
Abstract
This paper studies dynamic mechanism design in a Markovian environment and analyzes a direct mechanism model of a principal-agent framework in which the agent is allowed to exit at any period. We consider that the agent’s private information, referred to as state, evolves over time. The agent makes decisions of whether to stop or continue and what to report at each period. The principal, on the other hand, chooses decision rules consisting of an allocation rule and a set of payment rules to maximize her ex-ante expected payoff. In order to influence the agent’s stopping decision, one of the terminal payment rules is posted-price, i.e., it depends only on the realized stopping time of the agent. This work focuses on the theoretical design regime of the dynamic mechanism design when the agent makes coupled decisions of reporting and stopping. A dynamic incentive compatibility constraint is introduced to guarantee the robustness of the mechanism to the agent’s strategic manipulation. A sufficient condition for dynamic incentive compatibility is obtained by constructing the payment rules in terms of a set of functions parameterized by the allocation rule. The payment rules are then pinned down up to a constant in terms of the allocation rule by deriving a first-order condition. We show cases of relaxations of the principal’s mechanism design problem and provide an approach to evaluate the loss of robustness of the dynamic incentive compatibility when the problem solving is relaxed due to analytical intractability. A case study is used to illustrate the theoretical results.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Mechanism design theory provides a theoretical foundation for designing games that can induce desired outcomes. The players of the game have private information that is not publicly observable. Hence, the mechanism designer’s collective decisions have to rely on the players to reveal their private information. This information asymmetry is an important feature of mechanism design problems. The revelation principle allows the mechanism designer to focus on a class of incentive-compatible direct mechanisms to replicate equilibrium outcomes of indirect mechanisms. In the celebrated work by Vickery ([52]), it has been shown that the seller receives the same expected revenue independent of the mechanism within a large class of auctions. Vickrey–Clark–Groves (VCG) mechanism is an example of truthful mechanism to achieve a social–optimal solution. This work investigates mechanism design problems in a dynamic environment, in which a player, aka the agent, sends a sequence of messages based on the gathered information to the designer. The designer, aka the principal, chooses dynamic rules of encounter of the agent to maximize the profit based on the messages. Our model allows the agent to decide how to report his private information to the principal and whether to stop the mechanism immediately or continue to the future at the same time. These two coupled decision makings depend on the agent’s dynamic private information that endogenously depends on the past outcomes of the mechanism. The model covers different economic scenarios when the agent establishes an agreement with the principal to, for example, dynamically purchase private or public goods when his valuation stochastically changes over time or frequently consume experience goods when his preference is refined after every usage of the goods, while the agent is allowed to terminate this agreement at any period of time. Unlike the mechanism design with deadline or a solid commitment period, the agent in our model owns the right to stop. This additional freedom reduces the agent’s risk in the long-term relationship with the principal due to the uncertainty of the dynamic environment. However, agent’s such freedom complicates the principal’s characterization of the incentive compatibility in the dynamic environment. In this work, we aim to settle the design regimes of such dynamic mechanism by characterizing the allocation and the payment rules and elaborate the incentive compatibility of the mechanism when the agent with time-varying private information couples his decision making of how to reveal his private information with his optimal stopping decision.
Many real-world problems are fundamentally dynamic in nature. Research of dynamic mechanism design has studied many applications in optimal auctions (e.g., [18, 30]), screening (e.g., [1, 15, 16]), optimal taxation (e.g., [19, 34]), contract design (e.g., [55, 57]), matching market (e.g., [2, 3]), to name a few. In dynamic mechanism problems, there are mechanisms without private information. For example, in airline revenue management problems, an airline makes decisions about seat pricing on a flight by taking into account the time-varying inventory and the time evolution of the customer base. In this paper, however, we consider an information-asymmetric dynamic environment in which the agent privately possesses information that evolves over time. The time evolution of the private information may be caused by external factors, the past observations, as well as the decisions from the principal, as when the agent employs learning-by-doing regimes. For example, in repeated sponsored search auctions, the advertisers privately learn about the profitability of clicks on their ads based on evaluations of the past ads as well as observations from market analysis. In this work, we consider a dynamic environment, when the agent’s private information changes endogenously due to the outcomes of the past decision makings. Evidence in many economic scenarios has shown that people’s past decisions often play a significant role in shaping their future preferences ([56]). Business models have taken into account the belief that customers’ preferences can be changed endogenously by using the products or services to form the habit of the customers and encourage long-term shopping sprees. For example, many products and services, such as newspapers, online video streaming, software as a service, food delivery, provide free trial offers to attract new customers to commit long-term subscriptions.
Optimal stopping theory studies the timing decisions under conditions of uncertainty and has been successfully adopted in applications of economics, finance, and engineering. Examples include gambling problems (e.g., [17, 23]), option tradings (e.g., [4, 28, 33]), and quick detection problems (e.g., [29, 43, 51]). This paper studies a class of general dynamic decision-making models, in which the agent has the right to stop the mechanism at any period based on his current observations and the anticipations of the future. The agent adopts a stopping rule and is allowed to realize the stopping time in any period before the mechanism terminates naturally upon reaching the final period. In contract design problems, for example, allowing the stopping decision is made as a clause of a dynamic contract that specifies the agent’s right to terminate the agreement at any period. However, our optimal stopping setting is fundamentally different from the contract intra-deal renegotiation (i.e., renegotiation within the life of the contract) and the contract break. In general, a renegotiation occurs due to the failure of one party to fulfill its obligations or the inability of one party to meet its commitments. In such cases, one side of the participants seeks relief of its commitments or wishes to terminate the agreement before the term of that agreement has concluded (see, e.g., [49]). The consequence of the renegotiation might be the termination of the contract or a new contract with modified terms and clauses. Our stopping setting, however, is not due to any breach of the contract by any participant or the inability of maintaining the agreement; it is not a consequence of renegotiations of the contract. Instead, early termination due to the stopping rule is the right of the agent and lies in the commitment of the principal’s dynamic mechanism. Once the agent decides to terminate the contract at a specific period, he cannot break the dynamic contract by refusing the outcomes (i.e., allocations and payments) that have already been realized up to that period.
We consider a finite horizon Markovian environment, in which the agent can observe the private information, referred to as the state, that arrives dynamically at the beginning of each period. The dynamic information structure is governed by a stochastic process characterized by the principal’s decision rules, the transition kernels, and the agent’s strategic behaviors. After observing his state at each period, the agent chooses a strategy to report his state to the principal and decides whether to stop immediately or to continue. Conditioning on the reported information (including the stopping decision), the principal provides an allocation to the agent and induces a payment. The principal aims to maximize her ex-ante expected payoff by choosing feasible decision rules including a set of allocation rules and a set of payment rules. The principal provides three payment rules including an intermediate payment rule that specifies a payment based on the report when the agent decides to continue and two terminal payment rules. One of the terminal payment rules is state-dependent and the other is posted-price in the sense that this payment rule depends only on the realized stopping time. The posted-price payment rule enables the principal to influence the agent’s stopping decision without taking into account the agent’s private information. This state-independent terminal payment rule could be the early termination fee to disincentivize the agent from early stopping (when the preferences of the principal and the agent are not aligned), or it could be a reward to elicit the agent to stop at certain periods before the final period to fulfill the principal’s interests (when the preferences of the principal and the agent are aligned or partially aligned). Under some monotone conditions, the optimal stopping rule can be reformulated as a threshold rule with a time-dependent threshold function. The threshold rule simplifies the principal’s design of the posted-price payment rule as well as the agent’s reasoning process for decision makings.
The design problem in this work faces the challenges from the multidimensional interdependence of the agent’s joint decision of reporting and stopping at the current period and the planned ones for the future. On the one hand, by fixing the current and the planned future reporting strategies, the agent’s stopping decision is made by comparing the payoff if he stops immediately and the best-expected payoff he can anticipate from the future. On the other hand, with a fixed stopping decision, the (current and the planned future) reporting strategies are chosen by comparing the expected payoffs of different reporting strategies, which determines the expected instantaneous payoff at each period up to the effective time horizon pinned down by the stopping decision. Therefore, the agent’s stopping decision enters the principal’s characterization of the dynamic incentive compatibility through this dynamic interdependence. Given the mechanism, the stopping and the reporting decisions together determine the agent’s optimal behaviors. The coupling of these two decisions in the analysis of incentive compatibility distinguishes this work from other dynamic mechanism design problems.
We define the notion of dynamic incentive compatibility in terms of Bellman equations and address the challenge induced by the agent’s dynamic multidimensional decision makings via establishing a one-shot deviation principle (see, e.g., [12]). The one-shot deviation principle has uncovered a foundation of optimality in game theory. It states that if the agent’s deviation from truthful reporting is not profitable for one period, then any finite arbitrary deviations from truthfulness are not profitable. Monotonicity regarding the designer’s allocation rules with respect to the agent’s private information is an important result for the implementability of mechanism design. Consider a single good auction in which the states are bidders’ valuations for a single good and the outcomes are the probabilities for the agent to win the good. Here, the notion of monotonicity is that the probability of winning the good is non-decreasing in the reported state (see, e.g., [11, 35]). Myerson [35] has shown that monotonicity is sufficient for implementability in a one-dimensional domain. However, in general, monotonicity acts only as a necessary condition. Rochet [46] has constructed a necessary and sufficient condition, called cyclic monotonicity, under which one can design a mechanism such that truthful reporting is optimal for the rational agent. In this work, we describe a set of monotonicity conditions through inequalities characterized by functions of the allocation rules which we call potential functions. Given the optimality of the stopping rule, we represent each payment rule by the potential functions. By applying the envelope theorem, we formulate the potential functions in closed form in terms of the allocation rule. Our main results, Propositions 2-4, provide characterizations of the dynamic incentive compatibility when the agent with time-varying private information makes coupled decisions of reporting and stopping in a Markovian dynamic environment. The characterizations contribute as design principles by explicitly constructing the three payment rules in terms of the allocation rule and formulating the sufficient and the necessary conditions of dynamic incentive compatibility and facilitate a solid analytical view of dynamic mechanism design to elicit the agent’s truthful reporting and optimal stopping. The sufficient and the necessary conditions yield a revenue equivalence property for the dynamic environment. We also show that given the threshold function and the allocation rule, the state-independent payment rule is unique up to a constant. We observe that the posted-price payments from the state-independent payment rule are restricted by a class of regular conditions. Due to the analytical intractability, relaxation approaches are applied to the principal’s mechanism design problem. We also provide a sufficient condition to evaluate the loss of the robustness of the dynamic incentive compatibility due to the relaxations and the approximations used to solve the principal’s problem.
1.1 Related Work
General settings regarding the source of the dynamics in the related literature can be divided into two categories. On the one hand, the literature on dynamic mechanism design considers the dynamic population of participants with static private information. Parkes and Singh [39] have provided an elegant extension of the social-welfare-maximizing (efficiency) VCG mechanism to an online mechanism design framework that studies sequential allocation problems in a dynamic population environment. In particular, they have considered the setting when each self-interested agent arrives and departs dynamically over time. The private information in their model includes the arrival and the departure time as well as the agent’s valuation about different outcomes. However, the agents do not learn new private information or update their private information. Pai and Vohra [37] have proposed a dynamic mechanism model of a similar setting but focusing on the profit maximization (optimality) of the designer. Other works focusing on this setting include, e.g., [14, 21, 22, 37, 48, 54]. On the other hand, there are a number of works studying the problems of the static population where the underlying framework is dynamic because of the time evolution of the private information. This category of research has been pioneered by the work of Baron and Besanko [9] on the regulation of a monopoly and the contributions of Courty and Hao [15] on a sequential screening problem. There is a large amount of work in this category including, for instance, the dynamic pivot mechanisms (e.g., [10, 25]) and dynamic team mechanisms (e.g., [6, 8, 36]). Pavan et al. [42] have provided a general dynamic mechanism model in which the dynamic of the agents’ private information is captured by a set of kernels that is applicable for different behaviors of the time evolution including the learning-based and i.i.d. evolution. They have used a Myersonian approach and designed a profit-maximizing mechanism with monotonic allocation rules. Kakade et al. [25] have studied a dynamic virtual-pivot mechanism and provided conditions on the dynamics of the agents’ private information. They have shown an optimal mechanism under the environment they call separable. Bergemann and Välimäki [10] and Parkes [38] have provided surveys of recent advances in dynamic mechanism design.
The challenges of both settings of dynamics described above come from the information asymmetry between the designer and the agents. Most of the mechanism design problems study the direct revelation mechanism, in which guaranteeing the incentive compatibility becomes essentially important. In many dynamic population mechanism problems with static private information, the incentive compatibility constraints are essentially static ([25]). The mechanisms with dynamic private information, however, require efforts to guarantee incentive compatibility. Monotonicity is an important property of incentive-compatible mechanism design that is widely used in the literature on dynamic mechanism design (see, e.g., [18, 25, 42]).
Many situations in economics can be modeled as stopping problems. There is recent literature on the mechanism design with stopping time. Kruse and Strack [26] have studied optimal stopping as a mechanism design problem with monetary transfers. In their model, the agent privately observes a stochastic process of a payoff-relevant state. The incentive-compatible mechanism considered in their work contains two mechanism rules where one rule maps the agent’s report into a stopping decision and the other rule maps the agent’s report into a payment that is realized only at the stopping time. Hence, their model considers that the mechanism determines the optimal stopping decision for the agent based on the report and the agent has only one decision (i.e., reporting) to make. Pavan et al. [41] have described an application of their dynamic mechanism model to the optimal stopping problem, where the allocation rule provided by the principal is the stopping rule. Basic formats of stopping rules have been summarized in Lovász andWinkler [31] and for rigorous mathematical formulations of general stopping problems, see Peskir and Shiryaev [44].
1.2 Organization
The rest of the paper is organized as follows. In Sect. 2, we introduce the dynamic environment and specify the key concepts and notations. Section 3 formulates the dynamic principal-agent problem and determines the optimal stopping rule for the agent. In Sect. 4, we describe the implementability of the dynamic principal-agent model by defining the dynamic incentive compatibility constraint and reformulating the optimal stopping rule as a threshold rule. Section 5 characterizes the dynamic incentive compatibility by establishing the sufficient and the necessary conditions and showing the properties of revenue equivalence. In Sect. 6, we formally describe the optimization problem of the principal and show examples of its relaxations due to the analytical intractability. We also provide an approach to evaluate the loss of robustness of the dynamic incentive compatibility due to the relaxations. A case study is given in Sect. 6.2 as a theoretical illustration. Section 7 concludes the work.
2 Dynamic Environment
In this section, we describe the dynamic environment of the model. As conventions, let \({\tilde{x}}_{t}\) represent the random variable such that \(x_{t}\in X_{t}\) is a realized sample of \({\tilde{x}}\). By \(h^{x}_{s,t}\equiv \{x_{s},...x_{t}\}\in \prod _{k=s}^{t}X_{k}\), we denote the history of x from period s up to t (including t), with \(h^{x}_{t}\equiv h^{x}_{1,t}\), \(h^{x}_{t,t}\equiv h^{x}_{t,t-1} \equiv x_{t}\), for all \(t\in {\mathbb {T}}\). For any measurable set X, \(\varDelta (X)\) is the set of probability measures over X. Table 1 summarizes the main notations of this paper.
