
Abstract
Each person has their personal area which they do not want to share with others during social interactions. The size of this area usually depends on various factors such as their culture, personal traits, and acquaintanceship. The same applies to the case of human–robot interaction, especially when the robot is required to exhibit a certain level of social competence. Here, we propose a new robot navigation strategy to socially interact with people reflecting upon the social relationship between the robot and each person. To this end, we need a clear definition of interaction areas: (1) quality interaction area where people can be engaged in high-quality interactions with robots, and (2) private area not to be interfered with by the robot speech or action. A technical challenge in enhancing social human–robot interactions is how to enable robots to delineate the boundary of the two areas of each person. Specifically, the social force model (SFM) is designed by a fuzzy inference system, where the membership functions are optimized to give the robot the ability to navigate autonomously in the quality interaction area using a reinforcement learning algorithm. Finally, the proposed model was verified through simulations and experiments with a real robot that can generate a suitable SFM of each person, allowing the robot to maintain the quality of interaction with each person while keeping their private personal distance.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
People feel safe and comfortable within their own territory they keep from others. We should be respectful of other people’s territory and learn to adapt to such territory when interacting with others. Therefore, the interpersonal distance should be adaptively estimated to foster a better interaction through real-time responses from others, allowing one to modify their position not to trespass on others’ private areas. In the near future, domestic robots are expected to share the environment with humans and their perceptual and behavioral abilities must conform to our social norms. Therefore, domestic robots should be able to learn the proper social interaction distance and private area. However, it is difficult for the robot to estimate the social interaction distance of each person which may vary due to various social factors such as their culture, personal traits, and acquaintanceship. Although various researches have been conducted on the social model for mobile robot navigation [9, 19, 20], little attention has been paid to the dynamics of human social factors.
For mobile robot navigation in a human populated environment, collision avoidance is one of the most important concerns. Another important issue that needs increased attention is how to enable the robot to generate socially competent navigation behaviors, which should help people feel safe and comfort. These are important key challenges for human–robot symbiosis. The theory of Proxemics [2] and its related psychological concepts are frequently used for developing socially competent robot behaviors. This concept is integrated into various research endeavors, especially safe navigation considering social effects [3, 25, 26]. However, it is still a challenging problem to formalize this social science theory into a mathematic model for human-centered robot navigation.
Considering individuals’ social factors, our goal is to propose a dynamic social force model of human–robot social interaction. This enables the robot to adaptively estimate the human social interaction distance, especially their private area, in a public environment. This paper proposes a personalized social interaction model designed by a fuzzy inference system whose parameters are adjusted and optimized by a reinforcement learning method in an on-line manner. The estimated social force model is used as a cost map for the path planner to generate robot navigation paths to make people feel comfortable.
2 Related Work
In this section, we summarize the existing research related to interpersonal distance to mediate people’s interaction with others. First, we reference social science studies to give the definition of privacy and Proxemics. Then, we describe some studies based on the Proxemics theory to model human interaction areas and its application. Finally, we identify the technical challenges of modeling human interaction areas responding to individuals, social factors.
2.1 Privacy and Proxemics in Social Science
The key idea to formalize human–robot interaction is to understand and accommodate human behavior. Therefore, the knowledge of social science is of importance. First of all, Privacy was defined in human–robot interaction by Ruben and Smart [24]. They summarized that privacy is the ability of an individual or group to separate themselves and thereby express themselves selectively. The boundaries and content of what is considered private differ among cultures and individuals. Westin [31] mentioned that most of the animals seek privacy either as individuals or in the small groups. From this concept, we can get the idea of territoriality which is the defense of one area against intrusion by others. In his study, he reported three types of spacing observed among animals: personal distance between individuals, social distance between groups, and fight distance at which an intruder causes conflicts. At the same time, animals often gather in large groups. They seem to live in a tension between privacy and sociality. Zeeger studied human privacy in childhood [32], and found that 58 of 100 three-, four- and five-year-olds said they had a special place at the daycare center that belongs only to them. Newell