
Abstract
Purpose
For radiologists, identifying and assessing thelung nodules of cancerous form from CT scans is a difficult and laborious task. As a result, early lung growing prediction is required for the investigation technique, and hence it increases the chances of a successful treatment. To ease this problem, computer-aided diagnostic (CAD) solutions have been deployed. The main purpose of the work is to detect the nodules are malignant or not and to provide the results with better accuracy.
Methods
A neural network model that incorporates a feedback loop is the recurrent neural network. Evolutionary algorithms such as the Grey Wolf Optimization Algorithm and Recurrent Neural Network (RNN) Techniques are investigated utilising the Matlab Tool in this work. Statistical attributes are also produced and compared with other RNN with Genetic Algorithm (GA) and Particle Swarm Optimization (PSO)combinations for study.
Results
The proposed method produced very high accuracy, sensitivity, specificity, and precision and compared with other state of art methods. Because of its simplicity and possible global search capabilities, evolutionary algorithms have shown tremendous promise in the area of feature selection in the latest years.
Conclusion
The proposed techniques have demonstrated outstanding outcomes in various disciplines, outperforming classical methods. Early detection of lung nodules will aid in determining whether the nodules will become malignant or not.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The health industry is divided into distinct sectors. It is a high-priority industry, and people want the best possible care and services, regardless of cost. Even though it occupies a big percentage of the budget, it was not a socially effective expectation. A medical specialist usually reviews the patient's results. Due to subjectivity, visual complexity, and huge variances between Tiredness and many interpreters, human professional interpretation of images is fairly limited. Since comprehensive learning has been successful in another real-world application, it now offers intriguing medical imaging solutions and is regarded a crucial System for future health-related applications.
Aninterruption in initialanalysis and a deprivedprediction are the two chief reasonsfor a high lung cancer death rate [1]. Less developed nations accounted for approximately 58 percent of all lung cancer cases [2, 3]. The Lung cancer is considered as uniquetype of the most lethal cancers on the sphere, having the lowest success rate afterwards diagnosis and an annual surge in casualties [4,5,6].This remains a difficulty regardless of the number of investigators that are using machine learning frameworks. Because of the extensive amount of criteria that need to be hand-crafted in order to judge the best performance, it is not possible to achieve the same level of success again. [7,8,9,10]. Differentiation is an imperative aspect of calculation that organises images based on their commonalities [11,12,13]. Because of the poor quality of the image, traditional lung cancer prediction algorithms were unable to maintain the required degree of precision. This article provides information on the diagnosis as well as the Classification of lung cancer. The problem formulation in this work has been developed as the Modern medical imaging modalities produce large images that are extremely difficult to manually analyse and may lead to a lot of processing time to detect the Lung Nodules.As a result, this work addresses the issue of classifying lung nodules as cancerous or not by combining various intermediate stages of image processing with state-of-the-art Optimization and Deep Learning Classifier for easy analysis, bridging the knowledge gap from previous works in which deep learning algorithms were only used to solve temporal problems rather than Spatio-Temporal issues.This work also addresses the improvement in accuracy parameter, which calculates the percentage value of the correct tumour region of interest classification rate.In the pre-processing step, the median filter with a weighted value is employed to minimise noise in images, and in the post-processing stage, GLCM is used to extract features. Gray Wolf Optimization (GWO) with Recursive Neural Network (RNN) as a classifier is used to detect the disease at the final stage.
The main contribution of this method is to optimise and extract features from data and classify the type of tumour for easy perception. This will make it easier to detect and classify abnormalities. As a result, preventive diagnosis and assessment of Lung Cancer will be possible at an early stage, allowing for proper follow-up of recognised risk factors and accurate therapy when needed.
2 Literature survey
