
Abstract
Multiple recursive projection twin support vector machine (MPTSVM) is a recently proposed classifier and has been proved to be outstanding in pattern recognition. However, MPTSVM is computationally expensive since it involves solving a series of quadratic programming problems. To relieve the training burden, in this paper, we propose a novel multiple least squares recursive projection twin support vector machine (MLSPTSVM) based on least squares recursive projection twin support vector machine (LSPTSVM) for multi-class classification problem. For a \(K(K>2)\) classes classification problem, MLSPTSVM aims at seeking K groups of projection axes, one for each class that separates it from all the other. Due to solving a series of linear equations, our algorithm tends to relatively simple and fast. Moreover, a recursive procure is introduced to generate multiple orthogonal projection axes for each class to enhance its performance. Experimental results on several synthetic and UCI datasets, as well as on relatively large datasets demonstrate that our MLSPTSVM has comparable classification accuracy while takes significantly less computing time compared with MPTSVM, and also obtains better performance than several other SVM related methods being used for multi-class classification problem.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Support vector machine (SVM) [1, 2], being widely used for pattern classification and regression problems, was introduced by Vapnik and his co-workers in the early 1990s. Previous studies demonstrated the superiority of SVM [3–5]. By employing the structural risk minimization (SRM) principle [6], SVM tries to find a decision hyperplane that separates data points from two classes well by constructing two parallel support hyperplanes that the margin between them is maximized. However, SVM needs to solve a quadratic programming problem (QPP), which restricts its application to large scale problems. To address this issue, numerous approaches have been proposed [7–12].
For binary classification, some nonparallel hyperplane classifiers have attracted much attention. Mangasarian and Wild [9] proposed a generalized eigenvalue proximal support vector machine (GEPSVM) which aims at finding two nonparallel hyperplanes such that each hyperplane is closer to its own class and far from the other class as much as possible. This idea leads to solving two generalized eigenvalue problems which in turn reduces computation cost compared with SVM. Subsequently, an improved version of GEPSVM, called IGEPSVM [13], is proposed to remove the possible singularity problem of GEPSVM. In the spirit of GEPSVM, Jayadeva et. al. [10] proposed the twin support vector machine (TWSVM). Different from SVM, TWSVM solves two smaller sized QPPs rather than a single large one, which makes the learning speed of TWSVM be approximately four times faster than that of SVM. Both GEPSVM and TWSVM share the idea of nonparallel SVMs, which is in fact has been studied extensively [14–20].
Instead of finding nonparallel hyperplanes, the idea of seeking projection axes for SVMs has also been established. Ye et. al. [21] proposed a multi-weight vector projection support vector machine (MVSVM), whose purpose is to find two optimal weight vector projection directions, such that each class is centered around its own class centroid while is separated as much as possible from the other class in the projected space. Inspired by TWSVM and MVSVM, projection twin support vector machine (PTSVM) [22, 23] is proposed recently. The central thought of PTSVM is to find a projection axis one for each class, such that the within-class variance of the projected data points of its own class is minimized meanwhile projected data points of the other class scatter away as far as possible. PTSVM can be extended to find multiple orthogonal directions by a recursive procure. To accelerate the training speed of PTSVM, Shao et al. [24] adopted the idea of least squares [7, 14] and proposed a least squares projection twin support vector machine (LSPTSVM) by considering the equality constraints. An extra regularization term is introduced in the primal problem of LSPTSVM to remove the singularity problem that may appear in PTSVM.
As a natural extension of binary classification problem, multi-class classification has also drawn many attentions. Among all the methods, SVM and its variants [25–29] have been confirmed to have outstanding performance. Generally speaking, two types of strategies are widely used when SVMs are applied. One is the “decomposition-reconstruction” strategy which involves solving a series of small sized optimization problems, including the classical “one versus one” and “one versus rest” techniques [26–29]. The other one is the “all-together” strategy through solving one large scale optimization problem [25].
Being a successful multi-class classification tool, multiple recursive projection twin support vector machine (MPTSVM) [29] is a recently proposed SVM-type classifier, which is established based on binary PTSVM by utilizing the “one versus rest” technique. Though MPTSVM performs satisfactorily, it is computationally expensive since a series of QPPs are needed to be solved. For this purpose, in this paper, we extend the LSPTSVM to multi-class classification problem, and propose a multiple least squares recursive projection twin support vector machine (MLSPTSVM). Instead of solving complex QPPs in MPTSVM, our MLSPTSVM solves a series of linear equations, which leads to relatively fast training speed. For \(K(K>2)\) classes classification problem, our MLSPTSVM determines K groups of projection axes, one group for each class, such that the within-class variance of the projected data points of its own class is minimized while each projected class is far awat from the projected centers of the other classes. Specially, we apply the classical “one versus rest” multi-class classification technique to our MLSPTSVM by considering its advantage on computational efficiency. Preliminary experimental results on several real-world datasets and large datasets show the advantages of MLSPTSVM over MPTSVM and other SVM related methods for multi-class classification problem. The following are the highlights of our MLSPTSVM:
-
1.
MLSPTSVM considers both the linear and the nonlinear models, while the binary LSPTSVM ignores the nonlinear case.
-
2.
MLSPTSVM solves a series of linear equations, which makes it can handle the large datasets easily.
-
3.
MLSPTSVM could generate multiple orthogonal projection directions for each class, which may notably enhance its performance.
-
4.
The Sherman–Morrison–Woodbury (SMW) formulation and the reduced kernel technique are employed to reduce the complexity of nonlinear MLSPTSVM.
