
Abstract
Worldwide, old disposal sites of uranium mine and mill wastes are the objects of environmental restoration programs or have already been remediated. This is the case of Los Gigantes in Córdoba, Argentina, where uranium was extracted and processed in the 1980s; a local source of pollution to watercourses was generated as a consequence of disposal of solid and liquid wastes. The present study aims at describing the physicochemical characteristics of the surface watercourses that run across the complex, finding a grouping structure of the sampling sites according to their degree of pollution, and defining the variables that are significant to that grouping. The problem is addressed with both traditional and robust statistics techniques; additional chemometrical tools are also applied. It was found that streams close to the tailings and the pond exhibit lower pH and higher concentration of anions and metals compared to upstream watercourses. As the distance downstream to these pollution sources increases, all physicochemical parameters recover gradually, reaching levels close to background and complying with provincial and national regulations, proving that pollution is locally constrained.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Uranium mining remains controversial, principally because of environmental and health impacts associated with the early years of development of this industry. During the largely unregulated early phase several environmental impacts took place worldwide. Consequently many old disposal sites of uranium mine and mill tailings are now the objects of environmental restoration programs or have already been remediated. With over 430 nuclear reactors operational worldwide at the end of 2013, more than 70 under construction and many more under consideration, the provision of fuel for these long-lived facilities will be essential for the uninterrupted generation of significant amounts of base load electricity for decades to come. As a result, enhancing awareness of leading practices in uranium mining is increasingly important (International Atomic Energy Agency (IAEA) 2008; Nuclear Energy Agency (NEA) 2014).
Uranium mining and milling operations have been performed in Argentina since the 1950s. These activities took place in the past under a much less restrictive framework than current legislation. As a result different volumes of tailings and waste ponds exist that have been proved to be a source of pollution (Uranium Mining Environmental Restoration Project (PRAMU) 2005) and thus require to be adequately addressed. The country is currently running a “Uranium Mining Environmental Restoration Project” (PRAMU) to remediate legacies from former uranium mining and processing activities at eight different sites. This project, the first of its kind in the region, has so far enabled progress in civil works in the first site addressed, Malargüe, and financed baseline studies and radiological studies in two other sites: El Chichón and Los Gigantes (The World Bank 2014). This paper evaluates the situation of the former uranium production site Los Gigantes, Córdoba, Argentina.
Los Gigantes uranium mining site is located in the largely unpopulated mountainous granite Sierra Grande area, about 30 km southwest from the city of Villa Carlos Paz, Córdoba Province, Argentina (Fig. 1). In the area there have been recognized Paleozoic granitic rocks and detrital Quaternary sediments. In general, granites contain potassium feldspar, quartz, sodium plagioclase, biotite and muscovite and have a porphyritic texture which makes them easily strippable by weathering agents as well as structural factors, facilitating the entry and circulation of water. The presence of pegmatitic tabular intrusions with varying thicknesses and positions along rifts is frequent, especially the sub-horizontal or low angle rifts. This granite is the host rock for uranium mineralization (autunite and metaautunite). Rifts affecting these materials are the main ways for the circulation of water in them. There are many springs of meager flow that originate from these structures; most of these springs water emerges from horizontal to subhorizontal position fractures. The Quaternary in the area is mainly represented by a layer of loose granular material (regolith), which covers the granite bedrock. It has an important horizontal extension but is of little vertical development, with variable thickness from a few centimeters to 1.5–2.0 m. The sediment is predominantly sandy loam. Finally, fluvial deposits partially fill the main watercourses of the area, with thicknesses below the meter. It is generally sandy sediment. The ore is of very low grade, yielding only 300 g of uranium per ton. The open pit mine had an extension of 300 × 500 m. The exploitation was operated by a private company, under a contract with the Argentinean Comisión Nacional de Energía Atómica (CNEA), from 1982 to 1989.

