
Abstract
Saliency detection aims to automatically highlight the most important area in an image. Traditional saliency detection methods based on absorbing Markov chain only take into account boundary nodes and often lead to incorrect saliency detection when the boundaries have salient objects. In order to address this limitation and enhance saliency detection performance, this paper proposes a novel task-independent saliency detection method based on the bidirectional absorbing Markov chains that jointly exploits not only the boundary information but also the foreground prior and background prior cues. More specifically, the input image is first segmented into number of superpixels, and the four boundary nodes (duplicated as virtual nodes) are selected. Subsequently, the absorption time upon transition node’s random walk to the absorbing state is calculated to obtain the foreground possibility. Simultaneously, foreground prior (as the virtual absorbing nodes) is used to calculate the absorption time and get the background possibility. In addition, the two aforementioned results are fused to form a combined saliency map which is further optimized by using a cost function. Finally, the superpixel-level saliency results are optimized by a regularized random walks ranking model at multi-scale. The comparative experimental results on four benchmark datasets reveal superior performance of our proposed method over state-of-the-art methods reported in the literature. The experiments show that the proposed method is efficient and can be applicable to the bottom-up image saliency detection and other visual processing tasks.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Visual saliency detection simulates the human visual system aiming to automatically highlight the most important area in an image. The process of using an important part of an image instead of the full image reduces the computational costs for computer vision systems. Therefore, saliency detection has become a preprocessing stage in many applications including image segmentation [46], image retrieval [16], image classification [15], object detection [23, 36, 44], object recognition [31], object tracking [48], and video segmentation [38].
In the literature, extensive research has been carried out to develop saliency detection methods. The methods can be divided into three categories: bottom-up methods [6, 9, 12, 28, 49], top-down methods [8, 14, 27, 39], and mixed methods [4, 11, 47, 54]. The bottom-up methods are data-driven and mostly applied to real-time systems, utilizing color, edge, brightness, texture, and other low-level features to obtain the saliency maps in an efficient and effective manner. In the bottom-up methods, there exist many methods such as random walk-based methods [19, 33, 50] and region contrast models [7, 20]. On the other hand, the top-down methods are goal-driven (i.e., task dependent), including some cnn-based deep learning methods [21, 37, 40, 53], making use of high-level features. In general, top-down methods can get better performance but require large dataset for supervised training and are computationally expensive. The mixed methods integrate bottom-up and top-down methods to obtain final saliency results.
In our paper, we focus on the traditional bottom-up models. In the existing random walk models, one of an important work gets saliency detection by using absorbing Markov chain (MC) [19], which can get good results by considering boundary nodes as absorbing nodes to construct an absorbing Markov chain. Actually, background and foreground prior can play a complementary role in enhancing saliency detection. We consider to using both the boundary information and the foreground prior to duplicated as absorbing nodes, and propose a bidirectional absorbing Markov chains–based saliency detection model to get final saliency maps. Firstly, we use boundary and foreground prior to get the background and foreground possibilities. Then, we use an optimized function to fuse two kinds of information. Finally, we get the final saliency map by pointing saliency values of superpixels to each pixels.
In summary, the contributions of our work include:
-
1.
We present a novel bidirectional Markov chains model (BMC), which uses background and foreground prior information to construct two absorbing Markov chains.
-
2.
An optimization model is developed to combine both background and foreground possibilities, which are acquired through bidirectional absorbing Markov chains.
Related Works
In this section, we focus on the related state-of-the-art and other recently proposed models.
The research of saliency detection is originated from biological disciplines.
The Itti and Koch model [18] first computed saliency maps by using texture, orientation, intensity, and color contrast features. Since then, various models have emerged [13, 17, 22, 32, 51, 52, 55].
