
Abstract
Accurate classification of electrocardiogram (ECG) signals is of significant importance for automatic diagnosis of heart diseases. In order to enable intelligent classification of arrhythmias with high accuracy, an accurate classification method based intelligent ECG classifier using the fast compression residual convolutional neural networks (FCResNet) is proposed. In the proposed method, the maximal overlap wavelet packet transform (MOWPT), which provides a comprehensive time-scale paving pattern and possesses the time-invariance property, was utilized for decomposing the original ECG signals into sub-signal samples of different scales. Subsequently, the samples of the five arrhythmia types were utilized as input to the FCResNet such that the ECG arrhythmia types were identified and classified. In the proposed FCResNet model, a fast down-sampling module and several residual block structural units were incorporated. The proposed deep learning classifier can substantially alleviate the problems of low computational efficiency, difficult convergence and model degradation. Parameter optimizations of the FCResNet were investigated via single-factor experiments. The datasets from MIT-BIH arrhythmia database were employed to test the performance of the proposed deep learning classifier. An averaged accuracy of 98.79% was achieved when the number of the wide-stride convolution in fast down-sampling module was set as 2, the batch size parameter was set as 20 and wavelet subspaces of low frequency bands in MOWPT were selected as input of the classifier. These analysis results were compared with those generated by some comparison methods to validate the superiorities and enhancements of the proposed method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Cardiovascular disease (CVD) is a major contributor to the growing public health epidemic in chronic diseases. The past decades have witnessed a continuous increase of the incidence of CVD. A high mortality rate is also reported among the patients with CVD (World Health Organization 2017). Symptoms of arrhythmia in early onset of CVD have been widely reported in the clinical practices as well as the pathological researches. Arrhythmia is an important group of diseases in cardiovascular disease. Arrhythmia can occur on its own or with the other cardiovascular diseases. Therefore, an early detection of arrhythmias is essential for diagnosis early interventional treatment of this disease. The diagnosis of arrhythmia mainly depends on the ECG signal. Automatic detection of irregular heart rhythms from ECG signals is a significant task for the automatic diagnosis of cardiovascular disease.
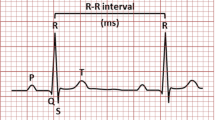
An electrocardiogram (ECG) is related to a potential waveform that traces the weak electrical response formed on the body surface by bioelectrical changes that occur to cardiac activation. The tissues and body fluids surrounding the human heart have electrical conductivity. The human body is likened to a three-dimensional volume conductor with length, width and thickness. The heart is like a power source, and the sum of countless changes in action potentials of myocardial cells can be transmitted and reflected to the body surface. There are potential differences between some body surface points. Some body surface points are isoelectric. The electrophysiological phenomenon of heart cells is the basis of heart movement. The heart conduction system generates and conducts about 100,000 electrical impulses per day under normal circumstances. It excites the muscle cells of the atrium and ventricle, causing them to contract and relax regularly and thereby realizing the function of “blood pump” (Ji 2006). A complete ECG is composed of multiple sets of ECG waveforms. A complete ECG data period contains the main wave groups such as P wave, QRS wave group and T wave. Each waveform information and characteristic wavelet have certain energy and physiological significance. QRS wave group generally has more energy with higher amplitude than P wave and T wave. As shown in Fig. 1.

The waveform of a typical ECG Signal in the time domain
ECG has been widely used in clinical practices due to the characteristics of reliable diagnosis, simple realization, non-invasive and harmless to patients. The performance of traditional intelligent fault diagnosis methods depends on feature extraction of dynamic signals, which requires expert knowledge and human labor (Cao et al. 2019a, b). The early diagnosis of arrhythmia mainly relies on experienced doctors to interpret the characteristics of ECG signals. It requires high professional knowledge of doctors. The accuracy of diagnosis is greatly affected by environmental factors and mental states. In addition, a large amount of ECG data will be generated when the patient is monitored for a long time, and therefore it cannot meet the current medical demands by merely relying on artificial interpretation and analysis. Automatic ECG signal diagnosis technology has become a research hotspot with the continuous development of computer science recently. It is providing doctors with increasingly efficient and reliable evidence for diagnosis.
Traditionally, the classification of ECG signals usually needs to be divided into three steps, i.e., signal preprocessing, feature extraction and pattern classification. The signal preprocessing aims at eliminating various types of noise in the ECG signal, including artifacts and baseline drift in the signal. A large number of methods have been reported in the literature for denoising of ECG signals. This includes the traditional filtering operations such as the use of low-pass filters (Slonim et al. 1993), Weiner filters (Chang and Liu 2011), adaptive filters (Thakor and Zhu 1991) and filterbanks (Afonso 2011). In addition, methods like the recursive least square (RLS) (Muhsin 2011), least mean square (LMS) (Islam et al. 2012), as well as the extended Kalman filters (Sayadi and Shamsollahi 2008), adaptive wavelet-Wiener filters (Smital et al. 2012) and adaptive filtering with neural networks (Poungponsri and Yu 2013) have also been explored. In a recently reported work, Pratik Singh et al. (2018) presented an ECG denoising method based on an effective combination of non-local means (NLM) estimation and empirical mode decomposition (EMD). Rashmi et al. (2017) proposed an efficient denoising method using wavelet transform, and the results showed that signal noise ratio (SNR) of ‘sym8’ wavelet transform is greater than that of the digital filter using the blackman window. A hybrid technique including the combination of Median filter, Savitzky–Golay filter, the extended Kalman filter and the discrete wavelet transform has been focused for separation of noise from ECG signal (Kaur and Rajni 2017). Zhang et al. (2017) proposed an ECG signals denoising method based on improved wavelet threshold algorithm which combines the soft and hard threshold. The experimental results indicate that the proposed algorithm can effectively filter out the noise of ECG signals. It can better retain the characteristic information of the ECG signal, has a higher signal-to-noise ratio and achieve a better denoising effect.
After the step of signal preprocessing, a series of feature indicators are extracted from the ECG waveforms. Feature selection algorithms such as principal component analysis and whale optimization algorithm (Zhang et al. 2018) can be employed to generate a more efficient and compact feature vectors. Other methods were also employed for extracting features from ECG signals. Elhaj extracted the linear and nonlinear features from the signals for automatic ECG beat recognition (Elhaj et al. 2016). Alickovic and Subasi (2015) proposed an autoregressive (AR) model in the feature extraction module for diagnosing heart diseases. Kumar et al. (2017) utilized a flexible analytic wavelet transform framework to decompose the raw ECG into different frequency bands and extracted the sample entropy of the sub-signals as features to diagnosis myocardial infarction. Cao et al. (2019a, b) applied the derived wavelet frames (DWFs) decomposition to decompose and reconstitute the segmented short samples of ECG signal. Özbay et al. (2011) computed detail and approximation wavelet coefficients of the ECG features to generate feature vectors. A dual tree complex wavelet transform (DTCWT) based feature extraction technique for automatic classification of cardiac arrhythmias was proposed by Thomas et al. (2015), and the feature set comprises of complex wavelet coefficients extracted from the fourth and fifth scale DTCWT decomposition of a QRS complex signal in conjunction with four other features (AC power, kurtosis, skewness and timing information) extracted from the QRS complex signal.