The rest of the paper is organized as follows: In Sect. 2, we provide the basic notations and give a brief review of TWSVM, PTSVM and LSPTSVM. Section 3 presents the details of MLSPTSVM under different requirement and its computational complexity. A variety of experimental results are demonstrated in Sect. 4. Finally, Sect. 5 concludes this paper.
2 Preliminaries
In this section, we consider the binary classification problem of classifying m data points in the n-dimensional real space \(\mathbb R^{n}\), with data points in class 1 and class 2 are represented by the matrices \(A=({\rm a}_{1},\ldots ,{\rm a}_{m_1})^{T}\in \mathbb {R}^{m_1\times n}\) and \(B=({\rm b}_{1},\ldots ,{\rm b}_{m_2})^{T}\in \mathbb {R}^{m_2\times n}\) respectively, where \(m=m_1+m_2\). In the following, we will give a brief review of TSVM, PTSVM and LSPTSVM.
2.1 Twin support vector machine
Twin support vector machine (TWSVM) [10] aims at determining two nonparallel hyperplanes \(x^{T}w^{(1)}+b^{(1)}=0\) and \(x^{T}w^{(2)}+b^{(2)}=0\), such that each hyperplane is close to data points of one class and far from the data points of the other class. The two hyperplanes are obtained by solving a pair of SVM-type QPPs as the following
and
where \(c_1\), \(c_2 > 0\) are penalty parameters, \(e_1\in \mathbb {R}^{m_1}\) and \(e_2\in \mathbb {R}^{m_2}\) are vectors of ones, and \(\xi ,\,\eta\) are vectors of nonnegative slack variables.
Through the K.K.T conditions [30], we can obtain the Wolf dual forms of problems (1) and (2) as follows
and
Here, \(Q=[A,e_1]\), \(P=[B,e_2]\), and \(\alpha =(\alpha _{1},\alpha _{2},\ldots ,\alpha _{m_2})^T\) and \(\gamma =(\gamma _{1},\gamma _{2},\ldots ,\gamma _{m_1})^T\) are the vectors of Lagrange multipliers.
Define \(u=[w^{(1)},b^{(1)}]^{T}\) and \(v=[w^{(2)},b^{(2)}]^{T}\). Then the two nonparallel hyperplanes can be obtained from the solution of problems (3) and (4), which are given by
and
respectively. Once vectors u and v are known from (5) and (6), the two separating hyperplanes \(x^{T}w^{(1)}+b^{(1)}=0\) and \(x^{T}w^{(2)}+b^{(2)}=0\) are obtained and the training process is finished. For predicting, a new data point \(\mathrm x\in \mathbb {R}^{n}\) is assigned to class \(i (i=1,2)\), depending on which of the two hyperplanes it lies closer to, i.e.,
where \(|\cdot |\) is the absolute value operation that computes perpendicular distance of \(\mathrm x\) to each hyperplane.
It should be noted that, \(Q^{T}Q\) and \(P^{T}P\) in (5) and (6) are positive semidefinite, and hence it is possible that they may not be well defined when taking inverse. Therefore, a regularization term \(\epsilon I\) can be introduced to avoid the possible ill-condition of \(Q^{T}Q\) and \(P^{T}P\), where \(\epsilon > 0\) and I is the identity matrix of appropriate dimension.
2.2 Projection twin support vector machine
Different from TWSVM who finds nonparallel hyperplanes, projection twin support vector machine (PTSVM) [22] aims at finding two projection axes \(w_1\) and \(w_2\), one for each class, such that the within-class variance of projected data points of its own class is minimized while projected data points from other class scatter away as far as possible. This idea leads to the formulations of PTSVM as
and
where \(c_{1}\) and \(c_{2}\) are trade-off parameters, and \(\xi _k,\,\eta _k\) are nonnegative slack variables.
Before determining solutions of (8) and (9), we first define
and
as the covariance matrices of the first and second class, respectively. Then problems (8) and (9) can be solved through their Wolf dual forms [30] which are given by
and
respectively, where \(\alpha =(\alpha _{1},\alpha _{2},\ldots ,\alpha _{m_2})^T\) and \(\gamma =(\gamma _{1},\gamma _{2},\ldots ,\gamma _{m_1})^T\) are Lagrange multiplier vectors, \(e_1\in \mathbb {R}^{m_1}\) and \(e_2\in \mathbb {R}^{m_2}\) are vectors of ones.
After obtaining \(\alpha\) and \(\beta\), \(w_{1}\) and \(w_{2}\) can be expressed by
For a new coming data point \(\mathrm x\in \mathbb {R}^{n}\), it is assigned to class \(i (i=1,2)\) depending on which of the two projected class centers it is closer to, i.e.,
where \(d_1\) and \(d_2\) represent the distances between the projection of \(\mathrm x\) and the projected center of corresponding class, which are given by
and
respectively.
It should be noticed that the above procedure requires the two variance matrices defined by (10) and (11) to be nonsingular. However, when there are not sufficient samples, the two variance matrices can be singular. To deal with this problem, PCA plus LDA [31, 32] technique has been employed in PTSVM. Furthermore, to enhance the performance, a recursive procure is introduced in PTSVM to obtain multiple projection axes for each class.