Lung cancer research is the most critical area of interest in the therapeutic sector. Early detection of the condition can aid in increasing the death rate of persons. This is exceedingly tedious, and their precision is determined by the number of operators available. Several researches have been published in the literature with the goal of distinguishing and categorising lung cancer protuberances using both traditional and deep learning methods.
In [14], researchers presented a study on lung cancer detection with helical CT scans. For distinguishing various lung regions, the k-mean clustering technique is used. The 84 percent sensitivity was attained using a knowledge based learning analysis. The researchers in [15] presented a framework for analysing lung growth using information mining approaches and streamlining methods. The authors of research [16] used the structural co-occurrence matrix (SCM) to excerpt features from the images and then classified them as cancerous or benign based on these features.The work in this topic has primarily focused on matrix-related maths to extract features; it tends to recognise tumours first and then classify them. Most of the time, determining whether tumours are cancerous or not is difficult because a significant amount of training and testing must be performed in the subsequent process of methodology, which is considered the work's constraint here.
The authors of the research [13] employed three distinct CAD detection approaches to recognize lung nodules in CT scans. Researchers employed feedforward neural networks to categorise lung nodules diagnosed in X-Ray pictures using just a few characteristics such as area, perimeter, and form in another study [17]. The work presented in this article has mostly focused on the use of X-rays to extract characteristics, recognise cancers, and classify them. Most of the time, determining whether a tumour is cancerous or not using X-rays is difficult because this modality has a tendency to miss soft tissues and also because a significant amount of training and testing is required in the subsequent procedure, which is regarded the work's limitation. The authors of [18] employed six different parameters in their feed-forward back propagation method. Thebulk of the research withthis concepts has concentrated on feed-forward back propagation, which recognises tumours first and then classifies them. Much of the time, evaluating whether tumours are cancerous or not is tough because the accompanying taking steps to ensure requires a substantial amount of training and testing, which is deemed the work's barrier here. The majority of the top solutions developed their segmentation algorithms using image segmented featuresin a challenge called LUNA16, which is a competition that was held in 2016 with the goal of detecting lung nodules in chest CT images [19,20,21,22]. The authors of article [23] utilise two prototypes, one constructedwith Deep Belief Networks(DBN) and the other on Convolutional Neural Networks(CNN). The LIDC dataset was utilized, with training samples scaled to 32 × 32 ROIs. They used the [24] technique for DBN, which comprises of the greedy layer-wise unsupervised learning algorithm for DBN. In numerous domains [25, 26], together with computer vision [27,28,29], recurrent neural networks (RNN) in addition to convolutional neural networks (CNN) have been deployed. Recurrent networks are typically employed to solve temporal challenges like time sequence or natural language dispensation. The issue at finger is a three-dimensional one.Following a comprehensive literature review on Lung Cancer Detection from a traditional Classifier to Deep Learning algorithms, two knowledge gaps were identified. The first gap is that Deep Learning approaches only solve Temporal problems, while Spatial–Temporal problems arising in various modern datasets are not addressed [30]. A Combination of Gray Wolf Optimization and RNN is used in this work. As a result, it's a classic supervised spatio-temporal problem, which represents Novelty of this work [31,32,33].The second gap is in terms of computational time as well as the accuracy and sensitivity of detecting the exact tumour region, both of which are taken into account in this work.As the accuracy and sensitivity improve, the proposed work's classification capacity overcomes the time parameter issue.
3 Methodology
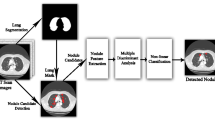
The methodology that has been proposed is depicted in Fig. 1. In this method, the initial image of a lung scan is obtained from a database and then put through a median filtering procedure in the pre-processing step [34]. This helps to reduce noise as well as any additional aberrations that may have been introduced during the image acquisition process. After that, the process of Feature Extraction is carried out using the Gray Level Co-Occurrence matrix (GLCM) approach. This is the step during which pertinent features are obtained and input to the GWO algorithm in order to achieve the best result possible based on the appearance and movement of pixels.

