
Abstract
Hydraulic conductivity is one of the important parameters to simulate water flow in porous environments that is suffer from uncertainty due to the different estimating approaches such as field and laboratory tests. Recently, artificial intelligence models have been applied to estimate hydrogeological parameters based on the available data. In this study, three individual artificial intelligence models including Larsen Fuzzy Logic (LFL), Least Square Support Vector Machine (LSSVM) and Hybrid Wavelet-Artificial Neural Network (WANN) were adopted to estimate hydraulic conductivity in Tabriz Urban Train based on grain size data. For optimal application of the advantages of the individual models, their output was used as the input of a nonlinear combiner. Comparison of the prediction results of this multiple model called Supervised Committee Machine Artificial Intelligence (SCMAI) with the individual models showed a 26% increase in Determination Coefficient (R2) and a 36% decrease in Root Mean Squared Error (RMSE) compared to the most accurate individual artificial intelligence model, i.e., WANN. The results showed that the SCMAI model has a better performance in predicting hydraulic conductivity compared to the individual models and the superiority of the SCMAI model is due to using the type of individual models and the use of special advantages and strengths of each of these models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Hydraulic conductivity is one of the most important hydrogeological variables through which many characteristics of water flow in porous media can be evaluated. The movement of water inside the soil is affected by initial humidity, degree of saturation and physical properties, including soil grain size distribution. It is very important for modeling water flow in the soil and is an important parameter for drain design in the construction of earth dams and embankments (Odong 2007). In addition, hydraulic conductivity is very important in some geotechnical problems such as seepage, settlement calculation and stability analysis (Boadu 2000).
With the increasing development of large cities, the need to build massive engineering projects such as the Urban Train increases. Proper management and control of groundwater at the site of such large structures is essential. Therefore, evaluation of parameters such as hydraulic conductivity that affect the flow of water in porous media is important for the optimal and reliable design of such structures, and its determination is one of the main objectives in geotechnical studies. Many parameters affect the hydraulic conductivity, such as soil texture properties including pore size, grain size distribution, grain shape, grain density, etc. (Engler 2010). Accordingly, this research focuses on grain size distribution.
Different techniques have been proposed for determining the hydraulic conductivity including field and laboratorial methods as well as calculations based on experimental formulas (Chapuis 1990; Ankeny et al. 1991; Chandel and Shankar 2021). Pumping test, slug test and packer test are among the field methods. So far, three different methods have been presented for determining this variable in the field for the slug test method (Cooper et al. 1967; Bouwer 1989; Hvorslev 1951) and several common methods have been proposed for the pumping test (Theis 1935; Cooper and Jacob 1946; Chow 1952; Neuman 1975). Also, five well-known methods including Fair and Hatch (1933), Carman (1956), Shepherd (1989), Alyamani and Şen (1993) and Hazen (1892) have been presented to determine this variable in the laboratory. Sperry and Peirce (1995) after evaluating the capability of the presented laboratorial methods and experimental formulas, it was concluded that the best method in this context is the experimental formula Hazen (1892) except for environments having particles with very irregular shapes and, in general, the experimental formula Alyamani and Şen (1993) is closer to the real results. Although these methods have various advantages such as recognizing subsurface conditions by drilling, they are time consuming and costly and require more manpower. Also, the variables measured by these methods have inherent uncertainty due to the nonlinear behavior and heterogeneous and anisotropic conditions in hydrogeological environments. In addition, all these recent methods were the result of solving the equations governing groundwater flow by different methods and with boundary conditions and constraints or experimental formulas. With the development of science and technology in the field of hydrogeology, AI models for determining hydrogeological variables have also expanded. Among the various AI methods, FL, SVM and WANN methods can be mentioned. In the last few years, various studies have been performed to estimate the hydrogeological variables using FL (Morankar et al. 2013; Tayfur et al. 2014; Nadiri et al. 2017; Khatibi and Nadiri 2021) and ANN (Schaap and Leij 1998; Chitsazan et al. 2015; Andalib and Nourani 2019; Faloye et al. 2022) methods. Also, review studies conducted on the estimation and prediction of hydrological and hydrogeological variables such as runoff, water level changes, storage coefficient, porosity, transmissibility, surface water and groundwater quality, river sediment transport, etc. have confirmed the success of AI methods such as SVM (Nourani and Andalib 2015; Hosseini and Mahjouri 2016; Eini et al. 2020; Gharekhani et al. 2022; Nadiri et al. 2022) and WANN (Nourani and Andalib 2015; Sharghi et al. 2019; Alizadeh et al. 2017; Li et al. 2022).
Hydrogeological variables such as hydraulic conductivity do not have constant and certain values and are associated with uncertainty in most cases (Tayfur et al. 2014; Javadi et al. 2021; Singh et al. 2022). However, FL (Table 1) (Tayfur et al. 2014; Sihag 2018) ANN (Sun et al. 2011; Sihag 2018; Faloye et al. 2022) and Neuro Fuzzy (NF) (Hurtado et al. 2009; Tayfur et al. 2014; Sezer et al. 2010; Faloye et al. 2022) methods have been used to estimate the hydraulic conductivity.
Ross et al. (2007) estimated the hydraulic conductivity via fuzzy logic analysis of grain size data with high accuracy. They defined the membership degree for soil samples based on the expert opinion, which may be another source of the subjectivity. In recent years, hydraulic conductivity has been estimated based on grain size data by using individual AI models that apply optimization algorithms (Table 1) (Erzin et al. 2009; Sedaghat et al. 2016).
