
Abstract
In many information system applications, the environment is dynamic and tremendous amount of streaming data is generated. This scenario enforces additional computational demand on the algorithm to process incoming instances incrementally using restricted memory and time compared to static data mining. Moreover, when the streams of data are collected from different sources, it may exhibit concept drift, which means the variation in the distribution of data and it can have a high degree of class imbalance. The problem of class imbalance occurs when there is a much lower number of an example representing one class than those of the other class. Concept drift and imbalanced streaming data are commonly found in real-world applications such as fraud detection, intrusion detection, decision support system and disease prediction. In this paper, the different concept drift detectors and handling approaches are analysed when dealing with imbalance data. A comparative analysis of concept drift is performed on various data sets like SEA synthetic data stream and real world datasets. Massive Online Analysis (MOA) tool is used to make the comparative study about different learners in a concept drifting environment. The performance measure such as Accuracy, Precision, Recall, F1-score and Kappa statistic has been used to evaluate the performance of the various learners on SEA synthetic data stream and real world dataset. Ensemble classifiers and single learners are employed and tested on the data samples of SEA synthetic data stream, electrical and KDD intrusion data set. The ensemble classifiers provide better accuracy when compared to the single classifier and ensemble based methods has shown good performance compared to strong single learners when dealing with concept drift and class imbalance data.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the advance in information technology, large volumes of data are generated by social networks, mobile phones, and sensor devices. The digital universe today has 2.7 zeta bytes of data and it is increasing day by day. The volumes of data generated by the applications like email, network monitoring (Pradeep et al. 2019), financial data prediction (Bay et al. 2006), oil spillage detection (Kubat et al. 1998a), traffic control, sensor measurement processing, credit card transaction, web click stream (Han and Kamber 2006) are so large, that it cannot be stored on disk. Hence performing a real-time analytics on the non-stationary data or streaming data has attracted the interest of researchers in recent years. Data stream are a sequence of data that arrive at the system in a continuous and changing manner. Data streams have some characteristics such as huge, timely ordered, rapidly changing and potentially infinite in length (Gama 2010). Therefore the conventional mining algorithm has to be improved to run on the streaming platform, where the data changes periodically. Furthermore, the shift in the data distribution is called class change or concept drift becomes more challenging in data streams. Some of the challenges associated with key data stream mining include data stream classification, clustering, frequent pattern mining, load shedding and sliding window computation (Aggarwal 2007). The data stream has to be processed sequentially on record-by-record basis or over the sliding window and can be used for various kinds of application.
In streaming environment, the data arrive at a higher rate and the traditional data mining algorithm cannot handle those streaming data. Therefore the classification algorithm has to be modified in order to handle the change in evolving data. Data stream classifiers may either be single incremental model or ensemble model (Wang et al. 2003a, b). The single classifier updates incrementally the training data to tackle the newly evolving stream class labels, which require complex modifications in the classifier. In ensemble-based classification, the output is a function of the predictions of different classifiers. Ensemble classifiers consist of a set of classifiers whose individual decisions are combined to predict new examples. Some of the other classification methods of data stream mining are Very Fast Decision Tree (Domingos and Hulten 2000; Jin and Agrawal 2003), On Demand classification (Aggarwal et al. 2004), Online Information Network (Last 2002).The ensemble-based classification improves the prediction accuracy and it can handle concept drift (Zliobaite 2010). The combination of prediction of different machine learning algorithm is referred to as ensemble based learning, which has been successfully used to improve the accuracy of the single classifier (Löfström 2015).
In streaming data, the data that belong to one set of class come on the fly at one instant of time and another set of data from another set of classes in another instant of time and this concept is represented as class drift or concept drift. Class drift can be divided into three categories namely, sudden, gradual, and recurring drifts (Brzezinski and Stefanowski 2014). Since the class keeps on changing with time, it is possible to create a serious problem of class imbalance (Chawla et al. 2004).
Class imbalance issues have recently attracted growing interest due to their classification difficulties caused by imbalanced class distributions and may lead to higher performance reductions in online learning, including concept drift detection. It is commonly seen in dataset such as cancer diagnosis where the malignant classes are under-represented, spam filtering (Nishida et al. 2008), fraud detection (Wei et al. 2013; Herland et al.2018), computer security (Cieslak et al. 2006), image recognition (Kubat et al. 1998b), risk management (Vijayakumar and Arun 2017) and fault diagnosis (Meseguer et al. 2010; Rigatos et al. 2013). The minority class examples which may carry useful information cannot be predicted correctly by the conventional machine learning algorithm due to the skewed distribution of data. Therefore an intelligent system has to be developed to solve the combined problem of concept drift and class imbalance. Figure 1, shows the steps involved in the classification of data streams.

Classification steps of processing data stream
The rest of this paper is organised as follows. Section 2 presents the introduction about concept drift. The concept drift detectors and handling approaches are discussed in Sects. 3 and 4. Ensemble based classification methods for data streams are presented in Sect. 5 and approaches for handling concept drift in the presence of imbalance data is discussed in Sect. 6. Performance metrics and tools for stream mining are given in Sects. 7 and 8. The experimentation results and discussion were discussed in Sect. 9 and conclusion in Sect. 10.
