
Abstract
Taking uncertainties of threats and vehicles’ motions and observations into account, the challenge we have to face is how to plan a safe path online in uncertain and dynamic environments. We construct the static threat (ST) model based on an intuitionistic fuzzy set (A-IFS) to deal with the uncertainty of a environmental threat. The problem of avoiding a dynamic threat (DT) is formulated as a pursuit-evasion game. A reachability set (RS) estimator of an uncertain DT is constructed by combining the motion prediction with a RRT-based method. An online path planning framework is proposed by integrating a sub goal selector, a sub tasks allocator and a local path planner. The selector and allocator are presented to accelerate the path searching process. Dynamic domain rapidly-exploring random tree (DDRRT) is combined with the linear quadratic Gaussian motion planning (LQG-MP) method when searching local paths under threats and uncertainties. The path that has been searched is further improved by using a safety adjustment method and the RRT* method in the planning system. The results of Mont Carlo simulations indicate that the proposed algorithm behaves well in planning safe paths online in uncertain and hostile environments.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
UAVs often plan paths online in the low altitude to avoid threats by the masking of obstacles to threats in missions, e.g., anti-terrorist, motivating this study. A planner is also required to deal with uncertainties to further improve its abilities of avoiding threats and obstacles. In summary, online planning a path under uncertainties, complicated threats, dense obstacles and multi-constraints, becomes a practical challenge [1–8].
The computational time of the discretization methods grows exponentially as the problem dimensions increase [1–3, 9–11]. The randomized RRT plans possible paths to the goal by growing a path tree, under the guidance of random samples in the planning space [1–3]. It is not nearly encumbered by the dimensions and complexity of a planning problem because its execution is independent of the environment [1–3, 12]. It checks constraints expediently [2]. It can be promoted by problem-specific heuristics [13, 14]. DDRRT is chosen to be the basis of our planning algorithm because it is efficient in obstacle-complex environments [15, 16]. The RRT-based estimators have advantages in both accuracy and efficiency when predicting the long-term possible DT paths under uncertain and limited information [17]. Thus, we propose a RRT-based RS estimation method with the consideration of the DT intention.
Uncertainties are inherent to the path planning problem. The methods, e.g., “relocalization”, “landmark” and partially observable Markov decision processes, etc., useful for robot navigation under uncertainties, are difficult to be utilized online because of the heavy computational overheads [18]. Inspired by the simultaneous localization and mapping method [19], the works of path planning and uncertainties processing are executed simultaneously.
An environmental threat is constructed by a ST model and a motion model. Two traditional methods are often applied to construct the ST model. One regards a threat area to be impassable, simplifying the threat excessively. The other method utilizes a probabilistic model. Albeit it is practicable, it is coarse because the complicated model parameters cannot be considered thoroughly and accurately [5]. Besides, the probabilistic model has no special mechanism for expressing the uncertainty of a threat. Therefore, the A-IFS based ST model is constructed. Threats can be mainly classified into two groups, i.e., ST and DT. The difference between them is that DT has a motion model while ST does not have. Thus, ST is a subcase of the more general DT.
1.1 Dealing with uncertainties
Huynh et al. [20] proposed the “information constrained” linear quadratic Gaussian (icLQG) motion planning method to control a vehicle under imperfect information. An initial plan, including waypoints and the sensing utilities at the waypoints, is approximated first. Then feedback control inputs are iteratively computed to locally optimize the plan in the space of distributions over position, that is, in information space.
Van den Berg et al. [21] proposed the LQG-MP method to deal with the uncertainties of the motion and observation of a vehicle. They approximate the non-linear models of the motion and observation by a local linearization using the first-order Taylor expansion. Then the apriori probabilistic distributions of vehicle states are estimated by a linear quadratic regulator and the Kalman filter under Gaussian noises. During the estimation, the regulator provides online feedback control inputs for the Kalman filter which predicts the distributions of vehicle states. When generating paths, the linear quadratic Gaussian controller is applied as an optimizer. Finally, a set of candidate paths are created by RRT, and the best path is selected by the estimated distributions of vehicle states on waypoints. LQG-MP is a useful approach for planning a path under uncertainties. But the candidate paths are difficult to be calculated online because of the heavy computational overhead.
Based on the studies of [21–23], Jaillet et al. [24] presented the environment-guided RRT for dynamic and uncertain robot systems. The costs on waypoints are calculated by a LQG-MP based cost model.
Melchior et al. [25] raised the particle-RRT that extends a tree node multiple times according to the likely environmental conditions to decrease the environmental uncertainty. The newly generated nodes are regarded as particles. The likelihoods of particles are calculated by the distribution of the environmental conditions. Then particles are grouped to create waypoints and the highly likely paths are acquired. But the method is computational-complex.
Pepy et al. [26] regarded an uncertain configuration as a spheroid centering at the estimated configuration, shaped by the state distribution at the configuration. Burns et al. [27] applied the Bernoullian utility to calculate the path cost, to minimize the environmental uncertainty on a roadmap. Fraichard et al. [28] took both uncertainties and non-holonomic constraints into account when planning a path. Guibas et al. [29] evaluated the collision probability bounds on vertexes of a roadmap by the environmental uncertainty.
1.2 Threat assessment
Hanson et al. [30] created ST models by the fuzzy logic theory and assessed threats by the belief network. But the method is too complex to be utilized online. Kabamba et al. [31] constructed the probabilistic models of radar and missile.
Aoude and his colleague discussed the RS of DT is hard to be predicted by the traditional probabilistic methods when the DT motion is uncertain, flexible and intelligent without a long-term tendency [17]. Thus, they proposed the more suitable RRT-based estimators in [17, 32–36].
Reference [33] presented the RRT-Reach method to estimate the RS of an uncertain DT. RRT-Reach operates in two modes, i.e., exploration and pursuit. It operates as RRT in the exploration mode and as the greedy RRT in the pursuit mode. The Gaussian process is applied to predict the DT motion patterns to guide the sampling process in the pursuit mode. The DT avoidance problem is modeled as a pursuit-evasion game in the zero-sum differential game theory in [34]. The works’ background is the intelligent transportation.
According to the traditional DT avoidance method based on the No-Fly Zone (NFZ) approach, if the occupied situation of a planning space by DT is identified, UAV will detour from the occupied spaces, as references [4, 37, 38] discuss. However, sometimes the threat areas is difficult to be avoided totally.
Karaman et al. [39, 40] proposed the RRT* method to find an asymptotic optimal path. The RRT* method firstly finds a path randomly. Then it replans and optimizes the path gradually by excluding non-optimal solutions. We regard the threats avoidance problem as an optimization problem. Thus, RRT* is directly reimplemented to plan a path under threats. However, the optimization process of RRT* is so slow that it may not be finished before the constraint time.
1.3 Assumptions and paper organization
We propose three background assumptions. a. UAV cannot avoid threats by simply increasing its speed or height. b. DT is a ground vehicle, which can adjust its path flexibly and intelligently with an intention of intercepting UAV. c. DT has the perfect knowledge of the UAV path planning.
The study is organized as follows. §2 describes the research problems mathematically. §3 proposes the threat assessment method. §4 offers an online path planning algorithm with the implementation and analysis. In §5, our simulation results are provided and discussed. In §6, conclusions are drawn.
2 Problem description
2.1 Online path planning under limited and uncertain information
We consider the following uncertainties. The threats on a possible UAV path are uncertain because they are also decided by the real-time UAV states. The threat information outside UAV Sensing Horizons (SHs) is unknown. The motions and observations of UAV and DT are uncertain. This is the first study which deals with the threats avoidance problem online under uncertainties.
The available information (\(I_{t}\)) includes: the distributions of UAV states calculated by the LQG-MP method; all observations (\(o\)) and states (\(s\)) at the time up to and including the present time (\(t\)); the past control inputs (\(u \subseteq U\)) before \(t\) where \(U\) is the set of allowable control inputs. The planning result is a feedback control sequence that can minimize the expected cost on a path from the start time 0 to an unspecific end time (\(T\)). The planning objective is similar to that in [20], expressed as: \(\min \limits _{U} \mathrm{C_{u}}(I_{t})=\min \limits _{U} \mathrm{E}\left[ \int _{0}^{T}l(t,s_{t},u(t,I_{t})dt|I_{t}\right]\) where \(l(t,s,u)\) denotes the instantaneous cost of the control input \(u_{t}\) at \(t\).
The continuous planning can hardly be finished online. Hence, it is approximated by a discrete-time model: \(\min \limits _{U} \mathrm{C_{u}}(I_{k})=\min \limits _{U} \mathrm{E}\left[ \sum \limits ^{N}_{k=0}l_{k}(s_{k},u_{k})|I_{k}\right]\). \(N\) is the number of time steps, \(N=T/\tau\). \(\tau\) is the duration of one control time step.
2.2 UAV motion model and dynamic constraints
The equations of motion and observation of UAV are defined as follows:
The UAV state vector \(s\) is defined as \(\left[ x,y,z,\theta ,\varphi ,v\right] ^\mathrm{T}\) where [\(x\), \(y\), \(z\)] denotes a location of UAV, \(\theta\) and \(\varphi\) denote the yaw angle and pitch angle respectively, \(v \subseteq [\mathrm{v_{min}}, \mathrm{v_{max}}]\) denotes a velocity. The control input \(u = (a_{v},\omega _{\theta }, \omega _{\varphi })\) incorporates an acceleration (\(a_{v}\)), a yaw steering (\(\omega _{\theta }\)) and a pitching motion (\(\omega _{\varphi }\)). \(u\) is corrupted by the process noise \(m = \left( \tilde{a}_{v}, \tilde{\omega }_{\theta },\tilde{\omega }_{\varphi }\right) \sim \mathrm{N}\left( 0, \begin{bmatrix} \sigma _{a_{v}}^{2}&0&0 \\ 0&\sigma _{\omega _{\theta }}^{2}&0\\ 0&0&\sigma _{\omega _{\varphi }}^{2} \end{bmatrix} \right)\). The turning radius (\(r\)) is bounded by the minimum turning radius, \(r \ge \mathrm{r_{min}}\). The straight path length (\(sl\)) before turning is bounded by \(\mathrm{sl_{min}}\), \(sl\ge \mathrm{sl_{min}}\).