2.3 Least squares projection twin support vector machine
By considering equality constraints in the primal problems of PTSVM, least squares projection twin support vector machine (LSPTSVM) [24] is proposed. However, LSPTSVM is not a direct least squares version of PTSVM. In fact, LSPTSVM introduces a regularization term in the primal objective function to remove the singularity problem that may happen in PTSVM and gains better generalization ability. This leads to following optimal problems
and
where \(c_1>0, c_2>0\) are trade-off parameters, \(v_1>0, v_2>0\) are regularization parameters, and \(\xi _k,\,\eta _k\) are slack variables.
By substituting the equality constraint into the objective function, we can derive the optimal axes \(w_1\) and \(w_2\) of (18) and (19) as
and
where \(e_1\in \mathbb {R}^{m_1}\), \(e_2\in \mathbb {R}^{m_2}\) are vectors of ones, I is the identity matrix with appropriate dimension, and \(S_1, S_2\) are defined as in (10) and (11) respectively. It is clear that different from PTSVM, LSPTSVM will not encounter the singularity problem due to the nonsingularity of the involved matrices \((\frac{S_1}{c_1}+(-B+\frac{1}{m_{1}}e_2e_{1}^{T}A)^{T}(-B+\frac{1}{m_{1}}e_2e_{1}^{T}A)+\frac{v_1}{c_1}I)\) and \((\frac{S_2}{c_2}+(A-\frac{1}{m_{2}}e_1e_{2}^{T}B)^{T}(A-\frac{1}{m_{2}}e_1e_{2}^{T}B)+\frac{v_2}{c_2}I)\). This makes LSPTSVM much more stable.
In order to further enhance the performance of LSPTSVM, multiple orthogonal directions for each class can also be obtained by using a recursive procedure. Suppose that the two groups of desired projection axes are \(W_1=\{w_1^{(t)},t=1,2,\ldots ,r\}\) and \(W_2=\{w_2^{(t)},t=1,2,\ldots ,r\}\), where \(w_1^{(t)}\) and \(w_2^{(t)}\) are obtained from (20) and (21) recursively, and r is the desired number of projection axes for each class. For testing, the label of a new coming data point \(\mathrm x\in \mathbb {R}^{n}\) can be similarly determined by (15), but with \(d_1\) and \(d_2\) are newly defined by
and
respectively, where \(||\cdot ||\) represents the 2-norm of a vector.
3 Multi-class least squares recursive projection twin support vector machine
In this section, we consider multi-class classification problem with the dataset \(T=\{(X,Y)\}\) contains \(K\ge 2\) classes, where \(X=\{{{\rm x}_1},\ldots ,{{\rm x}_m}\}\) consists of m data points and each data point is an n-dimensional vector, and \(Y\in \mathbb {R}^m\) is the corresponding output with each element belonging to \(\{1,\ldots ,K\}\). We further organize data points in the i-th class as \(A_i=({\rm x}_{i1},\ldots ,{\rm x}_{im_i})^{T}\in \mathbb {R}^{m_i\times n}\) and define \(B_i=({\rm \overline{x}}_{i1},\ldots ,{\rm \overline{x}}_{i\overline{m}_i})^{T}\in \mathbb {R}^{\overline{m}_i\times n}\) as the set of the rest \(K-1\) classes, where \(m_i\) is the number of data points in the i-th class and \(\overline{m}_i=m-m_i\) represents the number of data points in the rest \(K-1\) classes. In the following, we will present our multi-class least squares recursive projection twin support vector machine (MLSPTSVM) for the above K classes classification problem.
3.1 Linear MLSPTSVM
3.1.1 One projection axis
For K classes classification problem, linear MLSPTSVM generates K projection axes in the primal space, one for each class that separates one class from all the other classes in the same manner of binary LSPTSVM. Specifically, it requires that the projected points of one class are close to its projected center as much as possible while the distance from the projected center to the rest \(K-1\) classes are far away to some extent. Denote \(w_{i}\) the projection axis for the i-th class, \(i=1,2,\ldots K\). Then linear MLSPTSVM considers the following problem
where \(c_i>0\) is the trade-off parameter, \(v_{i}>0\) is the regularization parameter, and \(\xi _k\) are slack variables. We now give the geometric interpretation of problem (24). By employing the quadratic loss function, the first two terms of the objective function and the constraint are committed to minimize the empirical risk, which ensures the projected points of its own class are clustered around its projected center meanwhile the distances from the projected center to the rest classes are far away to some extents. Note that the nonnegative constraints of \(\xi _k\) are abandoned due to the usage of quadratic loss function. The last term in the objective function is a regularization term which is utilized to avoid the singularity problem of our model and reach better generalization ability, which is similar to classical SVM [1, 2] and improved TWSVM [15].
Problem (24) can be solved by the following process. We first define the within-class variance matrix \(S_i\) for the i-th class as
where \(e_i\in \mathbb {R}^{m_i}\) is the vector of ones. Substituting the constraint into the objective function, problem (24) is converted into an unconstrained problem which is given by
where \(\overline{e}_i\in \mathbb {R}^{\overline{m}_i}\) is the vector of ones. Set the gradient of the objective function in (26) with respect to \(w_i\) to zero, then
For simplicity, we define \(H_i=(A_i-\frac{1}{m_i}e_ie_i^{T}A_i)\in \mathbb {R}^{m_{i}\times n}\) and \(G_i=(B_i-\frac{1}{m_{i}}\overline{e_i}e_{i}^{T}A_i)\in \mathbb {R}^{\overline{m}_i\times n}\). Therefore, the optimal projection vector \(w_i\) of problem (24) can be obtained from (27) by
Here I is the identity matrix with appropriate dimension. Owes to the extra regularization term in problem (24), the singularity issue is ruled out since the involved matrix in (28) is positive definite.
