
Abstract
In this day and age, most environmental researchers use satellite data for monitoring and assessing of water quality indicators since the traditional methods are both time- and money-consuming. One of the most important water quality parameters that can be assessed in coastal waters and river estuaries using remote sensing techniques is suspended sediment concentration (SSC). It regulates primary production and has substantial influence on the migration of pollutants, temperature, and marine life. In this study, Moderate-Resolution Imagine Spectrometry (MODIS) images were used to retrieve the SSC along the southern coast of the Caspian Sea. MODIS of 250 m resolution data were utilized because they have the highest spatial resolution of all the MODIS bands. In situ data were gathered with multiple campaigns with fast motor boats, while the MODIS sensor was passing over the study area. The goal of this article is to apply artificial neural networks (ANN) to retrieve SSC from satellite remote sensing imagery. ANN function as an intelligent structure to model a variety of nonlinear relationships because iteration-based inversion methods need long computation times for common usage. Using a validation data set and a testing data set, the network could be validated. The learning process was more efficient which resulted in a shorter learning time. The validation data set played a vital role as a stopping criterion during the training procedure to overcome the overtraining problem. A robust relationship between MODIS bands 1 and 2 and in situ data was established based on a three-layer ANN with six neurons in the hidden layer. Root mean squared error and R 2 values for this model were 0.853 and 0.969 mg/L, respectively, for all data. Results of this study reveal that the SSC in the Caspian Sea gradually decreases from west to east.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
According to Morel and Prieur (1977), waters can be defined as belonging to two optical classification types: case I and case II. Waters that are highly affected by phytoplankton concentration, such as open ocean areas, are called case I waters. Case II waters, such as inland and coastal waters, are basically a function of resuspended sediment, colored dissolved organic matter (CDOM), dissolved matter, and strongly concentrated phytoplankton blooms (Miller et al. 2004).
Coastal regions are important economic and social zones. The coastal zones from 200 m above to 200 m below sea level occupy about 18 % of the globe's surface. They are where about 60 % of the human population live, they supply around 90 % of the world's fish catch and 25 % of primary productivity occurs in this area (Cracknell 1999). High-quality coastal waters can affect healthy habitat and local usages and attract local and overseas tourism.
The southern coast of the Caspian Sea is heavily polluted and thus, the Caspian environment is under tremendous stress due to extensive exploitation and discharge of large magnitudes of human waste, including industrial and agricultural wastewaters, municipal domestic sewage waters, heavy metals, oil and petroleum products, nutrients (phosphate and nitrate), and pesticides (Korshenko and Gul 2005).
The traditional methods for monitoring and assessing water quality include in situ data measurements or collecting the samples for analysis subsequently in the laboratory. The conventional methods are also based on the fixed stations. These methods provide careful measurements for a specific time and place. However, they are not suitable for water quality monitoring in large water bodies because they are expensive and do not provide proper observations for water quality assessment and managing purposes (Schmugge et al. 2002).
Remote sensing techniques provide both spatial and temporal views of surface water quality parameters that are not achieved by in situ measurements. The traditional methods tend to be time-consuming and do not provide sufficient data (Kaya et al. 2006). Applying remote sensing for assessing water quality parameters illustrates clearly the capability of these synoptic, frequent and relatively cheap measurements by aircraft and spacecraft instruments.
