
Abstract
Human activity recognition aims to identify the activities carried out by a person. Recognition is possible by using information that is retrieved from numerous physiological signals by attaching sensors to the subject’s body. Lately, sensors like accelerometer and gyroscope are built-in inside the Smartphone itself, which makes activity recognition very simple. To make the activity recognition system work properly in smartphone which has power constraint, it is very essential to use an optimization technique which can reduce the number of features used in the dataset with less time consumption. In this paper, we have proposed a dimensionality reduction technique called fast feature dimensionality reduction technique (FFDRT). A dataset (UCI HAR repository) available in the public domain is used in this work. Results from this study shows that the fast feature dimensionality reduction technique applied for the dataset has reduced the number of features from 561 to 66, while maintaining the activity recognition accuracy at 98.72% using random forest classifier and time consumption in dimensionality reduction stage using FFDRT is much below the state of the art techniques.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Since 1979, the year in which the first ever commercial handheld mobile phones were introduced, there has been no stopping in the growth of it. The mobile phones were used by 80% of the world population by the year 2011. In a very short period of time, mobile phones have become part of our life. The new generation smartphones are equipped with many features with the help of many sensors. With the use of these features in the smartphones, it is very easy to keep track of our daily activities. These kinds of assistive technologies can be useful for remote health care, for the disabled, the elderly and to those with important needs. Human activity recognition is a very active research field in which techniques for understanding human activities by interpreting attributes taken from motion, physiological signals, location and environmental information etc.,
Human activity recognition identifies the actions done by a person given a set of observations. The recognition can be done by using the information taken from sensors. The main objective of activity recognition system is to identify the actions performed by humans, from the collected data through sensors. The latest smartphones have motion, acceleration or inertial sensors, and by using the information taken from the sensors, recognition of activities is possible. Since it is possible to collect a large amount of data through the features available in smartphones but the challenge lies in processing the data and implementing it in real time applications. So, there is an important need for new data mining schemes to end these kinds of challenges. Since we have many features derived from sensors like accelerometer and gyroscope, it is essential to use feature selection algorithms to simplify the computing process by reducing the number of features. mRMR feature selection algorithm has been used in a study to reduce the dimensionality of features (Doewes 2017). Accordingly, in this paper fast feature dimensionality reduction technique has been employed for dimensionality reduction of features. Different classification methods were used for evaluating the result.
This paper has been constructed in the following way: previous work has been depicted in Sect. 2. The details about the activity recognition datasets have been presented in Sect. 3. The proposed work has been described in Sect. 5. The experimental results have been discussed in Sect. 6. The paper concludes with the outcomes and future work.
2 Related works
Major works have been done in dimensionality reduction techniques. We have proposed an algorithm called fast feature dimensionality reduction technique to reduce the number of features and avoid high computational cost. Most of the successful metric learning techniques suffer from computational cost.
2.1 Dimensionality reduction methods
Dimensionality reduction is the process of reducing the number of features by removing irrelevant features and keeping only important features. Feature selection and extraction methods are very important to attain dimensionality reduction for high dimensional data. Several works have been carried out in the past on feature selection and extraction methods to reduce the dimension of feature space.
Kira and Rendall (1992) proposed a feature selection algorithm called Relief which reduces the number of features by selecting only relevant features. In Partridge and Calvo (1998), presented a simple and fast algorithm to reduce the number of features. Their proposed method shows a fast convergence rate compared to other techniques. In Goldberger (2005), have proposed a novel scheme for learning a Mahalanobis distance measure to be used in the KNN classification technique. The performance of their proposed method is demonstrated using several datasets. But the method suffers from high computational cost. In Yang (2012a), Yang W et al. presented a fast neighborhood component analysis (FNCA) method. FNCA uses a local probability distribution model constructed based on its K nearest neighbors from both the same class and different classes. Compared to NCA, FNCA has significantly increased the training speed. Yang (2012b) proposed a novel nearest neighbor feature weighting algorithm, which learns a feature weighting vector by increasing the expected leave-one-out classification accuracy. Their proposed method works well with several datasets. Chetty (2015) have presented an information theory-based feature ranking algorithm. Random forests, ensemble learning, and lazy learning were used for the evaluation of their proposed method.