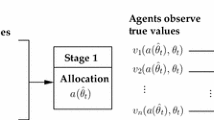
There are two rational (risk neutral, under the expected utility hypothesis) participants in the mechanism: a principal (indexed by 0, she) and an agent (indexed by 1, he). We consider a finite-time horizon with discrete time \(t \in {\mathbb {T}} \equiv \{1,2,\dots , T\}\). Let \({\mathbb {T}}_{t}\equiv \{t,t+1,\dots , T\}\), for all \(t\in {\mathbb {T}}\). At each period t, the agent observes his state \(\theta _{t}\in \varTheta _{t}\equiv {[{\underline{\theta }}_{t}, \bar{\theta }_{t}]} \subset {\mathbb {R}}\). Based on \(\theta _{t}\), the agent sends a report \(m_{t}\in M_{t}\) to the principal. In this paper, we restrict our attention on the direct mechanism ([20]), in which the message space coincides with the state space, i.e., \(M_{t}=\varTheta _{t}\), for all \(t\in {\mathbb {T}}\). Upon receiving the report \({\hat{\theta }}_{t}\), the principal specifies an allocation \(a_{t}\in A_{t}\) and a payment \(p_{t}\in {\mathbb {R}}\). Each \(A_{t}\) is a measurable space of all possible allocations. Let \(\sigma _{t}: \prod _{s=1}^{t}\varTheta _{s} \times \prod _{s=1}^{t-1}\varTheta _{s} \times \prod _{s=1}^{t-1} A_{s} \mapsto \varTheta _{t}\) be the reporting strategy at t, such that \({\hat{\theta }}_{t}=\sigma _{t} (\theta _{t}|h^{\theta }_{t-1}, h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1})\) is the report sent to the principal at period t, given his period-t true state \(\theta _{t}\) and the histories \(h^{\theta }_{t-1}, h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1}\). The allocation and the payment are chosen, respectively, by the decision rules \(\{\alpha , \phi \}\), where \(\alpha \equiv \{\alpha _{t} \}_{t\in {\mathbb {T}} }\) is a collection of (instantaneous) allocation rules \(\alpha _{t}: \prod _{s=1}^{t}\varTheta _{s} \mapsto A_{t}\) and \(\phi \equiv \{\phi _{t} \}_{t\in {\mathbb {T}}}\) is a collection of (instantaneous) payment rules \(\phi _{t}:\prod _{s=1}^{t}\varTheta _{s}\mapsto {\mathbb {R}}\), such that the principal specifies an allocation \(a_{t}=\alpha _{t}({\hat{\theta }}_{t}|h^{{\hat{\theta }}}_{t-1})\) and a payment \(p_{t} = \phi _{t}({\hat{\theta }}_{t}|h^{{\hat{\theta }}}_{t-1})\) when \({\hat{\theta }}_{t}\) is reported at the current period and \(h^{{\hat{\theta }}}_{t-1}\) has been reported up to \(t-1\).
The mechanism allows the agent to leave the mechanism at any period \(t\in {\mathbb {T}}\) by deciding whether to stop or continue at each period according to his optimal stopping rule. Hence, the agent’s decision of \(\sigma _{t}\) is coupled with his stopping decision at each period t. Therefore, the principal’s characterization of incentive compatibility has to take into account the agent’s coupled decision makings. To influence the agent’s stopping decision, the principal uses a terminal payment rule \(\rho : {\mathbb {T}} \mapsto {\mathbb {R}}\), with \(\rho (T)=0\), which is independent of agent’s reports and specifies an additional payment \(\rho (t)\) at period t if the agent decides to stop at t. To distinguish the intermediate periods and the terminal period, let \(\xi _{t}\equiv \phi _{t}\) when the agent realizes his stopping time at period t, such that the agent receives a payment \(p_{t} = \xi _{t}({\hat{\theta }}_{t}|h^{{\hat{\theta }}}_{t-1}) + \rho (t)\).
The mechanism is information-asymmetric because \(\theta _{t}\) is privately possessed by the agent for every \(t\in {\mathbb {T}}\) and the principal can learn the true state only through the report \({\hat{\theta }}_{t}\). The mechanism is dynamic because the agent’s state \(\theta _{t}\) evolves endogenously over time and the decisions of both the agent and the principal are made over multiple periods. The state dynamics lead to the time evolution of probability measures of the states. As a result, the expectations of future behaviors at different periods are in general different from each other.
2.1 Markovian Dynamics
We consider that the agent’s state endogenously evolves over time in a Markovian environment and describe the details of the dynamics and the underlying stochastic process that governs the state dynamics.
Definition 1
(Markovian Dynamics) The Markovian (endogenous) dynamics are characterized by a set of transition kernels \(K=\{K_{t}\}_{t\in {\mathbb {T}}}\), where \(K_{t}: \varTheta _{t-1} \times \prod _{s=1}^{t-1} A_{s} \mapsto \varDelta (\varTheta _{t})\) is the period-t transition kernel of the state, i.e., \({\tilde{\theta }}_{t}\sim K_{t}(\theta _{t-1}, h^{a}_{t-1})\). Let \(F_{t}(\cdot |\) \(\theta _{t-1}, h^{a}_{t-1} )\) be the cumulative distribution function (c.d.f.) of \({\tilde{\theta }}_{t}\), with \(f_{t}(\cdot | \theta _{t-1}, h^{a}_{t-1})\) as the probability density function (p.d.f.). \(F_{1}\) and \(f_{1}\) are given at the initial period.
In Markovian dynamics, the generation of the next-period state \(\theta _{t+1}\) depends on the current-period state \(\theta _{t}\) and the history of allocations \(h^{a}_{t}\). Hence, \(\theta _{t+1}\) is independent of the history of true states \(h^{\theta }_{t-1}\) given \(\theta _{t}\). From Ionescu–Tulcea theorem (see, e.g., [5]), the transition kernel K, the allocation rule \(\alpha \), and the agent’s reporting strategy \(\sigma \) define a unique stochastic process (i.e., a probability measure) that governs the state dynamics. Let \(\varXi _{\alpha ; \sigma }\) denote the stochastic process. Given any realizations of period-t state and history of states, we define the period-t interim process in the following definition.
Definition 2
(Interim Process) The interim process \(\varXi _{\alpha ;\sigma }\big [h^{\theta }_{t}\big ]\) at period \(t\in {\mathbb {T}}\) consists of
-
(i)
a deterministic process of the realized \(h^{\theta }_{t}\in \prod _{s=1}^{t} \varTheta _{s}\) up to time t, and
-
(ii)
a stochastic process starting from \(t+1\) that is uniquely characterized by period-t state \(\theta _{t}\), history of allocations \(h^{a}_{t}\in \prod _{s=1}^{t} A_{s}\), the allocation rule \(\alpha ^{T}_{t+1}\equiv \{\alpha _{s}\}_{s\in {\mathbb {T}}_{t+1}}\), and the planned reporting strategies \(\sigma ^{T}_{t+1}=\{\sigma _{s}\}_{s\in {\mathbb {T}}_{t+1}}\), given the kernels \(K^{T}_{t+1}\equiv \{K_{s}\}_{s\in {\mathbb {T}}_{t+1}}\).
Given the processes \(\varXi _{\alpha ;\sigma }\) and \(\varXi _{\alpha ;\sigma }[h^{\theta }_{t}]\), we specify the timing of the mechanism as follows.
-
I.
Ex-ante stage: there is no realization of state, i.e., before the mechanism starts. At this stage, the randomness of the future is characterized by \(\varXi _{\alpha ;\sigma }\).
-
II.
Interim stage (at period t): \(h^{\theta }_{t}\) are realized according to the Markovian dynamics. At each (period-t) interim stage:
-
1.
Given the current state \(\theta _{t}\), the agent chooses a report \({\hat{\theta }}_{t}=\sigma _{t}(\theta _{t}|h^{\theta }_{t-1}, h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1})\), and decides whether to stop immediately or continue to the next period.
-
2.
Upon receiving \({\hat{\theta }}_{t}\), the principal specifies an allocation \(a_{t}= \alpha _{t}({\hat{\theta }}_{t}|h^{{\hat{\theta }}}_{t-1})\), a payment \(p_{t} = \phi _{t}({\hat{\theta }}_{t}|h^{{\hat{\theta }}}_{t-1})\) or \(p_{t}=\xi _{t}({\hat{\theta }}_{t}|h^{{\hat{\theta }}}_{t-1})+\rho (t)\) if the agent decides to continue or to stop, respectively.
At each interim stage, the randomness of the future is characterized by \(\varXi _{\alpha ;\sigma }[h^{\theta }_{t}]\). We denote the corresponding expectations of \(\varXi _{\alpha ;\sigma }\) and \(\varXi _{\alpha ;\sigma }[h^{\theta }_{t}]\) by \({\mathbb {E}}^{\varXi _{\alpha ;\sigma }}\big [\cdot \big ]\) and \({\mathbb {E}}^{\varXi _{\alpha ;\sigma }[h^{\theta }_{t}]}\big [\cdot \big ]\), respectively. We suppress the notation \(\sigma \) when it is a truthful reporting strategy.
-
1.
3 Dynamic Principal-Agent Problem
In this section, we describe the principal-agent problem by identifying their respective objectives. Let \(u_{i,t}: \varTheta _{t} \times A_{t} \mapsto {\mathbb {R}}\) denote the (instantaneous) utility of the participant i for \(i\in \{0,1\}\) such that \(u_{i,t}(\theta _{t}, a_{t})\) is the utility that the participant i receives when the agent’s true state is \(\theta _{t}\) and the allocation is \(a_{t}\) for all \(t\in {\mathbb {T}}\). Given any allocation rule \(\alpha \), we assume that \(u_{i,t}\) is Lipschitz continuous in \(\theta _{t}\), for all \(\theta _{t}\in \varTheta _{t}\), all \(t\in {\mathbb {T}}\).
Given any reporting strategy \(\sigma \), define the ex-ante expected values of the principal and the agent, respectively, for any time horizon \(\tau \in {\mathbb {T}}\) as follows:
and
where \(\delta \in (0,1]\) is the discount factor. Let \(J^{\alpha ,\phi ,\xi ,\rho }_{0}(\cdot ;\sigma ):{\mathbb {T}} \mapsto {\mathbb {R}}\) and \(J^{\alpha ,\phi ,\xi ,\rho }_{1}(\cdot ;\sigma ): {\mathbb {T}} \mapsto {\mathbb {R}}\) denote the ex-ante expected payoffs of the principal and the agent, respectively, given as follows:
-
Principal:
$$\begin{aligned} \begin{aligned} J^{\alpha , \phi , \xi , \rho }_{0}(\tau ;\sigma )\; \equiv&Z^{\alpha , \phi , \xi }_{0}(\tau ;\sigma ) - \rho (\tau ) ; \end{aligned} \end{aligned}$$(1) -
Agent:
$$\begin{aligned} \begin{aligned} J^{\alpha , \phi , \xi , \rho }_{1}(\tau ;\sigma ) \;\equiv&Z^{\alpha , \phi , \xi }_{1}(\tau ;\sigma ) + \rho (\tau ). \end{aligned} \end{aligned}$$(2)
Similarly, we define the interim expected value of the agent evaluated at period t, when the histories are \((h^{\theta }_{t-1}, h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1})\), \(\theta _{t}\) is observed, and \(\sigma _{t}(\theta _{t})\) is reported, as follows, for any \(\tau \in {\mathbb {T}}_{t}\):
with \(Z^{\alpha , \phi , \xi }_{1,t}(\tau , \theta _{t}|h^{\theta }_{t-1})\equiv Z^{\alpha , \phi , \xi }_{1,t}(\tau , \theta _{t},\theta _{t};\sigma |h^{\theta }_{t-1})\) when \(\sigma \) is truthful at every period. Then, the corresponding period-t interim expected payoff of the agent can be defined as follows:
with \(J^{\alpha , \phi , \xi , \rho }_{1,t}(\tau , \theta _{t}|h^{\theta }_{t-1}) \equiv J^{\alpha , \phi , \xi , \rho }_{1,t}(\tau , \theta _{t},\theta _{t};\sigma |h^{\theta }_{t-1})\) when \(\sigma \) is truthful at every period.
At the ex-ante stage, the principal provides a take-it-or-leave-it offer to the agent by taking into account the agent’s stopping rule. Given the stopping rule, the time horizon \(\tau \) of the ex-ante expected payoffs can be calculated. The principal aims to maximize her ex-ante expected payoff (1) by anticipating the agent’s planned reporting strategy and the stopping time, by choosing the decision rules \(\{\alpha ,\phi ,\xi , \rho \}\). The agent with his planned reporting strategy \(\sigma \) decides whether to accept the offer by checking the following rational participation (RP) constraint:
under which the agent expects a nonnegative payoff by participating. Besides the RP constraint, the principal also wants to incentivize the agent to truthfully reveal his true state in the direct mechanism. To achieve this, the principal needs to impose the incentive compatibility (IC) constraint in addition to the RP constraint to guarantee that truthful reporting at each period is for the agent’s best interests.
With the knowledge of the Markovian dynamics, the agent can determine his current reporting strategy and plan his future behaviors. Suppose at period t, the agent observes \(\theta _{t}\) and reports \({\hat{\theta }}_{t}\). The report \({\hat{\theta }}_{t}\) leads to a current-period allocation \(a_{t}=\alpha _{t}({\hat{\theta }}_{t}|h^{{\hat{\theta }}}_{t-1})\). As a rational participant, the current-period decision making of the agent aims to maximize his interim expected payoff (4). Due to the Markovian dynamics, the probability measures of each of the future states depend on the current state \(\theta _{t}\) and the history of allocations \(h^{a}_{t}\). Hence, the agent’s decision of how to report his current-period state is independent of the past true states but depends on \(h^{a}_{t-1}\) and \(h^{{\hat{\theta }}}_{t-1}\) (through \(h^{a}_{t-1}\)), i.e., \({\hat{\theta }}_{t}=\sigma _{t}(\theta _{t}| h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1})\). (Hereafter, we will drop \(h^{\theta }\) in the notation of the agent’s reporting strategy.) Therefore, guaranteeing IC when the agent has reported truthfully at all past periods is sufficient to ensure IC when the agent has a history of arbitrary reports. Given the dependence of the future states on the histories, the agent can plan his future reporting strategies from period \(t+1\) onward to obtain an optimal interim expected payoff. As a result, the principal’s craft of IC constraint at each period needs to be coupled with the agent’s current and his planned future behaviors. As described in Sect. 3.2, the agent’s adoption of stopping rule further complicates the principal’s guarantee of IC.
3.1 Main Assumptions
We introduce the following assumptions to support our theoretical analysis of the dynamic model with optimal stopping time.
Assumption 1
Given any \(\{\alpha , \phi , \xi , \rho \}\) and \(\sigma \), the following holds, for all \(t\in {\mathbb {T}}\),
Assumption 1 guarantees that the expected absolute value of any period-t interim expected payoff is bounded for any time horizon \(\tau \in {\mathbb {T}}_{t}\). This assumption can be satisfied, for example, when the instantaneous payoff \(u_{i,t}(\theta _{t}, a_{t}) + p_{t}\) is uniformly bounded for any \(\theta _{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\), given \(\{\alpha , \phi , \xi , \rho \}\) and \(\sigma \). This assumption is essential to the existence of optimal stopping rule described in Sect. 3.2.