found that adults usually seek privacy when they feel sad or tired, or need to concentrate [18]. These studies are mostly related to the theory of Proxemics [2] which describes different interpersonal distances that people keep from others. These distances depend on the type of interaction and relationship between individuals. Human interaction areas could be defined by this theory as shown in Fig. 1a. Among the various types of human interaction area, Public area is the area often used to interact with strangers, Social area is to interact with acquaintances, Personal area is used for familiar people, and Intimate area is for intimate contacts. On the other hand, people also use the interpersonal space concept to approach to others person. For example, when we try get closer to the closed friend to get more quality of interaction but keep the distance for stranger to make the person more comfortable. On top of this, protecting one’s privacy is an essential prerequisite for forming long-term, stable relationships, and developing socially competent robots. The safety reason is one of the criteria that results in the comfortable feeling to interact with the robot [24]. Therefore, the robot should consider human’s private space to maintain the comfortable feeling and quality of interaction. Empirical research claims that spatial privacy rights are important to determine whether to accept the interaction with robots [8, 16, 29].
2.2 Social Science in Human–Robot Interaction
The private space of human can be grouped into geometric and potential field models [11]. The models are designed based on four different shapes i.e., concentric circle, egg shape, concentric ellipses or asymmetric shapes, which used to describe the personal space of the human [23]. The private space or personal space can model by the geometric functions, for example, ellipse or semi-ellipse function. These geometric models have crisp boundaries. Thus, they are appropriated to express sharp transitions between personal space and other free space. This group of models are suited for local path planning and obstacle avoidance. The examples of this group of modelling can be found in [10, 17, 19, 28]. However, the sharp transitions between spaces cause the robot movement when it operates in population-environment because the robot avoids intruding into the personal are.
Another group of models describes the personal space of the human with the potential field method. This group of models composed of the continuous functions assigning values to location around the human. This group of personal space models reflect the idea that human comfort is getting worse when an intruder approaches closer to humans. The example of this group of modelling can be found in [3, 7, 9, 20, 25, 26]. This group of personal space models are suited for the optimal path planning frameworks which would like to optimal path cost that comes from human’s response.
Human social factors are incorporated into a high-level representation. Human’s pose, speech, and gesture cues are often used to evaluate social interaction area to guide a robot in a socially compliant manner [15]. For example, Butler and Agah studied what type of approach behaviors make humans uncomfortable [1]. In [27], they investigated human traits influencing proxemic behaviors. These works proposed methods to design robot behaviors not to violate people’s privacy. The social relationship and genders were used as the social factors to generate the social interaction area and robot collision avoidance paths in human environments [21]. Several robot behaviors have already been implemented with the private space in mind, such as, standing in line [17], following a person [4], and passing a person in a hall [12].
Referring to the above literature, the actual size of interaction area at any given instance varies depending on social factors of people and on the task being performed. Therefore, adaptive space of human–robot interaction was proposed to deal with uncertainties of robot perception [5]. The method was based on the non-stationary model as skew-normal probability density functions, allowing smooth adaptation in situation awareness of a robot within the common human–robot interaction. Luber and Spinello addressed the problem of social-aware navigation among humans that meet the objective criteria such as travel time or path length as well as subjective criteria like human comfort feeling [13]. The method adapts the social interaction area based on learning from a set of dynamic motions observed in a public hall. In [22], the authors performed computer simulations that the robot should be able to prevent itself from intruding onto the human private area, but place itself in a location allowing social interaction, maximizing the degree of visiting the acceptable area and minimizing the degree of trespassing on the private area.
To recapitulate, a major weakness of previous works is a lack of adaptability in social interaction without considering individuals’ characteristics. In contrast, our approach enables the robot to learn to estimate the human private area during the interaction. The robot can learn parameters to update the private area through the human feedback. This social model can be integrated into a path planner to simultaneously ensure the human safety as well as the quality of interaction without intruding onto the private area (Fig. 1b). As the sizes of the quality interaction area and the private area vary from person to person, this work proposes a reinforcement learning based path planning approach for social robots capable of navigating outside the private area at all times.