In Wang (2016), have presented a modified ReliefF algorithm that overcomes the shortcomings of the ReliefF algorithm. Experimental results show the improvement in classification accuracy. Walse (2016) have used PCA to reduce the number of features. MLP is used for evaluating their proposed method. Francis (2017) have evaluated Nystrom KPCA and other methods for the classification tasks. Several real world datasets were used for evaluation. Doewes (2017) have used the mRMR method to reduce the number of features. SVM and MLP classifiers were used for evaluating the mRMR method. Zhang and Zhang (2018) have presented a dual-channel model to separate the spatial and temporal feature extraction. Their proposed method used two separate channels to capture the complementary static form information from the single frame and dynamic motion information from a multi-frame. In Jansi and Amutha (2018), have proposed a chaotic map based dimensionality reduction and a sparse based classifier. They have compared their proposed work with other methods.
The previous works Chetty (2015), Doewes (2017), Jansi and Amutha (2018), Kira and Rendall (1992), Wang (2016),and Yang (2012b) have concentrated only on accuracy and achieved in the range of 90–98% but did not work on computational cost. The work Goldberger (2005) has suffered from high computational cost. The authors Yang (2012a) claimed to have overcome the problem of Goldberger (2005) but did not concentrate much on accuracy. In Francis (2017), the authors have worked on both accuracy and computational cost and achieved 98.21% and 4.61 s. The authors Walse (2016) have worked on both computational cost and accuracy. They have achieved an accuracy of 96.17% and a computational cost of 128s. However, the scope for improvement is still wide open. We have used both accuracy and computational cost as our performance metrics. Our proposed method has performed exceptionally well compared to existing methods.
2.2 Human activity recognition
Human activity recognition has gained a lot of attention recently because of its application like ambient assisted living etc. Several authors have worked on human activity recognition systems. Some of their works have been listed below:
Meng (2008) have developed a fast human activity recognition system. They have implemented the human action recognition on reconfigurable architecture and achieved recognition accuracy of 80%. Reyes-ortiz (2015) have given a detailed study on human activity recognition. A compilation of several techniques has been exposed and studied. Chen (2016) have proposed a depth motion based human action recognition. Action recognition is performed using distance weighted Tikhonov matrix with an l2 regularized collaborative representation classifier. Asteriadis and Daras (2017) have proposed a novel multi-modal human activity recognition method. Their proposed method supports the online adaptivity of modalities, dynamically, according to their automatically inferred reliability.
All the previous works on HAR have either used a camera or wearable sensors for identifying the actions. Vision-based action recognition is time-consuming and the necessity of using the wearable sensors on the body may introduce constraints in the subject’s movement. On the other hand, smartphone sensors can be used for activity recognition, since nobody will feel uncomfortable in using it.
2.3 Human activity recognition using smartphone sensors
Human activity recognition based on inertial sensors has gained popularity recently and many researchers have investigated it in their work. Lately, the advent of using these inertial sensors in smartphones has opened a wide range of applications. Some of the works have been discussed below:
Anguita (2012) have proposed an inertial sensor-based human activity recognition system using smartphones. The hardware-friendly approach used for multiclass classification works well and overcomes the power constraints of mobile phones. In Anguita (2013)), have proposed a novel energy-efficient method for human activity recognition using smartphones for remote patient monitoring. They proposed a modified SVM for multiclass classification. In Bayat (2014), gave an elaborate study on how different types of human physical activities can be identified using a mobile phone. The authors have designed a new digital LPF to separate the gravity acceleration data from that of body acceleration data. Kwon (2014) proposed human activity recognition based on unsupervised learning methods with the data collected from smart phone sensors. Su (2014) have surveyed recent advances in human action recognition using smartphone sensors. The authors have reviewed core data mining techniques that were behind human activity recognition algorithms. Catal (2015) have proposed a novel activity prediction model and combined several machine learning classifiers with the average of probabilities combination rule. Their proposed model outperformed the MLP based recognition technique.
Ronao and Cho (2016) have presented a deep convolutional neural network to perform a smartphone-based effective HAR system using the 1D time-series signals. Their proposed work has extracted relevant and complex features. Tran and Phan (2016) have designed a system for human activity recognition using built-in sensors of smartphones. They have used six different activities and SVM for classification. San-Segundo (2016a) have presented an HMM-based human activity recognition and segmentation using a smartphone. Reyes-ortiz (2016) have presented transition-aware human activity recognition (TAHAR) system architecture. The proposed architecture can recognize physical activities using smartphones. Jain and Kanhangad (2016) have presented a behavioral biometrics-based gender recognition using smartphones. Gait data from the accelerometer and gyroscope sensors of a smartphone have been used for gender recognition. Akhavian and Behzadan (2016) have presented a construction workers’ activity recognition system using smartphones.