Block Diagram of Proposed method
In the final stage of the process, a technique called iterative RNN classification is utilised to classify tumours for malignancy, and performance metrics are computed in order to facilitate a more accurate interpretation of the findings.
The algorithm of the proposed method is presented below in stepwise manner, as a process flow.
-
Step 1: Import Lung CT Scan images from Medical database
-
Step 2: Induce Pre-Processing method in order to remove the artifacts induced during image acquisition.
In pre-processing, the Median filter is used, which replaces the value of a pixel with the median of the grey levels in its vicinity.
where \(\widehat{f}\left(x,y\right)\) is the filtered image.
\(g(s,t)\) is the received image with artefacts.
-
Step 3: Feature Extraction using Gray Level Co-Occurrence matrix (GLCM)
-
Step 4: Apply Features toOptimization Algorithms (in this case mainlyGWO algorithm) to attain optimal solution
-
i.
The GLCM determines how frequently a pixel appears.
-
ii.
Directions of GLCM are represented
-
i.
Consider universal set asMn .
where, M is the set of all integers.
A point (or pixel in Mn) X in Mn is an n-tuple of the form
X=(x1,x2,…,xn) where xi ∈M∀i= 1,2,3....n
An image I is a function from a subset of toMn to M.
Gray level co-occurrence matrix is a square Matrix denoted by
where K be the total number of grey levels in the image.
-
Step 5: Initiate Classification Process Via RNN Classifier
-
RNN Classifier is initiated
-
i.
Dataset–two phase for the training and the testing procedure to assess the tumor regions in Lung.
-
ii.
At this stage, the corresponding dataset's feature vectors and the classes that go with them are trained.
-
iii.
The output is the decision about whether or not the input image is cancerous or not.
-
i.
-
Tumor Localization is carried out by identifying whether effected by Tumor or not
-
Tumor Segmented area is measured and displayed otherwise Null is displayed
-
-
Step 6: Performance metrics are Computed for comparing the output results of applied Optimization Algorithms and RNN.
3.1 Feature extraction
Because the Deep Learning algorithm operates on the retrieved features, the feature extraction stage is the most significant in such a task. Even the most sophisticated machine-learning algorithm will not be able to get decent results if the features are not sufficiently meaningful and discriminative. Image attributes with second order statistics texture feature are estimated using the GLCM approach [35]. The spatial relationship between pixels is taken into account by the GLCM statistical approach. This matrix is a tool for collecting second order statistics, not the feature vector itself. The GLCM expresses the frequency of appearance of pairs of pixels with different grey-level intensities that are separated by a specified distance and orientation.
3.2 Particle swarm optimization
The initial swarm is often generated by randomly distributing all particles around the space, respectivelythrough a random amount of the initial velocity vector. The representation provided in Eq. (4) denotes the initial position in a random manner and the Eq. (5) computes the velocity, which can be written as
where
-
\({x}_{id}^{o}\) denotes the dthlocation value for the null valued particle.
-
\({x}_{id}^{o}\) symbolizesvelocity value.
-
\({r}_{1}\) and \({r}_{2}\) representarbitrary numbers amongst [0,1].
-
\({x}_{i}^{min}\) is inferior location bound.
-
\({x}_{i}^{max}\) is superiorlocationbound.
-
\(\Delta t\) is considered as the step extent.
-
n representamount of variables.
-
m represents the extent of the particular swarm.
Carry the process to update the position as well as the velocity of the swarm.
The updated value of the velocity as well as the Locationare considered to bereorganisedby means of Eqs. (6) and (7) correspondingly.
where i = 1, 2, 3…n; d = 1, 2, 3,.m.
Where
-
\({c}_{1}\) and \({c}_{2}\) represent the corresponding positive constants.
-
\({r}_{3}\) and \({r}_{4}\) representarbitrary number inside the range of [0,1].
-
w is the inertia of weight.
-
\({x}_{id}^{t}\) denotes the dthlocationvalue.
-
\({x}_{i}^{lb}\) denotes the dthlocation value of the best precedinglocation.
-
\({x}_{i}^{gb}\) denotes thesuperlativeparticle index.
-
\({v}_{id}^{t}\) Denotes the frequency of the dthlocation value alteration.
-
\({v}_{id}^{\left(t+1\right)}\) Denotes the frequency of the dthlocation value alteration (velocity) for particle i at time step t + 1.
$${x}_{id}^{\left(t+1\right)}={x}_{id}^{t}+{x}_{id}^{t+1}$$(7)where
-
\({x}_{id}^{t}\) Denotes the dthlocation value of the ith particle at time t.
-
\({x}_{id}^{\left(t+1\right)}\) Denotes the dthposition value of the ith particle at time t + 1.
-
\({v}_{id}^{\left(t+1\right)}\) Denotes the frequency of the dthlocation value alteration which is said as Velocity.
-
n represents number of variables whereas m represents theextent of the particular swarm.
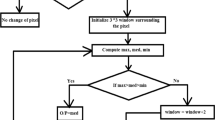
The process flow of the PSO algorithm which is explained by the help of above equations is represented as a flow chart in Fig. 2, which is best known for its exploration capability of search for the entire space by means of the particle’s velocity and location.