Gopalakrishnan et al. [13] used the hitting time to calculate the most salient seed, then calculated the distance between the other nodes and the selected seed to get the final results. In addition, Sun et al. [32] exploited the relationship between the saliency detection and the Markov absorption probability for saliency detection. Jiang et al. [19] proposed a saliency detection model by random walk via absorbing Markov chain, where absorbing nodes are duplicated from the four boundaries. Based on geodesic distances, Zhu et al. [55] integrated boundary connectivity into a cost function to obtain the final optimized saliency map. Li et al. [22] used a regularized random walks ranking model to get the saliency maps. Additionally, Zhang et al. [52] presented a data-driven salient region detection model based on absorbing Markov chain via multi-feature. Similarly, Zhang et al. [51] proposed an approach to detect salient objects by exploring patch-level and object-level cues via absorbing Markov chain. Zhang et al. [50] proposed a learnt transition probability matrix taking into account the importance of the transition probability matrix based on the aforementioned work.
Traditional Saliency Detection via Absorbing Markov Chain
Formally, let \(X = \{x_{1}, x_{2}, \dots , x_{n} \}\) be a dataset containing n data points, and saliency detection aims to solve the problem of determining the saliency values. One widely used approach to address this problem is to use Markov random walks. Jiang et al [19] introduced an absorbing Markov chain for the visual saliency detection. The expected absorbing time of every transient node is computed to measure its similarity with all-absorbing nodes. The transient nodes that have similar appearance with absorbing nodes can be absorbed faster, i.e., have less expected absorbing time. The saliency detection process is outlined below:
Step 1. Obtain the affinity matrix A
The input image is segmented into superpixels through the method of simple linear iterative clustering (SLIC) algorithm [2] which is based on a spatially localized version of k-means clustering, decomposing the input image in visually homogeneous regions, namely superpixels (see Fig. 5b) and then, we construct a graph G = (V,E), where V denotes the nodes and E denotes the edges between nodes. There are n original nodes and l duplicated nodes in V. The edge weight wij between node vi and vj can be calculated by feature vectors of two nodes. If node vi is a transient node, the neighbor node or the neighbor’s neighbor node vj is connected to node vi. Moreover, we acquire an affinity matrix A: aij = wij if vi and vj is connected; aii = 1, \(i=1,2,\dots ,n\); otherwise, aij = 0.
Step 2. Compute the transition matrix P
The degree matrix that records the sum of the weights connected to each node is written as \(D = diag({\sum }_{j}a_{ij})\). The transition matrix P is primitive [5]. Finally, the transition matrix P on the sparsely connected graph is given as P = D− 1 × A.
Step 3. Renumber the nodes in transition matrix P
There are two types of states in an absorbing Markov chain: one is called the transient state, and another is absorbing state.
In an absorbing Markov chain, if a state is not an absorbing state, it is called a transient state. For an absorbing chain having l absorbing states and n transient states, its transfer matrix P can be written as:
where Q is an n × n matrix giving transient probabilities between any transient states, R is a nonzero n × l matrix giving these probabilities from transient state to any absorbing state, 0 is an l × n zero matrix, and Il is an l × l identity matrix.
Step 4. Compute the expected time
For an absorbing chain P, all the transient states can enter the absorbing states in one or more steps, namely the matrix N with invertible matrix, where nij denotes the average transfer times between transient state i to transient state j. Supposing \(e = [1, 1, \dots , 1]_{1\times n}^{T}\) and In is an n × n identity matrix, the absorbed time for each transient state can be expressed as:
For each node vi, the expected time is \(s_{i} = {\sum }_{j}Z_{ij}\), \(j=1,2,\dots ,n\) [19].
The Proposed Approach
The above Markov chain model provides an effective saliency value for all data points. However, the main limitation of this method is that the output only depends on the superpixels of four boundaries as absorbing nodes. It may lead to incorrect prediction especially when the four boundaries have some salient objects. The limitation motivated us to develop a bidirectional absorbing Markov chains–based method, that captures the absorption time of all nodes to the foreground and background more effectively. Therefore, we implement a saliency optimization on the results of two types of absorption time to obtain the saliency detection values of all superpixels. Finally, a regularized random walk ranking based on the pixel-wise graph is used to diffuse the saliency values from the superpixel level to pixel level.
The pipeline is described in Fig. 1.