Define \(\chi ^{\alpha ,\phi ,\xi }_{1,t}\) as the difference between the interim expected values when \(\tau =t\) and \(\tau =t+1\), respectively, evaluated at period t as follows,
Here, \(\chi ^{\alpha , \phi , \xi }_{1,t}(\theta _{t})\) can be interpreted as the expected marginal change of deferring the stopping time from current period t to the next period \(t+1\). Hence, \(\chi ^{\alpha , \phi , \xi }_{1,t}(\theta _{t})\) characterizes the marginal incentive of agent’s stopping decision at period t. General optimal stopping problems do not require monotonicity assumptions on \(\chi ^{\alpha , \phi , \xi }_{1,t}(\theta _{t})\). However, as imposed in many economic models, there is a monotonicity condition referred to as the single crossing property (see, e.g., [45]): \(\chi ^{\alpha , \phi , \xi }_{1,t}(\theta _{t})\) crosses the horizontal axis just once, from negative to positive (resp. from positive to negative), as the state \(\theta _{t}\) increases (resp. decreases). A single crossing property applicable in our dynamic model is shown in the following assumption.
Assumption 2
\(\chi ^{\alpha , \phi , \xi }_{1,t}(\theta _{t})\) is non-decreasing in \(\theta _{t}\) for all \(t\in {\mathbb {T}}\).
This assumption is for the desideratum of establishing a threshold-based optimal stopping rule in Sect. 4.1. To ensure that Assumption 2 holds, we can, for example, make the derivative of \(\chi ^{\alpha ,\phi ,\xi }_{1,t}\) with respective to \(\theta _{t}\) nonnegative or impose the monotonicity of the utility function, payment rules, and their combinations, e.g., each of \({\mathbb {E}}^{\varXi _{\alpha ;\sigma }[h^{\theta }_{t}] }\Big [\xi _{t+1}({\tilde{\theta }}_{t+1}|h^{\theta }_{t})-\xi _{t}(\theta _{t}|h^{\theta }_{t-1})\Big ]\), \(\phi _{t}(\theta _{t})\), and \({\mathbb {E}}^{\varXi _{\alpha ;\sigma }[h^{\theta }_{t}] }\) \(\Big [u_{1,t+1}({\tilde{\theta }}_{t+1},\) \( \alpha _{t+1}({\tilde{\theta }}_{t+1}|h^{\theta }_{t}))\Big ]\) is non-decreasing in \(\theta _{t}\). This assumption can be naturally interpreted in many economic scenarios. For example, suppose that the principal aims to establish a multiperiod cooperation with an agent, who has time-evolving productivity (i.e., state) to finish the tasks assigned by the principal over time. Assumption 2 assumes that the agent with higher productivity is more incentivized by the mechanism to continue instead of stopping immediately than the agent with lower productivity.
Assumption 3
The probability density \(f_{t}(\theta _{t}|\theta _{t-1}, h^{a}_{t-1})>0\) for all \(\theta _{t}\in \varTheta _{t}\), \(\theta _{t-1}\in \varTheta _{t-1}\), \(h^{a}_{t-1}\in \prod _{s=1}^{t-1} A_{s}\), \(t\in {\mathbb {T}}\backslash \{1\}\).
Assumption 3 restricts our attention to a full support environment where each state has a strictly positive probability to be realized at each period. This assumption is imposed to support the uniqueness of the threshold-based optimal stopping rule and to ensure that the marginal effect of the change of the current state on the future states is bounded (as used in Lemma 8). Finally, the following assumption imposes a first-order stochastic dominance on the dynamics of the agent’s state.
Assumption 4
For all \(\theta '_t \ge \theta _t\in \varTheta _{t}\), \({\bar{\theta }}_{t+1}\in \varTheta _{t+1}\), \(h^{a}_{t}\in \prod _{s=1}^{t} A_{s}\), \(t\in {\mathbb {T}}\backslash \{T\}\),
Assumption 4 assumes that a larger state at current period leads to a larger state at the next period in the sense of a first-order stochastic dominance, i.e., the partial derivative of \(F_{t+1}\) with respect to \(\theta _{t}\) is non-positive. It is straightforward to see that Assumptions 1, 3, and 4 are spontaneously compatible to each other. However, since the monotonicity of the state dynamics influences the probability measures of the expectations taken in the term \(Z^{\alpha ,\phi ,\xi }_{1,t}\), the monotonicity of \(\chi ^{\alpha ,\phi ,\xi }_{1,t}\) specified by Assumption 2 is correlated with Assumption 4. Given its definition in (7), the monotonicity of \(\chi ^{\alpha ,\phi ,\xi }_{1,t}\) also relates to the monotonicity of the utility function, the allocation rule, and the payment rules. In Sect. 5, the characterizations of the dynamic incentive compatibility consider the case when all the above four assumptions are satisfied as well as a more general case without Assumption 2.
3.2 Optimal Stopping Rule
In this section, we construct the optimal stopping rule for the agent and identify the dynamic incentive compatibility constraints when the agent makes coupled decisions of reporting and stopping at each period. Let \(\varOmega [\sigma ]\) denote the agent’s stopping rule when he uses reporting strategy \(\sigma \). The optimality of \(\varOmega [\sigma ]\) is defined as follows.
Definition 3
(Optimal Stopping) Given \(\{\alpha ,\phi ,\xi , \rho \}\) and any reporting strategy \(\sigma \), the agent’s stopping rule \(\varOmega [\sigma ]\) is optimal if there exists a \(\tau ^{*}\) such that
Let \(\varOmega ^{*}[\sigma ]\) denote the optimal stopping rule when the agent adopts \(\sigma \).
Fix \(\{\alpha ,\phi ,\xi ,\rho \}\). To study the optimal stopping problem (9), we introduce the agent’s valuation function at period t as follows, for all \(\theta _{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\), any stopping rule \(\sigma \):
\(V^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t})=V^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t};\sigma )\) when \(\sigma \) is truthful, where the supremum is taken over all time horizon \(\tau \) of the process \(\varXi _{\alpha }[h^{\theta }_{t}]\) starting from t. The valuation function \(V^{\alpha , \phi , \xi , \rho }_{t}(\theta _{t}; \sigma )\) is the maximum interim expected payoff the agent can expect at period t by varying the time horizon when he has reported \(h^{{\hat{\theta }}}_{t-1}\), observes the current state \(\theta _{t}\) and reports \({\hat{\theta }}_{t}=\sigma _{t}(\theta _{t}| h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1})\), and plans to report future states by \(\{\sigma _{s}\}_{s\in {\mathbb {T}}_{t+1}}\). Note that the agent can modify his planned future reporting strategies at different periods to evaluate the valuation (10).
Suppose that Assumption 1 holds. Backward induction leads to the following Bellman equation, for any reporting strategy \(\sigma \):
-
(i)
for all \(t\in {\mathbb {T}}\backslash \{T\}\),
$$\begin{aligned} \begin{aligned}&V^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t}; \sigma ) \\&\quad = \max \Big ( J^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t, \theta _{t},\sigma _{t}(\theta _{t}| h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1});\sigma |h^{\theta }_{t-1}), {\mathbb {E}}^{\varXi _{\alpha }[h^{\theta }_{t}]}\big [ V^{\alpha ,\phi ,\xi ,\rho }_{t+1}({\tilde{\theta }}_{t+1};\sigma )\big ] \Big ); \end{aligned} \end{aligned}$$(11) -
(ii)
for \(t=T\),
$$\begin{aligned} V^{\alpha ,\phi ,\xi ,\rho }_{T}(\theta _{T};\sigma ) = J^{\alpha ,\phi ,\xi ,\rho }_{1,T}(T, \theta _{T},\sigma _{T}(\theta _{T}| h^{{\hat{\theta }}}_{T-1}, h^{a}_{T-1}); \sigma |h^{\theta }_{T-1}). \end{aligned}$$(12)
The backward induction yields an equivalent representation of \(V^{\alpha ,\phi ,\xi ,\rho }_{t}\) by comparing interim expected payoff if the agent stops at t and the expected valuation of the next period if the agent continues. Formulations (11) and (12) naturally lead to the following definition of a stopping region, for any reporting strategy \(\sigma \), \(t\in {\mathbb {T}}\):
Hence, the period-t stopping region is a set of states that are realized at period t such that the period-t valuation equals the period-t interim expected payoff if the agent stops at t. Based on the stopping region (13), we define the stopping rule, for any reporting strategy \(\sigma \):
The stopping rule \(\varOmega ^{*}[\sigma ]\) shown in (14) calls for stopping at period t if the realized state \(\theta _{t}\) is in the stopping region. Theorem 1.9 of Peskir and Shiryaev [44] has shown that \(\varOmega ^{*}[\sigma ]\) given in (14) solves (10). Since \(J^{\alpha ,\phi , \xi , \rho }(\tau ^{*};\sigma ) =\) \( {\mathbb {E}}^{{\tilde{\theta }}_{1}\sim K_{1}}\Big [\) \(V_{1,1}^{\alpha ,\phi , \xi , \rho }({\tilde{\theta }}_{1};\sigma )\Big ]\), \(\varOmega ^{*}[\sigma ]\) given in (14) is an optimal stopping rule. Interested readers may refer to Chapter 1 of Peskir and Shiryaev [44] for a rigorous characterization of general optimal stopping problems for Markovian processes.
The coupling of the reporting strategy and the optimal stopping decision is captured in (13) and (14). Given \(\{\alpha ,\phi ,\xi ,\rho \}\), the agent chooses the current \(\sigma _{t}\) and plans the future \(\{\sigma _{s}\}_{s\in {\mathbb {T}}_{t+1}}\) to maximize the current period valuation \(V^{\alpha ,\phi ,\xi , \rho }_{t}(\theta _{t};\sigma )\). For any reporting strategy \(\sigma \), \(\theta _{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\), we introduce
Here, \(\tau ^{\sup }_{t}[\theta _{t};\sigma ]\) is the smallest time horizon that leads to the maximum period-t interim expected payoff, when the agent uses \(\sigma \) and his true state is \(\theta _{t}\). On the one hand, the agent’s current \(\sigma _{t}\) and the planned future \(\{\sigma _{s}\}_{s\in {\mathbb {T}}_{t+1}}\) determine \(\tau ^{\sup }_{t}[\theta _{t};\sigma ]\). On the other hand, \(\tau ^{\sup }_{t}[\theta _{t};\sigma ]\) determines how far the agent should look into the future to maximize \(V^{\alpha ,\phi ,\xi , \rho }_{t}(\theta _{t};\sigma )\). This coupling complicates the incentive compatibility and we address the challenge in the next section.
4 Implementability
In this section, we formally define the incentive compatibility in our dynamic environment and formulate the optimal stopping rule as a threshold-based rule.
Definition 4
(Dynamic Incentive Compatibility) The dynamic mechanism \(\{\alpha ,\phi ,\) \(\xi , \rho \}\) is dynamic incentive-compatible (DIC) if, for all reporting strategy \(\sigma \),
-
(1)
for \(t\in {\mathbb {T}}\backslash \{T\}\),
$$\begin{aligned} \begin{aligned}&\max \Big (J^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t, \theta _{t}|h^{\theta }_{t-1}),\;\;\; {\mathbb {E}}^{\varXi _{\alpha }[h^{\theta }_{t}]}\big [ V^{\alpha ,\phi ,\xi ,\rho }_{t+1}({\tilde{\theta }}_{t+1})\big ] \Big )\\&\quad \ge \max \Big (J^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t, \theta _{t}, \sigma _{t}(\theta _{t}| h^{{\hat{\theta }}}_{t-1}, h^{a}_{t-1}); \sigma |h^{\theta }_{t-1}), {\mathbb {E}}^{\varXi _{\alpha ;\sigma }[h^{\theta }_{t}]}\big [ V^{\alpha ,\phi ,\xi ,\rho }_{t+1}({\tilde{\theta }}_{t+1};\sigma )\big ] \Big ); \end{aligned} \end{aligned}$$(16) -
(2)
for \(t=T\),
$$\begin{aligned} J^{\alpha ,\phi ,\xi ,\rho }_{1,T}(T, \theta _{T}|h^{\theta }_{T-1}) \ge J^{\alpha ,\phi ,\xi ,\rho }_{1,T}(T, \theta _{T}, \sigma _{T}(\theta _{T}| h^{{\hat{\theta }}}_{T-1}, h^{a}_{T-1}); \sigma |h^{\theta }_{T-1}); \end{aligned}$$(17)
i.e., the agent of state \(\theta _{t}\) maximizes his value at period t by reporting truthfully at all \(t\in {\mathbb {T}}\). The rules \(\{\alpha ,\phi ,\xi ,\rho \}\) are called implementable if the corresponding mechanism is dynamic incentive-compatible.
At the final period \(t=T\), the agent stops with probability 1. His incentive to misreport the true state is captured by the immediate instantaneous payoff. The condition (17) guarantees the non-profitability of misreporting and thus disincentivizes the agent from untruthful reporting. At each non-final period \(t\in {\mathbb {T}}\backslash \{T\}\), agent’s exploration of profitable deviations from truthful reporting strategy takes into account the misreporting of the current state as well as any possible planned future misreporting. In particular, when the agent’s optimal stopping rule calls for stopping if he reports truthfully, \(V_{t}^{\alpha ,\phi ,\xi , \rho }(\theta _{t}) = J^{\alpha ,\phi ,\xi , \rho }_{1,t}(t,\theta _{t}|h^{\theta }_{t-1})\); when the agent’s optimal stopping rule calls for continuing if he reports truthfully, \(V_{t}^{\alpha ,\phi ,\xi , \rho }(\theta _{t}) = {\mathbb {E}}^{\varXi _{\alpha }[h^{\theta }_{t}]}\big [ V^{\alpha ,\phi ,\xi ,\rho }_{t+1}({\tilde{\theta }}_{t+1}) \big ]\). There are three situations of deviations: (i) misreporting at t and stopping at t, (ii) misreporting at t, planned misreporting in the future and continuing, (iii) truthful reporting at t, planned misreporting in the future and continuing. The condition (16) ensures that no such deviations from truthfully reporting are profitable.
Let \({\hat{\sigma }}[t]=\{{\hat{\sigma }}[t]_{s}\}_{s\in {\mathbb {T}}}\) be any reporting strategy that differs from the truthful reporting strategy \(\sigma ^{*}\) at only one period \(t\in {\mathbb {T}}\), i.e., \({\hat{\sigma }}[t]\) is truthful at all periods before t and is planned to be truthful at all periods after t. We call \({\hat{\sigma }}[t]\) as a one-shot deviation strategy at t, for any \(t\in {\mathbb {T}}\). To simplify the notation, we denote the process \(\varXi _{\alpha ;{\hat{\sigma }}[t]}[h^{\theta }_{t}]\) with \({\hat{\theta }}_{t}={\hat{\sigma }}[t]_{t}(\theta _{t}| h^{\theta }_{t-1}, h^{a}_{t-1})\) by \(\alpha |\theta _{t}, {\hat{\theta }}_{t}\) and let \(\alpha |\theta _{t} = \alpha |\theta _{t}, \theta _{t}\) when the agent reports truthfully. Additionally, we omit \({\hat{\sigma }}[t]\) in the payoff and the valuation functions and only show \({\hat{\theta }}_{t}\) as a typical reported state using \({\hat{\sigma }}[t]_{t}\) unless otherwise stated. We denote the corresponding expectation by \({\mathbb {E}}^{\alpha |\theta _{t}, {\hat{\theta }}_{t}}[\cdot ]\).
