
Abstract
Online monitoring systems have been developed for real-time detection of high impedance faults in power distribution networks. Sources of distributed generation are usually ignored in the analyses. Distributed generation imposes great challenges to monitoring systems. This paper proposes a wavelet transform-based feature-extraction method combined with evolving neural networks to detect and locate high impedance faults in time-varying distributed generation systems. Empirically validated IEEE models, simulated in the ATPDraw and Matlab environments, were used to generate data streams containing faulty and normal occurrences. The energy of detail coefficients obtained from different wavelet families such as Symlet, Daubechies, and Biorthogonal are evaluated as feature extraction method. The proposed evolving neural network approach is particularly supplied with a recursive algorithm for learning from online data stream. Online learning allows the neural models to capture novelties and, therefore, deal with nonstationary behavior. This is a unique characteristic of this type of neural network, which differentiate it from other types of neural models. Comparative results considering feed-forward, radial-basis, and recurrent neural networks as well as the proposed hybrid wavelet-evolving neural network approach are shown. The proposed approach has provided encouraging results in terms of accuracy and robustness to changing environment using the energy of detail coefficients of a Symlet-2 wavelet. Robustness to the effect of distributed generation and to transient events is achieved through the ability of the neural model to update parameters, number of hidden neurons, and connection weights recursively. New conditions could be captured on the fly, during the online operation of the system.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
High impedance faults (HIF) represent great risks. In addition to be a serious hazard for people and animals, energized cables can produce electric arcs from the broken cable and therefore fire and explosions. HIF detection and location in distribution systems is difficult because the currents involved are of low amplitude, which prevents overcurrent protection devices from operating. Changes due to faults are not easily distinguished from those caused by consumer features and by system operations such as switching of capacitor banks and energizing of transformers (Sedighizadeh et al. 2010; Silva et al. 2018).
In distribution networks (DN) with distributed generation (DG), protection devices are usually less efficient. DG affects the power flow and inserts harmonic components in the system. These hamper feature extraction and HIF identification methods to keep a reasonable accuracy in given time periods. Changes in the settings of a protection system are usually required as protection devices designed for a specific electrical circuit can work improperly (Bretas et al. 2006a; Gomez et al. 2013; Xiangjum et al. 2004). Another issue is related to islanding. Islanding concerns the power system operation in standalone mode due to the occurrence of a fault (Ezzt et al. 2007); it leads to auto re-closing of the circuit breaker. Distributed generators lose synchronization with the main grid while supply energy continuously from the DG side (Ezzt et al. 2007; Gomez et al. 2013; Xiangjum et al. 2004).
A variety of methods have been proposed for HIF detection and location (Ghaderi et al. 2017; Sedighizadeh et al. 2010). Among these methods, different types of neural network structures have been considered (Baqui et al. 2011; Bretas et al. 2006a; Sedighi et al. 2005; Silva et al. 2013). The essential idea is to recognize and classify fault patterns in waveforms of the available signals (Garcia-Santander et al. 2005; Kim and Aggarwal 2000; Santos et al. 2017). Generally, approaches for HIF detection consider a feature selection method combined with a statistical or neural classifier (Bretas et al. 2006a, b; Sedighizadeh et al. 2010). Fault location is an important additional information to help decision making. To locate HIF, some methods estimate the distance to the fault point (Bretas et al. 2006b; Silva et al. 2013). Other methods consider devices and sensors appropriately placed on the smart grid, and a main central station for the identification of the HIF occurrence area (Santos et al. 2017). The vast majority of fault location studies assumes distribution systems without distributed generation (Etemadi and Sanaye-Pasand 2008; Kim and Aggarwal 2000; Mora-Florez et al. 2008).
Changes in the topology of smart grids have become an issue since self-generation (distributed generation) of electrical power became common (Bretas et al. 2006b). Non-adaptive HIF detection models need to be constantly reviewed and redesigned to deal with different sources of generation (Bretas et al. 2006b; Silva et al. 2018; Xiangjum et al. 2004). Additionally, offline-designed fault detection models depend on the choice of a mathematical structure, and availability of historical data to set their parameters based on multiple passes over the data. If new patterns and behaviors arise in a time-varying environment, such as that when distributed generation and a variety of transient events may take place, then offline-designed neural models cannot handle them effectively, but only by approximation.
Adaptive intelligent classification models, namely, evolving classifiers (Andonovski et al. 2018; Angelov and Gu 2018; Garcia et al. 2019; Leite et al. 2012, 2013; Lughofer et al. 2017; Mohamad et al. 2018; Pratama et al. 2014; Rubio 2014, 2009), are able to self-adapt their parameters and decision boundaries among classes according to novelties and new operating conditions observed from a data stream. Online parametrical and structural adaptation is essential in time-varying environments (Škrjanc et al. 2019). Any procedure or guideline on how to set the structure of a neural network in an offline fashion is not useful in online dynamical context. Therefore, different from any other classification neural network model to detect HIF in a microgrid that integrates various sources of distributed generation, the approach presented in this paper evolves autonomously over time, from scratch, to handle unpredictable system behaviors. No initial guesses about a proper number of neurons are needed. Formally, we want a map f from x to y so that \(y = f(x)\). We seek an approximation to f that allows us to predict the value of the output y given the input x. In classification, y is a class label, a value in a set \(\{C_1, \ldots , C_m\} \in \mathbb {N}^m\), and relation f specifies class boundaries. As the physical system is time-varying, function f must be time-varying to be able to track the nonstationarities of the physical system.
This paper proposes a nonlinear and nonstationary approach for detecting and locating HIF in smart grids with distributed generation. The approach consists of a discrete wavelet transform chosen from a family of transforms, as well as appropriate detail coefficients, to give the most discriminative features for fault detection. Wavelet transformation is based on current waveforms obtained from a main feeder. Features related to the energy of wavelet detail coefficients are used as inputs of a network we called adaptive artificial neural network (AANN) that is trained to detect HIF occurrences. A second AANN estimates the distance to the HIF point whenever it is triggered by the detection neural network. For fault location, the neural network input features are the effective values of the current and voltage waveforms on the main feeder. Feature selection and fault detection and location are performed on the main station using online data streams from properly placed sensors. The present study extends our previous conference paper Lucas et al. (2018) with a more complete literature review and new discussions and examples on the effect of wavelet transforms to generate discriminative features; and on how the evolving approach handles concept drift and shift in time-varying online environment. We also give further results on fault location.
