
Abstract
Research on sentiment analysis in English language has undergone major developments in recent years. Chinese sentiment analysis research, however, has not evolved significantly despite the exponential growth of Chinese e-business and e-markets. This review paper aims to study past, present, and future of Chinese sentiment analysis from both monolingual and multilingual perspectives. The constructions of sentiment corpora and lexica are first introduced and summarized. Following, a survey of monolingual sentiment classification in Chinese via three different classification frameworks is conducted. Finally, sentiment classification based on the multilingual approach is introduced. After an overview of the literature, we propose that a more human-like (cognitive) representation of Chinese concepts and their inter-connections could overcome the scarceness of available resources and, hence, improve the state of the art. With the increasing expansion of Chinese language on the Web, sentiment analysis in Chinese is becoming an increasingly important research field. Concept-level sentiment analysis, in particular, is an exciting yet challenging direction for such research field which holds great promise for the future.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
With an information boom led by user-generated Internet content, the task of processing enormous quantities of information available online is a formidable one beyond the capabilities of human processing. For instance, movie distributors and fans are increasingly interested in public sentiments regarding new movies. Business owners and customers are also more eager to discover how people perceive new products.
However, with the huge amount of information available online, collecting and aggregating movie and product reviews is a challenging task and machines have to be utilized to help researchers with data collection. One such approach is that of sentiment analysis, which has proved popular over the years [1].
Sentiment analysis is a “suitcase” research problem that requires tackling many NLP sub-tasks, including aspect extraction [2], subjectivity detection [3], concept extraction [4], named entity recognition [5], and sarcasm detection [6], but also complementary tasks such as personality recognition [7], user profiling [8], and multimodal fusion [9]. Much work has been done on English sentiment analysis, but there is lack of research in the Chinese language field. Fortunately, more researchers have started to conduct Chinese sentiment classification in the last decade [10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38].
There are two main approaches to Chinese sentiment analysis research: the monolingual approach and the bilingual approach. The former focuses on performing typical sentiment analysis tasks, such as polarity detection, directly based on Chinese language. The latter leverages on existing English language resources and machine translation techniques to work on Chinese natural language text.
Chinese sentiment classification, however, has certain characteristics that differ from English sentiment classification. The most notable feature of Chinese is the lack of inter-word spacing, as a string of Chinese text is made up of equally spaced graphemes that are called characters. In addition, Chinese words often consist of the combination of more than one Chinese character. Thus, it is necessary to segment Chinese words before analyzing the sentiments in Chinese texts. The above feature leads to the second characteristic that Chinese text is compositionally rich in terms of semantics.
Since modern Chinese characters evolve from pictograms, they can be decomposed into smaller semantic-aware particles, termed radicals. The third characteristic is that Chinese has a relatively different or even opposite syntactic structure as compared to other languages, especially English, and strategies have to be devised to resolve ambiguities present in Chinese syntactic parsing. For instance, Fig. 1 shows how syntax trees differ in English and Chinese of a same sentence. Whichever method is used, be it supervised or unsupervised, a sentiment language lexicon is usually required for sentiment classification.

Syntax trees for the sentence “Everything would have been all right if you hadn’t said that” in two languages
The rest of the paper is organizedy as follows: Section “Problem Definition” explains problem definition and review scope of this paper; Section “Construction of Corpora and Lexica” introduces recent and present research on sentiment corpora and lexica; Section “Monolingual Approaches” describes the different perspectives of sentiment classification methods in Chinese language; Section “Multilingual Approach” discusses multi-lingual sentiment classification methods in Chinese language; Section “Testing Dataset” reviews some popular experimental testing datasets and selected experimental results; finally, Section “Conclusion” concludes the paper and proposes some future research directions.
Problem Definition
The ultimate goal of sentiment analysis can be generally summarized as identifying sentiment or opinion labels of given texts. Depending on the types of final label, problems are usually divided into sentiment classification and emotion/subjectivity identification. Nevertheless, the two sub problems share similar workflow in achieving their final goals. We summarize the procedures and review Chinese sentiment analysis literatures on each of the procedure.
In particular, sentiment resources like sentiment lexica and corpora provide the foundation of all tasks. Due to the scarcity of Chinese sentiment resources, creating Chinese sentiment resources is a major branch of related research. Influenced by the negative effect of domain-dependency and in order to save human labor, many works aim to develop method that can create cross-domain sentiment resource in a semi-supervised manner. With the sentiment resource, research path bifurcates into machine learning based and knowledge based methods. Machine learning treats sentiment classification as either a binary (positive or negative) or multiple class classification problem. Traditional machine learning aims at manual development of features that could distinguish sentiment of text out of different domain knowledge. However, with an increasing trend, recent machine learning turns to building neural networks to learn capable features automatically. Meanwhile, some researchers spend energies on developing sentiment classifiers that work on these features.
The other school which follows the knowledge based method studies language rules and syntactical or semantic relations. We review the Chinese state of the art in Section “Monolingual Approaches.” Lastly, illustrated by the relatively numerous research conducted on English, another school of researchers utilizes a multilingual approach which transfers resource or method from the English research world to be employed in Chinese situation.
Construction of Corpora and Lexica
Corpus and lexicon are two seemingly similar, but in truth, differing structures of language expressions. Each of them leads to different sentiment classification methods, as illustrated in this paper.
Corpus
A corpus is a collection of complete and self-contained texts, e.g., the corpus of Anglo-Saxon verses [39]. In linguistics and lexicography, a corpus is defined as a body of texts, utterances, or other specimens considered more or less representative of a language and usually rendered in a machine-readable format. Currently, computer corpora may store millions of running words with features that can be analyzed by means of tagging (the process of attaching identifying and classifying labels onto words and other formations) and the use of concordant programs.
In sentiment classification, the corpus is fundamental to the training of the emotion system because it contains much information consisting of emotional expressions in the form of words, phrases, sentences, and paragraphs. Research on Chinese sentiment classification is hindered by a lack of large, labeled Chinese language corpora; hence, some researchers have attempted to expand or modify existing Chinese language corpus.