The pipeline of our proposed method
Construction of Three Graphs
The Initial Graph
Given an input image I, we use the SLIC [2] algorithm to segment the image into N superpixels. We extract visual features of average values of CIELAB color space and denote them as \(X = \{x_{1}, x_{2}, \dots , x_{N} \} \in R^{N \times 3}, x_{i} = (L^{*}_{i}, a^{*}_{i}, b^{*}_{i})\), where L∗ denotes the lightness, a∗ and b∗ indicating where the color falls along the green-red axis and blue-yellow axis. Next, we define an initial graph G = (V,E) on the dataset in Fig. 2, where \(V = \{ V_{1}, V_{2}, \dots , V_{N} \}\) denotes the node set and E denotes the edges (weighted by a matrix W ) between two nodes.

Construction of the initial graph
The edge set E is determined as follows: (1) Each node is connected to its neighbors and also connected to the nodes that have the same neighbors; (2) All the boundary nodes are connected. The weight of edge between node vi and vj is calculated by Eq. 3:
where σ is a constant, and xi, xj represents the feature vectors of graph nodes vi and vj respectively. The affinity matrix A is formulated as Eq. 4:
where M(i) is a node set, in which the nodes are all connected to nodes i. The degree matrix is given as \(D = diag({\sum }_{j}a_{ij})\).
The Second Graph
We construct another graph Gb = (Vb, Eb) with Nb nodes including N primary nodes and b duplicated nodes in Fig. 3, where \(V^{b} = \{ V_{1}, \dots , V_{N}, V_{N+1}, \dots , V_{N+b} \}\) denotes the node set and Eb denotes the edges (weighted by a matrix Wb) between two nodes.

Construction of the second graph. The superpixels with the pink dots are duplicated absorbing nodes, while the nodes in the blue box are transient nodes
Then, we duplicate b boundary superpixels as background absorbing nodes, that display outside the blue box with pink dots (see Fig. 3). Edge Eb is determined as follows:
-
(1)
The nodes (transient or absorbing) are associated with each other when superpixels in the image are adjacent or have the same neighbors. Additionally, the boundary nodes (i.e., superpixels on the boundary of the image) are fully connected to reduce the geodesic distance between similar superpixels;
-
(2)
Any pair of absorbing nodes (which are duplicated from the boundary nodes) are not connected;
-
(3)
The nodes duplicated from the foreground superpixels are also connected with the original nodes.
The weight of edge \(w^{b}_{ij}\) between nodes vi and vj is calculated by Eq. 3, the affinity matrix Ab is formulated as Eq. 4, and the diagonal (or degree) matrix is given as \(D^{b} = diag({\sum }_{j}a^{b}_{ij})\).
The Third Graph
We construct one more graph Gf = (Vf, Ef) with Nf nodes including N primary nodes and f duplicated nodes in Fig. 4, where \(V^{f} = \{ V_{1}, \dots , V_{N}, V_{N+1}, \dots , V_{N+f} \}\) denotes the node set and Ef denotes the edges (weighted by a matrix Wf) between two nodes.

Construction of the third graph. The superpixels above the image with blue dots are duplicated from the foreground superpixels as absorbing nodes. The superpixels in the image with yellow dots are transient nodes
In order to obtain more effective results, we duplicate f foreground superpixels as absorbing nodes, which are shown in the blue points above the image (see Fig. 4). Edge Ef is determined as follows:
-
(1)
Each transient or absorbing node is connected to the transient nodes which are the neighbors of it or have the same boundaries with its neighboring nodes;
-
(2)
All transient nodes on the boundary are connected;
-
(3)
Any pair of absorbing nodes (which are duplicated from the foreground) are unconnected. The nodes duplicated from the foreground superpixels are also connected with the original nodes.
The weight of edge \(w^{f}_{ij}\) between nodes vi and vj is calculated by Eq. 3, the affinity matrix Af is formulated as Eq. 4, and the degree matrix is given as \(D^{f} = diag({\sum }_{j}a^{f}_{ij})\).
Select Nodes by Foreground Prior
In the third graph, the duplicated nodes are selected by using the foreground information. The prior information is a significant cue in saliency detection and many other fields. There are many methods to obtain prior information. In our proposed method, we use boundary connectivity [55] to get the foreground prior.
Boundary connectivity (BC) is the proportion of the boundary superpixels to the whole same cluster superpixels (see Fig. 5c), which is defined as follows:
where N is the number of superpixels, \({\mathscr{H}}\) denotes the boundary area of image, and wij is the similarity between nodes i and j. We give an illustrative example of boundary connectivity in Fig. 5.

