
Abstract
Automated detection of different affect states for human beings using facial expressions has attracted an increasing level of research attention for high accuracy. In general, existing facial expressions databases have been used in automated affect state detection to achieve better efficiency. However, minimal real-time experiments data has been used for detecting affect state. To efficiently automate the affect recognition process, in this work, we proposed a new classifier framework and acquired experimentally real-time dataset for training and testing phase. The participants’ face images are captured and processed on the Region of Interest (ROI) to determine the feature points, and hence feature vectors are obtained. The facial feature vectors are given as an input to the proposed multiclass classifier, Multi-dimensional Support Vector Machine (MDSVM), which efficiently identifies and classifies the different affect state. The MDSVM is designed multi-dimensional, based on the two-dimensional valence-arousal emotional model. Thus, two SVMs are used, one in level-1, which classifies the input dataset into two classes based on valence, similarly the second SVM in level-2 classifies the input dataset into two categories based on arousal. The efficiency is improved by using the 8-cross-validation method. Thus, the methodology proposed in this work combines the advantage of reliable dataset acquired experimentally, significant 12 feature vectors obtained from facial expressions, prominently active multidimensional SVM, and 8-cross validation method. Experimental results illustrate the efficacy of the proposed system for accurately classifying the affect state into four categories, Relax, Sad, Angry, and Happy. The average accuracy obtained is 94.25% without k-fold cross-validation and 95.88% with 8-fold cross-validation.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The information transfer among human beings may be verbal or non-verbal. Among the different non-verbal communication methodologies like body language, eye contact, gesture, and facial expressions, the facial expression is used on a larger scale. The essential expressions on the face are joy, happy, fear, and anger. The happiness is expressed with a curved lip, a curved eye, and small smile representing the relax state.
The sadness is shown on the face with skewed eyebrows, and the angry affect state is conveyed with pressed eyebrows, slim, and stretched eyelids. Facial Expression Recognition (FER) is an exciting field for the computer vision field, and it is widely applicable for security, affect state identification, lie detection, operator fatigue detection, etc. (Lee and Lee 2019). There are two methodologies, to determine the facial elements, one is centered on appearance, which can distinguish effectively but not appropriate for real-time applications because calculation complication and storage requisite is high. The second approach is geometric based, which is ideal for real-time applications because it can be traced easily (Bavkar et al. 2015). The geometric features of face, eyes, mouth, nose, and eyebrows are essential in determining the facial expressions (Lozano-Monasor et al. 2017).
In this work, the FER is used to develop an automatic affect recognition system. Affect recognition is an approach to determine an individual’s emotional state and also to design an effective affect system to classify human emotions automatically (Lupien et al. 2007).
This type of system is developed based on the correlation between the amount of emotion induced by audio or images or video content and response from human beings (Anderson and McOwan 2006; Haag et al. 2004). Human affect can be determined automatically concerning the changes in multimedia content centered on the norms that human beings’ emotional variants bring deviations in the face, speech, iris, and also in physiological signals (Zheng et al. 2006; Paul et al. 2016).
The automatic affect identification system is developed based on modeling the affect state the researchers from the psychological department, have classified the affect based on the discrete method. Song and Zheng (2018) categorized the affect state one-dimensionally into six types as happiness, anger, disgust, surprise, sad, and fear. The critical problem with discrete methodology is, the additional situational and accurate examination should be performed to describe the affect state, which is a challenging task (Zhang et al. 2016; Zhao et al. 2018). The Two-dimensional methodology is used to overcome this problem.
Among the two types of two-dimensional models, Plutchik design was based on the emotional wheel model (Wu et al. 2010), and Russell model was based on the valence-arousal model (Philippot et al. 2002). Russell model was most generally used because the different types of affect states are well defined in this type of model (Wu et al. 2010). In this model, the valence establishes the state of mind as positive or negative, and the arousal defines the affect state as excited or bored. Figure 1 shows the two-dimensional model defined for affect sate.