Considering the inherent, unique and different abilities of each of the individual AI models, multiple models have been considered. Nadiri et al. (2013) presented the combined SCMAI method for the prediction of fluoride concentration. Tayfur et al. (2014) conducted a study to estimate the hydraulic conductivity using SICM model. Using electrical conductivity and saturation thickness, these researchers estimated the hydraulic conductivity and transmissibility of Tasuj plain through the use of FL, ANN and NF. Then they optimized the output values of each individual model, using ANN. Saemi and Ahmadi (2008) applied a composite model that was a combination of NF and Genetic Algorithm models to predict permeability. They used borehole data in their study. Their methodology was as follows: after running the NF model, they used the genetic algorithm to optimize the parameters and reduce the error containing data in NF model.
Hydraulic conductivity has been estimated based on grain size data by using composite artificial intelligence. Rogiers et al. (2012) estimated the hydraulic conductivity in the Neogene aquifer, northern Belgium, using the GLUE-ANN composite method based on grain size data. Kashani et al. (2020) predicted hydraulic conductivity in Tabriz plain using several AI models. These models including Multivariate Adaptive Regression Splines (MARS), M5 model Tree (M5Tree), Support Vector Machine (SVM) and Extreme Learning Machine (ELM) were. Then the results of these models were integrated and optimized with ANN model for more accuracy. Silt, clay, bulk density and electrical conductivity were used as model inputs to predict of hydraulic conductivity. The previous studies are summarized in Table 1.
In this study, SCMAI method was used to estimate the hydraulic conductivity in Tabriz Urban Train. Considering that the SCMAI model used in this study applies the output of individual AI models, LSSVM, LFL and WANN, the advantages of each of these methods are used to estimate the desired variable, which is hydraulic conductivity. ANN method is applied to combine the output of AI model as a nonlinear combiner method. Therefore, this method is the accumulation of the advantages of methods that are performed individually. Because each of the individual models has a unique strength, the estimated values of the individual models are combined in the SCMAI model. To the best of our knowledge, SCMAI method has not been adopted to estimate the hydraulic conductivity by using the grain sizes of soil samples and this research is the first try to predict hydraulic conductivity based on the soil grain size using SCMAI method.
Materials and methods
Study area
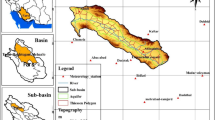
The city of Tabriz is located in East Azerbaijan province in northwestern Iran (Fig. 1). Tabriz Urban Train consists of 5 lines (4 main lines and one suburban line) measuring 100 km long. Line 1 is in use and line 2 is under construction. The other 3 lines are being studied and researched. In the current research, lines 1 and 2 were studied. Line 1 of Tabriz Urban Train starts from the southeast of Tabriz and then leads from the central part of the city to the southwest. Line 2 of Tabriz Urban Train starts from Gharamalek area in the west of Tabriz and reaches Baghmisheh neighborhood after passing through Ghods, Jomhouri, Daneshsara, and Abbasi streets. It then extends to the east and ends after passing through Marzdaran district near Tabriz International Exhibition Center (TURO 2019). The information used in this research has been obtained from Tabriz Urban Train Organization.

City of Tabriz and the position of the boreholes in Tabriz Urban Train
Data analysis
The study area is located on line 1 of Urban Train in the central part of Tabriz. Five boreholes are located along Timsar Mohagheghi Street from Amin Forked Road to the former Terminal Square, and 15 boreholes are located on Imam Street from Daneshgah Square to Saat Square. After studying and thoroughly examining the borehole data, from among these 20 boreholes, we used the data from 15 boreholes on line 1 of Urban Train for this study. The length of the studied area along line 2 of Tabriz Urban Train, which includes almost the entire length of line 2, is about 22 km. Geotechnical studies of this line included 133 boreholes, from among which the data of 34 boreholes were used in this study after a complete review of the information of all boreholes. From 15 boreholes of Line 1 and 34 boreholes of Line 2, 51 and 43 soil samples were selected at different depths, respectively. A total of 94 soil samples were selected from 49 boreholes and used. The position of the boreholes in Tabriz Urban Train is shown in Fig. 1.
The soil samples were selected from depths at 3m intervals. Depths of the boreholes along line 1 are at least 30 and at most 41 meters, and these depths along line 2 are 20 and 45 meters, respectively.
The purpose of this study was to predict the hydraulic conductivity using multiple artificial intelligence based on grain size distribution. In this research, the grain size data was the input of the individual models, and hydraulic conductivity was the output. Grain size data were obtained from hydrometer analysis, and grain size distribution tests were performed on the samples taken from different depths of the boreholes according to AASHTO T27 standard. D30, D60 and D80 were determined according to the grain size distribution curves. Hydraulic conductivity determination tests were carried out by LEFRANC test with constant and step drawdown pumping in the boreholes. 94 values of horizontal hydraulic conductivity were used in this research.
After examining the different modes for the number of data in the training and testing steps (trial and error), in the best case, 70% of the data was allocated for the training step and the remaining 30% for the testing step. The maximum and minimum hydraulic conductivity values are 0.00284 and 0.000000108 cm/sec, respectively. The average hydraulic conductivity value is 0.000146 cm/sec. The maximum values of D30, D60 and D80 are 0.94, 9.38 and 27.5 mm, respectively, their minimum values are 0.006, 0.076 and 0.152 mm, respectively, and their average values are 0.123, 0.845 and 3.142 mm, respectively (Table 2) (TURO (2019)).
The data selection method for training and testing steps was random so that the statistical characteristics of both clusters would be almost similar. In addition, the maximum and minimum values of the data were included in the training step data, because artificial intelligence models have strong interpolator and weak extrapolator capabilities. LFL, LSSVM and WANN models were used in this study to estimate the hydraulic conductivity. The output of these three individual models were then introduced into the multilayer perceptron neural network as input, and the neural network was used as the combiner of the new inputs.
