
Abstract
Social media has been remarkably grown during the past few years. Nowadays, posting messages on social media websites has become one of the most popular Internet activities. The vast amount of user-generated content has made social media the most extensive data source of public opinion. Sentiment analysis is one of the techniques used to analyze user-generated data. The Persian language has specific features and thereby requires unique methods and models to be adopted for sentiment analysis, which are different from those in English language. Sentiment analysis in each language has specified prerequisites; hence, the direct use of methods, tools, and resources developed for English language in Persian has its limitations. The main target of this paper is to provide a comprehensive literature survey for state-of-the-art advances in Persian sentiment analysis. In this regard, the present study aims to investigate and compare the previous sentiment analysis studies on Persian texts and describe contributions presented in articles published in the last decade. First, the levels, approaches, and tasks for sentiment analysis are described. Then, a detailed survey of the sentiment analysis methods used for Persian texts is presented, and previous relevant works on Persian Language are discussed. Moreover, we present in this survey the authentic and published standard sentiment analysis resources and advances that have been done for Persian sentiment analysis. Finally, according to the state-of-the-art development of English sentiment analysis, some issues and challenges not being addressed in Persian texts are listed, and some guidelines and trends are provided for future research on Persian texts. The paper provides information to help new or established researchers in the field as well as industry developers who aim to deploy an operational complete sentiment analysis system.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Today, the development of social networks and review websites has remarkably enhanced user-generated content. The analysis of user-generated content on the Internet has many benefits for analyzing customer behaviors, understanding customer needs and tendencies, and improving business and e-commerce. In recent years, social networks, blogs, forums, and customer review websites have provided individuals with an opportunity to exhibit their opinions on different topics. This has encouraged researchers to study the sentiment analysis field [1].
Sentiment analysis, also known as opinion mining, refers to a field of study, in which individuals’ opinions, sentiments, evaluations, appraisals, attitudes, and emotions towards entities such as products, services, organizations, individuals, issues, events, topics, and their attributes are examined [2, 3]. In this study, the terms “sentiment analysis” and “opinion mining” are used interchangeably. Sentiment analysis is associated with information retrieval, natural language processing (NLP), and the data mining of structured/unstructured data. Studies adopting sentiment analysis have had noticeable growth in recent years [4]. Figure 1 shows the number of documents and citations of “sentiment analysis” filed under WoS (2003–2016) [5]. The growing number of references to papers on sentiment analysis in recent years has highlighted the significance of the topic.

Number of documents and citations of “sentiment analysis” filed in accordance with the WoS (2003–2016) [5]
Some studies reviewed sentiment analysis methods adopted for texts in English [6,7,8,9,10]. In this regard, studies [11, 12] examined the sentiment analysis methods in Arabic texts; however, sentiment analysis in Persian texts has been disregarded. The Persian language is investigated in different countries. On the other hand, the analysis of Persian texts in international interactions is essential as many such countries need the sentiment analysis results for Persian texts. Some studies [13,14,15,16] highlighted multilingual methods; however, the Persian language was not included. In this addition, many scholars in the field of computer sciences need to know about the position of sentiment analysis in Persian texts to detect what to do, the remaining challenges, and gaps in the categorized methods and to investigate the research requirements of the domain. The influence and emotion of human studies in many sciences, including linguistics, psychology, sociology, cognitive sciences, marketing, and communication sciences, have been long considered [17]. Many scholars tend to use the sentiment analysis achievements with a focus on Persian language. Accordingly, the sentiment analysis methods of the Persian texts would contribute to the field. To this end, methodologies applied in Persian texts are surveyed and reviewed in the present study. Furthermore, these methodologies are discussed in the most recent works in terms of sentiment analysis. Finally, some suggestions are put forth to improve further studies in this field.
The first research on the Persian language was performed in 2012; hence, in this paper, we investigate published articles from 2012 to 2020. A total of 35 articles were found during the searches. Table 1 shows the number of reviewed papers over different years. In order to select papers, the queries “sentiment analysis,” “opinion mining,” “polarity detection,” “sentiment classification,” “sentiment lexicon,””sentiment resource,” and “sentiment dataset” with “Persian” keyword were submitted to the Google Scholar, science direct, Elsevier, and Springer service. Also, the queries “تحلیل احساس”, “تحلیل سنجمان”,”نظرکاوی”, “تشخیص قطبیت”, and ”طبقه بندی قطبیت” were submitted to the Civilica, Magiran, Elmnet, and Sid website for published Persian language papers.
In summary, the contributions of the present work can be summarized as follows:
-
Investigating recently published Persian sentiment papers from different perspectives including problem-solving approaches, contributions of these studies, and evaluation results.
-
Investigating recently sentiment analysis methods in Persian texts.
-
Investigating recently methods of constructing sentiment lexicon resources for Persian text.
-
Reviewing available datasets and classifying them based on important factors.
-
Clarifying issues, gaps, and subjects should be noticed in the Persian language regarding the review of all studies in Persian sentiment analysis and also state-of-the-art results in the English language.
This study is outlined as follows: “Constraints in Persian Sentiment Analysis” investigates the constraints of sentiment analysis in Persian texts from three perspectives. “Different Levels of Sentiment Analysis” describes different levels of sentiment analysis, “Sentiment Analysis Approaches” reviews sentiment analysis approaches, and “Sentiment Analysis Tasks” discusses sentiment analysis tasks. Sentiment analysis methodologies in Persian texts are surveyed in “A Review of Sentiment Analysis Methods in Persian Texts”. Methods used to construct sentiment lexicon resources are examined in “Methods of Constructing Sentiment Lexicon Resources for Persian Text.” In “Accessible and Standard Dataset in the Persian Language,” the existing standard Persian datasets are investigated. “Remaining Challenges and Future Developments” discusses the problems and gaps of sentiment analysis in Persian texts. Finally, some conclusions are provided in “Conclusion.”
Constraints in Persian Sentiment Analysis
Preprocessing Constraints
Persian alphabet contains 32 letters, and, unlike the English language, words are written from right to left. It has its specific grammar syntax and structure, which is different from other languages. Preprocessing tasks such as sentence tokenizing, word tokenizing, part of speech (POS) tagging, text chunking, lemmatizing, and stemming are used in sentiment analysis approaches. The more accurately the preprocessing is performed in Persian, the more appropriate prerequisites are prepared for the next steps. First, the use of compound words in text has made word tokenizing difficult. Detecting compound words from normal words needs higher accuracy since the compound words such as “پرداخت کننده” and “پشتیبانی کننده” are spaced in between. Second, informal and colloquial words such as “واسه”, “لپ تاپارو” and,“فک کنم” are used many times in opinion texts by users. Third, some words such as "کتاب های" have half-space; however, users do not write half-space when writing their opinions. Therefore, we need more accurate methods for word tokenizing in the Persian language.
Basiri et al. [18] and Asgarian et al. [19] examined the effect of preprocessing on sentiment analysis in Persian texts and approved its effectiveness. Since powerful preprocessing tools are not available for Persian, similar to that used for the English language, some sentiment analysis methods yielding acceptable results in the English texts maybe not achieve the same results in Persian. Moreover, some features of text classification originated from the English texts are not efficient for Persian texts and need further modifications.
Cultural Constraints
Individuals’ thoughts and subjectivity are significant in polarity identification and sentiment classification. Individuals’ perceptions of positive and negative words are different. The culture and characteristics of society affect individuals holding positive or negative opinions. The positive or negative criteria in each society differ from other societies. In this regard, a word may be positive in a society and negative or neutral in another society [20]. A society’s perspective toward a sentence may be judged positively; however, another society’s perspective may be judged negatively. Sentiment lexicon resources of the English language help to detect polarity even though the resources are constructed publicly and disregard the mentalities of individuals in a society. Each society has special expressions, idioms, and sarcasm intertwined with special sentiment values. The subjectivity and values of society play a significant role in determining polarity. Accordingly, we need resources to match polarity assigned to entities with the culture of society. English sentiment resources and their translation to the Persian language are in contrast with polarity and are not qualified, especially in the political and social domains.
Standard Resource Constraints
Sentiment analysis methods need text, sentences, and lexicons labeled with sentiment scores. Data accompanied with sentiment scores play a significant role in supervised learning methods. Moreover, deep neural network methods, which have recently been performing well, require massive annotated data. Furthermore, hybrid methods integrate sentiment lexicon resources with learning methods to increase accuracy remarkably. Another challenge in this field is that the preparation of annotated data is complicated and costly.