Human interaction area: a human interaction area according to proxemics [2]. b Our proposed interaction area considering the quality of interaction and human privacy

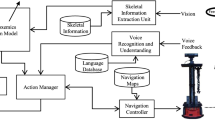
Overall process: Three main parts: (1) human social model designed by a fuzzy inference system (FIS), (2) reinforcement learning to update human social model by optimizing the parameters of the FIS, and (3) social path planner to generate socially competent navigation using social model
3 Personalized Social Interaction
3.1 Overall Process
We propose a novel method to navigate the robot capable of generating a socially competent path considering the human state as shown in Fig. 2. There are three main parts in the proposed method: (1) Human social model designed by an Asymmetric Gaussian function which its parameters are determine from a fuzzy inference system (FIS), (2) Reinforcement learning which used as a tool to update the parameters of the FIS, and (3) Social path planner to generate socially competent navigation using the human social model. During the human–robot interaction, the robot detects the human state and social factors, such as the social relationship between humans and the robot, to preliminary design human’s private area. These social factors are the crisp set of input data which gathered for the fuzzy inference system. These crisp set are converted to a fuzzy set using fuzzy linguistic variables, fuzzy terms, and membership functions. Afterward, an inference is based on a set of fuzzy rules. Lastly, the resulting fuzzy output is mapped to a crisp output using the output membership function, in the defuzziffier step. The output from the fuzzy inference system is the parameters to calculate the model of privacy area of the human which can be calculated by the Gaussian function. Based on preliminary human’s private area, the robot can estimate the social map that includes people’s private area and use it to generate its navigation paths to perform social interactions. However, with the preliminary estimate social map, the robot receives the reward which is the combination of interaction degree and unacceptable degree, and use it for update the parameters of input membership function by learning mechanism (R-Learning). The robot continues to navigate around humans based on the new estimate social map. Finally, the robot will navigate through the paths that generate based on the estimated social map to perform social interactions within the quality interaction area, while not intruding into the private area (Fig. 1b).
3.2 Human Social Model
The social factor describes the social cues of people such as their relationship with other people, personality traits, culture, and emotional states. Use of such information is important to ensure people’s privacy as well as their safety in social robot navigation planning. This section will summarize the mathematic model of our fuzzy social relationship [21]. Our proposed human’s social model is designed according to two concepts. First is a concept of asymmetric shape personal space [23] which describes the personal or private space of the human with the different size of the frontal area and lateral area. Second is the degree of surrounding environment which can be used as the cost for path planning algorithm. Our proposed method considers the discomfort feeling from humans which has the maximum value at the human location, and decrease at the location far away from the human position. Therefore, the asymmetric Gaussian function which is the simple mathematics function, is suit to the model asymmetric shape of personal space and possible to provide the degree of the surrounding environment.
3.2.1 Fuzzy Social Relationship Model
The human state and the social factor (e.g., relative positions between the robot and each person, social relationship between them, genders of each person, etc.) can be used to design the private area each person wants to secure and keep from others. The private area can be represented by a set of positions (x, y) surrounding each person to which force values are assigned as follows:
where n is the total number of persons, \(f_i\) is the repulsive force originating from the ith person which can be expressed by the bivariate Gaussian distribution function. Let A be the magnitude of the repulsive force which can be determined by a person’s physique. Also let \(\beta _{fr}\) and \(\beta _{si}\) be the size of the private area in the frontal and lateral directions, respectively, with respect to the ith person, as shown in Fig. 3. The repulsive force generating from the ith person \(f_i\left( x,y\right) \) is designed by
which presents the degree of discomfort of the i-th person. Its peak value is observed at his/her position which decreases as the distance from him/her increases. It is clear from Eq. 2 that the magnitude of the degree of discomfort depends not only on the amplitude A, but also on \(\beta _{fr}\) and \(\beta _{si}\). These terms can be updated by the human state and the social factors, respectively.