Artificial intelligence methods
Fuzzy Logic (FL)
The basis of fuzzy theory was first introduced by Zadeh (1965), which in recent years has shown a high ability in reducing the estimation error compared to the probabilistic method. Fuzzy Logic has a multi-valued view of events, which is contrary to explicit or divalent logic, in which everything is either right or wrong. In fact, the fuzzy method is appropriate for reducing the estimation and human error compared to other reliable theories (Chiu 1994; Nikravesh et al. 2003).
Hydrogeological data usually have an inherent estimation error and are not considered to be explicit and error-free data. For example, obtaining hydraulic conductivity from the LEFRANC test (pumping) has a noteworthy error. The membership function is a function by which input data are fuzzified. That is, each input to the fuzzy system is converted to a number at an interval of zero to one. Membership functions are defined for both output and input data. There are different types of membership functions, including Sigmoidal, Gaussian, Triangular, Trapezoidal, etc. In general, there are two discussions of modeling and fuzzy clustering in fuzzy logic. Fuzzy modeling is used to estimate the hydrogeological parameters such as porosity, hydraulic conductivity and transmissivity. Fuzzy modeling can be implemented in three fuzzy methods of MFL (Mamdani 1976), SFL (Sugeno 1985) and LFL (Larsen 1980). The difference between the SFL method and the other two methods is in their output. The membership function of the fuzzy system output data in the SFL method is a linear or constant relationship obtained by clustering method. The MFL output membership function can also vary depending on the type and nature of the data and the study, e.g., the Gaussian membership function. The first step in creating a fuzzy model is to classify the data so that different clustering methods can be used in terms of the type of the fuzzy model used. The subtractive clustering method is used for the SFL model, and the Fuzzy C-Means (FCM) method is used for the MFL and LFL methods.
Each fuzzy model consists of three main steps: (i) data fuzzification, which is done by defining the membership function; (ii) creating a connection between input and output, which is also done by a series of rules such as if-then; and (iii) the final step, which is the step of system review, the result aggregation and defuzzification. This is done by fuzzy operators including “AND”, “OR”, and “NOT”. The AND operator also behaves as minimization (min) and weighting factor (prod), and the OR operator as maximization factor. The LFL method was used in the present study.
Support Vector Machine (SVM)
Support Vector Machines (SVM) were introduced in 1995 by Vapnik and Cortes. SVM is an algorithm that finds a specific type of linear model that produces the maximum hyperplane margin. Maximizing the hyperplane margin leads to maximizing the decomposition between the clusters. The nearest training points to the maximum hyperplane margin are called support vectors, and only these vectors are used to define the boundary between the clusters. The decision-making rules that are defined and decompose the binary decision classes by an optimal plane are according to the Eq. (1) (Cortes and Vapnik 1995):
Where y is the output of the equation, yi is the value of the training sample class Xi and “.” represents the internal multiplication.
The vectors \(x=[ {x}_{1},{x}_{2},\dots ,{x}_{n}]\) represent an input data and the Xi vectors are the support vectors. Also, unlike neural networks, SVM does not have the problem of getting stuck in the local minima of the error function (Hong 2011).
The problem-solving steps in the support vector machines algorithm, like the neural network’s algorithm, are divided into two stages of training and testing. Types of SVM models include Support Vector Classification, Support Vector Regression, Least Squares Support Vector Machine, Linear Programming Support Vector Machine, and Nu-Support Vector Machines. The Least Squares Support Vector Machine (LSSVM) was used in this study. LSSVM is a modified SVM model and is an implementable machine learning method for classification and regression (Suykens et al. 2002). The LSSVM method uses linear Karush-Kuhn-Tucker (KKT) equations instead of the SVM quadratic programming problem. SVM uses a quadratic loss function without any rules, which leads to poorer estimation; therefore, weighted LSSVM is taken in order to prevent this, and in cases where the small weights are assigned to the data, the training method is presented in two stages (Shabri and Suhartono 2012). A training set of N data \({\left\{{x}_{i}, {y}_{i}\right\}}_{i=1}^{N}\) is considered where \({X}_{t}\in {R}^{d}\) is the input data and \({y}_{t}\in\) R is the output data.
Different kernel functions can be used according to the type of studies. There are different types of kernel functions such as Linear, Sigmoidal, Radial Basis and Polynomial. RBF kernel has been used in this study because this type of kernel has the highest efficiency in hydrological models (Suykens and Vandewalle 1999).
Wavelet-ANN Model (WANN)
Artificial Neural Network (ANN)
Neural networks have the ability to recognize a dynamic nonlinear system without any presuppositions in the modeling process. Neural network architecture in most predictive engineering problems consists of a three-layer system that includes the input layer, the hidden layer, and the output layer. In this structure, the input layer first processes the input data for transfer to the hidden layer. Then the hidden layer calculates the appropriate weight coefficients using transfer functions such as the Hyperbolic tangent or logic function before sending the information to the output layer. Three-layered network is based on a linear combination of the input variables, which is transformed by a non-linear activation function. This structure of the network is called the feed forward network because the communication between the neurons is such that they connect from the input layer to the hidden layer and from this layer to the output layer, but they do not communicate with each other within one layer of the neurons (Nourani and Andalib 2015).
Wavelet function
Wavelet Function is a function that has two important features: oscillatory and short-term; ψ(x) is the wavelet function if and only if the Fourier Transform ψ(ω) satisfies the following condition (Mallat 1998):
This condition is known as the Admissibility condition for the ψ(x) wavelet. Eq. (2) can be considered equivalent to the following equation:
This property of the function with mean of zero is not very restrictive, and many functions can be called wavelet function based on it. ψ(x) is the mother wavelet function in which the size and position of the functions used in the analysis change with the two mathematical operations of Translation and Dilation during the analyzed signal (Mallat 1998).
Finally, the wavelet coefficients can be calculated at any point in the signal (b) and for any value of the dilation (a) with Eq. (5) (Mallat 1998).
