
Abstract
This paper considers Stackelberg solutions for bilevel linear programming problems under fuzzy random environments. To deal with the formulated fuzzy random bilevel linear programming problem, α-level sets of fuzzy random variables are introduced and an α-stochastic bilevel linear programming problem is defined for guaranteeing the degree of realization of the problem. Taking into account vagueness of judgments of decision makers, fuzzy goals are introduced and the α-stochastic bilevel linear programming problem is transformed into the problem to maximize the satisfaction degree for each fuzzy goal. Through probability maximization in stochastic programming, the transformed stochastic bilevel programming problem can be reduced to a deterministic bilevel programming problem. An extended concept of Stackelberg solution is introduced and a computational method is also presented. A numerical example is provided to illustrate the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Decision making problems in decentralized organizations are often modeled as Stackelberg games (Simaan and Cruz 1973), and they are formulated as bilevel mathematical programming problems (Shimizu et al. 1997; Sakawa and Nishizaki 2009). In the context of bilevel programming, the decision maker at the upper level first specifies a strategy, and then the decision maker at the lower level specifies a strategy so as to optimize the objective with full knowledge of the action of the decision maker at the upper level. In conventional multi-level mathematical programming models employing the solution concept of Stackelberg equilibrium, it is assumed that there is no communication among decision makers, or they do not make any binding agreement even if there exists such communication. Computational methods for obtaining Stackelberg solutions to bilevel linear programming problems are classified roughly into three categories: the vertex enumeration approach (Bialas and Karwan 1984), the Kuhn-Tucker approach (Bard and Falk 1982; Bard and Moore 1990; Bialas and Karwan 1984; Hansen et al. 1992), and the penalty function approach (White and Anandalingam 1993). The subsequent works on bilevel programming problems under noncooperative behavior of the decision makers have been appearing (Nishizaki and Sakawa 1999, 2000; Gümüs and Floudas 2001; Nishizaki et al. 2003; Colson et al. 2005; Faisca et al. 2007) including some applications to aluminium production process (Nicholls 1996), pollution control policy determination (Amouzegar and Moshirvaziri 1999), tax credits determination for biofuel producers (Dempe and Bard 2001), pricing in competitive electricity markets (Fampa et al. 2008), supply chain planning (Roghanian et al. 2007) and so forth.
However, to utilize bilevel programming for resolution of conflict in decision making problems in real-world decentralized organizations, it is important to realize that simultaneous considerations of fuzziness (Sakawa 1993, 2000, 2001) and randomness (Stancu-Minasian 1984; Birge and Louveaux 1997; Sakawa and Kato 2008) would be required. Fuzzy random variables, first introduced by Kwakernaak (1978), have been developing (Kruse and Meyer 1987; Puri and Ralescu 1996; Liu and Liu 2003), and an overview of the developments of fuzzy random variables was found in (Gil et al. 2006). Studies on linear programming problems with fuzzy random variable coefficients, called fuzzy random linear programming problems, were initiated by Wang and Qiao (1993), Qiao et al. (1994) as seeking the probability distribution of the optimal solution and optimal value. Optimization models for fuzzy random linear programming problems were first considered by Luhandjula (1996; Luhandjula and Gupta 1996) and further developed by Liu (2001a, b) and Rommelfanger (2007). A brief survey of major fuzzy stochastic programming models was found in the paper by Luhandjula (2006). As we look at recent developments in the fields of fuzzy random programming, we can see continuing advances (Katagiri et al. 2004a, b, c, 2005a, b, 2006, 2008; Rommlfanger 2007; Ammar 2008; Xu and Liu 2008).
Under these circumstances, in this paper, we consider Stackelberg solutions for bilevel linear programming problems under fuzzy random environments. To deal with the formulated bilevel linear programming problem involving fuzzy random variables, α-level sets of fuzzy random variables are introduced and an α-stochastic bilevel linear programming problem is defined for guaranteeing the degree of realization of the problem. Taking into account vagueness of judgments of decision makers, fuzzy goals are introduced and the α-stochastic bilevel linear programming problem is transformed into the problem to maximize the satisfaction degree for each fuzzy goal. Following the probability maximization model (Charnes and Cooper 1963), the transformed stochastic bilevel programming problem can be reduced to a deterministic one. For the transformed problem, an extended concept of Stackelberg solution is introduced and a computational method is also presented. It is shown that the extended Stackelberg solution can be obtained through the combined use of the variable transformation method by Charnes and Cooper (1962) and the Kth best algorithm for bilevel linear programming problems by Bialas and Karwan (1984).