Proposition 1
Suppose that Assumption 1 holds. In Markovian dynamic environment, if the agent obtains no gain from untruthful reporting by using any one-shot deviation strategy \({\hat{\sigma }}[t]\), for any \(t\in {\mathbb {T}}\), \(\theta _{t}\in \varTheta _{t}\), and any history of truthful reports \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\), then he obtains no gain by using any untruthful reporting strategy for any arbitrary report history \(h^{{\hat{\theta }}}_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\), i.e.,
-
(i)
for \(t\in {\mathbb {T}}\backslash \{T\}\),
$$\begin{aligned} \begin{aligned}&\max \Big (J^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t, \theta _{t}|h^{\theta }_{t-1}),\;\;\; {\mathbb {E}}^{\alpha |\theta _{t} }\big [ V^{\alpha ,\phi ,\xi ,\rho }_{t+1}({\tilde{\theta }}_{t+1})\big ] \Big )\\&\quad \ge \max \Big (J^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t, \theta _{t},{\hat{\theta }}_{t}|h^{\theta }_{t-1}),\;\;\; {\mathbb {E}}^{\alpha |\theta _{t},{\hat{\theta }}_{t}}\big [ V^{\alpha ,\phi ,\xi ,\rho }_{t+1}({\tilde{\theta }}_{t+1})\big ] \Big ), \end{aligned} \end{aligned}$$(18) -
(ii)
for \(t=T\),
$$\begin{aligned} J^{\alpha ,\phi ,\xi ,\rho }_{1,T}(T, \theta _{T}|h^{\theta }_{T-1}) \ge J^{\alpha ,\phi ,\xi ,\rho }_{1,T}(T, \theta _{T}, {\hat{\theta }}_{T}|h^{\theta }_{T-1}). \end{aligned}$$(19)
Proof
See Appendix A. \(\square \)
Proposition 1 establishes a one-shot deviation principle for our dynamic mechanism. The one-shot deviation principle enables us to reduce the complexity of the characterization of the DIC and to focus on the analysis of the agent’s incentive compatibility at each period when he has reported truthfully at all past periods and plans to report truthfully at all future periods. As a result, we can restrict attention to the conditions (18) and (19) as the DIC constraints when the agent uses any one-shot deviation strategy at each period \(t\in {\mathbb {T}}\). In the rest of this paper, when it comes to the agent’s deviation from truthfulness, we focus on his one-shot deviation strategy \({\hat{\sigma }}[t]\) that reports \({\hat{\theta }}_{t} = {\hat{\sigma }}[t]_{t}(\theta _{t}| h^{\theta }_{t-1}, h^{a}_{t-1})\) at any single period \(t\in {\mathbb {T}}\). With a slight abuse of notation, we use \(h^{{\hat{\theta }}_{t}}_{s}\), \(s\ge t\), to denote the history of reports (including the planned reports) when the agent uses one-shot deviation strategy at t and reports \({\hat{\theta }}_{t}\).
Define the continuing value as, for any \(\theta _{t}, {\hat{\theta }}_{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\backslash \{T\}\),
with \(\mu ^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t},\theta _{t}) \equiv \mu ^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t})\) when the agent uses the truthful reporting strategy. The continuing value captures the agent’s maximum expected gain when he decides to continue to the next period instead of stopping immediately. Then, the stopping rule in (14) can be characterized by the continuing value as follows, for any one-shot deviation strategy \({\hat{\sigma }}[t]\) at any \(t\in {\mathbb {T}}\):
Define the marginal value \(L^{\alpha , \phi , \xi ,\rho }_{t}\) as follows, for any \(\theta _{t}, {\hat{\theta }}_{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\backslash \{T\}\):
with \(L^{\alpha , \phi , \xi ,\rho }_{t}(\theta _{t})=\) \(L^{\alpha , \phi , \xi ,\rho }_{t}(\theta _{t}, \theta _{t})\) when the agent uses the truthful reporting strategy. Hence, \(L^{\alpha , \phi , \xi ,\rho }_{t}\) \((\theta _{t},\hat{\theta }_{t})\) \(- \rho (t)\) captures the marginal change in the interim expected payoffs evaluated at t if the agent plans to stop at period \(t+1\) instead of stopping immediately at t when his true state is \(\theta _{t}\) and he reports \({\hat{\theta }}_{t}\).
Lemma 1
Given \(\{\alpha , \phi , \xi ,\rho \}\), we have, for any \(\tau \in {\mathbb {T}}\),
and, for any \(\theta _{t}\in \varTheta _{t}\), \(h^{\theta }_{t}\in \prod _{s=1}^{t-1} \varTheta _{s}\), \(t\in {\mathbb {T}}\), \(\tau \in {\mathbb {T}}_{t}\),
Proof
See Appendix B. \(\square \)
Lemma 2
Suppose that Assumption 2 holds. Then, \(L^{\alpha , \phi , \xi , \rho }_{t}(\theta _{t})\) is non-decreasing in \(\theta _{t}\), for all \(t\in {\mathbb {T}}\backslash \{T\}\).
The proof of Lemma 2 directly follows the formulation of \(J^{\alpha ,\phi ,\xi , \rho }_{1}\) in Lemma 1. Lemma 1 shows that the agent’s ex-ante expected payoff and his period-t interim expected payoff can be represented in terms of \(L^{\alpha , \phi , \xi , \rho }\), \(\rho \), and the expected payoffs when the agent stops at the starting periods (i.e., period 1 or period t, respectively). Lemma 2 establishes a single crossing condition that is necessary for the existence of the threshold-based stopping rule (see Sect. 4.1).
From Lemma 1, we can represent the continuing value in terms of \(L^{\alpha , \phi , \xi , \rho }_{t}\) as follows, for any \(\theta _{t}, {\hat{\theta }}_{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\backslash \{T\}\):
Let, for any \(\theta _{t}, {\hat{\theta }}_{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\backslash \{T\}\),
with \({\bar{\mu }}^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t},\theta _{t}) \equiv {\bar{\mu }}^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t})\). Then, we define the following auxiliary functions, for any \(\theta _{t}, {\hat{\theta }}_{t}\in \varTheta _{t}\), \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\), \(t\in {\mathbb {T}}\),
and
with \(U_{j,t}^{\alpha ,\phi , \xi , \rho }(\theta _{t},\theta _{t}|h^{\theta }_{t-1}) \equiv U_{j,t}^{\alpha ,\phi , \xi , \rho }(\theta _{t}|h^{\theta }_{t-1})\), for \(j\in \{S,{\bar{S}}\}\), where the subscripts S and \(\bar{S}\) represent “stop” and “nonstop,” respectively. Basically, \(U^{\alpha ,\phi , \xi , \rho }_{S,t}\) and \(U^{\alpha ,\phi , \xi , \rho }_{{\bar{S}},t}\) are the agent’s expected payoffs that are directly determined by his current reporting strategy \({\hat{\sigma }}[t]_{t}\) and planned truthful reporting strategies \(\{{\hat{\sigma }}[t]_{s}\}_{s\in {\mathbb {T}}_{t+1}}\), when he decides to stop at t and continue to \(t+1\), respectively. We can rewrite the DIC in Proposition 1 in terms of these auxiliary functions in the following lemma.
Lemma 3
The IC constraints (18) and (19) are equivalent to the following
and
for all \(\theta _{t}\), \( {\hat{\theta }}_{t}\in \varTheta _{t}\), \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1} \varTheta _{s}\), \(t\in {\mathbb {T}}\).
Conditions (29) and (30) reformulate the incentive constraints in (18) and (19). They ensure that misreporting is not profitable in the instantaneous payoff when the agent stops and continues, respectively. If (29) (resp. (30)) is satisfied, the optimality of the stopping rule guarantees that continuing (resp. stopping) is not profitable when the stopping rule calls for stopping (resp. continuing).
4.1 Threshold Rule
In this section, we revisit the optimal stopping rule and introduce a class of threshold-based stopping rule (see, e.g., [24, 27, 53]). Given the definition of \({\bar{\mu }}^{\alpha , \phi ,\xi , \rho }_{t}(\theta _{t}, {\hat{\theta }}_{t})\) in (26), we can rewrite the optimal stopping rule in (21) as, for any \({\hat{\sigma }}[t]\) that reports \({\hat{\theta }}_{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\),
with the corresponding stopping region
Hence, the principal can adjust \(\rho (t)\) to influence the agent’s stopping time by changing the stopping region \(\varLambda ^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t;{\hat{\theta }}_{t})\). In general, the stopping rule partitions the state space \(\varTheta _{t}\) into multiple zones, which leads to multiple stopping subregions. Suppose that, given \(<\alpha ,\phi ,\xi ,\rho>\) and \({\hat{\sigma }}[t]\), there are \(n_{t}\) stopping subregions at period t. Let \(\{\theta ^{\ell ;k}_{t}, \theta ^{r;k}_{t}\}\), \({\underline{\theta }}_{t}\le \theta ^{\ell ;k}_{t}\le \theta ^{r;k}_{t} \le {\bar{\theta }}_{t}\), denote the boundaries of the kth stopping subregion, such that the stopping region (32) is equivalent to
with \(\mathbf {\varLambda }^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t|n_{t})=\mathbf {\varLambda }^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t;\theta _{t}|n_{t})\) when the agent reports truthfully.
If there is only one stopping subregion, i.e., the stopping rule partitions the state space \(\varTheta _{t}\) into two regions, then the stopping rule is a threshold rule. The existence of a threshold rule depends on the monotonicity of \({\bar{\mu }}^{\alpha ,\phi ,\xi ,\rho }_{t}\) with respect to \(\theta _{t}\). The following lemma directly follows Lemma 2.
Lemma 4
Suppose that Assumption 2 holds. Then, \({\bar{\mu }}^{\alpha , \phi , \xi , \rho }_{t}(\theta _{t}, {\hat{\theta }}_{t})\) is non-decreasing in \(\theta _{t}\), for all \(t\in {\mathbb {T}}\backslash \{T\}\), any \({\hat{\theta }}_{t}\in \varTheta _{t}\).
Since \(\rho (t)\) is independent of states or reports, the monotonicity in Lemma 4 suggests a threshold-based stopping rule for the agent. Let \(\eta : {\mathbb {T}} \rightarrow \varTheta _{t}\) be the threshold function, for all \(t\in {\mathbb {T}}\), such that the agent chooses to stop the first time the state \(\theta _{t}\le \eta (t)\). Since the agent has to stop at the final period, we require \(\eta (T)={\bar{\theta }}_{T}\). Let \(\varOmega [{\hat{\sigma }}[t]]|\eta \) denote the stopping rule with the threshold function \(\eta \).
Definition 5
(Threshold Rule) Fix any \({\hat{\sigma }}[t]\), \(t\in {\mathbb {T}}\). We say that the stopping rule \(\varOmega [{\hat{\sigma }}[t]]|\eta \) is a threshold rule if there exists a threshold function \(\eta \) such that
We establish that the optimal stopping rule shown in (31) is a threshold rule in Lemma 5.
Lemma 5
Suppose that Assumption 2 holds. If the stopping rule \(\varOmega [{\hat{\sigma }}[t]]\) is optimal in the mechanism \(\{\alpha ,\phi ,\xi ,\rho \}\), then it is a threshold rule with a threshold function \(\eta \), denoted as \(\varOmega [{\hat{\sigma }}[t]]|\eta \).
Proof
See Appendix C. \(\square \)
Lemma 6 shows the uniqueness of the threshold function.
Lemma 6
Suppose that Assumptions 2 and 3 hold. Then, each threshold rule has a unique threshold function.
Proof
See Appendix D. \(\square \)
From (34), the payment rule \(\rho \) can be fully characterized by the threshold function \(\eta \) such that the principal can influence the agent’s stopping time by manipulating \(\eta \). For example, setting \(\eta (t)={\underline{\theta }}_{t}\) (resp. \(\eta _{t} = {\bar{\theta }}_{t}\)) forces the agent to continue (resp. stop) with probability 1.
5 Characterization of Incentive Compatibility
In this section, we characterize the dynamic incentive compatibility of the mechanism. We first introduce the length functions and the potential functions and show a sufficient condition by constructing the payment rules in terms of the potential functions based on the relationship between the length and the potential functions. Second, we pin down the payment rules in terms of the allocation rule by applying the envelope theorem.
Let, for any \(\theta _{t}\), \({\hat{\theta }}_{t}\in \varTheta _{t}\), \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\backslash {\{T\}}\),
with \(\pi ^{\alpha }_{t}(\theta _{t};\tau )=\pi ^{\alpha }_{t}(\theta _{t},\theta _{t};\tau )\). The term \(\pi ^{\alpha }_{t}(\cdot ;\tau )\) denotes the agent’s period-t expected payoff to go for a time horizon \(\tau >t\) without the current-period payment specified by \(\phi _{t}\). When \(\tau =t\), the term \(\pi ^{\alpha }_{t}(\cdot ;\tau )\) is the agent’s period-t instantaneous payoff if he stops at t. Define the length functions as, for any \(\theta _{t}\), \({\hat{\theta }}_{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\),
and, for any \(\tau \in {\mathbb {T}}_{t}\),
The length function \(\ell _{{\bar{S}},t}({\hat{\theta }}_{t},\theta _{t})\) (resp. \(\ell _{S,t}({\hat{\theta }}_{t},\theta _{t})\)) describes the change in the value of \(\pi ^{\alpha }_{t}\) (resp. \(\delta u_{1,t}\)) while keeping reporting \({\hat{\theta }}_{t}\) when the agent observes \({\hat{\theta }}_{t}\) instead of observing \(\theta _{t}\). From the definition of \(\pi ^{\alpha }_{t}\), it is straightforward to see that \(\ell ^{\alpha }_{S,t}({\hat{\theta }}_{t}, \theta _{t}) = \ell ^{\alpha }_{{\bar{S}},t}({\hat{\theta }}_{t}, \theta _{t};t)\).
Let \(\beta ^{\alpha }_{S,t}(\cdot ):\varTheta _{t}\rightarrow {\mathbb {R}}\) and \(\beta ^{\alpha }_{{\bar{S}},t}(\cdot ):\varTheta _{t}\rightarrow {\mathbb {R}}\) be the potential functions that depend only on \(\alpha \). Proposition 2 shows a sufficient condition for DIC by showing the constructions of the payment rules in terms of the potential functions and the threshold function (for \(\rho \)) and specifying the relationships between the potential functions and the length functions.