After K optimal projection axes \(w_i (i=1,\ldots ,K)\) are obtained from (28), the training stage is complete. For predicting, the label of a new coming data point \(\mathrm x\in \mathbb {R}^{n}\) is determined depending on which of the class center it is closer to in the projected space:
The whole process above leads to the following Algorithm 1.

3.1.2 Multiple orthogonal projection axes
In order to further enhance the performance of our MLSPTSVM, we can obtain multiple orthogonal projection axes for each class by a recursive procure. The recursive procure contains two steps: \((\mathrm i)\) determine projection axes \(w_i (i=1,\ldots ,K)\) one for each class by carrying out Algorithm 1, and normalize \(w_i\) to have unit norm, i.e., \(w_i = w_i /\Vert w_i\Vert\); \((\mathrm ii)\) generate new data points by projecting the original data points into projection subspace which is orthogonal to projection axis \(w_i\).
Denote \(W_i=\{w_i^{(j)}|j=1,\ldots ,r\}\) (\(1\le i\le K\)) as the set of multiple projection axes of the i-th class, where \(w_i^{(j)}\) is the j-th projection axis and r is the desired number of projection axes of the i-th class, respectively. Then, the decision function of a new coming data \(\mathrm x\in \mathbb {R}^{n}\) for multiple projection axes case is given by
Suppose that \(X^{(j)}\) is the j-th projected dataset and \({\rm x}_l^{(j)}\) is the l-th data point in dataset \(X^{(j)}\) (\(j=1,\ldots ,r; l=1,\ldots ,m\)). Then, the proposed recursive MLSPTSVM algorithm works as in Algorithm 2.

We show that the multiple projection axes obtained for each class by Algorithm 2 is actually orthogonal to each other.
Theorem 1
By implementing Algorithm 2, the resulting \(W_i\) is an orthonormal set for each \(i = 1,\ldots ,K\).
Proof
We here take the similar strategy in [22, 33, 34]. Since each \(w_i^{(j)}\) is a unit vector by performing Algorithm2, we need only to prove that \(w_i^{j}\) is orthogonal to \(w_i^{(j-k)}\) for all \(k = 1,\,2,\ldots ,j-1\). According to the definition of \(G_i\) and \(\overline{e_i}\) in Sect. 3.1.1, \(G_i^{T}\overline{e_i}\) is a linear combination of the row vectors of matrices \(A_i\) and \(B_i\), i.e. the input samples. By observing (28), this implies that in the j-th iteration, each projection axis \({w_i^{(j)}}\) is a linear combination of the input samples \({\rm x}_l^{(j)}\), where \(l=1,\ldots ,m\). For the newly obtained projected data in the j-th iteration (Step (3) in Algorithm 2), by multiplying \({w_i^{(j-1)}}^T\), we have
This means \(w_i^{(j-1)}\) is orthogonal to the input samples \({\rm x}_l^{(j)}\), which in turn implies that \(w_i^{(j)}\) is orthogonal to \(w_i^{(j-1)}\).
In the same way, we can justify that \(w_i^{(j)}\) is orthogonal to \(w_i^{(j-k)}\) for all \(k = 2,\ldots ,j-1\). Therefore, \(W_i\) is an orthonormal set for each \(i = 1,\ldots ,K\) and the proof is completed.
From Theorem 1, we see that each \(W_i\) spans an orthogonal subspace such that the discriminative information for classification are contained as much as possible.
3.2 Nonlinear MLSPTSVM
In this subsection, we extend the linear MLSPTSVM to the nonlinear case, which is ignored in LSPTSVM [24]. Consider the nonlinear kernel \(\mathcal {K}\), and let \(C = [A_1,\ldots ,A_K]^{T}\). Then the within-class variance of the i-th class in the kernel space can be written as
and nonlinear MLSPTSVM leads to the following unconstraint problem
where \(c_i>0\) is the trade-off parameter, \(v_{i}>0\) is the regularization parameter, and \(e_i\in \mathbb {R}^{m_i}\), \(\overline{e_i}\in \mathbb {R}^{\overline{m}_i}\) are vectors of ones. The optimal solution of problem (32) can be determined by
where \(\overline{H}_i=\mathcal {K}(A_i,C^T)-\frac{1}{m_{i}}e_ie_i^{T}\mathcal {K}(A_i,C^T)\) and \(\overline{G}_i=\mathcal {K}(B_i,C^T)-\frac{1}{m_{i}}\overline{e_i}e_{i}^{T}\mathcal {K}(A_i,C^T)\).
After the K optimal projection axes \(w_{i}\) (\(i = 1,\ldots ,K\)) are obtained, the label of a new coming data point \(\mathrm x\) is classified in the same way as the linear case. To get multiple projection axes, the similar procedure can be taken as in Algorithm 2, which will be omitted here.
3.3 Computational analysis
We analyze the computation complexity of our MLSPTSVM in this subsection. Suppose r is the desired number of projection axes for each class. From (28), we see that linear MLSPTSVM solves K classes classification problem mainly by giving K matrix inverses of size \(n \times n\), where \(n \ll m\). Thus the time complexity of linear MLSPTSVM is about \(O(Krn^3)\). Similarly, by observing (33), the nonlinear MLSPTSVM requires K matrix inverses of order \(m \times m\), and it takes \(O(Krm^3)\) time.