Suspended sediment monitoring is vital for river management and environmental protection (Azamathulla et al. 2013). Satellite platforms have been used for remote sensing studies of suspended sediment since the late 1970s (Ritchie and Schiebe 2000). During the past few years, researchers have employed different satellite sensors to study the suspended sediments: Advanced Very High-Resolution Radiometer (AVHRR) (Myint and Walker 2002; Froidefond et al. 1999; Kaya et al. 2006; Aguirre-Gomez 2000), Sea-viewing Wide Field-of-view Sensor (Sea WiFS) (Warrick et al. 2004; Binding et al. 2003; Figueras et al. 2004), Thematic Mapper (TM) (Tassan 1998; Östlund et al. 2001), Enhanced Thematic Mapper (ETM) (Ma and Dai 2005; Wang et al. 2007; Alparslan et al. 2007), Satellite Pour I'Observation de la Terre (SPOT) (Doxaran et al. 2002), Indian Remote Sensing (IRS) Satellite P6 LISS III (Prabaharan et al. 2013), and Medium-Resolution Imaging Spectrometer (MERIS) (Moore et al. 1999). Some studies have derived case 2 water algorithms which are based on one sensor. Eleveld et al. (2008), for instance, presented a single-band algorithm (named POWERS) which calculates the suspended particle matter concentration from SeaWiFS datasets for the turbid water of southern North Sea. Others benefited from multiple sensors' approach. In the study of Nechad et al. (2010), a space-based optical multisensor algorithm was developed to retrieve total suspended matter concentration in turbid water. This algorithm is suitable for any ocean color sensor including MERIS, Moderate Resolutions Imagine Spectrometry (MODIS), and SeaWiFS (Nechad et al. 2010). The innovation of this study is the hyperspectral calibration which is used to identify the best spectral interval for total suspended matter retrieval from remote-sensed reflectance, while the semiempirical approach takes into account assumptions on spatial and temporal variability of specific inherent optical properties (IOPs) (Nechad et al. 2010).
However, some characteristics of remote sensing instruments limit their application to operational monitoring of suspended sediments in coastal areas. The most common limitation is the spatial resolution of the instrument (Miller and McKee 2004). AVHRR and SeaWiFS sensors are of 1-km spatial resolution and are thus not suitable for estuaries and small local zones. While Landsat sensors like TM and ETM have good spatial resolution (30 m), their temporal resolution (a low frequency return time of 16 days) is not appropriate for coastal area monitoring. Cloud cover can reduce temporal sampling rates from Landsat and other high-resolution instruments even further. Another problem limiting the application of remote sensing data is related to the instrument's costs.
The MODIS instrument is a sensor on the Terra spacecraft that has provided comprehensive information about land, ocean, and atmospheric processes since February 2000. The global coverage consists of 36 spectral bands from 0.4 to 14.4 μm. Its spatial resolution depends on the wavelength (250, 500, or 1,000 m). MODIS collects measurements from the entire Earth surface every 1 to 2 days.
Numerous satellite remote sensing studies have demonstrated significant relationships between radiance or reflectance from spectral wave bands or combinations of wave bands and suspended sediments. In addition, they have tried to determine the optimal portions of the spectrum for tracking suspended sediment concentration (SSC). The results indicate that there is strong evidence that reflectance in both the visible (esp. red) and near-infrared portions of the spectrum can successfully track SSC (Pavelsky and Smith 2009; Doxaran et al. 2002; Ritchie et al. 1976, 2003). When the SSC increases, the amount of reflectance will be saturated (Ritchie et al. 2003). Other remote sensing investigations of suspended sediments have determined that many wavelengths can be used, and optimum wavelength is associated with SSC (e.g., Curran and Novo 1988).
Among alternatives for the design of a case 2 water algorithm, Doerffer and Fischer (1994) were among the first who used an optimization technique to extract water constituents from CZCS data. The proposed inverse modeling technique encompassed water and atmosphere in one model. Later, they developed a neural network based on a case 2 water algorithm for the ground processor of MERIS which has been designed mainly for ocean and coastal water remote sensing with special resolution of 300 m for nine bands in visual domain together with the revisit period of 1 to 3 days (Doerffer and Schiller 2007). The developed algorithm showed that a neural network can be efficient and accurate for the water color remote sensing.
The artificial neural network (ANN) has the ability to learn complex and nonlinear relationships that are difficult to model with conventional methods. The integration of remote sensing data is more convenient using neural networks since they allow the target classes to be defined in relation to their distribution in the corresponding domain of each data source (Pradhan and Buchroithner 2010). The ANN technique has become an increasingly popular tool for water quality modeling among environmental researchers during the last two decades (e.g., Keiner and Yan 1998; Panda et al. 2004). Keiner and Yan (1998) employed a model of neural network to monitor the coastal water quality of the mouth of the Delaware Bay. Their model was constituted by a three-layer neural network and applied back propagation error (BPE) in the training procedure.
This paper explores the application of MODIS images to suspended sediment monitoring in coastal waters of the southern part of the Caspian Sea. Also, a neural network algorithm was established to model a relationship between SSCs and MODIS near-infrared bands.
