
Abstract
Developing a susceptibility map is a crucial primary step for dealing with undesirable natural phenomena, gully erosion included. On the other hand, recent computational progress call for employing new methodologies to keep the solutions updated. In this work, the performance of a conventional artificial neural network (ANN) is improved by applying a metaheuristic algorithm (symbiotic organisms search—SOS) for generating the gully erosion susceptibility map of an area in Golestan Province, Northern Iran. A geo-database is created from the gully erosion inventory and twenty conditioning factors. After analyzing the interrelated relationships between the geo-database components, training and testing data sets are formed. The models are executed with proper configurations and according to the results, the SOS algorithm could enhance the training accuracy of the ANN from 92.8% to 98.4%, and testing accuracy from 89.8% to 91.4%. In addition, comparing the performance of the SOS with shuffled complex evolution (SCE-NN) and electromagnetic field optimization (EFO-NN) algorithms revealed the greater accuracy of the SOS. However, the SCE-NN and EFO-NN performed more accurately than conventional ANN. Therefore, it can be concluded that the use of metaheuristic techniques may improve the prediction ability of the ANN in gully erosion susceptibility mapping. Finally, a monolithic equation is extracted from the SOS–ANN model to be used as a predictive formula for similar purposes.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Gully erosion mostly exhibit on low to gentle slopes owing to flow concentration on susceptible soils (Nachtergaele and Poesen 2002). Compared to the preliminary forms of water erosion such as splash, sheet, inter rill, and rill, gullies appear to be more morphologically emerged and manifest as discernible dissected lands. The early form of gullies is generated once the runoff is concentrated either on the land surface or subsurface (underground tunnels shaped by soil dissolution with a roof ready to collapse). Ephemeral gullies normally disappear by a simple act of tillage, while permanent gullies cannot be eliminated by simple agricultural artifacts nor can be easily controlled. In general, gullies develop in a retrogressive manner from gully head-cuts; in that, once the hydrological drivers reach headcuts (e.g., riverine floods reaching adjacent gullies or any other form of runoff generation mechanism), they propagate backward from their headcuts (Poesen et al. 2003; Schmitt et al. 2006).
The monetary damages and casualties incurred from gullies are mainly associated with farmlands, agricultural machinery, livestock, and to a lesser degree, humans and rural residential developments (or any other land use that is ancillary to the use for such dwellings); however, most archives lack such data inclusiveness and integrity. On the other hand, a sizable amount of soil is annually washed away from gullies into dam reservoirs or other outlets, and many lands are degraded. Consequently, intangible costs of gully erosions can also be dramatically extensive (Valentin et al. 2005). This notion signifies the importance of studying gullying behavior (Poesen et al. 2011). Studies conducted on gullies can be categorized as measuring, modeling, monitoring, and managing (Vanmaercke et al. 2021). Monitoring-based studies often adopt a temporal assessment of satellite images using remote sensing techniques that have recently paved the way to scrutinize the geomorphodynamics of gullies (Borrelli et al. 2022; Jiang et al. 2021; Phinzi et al. 2021; Wang et al. 2016), or merely based on field surveys (Schmitt et al. 2006). Such analyses may further lead to conceptual and process-based numerical models (Modak et al. 2022). Modeling itself may encompass a wide spectrum of categories, including inventory-based heuristic, statistical, probabilistic, stochastic, and physically based models.
Recent advancements in the computer-assisted analysis have eased tedious modeling procedures with high iterations, which prompted the scientific community to get a grip on new pattern-seeking models. As such, data mining models helped modelers with extracting the emerging pattern from a complex natural phenomenon across a given area. In this way, special attention has been paid to elucidating the mechanism of predictive models by employing explainable methods (Al-Najjar et al. 2022; Hasanpour Zaryabi et al. 2022; Maxwell et al. 2021).
Machine/Deep learning models further made significant leverage in not only pattern extraction but predicting the spatial susceptibility of the studied phenomenon across a given area (Arabameri et al. 2020c; Conoscenti et al. 2018; Gayen et al. 2019; Pourghasemi et al. 2017; Roy et al. 2020). Some researchers went even beyond and used ensemble machine learning models with various optimization algorithms to automatically tune the hyper-parameters embedded in the models through significantly high modeling iterations (e.g., Band et al. (2020) and Arabameri et al. (2021)). Metaheuristic algorithms such as simulated annealing (Kirkpatrick et al. 1983), ant colony optimization (Dorigo 1992), particle swarm optimization (Kennedy and Eberhart 1995), harmony search (Geem et al. 2001), artificial bee colony (Karaboga 2005), imperialist competitive algorithm (Atashpaz-Gargari and Lucas 2007), and gravitational search algorithm (Rashedi et al. 2009) are some examples of the advanced optimization algorithms that found their way to spatial modeling of natural hazards.
Symbiotic organism search (SOS) algorithm is a rather recent metaheuristic algorithm, first expounded by Cheng and Prayogo (2014) and later on used by many others in different areas of science. Although it has found global interest for different optimization purposes (Esmaili and Khodashenas 2020), it has not been yet applied to gully spatial prediction. Therefore, this literature gap is tackled in this research. Based on this introduction, the main objectives of this study are to: (1) use the SOS algorithm to optimize the performance of a popular machine learning technique, namely, artificial neural network (ANN) for gully erosion susceptibility mapping (GESM) across loess and silt-rich gully prone region of the Golestan Province, Iran and (2) conduct a comparative assessment on gully spatial pattern prediction using different ensembles and address the most reliable one. The findings of this research may shed light on decision-making and urban planning by authorities in the intended area. Moreover, from the methodological point of view, the used algorithms can open new doors to the use of artificial intelligence techniques for predicting undesirable phenomena, such as erosion.