An illustrative example of boundary connectivity. a Input image. b The superpixels of input image. c The superpixels of similarity in each pitch. d The intuitive interpretation of boundary connectivity
Let fi be the foreground prior, it can be calculated by the following equation:
where σb = 1, σs = 0.25, da(i,j), and ds(i,j) denote the CIELAB color feature distance and spatial distance between the i-th and j-th superpixels respectively.
If superpixel i has a high value of fi, we can set it as a foreground prior node. Nodes with higher than average values (i.e., {i|fi > avg(f)}) are selected to form a set, which is duplicated as the set of absorbing nodes set (a subset of Vf). The graph Gf is therefore constructed.
Foreground and Background Possibility
Following the aforementioned procedures, the initial input image is segmented into superpixels by the SLIC method to form an initial graph G. Moreover, we choose boundary nodes and foreground nodes, and duplicate them as absorbing nodes to obtain two graphs Gb and Gf respectively. Next, we use Eqs. 3 and 4 to get the affinity matrix A. The degree matrix is written as \(D = diag({\sum }_{j}a_{ij})\). The transition matrix P is calculated as P = D− 1 × A, which can be reordered as l absorbing nodes and n transient nodes and broken down into four sub-matrices: Q, R, O, and Il (See Eq. 1).
Supposing \(e = [1, 1, \dots , 1]_{1\times n}^{T}\),
The absorbed time for each node vi can be obtained by \(s_{i} = {\sum }_{j}{((I_{n} - Q)^{-1} \times e)}_{ij}\), \(i,j=1,2,\dots ,n\), where \(e = [1, 1, \dots , 1]_{1\times n}^{T}\) and In is an identity matrix.
In graph Gb, the absorbing nodes are selected from the boundary. Then for each node vi, if the expected time is considerable that means it requires more time to transfer to the border, the node is more likely to be a foreground node; if the expected time is low, the node is more like to be a background one. We can set this value as the foreground possibility sf of node vi.
In graph Gf, the absorbing nodes are selected according to the foreground prior. Then for each node vi, if the expected time is considerable, the node is more likely to be a background node; otherwise, the node is more likely to be a foreground one. We can set this value as background possibility sb of node vi.
Superpixel-Level Saliency Optimization
We utilize background and foreground possibilities to obtain the superpixel-level saliency map. Towards the objective of assigning the foreground region value 1 and the background region value 0, the following optimization model presented in [55] is used:
where si is the superpixel-level saliency value (i.e., the expected time of absorption), and aij is obtained from the initial graph. In order to achieve a minimization of the objective function (7), the first term is designed to encourage a superpixel i with large background probability sb to obtain a small value si (close to 0), the second term is designed to encourage a superpixel i with large foreground probability sf to obtain a large value si (close to 1), and the third term is designed to encourage the smoothness to acquire continuous saliency values.
In order to obtain the value s which is represented the optimal solution of Eq. 7, we rewrite (7) as the matrix form:
where \(e = [1,1,\dots ,1]^{T}\), \(D^{b} = diag({\sum }_{j}a^{b}_{ij})\), \(D^{f} = diag({\sum }_{j}a^{f}_{ij})\), \(D = diag({\sum }_{j}a_{ij})\).
Let F(s) denote the function. To minimize F(s), the derivative of F(s) with respect to s is:
Supposing \(\frac {\partial F}{\partial s}=0\), we can obtain the superpixel-level saliency value s as follows:
Robust Pixel-Level Saliency Detection
From the above, we get the superpixel-level saliency result s. If we assign the value of a superpixel to each pixel in the superpixel, the most precise pixel-level results cannot be obtained. In order to obtain more efficient pixel-level saliency map, we employ a robust saliency ranking model [22] to get the saliency value. The optimal function of queries is computed by solving the following optimization problem:
where sp is the pixel-level saliency value that needs to be optimized, and \(\bar {s}\) pixelwise saliency value of s; aij denotes the edge weight between pixel i and j. The first term encourages the smoothness to acquire continuous saliency values. The second term encourages the pixel-level saliency value sp is close to the superpixel-level saliency value s, γ is the parameter to adjust the second term, we let γ = μ/2. μ is the controlling parameter. Y is the pixel-wise vector obtaining from the ssuperpixel. L is an n × n Laplacian matrix, n is the pixel number of the input image. If Y > Thigh, then k = 2, which means Y is foreground label. Otherwise, if Y < Tlow, then k = 1, which means Y is background label.
Therefore, we use the SLIC method to segment the image into superpixels in this work. The number of superpixels influences the results. In order to keep within limits of this, we use multi-scale fusion \(S_{final} = {\sum }_{h}{(s^{p})^{h}}\) to obtain the final saliency map, where \(h = 1, 2, \dots , H\), h means different scales. The whole algorithm of our proposed method is summarized in Algorithm 1.