A relative fine-grained scheme was initially proposed that annotated emotion in texts on three different levels; the document, paragraph and sentence levels [10]. Eight emotion classes (expectant, joy, love, surprise, anxiety, sorrow, angry, and hate) were used to annotate the corpus and to explore different emotion expressions in Chinese. However, such work has to be done manually, which can be laborious and time consuming. A Chinese Sentiment Treebank of social data was thus introduced by researchers to resolve this issue[40]. An algorithm was devised to crawl and label over 13,550 sentences from movie reviews on social websites, and a novel Recursive Neural Deep Model (RNDM) was developed to assign sentiment labels based on a recursive deep-learning technique.
Preparing the corpus is just the first step in sentiment classification. Much ignored research tasks could be explored by analyzing the developed corpus [11]. Unlike many existing English sentiment corpora, which had sentiment details only at the sentence level [41,42,43], Zhao et al. have created a global fine-grained corpus whose annotation scheme has not only introduced cross-sentence and global emotion information, but has also revealed new sentence-level elements. Furthermore, two new tasks (target-respect pair extraction and implicit polarity extraction) are proposed by their analysis. In addition to monolingual corpus, Lee et al. [44] collected and annotated a code-switching (with different languages appearing in one sentence) emotion corpus between English and Chinese from the posts of Weibo. A corpus-based method is usually utilized for machine learning. Kernel-based algorithms extract features such as lexical features, syntactic features, and semantic features, and data is then trained and tested through classification technique, e.g., naïve Bayes (NB), maximum entropy, and support vector machine (SVM). Over the past 5 years, neural networks have been dominating over kernel machines. Instead of manually designing features, neural networks learn features from the corpus. The learned features are then fed into classification systems to train a classifier, either kernel based or deep learning based.
Lexicon
As compared to a corpus-based method (employing machine-learning), the lexicon-based method is a more straightforward approach to sentiment analysis. Sentiment or emotion lexicon is a list of words and expressions used to express people’s subjective feelings, sentiments or opinions [45]. Sentiment lexica are vital to sentiment classification, since they serve as the evidential basis of sentiment polarity. Sentiment lexicon lists could be divided into three main classifications [12]; with examples such as Never-Ending Language Learner (NELL) [46] that contains only sentiment words, National Taiwan University Sentiment Dictionary (NTUSD) [47] and HowNet [48] that contain both sentiment words and sentiment polarities, and finally, SentiWordNet [49] and SenticNet [50] which contain words and their relevant polarity values.
Unlike their English language counterparts, resources available for Chinese sentiment lexica are rather limited. There are two main problems with the construction of a sentiment lexicon in Chinese: firstly, words in Chinese are semantically and syntactically ambiguous, which makes the computation of sentiment polarity a difficult task; secondly, resources that are available to construct a Chinese lexicon are either insufficient or unsuitable [13]. Nonetheless, researchers have devised ways to overcome these issues in order to construct Chinese sentiment lexica. There are three main methods used to construct a sentiment lexicon in Chinese. The first method is conducted through the manual construction of a sentiment lexicon. Sentiment words or expressions have to be collected manually, and the relevant sentiment polarities annotated by hand. It is labor-intensive and researchers may prefer not to apply this method directly. Instead, this is usually used at the end of the research process to verify the accuracy of automatic algorithms.
The second method is a dictionary-based approach. A dictionary is a resource that lists the words of a specific language and provides their meaning, synonyms and antonyms. The premise of this method is to provide researchers with a list of sentiment words (or otherwise, seed words) and their known sentiment polarities. Through the relations between the words and their respective synonyms and antonyms in the dictionary, more new words could be found and their respective sentiment polarities inferred. The new words too, will consist of synonyms and antonyms as well as their respective sentiment polarities. This process can be iterated many times and the size of the sentiment lexicon can grow increasingly larger. One popular dictionary is HowNet, an online common-sense knowledge base which unveils inter-conceptual relations and inter-attribute relations of concepts as found in Chinese and English bilingual lexica [51]. However, there are two issues associated with this dictionary. The first issue is that the list does not consider the context of the words [13]. Secondly, the entries in the list are relatively dated because the dictionary was created in 1999 and does not include recent words and expressions. Thus, many researchers have attempted to utilize this dictionary in improved ways.
Liu et al. have constructed a domain-specific sentiment lexicon that is applied to an aspect-based review mining scenario [14]. A framework is formulated to combine the constructed lexicon with an existing sentiment wordlist such as HowNet, which could then improve domain-specific sentiment data performance. Xu et al. [15] have presented a method that utilizes a large unlabeled corpus to correct and expand two popular Chinese sentiment dictionaries, such as HowNet and NTUSD [47]. In addition to expanding the traditional dictionaries, Xu et al. [16] also adopted a graph-based algorithm which automatically ranks works based on a few seed words. Similarities between words and multi-resources were utilized to improve the algorithm in an iterative manner, and the lexicon was finally modified through manual labeling. Wu et al. [12] have compiled a new Chinese sentiment lexicon termed “iSentiDictionary.” Seed words from existing sentiment dictionaries were collected and then classified into four categories. The researchers then proposed applying a self-training spreading method to ConceptNet so as to derive the lexicon.
The third method is to construct a sentiment lexicon that is based on a corpus. There are two commonly used methods for this approach [45]. The first method is to base a list of known seed words with sentiment orientations on a domain corpus. New words and their sentiment orientations can then be computed from the corpus. The second method is to adapt a general-purpose sentiment lexicon to a new one by utilizing a domain corpus for sentiment classification applications in the domain. Xu et al. [15] have utilized a large unlabeled corpus by Sogou, a Chinese search engine, to correct and expand current Chinese sentiment dictionaries. They also have proposed a method to compute the polarity strength of words in the dictionary. Su and Li [13] have proposed a bilingual method to construct a sentiment lexicon based on bilingual corpus and English seed words. English and Chinese are mutually translated and the sentiment orientations of Chinese words then derived from computing the PMI values of English seed words. In particular, the authors computed PMI values of each unknown Chinese and English seed word and constructed a context-aware sentiment lexicon.