To tackle this issue, some studies focused on transfer learning model such as bilingual (English, Persian) model [21] and structural correspondence learning (SCL) method to domain adaptation [22].
These resources are constructed in English; however, the Persian language still needs to construct sentiment resources. Some researchers of the Persian texts have been concerned with the standard corpus of the user’s opinions at sentence, feature, and document levels as well as their polarity labels.
Another concern in analyzing Persian texts is to construct sentiment lexicon. Labeling sentiment lexicon and domain-specific lexicon is troublesome and time-consuming. Moreover, sentiment lexicon labeling is not performed adequately in many sentiment analysis methods, and linguistic patterns, concepts, and even dependency parsing should be labeled to achieve high performance.
Different Levels of Sentiment Analysis
In general, sentiment analysis has been mainly investigated at three levels [2]:
Document Level: The task at this level is to determine whether a whole opinion document expresses a positive or negative sentiment. For example, given a product review, the system specifies whether the review expresses an overall positive or negative opinion about a product. This level of analysis assumes that each document expresses opinions on a single entity (e.g., a single product); hence, document-level sentiment classification is not applicable to documents which evaluate or compare multiple entities.
Sentence Level: The task at this level is performed on the sentences, i.e., to determine whether each sentence expresses a positive, negative, or neutral opinion.
Entity and Aspect Level: Both the document and sentence level analyses do not discover what individuals exactly liked and disliked. Aspect level performs a finer-grained analysis. Aspect level was earlier called feature level (feature-based opinion mining). Instead of considering language constructs (documents, paragraphs, sentences, clauses, or phrases), the aspect level directly goes through the opinion itself. It is based on the idea that an opinion consists of sentiment (positive or negative) and a target (of opinion). Opinion targets are described by entities and/or their different aspects. Accordingly, the goal at this analysis level is to discover sentiments of entities and/or their aspects. For example, the sentence “The iPhone’s call quality is good, but its battery life is short.” evaluates two aspects, call quality and battery life of the iPhones (entity). The sentiment of the iPhone’s call quality is positive; however, the sentiment of its battery life is negative. The call quality and battery life of the iPhones are the opinion targets. According to this analysis level, a structured summary of opinions about entities and their aspects can be produced, which turns unstructured text into structured data and can be used for all kinds of qualitative and quantitative analyses.
Sentiment Analysis Approaches
Currently, the most sentiment analysis approach can be divided into three general categories [23]: lexicon-based approach, machine learning approach, and concept-level approach. The main factor in the sentiment analysis field is sentiment lexicon, which is commonly used for expressing positive or negative sentiments [2] in terms such as good, excellent, terrible, and bad. Lexicon-based approach is based on sentiment lexicon resources and their sentiment score. It determines the polarity of a text based on the total sum of comprised positive or negative sentiment lexicons in a text. A sentiment lexicon resource includes a set of negative and positive scores assigned to corresponding words and phrases. In comparison with machine learning approach, the lexicon-based method is a suitable approach for sentiment analysis, since it needs fewer resources and does not need some annotated datasets.
Furthermore, a sentiment lexicon can also be used in a machine learning approach in order to make sentiment-related features. However, a lexicon-based approach suffers from word coverage of sentiment words in a text. Compared with the lexicon-based approach, a machine learning-based approach uses the most common machine learning algorithms to classify sentiment orientation. Machine learning approach is performed in three ways: supervised learning, unsupervised learning, and semi-supervised learning. Among these, the supervised learning approach has achieved more successful results. Feature engineering is critical in classification as the other applications of supervised machine learning. Sentiment classification using supervised learning approach usually formulates the classification problem as a positive and negative class. Many studies used the most common standard classifier for sentiment analysis such as Support Vector Machine (SVM), Naive Bayes, and Maximum entropy. This approach was first applied in Pang et al. [24] to classify movie reviews into two classes (positive/negative). They used Naïve Bayes, SVM classifiers, applied unigram, and bag-of-words as feature for sentiment classification. Later on, many other features and learning algorithms were tested by many scholars in other studies. Some features used by the researchers were sentiment words and phrases, terms and their frequency, POS tag, rules of opinions, sentiment shifters, and syntactic dependency [2, 3]. The approach uses big size previously annotated data. Training and testing data are normally applied for sentiment classification. Recently, deep neural network learning has also been applied to sentiment analysis and achieved promising results [25].
Some studies such as Turney [26] have adopted the unsupervised method. Since sentiment lexicons are often a major factor for sentiment classification, sentiment words and expressions are used for sentiment classification in an unsupervised manner. The study classifies opinions based on fixed syntactic patterns to be used to express opinions [26]. The syntactic patterns are recognized by POS tags. Then, the probability of co-occurrence of syntactic patterns and sentiment lexicons which have clear polarity by PMI measure in training data is computed.
Cambria et al. presented the third category, known as concept-level sentiment analysis [23, 27,28,29]. The concept-level sentiment analysis emphasizes on the semantic analysis of texts with regard to ontology and semantic network, thus providing an opportunity to gather sentimental and conceptual information about different opinions. With an emphasis on a large semantic knowledge base, the approach avoids to count keywords and the number of co-occurrences blindly; however, it relies on the implicit features associated with the linguistic concepts. Unlike purely syntactic methods, the concept-level approach is capable of detecting polarity expressed in a delicate manner. For example, the polarity of a sentence, which is obtained implicitly, can be discovered by concept analysis by linking concepts together. They introduced the CLSA (Concept-Level Sentiment Analysis) framework [30] to support concept-level sentiment analysis. When the concept-level approach is integrated with previous approaches, better results are achieved for sentiment classification [31, 32].
A Review of Sentiment Analysis Methods in Persian Texts
Different languages have been spoken around the world, and each language has own specific characteristics. In general, natural language processing methods, particularly sentiment analysis methods, should consider the characteristics of a language. Keramatfar and Amirkhani [5] mention languages, to which sentiment analysis research mainly contributes. English, Spanish, Turkish, and Chinese are at the top; however, Persian was not included. Persian needs new modified methods because it has specific characteristics and structures. A method for special task of sentiment analysis achieves different results for different languages. The sentiment analysis task was described in the previous section.
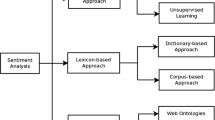
Figure 2 shows the sentiment analysis tasks and their adopted methods. Blue boxes show the tasks (namely, sentiment classification (polarity detection) and the construction of sentiment lexicon resources), on which Persian sentiment analysis studies have been conducted. White boxes refer to tasks for which no relevant article was found after reviewing all articles in Persian texts. Accordingly, future studies of Persian texts should be of concern. These include subjectivity detection, sentiment shifters, and fake review detection. Yellow boxes refer to aspect/feature extraction, and sarcasm detection for which there are only a few studies, as described in “Sentiment Analysis Tasks.” Orange boxes show methods adopted for two fundamental tasks of polarity detection and the construction of sentiment lexicon resources in the English texts, which are almost applied in Persian texts. As presented in Fig. 2, the concept-level sentiment analysis among methods of polarity detection has less been considered (green boxes).

The categories of sentiment analysis tasks and their methods. Blue: Sentiment analysis tasks researched in Persian texts. White: Sentiment analysis tasks with no relevant articles in Persian texts after reviewing various resources. Yellow: Sentiment analysis tasks, for which a few research studies have been found in Persian. Orange: Methods applied for two the tasks of detecting polarity and creating sentiment lexicon in Persian texts. Green: Methods have less been considered in research on Persian texts
In this paper, we investigated two tasks of polarity detection and the construction of sentiment lexicon resource as sentiment analysis studies on Persian texts have been mainly focused on these two main tasks. The rest of the tasks are gaps in the Persian language, implying issues for future research.
Shams et al. [33] performed the first sentiment analysis research on Persian texts in 2012. They created the initial seed of sentiment words, called PersianClues, and used the automatic translation of English sentiment lexicon, called Subjectivity Clues, with help of the English to Persian dictionary. They prepared the initial set for the next steps by eliminating possible errors and modifying the sentiment words. Then the LDA-based sentiment analysis method, called LDASA, was presented. This unsupervised sentiment classification method is performed using the initial seed set based on the concerned topic. It determined polarity based on topic and used LDA method to determine topic by weighting words. To evaluate initial sentiment lexicons, the seeds were set from 80 to 160 with 10 intervals and reached 92% to 100% accuracy. Finally, the SVM algorithm was selected to evaluate the whole model, in which the initial seeds were used as features. Accuracy of about 78% was achieved on average in the three domains of hotel, mobile, and camera.