In order to reduce the time complexity when calculating matrix inverses for nonlinear MLSPTSVM, we resort to the following Sherman–Morrison–Woodbury (SMW) formula [30]
Specifically, by (34), we can rewrite (33) as
where \(Y_i=(\frac{1}{c_{i}}\overline{H}_i^{T}\overline{H}_i+\frac{v_{i}}{c_{i}}I)^{-1}\) that can be further rewritten by (34) as
As we can observe from (35) and (36), the calculation of matrix inverse in (33) is converted into two smaller sized \(m \times m\) matrix inverses, that is, \((I+\frac{1}{v_{i}}\overline{H}_i\overline{H}_i^{T})^{-1}\in \mathbb {R}^{{m}_{i}\times {m}_{i}}\) and \((I + \overline{G}_iY_i\overline{G}_i^{T})^{-1}\in \mathbb {R}^{\overline{m}_{i}\times \overline{m}_{i}}\). Therefore, the computation complexity of nonlinear MLSPTSVM can be reduced to \(O(Krd^3)\), where \(d = max\{m_i, \overline{m}_i|i=1,\ldots ,K\}\).
Furthermore, if the number of data points m in dataset T is very large, then the rectangular kernel technique [8, 35] can be applied to reduce the dimensionality of nonlinear MLSPTSVM. Specifically, we can reduce \(\mathcal {K}(A_i,C^T)\) of size \(m_{i}\times m\) and \(\mathcal {K}(B_i,C^T)\) of size \(\overline{m}_i\times m\) to much smaller sizes \(m_{i}\times \widetilde{m}\) and \(\overline{m}_i\times \widetilde{m}\), respectively. Here \(\widetilde{m}\) is as small as 1–10 % of m and \(\overline{C}\) is an \(\widetilde{m} \times n\) random submatrix of C. Thus the complexity of nonlinear MLSPTSVM can be largely reduced. The rectangular kernel technique not only makes large scale problem tractable, but also leads to improved generalization performance by avoiding data overfitting [8].
4 Experimental results
To demonstrate the classification ability of MLSPTSVM, we perform our MLSPTSVM, the recently proposed MPTSVM [29], together with other four state-of-the-art binary classification methods, including SVM [1, 2], GEPSVM [9], TWSVM [10], and LSTSVM [14] on artificial datasets, publicly available UCI datasets [36] and some large datasets [37]. Note that the SVM, GEPSVM, TWSVM and LSTSVM are applied here to multi-class classification problem by using one vs rest technique. To clarify the fact that these binary classifiers are used in the multi-classification context, we re-term them as MSVM, MGEPSVM, MTWSVM, and MLSTSVM respectively, where the first letter “M” represents “multiple”. All the methods are implemented in MATLAB 2013a environment on a PC with Intel i5 processor (2.67 GHz), 2 GB RAM. MSVM is implemented by LIBSVM [38] due to its fast training speed. The dual QPPs arising in MSVM, MTWSVM and MPTSVM are solved using Mosek optimization toolbox, the eigenvalue problems in MGEPSVM are solved by a function ‘eig’, and the matrix inverse problems in several methods including MLSPTSVM are solved by calling operation ‘\(\backslash\)’. For parameter selection, all the parameters except for the number of projection axes in MPTSVM and MLSPTSVM, are selected from \(2^{-8}\) to \(2^{8}\) by employing the standard tenfold cross-validation technique [39]. Experiments are repeated five times on each dataset and the corresponding results are recorded, including the means and standard deviations of test accuracies, computing time which are obtained under the best parameters, and p values which are calculated by performing paired t-test in 5 % significance level. Specially, in order to compare the performances of various methods intuitively, we mark the highest accuracy on each dataset in bold.
4.1 Artificial examples
We first conduct experiments on two artificial examples to evaluate the performance of our MLSPTSVM in comparison to MPTSVM. The first dataset is a three-dimensional Xor dataset that consists of 153 samples with three classes of the same size, as shown in Fig. 1. This three-dimensional Xor dataset is obtained by randomly perturbing points around three intersecting lines. The second dataset is a cross plane dataset containing three classes, with 600 samples are generated in a two-dimensional plane, as shown in Fig. 2.

A three-dimensional Xor dataset with three classes

A two-dimensional crossplane dataset with three classes
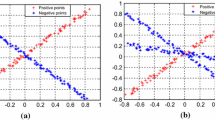
For the experiment on the first dataset, the number of projection axes for each class is set to 1 for both MLSPTSVM and MPTSVM. Fig. 3a, b show the classification results by plotting the distance distributions of MPTSVM and MLSPTSVM. Specifically, \(d_i\) (\(i=1,2,3\)) in Fig. 3 are the distances between the projected points and the i-th projected center. MLSPTSVM classifies the Xor dataset well with just two misclassified points, which is the same for MPTSVM.
For the second artificial dataset, Fig. 4a, b depict the three projection directions obtained by MPTSVM and MLSPTSVM, respectively. From Fig. 4, we see that the resulting directions for these two methods are very similar. To make the comparison clearer, the specific performances of MPTSVM and MLSPTSVM on the two datasets are reported in Table 1. As we can observe in Table 1, MLSPTSVM has comparable classification accuracy to that of MPTSVM but with considerably less computing time. Furthermore, by observing the p values, we see that 0.775 and 0.799 are much greater than 0.05, which implies that the performance of these two methods are essentially similar.