Experiments
The proposed method is evaluated on four widely used benchmark datasets: ASD [1], CSSD [43], ECSSD [43], and SED [3]. We compare our model with the following seventeen related state-of-the-art saliency detection algorithms: CA [12], FT [1], SEG [30], BM [41], SWD [10], SF [29], GCHC [45], LMLC [42], HS [43], PCA [26], DSR [24], MC [19], MR [46], MS [34], RBD [55], RR [22], and MST [35].
Benchmark Datasets and Parameter Setting
The ASD dataset is a subset of the MSRA dataset [25], which contains 1000 images with the accurate human-labeled ground truth. The CSSD dataset, namely complex scene saliency detection, contains 200 complex images. The ECSSD dataset, an extension of CSSD dataset, contains 1000 images with the accurate human-labeled ground truth. The SED dataset has two parts of SED1 and SED2: images in SED1 contain one object, images in SED2 contain two objects, and in total there are 200 images.
From the experiments, experientially, the tuning parameters in the proposed algorithm are set as follows: the edge weight σ2 = 0.1 in Eq. 3 to control the strength of weight between a pair of nodes, we let μ = 0.99, then calculate γ in Eq. 11 to obtain the final saliency value. We have conducted the experiment for the selection of superpixel numbers, the process is shown in Fig. 6 that proves the used superpixel numbers N which are 200, 250, 300 and 350 in the superpixel element is the optimal choice.

The selection of superpixel numbers
Evaluation of the Proposed Model
The precision-recall (PR) curves [1], F-measure curves [1], and the F-measure values are used as performance metrics. The precision is defined as the ratio of salient pixels correctly detected to all the pixels of extracted regions, while the recall is defined as the ratio of salient pixels correctly detected to the ground truth. They are formulated as:
where TP, FP, and FN represent the true positive, false positive, and false negative respectively. A PR curve is obtained by the threshold sliding from 0 to 255 to get the difference between the predicted saliency map and the manually labeled ground truth. F-measure is regarded as the overall performance measurement by calculating the weighted average between the precision and recall values, formulated as
where β2 = 0.3 is set to stress precision more than recall. According to different thresholds, we obtain the F-measure curve.
Quantitative Comparison
First, in ASD dataset, we give the comparison between our proposed method with the saliency detection via absorbing Markov chain based on background prior only and foreground prior only, respectively. From Fig. 7, the PR curve is better than the others, which suggests the effective of our model.

The comparison with background prior and foreground prior
We also compare the proposed method with superpixel-level saliency map and pixel-level saliency map on SED dataset, and the process is shown in Fig. 8 which proves the pixel-level saliency maps and superpixel-level saliency maps have similar PR curve, but the F-measures are 0.7877 and 0.7821, respectively; the pixel-level saliency maps are slightly better than the superpixel-level saliency maps.

The comparison of pixel-level saliency map and superpixel saliency map in our method
Then, the PR curves, F-measure curves, and the F-measure values on four benchmark datasets are shown in Figs. 9, 10, 11, and 12, where our proposed method outperforms 17 state-of-the-art methods. Figures 9 and 11 report the performance comparison on the ASD and CSSD dataset using the PR curve, F-measure curve, and the F-measure values. Compared with the 17 state-of-the-art methods, our method achieves a competitive performance according to the 3 terms. Figure 10 shows the performance comparison with the 17 state-of-the-art methods on the ECSSD dataset, the proposed method achieves a high value of precision in the recall range from 0.5 to 0.9 and the highest F-measure value. Figure 12 shows the evaluation results comparison with the 17 state-of-the-art methods on the SED dataset; the proposed method achieves a high precision with recall ranging from 0.7 to 1 and the highest F-measure value.