2 Concept drift in data streams
In the dynamic environments, the distribution of data varies over time and it leads to the condition of concept drift. The drift or the change may be caused because of various phenomenon governing the learning problem; however the classification models that address this change must be adaptive to continue as the appropriate predictor. Concept drift refers to the change in the underlying distribution of data. As the time passes the concept drift will lead to the prediction of trained classifier to be less accurate. Let \(x\) be the feature vector, \(y\) be the class label and the infinite sequence of data stream is denoted as \((x,y)\). The distribution of data chunk at time is represented as \(P_{t} (x,y)\). The term concept means that \(P_{t} (x,y) \ne P_{t + 1} (x,y).\) Concept drift occurs when the joint probability distribution of \(x\) and \(y\) namely, \(P(x,y_{{}} ) = p(x)P(y|x)\) changes where \(x\) is the feature vector and \(y_{i}\) is the class label and the concept drift can be caused by drifting \(p(x)\) over time (Kelly et al. 1999). Concept drift makes three fundamental changes to the key variable in Baye's theorem (Krawczyk and Wozniak 2015). First is the drift by prior probability \(P_{t} (y)\), which makes a change in learned decision boundaries. Identification of drift using prior probability can be done by finding the distance between two concepts that are estimated using total variation distance and Hellinger distance assessment method. Second is the drift by a condition where the decision boundary change is influenced by the condition. Third, is the drift caused by posterior probability \(P_{t} (y|x)\), where the change is influenced by the conflict of old and new decision boundary. Change in the previous probability of the class outcomes a shift in class imbalance status. An example of such case is that the class representing to be minority class may turn into majority class at any time.
Concept drift is of two types, real and virtual drift. In the real drift, the posterior probability varies over time independently which is given by \(p(y|x)\). In virtual drift, the change in distribution of one or more several class is given by \(p(x|y)\) and the marginal distribution of incoming data changes without affecting the posterior probability of classes. Virtual drift has no effect on the concept of the target. The shift in the underlying distribution of data can occur by moving from one concept to another suddenly or abruptly. The notion of drift can be said to be incremental with many intermediate concepts in between. Even at times, where the change is not abrupt, the drift may be gradual. A recurring drift can also occur when new concepts reoccur after a while that are not seen before or previously seen. Figure 2 shows the types of concept drift which can occur in the streaming data.

Types of concept drift
Adaptive learning can be used to handle concept drift. There are two types of adaptive learning, one being incremental and the other being the ensemble learning. Incremental learning is more helpful when it is applied to data streams that exhibit incremental or gradual drift with drift detectors. Bayesian classifiers such as Naïve Bayes, Hoeffding Trees, and Stochastic Gradient Descent Variations are some examples of incremental learners. Incremental learning happens whenever a new instance appears and adjusts to what new instances have learned, whereas in ensemble learning it uses multiple base learners and combines their predictions. Ensemble based method is the most common method for handling concept drift. The output of several classifiers is combined in ensemble learning to determine the final output of classification.
3 Concept drift detectors
The concept drift detector signals the change in data stream distribution. The main task of drift detector is to alarm the base learner about the updation or retraining of the model. To detect the change in concept, the current model's accuracy should be monitored and the window size should be updated accordingly. The drift detector is used primarily to decrease the deterioration of peak performance and to minimize restore time. The drift detection model utilizes the distinction between the two models in terms of accuracy to determine when to substitute the present model as it does not recognize the change in the target concept. The concept drift is signalled when the accuracy of the previously measured value is significantly reduced. When there is no classifier to detect the changes, we can use statistical tests like Welch’s test, Kolmogorov–Smirnov’s test formonitoring distribution changes and drift detector methods are shown in Fig. 3. The two sample Kolmogorov–Smirnov test is non-parametric, as it makes no assumption about the distribution of data. It compares the distribution of two samples by measuring a distance between the empirical distribution functions, taking into account both their location and shape. Two-sample t test is also the most popular tests used in quality measures. It calculates the t-statistic on the basis of mean, standard deviations and the number of observations in each sample. Some of the other statistical tests are Wald–Wolfowitz test (Sobolewski and Woźniak 2013), Wilcoxon rank sum test and Wilcoxon Signed-rank test (Wolfowitz 1949).

Concept drift detector methods
The concept drift detectors performance can be assessed by the number of true and false positive drift detected along with the delay in drift detection. The drift detection delay can be defined as the time difference between the appearance of the real drift and its detection. Hierarchical change detection tests (Cesare et al. 2011) is an online algorithm for detecting concept drift which produces a stream of sufficient instances and the graph is plotted between the number of false alarm and drift detection delay. The curve obtained is similar to the Receiver Operating Characteristics (ROC) curve, which is used for concept drift evaluation rather than classification. Some of the parametric simple drift detection methods are discussed below.
The Sequential Probability Ratio Test (Ray 1957) is the basics of many drift detection algorithms. Cumulative Sum (CUSUM) (Page 1954) is the method of sequential analysis to identify the concept drift which calculates the cumulative sum and each sample are assigned with certain weight. In the CUSUM test, when the mean of incoming data deviates from a certain threshold value, it raises an alarm. It detects the change in the value of the parameter and shows when the change is significant. The CUSUM algorithm extension is Page Hinkley (Mouss et al. 2004) which finds the distinction between the observed classification error and its average. The non-parametric tests such as cumulative sum test and Intersection confidence intervals-based change detection test (Cesare et al. 2011) are used to detect the concept drift.