After the step of feature extraction, classification is traditionally conducted using state-of-the-art classifiers such as support vector machines (SVM), neural networks (NN), cluster analysis (CA), random forests (RF), optimum-path forest (OPF) and some other classification tools (Yildirim 2018). Martis et al. (2013) automatically classified five types of ECG beats using HOS features (higher order cumulants) and three layer feed-forward Neural Networks (NN). Least Square-Support Vector Machine (LS-SVM) classifiers. Varatharajan et al. (2018) presented a big data classification approach using LDA with an enhanced SVM method for ECG signals in cloud computing. Diker et al. (2019) proposed a new technique for ECG signal classification using genetic algorithm wavelet kernel extreme learning machine. The threshold algorithm of Kolmogorov–Smirnov test was implemented to the detection of the transition between Atrial Fibrillation and Sinus Rhythm by Huang et al. (2010). Yeh et al. (2012) proposed a method of analyzing ECG signal to diagnose cardiac arrhythmias utilizing the cluster analysis (CA) method. Raman and Ghosh (2016) proposed an approach for classification of Heart Diseases based on ECG analysis using type2-fuzzy c-means (FCM) and SVM Methods. Li and Min (2016) proposed a method to classify ECG signals using wavelet packet entropy (WPE) and random forests (RF) following the Association for the Advancement of Medical Instrumentation (AAMI) recommendations and the inter-patient scheme. De Albuquerque et al (2016) introduced the Optimum-Path Forest (OPF) classifier to automatic arrhythmia detection in ECG patterns.
Most of the above methods for classifying ECG signals rely entirely on extracting manual features from ECG signals. This can be done by using traditional feature extraction algorithms or using human expert knowledge. The quality of the extracted features has a significant impact on the reliability and performance of the classification/prediction strategy (Lv 2018). Therefore, it is always desirable to be able to extract the most essential disease risk factor-related features. However, the waveform information and energy of ECG at different times are hugely different, and the information characteristic parameters range of ECG waveforms for different diseases is also uncertain. Manual features may not represent the fundamental differences between categories. It can’t represent the physiological and pathological potential risk factors of heart rhythm in ECG data, thus limiting the performance of classification recognition models.
Due to the ability to process large datasets and extract hidden patterns, Machine learning techniques have been widely used in medical diagnosis and health informatics, including cerebral micro-bleeding identification (Hong et al. 2019; Wang et al. 2019a, b, c, 2020), lung tumor identification (Wang et al. 2017), gingivitis identification (Li et al. 2019), alcoholism identification (Wang et al. 2019a, b, c), multiple sclerosis classification (Zhang et al. 2019), sensorineural hearing loss identification(Wang et al. 2019a, b, c), sign language recognition (Jiang and Zhang 2019), biosensor analysis (Zeng et al. 2019) and ECG classification (Huang et al. 2019). Owing to the outstanding performances of deep learning methodologies in pattern recognition problems, ECG classification using deep learning related techniques has become research hotspots. Various new algorithms and technologies are integrated into the ECG classification method, which is of great significance to achieve graded diagnosis and treatment and rational allocation of medical resources (Zhu 2013). Salloum and Kuo (2017) proposed the recurrent neural networks (RNNs) to develop an effective solution to identification and authentication in electrocardiogram (ECG)-based biometrics. Mostayed et al. (2018) proposed a recurrent neural network which consists of two bi-directional long-short-term-memory layers to detect pathologies in 12-lead ECG signals. Kiranyaz et al. (2015) proposed a real-time patient-specific ECG classification approach based on the 1D convolutional neural networks, which can be solely used to classify long ECG records of patients. Yin et al. (2016) proposed an ECG monitoring system integrated with the Impulse Radio Ultra Wideband (IR-UWB) radar based on CNN. Salem et al. (2018) proposed an ECG arrhythmia classification method using transfer learning from 2D deep CNN features, and the method was applied in the identification and classification of four ECG patterns. Huang et al. (2019) transformed five types of heart beats’ signals into time–frequency spectrograms and then trained a 2D-CNN for classifying arrhythmia types. Andersen et al. (2019) employed the RR intervals for training deep CNNs to identify Atrial Fibrillation. Sellami and Hwang (2019) proposed a deep convolutional neural network (DCNN) enhanced with batch-weighted loss function for accurate heartbeat classification Faust et al. (2018) utilized the heart rate sequence as the analysis object, and applied deep bidirectional long-short term memory networks to identify whether the sample had AF phenomenon. Erdenebayar et al. (2019) designed a DCNN with an intermediate fully connected layer to identify atrial fibrillation.
Through a comparative analysis of existing domestic and foreign arrhythmia classification algorithms, it is found that most of the research is still based on statistical pattern recognition classification algorithms. However, this kind of algorithm relies too much on the construction of the classification pattern space, resulting in the limitation of artificial construction. Moreover, this kind of algorithm includes two independent tasks of feature extraction and classification, There is a complexity of data reconstruction between the two tasks. The automatic arrhythmia classification algorithm based on deep neural network can learn the implicit features of heartbeat by neural network with multiple hidden layers. These implicit features are conducive to improving the recognition effect of heartbeats, and can avoid the complexity and limitations of artificially constructing the heartbeat pattern space.
However, the existing classification algorithms based on deep neural networks still have deficiencies.
-
1.
In order to meet the input data size requirements of existing convolutional neural network models, encoding or resampling operations are usually used in the data preprocessing stage to unify the data size. However, it will destroy some useful information of the original data, which will adversely affect the recognition ability of the model.
-
2.
ECG data is a signal on the one-dimensional time series, so that the local perception field in the one-dimensional convolutional neural network model is divided in the time dimension. As a result, it fails to establish a distributed heart beat feature expression in multiple dimensions and results in an unsatisfactory recognition effect.
-
3.
Due to too many network parameters, the time cost of training the model is large and the real-time performance is poor in the deep network model with multiple hidden layers.
In view of the shortcomings of the existing automatic classification algorithm of arrhythmia based on deep neural network, we aim to design an efficient automatic ECG arrhythmia classification method according to the data size of the authoritative ECG database and the characteristics of ECG signals.
In this paper, we propose an accurate ECG arrhythmia classification method using the fast compression residual convolutional neural networks (FCResNet), where wavelet packets decomposition (WPD) is used for preprocessing. The time domain signals of ECG, belonging to five heart beat types including normal beat (NOR), left bundle branch block beat (LBB), right bundle branch block beat (RBB), premature ventricular contraction beat (PVC), and atrial premature contraction beat (APC), were decomposed and reconstituted into sub-signal samples of different scales. Subsequently, the samples of the five arrhythmia types were utilized as input of the FCResNet such that the ECG arrhythmia types were identified and classified finally. Using ECG recordings from the MIT-BIH arrhythmia database as the training and testing data, the classification results show that the proposed FCResNet model can reach an averaged accuracy of 98.79%.
The rest of this paper is organized as below. In Sect. 2, we explain the dataset and methodologies used for the ECG arrhythmia classification, including method overview, database and segmentation, signal decomposition via MOWPT and the proposed FCResNet model. In Sect. 3, numerical evaluation and experimental results of ECG arrhythmia classification are shown, including performance evaluation of different sub-band reconstructed dataset in FCResNet, performance evaluation of different batch sizes in FCResNet. In Sect. 4, we show the model parameter optimization with results, and discuss the comparison with other existing approaches. Finally, we give the conclusion in Sect. 5.