Materials and methods
Case study area
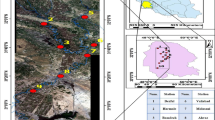
The Caspian Sea is the largest inland water body in the world (Kosarev and Yablonskaya 1994). It is surrounded by five countries: Iran, Federation of Russia, Azerbaijan, Turkmenistan, and Kazakhstan (see Fig. 1). The Caspian Sea has a surface area of ~436,000 km2. It is the world's largest lake, being 1,200-km long with an average width of 330 km (width varies between 204 and 566 km; De Mora et al. 2004). The Caspian Sea is divided into three parts. The shallow area is in the northern part, with an average depth of ~5 m and a maximum depth of 20 m. The middle part is relatively deep, with a maximum depth of ~788 m (De Mora et al. 2004). The southern part of the Caspian Sea is located north of Iran. Golestan, Mazanderan, and Guilan are three Caspian coastal counties of Iran. The deepest zone of the Caspian Sea, with around 1,025-m depth, was found in the southern part (Khoshravan 2007). The salinity gradient increases from north to south (Kosarev and Yablonskaya 1994). The salinity is low in Caspian Sea surface water but can affect some endemic zooplankton and phytoplankton species along a gradient from north to south. The sea level has changed during the past decades. By increasing around 2.5 m since 1997, the sea level is now around 27 m below mean global sea level (De Mora et al. 2004). There are nearly 130 rivers which drain into this sea (De Mora et al. 2004). The greatest flow input comes from the Volga, Emba, Ural, and Terek rivers. About 61 rivers are from the Iranian Caspian coast. Iranian rivers annually transmit around 33 million tons of sediments and 11 km3 of water into the Caspian Sea. The Sefidrud River has the most important role in the transportation of the sediment. The temperature is variable between different parts of the Caspian Sea. The surface water temperature in the southern part varies between 9 °C in winter and 26 °C in summer. The quality of the Caspian Sea water plays a great role in the fishing industry. Recent environmental changes in the Caspian Sea have attracted the attention of researchers.

Map of the study area (source: http://www.eurodialogue.org/files/fckeditor_files/caspian-sea_186.jpg)
{kind=link}
Data
In situ data
The in situ data were collected while the MODIS sensor onboard the Terra satellite was simultaneously passing over the study area. The samples were taken by motor boat in several missions over May 2007. The measurement depth was 0.5 m. Total suspended sediment concentration (milligrams per liter) was determined gravimetrically following the procedures outlined by Strickland and Parsons (1972). A known volume of water was filtered through preweighed 0.7-μm GF/F filters. Then, all filters were rinsed with Milli-Q water to eliminate salts and dried in a drying oven until they attained a constant weight after which reweighting was done on a high-precision balance and the new weight recorded. Samples were stored in acid-washed amber plastic bottles until filtered in water quality laboratory of Tarbiat Modares University. Stored samples were filtered within 3 days of collection. The concentration ranges of sediment samples were between 5.32 and 24.95 mg/L. The 57 samples were obtained within 30 min before or after a MODIS Terra overpass. The data collection was done in May in which the cloud cover is relatively minimum over the study area. For each in situ position, one pixel was taken from the corresponded satellite image.
Satellite remote sensing data
Because of its high temporal and spectral resolution and previous successful applications of MODIS images for monitoring coastal areas (Miller and McKee 2004; Katlane et al. 2013), the MODIS sensor was used as satellite data in this investigation. Also, MODIS data are free of charge and are readily available from the NASA MODIS website. Table 1 presents a list of 15 analyzed images used in the study.
Geometric and atmospheric corrections were carried out on the MODIS images. The geometric correction was done using known coordinate system in the study area (UTM, zone 39 north). The dark pixel approach was used for the atmospheric correction. This technique, which is based on the concept of zero water leaving radiance at near-infrared wavelengths, determines the pixel in the image with the lowest brightness value. This pixel is supposed to have zero ground radiance, so that its radiometric value shows the additional impact of the atmosphere and should be subtracted from all the pixels. The land and cloud masking were done using an experimental algorithm. The initial approach was to use the raw digital values of band 2 and then determine the minimum value for land. Anything greater than this value was considered land or cloud and masked. Since the value of Normalized Difference Vegetation Index (NDVI) is negative over water surfaces, this index was also used to check the accuracy of applied empirical threshold. By applying this simple but effective mask, we were able to eliminate land and clouds for processing thereby greatly reducing computation time. Bands 1 and 2 are the most interesting bands of MODIS images because they have the highest spatial resolution (250 m) of all MODIS bands. The wavelength ranges of MODIS bands 1 and 2 are 620–670 and 841–876 nm, respectively. These bands were used for retrieving the suspended sediments in coastal areas of the Caspian Sea.