Human’s private area: the privacy area of the human can be determine by using two factor. Frontal side \(B_fr\), which depends on human’s motion, and Lateral side \(B_si\) which can be determined by social signals
Let us assume that the robot is able to perceive the human state which consists of his/her position, velocity, and orientation with respect to the inertial coordinate frame denoted by \((x_i,y_i,\dot{x_i},\dot{y_i},\theta _{i})\). Let d be the distance between the i-th person’s position \((x_i,y_i)\) and any position (x, y) in their surrounding environment. \(\theta _i\) is the orientation of the person’s facing direction vector. The magnitude of velocity v can be computed by
Considering the motion of people, \(\beta _{fr}\) can be defined as follows:
where \({\sigma _{f0}}\) is chosen according to the different interpersonal social distance defined in [2]. Here \(\gamma _f\) is the normalization term, and \(\theta \) is the orientation of the vector that represents the position of any point in the environment with respect to the inertial coordinate system. Therefore, the robot would pay more attention in front of people rather than behind of them.
This paper also reflects social factors of people in relation to the robot, e.g., the gender, the relative distance, and the relationship degree, to estimate the design parameters of the private area in the lateral direction \(\beta _{si}\). Since the social factors vary depending on various conditions, it is difficult to group them as a binary function. Therefore, a fuzzy logic approach is used to quantify these parameters [21].
Gender is one of social factors that should be considered to model the private area. The input MF of gender is defined as a binary function subject to male (M) and female (Fe) which is given by
where g is the gender input.
Our next social factor is the relative distance which can be divided into two sets such as near (Near) or far (Far). It is represented by a sigmoid function. Let \(r_r\) be the input of the relative distance, \(a_r\) the steepness of the distribution of relative distance, and \(c_r\) the inflection point. Then the MFs of the relative distance is given as follows:
Likewise, the relationship degree describes the personal knowledge or experience with the robot which can be set by three Gaussian functions, familiar (Fam), acquaintance (Acq), and stranger (Str). Let \(r_i\) be the relationship degree that the robot perceives from people. Therefore, the relationship degree MFs are given as follows:
For the output of the fuzzy logic, there are several ranges in the human interaction area according to the theory of Proxemics [2]. The distance of human interpersonal space inspires us to estimate the private area of the human. Therefore, the concept of different parameters in determining the different social model for each person is chosen related to these interpersonal space concept. In [21], we separate the personal area into two group, far personal area (FPA) and near personal area (NPA). These interaction areas give the different standard deviations \(\sigma _{si}\). Therefore, four Gaussian functions are used to represent a change of standard deviation(\(\sigma _{si}\)) in each interaction area which is defined as
Thus, a detailed description of the proposed fuzzy rule is shown in Table 1. Combining the above-mentioned social factors, \(\beta _{si}\) can be defined as follows:
This means that, to prevent the robot from intruding onto the human private area, the robot is required to delineate the dynamic boundary of interaction areas based on the human social factors.
3.2.2 Learning Fuzzy Social Model
In this paper, the reinforcement learning method is used to learn from human feedback how to spot and respect the private area varying from one person to another. We integrate a reinforcement learning algorithm into fuzzy MFs. The MF, as the agent, learns to improve the private area in an attempt to increase the total amount of reward through human feedback. The action is then selected by the behavior policy in order to adjust the MFs to effectively update the social force (i.e., cost) map and to make a minimum cost path in the environment. This process is repeated until a maximum reward is reached in an iterative way.
Specifically, the R-Learning algorithm is used as the learner. Many reinforcement learners have to abandon the discounted future reward. In this work, with the average reward setting, R-Learning neither discounts nor divides experience into distinct episodes with a finite return [14]. This is well-suited to the social cost map generation in order to sustain long-term interactions that should take every interaction experience into account equally.
The transition matrix depends on the action by an agent. In this paper, the state S consists of the parameters of each MF. We focus only on mean values \(\varvec{\mu }\) of MFs to be learned, therefore, the state will consist of three means of Familiar, Acquaintance and Stranger functions, \(\varvec{\mu }\) = [\(\mu _{Fam}, \mu _{Acq}, \mu _{Str}\)]. The action, \(a \subset A\), is how each MF can be adjusted. To select the action a, the \(\varepsilon \)-greedy method is used to select the action that has maximum estimated state-action value Q. Therefore, the value of state S with the action a can be defined as
where \(S'\) is the next state, \(\alpha \) is a constant learning rate, R is the reward signal to be gained from the environment, and \(\bar{R}\) is the average reward value. In the real robot experiment, the robot can receive the reward in real time in the form of interaction and unacceptable degrees, respectively, from each person’s emotion or feeling. The interaction degree (ID) presents the degree of interaction quality or the degree of easiness of interaction, while unacceptable degree (UD) implies the degree of discomfort during human–robot interaction. The ID and UD are increasing and decreasing respectively when the robot gets closer to the human. Both degrees depend on the distance between the human and the robot. Therefore, the reward can be defined as
where \(k_1\) and \(k_2\) are the weights of each degree, and a constant c is used to prevent zero division. For simulation, ID and UD are collected from the generated path through the predefined ground truth social map. Therefore, the interaction and unacceptable degrees can be determined as
where p is a set of navigation path coordinates in the predefined social cost map. Therefore, this MF can be learned by \(\varvec{\mu }\) to maximize the reward having a maximum value of ID and a minimum value of UD. The complete R-Learning algorithm is given in Algorithm 1.


Algorithm flow chart
3.3 Path Planner
We use Transition based Rapidly-Exploring Random Tree (T-RRT) that can choose an optimal navigation path in the social cost map and collect the reward [6]. T-RRT takes advantage of two approaches. First, the exploration strength of the RRT algorithm rapidly grows random trees toward unexplored areas. Secondly, the features of stochastic optimization methods apply transition tests to accept or to reject potential states. This planner produces the path that efficiently follows the low-cost area and the saddle point of the cost map. Therefore, we use T-RRT for the exploration and optimal path generation, allowing the robot to evaluate the navigation cost as the social map is updated. More specifically, we employ T-RRT to navigate the robot through the space that separates the private area and the low quality interaction area.
4 Results and Analysis

Social map: comparison of social maps. Ground truth social map (left) initial social map (middle) and estimated social map after the learning process (right)

Private boundary: comparison of private area boundaries. Ground truth boundary (blue solid line), estimated boundary at initial setting (green dash line), and estimated boundary after the learning process (red dash line). (Color figure online)