The remainder of this paper is structured as follows. Section 2 discusses related literature. Section 3 describes discrete wavelet transforms and the proposed adaptive intelligent system for detecting and locating HIF in smart grids. Section 4 presents the methodology used to generate the data based on IEEE test feeders, and considerations about the different types of neural networks used to compare the performance of the proposed system. Sections 5 and 6 contain classification results and the conclusion.
2 Related literature
HIF detection and location in power distribution systems has been a challenge over the years. This section provides a general discussion about HIF detection and location methods. The purpose is to overview studies closely related to that addressed in this paper and to emphasize what makes the proposed evolving intelligent system different from previous approaches.
Wavelet analysis and a filter bank-based method for HIF detection were proposed in Ibrahim et al. (2010) and Wai and Yibin (1998). The method uses a two-level wavelet transform to extract attributes of current waveforms. The number of peaks due to high-frequency transients and the distance between peaks are used to identify HIF. An application example shows that the fault model can distinguish HIF occurrence from capacitor switching. The method is suitable for distribution networks without DG since it is not able to adapt to changes. The adaptive artificial neural network (AANN) proposed in this paper improves upon the models obtained in Ibrahim et al. (2010) and Wai and Yibin (1998) because it is able to capture changes during online operation. AANN is supplied with a data stream-based learning algorithm and, therefore, can handle high-frequency transients, which are common events when many sources of power generation in a smart grid exist.
A method to detect and estimate the distance to HIF in distribution systems was discussed in Silva et al. (2013). The method is based on the well-known multi-layer perceptron (MLP) neural network and its error backpropagation algorithm. The energy spectrum from wavelet detail coefficients extracted from current waveforms Santos et al. (2017) was considered as inputs to the neural network. Simulations were performed considering real HIF data obtained from field experiments. The network classified patterns efficiently and effectively, especially because related patterns are shown to the neural model previously for parameter adjustment. In a real context, and considering multiple sources of power generation, training data that reflect all possible situations are not available. In this case, a static model, such as the MLP network, may fail in detecting new faults because the current waveform patterns change over time, i.e., the patterns are different from those used to create the neural model. The AANN proposed in this paper overcomes this issue because its parameters and structure change to track the changes of the environment.
A method based on frequency components and MLP neural network model to estimate the distance to the fault point considering DG in a smart grid was evaluated in Bretas et al. (2006b). The method uses voltage and current harmonic components extracted from relays, as in Etemadi and Sanaye-Pasand (2008). The assumption of the existence of many sources of generation imposes considerable difficulties to the HIF detection problem, as reported in Ibrahim et al. (2010), Silva et al. (2013) and Wai and Yibin (1998). Evolving systems, as that proposed in this paper, extend the harmonic-component-based method, addressed in Bretas et al. (2006b), because it allows self-adjustment of detection and location neural models. Online learning provides to the neural models ability to handle new operating conditions, which cannot be predicted previously.
An energy-spectra-based method for HIF detection was proposed in Santos et al. (2017). Voltage and current waveforms are taken into account. Energy levels higher than a threshold obtained from protection devices throughout the network mean a HIF occurrence. A main station centralizes the data arriving from different devices, which reduces the time for fault location significantly. System robustness was verified considering DG, capacitor bank switching, and feeder energization. However, a threshold value for the energy is required to be offline changed according to the presence of additional sources of generation. In this paper, the proposed neural network evolves independently of prior assumptions on threshold values. Moreover, the key idea of the proposed evolving network is that the decision boundary between classes is not only nonlinear due to the intrinsic nonlinearity of neural networks, but also time varying. A main centralized station is considered.
3 Evolving intelligent framework
3.1 Discrete wavelet transform
Wavelet transforms deal with a limitation of the Fourier transform because they calculate the amplitude of frequency components of a signal over the time (Wai and Yibin 1998). The Fourier transform is quite often used for converting from the time to the frequency-domain representation. However, if the underlying signals are nonstationary, the Fourier transform does not evidence time-varying frequency components such as those of HIF voltages and currents. In this paper, different wavelet families are evaluated as electrical-signal feature extractors aiming at evidencing faulty and healthy conditions from online monitoring of smart grids subject to time-varying distributed generation.
Wavelet analysis is based on a prototype function called mother wavelet. This function has compact support, i.e., an output value exists for all \(x \in \left[ \alpha ,\beta \right]\). From the wavelet transform, a one-dimensional signal is converted into a two-dimensional function, where the coordinates are scale and translation factors. The wavelet transform uses a windowing function, where the scale factor is associated with the size of the windowing function, and the translation factor is associated with the mother wavelet passing through the evaluated signal. There are many types of mother wavelets, g(.), e.g. Daubechies, Haar, Symlet, Biorthogonal. Each mother wavelet has different scale and translation factors.
The discrete wavelet transform (DWT) is defined as
where x(n) is the original signal; n is the number of samples; k is the sampling index; g is a mother wavelet; and \(a := a_{0}^{m}\) and \(b := nb_{0}a_{0}^{m}\) are the scale and translation parameters, which depend on the integer m, the dilation parameter. Interchanging variables n and k, and dividing the term \(k-b\) by a, from (1) we have
DWT-based multi-resolution analysis is a decomposition process that can be iterated with successive approximations to obtain many resolution levels.
Let
be the discrete convolution between v(.) and g(.). Notice that (2) and (3) are structurally similar, where v(k) refers to the original signal x(k); \(g(i-k)\) is a filter function that refers to the wavelet function \(g(a_{0}^{-m}n-b_{0}k)\); and \(1/\sqrt{a}\) is the gain term that corresponds to \(1/\sqrt{a_{0}^{m}}\). Thus, DWT multi-resolution analysis can be realized as filter banks, where the filter function is the DWT.