In San-Segundo (2016c), have proposed a Human sensing system based on hidden Markov models (HMMs) for classification of physical activities. The system includes a HMMs training module, a feature extractor and an HAR module. San-Segundo (2016b)) presented an adaptation of strategies used in speech processing in human activity recognition and segmentation (HARS) system based on hidden Markov models (HMMs) for recognizing and segmenting different physical activities. Alveraz de la Concepcion (2017) have discussed the importance of the rehabilitation process for elders and proposed an algorithm called Ameva. Cao (2017) have proposed an efficient group-based context-aware classification method for human action recognition on smartphones. It uses the group-based method to improve classification accuracy. Dao (2017) have proposed a new method for human activity recognition. Their proposed work can detect the activity of a new user at the beginning itself.
The inertial sensors of smartphones are essential for HAR, but it produces more data which increases the computational cost. High computational cost leads to more power consumption. But the smartphones have power constraints. An efficient dimensionality reduction method is required to overcome the above-said problem. We have proposed a novel dimensionality reduction technique and used both accuracy and response time as performance metrics. Our proposed method has shown an excellent performance in comparison with the existing methods.
3 Activity recognition dataset
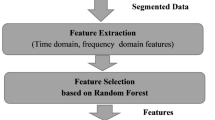
Figure 1 shows a human activity recognition system. In our approach, we have used two activity recognition datasets for experimental validation. They are (1) Publicly available (UCI HAR) activity recognition (AR) dataset. (2) Elderly AR dataset (own dataset for real-time data analysis).
3.1 UCI HAR dataset

Human activity recognition system (Chetty 2015)
This dataset contains labeled data collected from thirty subjects in the age bracket of 19–48 years. Each subject performed six different activities like standing, sitting, lying down, walking on flat ground, walking upstairs and walking downstairs by wearing a smartphone around the waist. A Samsung Galaxy S2 smartphone is used to collect the data, which consists of an accelerometer and a gyroscope to measure 3-axial linear acceleration and angular velocity respectively at a constant rate of 50Hz, which is enough to capture human body motion. The database contains a dataset with extracted features. The dataset contains multiple vectors; each vector consists of 561 features.
3.2 Elderly activity recognition (AR) dataset
We have created our own dataset to attain real time data analysis. A Smartphone is used to collect sensor data from 10 subjects aging 60 and more. Five male and five female subjects have participated in the data collection process. Sensoduino application is installed on the mobile to transfer the accelerometer data to the laptop (using Tera Term software) through Bluetooth. For every 100 ms, a value was generated, i.e., at a rate of 600 data per minute. Each subject performed five different activities like sitting, walking upstairs, walking downstairs, standing, and walking by wearing a smartphone around the waist. Time-domain features were extracted from raw sensor data. The dataset contains multiple vectors; each vector consists of 21 features.
4 Proposed feature dimensionality reduction method
High dimensional investigation rises as one of the significant areas of research. The transmission, processing, and storing of high dimensional data creates very great demands on computing systems. Hence, it is essential to decrease the dimensionality of the high dimensional data (Yang 2012a). In this section, we have proposed a dimensionality reduction technique.
We start by taking the inputs, the dataset \(n\times k\), the number of classes j, and the weights \(w_1\) & \(w_2\). Since the features extracted from IMU data do not change much in every vector, we have randomly selected only five feature vectors \(f_i\) from class \(c_1\) and it is arranged as a column vector \(f_{i1}'\). Similarly, five feature vectors are randomly selected from each class and arranged as column vectors. All these column vectors from all the classes are grouped together to form a matrix \(A_{ij}\).
The matrix \(A_{ij}\) is divided into five groups \(g_1 = f_{1j}, g_2 = f_{2j},\ldots ,g_5=f_{5j}\). Such that each group consists of one feature vector from each class. We have calculated the Euclidean distance between each feature from one vector with other vector in the group.
Similarly in all the groups the Euclidean distance has been calculated.
Now by changing the weights \(w_1\) & \(w_2\), the number of features has been reduced (Table 1).
Extensive work has been carried out with different classification techniques. Brief details about the classification techniques are given below.