Data and study area
Study area
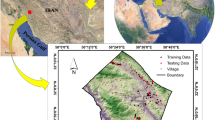
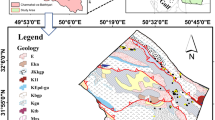
The study area geographically lies between 37° 30′ 00″ to 37° 50′ 00″ N latitude and 55° 31′ 40″ to 56° 2′ 10″ E longitude. Comprising parts of Marave-Tape and Kalaleh cities, it is extended for an area of approximately 784 km2 in the northeast of the Golestan Province, Iran (Fig. 1). Maximum and minimum elevation in the selected site are 160–1490 m a.s.l. A temperate Mediterranean climate prevailed in the area, with a minimum and maximum precipitation of 346 and 610 mm. Farmlands account for 45% of the entire study area (i.e., the predominant land use class), followed by rangelands (38%), forests (16%), and residential areas (1%). Grey-to-block shale and thin layers of siltstone and sandstone (Sanganeh FM) (symbolized as Qsw), Cenozoic in the era, is the widespread outcrop in the study area, covering 75.5% of the entire area. Table 1 summarizes the areal extent of the main geological formations in the study area.

Study area and spotted gullies
Inventory map
An inventory map is the basis of any spatial susceptibility modeling. In this study, the gully headcuts, representing gully developments, were taken from the repository of the Natural Resources and Watershed Management Organization of the Golestan Province. The points were positioned using a handheld GNSS device during extensive field surveys coupled with Google Earth imagery and mapped in ArcGIS software (Arabameri et al. 2020a).
The inventory map contains a total of 803 gully locations (i.e., headcuts) as illustrated in Fig. 1. As a rule of thumb, a 70:30% sample partitioning balance was adopted to split the samples into two groups for training (562 gullies) and testing (241 gullies), respectively. The former is used for model training and parameter tuning, while the latter group is kept apart to subsequently validate the model’s results. With the same division strategy, 803 non-erosion points were created, where no gully has been spotted. It is noteworthy that due to the abundance of gully samples, the chosen partitioning balance does not harm the data enrichment scheme, and each sampling group may well serve its assignment.
Conditioning parameters
Erosional processes and environmental phenomena generally occur and propagate under the presence and interaction of a set of environmental and human-induced changes. Environmental factors mainly include hydrological (distance to streams, drainage density), geological/geomorphological (lithology), pedological (surface and subterranean properties, including mineral soil, silt/clay/sand content, bulk density, and soil texture), and topological attributes of the area (altitude, slope, slope aspect, terrain ruggedness index—TRI, height above the nearest drainage—HAND, valley depth, plan curvature, topographic position index—TPI, and relative slope position—RSP). Human-induced changes or anthropogenic factors (translated into land use and distance to roads) mainly include the development activities that can alter, predispose, and trigger gully inanition or accelerate gully propagation mechanisms, such as unsupervised road constructions. Table 2 describes the causative role of each of the above-mentioned categories in gully initiation/development and the corresponding spatial scale of the acquired data. As detailed in Table 2, it was strived to employ all the conditioning factors that represent the gully propagation mechanism in the study area. Most notably, DEM (digital elevation model)-derivatives, known as morphometric indices containing (in) direct single or multiple hydrological/erosional attributes were adopted to assess any discernible relationship with gully evidence. Thematic maps of the selected gully conditioning factors (hereafter predictors) were produced in the ArcGIS environment (Fig. 2). Detailed explanations of the conditioning factors can be found in earlier works (Arabameri et al. 2020a, b).


Gully erosion conditioning factors. a TPI, b plan curvature, c altitude, d slope aspect, e slope, f HAND, g drainage density, h distance to stream, i TRI, j distance to road, k bulk density, l mineral soil, m clay content, n sand content, o RSP, p silt content, q valley depth, r land use, s soil texture, and t lithology
Frequency ratio analysis
Frequency ratio (FR) analysis is a bivariate statistical approach that is here used for quantifying the correlation between the sub-classes of each conditioning factor and the occurrence of gully erosion. This method, however, can be independently employed for susceptibility assessment of various natural disasters (Elmahdy et al. 2022; Guru et al. 2017; Lee and Pradhan 2007). Based on the FR formula, the FR value for the sub-class i is obtained as the ratio between the fraction of gully erosions that happened within it and the fraction of the area covered by it. The calculated FR values are presented in Table 3. As is known, the higher the FR, the larger the correlation between sub-class and erosion occurrence.
Importance analysis
In machine learning modeling, understanding the relative importance of each input factor is crucial. In this section, the results of an importance analysis are presented to delineate the role of each conditioning factor in predicting the gully erosion index (GEI). For this purpose, a well-known technique, namely, principal component analysis (PCA), is applied to the data set. This model creates orthogonal variables called principal components (PCs) composed of a linear combination of the original inputs (Abdi and Williams 2010). Each PC receives an eigenvalue with a threshold of 1, so that the PCs with eigenvalue ≥ 1 are significant (Kim et al. 1978). As shown in Fig. 3a, seven PCs satisfy this condition, and altogether account for 72.13% variation in the data set. These PCs are then exposed to the Varimax rotation method whose results are shown in Fig. 3b. The inputs with loading factors ≥ 0.75 and loading factors ≤ − 0.75 [Kaiser Criterion (Kaiser 1958)] are considered more important for predicting the GEI. PC1 suggests RSP, Valley Depth, Drainage Density, Dis. to Stream, HAND; PC3 suggests Slope and TRI; PC4 suggests Sand Content; and PC5 suggests TPI and Plan Curvature as the most important inputs. These results obtained from the PCA method are in good accordance with other methods such as Jackknife test performed by Arabameri et al. (2020a).