2 Fuzzy random bilevel linear programming
Fuzzy random variables, first introduced by Kwakernaak (1978), have been defined in various ways (Kwakernaak 1978; Puri and Ralescu 1996; Kruse and Meyer 1987; Liu and Liu 2003). In this paper, we give the definition of a fuzzy random variable as follows:
Definition 1
[Fuzzy random variable] Let \((\Upomega,A,P)\) be a probability space, \(F({\mathcal{R}})\) the set of all fuzzy numbers, and B the Borel σ-field of \({\mathcal{R}}\). Then, a map \(\tilde{\bar C}:\Upomega \rightarrow F({\mathcal{R}})\) is called a fuzzy random variable if
where \(\tilde{\bar C}_{\alpha}(\omega)=\left[\tilde{\bar C}_{\alpha}^{-}(\omega),\tilde{\bar C}_{\alpha}^{+}(\omega)\right]:=\left\{\tau \in {\mathcal{R}} \left| \mu_{\tilde{\bar C}(\omega)}(\tau)\geq \alpha\right.\right\}\) is an α-level set of the fuzzy number \(\tilde{\bar C}(\omega)\) for \(\omega \in \Upomega\).
Although there exist some minor differences in several definitions of fuzzy random variables, fuzzy random variables could be roughly understood to be a random variable whose observed values are fuzzy sets.
In this paper, we deal with bilevel linear programming problems involving fuzzy random variable coefficients in objective functions formulated as:
It is significant to note here that randomness and fuzziness of the coefficients are denoted by the “dash above” and “wave above” i.e., “–” and “∼”, respectively. In this formulation, \(\user2{x}_{1}\) is an n 1 dimensional decision variable column vector for the decision maker at the upper level (DM1), \(\user2{x}_{2}\) is an n 2 dimensional decision variable column vector for the decision maker at the lower level (DM2), \(z_{1}(\user2{x}_{1},\user2{x}_{2})\) is the objective function for DM1 and \(z_{2}(\user2{x}_{1},\user2{x}_{2})\) is the objective function for DM2. Elements \(\tilde{\bar{C}}_{ljk}, k=1,2,\ldots,n_{j}\) of coefficient vectors \(\tilde{\bar{\user2{C}}}_{lj}, l=1,2,\, j=1,2\) are fuzzy random variables of which observed values for each elementary event ω are fuzzy numbers \(\tilde{\bar{C}}_{ljk}(\omega)\) characterized by the membership function:
where the function L(t) = max{0, λ(t)} is a real-valued continuous function from [0, ∞) to [0, 1], and λ(t) is a strictly decreasing continuous function satisfying λ(0) = 1. Also, R(t) = max{0, ρ(t)} satisfies the same conditions. The parameters β ljk and γ ljk , representing left and right spreads of \(\mu_{\tilde{\bar{C}}_{ljk}(\omega)}(\cdot)\), are positive numbers. The parameter \(\bar{d}_{ljk}\) which is a mean value of \(\tilde{\bar{C}}_{ljk}\) is defined as \(\bar{d}_{ljk}=d_{ljk}^1+\bar{t}_{l} d_{ljk}^2\) using a random variable \(\bar{t}_l\) with mean M l . This definition of random variables is one of the simplest randomization modeling of coefficients using dilation and translation of random variables, as discussed by Stancu-Minasian (1990) and Katagiri et al. (2008).
In the following, let us denote the feasible region of Eq. 1 by X and let \(\tilde{\bar{\user2{C}}}_{l}=(\tilde{\bar{\user2{C}}}_{l1},\tilde{\bar{\user2{C}}}_{l2}), \user2{x}=(\user2{x}_{1}^{T},\user2{x}_{2}^{T})^{T}\). Figure 1 illustrates an example of the membership function of a fuzzy random variable \(\tilde{\bar{C}}_{ljk}\).

An example of the membership function \(\mu_{{\tilde{\bar{C}}_{{ljk}}(\omega)}}(\cdot)\)
Fuzzy random bilevel linear programming problems formulated as Eq. 1 are often seen in actual decision making situations. For example, consider a supply chain planning (Roghanian et al. 2007) where the distribution center (DM1) and the production part (DM2) hope to minimize the distribution cost and the production cost respectively. Since coefficients of these objective functions are often affected by the economic conditions varying at random, they can be regarded as random variables. In addition, since observed values of them are often ambiguous and estimated by fuzzy numbers, they are expressed by fuzzy random variables. Hence, the supply chain planning problem can be formulated as a bilevel linear programming problem involving fuzzy random variable coefficients.
Observing that each coefficient \(\tilde{\bar{C}}_{ljk}\) is a fuzzy random variable defined as a random variable of which observed values are L–R fuzzy numbers, each objective function \(\tilde{\bar{\user2{C}}}_{l}\user2{x}=\tilde{\bar{\user2{C}}}_{l1}\user2{x}_{1} + \tilde{\bar{\user2{C}}}_{l2}\user2{x}_{2}\) is also a fuzzy random variable of which observed values for elementary events ω are fuzzy numbers characterized by the membership function
An example of a membership function of an objective function for DMl is shown in Fig. 2.