Fuzzy input MFs: comparison of parameters of social relationship model (fuzzy membership function). Ground truth values (top), Initial parameters of membership functions (middle), and trained parameters of membership functions (bottom)

Social map error: the error between the ground truth cost and estimated cost on the social map. Fixed-parameters (blue) estimates the same cost of social map, the error is maintain. For our proposed (red), at the beginning, the error is high due to the incorrect parameters. As the learning process proceeds with updated parameters, the error converges to zero (red). (Color figure online)

Interaction degree: interaction degree presents the acceptable degree that the robot can receive from people along generated paths. High interaction degree means that the robot approaches close enough to have quality interactions with people

Unacceptable degree: unacceptable degree presents the total discomfort feeling that robot receive from people along the generated path. The robot should plan the path without entering the human private area
This section shows simulation and real experiment results with a humanoid robot Pepper. Our goal is to enable the robot to plan paths to visit every person in the environment without trespassing on their private area, but to keep the distance from which people are able to have high quality interactions. Figure 4 shows the algorithmic process flowchart implemented in this paper. First, the robot explores the environment to generate a geometric map. It can then create a social map by computing and assigning the social cost to the geometric map. Using the social map, the robot can generate the path to visit any person in the environment. Specifically, a genetic algorithm is used to determine the order of visiting people. After that, T-RRT path planner generates the low-cost path following the order of visiting people. To update the social map, R-learning adjusts the MF parameters by receiving the reward while visiting people. The social map is being updated until the robot gains the maximum rewards which maximize the interaction degree and minimize the unacceptable degree evaluated by people. The simulation results show that our proposed method has the capability to adjust and update the social map to gain the maximum interaction degree and minimum unacceptable degree in various conditions. We also perform real robot experiments to show that our proposed method can navigate the robot to interact with people at the proper distance. The social factors of each person, i.e., the gender and relationship degree of people in relation to the robot, are given to the robot in both simulations and real robot experiments.
4.1 Simulation Results
In the simulation, we assume that a geometric map is given or created by the robot. Our proposed model is to generate the social map by computing and updating social cost assigned to the geometric map. This social map is used to plan the robot navigation path in the environment. To validate the proposed model, we need to receive the reward from people. Therefore, the concept of social relationship model in [21] is used to model the ground truth social map of people whose relationship degree MFs are set to three Gaussian functions as follows: \(s_{Fam}\) = 0.15, \(\mu _{Fam}\) = 0.1 to Fam set, \(s_{Acq}\) = 0.15, \(\mu _{Acq}\) = 0.3 to Acq and \(s_{Str}\) = 0.15, \(\mu _{Str}\) = 0.8 to Str set. The ground truth MFs are shown in Fig. 7 (Top).
To estimate the human private area, the initial parameters of the relationship degree MFs in Eq. (7) are designed as follows: \(s_{Fam} = 0.15\), \(\mu _{Fam} = 0\) to Fam set, \(s_{Acq} = 0.15\), \(\mu _{Acq} = 0.5\) to Acq set, and \(s_{Str} = 0.15\), \(\mu _{Str} = 1\) to Str set as shown in Fig. 7 (Middle). These parameters can be adjusted by the learning process. Likewise the relative distance MFs are designed as follows: \(a_{Near} = -\,0.35\), \(c_{Near} = 300\) to Near set and \(a_{Far} = 0.35\), \(c_{Far} = 300\) to Far set.
For the output function, the social interaction area is split into four Gaussian sets. The parameters of Eq. (8) are as follows: \(\mu _{PA} = 0.035\), \(s_{PA}= 0.005\), \(\mu _{SA} = 0.045\), \(s_{SA}= 0.005\), \(\mu _{FPA} = 0.0035\), \(s_{FPA}= 0.06\), \(\mu _{NPA} = 0.0035\), \(s_{NPA}=0.065\). These parameters are decided based on the human interaction area concept [16] which determined the range of an individual’s interpersonal space with different social factors when the robot approached the person. Reflecting their results, we can determine the parameters for the output membership functions.
For the reinforcement learning process, we set the discrete states which consist of three mean values of each relationship MF, i.e., \(\mu _{Fam}, \mu _{Acq}, \mu _{Str}\). The action set for each function is simply defined as stay, move right, or move left, i.e., 0, \(+\,0.1, -\,0.1\). The MFs can be adjusted through iterative learning processes until gaining a maximum reward signal.
The ground truth and estimation social map can be seen and compared in Fig. 5. The results show that the estimated social cost map with the initial setting (Middle) is different compared to the ground truth map (Left). With an initial setting, the robot estimated the private area unsuitably for the people, causing the robot to generate paths that decrease their comfortable feeling. The learning process enables the robot to adjust the system parameters and re-estimate the human private area incorporating the feedback from the human. Therefore, the estimated social map after the learning process (Right) becomes similar to the ground truth map and can be used to generate paths that make people feel comfortable. To make it clearer, Fig. 6 shows that the private area boundary of the initial setting (green dash-line) is smaller than the ground truth (blue line). However as the learning process proceeds, the estimated private boundary becomes similar to the ground truth (red dash-line). The relationship degree MFs after the learning process can be seen in Fig. 7 (Bottom). The results of our proposed model can be compare to the fixed-parameters model which use the same parameters to estimate the social map (Fig. 7). The errors of estimated social maps for three, four, and five people, respectively, compared to ground truth social maps, are shown in Fig. 8. The result shows that, while navigating the initial and updated social cost maps, the robot was able to learn and adjust the MFs through the reward obtained from people. Finally, the errors converged to a value near zero (red). However, for the fixed-parameters model (blue), the error of social map is constant which mean the estimate social map is not change and different to the ground truth.
In this paper, we define the quality interaction area and the private area. Figure 9 shows the interaction degree with three, four, and five subjects, respectively. The results show that our proposed method increases the interaction degree of subjects during their interaction with the robot until it suits everyone. Figure 10 shows the results of the unacceptable degree. The results show that our method can reduce the unacceptable degree of subjects until they feel comfortable to interact with the robot. These results show that our proposed model outperforms the fixed-parameter for estimated the privacy area and more clearly with the number of humans in the environment. The results can be summarized in Table 2. We also perform the simulation with four subjects facing different directions. The results are consistent with the previous results obtained from the simulations with different numbers of subjects. The results show that our proposed method increases the quality interaction degree and reduces the unacceptable degree of the subjects, as shown in Table 3.