Results of the PCA analysis. a Scree plot and b Varimax-rotated factor loadings
Methodology
Figure 4 shows the methodology of this study which consists of four major steps:
-
(a)
Data provision: first, data are processed, and a geo-database is created. In addition, the relationship between gully erosion and conditioning factors is explored using the FR and IA techniques;
-
(b)
Model development: a conventional ANN and three metaheuristic-based ANNs are developed in this step. The models are optimized using the prepared data, and they predict the GEI for the whole area;
-
(c)
Mapping and interpretation: the research continues with developing GESMs and their interpretation; and
-
(d)
Accuracy assessment: finally, the obtained maps and prediction results of the models are assessed using different accuracy criteria. The models are then ranked, and a formula is derived from the best one.

Graphical strategy of the study
Algorithms
ANN
As a well-accepted predictive model, the initial idea of ANN was presented by McCulloch and Pitts in the 1940s (Abraham 2002), who demonstrated the computational capability of a network of neurons. By inventing learning rules along with perceptron networks, the first practical application of these models was in the 1950s (Esmaeili et al. 2014). Multi-layer Perceptron (MLP) network is among the most powerful types of ANNs. It is a globally known processor that can learn and reproduce the relationship between non-linear data (Hornik 1991). In these models, the duty of analysis is carried out by so-called “neuron” entities. Depending on the layer that the neuron lies in, it is extremely connected to other neurons in the previous and subsequent layers. The connection is accomplished by the weights, which along with biases are the variables of the network. In general, the network follows a forward path to adjust the weights and biases to achieve a suitable connection, eventually, a reliable estimation of the parameter of interest (Seyedashraf et al. 2018).
Figure 5 shows the ANN used in this study. As it can be seen, owing to the number of inputs (i.e., 20 conditioning factors) and targets (i.e., one GEI), this network owns 20 neurons in the input layer and one neuron in the output layer (see yellow squares). The number of neurons in the middle layer is user-defined and was selected as 25 after trying several values.

ANN configuration used in this study
Equation 1 expresses the analysis of a typical neuron in the ANN:
where AF() is the activation function of the neuron. If the neuron of interest is located in the hidden or input layers, then, the produced output will be passed to the next layer as a new input. Then, the same calculation is performed to produce a new output (Moayedi et al. 2019). Levenberg–Marquardt (LM) algorithm (More 1978) is used for training the ANN. Hence, this model is called LM-NN hereafter.
SOS
The SOS is one of the most capable optimizers that has successfully been applied to a wide variety of engineering problems (Chakraborty et al. 2022; Goldanloo and Gharehchopogh 2022). Jahanafroozi et al. (2022) showed the suitability of this technique for optimizing the ANN. The SOS was designed by Cheng and Prayogo (2014) inspired by the biological symbiotic association among species. To attain the optimum solution, the most successful organism is identified.
Based on the considered strategy, three steps are implemented as explained in the following:
-
(i)
Ecosystem initialization: the population is scattered within the space;
-
(ii)
Identifying the outstanding individual shown by \({X}_{\mathrm{b}}\);
-
(iii)
Mutualism: this step is carried out between two organisms of the ecosystem to improve their survival competency. In this regard, Eqs. 2 and 3 express this step for updating the candidate solution:
$${X}_{i\_\mathrm{new}}= {X}_{i}+ \gamma \left({X}_{\mathrm{b}}- {V}_{\mathrm{M}}\times {\mathrm{BF}}_{1}\right),$$(2)$${X}_{j\_\mathrm{new}}= {X}_{j}+ \mu \left({X}_{\mathrm{b}}- {V}_{\mathrm{M}}\times {\mathrm{BF}}_{2}\right),$$(3)where Xi and Xj signify the organisms in interaction, \(\gamma\) and \(\mu\) represent random values ranging in [0, 1], and \({\mathrm{BF}}_{1}\) and \({\mathrm{BF}}_{2}\) are benefit factors. In addition, the mutual vector that contains the organisms’ characteristics is shown by \({V}_{\mathrm{M}}\);
-
(iv)
Commensalism: it simply means the association of two species, where union is beneficial for one, and not harmful for the other one. This process is shown for Xj and Xi organisms as follows:
$${X}_{i\_\mathrm{new}}= {X}_{i}+ \lambda \left({X}_{\mathrm{b}}-{X}_{j}\right),$$(4)where \(\lambda\) is a random number with a uniform distribution between − 1 and 1. In this step, the fitness function is applied and compared to the one of the previous solution; if it shows more promise, the new solution replaces the old one; and
-
(v)
Parasitism: the algorithm mutates Xi to generate a parasite vector. Xj is then randomly selected to play the role of host for the parasite vector. Their fitness values are calculated and compared and the parasite vector replaces Xj if it provides a better fitness, otherwise, it is dropped.
Above steps are iterated until the algorithm meets a stopping criterion (Abdullahi and Ngadi 2016).