The Drift Detection Method (DDM) (Gama et al. 2004) uses binomial distribution to identify the behaviour of random variable which gives the classification errors count in the sample of size n. It calculates the probability of misclassification and standard deviation for each instance in the sample. If the error rate of the classification algorithm increases, then it will recommend that there is change in the underlying distribution, making the current learner to be inconsistent with the current data and providing the signal to update the model. DDM checks two conditions, whether it is in warning level or in drifting level. All the examples between the warning and drifting level are used to train a new classifier that will replace the non-performing classifier. DDM has difficulties in detecting the gradual drift. EDDM is the improved version of Drift Detection Method (Baena-Garcia et al. 2006). The performance of the classifier is based on the distance between two classification errors classification instead of considering only the number of error. It performs well in the case of gradual drift.
The algorithm Exponential Weighted Moving Average (EWMA) (Ross et al. 2012) detects drift by calculating the recent error rate estimate by gradually weighing down older information. In The Exponentially Weighted Moving Average for Concept Drift Detection (ECDD) (Nishida 2008) progress and probability of disappointment are identified online, taking into consideration the basic learner’s accuracy. In Statistical Test of Equal Proportions (STEPD) (Bifet and Gavald 2006) if the target concept is stationary, then the accuracy of a classifier for recent example will be equivalent to overall accuracy from the recent learning. If there is a huge decline of recent accuracy, then it means that the concept is changing. The warning and drift threshold level are utilized as the ones exhibited by DDM, EDDM and ECCD.
The Adaptive Sliding Window (ADWIN) (Bifet and Gavalda 2007), concept drift detector is the well-known method for comparing two sliding windows and to identify the drift by detection window. The input sequences of ADWIN are bounded, which can be achieved by rescaling of the data fixing the values of lower bound and upper bound. The input sequences of ADWIN are also limited, which can be achieved by rescaling the data by setting the values of lower bound and upper bound. The incoming instances window will expand until the average value shift is found within the window. If two separate sub windows are detected by the algorithm, their split point is considered to be the concept drift indicator. The concept drift learning (Wang et al. 2003a, b) is based on the adaptive size of the sliding window. The size of the window rises when there is no change and it shrinks when there is any change. The classifiers of the ensemble show greater accuracy when the base classifier is weak and unstable. The new member from the classifier ensemble can be built on the chunk of recent data in the concept drifting data stream, and the outdated member can be removed. The concept drift can be dealt by assigning weights to the ensemble members depending on the error rate (Maciel et al. 2015).
Drift Detection Ensemble (Du et al. 2014) has a series of detectors to make a drift decision and Selective Detector Ensemble (Woźniak et al. 2016) is used to detect sudden and incremental drift. The experimental results show that the basic drift detection technique surpasses the simple detector ensemble (Nikunj 2001).
4 Concept Drift handling approaches
The various concept drift handling approaches are shown in Fig. 4. The two main approach of handling concept drift at the algorithmic level is by using single classifier or ensemble classifier. The single classifiers are used for static data mining and it has forgetting mechanism. The ensemble-based classifier integrates the results from multiple classifiers to obtain better performance and prediction than a single classifier. Some of the traditional ensemble methods are Bagging, Random Forest (Breiman 2001), AdaBoost (Kidera et al. 2006). The primary benefit of using ensemble classification in streaming data is their capacity to cope with recurring concept drift.

Concept drift handling approaches
In ensemble-based classification, there are two types of approaches for identifying concept drift. One is the active ensemble strategy that utilizes techniques to identify the concept drift that triggers modifications and the other is a passive ensemble strategy that does not contain drift detectors. It continually updates the classifier whenever a new item is added.
The instances can be processed at the data level using a chunk-based method and an online learning strategy. It processes the information in chunks using chunk-based strategy and each chunk includes an unchanging number of instances. The training instance in each chunk is iterated several times by the learning algorithm. It enables the algorithm to learn the classifier of components. In the online learning strategy, each instance of instruction is processed one by one upon arrival. This approach is mainly used by the application which has inflexible memory and time constraints, and also by the application which cannot afford dealing out with each training example for more than one time. Even each training instance of a chunk can be processed independently by online learning strategy. Diversity for Dealing with Drifts (DDD) (Minku and Yao 2012) provides an assessment of small and high variety ensembles coupled with distinct methods for dealing with class change. DDD shows that information learned from the old concept can be used by training ensembles that learned the old concept with high diversity, using low diversity on the new concept to assist the learning of the new idea and it cannot handle recurring drifts.
5 Ensemble based classification for data streams
The data classification methods in the data stream environment uses sliding window, the size of which is determined by the drift speed. Hence the classification method which uses a variable window follows an active drift detection strategy and it updates the current model when the drift is detected, assuming the outdated model is not applicable. The size of the window increases when the rate of drift is slow. The dynamic sliding window length approach was employed by the FLOating Rough Approximation (FLORA) (Widmer and Kubat 1996) family of algorithm. But in passive drift detection strategy of learning the concept drift, it updates the model for every incoming stream of data, even though the drift has not occurred. The chunk-based algorithms generally adapt to concept drift by constructing new component classifiers from the new chunks of training examples. The component classifiers are built from the chunks of data that match distinct parts of the stream. The ensemble will therefore depict the various concepts available in the data stream. Ensemble method has been suggested as a good method for learning concept drift because of its ability to balance between stability and plasticity.