Humanoid robot experiment overall process

Humanoid robot experiment: (left) the real experiments with pepper. (Right) the blue area visualizes the estimate private area. The green line is the quality interaction area boundary Bi. The red line is the private area boundary Bp
4.2 Humanoid Robot Experiment
We perform the experiment with a humanoid robot Pepper developed by SoftBank Robotics Corp. A variety of sensors of Pepper and its innate perception capabilities are suitable for human–robot social interaction. We navigate the robot through the environment while interacting with as many people as possible therein. We test the proposed navigation method in the open-source environment of Robot Operating System (ROS). Specifically, Pepper needs to have prior knowledge about its environmental geometric map which can be stored in the map server. With several sensors, Pepper can localize itself required for the navigation task. Pepper also can detect and receive the human state and social factors to generate the social map to assign the social cost to the geometric map. This social map imposes constraints on the robot path, enabling the robot to avoid or interact with people. The robot also receives a reward from people to update the parameters of MFs to re-compute and update the social map. The overall process is illustrated in Fig. 11.
The Pepper robot visits everyone and keeps the distance to make them feel comfortable around it. However, as many uncertainties exist, it is likely that Pepper initially makes a rough estimate of the size of the private area which may not suitable for him/her to comfortably interact with it. For instance, Fig. 12a shows that Pepper is outside the boundary of the quality interaction area \(B_{i}\). During the interaction with Pepper, people give reward by the verbal answer to the question from the robot. This reward allow Pepper to evaluate the social distance with them, i.e., the positive reward when Pepper is within the area where they feel comfortable to interact with it, or the negative reward for the distance from which they feel difficult to interact or discomfort (outside the quality interaction area boundary \(B_{i}\) or inside the private area boundary \(B_{p}\)). Learning people’s social interaction model helps Pepper to re-estimate the human private area until gaining a maximum positive reward. Finally, Pepper can locate itself within the area to interact with people that separates the private area as shown in Fig. 12b. In order to evaluate our proposed model, a total of five subjects participated in the experiment. Each person has a different range of quality interaction area, which is represented by the green line \(B_{i}\) and private areas, which is represented by the red line \(B_{p}\). The results are shown in Figs. 13, 14, 15, 16 and 17. It was confirmed that the social map may not clearly designate the private area at the initial phase of interaction, which is unsuitable for the subjects. In case of Figs. 13, 14, 16, and 17, the robot is located away from the quality interaction area, therefore the robot receives hardly noticeable response from people, which is considered to be the negative reward, to update its parameters associated with the MF of the interaction degree. On the other hand, the robot receives the positive reward to update its parameters for the MF of the private area. In case of Fig. 15, the robot is initially located inside the private area. Therefore, the robot receives the negative reward to decrease the unacceptable degree and the positive reward to update the parameters associated with the interaction degree. Finally, our proposed social distance learning model enabled the robot to interact with the subjects at the proper distance between the boundaries of interaction and private areas as shown in Figs. 13, 14, 15, 16 and 17.