2-Dimensional valence- arousal model
The affect state information can be obtained from speech signals or facial expressions, or fMRI (Zheng et al. 2006), or thermal infrared imaging (Parrott 2001) and also can be obtained from physiological signals (Katsis et al. 2011). Different types of features are derived from the affect state information.
The elements may be of the frequency domain or time domain, or it may be a combined feature of time domain and frequency domain (Barry et al. 2007). The time-domain features are used to describe the complexity and also the activity of the time sequence by Barry (Barry et al. 2009). Power Spectral Density (PSD) evaluated by Morris (1995), which is a vital parameter in the frequency domain.
The author in his work (Soleymani and Pantic 2013), explained the significance of HOC parameters and also described the oscillatory features based on the time domain. The additional features which are used to describe the affect state are Short-Time Fourier Transform (STTFT) (Davidson 2003) and also Hilbert–Huang transform (Barry et al. 2007).
In the classification process, different machine learning methodologies are utilized for determining the affect state, which involves the data acquisition of a participant during a particular time, which expresses the specific type of affect state (Hossin and Sulaiman 2015).
Though there are many methodologies to categorize the facial expressions, high efficiency was obtained with the kNN (k nearest neighbor) algorithm (Lang et al. 1993; Lang et al. 1999) The classification process is efficient when SVM (Support Vector Machine) classifier is used (Rainville et al. 2006).
SVM performs classification better comparing with other classifiers as SVM maps the non-linear features into a higher magnitude where elements can be divided linearly. The complexity in computation is reduced by using kernel function in SVM (Ghimire and Lee 2013).
2 Materials and methods
2.1 Subjects
200 Male and female volunteers in the age group of 17–25 are considered for the experiment. Each participant undergoes the experiment for the four affect states with a rest of 10 min in-between each state. Thus dataset acquired for each affect state is 200, and therefore, a total of 800 datasets for this experimental analysis is considered.
Relax State | Happy State | Sad State | Anger State | Total |
|---|---|---|---|---|
200 | 200 | 200 | 200 | 800 |
2.2 Experimental setup
The participants for the experiment were explained in detail about the procedure to be followed, and they were also explained about the questionnaire, which has to be self-assessed after the completion of the experiment. The participants were requested to sign the consent form in which all the information are recorded in detail. The ambient light condition is retained in the experimental room throughout the experimental procedure. They were also maintained the same for all the participants of the experiment.
The Sony camera, DCM DFW-VL500, IEEE1394, is fixed in front of the participants in a suitable position to obtain their facial pictures clearly. After the participants having the confidence of a complete understanding of the process, the stimuli images were displayed.
After each set of pictures of affect state, the self-assessment ratings are obtained using non-verbal questionnaire self-assessment Manikin (SAM). In SAM, the affect states are valuated directly by displaying pictures. Thus affect states correspond to a sequence of images that changes in both valence and strength (Bradley and Lang 1994). Figure 2 explains the experimental procedure.

Experimental procedure
3 Proposed methodology
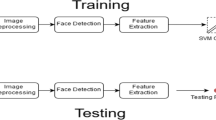
The framework of the proposed methodology is described in this section and represented in Fig. 3. The figure reveals three different modules of the proposed work for the identification of individual affect state. They are the Acquisition of facial images through the camera, Extraction of facial features, and Classification using MDSVM.

affect recognition using facial expressions recognition
3.1 Data Acquisition
For experimental facial image acquisition, emotional elicitation is required, which is commonly obtained by displaying emotional pictures from the International Affective Picture System (IAPS) database because the procedure used is efficient and straightforward (Uhrig et al. 2016; Koelstra et al. 2011).
The images from IAPS are used to provoke a particular affect state is displayed for 10 min, and during the last 5 min, the facial expressions were recorded by the camera, which is fixed in front of the participant. The intervention between different affect states avoided with 10 min rest period between the display of various affect state images. After completion of the process, the participants were requested to complete the SAM (Bradley and Lang 1994) questionnaire honestly.