Benchmark optimizers
Along with the SOS, two other algorithms, namely, SCE and EFO, are identically used as comparative benchmarks. The SCE and EFO were designed by Duan et al. (1993) and Abedinpourshotorban et al. (2016), respectively. Both of these techniques are among the quickest optimizers that have widely served in finding the global solution to many problems (Moayedi et al. 2021). The general optimization procedure is similar to other metaheuristic techniques, i.e., it starts with scattering the population and continues with updating the solutions and detecting the most optimum one. The SCE aims at positioning the individuals into some complexes and finding the local optimum in each complex, and then, the global solution of the problem. Likewise, the basis of the EFO is grouping some electromagnetic into three fields with respect to their fitness, and evaluating their interaction based on the attraction–repulsion rule. Further details and mathematical explanations of this algorithm can be found in the earlier literature, see (Gao et al. 2018; Zhang et al. 2022) for SCE and (Song et al. 2019; Talebi and Dehkordi 2018) for EFO.
Optimizer-ANN integration
To create a hybrid of ANN with a metaheuristic algorithm, the steps listed below should be followed (Asadi Nalivan et al. 2022; Mehrabi et al. 2020):
-
(a)
Determining the structure and properties of the ANN;
-
(b)
Converting the model to the equation format that predicts the GEI from conditioning factors;
-
(c)
Defining a cost function to address the solution quality;
-
(d)
Yielding the above items to a metaheuristic algorithm to optimize them;
-
(e)
Tuning the parameters of the metaheuristic algorithm; and
-
(f)
Running optimization and saving the best solution.
In fact, the optimization process plays the role of training for the ANN. In this work, a three-layer MLP network represents the ANN. For constructing its equation, the weights and biases are left as variables to be optimized. Mean square error (MSE) is defined as the cost function that measures the error of training in each iteration. Next, the population size and number of iterations are the parameters that are defined for each metaheuristic algorithm. During optimization, the algorithm tries to optimize the ANN and create the best equation for it.
Considering different behaviors of the SCE, EFO, and SOS algorithms, the most proper population size and the number of iterations for them were found by a trial-and-error effort (Mehrabi and Moayedi 2021). Finally, the population size and the number of iterations for the SCE, EFO, and SOS were obtained 10 and 3000, 50 and 50,000, 350 and 1000, respectively. the optimization progress is illustrated in Fig. 6 in which the reduction of MSE is depicted versus the iterations.

Optimization progress of the used algorithms
Hereafter, the conventional ANN is named LM-NN, while the developed hybrids are called SCE-NN, EFO-NN, and SOS-NN.
Accuracy criteria
To assess the accuracy of the used models, as well as the reliability of the produced GESMs several criteria are employed. These are also useful for comparing models and addressing the most suitable map.
Mean square error and mean absolute error
The first group of these criteria are the mean square error (MSE) and the mean absolute error (MAE), which are among the most popular error indicators. As formulated in Eqs. 5 and 6, they are based on the difference between the real and predicted GEIs (\({\mathrm{GEI}}_{{i}_{\mathrm{real}}}\) and \({\mathrm{GEI}}_{{i}_{\mathrm{predicted}}}\), respectively):
where Q signifies the number of samples taken into calculation.
AUROC, sensitivity, and specificity
It was explained that the MSE and MAE reflect the error of prediction. Three other indices, namely, the area under the receiving operating characteristic curve (AUROC), the sensitivity, and the specificity, are also used to quantify the accuracy of prediction (Arabameri et al. 2020b; Nguyen et al. 2019). As the name connotes, the AUROC is obtained by calculating the area beneath the ROC curve, varying between 0.5 and 1, which, respectively, stand for a random and ideal prediction. Assuming E and N as the number of erosion and non-erosion data, the formulation of the AUROC is as follows:
where TP and TN represent true positive and true negative, respectively. Moreover, sensitivity and specificity are expressed in Eqs. 8 and 9 to determine what portion of erosion and non-erosion data are correctly classified:
where FP and FN stand for false positive and false negative, respectively.
Results
As explained earlier, the primary objective of this study is to introduce and assess the suitability of a new hybrid methodology, namely, SOS-NN for analyzing the susceptibility to gully erosion in the North of Iran. After data processing and model optimization step, which have been explained above, the results are presented in this section by addressing GESM development and accuracy assessment in two separate parts.
Predicting GEI and developing GESMs
Once the models are properly trained using the erosion and non-erosion samples, they can be applied to the whole study area for producing the GESMs. In this process, the conditioning factors are extracted for all pixels of the area, and a GEI is predicted for each pixel. MATLAB and ArcMap are used for calculations and to visualize the results.
Figure 7 shows the GESMs produced by all four models. Note that, the primary maps were plotted with GEIs in the ranges [− 0.67, 2.01], [− 2.38, 3.14], [− 0.97, 4.22], and [− 0.88, 1.66], for the LM-NN, SCE-NN, EFO-NN, and SOS-NN, respectively. Next, the maps were subjected to a Natural Break classification for developing Fig. 7 in five categories ‘Very Low,’ ‘Low,’ ‘Moderate,’ ‘High,’ and ‘Very High.’ The use of Natural Break is common for categorizing the maps related to susceptibility and hazard assessment of various environmental phenomena (Mehrabi et al. 2020; Moayedi et al. 2020). This classification technique finds the breaks that maximize between-class differences and minimize within-class differences (Chen et al. 2013).

GESMs generated by the conventional and metaheuristic ANNs
Figure 8 shows the percentage of each susceptibility class in the obtained GESM. Despite the differences in the percentages, it can be generally said that the percentages of the areas labeled as ‘Low,’ ‘Moderate,’ and ‘High’ susceptible are considerably larger than ‘Very Low’ and ‘Very High’ classes. Another noticeable point is the difference in the tendency of models for identifying places with ‘Very Low’ susceptibility. The least percentage is 6.11% by EFO-NN, while the greatest is 17.51% by SOS-NN.