Experiment result with pepper robot: the interaction distance (blue line) converges to the area between the quality interaction area boundary \(B_i\) and the private area boundary \(B_p\) of Person 1. (Color figure online)

Experiment result with pepper robot: the interaction distance (blue line) converges to the area between the quality interaction area boundary \(B_i\) and the private area boundary \(B_p\) of Person 2. (Color figure online)

Experiment result with pepper robot: the interaction distance (blue line) converges to the area between the quality interaction area boundary \(B_i\) and the private area boundary \(B_p\) of Person 3. (Color figure online)

Experiment result with pepper robot: the interaction distance (blue line) converges to the area between the quality interaction area boundary \(B_i\) and the private area boundary \(B_p\) of Person 4. (Color figure online)

Experiment result with pepper robot: the interaction distance (blue line) converges to the area between the quality interaction area boundary \(B_i\) and the private area boundary \(B_p\) of Person 5. (Color figure online)
5 Conclusion
In this paper, a new proxemics learning strategy was proposed for social mobile robots toward realizing socially competent navigation behaviors by integrating a fuzzy inference system and a reinforcement learning method. The proposed method employed an individual’s state and social factor information to determine the size of the quality interaction area of each person in a shared environment. However, initial social maps may not correctly produce an accurate interaction distance to each person. This problem may cause the robot to intrude onto the human private area or remain away from the quality interaction area. The proposed method used the concept of learning from experiences to update the interaction distance with people reflecting their feedback. This concept improves the accuracy of social navigation map generation for the robot capable of avoiding the human private area while maintaining the path within the quality interaction area. The simulation and real robot experiments showed that our proposed method provides accurate social interaction cost maps through the reinforcement learning process which can increase the interaction degree and reduce the unacceptable degree at the same time.
There are some aspects of our proposed method that should be improved and expanded by future research. First, our proposed human’s area of privacy was designed by using a Gaussian model, then we tried to determine the good parameter for this model by using reinforcement learning as a kernel-based approximation scheme in human–robot interaction. Even though we have focused on an empirical study on developing new learning framework for socially competent robot exploration in human space, we will further consider a spectral learning scheme instead of this kernel based approach because kernel-based approximation scheme needs a big amount of training data (human–robot interaction in our problem) [30]. Second, we will investigate the effect of different parameters of the reinforcement learning algorithm, i.e., discounting factor, undiscounting factor or reward function and analysed in the analytical point of view. Third, the proposed method showed only the empirical results that it could be used to learn and model the human’s private area. The evaluation of the solution of each state on the problem will be considered and improved to verify the optimal solution for each state which could be improved the proposed private area model. Fourth, we will extend experiments under various dynamic environments populated with moving obstacles. Moreover, different social factors such as individual cultures and personality traits can be considered to design a more sophisticated social interaction map.
References
Butler JT, Agah A (2001) Psychological effects of behavior patterns of a mobile personal robot. Auton Robot 10(2):185–202
Edward H (1969) The hidden dimension: man’s use of space in public and in private. The Bodley Head Ltd, London
Pacchierotti E, Christensen HI, J P (2006) Embodied social interaction for service robots in hallway environments. Springer, Berlin
Gockley R, Forlizzi J, Simmons R (2007) Natural person-following behavior for social robots. In: 2007 2nd ACM/IEEE international conference on human–robot interaction (HRI), pp 17–24
Hansen ST, Svenstrup M, Andersen HJ, Bak T (2009) Adaptive human aware navigation based on motion pattern analysis. In: RO-MAN 2009—the 18th IEEE international symposium on robot and human interactive communication, Toyama, Japan, pp 927–932
Jaillet L, Cortes J, Simeon T (2008) Transition-based rrt for path planning in continuous cost spaces. In: 2008 IEEE/RSJ international conference on intelligent robots and systems, pp 2145–2150
Kessler J, Schroeter C, Gross HM (2011) Approaching a person in a socially acceptable manner using a fast marching planner. Springer, Berlin