Bagheri et al. conducted two studies [34, 35] on Persian sentiment analysis. They clarified characteristics of the Persian language, including various suffixes of verbs, various plural suffixes, and informal or colloquial words. Next, Modified Mutual Information (MMI) were proposed as appropriate features in Persian text, which improved Mutual Information (MI) measure. MMI was compared to MI and Term Frequency Variance (TFV), and the findings indicated that MMI as features with Naïve Bayesian classifier were better for Persian texts. Moreover, a dataset of 829 user’s opinions about mobile products was used for the experimental study.
Vaziripour et al. [36] analyzed the trend of sentiment changes for Iran’s nuclear negotiation time. They collected tweets in the political domain during time periods. To identify subtopics, Latent Dirichlet Allocation (LDA) method was applied for four weeks. The study would have some contribution to the field as it was the first study on the Persian language considering the trend of changing sentiment over time and it also performed sentiment analysis dynamically. A total of 274,032 tweets from 17,844 unique users were gathered and annotated. The study reached 70% accuracy by the SVM classifier with Brown cluster as feature.
Amiri et al. [37] used sentiment lexicon-based method for sentiment analysis of Persian texts. They extracted 7179 words, adjective, and expressions from Persian online resources. They included formal, informal, standard, and obsolete words and multi-word expressions, which have an effect on the polarity of texts. The words were annotated via social networks by volunteers having different levels of education, age groups, and sectors corresponding to the Persian society. In some cases, when there was no agreement on the polarity label, either the concerned label is discussed or it is determined manually or is labeled as neutral. Finally, sentiment lexicon resources were used for sentiment analysis process and 69% accuracy rate was obtained.
Alimardani and Aghaie [38, 39] proposed hybrid methods (supervised and lexicon-based) for sentiment classification. The study created sentiment lexicon using SentiWordNet in English and defined relationships in FarsNet (Persian WordNet). Three classifier Naïve Baysian, SVM, and logistic regression were applied for improved features by created resource. Present-Absent, TF, and TF-IDF as features are considered, and each feature is multiplied by sentiment value gained from the created resource. In this regard, sentiment lexicon was used as a weighted factor. Then various experimental studies were performed under different conditions, and 85.5% accuracy by SVM classifier with TF-IDF feature was gained in the best conditions. Furthermore, the study investigated different experiments for the influence of the number of positive/negative samples on the accuracy of the model, explained detail of results.
Sadidpour et al. [40] proposed a linguistic-based model to extract the word adjacency patterns to determine the review polarity. The study gathered data by a crawler from the political news. The 208,000 political news were collected from March 2013 to December 2015 on three news sites. Afterwards, they selected their dataset from gathered data. The dataset included about 14,000 news between 2 and 10 KB. They analyzed political subjects in Persian texts and gained about 90% accuracy for the extracted patterns. The positive of the study was that it was conducted on the data from a political domain.
Asgarian et al. [19] performed a complete study on the Persian language in 2018, which had many advantages than others. They also considered the impact of preprocessing on removing stop words, lemmatizing, converting informal to formal words, and spell checking on sentiment analysis. The experimental results of the study indicated that removing stop words and converting informal to formal words had positive effects on Persian sentiment analysis; however, lemmatizing and spell checking had no remarkable effect on Persian sentiment analysis. Moreover, Persian WordNet, called FerdosNet, was constructed and used for the next steps. They created sentiment lexicon resources based on FerdosNet and produced review dataset by using two methods. The first method, English SentiwordNet, was mapped, and the second method used a semi-supervised learning algorithm based on Hidden Markov Model (HMM). Then they did feature engineering for sentiment classification. To this end, some features, which applied the state-of-the-art sentiment classification methods for the English language, were examined for the Persian language. Comparative features included sentiment lexicon, POS tag, sentiment score of lexicon, numeral vectors in word2Vec, sentiment-specific word embedding, character n-gram, word n-gram, TF-IDF. BayesNet, LibLinear, SMO, KNN, Maximum Entropy, and Random Forest classifiers experimented by the mentioned features, whose experimental results were described. The mentioned study presented a roadmap for classifiers and feature selection for those who need to analyze the sentiment of Persian texts.
Dashtipour et al. [41] presented a hybrid framework for the Persian sentiment analysis. They integrated linguistic rules and deep learning to optimize polarity detection. In their work, some dependency rules were extracted for precise sentiment classification. Moreover, the study uses deep neural network models, including CNN and LSTM to further improve the performance. The presented framework was tested by product and hotel review dataset. The various experimental studies were performed under different conditions, and 86.26% accuracy by dependency-based rules and LSTM classifier was gained in the best conditions.
Ghasemi et al. [21] propose a bilingual deep learning framework to benefit from available training data of English. They deployed bilingual embedding to model sentiment analysis as a transfer learning model which transfers a model from a rich-resource language to low-resource ones. Bilingual sentiment analysis model trains a model on both Persian and English resources and uses it on Persian. The model is evaluated by two datasets from English and Persian which are in the same domain. For English, the electronic product reviews of the Amazon website are used. For Persian, the electronic product reviews of the Digikala website are used. Then various experimental studies were performed under different conditions, and f-measure = 91.82% by LSTM-CNN deep neural network architecture based on VecMap embedding methodology was gained in the best conditions.
Table 1 compares studies on the polarity detection of Persian texts. In this table, the studies are examined in the following terms:
(a) General Polarity Detection Approach: As mentioned in “Sentiment Analysis Approaches,” the general approach includes sentiment lexicon-based approach, supervised and unsupervised machine learning approach, and concept-level approach. We examined to detect which research belongs to which categories. As shown in Table 2, Bagheri et al. and Vaziripour et al. [34,35,36] used supervised learning, Amiri et al. [37] used lexicon-based for sentiment classification, and Alimardani and Aghaie and Dashtipour et al. [38, 39, 41] applied the hybrid approach. Moreover, the unsupervised machine learning approach has not been used for classifying documents or sentences in Persian texts. It is worthy to investigate these approaches and examine the results in future research. In addition, concept-level approach has less been considered in research on Persian texts.
(b) Algorithm: In this column, we explain algorithms used for classification such as Naïve Bayes, maximum entropy, SVM, logistic regression, CNN, and LSTM.
(c) Using Features for Classification: The polarity detection task is often modeled as a classification problem, relying on features extracted from the text to feed a classifier. In this column, we compared features concerned in each research study. Classification methods used various features for classifying, as each feature can achieve different performance expressed by accuracy in Table 2.
Various feature such as bag-of-words, terms and their frequency, present-absent word, POS tag, sentiment shifter, and syntactic dependency or their combination were examined to classify English texts. Some of the most commonly used features in sentiment classification are described below:
-
Term and Frequency: Unigram and n-gram along with the frequency of occurrence are common feature for text classification. In some cases, the position of the word may be considered. Weighted TF-IDF from information retrieval was widely used as well. Similar to traditional text classification, these features are effective for opinion classification.
-
Part-of-Speech (POS) Tag: The POS tag of each word in the sentence can be important too. Words have different POS tags such as noun, adjective, adverb, and verb which have different behaviors. For example, adjectives are significant indicators for detecting opinion; hence, some researchers consider adjectives as special features. Moreover, we can all apply the other POS tags and n-grams as features.
-
Rules of Opinions: Disregard fewer sentiment words and phrases, many other phrases or their combinations are exploited for expressing and implying opinions and sentiment.
-
Sentiment Shifter: Sentiment shifters cause reverse sentiment orientation (positive to negative or vice versa). The main sentiment shifter is negation words. For example, in the sentence “I don’t like this movie” has “like” as a positive word but “don’t” as negation word causes reversing sentiment orientation. In addition, there are some other types of sentiment shifter which do not cause shift sentiment orientation in all occurrences so it should be handled carefully. For example, “not” in “not only … but also” does not reverse sentiment orientation.
-
Syntactic Dependency: This feature based on dependency parsing or dependency tree is produced and researchers tried to examine this feature.
-
Sentiment Lexicon: In many studies, sentiment lexicons with their sentiment value are used as feature.