Flow chart of particle swarm optimization
3.3 Genetic algorithm
By modelling the evolution of a population until the best-fitting individuals survive, genetic algorithms discover the optimal value of a criterion. Individuals obtained through crossing-over, mutation, and selection of individuals from the preceding generation are the survivors as shown in flow chart in Fig. 3. In this case, GA plainly depends on the intrinsic characteristics and features that have been conveyed to the upcoming individuals, with a grain of salt added to their behavioral attributes [36]. We believe that GA is a good contender for determining the optimal combination of segmentation results for two reasons. The first reason is that an evaluation criterion is difficult to distinguish. GA is an optimization method that does not require the fitness function to be differentiated but merely evaluated. Second, if the population is large enough in comparison to the size of the search space, we have a decent chance of achieving the optimal value of fitness.

Flow chart of Genetic algorithm
The selection of chromosomes dependent up on the fitness values uses the subsequent probability equation
where f(x) is the fitness function
C represents cth number of chromosomes
And k represents value varies from 1 to n.
During this process crossover and rotation play a significant role in generation of new population based on the provided conditions. If the condition is not satisfied the entire population has to be processes through operators once again.
The various steps of a Genetic Algorithm procedure are as follow:
-
i.
Making the first group of people.
-
ii.
Estimate each person's fitness level by decoding the strings.
-
iii.
The process ends when the end condition is met, which is when the maximum number of generations has been reached.
-
iv.
Use the operator i.e., reproduction, to make a new mating pool.
-
v.
Use the operators, like crossover and mutation, to make a new population.
-
vi.
Stop if the condition is met; if not, go back to step 1. (ii).
3.4 GWO algorithm
Because of its few control parameters, adaptive exploration behaviour, and simplicity of mechanism, the GWO method has been frequently employed to solve the feature selection problem. Here, the implemented GWO is a unique meta-heuristic technique [37,38,39] that is based on the hunting behaviour and community leadership of grey wolves. Most of the times theychoose to live and hunt in packs that have a very tight progressive social system.The alpha wolf is also referred to as the dominant wolf because all of the other wolves in the pack are obligated to follow its orders [40]. When it comes to decision-making and other areas of the pack, beta wolves provide assistance to alpha wolves. The number of grey wolves in Omega is lower. The omega wolf will always offer all of the other dominant wolves something to eat. The Delta class is the fourth one in the whole group. The omega pack is ruled by the delta wolves, however they are obligated to obey commands from the alpha and beta packs [41,42,43,44].
During the first stage, grey wolves locate, stalk, and close in on their prey in order to kill it. After some time has passed, they will continue to pursue, circle, and harass the prey until it becomes immobile. Finally, they attempt to terrify the target animal into stopping its movement so that they can seize it.
3.4.1 GWO algorithm
In the GWO algorithm the hunting (optimization) is guided by α, β and δ. The ω wolves follow these three wolves.
Grey wolves encircle prey during the hunt
mathematically model encircling behavior.
where X indicates the position vector of a grey wolf
t indicates current iteration.
A and B are coefficient vectors.
The alpha usually leads the hunt. The beta and delta might also hunt from time to time. To mathematically mimic grey wolf hunting behaviour, we assume that the alpha (best candidate solution), beta, and delta have superior knowledge of prospective prey locations.
Encircled behaviours for respective wolves are provided by following:
where \({X}_{\alpha }\), \({X}_{\beta }\), \({X}_{\delta }\) are search agents.
The updated positions are provided by
The Final position is provided by the average of all the updated positions
3.5 RNN classifier
One sort of neural network model that incorporates a feedback loop is the recurrent neural network. RNN is made up of four layers: input, hidden layer, output layer, and feedback link. The activation function is used to link two layers together. The network output is re-input to the network through the feedback connection. Here one can vary the architecture so that the network unrolls ‘n’ time steps as shown in Fig. 4.

RNN Layers
Mathematically the output y at time t is computed as
Here, ⋅ represents the dot product.
- yt:
-
represents the output of the network at time t
- Wx:
-
represents weights associated with inputs in recurrent layer
- Wh:
-
represents weights associated with hidden units in recurrent layer
- bh:
-
represents he bias associated with the recurrent layer
- ht:
-
represents hidden units/states at time
- wy:
-
represents weights associated with the hidden to output unit
- by:
-
represents the bias associated with the feedforward layer
The income results are sent hind to the participation layer at this stage of the process. The selected postpone lines as well as info hubs on the first layer are utilised in order to transmit input weight to the concealed layer. However, the feedforward back-propagation stage is not the same as the network. This phase uses detailed delay lines along with the input nodes to transport the return from the respective output layer towards the input layer. A wide diversity of neuronal cells can be found in the buried layer. On the other hand, the output layer is home to just one single yield neuron. Both the hidden and output layers perform their initial work with the help of hyperbolic tangent functions.
4 Results and analysis
The input CT image of a lung cancer, shown in Figure 5, obtained from the Kaggle [36] Medical Image database, which is the most popular and widely used database in the area. The input image is pre-processed with the Median filter to remove any artefacts created during the image capture process, as shown in Fig. 6, for experimentation, and the outcome is shown in Fig. 7.