The PR curves, F-measure curves, and F-measure values for different methods on ASD dataset

The PR curves, F-measure curves, and F-measure values for different methods on ECSSD dataset

The PR curves, F-measure curves, and F-measure values for different methods on CSSD dataset

The PR curves, F-measure curves, and F-measure values for different methods on SED dataset
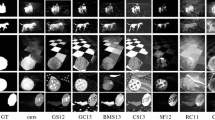
Figure 13 presents output of the estimated saliency maps on sample images selected from the four datasets. It can be seen that our proposed method can overall achieve the best saliency results as compared with other state-of-the-art methods.

Examples of output saliency maps results using different algorithms on the ASD, CSSD, ECSSD, and SED datasets
Failure Cases Analysis
In this work, the idea of bidirectional absorbing Markov chains is proposed. The proposed method is effective for most images on the four benchmark datasets, and the final results are overall better than the superpixel-level saliency maps (Fig. 14 c and d). However, if the appearances of four boundaries and the foreground prior are similar to each other, which forms an overlapping area that has the similar transient time between the two directions, the model fails to detect saliency maps with high precision. Furthermore, the small objects in the first image cannot be detected in the final saliency map (as shown in Fig. 14), since the objects encompass a small number of pixels.

Examples of our failure examples. a Input images. b Ground truth. c Superpixel-level saliency maps. d Final saliency maps
Conclusion
In this paper, we propose a novel saliency detection method based on bidirectional absorbing Markov chains by taking into account both the boundary and foreground prior cues. An optimization model is developed to combine background and foreground possibilities, which are acquired through bidirectional absorbing Markov chains.
The proposed approach outperforms seventeen recently proposed state-of-the-art approaches over four benchmark datasets as a whole.
Although the model can get efficient results, it just uses the CIELab feature of image. In future, we intend to employ multimodal features to address this limitation and improve the overall performance. In addition, we intend to exploit our proposed saliency detection algorithm to other vision tasks including video saliency detection, image segmentation, and object detection.
References
Achanta R, Hemami S, Estrada F, Susstrunk S. Frequency-tuned salient region detection. In: IEEE conference on Computer vision and pattern recognition; 2009. p. 1597–1604.
Achanta R, Shaji A, Smith K, Lucchi A, Fua P, Süsstrunk S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans Pattern Anal Mach Intell 2012;34(11):2274–2282.
Alpert S, Galun M, Brandt A, Basri R. Image segmentation by probabilistic bottom-up aggregation and cue integration. IEEE Trans Pattern Anal Mach Intell 2012;34(2):315–327.
Borji A. Boosting bottom-up and top-down visual features for saliency estimation. In: IEEE conference on Computer vision and pattern recognition; 2012. p. 438–445.
Charles M, Grinstead J, Snell L. Introduction to probability. Providence: American Mathematical Society; 1997.
Chen C, Li Y, Li S, Qin H, Hao A. A novel bottom-up saliency detection method for video with dynamic background. IEEE Signal Process Lett 2018;25(2):154–158.
Cheng MM, Zhang GX, Mitra NJ, Huang X, Hu SM. Global contrast based salient region detection. In: IEEE Computer society conference on computer vision and pattern recognition; 2011. p. 409–416.
Cholakkal H, Johnson J, Rajan D. Backtracking ScSPM image classifier for weakly supervised top-down saliency. In: Proceedings of IEEE conf. on computer vision and pattern recognition; 2016. p. 5278–5287.
Du J, Li W, Xiao B, Nawaz Q. Medical image fusion by combining parallel features on multi-scale local extrema scheme. Knowl-Based Syst 2016;113:4–12.
Duan L, Wu C, Miao J, Qing L, Fu Y. Visual saliency detection by spatially weighted dissimilarity. In: Proceedings of IEEE conf. on computer vision and pattern recognition; 2011. p. 473–480.