An example of a membership function of an objective function for DMl
3 Level set-based optimization approach
Observing that Eq. 1 involves fuzzy random variables in the objective functions, we first introduce the α-level set of the fuzzy random variables. The α-level set of the fuzzy random variables \(\tilde{\bar{C}}_{ljk}\) is defined as the ordinary set for which the degree of their membership functions for each elementary event ω exceeds the level α:
For notational convenience, in the following, let \(\tilde{\bar{\user2{C}}}_{l\alpha}=(\tilde{\bar{\user2{C}}}_{l1\alpha},\tilde{\bar{\user2{C}}}_{l2\alpha}), l=1,2\) be an α-level set defined as the Cartesian product of α-level sets \(\tilde{\bar{C}}_{ljk\alpha}\) of fuzzy random variables \(\tilde{\bar{C}}_{ljk}, j=1,2, k=1,2,\ldots,n_{j}\).
Now suppose that DM1 decides that the degree of all of the membership functions of the fuzzy random variables involved in Eq. 1 should be greater than or equal to some value α. Then for such a degree α, Eq. 1 can be interpreted as the following stochastic bilevel linear programming problem which depends on the coefficient vectors \((\bar{\user2{C}}_{11},\bar{\user2{C}}_{12}) \in (\tilde{\bar{\user2{C}}}_{11\alpha},\tilde{\bar{\user2{C}}}_{12\alpha})\) and \((\bar{\user2{C}}_{21},\bar{\user2{C}}_{22}) \in (\tilde{\bar{\user2{C}}}_{21\alpha},\tilde{\bar{\user2{C}}}_{22\alpha})\)
Observe that there exists an infinite number of such problems depending on the coefficient vector \((\bar{\user2{C}}_{11},\bar{\user2{C}}_{12}) \in (\tilde{\bar{\user2{C}}}_{11\alpha},\tilde{\bar{\user2{C}}}_{12\alpha})\) and \((\bar{\user2{C}}_{21},\bar{\user2{C}}_{22}) \in (\tilde{\bar{\user2{C}}}_{21\alpha},\tilde{\bar{\user2{C}}}_{22\alpha})\), and the values of \((\bar{\user2{C}}_{11},\bar{\user2{C}}_{12})\) and \((\bar{\user2{C}}_{21},\bar{\user2{C}}_{22})\) are arbitrary for any \((\bar{\user2{C}}_{11},\bar{\user2{C}}_{12}) \in (\tilde{\bar{\user2{C}}}_{11\alpha},\tilde{\bar{\user2{C}}}_{12\alpha})\) and \((\bar{\user2{C}}_{21},\bar{\user2{C}}_{22}) \in (\tilde{\bar{\user2{C}}}_{21\alpha},\tilde{\bar{\user2{C}}}_{22\alpha})\) in the sense that the degree of all of the membership functions for the fuzzy random variables in Eq. 2 exceeds the level α. However, if possible, it would be desirable for DM1 to choose \((\bar{\user2{C}}_{11},\bar{\user2{C}}_{12}) \in (\tilde{\bar{\user2{C}}}_{11\alpha},\tilde{\bar{\user2{C}}}_{12\alpha})\) and \((\bar{\user2{C}}_{21},\bar{\user2{C}}_{22}) \in (\tilde{\bar{\user2{C}}}_{21\alpha},\tilde{\bar{\user2{C}}}_{22\alpha})\) in Eq. 2 to minimize the objective functions under the constraints. From such a point of view, for a certain degree α, it seems to be quite natural to have Eq. 2 as the following α-stochastic bilevel linear programming problem:
4 Stackelberg solutions through probability maximization
Considering vague natures of the decision makers’ judgment, it is natural to assume that decision makers may have vague or fuzzy goals for each of the objective functions in the α-stochastic bilevel linear programming problem Eq. 3. In a minimization problem, a goal stated by decision makers may be to achieve “substantially less than or equal to some value.” This type of statement can be quantified by eliciting a corresponding membership function.
In this paper, we express the fuzzy goals of DM1 and DM2 for their own objective function values as μ1 and μ2, respectively.
On the other hand, it should be stressed here that not only fuzziness but also randomness must be properly reflected in the obtained solution of problem Eq. 3 because the original problem involves fuzzy random variables.
In this paper, assuming that the decision makers are interested in the probability that each objective function attains a goal value rather than the expectation or variance of each membership function, we consider the following problem as one of reasonable decision making problems for Eq. 3:
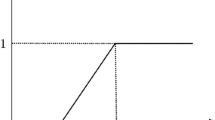
where h l is a permissible level for μ l (·). The function μ l is a membership function of the fuzzy goal of DMl, and it is defined as a real-valued non-increasing continuous function by considering that Eq. 3 is the minimization problem. Figure 3 illustrates a possible shape of non-increasing membership functions μ l , l = 1, 2 of the fuzzy goals of the DMs for the objective function values. This figure shows that the value of membership function μ l should be 1 if the decision maker is fully satisfied with the corresponding objective function value, and 0 if the decision maker is not satisfied at all.