Percentage of GES classes in Fig. 7
Based on Fig. 7, all models have performed successful prediction of GES over the study area, as it may be understood from controlling the location of the erosion points with susceptibility classes. A more detailed analysis in this regard is presented in Table 4, which reports the percentage of the erosion/non-erosion points fallen within the susceptibility classes. As a general favorable trend, the portion of erosion points increases, and adversely, the portion of non-erosion points falls with the increase of susceptibility level. For instance, 91.8%, 75.08%, 77.39%, and 91.27% of the training erosions, and 88.79%, 79.65%, 72.6%, and 87.13% of the testing erosions are found in the ‘High’ and ‘Very High’ susceptibility classes.
Training and testing accuracy
Five accuracy criteria introduced in “Mean square error and mean absolute error” are here calculated for the performance of all models to examine the accuracy of training and testing stages. Considering error criteria for the training stage, the LM-NN, SCE-NN, EFO-NN, and SOS-NN achieved MSEs 0.1188, 0.1104, 0.0886, 0.0635, and 0.0635, and MAEs 0.2851, 0.2379, 0.2205, and 0.1867, respectively. Figure 9 shows the histogram of training errors (Errori = \({\mathrm{GEI}}_{{i}_{\mathrm{real}}}\) − \({\mathrm{GEI}}_{{i}_{\mathrm{predicted}}}\)). As known for a histogram diagram, the higher the frequency around zero, the higher the accuracy. Based on the reported values and illustrations, it can be said that all four models have been properly trained by analyzing the erosion and non-erosion patterns.

Histogram of training errors by a LM-NN, b SCE-NN, c EFO-NN, and d SOS-NN
Based on the same accuracy criteria for the testing stage, the MSEs 0.1350, 0.1239, 0.1183, and 0.1235, and the MAEs 0.3022, 0.2493, 0.2533, and 0.2601 were obtained for the used models. Figure 10 illustrates the histogram diagrams for the testing data. These results indicate an acceptable level of error in predicting the GEI over the study area.

Histogram of training errors by a LM-NN, b SCE-NN, c EFO-NN, and d SOS-NN
Moreover, Fig. 11a, b depicts the ROC diagrams plotted for the training and testing stages, respectively. From these diagrams, it can be seen that all curves cover a large area beneath them, indicating an acceptable accuracy. Quantitatively speaking, the obtained AUROCs are 0.928, 0.925, 0.957, and 0.984 for the training data, and 0.898, 0.905, 0.915, and 0.914 for the testing data. Besides, the sensitivities of 88.79%, 81.14%, 91.10%, and 95.37% for the training phase and 86.72%, 86.31%, 87.14%, and 80.50% for the testing phase demonstrate a high accuracy of the models in classifying the erosion pixels, while the specificities 83.81%, 88.97%, 86.83%, and 90.57% for the training phase and 83.88%, 83.88%, 85.54%, and 91.32% for the testing phase, show a high accuracy of the models in classifying non-erosion pixels.

Plotted ROC curves and calculated AUROCs for the a training and b testing phases
SOS-based GEI formula
This section exhibits a monolithic equation that can be used to directly predict the GEI by exposing the conditioning factors. This formula is extracted from the implemented SOS-NN model, since it presented the most accurate analysis of gully erosion. There are two components for this equation: (i) Eq. 10 is the linear part that is performed in the output layer of the ANN to calculate the GEI. It is constructed by receiving the outputs of the hidden layer (i.e., Y1, Y2, …, Y25) multiplied by the 25 corresponding weights, and eventually summing up with a bias (see Fig. 5):
where Yi (i = 1,2, …, 25) is calculated by the non-linear parts as follows:
where W1,i (i = 1,2, …, 20) is given in Table 5. In addition, the function Tansig is expressed as follows:
Discussion
Due to the undesirable impacts of gully erosion on the surrounding areas (Poesen et al. 2003), providing a susceptibility map may highly improve the preparedness against the effects of this phenomenon. Considering the incorporation of several environmental factors in the occurrence of gully erosion, this may be considered a complex process (Pal et al. 2022; Valentin et al. 2005). Therefore, proper predictions in this sense require sufficient computational potential. Many studies have highlighted the great capability of machine learning techniques, and most notably ANNs, in susceptibility assessment of gully erosion. On the other hand, it has been shown that ANNs may experience accuracy enhancement when they are well-coupled with optimization algorithms.
In this work, an ANN was optimized by three metaheuristic techniques (i.e., SCE, EFO, and SOS) for gully erosion susceptibility analysis of a Northern area of Iran. Models were compared with conventional ANN to investigate the effect of SCE, EFO, and SOS on its accuracy. The analysis of the results indicated significant enhancements in terms of most accuracy indicators. For instance, the testing AUROC climbed from 0.898 to 0.905, 0.915, and 0.914, and after applying the SCE, EFO, and SOS, respectively. For a convenient comparison, Table 6 gives a summary of all five accuracy indicators used in this study, and Fig. 12a, b depicts the Taylor diagrams for the training and testing stages.

Taylor diagrams of the a training and b testing phases
By comparing the models, the superiority of the SOS with respect to the SCE and EFO is demonstrated. As shown in Fig. 6, the SOS was also the quickest algorithm (considering the number of iterations) in stabilizing the solution. This algorithm could optimize the ANN in 1000 iterations, while the SCE and EFO required threefolds and fiftyfolds of it, respectively. In contrast, by considering the time of optimization, the EFO was the fastest algorithm. The respective time of optimization for the SCE, EFO, and SOS was 9605, 605, and 46,255 s.