One drawback of currently developed approaches is that they do not consider the fuzziness of the intensity-of-word sentiment polarity, as Wang et al. pointed out in [17]. They found some sentiment words to possess opposite polarities in different lexica, for the reason that words in different contexts may have different sentiment polarities, and most existing methods for identifying word sentiment polarity are based on a cantor set model [17]. In order to solve this problem, they proposed a fuzzy computing model (FCM) to identify word sentiment polarity. It consists of three major parts: sentiment words datasets, a key sentiment lexicon (KSL), and a key sentiment morpheme set (KMS). In the paper, they firstly computed three polarities from the sentiment dataset, KSL and KMS respectively. They then built a classification function of fuzzy classifier and adjusted the parameters. The key twist in their method was to define fuzzy sets and membership functions for positive and negative sentiment categories and to design proper classifiers and a defuzzification algorithm. The results of the experiment demonstrated benchmarking performance of the model.
In addition to building lexica directly from Chinese language, some researchers have used the bilingual approach. Gao et al. developed a method to learn a sentiment lexicon for the target language with English sentiment lexica. In [52], the target language was Chinese. They modeled the lexicon learning as a bilingual word graph that had two layers: layer one for English and layer two for Chinese. In each layer, synonym word relations linked the sentiment words together with a positive weight and vice versa for antonym word relations, albeit with a negative weight in place. These two layers were connected by an inter-language sub-graph, which contained labeled words in the English layer and unlabeled words in the Chinese layer. Given the seeds in the English layer, sentiment polarities of Chinese words were learnt from the bilingual word graph construction and an algorithm for bilingual word graph-label propagation.
Peng and Cambria [53] presented a resource dependent mapping method for the construction of a Chinese sentiment resource, termed CSenticNet (Fig. 2) by utilizing both English sentiment resources [50] and the Chinese knowledge base NTU Multi-lingual Corpus [54]. Since the English sentiment resource was semantically connected to emotions at concept level, the authors also developed a language-specific emotion categorization model (Fig. 3).

CSenticNet

Hourglass model in Chinese language
Monolingual Approaches
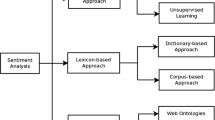
Chinese text has its own characteristics that other languages do not have. Thus a specific preprocessing, segmentation is the first step. Existing segmentation tools (segmentor) were firstly presented and analyzed in this section. Followed are two major methods used to perform sentiment classification for the monolingual approach; namely machine learning based and knowledge based [55], as shown in Fig. 4. The machine learning based approach treats the sentiment classification as a topic-based categorization problem. The topic in question is the sentiment and is classified as either positive or negative.

Monolingual sentiment analysis techniques
The knowledge based method uses the sentiment lexicon, which consists of sentiment polarity for each word, to label the sentiments of words in a document. The polarity of the document is then computed by synthesizing the polarity of each word on the basis of different logics such as syntactic rules, direct summation, and more.
Preprocessing
Unlike English that text processing starts with tokenization, Chinese texts processing starts with word segmentation. There are three most popular Chinese word segmentors available: ICTCLAS, THULAC, and Jieba segmentor. ICTCLAS was developed by Dr. Zhang Huaping and is considered as the benchmark in Chinese word segmentation [27]. It provides with API in C++, Java, Python and so forth. THULAC [56] was invented by Tsinghua University. Similar with ICTCLAS, THULAC also incorporates Part-Of-Speech (POS) tagging in the software. JiebaFootnote 1 is an open source Chinese text segmentor which has the easiest and fastest adaptation in Python, compared with Python APIs from other segmentors. Tsinghua university has made an experimental comparison in accuracy and speed of these segmentors. Results are shown in Table 1.Footnote 2
As we can conclude from Table 1, ICTCLAS has the highest accuracy but the slowest speed. Jieba is the fastest segmentor, however its accuracy is the lowest. THULAC is the best among the three segmentors in the trade-off between speed and accuracy. Furthermore, Jieba supports up to 9 programming languages. Whereas the other two cannot compete with. Followed by segmentation of Chinese text, many other text preprocessings like tokenlization and POS tagging and so forth can be conducted with softwares like NLTK [57], Scikit-learn [58] etc.
Machine Learning-Based Approach
The machine learning approach is usually a supervised approach that does not need predefined semantic rules but requires a labeled dataset. It is redirected to be a text classification problem. The general methodology of a supervised approach is as follows: The first step involves the extraction of features. The features are usually classified into the following categories: lexical feature, syntactic feature and semantic feature. For example, negation tag, n-gram (unigram, bigram, etc.), Parts of Speech (POS) tag, and so on and so forth.
The next step is to train and test the data by using classification techniques, such as NB, maximum entropy, SVM and others. This process is illustrated in Fig. 5. Beyond this traditional machine learning methodology, recent utilization of neural networks emancipates researchers from feature-engineering which further assists in classification task. Tan and Zhang [18] conducted an empirical study of sentiment categorization on Chinese documents. They tested four features—mutual information (MI), information gain (IG), chi-square (CHI), and document frequency (DF)—and five learning algorithms—centroid classifier, k nearest neighbor (kNN), winnow classifier, NB and SVM. Their results showed that the IG and SVM features provided the best performances for sentiment categorization coupled with domain or topic dependent classifiers.

Machine learning-based processing for Chinese sentiment analysis
Historically, research direction could be classified into three major groups based on the different procedures used in machine learning sentiment classification. The first group focused on studying features. In addition to the commonly employed N-gram feature, Zhai et al. pointed out [19] that seldom used structures like sentiment words, substrings, substring-groups, and key-substring-groups can also be used to extract features. Their analysis suggested that different types of features have different capabilities of discrimination, and substring-group features may have the potential for better performance. Su et al. [20] tried making use of semantic features and applied word2vec, which utilized neural network models to learn vector representations of words. After the extraction of deep semantic relations (features), word2vec is used to learn the vector representations of candidate features. The authors finally applied SVM as a classification technique on their features and achieved an accuracy level of over 90%.