Saraee and Bagheri [47] investigated and compared appropriate features with Naïve Bayesian classifier in the sentiment classification. Four features of document frequency, term frequency variance, MI, and MMI, were applied for the sentiment classification and comparison. In general, findings indicated that MMI feature reached better f-measure than three other features.
Some studies such as Asgarian et al. [19] performed feature engineering for sentiment classification, to this end, some features which applied for sentiment classification methods of the English language in the state-of-art Persian language. Comparative features included sentiment lexicon, POS tag, sentiment score of lexicon, character n-gram, word n-gram, TF-IDF, numeral vectors in word2Vec, and sentiment-specific word embedding.
Alimardani and Aghaie [38] applied three classifiers (namely, Naïve Baysian, SVM, and logistic regression) to improve features by creating sentiment lexicon resources. Present-Absent, TF, and TF-IDF are considered as features, and each feature was multiplied by sentiment value gained from the created resource. In this regard, sentiment lexicon was used as a weighted factor and an enriching feature.
In general, in the sentiment analysis of each language, feature engineering process often fails to retrieve rich information of relationships and determine polarity that captured from link between concept of text and concepts in the human mind because of feature sparsity and unawareness of the context. Methods using word embedding attempt to eliminate these gaps [48].
(d) Whether the Study Creates Sentiment Lexicon or Not and Use It: Some studies rely on sentiment lexicons or use sentiment lexicons along with machine learning methods. Since sentiment lexicon resources have been constructed lately, their number is limited and have not efficient in specific applications. Accordingly, some studies aimed to create their own resources using the scientific methods. The column refers to this issue. We investigate studies that their contribution is constructing sentiment lexicon and then using it for polarity detection in more detail in “Methods of Constructing Sentiment Lexicon Resources for Persian Text” and Table 4.
(e) Domain: Sentiment analysis performs user opinioned data in various domains. In English analysis methods, some studies proposed it generally; however, some studies focused on the specific domain such as product, political, finance, medical, and social. The studies in Persian texts were done in various domains but not all domains, as shown in Table 2. The most popular domains are as follows:
-
Product Review Domain: The analysis of users’ opinions about products and services is the requirement of an e-commerce website. Business owners plan to improve business by getting customer feedback on products and services. Most published studies in a scientific document related to products and services and the subject such as movies, hotels, restaurants, mobile, laptops, and software are considered.
-
Political Domain: The analysis of users’ opinions is about various political subjects on Twitter and news websites. Since specific political terms and irony sentences are used in the political domain, it has unique requirements.
-
Social Domain: It has a very high diversity in the subject. World studies in social domain have less been published on the Internet, and special organizations and governments activated in this domain for social cognition. Sentiment analysis on the social domain is significant for futurology as it has great potentials to study for future research direction.
-
Medicine Domain: It identifies users’ opinions about medical issues, drugs, and side effects of drugs.
One method may achieve acceptable accuracy in one domain; however, it may not be efficient in another domain, so the domain of data is essential to analyze. Some domains need more resources to support sentiment classification. In this regard, for example, Noferesti and Shamsfard [49, 50] analyzed users’ opinions about the drug in the English texts. They constructed a knowledge base for polar facts for the drug domain by using web resources to support sentiment classification.
Due to the importance of the domain, one of the columns in Table 2 is assigned to the domain [21, 22, 34, 35, 38, 43,44,45,46] focused on the products and services domain, and Vaziripour et al. [36, 40] studied the political domain, and Amiri et al. [37, 51, 52] analyzed data generally. So far, no research has been conducted in social, medical, and finance domains of the Persian language. Hence, researchers can contribute to these domains in future research.
(f) Dataset: Studies evaluate the proposed methods by opinion dataset or corpus. Some cases apply to the gathered and published standard data. In contrast, other cases collected data for their own study. Thus, this column reports data gathering resources, number of records, number of positive/negative data, and the number of training and testing data. It is important to know that the accuracy had been achieved for how much data.
(g) Accuracy: The accuracy of the method was achieved in the studies mentioned in this column. Some studies used accuracy measure, and some others used precision, recall, and f-score measures. Moreover, the methods presented under different conditions (for example, different datasets) reported different accuracy rates for evaluation as such we selected the best accuracy rate and mentioned it in Table 2.
(h) Advantages: This column refers to advantages of mentioned study.
As shown in Table 2, the number of studies on the Persian language is small compared to those in English, and each of them has dealt with different aspects.
Sentiment Analysis Tasks
The key sentiment analysis tasks are as follows [8, 30]:
Subjectivity Detection: In subjectivity detection, opinionated texts are separated from texts containing no opinion. The task is to automatically categorize text into subjective or opinionated (i.e., positive or negative) versus objective or neutral classes.
Sentiment Classification (Polarity Detection): The most basic and well-known task in sentiment analysis is sentiment classification; hence, the terms sentiment classification and sentiment analysis are used interchangeably in many studies. Sentiment classification is to categorize opinions into two classes (positive/negative) or three classes (positive/negative/ neutral) by adopting supervised, unsupervised, or lexicon-based methods.
Construction of Sentiment Lexicon Resource: Another fundamental task of sentiment analysis is constructing resources of sentiment lexicon by a scientific approach. In the past years, many studies focused on producing sentiment lexicon resources. The major role of sentiment lexicon resources is to provide the lexicon-based approach. Moreover, the application of the sentiment lexicon to enhance features in the classification of hybrid approaches is approved.
Aspect/Feature Extraction: Aspect Extraction aims to extract the aspects/features of a product or a service from a text. Aspects are opinion targets, i.e., the specific features of a product or service liked or disliked by users. For example, screen and battery are two features of a mobile phone. We reviewed three Persian studies focusing on this task. Golpar-Rabooki et al. [53] presented a model for aspect extraction based on the iteration of nouns in a text. They improved their work based on the iteration and dual propagation in their second study [54]. In their third study [55], they used syntactic dependency parsing for aspect extraction and achieved results better than those of the two previous methods.
Sarcasm Detection: Sarcasm is a sophisticated form of speech act, by using which speakers or writers say or write the opposite of what they mean. In the sentiment analysis context, this term indicates that when one says something positive, he/she actually means negative, and vice versa. Sarcasm is a complicated form to be dealt with. Sarcastic sentences are more frequent in online discussions and commentaries on politics. Some studies have addressed this issue in English, but only one research has recently been done in Persian. Golazizian et al. [56] presented first model and first dataset for sarcasm detection. To this end, first, a neural network model pre-trained on a large unlabeled dataset containing Persian tweets with emoji occurrences to predict emojis. Then, it was fine-tuned on a manually labeled irony dataset to detect sarcasm. A BiLSTM network is employed as the basis of model which is improved by attention mechanism. Additionally, a Persian dataset for irony detection, called MirasIrony, containing 4339 manually-labeled tweets is constructed.
Sentiment Shifter Management: In sentiment analysis, negation plays a key role in polarity detection and can shift the sentiment value. It may turn a positive polarity into a negative one and vice versa. Accordingly, it is necessary to recognize and apply negation in any sentiment analysis system. The important shifters are negation clues such as “بی”, “نا”, and “ضد” in a sentence even though they are not sufficient. Negation handling needs deep semantic understanding of the text and is complicated [57].
Methods of Constructing Sentiment Lexicon Resources for Persian Text
One of the tasks in sentiment is constructing sentiment lexicon. Sentiment lexicon with sentiment value support lexicon-based and hybrid methods in each language. Hybrid methods apply sentiment lexicon in reinforcing features in sentiment classification. To this end, they created sentiment lexicon resources such as SentiWordNet, General Inquier, MPQA, SenticNet, and Vader in the English language. It is paramount important to create such resources in other languages and use the benefit of them. In this section, we investigate and compare studies, of which their contribution is to construct sentiment lexicon for the Persian language.
Dehdarbehbahani et al. [51] detected polarity value by constructing a multilingual semantic network from external resource WordNet. Semantic network interconnected Persian graph to English graph and utilized random walk algorithm for determining the polarity of Persian words. They reached MAP (mean average precision) = 0.658 and accuracy = 0.914 in their evaluation results.
