, 10, 11 and 12. It can be inferred from the main effects plot for each factor level, Fig. 7, the best factor level combination for the MST is CA4, SF1, BC4 and SR4 for without machine failure case. This best factor level combination for MST can easily be interpreted as control architecture = 4 (Semi-heterarchical II), sequencing flexibility level = 1 (sequencing flexibility = 0), buffer capacity = 6 and part sequencing rule is LPT. Similarly, for the machine failure case as shown in Fig. 8, the best factor combination for the MST is CA4, SF2, BC1, and SR2. The best factor combinations for the AMU and AWQ can be easily interpreted from Figs. 9, 10, 11 and 12, for without machine failure and machine failure cases respectively. The best factor combinations for different performance measures are presented in Table 12.

Main effects plot for SN ratios without failure (MST)

Main effects plot for SN ratios with failure (MST)

Main effects plot for SN ratios without failure (AMU)

Main effects plot for SN ratios with failure (AMU)

Main effects plot for SN ratios without failure (AWQ)

Main effects plot for SN ratios with failure (AWQ)
It is evident from the above figures and tables that control architecture (SHe II) is found to influence the performance measures the most. The effects of other factors are seen to be relatively less prominent. The factors contributing to the system performance are identified by the statistical treatment of the results through ANOVA.
Analysis of Variance (ANOVA) for Matrix Experiments Results
The calculations for ANOVA analysis are done using MINITAB at a 95% confidence interval and are presented in Tables 13 and 14, for without machine failure and machine failure cases respectively. The simulation results from the matrix experiments are used to carry out the ANOVA analysis. The F-value indicates how significantly a factor affects system performance (Phadke 1989).
From Table 13, for without machine failure case, the F value for the control architecture is the highest (54.76). Hence, the change in the control architecture level significantly affects system performance. The other factors appear to affect the system performance relatively less significant than control architecture. The relative significance of factors for makespan after ANOVA analysis is in complete agreement with that obtained by ANOMA as shown in Fig. 7. In Fig. 7, the curve under the control architecture (CA) varies the most, implying that control architecture affects the system significantly as compared to other factors. Similarly, for other system factors, relative factor significance can be evaluated. For the case of AMU, control architecture again has the highest F value (76.97) inferring that CA is the significant factor for AMU also. As far as AWQ is concerned, the F value of CA is highest (2.00); which implies that CA is the most significant factor. To summarize the ANOVA results, it can be concluded that control architecture (CA) is the most significant factor for contribution towards system performance. On the same lines for machine failure case; Table 14, it can be stated that control architecture (CA) is also the most significant factor contributing to system performance.
Multiple Response Optimization Using Grey Relational Analysis (GRA)
For converting multiple performance measures namely simultaneous optimization of MST, AMU, and AWQ into one performance measure, grey relational analysis (GRA) has been utilized. To perform the GRA on the data obtained from Taguchi’s orthogonal arrays, the following steps have been suggested for multi-characteristics optimization (Kuo et al. 2008). The S/N values for MST, AMU, and AWQ for all 16 sequences or matrix experiments are tabulated in Table 15. In the present study, S/N ratios obtained from Taguchi’s matrix experiments are normalized using a linear data pre-processing method for MST and AWQ which is stated:
and, the AMU can be expressed as:
where \(x_{i}^{*}\)(k) is the sequence after pre-processing; \(x_{i}^{o}\)(k) is the original sequence of S/N ratios;
i = 1, 2, 3…., m and k = 1, 2,…., n with m = 18 and n = 4;
max_\(x_{i}^{o}\)(k) is the largest value of \(x_{i}^{o}\)(k);
min_\(x_{i}^{o}\)(k) is the minimum value of \(x_{i}^{o}\)(k).
Using Eqs. 7 and 8 the S/N ratios have been normalized and tabulated in Table 16. The larger normalized S/N ratio corresponds to the better performance, and the best-normalized S/N ratio is equal to unity.