\(\mathrm{h}(s, n)\) is the observation equation. \(\bar{x} = x_{k} - x_{k-1}\), \(\bar{y}=y_{k}-y_{k-1}\), \(\bar{z}=z_{k}-z_{k-1}\). The observation noise \(n=\left( \tilde{x}, \tilde{y}, \tilde{z}, \tilde{\theta }, \tilde{\varphi }\right)\) \(\sim \mathrm{N}\left( 0, \begin{bmatrix} \sigma _{x}^{2}&0&0&0&0\\ 0&\sigma _{y}^{2}&0&0&0\\ 0&0&\sigma _{z}^{2}&0&0\\0&0&0&\sigma _{\theta }^{2}&0\\0&0&0&0&\sigma _{\varphi }^{2}\end{bmatrix}\right)\).
Dynamic constraints often arise from the set of control inputs [1–3]. They restrict the allowable velocities at each waypoint on a path. Since the constraints are complicated, the state transitions via control inputs are often difficult to be parameterized. However, the RRT-based methods can directly handle the constraints by the piecewise constraint-checking approach. A path tree extension can be executed only if it satisfies all constraints. Thus, all the sub paths or branches on the path tree are surely feasible.
2.3 Dynamic threat avoidance
The DT avoidance problem is formulated as a zero-sum differential game with multi-constraints, free final time and perfect UAV path planning information. The formulation derives from [41, 42]. Let \(t_{f}\) be the estimated earliest time DT threatens UAV. \(t_{f}=+\infty\) indicates that UAV can reach goal without DT threat. \(t_{f}=0\) means DT has already threatened UAV. UAV aims to maximize \(t_{f}\) while DT aims to minimize \(t_{f}\). We assume that only one DT and one UAV participate in the game (\(G\)) to clearly describe the DT avoidance problem. \(G\) terminates when UAV reaches goal with a practical safe and feasible path.
Let the subscript 1 and 2 denote DT and UAV respectively. The payoff function of \(G\) is expressed as \(\mathrm{J}(s_{t},u_{t},t)=t_{f}\) where \(s_{t}\subseteq S\) denotes the state of DT or UAV at the time \(t\), \(u_{t}\subseteq U\) is the control input of DT or UAV with constraints. We suppose that \(G\) admits a saddle point \((\gamma _{1}^{*},\gamma _{2}^{*})\subseteq U_{1}\times U_{2}\) in the set of feedback control inputs. If both players execute that control strategy, the optimal payoff function value is \(\mathrm{J}(s_{t},t)^{*}=\max \limits _{r_{2}^{*}\subseteq U_{2}}\min \limits _{r_{1}^{*}\subseteq U_{1}}\{\mathrm{J}(s_{t},u_{t},t)\}\).
We cannot consider the full set of control inputs of DT and UAV online due to the high computational overhead. Thus, the feasible sets of control inputs \(\tilde{U}_{1} \subseteq U_{1}\) and \(\tilde{U}_{2} \subseteq U_{2}\) are approximated. The objective payoff function value is approximate by a practical one: \(\tilde{\mathrm{J}}(s_{t},t)^{*}=\max \limits _{r_{2}^{*}\subseteq \tilde{U}_{2}}\min \limits _{r_{1}^{*}\subseteq \tilde{U}_{1}}\{\mathrm{J}(s_{t},u_{t},t)\}\).
3 Threat assessment
3.1 Static threat model construction
We construct the ST model based on A-IFS to deal with the uncertainty of a threat. A-IFS is characterized by a membership function, a non-membership function and a hesitancy function [43]. It deals with the vagueness flexibly according to the human empirical knowledge. It also helps to extract more information from data. It provides plenty of rules and aggregation operators to quantize and aggregate information without any loss [43].
Let \(X\) be a fixed set. The A-IFS \(A\) in \(X\) is defined as: \(A\) is a nonempty set, \(A=\{\langle a, \mu (a), v(a)\rangle | a \subseteq X \}\), \(\mu (a)\) and \(v(a)\) are the functions of membership and non-membership of \(A\), \({\mu (a)}: X\rightarrow [0,1]\), \(a\subseteq X \rightarrow \mu (a)\subseteq [0,1]\), \(v(a): X\rightarrow [0,1]\), \(a\subseteq X \rightarrow v(a)\subseteq [0,1]\), \(\mu (a)+v_{A}(a) \le 1\). \(\pi (a)=1-\mu (a)-v(a)\) is the hesitancy degree of \(a\) to \(A\) or the intuitionistic index of \(a\) in \(A\).
The membership function is defined as the active threat function of a threat. The nonmembership function is defined as the threat-free function of UAV according to the real-time states of UAV. Moreover, a certainty function is proposed to deal with the uncertainty of a threat.
We take radar for an example to describe the processes of the ST model construction and threats avoidance. The height of the radar detection boundary \(h_{B}=\mathrm{K_{R}}\cdot L^{2}\). \(\mathrm{K_{R}}\) is the radar characteristic coefficient. \(L\) is the horizontal distance from the radar center. The area below \(h_{B}\) is termed as the radar blind spot [44] which can be utilized by UAV. The static model of DT is the same as the radar model except its \(h_{B}\) is set to be zero. The radar membership function is defined according to a basic damage probabilistic model in [44], as:
where \(R\) denotes the radial distance from the radar center. \(\mathrm{R_{max}}\) denotes the maximum threat radius. We only consider the threat within the \(\mathrm{R_{max}}\).
UAV can reduce risks by applying strategies, i.e., turning to fly away from threats and increasing its speed. Thus, two parameters are considered in the non-membership function: \(v_{T}\) denotes the speed of UAV, \(\alpha _{T} (0\le \alpha _{T}\le \pi )\) denotes the absolute value of the angle between the direction of the velocity and the line from UAV to the center of a threat. Accordingly, the non-membership function is defined as:
where \(v_{p}\) is the threshold of the UAV penetration speed.
The certainty function of the radar model is defined as:
where \(N_{e}\) denotes the number of threats in which UAV exposes. \(\delta _{q}\) denotes the standard deviation of the UAV state distribution at a candidate waypoint \(q\) estimated by LQG-MP. The weights \(\omega _{N}+\omega _{\delta }=1\). \(\omega _{C}\) aims to bound the influence of \(\mathrm{CF}\) and make \(\mathrm{CF} \le 1\). \(\mathrm{CF}\) is defined to reduce \(N_{e}\) and \(\delta _{q}\) to decrease the threat and increase the control certainty on a path.
We weight \(\left[ \mathrm{\mu _{D}}(a), \mathrm{V_{D}}(a)\right]\)as: \(\left[ \mathrm{\mu _{D}}^{'}(a), \mathrm{V_{D}}^{'}(a)\right] ^\mathrm{T}=\mathrm{CF}(a) \cdot \left[ \mathrm{\mu _{D}}(a), \mathrm{V_{D}}(a)\right] ^\mathrm{T}\). We make conservative assessment of a threat to promote the safety of a path, i.e., \(\mathrm{\mu _{D}^{'}}(a)\) has a priority over \(\mathrm{V_{D}^{'}}(a)\). If \(\mathrm{\mu _{D}^{'}}(a) = 1 \,or\, 0\), set \(\mathrm{V_{D}^{'}}(a) = 0\). If \(\mathrm{\mu _{D}^{'}}(a) + \mathrm{V_{D}^{'}}(a) > 1\), a normalization is executed to make \(\mathrm{\mu _{D}^{'}}(a) + \mathrm{V_{D}^{'}}(a)= 1\). The score function of A-IFS is employed to calculate the threat level of \(a\), i.e., \(\mathrm{Tl}(a)=\mathrm{\mu _{D}}(a)- \mathrm{V_{D}}(a)\), if \(\mathrm{V_{D}}(a) > \mathrm{\mu _{D}}(a)\), set \(\mathrm{Tl}(a) = 0\). If the threat levels of two threats are equal, the threat with the bigger \(\mathrm{CF}\) value is more dangerous.
3.2 Reachability set estimation
The DT assessment is the same as the ST assessment given the RS. The RS estimation incorporates the processes of motion prediction and RS searching. The DT motion predictions are applied to guide the path searching process.
3.2.1 Dynamic threat motion prediction
The particle filter (PF) [45] is utilized for the DT motion prediction. The equations of the states transition and the observation of DT are defined as:
A DT state is denoted by \(s= [x, \dot{x}, y, \dot{y} ]^\mathrm{T}\) where \([x,y]\) denotes a position, \(\dot{x}\) and \(\dot{y}\) denote the velocities in the \(x\) and \(y\) directions, respectively. \(\omega _{k}\) and \(\upsilon _{k}\) are white Gaussian noises, \(\omega _{k} = \begin{bmatrix} \omega _{xk}\\ \omega _{yk} \end{bmatrix}\sim \mathrm{N}\left( 0,\begin{bmatrix} \sigma _{\omega _{x}}^{2}&0\\ 0&\sigma _{\omega _{y}}^{2}\end{bmatrix}\right)\), \(\upsilon _{k} \sim \mathrm{N}(0, 1)\).