DWTs can be realized using multi-stage filter banks. The original signal x(n) is successively passed through low l(.) and high h(.) pass filters according to the scheme shown in Fig. 1. The low and high-frequency components of x(n) are called approximation and detail coefficients, respectively (Wai and Yibin 1998). Detail coefficients are denoted d1 and d2; ‘\(2\downarrow\)’ means downsampling of 2, i.e., the signal is decomposed in two parts containing higher and lower frequencies; half of the samples are maintained. In this paper, DWT is used to extract features from raw current data, and provide fault indicators to neural network models. Different from a great part of approaches to feature extraction, the energy related to detail coefficients is considered—as will be addressed in the Methodology section. The use of the energy within a time window works as a low-pass filter since individual samples are squared and averaged.

Realization of a discrete wavelet transform
3.2 Evolving intelligent systems
Intelligent systems are widely applied in clustering, classification, control, and prediction problems. Evolving systems is a class of intelligent systems that include mainly fuzzy, neural, and neurofuzzy modeling methods capable of learning from online data streams (Bezerra et al. 2016; Škrjanc et al. 2019). Examples of such systems are given in Hyde et al. (2017), Leite et al. (2019, 2015), Pratama et al. (2017) and Silva et al. (2018). Evolving methods follow a set of procedures in which the central idea is to develop modular models (local models) from scratch as new information arises.
Evolving connectionist systems were introduced in Kasabov (2007) and Watts (2009), as a general term to refer to neural networks with the following specific capabilities:
Structural and parametric adaptation to changing environments, where neurons and connections can be added or removed at any time;
Continuous life-long learning;
Non-exponential growth (scalability) to large amounts of data;
Single-pass (sample-per-sample) incremental training;
Ability to track nonstationarities (concept changes) without accumulating data in memory and/or retraining the neural model from scratch.
Most evolving neural networks are composed by local models, represented by a neuron and adjacent connections (Škrjanc et al. 2019). Local estimations are combined to provide global estimations. Evolving networks are supplied with an incremental learning algorithm that adds new local elements to the net structure if recent data indicate significant differences from what is currently known. In other words, instead of updating the parameters of existing local models to a different class or concept, an evolving network has its structure augmented—being this is an essential feature to avoid ‘catastrophic forgetting’ of information about past events or behaviors. Information revealed from a data stream is seized and stored in local models that can be accessed at any time.
The adaptive artificial neural network, AANN, as described next, is a neural model within the evolving connectionist systems framework. Therefore, evolving intelligence is for the first time considered in the context of HIF detection and location in smart grids with DG.
As HIF classification requires a decision to be made in milliseconds, fast data processing and recursive adaptation procedures are fundamental. Nevertheless, advanced evolving neural structures and more elaborate learning algorithms may be prohibited unless distributed computing is considered. Within the evolving intelligent systems framework, AANN was chosen in this study because the number of operations needed to perform data processing and model adaptation is relatively low.
3.3 Adaptive neural network
An AANN consists of three layers of neurons as shown in Fig. 2. The first and third layers are called input and output layers, and the intermediate layer is the evolving layer. The evolving layer has its connections and neurons developed over time, which is the key feature that differ it from a traditional Multi-Layer Perceptron neural network. This evolving framework is particularly interesting for HIF identification due to its simplicity and fast adaptation.

AANN architecture: the intermediate layer evolves over time
The evolving layer starts with no neurons, i.e., \(n=0\). The first input sample, \(\mathbf {I}_{(j)} = [I_1 ~ I_2 ~ \ldots ~ I_m]'\), \(j=1\), causes the creation of the first neuron. Its input weights, \(\mathbf {W}_{i1} = [W_{11} ~ W_{21} ~ \ldots ~ W_{m1}]'\), match the sample \(\mathbf {I}_{(1)}\). When the next sample arises, a similarity measure is used to calculate how close is the sample to the available neurons, i.e., the sample is compared to the input weights \(\mathbf {W}_{ik}\) of each evolving neuron k; \(k=1,\ldots ,n\). The activation of a neuron based on a sample is given by their similarity. For instance, the activation of the kth neuron of the evolving layer is
where \(D_{jk}\in [0,1] ~ \forall j,k,\) is a normalized distance metric or divergence Cha (2007). Consider the input weight vector of the kth neuron, \(\mathbf {W}_{ik}\), and the jth input vector, \(\mathbf {I}_{(j)}\)—being both m-dimensional column vectors. The Minkowski distance between \(\mathbf {W}_{ik}\) and \(\mathbf {I}_{(j)}\) is
Activation based on (4) and (5) suggests that a sample \(\mathbf {I}_{(j)}\) that matches a pattern \(\mathbf {W}_{ik}\) produces full activation of the neuron. Contrariwise, examples that are far away from a pattern result in a near-zero activation value. In this paper, we use the Euclidean distance, i.e., \(p=2\), what provides a hyper-spherical geometry to intermediate-layer neurons.
Different methods to process data through AANNs are addressed in Watts (2009). In the One-to-N method, only the most activated neuron of the evolving layer transmits an output signal to the output layer. In the Many-to-N method, the neurons that have an activation value greater than a threshold, \(A_{thr}\), transmit their outputs forward. In this paper, the One-to-N method is used as only the class related to the most active neuron is required. The Many-to-N method may be useful in nonlinear function approximation and prediction problems because the weighted contribution of different local models form a real-valued output, similar to the Takagi–Sugeno approach in fuzzy modeling.
The output, \(A_{k}\), of an evolving neuron is multiplied by the weights between the evolving and output layers, \(\mathbf {W}_{kl}\). The output neuron sums the weighted activation levels of the evolving neurons, and uses a saturated linear function to limit its output \(\hat{O}_1\) to [0, 1]. In fault detection, the output is rounded to the nearest integer. In fault location, output data are real values in [0, 1].