In this study, regression analyses and artificial neural networks were considered to establish an accurate model of SSC field data and remote sensing reflectance of MODIS bands 1 and 2. A large number of studies have shown a nonlinear relationship between suspended sediments and their radiance or reflectance (Ritchie et al. 1976; Curran and Novo 1988).
Linear regression analysis can estimate nonlinear functions with two limitations: first, linear regression needs perfect information about the nature of the function's nonlinearity. Second, it can approximate the nonlinear functions only over small ranges. However, a neural network can reasonably approximate the nature of linear and nonlinear transfer function (Keiner and Yan 1998).
Artificial neural network
Definition and background
In the present investigation, an ANN was also applied, which is a feed-forward multilayer perceptron (MLP). An MLP ANN has several layers: input layer, hidden layer(s), and output layer. There are many nodes in each layer, called neurons.
The structure of one neuron is shown in Fig. 2. The overall behavior of each neuron can be modeled as Eq. (1):

A simple model of neurons that mentions synaptic and somatic operations
where y j is the j th output associated with j th node, x i is i th input, w ij is the synaptic weight associated with the i th input of the j th node and b j is the bias associated with the j th node. Here, f is the nonlinear activation function.
The learning process
Learning is a process by which the associated weights of an ANN change through an environmental function in order to simulate it. The type of learning is dependent on the change procedure of the weights. So, the two types of learning are categorized as error correction learning and memory-based learning. The network learns through the training procedure. There are two different styles with which to train a network: incremental training and batch mode training. The stopping criterion can be different. For example, the maximum epoch and/or the minimum root mean squared error (RMSE) are popular stopping criteria.
The training process
In the training procedure, the network learns to train the input data set with the correct behavior to give the right output data. The training data set has pairs of input values and target true output values. In the present investigation, the training data set includes pairs of many in situ measurements as target true output values and MODIS reflectance at the same place and time as input values.
Generalizing process and preprocessing
In a practical problem, it is important to construct a system that generalizes well with unseen examples. These data are used to test the network after the training process. A critical problem that a neural network faces is overtraining; the network may never be trained efficiently. A tradeoff between these two problems was confronted, and an optimized number of neurons was chosen (Haykin 1998).
Result
Regression analysis
Different regression models were applied to obtain a good relationship between remote sensing reflectance data and in situ-suspended sediment data. The results are shown in Table 2. In this table, F is the ratio of mean square regression to mean square error. All regression models were significant. For both band 1 and band 2, the best result belonged to the power regression model because it had the maximum R 2 and the highest F-ratio.
A linear regression model was also established with combination of bands 1 (red, 620–670 nm) and 2 (near-infrared, 841–876 nm) and was presented as Eq. (2). The values of R 2 and RMSE for this equation were 0.855 and 1.834, respectively.
Network architecture
In order to model a nonlinear relationship between SSC and its remote sensing reflectance, a three-layer ANN, including input layer, one hidden layer, and output layer, was established. The input layer consisted of band 1 and band 2 from the MODIS sensor, and the output layer consisted of SSC. Since the number of hidden layer neurons depends on the complexity of the function that must be modeled, so the number of hidden layer neurons varied between 1 and 10. While network training with too many neurons is a time-consuming procedure, the network using too few neurons might never converge to a proper solution. Therefore, a hidden layer with six neurons was employed.
A Tan-sigmoid activation function and a linear function were used in the hidden layer and output layer, respectively. Network weights and biases were randomly selected between −1 and +1. Before presenting data to the network, all data were normalized to between −1 and +1. So all input values and corresponding target true output values were passed through the function as Eq. (3):
where x is the input data vector or corresponding target true data vector, the mean operator is the average of vector members, and the min and max operators are the minimum and maximum member in each vector. This transformation accelerated the learning procedure and decreased the learning time.