The grey relational coefficient gives the relationship between the best (reference) and the actual normalized S/N ratio. To calculate the grey relational coefficient following formula can be used:
where \(\Delta_{oi} \left( k \right)\) is the deviation sequence of the reference sequence \(x_{o}^{*}\)(k) and comparability sequence \(x_{i}^{*}\)(k), i.e., \(\Delta_{oi} \left( k \right)\) = |\(x_{o}^{*}\)(k) − \(x_{i}^{*}\)(k)| is the absolute value of the difference between \(x_{o}^{*}\)(k) and \(x_{i}^{*}\)(k), ζ is the distinguishing factor and is taken as 0.5 in this study.
Using Table 16, deviation sequences for all the 16 sequences are calculated and presented in Table 17. From the deviation sequences in Table 17 and Eq. 9, the grey relational coefficients are calculated and presented in Table 18. The grey relational grade obtained from grey relational analysis shows the relational degree between the reference sequence, \(x_{o}^{*}\)(k) = 1; and the 16 comparability sequences, \(x_{i}^{*}\)(k); where i = 1,2,…,m and k = 1,2,…n with m = 16 and n = 3 in this study. The grey relational grade is a weighting-sum of the grey relational coefficients and can be expressed as:
where wk is the weight of the kth machining characteristics, and \(\sum\nolimits_{k = 1}^{n} {w_{k} = 1 }\).
The grey relational grade shows the influence of which comparability sequence can have over the reference sequence. In this paper, both the comparability and the reference sequence are treated as equal. Hence, wk is equal for coefficients of all the performance characteristics.
From Table 18 it is seen that experiment No. 13 for without machine failure, and experiment No. 16 for machine failure has the highest grey relational grade, i.e., 0.7413 and 0.7460, respectively. Thus, experiment No. 13 and experiment No. 16 give the best multiple-attributes performance out of 16 experiments for without failure and with failure cases, respectively. Normally, the larger grey relational grade corresponds to a better performance.
To evaluate the effect of system factors on multi-performance attributes, ANOVA is performed on grey relational grade values for without failure and failure cases as shown in Table 19. Taguchi’s approach is used to generate response Table 20 that is been used for studying the effect of each level of system factor on grey relational grade. It can be seen from Table 20, that the best combination of the system factor levels is CA4 (CA = SHe II), SFL2 (SF = 1), BC4 (BC = 24), SR3 (SR = SPT) and CA4 (CA = SHe II), SFL3 (SF = 2), BC1 (BC = 6), SR3 (SR = SPT) for without machine failure and machine failure cases respectively.
Finally, a confirmatory experiment is performed based on the optimal system factors level, CA4 (CA = SHe II), SFL2 (SF = 1), BC4 (BC = 24), SR3 (SR = SPT) and CA4 (CA = SHe II), SFL3 (SF = 2), BC1 (BC = 6), SR3 (SR = SPT) for without machine failure and machine failure cases respectively. The grey relational grade calculated on this optimal system-level combinations for without machine failure and with machine failure cases, respectively. The predicted and experimental values of grey relational grades for without machine failure and with machine failure cases are summarized in Table 21. The optimum combination of input parameters are verified with the results predicted by the Taguchi approach. The optimum S/N ratio (ηopt) under the optimum conditions is calculated using Eq. (11).
where ηm is the overall mean of S/N ratios of grey relational grades, ηi is the mean of the S/N ratio for optimum levels, and “q”: is the number of input parameters.
Discussion
In the present research, an FMS scheduling problem with six parts and six machines has been studied. To evaluate the FMS, various design and control factors are considered. The design factors considered are control architecture (CA), sequencing flexibility (SF) and buffer capacity (BC) while control factors include sequencing rules and dispatching rules (SR). The machines in the FMS exercise autonomy by taking the decisions on their own while coordinating and cooperating with other machines to attain their goals as agents. One hierarchical control architecture, and three distributed control architectures referred to as Hi and He, SHe I, SHe II respectively; are considered in this study. To highlight the advantage of employing multi-agent based FMS control, two operational modes, namely with machine failure and without machine failure are also studied. The performance is evaluated in terms of three performance measures, namely MST, AMU and AWQ. To carry out the research, the problem is simulated for different system configurations, and the required results are obtained. Taguchi’s orthogonal array technique is followed to conduct simulation experiments and to obtain optimal results, and Grey relational analysis is used for system performance optimization. The following sub-sections discuss the results obtained and highlight the observations made.