Location of the ex-mining industrial complex Los Gigantes in Córdoba, Argentina. The gray surface on the right corresponds to populated areas
Mined ore was heap leached on-site; this process implied that the ore that was removed from the open-pit was crushed in a large mill, ground to sand consistency and mounded above grade on a prepared pad with an impermeable asphaltic membrane in its bottom. The ore was then leached with sulfuric acid so the uranium was mobilized: UO3 + 2H+ ====> UO2 2+ + H2O. The uranyl ion in solution forms stable complexes with the sulphate ion. The uranium in this pregnant leach liquor was recovered by ion exchange technique and then recovered from the eluate by precipitation with ammonium hydroxide: 2UO2SO4 + 6NH4OH ====> (NH4)2U2O7 + 2 (NH4)2SO4 + 3H2O. The diuranate was finally dewatered and dried to yield U3O8 (yellowcake). The effluent and leached residue were neutralized by the addition of Ca(OH)2 and discharged as a slurry into the waste retention pond.
When the mine had effectively ceased operation, 206 tons of uranium had been produced as ammonium diuranate. As a result of mineral extraction and processing, 3.5 million tons of solid wastes were generated and disposed of in separate piles: 2.5 million tons of tailings, 600,000 tons of low-grade (marginal) ore and 1 million tons of sterile overburden. Furthermore, 105 m3 of slurry along with 105 m3 of liquid effluents were collected and stored in a still pond (PRAMU 2005) (Fig. 2).

Waste facilities in Los Gigantes mining area
The major concern in mill tailings from a geochemical standpoint is the generation of acid pore waters. In low-pH waters, desorption of radionuclides and hazardous elements occurs, increasing their concentration. Seepage of such acid waters, in particular from unlined mill tailings, may affect the surrounding environment, including soils, surface water, and groundwater. In acid water leaching from tailings, dissolved uranium and daughter products can reach levels that are a direct threat to nearby ecosystems (Abdelouas 2006).
The watercourses that run across the industrial complex are headstreams of the San Antonio River Basin that flows down into the San Roque Lake. This lake is the major water source which provides drinking water to Villa Carlos Paz and Córdoba cities, the former located 30 km northeast from the industrial complex (Fig. 1). On the basis of previous hydrological research (Instituto Nacional del Agua (INA) 2001; División Química del Agua y del Suelo (DQAS) 2012) it is possible to determine that the streams that run through the mining solid or liquid wastes contribute with a flow rate of only 11.5 l s−1. Considering that the principal collector of the basin, the San Antonio River, has a mean discharge of 1057 l s−1 before it flows into the lake, this input is less than 1 %.
At a regional scale, the zone coincides with the fracture parallel to the mountain range, Los Gigantes, a groundwater recharge and discharge area, where water outflows as springs. The specific land where the industrial complex was built is known as La Mesada; it is part of the Achala batholith, a formation of fractured granitic rocks which holds an aquifer that is defined as poor according to its low permeability: 10−2 to 10−4 m3 day−1 (Instituto Nacional del Agua (INA) 2001). The drainage system is related to the structure of the underlying rock (Fig. 3). The region has a high drainage density and an angular drainage pattern, governed by fractured and diaclased granites and pegmatites. Steep natural slopes occur along with a shallow vegetation cover. The occurrence of severe convective storms and orographic effect result in a marked tendency to sudden rising and flooding. Rainfall makes up for the largest runoff volume during the summer time. During the dry months, the drainage system is supplied from underground flows. The River Cajón subbasin has a length of 0.13 km; in addition the river’s frequency is 2.28 rivers km−2, which altogether indicate short catchment response time.

El Cajón subbasin runoff structure. At a regional scale water flows due east
Rainwater falls on the mining wastes before infiltrating into the granitic rocks, thus altering, locally, its chemical characteristics. As a result, acid mining drainage, characterized by low pH and high concentration of cations and anions is found in the most impacted sites. Ions come from both natural occurring minerals that mobilize in contact with the acidic water and chemical products used in the industrial process such as sulphuric acid and calcium hydroxide. Previous monitoring data showed that the contamination sources are basically presently contained, with background values of chemical constituents (uranium, radon, heavy metals and other ions) downstream from the confluence of the Cambuche and Cajón Rivers (Fig. 2). The main concern is with its potential impact on spreading contamination downstream by eroded waste rock or polluted run-off from the site. The primary goal of the restoration works will be to keep the long-term leaching and off-site tailings transport to a minimum (Argentina 2003).