Fang Y, Lin W, Lau CT, Lee BS. 2011. A visual attention model combining top-down and bottom-up mechanisms for salient object detection. In: IEEE international conference on Acoustics, speech and signal processing; 2011. p. 1293–1296.
Goferman S, Zelnik-Manor L, Tal A. Context-aware saliency detection. IEEE Trans Pattern Anal Mach Intell 2012;34(10):1915–1926.
Gopalakrishnan V, Hu Y, Rajan D. Random walks on graphs for salient object detection in images. IEEE Trans Image Process 2010;19(12):3232–3242.
He S, Lau RW, Yang Q. Exemplar-driven top-down saliency detection via deep association. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016. p. 5723–5732.
Hu W, Hu R, Xie N, Ling H, Maybank S. Image classification using multiscale information fusion based on saliency driven nonlinear diffusion filtering. IEEE Trans Image Process 2014;23(4):1513–1526.
Hussain CA, Rao DV, Masthani SA. Robust pre-processing technique based on saliency detection for content based image retrieval systems. Procedia Comput Sci 2016;85:571–580.
Itti L, Koch C. Computational modelling of visual attention. Nature Rev Neurosci 2001;2(3):194–203.
Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans Pattern Anal Mach Intell 1998;20(11):1254–1259.
Jiang B, Zhang L, Lu H, Yang C, Yang MH. Saliency detection via absorbing Markov chain. In: Proceedings of IEEE int. Conf. on computer vision; 2013. p. 1665–1672.
Jiang H, Wang J, Yuan Z, Wu Y, Zheng N, Li S. 2013. Salient object detection: a discriminative regional feature integration approach. In: IEEE conference on Computer vision and pattern recognition; 2013. p. 2083–2090.
Lee G, Tai YW, Kim J. Eld-net: an efficient deep learning architecture for accurate saliency detection. IEEE Trans Pattern Anal Mach Intell 2018;40(7):1599–1610.
Li C, Yuan Y, Cai W, Xia Y, Dagan Feng D. Robust saliency detection via regularized random walks ranking. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015. p. 2710–2717.
Li G, Yu Y. Deep contrast learning for salient object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016. p. 478–487.
Li X, Lu H, Zhang L, Ruan X, Yang MH. Saliency detection via dense and sparse reconstruction. In: Proceedings of IEEE int. Conf. on computer vision; 2013. p. 2976–2983.
Liu T, Yuan Z, Sun J, Wang J, Zheng N, Tang X, Shum H. Learning to detect a salient object. IEEE Trans Pattern Anal Mach Intell 2011;33(2):353–367.
Margolin R, Tal A, Zelnik-Manor L. What makes a patch distinct?. In: IEEE conference on Computer vision and pattern recognition; 2013. p. 1139–1146.
Murabito F, Spampinato C, Palazzo S, Giordano D, Pogorelov K, Riegler M. Top-down saliency detection driven by visual classification. Comput Vis Image Underst 2018;172:67–76.
Peng H, Li B, Ling H, Hu W, Xiong W, Maybank SJ. Salient object detection via structured matrix decomposition. IEEE Trans Pattern Anal Mach Intell 2017;39(4):818–832.
Perazzi F, Krähenbühl P, Pritch Y, Hornung A. Saliency filters: contrast based filtering for salient region detection. In: Proceedings of IEEE conf. on computer vision and pattern recognition; 2012. p. 733–740.
Rahtu E, Kannala J, Salo M, Heikkilä J. Segmenting salient objects from images and videos. In: Proceedings of European conf. on computer vision; 2010. p. 366–379.
de San Roman PP, Benois-Pineau J, Domenger JP, Paclet F, Cataert D, De Rugy A. Saliency driven object recognition in egocentric videos with deep CNN: toward application in assistance to neuroprostheses. Comput Vis Image Underst 2017;164:82–91.
Sun J, Xie J, Liu J, Sikora T. Image adaptation and dynamic browsing based on two-layer saliency combination. IEEE Trans Broadcast 2013;59(4):602–613.
Sun J, Lu H, Liu X. Saliency region detection based on Markov absorption probabilities. IEEE Trans Image Process 2015;24(5):1639–1649.
Tong N, Lu H, Zhang L, Ruan X. Saliency detection with multi-scale superpixels. IEEE Signal Process Lett 2014;21(9):1035–1039.
Tu WC, He S, Yang Q, Chien SY. Real-time salient object detection with a minimum spanning tree. In: Proceedings of IEEE conf. on computer vision and pattern recognition; 2016. p. 2334–2342.
Tu Z, Zheng A, Yang E, Luo B, Hussain A. A biologically inspired vision-based approach for detecting multiple moving objects in complex outdoor scenes. Cogn Comput 2015;7(5):539–551.