Learning consists in fitting a new sample using the weights of an evolving neuron, or adding a new neuron to the network structure. The decision between creating a neuron and updating weights is based on the novelty of the input vector. In case of novelty, the activation degree of the most active neuron is less than a threshold, \(A_{thr}\). New neurons can also be added to the network by measuring the output error and comparing it to a second threshold, \(E_{thr}\). If the values of activation and error are greater and smaller than such threshold values, respectively, no neurons are created. Learning in this case consists in updating the weights of the most activated neuron to fit the new information—being this a common evolving approach in related studies (Kasabov 2007; Leite et al. 2013).
If a neuron is added to the AANN, its input weight vector \(\mathbf {W}_{in}\), \(i = 1,\ldots ,m\), matches the input \(\mathbf {I}_{(j)}\); and its output weight \(\mathbf {W}_{n1}\) is set to the desired output \(\varvec{O}_{(j)}\), when it becomes available. A new neuron in the evolving layer is, in principle, the copy of a sample whose level of novelty is high, according to the threshold values. The information brought by such sample is fully captured by the new neuron. Updating the parameters of other neurons is therefore needless. Naturally, the neural network structure can start its operation from scratch, that is, with no intermediate-layer neurons.
Adaptation of input weights are given by
whereas the output weight is updated based on
Notice that (6) and (7) are recursive equations; \(\eta _1\) and \(\eta _2\) are learning rates; \(A_k\) is the activation level of the kth evolving neuron (4); and
is the estimation error. Equations (6) and (7) guide input and output weights to more appropriate values over time. The last term of (6) refers to the difference (negative or positive) between the current input data and input weights. Input weights (cluster prototypes) are moved toward regions of the data space containing a greater amount of samples. The last term of (7) contains the neural net estimation error (negative or positive). Therefore, while (6) is responsible to reduce the distance between weight vectors and data samples, (7) stands for the minimization of the overall estimation error.
Neuron aggregation combines two neurons into one to keep the model structure compact. The resulting neuron represents all the data inside the region of the data space covered by the original neurons (Watts 2009). Input and output distances among neurons are calculated. If both distances are less than a threshold, \(D_{thr}\), then neurons are aggregated. Input and output distances between two evolving neurons, say, neurons o and p, are computed as
where m is the number of inputs, and
The resulting neuron has as input and output weights the mean values of the combined neurons.
The AANN learning algorithm is summarized below. Notice that the algorithm can be applied to a preconceived network structure. It adds neurons and updates weights similarly. Evolving neural networks are natural candidates for nonstationary classification applications. The approach presented in this section is particularly simple and fast, which is a requirement of the HIF-detection application in question. Notice also that there is no separation of training and test data. The neural model is developed on the fly, online, sample-by-sample. First, an estimated output is given based on the current input data. When the actual output values become available, the input-output data pair is used for an adaptation step, if necessary. In case such input-output pair is considerably different from what is known about the system, i.e., different from the usual patterns represented by the intermediate-layer weight vectors, then a new neuron is created. The weights linked to the new neuron match the sample responsible for its creation. The idea behind such step-by-step testing-before-training learning approach has been employed in many other evolving intelligent methods of the literature (Škrjanc et al. 2019).

An AANN model is supplied with the online incremental learning algorithm described above. The model is, therefore, capable of updating its connectionist structure and parameters over time if necessary, which dictates changes of the decision boundaries among the classes of the problem. Figure 3 shows an example of a sequence of model changes driven by a data stream. First, in a given instant of time, two classes are separated by a nonlinear decision boundary provided by the AANN (Fig. 3a). Then, a slow gradual lateral drift of the data of each class takes place. AANN updates its parameters to track the changes, that is, to move gradually the decision boundary (Fig. 3b). A fast drift of the data, related to Class 2, to the top right corner arises. The AANN decision boundary is changed quickly, since new neurons are created to represent such data samples belonging to a new region of the data space (Fig. 3c). Finally, data samples from a new never-before-seen class (Class 3) arise. New neurons are created, and associated to such new class, which causes an abrupt change (concept shift) of the decision boundary (Fig. 3d).

Examples of parametric and structural changes of AANN to update class boundaries and keep track of gradual and abrupt changes of the data stream
4 Methodology
4.1 IEEE distribution networks and the HIF model
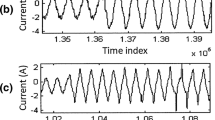
IEEE models of distribution systems, namely the 13-node and 34-node test feeders, were considered as shown in Figs. 4 and 5. Three distributed generators were added to each network, being two of them continuous and time-invariant. The other power source is time varying and may represent sources supplied by, e.g., wind (which changes due to wind speed variations), photovoltaic energy (which changes due to variations in luminosity), and so on. The continuous power generators contribute with 74 and 82 KVA to the network while the time-varying source adds from 116 to 162 KVA. The generator circuit consists of a continuous power source with adjustable voltage coupled with a DC-AC converter. Third and fifth order harmonics with amplitude of 10% and 5% of that of the fundamental waveform are added to the DG signals. Notice in Fig. 6 how distributed generation affects the current waveform and the detail coefficient of a wavelet transform, such as the D1 coefficient of a Symlet wavelet in the case. Time-varying distributed generation imposes significant difficulties to fault detection and identification systems.

IEEE 13-node test feeder model

IEEE 34-node test feeder model

Example of how distributed generation may affect currents and wavelet detail coefficients in a distribution system
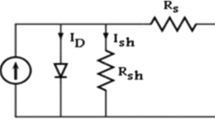
A HIF can be modeled in ATP Draw using passive components. The model known as the anti-parallel diode model (Costa et al. 2015; Emanuel et al. 1990; Torres et al. 2014; Zamanan and Sykulski 2014) is taken into consideration, see Fig. 7. Aspects of a real HIF behavior, such as nonlinearities, asymmetries, low-frequency transients and high-order harmonics, are included in this model. In the figure, \(D_i\), \(L_i\), \(R_i\) and \(V_i\) refer to values of the positive and negative components of the passive AC circuit. Inductances \(L_i\) are included to represent the high inductance, which is typical in circuits that produce arcs (Zamanan and Sykulski 2014).