Some of the ensemble based algorithms are discussed. Streaming Ensemble Algorithm (SEA) is one of the most common algorithms in this category (Street and Kim 2001). A series of consecutive non-overlapping windows are used to make the data stream into chunks. It uses the diversity and accuracy as the measure to replace the weakest base classifier. The new classifier's performance is measured on the basis of the new incoming training chunk and the new classifier then replaces the existing classifier whose performance on the training chunk is worse than the new classifier's performance. The accuracy measurement is important, since the ensemble should correctly classify the most recent examples to adapt to concept drift.C4.5 decision tree is used as the base classifier and it compares the ensemble accuracy with the pruned and unpruned decision tree. The combined predictions are based on simple majority voting. Depending on the chunk size and the size of the ensemble, it has a strong mechanism of recovery to deal with concept drift.
The restructuring of ensemble can also be done using Accuracy Weighted Ensemble (AWE) (Wang et al. 2003a). It provides a generic framework for detecting the concept drift and based on the prediction error on their new training chunks, it assigns weight to each classifier of the ensemble. The mean square error is used to estimate the prediction error. Each classifier component in the ensemble is weighted and only the K classifier with highest weight is kept in the ensemble. The output is based on the decision made by the weighted voting of the classifiers. In the case of sudden concept drift, the pruning strategy used in AWE can reduce the classification accuracy and delete many component classifiers. Furthermore, the computation time is increased as the evaluation of the new candidate classifier needs K-fold cross validation within the current chunk. This algorithm achieves better accuracy when the size of the ensemble is greater than a single classifier and it will improve its performance gradually over time.
Learn ++ for non-stationary environments called Learn ++ . NSE (Elwell and Polikar 2011) is a chunk-based ensemble method that temporarily discards information based on changes in the data stream. The reaction to the drift is based on the weight associated with the base classifier. The algorithm weights the component classifiers depending on their difficulty measures in terms of the ensemble performance. The training of Learn ++ .NSE begins with comparing the ensemble on a chunk of new examples. Subsequently, the algorithm identifies which example are correctly predicted through the existing ensemble and gives lower weights to those examples, as they may be much less difficult. Using the chunk of examples with the updated weights, a new component classifier is created and it is added to the ensemble. Then, the evaluation is done for all the ensemble members and their weights are calculated based on the weighted errors. The algorithm weights the ensemble member using the sigmoid function, which considers the recent performance of the given component classifier. The base classifiers help in dealing with recurrent drifts.
Dynamic Weighted Majority (DWM) is another popular ensemble based approach, where performances of the individual classifiers along with the overall ensemble performance are combined to overcome the concept drift (Zico Kolter and Maloof 2007). If the DWM’s component classifier misclassifies, the weight is decreased by a user specified factor. It is an extension of weighted majority algorithm and it considers the dynamic nature of data streams to detect the concept drift. The DWM can add or remove the component classifier according to the overall performance of the entire ensemble.
In Accuracy Updated Ensemble (AUE) all the component classifier are updated incrementally with a portion of new chunk of data (Brzezinski and Stefanowski 2011). The classifier is weighted with the help of non-linear error function, which helps in choosing the better component classifier. The problem of creating the poor base classifier is also reduced, since it process only small chunks of data. It also contains techniques for improving the computational cost and pruning of the component classifiers in the ensemble. AUE algorithm is constructed with Hoeffding Trees, which helps in achieving high classification accuracy in detecting the drifts.
6 Concept Drift with class imbalance handling approaches
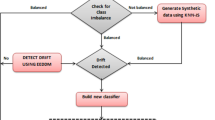
Class imbalance data can lead to significant performance reduction and poses difficult challenges for drift detection. The skewed distribution makes many conventional machine learning algorithms less effective, especially in predicting minority class examples. A number of solutions have been proposed at the data and algorithm levels to deal with class imbalance. Several methods have been proposed to handle the issues of concept drift together with the imbalanced class data which is shown in Fig. 5.

Taxonomy of Concept drift with class imbalance handling approaches
The Drift Detection Method for Online Class Imbalance (DDM-OCI) (Wang et al. 2013) solves the issues of concept drift over imbalanced data streams online using minority class recall. When the metric of minority class recall experiences a significant drop, a concept drift is confirmed. However, the usage of minority class recall is ineffective, when the concept drift affects the majority class. The Linear Four Rates (LFR) approach (Wang and Abraham 2015) extends the DDM-OCI and if anyone of the rate exceeds the bound, the LFR approach confirms the concept drift. Instead of using multiple rates for each class, the Prequential Area Under the ROC Curve (PAUC) designs an overall performance measure for the classification of online stream data (Brzezinski and Stefanowski 2015). Although a PAUC-Page Hinckley (PAUC-PH) method modifies the AUC for evaluating online classifiers, it requires gathering of recently received instances (Wang et al. 2015). By deciding the class size and updating the size of class incrementally, the time decay factor emphasizes the concept drift and weakens the impact of old data on class distribution.
The Recursive Least Square Adaptive Cost Perceptron (RLSACP) modifies the error function to update the perceptron weights (Ghazikhani et al. 2013). The error function includes the components of model adaptation using forgetting mechanism and class imbalance handling using the error weighting function. According to the classification accuracy or the imbalance rate of recent data, the RLSACP updates the error weights incrementally. The perceptron based models do not work well on the newly arrived data streams. The ensemble size is an important factor in handling the concept drift and imbalanced data distribution. The time decay factor defines and updates the imbalanced degree in online learning. This factor emphasizes the pattern of recently arrived data and weakens the impact of old data. The first sequential learning method is Meta-cognitive Online Sequential extreme learning machine (MOS-ELM), which is self-regulated and it is utilized for both binary and multi-class data stream with concept drift (Mirza et al. 2016).