There are many types of wavelet functions, the most important and widely used of which are the Daubechies, Haar, Symlet, Morlet, Mexican hat, Coiflet and Meyer Wavelet Functions (Mallat 1998). The different types of these functions have been described in the MATLAB software toolbox.
In general, WANN method is used in the simulation and prediction of signals. That is, the signal is converted into several sub-series using wavelet decomposition, one of which is the estimate or background of the main series, and the rest of the sub-series are the details. Then, by considering these sub-series as the input of the neural network, the signals are predicted and analyzed.
In this study, the data were decomposed according to their number in two and three levels. The results showed that with the decomposition level 2, more desirable results are obtained. Accordingly, each of the input signals were decomposed into two sub-signals using discrete wavelet transform. Also in this study, db2, db3, db4 and db5 were used to analyze the signals, and db4 was selected due to the better results obtained. In addition, the mathematical relationships related to hybrid wavelet-artificial intelligence models have been explained in detail in the research works of Nourani et al. (2014).
Supervised Committee Machine Artificial Intelligence (SCMAI)
Individual LSSVM, WANN and LFL models were used to implement this model. Each of these models was implemented individually; then their output was optimized using artificial neural network. That is, the output of individual models, which was the same as hydraulic conductivity, was used as the input of the Artificial Neural Network. To implement the individual models, grain size data (D30, D60 and D80), which are effective factors in the hydraulic conductivity, was used as input for individual models. In this study, the Supervised Committee Machine Artificial Intelligence (SCMAI) model, which uses an Artificial Neural Network has been presented, as a nonlinear combiner instead of simple averaging and weighted averaging methods. The mathematical expression of the SCMAI model is:
Where \({\widehat{k}}_{i}\) represents the output of individual AI models, which is considered as the i-th input for Artificial Neural Network. f1 and f2 represent the Activation Functions for the hidden layer and the output layer, respectively. oj is the j-th output of the nodes in the hidden layer. bk, bj, and wkj, wji are the biases and weights of the output layer and the hidden layer, respectively. ok is the final output of the SCMAI model. Weights and Biases are optimized with the Levenberg-Marquardt (LM) Training Algorithm. Figure 2 shows the general framework of the SCMAI model.

General framework of the SCMAI model
Evaluation criteria
In order to measure the accuracy of the models in making predictions, the validation of the models is performed. Various criteria are used for this purpose, two of the most widely used of which were applied in this study. DC or R2 (Determination Coefficient) is calculated according to Eq. (9) and RMSE (Root Mean Squared Error) according to Eq. (10) (Legates and McCabe 1999):
Where DC (R2), RMSE,\({Q}_{i},\) \({\widehat{Q}}_{i , }\stackrel{-}{Q }\) and n are determination coefficient, root mean squared error, observed data, computed values, mean of observed data and number of observations, respectively. The best result obtained when the value of Eq. (9) gets closer to one, and the value of Eq. (10) get closer to zero.
Results
LFL
To implement the LFL model, first the MFL model was created based on the inputs and outputs. The FCM clustering method was used in the MFL model. The optimal number of clusters was determined by trial and error. In this method, the input and output membership functions were Gaussian. The LFL model was implemented after applying the MFL model based on its results. The LFL method is similar to the MFL method with the main difference of using the product operator for the fuzzy implication, which scales the output fuzzy set. To achieve the best result, the LFL model was implemented with the same clusters after implementing the MFL model with the clusters 3, 6, 9, 12, 14, 15 and 18. The best results for training and testing steps were obtained with 15 clusters. Figure 3 shows the relationship between clustering and RMSE of the testing step, where the lowest value for RMSE is obtained in clustering 15. This value for RMSE is 0.000236 cm/sec. In the LFL model, R2 and RMSE were 0.85 and 0.000144 cm/sec in the training step and 0.64 and 0.000236 cm/sec in the testing step, respectively (Table 3 and Fig. 5a).

Relationship between clustering and RMSE of the testing step
LSSVM
As mentioned earlier, in SVM implementation, first the SVM type was determined (LSSVM). Next, the regulator values (γ) and the Kernel variable (σ) were determined. These values were determined by coding in MATLAB software and then optimized using trial and error method. In this study, it was found that the optimal determination of γ and σ values is very effective on the results of the SVM model. The best values for γ and σ variables were 2.8 and 7.9, respectively, which led to the optimal result for the SVM model. From among the types of Kernel Functions, namely RBF, Poly, Lin and MLP functions, RBF type kernel was selected in this research. In this model, R2 and RMSE values in the training step were 0.88 and 0.000129 cm/sec, respectively, and in the testing step they were 0.64 and 0.000238 cm/sec, respectively (Table 3 and Fig. 5b).
WANN
In WANN model, data preprocessing is performed by wavelet transform and then the results of this processing are used as the input of ANN model. The efficiency of the WANN model depends on the variables such as the type of Wavelet Function, the decomposition level, and the number of hidden neurons. In this study, trial and error method was used to determine the type of Wavelet Function for decomposition input signals, and it was observed that among the wavelets, the db4 Wavelet Function as the mother wavelet was more accurate than the other functions. The mother Wavelet Functions studied in this study were db2, db3, db4 and db5. The reason that the db4 mother wavelet performs better than the other db’s may be due to its wavelet form, which is in good agreement with the data series analyzed in the study. In this study, the data were decomposed at 2 and 3 levels. The results showed that better outcomes can be achieved at decomposition level 2 due to the number of data (Fig. 4). After decomposing the data with db4 and at decomposition level 2, the decomposed data are entered into the Multilayer Perceptron Neural Network. Trial and error method was used to select the number of the hidden neurons, and it was observed that the best results were obtained when the number of the hidden neurons was considered to be 3. When the sub-series enter the neural network as input, the neural network assigns a specific weight to each of the decomposition sub-series. For example, the neural network assigns a higher weight to d2 at decomposition level 2, because d2 has the highest dependence on the main signal of hydraulic conductivity compared to other sub-signals and has a significant role in estimating the hydraulic conductivity. In this model, R2 and RMSE of the training step were 0.88 and 0.000128 cm/sec, respectively, and in the testing step, 0.69 and 0.000222 cm/sec, respectively (Table 3 and Fig. 5c).