Najafzadeh et al. [52] presented a self-training method as a semi-supervised approach for Persian sentiment analysis. This study was the first research on the Persian language using a semi-supervised approach. The method determines sentiment label by self-constructed lexicon (dynamic and without human expert); therefore, it extracts sentiment attributes automatically. Furthermore, Hidden Markov Model classifier of attributes with rule-based usage was employed for the sentiment analysis process. The advantage of this study are (1) extracting sentiment attributes automatically instead of human expert, (2) using some colloquial n-grams as a heuristic approach for the Persian language to cover unexplored Persian language challenges, and (3) using ordered pairs (POS tag, polarity tag) as states of Hidden Markov model to increase the accuracy of Persian sentiment analysis.
Asgarian et al. [58] constructed Persian sentiment lexicon called HesNegar by using FerdosNet lexicon network and mapping English sentiment lexicon (SentiWordNet). To construct HesNegar, the first constructed FerdosNet by mapping Princeton WordNet and English-Persian dictionary; then, they mapped sentiment score in English sentiment lexicon to corresponding semantic group of HesNegar. Persian sentiment lexicons were categorized four parts adjective, noun, verb, and adverbial. They reported precision = 89% for produced sentiment lexicon. Moreover, a dataset with 3080 user’s opinions is annotated by referees and utilized for evaluation.
Dehkharghani [20] proposed a Persian sentiment lexicon called Sentifars by translation method in 2019. He extracted sentiment lexicon from four English sentiment lexicon resources and their translation. Next, sentiment lexicon annotated manually to prepare data for supervised learning logistic regression method. The logistic regression classifier learned the polarity of the Persian lexicon from the polarity score of equivalent in English sentiment lexicon resource. In this case, the polarity of the equivalent lexicon in the English language was determined as a feature in classification. Accuracy = 95.92% is best condition as such four resources and their polarities were considered. Created resource is produced publicly and domain-independent.
Sabeti et al. [59] proposed LexiPers sentiment lexicon by semi-supervised with FarsNet ontology, selected seed set, and labeled by human expert. Then they extended the seed set by using a semi-supervised method and the PMI algorithm.
In general, sentiment lexicon construction methods are divided into three broad categories: (1) Manual method, (2) Dictionary-based method, and (3) Corpus-based method. These three categories and their advantages and disadvantages are discussed in Table 3.
(1) Manual Method: In this method, human experts were asked to label the sentiment value of lexicons and use a majority vote if the expert did not agree with polarity, the majority votes are accepted. The Kappa criterion is used to evaluate confidence value.
The advantage of manual methods compared to the other two methods is high accuracy. Labeling with manual methods is hard and time-consuming and has many costs, which are its disadvantages [64]. Only a certain amount of data can be labeled in a given period of time. In some Persian studies (e.g. [61] and [37]), words have been labeled manually.
(2) Dictionary-Based Method: The second category is methods labeling sentiment lexicon based on dictionaries such as WordNet and English-Persian dictionaries. This method has two advantages. First, English-Persian dictionaries are available. Second, English sentiment lexicon resources which previously prepared labels of polarity are used easily. Further, this method has three disadvantages. The first one is that the context of the lexicon is not considered. Second, public dictionaries have not aware of domain-specific information and appropriate domain-specific sentiment lexicon. Therefore, dictionary-based methods do not notice the context and domain. Third, dictionary-based methods use semantic relations such as synonym and antonym; however, the relations of dictionaries do not update regularly. The previous studies [19, 20, 33, 38, 39, 51, 55, 58] for Persian texts are included in this category.
(3) Corpus-Based Method: This method extracts sentiment lexicon from a corpus of users’ opinions using an unsupervised and supervised manner. The corpus-based method has less accurate than a manual method; however, cost and time of the corpus-based method were affordable.
Advantage of corpus-based method is that it facilitates construct the domain-specific sentiment lexicon more effectively. Because the data of corpus usually belong to a specific domain, constructing domain-specific sentiment lexicon is successful. This method has two disadvantage: First, the extracted sentiment lexicons depend only on the corpus data and the lexicon occurrence in the corpus. Second, it is difficult to preparing corpus which covers whole sentiment lexicon well. Najafzadeh et al. [52] presented a corpus-based method for constructing sentiment lexicon in Persian texts.
Some studies use mixed methods to take advantages of both categories. For example, a small set of sentiment lexicons as seed set is first labeled manually, and then the remained lexicons are labeled based on dataset in a supervised or unsupervised manner. Akhoundzade and Devin [62] extracted new sentiment lexicon by cosine similarity (by Word2Vec) and the minimum edit distance from unlabeled data in unsupervised manner.
Since online reviews have rating scores assigned by their reviewers (e.g., 1–5 stars), the positive and negative classes are determined. Moradi et al. [63] used ratting score as measure to determine positive and negative class. This solution achieves acceptable results in the document-level sentiment analysis, while errors in some cases occur in the sentence level sentiment analysis. This is because reviewers usually express both advantages and disadvantages of the sentences so that positive and negative sentences are written together, and no overall rating score can be assigned to each sentence as a sentiment value.
In Table 4, we investigate and compare studies which contributed to the creation of sentiment lexicon for the Persian language, and then apply them for polarity detection. The columns of Table 4 are as follows:
(1) General Method: The general method of sentiment lexicon resource construction, described in the previous section, is mentioned in this column.
(2) Partial Method of Sentiment Lexicon Resource Construction: The details of construction method are described in this column.
(3) Domain: The domain of the evaluation or the scope of constructed sentiment lexicon is discussed in studies or some cases domain of evaluation data. As described in “A Review of Sentiment Analysis Methods in Persian Texts,” data can belong to different domain such as political, medical, social, products, and services. As shown in Table 4, most studies [19, 20, 37,38,39, 51, 52, 58,59,60] in the Persian language present sentiment lexicon publicly.
(4) Dataset: The column refers to a dataset or corpus used to extract sentiment lexicon. In some cases, the column refers to the dataset used to evaluate the proposed method.
(5) Accuracy of Generated Sentiment Lexicons: The column refers to the accuracy of generated sentiment lexicons, in which the study was revealed. Some studies reported accuracy measures, and others used precision, recall, and f-score measures used for evaluation. Moreover, whenever presented methods in some studies report different accuracies under different conditions (for example, different datasets) to evaluate, we selected the best accuracy from all values and reported in Table 4.
(6) Advantage: The column describes the advantage of the proposed method in the study.
(7) Accuracy After Using Sentiment Lexicons in Classification Algorithm: After genesis generated by sentiment lexicons, many studies use them in supervised and unsupervised machine learning algorithms. The column refers to accuracy rate after use.
Accessible and Standard Dataset in the Persian Language
Sentiment Lexicon Resource
There are some sentiment lexicon resources such as SentiwordNet [65], MPQA [66], General Inquirer [67], SenticNet [27], and VADER [68] to sentiment analysis in the English language. Creating and using sentiment lexicons has many benefits in other languages. Few resources have been created for the Persian language, which are described next. Published and accessible resources with their properties are shown in Table 5. The columns are described as follows:
(a) Name: Name of corpus or dataset which is renowned.
(b) Lexicon/sentence/document/fact: The column identifies that dataset consists of a lexicon, sentence, document, or fact with polarity value.
(c) Number: This column reports the number of words, number of sentences, and number of documents.
(d) Domain: This column reported the domain of sentiment lexicon or dataset which is constructed based on. As described in “A Review of Sentiment Analysis Methods in Persian Texts,” resources can belong to different domains such as political, medical, social, and products and services. Moreover, some resources constructed for a specific domain are not efficient for other domains. For example, the resource produced in the domain of laptop products does not have the efficiency in medical domain. In addition, the resource of sentiment word is usually dependent on the domain [69, 70] and the polarity of words in one domain is sometimes opposite to the other domain.
(e) Publisher: This column refers to the institution, laboratory, or authors which published the dataset.
LexiPers
LexiPers Sentiment Lexicon [59] consists of a subset of FarsNet version 2 lexicons which annotated automatically by positive/negative/neutral labels. In this project, the synonymous set of an adjective, number of 4261 synsets, are annotated manually by a human expert as a seed set. The seed set as a gold standard is also used to develop and test the word labeling system and classify documents. The dictionary was produced by the Natural Language Processing and Intelligent Planning Laboratory of Sharif University, and Guilan NLP Group.