Xiang [21] presented a novel algorithm based on an ideogram. The method does not need a corpus to compute a word’s sentiment orientation, but instead requires the word itself and a pre-computed character ontology (a set of characters annotated with sentiment information). The results revealed that their proposed approach outperforms existing ideogram-based algorithms. Some researchers developed novel neural features by combining the compositional characteristic of Chinese with deep learning methods. Chen et al. [59] started to decompose Chinese words into characters and proposed a character-enhanced word embedding model (CWE). Sun et al. [60] started decompose Chinese characters to radicals and developed a radical-enhanced Chinese character embedding. However, they only selected one radical from each character to enhance the embedding.
Shi et al. [61] began to train pure radical-based embedding for short-text categorization, Chinese word segmentation and web search ranking. Yin et al. [62] extend the pure radical embedding by introducing multi-granularity Chinese word embeddings. However, none of the above embeddings have considered incorporating sentiment information and apply the radical embeddings to the task of sentiment classification. Then, Peng et al. [63] developed a radical-based hierarchical Chinese embedding that leveraged on sentiment information. Their embedding achieves better results than general Chinese word or character level embedding in sentence-level sentiment analysis.
As compared to the first group, however, the second group that focuses on studying different classification model is more popular. Xu et al. [22] proposed an ensemble learning algorithm based on a random feature space-division method at document level, or Multiple Probabilistic Reasoning Model (M-PRM). The algorithm captures and makes full use of discriminative sentiment features. Li et al. [40] introduced a novel Recursive Neural Deep Model (RNDM) which can predict sentiment labels based on recursive deep learning. It is a model that focuses on sentence-level binary sentiment classification and claims to outperform NB and SVM. Cao et al. introduced a joint model which incorporated SVM and a deep neural network [23]. They considered sentiment analysis as a three-class classification problem, and designed two parallel classifiers before merging the two classifiers’ results as the final output. The first classifier was a word-based vector space model, in which unlabeled data was firstly identified and then added to a sentiment lexicon. Features were then extracted from the sentiment lexicon and labeled training data.
Before building the SVM classifier, training data was then processed in order to make it more balanced. The second classifier was a SVM model, in which distributed paragraph representation features were learnt from a deep convolutional neural network. Finally, the two classifiers’ results were merged with an emphasis on neutral output, or, the second classifier’s output. Liu et al. used a self-adaptive hidden Markov model (HMM) in [24] to conduct emotion classification. They used Ekman’s [64] six well-known basic emotion categories: happiness, sadness, fear, anger, disgust, and surprise. Initially, they designed a category-based feature. For each emotion category, they computed the MI, CHI, term frequency-inverse document frequency (TF-IDF) and expected cross entropy (ECE). The four results formed the four dimensions of the category-based feature. Then, a modified HMM-based emotional classification model was built, featuring a self-adaptive capability through the use of a particle swarm optimization (PSO) algorithm to compute the parameters. The model performed better than SVM and NB in certain emotion categories.
The third group has attempted to develop new machine-learning based approaches in Chinese sentiment classification. Wei et al. [65] presented a clustering-based Chinese sentiment classification method. Sentiment sequences were first built from micro-blogs such as Weibo, and Longest Common Sequence algorithms were then applied to compute the differences between two sentiment sequences. Following, a k-medoids clustering algorithm was applied at the end of the process. This method does not require a training data and yet provides efficient and good performance for short Chinese texts.
Ku et al. [25] applied morphological structures and relations between sentence segments to Chinese sentiment classification. CRF and SVM classifiers were used in the model and results indicate that structural trios benefit sentence sentiment classification. Xiong [26] developed an ADN-scoring method using appraisers, degree adverbs, negations, and their combinations for sentiment classification of Chinese sentences. A particle swarm optimization (PSO) algorithm was also used to optimize the parameters of the rules for the method.
Chen et al. proposed a joint fine-grained sentiment analysis framework at the sub-sentence level with Markov logic in [66]. Unlike other sentiment analysis frameworks where subjectivity detection and polarity classification were employed in a sequential order, Chen et al. separated subjectivity detection and polarity classification as isolated stages. The two separated stages were learnt by local formulas in Markov logic using different feature sets, like context POS or sentiment scores. Next, they were integrated into a complete network by global formulas. This, in turn, prevented errors from propagating due to chain reactions.
In addition to the classical binary or ternary label classification problem (positive, negative, or neutral), multi-label classification research has also recently gained popularity. Liu et al. [67] proposed a multi-label sentiment analysis prototype for micro-blogs and also compared the performance of 11 state of the art multi-label classification methods (BR, CC, CLR, HOMER, RAkEL, ECC, MLkNN, RF-PCT, BRkNN, BRkNN-a and BRkNN-b) on two micro-blog datasets. The prototype contained three main components: text segmentation, feature extraction, and multi-label classification. Text segmentation segmented a text into meaningful units. Feature extraction extracted both sentiment features and raw segmented words features and represented them in a bag of words form. Multi-label classification compared all 11 methods’ classification performances. Detailed experimental results suggested that no single model outperformed others in all of the test cases.
Knowledge-Based Approach
Another popular approach is the knowledge-based approach or usually termed the unsupervised approach. After the preprocessing of texts, knowledge-based approach divides into two branches. The first branch relies on a sentiment lexicon to find the sentiment polarity of each phrase obtained in the step before. It then sums up the polarities of all phrases in sentences, paragraphs or documents (based on required granularity). If the summation is greater than zero, the sentiment of this granularity will then be positive and vice versa if the summation is less than zero. The second branch tries to explore syntactic rules and other logic.
For instance, semantic orientation (SO) is estimated from the extracted phrases using the Point Wise Index algorithm. Eventually, the average SO of all phrases is computed. If the average value is greater than zero, the sentiment of the phrases in the document is classified as positive and vice versa if the average value is less than zero. Researchers tend to prefer the second branch due to the greater flexibility offered. Zhang et al. [28] proposed a rule-based approach with two phases: the sentiment of each sentence is first decided based on word dependency; and, aggregating the sentences’ sentiments then generates the sentiment of each document.
Zagibalov et al. [29] presented a method that does not require any annotated training data and only requires information on commonly occurring negations and adverbials. The performance of their method is close to, and sometimes outperforms, supervised classifiers. Recent research [30] considers both positive/ negative sentiment and subjectivity/objectivity as a continuum. The unsupervised techniques were used to determine the opinions present in the document. The techniques include a one-word seed vocabulary, iterative retaining for sentiment processing and a criterion of “sentiment density.” Due to lexical ambiguity of Chinese language, much work has been conducted on fuzzy semantics in Chinese.