An environmental baseline and radiological study has recently been completed as the first step of the corresponding restoration plan. This study included periodic sampling of sediments, surface waters and groundwater for the physicochemical characterization and assessment of water quality, along with the development of a bioindicator based on benthonic diatoms communities. As a result, a large data set that imposes computational treatment has been generated. A first challenge arises from the fact that measurements are multivariate in nature and variables generally do not follow statistical normal distributions. In fact, in environmental chemistry it is very frequent to find lognormal distributions, which are particularly common for trace elements in natural waters, and also no statistical modeled distributions at all. Furthermore, when normal distributions occur it is almost the rule that the assumed normal distribution models (e.g. a linear regression model with normal errors) describe fairly well most observations, but fail to account for some observations that follow no pattern at all. Such atypical data are called outliers, and even a single outlier can have a large distorting influence on a classical statistical method under the assumption of normality or linearity, leading to results with unacceptable low statistical efficiency (Maronna et al. 2006). Before using classical statistics methods, the data should be transformed and tested for normality. If this cannot be provided by data transformation algorithms, non-classic statistics methods, e.g. robust statistics have to be applied (Einax et al. 1997).
The robust approach to statistical modeling and data analysis aims at deriving methods that produce reliable parameter estimates and associated tests and confidence intervals, not only when the data follow a given distribution exactly, but also when this happens only approximately, and even when there is no statistical distribution at all. Robust methods fit the bulk of the data correctly: if the data contain no outliers the robust method gives approximately the same results as the classical method, while if a small proportion of outliers are present the robust method gives approximately the same results as the classical method applied only to the bulk data. As a consequence of better fitting the bulk of the data, robust methods provide a very reliable method for detecting outliers, even in high-dimensional multivariate situations (Maronna et al. 2006).
The existence of outliers in environmental databases is a very important topic since they can have a considerable influence on the results of the analysis. There exist rigid definitions of outliers that consider them as “aberrant values that might be obtained through a wrong operation, going from a wrong setting of an instrument to transcription errors” (Massart et al. 1997), for which they have to be detected and removed. However, the presence of extreme values (provided their correct measurement) can also represent phenomena of interest. In fact, in polluted-site studies, it is common to find that the data contain some extremely high values that should not be eliminated (Berthold and Hand 2003; British Columbia Ministry of Environment (BCME) 2001).
This work presents the results of five surface water sampling campaigns developed for the Site Characterization Project “Study of the technical feasibility for the design and installation of a permeable reactive barrier” (Cicerone et al. 2009). The aim of the data analysis is to study the degree of pollution of watercourses that run across the mining complex. Sampling sites are classified according to their degree of pollution, a grouping structure of these sites according to their physicochemical characteristics is found, variables that are significant to that grouping are defined. The problem is addressed with both traditional and robust statistics techniques; additional chemometrical tools are also applied.
Methodology
Sampling and analytical methods
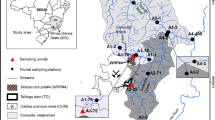
Samples were collected from 27 sites distributed throughout Los Gigantes mining complex (Fig. 5 in “Results”) during five sampling campaigns: (1) April 2010, (2) August 2010, (3) November 2010, (4) March 2011, and (5) November 2011. Sampling sites 3, 4, 5, 10, 13, 14 and 15 locate upstream from the exploitation; sites 16 and 29 are springs flowing from the still pond area; sites 31, 32 and 34 locate on springs that emerge from the tailings area, samples taken approximately 200 m (sites 31 and 32) and 400 m (site 34) from the piles; sites 62 and 63 locate on a creek, 600 and 1300 m downstream from the tailings, respectively; sites 1 and 28 are situated along the Del Cajón River within the complex; sites 8, 11, 33 and 73 are situated along the Cambuche River within the complex; sites 43, 46, 47, 75, 76, RIC and RSA locate along different water courses 1 km and further from the exploitation. Sample collection was performed according to EPA Method 0012.1 and Method 0008.7. Temperature, pH, electrical conductivity (EC), dissolved oxygen concentration (DO) and turbidity were measured in the field with a multiparameter Sension 156 HACH®. ICP optical spectrometry was used for the determination of Mn, Be, Cu, Zn, U, As, B, Pb (EPA Method 200.7); Ca, Mg and Fe were determined by means of atomic absorption spectrometry (EPA Method 242.1), chloride and sulfate were measured with ionic chromatography (EPA Method 300.0).