Evaluation of mother wavelet functions for decomposition levels 2 and 3
SCMAI
After implementing three individual models, the output of these individual models, which is the hydraulic conductivity, was used as the input of the SCMAI model such that each of these models was implemented individually, and their output was combined and optimized using ANN. The LM Training Algorithm was used in ANN, which was used as a nonlinear combiner of the individual models. The reason for this selection was its acceptable accuracy and speed. TANSIG and PURELIN were selected as the Transfer Functions for the hidden layer and output layer, respectively. Epoch type was used for the training process. After implementing the SCMAI model, it was observed that the results of estimating the hydraulic conductivity became more desirable than those of the individual models and this model had a much higher efficiency. In SCMAI model, R2 and RMSE of the training step were 0.92 and 0.000103 cm/sec, respectively, and in the testing step they were 0.87 and 0.000141 cm/sec, respectively (Table 3 and Fig. 5d).

Comparison of computed and observed (K) using a LFL; b LSSVM; c WANN and d SCMAI
Discussion
In this study, it was observed that the SCMAI model performed the hydraulic conductivity estimation with high accuracy and that better results were obtained compared to the results of the individual models. For example, the maximum R2 and the minimum RMSE of the testing step are related to the individual models of WANN model, which are equal to 0.69 and 0.000222 cm/sec, respectively. These values for the SCMAI model were 0.87 and 0.000141 cm/sec, respectively, which indicate the significant promotion of the estimation of the hydraulic conductivity compared to those of the individual models (Table 3). Also, comparison of the results of this study showed that the two individual models LFL and LSSVM show approximately similar results in predicting hydraulic conductivity in the testing step (Table 3). In the training step, among the three individual models, the WANN model, having R2 = 0.88 and RMSE = 0.000128 cm/sec, has provided better results than the other two individual models. At this step, among the two individual models LFL and LSSVM, the LSSVM model performed better than the LFL model. In LSSVM and LFL models, R2 and RMSE of the training step were 0.88 and 0.000129 cm/sec and 0.85 and 0.000144 cm/sec, respectively (Table 3).
For visual comparison, proximity of the computational values of all the four models (three individual and one SCMAI) to the observational values of the testing step was plotted in curves (Figs. 6a-e). According to Figs. 6(a and e), it was observed that the degree of proximity of the observed and computed values of the hydraulic conductivity had increased in the SCMAI model, and the measurement error had decreased as a result. This important result showed that the SCMAI model can significantly improve the computed values obtained from individual models. As a result, instead of using an individual model, several individual models can be used simultaneously in the studies related to estimating geotechnical variables such as hydraulic conductivity, and more desirable results can be obtained by combining their outputs. Also, by carefully examining Figs. 6(a and e), it was concluded that the SCMAI model was able to bring 13 of the 28 computed values of the testing step closer to the observed data (Points 2, 3, 4, 5, 6, 7, 9, 11, 17, 20, 21, 22 and 28) (46% of the values). It means that in these 13 points, the SCMAI model has been able to perform better than all three individual models in bringing the computed values closer to the observed data. That the proximity of the observational and computational values was better observed at 2 points. The observational and computational values at point 2 of the curve were 0.00150 and 0.00153 cm/sec, respectively, and at point 28 of the curve they were 0.00143 and 0.00139 cm/sec, respectively. In 7 of the remaining 15 points, the SCMAI model has performed better than the two individual models (points 1, 12, 13, 14, 15, 19 and 24) (25% of the values). In 5 of these 15 points, this model has performed better than an individual model (points 8, 10, 16, 26 and 27) (18% of the values). Only in 3 of these 15 points, all three individual models have performed better than the SCMAI model (points 18, 23 and 25) (11% of the values). In general, it can be said that the SCMAI model has been effective in bringing about 89% of the computed values closer to the observed data.

Comparison of curves of computed and observed K (cm/sec); a observed with LFL, LSSVM, WANN and SCMAI; b observed with LFL, c observed with LSSVM, d observed with WANN and e observed with SCMAI
According to Fig. 6a, it was observed that although the SCMAI model provides better results in estimating the hydraulic conductivity, each of the individual models used in this study have certain strengths and advantages over the others. For example, the computed values of the LFL model are closer to the observed data than those obtained from the other models at 4 points (12, 13, 19 and 27). Also, this number in LSSVM model is 4 points (8, 10, 14 and 16) and in WANN model, which renders better results than the other individual models, this number is 7 points (1, 15, 18, 23, 24, 25 and 26) (Figs. 6a-d).
Using the SCMAI model, Nadiri et al. (2013) predicted the groundwater fluoride concentration in Mako Plain. For this purpose, they used NF, MFL, SFL and ANN models and used ANN as a nonlinear combiner. The results obtained by these researchers showed that among the individual models, the MFL model has lower accuracy than the other models. In contrast, ANN model has a higher efficiency. These results were optimized by SCMAI and better results were obtained compared to each model. In another study conducted by Tayfur et al. (2014), the SICM model was implemented to estimate the hydraulic conductivity in Tasuj Plain. In this study, NF, MFL, SFL and ANN models were used as individual models and ANN was used as a nonlinear combiner.
The difference between the present study and the previous studies is that LFL, WANN and LSSVM models were used in this study as the latest methods in estimating hydraulic conductivity, and ANN model was used as a nonlinear combiner. The estimation values by these models were optimized by SCMAI model, and better results were obtained (Table 1). Another difference between the present study and the study of Tasuj plain (SICM model) is that in this study, hydraulic conductivity was estimated based on grain size distribution, which is one of the important parameters in permeability, while this variable was estimated from geophysical data such as electrical conductivity in Tasuj plain (Table 1).