Li et al. [31] claimed that polarities and strengths’ judgment of sentiment words obey a Gaussian distribution, and thus proposed a Normal distribution-based sentiment computation method for quantitative analysis of semantic fuzziness of Chinese sentiment words. Zhuo et al. [32] presented a novel approach based on the fuzzy semantic model by using an emotion degree lexicon and a fuzzy semantic model. Their model includes text preprocessing, syntactic analysis, and emotion word processing. Optimal results of their model are achieved when the task is clearly defined. The unsupervised approach can also be applied on aspect-level sentiment classification. Su et al. [33] presented a mutual reinforcement approach to study the aspect-level sentiment classification. An attempt to simultaneously and iteratively cluster product aspects and sentiment words was performed. The authors constructed an association set of the strongest n-sentiment links, which was used to exploit hidden sentiment association in reviews.
Some recent research work also studied the discourse and dependency relations of Chinese data. In [34], Wu et al. studied the combination problem of Chinese opinion elements. Opinion topics (topic, feature, item, opinion word) were extracted from documents based on lexica. Features were then combined with three sentence patterns (general sentences, equative sentences and comparative sentences) in order to predict the opinion. These sentence patterns determined how the opinion elements in the sentence should be computed to yield the sentiment of a whole sentence. Quan et al. went further in sentiment classification using dependency parsing in [68]. They integrated a sentiment lexicon with dependency parsing to develop a sentiment analysis system. They firstly conducted a dependency analysis (nsubj, nn, advmod, punct) of sentences so as to extract emotional words. Based on these, they established sentiment dictionaries from a lexicon (HowNet) and calculated word similarities to predict the sentiment of sentences.
So far, we have seen that Chinese sentiment analysis research has restricted elementary components to word or character level. Even though state-of-the-art algorithms (either machine learning based or knowledge based) performed reasonably well, word level analysis did not reflect real human reasoning faithfully. Instead, concept level reasoning needs to be explored as it has been demonstrated to be closer to the truth [69]. Our mental world is a relational graph whose nodes are various concepts. As Fig. 6 from [70] shows, NLP research is gradually shifting from lexical semantics to compositional semantics. To the best of our knowledge, there is no current work on concept level Chinese sentiment analysis. Related works in the future are thus expected to be promising.

Evolution of NLP research through three different eras from [70]
Mix Models
Finally, there is also a branch of researchers who have combined the machine learning approach with a knowledge based approach. Zhang et al. [35] introduced a variant of self-training algorithm, named EST. The algorithm integrates a lexicon-based approach with a corpus-based approach and assigns an agreement strategy to choose new, reliable labeled data. The authors then proposed a lexicon-based partitioning technique to split the test corpus and embed EST into the framework. Yuan et al. [36] conducted Chinese micro-blog sentiment classification using two approaches. For the unsupervised approach, they integrated a Simple Sentiment Word-Count Method (SSWCM) with three Chinese sentiment lexica. For the supervised approach, they tested three models (NB Classifier, Maximum Entropy Classifier, and Random Forests Classifier) with multiple features.
Their results indicated that the Random Forests Classifier provided the best performance among the three models. Li et al. [71] presented a model that boasted the combination of a lexicon-based classifier and a statistical machine learning based classifier. The output of the lexicon-based classifier was simply the sum of the sentiment scores of each word in the sentence. For the machine learning-based classifier, they selected unigram- and weibo-based features from many candidate features so as to train a SVM classifier. Finally, the system gave a linear combination of the two classifiers’ outputs. Likewise, in [72], Wen et al. introduced a method based on class sequential rules for emotion classification of micro-blog texts. They firstly obtained two emotion labels of sentences from lexicon-based and SVM-based methods. Then, the conjunctions of previous emotion labels sequences were formed and class sequential rules (CSR) were mined from the sequences. Eventually, features were extracted from CSRs and a corresponding SVM classifier was trained to classify the whole text.
Multilingual Approach
Natural language processing research in English language dates back to the 1950s [70]. Within this general multi-disciplinary field, English sentiment analysis only developed about twenty years ago. In comparison, Chinese sentiment classification is a relatively new field with a history only dating back about ten years. As such, resources available for sentiment classification in English are more abundant than those in Chinese, and some researchers have therefore taken advantage of the established English sentiment classification structure to conduct research on Chinese sentiment classification.
Wan [37] proposed a method that incorporates an ensemble of English and Chinese classifications. Chinese language reviews were first translated into English via machine translation. An analysis on both English and Chinese reviews was then conducted and their results combined to improve the overall performances of the sentiment classification. The problem of the above-mentioned approach is that the output of machine translation is unreliable if the domain knowledge is different for the two languages. This could lead to an accumulation of errors and reduce the accuracy of translation. As a result, some researchers formulate this into a domain adaptation. Wei and Pal [73] showed that, rather than using automatic translation, the application of techniques like structural correspondence learning (SCL) that link two languages at the feature-level can greatly reduce translation errors. Additionally, He et al. [38] proposed a method that does not need domain and data specific parameter knowledge.
Language-specific lexical knowledge from available English sentiment lexica is incorporated through machine translation into latent Dirichlet allocation (LDA) where sentiment labels are considered topics [74]. This process does not introduce noise to the process due to the high accuracy of the lexicon translation and does not need labeled corpus for training. Finally, instead of solely improving the performance of Chinese language analysis, Lu et al. [75] developed a method that could jointly improve the sentiment classification of both languages. Their approach involves an expectation maximization algorithm that is based on maximum entropy. It jointly trains two sentiment classifiers (each language a classifier) by treating the sentiment labels in the unlabeled parallel text as unobserved latent variables. Together with the inferred labels of the parallel text, the joint likelihood of the language-specific labeled data will then be regularized and maximized. Zhou et al. [76] incorporated sentiment information into Chinese-English bilingual word embeddings using their proposed denoising autoencoder. Chen et al. [77] introduced a semi-supervised boosting model to reduce the transferred errors of cross-lingual sentiment analysis between English and Chinese.