Database pretreatment
The database that arises from surface waters characterization consists of 138 objects (samples) and 17 physicochemical measured parameters. Initially, there were concentration levels below the detection limits; these were replaced by random numbers that ranged between zero and the corresponding detection limit. On the other hand the database contained a total of 45 missing data, distributed among 13 variables of 29 samples. Incomplete data matrices are a problem that is repeatedly encountered in environmental research (Junninen et al. 2004; Mwale et al. 2012). Missing values were filled up by using an artificial neural network of the class Self Organized Map (Folguera et al. 2015; García-Reiriz et al. 2011; Magallanes et al. 2011; Zupan et al. 1997).
Those variables with lognormal distribution were log10 transformed. Finally, every parameter distribution was scaled from 0 to 1 using minimax transformation (Zupan and Gasteiger 1999): \(e = \frac{{x - { \hbox{min} }}}{{{ \hbox{max} } - { \hbox{min} }}}\), where min and max are the minimum and maximum values of the variable, respectively, x is a value within the range of the variable and e is the scaled value, which results non dimensional.
Data analysis
First of all, with the objective of summarizing the water quality data in a single number that expresses the level of pollution of the sampling sites, the Canadian Council of Ministers Water Quality Index (WQI) (Canadian Council of Ministers of the Environment (CCME) 2001) was calculated for each sample. This index compares the measured data with specified quality objectives, which in our case were the guidelines for the protection of aquatic life defined in the national legislation (Argentinean Legislation 1993). According to the index value obtained, water quality is ranked from excellent to poor (index 100 to 0, respectively). Additionally, the relationships among environmental variables were assessed by means of their correlation matrix.
On the other hand, the multivariate structure of the data was studied by means of principal component analysis (PCA). This is a widespread chemometrical method which tries to explain the covariance structure of data by a small number of weighed linear combinations of variables, called components (Berthold and Hand 2003; Massart et al. 1997). Because PCA is concerned with data reduction, it is widely used for the analysis of high-dimensional data which are usually present in environmental analysis. The first component corresponds to the direction in which the projected observations have the largest variance. The second component corresponds to an orthogonal direction to the first one that again maximizes the variance of the data points projected on it. Continuing in this way, the method produces a number of principal components equal to the number of variables, which tie in with the eigenvalues and eigenvectors decomposition of the empirical covariance matrix. The very first PC’s explain the largest possible variation in the data and therefore those PC’s account for most of the information. Unfortunately, the classical variance (which is being maximized) and the classical covariance matrix (which is being decomposed) are very sensitive to anomalous observations. The first components are often attracted towards outlying points, and may not capture the variation of the regular observations. Therefore, data reduction based on classical PCA (CPCA) becomes unreliable if outliers are present in the data (Hubert et al. 2003). The goal of robust PCA (RPCA) methods is to obtain principal components that are not heavily influenced by outliers. The method proposed by Verboven and Hubert (2005) starts from an n × p data matrix X, where n stands for the number of objects and p for the number of variables. Robust estimates of the center μ and the scatter matrix ∑ of X are obtained by the minimum covariance determinant (MCD) estimator. The MCD method looks for the h(>n/2) (out of n) observations whose classical covariance matrix has the lowest possible determinant, that is the subset of observations with the minimum spatial volume, which implies to leave out the possible outliers. The raw MCD estimate of location is then the average of these h points, whereas the raw MCD estimate of scatter is their covariance matrix.