Effect of Design Factors (Control Architecture, Sequencing Flexibility, and Buffer Capacity)
The control architecture lays down a structure through which all information is shared by various decision-making entities. At the shop floor, various activities are carried out in synchronization with each other with the exchange of information between different decision points. In the absence of the right information, the right decision cannot be taken. The control architecture helps in information exchange and decision making effectively. It can be said that all shop-floor activities are dependent on the control architecture or in other words, control architecture is the most important factor than the planning, design and control activities at the shop floor. It is observed that the design factor namely control architecture has a statistically major contribution in the system performance. The effect is visible under the with machine failure and without machine failure cases, respectively. With hierarchical control architecture (Hi), the decision-making entities are not autonomous; there occurs a delay in receiving and implementing instructions from the central decision-making entity. This results in delay leading to system performance deterioration due to the inability of real-time decision-making and implementation. Therefore, Hi control architecture always performs poorly, compared to distributed control architectures. However, as we move from hierarchical control architecture to distributed control architecture (i.e., from Hi to He and SHe I/II), there is an improvement in the system performance. It can be attributed to the delegation or distribution of decision-making ability to lower decisional entities, i.e., machine agents in this case. This results in real-time decision making, irrespective of any disturbance (machine failure) taking place or not. Thus, improved system performance is attained. It is further seen that among the distributed control architectures, SHe II (semi-heterarchical) exhibits better system performance than all the control architectures. Hence, distributed control architecture; specifically, SHe II exhibits better system responsiveness against disturbances (with or without machine failure) with improved system performance. This observation is in agreement with the other researchers (Barbosa et al. 2015; Rey et al. 2014; Borangiu et al. 2014; Pach et al. 2014; Sallez et al. 2009, 2010; Trentesaux 2009).
As sequencing flexibility (SF) is increased, more options of alternative sequences are available to process a job, and the best decision (smallest operation time) is selected which yields better system performance, as compared to SF = 0 (fixed sequence). As discussed above, in the distributed control architectures, i.e., He, SHe I and SHe II; a better decision is always taken. It is because in these control architectures machine agents interact with each other to gather information within the least possible time. As all the required information is available in no-time, in all SF > 0 cases; the instant decision regarding part sequencing is made. Hence, this quick decision making makes these distributed control architectures to outperform hierarchical control architecture (Hi). The sequencing flexibility level > 0 (SF = 1, 2) is often beneficial while no sequencing flexibility level (SF = 0) produces poor results due to long queues leading to system blockage. Moreover, at SF = 0 parts are assigned to machines and get processed in fixed sequences. If the machine is busy, parts have to wait to get processed leading to queue formation at the machine. As sequencing flexibility is increased from 0 to 1, maximum performance benefit or improvement is achieved. Hence, for our problem SF = 1 is best suited as maximum performance is achieved here. It is because, for SF = 1, the system provides a better balance between long operation times and long queues than SF > 1. This finding is in coherence with the research studies existing in the literature (Khan and Ali 2015; Joseph and Sridharan 2011b).
The design decision of buffer capacity (BC) signifies the number of parts being processed at a time in the system. It regulates the work-in-process being present in the system. Generally, the higher the BC, the better is the system performance. It is because the high number of parts absorb machine idle time, resulting in better makespan time and high average machine utilization. In our case, for BC = 24 system performance is highest for all the three performance measures. However, it is seen that the effect BC is not statistically significant on system performance for both machine failure and without machine failure cases. It is because, in the presence of control architecture as a factor, the effect of BC has become insignificant. Some observations related to BC are presented in the literature (Francas et al. 2011).
Effect of Control Factors (Sequencing and Dispatching Rules)
It is further observed that the SPT/MINQ scheduling rule combination is yielding better performance for all the three system performance metrics. In this study, SPT/MINQ combination of sequencing and dispatching rule is performing best as compared to other combinations of rules. It is in complete agreement with the other researchers also, e.g., Ali and Wadhwa (2010) for an FMS problem, concluded MINQ/SPT as the best rule; similar results were also found by Joseph and Sridharan (2011a). However, depending upon the conditions considered by researchers for their studies, different control rule combinations have been concluded best.