Distance distribution of MPTSVM and MLSPTSVM on Xor dataset

Projection directions of MPTSVM and MLSPTSVM on crossplane dataset
4.2 UCI datasets
In this subsection, we further experiment on six UCI benchmark datasets [36], whose details are listed in Table 2. The experimental results for linear and nonlinear cases of our MLSPTSVM, as well as the other five methods, i.e., MSVM, MGEPSVM, MTWSVM, MLSTSVM and MPTSVM are summarized in Tables 3 4, respectively. For nonlinear classifiers, Gaussian kernel is selected for all the methods. The SMW technique [30] is employed to simplify the calculation of matrix inverses for our nonlinear MLSPTSVM. The optimal numbers of projection axes that are selected from 1 to the dimension of each dataset are listed in the brackets for MPTSVM and MLSPTSVM.
For the linear case, from Table 3, we observe that MLSPTSVM and MPTSVM can obtain the highest accuracies on most of the datasets among all the methods, which indicate that they have better generalization capability than the others. Furthermore, we see that MLSPTSVM has comparable accuracies to those of MPTSVM since most of p values between them are larger than 0.05. On the other side, MLSPTSVM takes significantly less computing time than MPTSVM as one can see in Table 3. For example, MLSPTSVM takes 0.017(s) on Glass dataset while MPTSVM needs almost 0.431(s). However, MLSPTSVM is a bit slower than MGEPSVM and MLSTSVM, which mainly because multiple projection axes are needed on most datasets for MLSPTSVM.
For the nonlinear case, the employed Gaussian kernel is defined by \({\mathcal {K}}(x,z) = \exp \left( { - \frac{{\left\| {x - z} \right\|^{2} }}{{2p^{2} }}} \right)\), where p is the kernel parameter. From Table 4, we can see that MLSPTSVM and MPTSVM outperform the other methods in terms of classification accuracy, while these two methods achieve comparable performance by observing both the accuracies and p values. For example, MPTSVM and MLSPTSVM obtain accuracies 97.47 and 98.01 % on Pathbased dataset, while the corresponding p value is 0.084. With regard to time consumption, from Table 4, it can be seen that MLSPTSVM takes almost the fewest computing time compared with its competitors. Specially, MLSPTSVM takes significantly less time than MPTSVM as in the linear case. Furthermore, only one projection axis is enough for MLSPTSVM to get the highest accuracy on three datasets, i.e., Seeds, Wine and Pathbased, while the corresponding computing times are very competitive. This demonstrates the superiority of our MLSPTSVM.
In summary, from Tables 3 and 4, we conclude that MLSPTSVM and MPTSVM outperform other methods in both linear and nonlinear cases, and there is no statistical difference in classification accuracy between these two methods since most of corresponding p values are larger than 0.05. However, it is evident that MLSPTSVM takes considerable less computing time compared with MPTSVM. In addition, the optimal number of projection axes varies from different datasets for both MPTSVM and our MLSPTSVM.
4.3 Large datasets
As one observes in Sect. 3, our MLSPTSVM tends to extremely fast since it only needs to solve a series of linear equations. In this subsection, we argue the above viewpoint by exhibiting the ability of our MLSPTSVM on dealing with large scale datasets. Note that MSVM, MTWSVM and MPTSVM involve solving complex QPPs with high computational complexity, which makes them fail on large datasets. Therefore, we only present the experimental results of our MLSPTSVM, MGEPSVM and MLSTSVM. Eight large datasets [37] are used for comparison, whose details are summarized in Table 5. Here, the Mnist dataset is generated by randomly selecting 30 % samples in each class of the original dataset, and the other datasets are combined by the training set and testing set. Since our linear MLSPTSVM requires to determine the inversion of matrices whose orders are input space dimension, we perform dimensionality reduction step before classifying on high-dimensional datasets. Therefore, we first employ LDA [31] on USPS, Reuster300 and Mnist datasets for dimensionality reduction. Furthermore, the number of projection axes are selected from 1 to 8 for the convenience of further analyzing in Sect. 4.4.
For the linear case, we report the experimental results of the three involved methods on the above large datasets in Table 6. Table 6 demonstrate that our MLSPTSVM outperforms MLSTSVM and MGEPSVM on most datasets in terms of classification accuracy, and the corresponding p values between them are all much smaller than 0.05, which indicates the effectiveness of our MLSPTSVM over MLSTSVM and MGEPSVM. For example, for Shuttle dataset, MGEPSVM and MLSTSVM gain 67.77 and 90.12 % accuracy respectively while MLSPTSVM can reach to 91.19 %. Meanwhile, the two corresponding p values are all close to 0. It can also be observed that our MLSPTSVM is a bit slower than MGEPSVM and MLSTSVM, which is mainly because that the optimal number of projection axes is needed to be searched. However, this also the source of great performance of MLSPTSVM. In conclusion, the results in Table 6 demonstrate the feasibility of our linear MLSPTSVM on large datasets.
For the nonlinear case, four datasets in Table 5 are considered, i.e., Page-blocks, Satimage, Pendigits and Mnist, and the Gaussian kernel is used in nonlinear MLSPTSVM. We employ the rectangular kernel technique [8, 35] to reduce the dimensionality and select 1 % of training samples to perform the kernel transformation. The corresponding experimental results of nonlinear MGEPSVM, MLSTSVM and MLSPTSVM on these four large datasets are reported in Table 7. From Table 7, we find that nonlinear MLSPTSVM also handle large datasets well while with acceptable computational time. For example, for Pendigis dataset, nonlinear MLSPTSVM gains as high as 98.42 % accuracy compared with 90.55 % for linear MLSPTSVM, but with 1.56(s) computational time. The phenomena further confirms the ability of our MLSPTSVM to deal with large scale datasets. Besides, nonlinear MLSPTSVM can obtain comparable classification accuracy with MLSTSVM, while these two methods outperform MGEPSVM to a large extent.