The physicochemical database was analyzed using both CPCA and RPCA, with a twofold goal: firstly, to find linear combinations of the original variables that contain most of the information, displaying the objects structure in the new PC subspace (score graphic) and analyzing variables contributions (loadings) to that structure; secondly, to flag extreme values by use of a diagnostic plot. The latter displays on the horizontal axis the score distance within the PC1–PC2 plane, \({\text{SD}} = \sqrt {t_{i}^{T} L^{ - 1} t_{i} }\), where L is the eigenvalues’ matrix and t i is the vector’ scores of the object i. On the vertical axis, the orthogonal distance to the PC1–PC2 plane \({\text{OD}} = \left\| {x_{i} - \hat{\mu }_{i} - P_{p,k} t_{i} } \right\|\) where x i is the vector of object i, \(\hat{\mu }_{i}\) is the average vector of the data matrix and \(P_{p,k}\) is the loading matrix (Fig. 4). The algorithm defines two respective cut-off values beyond which objects are considered anomalous (Verboven and Hubert 2005).

Projection of point ‘a’ from the space defined by the original variables X 1, X 2 and X 3 on a two-dimensional PC1–PC2 subspace. a–a′ is the orthogonal distance (OD); o–a′ is the score distance (SD)
To better visualize the structure of the data that emerges from their physicochemical characteristics, samples were clustered on the bases of their PCA scores, both classical and robust. The methods used for this purpose where k-means and silhouette plotting (Berthold and Hand 2003; Massart et al. 1997). K-means is a non-hierarchical clustering algorithm that treats each observation (sample) as an object having a neighboring location in the multidimensional space, in our case defined by the principal components. Objects are classified into k-clusters obtained iteratively by use of an optimization technique that minimizes within-cluster Euclidean distance (the distance of each point to the centroid of the cluster it was assigned to) or maximizes between-cluster distance (Massart et al. 1997). The number of clusters, k, is defined by the operator. Next, the silhouette plot can be used to visualize the resulting clusters and to assess how well-separated they are. This graphic displays a measure of how close each point in one cluster is to points in the neighboring clusters, which is called the silhouette value. This measures ranges from 1, indicating points that are very distant from neighboring clusters, through 0, indicating points that are barely distinguishable from one cluster or another, to −1, indicating points that are probably assigned to the wrong cluster or that belong to more than one cluster (Kaufman and Rousseeuw 1990).
Results
As it was expected, surface waters physicochemical characteristics varied greatly depending on the sampling sites positions relative to the pollution sources (Fig. 5; Table 1). The unaffected surface waters (upstream from the mine) were characterized by circumneutral pH and low conductivity (less than 60 µS cm−1), meaning that the cations and anions background levels are globally low. Samples collected at highly impacted sites, springs flowing from the still pond area (sites 16 and 29) and the tailings area (sites 31, 32 and 34), showed low pH values, high conductivity, high concentration of sulphate and significantly enrichment in Ca, Mg, Fe, and trace elements. In some cases concentrations of Mn, Be, Cu, Zn and U appear above the guidelines defined by the national legislation for the protection of aquatic life—Mn 100 μg l−1, Be 0.05 μg l−1, Cu 2 μg l−1, Zn 30 μg l−1, U 20 μg l−1 (Argentinean Legislation 1993). As the distance to the pollution sources increases downstream (sites 28, 1, 8, 33, 11, 73, situated on the rivers downstream from the springs confluences) pH rises, while EC as well as concentrations of sulphate, chloride and metals decrease (probably due to dilution effects, precipitation of metals as oxides and atmospheric carbon dioxide equilibrium). Concentrations levels close to the background values and within the national guidelines are found in the sites sampled right out of the exploitation, that is, site 43 in the case of the Del Cajón River (1000 m from the exploitation), and site 46 in the case of the Cambuche River (4000 m from the exploitation).

Water sampling sites in Los Gigantes. The grouping that result from PCA analysis, according to their level of impact, is mapped here
Table 2 shows the correlation matrix between physicochemical parameters. In general, cations are correlated positively among themselves and negatively with pH, due to the fact that acidic conditions solubilize minerals such as potassium feldespate (pertitic microcline), sodium plagioclase, muscovite, oxides (quartz, zircon, rutile) and salts (apatite) nonspecifically. Ca and Mg exhibit the highest correlation (0.91), both cations have a large correlation coefficient with sulphate as well (0.72 and 0.70, respectively) which can be explained in terms of the high contents of Ca and Mg sulphate in the dam and the piles. These compounds arose from the neutralization of sulphuric acid with calcium hydroxides (with significant contents of magnesium).