Network training
The back propagation algorithm which is based on the gradient descent method, conjugate gradient, is not efficient enough to speed up convergence. However, the other popular method, quasi-Newton, is more efficient, but due to the necessity of computing the Hessian matrix, it suffers the storage and the computational requirements. To avoid computing the Hessian matrix, the Marquardt method was used as a quicker training algorithm (Hagan and Menhaj 1994) to approach second-order training speed. Batch training was applied to update weights and biases once an epoch 57 data points were gathered from the south coastal region of the Caspian Sea. All of them were divided randomly into three groups. The first group of data was selected as training data set. It was 60 % of the data. Two other groups were validation and testing data sets which will be introduced in the following sections.
Network validation
Previous studies have attempted to validate the trained network with only test data (Zhang et al. 2002; Keiner and Yan 1998). On the other hand, they used the minimum value of RMSE and/or the maximum number of epochs as stopping criteria. This method may not give us adequate answers. Here, another stopping criterion was used as well as minimum RMSE and maximum number of epochs that is mentioned in the following paragraph.
The second group of data was used as validation data set. It was 20 % of the data. After each training epoch, calculated error through the network was monitored by this data set. Validation error was intended to decrease with training error, while the network was training during the initial epochs. When the network began to overfit or overtrain the data, validation error would be increased. When the validation error was increased after passing a specified number of epochs, the training process was stopped to control for overfitting. Then all of weights and biases were chosen before the validation error had been increased.
Network testing
The rest of sample data was considered as the testing data set. The model validation was carried out with the testing data set. For each architecture with a specific number of neurons, the training process was repeated so that the values of RMSE and R 2 for the training data set were better than the validation data set and the testing data set. The resulting table of neural networks (Table 3) shows that the values of RMSE and R 2 are functions of the number of hidden layer neurons. With an increase in the number of hidden layer neurons, RMSE value is decreased and the R 2 value is increased. During the training process, it was found that when the number of hidden layer neurons was very low or very high, so it was difficult to achieve the suitable values of RMSE and R 2. These two conditions occurred because of the network divergence or network overtraining.
The whole flowchart of retrieving SSC using the proposed ANN is shown in Fig. 3. As it was shown in this scheme, both the satellite and ground truth data were prepared as input and output network data, respectively. Then, they were divided into three groups: training, validation, and testing data. By choosing the proper network architecture, including the number of hidden layers and the number of hidden neurons, the learning process began. In each epoch, the training procedure was done by presenting whole training data set and network weights were changed to a more accurate model. In order to validate the model, the validation data set was presented to the network. If the validation data set error was not increased, next epoch would continue. Eventually, the final accuracy of the model would be assessed using the testing data set.

Flowchart of proposed ANN methodology to retrieve SSC
For an ANN with six neurons, the RMSE values of the training data set, validation data set, and testing data set, with respect to epoch, were calculated. The simulation of training, validation, and testing examples by the network during the training procedure is shown in Fig. 4. Increasing of the validation data set error occurred at epoch 11, so the training procedure was stopped at this point. A clear and important point in this study was that a proper answer could be obtained, while the number of epochs was effectively decreased. With a data distribution over the interval of [−1 +1] with a zero mean, the use of log-sig instead of Tan-sig which produces zero mean output data, and also the monitoring of training ANN structure using validation data set error, the number of epochs was reduced. Consequently, a big problem of ANN, overtraining, was solved dynamically during the training procedure.

The simulation of training, validation, and testing examples by the network during the training procedure: increase of validation data set error occurred at epoch 11, so the training procedure is stopped at this point
The result of the comparison between the SSC estimated by the network and the in situ data was illustrated in Fig. 5. They clearly indicate that the ANN model has operated well. The values of RMSE and R 2 obtained from this model with training, validation, testing, and the whole data set are respectively: 0.509 and 0.985 mg/L, 1.849 and 0.910 mg/L, 0.797 and 0.982 mg/L, and 0.853 and 0.969 mg/L. The average amount of SSC during May 2007 along the southern coast of the Caspian Sea is illustrated in Fig. 6.