Input lung CT scan image

Input image with noise

Pre-processed input image with noise
Later, the median filter output is exposed to a Feature Extraction process, where it is handled with the GLCM, as illustrated in Fig. 8, and a feature extraction procedure is carried out. Following that, the image is subjected to Grey Wolf Optimization Algorithm to attain optimal image as shown in Fig. 9 and then it is fed to Recurrent Neural Network (RNN) Technique for classification for the purpose of detection of cancerous part as presented in Fig. 10.

Feature extracted image

Gray wolf optimized image

Cancer detected output image
To check how well the proposed method works, a graph of mean square error (MSE) versus iterations (or Epochs) and MSE for both training dataset and validation is shown.
In the graphical representation displayed in Fig. 11, dotted lines suggest the optimal MSE that must be low. The validation value, which is represented by that of the demarcation line, is the MSE that needs to be fulfilled after 46 epochs in order for the model to be considered valid. The error histogram in Fig. 12 is represented by the red line, which indicates that the RNN Training method was being used. When the error is quite tiny, the location of the error in relationship to the learning value is shown by this line. Following the completion of 46 epochs, the histogram is displayed at the zero-error line, with the colours blue and green signifying learning and validation, respectively. Figure 13 displays, in a similar manner, an approximation of the gradient in regard to the validation check after a total of 46 epochs have passed.

Detection performance validation in lung cancer nodules

CNN training data error histogram of detection in lung cancer nodules

Gradient estimation of detection in lung cancer nodule
The confusion matrix defines the performance of a classification method. A confusion matrix shows how many correct and incorrect predictions the model made. The amount of valid predictions for each class is distributed diagonally. Figure 14 depicts the confusion matrix forDetection in Lung Cancer Nodule.

Confusion matrix graph of detection in lung cancer nodule
Figure 15 depicts the ultimate receiver operating characteristics (ROC), which are visually plotted between the false positive rate and the genuine positive rate. It is a graph that illustrates the performance of the proposed model at all classification thresholds, and also a graphical representation of a binary classifier system's diagnostic capabilities as its discriminating threshold is adjusted. Its earliest use was in the theory of signal detection, but it has since found applications in a wide range of domains, such as machine learning, radiography, medicine, and even natural disasters. The ROC curve is most commonly used to demonstrate the correlation among both sensitivity and specificity for just a testing method cut-off value. The area as well as the ROC graph must be in the range "0.9 to 1." As a result, the final ROC using our graph approaches the best value of '1', as illustrated by the green line.

Final ROC graph of detection in lung cancer nodule
Comparison between the existing and proposed methods based on the parameters are shown in below Table 1.
Table 1 evaluates the entire work for existing procedures as well as the proposed process, as well as essential characteristics such as the dice similarity coefficient (DSC) and Jaccard similarity index (JSI). A graphical representation of the DSC and JSI comparison is plotted as shown in Fig. 16. The plot shows that the proposed GWO + RNN significantly outperformed the previous methods GA + RNN and PSO + RNN in terms of DSC and JSI for its exactness and ability to determine similarity because it works in Spatio-Temporal conditions as well. The dice similarity coefficient (DSC) is used to figure out the ratio of actual tumour and non-tumor pixels, which is then compared to the ratio of expected tumour and non-tumor pixels. In this case, the parameter Dice similarity coefficient (DSC) is used to calculate the exact amount of ratio of available real tumour and available non-tumor pixels to anticipated tumour and non-tumor pixels. The JACCARD similarity index (JSI) is used to determine the percentage of similarity among actual Lung cancerous nodule pixels in the region of attention and the numeral of anticipated tumour pixels.

Statistical comparison DSC and JSI
The dice similarity coefficient (DSC) and the Jaccard similarity index (JSIC) are two binary image similarity criterion that are used to assess segmentation performance (JSI). In addition to these two similarity indices, this study includes three pixel-based segmentation evaluation measures. These metrics are determined by viewing the picture segmentation task as a dense pixel classification task.The result is known as a "True Positive" in these equations when the model accurately predicts the positive class (TP). The term FP denotes a positive result predicted by the model, whereas TN denotes a negative result predicted by the model. The phrase "False Negative" is used when the model predicts the negative class inaccurately.
As seen in the computation, DSC outperforms total pixel accuracy because it takes into account both false alarms and missed data in each class. DICE is also said to be superior because it calculates both the number of correctly labelled pixels and the precision of the segmentation borders. DICE is also commonly used in cross-validation to assess system performance repeatability.
The suggested method offers a substantial advantage in terms of DSC and JSI values when compared to earlier approaches in lung cancer detection and classification, as shown by the Tabular column and graphical representation. In comparison to earlier approaches, the suggested RNN + GWO generates much better dice-similarity coefficient (DSC) values.
Table 2 also includes metrics such as sensitivity, accuracy, specificity, and precision. Figure 17 also includes a graphical plot depiction for comparing parameters such as sensitivity, accuracy, specificity, and precision.The plot demonstrates that the proposed method provides the best optimal metrics. It can also be seen that there is a trade-off between previous methods GA + RNN and PSO + RNN, indicating that one method outperforms the other in two metrics, whereas proposed GWO + RNN outperforms both.The fraction of picture pixels correctly classified, as specified above, is called accuracy. Overall pixel precision is another name for it. It is the most basic performance metric; however, it has the drawback of misrepresenting image segmentation performance when there is a class imbalance.