In the case of CPCA the capture of variance for the first three components is 59, 13 and 7 %, respectively (accumulated variance 79 %). For RPCA the capture of variance is slightly higher: 62, 16 and 6 % (accumulated variance 84 %).
The RPCA analysis reveals the existence of four groups of samples (Fig. 6): group 1 consists of samples that correspond to the most impacted sites, average WQI = 58.1; group 2 comprises samples from sites with an intermediate level of impact, average WQI = 80.5; group 3 corresponds to samples from the least impacted sites, average WQI = 98.4; group 4 includes most samples of the forth campaign, except for those that were collected at the most impacted sites thus assigned to group 1. Table 3 shows the loadings of the first three PC’s: cations (except As) and anions concentrations have positive loadings to PC1, while pH and DO have negative loadings.

Robust PCA scores of water samples
Since mining impact implies an increase in the concentrations of ions in water bodies as well as a decrease in pH it can be concluded that sites separate along PC1 according to their degree of pollution. Thus, sites with a minimum impact show low scores on PC1, while highly positive scores along PC1 are indicative of mining pollution. Group 4 appears as a whole different group, separated from group 3 along PC2. The former group comprises samples taking during the fourth campaign, which was conducted during a period of unusually high rainfall. The exceptional weather conditions might account for the differences among the variables that make the greatest contributions to PC2, since these unusual rainfalls might have occasioned a decrease in some compounds concentration levels as a result of dilution as well as a more significant increase in other ions due to mobilization from mining wastes.
As regards CPCA, samples scores lead to the similar clustering as RPCA. However, there exists a difference in the parameters loadings on the PC’s (Table 3). PC1 and PC2 are mostly characterized by the same variables in both CPCA and RPCA, but their order is different. In CPCA the loading for pH on PC1 is in fourth place, while as a result of RPCA this parameter holds the seventh place. Arsenic and turbidity make a similar contribution to PC2 in CPCA, while in the robust version As loading is one order larger compared to that of turbidity. Cations loadings order for the first two principal components differs as well. In the case of PC3 parameters make their contributions in the same order for both PCA methods.
The partitioning technique applied to PCA scores (Fig. 7) confirms PCA results: sites are grouped in four clusters: silhouette 1 comprises samples from sites with an intermediate level of impact (group 2 in Fig. 6), silhouette 2 includes most samples of the forth campaign, except for those collected at the most impacted sites (group 4 in Fig. 6), silhouette 3 corresponds to the most impacted sites (group 1 in Fig. 6) and silhouette 4 comprises the least impacted sites (group 3 in Fig. 6). Both CPCA and RPCA throw identical results as regards sites assignment to each silhouette although there exists a slight difference in the sites silhouette values, these being higher in the robust version.

Silhouette plot. Each silhouette corresponds to a group of sites with a specific impact level
The diagnostic plot obtained from RPCA (Fig. 8) spots as outliers two types of samples: first, those taken at highly impacted sites (mean WQI = 52); a second group of samples consisting on samples with WQI = 100 and samples with extreme values in one or two parameters but below the guidelines in the rest. Table 4 shows the average values of the physicochemical parameters measured in the bulk of the data (data without outliers), and, separately, in the two groups of outliers. The latter locate clearly far away from the majority of the data, i.e. their physicochemical parameters means are different. If the corresponding classical statistics were calculated including them, the results would be inaccurate. This is the reason why the classical method (Fig. 9) is less efficient in the detection of extreme values: the number of sites labeled as such is lower than those detected with the robust technique.

Robust diagnostic plot. Objects beyond the horizontal and/or vertical lines are considered outliers. Numbers before hyphens indicate sampling sites, numbers after hyphens indicate sampling campaign

Classic diagnostic plot. Objects beyond the horizontal and/or vertical lines are considered outliers. Numbers before hyphens indicate sampling sites, numbers after hyphens indicate sampling campaign
In Fig. 5 the groups of sites obtained with PCA are mapped on the mining area. This image reveals the relationship between the location of the sites relative to the waste facilities and their level of mining impact. The group of the most impacted sites comprises the area close to the piles of solid wastes and the still ponds; the group of sites with an intermediate impact locate either further from the contamination sources or enjoy the dilution effect of clean incoming streams; the group of least impacted sites correspond to two different zones: the area upstream from the piles and ponds, and the area downstream of these where the rivers recover naturally.