An example of a membership function \(\mu_{l} (\cdot)\) of a fuzzy goal
It should be stressed here that Eq. 4 can be interpreted as an optimization problem based on an extended probability maximization model that was originally introduced in a framework of stochastic programming Eq. 9.
In more general, expectation optimization, variance minimization, probability maximization and fractile criterion optimization (Charnes and Cooper 1963; Kataoka 1963; Stancu-Minasian 1984; Birge and Louveaux 1997; Sakawa and Kato 2008) are typical optimization models for objective functions involving random variables. For instance, let the objective function represent a profit. If the decision maker wishes to simply maximize the expected profit without caring about the fluctuation of the profit, the expectation optimization model to optimize the expectation of the objective function is appropriate. On the other hand, if the decision maker hopes to decrease the fluctuation of the profit as little as possible from the viewpoint of the stability of the profit, the variance minimization model to minimize the variance of the objective function is useful. In contrast to these two types of optimizing approaches, as satisficing approaches, the probability maximization model and the fractile criterion optimization model have been proposed. When the decision maker wants to maximize the probability that the profit is greater than or equal to a certain permissible level, probability maximization model is recommended. In contrast, when the decision maker wishes to optimize such a permissible level as the probability that the profit is greater than or equal to the permissible level is greater than or equal to a certain threshold, the fractile criterion optimization model will be appropriate.
Realizing that Eq. 4 is a deterministic bilevel programming problem under noncooperative environments, we reformulate the following problem of finding a Stackelberg solution to Eq. 4:
Following the definition of Stackelberg solutions, for any feasible decision \(\hat{\user2{x}}_{1}\) given by DM1,DM2 is assumed to select a decision \(\user2{x}_{2}(\hat{\user2{x}}_{1})\) which is an optimal solution to the following problem:
The optimal solution \(\user2{x}_{2}(\hat{\user2{x}}_{1})\) to Eq. 6 is called a rational reaction for \(\hat{\user2{x}}_{1}\). Let us denote the set of rational reactions for \(\hat{\user2{x}}_{1}\) by \(RR(\hat{\user2{x}} _{1})\). Then, DM1 should select a solution \((\user2{x}_{1}, \user2{x}_{2})\) to optimize h 1 from among the inducible region \(IR=\{(\user2{x}_{1},\user2{x}_{2}) \mid (\user2{x}_{1},\user2{x}_{2}) \in X, \user2{x}_{2} \in RR(\user2{x}_{1})\}\). To be more explicit, DM1 selects an optimal solution to the following problem:
The optimal solution to Eq. 7 is a Stackelberg solution to problem Eq. 4.
Then, we are ready to define a P-α-Stackelberg solution as an extended solution concept of original Stackelberg solution.
Definition 2
[P-α-Stackelberg solution] A feasible solution \((\user2{x}_{1}^*, \user2{x}_{2}^*) \in X\) is called a P-α-Stackelberg solution, meaning a Stackelberg solution through probability maximization using α-level set, if \((\user2{x}_{1}^*, \user2{x}_{2}^*)\) is an optimal solution to the following bilevel programming problem:
In what follows, we discuss how to solve problem Eqs. 8 or 7 in order to obtain a P-α-Stackelberg solution. Let \(\bar{C}_{ljk\alpha}^{L}(\omega)\) and \(\bar{C}_{ljk\alpha}^{R}(\omega)\) be τ satisfying \(L((\bar{d}_{ljk}(\omega)-\tau)/\beta_{ljk}) = \alpha\) and τ′ satisfying \(R((\tau'-\bar{d}_{ljk}(\omega))/\gamma_{ljk}) = \alpha\), respectively. Then, the α-level set of \(\tilde{\bar{C}}_{ljk}(\omega)\) becomes a closed interval \([\bar{C}_{ljk\alpha}^{L}(\omega), \bar{C}_{ljk\alpha}^{R}(\omega)]\) which varies randomly dependent on each elementary event ω, as shown in Fig. 4.