Statistical comparison of accuracy, sensitivity, specificity and precision
The significant Accuracy (ACC) factor is used to calculate the percentage value of the correct tumour region of interest classification rate,whereas the Sensitivity (SE) parameter is used to approximate the exact percentage value of how sensitive the technique is to compute the specific value of the Lung Cancer tumour identification rate, and it is also defined as the ratio of optimally segmented to complete positive cases.To estimate the accuracy, calculate the proportion of true positive and true negative cases in all evaluated cases, where Sensitivity quantifies the techniques' ability to identify the correct Tumor area pixel[37].
Moreover, the parameters Specificity (SP) and Precision (PR) were evaluated, where Specificity (SP) discusses the rate values calculated between true negative (TN) values and true positive (TP) values and Precision (PR) designates the number of digits in terms of percentage that are used to convey a value, and its equation to compute. It is also defined as the proportion of correctly segmented negativity.Precision is the number of disease pixels in the results of automatic segmentation that match the disease pixels in the ground truth, as explained above. Because over-segmentation can hurt precision, it is an important measure of how well segmentation is working. Low precision scores result from over-segmentation.
The suggested fusion method using RNN + GWO has a considerable advantage in terms of all parametric values when compared to previous combinational approaches in lung cancer detection and classification, as shown by the Tabular column and graphical representation of statistical parameters.
As a concluding note on the results obtained, it is suggested that optimization algorithms based on Deep Learning Networks can provide optimal results by providing proper classification while overcoming the complexities of medical images acquired from various Imaging modalities. Furthermore, AI techniques ranging from machine learning to deep learning are widely used in healthcare for disease diagnosis, drug discovery, and patient risk identification [38]. However, human interpretation is required because these algorithms act as a supporting character in overcoming the obstacles that the Health Community and Health Providers face.
5 Conclusion
Feature Extraction and Training the features for lung cancer detection is the primary purpose of the proposed system, which uses categorization algorithms to mine relevant and correct data. The capacity of deep learning to do feature engineering on its own is its major advantage over other machine learning algorithms. This analyses the data in order to find related features and include them into the learning process. It takes advantage of the input's spatial coherence. This system including RNN for lung cancer evaluation proposes a unique CAD approach for categorization of lung nodules based on the grey wolf optimizer and RNN. The suggested method includes image pre-processing involving filters, then the main nodule segmentation for parting, the feature extraction by GLCM, feature optimization, and the classification of Lung Nodules for their severity.For statistical analysis, significant metrics such as Dice similarity coefficient (DSC) and Jaccard similarity index (JSIC), as well as Accuracy, Sensitivity, Specificity, and Precision, were computed, and it was discovered that the proposed hybrid methodology involving GWO and RNN performed better than other combinations.
Data availability
The processed data are available upon request from authors.
References
Capocaccia R, Gatta G, Dal Maso L. Life expectancy of colon, breast, and testicular cancer patients: an analysis of US-SEER population-based data. Ann Oncol. 2015;26(6):1263–8.
Ferlay J, Soerjomataram I, Dikshit R, Eser S, Mathers C, Rebelo M, Parkin DM, Forman D, Bray F. Cancer incidence and mortality worldwide: sources, methods and major patterns in globocan 2012. Int J Cancer. 2015;136(5):E359–86. https://doi.org/10.1002/ijc.29210.
Wong MCS, Lao XQ, Ho K-F, Goggins WB, Tse SLA. Incidence and mortality of lung cancer: global trends and association with socioeconomic status. Sci Rep. 2017;7(1):14300.