Conclusion
The SCMAI model was used in this study. This model combined the output of individual AI models to estimate the hydraulic conductivity in Tabriz Urban Train (lines 1 and 2) such that the outputs of LSSVM, WANN and LFL models were entered into ANN, and a new hydraulic conductivity was estimated as the output. This study showed that by using this model, more desirable results can be achieved in estimating the hydraulic conductivity than the results of the individual models used in this study. SCMAI model led to a significant improvement in the results due to using the advantages of all the individual models so that the R2 testing step of the SCMAI model was promoted by about 26% compared to the R2 value of the testing step of WANN model. Also, the RMSE of this model decreased by about 36% compared to that of WANN model. Also, in the testing step, the SCMAI model has an increase of about 36% in the R2 value compared to both LSSVM and LFL models. And the RMSE of this model has decreased by about 41% compared to LSSVM model and by about 40% compared to LFL model in the testing step. The WANN model provides better results among the three individual models. Also, LFL and LSSVM models provide almost similar results in estimating the hydraulic conductivity and proximity of observational and computational values in the testing step.
Another result of this study was that although the individual models provided less R2 and more RMSE than SCMAI model, each of them was closer to the observed data due to their inherent abilities in some parts of the curve (compared to SCMAI model).
This study showed that SCMAI model, with the ability to use the capabilities and combine the results of different models, can be used to estimate other hydrogeological variables such as storage coefficient, transmissibility, etc. In addition, for other studies, it is suggested that in addition to grain size data, other parameters affecting hydraulic conductivity can be used to achieve hydraulic conductivity in Tabriz Urban Train. It is also possible to use other individual AI models along with the three individual models used in this study and to use a nonlinear combiner other than ANN for combining the individual models.
Data availability
The data that support the findings of this study areavailable from the corresponding author, upon reasonable request.
Abbreviations
- AI:
-
Artificial Intelligence
- SVM:
-
Support Vector Machine
- LSSVM:
-
Least Square Support Vector Machine
- ANN:
-
Artificial Neural Network
- WANN:
-
Hybrid Wavelet –Artificial Neural Network
- FL:
-
Fuzzy Logic
- LFL:
-
Larsen Fuzzy Logic
- MFL:
-
Mamdani Fuzzy Logic
- SFL:
-
Sugeno Fuzzy Logic
- KKT:
-
Karush Kuhn Tucker
- GLUE ANN:
-
Generalized Likelihood Uncertainty Estimation ANN
- LM:
-
Levenberg Marquardt
- M5Tree:
-
M5 model Tree
- FCM:
-
Fuzzy C-Means
- NF:
-
Neuro Fuzzy
- SCMAI:
-
Supervised Committee Machine Artificial Intelligence
- RMSE:
-
Root Mean Squared Error
- DC (R2):
-
Determination Coefficient
- MLP:
-
Multi-Layer Perceptron
- RBF:
-
Radial Basis Function
- Poly:
-
Polynomial
- Lin:
-
Linear
- SICM:
-
Supervised Intelligent Committee Machine
- K:
-
Hydraulic Conductivity
- MARS:
-
Multivariate Adaptive Regression Splines
- ELM:
-
Extreme Learning Machine
References
Alizadeh MJ, Jafari Nodoushan E, Kalarestaghi N, Chau KW (2017) Toward multi-day-ahead forecasting of suspended sediment concentration using ensemble models. Environ Sci Pollut Res 24:28017–28025. https://doi.org/10.1007/s11356-017-0405-4
Alyamani MS, Şen Z (1993) Determination of hydraulic conductivity from complete grain-size distribution curves. Groundwater 31:551–555. https://doi.org/10.1111/j.1745-6584.1993.tb00587.x
Andalib G, Nourani V (2019) Application of wavelet denoising and artificial intelligence models for stream flow forecasting. Adv Res Civ Eng 1:1–8. https://doi.org/10.30469/ARCE.2019.82733
Ankeny MD, Ahmed M, Kaspar TC, Horton R (1991) Simple field method for determining unsaturated hydraulic conductivity. Soil Sci Soc Am J 55:467–470. https://doi.org/10.2136/sssaj1991.03615995005500020028x
Boadu FK (2000) Hydraulic conductivity of soils from grain-size distribution: new models. J Geotech Geoenviron Eng 126:739–746. https://doi.org/10.1061/(asce)1090-0241(2000)126:8(739)
Bouwer H (1989) The Bouwer and rice slug test — An update. Groundwater 27:304–309. https://doi.org/10.1111/j.1745-6584.1989.tb00453.x
Carman PC (1956) Flow of gases through porous media. Butterworths, London, p 182
Chandel A, Shankar V (2021) Evaluation of empirical relationships to estimate the hydraulic conductivity of borehole soil samples. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2021.1902872
Chapuis RP (1990) Sand-bentonite liners: predicting permeability from laboratory tests. Can Geotech J 27:47–57. https://doi.org/10.1139/t90-005
Chitsazan N, Nadiri AA, Tsai FTC (2015) Prediction and structural uncertainty analyses of artificial neural networks using hierarchical Bayesian model averaging. J Hydrol 528:52–62. https://doi.org/10.1016/j.jhydrol.2015.06.007
Chiu SL (1994) Fuzzy model identification based on cluster estimation. J Intell Fuzzy Syst 2:267–278. https://doi.org/10.3233/IFS-1994-2306
Chow VT (1952) On the determination of transmissibility and storage coefficients from pumping test data. Eos Trans Am Geophys Union 33:397–404. https://doi.org/10.1029/TR033i003p00397