The Majority Weighted Minority Oversampling Technique (MWMOTE) classifies the minority instances and assigns weights to them according to the distance of nearest majority instances (Barua et al. 2014). Moreover, the MWMOTE exploits most informative minority instances to interpolate the synthetic instances inside a minority class cluster. The effectiveness of resampling techniques is analysed (Hao et al. 2014). The sampling rate detection becomes more complicated under multi-class datasets than the binary class datasets (Saez et al. 2016). Recently, the resampling techniques are extended to an online learning model. The ensemble learning model takes into account multiple individual classifiers as base learners and improves the accuracy of ensemble classification (Błaszczýnski and Stefanowski 2015). The Weighted extreme learning machines (WOS-ELM) are used to maintain the old data patterns (Mirza et al. 2013). To handle the gradual and sudden concept drift, the WELM technique utilizes the threshold-based technique and hypothesis testing. The ESOS-ELM is assumed that the rate of imbalanced class distribution is known in advance. However, it is not suitable for real-time streaming data. A new ensemble method with incremental learning, named as Diversity for Dealing with Drifts (DDD) is presented in (Minku and Yao 2012). It assigns weight to each member based on the prequential accuracy. When there is no convergence to the already identified data patterns, the internal drift detector confirms the presence of concept drift. However, it selects highly diverse classifiers for both the gradual and concept drift, resulting in poorer classification accuracy (Ditzler and Polikar 2013; Wang et al. 2016). Thus, it is necessary to handle both the concept drift and imbalanced class distribution issues during big data streaming analysis. Table 1. Illustrates the various algorithms and techniques used in handling concept drift and class imbalance problem with its advantages and limitations.
7 Evaluation metrics
The experimental evaluation for any machine learning algorithm depends on the performance evaluation metrics for any learning task and the streaming settings. Some of the well-known performance metrics to determine the accuracy is precision, recall, sensitivity, specificity, mean absolute error and root mean square error. In the case of streaming environment, few other performance evaluation metrics is used.
(i) RAM-Hours: This measure gives the computational resources used by the streaming algorithms depending on the cloud computing service. Every GB of RAM deployed for 1 h is equal to one RAM-Hour.
(ii) Kappa Statistic: It is the performance measure, which takes into account the class imbalance (Bifet et al. 2013). It takes the true label of the underlying dataset as input along with the prior probability of the predictions done by the classifier. The kappa statistics value lies between 0 and 1.The Kappa statistics, K is defined by
where P0 is the accuracy rate of the classifier and Pc is the accuracy rate of the random classifier. When the value of K is zero, the accuracy obtained is random. When K is 1, the prediction is correct.
(iii) Sensitivity: It measures the percentage of positive examples correctly classified. It is also called as recall. TP is true positive and FN is false negative, indicating the positive examples that are incorrectly predicted as negative.
(iv) Specificity: It calculates the percentage of negative examples in which TN is True Negative and FP is False Positive are correctly classified as negatives.
(v) Geometric Mean (G-Mean): It measures the true positive rate (TPR) and the true negative rate (TNR). True positive rate measures the percentage of positive examples correctly predicted as positive and true negative rate measures the percentage of negatives that are correctly predicted as negatives. If the G mean value is high, then there is high accuracy.
(vi) Precision: It measures the percentage of positive examples which are predicted as positive.
(vii) F-measure: It is the measure of harmonic mean of sensitivity and precision. The general formula for positive real \(\beta\) is.
8 Tools for stream mining
The various toolsare presented that can be used for the analysis of streaming data. The tools help the researchers to directly test their ideas directly.
Massive Online Analysis (MOA): This tool is implemented in Java and it is the extension of WEKA(Bifet et al. 2011).The MOA framework provides data generators, learning algorithms, evaluation methods and statistical measure to evaluate the performance of mining task. MOA can be used via command line interface or through Graphical User Interface.
Advanced Data mining and Machine Learning System (ADAMS): It is the workflow engine, which is used to maintain the knowledge workflow. It can be combined with frameworks such as WEKA and SAMOA (Morales and Bifet 2015) to perform data analytics task.
StreamDM: It is the framework which performs data stream mining using Spark streaming. Scalable Advanced Massive Online Analysis (SAMOA): The data stream mining and distributed computing can be performed using SAMOA. It has a framework which allows the user to work with the stream processing execution engine and to deal with learning problems.
Amazon Kinesis: It enables to build custom applications that can collect and process large streams of data records in real time (Mathew and Varia 2013).
Apache Storm: It is a distributed real time computing system, which process over one million tuples per second (Storm 2011). It runs on YARN and it is integrated with the Hadoopsystems. It guarantees that each unit of data is processed atleast once.
9 Experimental results and discussion
Real world and synthetic dataset is used for evaluation of various algorithms. SEA is the frequently used synthetic stream which contains three features with random values between 0 and 1. The threshold is calculated using the sum of first two features and it is assigned as class label for each instance. The threshold is adjusted periodically, so that the abrupt concept drift is simulated in the stream.