3.2 Feature extraction
The participant’s face was detected and resized as 256 × 256 pixels using the Haar classifier. The main objective of this step was to fix the boundary for the face. The Region of Interest (ROI) was obtained, and landmark was detected such that the contours could be determined to identify the positions of other face parts, eyes, eyebrows, nose, and lips for further processing. The eyes were determined using a circular Hough transform, and the landmark points were defined, and thus four points for the left eye and four points for the right eye were identified. The next stage was to set the location of the nose by using the Haar classifier, thus considering the nose tip as a reference point.
The next step is to determine the eyebrows both left and right, which is at the top position of the respective eyes. These are identified with a gradient-based Sobel detector, which determines the parts efficiently. The lips used as a reference, are located at the bottom of the nose and identified using a Sobel detector.
The width of the lips was determined. The parameters were defined from the landmark reference points considered. Left eye upper corner and left eyebrow center distance, right eye upper corner and right eyebrow center distance, nose centre and lips center distance, left eye lower corner and lips left corner distance, right eye lower corner and lips right corner distance, thus totally 18 points and from these points 12 feature vectors are determined. OpenCV tool, Python, and dlib have been used for the implementation of facial feature extraction.
Figure 3 shows the detection of Lips, Eyes, Eyebrows, and Nose feature points. Facial expressions are due to the actions of muscles in the face below the skin. Thus, each muscle on the face is denoted by a couple of essential points, called dynamic point and fixed point. The points which non-static during expression are termed as dynamic points while the static points are classified as fixed points. Examples of static points are the outer corner of the eye, nose root, and face edge (Bavkar et al. 2015). Figure 4 explains the steps in obtaining the features points from the face. Figure 5 shows the detection of facial marks.

Steps in obtaining features points from the face

ROI—lips, eyes, eyebrows and nose feature points detected
The above feature points were used to determine the following feature vectors:
-
1.
Left eye height-fvt1 = P1–P2
-
2.
Left eye width- fvt2 = P4–P3
-
3.
Right eye height- fvt3 = P5–P6
-
4.
Right eye width- fvt4 = P8–P7
-
5.
Left eyebrow width- fvt5 = P11–P10
-
6.
Right eyebrow width- fvt6 = P14–P13
-
7.
Lip width- fvt7 = P17–P16
-
8.
Left eye upper corner and left eyebrow center distance
fvt8 = P12–P1
-
9.
Right eye upper corner and right eyebrow center distance
fvt9 = P15–P5
-
10.
Nose center and lips center distance
fvt10 = P9–P18
-
11.
Left eye lower corner and lips left corner distance
fvt11 = P2 – P16
-
12.
Right eye lower corner and lips right corner distance
fvt12 = P6 – P17
3.3 SVM classification
The primary objective of the support vector machine is to categorize the input feature set into two classes, and it was designed by Vapnik (1999), Burges (1998). The input feature vector of SVM is estimated into a feature space of higher dimensionality.
Thus the SVM with input feature vectors defines the decision boundary, which determines the optimal hyperplane that splits the two categories.
This hyperplane is linear, and the distance between the two groups is maximized. With \(\varvec{t}_{i}\). as input feature vector and \(y_{i}\). As the respective output class, the input training samples are \(\left( {\varvec{t}_{i} , y_{i} } \right)\), where i = 1, 2,…,N. Thus, the primary purpose is to find an estimate of y, which is denoted by z in Eq. (1).
The kernel function is defined by Mercer’s theorem and is given by the Eq. (2).
Polynomial function, exponential RBF, and Gaussian RBF are the different kernel functions used in SVM, among which Gaussian RBF kernel, given in Eq. (3), performs efficiently compared to other kernels.