Wang L, Wang L, Lu H, Zhang P, Ruan X. Saliency detection with recurrent fully convolutional networks. In: European conference on computer vision; 2016. p. 825–841.
Wang W, Shen J, Porikli F. Saliency-aware geodesic video object segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2015. p. 3395–3402.
Wang X, Lv Q, Wang B, Zhang L. Airport detection in remote sensing images: a method based on saliency map. Cogn Neurodyn 2013;7(2):143–154.
Wang Z, Ren J, Zhang D, Sun M, Jiang J. A deep-learning based feature hybrid framework for spatiotemporal saliency detection inside videos. Neurocomputing 2018;287:68–83.
Xie Y, Lu H. Visual saliency detection based on Bayesian model. In: Proceedings of the 18th IEEE int. Conf. on image processing; 2011. p. 645–648.
Xie Y, Lu H, Yang MH. Bayesian saliency via low and mid level cues. IEEE Trans Image Process 2013; 22(5):1689–1698.
Yan Q, Xu L, Shi J, Jia J. Hierarchical saliency detection. In: IEEE conference on Computer vision and pattern recognition; 2013. p. 1155–1162.
Yan Y, Ren J, Zhao H, Sun G, Wang Z, Zheng J, Marshall S, Soraghan J. Cognitive fusion of thermal and visible imagery for effective detection and tracking of pedestrians in videos. Cogn Comput 2018; 10(1):94–104.
Yang C, Zhang L, Lu H. Graph-regularized saliency detection with convex-hull-based center prior. IEEE Signal Process Lett 2013;20(7):637–640.
Yang W, Li D, Wang S, Lu S, Yang J. Saliency-based color image segmentation in foreign fiber detection. Math Comput Model 2013;58(3-4):852–858.
Yuan Y, Li D, Meng MQH. Automatic polyp detection via a novel unified bottom-up and top-down saliency approach. IEEE J Biomed Health Inf 2018;22(4):1250–1260.
Zhan J, Zhao H, Zheng P, Wu H, Wang L. Salient superpixel visual tracking with graph model and iterative segmentation. Cognitive Computation. 2019:1–12.
Zhang J, Sclaroff S. Saliency detection: a boolean map approach. In: Proceedings of the IEEE international conference on computer vision; 2013. p. 153–160.
Zhang L, Ai J, Jiang B, Lu H, Li X. Saliency detection via absorbing Markov chain with learnt transition probability. IEEE Trans Image Process 2018;27(2):987–998.
Zhang Q, Luo D, Li W, Shi Y, Lin J. Two-stage absorbing Markov chain for salient object detection. In: IEEE international conference on Image processing; 2017. p. 895–899.
Zhang W, Xiong Q, Shi W, Chen S. Region saliency detection via multi-feature on absorbing Markov chain. Vis Comput 2016;32(3):275–287.
Zhao R, Ouyang W, Li H, Wang X. Saliency detection by multi-context deep learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015. p. 1265–1274.
Zhu G, Wang Q, Yuan Y. Tag-saliency: Combining bottom-up and top-down information for saliency detection. Comput Vis Image Underst 2014;118:40–49.
Zhu W, Liang S, Wei Y, Sun J. Saliency optimization from robust background detection. In: Proceedings of IEEE conf. on computer vision and pattern recognition; 2014. p. 2814–2821.
Funding
This work was supported by China Scholarship Council, the National Natural Science Foundation of China (No. 913203002), the Pilot Project of Chinese Academy of Sciences (No. XDA08040109), the Fundamental Research Funds for the Central Universities of China (Grant No. ACAIM190302), and Universities Joint Key Laboratory of Photoelectric Detection Science and Technology in Anhui Province (Grant No. 2019GDTCZD02).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Informed Consent
All procedures followed were in accordance with the ethical standards of the responsible committee on human experimentation (institutional and national) and with the Helsinki Declaration of 1975, as revised in 2008 (5). Additional informed consent was obtained from all patients for which identifying information is included in this article.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by the any of the authors
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Jiang, F., Kong, B., Li, J. et al. Robust Visual Saliency Optimization Based on Bidirectional Markov Chains. Cogn Comput 13, 69–80 (2021). https://doi.org/10.1007/s12559-020-09724-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-020-09724-6