The results of ANN on a training, b validation, c testing, and d total example for SSC

A map of suspended sediment concentration in the southern part of the Caspian Sea on May 2007, estimated by the neutral network
Discussion
The algorithms developed in this study were compared with those of band ratios, band differences, and some other possible combinations of visible and near-IR bands to find the best one for comparison. These algorithms were quite different in the selected bands when compared with those used in other studies (e.g., Keiner and Yan 1998). In order to indicate the significance of the regression models, the R 2 and F-ratio have been calculated. The most successful combination was power regression model because it had the maximum R 2 and the highest F-ratio.
However, these statistical results show that regression analysis is not good enough (in comparison to ANN) to characterize the relationship between both the digital data MODIS and the suspended sediment parameter in this study. According to the Keiner and Yan (1998), the main reason is the poor ability of regression analysis to model the unknown nonlinear transfer function in surface waters.
In order to obtain surface water suspended sediment concentration from satellite remote sensing data, this study shows that it can be estimated significantly using the empirical neural network algorithm. The ANN could also be successfully applied to the other concentrations outside the training range so that all regions are well covered by the ANN technique without getting strange results. Consequently, the study also demonstrated that remote sensing is a valuable tool in obtaining information on the processes taking place in surface water suspended sediment monitoring.
Figure 6 shows a map of the SSC in the southern part of the Caspian Sea that is extended along the north Alborz Mountain, and it has 865-km length. This SSC map is as a result of more than 100 rivers in this region that discharge water and sediment to the Caspian Sea and also resuspension near the shoreline. It indicates that the SSC gradually decreases from west to east. That is mainly because of the Sefidrud River, which is located in the southwestern coast, and is the largest sediment source of the Caspian Sea compared to drainage area, water, and sediment discharge with 5.2 million ton a year. The other rivers that contribute in the sediment discharge along with Sefidrud in this region are Astara, Lisar, Kargarud, Shafarud, Pasikhan, Polrud, and Chulkrud. Higher values in this map belong to the shallower waters near the Caspian Sea coasts due to the resuspension of the bottom sediments and river inflow and lower values belong to the deeper waters of the central part.
Southern coast of the Caspian Sea has been steadily polluted with anthropogenic sources (fertilizer and pesticides used in agriculture and increased nutrient load of river flows due to deforestation of woodland) since the early 1980s. Thus, the result of suspended sediment concentration over the Caspian Sea lacks information on the typical content of algae and CDOM that can be observed together with SSC. Indeed algae and CDOM can strongly absorb radiation in the visual bands (400–710 nm) and therefore in band 1. The technique still needs to be improved through the addition of new input layers, which can fully simulate the resuspension of suspended particles, such as salinity, velocity of flow, sea surface temperature, and hydrodynamic conditions of coastal water.
Conclusion
Coastal waters often need special local algorithms to estimate suspended sediment and to realize differences in their optical properties in a variety of times and places. These differences usually occur because of different factors, such as river discharges and their sediment load, phytoplankton, and sediment resuspension. Thus, it is important to gather field data at the same time that satellites are passing over the study area. The use of satellite remote sensing enables efficient monitoring of spatial and temporal water quality variations in case 2 waters. Remote-sensing technology was used to retrieve suspended sediment as one of the most important water quality indicators in southern coast of the Caspian Sea. This investigation proved the following: obvious successful application of remote sensing in coastal regions, the great usefulness of MODIS images to monitor suspended sediment, and the establishment of ANN methods as efficient for relating remote sensing reflectance and in situ measurements in the southern coast of the Caspian Sea. The wide range of SSC is caused by the many rivers which convey suspended sediment loads from the Alborz Mountains and discharge into the Caspian Sea, with different inputs along the shore. Another important reason is human activities that change the natural behavior of water constituents of the rivers.
Because of the accurate modeling of nonlinear relationships by ANN (in comparison with regression analyses) and the best art of ANN training algorithms (the Marquardt method), adding a third stopping criterion as a validation data set to decrease the learning time and prevent overtraining is advised. Thus, this methodology is suggested as the cheapest because MODIS images are free of charge.