Kim Y, Mutlu B (2014) How social distance shapes human–robot interaction. Int J Hum Comput Stud 72(12):783–795
Kirby R, Simmons R, Forlizzi J (2009) Companion: a constraint-optimizing method for person-acceptable navigation. In: The proceedings of the IEEE international symposium on robot and human interactive communication
Lam CP, Chou CT, Chiang KH, Fu LC (2011) Human-centered robot navigation; towards a harmoniously human; robot coexisting environment. IEEE Trans Robot 27(1):99–112
Lindner F (2015) A conceptual model of personal space for human-aware robot activity placement. In: 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS), Hamburg, pp 5770–5775
Lu DV, Smart WD (2013) Towards more efficient navigation for robots and humans. In: 2013 IEEE/RSJ international conference on intelligent robots and systems, pp 1707–1713
Luber M, Spinello L, Silva J, Arras KO (2012) Socially-aware robot navigation: a learning approach. In: 2012 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 902–907
Mahadevan S (1996) Average reward reinforcement learning: foundations, algorithms, and empirical results. Mach Learn 22(1):159–195
Mead R (2012) Space, speech, and gesture in human-robot interaction. In: Proceedings of the 14th ACM international conference on multimodal interaction, New York, USA, pp 333–336
Walters ML, Dautenhahn K, RB (2009) An empirical framework for human-robot proxemics. In: Proceedings of new frontiers in human–robot interaction symposium at the AISB09 convention, pp 144–149
Nakauchi Y, Simmons R (2000) A social robot that stands in line. In: Proceedings of 2000 IEEE/RSJ international conference on intelligent robots and systems (IROS 2000), vol 1, Takamatsu, Japan, pp 357–364
Newell PB (1998) A cross-cultural comparison of privacy definitions and functions: a systems approach. J Environ Psychol 18(4):357–371
Pandey AK, Alami R (2010) A framework towards a socially aware mobile robot motion in human-centered dynamic environment. In: 2010 IEEE/RSJ international conference on intelligent robots and systems, Taipei, pp 5855–5860
Papadakis P, Rives P, Spalanzani A (2014) Adaptive spacing in human-robot interactions. In: 2014 IEEE/RSJ international conference on intelligent robots and systems, Chicago, USA, pp 2627–2632
Patompak P, Jeong S, Chong NY, Nilkhamhang I (2016) Mobile robot navigation for human–robot social interaction. In: 2016 16th International conference on control. automation and systems (ICCAS), Gyeongju, Korea, pp 1298–1303
Patompak P, Jeong S, Chong NY, Nilkhamhang I (2017) Learning social relations for culture aware interaction. In: 14th Ubiquitous robots and ambient intelligence (URAI), Jeju, Korea, pp 1298–1303
Rios-Martinez J (2013) Socially-aware robot navigation: combining risk assessment and social conventions. Dissertation INRIA Sophia-Antipolis, France
Rueben M, Smart WD (2016) Privacy in human–robot interaction survey and future work. In: We robot 2016: the fifth annual conference on legal and policy issues relating to robotics, University of Miami School of Law
Sisbot EA, Marin-Urias LF, Alami R, Simeon T (2007) A human aware mobile robot motion planner. IEEE Trans Robot 23(5):874–883
Svenstrup M, Bak T, Andersen HJ (2010) Trajectory planning for robots in dynamic human environments. In: 2010 IEEE/RSJ international conference on intelligent robots and systems, Taipei, pp 4293–4298
Takayama L, Pantofaru C (2009) Influences on proxemic behaviors in human–robot interaction. In: International conference on IEEE/RSJ intelligent robots and systems, IROS 2009, pp 5495–5502
Tomari R, Kobayashi Y, Kuno Y (2012) Empirical framework for autonomous wheelchair systems in human-shared environments. In: 2012 IEEE international conference on mechatronics and automation, Chengdu, pp 493–498
Tora E, Cuijpers RH, Juolia JF, Van Der Pol D (2012) Modelling and testing proxemic behavior for humanoid robots. Int J Humanoid Robot 09(04):1250,028
Tutsoy O, Brown M (2016) Reinforcement learning analysis for a minimum time balance problem. Trans Inst Meas Control 38(10):1186–1200
Westin A (1970) Privacy and freedom. Bodley Head, London
Zeeger SK, Readdick CA, Hansen-Gandy S (1994) Daycare children’s establishment of territory to experience privacy. Child Environ 11:265–271
Acknowledgements
This work was supported by the EU-Japan coordinated R&D project on “Culture Aware Robots and Environmental Sensor Systems for Elderly Support” commissioned by the Ministry of Internal Affairs and Communications of Japan and EC Horizon 2020.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics
This work was conducted in accordance with the JAIST ethical guidances for research.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Patompak, P., Jeong, S., Nilkhamhang, I. et al. Learning Proxemics for Personalized Human–Robot Social Interaction. Int J of Soc Robotics 12, 267–280 (2020). https://doi.org/10.1007/s12369-019-00560-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12369-019-00560-9