2 Datasets and methods
2.1 Method overview
The overall procedures of the proposed ECG arrhythmia classification model are shown in Fig. 2. The original ECG signals were shared by the MIT-BIH arrhythmia database (Moody and Mark 2001). There are five ECG types including normal beat (NOR), left bundle branch block beat (LBB), right bundle branch block beat (RBB), premature ventricular contraction beat (PVC), atrial premature contraction beat (APC). Each ECG record annotation was made by two or more cardiologists independently so that disagreements were resolved. First of all, the input ECG signals were divided into data recordings with an identical duration of 10 s. Afterward, each ECG signal record is decomposed and reconstituted into sub-signal samples of different scales by using the wavelet packet decomposition. The ECG reconstructed sub recordings are fed into the proposed FCResNet. Finally, classification of the five ECG types is performed in the FCResNet classifier automatically and intelligently.

Overall procedures in ECG arrhythmia classification based on proposed FCResNet
2.2 Introduction of typical arrhythmia types
Arrhythmia refers to the abnormality of the heart's starting position, conduction velocity, activation sequence, heartbeat frequency and rhythm. The reliability and stability of cardiac electrical activity mainly depend on the frequency and type of arrhythmia. Arrhythmia usually affects the pumping efficiency of the heart and the timing of contractions. Therefore, the timely and accurate identification of arrhythmia plays an irreplaceable role in the treatment of heart disease patients (Zhao 2015).The following are several common types of arrhythmia:
-
1.
Left bundle branch block beat (LBB)
LBB refers to conduction block under the His bundle and atrioventricular bundle. The probability of LBB is lower than that of RBB. The characteristics of LBB on ECG are as follows.
(1) The QRS wave period is usually greater than 0.12 s.
(2) The QRS wave is deformed. For example, the R wave will be distorted, notched, too wide, etc.
(3) The directions of QRS complex and ST-T segment are different.
-
2.
Right bundle branch block beat (RBB)
The characteristics of LBB on ECG are as follows.
(1) The QRS time limit is usually greater than 0.12 s.
(2) The S wave time limit is usually greater than 0.04 s, the wave width increases significantly, but the amplitude is not large.
(3) The directions of ST-T and QRS waves are different.
-
3.
Premature ventricular contraction beat (PVC)
The most common type of arrhythmia is PVC. When sinus arousal has not been transmitted to the ventricle, the heart will beat in advance. The characteristics of PVC on ECG are as follows.
(1) The QRS wave group is generated in advance, but no P wave is generated.
(2) The direction of T wave is inconsistent with QRS complex.
(3) The QRS complex waveform is too wide and distorted.
(4) There is a complete compensation interval. The early part of the premature beat is made up by the part after the premature beat.
-
4.
Atrial premature contraction beat (APC).
Early atrial ectopic heart beats can cause AVC. The characteristics of atrial premature beats on the electrocardiogram are as follows.
-
1.
The P wave is generated in advance (the P wave is superimposed on the T wave of the previous sinus beat).
-
2.
The shape of sinus P wave is different from P wave.
-
3.
The PR interval is normal or slightly longer.
-
4.
The QRS complex after P is abnormal, distorted and deformed.
-
5.
Incomplete compensation intervals usually occur.
Waveforms of the ECG signals are shown in Fig. 3.

Waveforms (V5 lead) of normal beat and that of the other four ECG arrhythmia diseases (Huang et al. 2019)
2.3 Database and segmentation
All ECG recordings are obtained from the MIT-BIH (Massachusetts Institute of Technology-Beth Israel Hospital, MIT-BIH) arrhythmia database to evaluate the performance of the proposed technique. MIT-BIH ECG database is jointly constructed by Massachusetts Institute of Technology and Beth Israel Hospital. The MIT-BIH ECG database was published on the Internet in 1999 with the support of the National Research Resource Center and the National Institutes of Health, and all ECG records of the database can be downloaded and used by researchers for free. The MIT-BIH ECG database includes many sub-databases in which specific types of ECG fragments are recorded. Among the sub-databases, the MIT-BIT arrhythmia database is widely used in the design and analysis of various arrhythmia methods. The MIT-BIH arrhythmia database is the first experimental data database to be widely used to evaluate arrhythmia detection standards, and many researches about ECG at home and abroad are based on this database. For example, Kiranyaz et al. (2015) and Zhai and Tin (2018) used the database as an experimental data source to carry out research work on a variety of arrhythmia self-classification algorithms. Since 1980, it has been used in arrhythmia detection and cardiac dynamics basic research at about 500 locations worldwide (Labati et al. 2018). In order to facilitate the comparative analysis with the existing algorithms, this article selects the MIT-BIT arrhythmia database as the experimental data source in the subsequent chapters.
The database contains normal beat and a few common types of life threatening arrhythmias. The database was created in 1980 as a reference standard for arrhythmia detectors. The database comprises of 48 recordings, each containing 30 min of ECG segment selected from 24 h recordings of 48 different patients. The first 23 recordings correspond to the routine clinical recordings while the remaining recordings contain the complex ventricular, junctional, and supraventricular arrhythmias (Moody and Mark 2001). These ECG records were sampled at 360 Hz and band pass filtered at 0.1–100 Hz. Comparisons of the dataset used in this work are summarized in Table 1.
The signals were divided into 2520 samples for ECG classification, and each sample was re-segmented of 10 s. The related information of the employed data from the MIT-BIH arrhythmia database is listed in Table 1. As Table 1 shows, samples of NOR were obtained from records 100, 105 and 215. Samples of LBB were derived from records 109, 111 and 214. Samples of RBB were obtained from records 118, 124 and 212. Samples of APC were obtained from records 207, 209 and 232. For the above four types, Each type of ECG signals has 450 samples for the training set and 90 samples for the testing set. Samples of PVC were obtained from records 106 and 233. The type of PVC has 300 samples for the training set and 60 samples for the testing set.
2.4 Signal decomposition via MOWPT
The ECG signal is a non-stationary signal with strong impact characteristics (Shen and Shen 2010). The amplitude of the ECG is a few millivolts. As a result, ECG is extremely susceptible to environmental noise and other factors. Noise is generated due to interferences such as medical equipment and human activities in the process of collecting ECG signals. Studies have shown that ECG signals usually have the following three sources of interference (Yao 2012):
-
(1)
Power frequency interference
Power frequency interference is caused by the capacitance and electrodes distributed in the human body. The interference amplitude of ECG signals collected under different external environments can reach 0–50% of the peak value of the R wave. Moreover, the frequency of power frequency interference fluctuates randomly within a certain range centering on 50 Hz as the power grid load changes.
-
(2)
Electromyogram interference
There is a typical skin potential of 30 mV between the inside and outside of the human epidermis. This electric potential will change with the movement state of human body limbs. For example, the skin potential drops to about 25 mV when the limb is stretched. This 5 mV skin potential change reflects the noise caused by myoelectric contraction. We call it myoelectric interference. It will also produce EMG noise caused by the random contraction of many muscle fibers if the subject is nervous or cold. In addition, some diseases such as hyperthyroidism can also produce myoelectric noise. The frequency range of EMG interference is between 5 and 2000 Hz. The spectral characteristics are close to white noise and usually appear as rapidly changing and irregular waveforms.
-
(3)
Baseline drift
The baseline drift noise is mainly caused by limb activity, breathing, ECG acquisition mode and acquisition circuit. It is characterized by a slow change in baseline drift. It belongs to a low-frequency signal with a frequency range of 0.05 Hz to a few Hz and energy mainly around 0.1 Hz. At the same time, the amplitude variation range is about 15% of the highest amplitude in the ECG signal. The baseline drift noise is very close to the spectral distribution of the S-T segment in the heartbeat signal. It is easy to cause severe distortion of the S-T segment and affect the recognition effect of heart beats in the later stage if the filtering method is not properly selected.