4.1 Naive Bayes
This classifier is based on Bayes theorem and calculates probabilities in order to perform Bayesian inference. This method is based on supervised learning. It is a straight forward method to train the model, and performs quiet well in terms of accuracy.
4.2 k-NN
K nearest neighbors is a very simple algorithm that stores the available cases and classifies a new case based on the distance function. KNN is used in statistical estimation and pattern recognition.
4.3 Random forest
Random forest technique is based on ensemble learning methods for regression and classification. It constructs a number of decision trees at the time of training and gives out the mode of the classes as output class.
4.4 Deep learning
The recent trend in feature classification is deep learning. More robust features can be extracted. Complexity of feature extraction can be reduced by increasing the number hidden layers (Ronao and Cho 2016).
5 Experimental results
To evaluate the performance of the proposed feature dimensionality reduction approach for human activity recognition, we have used two datasets. One is a publicly available online dataset, and the other one is an own dataset. We have used MATLAB 2017a for simulation work. The performance parameters are deduced from the confusion matrix. The following metrics are used as performance parameters. They are
-
The performance parameters can be deduced from the confusion matrix. They are
-
True positives (TP): The number of positive instances that were classified as positive.
-
True negatives (TN): The number of negative instances that were classified as negative.
-
False positives (FP): The number of negative instances that were classified as positive.
-
False negatives (FN): The number of positive instance that were classified as negative.
Accuracy A is the mostly used performance evaluation measure to find out the overall classification performance for all classes.
F-score F is derived by finding the harmonic mean of precision and recall. F-score is calculated using the following equation.
Precision P is obtained by using the following equation.
Recall R is calculated by using the following equation.
5.1 UCI HAR dataset
We have used 70% of the online dataset. It consists of 561 features. Each record consists of the following attributes:
-
(a)
Triaxial acceleration.
-
(b)
Triaxial Angular velocity.
-
(c)
Vector of 561 features with frequency and time domain variables.
-
(d)
It’s activity label.
-
(e)
An identifier of the subject.
Figure 2 shows the accuracy versus number of features used. We have used different values of \(w_1\) and \(w_2\) to reduce the number of features. We have used \(w_2 = 0.7\) (constant) and changed \(w_1\) from 0.2 to 0.4 (increased insteps of 0.05 from 0.2). The number of features were 195, 133, 96, 66 and 39 when \(w_1\)=0.2, 0.25, 0.30, 0.35 and 0.40 respectively.

Accuracy (%) vs number of features (UCI HAR dataset)
We have chosen \(w_1 = 0.35\) and \(w_1 = 0.70\) (i.e., 66 features only) for calculating performance parameters. It has not only reduced 88% of features but also shown the best classification performance. We have used classifiers such as k-NN, random forest, Naive Bayes, and deep learning for evaluating the proposed approach.
We have organized the classification results in a confusion matrix. Tables 2, 3, 4, and 5 are showing the confusion matrix of all four classifiers. From these confusion matrices, we can calculate the performance parameters like accuracy, precision, F-score, and Recall. The results are plotted as shown in Figs. 3 and 4.

F-score of each activity using different classifiers (UCI HAR dataset)

Precision of each activity using different classifiers (UCI HAR dataset)
Table 6 shows the classifier performance of proposed FFDRT for UCI HAR dataset. FFDRT with kNN, we have attained 98.45% accuracy and 95.35% recall. FFDRT with Random Forest, we have attained 98.72% accuracy and 96.15% recall. FFDRT with Deep Learning, we have attained 98.68% accuracy and 96.05% recall. FFDRT with Nave Bayes, we have attained 93.00% accuracy and 81.69% recall. The performance of kNN, random forest, and deep learning are extremely good compared to Naive Bayes.
5.2 Elderly AR dataset
Our dataset consists of 21 features in each vector. 80% of the dataset was used for training and 20% for testing.
Figure 5 shows the accuracy versus the number of features used. We have used different values of \(w_1\) and \(w_2\) to reduce the number of features. We have used \(w_2\) = 4 (constant) and changed \(w_1\) from 0.5 to 2. The number of features were 10, 7, 5 and 2 when \(w_1\)=0.5, 0.75, 1 and 2 respectively.

Accuracy (%) vs number of features (elderly AR dataset)
We have chosen \(w_1\) = 1 and \(w_2\) = 4 (i.e., 5 features only) for calculating the performance parameters. It has not only reduced 76% of features but also shown the best classification performance. We have used classifiers such as k-NN, and random forest for evaluating the proposed approach.