Ahmed SM, Kovela B, Gunjan VK. IoT based automatic plant watering system through soil moisture sensing—a technique to support farmers’ cultivation in Rural India. In: Advances in cybernetics, cognition, and machine learning for communication technologies. Singapore: Springer; 2020. pp. 259–268.
Sharma D, Jindal G. Computer aided diagnosis system for detection of lung cancer in CT scan images. Int J Comput Electr Eng. 2011;3(5):714–8.
Singh N, Ahuja NJ. Bug model based intelligent recommender system with exclusive curriculum sequencing for learner-centric tutoring. Int J Web-Based Learn Teach Technol. 2019;14(4):1–25.
Janarthanan R, Balamurali R, Annapoorani A, Vimala V. Prediction of rainfall using fuzzy logic. Mater Today Proc. 2021;37:959–63.
Bhatnagar D, Tiwari AK, Vijayarajan V, Krishnamoorthy A. Classification of normal and abnormal images of lung cancer. In: IOP Conference Series: Materials Science and Engineering (Vol. 263, No. 4, p. 042100). IOP Publishing; 2017, November.
Kumar S, Ansari MD, Gunjan VK, Solanki VK. On classification of BMD images using machine learning (ANN) algorithm. In: ICDSMLA 2019. Singapore: Springer; 2020. pp. 1590–1599.
Sudipta R, Shoghi KI. Computer-aided tumor segmentation from T2-weighted MR images of patient-derived tumor xenografts. In: International conference on image analysis and recognition. Cham: Springer; 2019. pp. 159–171.
Chaudhary A, Singh SS. Lung cancer detection on CT images by using image processing. In: 2012 International Conference on Computing Sciences. IEEE; 2012, September. pp. 142–146.
Mishra B, Singh N, Singh R. Master-slave group based model for co-ordinator selection, an improvement of bully algorithm. In: 2014 International conference on parallel, distributed and grid computing. IEEE; 2014. pp. 457–460.
Pratap GP, Chauhan RP. Detection of lung cancer cells using image processing techniques. In: 2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES). IEEE; 2016, July. pp. 1–6.
Surya Narayana G, Kolli K, Ansari MD, Gunjan VK. A traditional analysis for efficient data mining with integrated association mining into regression techniques. In: ICCCE 2020. Singapore: Springer; 2021. pp. 1393–1404.
Gurcan MN, Sahiner B, Petrick N, Chan HP, Kazerooni EA, Cascade PN, Hadjiiski L. Lung nodule detection on thoracic computed tomography images: Preliminary evaluation of a computer-aided diagnosis system. Med Phys. 2002;29(11):2552–8.
Krishnaiah V, Narsimha G, Chandra NS. Diagnosis of lung cancer prediction system using data mining classification techniques. Int J Comput Sci Inf Technol. 2013;4(1):39–45.
Prasad PS, Sunitha Devi B, Janga Reddy M, Gunjan VK. A survey of fingerprint recognition systems and their applications. In: International Conference on Communications and Cyber Physical Engineering 2018. Singapore: Springer; 2018. pp. 513–520.
Roy S, Whitehead TD, Li S, Ademuyiwa FO, Wahl RL, Dehdashti F, Shoghi KI. Co-clinical FDG-PET radiomic signature in predicting response to neoadjuvant chemotherapy in triple-negative breast cancer. Eur J Nucl Med Mol Imaging. 2022;49(2):550–62.
Rashid E, Ansari MD, Gunjan VK, Ahmed M. Improvement in extended object tracking with the vision-based algorithm. In: Modern approaches in machine learning and cognitive science: a walkthrough. Cham: Springer: 2020. pp. 237–245.
Camarlinghi N, Gori I, Retico A, Bellotti R, Bosco P, Cerello P, Gargano G, Torres EL, Megna R, Peccarisi M, et al. Combination of computer-aided detection algorithms for automatic lung nodule identification. Int J Comput Assist Radiol Surg. 2012;7(3):455–64.
Abdullah AA, Shaharum SM. Lung cancer cell classification method using artificial neural network. Inf Eng Lett. 2012;2(1):49–59.
Kuruvilla J, Gunavathi K. Lung cancer classification using neural networks for ct images. Comput Methods Programs Biomed. 2014;113(1):202–9.
Kashyap A, Gunjan VK, Kumar A, Shaik F, Rao AA. Computational and clinical approach in lung cancer detection and analysis. Procedia Comput Sci. 2016;89:528–33.
Setio AAA, Traverso A, de Bel T, Berens MS, Bogaard CVD, Cerello P, et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the LUNA16 challenge. Med Image Analysis. 2017;42:1–13.
Armato SG, McLennan G, Bidaut L, McNitt-Gray MF, Meyer CR, Reeves AP, et al. The Lung Image Database Consortium (LIDC) and Image Database Resource Initiative (IDRI): a completed reference database of lung nodules on CT scans. Med Phys. 2011;38(2):915–31.