The features of ECG signal are concentrated on the lower frequency band of the frequency domain, and Afonso et al. (1995) assert that the effective frequency band does not exceed 25 Hz. From the perspective of signal processing, wavelet transform algorithm has achieved good results in ECG baseline wandering elimination, QRS complex analysis and feature extraction (McDarby et al. 1998; Banerjee and Mitra 2010; Tripathy and Dandapat 2016). However, the traditional wavelet transform has a weak ability to identify repeated transient impacts (Wang et al. 2010). In this paper, we apply the method of maximal overlap wavelet packet transform (MOWPT) to the ECG data pre-processing.
Wavelet packet transform is a further development based on wavelet transform, which has higher resolution than wavelet transform. It overcomes the shortcomings of poor frequency resolution of the wavelet transform in the high frequency band. It can divide the high-frequency part more finely. It has the characteristic of frequency band adaptive selection, which matches the original signal spectrum by itself. Therefore, it can improve the time–frequency resolution and help obtain more detailed information about the signal.
In general, the wavelet packet transform (DWT) decomposes an input signal into scaling and wavelet coefficients by means of convolution with low- and high-pass filters respectively, in various sub bands or levels. The discrete wavelet packet transform (DWPT) is an orthonormal transform, which can be implemented efficiently using a very simple modification of the DWT pyramid algorithm (Percival and Walden 2000). In contrast to the DWT, the decomposition process of the DWPT is performed on both the scaling and wavelet coefficients. It promotes uniform frequency bands. According to (Mallat 1999), the DWPT coefficients at any level j is obtained from the convolution of the sampled original signal with the infinite impulse response filters g and h, as follows
where \(S_{0}^{0}\) is the original signal; \(z = 2m\) is the node number, where \(m \subset N\) and at scale \(j\), \(m \le 2^{j - 1} - 1\); the node zero component \(S_{j}^{0} (k)\) represents the decomposition packet coefficients of the lowest frequency band at scale \(j\), whereas at any other node, i.e., for (\(z \ne 0\)), \(S_{j}^{z} (k)\) represents the decomposition packet coefficients of the higher frequency bands at scale \(j\). The scaling and wavelet filters \(g\) and \(h\) present the following properties (Percival and Walden 2000)
According to Eqs. (1) and (2), the DWPT coefficients are computed in alternate samplings due the process of the down-sampling by a factor of 2 (time-variant property). The MOWPT decomposes also an input signal in coefficients for several levels through low- and high-pass filters, presenting uniform frequency output bands. In contrast to the DWPT, there is no down-sampling by a factor of two in MOWPT (time-invariant transform). In the reconstruction or synthesis, the decomposition coefficients are convolved to the reverse low- and high-filters in order to reconstruct the original signal. The MOWPT algorithm has all the advantages of DWPT. It can further decompose the high-band signal and improve the frequency resolution of the signal. Figure 4 depicts the process of decomposition and reconstruction of a signal \(x\) using a two-level decomposition tree of the MOWPT.

The process of decomposition and reconstruction using MOWPT (decomposition level is 2) (Alves et al. 2016)
According to (Mallat 1999), the MOWPT decomposition and reconstruction coefficients at any level j are given by
Referring to the sampling frequency and bandwidth of the original record, the number of decomposition layers is set to 4. Figure 5 shows samples representing each type.

Examples of short ECG recordings and their reconstructed sub recordings
2.5 Residual neural network theory
The residual neural network was produced in 2015. It draws on the ideas of Highway networks (Srivastava et al. 2015). For traditional convolutional neural networks, the learning ability of the network will increase as the depth of the network increases. However, the convergence speed of the network will slow down and the time required for training will also become longer. When the network depth reaches a certain number of layers, the learning rate will decrease and the accuracy rate will not be effectively improved or there is a risk of decline. This phenomenon is called “degradation”. The emergence of residual neural network is to overcome these degradation phenomena.
For the general conventional convolutional neural network, the input of each layer is derived from the output of the previous layer (Qin 2019). The network model is shown in Fig. 6a, which we call the Plain Network. The data is processed by the filter every time it passes through the convolution/pooling operation of the previous layer. The processing result is to make the input vector have a smaller size after the pooling operation. The purpose is to reduce the number of network parameters and prevent the occurrence of overfitting. If we perform gradient calculations in a network with many layers, our network will be easily paralyzed. Therefore, we used a new network structure-residual neural network to solve the problem of the gradient disappearance or gradient explosion in the deep network.

Common structure block and residual structure block (He et al. 2016)
The network structure of the residual network is shown in Fig. 6b. It is similar to a "short circuit" structure. The output of the previous layers does not go through the processing of the middle multiple network layers but directly serves as the input part of the network layer behind. The "clear" data in the front and the “fuzzy” data after multiple processing are passed into the neural layer as the input of the network layer (Ji 2019). Compared with the network model without adding the "short circuit" structure, the input data is more clear.
The residual structure ResNet has transformed the learning objectives. It no longer learns a complete mapping relationship from input to output, but the difference between the optimal solution \(H(x)\) and the input congruent mapping \(x\), The residual calculation formula is as follows
The processing of each layer in the ordinary structure is closely related to the output of the previous layer. In the residual network, the input data comes from different combinations of the previous network structure and not only depends on the output of the previous layer. In this way, rich reference information is introduced to extract the features of the input data (Liu 2018). As the paths in the network are relatively independent and independent of each other, the regularization effect of the overall network structure is better.
2.6 Proposed convolutional networks
Convolutional neural network (CNN) is a special deep feedforward neural network designed by the inspiration of the concept of “receptive field” in the field of biological neuroscience (Wang 2008). The general CNN structure consists of an input layer, multiple alternating convolutional and pooling layers (down sampling layers), a fully connected layer, and an output layer. The non-linear fitting ability of the deep neural networks will increase with the increase of the number of layers and the number of neurons. At the same time, the problem of gradient disappearance will occur in the simple stacked network layers. The network can be converged by means of specification initialization and introduction of a median normalization layer. However, the accuracy of the model will decrease as the depth deepens (He et al. 2016; Yu et al. 2016) when the accuracy of the network model reaches saturation. Such problems are not caused by overfitting. An implicit abstract mapping relationship is learned by adjusting parameters in a neural network, but it is difficult to be optimized in deeper networks. In the learning process of the residual convolutional neural networks algorithm, multiple consecutively stacked non-linear computing layers (such as four-layer convolution) are used to fit the residual between the input data and the mapped output data. The closer this residual value is to 0, the closer the features extracted by this network are to the original input. CNNs composed of residual block local deep neural networks units can solve problems such as difficulty in convergence and tuning of deep networks, and it overcomes the problem of CNN degradation as networks layers increase.
In this section, we propose the fast compression residual convolutional neural networks (FCResNet). As shown in Fig. 7, FCResNet is mainly composed of several modules: a fast down-sampling module, 3 residual convolution modules and a classification module.