3.4 Multi-class classification methods
Ms are designed to classify the input features into two classes, and many advanced methodologies have been designed to extend the approach to classify the input into N-classes (Weston and Watkins 1999). ‘One-Against-All’ method is an approach in which the mth SVM, the mth class, is categorized as positive, and the residual classes are categorized as negative.
The important problem in this method is that it involves more number of training samples. The drawback is overcome by using the ‘One-Against-One’ methodology in which there are m(m−1)/2, two-class classifiers. The primary method used in this algorithm is that the positive samples are used to train the initial classifier, whereas negative samples train the other classifier considered.
The different voting algorithms are used to combine the classifier outcomes (Friedman 1997). The major shortcoming of this methodology is that the training phase is faster compared to the testing phase when the number of categories is vast. Directed Acyclic Graph SVM (DAGSVM) is the upgraded version of ‘One-Against-One’, in which the training stage is similar in which the training classifiers are m(m-1)/2.
Still, the decision begins from the root, and the final decision concludes in leaf during the testing phase. Therefore in this methodology, the input feature vector is given m-1 times. Another approach to classifying the input data into m class using SVM is, training the entire nodes of the tree by using only two-classes. The similarity between the samples is determined based on the probabilistic outputs, and thus the samples are assigned to the sub-nodes of the former class. This step is continued for the remaining nodes.
The major disadvantage of this methodology is the enormous time required for training. In the proposed method, the architecture developed for the classification process is based on the valence-arousal model. Thus multi-classification is performed in a layered manner utilizing fewer classifiers compared to the previous methods; therefore, the time required for training is less compared to the earlier methods.
Algorithm 1 The facial expressions are acquired experimentally from the participants.
The face feature is obtained from facial expressions. The database is divided into two portions, one is 75% of the dataset as the training dataset, and the other 25% of the dataset is used as a testing dataset.
Training phase
-
1.
Let the training dataset be defined as \(\{ (\varvec{t}_{i} , y_{i} )\}_{i = 1}^{N}\)
where \(\varvec{t}_{i}\). is the 12 feature vectors, \(y_{i}\). is the corresponding output class, i = 1,2, …, N
-
2.
The kernel function is defined in Eq. (4), which transfers feature vectors from the lower dimension to a higher dimension, and Gaussian RBF is used.
ij th element of matrix in \(\varphi \left( {t_{j} } \right)\).
-
3.
The objective function, which determines the suitable weight wave, increases the significant feature’s contribution more to the classification, is maximized. Thus the value o is determined using Eq. (5).
With the following constraints
where i = 1,2,…N
-
4.
Thus the weight vector is given by Eq. (7)
Testing Phase The feature vectors obtained from the testing dataset are used with the weight vectors derived from the training phase. The output class is determined for the testing dataset, and hence the classification accuracy is determined.
3.5 Multi-Dimensional SVM (MDSVM)
The affect state is classified appropriately with high efficiency using the proposed MDSVM algorithm. In the proposed methodology, the architecture is modified with SVM in a two-layered structure combined to make suitable decisions.
The modified layered architecture is based on the two-dimensional emotional model considering the x-axis value as valence and y-axis value as arousal.
The architecture is characterized such that the first layer is capable of distinguishing the valence as positive and negative.
Similarly, the second layer is described, such that it differentiates between the arousal values as high and low. The MDSVM classifies the input feature vector efficiently into four class output. The architecture of MDSVM is shown in Fig. 6.

Multi-dimensional SVM (MDSVM)
Algorithm 2: MDSVM
-
1.
The face images of 200 participants are captured using a camera during display of affect provoking images.
-
2.
Feature points are extracted from facial expressions, and from these feature points, feature vectors are determined.
-
3.
This experimentally acquired data is separated into training and testing datasets. The training dataset considered is 75% of the entire database, and the testing dataset is 25% of the entire database.
-
4.
The SVM classifier is described with the Gaussian kernel. The training dataset defined is \(\{ (t_{i} , y_{i} )\}_{i = 1}^{N}\). Lagrange multiplier \(\gamma\) is determined to maximize the objective function.