An example of the α-level set of \(\tilde{\bar{C}}_{{ljk}}(\omega)\)
Accordingly, the constraint \(\bar{\user2{C}}_{1} \in \tilde{\bar{\user2{C}}}_{1\alpha}\) is equivalent to \(\bar{\user2{C}}_{1} \in [\bar{\user2{C}}_{1\alpha}^{L}, \bar{\user2{C}}_{1\alpha}^{R}]\). Since \(\bar{\user2{C}}_{1\alpha}^{L}(\omega) \geq \bar{\user2{C}}_{1}(\omega)\) for any random variable \(\bar{\user2{C}}_{1}\in [\bar{\user2{C}}_{1\alpha}^{L}, \bar{\user2{C}}_{1\alpha}^{R}]\), it holds that
for any any random variable \(\bar{\user2{C}}_{1}\in [\bar{\user2{C}}_{1\alpha}^{L}, \bar{\user2{C}}_{1\alpha}^{R}]\) because μ1 is a nonincreasing function. Therefore, maximizing \({Pr}\left\{\omega\left|\mu_{1}(\bar{\user2{C}}_{1\alpha}(\omega)\user2{x}) \geq h_{1}\right.\right\}\) under the constraint \(\bar{\user2{C}}_{1} \in \tilde{\bar{\user2{C}}}_{1\alpha}\) is equivalent to maximizing \({Pr}\left\{\omega\left|\mu_{1}(\bar{\user2{C}}_{1\alpha}^{L}(\omega)\user2{x}) \geq h_{1}\right.\right\}\). By applying the similar transformation to the objective function of DM2, we obtain the following two-level linear programming problem as the equivalent problem of (8):
Since μ l (·), l = 1, 2 are nonincreasing, Eq. 9 can be rewritten as:
where μ * l (·) is a pseudo-inverse function of μ l (·) defined by \(\mu_{l}^{*}(h_l)=\sup\{y \mid \mu_{l}(y) \geq h_l \}\).
In view of \(\alpha=L((\bar{d}_{ljk}(\omega)-\bar{C}_{ljk\alpha}^{L}(\omega))/\beta_{ljk})\) in Eq. 10, it holds that
where \(L^{*}(\cdot)\) is a pseudo-inverse function of \(L(\cdot)\) defined by \(L^{*}(\alpha)=\sup\{\tau \mid L(\tau) \geq \alpha \}\). Supposing that \(\user2{d}_{l}^{2}\user2{x} > 0, l=1,2\) for any feasible solution \(\user2{x} \in X = \{ \user2{x} \in R^{(n_1+n_2)} \mid A_1\user2{x}_1 + A_2\user2{x}_2\leq \user2{b}, \user2{x}_j \geq {\bf 0}, j=1, 2 \}\), we can rewrite objective functions in Eq. 10 as follows.
Therefore, Eq. 10 can be transformed as:
Since distribution functions \(T_{l}(\cdot)\) are generally nondecreasing, Eq. 11 is finally reduced into the following deterministic bilevel linear fractional programming problem.
For bilevel linear fractional programming problems, it is shown that Stackelberg solutions exist at some extreme point of the feasible region (Calvete and Gale 2004).
Therefore, we can construct the following computational method for obtaining P-α-Stackelberg solutions through the combined use of the variable transformation method by Charnes and Cooper (1962) and the Kth best algorithm for bilevel linear programming problems by Bialas and Karwan (1984).
4.1 The computational method for obtaining P-\(\varvec{\alpha}\) Stackelberg solutions
Step 1: Let i≔ 1. Removing the objective function of DM 2 from Eq. 12, solve the following problem:
Observing that Eq. 13 is a linear fractional programming problem and the denominator of the objective function is positive as discussed in Eq. 10, it can be transformed into an equivalent linear programming problem by the variable transformation method by Charnes and Cooper (1962). To be more specific, introducing the variable transformation
and letting \(\user2{y}_1 = t \cdot \user2{x}_1, \user2{y}_2 = t \cdot \user2{x}_2\), Eq. 13 is transformed into the following linear programming problem:
Observing that Eq. 14 is a linear programming problem, we can obtain an optimal solution by the simplex method. Using the optimal solution to Eq. 14 denoted by \((\user2{y}_{1[1]}^{T}, \user2{y}_{2[1]}^{T}, t_{[1]})^{T}\), we can obtain
which is an extreme point of the feasible region of Eq. 13 as shown in Stancu-Minasian (1992). Let W be a set of feasible extreme points to be searched and U a set of feasible extreme points that had been searched. Let \(W := \{(\user2{x}_{1[1]}^T, \user2{x}_{2[1]}^T)^T\}\) and U ≔ ∅. Go to step 2.
Step 2: In order to check whether the present extreme point \((\user2{x}_{1[i]}^{T}, \user2{x}_{2[i]}^{T})^{T}\) exists in the inducible region IR, i.e., \(\user2{x}_{2[i]}\) is a rational reaction for \(\user2{x}_{1[i]}\) or not, we solve the following problem:
Observing that Eq. 15 is a linear fractional programming problem and the denominator of the objective function is positive, it can be transformed into an equivalent linear programming problem by the variable transformation method by Charnes and Cooper (1962). Namely, introducing the variable transformation
and letting \(\user2{w}_{2} := u \cdot \user2{x}_{2} \), Eq. 15 is transformed into the following linear programming problem:
Observing that Eq. 16 is a linear programming problem, we can find an optimal solution \((\user2{w}_{2[i]}^{T}, u_{[i]})^{T}\) by the simplex method. If \(\user2{w}_{2[i]}/u_{[i]} = \user2{x}_{2[i]}\), then the current extreme point \((\user2{x}_{1[i]}^{T}, \user2{x}_{2[i]}^{T})^{T}\) exists in IR, i.e., it is a P-α-Stackelberg solution and the algorithm is terminated. Otherwise, go to step 3.