Proposition 2
Fix an allocation rule \(\alpha \) and a threshold function \(\eta \). Suppose that Assumptions 1, 3, and 4 hold. The dynamic mechanism is dynamic incentive-compatible if the following statements are satisfied:
-
(i)
The payment rules \(\phi \), \(\xi \), and \(\rho \), respectively, are constructed as, for all \(t\in {\mathbb {T}}\),
$$\begin{aligned} \phi _{t}(\theta _{t})= & {} \delta ^{-t}\beta ^{\alpha }_{\bar{S},t}(\theta _{t}) - \delta ^{-t}{\mathbb {E}}^{\alpha |\theta _{t}}\Big [\beta ^{\alpha }_{{\bar{S}},t+1}({\tilde{\theta }}_{t+1}) \Big ] -u_{1,t}(\theta _{t}, \alpha _{t}(\theta _{t}|h^{\theta }_{t-1} )), \end{aligned}$$(38)$$\begin{aligned} \xi _{t}(\theta _{t})= & {} \delta ^{-t}\beta ^{\alpha }_{S,t}(\theta _{t})-u_{1,t}(\theta _{t},\alpha _{t}(\theta _{t}|h^{\theta }_{t-1})), \end{aligned}$$(39)$$\begin{aligned} \rho (t)= & {} \delta ^{-t}{\mathbb {E}}^{\alpha |\eta (t)}\Big [\sum _{s=t}^{T-1} \big (\beta ^{\alpha }_{S,s+1}({\tilde{\theta }}_{s+1}\vee \eta (s+1))-\beta ^{\alpha }_{S,s}({\tilde{\theta }}_{s}\vee \eta (s)) \big ) \nonumber \\&- \big (\beta ^{\alpha }_{{\bar{S}},s+1}({\tilde{\theta }}_{s+1}\vee \eta (s+1))-\beta ^{\alpha }_{{\bar{S}},s}({\tilde{\theta }}_{s}\vee \eta (s)) \big ) \Big ]. \end{aligned}$$(40) -
(ii)
\(\beta ^{\alpha }_{{\bar{S}},t}\) and \(\beta ^{\alpha }_{S,t}\) satisfy, for all \(\theta _{t}\), \({\hat{\theta }}_{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\),
$$\begin{aligned}&\beta ^{\alpha }_{S,t}({\hat{\theta }}_{t})- \beta _{S,t}^{\alpha }(\theta _{t})\le \ell ^{\alpha }_{S,t}({\hat{\theta }}_{t},\theta _{t}), \end{aligned}$$(41)$$\begin{aligned}&\beta ^{\alpha }_{{\bar{S}},t}({\hat{\theta }}_{t})-\beta ^{\alpha }_{{\bar{S}},t}(\theta _{t})\le \inf _{\tau \in {\mathbb {T}}_{t}}\Big \{\ell ^{\alpha }_{{\bar{S}},t}({\hat{\theta }}_{t},\theta _{t};\tau )\Big \}-\sup _{\tau '\in {\mathbb {T}}_{t}}\rho (\tau '), \end{aligned}$$(42)and
$$\begin{aligned} \beta ^{\alpha }_{{\bar{S}},t}(\theta _{t}) \ge \beta ^{\alpha }_{S,t}(\theta _{t}) \text { and } \beta ^{\alpha }_{{\bar{S}},T}(\theta _{T}) = \beta ^{\alpha }_{S,T}(\theta _{T}). \end{aligned}$$(43) -
(iii)
\(\beta ^{\alpha }_{{\bar{S}},t}\) and \(\beta ^{\alpha }_{S,t}\) are constructed in terms of \(\alpha \) such that the following term is non-decreasing in \(\theta _{t}\), for all \(t\in {\mathbb {T}}\):
$$\begin{aligned} \begin{aligned} \chi ^{\alpha }_{1,t}(\theta _{t}) = {\mathbb {E}}^{\alpha |\theta _{t}}\Big [\beta ^{\alpha }_{S,t+1}({\tilde{\theta }}_{t+1}) - \beta ^{\alpha }_{{\bar{S}},t+1}({\tilde{\theta }}_{t+1}) \Big ] -\big (\beta ^{\alpha }_{S,t}(\theta _{t})-\beta ^{\alpha }_{{\bar{S}},t}(\theta _{t}) \big ). \end{aligned} \end{aligned}$$(44)
Proof
See Appendix E. \(\square \)
In Proposition 2, the first statement (i) shows three conditions (38)-(40) to construct the three payment rules in terms of the allocation rule and the threshold function (for \(\rho \)) through the potential functions and the utility function, such that if the potential functions satisfy the conditions (41)-(43) in the second statement (ii), then the mechanism \(\{\alpha , \phi ,\xi ,\rho \}\) is DIC. Importantly, the construction of \(\rho \) in (40) is based on the setting when the agent’s optimal stopping rule is a threshold rule with a unique threshold function. The existence of such threshold rule is established under Assumption 2. Therefore, Proposition 2 imposes an additional condition for the construction of the potential functions in the third statement (iii) to guarantee the monotonicity in Assumption 2. The explicit constructions of the potential functions is constructed from the necessity of the DIC.
Define with a slight abuse of notation, for any \(\theta _{t}, {\hat{\theta }}_{t}\in \varTheta _{t}\), \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\),
with \({\bar{\mu }}^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t};\tau )= {\bar{\mu }}^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t}, \theta _{t};\tau )\), and, for any \(\theta _{t}, {\hat{\theta }}_{t}\in \varTheta _{t}\), \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\), \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\)
with \(U^{\alpha ,\phi ,\xi ,\rho }_{t}(\tau , \theta _{t}|h^{\theta }_{t-1})=U^{\alpha ,\phi ,\xi ,\rho }_{t}(\tau , \theta _{t}, \theta _{t}|h^{\theta }_{t-1})\).
The following lemma takes advantage of the quasilinearity of the payoff function and formulates the partial derivative of \(U^{\alpha ,\phi ,\xi ,\rho }_{t}(\tau , \theta _{t}|h^{\theta }_{t-1})\) with respect to \(\theta _{t}\).
Lemma 7
Suppose that Assumption 3 holds. In any DIC mechanism, \(\{\alpha ,\phi ,\xi ,\rho \}\) satisfy, for any \(\theta _{t}\in \varTheta _{t}\), \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\), \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\),
where
Proof
See Appendix F. \(\square \)
We establish the explicit formulations of the potential functions in the following proposition.
Proposition 3
Fix any allocation rule \(\alpha \). Suppose that Assumptions 1, 3, and 4 hold. Suppose additionally that \(u_{1,t}(\theta _{t}, a_{t})\) is a non-decreasing function of \(\theta _{t}\). In any DIC mechanism \(\{\alpha , \phi , \xi , \rho \}\), with \(\phi \), \(\xi \), and \(\rho \) constructed in (38)-(40) respectively, the potential functions \(\beta ^{\alpha }_{S,t}\) and \(\beta ^{\alpha }_{{\bar{S}},t}\) are constructed in terms of \(\alpha \) as follows, for any arbitrary fixed state \(\theta _{\epsilon ,t}\in \varTheta _{t}\), any \(\theta _{t}\), \({\hat{\theta }}_{t}\in \varTheta _{t}\), \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\), \(t\in {\mathbb {T}}\),
where \(\gamma _{t}^{\alpha }(\tau ,\theta _{t}|h^{\theta }_{t-1}) \equiv \frac{\partial U^{\alpha ,\phi ,\xi ,\rho }_{t}(\tau ,r|h^{\theta }_{t-1}) }{ \partial r }\Big |_{r= \theta _{t}} \), where \(\alpha \) satisfies the conditions (41)-(43).
Proof
See Appendix G. \(\square \)
Proposition 3 provides explicit formulations of the potential functions that depend only on the allocation rule \(\alpha \), up to a constant shift (determined by \(\theta _{\epsilon ,t}\)). As a result, the payment rules \(\phi \) and \(\xi \) can be pinned down up to a constant given \(\alpha \). Such results lead to the celebrated revenue equivalence theorem, which is important in mechanism design problems in static settings (e.g., [35, 52]) as well as in dynamic environments (e.g., [27, 42] ). The following proposition summarizes the property of the revenue equivalence of our dynamic mechanism.
Proposition 4
Fix an allocation rule \(\alpha \). Suppose that Assumptions 1, 3, and 4 hold. Suppose additionally that \(u_{1,t}(\theta _{t}, a_{t})\) is a non-decreasing function of \(\theta _{t}\). Let \(\theta ^{a}_{\epsilon ,t}\), \(\theta ^{b}_{\epsilon ,t}\in \varTheta _{t}\) be any two arbitrary states. Let \(\phi ^{a} \equiv \{\phi ^{a}_{t}\}\) and \(\phi ^{b}\equiv \{\phi ^{b}_{t}\}\) (resp. \(\xi ^{a}\) and \(\xi ^{b}\)) be two payment rules constructed according to (38) (resp. (39)) by the potential function \(\beta ^{\alpha }_{{\bar{S}},t}\) formulated in (48) (resp. \(\beta ^{\alpha }_{S,t}\) formulated in (47)) with \(\theta ^{a}_{\epsilon ,t}\) and \(\theta ^{b}_{\epsilon ,t}\), respectively, as the lower limit of the integral. Define \(\rho ^{a}\) and \(\rho ^{b}\) in the similar way, for some threshold functions \(\eta ^{a}\) and \(\eta ^{b}\), respectively. Then, there exist constants \(\{C_{\tau }\}_{\tau \in {\mathbb {T}}}\) such that, for any \(\theta _{t}\in \varTheta _{t}\), \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\),
Proof
See Appendix I. \(\square \)
Proposition 4 implies that different DIC mechanisms with the same allocation rule result in equivalent expected sum of payments paid by the principal up to a constant for any time horizon \(\tau \in {\mathbb {T}}_{t}\) given any \(t\in {\mathbb {T}}\). The following corollary shows the uniqueness of the state-independent payment rule \(\rho \) for any given threshold function \(\eta \).
Corollary 1
Fix an allocation rule \(\alpha \). Suppose that Assumptions 1, 3, and 4 hold. Suppose additionally that \(u_{1,t}(\theta _{t}, a_{t})\) is a non-decreasing function of \(\theta _{t}\). Let \(\eta \) be any threshold function such that \(\eta (t)\in \varTheta _{t}\), for each \(t\in {\mathbb {T}}\), and let \(\theta ^{a}_{\epsilon ,t}\), \(\theta ^{b}_{\epsilon ,t}\in \varTheta _{t}\) be any two arbitrary states. Construct two state-independent payment rules \(\rho ^{a}\) and \(\rho ^{b}\) according to (40) with \(\eta \) in which the potential functions are formulated in (47) and (48) with \(\theta ^{a}_{\epsilon ,t}\) and \(\theta ^{b}_{\epsilon ,t}\), respectively, as the lower limit of the integral. Then, there exist constants \(\{C^{\rho }_{t}\}_{t\in {\mathbb {T}}}\) such that, for any \(t\in {\mathbb {T}}\),
with \(\rho ^{a}(T)=\rho ^{b}(T)=C^{\rho }_{t}=0\).
If the mechanism does not satisfy the monotonicity condition specified in Assumption 2, we cannot guarantee a threshold rule (with a unique threshold function) for the mechanism. Hence, as shown in (33), the optimal stopping rule partitions the state space into multiple stopping subregions. Let \(\mathbf {\varTheta }_{t}\equiv \{\theta ^{k;j}_{t}\}_{k=1, j=\{k, r\} }^{k=n_{t}}\) denote the set of boundaries of stopping region \(\mathbf {\varLambda }^{\alpha ,\phi ,\xi ,\rho }_{1,t}(t|n_{t})\) given in (33). Define an operator
Here, \(\theta _{t} \sqcup \mathbf {\varTheta }_{t}\) makes \(\theta _{t}\) equal to its closest boundary for any \(\theta _{t}\in \varTheta _{t}\) which is in any stopping subregion. The following corollary shows a sufficient condition for the DIC mechanism when Assumption 2 does not hold.
Corollary 2
Fix an allocation rule \(\alpha \). Suppose that Assumptions 1 and 3 hold. The dynamic mechanism is dynamic incentive-compatible if the payment rules \(\phi \) and \(\xi \) are constructed in (38) and (39), respectively, and \(\rho \) is constructed as:
where the potential functions \(\beta ^{\alpha }_{S,t}\) and \(\beta ^{\alpha }_{{\bar{S}},t}\) satisfy the conditions (41)-(43).
Given the stopping region \(\mathbf {\varLambda }_{1,t}^{\alpha ,\phi ,\xi ,\rho }\) with \(\mathbf {\varTheta }_{t}\), the proof of Corollary 2 directly follows Proposition 2. The construction of \(\rho \) in (51) is equivalent to (40) if the formulations of the potential functions satisfy the monotonicity condition (44) in Proposition 2 (thus Assumption 2 holds). The following corollary summarizes that the main results shown in Propositions 3 and 4 and Corollary 1 hold for the general optimal stopping rule.
Corollary 3
Fix an allocation rule \(\alpha \). Suppose that Assumptions 1 and 3 hold. In DIC mechanism with \(\phi \), \(\xi \), and \(\rho \) constructed in (38), (39), and (51) respectively, (i) the potential functions are formulated in terms of \(\alpha \) in (47) and (48); (ii) the results of the revenue equivalence shown in Proposition 4 and Corollary 1 hold.
However, the sufficient condition given by Corollary 2 requires the principal to determine \(n_{t}\) and all the boundaries of the \(n_{t}\) stopping subregions. If the formulations of the potential functions maintain the monotonicity specified by Assumption 2, then the principal’s mechanism design problem only needs to deal with a unique threshold function \(\eta (t)\).
From the construction of \(\rho \) in (40) and the formulations of the potential functions in Proposition 3, \(\rho \) can be completely modeled by \(\alpha \) and \(\eta \), given the transition kernels. Specifically, at each \(t\in {\mathbb {T}}\), one \(\eta (t)\in \varTheta _{t}\) leads to \(\rho \) that is constructed by (40) and satisfies (50). Let \(r\equiv \{r_{1},\dots ,r_{T}\}\in {\mathbb {R}}^{T}\) be any sequence of real values. Define
Hence, \(\mathring{{\mathscr {R}}}\) is the set of payment sequences that \(\rho \) can specify from \(t=1\) to \(t=T\), given \(\alpha \) and \(\eta \).
Corollary 4
Fix an allocation rule \(\alpha \). Suppose that Assumptions 1, 3, and 4 hold. Suppose additionally that \(u_{1,t}(\theta _{t}, a_{t})\) is a non-decreasing function of \(\theta _{t}\). Let \(\eta \) be a threshold function. Suppose that \(\rho \) specifies a sequence of payments \(r=\{r_{t}, \dots , r_{T}\}\), where \(r_{t} = \rho (t)\), \(t\in {\mathbb {T}}\). Then, the following statements hold.
-
(i)
In DIC mechanisms, \(\rho \) cannot punish the agent for stopping; i.e., \(r_{t}\ge 0\), for all \(t\in {\mathbb {T}}\).
-
(ii)
\(\rho \) with \(\alpha \) implements the optimal stopping rule (14) if and only if \(r\in \mathring{{\mathscr {R}}}\).
-
(iii)
Fix any \(r\in \mathring{{\mathscr {R}}}\). Let \(r'\) differ from r in arbitrary periods, such that for some t, \(r'_{t} = r_{t} + \epsilon _{t}\), for some nonzero \(\epsilon _{t}\in {\mathbb {R}}\). Suppose \(r'\not \in \mathring{{\mathscr {R}}}\) due to these \(r'_{t}\)’s. Then, posting \(r'\) may fail the incentive compatibility constraints.
-
(iv)
Let \(\phi \) and \(\xi \) be constructed in Proposition 2. If the mechanism does not involve \(\rho \), then \(\{\alpha ,\phi ,\xi \}\) is dynamic incentive-compatible if and only if there exists \(\eta (t)\in \varTheta _{t}\) such that, for all \(t\in {\mathbb {T}}\),
$$\begin{aligned} \begin{aligned}&{\mathbb {E}}^{\alpha |\eta (t)}\Big [\sum _{s=t}^{T-1} \big (\beta ^{\alpha }_{S,s+1}({\tilde{\theta }}_{s+1}\vee \eta (s+1))-\beta ^{\alpha }_{S,s}({\tilde{\theta }}_{s}\vee \eta (s)) \big ) \\&\quad - \big (\beta ^{\alpha }_{{\bar{S}},s+1}({\tilde{\theta }}_{s+1}\vee \eta (s+1))-\beta ^{\alpha }_{{\bar{S}},s}({\tilde{\theta }}_{s}\vee \eta (s)) \big ) \Big ] = 0, \end{aligned} \end{aligned}$$(53)where \(\beta ^{\alpha }_{{\bar{S}},t}\) and \(\beta ^{\alpha }_{S,t}\) are constructed in terms of \(\alpha \) in Proposition 3.
The following proposition shows a necessary condition for DIC that follows Lemma 7.