The architecture of the proposed FCResNet
Convolutional layer with a stride of 3 in the fast down-sampling module is shown in Fig. 8. In neural networks, the pooling layer can also be used for data compression, reducing overfitting and improving the model's fault tolerance. However, the nonlinearity of the pooling layer is fixed and nulearnable. The pooling layer will lose most of the original image information, while increasing network depth and space–time efficiency. Compared with the pooling layer, using convolutional layer with a stride to compress the input data can adaptively learn the convolution kernel and achieve the purpose of down sampling. Therefore, we use convolutional layer with a stride instead of pooling layer.

Convolutional layer with a stride of 3 in the fast down-sampling module
In the fast down-sampling module, two convolutional layers with a stride of 3 are the principle part, and each convolutional layer is followed by a random dropout layer and a batch-normalization layer to enhance the generalization of the model. The input sample length is 3600. The fast down-sampling module effectively reduces the calculation of subsequent deep networks. Meanwhile, it reduces data redundancy and facilitates model learning.
The residual convolution module consists of convolutional layers in series and residual short circuit follows this. Then, the max-pooling layer is added to down-sample the feature vectors.
Finally, the classification module consists of 1 flatten layer, 2 full connection layers and a softmax classifier. Before flatten layer, a convolution layer is used to reduce the dimension of the feature vectors. After flatten layer, a random dropout layer is used to prevent overfitting.
The explanations for the applied functions in the FCResNet model are shown in Table 2.
3 Experimental results
3.1 Evaluation metrics
We used the precision, recall, f1-score, accuracy and loss that were used as the performance evaluation criteria in the pattern recognition field for the performance analysis of each class. The precision, recall, f1-score, and accuracy for each class was calculated through Eqs. (10), (11), (12), and (13).
where TP stands for true positive, meaning the correct classification as arrhythmia; TN stands for true negative, meaning correct classification as normal; FP stands for false positive, meaning incorrect classification as arrhythmia; FN represents false negative, meaning incorrect classification as normal (Yin et al. 2016).
As for the metric of loss, it is defined as the difference between the predicted value of the model and the true value for a specific sample. This metric has several distinct types of mathematical expressions. In this study, we choose the function of categorical cross entropy loss
where \(n\) represents the number of samples; \(m\) represents the number of categories; \(\hat{y}\) represents the predictive output value; and \(y\) represents the actual value.
3.2 Performance evaluation of different down-sampling module in FCResNet
The down-sampling module mainly undertakes two functions:
First, quickly reducing the dimension of the feature vector and reducing the calculation of the entire model; Second, concentrating the waveform features of the electrocardiogram to remove redundant details (Cao et al. 2019a, b). The results of the sixfold cross-validation of the FCResNet using down-sampling modules containing different number of wide-stride convolution (WSConv) layer are shown in Fig. 9, and the number of the epoch is 100. It is particularly noteworthy that large-scale data redundancy is not conducive to the improvement of accuracy if the sample is directly processed by the residual convolution module. The over-fitting problem is exacerbated and the loss value is quickly diverged. Regard less of the number of WSConvs, various down-sampling modules effectively improve accuracy and reduce loss values. It can be seen that the cross-validation results of the model are scattered and the model is not stable enough when only one WSConv is used or four WSConvs are used continuously.

Performance of different fast down-sampling convolutional module
The accuracy is greatly improved and the model is stable when two WSConvs or three WSConvs are used. The cross-validation results using two WSConvs is similar to that using three WSConvs. In order to simplify the model structure and improve the model calculation efficiency, the fast down-sampling module containing two WSConvs is used herein.
3.3 Performance evaluation of different batch sizes in FCResNet
The batch size is a significant parameter for the learning process of this proposed FCResNet model. In order to achieve the best classification performance of ECG heart rhythm abnormalities, the step of model parameter optimization is indispensable.
To evaluate the importance of the batch size of the proposed FCResNet model, a series of contrast experiments with different parameter sets were conducted. We tested the contrast experiments with 5 different batch sizes (10, 20, 30, 40, 50) when keeping the value of the other parameters unchanged.
We set the number of iteration steps as 100. Figure 10 represents the average test accuracy by five different batch sizes. Increasing batch size within a reasonable range can improve memory utilization. The parallelization efficiency of large matrix multiplication is improved. The number of iterations required to run an epoch (full data set) is reduced. The speed of processing the same amount of data has become faster. At the same time, the number of epochs required to achieve the same accuracy is increasing as the batch size increases. Due to the contradiction between the above two factors, the final convergence accuracy will fall into different local extreme values. Therefore, the final convergence accuracy will be optimal when the batch size increases to some value.

Comparison of average test accuracy by different batch size
From the figures behind, we can find that the model classification accuracies under these five size parameters have all exceeded 95%. This shows that the proposed FCResNet model has stability and high classification performance. The proposed FCResNet model achieves the average test accuracy of 97.74% with the batch size of 10. It achieves the best average test accuracy of 98.79% with the batch size of 20. The classification accuracy begins to decline when the batch size exceeds 20. From the experimental comparisons demonstrated above, we can conclude that the proposed FCResNet model show the best classification performance when the batch size parameter is 20.
3.4 Performance evaluation of different sub-band reconstructed datasets in FCResNet
Different frequency bands of the ECG recordings carry different message. The wavelet packet can fidelity decompose the information of each frequency band, making the features of various ECGs more recognizable in each frequency band. In this section, the performance of training CNN with reconstructed sub-signals in different frequency bands is studied experimentally, and the experiment results are shown in Fig. 11.

Comparison of average test accuracy by different reconstructed sub-signal
From the Fig. 11 we can find that the classification test accuracy using raw ECG signal as input achieves 92.56%. The performance of the reconstructed sub-signal with lower frequency is better than the higher frequency. The reconstructed ECG dataset of \(wp_{4}^{1}\) ([0, 11.25 Hz]) achieves the best average test accuracy of 98.79%. The reconstructed ECG dataset of \(wp_{3}^{1}\) ([0, 22.5 Hz]) achieves the best average test accuracy of 95.33%. While the test accuracy using other reconstructed ECG dataset is lower than 93%. It confirms that the features of ECG signal are concentrated on the lower frequency band of the frequency domain (Afonso et al. 1995). From the experimental comparisons demonstrated above, we can conclude that when the reconstructed ECG dataset of \(wp_{4}^{1}\) ([0, 11.25 Hz]) as the input, the proposed FCResNet model shows the best classification performance.
4 Discussion
4.1 Model parameter optimization with results
From the “PERFORMANCE EVALUATION” part above, we know that the proposed FCResNet model achieves the best classification performance with the batch size of 20 and the reconstructed ECG dataset of \(wp_{4}^{1}\) ([0, 11.25 Hz]) being the model input.
The optimized model results are shown in Figs. 12, 13 and 14. Figures 12 and 13 represent the test accuracy value curve and the loss value curve of the proposed FCResNet respectively. As the number of iteration steps increases, the accuracy curve exhibits a convergence trend close to the value of 1, the loss curve exhibits a convergence trend close to the value of 0. The two curves maintain a relatively stable state during convergence. The optimized ECG arrhythmia classification model achieves a good average test accuracy of 98.79% and average loss value of 0.0255.

The test accuracy value curve of the proposed FCResNet

The loss value curve of the proposed FCResNet

The normalized confusion matrix of the best result achieved
Figure 14 shows the results of the confusion matrix for the performance of user recognition using the proposed FCResNet based ECG signals. It can be seen from Fig. 11 that the prediction accuracy rates of the model for 5 different arrhythmia types of ECG records are close to each other. Regardless of any type of ECG signal, this method can classifies ECG arrhythmia with high accuracy. This proves the stability and effectiveness of the proposed method.