Conclusions
In this work, a simulation study of a distributed scheduling approach is undertaken to perform multi-response optimization for FMS. It is observed that among the design factors, only control architecture is the statistically significant factor that contributes to the system performance. It is found that distributed control architectures outperform the hierarchical control architecture. As evident from the results obtained, it can be stated that sequencing flexibility does not produce any significant effect. The developed multi-agent based semi-heterarchical control architecture (SHe II) exhibits better global as well as local system performance than other control architectures. Hence, SHe II control architecture is best suited to the industrial scenarios that evolve to the dynamicity and perturbations. Despite all diligent efforts done in this study, some limitations still exist and to be overcome in future research. The main limitation of this research work is that this simulation model applies to a limited realm of shop floor control of FMS. This model can further be extended by considering more system factors, physical constraints, more operational and control strategies for the shop floor control. The simulation experiment results must be validated with practical experiments. To overcome the limitations, future research can focus on considering more flexibility types, e.g., routing flexibility, external disturbances like order cancellation, operation types, re-scheduling, etc.
References
Agarwal, R., Chowdhury, M. M. H., & Paul, S. K. (2018). The Future of Manufacturing Global Value Chains, Smart Specialization and Flexibility!, Global Journal of Flexible Systems Management, 19(Suppl 1), S1–S2.
Aized, T., Takahashi, K., Hagiwara, I., & Morimura, H. (2008). Resource breakdown modelling and performance maximization of a multiple product flexible manufacturing system. International Journal of Industrial and Systems Engineering, 3(3), 324–347.
Ali, M. (2012). Impact of routing and pallet flexibility on flexible manufacturing system. Global Journal of Flexible Systems Management, 13(3), 141–149.
Ali, M., & Ahmad, Z. (2014). A simulation study of FMS under routing and part mix flexibility. Global Journal of Flexible Systems Management, 15, 277–294.
Ali, M., & Murshid, M. (2016). Performance evaluation of flexible manufacturing system under different material handling strategies. Global Journal of Flexible Systems Management, 17(3), 287–305.
Ali, M., & Saifi, M. A. (2011). A decision support system for flexibility enabled discrete part manufacturing system. Global Journal of Flexible System Management, 12(3), 1–8.
Ali, M., & Wadhwa, S. (2010). The effect of routing flexibility on a flexible system of integrated manufacturing. International Journal of Production Research, 48(19), 5691–5709.
Barbosa, J., Leitão, P., Adam, E., & Trentesaux, D. (2015). Dynamic self-organization in holonic multi-agent manufacturing systems: The ADACOR evolution. Computers in Industry, 66, 99–111.
Baykasoglu, A., & Ozbakır, L. (2008). Analyzing the effect of flexibility on manufacturing systems performance. Journal of Manufacturing Technology Management, 19(2), 172–193.
Borangiu, T., Răileanu, S., Berger, T., & Trentesaux, D. (2014). Switching mode control strategy in manufacturing execution systems. International Journal of Production Research, 53(7), 1950–1963.
Browne, J., Dubois, D., Rathmill, K., Sethi, S. P., & Stecke, K. E. (1984). Classification of flexible manufacturing systems. FMS Magazine, 2(2), 114–117.
Cardin, O., Trentesaux, D., Thomas, A., Castagna, P., Berger, T., & El-Haouzi, H. B. (2017). Coupling predictive scheduling and reactive control in manufacturing hybrid control architectures: State of the art and future challenges. Journal of Intelligent Manufacturing, 28, 1503–1517.
Chan, F. T. S. (2004). Impact of operation flexibility and dispatching rules on the performance of a flexible manufacturing system. International Journal of Advanced Manufacturing Technology, 24(5–6), 447–459.
Chan, F. T. S., Bhagwat, R., & Wadhwa, S. (2008). Comparative performance analysis of a flexible manufacturing system: A review-period-based control. International Journal of Production Research, 46(1), 1–24.
Chen, K., & Chen, C. (2010). Applying multi-agent technique in multi-section flexible manufacturing system. Expert Systems with Applications, 37(11), 7310–7318.
Choi, S.-H., & James, S. L. (2004). A sequencing algorithm for makespan minimization in FMS. Journal of Manufacturing Technology Management, 15(3), 291–297.