High impedance fault model
The HIF model is useful to generate fault samples to evaluate the performance and robustness of pattern recognition models and methods. Similar to the distributed generators, HIF also introduce harmonics to the current waveform, as previously remarked by, e.g., Emanuel et al. (1990). HIF harmonics are also nonstationary, which leads Fourier transform and frequency-domain methods to be less efficient.
HIF change a power distribution network mainly because the load is partially disconnected. For instance, in Fig. 8, the impedance \(Z_2 = \sqrt{R^2_2 + X_{L_2}^2}\) is disconnected in consequence of the fault. As a result, voltages and currents change because the equivalent impedance, \(Z_1 + Z_{HIF}\), where \(Z_1 = \sqrt{R^2_1 + X_{L_1}^2}\), is different. Since the impedance of a power system tends to be proportional to its length, the relationship between voltages and currents is useful to estimate the distance to the fault point.

Example where a HIF isolates the \(Z_2\) part of the system
Meanwhile, an intelligent classifier may be developed to identify particular nonlinear patterns on the data; however, the fault current pattern may change over time due to several non-controlled aspects, such as DG, noise, and nonlinearities (Ghaderi et al. 2017, 2015). Different HIF locations and types of contact surfaces impose further difficulties. Contrasting current signatures may take place in such a way that non-adaptive intelligent classifiers would require a historical dataset containing samples that represent all possible occurrences for offline training, which is infeasible. The proposed learning method evolves a neural network on-demand, in real-time, according to new information found in the data stream. Therefore, a historical dataset is not needed. Parameter learning and structural development start from scratch, without prior training. The data are processed and then used for model adaptation if necessary.
4.2 Feature extraction
Different wavelet transforms, Daubechies, Symlet, and Biorthogonal, are used to extract features from raw current and voltage data. For each wavelet, a two-level decomposition is performed, where only detail coefficients are analyzed. The idea is that the system behavior under a fault condition becomes evident from the signature or the energy of a specific detail coefficient.
A time window containing two cycles of sinusoidal waves is assumed. This is equivalent to 33 ms, hence the 60 Hz frequency of the underlying power system. A 50 \(\upmu\)s sampling period was used for the acquisition of voltage and current signals (measures from the secondary winding of power transformers). Current data into a time window is passed forward to a DWT algorithm. Detail coefficients from multilevel decomposition are calculated. The energy of a detail coefficient, \(D_i\), is given as
where x is the amplitude of the data in a time window, and \(N = 667\) is the number of samples in the time window. Notice that the square term in relation (11) suppresses noise in a natural way. In other words, the energy of detail coefficients gives reliable and robust samples to be used as inputs of fault detection and identification models.
The energy of the first and second wavelet detail coefficients obtained from current signals is used for HIF detection, whereas the voltage and current expressed in effective values are used for HIF location. HIF location methods using voltage and current waveforms directly were considered in Garcia-Santander et al. (2005), Santos et al. (2017) and Silva et al. (2013). The relationship between voltages and currents are correlated with the distance between the HIF and the monitoring point (Etemadi and Sanaye-Pasand 2008).
An AANN model is used to detect HIF, i.e., to distinguish HIF from common phenomena in a smart grid with distributed generation. If a HIF is detected, the output of the detection AANN (\(\{0,1\}\)) triggers a second AANN, which is useful to estimate the HIF location. Notice that the neural networks have a different pair of inputs. The first uses the energy of the first and second current detail coefficients. The second uses the effective values of the voltage and current waveforms. Energies and effective values are calculated at every two cycles. The output of the location AANN is an estimation of how distant is the HIF from the monitoring station.
4.3 Parameters of neural network models
Neural networks are known to be able to deal with nonlinear relations between variables and classes. This section describes the initial parameters of the proposed evolving neural network, AANN, and those of other neural networks used to compare the system performance. The alternative neural models are: feed-forward multi-layer perceptron (MLP) (Haykin 2008), radial basis function (RBF) (Yee and Haykin 2001), and recurrent Elman (ELM) (Haykin 2008) neural networks. Classifiers are trained and tested using the same data. The inputs of the HIF detection networks are the energy of the first and second detail coefficients of the current waveform calculated based on a two-cycle time window. The output refers to the presence or absence of faults in the power system.
A second neural network (of the same type of the first) is used to locate HIF when trigged by the first neural network. Its inputs are the effective values of the current and voltage waveforms based on a two-cycle time window. Its output is the normalized distance to the fault point. Details on the parameterization of the different neural classifiers are given below.
MLP: The patternnet and train Matlab functions were used to build a feed-forward network model. Neurons of the single hidden layer contain sigmoidal activation functions, whereas output neurons use softmax functions. Simulations pointed that 30 and 39 hidden neurons in the detection and location networks, respectively, provided the best overall performance. The training algorithm is the Scaled Conjugate Gradient, which in Matlab requires no learning rate definition. The usual number of training epochs of each network was between 1000 and 2000.
RBF: 3-layer RBF neural networks were created using the Matlab neural network toolbox. Spreads of radial functions are initial parameters to be set. Simulations suggested that near-zero, small initial spread values provide the best performance. A near-zero value makes an RBF network play the role of a nearest neighbor classifier. For HIF detection, the spread was set to 0.5 and the number of hidden neurons to 50. For fault location, the spread was 0.6 and the number of hidden neurons, 67. Neurons of the hidden layer have competitive activation based on the Euclidean distance between samples and centroids.