Testing Dataset
For a long period of time, sentence sentiment classification has been a central topic for Chinese sentiment analysis. There are certain general Chinese sentiment datasets that were experimented. We select three most popular datasets and present some experimental results that were conducted on them in Table 2.
The first dataset “ChnSentiCorp” was introduced by Tan and Zhang [18]. It contains 1021 documents in three domains: education, movie and house. Meanwhile, Tan also collected a large scale hotel review dataset which contains 5000 positive and 5000 negative short texts.Footnote 3
The second dataset, IT168TEST, is a product review dataset presented by Zagibalov and Carroll in [30]. This dataset contains over 20000 reviews, in which 78% were manually labeled as positive and 22% labeled as negative. The third dataset is provided by the 8th SIGHAN Workshop on Chinese Language Processing (SIGHAN-8). It is for a task of topic-based Chinese message polarity classification. Note that even though some research has obtained remarkable results on some dataset, such as [19, 35], it does not mean the task of Chinese sentiment classification is well solved.
Some above excellent experimental results may due to particular experimental settings, such as feature engineering or adaptation [35], which may not be applicable in other experimental settings. Plenty of research space is still available, as a general method is at our best interest. For example, on the same “IT168TEST” dataset, a later work by Fu and Xu [78] which achieved lower results compared with [19] still received popularity, because it proposed a more general method with neural networks.
In addition to the above three datasets, more researchers create their own experimental testing datasets. Some create their datasets in replacing of the popular ones [20, 34, 36]. Some create datasets due to specific problem definition, such as [13, 14, 22, 24, 28, 31, 33, 67, 79, 80]. When we research into their sources, we find most of them originate from such as but not limited to: AmazonCN [13, 28, 80], 360buy [14], Weibo [20, 24, 67, 79], Mtime [22] etc. Majority of their domains are reviews and blogs in hotels, products, and movies.
Conclusion
With the recent debut of Alibaba’s (considered to be China’s—and to some extent, the world’s—largest online commerce company) in the New York Stock Exchange (NYSE), China’s growing impact on the world’s technology and finance industries is greater than ever. As China’s leading Internet-based company, Alibaba generates countless amounts of new information entries each day through product descriptions, customer reviews, and more, and these data are often only available in Chinese language. Effective sentiment analysis of such a colossal amount of Big Data available online could provide invaluable added value to the government, business owners and Internet users in China. Although sentiment analysis in English language is well studied, research in Chinese sentiment analysis is substantially less developed.
Thus, this timely survey reviews past and recent research Chinese sentiment analysis, especially on major task sentiment classification. In particular, the construction of sentiment corpus and lexicon was first introduced and summarized. Following, a survey of monolingual sentiment classification in Chinese via three different approaches (machine learning based, knowledge based and mixed approaches) was conducted. Sentiment classification based on the multilingual approach was then introduced.
We realized that current research on sentiment analysis seldom considers the study of concept-level knowledge in texts. We proposed that the cognitive representation used by human beings may be organized in the format of conceptual connections, whereby each word activates a cascade of semantically-related concepts, and such approaches could greatly increase the capacity of the limited resources available.
Notes
References
Cambria E, Wang H, White B. Guest editorial: big social data analysis. Knowl-Based Syst. 2014;69: 1–2.
Poria S, Cambria E, Gelbukh A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl-Based Syst. 2016;108:42–9.
Chaturvedi I, Cambria E, Vilares D. 2016. Lyapunov filtering of objectivity for Spanish sentiment model. In: IJCNN. Vancouver; p. 4474–4481.
Rajagopal D, Cambria E, Olsher D, Kwok K. 2013. A graph-based approach to commonsense concept extraction and semantic similarity detection. In: WWW. Rio De Janeiro; p. 565–570.
Ma Y, Cambria E, Sa G. 2016. Label embedding for zero-shot fine-grained named entity typing. In: COLING. Osaka; p. 171–180.
Poria S, Cambria E, Hazarika D, Vij P. 2016. A deeper look into sarcastic tweets using deep convolutional neural networks. In: COLING. p. 1601–1612.
Majumder N, Poria S, Gelbukh A., Cambria E. Deep learning based document modeling for personality detection from text. IEEE Intell. Syst. 2017;32(2):74–9.
Mihalcea R, Garimella A. What men say, what women hear: finding gender-specific meaning shades. IEEE Intell Syst. 2016;31(4):62–7.
Poria S, Chaturvedi I, Cambria E, Hussain A. 2016. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In: ICDM. Barcelona; p. 439–448.
Quan C, Ren F. 2009. Construction of a blog emotion corpus for chinese emotional expression analysis. In: Proceedings of the 2009 conference on empirical methods in natural language processing: volume 3-volume 3. Association for Computational Linguistics; p. 1446–1454.
Zhao Y. , Qin B., Liu T. Creating a fine-grained corpus for chinese sentiment analysis. IEEE Intell Syst. 2014;30(5):36–43.
Hui-Hsin W, Tsai A C-R, Tsai R T-H, Hsu J Y-J. Building a graded chinese sentiment dictionary based on commonsense knowledge for sentiment analysis of song lyrics. J Inf Sci Eng. 2013;29(4):647–62.
Yan S, Li S. 2013. Constructing chinese sentiment lexicon using bilingual information. In: Chinese lexical semantics. Springer; p. 322–331.
Liu L, Lei M, Wang H. Combining domain-specific sentiment lexicon with hownet for chinese sentiment analysis. J Comput 2013;8(4):878–83.
Hongzhi X, Zhao K, Qiu L, Changjian H. 2010. Expanding chinese sentiment dictionaries from large scale unlabeled corpus. In: PACLIC. p. 301–310.
Ge X, Meng X, Wang H. 2010. Build chinese emotion lexicons using a graph-based algorithm and multiple resources. In: Proceedings of the 23rd international conference on computational linguistics. Association for Computational Linguistics; p. 1209–1217 .
Wang B, Huang Y, Xian W, Li X. A fuzzy computing model for identifying polarity of chinese sentiment words. Comput Intell Neurosci. 2015;2015.