4.2 Comparison with DWPT preprocessing method
We compared the performance of DWPT preprocessing method with MOWPT preprocessing method under the proposed FCResNet model. In the proposed FCResNet model, the learning rate is set as 0.001, the batch size parameter is 20 and the reconstructed ECG dataset of ([0, 11.25 Hz]) is set as input. From the Table 3, it can be seen that the MOWPT preprocessing method presented a better classification accuracy than that DWPT preprocessing method. Using MOWPT preprocessing method and FCResNet model in ECG arrhythmia can achieve a precision rate of 99.39%, a recall rate of 95.16%, a F1-score of 97.23% and a accuracy of 98.79%. Using DWPT preprocessing method and FCResNet model in ECG arrhythmia can achieve a precision rate of 98.35, a recall rate of 91.31%, a F1-score of 94.70% and a accuracy of 97.66%. Compared with the DWPT, the details of the MOWPT are related to the zero-phase filter (Zhou 2018). Therefore, it is easy to list the features of the original time series in the multi-resolution analysis with physical meaning. It explains why the MOWPT preprocessing method presented a better classification accuracy than that DWPT preprocessing method.
4.3 Comparison with other existing approaches
In the proposed framework, FCResNet is chosen as the classification network which uses the fully connected layer to do the classification task. Therefore, we test whether using different classifiers can optimize the performance of the model or not. The experiment runs on a PC with 16 GB of memory and 16 GB of GPU memory.
We compared the performance of the proposed FCResNet model with previous ECG arrhythmia classification works, including SVM (Support Vector Machine), RNN (Recurrent Neural Network), RF (Random Forest), K-NN(K Nearest Neighbor).
-
1.
FFNN classifier
Feed forward neural network ( FFNN) is a classifier that feeds information from the front (input) to the back (output). The neurons in each layer of the network have their inputs from the output signals of the preceding layer only. The set of output signals of the neurons in the output layer of the network constitutes the overall response of the network supplied by the source nodes in the input layer.
-
2.
SVM classifier
Support Vector Machine (SVM) is a binary classification model, which constructs a maximum margin hyperplane in high dimensional space to separate positive and negative samples. Here, linear kernel SVM is used and the penalty factor is set to be 1.
-
3.
RNN classifier
Recurrent Neural Network (RNN) is a type of recursive neural network. It introduces a feedback mechanism in the hidden layer to achieve efficient processing of sequence data. It takes sequence data as input, performs recursion in the evolution direction of the sequence, and all nodes (recurring units) are chained connected.
-
4.
RF classifier
Random forest (RF) is an algorithm that integrates multiple decision trees through the idea of ensemble learning. It uses the bootsrap resampling method to extract multiple samples from the original sample, models the decision tree for each bootsrap sample, and combines the predictions of multiple decision trees, finally the prediction result is obtained by voting.
-
5.
KNN classifier
K-Nearest Neighbor is a classifier based on instance-based learning. It uses the distances between samples for classification. The strategy is that the label of a sample depends on labels of the k existing samples closest to it. In this experiment, k is set to 3 and the distances between the samples are calculated by the Euclidean distance.
We also compared the classification performance of the proposed FCResNet model with multi-scale decomposition enhanced residual CNN (Cao et al. 2019a, b) and 2Dimension CNN (Huang et al. 2019).
Table 4 presents performance comparison with other existing approaches. These comparative experiments have the same number of the test set and types of arrhythmia for clearer comparison. The datasets from MIT-BIH arrhythmia database were employed to test the performance of these experimental classifiers. 2520 samples of the five arrhythmia types were utilized as input to the experimental classifiers such that the ECG arrhythmia types were identified and classified.
Table 4 Comparison with existing classification approaches As can be seen from Table 4, our proposed FCResNet model achieved the best precision rate, recall rate, F1-score and average accuracy in comparison with these previous ECG arrhythmia classification works. The proposed FCResNet model achieved successful performance compared to other previous works while introducing the different approach of classifying ECG arrhythmia using MOWPT and fast compression residual convolutional neural networks.
What’s more, we also compared with feature extraction-pattern classification approaches.
-
6.
Kernel Principal Component Analysis (KPCA)
Principal component analysis (PCA) is a mathematical technique whose purpose is to transform a number of correlated variables into a number of uncorrelated variables called “principal components” (PC). These PCs account for the maximum variance of the data set. The redundancy of the original variables means that they are measuring the same concept (Jolliffe 1986). The basic idea of KPCA is to map the original data into a high dimensional space via a specific function and then to apply the standard PCA algorithm on it. The linear PCA in the high dimensional feature space corresponds to a nonlinear PCA in the original input space and can find the most interesting direction (Müller et al. 2001).
-
7.
Autoregressive Modelling (AR)
AR is a signal feature extraction method where the output variable is predicted based on linearly depending on its own previous values. The autoregressive framework assumes that the EEG signal can be modeled as a linear combination of the signals at the previous time points (Lawhern et al. 2012).
From the Table 4, we can observe that the classification accuracy of the two feature-extraction–pattern classification approach is similar to that of the proposed method in this paper. The two feature-extraction-pattern classification approach are comprised of three components including data preprocessing, feature extraction and classification of ECG signals. Compared with the proposed FCResNet classifier, the feature-extraction processing of feature-extraction-pattern approaches is much more complex. It greatly increases the efficiency and convenience of ECG classification.
In summary, the proposed method in this paper is a simple and efficient method with high classification accuracy. The method proposed obtains the classification results comparable to the best research results without involving the professional knowledge of electrocardiogram. It is foreseeable that with the further accumulation of datasets, especially the increase of abnormal ECG samples and pattern subdivision, the deep learning model can achieve a more powerful classification ability.
5 Conclusion
In this paper, we proposed an ECG arrhythmia classification method using maximal overlap wavelet packet transform and fast compression residual convolutional neural networks.
ECG signals, belonging to five different types, were obtained from the MIT-BIH arrhythmia database. The ECG signals were segmented into records of the duration of 10 s. 2520 records were selected for ECG classification. In the procedure of the proposed method, the time domain signals of ECG were decomposed and reconstituted into sub-signal samples of different scales using MOWPT. Subsequently, the samples of the five arrhythmia types were utilized as input to the FCResNet such that the ECG arrhythmia types were identified and classified finally. Using ECG recordings from the MIT-BIH arrhythmia database as the training and testing data, the classification results show that the proposed FCResNet model can reach an averaged accuracy of 98.79%. It is validated that the proposed FCResNet classifier using ECG sub-signal samples of different scales as input can achieve improved classification accuracy without additional manual pre-processing of the ECG signals.
In addition, in order to achieve the best classification performance, a series of contrast experiments with different parameter sets were made. We found that the classifier achieved the best classification performance with high accuracy and low loss when the number of the wide-stride convolution (WSConv) in fast down-sampling module is 2, the batch size parameter is 20 and the reconstructed ECG dataset of ([0, 11.25 Hz]) being the model input.