PF estimates the distributions of the DT states by approximating the discrete positions and weights of particles. The PF iteration is as follows.
-
1.
A set of initial particles \(\{p_{0}^{i}\}^{N_{s}}_{i=1}\) are randomly and uniformly sampled around the initial DT position. The weights of particles are set to be \(1/N_{s}\).
-
2.
The particles \(\{p_{k}^{i}\}^{N_{s}}_{i=1}\) in the \(k\)th time step are predicted from \(\{p_{k-1}^{i}\}^{N_{s}}_{i=1}\) by the states transition equation. Their weights \(\{\omega _{k}^{i}\}^{N_{s}}_{i=1}\) are calculated subject to \(\{\omega _{k}^{i}\}^{N_{s}}_{i=1}=\{\omega _{k-1}^{i}\}^{N_{s}}_{i=1}\mathrm{L}(o_{k}'|s_{k})\). \(\mathrm{L}(o_{k}'|s_{k})\) is the likelihood function reflecting the similarity between \(s_{k}\) and the actual observation \(o_{k}'\). We express the observation function by \(o_{k}=\mathrm{H}s_{k}+\mathrm{Q}v_{k}\). Then we calculate the weights of the particles in the \(k\)th iteration by \(p(w_{k}^{i})= \frac{1}{2\pi \sqrt{\det (\mathrm{Q})}}e^{-(o_{k}'-\mathrm{H}s_{k})^\mathrm{T}\mathrm{Q^{-1}}(o_{k}'-\mathrm{H}s_{k})}\) where \(\det (\mathrm{Q})\) is the determinant of \(\mathrm{Q}\).
-
3.
The weights are normalized. New particles are generated by “resampling” from the obtained particles to avoid the particle degeneration. The DT state is predicted by the mean of the resampled particles. Go back to step 2.
In the resampling process, the particles with higher weights or higher probabilities to be corrected have higher probabilities to be kept. The iteration is as follows. Firstly, a uniformly and randomly distributing number \(\xi _{i}\in [0,1]\) is created. Then the first particle with the cumulative weights \(a_{\omega _{j}}\ge \xi _{i}\), \(a_{\omega _{j}} = \omega _{1}+\omega _{2}+\ldots +\omega _{j}\) is returned. The loop is executed \(N_{s}\) times to make \(N_{s}\) new particles.

DT path tree updating by the guidance of a new observation
3.2.2 Reachability set searching
The RS of an uncertain DT is searched by the RRT-based method under imperfect motion data. A time stamp (TS) is explicitly added on each node of the DT or UAV path trees as a kind of time heuristics. A TS is the predicted earliest time of a vehicle arriving at a tree node based on the Dubins distance. TS helps our method to identify low time paths and approximate a more realistic RS as well as combining a path with time.
Figure 1 shows the DT path tree (\(TTree\)) updating by the guidance of a new observation. The crosses denote the observed positions of DT. The blue points denote the particles in PF. The red dotted line denotes a predict DT path. The root of \(TTree\) is relocated to the new observation. An extension is made from the new \(TTree\) root along the predicted path. A new \(TTree\) node \(TNode_{new}\) is created as the unique child of the root. The outdated nodes of which the TSs are less than or equal to the TS of \(TNode_{new}\) are deleted, so do the relevant edges, as the black nodes and dash-dot lines show. Then we reconnect the remaining parts of \(TTree\) through \(TNode_{new}\) and update the TSs of all the \(TTree\) nodes.

Interpretation of DT being reachable to \(q_{i}\)
A reachable node is defined as a UAV path tree (\(PathTree\)) node that DT can reach by a possible path. Fig. 2 shows the interpretation of DT reached \(q_{i}\). The red-node and blue-node trees denote \(TTree\) and \(PathTree\), respectively. We check whether DT is reachable to \(q_{i}\) through \(TNode_{j}\) as follows.
-
1.
The horizontal projection point (\(\mathrm{HP}(q_{i})\)) of \(q_{i}\) is computed. The horizontal boundary (\(\mathrm{TB}(q_{i})\)) of the DT threat around \(\mathrm{HP}(q_{i})\) is calculated depending on the maximum threat radius (\(\mathrm{RD_{max}}\)) of the static DT model.
-
2.
We search for a point \(q_{B}\) on \(\mathrm{TB}(q_{i})\), satisfying: \(q_{B}\) is a point on \(\mathrm{TB}(q_{i})\); the line between \(q_{B}\) and \(q_{i}\) is obstacle-free; the line between \(TNode_{j}\) and \(q_{B}\) is obstacle-free; the estimated time DT reached \(q_{B}\) is less than the TS of \(q_{i}\).
DT is reachable to \(q_{i}\) through \(TNode_{j}\) if such \(q_{B}\) is found. If DT is reachable to \(q_{i}\), it may also threaten the neighbors of \(q_{i}\). Thus, the estimator continues searching for reachable nodes among the neighbors on the UAV path tree. We call \(q_{i}\) as the directly DT reachable node, the reachable neighbors as the indirectly reachable nodes. The estimated shortest distances between DT and its reachable nodes are computed to assess the DT threats on the nodes.

RS searching operators with target-bias based on RRT
We extend four RRT-based RS searching operators to rapidly approximate the RS. Each possible DT path on its path tree is regarded as a possible DT motion pattern or strategy. Fig. 3 shows the four target-bias operators. “goal-bias-connect” is the sub operator of the other three operators. “multi-reach” is the sub operator of “multi-connect”. The dotted lines denote the pursuit directions of \(TTree\) nodes to \(PathTree\) nodes.
“Connect” and “Greedy-Connect” are two basic RRT extension operators. \(\mathrm{Connect}(Tree, q_{n}, q_{s})\) extends \(q_{n}\) one step further to \(q_{s}\). The extension function is \((u, q_{new}, e_{new}) = \mathrm{Extend}(q_{n}, le, q_{s}, U)\) where \(q_{new}\) and \(e_{new}\) are the newly created tree node and branch, respectively. \(u \in U\) is the control input on \(e_{new}\), \(le\) is the length of the extension. \(\mathrm{Greedy-Connect}(Tree, q_{n}, q_{s})\) extends \(q_{n}\) steps towards \(q_{s}\) by “Connect” greedily, until the extension reaches \(q_{s}\) or the extension is blocked by obstacles.
-
1.
\(\mathrm{goal-bias-connect}(q_{i}, TNode_{j}, TTree)\) is executed as follows. If DT is reachable to a \(PathTree\) node (\(q_{i}\)) through \(q_{i}\)’s nearest \(TTree\) node (\(TNode_{j}\)), then \(\mathrm{Greedy-Connect}(TTree, TNode_{j}, q_{B})\) is executed. \(q_{B}\) is the same as that in Fig. 2. The indirectly reachable nodes is searched among the neighbors of \(q_{i}\) on \(PathTree\). Otherwise, \(\mathrm{Connect}(TTree, TNode_{j}, q_{B})\) is used to explore the planning space.
-
2.
In \(\mathrm{reach}(q_{i}, TTree)\), the k-near \(TTree\) nodes (\(TNode_{j}, 1\le j \le k\)) of \(q_{i}\) are found and sorted by their TSs. \(\mathrm{goal-bias-connect}(q_{i}, TNode_{j}, TTree)\) are executed in turn until \(TTree\) reaches \(q_{i}\) by an extension or all \(TNode_{j}\) have been tried. Fig. 3 is an illustration when \(k=3\).
-
3.
In \(\mathrm{multi-reach}(TNode_{j}, PathTree, TTree)\), the k-near \(PathTree\) nodes (\(q_{i}, 1\le i \le k\)) of a \(TTree\) node (\(TNode_{j}\)) are found and sorted by their TSs. Then, \(\mathrm{goal-bias-connect}(q_{i}, TNode_{j}, TTree)\) are executed in turn until a \(q_{i}\) is reached by DT or no \(q_{i}\) is reachable. The operator aims to increase the probability of capturing reachable nodes through a \(TTree\) node.
-
4.
\(\mathrm{multi-connect}(q_{s}, TTree, PathTree)\) is designed to enlarge RS and keep the diversity of RS by the guidance of random samples. It executes in two steps, i.e., exploration and pursuit. In the exploration step, a random sample \(q_{s}\) is generated and the k-near \(TTree\) nodes (\(TNode_{j}\, 1\le j \le k\)) of \(q_{s}\) are found and sorted by the TSs, then \(\mathrm{Connect}(TTree, TNode_{j}, q_{s})\) are executed, as Fig. 3d shows. In the pursuit step, \(\mathrm{multi-reach}(TNode_{j}, PathTree, TTree)\) are executed in turn, until DT is reachable to a \(q_{i}\) or all \(TNode_{j}\) have been tried, as Fig. 3e shows. Fig. 3f shows a possible result of “multi-connect” and \(q_{new}\) is identical with \(q_{B}\). \(\mathrm{RD}_{max}\) and \(\mathrm{HP}(q_{i})\) are the same as those in Fig. 2.
“multi-connect” utilizes “Connect” in the exploration step. “Connect” has the guarantee of probabilistic completeness [1, 2]. Thus, “multi-connect” operator is also probabilistic complete. However, computing the full RS online is computationally complex. Thus, “multi-connect” and “reach” are called randomly subject to a certain probability threshold. “goal-bias-connect” and “multi-reach” do not run independently but being executed as sub operators.