Step 3: Let W [i] be a set of feasible extreme points which are adjacent to \((\user2{x}_{1[i]}^{T}, \user2{x}_{2[i]}^{T})^{T}\) and satisfy \(Z_{1\alpha}^{P}(\user2{x}_{1},\user2{x}_{2}) \leq Z_{1\alpha}^{P}(\user2{x}_{1[i]},\user2{x}_{2[i]})\). Let \(U := U \cup \{(\user2{x}_{1[i]}^{T}, \user2{x}_{2[i]}^{T})^{T}\}\) and \(W := (W \cup W_{[i]} ) \backslash U\), and go to step 4.
Step 4: Let i ≔ i +1. Choose an extreme point \((\user2{x}_{1[i]}^{T}, \user2{x}_{2[i]}^{T})^{T}\) such that
and return to step 2.
It should be noted here that the proposed computational method uses nothing but the variable transformation method, the simplex method and the pivot operation for obtaining a P-α-Stackelberg solution.
5 Numerical example
In order to demonstrate the feasibility and efficiency of the proposed computational methods, consider the following bilevel linear programming problem involving fuzzy random variable coefficients:
where \(\tilde{\bar{\user2{C}}}_{lj}, l=1,2,\, j=1,2\) are vectors whose elements \(\tilde{\bar{C}}_{ljk}, k=1,2,3\) are fuzzy random variables, and each of \(\bar{t}_l, l=1,2\) is a Gaussian random variable whose mean 0 and variance 12.
Values of coefficients in constraints are shown in Table 1, and values of \(\bar{\user2{d}}_{l}^{1}, \bar{\user2{d}}_{l}^{2}, \user2{\beta}_{l}\) and \(\user2{\gamma}_{l}, l=1,2\) are shown in Table 2.
In this numerical experiment, the hypothetical decision makers determine the permissible levels h 1 = 0.80, h 2 = 0.80 and the degree of realization of the problem α = 0.6. In step 1, after transforming Eq. 13 into Eq. 14 by the variable transformation method, Eq. 14 is solved by the simplex method. For the obtained value of \((\user2{x}_{1[1]}^{T}, \user2{x}_{2[1]}^{T})^{T}=(10.00,0.00,0.00,28.00,0.00,40.00)^{T}\), let \(W:= \{(\user2{x}_{1[1]}^{T}, \user2{x}_{2[1]}^{T})^{T}\}, U:= \emptyset\). In step 2, after transforming Eq. 15 into Eq. 16 by the variable transformation method, we solve Eq. 16 by the simplex method in order to obtain the rational reaction for \(\user2{x}_{1[1]}\). Since the optimal solution to Eq. 16 \(\user2{w}_{2[1]}/u_{[1]}=(0.00,0.00,28.00)^{T}\) is not equal to \(\user2{x}_{2[1]}=(28.00,0.00,40.00)^{T}\), the current extreme point \((\user2{x}_{1[1]}^{T}, \user2{x}_{2[1]}^{T})^{T}\) is not a P-α-Stackelberg solution. In step 3, we enumerate feasible extreme points \((\user2{x}_{1}^{T}, \user2{x}_{2}^{T})^{T}\) which are adjacent to \((\user2{x}_{1[1]}^{T}, \user2{x}_{2[1]}^{T})^{T}\) and satisfy \(Z_{1\alpha}^{P}(\user2{x}_{1},\user2{x}_{2}) \leq Z_{1\alpha}^{P}(\user2{x}_{1[1]},\user2{x}_{2[1]})\), and make W [1]. Then, let \(U:= U \cup (\user2{x}_{1[1]}^{T}, \user2{x}_{2[1]}^{T})^{T}\) and \(W:= (W \cup W_{[1]} ) \backslash U\). In step 4, we find a feasible extreme point \((\user2{x}_{1}^{T}, \user2{x}_{2}^{T})^{T}\) in W whose \(Z_{1\alpha}^{P}(\user2{x}_{1},\user2{x}_{2})\) is the greatest and let it be the next extreme point \((\user2{x}_{1[i+1]}^T, \user2{x}_{2[i+1]}^T)^T\). Then, let i ≔ i +1 and return to step 2. By repeating the procedures, we can obtain a P-α-Stackelberg solution
From the viewpoint of maximizing \(Z_{l\alpha}^{P}(\user2{x}_{1},\user2{x}_{2})\), it is desirable for DM1 to give larger values to decision variables x jk that the corresponding \(d_{1jk}^{1}, d_{1jk}^{2}\) are small and the value of β1jk is large. On the other hand, it is desirable for DM2 to give larger values to decision variables x 2k that the corresponding \(d_{2jk}^{1}, d_{2jk}^{2}\) are small and the value of β2jk is large. With respect to this example, \((\user2{x}_{1,P\alpha}^{T}, \user2{x}_{2,P\alpha}^{T})^{T}\) becomes Stackelberg equilibrium as a result of strategy selection by DM1 and by DM2 mentioned above.