Sahu H, Singh N. Software-defined storage. In: Innovations in software-defined networking and network functions virtualization. IGI Global; 2018. pp. 268–290.
Hua KL, Hsu CH, Hidayati SC, Cheng WH, Chen YJ. Computer-aided classification of lung nodules on computed tomography images via deep learning technique. OncotargetsTher. 2015;8:2015–22.
Hinton GE, Osindero S, Teh YW. A fast learning algorithm for deep belief nets. Neural Comput. 2006;18:1527–54.
Lakshmanna K, Shaik F, Gunjan VK, Singh N, Kumar G, Shafi RM. Perimeter degree technique for the reduction of routing congestion during placement in physical design of VLSI circuits. Complexity. 2022;2022.
Cui Z, Ke R, Pu Z, Wang Y. Stacked bidirectional and unidirectional LSTM recurrent neural network for forecasting network-wide traffic state with missing values. Transp Res Part C Emerg. 2020;118:102674.
Srivastava V, Kumar D, Roy S. A median based quadrilateral local quantized ternary pattern technique for the classification of dermatoscopic images of skin cancer. Comput Electr Eng, Elsevier. 2022;102:108259. https://doi.org/10.1016/j.compeleceng.2022.108259.
Shi X, Chen Z, Wang H, Yeung DY, Wong WK, Woo WC. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv Neural Inf Process Syst. 2015;28.
Donahue J, Hendricks LA, Rohrbach M, Venugopalan S, Guadarrama S, Saenko K, Darrell T. Long-term recurrent convolutional networks for visual recognition and description. arXiv:1411.4389.
Pal D, Reddy PB, Roy S. Attention UW-Net: A fully connected model for automatic segmentation and annotation from Chest X-ray. Comput Biol Med, ELSEVIER. 2022:106083. https://doi.org/10.1016/j.compbiomed.2022.106083.
Chollet F. Deep learning with Python. Simon and Schuster, 2021. ISBN 9781617294433.
Dataset, Kaggle. https://www.kaggle.com/navoneel/brain-mriimages-for-brain-tumor-detection. Accessed 3 Jan 2021.
Dash S, Verma S, Kavita, Khan MS, Wozniak M, Shafi J, Ijaz MF. A hybrid method to enhance thick and thin vessels for blood vessel segmentation. Diagnostics (Basel). 2021;11(11):2017. https://doi.org/10.3390/diagnostics11112017.
Kumar Y, Koul A, Singla R, Ijaz MF. Artificial intelligence in disease diagnosis: a systematic literature review, synthesizing framework and future research agenda. J Ambient Intell Humaniz Comput. 2022:1–28.
Srinivasu PN, SivaSai JG, Ijaz MF, Bhoi AK, Kim W, Kang JJ. Classification of skin disease using deep learning neural networks with MobileNet V2 and LSTM. Sensors. 2021;21(8):2852.
Vulli A, Srinivasu PN, Sashank MSK, Shafi J, Choi J, Ijaz MF. Fine-tuned DenseNet-169 for breast cancer metastasis prediction using FastAI and 1-cycle policy. Sensors. 2022;22(8):2988.
Ijaz MF, Attique M, Son Y. Data-driven cervical cancer prediction model with outlier detection and over-sampling methods. Sensors. 2020;20(10):2809.
Dash S, Verma S, Bevinakoppa S, Wozniak M, Shafi J, Ijaz MF. Guidance image-based enhanced matched filter with modified thresholding for blood vessel extraction. Symmetry. 2022;14(2):194.
Mandal M, Singh PK, Ijaz MF, Shafi J, Sarkar R. A tri-stage wrapper-filter feature selection framework for disease classification. Sensors. 2021;21(16):5571.
Srinivasu PN, Ahmed S, Alhumam A, Kumar AB, Ijaz MF. An AW-HARIS based automated segmentation of human liver using CT images. Comput Mater Contin. 2021;69(3):3303–19.
Author information
Authors and Affiliations
Contributions
All authors have participated in (a) conception and design, or data analysis and interpretation; (b) drafting the paper or critically reviewing it for significant intellectual content; and (c) approval of the final result. This manuscript is not currently being reviewed by another journal or other publishing venue and has not been submitted to one. All authors are not affiliated with any entity that has a direct or indirect financial interest in the subject matter mentioned in the research.
Corresponding author
Ethics declarations
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Competing of interests
Authors have no conflicts of interest to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gunjan, V.K., Singh, N., Shaik, F. et al. Detection of lung cancer in CT scans using grey wolf optimization algorithm and recurrent neural network. Health Technol. 12, 1197–1210 (2022). https://doi.org/10.1007/s12553-022-00700-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12553-022-00700-8