Proposition 5
Suppose that Assumptions 1 and 3 hold. In any DIC mechanism \(\{\alpha , \phi ,\) \(\xi ,\rho \}\), the following conditions hold: for any arbitrary fixed state \(\theta _{\epsilon ,t}\in \varTheta _{t}\), any \(\theta _{t}\), \({\hat{\theta }}_{t}\in \varTheta _{t}\), \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\), \(t\in {\mathbb {T}}\),
where \(\gamma _{t}^{\alpha }(\tau ,\theta _{t}|h^{\theta }_{t-1}) \equiv \frac{\partial U^{\alpha ,\phi ,\xi ,\rho }_{t}(\tau ,r|h^{\theta }_{t-1}) }{ \partial r }\Big |_{r= \theta _{t}}\).
Proof
See Appendix H. \(\square \)
Proposition 5 establishes a first-order necessary condition for DIC. This necessary condition takes advantage of the envelope condition established in Lemma 7 to characterize the necessity of DIC in terms of the allocation rule. Note that the conditions (54) and (55) hold for both formulations of \(\rho \) in Proposition 2 and Corollary 2, respectively.
6 Principal’s Optimal Mechanism Design
At the ex-ante stage, the principal provides a take-it-or-leave-it offer by designing the decision rules \(\{\alpha ,\phi ,\xi ,\rho \}\) to maximize her ex-ante expected payoff (1). The time horizon of the principal’s optimization problem is the mean first passage time, \({\bar{\tau }}\). Given the agent’s optimal stopping rule, \({\bar{\tau }}\) is determined by \(\{\alpha ,\phi ,\xi ,\rho \}\) and the stochastic process \(\varXi _{\alpha }\). Propositions 2 and 3 imply that \(\phi \) and \(\xi \) can be represented by \(\alpha \). From Corollary 4, \(\rho \) can be fully characterized by \(\alpha \) and \(\eta \). Then, we can determine \({\bar{\tau }}\) by \(\alpha \), \(\eta \), and \(\varXi _{\alpha }\), i.e., \({\bar{\tau }} = \lambda (\alpha ,\eta ; \varXi _{\alpha })\). Specifically,
Since the principal’s mechanism design problem is finite horizon, i.e., \(T<\infty \), \({\bar{\tau }}\) always exists.
Given \(\{\alpha ,\phi ,\xi ,\rho \}\), the agent decides whether to participate at the ex-ante stage, by checking the rational participation (RP) constraint,
i.e., the ex-ante expected payoff of the agent is nonnegative. Since the decision making at the ex-ante stage involves no private information, the principal’s evaluation of \({\bar{\tau }}\) coincides with the agent’s. Hence, the principal’s problem is
The mechanism design problem formulated in (58) can be generally applicable to principal-agent models in different economic environments, in which the agent’s private information endogenously changes over time. The mechanism could be a dynamic contract, in which the principal commits to a T-period contract and the agent is allowed to unilaterally terminate the contract without advance notification. As an illustration, consider that the principal is an employer and the agent is an employee. The employee’s state is his attitude towards work, which dynamically changes over time due to the time-evolving development of employee loyalty. The employer’s mechanism design problem is to seek an optimal way to design and allocate inter-temporal work and salary arrangements to facilitate the ongoing development of employee loyalty and to specify compensation or penalty policy to influence the employee’s unilateral termination of the contract and hedge the corresponding risk of losing profit. Other applications include dynamic subscription policies (e.g., magazine, online courses, and customized products), insurance, and leasing. Allowing for the early termination provides additional flexibility for the agent and reduces his risk due to the uncertainty of the dynamic environment, thereby increasing the attractiveness of the principal’s offer.
Exactly solving the mechanism design problem (58) needs to satisfy the following criteria: (C1) game-theoretic constraints, i.e., DIC and RP, (C2) profit-maximizing, assuming truthful reporting, and (C3) computational constraints (e.g., scale, size, speed, accuracy of approximation, and complexity). The classic economic analysis of mechanism design focuses on criteria C1 and C2, based on some distributional assumptions about the participants (e.g., a known probability distribution of the private information, known dynamics, etc.). Algorithmic mechanism design studies the mechanism design problem by applying approaches, such as robust analysis and algorithmic approximations, and taking into account the computational constraints as important ones, in addition to the classic game-theoretic analysis. When it is not possible to exactly solve the mechanism design problem (due to that, e.g., the incentive compatibility constraint is too strong), we need to relax the aforementioned three criteria.
Relaxations can be applied to each of the criteria or the hybrid of them. Mechanism design problems can be analytically relaxed by, for example, imposing additional assumptions and conditions that reduce the strength of C1 or relax the optimality of C2. Computational relaxations, usually referred to as approximations, are considered due to the analytical intractability or because C3 is not satisfied. However, relaxations, especially the computational ones, may inevitably lose the robustness of the incentive compatibility to the agent’s strategic reporting; i.e., the agent may gain profits by deviating from truthful reporting. As highlighted in the algorithmic mechanism design, addressing the tension between the game-theoretic constraints and the computational ones is the central challenge when the economic models are used in practice.
Nevertheless, the game-theoretic guarantee of strong incentive compatibility is important with the theoretical and the practical interest ([7, 32, 40]). For example, strong incentive compatibility leads to the simplicity of the agent’s reasoning in the decision making and the dynamic stability such that the agent does not need to modify the reporting strategy in response to changes in the environment and other agents’ behaviors in the multiagent cases. Strong incentive compatibility may also provide normative advice in the sense that the system is fair because agents cannot game the system to their advantage. Moreover, for empirical analysis, reasonably assuming that reporting is truthful enables the empirical work to adjust mechanism parameters or to reshape economic policies without predicting the corresponding complicated strategic responses (i.e., strategic reporting) of the agents.
6.1 Relaxation
It is beyond the scope of this paper to design efficient computational algorithms and analyze computational relaxations. We restrict attention to analytical relaxations and provide examples of such relaxations in this section.
The principal’s mechanism design problem (58) can be relaxed by applying a first-order approach (see, e.g., [47, 50]) to modify the objective function, which requires the principal to choose decision rules with which her ex-ante expected payoff is at a stationary point; i.e., \(\beta ^{\alpha }_{S,t}\) and \(\beta ^{\alpha }_{{\bar{S}},t}\) satisfy the conditions in Proposition 3 and \(\{\phi ,\xi ,\rho \}\) are constructed according to (38)-(40). Specifically, the original ex-ante expected payoff function (1) can be rewritten as follows:
Lemma 8
Suppose that Assumptions 1, 3, and 4 hold. Suppose additionally that the utility function \(u_{1,t}(\theta _{t}, a_{t})\) is non-decreasing in \(\theta _{t}\). Then, \(J^{\alpha ,\phi ,\xi ,\rho }_{1,t}\) is a non-decreasing function of \(\theta _{t}\), for all \(t\in {\mathbb {T}}\).
Proof
See Appendix J. \(\square \)
From Lemma 8, the condition \(J^{\alpha ,\phi ,\xi , \rho }_{1,1}({\bar{\tau }},\theta _{1}) \ge 0\) implies the RP constraint (57) due to \(J^{\alpha , \phi ,\xi ,\rho }_{1}({\bar{\tau }}) = {\mathbb {E}}^{\varXi _{\alpha }}\Big [J^{\alpha , \phi ,\xi ,\rho }_{1,1}({\bar{\tau }}, {\tilde{\theta }}_{1}) \Big ]\). Therefore, under the assumption that \(J^{\alpha ,\phi ,\xi , \rho }_{1,1}({\bar{\tau }},\underline{\theta _{1}})=0\), the principal’s mechanism design problem can be solved by the following constrained dynamic programming:
The relaxed problem (60) is independent of the payment rules \(\{\phi , \xi , \rho \}\).
Corollary 5
Suppose that Assumptions 1, 3, and 4 hold. Suppose additionally that the utility function \(u_{1,t}(\theta _{t}, a_{t})\) is non-decreasing in \(\theta _{t}\). If the problem (60) has solutions, then there exist payment rules \(\{\phi ^{*}, \xi ^{*}, \rho ^{*}\}\) such that the mechanism decision rules \(\{\alpha ^{*}, \phi ^{*}, \xi ^{*}, \rho ^{*}\}\) maximize (58). The resulting mechanism is DIC and satisfies \(J^{\alpha ,\phi ,\xi ,\rho }_{1,1}({\bar{\tau }},{\underline{\theta }}_{t})=0\).
However, the constrained dynamic programming (60) in general does not have closed-form solutions and computational approximations are necessary. As mentioned earlier in this section, approximations may reduce the robustness of the DIC, i.e., there exist \(\epsilon _{S,t}\ge 0\) and \(\epsilon _{{\bar{S}},t}\ge 0\), \(t\in {\mathbb {T}}\), such that, for all \(\theta _{t}\), \({\hat{\theta }}_{t}\in \varTheta _{t}\), \(h^{\theta }_{t-1}\in \prod _{s=1}^{t-1}\varTheta _{s}\),
and
The inequalities (61) and (62) imply that the agent cannot improve his payoff by more than \(\epsilon _{S,t}\) (resp. \(\epsilon _{{\bar{S}},t}\)) through misreporting his true state if he decides to stop at t (resp. to continue at t). We say that such mechanism with \(\{\alpha ,\phi ,\xi ,\rho \}\) is \(\big \{\epsilon _{S,t}, \epsilon _{{\bar{S}},t}\big \}\)-DIC. Define the deviations, for \(t\in {\mathbb {T}}\),
and
where \(\pi ^{\alpha }_{t}\) is given in (35).
Proposition 6
Suppose that Assumptions 1, 3, and 4 hold. Let \(\alpha ^{\circ }\) be an approximated optimal allocation rule as a solution to (60). Let \(\beta ^{\alpha ^{\circ }}_{{\bar{S}},t}\) and \(\beta ^{\alpha ^{\circ }}_{S,t}\), respectively, be constructed according to (47) and (48). If the payment rules \(\phi ^{\circ }\) and \(\xi ^{\circ }\) are constructed according to (38) and (39), respectively, and \(\rho ^{\circ }\) is constructed according to (40) (with an additional assumption that \(u_{1,t}(\theta _{t},a_{t})\) is non-decreasing in \(\theta _{t}\)) or (51), then
-
(i)
the mechanism is \(\Big \{d^{\alpha ^{\circ }}_{S,t}, d^{\alpha ^{\circ }}_{{\bar{S}},t}+\sup _{\tau \in {\mathbb {T}}_{t}}\Big \{\rho ^{\circ }(\tau ) \Big \}\Big \}\)-DIC, when \(d^{\alpha ^{\circ }}_{S,t}>0\) and \(d^{\alpha ^{\circ }}_{{\bar{S}},t}> -\sup _{\tau \in {\mathbb {T}}_{t}}(\rho ^{\circ }(\tau ))\);
-
(ii)
the mechanism is DIC, when \(d^{\alpha ^{\circ }}_{S,t}\le 0\) and \(d^{\alpha ^{\circ }}_{{\bar{S}},t}\le -\sup _{\tau \in {\mathbb {T}}_{t}}(\rho ^{\circ }(\tau ))\).
Proof
See Appendix K. \(\square \)
Proposition 6 provides an approach to evaluate the worst-case scenario of the agent’s strategic misreporting; i.e., the most profitable deviations from truthfulness, when the allocation rule \(\alpha ^{\circ }\) is an approximate solution of the relaxed problem (60). If the payment rules are constructed according to (38)-(40) in Proposition 2, then the mechanism is \(\Big \{d^{\alpha ^{\circ }}_{S,t}, d^{\alpha ^{\circ }}_{{\bar{S}},t}+\sup _{\tau \in {\mathbb {T}}_{t}}\Big \{\rho ^{\circ }(\tau ) \Big \} \Big \}\)-DIC. The evaluation approach also provides a sufficient condition for DIC, i.e., if \(d^{\alpha ^{\circ }}_{S,t}\le 0\) and \(d^{\alpha ^{\circ }}_{{\bar{S}},t}\le -\sup _{\tau \in {\mathbb {T}}_{t}}(\rho ^{\circ }(\tau ))\), then the mechanism is DIC.
6.2 Case Study
We consider a dynamic resource allocation problem to illustrate the verification of the theoretical conditions shown in Propositions 2, 3, and 5 . Note that this example is crafted as analytically tractable for the purpose of illustration. Consider that the principal allocates resource \(a_{t}\in A_{t}=[0,{\bar{a}}_{t}]\) to the agent based on his state \(\theta _{t}\) at each time \(t\in {\mathbb {T}}\). Suppose that \(\varTheta _{t}=[{\underline{\theta }}, {\bar{\theta }}]\subset {\mathbb {R}}_{+}\), for all \(t\in {\mathbb {T}}\), the dynamics of the agent’s state follow a nonlinear autoregressive model: (see, e.g., [13]): for \(t\in {\mathbb {T}}\backslash {\{T\}}\),
where \(\zeta (\theta _{t})\) is a nonlinear, non-decreasing, and Lipschitz continuous function of \(\theta _{t}\) with bounded derivative and \(\min _{\theta _{t}\in \varTheta _{t}}\zeta (\theta _{t})={\underline{\theta }}\) and \(\max _{\theta _{t}\in \varTheta _{t}}\zeta (\theta _{t})<{\bar{\theta }}\), and \(b_{t}\) is distributed over \(B=[0, {\bar{\theta }} - \zeta ({\bar{\theta }})]\). Since \(\zeta \) is non-decreasing in \(\theta _{t}\), the condition in Assumption 4 is satisfied. Suppose that \(\zeta \) and the distribution of \(b_{t}\) are set such that Assumption 3 holds. Suppose additionally that the initial kernel has \(F_{1}\) and \(f_{1}\) such that \(\frac{1-F_{1}(\theta _{1}) }{f_{1}(\theta _{1})}\) is non-increasing in \(\theta _{1}\). According to (65), \(\theta _{k}\), for \(k\in {\mathbb {T}}_{t}\), can be represented in terms of \(\theta _{t}\); i.e., there exists some function \({\bar{\zeta }}_{t,k}:\varTheta _{t}\times B^{k-t}\mapsto \varTheta _{k}\), such that \(\theta _{k}={\bar{\zeta }}_{t,k}(\theta _{t};h^{b}_{t+1,k})\). The utility functions of the agent and the principal are given as follows, respectively:
where \(\kappa \) is an increasing linear function of \(\theta _{t}\) and \(c_{1}\in {\mathbb {R}}_{+}\), and
where \(c_{2}\in {\mathbb {R}}_{-}\) and \(c_{3}\in {\mathbb {R}}_{+}\) are two nonzero real numbers. It is straightforward to see that the agent’s utility function \(u_{1,t}\) is Lipschitz continuous. We assume that both the principal’s and the agent’s utility functions are bounded, i.e., there exist constants \(k<\infty , k'<\infty \), \(\{g_{t}\}_{t\in {\mathbb {T}}}\) with \(|g_{t}|<\infty \), and \(\{g'_{t}\}_{t\in {\mathbb {T}}}\) with \(|g'_{t}|<\infty \), such that \(|u_{0,t}(\theta _{t}, a_{t})|\le k|\theta _{t}|+ g_{t}\) and \(|u_{1,t}(\theta _{t}, a_{t})|\le k'|\theta _{t}|+ g'_{t}\). By applying the partial derivatives in Lemma 7 to the agent’s ex-ante and interim expected payoff functions, we obtain that the boundedness condition in Assumption 1 is satisfied.