Chou, C., Cao, H., & Cheng, H. H. (2013). A bio-inspired mobile agent-based integrated system for flexible autonomic job hop scheduling. Journal of Manufacturing Systems, 32, 752–763.
Deng, J. (1989). Introduction to grey system. The Journal of Grey System, 1(1), 1–24.
El-Khalil, R. (2013). Simulation and modelling: Operating and managing a new axle manufacturing system. International Journal of Industrial and Systems Engineering, 13(2), 219–232.
Erol, R., Sahin, C., Baykasoglu, A., & Kaplanoglu, V. (2012). A multi-agent based approach to dynamic scheduling of machines and automated guided vehicles in manufacturing systems. Applied Soft Computing Journal, 12, 1720–1732.
Francas, D., Löhndorf, N., & Minner, S. (2011). Machine and labor flexibility in manufacturing networks. International Journal of Production Economics, 131(1), 165–174.
Girish, B., & Jawahar, N. (2009). A particle swarm optimization algorithm for flexible job shop scheduling problem. In 5th annual IEEE conference on automation science and engineering, Bangalore, India (pp. 298–303).
Gunasekaran, A., & Ngai, E. W. (2012). The future of operations management: An outlook and analysis. International Journal of Production Economics, 135(2), 687–701.
He, N., Zhang, D. Z., & Li, Q. (2014). Agent-based hierarchical production planning and scheduling in make-to-order manufacturing system. International Journal of Production Economics, 149, 117–130.
Ihsan, S., & Omer, B. K. (2003). Reactive scheduling in a dynamic and stochastic FMS environment. International Journal of Production Research, 41(17), 4211–4231.
Jimenez, J. F., Bekrar, A., Rey, G. Z., Trentesaux, D., & Leitão, P. (2016). Pollux: A dynamic hybrid control architecture for flexible job shop systems. International Journal of Production Research, 55(15), 4229–4247.
Joseph, O. A., & Sridharan, R. (2011a). Analysis of dynamic due-date assignment models in a flexible manufacturing system. Journal of Manufacturing Systems, 30, 28–40.
Joseph, O. A., & Sridharan, R. (2011b). Effects of routing flexibility, sequencing flexibility and scheduling decision rules on the performance of a flexible manufacturing system. The International Journal of Advanced Manufacturing Technology, 56, 291–306.
Katic, M., & Agarwal, R. (2018). The Flexibility paradox: Achieving ambidexterity in high-variety, low-volume manufacturing. Global Journal of Flexible Systems Management, 19(Suppl 1), S69–S86.
Khan, W. U., & Ali, M. (2015). Effect of sequencing flexibility on the performance of flexibility enabled manufacturing system. International Journal of Industrial and Systems Engineering, 21(4), 474–498.
Kuo, Y., Yang, T., & Huang, G. W. (2008). The use of a grey-based Taguchi method for optimizing multi-response simulation problems. Engineering Optimization, 40(6), 517–528.
Leitão, P. (2009). Agent-based distributed manufacturing control: A state-of-the-art survey. Engineering Applications of Artificial Intelligence, 22, 979–991.
Leitão, P., Barbosa, J., & Trentesaux, D. (2012). Bio-inspired multi-agent systems for reconfigurable manufacturing systems. Engineering Applications of Artificial Intelligence, 25, 934–944.
Maione, G., & Naso, D. (2003). A genetic approach for adaptive multi-agent control in heterarchical manufacturing systems. IEEE Transactions on Systems Man and Cybernetics—Part A Systems and Humans, 33(5), 573–588.
Monostori, L., Váncza, J., & Kumara, S. R. T. (2006). Agent-based systems for manufacturing. CIRP Annals—Manufacturing Technology, 55, 697–720.
Motaghedi-larijani, A., Sabri-laghaie, K., & Heydari, M. (2010). Solving flexible job shop scheduling with multi objective approach. International Journal of Industrial Engineering & Production Research, 21(4), 197–209.
Nouiri, M., Bekrar, A., Jemai, A., Niar, S., & Ammari, A. C. (2018). An effective and distributed particle swarm optimization algorithm for flexible job-shop scheduling problem. Journal of Intelligent Manufacturing, 29, 603–615.