6 Conclusion
In this paper, computational methods for obtaining Stackelberg solutions for bilevel linear programming problems involving fuzzy random variable coefficients have been presented. To deal with the formulated bilevel linear programming problem involving fuzzy random variables, α-level sets of fuzzy random variables were introduced and an α-stochastic bilevel linear programming problem was defined for guaranteeing the degree of realization of the problem. Taking into account vagueness of judgments of decision makers, fuzzy goals were introduced and the α-stochastic bilevel linear programming problem has been transformed into the problem to maximize the satisfaction degree for each fuzzy goal. Through the use of probability maximization in stochastic programming, the transformed stochastic bilevel programming problem was reduced to a deterministic bilevel programming problem. For the transformed problem, an extended concept of Stackelberg solution was introduced and a computational method was also presented. It is significant to note here that the extended Stackelberg solution can be obtained through the combined use of the variable transformation method and the Kth best algorithm for bilevel linear programming problems. To illustrate the proposed computational method, a numerical example for obtaining the extended Stackelberg solution was provided. As one of future works, the proposed method may be extended by considering not only fuzzy random objective functions but also fuzzy random constraints. Extensions to other stochastic programming models will be considered elsewhere. Further considerations from the view point of fuzzy random cooperative bilevel programming will be required in the near future.
References
Ammar EE (2008) On solutions of fuzzy random multiobjective quadratic programming with applications in portfolio problem. Inf Sci 178(2):468–484
Amouzegar MA, Moshirvaziri K (1999) Determining optimal pollution control policies: an application of bilevel programming. Eur J Oper Res 119(1):100–120
Bard JF, Falk JE (1982) An explicit solution to the multi-level programming problem. Comput Oper Res 9(1):77–100
Bard JF, Moore JT (1990) A branch and bound algorithm for the bilevel programming problem. SIAM J Sci Stat Comput 11(2):281–292
Bialas WF, Karwan MH (1984) Two-level linear programming. Manag Sci 30(8):1004–1020
Birge JR, Louveaux F (1997) Introduction to stochastic programming. Springer, London
Calvete HI, Gale C (2004) A note on bilevel linear fractional programming problem. Eur J Oper Res 152(1):296–299
Charnes A, Cooper WW (1962) Programming with linear fractional functionals. Nav Res Logist Q 9(3–4):181–186
Charnes A, Cooper WW (1963) Deterministic equivalents for optimizing and satisficing under chance constraints. Oper Res 11(1):18–39
Colson B, Marcotte P, Savard G (2005) A trust-region method for nonlinear bilevel programming: algorithm and computational experience. Comput Optim Appl 30(3):211–227
Dempe S, Bard JF (2001) Bundle trust-region algorithm for bilinear bilevel programming. J Optim Theory Appl 110(2):265–268
Faisca NP, Dua V, Rustem B, Saraiva PM, Pistikopoulos EN (2007) Parametric global optimisation for bilevel programming. J Glob Optim 38(4):609–623
Fampa M, Barroso LA, Candal D, Simonetti L (2008) Bilevel optimization applied to strategic pricing in competitive electricity markets. Comput Optim Appl 39(2):121–142
Gil MA, Lopez-Diaz M, Ralescu DA (2006) Overview on the development of fuzzy random variables. Fuzzy Sets Syst 157(19):2546–2557
Gümüs ZH, Floudas CA (2001) Global optimization of nonlinear bilevel programming problems. J Glob Optim 20(1):1–31
Hansen P, Jaumard B, Savard G (1992) New branch-and-bound rules for linear bilevel programming. SIAM J Sci Stat Comput 13(5):1194–1217
Katagiri H, Ishii H, Sakawa M (2004a) On fuzzy random linear knapsack problems. Cent Eur J Oper Res 12(1):59–70
Katagiri H, Sakawa M, Ishii H (2004b) Fuzzy random bottleneck spanning tree problems using possibility and necessity measures. Eur J Oper Res 152(1):88–95
Katagiri H, Sakawa M, Kato K, Nishizaki I (2004c) A fuzzy random multiobjective 0–1 programming based on the expectation optimization model using possibility and necessity measures. Math Comput Model 40(3–4):411–421
Katagiri H, Mermri EB, Sakawa M, Kato K, Nishizaki I (2005a) A possibilistic and stochastic programming approach to fuzzy random MST problems. IEICE Trans Inf Syst E88-D(8):1912–1919
Katagiri H, Sakawa M, Ishii H (2005b) A study on fuzzy random portfolio selection problems using possibility and necessity measures. Sci Math Jpn 61(2):361–369