Since Assumptions 1, 3, and 4 hold, Lemma 8 yields that the principal’s mechanism design problem can be reduced to (60) which takes the following form:
Instead of solving the constrained dynamic programming (68), we follow a shortcut procedure (see, e.g., [50]) by first ignoring the constraints. Hence, the allocation rule \(\alpha ^{*}_{t}\) that maximizes (68) (without constraints) is
Based on the given environment (i.e., with all non-designed variables), \(\alpha ^{*}_{t}(\theta _{t})\) is non-decreasing in \(\theta _{t}\). Greedy algorithms can be used to choose \({\bar{\tau }}^{*}\) such that the pair \(\{\alpha ^{*}, \tau ^{*}\}\) leads to the maximum value \(J^{\alpha ^{*}}_{0}({\bar{\tau }}^{*})\). Then, the corresponding threshold \(\eta \) can be determined or approximated according to (56).
From Proposition 3, the potential functions are constructed as follows:
and
For simplicity, let, for \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\),
It is straightforward to verify that \(D^{\alpha ^{*}}_{t,\tau }(\theta _{t})\ge 0\), for all \(\theta _{t}\in [{\underline{\theta }}, {\bar{\theta }}]\), \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\). Hence, the R.H.S. of (71) attains the maximum when \(\tau =T\). Since \(u_{1,t}\) is increasing in \(\theta _{t}\) and Assumptions 1, 3, and 4 hold, from Proposition 3, we can construct the payment rules according to (38), (39), and (40) in Proposition 2, respectively, as follows:
and
The length function (36) is given as, for all \(t\in {\mathbb {T}}\),
From (76), we have
Hence, the allocation rule \(\alpha ^{*}_{t}\) in (69) satisfies condition (41) in Proposition 2 and condition (54) in Proposition 5.
Next, we check condition (55) in Proposition 5. Let, for \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\),
and
Then, the length function (37) is given as, for \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\),
Let \({\hat{\theta }}_{t}\ge \theta _{t}\in [{\underline{\theta }}, {\bar{\theta }}]\). Due to the monotonicity of \(\kappa \) and \(\alpha ^{*}\) and \(D^{\alpha ^{*}}_{t,s}(\theta _{t})\ge 0\), for all \(\theta _{t}\in [{\underline{\theta }}, {\bar{\theta }}]\), \(s\in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\), we have, from (80),
From the construction of the potential function \(\beta ^{\alpha ^{*}}_{{\bar{S}},t}\) in (71), we have
Let \({\hat{\theta }}_{t}\le \theta _{t}\in [{\underline{\theta }}, {\bar{\theta }}]\). Then,
Since \(\alpha ^{*}_{t}\) is non-decreasing, \(\int ^{{\hat{\theta }}_{t}}_{\theta _{t}}\alpha ^{*}_{t}({\hat{\theta }}_{t}|h^{\theta }_{t-1})\frac{d\kappa (x)}{dx}\Big |_{x=r}dr\ge \int ^{{\hat{\theta }}_{t}}_{\theta _{t}}\alpha ^{*}_{t}(r|h^{\theta }_{t-1})\frac{d\kappa (x)}{dx}\Big |_{x=r}dr\). From the fact that \(0\le D^{\alpha ^{*}}_{t,t}(\theta '_{t})\le D^{\alpha ^{*}}_{t,\tau }(\theta '_{t})\) for any \(\theta '_{t}\in [{\underline{\theta }}, {\bar{\theta }}]\), \(\tau \in {\mathbb {T}}_{t}\), we have \(\int ^{{\hat{\theta }}_{t}}_{{\theta }_{t}}D^{\alpha ^{*}}_{t,t}(r)dr\ge \int ^{{\hat{\theta }}_{t}}_{{\theta }_{t}}D^{\alpha ^{*}}_{t,\tau }(r)dr\), for all \(\tau \in {\mathbb {T}}_{t}\), \(t\in {\mathbb {T}}\). Then, it is straightforward to see that condition (55) is satisfied when \({\hat{\theta }}_{t}\le \theta _{t}\), given the construction of \(\beta ^{\alpha ^{*}}_{{\bar{S}}}\) in (71). Hence, the allocation rule \(\alpha ^{*}_{t}\) in (69) satisfies condition (55) in Proposition 3.
Finally, we use the evaluation approach in Proposition 6. From (77), the deviation \(d^{\alpha ^{*}}_{S,t}=0\). The deviation \(d^{\alpha ^{*}}_{{\bar{S}},t}\) in (64) can be written as
The following corollary summarizes the results of this case study by using the results in Propositions 2, 3, and 6 .
Corollary 6
Consider the state dynamics (65). The agent optimizes his interim expected payoff at each period with the utility function (66). The principal optimizes her ex-ante expected payoff with the utility function (67). Suppose that \(\{\alpha ^{*},\eta ^{*}\}\) maximizes (68) by ignoring the constraints. Let \(\phi \), \(\xi \), and \(\rho \) be constructed by \(\beta ^{\alpha ^{*}}_{S,t}\) and \(\beta ^{\alpha ^{*}}_{{\bar{S}},t}\) given in (70) and (71), respectively. Then, the mechanism with \(\{\alpha ^{*}, \phi ,\xi ,\rho \}\) admits \(\big \{0, d^{\alpha ^{*}}_{{\bar{S}},t}+\rho (t)\big \}\)-DIC, where \(d^{\alpha ^{*}}_{{\bar{S}},t}\) is given in (83). The mechanism is DIC if, for any \(t\in {\mathbb {T}}\),
where \(D^{\alpha ^{*}}_{t,T}\) and \(\rho (t)\) are given in (72) and (75), respectively.
As stated in Corollary 6, the mechanism with decision rules that solves (68) is in general not DIC. Condition (84) is directly from the statement (ii) of Proposition 6. The mechanism is DIC if the non-designed components of the model (i.e., \(\kappa \), \({\bar{\theta }}\), \({\underline{\theta }}\), and \(\xi \)) satisfy condition (84).
7 Conclusion
This work focuses on the theoretical characterizations of the incentive compatibility of a finite horizon dynamic mechanism design problem, in which the agent has the right to stop the mechanism at any period. We have studied an optimal stopping time problem under this dynamic environment for the agent to optimally select the time of stopping. A state-independent payment rule has been introduced that delivers a payment only at the realized stopping time. This payment rule enables the principal to directly influence the realization of the agent’s stopping time. We have also shown that under certain conditions, the optimal stopping problem can be fully represented by a threshold rule. Dynamic incentive compatibility has been defined in terms of the Bellman equations. A one-shot deviation principle has been established to address the complexity from the dynamic nature of the environment and the coupling of the agent’s reporting choices and stopping decisions. By relying on a set of formulations characterized by the non-monetary allocation rule and the potential functions, we have constructed the payment rules to obtain the sufficiency argument of the dynamic incentive compatibility. The quasilinear payoff formulation enables us to derive a necessary condition for the dynamic incentive compatibility from the envelope theorem which determines the explicit formulation of the potential functions. These settings naturally lead to the revenue equivalence.
Our analysis provides a new design paradigm for optimal direct mechanism in general quasilinear dynamic environments when the dynamic incentive compatibility takes into account not only the agent’s reporting behaviors but also his stopping decisions. From the necessary and the sufficient conditions, we can design the state-independent terminal payment rule by the allocation rule and the threshold function. As a result, the expected first-passage time (i.e., the expected time horizon of the principal’s ex-ante expected payoff) seen at the ex-ante stage is fully determined by the allocation rule and the threshold function given the transition kernels of the state. We have described the principal’s optimal mechanism design by applying a relaxation approach that reformulates the principal’s optimal mechanism design by making the principal make decisions at a stationary point. Hence, the principal’s optimization problem can be handled by finding the optimal allocation rule and the optimal threshold function. A regular condition has been provided as a design principle for the state-independent payment rule. An evaluation approach has been provided to evaluate the loss of the robustness of the dynamic incentive compatibility due to relaxations or computational approximations. In a case study, we have shown an example of a relaxed mechanism design and used the evaluation approach to obtain an approximate dynamic incentive-compatible mechanism.
The extension to multiple-agent environments would be a natural next step. In environments with multiple agents, allowing the early exit of each agent leads to a dynamic population over time, which is state-dependent. The relationships between population and individual payoffs could complicate the analysis of the incentive compatibility. One non-trivial extension could introduce the arrivals of new agents whose incentives of participation are characterized by both dynamic rational participation constraints as well as the history of the mechanism. Involving renegotiation after the agent realizes the stopping time is another direction of non-trivial extensions, especially when the agent can predict and plan how he will renegotiate with the principal. In the agent’s decision makings, he can leverage this prediction into his joint decision of reporting and stopping at each period. Due to the dynamics of the agent’s state, the (planned) renegotiation also changes over time. As a result, the principal’s mechanism design needs to address the effect of the predicted renegotiation on the characterization of the dynamic incentive compatibility.
References
Akan M, Ata B, Dana JD Jr (2015) Revenue management by sequential screening. J Econ Theory 159:728–774
Akbarpour M, Li S, Gharan SO (2020) Thickness and information in dynamic matching markets. J Political Econ 128(3):783–815
Anderson A, Smith L (2010) Dynamic matching and evolving reputations. Rev Econ Stud 77(1):3–29
Ano K (2009) Optimal stopping problem with uncertain stopping and its application to discrete options. In Presented at the 2nd Symposium on Optimal Stopping with Applications
Ash RB (2014) Real analysis and probability: probability and mathematical statistics: a series of monographs and textbooks. Academic press, Cambridge
Athey S, Segal I (2013) An efficient dynamic mechanism. Econometrica 81(6):2463–2485
Azevedo EM, Budish E (2019) Strategy-proofness in the large. Rev Econ Stud 86(1):81–116
Bapna A, Weber TA (2005) Efficient dynamic allocation with uncertain valuations. Available at SSRN 874770
Baron DP, Besanko D (1984) Regulation and information in a continuing relationship. Inf Econ Policy 1(3):267–302
Bergemann D, Välimäki J (2010) The dynamic pivot mechanism. Econometrica 78(2):771–789
Berger A, Müller R, Naeemi SH (2010) Path-monotonicity and truthful implementation. Technical Report 603, Maastricht University
Blackwell D (1965) Discounted dynamic programming. Annal Math Stat 36(1):226–235
Blasques F, Koopman SJ, Lucas A (2020) Nonlinear autoregressive models with optimality properties. Econ Rev 39(6):559–578
Board S, Skrzypacz A (2016) Revenue management with forward-looking buyers. J Polit Econ 124(4):1046–1087
Courty P, Hao L (2000) Sequential screening. Rev Econ Stud 67(4):697–717
Deb R, Said M (2015) Dynamic screening with limited commitment. J Econ Theory 159:891–928
Dubins LE, Sudderth WD (1977) Countably additive gambling and optimal stopping. Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete 41(1):59–72
Eső P, Szentes B (2007) Optimal information disclosure in auctions and the handicap auction. Rev Econ Stud 74(3):705–731
Findeisen S, Sachs D (2016) Education and optimal dynamic taxation: the role of income-contingent student loans. J Public Econ 138:1–21
Fudenberg D, Tirole J (1991) Game theory. MIT Press, Cambridge
Gallien J (2006) Dynamic mechanism design for online commerce. Oper Res 54(2):291–310
Gershkov A, Moldovanu B (2009) Dynamic revenue maximization with heterogeneous objects: a mechanism design approach. Am Econ J Microecon 1(2):168–98
He XD, Hu S, Obłój J, Zhou XY (2019) Optimal exit time from casino gambling: Strategies of precommitted and naive gamblers. SIAM J Control Optim 57(3):1845–1868
Jacka S, Lynn J (1992) Finite-horizon optimal stopping, obstacle problems and the shape of the continuation region. Stochast Stochast Rep 39(1):25–42
Kakade SM, Lobel I, Nazerzadeh H (2013) Optimal dynamic mechanism design and the virtual-pivot mechanism. Oper Res 61(4):837–854
Kruse T, Strack P (2015) Optimal stopping with private information. J Econ Theory 159:702–727
Kruse T, Strack P (2018) An inverse optimal stopping problem for diffusion processes. Math Operat Res 44(2):423–439
Lamberton D, et al. (2009) Optimal stopping and american options. Ljubljana Summer School on Financial Mathematics, p 134
Li S, Yılmaz Y, Wang X (2014) Quickest detection of false data injection attack in wide-area smart grids. IEEE Trans Smart Grid 6(6):2725–2735
Lin W-Y, Lin G-Y, Wei H-Y (2010) Dynamic auction mechanism for cloud resource allocation. In: Proceedings of the 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, pp 591–592. IEEE Computer Society
Lovász L, Winkler P (1995) Efficient stopping rules for markov chains. In: Proceedings of the 27th annual ACM symposium on Theory of computing, pp 76–82
Lubin B, Parkes DC (2012) Approximate strategyproofness. Current Sci 103(9):1021–1032
Lundgren R, Silvestrov DS (2010) Optimal stopping and reselling of european options. In: Rykov V, Balakrishnan N, Nikulin M (eds) Mathematical and statistical models and methods in reliability. Springer, Berlin, pp 371–389
Makris M, Pavan A (2021) Taxation under learning-by-doing. J Political Econ (in press)
Myerson RB (1981) Optimal auction design. Math Oper Res 6(1):58–73
Nazerzadeh H, Saberi A, Vohra R (2013) Dynamic pay-per-action mechanisms and applications to online advertising. Oper Res 61(1):98–111
Pai MM, Vohra R (2013) Optimal dynamic auctions and simple index rules. Math Oper Res 38(4):682–697
Parkes DC (2007) Online mechanisms. In: Nisan N, Roughgarden T, Tardos E, Vazirani VV (eds) Algorithmic game theory. Cambridge University Press, Cambridge, pp 411–440
Parkes DC, Singh S (2003) An mdp-based approach to online mechanism design. In: Proceedings of the 16th international conference on neural information processing systems, pp 791–798
Pathak PA, Sönmez T (2008) Leveling the playing field: sincere and sophisticated players in the boston mechanism. Am Econ Rev 98(4):1636–52
Pavan A, Segal I, Toikka J (May 2009) Dynamic mechanism design: Incentive compatibility, profit maximization and information disclosure. Discussion Papers 1501, Northwestern University, Center for Mathematical Studies in Economics and Management Science
Pavan A, Segal I, Toikka J (2014) Dynamic mechanism design: a myersonian approach. Econometrica 82(2):601–653
Peng G, Zhu Q (2020) Sequential hypothesis testing game. In Proceedings of the 54th annual conference on information sciences and systems (CISS), IEEE, pp 1–6
Peskir G, Shiryaev A (2006) Optimal stopping and free-boundary problems. Birkhäuser, Basel
Quah JK-H, Strulovici B (2012) Aggregating the single crossing property. Econometrica 80(5):2333–2348
Rochet J-C (1987) A necessary and sufficient condition for rationalizability in a quasi-linear context. J Math Econ 16(2):191–200
Rogerson WP (1985) The first-order approach to principal-agent problems. Econometrica 53(6):1357–1367
Said M (2012) Auctions with dynamic populations: efficiency and revenue maximization. J Econ Theory 147(6):2419–2438
Salacuse JW (2000) Renegotiating international project agreements. Fordham Int’l L.J., 24:1319
Tadelis S, Segal I (2005) Lectures in contract theory. Lecture notes for UC Berkeley and Stanford University
Tartakovsky AG, Veeravalli VV (2008) Asymptotically optimal quickest change detection in distributed sensor systems. Sequential Anal 27(4):441–475
Vickrey W (1961) Counterspeculation, auctions, and competitive sealed tenders. J Finance 16(1):8–37
Villeneuve S (2007) On threshold strategies and the smooth-fit principle for optimal stopping problems. J Appl Probability 44(1):181–198
Vulcano G, Van Ryzin G, Maglaras C (2002) Optimal dynamic auctions for revenue management. Manage Sci 48(11):1388–1407
Williams N (2011) Persistent private information. Econometrica 79(4):1233–1275
Zhang W (2012) Endogenous preferences and dynamic contract design. The B.E. J Theor Econ, vol 12, no 1
Zhang Y (2009) Dynamic contracting with persistent shocks. J Econ Theory 144(2):635–675
Acknowledgements
This research is partially supported by awards ECCS-1847056 and CNS-2027884 from National Science of Foundation (NSF), and grant W911NF-19-1-0041 from Army Research office (ARO).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
For notational compactness, we suppress the notations \(h_{t-1}^{\theta }\), \(h_{t-1}^{{\hat{\theta }}}\), and \(h^{a}_{t-1}\) from \(\alpha , \phi , \xi \), and \(\sigma \).