References
Afonso VX, Tompkins WJ, Nguyen TQ et al (1995) Filter bank-based processing of the stress ECG. In: Proceedings of IEEE 17th international conference of the engineering in medicine and biology society, vol 2. IEEE, pp 887–888
Alickovic E, Subasi A (2015) Effect of multiscale PCA de-noising in ECG beat classification for diagnosis of cardiovascular diseases. Circuits Syst Signal Process 34(2):513–533
Alves DK, Costa FB, Ribeiro RL et al (2016) Real-time power measurement using the maximal overlap discrete wavelet-packet transform. IEEE Trans Ind Electron 64(4):3177–3187
Andersen RS, Peimankar A, Puthusserypady S (2019) A deep learning approach for real-time detection of atrial fibrillation. Expert Syst Appl 115:465–473
Banerjee S, Mitra M (2010) ECG feature extraction and classification of anteroseptal myocardial infarction and normal subjects using discrete wavelet transform. In: International conference on systems in medicine and biology. IEEE, pp 55–60
Cao XC, Chen BQ, Yao B et al (2019) Combining translation-invariant wavelet frames and convolutional neural network for intelligent tool wear state identification. Comput Ind 106:71–84
Cao XC, Yao B, Chen BQ (2019) Atrial fibrillation detection using an improved multi-Scale decomposition enhanced residual convolutional neural network. IEEE Access 7:89152–89161
Chang KM, Liu SH (2011) Gaussian noise filtering from ecg by wiener filter and ensemble empirical mode decomposition. J Signal Process Syst 64(2):249–264
De Albuquerque VHC, Nunes TM, Pereira DR et al (2016) Robust automated cardiac arrhythmia detection in ECG beat signals. Neural Comput Appl 29:679–693
Diker A, Avci D, Avci E et al (2019) A new technique for ECG signal classification genetic algorithm Wavelet Kernel extreme learning machine. Optik 180:46–55
Dutta S, Chatterjee A, Munshi S (2010) Correlation technique and least square support vector machine combine for frequency domain based ECG beat classification. Med Eng Phys 32(10):1161–1169
Elhaj FA, Salim N, Harris AR et al (2016) Arrhythmia recognition and classification using combined linear and nonlinear features of ECG signals. Comput Methods Programs Biomed 127:52–63
Erdenebayar U, Kim H, Park JU et al (2019) Automatic prediction of atrial fibrillation based on convolutional neural network using a short-term normal electrocardiogram signal. J Korean Med Sci 34(7):64–74
Faust O, Shenfield A, Kareem M et al (2018) Automated detection of atrial fibrillation using long short-term memory network with RR interval signals. Comput Biol Med 102:327–335
Güler İ, Übeylı ED (2005) ECG beat classifier designed by combined neural network model. Pattern Recognit 38(2):199–208
He K, Zhang X, Ren S et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 770–778
Hong J, Cheng H, Zhang YD et al (2019) Detecting cerebral microbleeds with transfer learning. Mach Vis Appl 30(7–8):1123–1133
Huang C, Ye S, Chen H et al (2010) A novel method for detection of the transition between atrial fibrillation and sinus rhythm. IEEE Trans Biomed Eng 58(4):1113–1119
Huang J, Chen B, Yao B et al (2019) ECG arrhythmia classification using STFT-based spectrogram and convolutional neural network. IEEE Access 7:92871–92880
Islam MZ, Sajjad GMS, Rahman MH et al (2012) Performance comparison of modified LMS and RLS algorithms in de-noising of ECG signals. Int J Eng Technol 2(3):466–468
Ji H (2006) Research on key technologies of automatic analysis of ECG signals. National University of Defense Technology, Changsha
Ji T (2019) Research on remote sensing image scene classification based on convolutional neural network. Henan University, Kaifeng
Jiang X, Zhang YD (2019) Chinese sign language fingerspelling via six-layer convolutional neural network with leaky rectified linear units for therapy and rehabilitation. J Med Imaging Health Inform 9(9):2031–2090
Jolliffe IT (1986) Principal component analysis
Kallas M, Francis C, Kanaan L, Merheb D, Honeine P, Amoud H (2012) Multi-class SVM classification combined with kernel PCA feature extraction of ECG signals. In: International conference telecommunication, pp 1–5
Kaur H, Rajni H (2017) A Novel approach for denoising electrocardiogram signal using hybrid technique. J Eng Sci Technol 12:1780–1791
Kiranyaz S, Ince T, Gabbouj M (2015) Real-time patient-specific ECG classification by 1-D convolutional neural networks. IEEE Trans Biomed Eng 63(3):664–675
Kumar RG, Kumaraswamy YS (2012) Investigating cardiac arrhythmia in ECG using random forest classification. Int J Comput Appl 37(4):31–34
Kumar M, Pachori R, Acharya U (2017) Automated diagnosis of myocardial infarction ECG signals using sample entropy in flexible analytic wavelet transform framework. Entropy 19(9):488
Labati RD, Mu OE, Piuri V et al (2018) Deep-ECG: convolultional neural networks for ECG biometric recognition. Pattern Recognit Lett 126:78–85
Lawhern V, Hairston WD, Mcdowell K et al (2012) Detection and classification of subject-generated artifacts in EEG signals using autoregressive models. J Neurosci Methods 208(2):181–189
Li T, Min Z (2016) ECG classification using wavelet packet entropy and random forests. Entropy 18(8):285
Li W, Jiang X, Sun W et al (2019) Gingivitis identification via multichannel gray-level co-occurrence matrix and particle swarm optimization neural network. Int J Imaging Syst Technol 30(2):401–411
Liu C (2018) Research and design of handwritten digit recognition based on convolutional neural network. Chengdu University of Technology, Chengdu
Lv Q (2018) Research on classification and recognition of cardiovascular diseases based on deep learning. Zhengzhou University, Zhengzhou
Mallat S (1999) A wavelet tour of signal processing. Elsevier, New York
Martis RJ, Acharya UR, Lim CM et al (2013) Application of higher order cumulant features for cardiac health diagnosis using ECG signals. Int J Neural Syst 23(04):1350014
McDarby G, Celler BG, Lovell NH (1998) Characterising the discrete wavelet transform of an ECG signal with simple parameters for use in automated diagnosis. In: Proceedings of the 2nd international conference on bioelectromagnetism (Cat. No. 98TH8269). IEEE, pp 31–32
Melgani F, Bazi Y (2008) Classification of electrocardiogram signals with support vector machines and particle swarm optimization. IEEE Trans Inf Technol Biomed 12(5):667–677
Moody GB (2001) The impact of the MIT-BIH arrhythmia database. IEEE Eng Med Biol Mag 20(3):45–50
Mostayed A, Luo J, Shu X, et al (2018) Classification of 12-lead ECG signals with Bi-directional LSTM network. arXiv preprint arXiv:1811.02090
Muhsin NK (2011) Noise removal of ECG signal using recursive least square algorithms. Al-Khwarizmi Eng J 7(1):13–21
Müller K-R, Mika S, Rätsch G et al (2001) An introduction to kernel-based learning algorithms. IEEE Trans Neural Netw 12(2):181
Özbay Y, Ceylan R, Karlik B (2011) Integration of type-2 fuzzy clustering and wavelet transform in a neural network based ECG classifier. Expert Syst Appl 38(1):1004–1010
Park J, Lee K, Kang K (2013) Arrhythmia detection from heartbeat using k-nearest neighbor classifier. In: IEEE international conference on bioinformatics and biomedicine, IEEE Computer Society, pp 15–22
Percival DB, Walden AT (2000) Wavelet methods for time series analysis. Cambridge University Press, Cambridge
Poungponsri S, Yu XH (2013) An adaptive filtering approach for electrocardiogram (ECG) signal noise reduction using neural networks. Neurocomputing 117:206–213