This study also attained significant improvements with respect to previous works carried out for the same/a similar study area. For example, Arabameri et al. (2020a) defined several data-division scenarios for testing the ability of conventional machine learning models. The highest accuracy of prediction was obtained by ANN with AUC = 0.868, which is considerably lower than the AUCs of the hybrid models tested in this work. Likewise, the hybrid models of this study outperformed several ensembles presented by Arabameri et al. (2020b). Moreover, the ANN model employed by Liu et al. (2023) produced a GESM with AUC = 0.904 when the best scenario (i.e., using 50% of erosions) was considered. This accuracy is less than the hybrid models in this study. From this paragraph, it can be deduced that the assistance of metaheuristic algorithms has improved the prediction accuracy of gully erosion.
The generated susceptibility maps in Fig. 7 were interpreted to identify the regions with critical susceptibility. Although there were differences regarding the fraction of these regions in the map of each model, the distribution of ‘High’ and ‘Very High’ susceptible areas was in good accordance together, based on which, these regions could be detected with a higher probability. From a practical point of view, this zonation may interest the relevant authorities to adapt their planning for establishing facilities (e.g., pipelines) and construction projects (e.g., road construction) within the study area.
However, there are some ideas that could be regarded in future projects to overcome the limitations of this study. First, due to the dimension of the adopted data, which itself called for the use of a deep network, the computations handled by each of the LM, SCE, EFO, and SOS algorithms were huge. More precisely, in the used ANN (see Fig. 5), a total of (20 × 25 =) 500 weights connect the first and second layers along with 25 biases and (25 × 1 =) 25 weights that connect the second and third layers along with one bias, which altogether yields 551 to-be-adjusted variables. It was basically the reason that the extracted formula is composed of many terms. It is believed that the optimization of the database by eliminating insensitive conditioning factors (e.g., ten inputs with reference to “Importance analysis”) could tangibly reduce the computational cost of this process. It is also worth mentioning that manual use of the ANN-based formula presented in “SOS-based GEI formula” requires normalizing inputs and unnormalizing the outputs, because these processes are automatically carried out in the MATLAB environment (Mehrabi 2021). Therefore, it may be more convenient if the user constructs an ANN using the given weights and biases. Concerning the case study, the focus of this research was on a specific region in Northern Iran, and the models are recommended for different study areas to see if the results are generalizable to different geological and environmental conditions. Moreover, to achieve a more comprehensive assessment of metaheuristic techniques, comparative studies are highly recommended. Although the SOS could optimize the ANN and enhance its accuracy by up to 91%, newer algorithms may enhance this accuracy even further.
Conclusions
Gully erosion susceptibility mapping (GESM) is a fundamental step toward mitigating the damages caused by this phenomenon. In this research, novel methodologies were used for GESM in the north of Iran. An artificial neural network (ANN) was optimized using symbiotic organisms search (SOS), shuffled complex evolution (SCE), and electromagnetic field optimization (EFO) metaheuristic algorithms. By comparing the maps developed by the conventional and optimized versions of the ANN, it was shown that metaheuristic algorithms can improve the ANN’s response to this issue. In terms of MSE, the training error of the ANN was reduced from 0.1188 to 0.1104, 0.0886, and 0.0635 after the incorporation of SCE, EFO, and SOS, respectively. Likewise, the testing MSE experienced a fall from 0.1350 to 0.1239, 0.1183, and 0.1235. To sum up, the performance of the four models was confirmed for producing reliable gully erosion susceptibility maps which can be considered for decision-making and relevant planning within the study area. This study, however, can be further improved by data optimization and using more metaheuristic techniques in future projects.
Availability of data and materials
The data used for the current study is available upon the reasonable request from the authors.
References
Abdi H, Williams LJ (2010) Principal component analysis. Wiley Interdiscip Rev Comput Stat 2:433–459
Abdullahi M, Ngadi MA (2016) Symbiotic organism search optimization based task scheduling in cloud computing environment. Futur Gener Comput Syst 56:640–650
Abedinpourshotorban H, Shamsuddin SM, Beheshti Z, Jawawi DN (2016) Electromagnetic field optimization: a physics-inspired metaheuristic optimization algorithm. Swarm Evol Comput 26:8–22
Abraham TH (2002) (Physio) logical circuits: the intellectual origins of the McCulloch–Pitts neural networks. J Hist Behav Sci 38:3–25
Al-Najjar HA, Pradhan B, Beydoun G, Sarkar R, Park H-J, Alamri A (2022) A novel method using explainable artificial intelligence (XAI)-based Shapley additive explanations for spatial landslide prediction using time-series SAR dataset. Gondwana Research