Massive Online Analysis (MOA) framework (Bifet et al. 2010) is used to compare the performance of different learners. Prequential method is used which evaluates the classifier on the stream by testing with each example in sequence. The performance measure such as Accuracy, Precision, Recall, F1-score and Kappa statistic has been used to evaluate the performance of the various learners. The ensemble based classification algorithm such as Accuracy Updated Ensemble, Dynamic Majority Voting, Learn NSE, Accuracy Weighted Ensemble when compared with Naïve Bayesian has been proven to give better accuracy. The electrical and synthetic dataset are used show the accuracy given by ensemble based classification algorithm. Table 2 shows the performance of various classifiers on SEA Synthetic Data stream. Figure 6 shows the accuracy of SEA synthetic Data stream using various classifiers.The ensemble classifiers such as Accuracy Updated Ensemble, Accuracy Weighted Ensemble are giving better accuracy and recall for SEA synthetic datastream when compared with the single classifier.

Accuracy of SEA synthetic data stream using data stream classifiers
The real world electrical dataset (Harries and Wales 1999) is used, which contains 45,312 instances and each example refers to the period of 30 min from the Australian New South Wales Electricity Market. The class label identifies the demand or change of the price (UP or DOWN) in New South Wales relative to a moving average of the last 24 h. In this dataset, the electricity prices are not stationary and are affected by the market supply and demand.
Table 3 shows the Performance of various classifiers on Electrical Dataset. Figure 7 shows the accuracy, F1-score, recall, precision, kappa statistic measure using various learners on Electrical Dataset.

Performance of data stream classifier on electrical dataset
In addition, other real time intrusion dataset, KDD (KDD 2007) is used which has 41 features and the class label defines whether there is attack or not. The original dataset has 24 training attack types. The original labels of attack types are changed to label abnormal in our experiments and we keep the label normal for normal connection. This way we simplify the set to two class problem. Table 4 shows the performance of various classifier’s on Intrusion Dataset. Figure 8 shows the accuracy for electrical dataset based on number of instances processed and Fig. 9 shows the performance of different classifier on intrusion dataset.

Accuracy for electrical dataset based on number of instances processed

Performance of data stream classifier on intrusion dataset
The drift detectors such as CUSUM, Page Hinkley, Exponential Weighted Moving Average(EWMA), Adaptive Sliding Window(ADWIN) and DDM is used in the electrical dataset to identify the change in the concept drift and DDM gives better accuracy in detecting the drift. Table 5 shows the performance of various drift detectors on electrical dataset.
The concept drift detectors is used in the dataset to identify the drift and Fig. 10 shows the accuracy of drift using various drift detectors in the electrical dataset.

Accuracy of various drift detectors on Electrical dataset
10 Conclusion and future work
The state of the art on ensemble methodologies to address the problem of class imbalance and concept drift has been reviewed in the paper along with the comparative study of different classifiers on the class imbalance dataset with concept drift. Various concept drift detection methodologies such as statistical test, non-parametric test and other methods are discussed. The individual and combined challenges in online class imbalance learning with concept drift along with example applications are discussed in the paper. Different concept drift detection is applied on the synthetic and real world data sets. It is noticed from this study that the class distribution has high impact on the classification process and the ensemble based algorithm has shown better accuracy when compared with the single classifier when dealing with concept drift. In future, deep learning approaches can be used to deal with the skewness in the distribution of datawith concept drift for various applications.
Change history
06 June 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s12652-022-04066-7
References
Aggarwal C, Han J (2004). On Demand Classification of Data Streams. In: Proceedings of 2004 International Conference on Knowledge Discovery and Data Mining (KDD’ 04). Seattle, WA
Aggarwal CC (2007) An Introduction to Data Streams. In: Aggarwal CC (ed) Data streams. Advances in database systems, vol 31. Springer, Boston
Baena-Garcia M, Campo-Avila J, Fidalgo R, Bifet A, Gavaldμa R, Morales-Bueno R (2006) Early drift detection method. In: International workshop on knowledge discovery from data streams of IWKDDS’06, vol 6, Citeseer, pp 77–86
Barua S, Islam MM, Yao X, Murase K (2014) MWMOTE–majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans Knowl Data Eng 26(2):405–425
Bay S, Kumaraswamy K, Anderle MG, Kumar R, Steier DM (2006) Large-scale detection of irregularities in accounting data. In: Proceedings of the sixth international conference on data mining, ICDM '06. IEEE Computer Society, Washington, DC, pp 75–86
Bifet A, Gavald R (2006) Kalman filters and adaptive windows for learning in data streams. In: LjupcoTodorovski NL (ed) Discovery Science. 4265 of Lecture Notes in Computer Science. Springer, New York, pp 29–40
Bifet A, Gavalda R (2007) Learning from time-changing data with adaptive windowing. In: Proceedings of SIAM international conferene on data mining (SDM). SIAM, pp 443–448
Bifet A, Holmes G, Kirkby R, Pfahringer B (2010) MOA: massive online analysis. Mach Learn 11:1601–1604
Bifet A, Holmes G, Kirkby R, Fahringer PB (2011) In: MOA: DATA STREAM MINING—a practical approach. The University of Waikato, pp 107–139
Bifet A, Read J, Žliobaitė I, Pfahringer B, Holmes G (2013) Pitfalls in benchmarking data stream classification and how to avoid them. In: Blockeel KKH (ed) Machine learning and knowledge discovery in databases. ECML PKDD. Springer, Berlin, Heidelberg, pp 81–88
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Brzezinski D, Stefanowski J (2011) Accuracy updated ensemble for data streams with concept drift. 6th HAIS Int Conf Hybrid Artif Intell Syst II:155–163
Brzezinski D, Stefanowski J (2014) Reacting to different types of concept drift: The accuracy updated ensemble algorithm. IEEE Trans Neural Netw Learn Syst 25(1):81–94
Brzezinski D, Stefanowski J (2015) Prequential auc for classifier evaluation and drift detection in evolving data streams. New Front Min Complex Patterns 8983:87–101
Błaszczýnski J, Stefanowski J (2015) Neighbourhood sampling in bagging for imbalanced data. Spec Issue Inf Process Mach Learn Appl Eng Neurocomput 150:529–542
Cesare A, Boracchi G, Roveri M (2011) A just-in-time adaptive classification system based on the intersection of confidence intervals rule. Neural Netw 24(8):791–800
Cesare A, Boracchi G, Roveri M (2017) Hierarchical Change-Detection Tests. IEEE Trans Neural Netw Learn Syst 28:246–258
Chawla NV, Bowyer KW, Hall LO, Philip Kegelmeyer W (2002) SMOTE: synthetic minority over-sampling technique. Artif Int 16(1):321–357
Chawla N, Japkowicz N, Kotcz A (2004) Editorial: special issue on learning from imbalanced data sets. ACM SIGKDD Explor Newsl 6(1):1–6
Cieslak DA, Chawla NV, Striegel A. (2006). Combating imbalance in network intrusion datasets. 2006 IEEE international conference on granular computing, (pp. 732–7).