Conclusions
Restoration of abandoned uranium mines in Argentina has been taking place since 2005. Environmental monitoring plans imply handling large multivariate, non-normal distributed, outliers carrying data sets. This poses a computational challenge that must be addressed by use of proper chemometrical methods.
The analysis of surface water samples from the mining and milling complex Los Gigantes shows that there still exist pollution sources that need to be correctly addressed. Surface streams close to the tailings and the pond exhibit lower pH and higher concentration of anions and metals compared to upstream watercourses. All physicochemical parameters recover gradually downstream from the complex, reaching levels close to background and complying with provincial and national regulations at the sampling sites located outside of the mining complex proving thus that pollution is locally constrained.
CPCA grouped objects in four clusters according to their level of mining pollution. The same result was obtained with RPCA, and confirmed by k-means clustering and silhouette plotting. In both CPCA and RPCA the first PC, separated samples according to their general level of pollution. Along the second PC it was possible to identify a complete sampling campaign performed under exceptional weather conditions. The variables loadings order and magnitudes differed if they were calculated with CPCA or RPCA. Mapping the four groups allowed seeing the spatial distribution of zones with a different degree of mining impact. Samples with extreme values were detected by means of a diagnostic plot in the classical and robust versions; in the robust plot a larger number of outliers were spotted. These results show that the classical definition of outliers, that considers them as aberrant values that have to be removed, might not be applicable to environmental problems because they can actually imply an important piece of information.
So far it has been shown that in certain cases CPCA and RPCA are likely to throw dissimilar results, which in the case of environmental management might lead to different decision making. Assessing which method is more efficient for the purposes of the study becomes then necessary. In our case, identification of parameters that are able to separate samples according to their levels of impact is of high importance for the monitoring plan; so is the recognition of pristine and extremely polluted sites. It has been pointed out that the presence of extreme values in a population attracts statistic parameters that are calculated upon normality assumption towards those outliers, thus leading to unreliable results. Since ROBPCA does not include extreme values in the variance and covariance estimation, their distorting influence is averted, thus this method is preferred over CPCA.
After an exploratory campaign, robust statistics proved to be a reliable tool for the detection of sampling sites of interest for the monitoring plan; highly polluted sites were spotted as well as pristine sites. Identification of the former is crucial to environmental management since it allows planning the resources assignment where they are needed, including the level or goals to be achieved by the restitution/remediation/restoration actions. Recognition of clean sites might be useful for the definition of quality targets in a restoration process. Finally, robust techniques are suitable for finding the most contributing physicochemical parameters, which are also a key step for directing reasonable efforts in the monitoring plan and for identification of potential sources of contamination.
References
Abdelouas A (2006) Uranium mill tailings: geochemistry, mineralogy, and environmental impact. Elements 2(6):335–341
Argentina (2003) Argentina Mining and Milling Uranium Wastes Sites Restoration (PRAMU) environmental assessment. Joint Convention on the Safety of Spent Fuel Management and on the safety of radioactive waste management. National report
Argentinean Legislation (1993) Regulation decree 831/93 of Hazardous Wastes National Law 24.051. In: Official sate bulletin 27.630. Buenos Aires
Berthold MR, Hand DJ (2003) Intelligent data analysis: an introduction, 2nd edn. Springer, Berlin