Arabameri A, Asadi Nalivan O, Chandra Pal S, Chakrabortty R, Saha A, Lee S, Pradhan B, Tien Bui D (2020a) Novel machine learning approaches for modelling the gully erosion susceptibility. Remote Sens 12:2833
Arabameri A, Asadi Nalivan O, Saha S, Roy J, Pradhan B, Tiefenbacher JP, Thi Ngo PT (2020b) Novel ensemble approaches of machine learning techniques in modeling the gully erosion susceptibility. Remote Sens 12:1890
Arabameri A, Chen W, Loche M, Zhao X, Li Y, Lombardo L, Cerda A, Pradhan B, Bui DT (2020c) Comparison of machine learning models for gully erosion susceptibility mapping. Geosci Front 11:1609–1620
Arabameri A, Chandra Pal S, Costache R, Saha A, Rezaie F, Seyed Danesh A, Pradhan B, Lee S, Hoang N-D (2021) Prediction of gully erosion susceptibility mapping using novel ensemble machine learning algorithms. Geomat Nat Haz Risk 12:469–498
Asadi Nalivan O, Mousavi Tayebi SA, Mehrabi M, Ghasemieh H, Scaioni M (2022) A hybrid intelligent model for spatial analysis of groundwater potential around Urmia Lake, Iran. Stochast Environ Res Risk Assess 37:1–18
Atashpaz-Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In: 2007 IEEE congress on evolutionary computation. Ieee, pp 4661–4667
Band SS, Janizadeh S, Chandra Pal S, Saha A, Chakrabortty R, Shokri M, Mosavi A (2020) Novel ensemble approach of deep learning neural network (DLNN) model and particle swarm optimization (PSO) algorithm for prediction of gully erosion susceptibility. Sensors 20:5609
Borrelli P, Poesen J, Vanmaercke M, Ballabio C, Hervás J, Maerker M, Scarpa S, Panagos P (2022) Monitoring gully erosion in the European Union: a novel approach based on the Land Use/Cover Area frame survey (LUCAS). Int Soil Water Conserv Res 10:17–28
Chakraborty S, Nama S, Saha AK (2022) An improved symbiotic organisms search algorithm for higher dimensional optimization problems. Knowl-Based Syst 236:107779
Chen J, Yang S, Li H, Zhang B, Lv J (2013) Research on geographical environment unit division based on the method of natural breaks (Jenks). Int Arch Photogramm Remote Sens Spat Inf Sci 3:47–50
Cheng M-Y, Prayogo D (2014) Symbiotic organisms search: a new metaheuristic optimization algorithm. Comput Struct 139:98–112
Conoscenti C, Agnesi V, Cama M, Caraballo-Arias NA, Rotigliano E (2018) Assessment of gully erosion susceptibility using multivariate adaptive regression splines and accounting for terrain connectivity. Land Degrad Dev 29:724–736
Dorigo M (1992) Optimization, learning and natural algorithms. Ph D Thesis, Politecnico di Milano
Duan Q, Gupta VK, Sorooshian S (1993) Shuffled complex evolution approach for effective and efficient global minimization. J Optim Theory Appl 76:501–521
Elmahdy SI, Mohamed MM, Ali TA, Abdalla JE-D, Abouleish M (2022) Land subsidence and sinkholes susceptibility mapping and analysis using random forest and frequency ratio models in Al Ain, UAE. Geocarto Int 37:315–331
Esmaili SK-SE-K, Khodashenas S (2020) Comparison of the symbiotic organisms search algorithm with meta-heuristic algorithms in flood routing model. J Water Soil 34:365–378
Esmaeili M, Osanloo M, Rashidinejad F, Aghajani Bazzazi A, Taji M (2014) Multiple regression, ANN and ANFIS models for prediction of backbreak in the open pit blasting. Eng Comput 30:549–558
Gao X, Cui Y, Hu J, Xu G, Wang Z, Qu J, Wang H (2018) Parameter extraction of solar cell models using improved shuffled complex evolution algorithm. Energy Convers Manage 157:460–479
Gayen A, Pourghasemi HR, Saha S, Keesstra S, Bai S (2019) Gully erosion susceptibility assessment and management of hazard-prone areas in India using different machine learning algorithms. Sci Total Environ 668:124–138
Geem ZW, Kim JH, Loganathan GV (2001) A new heuristic optimization algorithm: harmony search. SIMULATION 76:60–68
Goldanloo MJ, Gharehchopogh FS (2022) A hybrid OBL-based firefly algorithm with symbiotic organisms search algorithm for solving continuous optimization problems. J Supercomput 78:3998–4031
Guru B, Seshan K, Bera S (2017) Frequency ratio model for groundwater potential mapping and its sustainable management in cold desert, India. J King Saud Univ Sci 29:333–347
Hasanpour Zaryabi E, Moradi L, Kalantar B, Ueda N, Halin AA (2022) Unboxing the black box of attention mechanisms in remote sensing big data using XAI. Remote Sens 14:6254
Hornik K (1991) Approximation capabilities of multilayer feedforward networks. Neural Netw. https://doi.org/10.1016/0893-6080(91)90009-T
Jahanafroozi N, Shokrpour S, Nejati F, Benjeddou O, Khordehbinan MW, Marani A, Nehdi ML (2022) New heuristic methods for sustainable energy performance analysis of HVAC systems. Sustainability 14:14446
Jiang C, Fan W, Yu N, Nan Y (2021) A new method to predict gully head erosion in the Loess Plateau of China based on SBAS-InSAR. Remote Sens 13:421
Kaiser HF (1958) The varimax criterion for analytic rotation in factor analysis. Psychometrika 23:187–200
Karaboga D (2005) An idea based on honey bee swarm for numerical optimization. Technical report-tr06, Erciyes university, engineering faculty, computer
Kennedy J, Eberhart R (1995) Particle swarm optimization. In: Proceedings of ICNN'95-international conference on neural networks. IEEE, pp 1942–1948
Kim J-O, Ahtola O, Spector PE, Kim J-O, Mueller CW (1978) Introduction to factor analysis: what it is and how to do it. Sage, London
Kirkpatrick S, Gelatt CD Jr, Vecchi MP (1983) Optimization by simulated annealing. Science 220:671–680