-
5.
The input feature vector is given as input to Level 1 SVM (Algorithm 1), which separates the input data into two classes C1 and C2 based on the valence as positive and negative.
-
6.
The output of Level1 is given as input to Level 2 SVM (Algorithm 1) to separate each class C1 and C2 into two classes based on the arousal as high and low.
-
7.
The output four classes defined are {C11, C12, C21, C22} which is based on the input of Level 2 {C1, C2}
-
8.
Thus from step 5, the estimated type of training dataset is determined. Classification efficiency is determined using the confusion matrix for the Training dataset.
-
9.
Steps from 5 to 9 are repeated for Test dataset, and classification efficiency is also determined.
The classification efficiency for a different type of multiclass algorithms is also determined and compared with the proposed MDSVM algorithm.
4 Results and discussion
The performance of the developed multi-class classifier MDSVM is statistically evaluated using the confusion matrix, represented using rows and columns. Rows represent expected class from the input, and columns represent the actual classes. The variable Ki is used to describe the actual type while the variable \(\hat{K}_{j} \left( { 1 \le {\text{i }} \le {\text{c }}} \right)\) represents the expected type. The range of values is \(1 \le {\text{i}}, {\text{j }} \le {\text{c}}\).
The confusion matrix for a four-class problem is shown in Table 1, in which the values along the diagonals are the total number of data that are classified appropriately. In contrast, the values other than the diagonals are the data which are not categorized appropriately. In Table 1, consider, for example, Eaa, in which both actual class and estimated class are the same, that is ‘class a’. Consider Eba, in which the data belongs to ‘class b’, but it was estimated as if it belongs to ‘class b’.
The Eq. (8) is the formula to calculate the classification accuracy with n representing the entire number of the dataset.
The classification accuracy is calculated by dividing the number of the correctly classified dataset by the total number of datasets considered.
Among 200 participants, 75% of experimental data, that is, 150 participant’s facial expression, are used for training and 25% of the experimental dataset; that is, 50 participant’s facial expression features are used during the testing phase.
The dataset is divided randomly. The dataset is given as input to the Level 1 SVM classifier, and the output of Level 1 SVM is given as input to the Level 2 SVM classifier. Table 2 is the coin matrix for the training dataset, which tabulates the classification accuracy for affect state of relax, happy, sad, and angry.
Thus, considering the training phase, it can be observed that feature vector points can easily distinguish between relax and happy. Still, the classifier misinterpretation rate is high between sad and angry, since there are almost similar changes in the eyebrows for both angry and sad. Table 3 is the confusion matrix for the testing dataset, which tabulates the classification accuracy for different affects states. A similar tendency can be observed in the training dataset, that is, classification efficiency is high for relax and happy, but the error is high for sad and angry.
The performance of the proposed multiclass system MDSVM is compared with the other multiclass technique. These multiclass algorithms were evaluated with the same experimental dataset. Table 4 summarizes the comparison between the different types of Multiclass classification algorithms. The average classification accuracy of the proposed MDSVM is 94%, which is high compared to other multiclass algorithms. Figure 7 shows the graphical representation of the comparison between different Multiclass classification algorithms.

Graphical representation of comparison between different types of multiclass
Classification algorithm The cross-Validation method is used to enhance classification accuracy. In this method, the database is divided into k sub-groups. Among these k sub-groups, for testing one group is used, the remaining other groups are used for training (Revina and Emmanuel 2018). The validation process is iterated k times. In this work, the dataset consists of 200 records, which is partitioned into eight folds, and each fold consists of 25 records. Eight-fold cross-validation methodology is applied. 50 datasets are used for testing, the remaining 150 datasets for training, and the results are averaged to determine the performance. The results show improvement compared to the dataset without 8-fold cross-validation. Table 5 shows the confusion matrix for the dataset without 8-fold cross-validation, and Table 6 shows the confusion matrix for the dataset with 8-fold cross-validation.