ELM: 3-layer ELM neural networks were investigated. Neurons of the single hidden layer are based on sigmoidal functions whereas output neurons use softmax functions. The hidden layer is connected to context units through back connections. Context units save a copy of the previous output values of the hidden neurons. Thus, the ELM network maintains a sort of short-term memory, which potentially allows it to perform sequential tasks better than feed-forward networks. Simulations recommended 30 and 45 hidden neurons to the detection and location models, respectively. The training algorithm is the Gradient Descent. The number of training epochs varied from 1000 to 2000.
AANN: The AANN detection and location models, as described in the previous section, use the following parameters: \(A_{thr} = 0.9\); \(E_{thr} = 0.05\); \(D_{thr} = 0.1\); \(\eta _1 = \eta _2 = 0.02\). Generally, if \(A_{thr}\), \(E_{thr}\) and \(D_{thr}\) are set within the ranges [0.8, 0.95], [0.02, 0.1] and [0.05, 0.2], respectively, the learning algorithm produces slightly larger or smaller, but consistent and effective structures in different detection problems considering different smart grids. Their roles are essentially the same; they are important for the decision on either updating the parameters or expanding/contracting the neural network. The choice of parameters is subjective as the number of neurons in the evolving layer (patterns in a data stream) is unpredictable and time-varying. The number of neurons also varies depending on the wavelet and detail coefficient used in preprocessing steps. Usual values for the final number of evolving neurons range from 14 to 34 for HIF detection, and from 27 to 48 for HIF location.
4.4 Training and testing datasets
Three ATP simulations were performed from the IEEE 13-node and 34-node feeders. All datasets generated are balanced. In other words, after windowing the time after every two cycles of the current and voltage waveforms, training (testing) datasets contain, 119 (299) samples—being 60 (150) samples related to the normal operation of the system and 59 (149) samples related to HIF. Notice that the separation between training and testing data is useful for offline training of the other neural models under comparison. AANN learns online, from test data, and, therefore, all the data are scanned only once.
The first simulation intends to construct a dataset to train the classifiers. HIF and usual events, such as capacitor switching and transformer energizing, were considered. The latter are common transient events that should be classified as normal operation situations. The simulation time was 4 s, which produced the 119 training samples.
The second simulation uses the 13-node and 34-node feeders without distributed generation to provide datasets to test the classifiers. The testing datasets contain new situations such as HIF in different nodes and different transient events. The simulation time was 10 s.
The third simulation considers distributed generation and the same 13-node and 34-node feeders. The datasets are also used to test the classifiers; they involve novelties such as those associated to the effects of time-varying distributed generation, HIF in different nodes, and usual, but different, transients. The simulation time was also 10 s.
5 Results
Different wavelet transforms, Daubechie 7 (db7), Symlet 2 and 7 (sym2, sym7), and Biorthogonal 5.5 (bior5.5), as well as different detection and location neural models, namely, feed-forward MLP, radial-basis RBF, recurrent ELM, and evolving AANN, are compared in this section. The distribution systems, viz., the IEEE 13-node and 34-node test feeders, were subject to HIF, distributed generation, and usual transients.
First, the detection and location classification systems are compared using the test datasets, with and without distributed generation. Different pairs of neural networks and different wavelet families were contrasted in the sense of estimation of the distance to the fault point. Figures 9 and 10 show the overall performance of the HIF detection and location systems for the 13-node and 34-node feeders.

Performance of the different wavelet-neural systems for the 13-node feeder

Performance of the different wavelet-neural systems for the 34-node feeder
From Fig. 9 we notice that the effect of distributed generation reduced the accuracy of all classification systems—as expected due to the introduction of additional harmonic components. Interestingly, the average performance reduction of the evolving AANN is smaller than that of the remaining neural models. Its accuracy reduced about 1.8% against 4.0%, 6.0% and 6.6% of the ELM, RBF and MLP neural networks, respectively, for the 13-node feeder. In other words, from the results we can infer that the AANN system has shown to be more robust to the effects of distributed generation.
The sym2 mother wavelet produced detail coefficients that are more discriminative of faulty conditions. The highest performance in both scenarios, with and without DG, was achieved using a combination of sym2 and detection and location AANNs. The highest performance for the 13-node feeder was \(97.3\%\) and \(96.3\%\) for the sym2-AANN system, with and without DG.
AANN robustness to changes is explained by its evolving structure and ability to self-adapt parameters. After processing the data stream that is used to train the other neural models, the location AANN developed 15 neurons when coupled to the detection sym2-AANN model. Its structure evolved from 15 to 29 and 21 neurons for the 13-node feeder with and without DG, respectively. Structural and parametric adaptability to novelties is the key aspect to AANN robustness to changes, and efficiency.
Figure 10 shows the results for the 34-node feeder. Similar tendencies compared to those for the 13-node feeder can be observed, though performance reduction due to distributed generation is certainly higher. HIF and DG in a larger distribution system, such as the 34-node feeder, may be noted from a main station in more varied ways. Therefore, a higher difference on the accuracy of a same wavelet-neural system due to the existence of DG is reasonable. Nevertheless, AANN presented the smallest accuracy reduction and the highest robustness among the neural models. Accuracies decreased in average \(3.9\%\), \(9.0\%\), \(9.0\%\) and \(10.4\%\) for the AANN, ELM, RBF and MLP, respectively. Furthermore, the sym2-AANN and sym7-AANN combinations provided the best detection and location results for the DG and non-DG 34-node feeder context, respectively, considering all possibilities of wavelet families and neural networks. An accuracy of \(96.0\%\) and \(92.0\%\) can be noticed from Fig. 10.
The decision boundaries of the detection neural networks for the 34-node system using sym2 for feature extraction, whether or not under the influence of DG, are shown in Figs. 11 and 12. For the system with and without DG, the accuracies were 90–94%, 86–93%, 84–91% and 81–88%, regarding correct discriminations between HIF and normal occurrences for AANN, ELM, RBF and MLP, respectively.