We have organized the classification results in a confusion matrix. Tables 7 and 8 are showing the confusion matrix of the two classifiers. From these confusion matrices, we can calculate the performance parameters like accuracy, precision, F-score, and Recall. The results are plotted as shown in Figs. 6 and 7.

F-score of each activity using different classifiers (elderly AR dataset)

Precision of each activity using different classifiers (elderly AR dataset)
Table 9 shows the classifier performance of proposed FFDRT for elderly AR dataset. FFDRT with kNN, we have attained 94.73% accuracy and 87.50% recall. FFDRT with random forest, we have attained 93.56% accuracy and 85% recall. The accuracy and recall of kNN and Random Forest are very close, but kNN holds the better performance.
5.3 Result comparison with other works
For the comparative study, we have used the evaluation results of the publicly available online dataset since many researchers have used the same dataset.
Information theory based dimensionality reduction method used in Chetty (2015) reduced the number of features to 128 and achieved an accuracy of 55.31% using Naive Bayes and 94.29% using random forest. While minimum redundancy maximum relevance method used in Doewes (2017) reduced the number of features to 201 and achieved an accuracy of 95.15% using SVM. We have reduced the number of features to 128 and 201 by adjusting the weights w1 and w2 for comparison using our proposed method. The same classifiers used in Chetty (2015) and Doewes (2017) were used for evaluation of our proposed method. The proposed fast feature dimensionality reduction technique has achieved an accuracy of 94.88% using Naive Bayes, 98.78% using random forest and 97.25% using SVM which is 39.57% (Chetty 2015, 4.49% (Chetty 2015) and 2.1% (Doewes 2017) greater than the existing methods respectively.
The comparison chart shown in Fig. 8 clearly shows that the fast feature dimensionality reduction technique with different classifiers is performing exceptionally well in terms of accuracy.

Table 10 shows comparison between the proposed fast feature dimensionality reduction technique with state of the art dimensionality reduction techniques. Table 10 clearly shows the proposed method is very effective in reducing the response time compared to others techniques (Francis 2017; Goldberger 2005; Kira and Rendall 1992), and (Walse 2016) by a huge margin. When Nystrom KPCA (Francis 2017) was used to reduce the feature dimension, it took 4.61 s. Similarly, when NCA (Goldberger 2005), ReliefF (Kira and Rendall 1992), and PCA (Walse 2016) were used, it took 2037.38 s, 107.30 s, and 128 s respectively. Compare to these methods, our proposed method just took 1.74 s to reduce the feature dimension, which is 2.65% (Francis 2017), 1170% (Goldberger 2005), 61.5% (Kira and Rendall 1992) and 74.5% (Walse 2016) lesser than the existing methods respectively.
6 Conclusion
In this paper, we have proposed a novel feature dimensionality reduction method (fast feature dimensionality reduction technique). We have used two activity recognition datasets for experimental validation. One of the dataset (UCI data repository) used is available in the public domain. The number of features in each feature vector is 561. The number of features were reduced from 561 to 66 (i.e., only 11% of the total features were used) by changing the weights in our proposed algorithm. We have examined our proposed method with several classification techniques such as kNN, random forest and deep learning with an accuracy of 98.45%, 98.72% and 98.68% respectively. The results are very promising in terms of activity recognition accuracy compared to existing methods (Chetty 2015; Doewes 2017). The response time (processing time) of the proposed method is also very less (1.737 s) when compared to existing methods (Francis 2017; Goldberger 2005; Kira and Rendall 1992; Walse 2016). We have also used our proposed method for the elderly activity recognition dataset (own dataset) and attained an accuracy of 94.73%, and 93.56% using kNN and random forest. The response time of the proposed method for this dataset (elderly AR dataset) is just 0.062 s. The advantages of the proposed method are the high accuracy rate and the reduced computational cost. For future work, we can use our method to non IMU sensor data like computer vision data and study the performance.