Lee S, Pradhan B (2007) Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 4:33–41
Liu G, Arabameri A, Santosh M, Nalivan OA (2023) Optimizing machine learning algorithms for spatial prediction of gully erosion susceptibility with four training scenarios. Environ Sci Pollut Res 30:46979–46996
Maxwell AE, Sharma M, Donaldson KA (2021) Explainable boosting machines for slope failure spatial predictive modeling. Remote Sens 13:4991
Mehrabi M (2021) Landslide susceptibility zonation using statistical and machine learning approaches in Northern Lecco, Italy. Nat Hazards. https://doi.org/10.1007/s11069-021-05083-z
Mehrabi M, Moayedi H (2021) Landslide susceptibility mapping using artificial neural network tuned by metaheuristic algorithms. Environ Earth Sci 80:1–20
Mehrabi M, Pradhan B, Moayedi H, Alamri A (2020) Optimizing an adaptive neuro-fuzzy inference system for spatial prediction of landslide susceptibility using four state-of-the-art metaheuristic techniques. Sensors 20:1723
Moayedi H, Mehrabi M, Mosallanezhad M, Rashid ASA, Pradhan B (2019) Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng Comput 35:967–984. https://doi.org/10.1007/s00366-018-0644-0
Moayedi H, Mehrabi M, Bui DT, Pradhan B, Foong LK (2020) Fuzzy-metaheuristic ensembles for spatial assessment of forest fire susceptibility. J Environ Manage 260:109867
Moayedi H, Ghareh S, Foong LK (2021) Quick integrative optimizers for minimizing the error of neural computing in pan evaporation modeling. Eng Comput:1–17
Modak P, Mandal M, Mandi S, Ghosh B (2022) Gully erosion vulnerability modelling, estimation of soil loss and assessment of gully morphology: a study from cratonic part of eastern India. Environ Sci Pollut Res:1–32
More JJ (1978) The Levenberg-Marquardt algorithm: implementation and theory. Numerical analysis. Springer, Berlin, pp 105–116
Nachtergaele J, Poesen J (2002) Spatial and temporal variations in resistance of loess-derived soils to ephemeral gully erosion. Eur J Soil Sci 53:449–463
Nguyen H, Mehrabi M, Kalantar B, Moayedi H, MaM A (2019) Potential of hybrid evolutionary approaches for assessment of geo-hazard landslide susceptibility mapping. Geomat Nat Haz Risk 10:1667–1693. https://doi.org/10.1080/19475705.2019.1607782
Pal S, Paul S, Debanshi S (2022) Identifying sensitivity of factor cluster based gully erosion susceptibility models. Environ Sci Pollut Res 29:1–20
Phinzi K, Holb I, Szabó S (2021) Mapping permanent gullies in an agricultural area using satellite images: efficacy of machine learning algorithms. Agronomy 11:333
Poesen J, Nachtergaele J, Verstraeten G, Valentin C (2003) Gully erosion and environmental change: importance and research needs. CATENA 50:91–133
Poesen J, Torri D, Vanwalleghem T (2011) Gully erosion: procedures to adopt when modelling soil erosion in landscapes affected by gullying. Handbook of erosion modelling. Wiley Online Library, New York
Pourghasemi HR, Yousefi S, Kornejady A, Cerdà A (2017) Performance assessment of individual and ensemble data-mining techniques for gully erosion modeling. Sci Total Environ 609:764–775
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) GSA: a gravitational search algorithm. Inf Sci 179:2232–2248
Roy P, Chakrabortty R, Chowdhuri I, Malik S, Das B, Pal SC (2020) Development of different machine learning ensemble classifier for gully erosion susceptibility in Gandheswari Watershed of West Bengal, India. Mach Learn Intell Decision Sci:1–26
Schmitt A, Rodzik J, Zgłobicki W, Russok C, Dotterweich M, Bork H-R (2006) Time and scale of gully erosion in the Jedliczny Dol gully system, south-east Poland. CATENA 68:124–132
Seyedashraf O, Mehrabi M, Akhtari AA (2018) Novel approach for dam break flow modeling using computational intelligence. J Hydrol 559:1028–1038. https://doi.org/10.1016/j.jhydrol.2018.03.001
Song S, Jia H, Ma J (2019) A chaotic electromagnetic field optimization algorithm based on fuzzy entropy for multilevel thresholding color image segmentation. Entropy 21:398
Talebi B, Dehkordi MN (2018) Sensitive association rules hiding using electromagnetic field optimization algorithm. Expert Syst Appl 114:155–172
Valentin C, Poesen J, Li Y (2005) Gully erosion: Impacts, factors and control. CATENA 63:132–153
Vanmaercke M, Panagos P, Vanwalleghem T, Hayas A, Foerster S, Borrelli P, Rossi M, Torri D, Casali J, Borselli L (2021) Measuring, modelling and managing gully erosion at large scales: a state of the art. Earth Sci Rev 218:103637
Wang R, Zhang S, Pu L, Yang J, Yang C, Chen J, Guan C, Wang Q, Chen D, Fu B (2016) Gully erosion mapping and monitoring at multiple scales based on multi-source remote sensing data of the Sancha River Catchment, Northeast China. ISPRS Int J Geo Inf 5:200
Zhang J, Sun L, Zhong Y, Ding Y, Du W, Lu K, Jia J (2022) Kinetic model and parameters optimization for Tangkou bituminous coal by the bi-Gaussian function and Shuffled Complex Evolution. Energy 243:123012
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by MM, OAN, and MS. The first draft of the manuscript was written by MM, OAN, MK, and AK. MS and HM commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mehrabi, M., Nalivan, O.A., Scaioni, M. et al. Spatial mapping of gully erosion susceptibility using an efficient metaheuristic neural network. Environ Earth Sci 82, 459 (2023). https://doi.org/10.1007/s12665-023-11106-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-023-11106-8