3.3 Threats aggregation
The DT assessment is similar to the ST assessment, given the RS. The threats aggregation is required to both calculate an average threat level and emphasize the roles of high risk threats [43]. Thus, the Intuitionistic Fuzzy Weighted Averaging (IFWA) operator [43] is utilized due to its satisfaction of the requirement. \(\mathrm{IFWA_{\omega }}\left( a_{1},a_{2},\ldots ,a_{n}\right) =\omega _{1}a_{1}\oplus \omega _{2}a_{2}\oplus \ldots \oplus \omega _{n}a_{n}= \left( 1-\prod \limits ^{n}_{i=1}\left( 1-\mu _{a_{i}}\right) ^{\omega _{i}},\prod \limits ^{n}_{i=1}v^{\omega _{i}}_{a_{i}}\right)\) where \(\oplus\) is an A-IFS operator, \(\omega _{i}\) is the weight of a threat \(a_{i}\), \(\sum \limits _{i=1}^{n}\omega _{i}=1\), \(\mu _{a_{i}}\) is the membership degree of \(a_{i}\) and \(v_{a_{i}}\) is the non-membership degree. The reliability of IFWA is also demonstrated because the aggregation of the membership degrees in IFWA is similar to the aggregation of the damaged probabilities of UAV, as formula 3 shows.
where \(P_{k}\) is the damaged probability of UAV after it has exposed in threats for \(k\) times, \(P_{j}\) is the damaged probability of UAV at the \(j\)th exposure.
If UAV has exposed in \(k-1\) threats, the membership degree of the \(k\)th threat will increase to \(\mu _{k}^{'}=1-\left( 1-\mu _{k}\right) \prod \limits ^{k-1}_{i=1}\left( 1-\mu _{i}\right)\) where \(\mu _{i}\) is the membership degree of the \(i\)th threat.
The risk in the threats intersection area is higher than that in the equivalent area of any single threat. We also aggregate the threats in the intersection area by the IFWA operator. The weight of a threat (\(r_{i}\)) in the intersection area is set to be \(1/m_{r}\) where \(m_{r}\) is the number of threats in the area.

Radar threat assessment and safety adjustment
3.3.1 Threats aggregation on a tree node or an edge
Figure 4 shows threats aggregation on a tree node or an edge. The violet dotted circles denote the boundaries of the distributions of UAV states at path tree nodes. We straightly use the result of LQG-MP [21] to calculate the standard variance of the apriori probabilistic distribution of the UAV states at each tree node \(q_{i}\) off-line. A “Threat Boundary” is decided by the maximum threat radius. The membership degree in the red area is biggest and the degree in the dark blue area is smallest. The transition of colors from red to dark blue denotes the decreasing of the degree. This color expression is used in the following figures.
A set of particles \(p_{j}, 1\le j \le m\) (\(m\) = 60) are sampled around a tree node \(q_{i}\), as the violet nodes in Fig. 4. The positions distribution of the particles \(Pos(p_{j})\) \(\sim \mathrm{N}(Pos(q_{i}), \delta _{q_{i}}^{2})\) where \(\delta _{q_{i}}^{2}\) denotes the variance of the UAV state distribution at \(q_{i}\). Each particle \(p_{j}\) is regarded as a likely state of UAV. The threat level at the node \(q_{i}\) is defined as the mean of the threat levels of \(p_{j}\), \(\mathrm{Tl}(q_{i})=\sum \limits ^{m}_{j=1} \omega _{p_{j}} Tl(p_{j})\). The weight \(\omega _{p_{j}}\) is set to be \(1/m\).
The threats on an edge between two adjacent tree nodes are aggregated by \(\frac{1}{le}\int _{\mathrm{\xi }}a(\zeta , s(\zeta ))\mathrm{d_{\xi }}\) where \(le\) is the length of the edge, \(\mathrm{\xi }\) is the function of the edge, \(\zeta\) denotes a point on \(\mathrm{\xi }\), \(\mathrm{d_{\xi }}\) is the unit arc length, \(a(\zeta ,s(\zeta ))\) is the threat at \(\zeta\), \(s(\zeta )\) is the UAV state. The integral is not a Riemann integral because it utilizes “\(\oplus\)” instead of “+”. To relieve the computational overhead, the integral is replaced by a discretization method for the online problem. Fig. 4 shows the threats aggregation on \(edge_{i-1,i}\) between \(q_{i-1}\) and \(q_{i}\). \(edge_{i-1,i}\) is discretized into \(n_{q}\) secondary nodes (\(sq_{j}, 1\le j \le n_{q}\)). The threats on \(q_{i}\) and \(sq_{j}\) are aggregated by IFWA where the weights are set to be 1/\((n_{q}+1)\), \(n_{q}=10\).
4 Online path planning
In an uncertain and dynamic environment, no global path can be immediately generated based on the apriori information [46–48]. Thus, the global planning problem is subdivided into a series of simpler but practical sub tasks according to the real-time feedback information and planning situations.

Model of the online path planning algorithm
4.1 Model of the online path planning algorithm
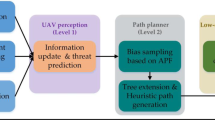
Our planning model mainly incorporates a Threat Assessor (TA) and a Path Planner (PP), as Fig. 5 shows. The distributions of UAV states are estimated by LQG-MP beforehand, to help TA and PP to deal with the uncertainties of the motion and observation of UAV. TA aims to provide quantized results of threats assessment for PP to handle threats. After a local path is searched, a safety adjustment is executed to further reduce the threat on the path. If a global path is found, the path will be optimized in the remaining planning time. The environmental information is updated and provided for TA and PP.
4.2 Sub goal selection
Our sub goal selection is inspired by the work in [48] which selects sub goals by A*. But the predefined sub goals become invalid in an uncertain and dynamic environment. Thus, we select sub goals online according to both the apriori information and the real-time planning situations. We assume: the distribution of obstacles is known; the threat information inside SHs is noise-free. We select sub goals on the boundaries of SHs and plan local paths within SHs.
The heuristic sub goal selection process is shown by formula 4. a. The boundary of the present SH is discretized into 60 points to construct a point set (\(SG\)). b. The obstacle-occupied, high risk and flight-constraints-violated points are removed from \(SG\). If the threat level on a point exceeds a specified threshold (0.5 in this study), the point is regarded as a high risk point. c. The costs \(Cost_{SG}\) of the remaining points are calculated, and the point with the minimum cost is chosen to be the present sub goal (\(SubGoal\)).
\(\mathrm{s.t.} \ \left( SG\subseteq \partial win(Lu)\right) \cap \left( SG - SG_{Obs}- SG_{HR} - SG_{CV}\right)\)
\(Lu\) denotes a UAV location. \(\partial win(Lu)\) denotes the boundary of the present SH centering at \(Lu\). \(SG_{obs}\) denotes the obstacle-occupied points. \(SG_{HR}\) denotes the high risk points. \(SG_{CV}\) denotes the flight-constraints-violated points. If the global goal (\(Goal\)) is inside the present SH, then set \(SubGoal = Goal\).
\(Cost_{SG}\) is defined according to the key idea of the artificial potential field method. We regard obstacles and threats as repulsion forces against path planning and \(SubGoal\)s as attraction forces for path planning. \(Cost_{SG}\) is used to accelerate the path searching process and reduce the threat on a path, as:
where \(C_{\gamma _{k}}\) is the weight and \(\sum \limits _{k=1}^{4} C_{\gamma _{k}} =1\). We denote the line from the end of the last local path \(End_{j}\) to \(SG\) as \(Line_{ETSG}\) and the line from the \(SG\) to \(Goal\) as \(Line_{SGTG}\). \(L_{ETSG}\) and \(L_{SGTG}\) partially reflect the obstacle complexities on \(Line_{ETSG}\) and \(Line_{SGTG}\) respectively. \(N_{R}\) is the number of STs intersecting with \(Line_{ETSG}\). \(R_{i}\) is the maximum threat radius of the \(i\)th ST, \(\omega _{i} = 1/N_{R}\). \(R_{D}\) is the estimated motion radius of DT in the shortest time UAV reached a \(SG\). If the DT threat area does not intersect with \(Line_{ETSG}\), then set \(R_{D} = 0\), otherwise, \(R_{D}=\sqrt{v_{D}(t_{E}+(LL_{ETSG}/v_{uav}))}\) where \(v_{D}\) and \(v_{uav}\) are the present velocities of DT and UAV, respectively, \(t_{E}\) is the earliest time UAV reached \(End_{j}\), \(LL_{ETSG}\) is the length of \(Line_{ETSG}\).
where \(N_{os_{1}}\) is the number of the obstacles on \(Line_{ETSG}\). \(H_{os_{i}}\) is the height of an obstacle on \(Line_{ETSG}\). \(W_{os_{i}}\) is the width of the projection of an obstacle in the vertical direction of \(Line_{ETSG}\). \(L_{\gamma _{k}}\) is the weight, \(\sum \limits _{k=1}^{3}L_{\gamma _{k}}=1\). \(L_{SGTG}=L_{\gamma _{1}}LL_{SGTG}+L_{\gamma _{2}}\sum \limits _{i=1}^{N_{os_{2}}}GH_{os_{i}}+L_{\gamma _{3}}\sum \limits _{i=1}^{N_{os_{2}}}GW_{os_{i}}\) where \(N_{os_{2}}\) is the number of the obstacles on \(Line_{SGTG}\). \(LL_{SGTG}\) is the length of \(Line_{SGTG}\). \(GH_{os_{i}}\) is the height of an obstacle on \(Line_{SGTG}\). \(GW_{os_{i}}\) is the width of the projection of an obstacle in the vertical direction of \(Line_{SGTG}\). The minimum cuboid bounding boxes of obstacles are used to simplify the calculation of \(Cost_{SG}\).