Ditzler G, Polikar R (2013) Incremental learning of concept drift from streaming imbalanced data. IEEE Trans Knowl Data Eng 25(10):2283–2301
Domingos P, Hulten G (2000) Mining High-Speed Data Streams. In: Proceedings of the Association for Computing Machinery Sixth International Conference on Knowledge Discovery and Data Mining
Du L, Song Q, Zhu L, Zhu X (2014) A selective detector ensemble for concept drift detection. Comp J 58(3):457–471
Elwell R, Polikar R (2011) Incremental learning of concept drift in nonstationary environments. IEEE Trans. Neural Netw. 22(10):1517–2153
Gama J (2010) Knowledge discovery from data streams. Chapman & Hall/CRC, London
Gama J, Medas P, Castillo G, Rodrigues P (2004) Learning with drift detection. In: Bazzan ALC, Labidi S (eds) Advances in artificial intelligence – SBIA 2004. SBIA 2004. Lecture notes in computer science, vol 3171. Springer, Berlin, Heidelberg
Ghazikhani A, Monsefi R, Yazdi HS (2013) Recursive least square perceptron model for non-stationary and imbalanced data stream classification. Evol Syst 4(2):119–131
Han J, Kamber M (2006) Data Mining: concepts and techniques, 2nd edn. Morgan Kaufmann Publishers, Burlington
Hao M, Wang Y, Bryant SH (2014) An efficient algorithm coupled with synthetic minority over-sampling technique to classify imbalanced Pub Chem bioassay data. Anal Chim Acta 806(2):117–127
Harries M, Wales NS (1999) SPLICE-2 Comparative evaluation: electricity pricing. Technical report, South Wales University
Herland M, Khoshgoftaar TM, Bauder RA (2018) Big Data fraud detection using multiple medicare data sources. Big Data 5:29
Jin R, Agrawal G (2003) Efficient decision tree construction on streaming data. In: Proceedings of ACM SIGKDD Conference
KDD Cup 1999 (2007) https://kdd.ics.uci.edu./databases/kddcup99/kddcup99.html. Accessed 14 May 2019
Kelly MG, Hand DJ, Adams NM (1999) The impact of changing populations on classifier performance. In: Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 367–371
Kidera T, Ozawa S, Abe S (2006) An incremental learning algorithm of ensemble classifier systems. In: Proceedings of the international joint conference on neural networks, IJCNN 2006, part of the IEEE world congress on computational intelligence, WCCI, Vancouver, pp. 3421–3427
Krawczyk B, Wozniak M (2015) Weighted Naïve Bayes Classifier with Forgetting for Drifting Data Streams. IEEE International Conference on Systems, Man and Cybernetics. Kowloon, pp 2147–2152
Kubat M, Holte RC, Matwin S (1998a) Machine learning for the detection of oil spills in satellite radar images. Mach Learn 30(2):195–215
Kubat M, Holte RC, Matwin S (1998b) Machine learning for the detection of oil spills in satellite radar images. Mach Learn 30(2–3):195–215
Last M (2002) Online classification of nonstationary data streams. Intell Data Anal 6(2):129–147
Löfström T (2015) On Effectively Creating Ensembles of Classifiers: Studies on Creation Strategies, Diversity and Predicting with Confidence . Stockholm University,Ph.D. thesis
Maciel BI, Santos SG, Barros RS (2015) A Lightweight Concept Drift Detection Ensemble. In: IEEE 27th international conference on tools with artificial intelligence (ICTAI), 1061–1068
Mathew S, Varia J (2013) Overview of amazon web services. Amazon Whitepapers, Jan 2014
Meseguer J, Puig V, Escobet T (2010) Fault diagnosis using a timed discrete-event approach based on interval observers: application to sewer networks. IEEE Trans Syst Man Cybern Part A Syst Hum 40(5):900–916
Minku LL, Yao X (2012) DDD: a new ensemble approach for dealing with concept drift. IEEE Trans Knowl Data Eng 24(4):619–663
Mirza B, Lin Z (2016) Meta-cognitive online sequential extreme learning machine for imbalanced and concept-drifting data classification. Neural Netw 80:79–94
Mirza B, Lin Z, Toh K-A (2013) Weighted online sequential extreme learning machine for class imbalance learning. Neural Process Lett 38(3):465–486
Morales GDF, Bifet A (2015) SAMOA: scalable advanced massive online analysis. Mach Learn Res 16:149–151
Mouss H, Mouss D, Mouss N, Sefouhi L (2004) Test of Page-Hinkley, an approach for fault detection in an agro-alimentary production system. Proc Asian Control Conf 2:815–818
Nishida K (2008) Learning and Detecting Concept Drift. Hokkaido University: A Dissertation: Doctor of Philosophy in Information Science and Technology, Graduate School of Information Science and Technology.