References
Aguirre-Gomez R (2000) Detection of total suspended sediments in the North Sea using AVHRR and ship data. Int J Rem Sens 21:1583–1596
Alparslan E, AydÖner C, Tufekei V, Tufekei H (2007) Water quality assessment at Ömerli Dam using remote sensing techniques. Environ Monit Assess 135:391–398
Azamathulla HM, Cuan YC, Ghani AA, Chang CK (2013) Suspended sediment load prediction of river systems: GEP approach. Arab J Geosc 6:3469–3480
Binding CE, Bowers DG, Mitchelson-Jacob EG (2003) An algorithm for the retrieval of suspended sediment concentrations in the Irish Sea from SeaWiFS ocean colour satellite imagery. Int J Rem Sens 24:3791–3806
Cracknell AP (1999) Remote sensing techniques in estuaries and coastal zones—an update. Int J Rem Sens 19:485–496
Curran PJ, Novo EMM (1988) The relationship between suspended sediment concentration and remotely sensed spectral radiance: a review. J Coast Res 4:351–368
De Mora S, Sheikholeslami MR, Wyse E, Azemard S, Cassi R (2004) An assessment of metal contamination in coastal sediments of the Caspian Sea. Mar Pollut Bul 48:61–77
Doerffer R, Fischer J (1994) Concentrations of chlorophyll, suspended matter, and gelbstoff in case II waters derived from satellite coastal zone colour scanner data with inverse modeling methods. J Geophy Res 99:7457–7466
Doerffer R, Schiller H (2007) The MERIS case 2 water algorithm. Int J Remot Sens 28(3):517–535
Doxaran D, Froidefrond JM, Lavender S, Castaing P (2002) Spectral signature of highly turbid waters: application with SPOT data to quantify suspended particulate matter concentrations. Rem Sens Environ 81:149–161
Eleveld MA, Pasterkamp R, Van der Woerd HJ, Pietrzak J (2008) Remotely sensed seasonality in the spatial distribution of sea-surface suspended particulate matter in the southern North Sea. Estuarin Coast Shelf Sci 80:103–113
Figueras D, Karnieli A, Brenner A, Kaufman YJ (2004) Masking turbid water in the southeastern Mediterranean Sea utilizing the SeaWiFS 510 nm spectral band. Int J Rem Sens 25:4051–4059
Froidefond JM, Castaing P, Prud'homme R (1999) Monitoring suspended particulate matter fuxes and patterns with the AVHRR/NOAA-11 satellite: application to the Bay of Biscay. Deep-Sea Res II 46:2029–2055
Hagan MT, Menhaj MB (1994) Training feedforward networks with the Marquardt algorithm. IEEE Trans Neu Net 5(6):989–993
Haykin S (1998) Neural network: a comprehensive foundation, 2nd edn. Prentice Hall, USA
Katlane R, Nechad B, Ruddick K, Zargouni F (2013) Optical remote sensing of turbidity and total suspended matter in the Gulf of Gabes. Arab J Geosc 6:1527–1535
Kaya S, Seker DZ, Kabdasli S, Musaoglu N, Yuasa A, Shrestha MB (2006) Monitoring turbid freshwater plume characteristics by means of remotely sensed data. Hydro Pro 20:2429–2440
Keiner LE, Yan X (1998) A neural network model for estimating sea surface chlorophyll and sediments from Thematic Mapper Imagery. Rem Sens Environ 66:153–165
Khoshravan H (2007) Beach sediments, morphodynamics, and risk assessment, Caspian Sea coast, Iran. Quat Int 167–168:35–39
Korshenko AN, Gul AG (2005) Pollution of the Caspian Sea. In: Kostianoy AG, Kosarev AN (eds) The Caspian Sea environment (Handbook of Environmental Chemistry). Springer, Heidelberg, pp 109–142, ISBN: 9783540282815
Kosarev AN, Yablonskaya EA (1994) The Caspian Sea. SPB Academic Publishing, The Hague
Ma R, Dai J (2005) Investigation of chlorophyll-a and total suspended matter concentrations using Landsat ETM and field spectral measurement in Taihu Lake, China. Int J Rem Sens 26:2779–2795
Miller RL, McKee BA (2004) Using MODIS Terra 250 m imagery to map concentration of total suspended matter in coastal waters. Rem Sens Environ 93:259–266
Miller RL, McKee BA, D'Sa EJ (2004) Monitoring bottom sediment resuspension and suspended sediments in coastal waters. In: Miller RL, Del Castillo CE, McKee BA (eds) Remote sensing of aquatic coastal environments: technologies, techniques and application. Kluwer, Netherlands, pp 104–105