Illustration of sub goals selection and sub tasks allocation
Figure 6 shows the \(SubGoal\)s selection process. A green cross denotes a UAV location when a local planning starts. The circles denote SH boundaries. The blue and red crosses denote the start position and \(Goal\) of the global planning, respectively. A star denotes a \(SubGoal\). Because \(Goal\) is inside the seventh SH, we set \(SubGoal_{7} = Goal\).
4.3 Sub tasks allocation
We improve the online planning frame in [12] for the sub tasks allocation. Time Horizon (TH) is defined as the maximum allocated time for a local planning. TH should be long enough to ensure that most local planning can find a path [12]. The definition of TH should also take the UAV motion into account to ensure that a path is planned before its execution.
A local planning task incorporates the sub tasks of path searching and safety adjustment. If no local path towards the present \(SubGoal\) is found in TH, the sub tasks allocator will reserve the valid intermediate result and start the next iteration based on the intermediate result. \(SubGoal_{4}\) and the dashed-line circle in Fig. 6 show that the fourth local planning does not find a local path towards \(SubGoal_{4}\). In this case, the valid sub path from \(SubGoal_{3}\) to \(End_{4}\) is kept and the fifth iteration is started based on the valid sub path. Our algorithm classifies path tree nodes by their TSs and neglects the nodes outside the present TH to decrease the computational overhead.
If the planning does not time out when \(Goal\) is reached, RRT* will optimize the path in the remaining time. The planning process combines the strategies of optimizing and feeding back. Thus, it has the advantages of both strategies.
4.4 Local path planning
4.4.1 Local path searching
UAV can effectively avoid threats by flying in the low altitude to utilize the radar blind spots and the masking of obstacles. DDRRT is efficient in obstacle-intense environments in the low altitude [15, 16]. If the extension of a node is blocked by obstacles, a dynamic domain (DD) is added to the node to reduce the scope where the node can be extended. This means a sample outside the DD of its nearest tree node is directly deleted. In this way, the sampling space reduction guides DDRRT in refining a path to quickly avoid obstacles. To explicitly deal with threats and uncertainties, we define a novel threat and uncertainty based dynamic domain (TUDD) as follows.
where \(p_{c}(q_{i})\) is the probability that UAV is obstacle-free at \(q_{i}\), weighted by \(k_{c}\). \(p_{c}\) is used to deal with the uncertainties of a vehicle’s motion and observation. \(\mathrm{Tl}(q_{i})\) is the threat level on \(q_{i}\) and \(k_{T}\) is the influence coefficient of \(\mathrm{Tl}(q_{i})\).
Instead of computing \(p_{c}\) exactly, an approximation of \(p_{c}\) is applied to promote the computational efficiency [21, 22]. The approximation is reliable since a \(p_{c}\) is just an indicative probability that a collision is avoided. Computational efficiency is more crucial than the accuracy of \(p_{c}\) during the path searching process. A \(c_{t}\) denotes the number of the standard deviation that UAV can deviate from the candidate path before colliding with an obstacle at a \({q_{i}}\). A \(c_{t}\) is computed by the smallest distance between UAV and obstacles, and the distribution of UAV positions at a \(q_{i}\). The distribution is obtained by LQG-MP off-line. For a \(n\) dimensional multivariate Gaussian distribution of UAV positions, the \(p_{c}\) of UAV at a \(q_{i}\) is approximated by \(\mathrm{\Gamma }(\mathrm{n/2},c_{t}^{2}/2)\) where \(\mathrm{\Gamma }\) is the regularized Gamma distribution function. \(p_{c}\) provides a lower bound of the probability of avoiding a collision at each tree node [21, 22]. The quality (\(Q\)) of a path (\(\mathrm{\Pi }\)) is defined by multiplying the \(p_{c}\) on all the waypionts:
A “GoalZoom” method is applied in the sampling process to promote the path searching ability of DDRRT, especially when large obstacle-free spaces exist. The “GoalZoom” method picks, with a probability (\(P\)), samples in the sphere centered at the \(SubGoal\) with the radius of \(min_{\forall i}\mathrm{D}(q_{i}, SubGoal)\) where “D” denotes the Euclidean distance”, \(q_{i}\) denotes a path tree node [13].
Once a sample (\(q_{s}\)) is created, its k-near tree nodes (\(q_{i}, 1\le i \le k\)) are selected, and the node (\(q_{n}\)) with the minimum cost distance to \(q_{s}\) is chosen. If \(q_{s}\) falls into the TUDD of \(q_{n}\), \(\mathrm{Connect}(Tree, q_{n}, q_{s})\) will be executed. The method helps the tree to select locally optimized extensions. The cost distance between a \(q_{i}\) and \(q_{s}\) is defined as:
where \(D_{\gamma _{i}}\) is the weight and \(\sum \limits _{i=1}^{3}D_{\gamma _{i}}=1\). \(D\) denotes the Euclidean distance. A node’s direction is as crucial as its location. We define it as the direction of its in-edge which ends at the node on the path tree. \(0\le Py\le \pi\) is the sum of the absolute values of angles of elevation and yaw between the directions of \(q_{i}\) and the line from \(q_{i}\) to \(q_{s}\). We define that the angle of elevation will increase the path cost whereas the angle of depression will not. That guides the planner in searching paths in the low altitude. \(Tl_{s}\) is the threat level on the line between \(q_{i}\) and \(q_{s}\), calculated as the threats aggregation on a tree edge.
4.4.2 Safety adjustment
If a path reaches the present \(SubGoal\), the safety adjustment is executed to reduce the threat on the path. As Fig. 4 shows, the red nodes and edges are the adjusted ones. The waypoints \(q_{i}\) on the path are adjusted in turn. As discussed in Sect. 3.3.1, the particles \(p_{j}\) around a tree node \(q_{i}\) have been obtained.
-
1.
The weights \(\omega _{p_{j}}\) of particles \(p_{j}\) are reassigned to be \(\min \left\{ \frac{1}{k_{T}\cdot \mathrm{Tl}(p_{j})}, 1\right\}\) where \(k_{T}\) and \(\mathrm{Tl}(p_{j})\) are the same as those in formula 7.
-
2.
After normalization, the final \(\omega _{p_{j}}\) are obtained. A particle stands for a likely UAV state under a control input. The weights reassignment adds a kind of bias to the possible control inputs to reduce the threat on a path.
-
3.
The new state (\(s\)) of \(q_{i}\) is estimated by \(s(q_{i}^{'}) = \sum \limits _{j=1}^{N_{s}}\omega _{p_{j}}\cdot s(p_{j})\). The new edge is also determined. If the collision probability of \(q_{i}^{'}\) or the new edge exceeds a certain threshold (0.5 in this study) or a constraint is violated, the adjustment on \(q_{i}\) fails and the method will adjust the next waypoint.
4.4.3 Path optimizing
RRT* optimizes its solution towards the asymptotically optimal path over time [37, 39, 40]. After a path towards \(Goal\) is searched, RRT* is used to optimize the remaining part of the path which will not be executed in the remaining planning time \(t_{r}\). The remaining path starts at a waypoint (\(Root_{r}\)) which is the nearest to UAV on the path while UAV cannot reach in \(t_{r}\). We denote the sub tree rooting at \(Root_{r}\) as the remaining path tree which is extended by our modified DDRRT and optimized by RRT* in \(t_{r}\).
In RRT*, the upper cost bound (\(\mathrm{UB}(q)\)) of a tree node (\(q\)) is defined as the actual cost of the path from \(q\) to \(Goal\) computed by formula 9. If no such path exists, \(\mathrm{UB}(q)\) is set to be \(\infty\). The lower bound (\(\mathrm{LB}(q)\)) is defined as the predicted lowest cost distance from \(q\) to \(Goal\), i.e., \(D_{C}(q, Goal)\). Once we find a new path from \(q\) to \(Goal\) and \(q\) is the farther node of \(Goal\) on the path, \(\mathrm{UB}(q)\) is set to be \(\mathrm{LB}(q)\) and the following iterations are executed along the remaining path. For each waypoint (\(q_{i}\)) and its father waypoint (\(q_{i-1}\)) on the path, if \(\mathrm{UB}(q_{i-1}) > \mathrm{UB}(q_{i})+D_{C}(q_{i-1}, q_{i})\), then set \(\mathrm{UB}(q_{i-1})\) to be \(\mathrm{UB}(q_{i})+D_{C}(q_{i-1}, q_{i})\). Each children node (\(ch_{j}\)) of \(q_{i-1}\) except \(q_{i}\) on the remaining path tree will be checked. If \(\mathrm{LB}(ch_{j})+D_{C}(q_{i-1},ch_{j}) > \mathrm{UB}(q_{i-1})\), the sub tree rooted at \(ch_{j}\) will be safely removed because it cannot provide a better solution than the newly found path. If \(\mathrm{UB}(q_{i-1}) \le \mathrm{UB}(q_{i})+D_{C}(q_{i-1}, q_{i})\), the present execution of the path optimizing method will be terminated and the sub tree rooted at \(q_{i}\) will be checked whether it can be removed.
RRT* generates a series of solutions to get a less costly path. The pruning of tree nodes can improve the computational efficiency of RRT* [37, 39, 40].