4.4 Parameters analysis
Linear MLSPTSVM contains two sets of penalty parameters \(c_i\) and \(v_i\), \(i = 1,2,\ldots ,K\), which are needed to be selected independently. Moreover, the number of projection axes is also considered as a parameter. In this subsection, we analyze the influence of these parameters to the performance of our MLSPTSVM on four large datasets, i.e., Page-blocks, USPS, Pendigits and Shuttle, respectively. For convenience, we use the same \(c_i\) and \(v_i\) for each \(i = 1,2,\ldots ,K\), that is, \(c_i\) = c and \(v_i\) = v for some c and v.
We first consider the effect of parameters c and v on the test accuracy, which is shown in Fig. 5. Here, the grid search method is employed, and the corresponding accuracy is obtained under the optimal number of projection axes, while parameters c and v are changing within the set \(\{2^{-8},\ldots ,2^{8}\}\). From Fig. 5, we observe that the accuracy varies greatly along with the change of parameters c and v, which implies that c and v have a great impact on the classification accuracy. Thus, to achieve better performance, it is necessary to select the suitable parameters c and v.

Relationship between parameters c, v and classification accuracy
We next depict the relationship between the number of projection axes and classification accuracy in Fig. 6. Here, the number of projection axes is selected from 1 to 8. As we can see from Fig. 6, multiple orthogonal projection axes are required for the four datasets in order to reach higher accuracy, and for different datasets, the optimal number of projection axes varies. For example, USPS dataset needs six projection axes while Shuttle dataset only needs two. However, it should be noted that sometimes one projection axis is enough for MLSPTSVM, as we can observe in Tables 3 and 4. This shows that on one hand, multiple orthogonal projection axes may necessary for some datasets; on the other hand, for some datasets, redundant projection axes may bring confused classification information [40]. Moreover, by observing Fig. 6, we see that with the increase of the number of projection axes, the accuracy increases until it is up to a maximum, and then decreases in general, although there may be some specifications as in Fig. 6a. In summary, a proper number of projection axes can improve the performance of MLSPTSVM to a much extent.

Relationship between the numbers of projection axes and classification accuracy
For nonlinear MLSPTSVM, the kernel parameter p needs to be considered. We next show the relationship between kernel parameter p and classification accuracy on four UCI datasets in Table 2, i.e., Seeds, Dermatology, Wine, and Pathbased. We draw the parameter-accuracy curves in Fig. 7 on these four datasets with parameter p belonging to \(\{2^{-8},\ldots ,2^{8}\}\). Here, each accuracy is obtained under the optimal parameters c, v and the number of projection axes. From Fig. 7, we can see that kernel parameter p has a great influence on classification accuracy. For example, for dataset Wine, the lowest accuracy is 38.12 % while the highest one can reach to 100 %. Thus, a suitable kernel parameter is crucial for nonlinear MLSPTSVM to achieve better performance.

Relationship between the kernel parameter and classification accuracy
5 Conclusions
In this paper, a novel multiple least squares recursive projection twin support vector machine for multi-class classification is proposed, termed as MLSPTSVM. For K classes classification problem, our MLSPTSVM solves K groups of primal problems directly by solving a series of linear equations, which leads to its fast training speed. A recursive procure is further introduced to MLSPTSVM to generate multiple projection directions. Preliminary experimental results show that our MLSPTSVM has comparable classification accuracy with MPTSVM but with dramatically less computing time. Besides, experiments on some large datasets further demonstrate the effectiveness of our MLSPTSVM. For practical convenience, we upload our MLSPTSVM MATLAB code upon http://www.optimal-group.org/Resource/MLSPTSVM.html. As we know, extracting features is crucial for classification, especially when faced with high-dimensional data. Thus, exploring effective feature selection/extraction methods to improve the performance of MLSPTSVM will be one of our future works.