Qin S (2019) Research on handwritten digit recognition based on deep residual network. Xidian University of Electronic Science and Technology, Xi’an
Raman P, Ghosh S (2016) Classification of heart diseases based on ECG analysis using FCM and SVM methods. Int J Eng Sci 2016:6739–6744
Rashmi N, Begum G, Singh V (2017) ECG denoising using wavelet transform and filters. In: International conference on wireless communications, signal processing and networking (WiSPNET), pp 2395–2400
Salem M, Taheri S, Yuan JS (2018) ECG arrhythmia classification using transfer learning from 2-dimensional deep CNN features. In: IEEE biomedical circuits and systems conference (BioCAS), pp 1–4
Salloum R, Kuo CCJ (2017) ECG-based biometrics using recurrent neural networks. In: International conference on acoustics, speech and signal processing (ICASSP), pp 2062–2066
Sayadi O, Shamsollahi MB (2008) ECG denoising and compression using a modified extended Kalman filter structure. IEEE Trans Biomed Eng 55(9):2240–2248
Sellami A, Hwang H (2019) A robust deep convolutional neural network with batch-weighted loss for heartbeat classification. Expert Syst Appl 122:75–84
Shen Y, Shen Z (2010) A nonlinear non-stationary adaptive signal processing method—a review of Hilbert-Huang transform: development and application. Autom Technol Appl 29(5):1–5
Singh P, Shahnawazuddin S, Pradhan G (2018) An efficient ECG denoising technique based on non-local means estimation and modified empirical mode decomposition. Circuits Syst Signal Process 37(5):1–21
Slonim TYM, Slonim MA, Ovsyscher EA (1993) The use of simple FIR filters for filtering of ECG signals and a new method for post-filter signal reconstruction. In: Computers in cardiology conference, pp 871–873
Smital L, Vitek M, Kozumplík J et al (2012) Adaptive wavelet wiener filtering of ECG signals. IEEE Trans Biomed Eng 60(2):437–445
Srivastava RK, Greff K, Schmidhuber J (2015) Highway networks. Comput Sci 1505:387–392
Thakor NV, Zhu YS (1991) Applications of adaptive filtering to ECG analysis: noise cancellation and arrhythmia detection. IEEE Trans Biomed Eng 38(8):785–794
Thomas M, Das MK, Ari S (2015) Automatic ECG arrhythmia classification using dual tree complex wavelet based features. AEU Int J Electron Commun 69(4):715–721
Tripathy RK, Dandapat S (2016) Detection of cardiac abnormalities from multilead ECG using multiscale phase alternation features. J Med Syst 40(6):143
Übeyli ED (2009) Combining recurrent neural networks with eigenvector methods for classification of ECG beats. Digital Signal Process 19(2):320–329
Varatharajan R, Manogaran G, Priyan MK (2018) A big data classification approach using LDA with an enhanced SVM method for ECG signals in cloud computing. Multimed Tools Appl 77(8):10195–10215
Wang Y, He Z, Zi Y (2010) Enhancement of signal denoising and multiple fault signatures detecting in rotating machinery using dual-tree complex wavelet transform. Mech Syst Signal Process 24(1):119–137
Wang Y, Zhou T, Lu H et al (2017) Computer aided diagnosis model for lung tumor based on ensemble convolutional neural network. Sheng wu yi xue gong cheng xue za zhi Journal of biomedical engineering Shengwu yixue gongchengxue zazhi 34(4):543–551
Wang SH, Xie S, Chen X et al (2019a) Alcoholism identification based on an AlexNet transfer learning model. Front Psychiatry 10:205
Wang SH, Zhang YD, Yang M et al (2019b) Unilateral sensorineural hearing loss identification based on double-density dual-tree complex wavelet transform and multinomial logistic regression. Integr Comput Aided Eng 26(4):411–426
Wang S, Tang C, Sun J, et al (2019c) Cerebral micro-bleeding detection based on densely connected neural network. Front Neurosci 13
Wang S, Sun J, Mehmood I et al (2020) Cerebral micro-bleeding identification based on a nine-layer convolutional neural network with stochastic pooling. Concurr Comput Pract Exp 32(1):5130–5145
Wang Q (2008) Multivariate ECG information database. China Union Medical University
World Health Organization (2017) Cardiovascular diseases (CVDs). https://www.who.int/mediacentre/factsheets/fs317/en/. Accessed 18 Apr 2018
Yao C (2012) Research on key technologies of intelligent analysis of ECG signals. Jilin University, Changchun
Yeh YC, Chiou CW, Lin HJ (2012) Analyzing ECG for cardiac arrhythmia using cluster analysis. Expert Syst Appl 39(1):1000–1010
Yildirim Ö (2018) A novel wavelet sequence based on deep bidirectional LSTM network model for ECG signal classification. Comput Biol Med 96:189–202
Yin W, Yang X, Zhang L et al (2016) ECG monitoring system integrated with IR-UWB radar based on CNN. IEEE Access 4:6344–6351
Yu SN, Chou KT (2008) Integration of independent component analysis and neural networks for ECG beat classification. Expert Syst Appl 34(4):2841–2846
Yu L, Chen H, Dou Q et al (2016) Automated melanoma recognition in dermoscopy images via very deep residual networks. IEEE Trans Med Imaging 36(4):994–1004
Zeng N, Wang Z, Zhang H, Kim KE, Li Y, Liu X (2019) An improved particle filter with a novel hybrid proposal distribution for quantitative analysis of gold immune chromate graphic strips. IEEE Trans Nanotechnol 18(1):819–829
Zhai X, Tin C (2018) Automated ECG Classification using dual heartbeat coupling based on convolutional neural network. IEEE Access 1:1
Zhang J, Lin JL, Li XL, et al (2017) ECG signals denoising method based on improved wavelet threshold algorithm. In: Advanced information management, communicates, electronic and automation control conference, IEEE, pp 1779–1784
Zhang X, Liu Z, Miao Q et al (2018) Bearing fault diagnosis using a whale optimization algorithm-optimized orthogonal matching pursuit with a combined time–frequency atom dictionary. Mech Syst Signal Process 107:29–42
Zhang YD, Govindaraj VV, Tang C et al (2019) High performance multiple sclerosis classification by data augmentation and AlexNet transfer learning model. J Med Imaging Health Inform 9(9):2012–2021
Zhao Y (2015) Research on classification of abnormal ECG signals based on wavelet analysis and neural network. Taiyuan University of Technology, Taiyuan
Zhao Q, Zhang L (2015) ECG feature extraction and classification using wavelet transform and support vector machines. In: International conference on neural networks & brain, pp 1089–1092
Zhou H (2018) Linear system parameter identification based on improved maximum overlapping discrete wavelet packet transform. Nanjing University of Aeronautics and Astronautics, Nanjing
Zhu HH (2013) Research on ECG recognition critical methods and development on remote multi-bod-characteristic-signal monito-ring system. University of Chinese Academy of Sciences, Beijing
Acknowledgements
This research is supported financially by National Natural Science Foundation of China (no. 51605403), the Fundamental Research Funds for the Central Universities under Grant 20720190009, International Science and Technology Cooperation Project of Fujian Province of China under Grant 2019I0003.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Huang, JS., Chen, BQ., Zeng, NY. et al. Accurate classification of ECG arrhythmia using MOWPT enhanced fast compression deep learning networks. J Ambient Intell Human Comput 14, 5703–5720 (2023). https://doi.org/10.1007/s12652-020-02110-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-020-02110-y