4.5 Algorithms implementation
Algorithm 1 is the RS estimation algorithm. “PFPrediction” is the DT motion prediction function by PF. “Update” is the \(TTree\) updating function. \(RandNum\) is a uniformly and randomly distributing number in [0,1]. “reach” and “multi-connect” are the RS searching operators. \(q_{dr}\) is a directly DT reachable node. “RSCal” aims to search for indirectly reachable nodes among the neighbors of \(q_{dr}\) on \(PathTree\). “DistCal” aims to estimated the nearest distance set \(DS\) between DT and its reachable nodes by the DT motion state \(DTState\) and the predicted earliest time \(t_{rs}\) DT reaches the nodes in RS.


Algorithm 2 shows the pseudocode of our path planning method. \(T_{p}\) is the duration of the present planning and \(TH_{p}\) is the allocated total planning time. \(T_{lp}\) is the duration of the present local planning and \(TH_{lp}\) is the TH. “TreeExplore” is the improved heuristic DDRRT for the \(PathTree\) extension. \(q_{n}\) indicates an unsuccessfully extended \(PathTree\) node. DD denotes the predefined dynamic domain. “TtCal” aims to calculate the threat level on a node. “IFWA” is the threats aggregation function. “RSE” denotes the RS estimator introduced in algorithm 1. “TUDDCal” aims to calculate the TUDD subject to formula 7. In the \(PathTree\) updating process, the TSs of all the \(PathTree\) nodes are updated. “SafetyAdjustment” is the safety adjustment function. “FindFreePathNode” aims to find \(Root_{r}\), as discussed in Sect. 4.4.3. The remaining part of the path is optimized in \(TH_{p}-T_{p}\) by RRT*.
4.6 Algorithm analysis
The result of RRT or DDRRT does not converge to the optimal path [1–3, 15, 16]. RRT* optimizes a path towards the asymptotically optimal one over time, by improving the topological structure of the path tree [40]. Our method avoid threats explicitly in the path searching process under uncertainties. It reduces the threat on a local path by the safety adjustment. If a path towards \(Goal\) is found, it is optimized by RRT* in the remaining planning time. Therefore, our result is an improved one without the guarantee of the optimization.
The randomized path planning methods do not have any running time upper-bound, i.e., a complete plan is not surely returned within an acceptable time [40]. Let \(n\) be the number of samples. The asymptotic time complexities of both RRT and RRT* are \(O(n \log n)\) in terms of the number of simple operations, such as comparisons, additions, and multiplications [40]. Collision Detection (CD) is a time-costly high-level function in a RRT-based method [1, 15, 16]. DDRRT reduces the number of CD called by the sampling space reduction to accelerate its path searching process [15, 16]. Our method adopts a similar sampling space reduction method to DDRRT in the path searching process. Thus, the time complexity of our path searching process is not higher than \(O(n \log n)\). The time complexity of our path planning method is not higher than \(O(n \log n)\).
RRT, RRT* and DDRRT are probabilistically complete [1, 15, 16, 40]. The probabilities that the planners fail to return a solution, if one exists, decay to zero as the number of samples approaches infinity. Our method is still probabilistically complete since it does not destroy this completeness. Like RRT-reach, our RS estimator has no guarantee of the probabilistic completeness for the sake of computational efficiency. As discussed in Sect. 2.2, our method has advantage in planning under complex and dynamic constraints.
5 Simulation results
5.1 Simulation environments setting
We perform experiments to verify that our algorithm can be applied online in an uncertain and hostile environment. The RS estimator is executed in parallel with the UAV path planner. We make 100 Monte Carlo simulations for each method in each scenario. The experiments are done on computers with Intel Pentium 4, 2.5 GHz CPU, 1GB RAM, Windows XP OS and Matlab R2010a.
The environments are created according to the real world planning system. The duration of one path tree extension step \(\mathrm{\tau } = 1\) second. One extension step length \(le = v\cdot \mathrm{\tau }\) where \(v\) is the velocity of a vehicle. The radius of DD is set to be an optimal value \(10\cdot le\) [15, 16]. In the 2D environment, we set the UAV motion parameters as: \(\mathrm{v_{min}}=0.5\) units/s, \(\mathrm{v_{max}}=1.5\) units/s, \(\mathrm{a_{v}}=0.02\) units/\(\mathrm{s^{2}}\), \(\mathrm{r_{min}}= \mathrm{sl_{min}} = 5\) units; the DT velocity \(\mathrm{v_{D}}\) = 1 unit/s; TH= 15 seconds; UAV starts at [10, 90], ends at [95, 5]; DT starts at [10,10]; the maximum threat radius of radar \(\mathrm{R_{max}} = 38\) units; the maximum static threat radius of DT \(\mathrm{RD_{max}} = 10\) units; the radius of SH is 33 units; the \(\mathrm{v_{p}}\) in the non-membership function is 1 unit/s. In the 3D environment, the motion parameters of UAV and DT are set to be five times of those in the two dimensional scenario; the radar characteristic coefficient \(\mathrm{K_{R}}=0.003\); TH=25 seconds; UAV starts at [950, 80 ,80], ends at [50, 950, 100]; DT starts at [950,950,0]; \(\mathrm{R_{max}}\) = 380 units; \(\mathrm{RD_{max}} = 50\) units; \(\mathrm{v_{p}}\) = 5 units/s; the radius of SH is 150 units.
The heuristic parameters are set as follows. We use the asymptotic k-near neighbors searching method in [40], the lower bound of \(k\) is set to be 3. In the GoalZoom heuristics, \(P= 0.3\). In Algorithm 1, \(P_{itd} = 0.5\). In formula 2, \(\omega _{N} = 0.7\), \(\omega _{\delta } = 0.3\), \(\omega _{C} = 1\). In formula 5, \(C_{\gamma _{1}} = C_{\gamma _{3}} = 0.3\), \(C_{\gamma _{2}} = C_{\gamma _{4}} = 0.2\). In formula 7, \(k_{c} = 1\), \(k_{T} = 5\). In formula 9, \(D_{\gamma _{1}} = 0.5\), \(D_{\gamma _{2}} = 0.1\), \(D_{\gamma _{3}} = 0.4\). The weights of the formula 6 in the 2D scenario are set as: \(L_{\gamma _{1}}=0.7\), \(L_{\gamma _{2}}=0\), \(L_{\gamma _{3}}=0.3\); in the 3D scenario: \(L_{\gamma _{1}}=0.7\), \(L_{\gamma _{2}}=L_{\gamma _{3}}=0.15\).
5.2 Planning results
The elements in Figs. 7 and 8 are interpreted as follows. The blue and red diamonds denote the start location and the \(Goal\) of planning, respectively. The red curve indicates a UAV path smoothed by the Dubins curve. A colored area denotes a radar threat area masked by obstacles. The blue-branch and magenta-branch trees denote the UAV and the DT path trees, respectively. A red star denotes a directly DT reachable node. A red circle centering at a red star denotes an estimated DT reachable range which includes both the directly and indirectly DT reachable nodes. A green star denotes a \(SubGoal\). A blue circle denotes a SH boundary in the 2D scenario. A cyan cross denotes a UAV location when selecting a \(SubGoal\) in the 3D scenario. The obstacle environments derive from the puzzles of Bug Trap and Labyrinth [1, 2, 15, 16] which can test a sampling based planning algorithm. It is rather complicated due to the following reasons: the environment includes narrow hallways and traps composed by complex obstacles (convex and nonconvex); it invalidates the traditional Euclidean distance based heuristics. Moreover, the planning is required to deal with uncertainties and avoid threats especially DT. Meanwhile, it must plan paths online under limited and real-time threat information.

The two dimensional simulation results
Figure 7 shows the simulation results in a 2D environment. Figure 7 verifies that our Safe-RRT is effective, because of the following reasons: the UAV path tree is inclined to search low risk path in the low-threat or threat-free areas; the result path keeps an appropriate distance from obstacles to avoid collision. The high path searching ability of our Safe-RRT in obstacle-complex environments is also verified. That is because the result path is able to get through narrow hallways with a small number of tree branches. The ability can benefit the threats avoidance ability of Safe-RRT by utilizing the masking of obstacles to threats. The planner also avoids DT by utilizing the masking of obstacles, e.g., it utilizes obstacle in the lower right corner of Fig. 7b to avoid DT.
Figure 7a, b, c show the intermediate and final results of Safe-RRT. They show both the process of UAV path planning and the updating processes of DT path tree and DT path. The sub goal selections conform to formula 4. The black lines in Fig.7a and b denote the DT pursuing path which is searched online. DT is not required to finish the whole path due to its limited velocity. Our DT motion simulation satisfies the requirement of the DT avoidance model in Sect. 2.3, because: the DT path is flexible and intelligent with a strong bias of threatening UAV; DT tries to pursue the UAV path tree nodes by diversely extending its path tree. Meanwhile, the large DT path tree can better estimate the RS to assess the DT threat from the UAV path planning point of view.
Figure 7d shows a plan of the Threat Assessment based DDRRT method (TADDRRT). TADDRRT has the same planning process as our algorithm. It is the reimplementation of DDRRT in hostile environments. It does not consider the uncertainties of UAV motion and observation. Its result path is closer to obstacles causing a higher collision probability than that of Safe-RRT. Thus, our consideration of the uncertainties is appropriate. If we pre-expand obstacles as traditional methods do, albeit the path can keep away from obstacles, the narrow hallways may be blocked by the expansion. TADDRRT has no heuristics of “GoalZoom”, “k-neighbors” and “RRT*”. Meanwhile, it underestimate the certainty degrees of threats, further underestimate threats, because it sets the standard deviations of the distributions of UAV states to be zero in formula 2. Thus, the result of TADDRRT is more inclined to get through high risk areas near threat centers than those of Safe-RRT. Thus, the result path of TADDRRT is more risky than those of Safe-RRT. That testifies our improvements based on TADDRRT are effective. Figure 7e shows the last part of path is zigzag. That is because the RS in the last iteration is big, Safe-RRT creates more tree nodes to avoid DT more explicitly. That also testifies the good threats avoidance ability of Safe-RRT. Figure 7f shows that the fourth \(SubGoal\) in the lower right corner is not reached in TH. Safe-RRT starts the fifth local planning based on the result of the fourth iteration.