Persian Lexicons with Polarity Label
Persian lexicons with polarity label [51] which constructed by the lab of Intelligent Information Systems at the University of Tehran, consist of two datasets: (1) A set extracted from annotated Persian adjective: This is constructed by the Persian adjectives of FarsNet. Each entry is specified as positive/negative/neutral. In this regard, more than 3588 adjectives are extracted and evaluated by four referees. (2) A set of adjectives, verbs, and nouns are extracted from FarsNet. Each word in the set assigns sentiment value by the semi-supervised machine learning method. The value smaller than zero is assigned to a negative word, and the value > 0 assigned to positive words. In the neutral words do not determine explicitly, and neutral words can be determined by a threshold between positive and negative words. The set consists of 3588 adjectives, 4073 verbs, and 7325 nouns, and all words are extracted version 1 of FarsNet.
PreSent
Persian Sentiment Analysis and Opinion Mining Lexicon (PreSent) presents real-valued polarity labels, in the range from −1 to 1, for thousands of Persian words and expressions [60, 71]. PerSent 1.0 is the first version of the lexicon including about 1500 Persian words. PerSent 2.0 is the second version of the lexicon, which includes about 1500 Persian words from the first version plus 700 idiomatic words and expressions. The idiom list has been shown particularly useful for analyzing highly informal texts such as user-contributed contents, e.g., movie reviews or product reviews.
Datasets of User Opinions
The datasets or corpora of user opinions are other resources which prepared for sentiment analysis. They consist of sentences or documents with positive/negative polarity. In the Persian language, SentiPers and HelloKish datasets were published, the most important are described in the next section.
SentiPers
SentiPers [61] consist of Persian sentences with sentiment value used for sentiment analysis. Regarding their features, it is the first dataset for Persian sentiment analysis. The domain of sentences is digital products. Moreover, the sentences of the dataset are formal, informal, or colloquial sentences, and the dataset contains 1100 annotated sentences. It produced by Guilan NLP Group.
HelloKish Sentiment Dataset
HelloKish sentiment dataset [63] annotated by the author’s sense and perspective. Dataset gathered from user comments on HelloKish website. When the study was doing, the number of the second registered comments on the website is 3312, and users entered to specify the rate of customer satisfaction in 642 items by website options. Comments are divided into two categories: opinions whose percentage of satisfaction is ≤ 30% as negative, and opinions whose percentage of satisfaction is ≥ 70% as positive. Accordingly, 102 opinions were placed in a negative category, and 447 opinions were placed in a positive category. The mean of number of words in each opinion is 109 words.
MirasOpinion
MirasOpinion dataset [46] is crawled from the Digikala website, one of the largest e-commerce websites in Iran. A total of 2.5 million comments have been crawled, and after some pre-processing, they reduce its size to one million comments. Then the corpus had been labeled using crowd-sourcing; a telegram bot is used to send the unlabeled data to several users. The bot asks them to label the represented document as positive, negative, or neutral. The dataset contains 93,868 annotated documents (positive comments = 49,515/negative comments = 14,882/neutral comments 29,471). It produced by Miras-tech group.
Results of the Review of Published Dataset
With the advent of machine learning models in sentiment analysis tasks, having a large amount of training data plays an essential role in achieving accurate models. Creating valid training data, however, is a challenging issue in Persian language. As shown in Table 5, from the six published datasets, three datasets labeled lexicon, two datasets labeled the document, and one other dataset labeled the sentence. Accordingly, we need to construct more Persian datasets, especially at sentence and document levels. Furthermore, we require training data for different domains such as political, social, medical, and drug.
In the lexicon-based approach, the resource covering the lexicons of text and is comprehensive more reaching a better accuracy. Thus, number of sentiment lexicons is important, and comprehensive resources have high performance. Furthermore, the resources are constructed publicly; however, we need to resource with domain-dependent polarity in many applications.
Remaining Challenges and Future Developments
The Persian sentiment tasks have witnessed a great progress in recent years. However, they suffer from some shortcomings, which make them far from the real polarity detection. In this section, we describe issues and gaps, and subjects should be noticed in the Persian language regarding the review of all studies in Persian sentiment analysis and also state-of-art results in the English language. The extracted main points are as follows, which can be the start point for future research on Persian sentiment analysis:
(1) Sentiment Shifter: As mentioned in “Sentiment Analysis Tasks,” shifters cause changing sentiment orientation of sentences. However, negation clues such as “بی” and”عدم” are important shifters; they are not sufficient and shifter management is complicated. One of the challenges in sentiment analysis is shifter management, which was investigated in the English language. Shifter management in the Persian language is less considered and needs to be investigated.
(2) Improve the Performance of Tokenization: More powerful preprocessing tools are available in the Persian language, which promote the accuracy of the sentiment analysis methods. Tokenizer has a profound effect on the sentiment analysis. The tokenizer with acceptable accuracy facilitates the preprocessing of sentiment analysis, especially word embedding for deep neural network methods. Thus, it is suggested to study methods and implementations in the Persian language to reach an acceptable accuracy for the tokenizer.
(3) Lack of Tools: Diverse tools, applications, and packages for English language are produced by developers and published on the Internet. They are constructed based on existing various methods. The Persian language suffers from a lack of tools, applications, and packages. The availability of implementations facilitates develops sentiment analysis research in the Persian language. It is suggested to implement tools by scientific methods in Persian language. Furthermore, some research labs develop tools for the advancement of self-works; however, they do not tend to publish them on the Internet and publicly available because of different reasons. This subject performs parallel works and leads to the decreased growth of Persian sentiment analysis.
(4) Concept Parsing: Concept-level sentiment analysis approach considers concepts and implicit semantics of texts. It focuses on the analysis of a text by ontology and semantic networks, which allow the aggregation of effective and conceptual information. Studies on the Persian language less use the approach; therefore, we recommend using the concept-level approach for Persian texts. While concept parser with acceptable accuracy is essential for the concept-level sentiment analysis, we need to study concept parsing methods for Persian text in future works.
(5) Implicit Opinion: Opinion texts are classified into two categories: explicit and implicit opinion. The explicit opinion uses a sentiment lexicon clearly; however, the implicit opinion does not use a sentiment lexicon in text. The implicit opinion is an objective sentence indicating the opinion [2]. For example, the sentence “The device does not antenna” does not contain sentiment lexicon; however, it expresses fact which is negative. The studies on explicit opinion on English text are remarkable and they reach acceptable accuracy. On the other hand, few studies focus on analyzing implicit opinion. The second category presents specific methods [17, 72]; however, it is far away from a comprehensive solution. Many user’s opinions submitted on the website are implicit; however, they are removed from standard datasets, thereby better to include them in sentiment analysis research. To this end, we suggest investigating implicit opinions for the Persian language in future research.
(6) Extending Methods that Require Less Labeled Data: Since the Persian language has the constraint of the standard dataset, we suggest paying more attention to methods that require fewer data such as transfer learning, domain adaption model, unsupervised, and semi-supervised methods. Unsupervised methods do not require large numbers of data with sentiment label, and semi-supervised methods require less data with sentiment label.
(7) Context Sensitive Sentiment Lexicon: Since the polarity of sentiment lexicon is not static and depends on the context, many articles examine this subject in English text [73, 74]. As one of the shortcomings, the issue has not been less addressed in studies on the Persian language. It is suggested to regard context-based sentiment analysis in Persian texts in future research.
(8) Sentiment Knowledge Base: Creating a knowledge base with the sentiment value facilitates the sentiment analysis system, creating domain-specific knowledge. For example, polarized facts in drug domain have a significant impact on the accuracy of the analysis results. Noferesti et al. [49] examined the effect of polarized facts on the analysis of users' opinions about drugs in English. Future researchers are suggested to create a knowledge base of polarized facts to deal with the sentiment analysis of Persian texts.
(9) Low-Resource: Sentiment lexicon resources and standard annotated dataset for Persian sentiment analysis have constraints. There is no appropriate resource for various domains yet. As shown in Table 5, the existing resources have been mainly created for public and commercial domains, and political, social, and financial domains have been less considered. Moreover, the created resources have low number of data and have no performance in many applications such as deep learning. To this end, we need to construct sentiment lexicons resources and well-defined dataset in various domains in the Persian language.
(10) Domain-Specific Sentiment Analysis Methods: Public sentiment analysis methods are not efficient for some domains. Accordingly, we require customized methods for different domains such as political, social, medical, and drug. To this end, in addition to domain-specific resources such as annotated datasets and knowledge base, we also need to present domain-specific methods for the Persian language in future works.