Nishida K, Shimada S, Ishikawa S, Yamauchi K (2008) Detecting sudden concept drift with knowledge of human behavior. In: IEEE international conference on systems, man and cybernetics, pp 3261–3267
Oza NC (2001) Online Ensemble Learning. Berkeley, CA: PhD thesis, The University of California
Page ES (1954) Continuous inspection schemes. Biometrika 41(1/2):100–115
Pradeep Mohan Kumar K, Saravanan M, Thenmozhi M, Vijayakumar K (2019) Intrusion detection system based on GA-fuzzy classifier for detecting malicious attacks. Wiley, New York, https://doi.org/10.1002/cpe.5242
Ray WD (1957) A Proof that the Sequential Probability Ratio Test (S.P.R.T.) of the General Linear Hypothesis Terminates with Probability Unity. Ann. Math. Statist., 28(no. 2), 521--523.
Rigatos G, Siano P, Zervos N (2013) An approach to fault diagnosis of nonlinear systems using neural networks with invariance to Fourier transform. J Ambient Intell Hum Comput. https://doi.org/10.1007/s12652-012-0173-4
Ross GJ, Adams NM, Tasoulis D, Hand D (2012) Exponentially weighted moving average charts for detecting concept drift. Int J Pattern Recognit Lett 33(2):191–198
Saez JA, Krawczyk B, Wozniak M (2016) Analyzing the oversampling of different classes and types of examples in multi-class imbalanced datasets. Pattern Recognit 57:164–217
Sobolewski P, Woźniak M (2013) Comparable Study of Statistical Tests for Virtual Concept Drift Detection. In: J. K. Burduk R. (Ed.), Proceedings of the 8th International Conference on Computer Recognition Systems CORES. 226. Advances in Intelligent Systems and Computing. Springer, Heidelberg
Storm (2011) https://storm-project.net. Accessed 11 Jan 2019
Street W and Kim YS (2001). A streaming ensemble algorithm (SEA) for large-scale classification. In: Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining (KDD '01). ACM, New York, pp 377–382
Vijayakumar K, Arun C (2017) Automated risk identification using NLP in cloud based development environments. J Ambient Intell Hum Comput. https://doi.org/10.1007/s12652-017-0503-7
Wang H, Abraham Z (2015) Concept drift detection for streaming data. In: International Joint Conference of Neural Networks, pp 1–9
Wang H, Fan H, Yu PS, Han J (2003a) Mining concept-drifting data streams using ensemble classifiers. In: Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining (KDD '03). ACM, New York, pp. 226–235
Wang H, Fan W, Yu P, Han J (2003b) Mining Concept-Drifting Data Streams using Ensemble Classifiers. 9th ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), Washington DC
Wang S, Minku LL, Ghezzi D, Caltabiano D, Tino P, and Yao X (2013) Concept drift detection for online class imbalance learning. International Joint Conference on Neural Networks (IJCNN ’13), pp 1–10
Wang S, Minku LL, Yao X (2015) Resampling-based ensemble methods for online class imbalance learning. IEEE Trans Knowl Data Eng 27(5):1356–1368
Wang S, Minku L L, Yao X (2016) Dealing with multiple classes in online class imbalance learning. Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), (pp. 2118–2124).
Wei W, Li J, Cao L, Ou Y, Chen J (2013) Efective detection of sophisticated online banking fraud on extremely imbalanced data. World Wide Web 16(4):449–475
Widmer G, Kubat M (1996) Learning in the presence of concept drift and hidden contexts. Mach Learn 23(1):69–101
Wolfowitz J (1949) On Wald's proof of the consistency of the maximum likelihood estimate. Ann Math Stat 20:601–602
Woźniak M, Ksieniewicz P, Cyganek B, Walkowiak K (2016) Ensembles of Heterogeneous Concept Drift Detectors—Experimental Study. In: Saeed HWK (Ed.), Computer Information Systems and Industrial Management. CISIM 2016. 9842. Cham: Lecture Notes in Computer Science, Springer, New York
Zico Kolter J, Maloof MA (2007) Dynamic weighted majority: an ensemble method for drifting concepts. J Mach Learn Res 8:2755–2790
Zliobaite I (2010) Learning under concept drift: an overview. Technical report, Faculty of Mathematics and Informatics, Vilnius University. arXiv:1010.4784
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Publisher's Note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s12652-022-04066-7
About this article

Cite this article
Priya, S., Uthra, R.A. RETRACTED ARTICLE: Comprehensive analysis for class imbalance data with concept drift using ensemble based classification. J Ambient Intell Human Comput 12, 4943–4956 (2021). https://doi.org/10.1007/s12652-020-01934-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-020-01934-y