Tan S, Zhang J. An empirical study of sentiment analysis for chinese documents. Expert Syst Appl. 2008; 34(4):2622–9.
Zhai Z, Hua X, Kang B, Jia P. Exploiting effective features for chinese sentiment classification. Expert Syst Appl 2011;38(8):9139–46.
Zengcai S, Hua X, Zhang D, Yunfeng X. 2014. Chinese sentiment classification using a neural network tool - word2vec. In: 2014 International conference on multisensor fusion and information integration for intelligent systems (MFI). IEEE; p. 1–6.
Xiang L. 2011. Ideogram based chinese sentiment word orientation computation. arXiv preprint arXiv:1110.4248.
Wei X, Liu Z, Wang T, Liu S. Sentiment recognition of online chinese micro movie reviews using multiple probabilistic reasoning model. J Comput 2013;8(8):1906–11.
Cao Y, Chen Z, Ruifeng X, Chen T, Gui L. A joint model for chinese microblog sentiment analysis. ACL-IJCNLP 2015;2015:61.
Li L, Luo D, Liu M, Zhong J, Ye W, Sun L. 2015. A self-adaptive hidden markov model for emotion classification in chinese microblogs. In: Mathematical problems in engineering .
Lun-Wei K, Huang T-H, Chen H-H. 2009. Using morphological and syntactic structures for chinese opinion analysis. In: Proceedings of the 2009 conference on empirical methods in natural language processing: volume 3-volume 3. Association for Computational Linguistics; p. 1260–1269.
Xiong W, Jin Y, Liu Z. Chinese sentiment analysis using appraiser-degree-negation combinations and pso. J Comput 2014;9(6):1410–7.
Zhang H-P, Hong-Kui Y, Xiong D-Y, Liu Q. 2003. Hhmm-based chinese lexical analyzer ictclas. In: Proceedings of the second SIGHAN workshop on Chinese language processing-volume 17. Association for Computational Linguistics; p. 184–187 .
Zhang C, Zeng D, Li J, Wang F-Y, Zuo W. Sentiment analysis of chinese documents: from sentence to document level. J Amer Soc Inf Sci Technol 2009;60(12):2474–87.
Zagibalov T, Carroll J. 2008. Automatic seed word selection for unsupervised sentiment classification of chinese text. In: Proceedings of the 22nd international conference on computational linguistics-volume 1. Association for Computational Linguistics; p. 1073–1080.
Zagibalov T, Carroll J. 2008. Unsupervised classification of sentiment and objectivity in chinese text. In: Third international joint conference on natural language processing; p. 304.
Li R, Shi S, Huang H, Chao S, Wang T. 2014. A method of polarity computation of chinese sentiment words based on gaussian distribution. In: Computational linguistics and intelligent text processing. Springer; p. 53–61.
Zhuo S, Xing W, Luo X. 2014. Chinese text sentiment analysis based on fuzzy semantic model. In: 2014 IEEE 13th International conference on cognitive informatics & cognitive computing (ICCI* CC). IEEE; p. 535–540.
Qi S, Xinying X, Guo H, Guo Z, Xian W, Zhang X, Swen Bs, Zhong S. 2008. Hidden sentiment association in chinese web opinion mining. In: Proceedings of the 17th international conference on World Wide Web. ACM; p. 959–968.
Shih-Jung W, Chiang R-D. Using syntactic rules to combine opinion elements in chinese opinion mining systems. J Converg Inf Technol. 2015;10(2):137.
Zhang P, He Z. A weakly supervised approach to chinese sentiment classification using partitioned self-training. J Inf Sci. 2013;39(6):815–31.
Bo Y, Liu Y, Li H, Phan T T T, Kausar G, Sing-Bik CN, Wahi W. 2013. Sentiment classification in chinese microblogs: lexicon-based and learning-based approaches. In: International Proceedings of economics development and research (IPEDR), p. 68 .
Wan X. 2008. Using bilingual knowledge and ensemble techniques for unsupervised chinese sentiment analysis. In: Proceedings of the conference on empirical methods in natural language processing. Association for Computational Linguistics; p. 553–561 .
He Y, Alani H, Zhou D. 2010. Exploring english lexicon knowledge for chinese sentiment analysis. In: CIPS-SIGHAN joint conference on Chinese language processing.
McArthur T, McArthur F, Vol. 186. The Oxford companion to the English language. Oxford: Oxford University Press; 1992.
Li C, Bo X, Gaowei W, He S, Tian G, Hao H. 2014. Recursive deep learning for sentiment analysis over social data. In: Proceedings of the 2014 IEEE/WIC/ACM international joint conferences on web intelligence (WI) and intelligent agent technologies (IAT)-volume 02. IEEE Computer Society; p. 180–185.
Minqing H, Liu B. 2004. Mining and summarizing customer reviews. In: Proceedings of the tenth ACM SIGKDD international conference on knowledge discovery and data mining. ACM; p. 168–177.
Li Z, Jing F, Zhu X-Y. 2006. Movie review mining and summarization. In: Proceedings of the 15th ACM international conference on information and knowledge management. ACM; p. 43–50.
Toprak C, Jakob N, Gurevych I. 2010. Sentence and expression level annotation of opinions in user-generated discourse. In: Proceedings of the 48th annual meeting of the association for computational linguistics. Association for Computational Linguistics; p. 575–584.
Lee S Y M, Wang Z. Emotion in code-switching texts: corpus construction and analysis. ACL-IJCNLP 2015; 2015:91.
Liu B. Sentiment analysis and opinion mining. Synth Lect Human Lang Technol 2012;5(1):1–167.
Carlson A, Betteridge J, Kisiel B, Settles B, Hruschka E R Jr, Mitchell TM. 2010. Toward an architecture for never-ending language learning. In: AAAI, vol. 5, p. 3.
Lun-Wei K, Liang Y-T, Chen H-H. 2006. Opinion extraction, summarization and tracking in news and blog corpora. In: AAAI spring symposium: computational approaches to analyzing weblogs, vol. 100107.
Dong Z, Dong Q. 2006. HowNet and the computation of meaning. World Scientific.