Figure 8 shows the graphical representation of a comparison between classification accuracy without k-fold and with the k-fold cross-validation method.

Graphical representation of comparison between classification accuracy between without k-Fold and with k-fold cross over validation method
The results show improvement compared to the dataset without 8-fold cross-validation (Morris 1995). Table 7 tabulates the comparison between the proposed work and the previous work.
5 Conclusion
The present work focused on attaining a computationally efficient automatic FER system with higher accuracy, which has several applications like behavior understanding, mental disorders determination, affect recognition, etc. In this work, the FER system identifies the affect state based on the standard two-dimensional valence-arousal model, which determines the four Affect state—happy, sad, relax, and angry efficiently. The dataset obtained experimentally in real-time set-up from 200 participants. Facial expressions captured after displaying affect induced images to the participants and extracted 12 significant feature vectors from facial features. The classification process with the proposed MDSVM classifier is useful in classifying the input dataset into four affect states with an average accuracy of 94.25% without 8-fold cross-validation and 95.88% with 8-fold cross-validation. The results prove that the proposed method is efficient compared to the other types of Multiclass classifications methods. The main limitation of this methodology is that the possibility of the human being to conceal his/her real emotions by different external facial expressions, which leads to misclassification of affect state. In the future, to overcome this limitation, the multimodal signal can be used, which is a combined feature of facial features and physiological signals that may offer a more accurate affect state classification.
Change history
01 June 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s12652-022-04015-4
References
Anderson K, McOwan PW (2006) A real-time automated system for the recognition of human facial expression. IEEE Trans Syst Man Cybern Part B (Cybernetics) 36(1):96–105
Barry RJ, Clarke AR, Johnstone SJ, Magee CA, Rubhy JA (2007) EEG differences between eyes-closed and eyes-open resting conditions. Clin Neurophysiol 118(12):2765–2773
Barry RJ, Clarke AR, Johnstone SJ, Magee CA, Brown CR (2009) EEG differences in children between eyes-closed and eyes-open resting condition. Clin Neurophysiol 120(10):1806–1811
Bavkar SS, Rangole JS, Deshmukh VU (2015) Geometric approach for human emotion recognition using facial expression. Int J Comput Appl 118(14):17–22
Bradley MM, Lang PJ (1994) Measuring emotion: the Self-assessment manikin and the semantic differential. J Behav Ther Exp Psychiatry 25(1):49–59
Burges CJC (1998) A tutorial on support vector machine for pattern recognition. Data Min Knowl Disc 2(2):121–167
Davidson RJ (2003) Affective neuroscience and psychophysiology: toward a synthesis. Psychophysiology 40(5):655–665
Friedman JH (1997) Another approach to polychotomous classification. Technical report—Department of Statistics, Stanford University
Ghimire D, Lee J (2013) Geometric feature-based facial expression recognition in image sequences using multi-class adaboost and support vector machines. Sensors 13(6):7714–7734
Haag A, Goronzy S, Schaich P, Williams J (2004) Emotion recognition using bio-sensors: First steps towards an automatic system. In: Tutorial and research workshop on affective dialogue systems, pp 36–48
Hossin M, Sulaiman MN (2015) A Review on evaluation metrics for data classification evaluations. Int J Data Min Knowl Manag Process 5(2):1–11
Katsis CD, Katertsidis NS, Fotiadis DI (2011) An integrated system based on physiological signals for the assessment of affective states in patients with anxiety disorders. Biomed Signal Process Control 6(3):261–268