References
Akhavian R, Behzadan AH (2016) Smartphone-based construction workers activity recognition and classification. Autom Constr 71:198–209
Alveraz de la Concepcion MA et al (2017) Mobile activity recognition and fall detection system for elderly people using Ameva algorithm. Pervasive Mob Comput 34:3–13
Anguita D et al (2012) Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. Springer lecture notes in computer science, pp 216–223
Anguita D et al (2013) Energy efficient smartphone-based activity recognition using fixed-point arithmetic. J Univers Comput Sci 19:1295–1314
Asteriadis S, Daras P (2017) Landmark-based multimodal human action recognition. Multimed Tools Appl 76:4505–4521
Bayat A et al (2014) A study on human activity recognition using accelerometer data from smartphones. Proc Comput Sci 34:450–457
Cao L et al (2017) GCHAR: an efficient group-based contextaware human activity recognition on smartphone. J Parallel Distrib Comput 118:67–80
Catal C et al (2015) On the use of ensemble of classifiers for accelerometer-based activity recognition. Appl Soft Comput 37:1–5
Chen C et al (2016) Real-time human action recognition based on depth motion maps. J. Real-Time Image Process 12:155–163
Chetty G et al (2015) Smart phone based data mining for human activity recognition. Proc Comput Sci 46:1181–1187
Dao MS et al (2017) Daily human activities recognition using heterogeneous sensors from smartphones. Proc Comput Sci 111:323–328
Doewes A et al (2017) Feature selection on human activity recognition dataset using minimum redundancy maximum relevance. In: IEEE international conference on consumer electronics, Taiwan, pp 171–172
Francis DP et al (2017) Empirical evaluation of kernel pca approximation methods in classification tasks. arXiv:1712.04196
Goldberger J et al (2005) Neighbourhood components analysis. Advances in neural information processing systems, vol 17. MIT Press, Cambridge, pp 513–520
Jain A, Kanhangad V (2016) Investigating gender recognition in smartphones using accelerometer and gyroscope sensor readings. In: IEEE international conference on computational techniques in information and communication technologies (ICCTICT), pp 597–602
Jansi R, Amutha R (2018) A novel chaotic map based compressive classification scheme for human activity recognition using a tri-axial accelerometer. Multimed Tools Appl 77(23):31261–31280
Kira K, Rendall LA (1992) The feature selection problem: traditional methods and a new algorithm. In: AAAI-92 proceedings, pp 129–134
Kwon Y et al (2014) Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst Appl 41:6067–6074
Meng H et al (2008) Real-time human action recognition on an embedded, reconfigurable video processing architecture. J Real-Time Image Process 3:163–176
Partridge M, Calvo RA (1998) Fast dimensionality reduction and simple PCA. Intell Data Anal 2:203–214
Reyes-Ortiz J et al (2015) Human activity and motion disorder recognition: towards smarter interactive cognitive environments. In: ESANN 2013 proceedings. Computational intelligence and machine learning, pp 403–412
Reyes-ortiz J et al (2016) Transition-aware human activity recognition using smartphones. Neurocomputing 171:754–767
Ronao CA, Cho SB (2016) Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst Appl 59:235–244
San-Segundo R et al (2016a) Human activity monitoring based on hidden Markov models using a smartphone. IEEE Instrum Meas Mag 19:27–31
San-Segundo R et al (2016b) Segmenting human activities based on HMMs using smartphone inertial sensors. Pervasive Mob Comput 30:84–96
San-Segundo R et al (2016c) Feature extraction from smartphone inertial signals for human activity segmentation. Signal Process 120:359–372
Su X et al (2014) Activity recognition with smartphone sensors. Tsinghua Sci Technol 19:235–249
Tran DN, Phan DD (2016) Human Activities recognition in android smartphone using support vector machine. In: IEEE international conference on intelligent systems, modelling and simulation, pp 64–68
Walse KH et al (2016) PCA based optimal ANN classifiers for human activity recognition using mobile sensors data. In: Proceedings of first international conference on information and communication technology for intelligent systems, vol 1. Springer, Cham, pp 429–436
Wang Z et al (2016) Application of Relieff algorithm to selecting feature sets for classification of high resolution remote sensing image. In: IEEE international geoscience and remote sensing symposium, pp 755–758
Yang W et al (2012a) Fast neighborhood component analysis. Neurocomputing 83:31–37
Yang W et al (2012b) Neighborhood component feature selection for high-dimensional data. J Comput 7:161–168
Zhang K, Zhang L (2018) Extracting hierarchical spatial and temporal features for human action recognition. Multimed Tools Appl 77:16053–16068
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mohammed Hashim, B.A., Amutha, R. Human activity recognition based on smartphone using fast feature dimensionality reduction technique. J Ambient Intell Human Comput 12, 2365–2374 (2021). https://doi.org/10.1007/s12652-020-02351-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-020-02351-x