Ouelhadj, D., & Petrovic, S. (2009). A survey of dynamic scheduling in manufacturing systems. Journal of Scheduling, 12(4), 417–431.
Pach, C., Berger, T., Bonte, T., & Trentesaux, D. (2014). ORCA-FMS: A dynamic architecture for the optimized and reactive control of flexible manufacturing scheduling. Computers in Industry, 65(4), 706–720.
Pezzellaa, F., Morgantia, G., & Ciaschettib, G. (2008). Genetic algorithm for the flexible job-shop scheduling. Computers & Operations Research, 35, 3202–3212.
Phadke, M. S. (1989). Quality engineering robust design. Englewood Cliffs: Prentice-Hall.
Rachamadugu, R., Nandkeolyar, U., & Schriber, T. J. (1993). Scheduling with sequencing flexibility. Decision Science, 24(2), 315–341.
Rajabinasab, A., & Mansour, S. (2011). Dynamic flexible job shop scheduling with alternative process plans: An agent-based approach. International Journal of Advanced Manufacturing Technology, 54, 1091–1107.
Rey, G. Z., Bonte, T., Prabhu, V., & Trentesaux, D. (2014). Reducing myopic behavior in FMS control: A semi-heterarchical simulation–optimization approach. Simulation Modelling Practice and Theory, 46, 53–75.
Sallez, Y., Berger, T., Raileanu, S., Chaabane, S., & Trentesaux, D. (2010). Semi-heterarchical control of FMS: From theory to application. Engineering Applications of Artificial Intelligence, 23(8), 1314–1326.
Sallez, Y., Berger, T., & Trentesaux, D. (2009). A stigmergic approach for dynamic routing of active products in FMS. Computers in Industry, 60, 204–216.
Sethi, A. K., & Sethi, S. P. (1990). Flexibility in manufacturing: A survey. International Journal of Flexible Manufacturing System, 2, 289–328.
Shen, W., & Norrie, D. H. (1999). Agent-based systems for intelligent manufacturing: A state-of-the-art survey. Knowledge and Information Systems, 1, 129–156.
Singholi, A., Ali, M., & Sharma, C. (2013). Evaluating the effect of machine and routing flexibility on flexible manufacturing system performance. International Journal of Services and Operations Management, 16(2), 240–261.
Solke, N. S., & Singh, T. P. (2018). Analysis of relationship between manufacturing flexibility and lean manufacturing using structural equation modelling. Global Journal of Flexible Systems Management, 19(2), 139–157.
Teich, E., & Claus, T. (2017). Measurement of load and capacity flexibility in manufacturing. Global Journal of Flexible Systems Management, 18(4), 291–302.
Trentesaux, D. (2009). Distributed control of production systems. Engineering Applications of Artificial Intelligence, 22(7), 971–978.
Wadhwa, S., Ducq, Y., Ali, M., & Prakash, A. (2008). Performance analysis of a flexible manufacturing system under planning and control strategies. Studies in Informatics and Control, 17(3), 273–284.
Wadhwa, S., Ducq, Y., Ali, M., & Prakash, A. (2009). Performance analysis of flexible manufacturing system. Global Journal of Flexible System Management, 10(3), 23–34.
Wadhwa, S., Rao, K. S., & Chan, F. T. S. (2005). Flexibility-enabled lead-time reduction in flexible system. International Journal of Production Research, 43(15), 3131–3163.
Wang, L., Tang, D., Gu, W., Zheng, K., Yuan, W., & Tang, D. (2012). Pheromone-based coordination for manufacturing system control. Journal of Intelligent Manufacturing, 23, 747–757.
Xiong, W., & Fu, D. (2018). A new immune multi-agent system for the flexible job shop scheduling problem. Journal of Intelligent Manufacturing, 29, 857–873.
Yadav, A., & Jayswal, S. C. (2018). Modelling of flexible manufacturing system: a review. International Journal of Production Research, 56, 2464–2487.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hussain, M.S., Ali, M. A Multi-agent Based Dynamic Scheduling of Flexible Manufacturing Systems. Glob J Flex Syst Manag 20, 267–290 (2019). https://doi.org/10.1007/s40171-019-00214-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40171-019-00214-9