Koelstra S, Muhl C, Soleymani M, Lee JS, Yazdani A, Ebrahimi T, Patras I (2011) Deap: a database for emotion analysis; using physiological signals. IEEE Trans Affect Comput 3(1):18–31
Lang PJ, Greenwald MK, Bradley M, Hamm AO (1993) Looking at pictures: affective, facial, visceral and behavioral reactions. Psychophysiology 30(3):261–273
Lang PJ, Bradley MM, Cuthbert BN (1999) International Affective Picture System (IAPS): technical manual and affective Ratings. The Center for Research in Psychophysiology, University of Florida, G
Lee K, Lee EC (2019) Comparison of facial expression recognition performance according to the use of depth information of structured-light type RGB-D camera. J Ambient Intell Hum Comput, pp 1–17
Lozano-Monasor E, López MT, Vigo-Bustos F, Fernández-Caballero A (2017) Facial expression recognition in ageing adults: from lab to ambient assisted living. J Ambient Intell Hum Comput 8(4):567–578
Lupien SJ, Maheu F, Tu M, Fiocco A, Schramek TE (2007) The effects of stress and stress hormones on human cognition: implications for the field of brain and cognition. Brain Cogn 65(3):209–237
Morris JD (1995) Observations: sam: The Self-assessment Manikin: an efficient cross-cultural measurement of emotional response. J Advert Res 35(6):63–68
Parrott WG (2001) Emotions in social psychology: essential readings. Psychology Press, Philadelphia
Paul A, Ahmad A, Rathore MM, Jabbar S (2016) Smartbuddy: defining human behaviors using big data analytics in social internet of things. IEEE Wirel Commun 23(5):68–74
Philippot P, Chapelle G, Blairy S (2002) Respiratory feedback in the generation of emotion. Cogn Emot 16(5):605–627
Rainville P, Bechara A, Naqvi N, Damasio AR (2006) Basic emotions are associated with distinct patterns of cardiorespiratory activity. Int J Psychophysiol 61(1):5–18
Revina IM, Emmanuel WS (2018) A survey on human face expression recognition techniques. J King Saud Univ Comput Inf Sci. https://doi.org/10.1016/j.jksuci.2018.09.002
Soleymani M, Pantic M (2013) Multimedia implicit tagging using EEG signals. In: IEEE International Conference on multimedia and expo, p 1–6
Song P, Zheng W (2018) Feature selection based transfer subspace learning for speech emotion recognition. In: IEEE Transactions on Affective Computing, p 1–11
Uhrig MK, Trautmann N, Baumgärtner U, Treede RD, Henrich F, Hiller W, Marschall S (2016) Emotion elicitation: a comparison of pictures and films. Front Psychol 7(180):1–12
Vapnik V (1999) The nature of statistical learning theory. Springer, New York
Weston J, Watkins (1999) Multi-class support vector machines. In: Proceedings of ESAN99, Brussels, Belgium
Wu G, Liu G, Hao M (2010) The analysis of emotion recognition from GSR based on PSO. In: International Symposium on Intelligence information processing and trusted computing, pp. 360-363
Zhang T, Zheng W, Cui Z, Zong Y, Yan J, Yan K (2016) A deep neural network driven feature learning method for multi-view facial expression recognition. IEEE Trans Multim 18(12):2528–2536
Zhao B, Wang Z, Yu Z, Guo B (2018) Emotion sense: emotion recognition based on wearable wristband. In: Proceedings of the 2018 IEEE Smart World, Ubiquitous Intelligence Computing, advanced trusted computing, scalable computing communications, cloud big data computing, internet of people and smart city innovation, Guangzhou, China, 8(12): 346–355
Zheng W, Zhou X, Zou C, Zhao L (2006) Facial expression recognition using kernel canonical correlation analysis. IEEE Trans Neural Netw 17(1):233–238
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s12652-022-04015-4
About this article

Cite this article
Meshach, W.T., Hemajothi, S. & Anita, E.A.M. RETRACTED ARTICLE: Real-time facial expression recognition for affect identification using multi-dimensional SVM. J Ambient Intell Human Comput 12, 6355–6365 (2021). https://doi.org/10.1007/s12652-020-02221-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-020-02221-6