Cooper HH, Bredehoeft JD, Papadopulos IS (1967) Response of a finite-diameter well to an instantaneous charge of water. Water Resour Res 3:263–269. https://doi.org/10.1029/WR003i001p00263
Cooper HH, Jacob CE (1946) A generalized graphical method for evaluating formation constants and summarizing well-field history. Eos Trans Am Geophys Union 27:526–534. https://doi.org/10.1029/TR027i004p00526
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297. https://doi.org/10.1007/bf00994018
Eini MR, Javadi S, Delavar M et al (2020) Development of alternative SWAT-based models for simulating water budget components and streamflow for a karstic-influenced watershed. Catena 195:104801. https://doi.org/10.1016/j.catena.2020.104801
Engler TW (2010) Fluid flow in porous media. Petroleum Eng 524:21–236
Erzin Y, Gumaste SD, Gupta AK, Singh DN (2009) Artificial neural network (ANN) models for determining hydraulic conductivity of compacted fine-grained soils. Can Geotech J 46:955–968. https://doi.org/10.1139/T09-035
Fair GM, Hatch LP (1933) Fundamental factors governing the streamline flow of water through sand. J Am Water Works Assoc. https://www.jstor.org/stable/41225921. Accessed 6 Jan 2022
Faloye OT, Ajayi AE, Ajiboye Y et al (2022) Unsaturated hydraulic conductivity prediction using artificial intelligence and multiple linear regression models in biochar amended sandy clay loam soil. J Soil Sci Plant Nutr 22:1589–1603. https://doi.org/10.1007/s42729-021-00756-x
Gharekhani M, Nadiri AA, Khatibi R, Sadeghfam S, Asghari Moghaddam A (2022) A study of uncertainties in groundwater vulnerability modelling using Bayesian model averaging (BMA). J Environ Manag 303:114168. https://doi.org/10.1016/j.jenvman.2021.114168
Hazen A (1892) Some physical properties of sands and gravels. Massachusetts state board of health 24th Annual Report, pp 539–556
Hong WC (2011) Traffic flow forecasting by seasonal SVR with chaotic simulated annealing algorithm. Neurocomputing 74:2096–2107. https://doi.org/10.1016/j.neucom.2010.12.032
Hosseini SM, Mahjouri N (2016) Integrating Support Vector Regression and a geomorphologic Artificial Neural Network for daily rainfall-runoff modeling. Appl Soft Comput J 38:329–345. https://doi.org/10.1016/j.asoc.2015.09.049
Hurtado N, Aldana M, Torres J (2009) Comparison between neuro-fuzzy and fractal models for permeability prediction. Comput Geosci 13:181–186. https://doi.org/10.1007/s10596-008-9095-9
Hvorslev MG (1951) Time lag and soil permeability in groundwater observations. Bulletin No. 36, Us Army Corps of Engineering, Waterways Experiments Stations, Vicksburg, Mississippi, p 49
Javadi S, Saatsaz M, Hashemy Shahdany SM et al (2021) A new hybrid framework of site selection for groundwater recharge. Geosci Front 12. https://doi.org/10.1016/j.gsf.2021.101144
Kashani H, Ghorbani M, Shahabi MA et al (2020) Multiple AI model integration strategy—Application to saturated hydraulic conductivity prediction from easily available soil properties. Soil Tillage Res 196:104449. https://doi.org/10.1016/J.STILL.2019.104449
Khatibi R, Nadiri AA (2021) Inclusive Multiple Models (IMM) for predicting groundwater levels and treating heterogeneity. Geosci Front 12:713–724. https://doi.org/10.1016/j.gsf.2020.07.011
Larsen PM (1980) Industrial applications of fuzzy logic control. Int J Man Mach Stud 12:3–10. https://doi.org/10.1016/S0020-7373(80)80050-2
Legates DR, McCabe GJ (1999) Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour Res 35:233–241. https://doi.org/10.1029/1998WR900018
Li Z, Sun Z, Liu J et al (2022) Prediction of river sediment transport based on wavelet transform and neural network model. Appl Sci 12:647. https://doi.org/10.3390/app12020647
Mallat SG (1998) A wavelet tour of signal processing. Academic, San Diego, p 557
Mamdani EH (1976) Advances in the linguistic synthesis of fuzzy controllers. Int J Man Mach Stud 8:669–678. https://doi.org/10.1016/S0020-7373(76)80028-4
Morankar DV, Srinivasa Raju K, Nagesh Kumar D (2013) Integrated sustainable irrigation planning with multiobjective fuzzy optimization approach. Water Resour Manag 27:3981–4004. https://doi.org/10.1007/s11269-013-0391-3
Nadiri AA, Chitsazan N, Tsai FTC, Moghaddam AA (2014) Bayesian artificial intelligence model averaging for hydraulic conductivity estimation. J Hydrol Eng 19(3):520–532. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000824
Nadiri AA, Fijani E, Tsai FTC, Moghaddam AA (2013) Supervised committee machine with artificial intelligence for prediction of fluoride concentration. J Hydroinform 15:1474–1490. https://doi.org/10.2166/hydro.2013.008
Nadiri AA, Habibi I, Gharekhani M, Sadeghfam S, Barzegar R, Karimzadeh S (2022) Introducing dynamic land subsidence index based on the ALPRIFT framework using artificial intelligence techniques. Earth Sci Inform 15(2):1007–1021. https://doi.org/10.1007/s12145-021-00760-w
Nadiri AA, Sedghi Z, Khatibi R, Gharekhani M (2017) Mapping vulnerability of multiple aquifers using multiple models and fuzzy logic to objectively derive model structures. Sci Total Environ 593–594:75–90. https://doi.org/10.1016/j.scitotenv.2017.03.109
Neuman SP (1975) Analysis of pumping test data from anisotropic unconfined aquifers considering delayed gravity response. Water Resour Res 11:329–342. https://doi.org/10.1029/WR011i002p00329