(11) Deep Neural Network Learning Solution: Deep neural network learning methods have achieved acceptable results in English [75, 76]. Some studies [21, 22, 41, 42, 44,45,46] have recently applied deep learning models to solve Persian challenges, but it has great potential to study for future research direction. According to the diverse challenges of Persian language, it is possible to apply the learning methods of deep neural networks for Persian sentiment analysis and take advantage from their findings.
(12) Multimodal Sentiment Analysis: In recent years, the sentiment analysis of textual data has highly contributed to the sentiment analysis research. The sentiment analysis of audio and visual data has recently attracted the attention of the scientific community. Sentiment analysis of audio is ignored in research on Persian texts. The analysis of Persian audio data is different from the English ones and requires further studies in the future.
Today, we are seeing a shift toward an increasingly multimodal social web. Multimodal sentiment analysis is a new dimension of the traditional text-based sentiment analysis, which goes beyond the analysis of texts, and includes other modalities such as audio and visual data. For example, vloggers post their opinions on YouTube, and photos commonly accompany user posts on Instagram and Twitter. Multimodal sentiment analysis is still in its infancy in all language and more research and industry investment is needed to demonstrate its full potential. Dashtipour et al. [77] presented a context-aware multimodal sentiment analysis framework for Persian, that simultaneously exploits acoustic, visual, and textual cues to more accurately determine the expressed sentiment. Their work is first study on multimodal Persian sentiment analysis, and this field has great potentials to study for future research direction.
Some challenges such as feature extraction, sarcasm detection, fake review by opinion text, and polarity detection of implicit opinion are less studied in Persian text. In this regard, future studies should investigate them. Furthermore, many challenges have remained for sentiment analysis in the English language. Some studies performed to resolve these challenges. In this regard, the Persian language deserves to be similar to English language to reach such results.
Conclusion
Sentiment analysis, as a hot research topic–related NLP, social network analysis, and computational cognitive science domains, focuses on user opinion about entities. The ideal goal of a sentiment analysis system is to gain an understanding of text to be able to determine polarity of text. In this paper, studies on sentiment analysis and opinion mining in Persian language are reviewed. We presented an overview of different aspects of recent Persian sentiment analysis studies, including approaches, methods, tasks, levels, datasets, research contributions, and evaluations. We reviewed 35 Persian sentiment papers from 2012 to 2021 to investigate recent studies and find new trends according to the state-of-the-art development of sentiment analysis. To this end, some methods adopted in main studies on English texts are examined. Existing methods in English language can be generalized to the Persian language; however, they need to be studies delicately and practically with regard to the characteristics of the Persian language, differences of between languages, and preprocessing facilities. In addition, qualified resources such as sentiment lexicon resource, a knowledge base with polarity, dataset with polarity labels in various domains play a significant role in Persian sentiment analysis and should be equipped with scientific approaches.
Finally, we mentioned the future trends and important challenges of available methods including the issues related to sentiment shifter, lack of tools, concept parsing, implicit opinion, context sensitive sentiment lexicon, sentiment knowledge base, low-resource, domain-specific sentiment analysis methods, multimodal sentiment analysis, and deep neural network learning solution improve the performance of tokenization, extending methods that require less labeled data.
References
Cambria E, Poria S, Hussain A, Liu B. Computational intelligence for affective computing and sentiment analysis [Guest Editorial]. IEEE Comput Intell Mag. 2019;14(2):16–7.
Liu B. Sentiment analysis and opinion mining. Synthesis lectures on human language technologies. 2012;5(1):1–167.
Liu B. Sentiment analysis and subjectivity. Handbook of natural language processing. 2010;2:627–66.
Piryani R, Madhavi D, Singh VK. Analytical mapping of opinion mining and sentiment analysis research during 2000–2015. Inf Process Manag. 2017;53(1):122–50.
Keramatfar A, Amirkhani H. Bibliometrics of sentiment analysis literature. J Inf Sci. 2019;45(1):3–15.
Jebaseeli AN, Kirubakaran E. A survey on sentiment analysis of (product) reviews. Int J Comput Appl. 2012;47(11).
Medhat W, Hassan A, Korashy H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng J. 2014;5(4):1093–113.
Ravi K, Ravi V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl-Based Syst. 2015;89:14–46.
Hussein DMEDM. A survey on sentiment analysis challenges. J King Saud Univ Eng Sci. 2018;30(4):330–338.
Montoyo A, MartíNez-Barco P, Balahur A. Subjectivity and sentiment analysis: An overview of the current state of the area and envisaged developments. Decis Support Syst. 2012;53(4):675–9.
Boudad N, Faizi R, Thami ROH, Chiheb R. Sentiment analysis in Arabic: A review of the literature. Ain Shams Eng J. 2017;2479–2490.
Badaro G, Baly R, Hajj H, El-Hajj W, Shaban KB, Habash N, Al-Sallab A, Hamdi A. A survey of opinion mining in Arabic: a comprehensive system perspective covering challenges and advances in tools, resources, models, applications, and visualizations. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP). 2019;18(3):1–52.
Dashtipour K, Poria S, Hussain A, Cambria E, Hawalah AY, Gelbukh A, Zhou Q. Multilingual sentiment analysis: state of the art and independent comparison of techniques. Cogn Comput. 2016;8(4):757–71.
Lo SL, Cambria E, Chiong R, Cornforth D. Multilingual sentiment analysis: from formal to informal and scarce resource languages. Artif Intell Rev. 2017;48(4):499–527.
Can EF, Ezen-Can A, Can F. Multilingual sentiment analysis: an RNN-based framework for limited data. arXiv preprint arXiv:1806.04511. 2018.
Speer R, Chin J, Havasi C. Conceptnet 5.5: An open multilingual graph of general knowledge. In Thirty-First AAAI Conference on Artificial Intelligence. 2017.
Balahur A, Hermida JM, Montoyo A. Detecting implicit expressions of sentiment in text based on commonsense knowledge. In Proceedings of the 2nd workshop on computational approaches to subjectivity and sentiment analysis. Association for Computational Linguistics. 2011.
Basiri ME, Naghsh-Nilchi AR, Ghassem-Aghaee N. A framework for sentiment analysis in persian. Open Transactions on Information Processing. 2014;1(3):1–14.
Asgarian E, Kahani M, Sharifi S. The impact of sentiment features on the sentiment polarity classification in Persian reviews. Cogn Comput. 2018;10(1):117–35.
Dehkharghani R. SentiFars: a Persian polarity lexicon for sentiment analysis. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP). 2019;19(2):21.
Ghasemi R, Ashrafi Asli SA, Momtazi S. Deep Persian sentiment analysis: cross-lingual training for low-resource languages. J Inf Sci. 2020;0165551520962781.
Dastgheib MB, Koleini S, Rasti F. The application of deep learning in Persian documents sentiment analysis. International Journal of Information Science and Management (IJISM). 2020;18(1):1–15.
Cambria, E. An introduction to concept-level sentiment analysis. In Mexican International Conference on Artificial Intelligence. Springer. 2013.
Pang B, Lee L, Vaithyanathan S. Thumbs up?: sentiment classification using machine learning techniques. In Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10. Association for Computational Linguistics. 2002.
Fu X, Yang J, Li J, Fang M, Wang H. Lexicon-enhanced LSTM with attention for general sentiment analysis. IEEE Access. 2018;6:71884–91.
Turney PD. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews. In Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics. 2002.
Poria S, Cambria E, Winterstein G, Huang G-B. Sentic patterns: dependency-based rules for concept-level sentiment analysis. Knowl-Based Syst. 2014;69:45–63.
Cambria E, Hussain A. Sentic computing: a common-sense-based framework for concept-level sentiment analysis. Springer. 2015;1.
Cambria E, Schuller B, Xia Y, Havasi C. New avenues in opinion mining and sentiment analysis. IEEE Intell Syst. 2013;28(2):15–21.
Cambria E, Poria S, Bisio F, Bajpai R, Chaturvedi I. The CLSA model: a novel framework for concept-level sentiment analysis. In International Conference on Intelligent Text Processing and Computational Linguistics. Springer. 2015.
Rajabi Z, Hourali M, Valavi M. A context-based model for disambiguating the sentiment concepts using the common-sense knowledge. C4I Journal. 2018;2(2):32–47.
Rajabi Z, Valavi MR, Hourali M. A context-based disambiguation model for sentiment concepts using a bag-of-concepts approach. Cogn Comput. 2020;12(6):1299–312.