The three dimensional simulation results
Figure 8 shows our planning results in a 3D environment. The good abilities of path searching, threats avoidance and uncertainties processing of our planner are certified. The effectiveness of our RS estimator is also verified.
Figure 8a and b are two intermediate results of our planner at the one-fourth and three-fourths planning time of a plan, showing the processes of UAV path planning and DT pursuing UAV. The paths can keep appropriate distances from obstacles. That verifies our dealing with the uncertainties of UAV motion and observation is effective. The good threats avoidance ability of Safe-RRT is also certified by Fig. 8a and b. That is because of the following reasons: the paths can avoid radar threats by utilizing the radar blind spots and the masking of obstacles to threats in the low altitude; there are many DT reachable areas in Fig. 8b, however, Safe-RRT can still find some relatively safe areas to avoid threats. Figure 8a and b show that the DT path tree grows towards the UAV path tree with strong bias. DT can flexibly and intelligently adjust its path to pursue UAV. The observations verify the DT motion simulation is reliable and our RS estimator is effective.
Figure 8c is a detail of Fig. 8a, showing the DT pursuing UAV by enlarging its path tree. That certifies the reliability of our DT motion simulation and the effectiveness of the RS estimation. Figure 8c also shows our planner can find a path in the narrow hallway in the middle of Fig. 8a with a small amount of branches. That verifies the good path searching ability of our planner. Figure 8d is a detail of Fig. 8b, showing that UAV avoids DT by the masking of obstacles. The red circles denote the DT reachable ranges. Fig. 8d especially shows that the planner can utilize the masking of the obstacle at the top right of Fig. 8b to avoid DT. That verifies our DT avoidance method is effective.
5.3 Results and analyses
The comparisons are made between Safe-RRT and TADDRRT, NFZ-DDRRT, RRT*, as the statistical results in Table 1. The TUDDs of the nodes in RS are set to be zero in NFZ-DDRRT according to the discussion in Sect. 1.2. NFZ-DDRRT is reimplemented with the same ST avoidance ability as TADDRRT. All approaches share our planning framework.
PST is the path searching time. NCDC is the number of collision detection called in the path searching process. ESR = NTN/NCDC is the extension success rate of path tree nodes. NTN is the number of the UAV path tree nodes. TSI is the time of one path searching iteration, TSI = PST/NCDC. PST, NCDC and TSI reflect the time complexity of the path searching phase of a RRT-based algorithm. ESR reflects the reliability of the heuristic sampling space reduction to some extent. FR is the failure rate, an execution fails if no path towards \(Goal\) is returned in the available planning time which is set to be 80 and 160 s in the 2D and 3D scenarios, respectively. PC is the path cost computed by formula 9. Q(\(\mathrm{\Pi }\)) is the path quality calculated by formula 8. PST, NCDC, ESR and TSI are the technical indicators in the path searching process. Other technical indicators are collected after a whole planning ends.
The PST and NCDC of our Safe-RRT are the lowest in both the 2D and 3D environments, verifying its best path searching ability. That also verifies the effectiveness of our heuristics in Safe-RRT comparing to TADDRRT. The ESRs of Safe-RRT and TADDRRT are higher than the other two methods, demonstrating our sampling space reduction is effective. The TSI of Safe-RRT is higher than TADDRRT because Safe-RRT devotes extra time to handle uncertainties. The highest TSI of Safe-RRT also contributes to the best Q(\(\mathrm{\Pi }\)). The PC of Safe-RRT is the best. The PC of TADDRRT is inferior to Safe-RRT, because: it is less heuristic than Safe-RRT; its path is more risky than Safe-RRT because it underestimates threats, as discussed in Sect. 5.2. The PC of NFZ-DDRRT is far worse than TADDRRT because it tries to totally detour from DT causing a longer and possibly more risky path. RRT* has the worst PC because its optimizing time is not satisfied. The better FRs certify Safe-RRT and TADDRRT are far more robust than the other two methods.
Table 2 compares our Heuristic sub goal selection Method (HM) with the traditional Euclidean Distance Based Method (EDBM). The difference between HM and EDBM derives from the principle described in formula 5: HM not only takes the distances into account, but also considers the problems of obstacles avoidance and threats avoidance, EDBM just considers the distances. Both methods are integrated into our path planning system. TTA is the total radar threat amount calculated by adding the radar membership degrees on all the waypoints and secondary waypoints on a path. We discretize a sub path between two adjacent waypoints into 10 secondary waypoints when computing TTA. HM has lower PST, NTN, NCDC, TTA, PC and FR than EDBM, verifying that our sub goals can lead the planner rapidly finding a low cost and low threat path while avoiding the local optimum to some extent. The higher ESR demonstrates HM is able to select sub goals in less obstacle-occupied spaces. Thus, HM is more informative and effective than EDBM.
Table 3 compares the ST avoidance ability of Safe-RRT with those of TADDRRT and RRT*. ATP is the aggregated radar threat on the result path. It is calculated by aggregating the radar threats on all waypoints on the path using IFWA. NHTW is the number of high radar threat waypoints of which the threat levels exceed 0.5. Our method has less ATP, TTA and NHTW than TADDRRT, verifying our heuristic improvements can promote the ST avoidance ability. The result of RRT* is far inferior to those of Safe-RRT and TADDRRT, because its long optimizing time is not satisfied.
Our Extended RRT based RS estimator (ExRRT) is compared with RRT-Reach and RRT in Table 4. We suppose RRT-Reach [33] is provided with the same information of DT motion prediction as ExRRT. The probabilistic threshold, determining the execution probabilities of the modes of exploration and pursuit, is set to be 0.5 in RRT-Reach as ExRRT. RRT is totally random. The results of the three estimators are applied to our planning system.
ADTP is the aggregated actual DT threat on the UAV path calculated in the same way as ATP. TDTA is the total actual DT threat amount on the UAV path calculated in the same way as TTA. ETDTA is the estimated total DT threat amount on the UAV path. ETDTA/TDTA reflects the reliability and accuracy of a RS estimator. TFP is the time that a UAV path tree node is first pursued by DT. PD is the path duration. It is meaningless to simply compare TFP, since the PDs of different methods vary a lot. Therefore, TFP/PD is applied to reflect the effectiveness of an estimator. RSS is the RS size. Because the RS estimation is from the UAV path planning point of view, an earlier TFP/PD or a bigger RSS indicates the higher effectiveness of an estimator.
ExRRT contributes to less ADTP and TDTA, verifying it is more effective in helping the planner to avoid DT. The biggest ETDTA/TDTA verifies that ExRRT is the most effective and accurate. The earliest TFP/PD and the largest RSS prove that ExRRT is the most effective. ExRRT is superior to the RRT-Reach and far better than RRT in both environments.
Table 5 compares our A-IFS based threat model with the probabilistic model. In the probabilistic model, the nonmembership degree is set to be zero and the certainty value is set to be one. PSR is the penetration success rate computed by aggregating the damaged probabilities of UAV on all the waypoints by formula 3. All the two models are integrated into our planning system. The less PST and NCDC verify that our model can accelerate the path searching process. That is because the functions of nonmembership and certainty can help the path tree to quickly pass through threat areas. The probabilistic model is inclined to guide the path tree in detouring from threats. That causes the longer result path and the longer path planning time. That further results in a bigger PC. The higher PSR verifies that our model is more effective in helping the planner to avoid threats. The better Q(\(\mathrm{\Pi }\)) testifies the advantage of our consideration of uncertainties of UAV motion and observation in the A-IFS based model. Accordingly, our model is more suitable for planning a path in an uncertain and hostile environment.
6 Conclusions
To deal with the uncertainties of environmental threats and to ensure the safety of the low altitude flight, we propose an online safe path planning algorithm for UAV. We consider the uncertainties of threats and vehicles’ motions and observations during the planning process. A threat model is constructed based on A-IFS. It is verified to be more effective than the probabilistic one to describe an uncertain threat. The RS estimator of an uncertain DT is constructed based on the RRT extension and the particle filter prediction. Comparing with the traditional approaches, it is a more accurate method which is able to estimate more possible paths of DT with the intention of intercepting UAV. An online path planning method is proposed to avoid threats and obstacles when both the UAV motion and observation is uncertain. Our sub goal selection method is verified to be more effective than EDBM in accelerating the path searching process and creating a low cost path. Our planer is verified to be able to avoid threats and obstacles under uncertainties more effectively than the traditional methods. The major contributions are as follows:
-
1.
A static threat model and a threat assessment method are proposed based on A-IFS to deal with the uncertainty of a threat.
-
2.
The DT intention is taken into account in designing the RS estimator of DT to deal with the uncertainties of the DT motion and observation.
-
3.
A fast online path planning algorithm is proposed to avoid threats and obstacles when both the UAV motion and observation is uncertain.
The future work is to solve the UAVs cooperation problem.