Nikravesh M, Zadeh LA, Aminzadeh F (2003) Soft computing and intelligent data analysis in oil exploration. In: Dev Pet Sci. http://www.sciencedirect.com/science/article/pii/S0376736103800055. Accessed 6 Jan 2022
Nourani V, Andalib G (2015) Daily and monthly suspended sediment load predictions using wavelet based artificial intelligence approaches. J Mt Sci 12:85–100. https://doi.org/10.1007/s11629-014-3121-2
Nourani V, Hosseini Baghanam A, Adamowski J, Kisi O (2014) Applications of hybrid wavelet-Artificial Intelligence models in hydrology: A review. J Hydrol 514:358–377. https://doi.org/10.1016/j.jhydrol.2014.03.057
Odong J (2007) Evaluation of empirical formulae for determination of hydraulic conductivity based on grain-size analysis. J Am Sci 3:54–60
Rogiers B, Mallants D, Batelaan O et al (2012) Estimation of hydraulic conductivity and its uncertainty from grain-size data using GLUE and artificial neural networks. Math Geosci 44:739–763. https://doi.org/10.1007/s11004-012-9409-2
Ross J, Ozbek M, Pinder GF (2007) Hydraulic conductivity estimation via fuzzy analysis of grain size data. Math Geol 39:765–780. https://doi.org/10.1007/s11004-007-9123-7
Saemi M, Ahmadi M (2008) Integration of genetic algorithm and a coactive neuro-fuzzy inference system for permeability prediction from well logs data. Transp Porous Media 71:273–288. https://doi.org/10.1007/s11242-007-9125-4
Schaap MG, Leij FJ (1998) Using neural networks to predict soil water retention and soil hydraulic conductivity. Soil Tillage Res 47:37–42. https://doi.org/10.1016/S0167-1987(98)00070-1
Sedaghat A, Bayat H, Safari Sinegani AA (2016) Estimation of soil saturated hydraulic conductivity by artificial neural networks ensemble in smectitic soils. Eurasian Soil Sci 49:347–357. https://doi.org/10.1134/S106422931603008X
Sezer A, Göktepe BA, Altun S (2010) Adaptive neuro-fuzzy approach for sand permeability estimation. Environ Eng Manag J 9:231–238. https://doi.org/10.30638/eemj.2010.033
Shabri A, Suhartono (2012) Streamflow forecasting using least-squares support vector machines. Hydrol Sci J 57:1275–1293. https://doi.org/10.1080/02626667.2012.714468
Sharghi E, Nourani V, Najafi H, Gokcekus H (2019) Conjunction of a newly proposed emotional ANN (EANN) and wavelet transform for suspended sediment load modeling. Water Sci Technol Water Supply 19:1726–1734. https://doi.org/10.2166/ws.2019.044
Shepherd RG (1989) Correlations of permeability and grain size. Groundwater 27:633–638. https://doi.org/10.1111/j.1745-6584.1989.tb00476.x
Sihag P (2018) Prediction of unsaturated hydraulic conductivity using fuzzy logic and artificial neural network. Model Earth Syst Environ 4:189–198. https://doi.org/10.1007/s40808-018-0434-0
Singh AK, Kumar P, Ali R et al (2022) Application of machine learning technique for rainfall-runoff modelling of highly dynamic watersheds. https://doi.org/10.20944/PREPRINTS202206.0163.V1
Sperry JM, Peirce JJ (1995) A model for estimating the hydraulic conductivity of granular material based on grain shape, grain size, and porosity. Groundwater 33:892–898. https://doi.org/10.1111/j.1745-6584.1995.tb00033.x
Sugeno M (1985) Industrial applications of fuzzy control. North-Holland, New York, p 269
Sun J, Zhao Zhiye Z, Zhang Y (2011) Determination of three dimensional hydraulic conductivities using a combined analytical/neural network model. Tunn Undergr Sp Technol 26:310–319. https://doi.org/10.1016/j.tust.2010.11.002
Suykens JAK, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9:293–300. https://doi.org/10.1023/A:1018628609742
Suykens JAK, Van GT, Brabanter, JosDe, De MB, Vanderwalle J (2002) Least squares support vector machines. World scientific Publishing, Singapore
Tayfur G, Nadiri AA, Moghaddam AA (2014) Supervised intelligent committee machine method for hydraulic conductivity estimation. Water Resour Manag 28:1173–1184. https://doi.org/10.1007/s11269-014-0553-y
Theis CV (1935) The relation between the lowering of the Piezometric surface and the rate and duration of discharge of a well using ground-water storage. Eos Trans Am Geophys Union 16:519–524. https://doi.org/10.1029/TR016i002p00519
TURO (2019) Tabriz urban railway organization report, Tabriz (In Persian)
Zadeh LA (1965) Information and control. Fuzzy Sets 8(3):338–353
Author information
Authors and Affiliations
Contributions
Ramin Vafaei Poursorkhabi and Mohammad Khalili-Maleki: Conceptualization, Writing- original draft, Software, Formal analysis, Visualization.
Ata Allah Nadiri: Formal analysis; Writing- original draft, Visualization: Rouzbeh Dabiri: Writing, Review and editing, Supervision.
Corresponding author
Ethics declarations
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Competing interests
This manuscript has not been published or presented elsewhere in part or in entirety and is not under consideration by another journal. There are no conflicts of interest to declare.
Additional information
Communicated by: H. Babaie
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Khalili-Maleki, M., Poursorkhabi, R.V., Nadiri, A.A. et al. Prediction of hydraulic conductivity based on the soil grain size using supervised committee machine artificial intelligence. Earth Sci Inform 15, 2571–2583 (2022). https://doi.org/10.1007/s12145-022-00848-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-022-00848-x