HIF classification considering the 13-node feeder without distributed generation

HIF classification considering the 34-node feeder with distributed generation
A main difference between the decision boundaries can be noticed in the upper left corner of Figs. 11 and 12, where normal and HIF data superpose with one another. The MLP and RBF learning algorithms become indecisive about the values of connection weights because they are based on spatial information only. While some data samples in the region suggest adaptation of connection parameters in one direction, other samples recommend the opposite. ELM and AANN use not only spatial, but also temporal information to deal with such conflict. Different from MLP and RBF, hidden recurrences in ELM undoubtedly help the neural network to move its HIF boundary toward the conflicting region. However, AANN, by considering a data stream and structural and parametric adaptation, is more flexible to handle conflicts because new neurons are evolved to represent different patterns in a same region. The conflicting region is partitioned in smaller sub-regions, which are represented by different neurons.
Results on HIF location are valuable as supplementary information to assist decision making. Detected HIFs activate the location neural models, which, in turn, utilizes the effective values of the current and voltage waveforms—measured at the monitoring station based on two cycles—to provide an estimation of the distance to the fault point. Figure 13 summarizes the percentage error produced by the location models in function of the distance to the fault point. Notice that the evolving AANN location model produces the best estimates in both smart grids either considering the existence of DG sources or not. The percentage error is clearly greater when DG sources exist in a power system, and slightly greater for the larger 34-node grid compared to the 13-node grid. Usual values for the final number of evolving neurons in the location AANN range from 27 to 48 depending on the type of wavelet used.

Performance of different neural models on HIF location
A general observation from the experiments is that harmonics due to distributed generation and common transient events are perceived as perturbation in the input data vectors of the neural classifiers. The effective value of current and voltage waveforms as well as features extracted from the currents, such as the energy of detail coefficients of the sym2 wavelet, may significantly improve the performance of a HIF detection and location system. HIF detection and location performance tend to deteriorate for larger distribution systems subject to a larger variety of phenomena. The use of an evolving neural network, such as AANN, has rather shown efficiency and robustness to changing environments.
6 Conclusion
This paper presents an evolving intelligent method for high impedance fault detection and location in time-varying distributed generation systems. The method is based on wavelet transforms and a pair of structurally adaptive neural networks. Wavelet transformation is useful to generate features to discriminate between faults and usual events in a smart grid. The detection neural network uses the energy of the first and second detail coefficients of the wavelet transform of current waveforms calculated over a two-cycle time window, and triggers a fault location neural network. The location network processes effective values of voltage and current waveforms to estimate the distance to the fault point. A specific wavelet transform, Symlet 2 (sym2), allowed the proposed adaptive system to differentiate fault patterns from events such as capacitor switching and transformer energizing. Moreover, effects of time-varying distributed generation were taken into consideration.
Results have shown advantages on the use of the sym2 wavelet as feature extraction method compared to db7, sym7, and bior5.5 in scenarios with and without distributed generation. The proposed AANN detection model achieved accuracies of about 91.0–97.3%. These accuracies are better than those reached by a feed-forward MLP, a radial-basis RBF, and a recurrent Elman neural network. The AANN location model provided distance errors of less than 5% and 9.9% in a 13-node and a 34-node grid of approximately 4 and 55 km long, respectively—both grids subject to time-varying distributed generation. The evolving AANN clearly outperformed the remaining neural models in all cases of HIF location. Additionally, AANN has shown to be more robust than MLP, RBF and ELM in dealing with variations and novelties considering different distribution systems. The key point is that AANN provides more flexible decision boundaries between classes because new neurons are incrementally added to its structure to represent different patters occurring in regions with conflicting data.
In the future, the proposed evolving intelligent system will be supplied with new online learning procedures, and tested on very large smart grids. As processing time is a typical concern, evolving models and algorithms will be realized in hardware.
References
Andonovski G, Music G, Blazic S, Skrjanc I (2018) Evolving model identification for process monitoring and prediction of non-linear systems. Eng Appl Artif Intell 68:214–221
Angelov P, Gu X (2018) Deep rule-based classifier with human-level performance and characteristics. Inf Sci 463:196–213
Baqui I, Zamora I, Mazn J, Buigues G (2011) High impedance fault detection methodology using wavelet transform and artificial neural networks. Electr Power Syst Res 81:1325–1333
Bezerra C, Costa B, Guedes LA, Angelov P (2016) An evolving approach to unsupervised and real-time fault detection in industrial processes. Expert Syst Appl 63:134–144
Bretas AS, Moreto M, Salim RH, Pires LO (2006) A novel high impedance fault location for distribution systems considering distributed generation. In: IEEE/PES transmission and distribution conference, pp 433–439
Bretas AS, Pires L, Moreto M, Salim RH, Huang D, Li K, Irwing G (2006) A bp neural network based technique for hif detection and location on distribution systems with distributed generation. Int Conf Intell Comput 4114:608–613
Cha SH (2007) Comprehensive survey on distance/similarity measures between probability density fuctions. Int J Math Models Methods Appl Sci 1(4):300–307