Proof of Proposition 1
The proof of the only if part directly follows from the optimality of truthful reporting and here we only provide the proof of the if part. Suppose, on the contrary, the truthful reporting strategy \(\sigma ^{*}\) satisfies (18) and (19) but not (16) and (17). Then there exists a reporting strategy \(\sigma '\) and a state \(\theta _{t}\), at period \(t\in {\mathbb {T}}\), such that \(V^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t};\sigma ')> V^{\alpha ,\phi ,\xi ,\rho }_{t}(\theta _{t};\sigma ^{*})\). Suppose that the optimal stopping rule with \(\sigma ^{*}\) calls for stopping and the agent decides to continue by using \(\sigma '\), i.e.,
Hence, there exists some \(\varepsilon >0\) such that
Let \(\sigma ''\) be the reporting strategy such that if \(\sigma ''\) and \(\sigma '\) have the same reporting strategies from period t to \(t+k\), for some \(k\ge 0\), then
Here, (87) implies that any deviation(s) for the periods from t to \(t+k\) (reporting truthfully for all other periods) can improve the value \(V^{\alpha ,\phi ,\xi ,\rho }_{t}\).
Let \({\hat{\sigma }}^{s}\) denote the reporting strategy that differs only at period s from \(\sigma ^{*}\) and \({\hat{\sigma }}^{s}_{s} = \sigma ''_{s}\), for \(s\in [t,t+k]\). Then, we have
Now, we look at period \(t+k-1\). Because \(\sigma ^{*}\) satisfies (18) and (19), we have, for all \(\theta _{t+k-1}\in \varTheta _{t+k-1}\),
Then,
Backward induction yields
which contradicts the fact that \(\sigma ^{*}\) satisfies (18) and (19).
Following the similar analysis, we can prove the cases when the optimal stopping rule with truthful \(\sigma ^{*}\) (1) calls for stopping and the agent decides to stop, (2) calls for continuing and the agent decides to continue, and (3) calls for continuing and the agent decides to stop. \(\square \)
Proof of Lemma 1
We prove (23) here. The proof of (24) can be done analogously. For any \(\tau \in {\mathbb {T}}\), the agent’s ex-ante expected payoff (2) can be written as
From law of total expectation, we have
\(\square \)
Proof of Lemma 5
Let \({\hat{\sigma }}[t]\) be the one-shot deviation strategy that reports \({\hat{\theta }}_{t}\) for the true state \(\theta _{t}\) at t. Let \(\varOmega ^{*}[{\hat{\sigma }}[t]]\) be the optimal stopping time rule defined in (14) with the stopping region \(\varLambda ^{\alpha , \phi , \xi , \rho }_{1,t}(t;{\hat{\sigma }}[t])\) given in (13) (equivalently, (32)). Suppose that at period t the agent observes a state \(\theta _{t}\in \varLambda ^{\alpha , \phi , \xi , \rho }_{1,t}(t;{\hat{\sigma }}[t])\). Hence, the agent stops at t optimally. Then, we obtain, for every \(\theta '_{t}\le \theta _{t}\),
where the inequality is due to Lemma 4. Therefore, \(\theta '_{t}\in \varLambda ^{\alpha , \phi , \xi , \rho }_{1,t}(t;{\hat{\sigma }}[t])\) for every \(\theta '_{t}\le \theta _{t}\), which implies that \(\varLambda ^{\alpha , \phi , \xi , \rho }_{1,t}(t;{\hat{\sigma }}[t])\) is an interval left-bounded by \({\underline{\theta }}_{t}\). Since \(L^{\alpha , \phi , \xi , \rho }_{t}\) is continuous, \(\varLambda ^{\alpha , \phi , \xi , \rho }_{1,t}(t;{\hat{\sigma }}[t])\) is closed. Hence, according to Assumption 3, there exists some \(\eta (t)\in \varTheta _{t}\) such that \(\varLambda ^{\alpha , \phi , \xi , \rho }_{1,t}(t;{\hat{\sigma }}[t]) = [{\underline{\theta }}_{t}, \eta (t)]\). \(\square \)
Proof of Lemma 6
Let \(\varOmega [{\hat{\sigma }}[t]]|\eta \) and \(\varOmega [{\hat{\sigma }}[t]]|\eta '\) denote the optimal stopping rule with threshold functions \(\eta \) and \(\eta '\), respectively. Let \(\tau _{\eta }\) and \(\tau _{\eta '}\) denote the expected realized stopping time from \(\varOmega [{\hat{\sigma }}[t]]|\eta \) and \(\varOmega [{\hat{\sigma }}[t]]|\eta '\), respectively. Without loss of generality, suppose \(\eta (t)<\eta '(t)\) for some \(t\in {\mathbb {T}}\). Here, we obtain the probability of \(\tau _{\eta }=t\) as:
We can obtain \(P_{r}(\tau _{\eta '}=t)\) in a similar way. Then,
Since \(\tau _{\eta }=\tau _{\eta '}\), the probabilities \(P_{r}(\tau _{\eta '}=t)\) and \(P_{r}(\tau _{\eta }=t)\) are equal, i.e., (91) equals 0. However, from Assumption 3, we know \({\mathbb {E}}^{\alpha |\theta _{t-1}}\Big [{\mathbf {1}}_{\{\eta (t)\le {\tilde{\theta }}_{t} \le \eta '(t) \} } \Big ]>0\) and \(P_{r}(\tau _{\eta }>t-1)>0\), which implies that
This contradiction implies that \(\eta \) is unique. \(\square \)
Proof of Proposition 2
From the construction of \(\xi \) in (39), we have
From the definition of \(\ell ^{\alpha }_{S,t}\) in (36) and the condition (41),
which implies
i.e.,
From the construction of \(\phi \) in (38), we have, for any \(\tau \in {\mathbb {T}}_{t+1}\),
From the condition (42), we have
From the condition (43), \(\beta ^{\alpha }_{{\bar{S}},t}(\theta _{t})\ge \beta ^{\alpha }_{S,t}(\theta _{t})\), for all \(\theta _{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\). Hence, \(\beta ^{\alpha }_{{\bar{S}},t}(\theta _{t})\ge \xi _{t}(\theta _{t})\) \(+ u_{1,t}(\theta _{t},\alpha _{t}(\theta _{t}))\), for all \(\theta _{t}\in {\mathbb {T}}\), \(t\in {\mathbb {T}}\). Then,
Hence, from (96), we have
From the construction of \(\rho \) in (40) and Lemma 2, we have, for some \(\tau '\in {\mathbb {T}}_{t}\)
which can be further bounded as
Hence, from the definition of \(U^{\alpha ,\phi ,\xi ,\rho }_{{\bar{S}},t}\), we have
Therefore, we can conclude that the mechanism is DIC. \(\square \)
Proof of Lemma 7
Let \({\tilde{m}}_{t}\) be uniformly distributed over (0, 1). Given the kernel \(K_{t}\), define the inverse of \(F_{t}(\cdot |\theta _{t-1}, a_{t-1})\) as follows:
Let \(\theta _{t}\in \varTheta _{t}\) and \(\theta _{t+1}\in \varTheta _{t+1}\) be any two realized states at two adjacent periods, for any \(t\in {\mathbb {T}}\backslash \{T\}\). Then, we have
Then, for any sequence of realized states \(\{\theta _{t},\theta _{t+1},\dots , \theta _{t+k}\}\), for some \(k>1\), we have
In any DIC mechanism, truthful reporting strategy is optimal. Then, the envelope theorem yields the following:
\(\square \)
Proof of Proposition 3
Since \(u_{1,t}(\theta _{t}, a_{t})\) is a non-decreasing function of \(\theta _{t}\), then \( \frac{\partial u_{1,t}(r, a_{t})}{\partial r}\Big |_{r = \theta _{t}} \ge 0 \) , for all \(t\in {\mathbb {T}}\). From Assumption 4, we have \(\frac{\partial F_{t+1}(\theta _{t+1}|r, a^{t})}{\partial r}\Big |_{r=\theta _{t}} \le 0\). Therefore, from Lemma 46, the term \(\gamma ^{\alpha }_{t}(\tau , \theta _{t}|h^{\theta }_{t-1})\) is nonnegative.
From the definition of \(\chi ^{\alpha , \phi , \xi }_{1,t}(\theta _{t})\) in (7), we have
Substituting the constructions of \(\phi \) and \(\xi \) given by (38) and (39), respectively, yields
Given the formulations of \(\beta _{S,t}\) and \(\beta _{{\bar{S}},t}\) in (47) and (48), respectively, we have
Since \(\gamma ^{\alpha }_{t}\) is nonnegative for all \(t\in {\mathbb {T}}\), then
Taking partial derivative of \(\chi ^{\alpha , \phi ,\zeta }_{1,t}\) given in (101) with respect to \(\theta _{t}\) gives
From Lemma 7, we have
where the second equality is from the fact that \(\gamma ^{\alpha }_{t}\) is nonnegative; and
Also, Assumption 4 implies that \(G_{t,t+1}(\theta _{t+1})\ge 0\) for all \(\theta _{t+1}\in \varTheta _{t+1}\). Hence, we have
Therefore, the constructions of potential functions given in (47) and (48) satisfy the monotonicity condition specified by Assumption 2, i.e., the statement (iii) in Proposition 2 is satisfied. \(\square \)
Proof of Proposition 5
Fix an arbitrary \({\hat{\theta }}_{\epsilon ,t}\in \varTheta _{\epsilon }\). We discuss the following two cases:
1.1 1. \(\varvec{\theta _{t}\in \varLambda _{t}(t)}:\)
Let \({\hat{\theta }}_{t} \in \varLambda _{t}(t)\). Without loss of generality, suppose \({\hat{\theta }}_{t}\le \theta _{t}\). Let \(\theta \), \(\theta ^{1}\), \(\theta ^{2}\in \bar{\varTheta }_{t} \equiv [\hat{\theta }_{t}, \theta _{t}]\). Since the mechanism is DIC, there exists \(\xi \) such that
Define
DIC implies that
Then, we obtain
By Assumption 1, we have that \(B_{t}\) is Lipschitz continuous. Thus, \(B_{t}\) is differentiable almost everywhere. Therefore, we have
Applying envelope theorem to \(B_{t}\) yields
Therefore, we have
From the definition of \(\ell ^{\alpha }_{S,t}(\theta _{t},{\hat{\theta }}_{t})\), we have
1.2 2. \(\theta _{t}\not \in \varLambda _{t}(t):\)
Similar to the case when \(\theta _{t}\in \varLambda _{t}(t)\), DIC implies the existence of \(\phi \) and \(\xi _{s}\) such that
Define
Since the mechanism is DIC, we have
Envelope theorem yields the following:
From the definition of \({\bar{\mu }}^{\alpha ,\phi , \xi ,\rho }_{t}\), (105) can be extended as follows:
Since the mechanism is DIC, we have
which is equal to
Hence, the condition (55) is satisfied. \(\square \)
Proof of Proposition 4
Let \(\theta ^{a}_{\epsilon ,t}\), \(\theta ^{b}_{\epsilon ,t}\in \varTheta \) associate with \(\beta ^{\alpha ;a}_{{\bar{S}}, t}\) and \(\beta ^{\alpha ;b}_{{\bar{S}}, t}\), respectively. For any period \(t\in {\mathbb {T}}\backslash \{1\}\), time horizon \(\tau \in {\mathbb {T}}\),
Hence, we have
Induction gives the following
\(\square \)
Proof of Lemma 8
It is straightforward to see that
From Assumption 4, we have \(G_{t,s}(h^{{\tilde{\theta }}}_{t,s}) \ge 0\). Since \(u_{1,t}\) is a non-decreasing function of \(\theta _{t}\), \(\frac{ \partial J^{\alpha ,\phi ,\xi ,\rho }_{1,t}(\tau ,r|h^{\theta }_{t-1}) }{ \partial r }\) \(\Big |_{r= \theta _{t}}\ge 0\). Therefore, \(J^{\alpha ,\phi ,\xi ,\rho }_{1,t}(\tau ,r|h^{\theta }_{t-1})\) is a non-decreasing function of \(\theta _{t}\), for all \(t\in {\mathbb {T}}\). \(\square \)
Proof of Proposition 6
From the construction of \(\phi \) in (38), we have, for any \(\tau ',\tau ''\in {\mathbb {T}}_{t+1}\),
From the definition of \(d^{\alpha }_{{\bar{S}}, t}\) in (64), we have for any \(\tau '\), \(\tau ''\in {\mathbb {T}}_{t}\),
From the condition (43), \(\beta ^{\alpha }_{{\bar{S}},t}(\theta _{t})\ge \beta ^{\alpha }_{S,t}(\theta _{t})\), for all \(\theta _{t}\in \varTheta _{t}\), \(t\in {\mathbb {T}}\). Hence, \(\beta ^{\alpha }_{{\bar{S}},t}(\theta _{t})\ge \) \( \xi _{t}(\theta _{t}) + \) \( u_{1,t}(\theta _{t},\) \(\alpha _{t}(\theta _{t}))\), for all \(\theta _{t}\in {\mathbb {T}}\), \(t\in {\mathbb {T}}\). Then,
Hence, from (111), we have, for any \(\tau '\in {\mathbb {T}}_{t}\)
From the construction of \(\rho \) in (40) and Lemma 2, we have, for some \(\tau '\in {\mathbb {T}}_{t}\)
which is equal to
Hence, from the definition of \(U^{\alpha ,\phi ,\xi ,\rho }_{{\bar{S}},t}\), we have
Following the similar way, we can prove the following
where \(d^{\alpha }_{S,t}\) is defined in (63).
Therefore, we can conclude that the mechanism is \(\Big \{d^{\alpha ^{\circ }}_{S,t}, d^{\alpha ^{\circ }}_{{\bar{S}},t}+\sup _{\tau \in {\mathbb {T}}_{t}}\Big \{\rho ^{\circ }(\tau ) \Big \}\Big \}\)-DIC if \(d^{\alpha }_{S,t}>0\) and \(\Big [d^{\alpha }_{t}+ \sup _{\tau \in {\mathbb {T}}_{t}}\) \(\Big \{\rho (\tau ) \Big \}>0\); otherwise, the mechanism is DIC. We can prove the case when the payment rule \(\rho \) is constructed according to (51) by following the similar way. \(\square \)
Rights and permissions
About this article

Cite this article
Zhang, T., Zhu, Q. On Incentive Compatibility in Dynamic Mechanism Design With Exit Option in a Markovian Environment. Dyn Games Appl 12, 701–745 (2022). https://doi.org/10.1007/s13235-021-00388-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13235-021-00388-x