Shams M, Shakery A, Faili H. A non-parametric LDA-based induction method for sentiment analysis. In The 16th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP 2012). IEEE. 2012.
Bagheri A, Saraee M, de Jong F. Sentiment classification in Persian: introducing a mutual information-based method for feature selection. In 2013 21st Iranian Conference on Electrical Engineering (ICEE). IEEE. 2013.
Bagheri A, Saraee M. Persian sentiment analyzer: a framework based on a novel feature selection method. International Journal of Artificial Intelligence. 2014;12(2):115–29.
Vaziripour E, Giraud-Carrier C, Zappala D. Analyzing the political sentiment of Tweets in Farsi. In Tenth International AAAI Conference on Web and Social Media. 2016.
Amiri F, Scerri S, Khodashahi M. Lexicon-based sentiment analysis for Persian text. In Proceedings of the International Conference Recent Advances in Natural Language Processing. 2015.
Alimardani S, Aghaie A. Opinion mining in Persian language using supervised algorithms. J Inf Syst Telecommun (JIST). 2015;135–141.
Alimardani S, Aghaie A. Opinion mining in Persian language using supervised algorithms and sentiment lexicon. Int J Inf Technol Manag. 2015;7:345–62.
Sadidpour S, Shirazi H, Sharef NM, Minaei-Bidgoli B, Sanjaghi ME. Context-sensitive opinion mining using polarity patterns. Int J Adv Comput Sci Appl (IJACSA). 2016;7:145–50.
Dashtipour K, Gogate M, Li J, Jiang F, Kong B, Hussain A. A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing. 2020;380:1–10.
Dashtipour K, Gogate M, Adeel A, Ieracitano C, Larijani H, Hussain A. Exploiting deep learning for persian sentiment analysis. In International Conference on Brain Inspired Cognitive Systems. Springer. 2018.
Bagheri A. Integrating word status for joint detection of sentiment and aspect in reviews. J Inf Sci. 2019;45(6):736–55.
Roshanfekr B, Khadivi S, Rahmati M. Sentiment analysis using deep learning on Persian texts. In 2017 Iranian Conference on Electrical Engineering (ICEE). IEEE. 2017.
Zobeidi S, Naderan M, Alavi SE. Opinion mining in Persian language using a hybrid feature extraction approach based on convolutional neural network. Multimed Tools Appl. 2019;78(22):32357–78.
Ashrafi Asli SA, Sabeti B, Majdabadi Z, Golazizian P, Momenzadeh O. Optimizing annotation effort using active learning strategies: a sentiment analysis case study in persian. In Proceedings of The 12th Language Resources and Evaluation Conference. 2020.
Saraee M, Bagheri A. Feature selection methods in Persian sentiment analysis. in International Conference on Application of Natural Language to Information Systems. Springer. 2013.
Li Y, Guo H, Zhang Q, Gu M, Yang J. Imbalanced text sentiment classification using universal and domain-specific knowledge. Knowl-Based Syst. 2018;160:1–15.
Noferesti S, Shamsfard M. Using linked data for polarity classification of patients’ experiences. J Biomed Inform. 2015;57:6–19.
Noferesti S, Shamsfard M. Resource construction and evaluation for indirect opinion mining of drug reviews. PLoS One. 2015;10(5):e0124993.
Dehdarbehbahani I, Shakery A, Faili H. Semi-supervised word polarity identification in resource-lean languages. Neural Netw. 2014;58:50–9.
Najafzadeh M, Rahati Quchan S, Ghaemi R. A semi-supervised framework based on self-constructed adaptive lexicon for Persian sentiment analysis. Signal and Data Processing. 2018;15(2):89–102.
Golpar-Rabooki E, Zarghamifar S, Rezaeenour J. Feature extraction in opinion mining for Persian text. In 2nd National Conference on Computer Science. 2013.
Golpar-Rabooki E, Zarghamifar S, Rezaeenour J. Feature extraction and vocabulary expansion in opinion mining for Persian text. In 2nd National Conference on Applied Research in Computer Science and Information Technology. 2015.
Golpar-Rabooki E, Zarghamifar S, Rezaeenour J. Feature extraction in opinion mining through Persian reviews. Journal of AI and Data Mining. 2015;3(2):169–79.
Golazizian P, Sabeti B, Asli SAA, Majdabadi Z, Momenzadeh O. Irony detection in Persian language: a transfer learning approach using emoji prediction. In Proceedings of The 12th Language Resources and Evaluation Conference. 2020.
Zirpe S, Joglekar B. Polarity shift detection approaches in sentiment analysis: a survey. in 2017 International Conference on Inventive Systems and Control (ICISC). IEEE. 2017.
Asgarian E, Kahani M, Sharifi S. HesNegar: Persian sentiment WordNet. Signal and Data Processing. 2018;15(1):71–86.
Sabeti B, Hosseini P, Ghassem-Sani G, Mirroshandel SA. LexiPers: an ontology based sentiment lexicon for Persian. In GCAI. 2016.
Dashtipour K, Hussain A, Zhou Q, Gelbukh A, Hawalah AY, Cambria E. PerSent: a freely available Persian sentiment lexicon. In International Conference on Brain Inspired Cognitive Systems. Springer. 2016.
Hosseini P, Ramaki AA, Maleki H, Anvari M, Mirroshandel SA. SentiPers: a sentiment analysis corpus for Persian. arXiv preprint arXiv:1801.07737. 2018.
Akhoundzade R, Devin KH. Persian sentiment lexicon expansion using unsupervised learning methods. In 2019 9th International Conference on Computer and Knowledge Engineering (ICCKE). IEEE. 2019.
Moradi M, Parvane K, Bahram V. Constructing tagged corpora with a web approach as a corpus. In 2th symposium on computational Linguistics. 2012.
Deng S, Sinha AP, Zhao H. Adapting sentiment lexicons to domain-specific social media texts. Decis Support Syst. 2017;94:65–76.
Esuli A, Sebastiani F. Sentiwordnet: a publicly available lexical resource for opinion mining. in Proceedings of LREC. Citeseer. 2006.
Wilson T, Wiebe J, Hoffmann P. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing. 2005.
Stone PJ, Dunphy DC, Smith MS. The general inquirer: a computer approach to content analysis. 1966.
Gilbert CHE. Vader: a parsimonious rule-based model for sentiment analysis of social media text. In Eighth International Conference on Weblogs and Social Media (ICWSM-14). Available at (20/04/16) http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf. 2014.
Tan S, Wu Q. A random walk algorithm for automatic construction of domain-oriented sentiment lexicon. Expert Syst Appl. 2011;38(10):12094–100.
Huang S, Niu Z, Shi C. Automatic construction of domain-specific sentiment lexicon based on constrained label propagation. Knowl-Based Syst. 2014;56:191–200.
Dashtipour K, Raza A, Gelbukh A, Zhang R, Cambria E, Hussain A. PerSent 2.0: Persian sentiment lexicon enriched with domain-specific words. In International Conference on Brain Inspired Cognitive Systems. Springer. 2019.
Liao J, Wang S, Li D. Identification of fact-implied implicit sentiment based on multi-level semantic fused representation. Knowl-Based Syst. 2019;165:197–207.
Hung C. Word of mouth quality classification based on contextual sentiment lexicons. Inf Process Manag. 2017;53(4):751–63.
Saif H, He Y, Fernandez M, Alani H. Contextual semantics for sentiment analysis of Twitter. Inf Process Manag. 2016;52(1):5–19.
Zhang L, Wang S, Liu B. Deep learning for sentiment analysis: a survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery. 2018;8(4):e1253.
Young T, Hazarika D, Poria S, Cambria E. Recent trends in deep learning based natural language processing. IEEE Comput Intell Mag. 2018;13(3):55–75.
Dashtipour K, Gogate M, Cambria E, Hussain A. A novel context-aware multimodal framework for Persian sentiment analysis. arXiv preprint arXiv:2103.02636. 2021.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Informed Consent
Informed consent was not required as no human or animals were involved.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by any of the authors.
Conflict of Interest
The authors declare no competing interests.
Rights and permissions
About this article

Cite this article
Rajabi, Z., Valavi, M. A Survey on Sentiment Analysis in Persian: a Comprehensive System Perspective Covering Challenges and Advances in Resources and Methods. Cogn Comput 13, 882–902 (2021). https://doi.org/10.1007/s12559-021-09886-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-021-09886-x