British Columbia Ministry of Environment (BCME) (2001) Outliers, a Guide for data analysts and interpreters on how to evaluate unexpected high values. Contaminated sites statistical applications guidance document 12-8 (Internet). http://www.env.gov.bc.ca/epd/remediation/guidance/technical/pdf/12/gd08_all.pdf. Accessed 2 Nov 2014
Canadian Council of Ministers of the Environment (CCME) (2001) CCME Water Quality Index 1.0, user’s manual. In: Canadian Council of Ministers of the Environment (eds) Canadian environmental quality guidelines for the protection of aquatic life, Winnipeg
Cicerone D, Gómez del Río J, Sánchez Proaño P, Grande Cobián D (2009) Technical feasibility study for the design and installation of a permeable reactive barrier. Comisión Nacional de Energía Atómica internal report: PP-SNAGQ_DAS-01
División Química del Agua y del Suelo (DQAS) (2012) Comisión Nacional de Energía Atómica internal report IN-GQ_DQAS-00
Einax JW, Zwanziger HW and Geiß S (1997) Chemometrics in environmental analysis. VCH Verlagsgesellschaft mbH Weinheim
Folguera L, Zupan J, Cicerone DS, Magallanes JF (2015) Self-organizing maps for imputation of missing data in incomplete data matrices. Chemometr Intell Lab 143:146–151
García-Reiriz A, Magallanes JF, Zupan J, Líberman S (2011) Artificial neural networks to evaluate the boron concentration decreasing profile in blood-BPA samples of BNCT patients. Appl Radiat Isotopes 69:1793–1795
Hubert M, Rousseuw PJ, Branen KV (2003) ROBPCA: a new approach to robust principal component analysis. Technometrics 47(1):64–79
Instituto Nacional del Agua (INA) (2001) Investigación Hidrogeológica en el Área Los Gigantes. Subsecretaría de Recursos Hídricos de la Nación, Ministerio de Panificación Federal, Inversión Pública y Servicios de la República Argentina. Technical report IT-201
International Atomic Energy Agency (IAEA) (2008) Estimation of global inventories of radioactive waste and other radioactive materials. Technical document IAEA-TECDOC-1591
Junninen H, Niska H, Tuppurainen K, Ruuskanen J, Kolehmainen M (2004) Methods for imputation of missing values in air quality data sets. Atmos Environ 38:2895–2907
Kaufman L, Rousseeuw PJ (1990) Finding groups in data: an introduction to cluster analysis. Wiley, New York
Magallanes JF, García Reiriz AG, Líberman S, Zupan J (2011) Kohonen classification applying ‘missing variables’ criterion to evaluate the pboronophenylalanine human-body-concentration decreasing profile of boron neutron capture therapy patients. J Chemometrics 25(6):340–347
Maronna RA, Douglas DM, Yohai VJ (2006) Robust statistics, theory and methods. Wiley, England
Massart DL, Vandeginste BGM, Buydens LMC, De Jong S, Lewi PJ, Smeyers-Verbeke J (1997) Handbook of chemometrics and qualimetrics. Elsevier, Amsterdam
Mwale F, Adeloye A, Rustum R (2012) Infilling of missing rainfall and streamflow data in the Shire river basin, Malawi. A self organizing map approach. Phys Chem Earth 50–52:34–43
Nuclear Energy Agency (NEA) (2014) Managing environmental and health impacts of uranium mining. Organization for Economic Cooperation and Development. NEA 7062, Paris
The World Bank (2014) Restructuring paper on a proposed project restructuring of Argentina mining environmental restoration project (P110462). Report 79771-AR
Uranium Mining Environmental Restoration Project (PRAMU) (2005) Evaluación Ambiental, document Marco. Comisión Nacional de Energía Atómica. Internal report INF-04-010
Verboven S, Hubert M (2005) LIBRA: a MATLAB library for robust analysis. Chemometr Intell Lab 75:127–136
Zupan J, Gasteiger J (1999) Neural networks in chemistry and drug design. Wiley-VCH, Weinheim
Zupan J, Novič M, Ruisánchez I (1997) Kohonen and counterpropagation artificial neural networks in analytical chemistry. Chemometr Intell Lab 38:1–2
Acknowledgments
This study was made possible with the financial support provided by the Comisión Nacional de Energía Atómica through the project PP-SNA_GQ_GQA-DSA-01. The authors would like to thank the coworkers of the División Química del Agua y del Suelo and División Química Analítica of the Centro Atómico Constituyentes.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Folguera, L., Magallanes, J. & Cicerone, D. Analysis of the environmental liabilities generated by past activities in uranium mining exploitation in the Province of Córdoba, Argentina. Environ Earth Sci 75, 407 (2016). https://doi.org/10.1007/s12665-015-5178-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-015-5178-9