Moore GF, Aiken J, Lavender SJ (1999) The atmospheric correction of water colour and the quantitative retrieval of suspended particulate matter in case II waters: application to MERIS. Int J Rem Sens 20:1713–1733
Morel A, Prieur L (1977) Analysis of variation in ocean colour. Limn Ocean 22(4):709–722
Myint SW, Walker ND (2002) Quantification of surface suspended sediments along a river dominated coast with NOAA AVHRR and SeaWiFS measurements: Louisiana, USA. Int J Rem Sens 23:3229–3249
Nechad B, Ruddick KG, Park Y (2010) Calibration and validation of a generic multisensor algorithm for mapping of total suspended matter in turbid waters. Rem Sens Environ 114:854–866
Östlund C, Flink P, Strombeck N, Pierson D, Lindell T (2001) Mapping of the water quality of Lake Erken, Sweden, from Imaging Spectrometry and Landsat Thematic Mapper. Sci Total Environ 268:139–154
Panda SS, Garg V, Chaubey I (2004) Artificial neural network application in lake water quality estimation using satellite imagery. J of Environ Info 4:65–74
Pavelsky TM, Smith LC (2009) Remote sensing of suspended sediment concentration, flow velocity, and lake recharge in the Peace‐Athabasca Delta, Canada. Water Resour Res 45:W11417. doi:10.1029/2008WR007424
Prabaharan S, Manonmani R, Ramalingam M, Vidhya R, Subramani T (2013) Decision of threshold values for extraction of turbidity for inland wetland using IRS P6 LISS III data. Arab J Geosc 6:109–114
Pradhan B, Buchroithner MF (2010) Comparison and validation of landslide susceptibility maps using an artificial neural network model for three test areas in Malaysia. Environ Eng Geosc 16(2):107–126
Ritchie JC, Schiebe FR (2000) Water quality. In: Schultz GA, Engman ET (eds) Remote sensing in hydrology and water management. Springer, Berlin, pp 287–303
Ritchie JC, Schiebe FR, McHenry JR (1976) Remote sensing of suspended sediments in surface waters. Photo Eng Remote Sens 42:1539–1545
Ritchie JC, Zimba PV, Everitt JH (2003) Remote sensing techniques to assess water quality. Photo Eng Rem Sens 69:695–704
Schmugge TJ, Kustas WP, Ritchie JC, Jackson TJ, Rango A (2002) Remote sensing in hydrology. Adv Water Resources 25:1367–1385
Strickland, J D H, Parsons T R (1972) A practical handbook of seawater analysis. Bulletin 167, (2nd ed.). Fisheries Research, 310 pp. Ottawa, Board of Canada
Tassan S (1998) A procedure to determine the particulate content of shallow water from Thematic Mapper data. Int J Rem Sens 19:557–562
Wang JJ, Lu XX, Zhou Y (2007) Retrieval of suspended sediment concentrations in the turbid water of the Upper Yangtze River using Landsat ETM+. Chinese Sci Bul 52:273–280
Warrick JA, Merters LAK, Siegel DA, Mackenzie C (2004) Estimating suspended sediment concentrations in turbid coastal waters of the Santa Barbara Channel with SeaWiFS. Int J Rem Sens 25:1995–2002
Zhang Y, Pulliainen J, Koponen S, Hillikainen Hallikainen M (2002) Application of an empirical neural network to surface water quality estimation in the Gulf of Finland using combined optical data and microwave data. Rem Sens Environ 81:327–336
Acknowledgments
The authors would like to thank the Caspian Environmental Center (CEP) for their help and useful guidance. We also acknowledge the Iran national space organization for helping us to prepare the satellite images from the NASA MODIS website. Thanks to the Iran fisheries organization for providing motor boats and TMU for funding this project and for providing use of its laboratory measurement facilities.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Moridnejad, A., Abdollahi, H., Alavipanah, S.K. et al. Applying artificial neural networks to estimate suspended sediment concentrations along the southern coast of the Caspian Sea using MODIS images. Arab J Geosci 8, 891–901 (2015). https://doi.org/10.1007/s12517-013-1171-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12517-013-1171-3