References
Cortes C, Vapnik V (1995) Support vector networks. Mach Learn 20(3):273–297
Burges C (1998) A tutorial on support vector machines for pattern recognition. Data Min Knowl Discov 2:121–167
Noble W (2004) Support vector machine applications in computational biology. In: Schöelkopf B, Tsuda K, Vert J-P (eds) Kernel methods in computational biology. MIT Press, Cambridge, pp 71–92
Li Y, Shao Y, Jing L, Deng N (2011) An efficient support vector machine approach for identifying protein s-nitrosylation sites. Protein Pept Lett 18(6):573–587
Li Y, Shao Y, Deng N (2011) Improved prediction of palmitoylation sites using PWMs and SVM. Protein Pept Lett 18(2):186–193(8)
Vapnik V (1998) Statistical learning theory. Wiley, New York
Suykens J, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9(3):293–300
Fung G, Mangasarian O (2005) Multicategory proximal support vector machine classifiers. Mach Learn 59:77–97
Mangasarian O, Wild E (2006) Multisurface proximal support vector classification via generalize eigenvalues. IEEE Trans Pattern Anal Mach Intell 28(1):69–74
Jayadeva R, Khemchandani R, Chandra S (2007) Twin support vector machines for pattern classification. IEEE Trans Pattern Anal Mach Intell 29(5):905–910
Qi Z, Tian Y, Shi Y (2015) Successive overrelaxation for laplacian support vector machine. IEEE Trans Neural Netw Learn Syst 26(4):674–683
Tanveer M (2015) Robust and sparse linear programming twin support vector machines. Cogn Comput 7(1):137–149
Shao Y, Deng N, Chen W, Wang Z (2013) Improved generalized eigenvalue proximal support vector machine. IEEE Signal Process Lett 20(3):213–216
Kumar M, Gopal M (2009) Least squares twin support vector machines for pattern classification. Expert Syst Appl 36(4):7535–7543
Shao Y, Zhang C, Wang X, Deng N (2011) Improvements on twin support vector machines. IEEE Trans Neural Netw 22(6):962–968
Shao Y, Deng N (2012) A coordinate descent margin based-twin support vector machine for classification. Neural Netw 25:114–121
Qi Z, Tian Y, Shi Y (2012) Laplacian twin support vector machine for semi-supervised classification. Neural Netw 35:46–53
Shao Y, Chen W, Deng NY (2014) Nonparallel hyperplane support vector machine for binary classification problems. Inf Sci 263(1):22–35
Tian Y, Qi Z, Ju X (2014) Nonparallel support vector machine for pattern classification. IEEE Trans Cybern 44(7):1067–1079
Wang Z, Shao Y, Bai L, Deng N (2014) Twin support vector machine for clustering. IEEE Trans Neural Netw Learn Syst. doi:10.1109/TNNLS.2014.2379930
Ye Q, Zhao C, Ye N, Chen Y (2010) Multi-weight vector projection support vector machines. Pattern Recognit Lett 31(13):2006–2011
Chen X, Yang J, Ye Q, Liang J (2011) Recursive projection twin support vector machine via within-class variance minimization. Pattern Recognit 44(10):2643–2655
Shao Y, Wang Z, Chen W, Deng N (2013) A regularization for the projection twin support vector machine. Knowl-Based Syst 37:203–210
Shao Y, Deng N, Yang Z (2012) Least squares recursive projection twin support vector machine for classification. Pattern Recognit 45(6):2299–2307
Weston J, Watkins C (1998) Multi-class support vector machines. Technical report CSD-TR-98-04
Schwenker F (2000) Hierarchical support vector machines for multi-class pattern recognition. In: Fourth international conference on knowledge-based intelligent information engineering systems & allied technologies, vol 2, pp 561–565
Lee Y, Lin Y, Wahba G (2004) Multicategory support vector machines: theory and application to the classification of microarray data and satellite radiance data. J Am Stat Assoc 99(465):67–81
Yang Z, Shao Y, Zhang X (2013) Multiple birth support vector machine for multi-class classification. Neural Comput Appl 22(1Suppl):153–161
Li C, Huang Y, Wu H, Shao Y, Yang Z (2014) Multiple recursive projection twin support vector machine for multi-class classification. Int J Mach Learn Cybern. doi:10.1007/s13042-014-0289-2
Golub G, Van Loan C (1996) Matrix computations, 3rd edn. Johns Hopkins University Press, Baltimore
Belhumeur P, Hespanha J, Kriegman D (1997) Eigenfaces vs. fisherfaces: recognition using class specific linear projection. IEEE Trans Pattern Anal Mach Intell 19(7):711–720
Yang J (2003) Why can LDA be performed in PCA transformed space? Pattern Recognit 36(2):563–566
Bishop C (2006) Pattern recognition and machine learning. Springer, New York
Tao Q, Chu D, Wang J (2008) Recursive support vector machines for dimensionality reduction. IEEE Trans Neural Netw 19(1):189–193
Lee YJ, Mangasarian O (2001) RSVM: reduced support vector machines. Technical report 00-07. Data Mining Institute, Computer Sciences Department, University of Wisconsin, Madison (2001)
Blake C, Merz C (1998) UCI repository for machine learning databases. http://www.ics.uci.edu/mlearn/MLRepository.html
Chang C, Lin C (2011) LIBSVM: a library for support vector machines. http://www.csie.ntu.edu.tw/cjlin/libsvmtools/datasets
Chang C, Lin C (2011) LIBSVM : a library for support vector machines. ACM Trans Intell Syst Technol 2(27):1–27
Duda R, Hart P, Stork D (2012) Pattern classification, 2nd edn. Wiley, New York
Jin Z, Yang J, Hu Z, Lou Z (2001) Face recognition based on the uncorrelated discriminant transformation. Pattern Recognit 34:1405–1416
Acknowledgments
The authors would like to thank the editors and reviewers for their valuable comments and helpful suggestions, which improved the quality of this paper. This work is supported by the National Natural Science Foundation of China (Nos. 11201426, 11371365, 11426202 and 11426200), the Zhejiang Provincial Natural Science Foundation of China (Nos. LQ12A01020, LQ13F030010, LY15F030013, and LQ14G010004), the Ministry of Education, Humanities and Social Sciences Research Project of China (No. 13YJC910011) and the Science Foundation of Chongqing Municipal Commission of Science and Technology (Grant No. CSTC201 4jcyjA40011) and Scientific and Technological Research Program of Chongqing Municipal Education Commission (Grant No. KJ1400513).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yang, ZM., Wu, HJ., Li, CN. et al. Least squares recursive projection twin support vector machine for multi-class classification. Int. J. Mach. Learn. & Cyber. 7, 411–426 (2016). https://doi.org/10.1007/s13042-015-0394-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-015-0394-x