Katagiri H, Sakawa M, Nishizaki I (2006) Interactive decision making using possibility and necessity measures for a fuzzy random multiobjective 0–1 programming problem. Cybern Syst 37(1):59–74
Katagiri H, Sakawa M, Kato K, Nishizaki I (2008) Interactive multiobjective fuzzy random linear programming: maximization of possibility and probability. Eur J Oper Res 188(2):530–539
Kataoka S (1963) A stochastic programming model. Econometorica 31(1–2):181–196
Kruse R, Meyer KD (1987) Statistics with vague data. D. Riedel Publishing Company, Dordrecht
Kwakernaak H (1978) Fuzzy random variables-I. Definitions and theorems. Inf Sci 15(1):1–29
Liu B (2001) Fuzzy random chance-constrained programming. IEEE Trans Fuzzy Syst 9(5):713–720
Liu B (2001) Fuzzy random dependent-chance programming. IEEE Trans Fuzzy Syst 9(5):721–726
Liu YK, Liu B (2003) Fuzzy random variables: a scalar expected value operator. Fuzzy Optim Decis Mak 2(2):143–160
Luhandjula MK (1996) Fuzziness and randomness in an optimization framework. Fuzzy Sets Syst 77(3):291–297
Luhandjula MK (2006) Fuzzy stochastic linear programming: survey and future research directions. Eur J Oper Res 174(3):1353–1367
Luhandjula MK, Gupta MM (1996) On fuzzy stochastic optimization. Fuzzy Sets Syst 81(1):47–55
Nicholls MG (1996) The applications of non-linear bi-level programming to the aluminium industry. J Glob Optim 8(3):245–261
Nishizaki I, Sakawa M (1999) Stackelberg solutions to multiobjective two-level linear programming problems. J Optim Theory Appl 103(1):161–182
Nishizaki I, Sakawa M (2000) Computational methods through genetic algorithms for obtaining Stackelberg solutions to two-level mixed zero-one programming problems. Cybern Syst 31(2):203–221
Nishizaki I, Sakawa M, Katagiri H (2003) Stackelberg solutions to multiobjective two-level linear programming problems with random variable coefficients. Cent Eur J Oper Res 11(3):281–296
Puri ML, Ralescu DA (1996) Fuzzy random variables. J Math Anal Appl 114(2):409–422
Qiao Z, Zhang Y, Wang GY (1994) On fuzzy random linear programming. Fuzzy Sets Syst 65(1):31–49
Roghanian E, Sadjadi SJ, Aryanezhad MB (2007) A probabilistic bi-level linear multi-objective programming problem to supply chain planning. Appl Math Comput 188(1):786–800
Rommelfanger H (2007) A general concept for solving linear multicriteria programming problems with crisp, fuzzy or stochastic values. Fuzzy Sets Syst 156(17):1892–1904
Sakawa M (1993) Fuzzy sets and interactive multiobjective optimization. Plenum Press, New York
Sakawa M (2000) Large scaleinteractive fuzzy multiobjective programming. Physica-Verlag, Heidelberg
Sakawa M (2001) Genetic algorithms and fuzzy multiobjective optimization. Kluwer Academic Publishers, Boston
Sakawa M, Kato K (2008) Interactive fuzzy multi-objective stochastic linear programming. In: Fuzzy multi-criteria decision making—theory and applications with recent developments. Springer, New York, pp 375–408
Sakawa M, Nishizaki I (2009) Cooperative and noncooperative multi-level programming. Springer, New York
Shimizu K, Ishizuka Y, Bard JF (1997) Nondifferentiable and two-level mathematical programming. Kluwer Academic Publishers, Boston
Simaan M, Cruz JB Jr. (1973) On the Stackelberg strategy in nonzero-sum games. J Optim Theory Appl 11(5):533–555
Stancu-Minasian IM (1984) Stochastic programming with multiple objective functions. D. Reidel Publishing Company, Dordrecht
Stancu-Minasian IM (1990) Overview of different approaches for solving stochastic programming problems with multiple objective functions. In: Stochastic versus fuzzy approaches to multiobjective mathematical programming under uncertainty. Kluwer Academic Publishers, Dordrecht/Boston/London, pp 71–101
Stancu-Minasian IM (1992) Fractional programming. Kluwer Academic Publishers, Dordrecht/Boston/London
Wang GY, Qiao Z (1993) Linear programming with fuzzy random variable coefficients. Fuzzy Sets Syst 57(3):295–311
White DJ, Anandalingam G (1993) A penalty function approach for solving bi-level linear programs. J Glob Optim 3(4):397–419
Xu J, Liu Y (2008) Multi-objective decision making model under fuzzy random environment and its application to inventory problems. Inf Sci 178(14):2899–2914
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Sakawa, M., Katagiri, H. & Matsui, T. Stackelberg solutions for fuzzy random bilevel linear programming through level sets and probability maximization. Oper Res Int J 12, 271–286 (2012). https://doi.org/10.1007/s12351-010-0090-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12351-010-0090-2