Costa FB, Souza BA, Brito NS, Silva JAC (2015) Real-time detection of transients induced by high impedance faults based on the boundary wavelet transform. IEEE Trans Ind Appl 51(6):5312–5323
Emanuel A, Cyganski D, Orr J, Shiller S, Gulachenski E (1990) High impedance fault arcing on sandy soil in 15 kv distribution feeders: contributons to the evaluation of the low frequency spectrum. IEEE Trans Power Deliv 5(2):676–686
Etemadi AH, Sanaye-Pasand M (2008) High-impedance fault detection using multi-resolution signal decomposition and adaptive neural fuzzy inference system. IET Gener Transm Distrib 2(1):110–118
Ezzt M, Marei MI, Abdel-Rahman M, Mansour MM (2007) A hybrid strategy for distributed generators islanding detection. In: IEEE Power Engineering Society conference & expo, pp 1–7
Garcia C, Leite D, Skrjanc I (2019) Incremental missing-data imputation for evolving fuzzy granular prediction. IEEE Trans Fuzzy Syst 1–15. https://doi.org/10.1109/TFUZZ.2019.2935688
Garcia-Santander L, Bastard P, Petit M, Gal I, Lopez E, Opazo H (2005) Down-conductor fault detection and via a voltage based method for radial distribution networks. IEEE Proc Gener Transm Distrib 152(2):180–184
Ghaderi A, Ginn HL, Mohammadpour HA (2017) High impedance fault detection: a review. Electr Power Syst Res 143:376–388
Ghaderi A, Mohammadpour HA, Ginn H (2015) High impedance fault detection method efficiency: simulation vs real-world data acquisition. In: IEEE power & energy conference, pp 1–5
Gomez JC, Vaschetti J, Coyos C, Ibarlucea C (2013) Distributed generation: impact on protections and power quality. IEEE Latin Am Trans 11(1):460–465
Haykin S (2008) Neural networks and learning machines, 3rd edn. Pearson, London
Hyde R, Angelov P, Mackenzie A (2017) Fully online clustering of evolving data streams into arbitrarily shaped clusters. Info Sci 382:96–114
Ibrahim DK, Eldin E, Aboul-Zahab E, Saleh S (2010) Real time evaluation of DWT-based high impedance fault detection in EHV transmission. Electr Power Syst Res 80:907–914
Kasabov N (2007) Evolving connectionist systems: the knowledge engineering approach. Springer, Secaucus
Kim CH, Aggarwal R (2000) Wavelet transforms in power systems. Power Eng J 14(2):81–87
Leite D, Andonovski G, Škrjanc I, Gomide F (2019) Optimal rule-based granular systems from data streams. IEEE Trans Fuzzy Syst 1–14. https://doi.org/10.1109/TFUZZ.2019.2911493
Leite D, Ballini R, Costa P, Gomide F (2012) Evolving fuzzy granular modeling from nonstationary fuzzy data streams. Evol Syst 3(2):65–79
Leite D, Costa P, Gomide F (2013) Evolving granular neural networks from fuzzy data streams. Neural Netw 38:1–16
Leite D, Palhares R, Campos V, Gomide F (2015) Evolving granular fuzzy model-based control of nonlinear dynamic systems. IEEE Trans Fuzzy Syst 23(4):923–938
Lucas F, Costa P, Batalha R, Leite D (2018) High impedance fault detection in time-varying distributed generation systems using adaptive neural networks. In: International joint conference on neural networks (IJCNN), pp 1–8
Lughofer E, Pratama M, Skrjanc I (2017) Incremental rule splitting in generalized evolving fuzzy systems for autonomous drift compensation. IEEE Trans Fuzzy Syst PP(99):1-1
Mohamad S, Sayed-Mouchaweh M, Bouchachia A (2018) Active learning for classifying data streams with unknown number of classes. Neural Netw 98:1–15
Mora-Florez J, Melendez J, Carrillo-Caicedo G (2008) Comparison of impedance based fault location methods for power distribution systems. Electr Power Syst Res 78(4):657–666
Pratama M, Anavatti SG, Angelov P, Lughofer E (2014) Panfis: a novel incremental learning machine. IEEE Trans Neural Netw Learn Syst 25(1):55–68
Pratama M, Lughofer E, Lim C, Rahayu W, Dillon T, Budiyono A (2017) A novel evolving semi-supervised classifier. Int J Fuzzy Syst 19:863–880
Rubio JJ (2009) Sofmls: online self-organizing fuzzy modified least-squares network. IEEE Trans Fuzzy Syst 17(6):1296–1309
Rubio JJ (2014) Evolving intelligent algorithms for the modeling of brain and eye signals. Appl Soft Comput 14(B):259–268
Santos WC, Lopes FV, Brito NSD, Souza B (2017) High impedance fault identification on distribution networks. IEEE Trans Power Deliv 32(1):23–32
Sedighi AR, Haghifam MR, Malik OP (2005) Soft computing applications in high impedance fault detection in distribution systems. Electr Power Syst Res 76:136–144
Sedighizadeh M, Rezazadeh A, Elkalashy NI (2010) Approaches in high impedance fault detection: a chronological review. Adv Electr Comput Eng 10(3):114–128
Silva JA, Neves WL, Costa FB, Souza BA, Santos WC (2013) High impedance fault location; case study using wavelet transform and artificial neural networks. In: International conference on electricity distribution, pp 1–4
Silva S, Costa P, Gouvea M, Lacerda A, Alves F, Leite D (2018) High impedance fault detection in power distribution systems using wavelet transform and evolving neural network. Electr Power Syst Res 154:474–483
Škrjanc I, Iglesias JA, Sanchis A, Leite D, Lughofer E, Gomide F (2019) Evolving fuzzy and neuro-fuzzy approaches in clustering, regression, identification, and classification: a survey. Inf Sci 490:344–368
Torres V, Guardado JL, Ruiz HF, Maximov S (2014) Modeling and detection of high impedance faults. Int J Electr Power 61(1):163–172
Wai DC, Yibin X (1998) A novel technique for high impedance fault identification. IEEE Trans Power Deliv 13(3):738–744
Watts JM (2009) A decade of evolving connectionist systems: a review. IEEE Trans Syst Man Cybern 39:253–269
Xiangjum Z, Li KK, Chan WL, Sheng S (2004) Multi-agents based protection for distributed generation systems. In: IEEE international conference on electric utility deregulation, restructuring and power technology, pp 393–397
Yee P, Haykin S (2001) Regularized radial basis function networks: theory and applications. Wiley, New York
Zamanan N, Sykulski J (2014) The evolution of high impedance fault modeling. In: IEEE international conference on harmonics and quality of power, pp 77–81
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
This study was funded by Instituto Serrapilheira (Grant no. Serra-1812-26777) and Javna Agencija za Raziskovalno Dejavnost RS (Grant no. P2-0219).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Lucas, F., Costa, P., Batalha, R. et al. Fault detection in smart grids with time-varying distributed generation using wavelet energy and evolving neural networks. Evolving Systems 11, 165–180 (2020). https://doi.org/10.1007/s12530-020-09328-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12530-020-09328-3