Baccianella S, Esuli A, Sebastiani F. 2010. Sentiwordnet 3.0: an enhanced lexical resource for sentiment analysis and opinion mining. In: LREC, vol. 10, p. 2200–2204.
Cambria E, Poria S, Bajpai R, Schuller. B. 2016. SenticNet 4: a semantic resource for sentiment analysis based on conceptual primitives. In: COLING; p. 2666–2677.
Dong Z, Dong Q, Hao C. 2010. Hownet and its computation of meaning. In: Proceedings of the 23rd international conference on computational linguistics: demonstrations. Association for Computational Linguistics; p. 53–56.
Gao D, Wei F, Li W, Liu X, Zhou M. 2015. Cross-lingual sentiment lexicon learning with bilingual word graph label propagation. Comput Linguist.
Peng H, Cambria E. 2017. CSenticNet: a concept-level resource for sentiment analysis in Chinese languagel. In: CICLing.
Tan L, Bond F. Building and annotating the linguistically diverse ntu-mc (ntu-multilingual corpus). Int J Asian Lang Proc 2012;22(4):161–74.
Cambria E. Affective computing and sentiment analysis. IEEE Intell Syst 2016;31(2):102–7.
Li Z, Sun M. Punctuation as implicit annotations for chinese word segmentation. Comput Linguist 2009; 35(4):505–12.
Bird S, Klein E, Edward L. 2009. Natural language processing with Python: analyzing text with the natural language toolkit. O’Reilly Media Inc.
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E. Scikit-learn: machine learning in Python. J Mach Learn Res 2011;12:2825–30.
Chen X, Lei X, Liu Z, Sun M, Luan H. 2015. Joint learning of character and word embeddings. In: IJCAI, p. 1236–1242.
Sun Y, Lin L, Yang N, Ji Z, Wang X. 2014. Radical-enhanced chinese character embedding. In: LNCS, vol. 8835, p. 279–286.
Shi X, Zhai J, Yang X, Xie Z, Liu C. 2015. Radical embedding: delving deeper to chinese radicals. In: ACL, p. 594–598.
Yin R, Wang Q, Li R, Li P, Wang B. 2016. Distributed representations of words and phrases and their compositionality. In: EMNLP, p. 981–986.
Peng H, Cambria E, Zou X. 2017. Radical-based hierarchical embeddings for chinese sentiment analysis at sentence level. In: The 30th International FLAIRS conference. Marco Island.
Eckman P. 1972. Universal and cultural differences in facial expression of emotion. In: Nebraska symposium on motivation, vol. 19. University of Nebraska Press Lincoln; p. 207–284 .
Wei G, An H, Dong T, Li H. 2014. A novel micro-blog sentiment analysis approach by longest common sequence and k-medoids. PACIS, p. 38.
Chen Z, Huang Y, Tian J, Liu X, Kun F, Huang T. 2015. Joint model for subsentence-level sentiment analysis with markov logic. J Assoc Inf Sci Technol.
Liu S M, Chen J-H. A multi-label classification based approach for sentiment classification. Expert Syst Appl 2015;42(3):1083–93.
Quan C, Wei X, Ren F. 2013. Combine sentiment lexicon and dependency parsing for sentiment classification. In: 2013 IEEE/SICE International symposium on system integration (SII). IEEE; p. 100–104.
Cambria E, Hussain A. Sentic computing: a common-sense-based framework for concept-level sentiment analysis. Cham: Springer; 2015.
Cambria E, White B. Jumping nlp curves: a review of natural language processing research. IEEE Comput Intell Mag 2014;9(2):48–57.
Li Q, Zhi Q, Li M. An combined sentiment classification system for sighan-8. ACL-IJCNLP 2015;2015: 74.
Wen S, Wan X. 2014. Emotion classification in microblog texts using class sequential rules. In: Twenty-Eighth AAAI conference on artificial intelligence.
Wei B, Pal C. 2010. Cross lingual adaptation: an experiment on sentiment classifications. In: Proceedings of the ACL 2010 conference short papers. Association for Computational Linguistics; p. 258–262.
Poria S, Chaturvedi I, Cambria E, Bisio F. 2016. Sentic LDA: improving on LDA with semantic similarity for aspect-based sentiment analysis. In: IJCNN, p. 4465–4473.
Bin L, Tan C, Cardie C, Tsou B K. 2011. Joint bilingual sentiment classification with unlabeled parallel corpora. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies-volume 1. Association for Computational Linguistics; p. 320–330.
Zhou H, Chen L, Shi F, Huang D. 2015. Learning bilingual sentiment word embeddings for cross-language sentiment classification. In: ACL.
Chen Q, Li W, Lei Y, Liu X, He Y. 2015. Learning to adapt credible knowledge in cross-lingual sentiment analysis. In: Proc. 53rd Annu. meeting assoc. comput. linguist.
Xianghua F, Yingying X. 2015. Recursive autoencoder with hownet lexicon for sentence-level sentiment analysis. In: Proceedings of the ASE bigdata & socialinformatics 2015. ACM; p. 20 .
Huang Z, Zhao Z, Liu Q, Wang Z. 2015. An unsupervised method for short-text sentiment analysis based on analysis of massive data. In: International conference of young computer scientists, engineers and educators. Springer; p. 169–176.
Zhang D, Hua X, Zengcai S, Yunfeng X. 2015. Chinese comments sentiment classification based on word2vec and svm perf, Vol. 42.
Acknowledgments
A. Hussain was supported by the National Science Foundation of China (NSFC) and UK Royal Society of Edinburgh (RSE) funded joint project (No. 61411130162), and also the UK Engineering and Physical Sciences Research Council (EPSRC) Grant No. EP/M026981/1.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no conflict of interest.
Informed Consent
Informed consent was not required as no human or animals were involved.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by any of the authors.
Additional information
Informed Consent
Informed consent was not required as no human or animals were involved.
Rights and permissions
About this article

Cite this article
Peng, H., Cambria, E. & Hussain, A. A Review of Sentiment Analysis Research in Chinese Language. Cogn Comput 9, 423–435 (2017). https://doi.org/10.1007/s12559-017-9470-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-017-9470-8