Abbreviations
- A-IFS:
-
An intuitionistic fuzzy set
- ST:
-
Static threat
- DT:
-
Dynamic threat
- RS:
-
Reachability set
- DDRRT:
-
Dynamic domain rapidly-exploring random tree
- LQG-MP:
-
Linear quadratic Gaussian motion planning
- NFZ:
-
No-fly zone
- SH:
-
Sensing horizon
- PF:
-
Particle filter
- TS:
-
Time stamp
- IFWA:
-
Intuitionistic fuzzy weighted averaging
- TH:
-
Time horizon
- DD:
-
Dynamic domain
- TUDD:
-
Threat and uncertainty based dynamic domain
- CD:
-
Collision detection
References
LaValle SM (2006) Planning algorithms. Cambridge University Press, Cambridge
LaValle SM, Kuffner JJ (2001) Randomized kinodynamic planning. Int J Robotic Res 20(5):378–400
Desaraju VR (2010) Decentralized path planning for multiple agents in complex environments using rapidly-exploring random trees. Ph.D. dissertation, Massachusetts Institute of Technology
Fiorini P, Shiller Z (1998) Motion planning in dynamic environments using velocity obstacles. Int J Robot Res 17:760–772
Miller B, Stepanyan K, Miller A, Andreev M (2011) 3D path planning in a threat environment. In: Proceedings of the 50th IEEE Conference on Decision and Control and European Control Conference (CDC-ECC). Orlando, USA pp 6864–6869
Anderson SJ, Peters SC, Pilutti TE, Iagnemma K (2010) An optimal-control-based framework for trajectory planning, threat assessment, and semi-autonomous control of passenger vehicles in hazard avoidance scenarios. Int J Vehicle Auton Syst 8(2):190–216
Gonsalves P, Cunningham R, Ton N, Okon D (2000) Intelligent threat assessment processor (ITAP) using genetic algorithms and fuzzy logic. In: Proceedings of the Third International Conference on Information Fusion. Paris, France pp 11–18
Yang G, Kapila V (2002) Optimal path planning for unmanned air vehicles with kinematic and tactical constraints. In: Proceedings of the 41st IEEE Conference on Decision and Control. Las Vegas, USA pp 1301–1306
Pan Su, Li Yan, Li Yingjie, Shiu Simon Chi-Keung (2013) An auto-adaptive convex map generating path-finding algorithm: genetic convex. Int J Mach Learn Cybern 4(5):551–563
Zhongxing M, Huibin W, Xu M, Dai P (2014) Evaluation of path stretch in scalable routing system. Int J Mach Learn Cybern. doi:10.1007/s13042-014-0285-6
Chang WL, Zeng D, Chen RC, Guo S (2013) An artificial bee colony algorithm for data collection path planning in sparse wireless sensor networks. Int J Mach Learn Cybern. doi:10.1007/s13042-013-0195-z
Petti S, Fraichard T (2005) Safe motion planning in dynamic environments. In: Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems. Edmonton, Canada pp 2210–2215
Urmson C, Simmons RG (2003) Approaches for heuristically biasing RRT growth. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas, USA pp 1178–1183
Lee J, Pippin C, Balch T (2008) Cost based planning with RRT in outdoor environments. In: Proceedings of the IEEE/RSJ international conference on intelligent robots and systems. Nice, France pp 684–689
Yershova A, Jaillet L, Simeon T, LaValle SM (2005) Dynamic-domain RRTs: Efficient exploration by controlling the sampling domain. In: Proceedings of the IEEE International Conference on Robotics and Automation. Barcelona, Spain pp 3856–3861
Jaillet L, Yershova A, La Valle SM, Simon T (2005) Adaptive tuning of the sampling domain for dynamic-domain RRTs. In: IEEE/RSJ International Conference on Intelligent Robots and Systems. Edmonton, Canada pp 2851–2856
Aoude G, Joseph J, Roy N, How J (2011) Mobile agent trajectory prediction using Bayesian nonparametric reachability trees. In: Proceedings of the AIAA Infotech@ Aerospace. AIAA, St. Louis pp 1587–1593
Koenig S, Simmons R (1998) Xavier: a robot navigation architecture based on partially observable markov decision process models. Artificial Intelligence Based Mobile Robotics, Case Studies of Successful Robot Systems, pp 91–122
Bailey T, Durrant-Whyte H (2006) Simultaneous localization and mapping (SLAM). IEEE Robotic Automat Mag 13(3):108–117
Huynh VA, Roy N (2009) icLQG: combining local and global optimization for control in information space. In: Proceedings of the IEEE International Conference on Robotics and Automation. Kobe, Japan pp 2851–2858
Van Den Berg J, Abbeel P, Goldberg K (2011) LQG-MP: Optimized path planning for robots with motion uncertainty and imperfect state information. Int J Robot Res 30(7):895–913
Cheng P (2005) Sampling-based motion planning with differential constraints. Ph.D. dissertation, University of Illinois
Shkolnik A, Walter M, Tedrake R (2009) Reachability-guided sampling for planning under differential constraints. In: Proceedings of the IEEE International Conference on Robotics and Automation. Kobe, Japan pp 2859–2865
Jaillet L, Hoffman J, Van den Berg J, Abbeel P, Porta JM, Goldberg K (2011) Eg-rrt: Environment-guided random trees for kinodynamic motion planning with uncertainty and obstacles. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. San Francisco, USA pp 2646–2652
Melchior NA, Kwak JY, Simmons R (2007) Particle RRT for path planning in very rough terrain. In: proceedings of the conference on NASA Science Technology. Roma pp 1617–1624
Pepy R, Lambert A (2006) Safe path planning in an uncertain-configuration space using RRT. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Beijing, China pp 5376–5381
Burns B, Brock O (2007) Sampling-based motion planning with sensing uncertainty. In: Proceedings of the IEEE International Conference on Robotics and Automation. Roma pp 3313–3318
Fraichard T, Mermond R (1998) Path planning with uncertainty for car-like robots. proceedings of the IEEE International Conference on Robotics and Automation. Leuven, Belgium pp 27–32
Guibas LJ, Hsu D, Kurniawati H, Rehman E (2009) Bounded uncertainty roadmaps for path planning. Algorithm Found Robot VIII 57:199–215
Hanson ML, Sullivan O, Harper KA (2001) On-line situation assessment for unmanned air vehicles. In: Proceedings of the FLAIRS Conference. Florida pp 44–48
Kabamba PT, Meerkov SM, Zeitz FH (2005) Optimal UCAV path planning under missile threats. World Congress 1: 2002–2008
Aoude GS (2011) Threat assessment for safe navigation in environments with uncertainty in predictability. Ph.D. dissertation, Massachusetts Institute of Technology
Aoude GS, Luders BD, Joseph JM, Roy N, How JP (2013) Probabilistically safe motion planning to avoid dynamic obstacles with uncertain motion patterns. Autonom Robot 35:51–76
Aoude GS, Luders BD, How JP, Pilutti TE (2010) Sampling-based threat assessment algorithms for intersection collisions involving errant drivers. In: proceedings of the IFAC Symposium on Intelligent Autonomous Vehicles. Lecce, France
Aoude GS, Luders BD, Lee KK, Levine DS, How JP (2010) Threat assessment design for driver assistance system at intersections. In: Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems. Funchal, Portugal pp 1855–1862
Aoude GS, Luders BD, Levine DS, How JP (2010) Threat-aware path planning in uncertain urban environments. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Taipei, pp 6058–6063
Frazzoli E, Dahleh MA, Feron E (2002) Real-time motion planning for agile autonomous vehicles. J Guidance Control Dyn 25(1):116–129
Phillips M, Likhachev M (2011) Sipp: Safe interval path planning for dynamic environments. In: Proceedings of the IEEE International Conference on Robotics and Automation. Shanghai pp 5628–5635
Karaman S, Frazzoli E (2010) Optimal kinodynamic motion planning using incremental sampling-based methods. In: Proceedings of the 49th IEEE Conference on Decision and Control. Georgia pp 7681–7687
Karaman S, Frazzoli E (2011) Sampling-based algorithms for optimal motion planning. Int J Robot Res 30(7):846–894
Isaacs R (2012) Differential games: a mathematical theory with applications to warfare and pursuit, control and optimization. Courier Dover Publications, New York
Ehtamo H, Raivio T (2001) On applied nonlinear and bilevel programming or pursuit-evasion games. J Optim Theory Appl 108(1):65–96
Zeshui Xu (2007) Intuitionistic fuzzy aggregation operators. IEEE Trans Fuzzy Syst 15(6):1179–1187
Ye Wen, Fan Hongda, Zhu Aihong (2011) Mission Planning for Unmanned Aerial Vehicles. National Defense Industry Press, BeiJing
Carpenter J, Clifford P, Fearnhead P (1999) Improved particle filter for nonlinear problems. IEEE Proceedings-Radar, Sonar and Navigation 146(1): 2–7
Hsu D, Kindel R, Latombe JC, Rock S (2002) Randomized kinodynamic motion planning with moving obstacles. Int J Robot Res 21(3):233–255
Kim Y, Gu D-W, Postlethwaite I (2008) Real-time path planning with limited information for autonomous unmanned air vehicles. Automatica 44(3):696–712
Seok JH, Oh C, Lee JJ, Lee HJ (2011) Integrated path planning for a partially unknown outdoor environment. In: Proceedings of the IEEE/SICE International Symposium on System Integration. Kyoto pp 643–648
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wen, N., Su, X., Ma, P. et al. Online UAV path planning in uncertain and hostile environments. Int. J. Mach. Learn. & Cyber. 8, 469–487 (2017). https://doi.org/10.1007/s13042-015-0339-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-015-0339-4