
Abstract
Industrial and agricultural development, population increase, limitations in water resources renewability, lack of timely management of water resources, and the recent years' droughts have caused pressure on groundwater. One of the aquifers that have faced a sharp drop in water level in recent years is the Aspas aquifer in Fars province. In this study, the condition of the groundwater level (GWL) in this aquifer was analyzed using the data of the gravity recovery and climate experiment (GRACE) Satellite. In addition, pre-processing tools, such as complementary ensemble empirical mode and decomposition (CEEMD) and wavelet transform (WT), were utilized. The support vector regression (SVR) and artificial neural networks (ANN) models were used in two simple and hybrid ways with pre-processing tools. According to the results, combining the models with pre-processing tools has improved their efficiency. As a result, the coefficient of determination (R2) has been improved from 0.927 in ANN to 0.938 in W-ANN and 0.998 in CEEMD-ANN. The R2 has reached from 0.918 in the SVR to 0.949 in the W-SVR and 0.948 in the CEEMD-SVR. The comparison between the results of processing algorithms of GRACE satellite in the test phase determined that the GFZ processing algorithm shows the best performance. CEEMD-ANN performance was compared to GFZ algorithm. In addition, a new approach was utilized to forecast the GWL shifts. The results indicated that the new approach provides a suitable estimate of the groundwater in the shortest time with the lowest cost. Therefore, this approach can be used to predict the GWL in other aquifers.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
A significant share of Iran's drinking water is supplied from groundwater sources. This issue has been one of the challenges raised in the past few years. Ground water level drop (GWL) in recent years has caused different researchers around the world to look for various solutions to estimate and predict the GWL to use these estimates to check the condition of groundwater more accurately. The necessity of using new up-to-date equipment and facilities is an inevitable issue with which humanity deals in many sciences. Satellite equipment is a part of these facilities. The GWL measurement satellites provide users with processing algorithms according to the micro-scales they make. Using these algorithms, if having an acceptable accuracy, can have many advantages. For this purpose, it is necessary to be able to examine them with the values obtained from the observational data and, by correcting them, provide updated and accurate estimates for the current and future periods. In recent years, the use of outcomes from the Gravity Recovery and Climate Experiment (GRACE) Satellite has been expanded to study the state of the GWL. In the following, we will refer to some of the studies conducted in the field of using the data of the GRACE Satellite to investigate the changes in the GWL.
Faraji et al. (2016) evaluated the gravimetric GRACE Satellite data in estimating GWL changes in Qazvin province. GLDAS land surface model and observational data of the regional wells were used to validate the data of the GRACE Satellite. The results demonstrated that the GRACE satellite, as a gravity-measuring satellite that was produced only to estimate water storage changes, provides users with a good estimate of the water storage changes as well as changes in the GWL. Behzadi Sheikh Robat (2017) investigated the changes in the GWL and mass caused by geodynamic effects using data from the GRACE satellite. In order to a better revelation of the changes in the gravity field, three Gaussian, Fan, and Destriping filters were used. Terrestrial data have high power and resolution compared to GRACE data for retrieving GWL changes, but the results obtained from GRACE Satellite data provide an acceptable map after applying the mentioned filters.
Frapart and Ramilin (2018) showed that the GRACE Satellite data is a suitable source of information for evaluating groundwater storage. Among other things, in this research, the main methods to monitor the changes in groundwater and the applications of the GRACE Satellite data for it were investigated. Soleimani et al. (2021) by the images obtained from the GRACE Satellite evaluated the fluctuations of the GWL in the Jiroft plain. They stated that the JPL algorithm was the most suitable model for monitoring the level of the Jiroft Plain. Liu et al. (2021) investigated groundwater level forecasting of a region in the northeastern United States using GRACE satellite data. They used support vector machines (SVMs), combined with the data assimilation (DA) technique. The results showed that the SVMs (SVM-DA) models forced with limited climate variables, can forecast the changes in groundwater levels up to 3-month lead times at most of the locations. Ghosh and Bera (2023) estimated groundwater level and storage changes using innovative trend analysis (ITA), GRACE data, and Google Earth Engine (GEE) in a region of India. The general results state a sharp decrease in the groundwater level and water storage. The main reasons for these worrisome challenges are the geological structure and excessive extraction of groundwater for drinking and irrigation uses.
There have been many studies on groundwater, in most of which intelligent models have been used to model the GWL, and among which, the support vector regression (SVR) model has had a good performance. In the following, some groundwater studies with this model will be mentioned. Sattari et al. (2017) used the SVR and M5 tree models to predict the GWL in the Ardabil Plain. The results showed that the performance of the models is good. Mirarabi et al. (2019) were used the SVR and the artificial neural network (ANN) models for the GWL prediction. They stated that SVR outperforms ANN. Aderemi et al. (2023) used machine learning models such as regressions models, deep auto-regressive models, and nonlinear autoregressive neural networks with external input (NARX) to forecast groundwater levels using the groundwater region 10 at Karst belt in South Africa. The results showed that NARX and Support Vector Machine (SVM) have better performance than other models used.
In the past years, pre-processing tools like wavelet transform (WT) and empirical mode decomposition (EMD) have been noticed, and their combination with different models created hybrid models. In the following, we refer to some of the studies that have been conducted in the field of using these tools to investigate the changes in the level of groundwater.
Adamowski and Chan (2011) to forecast the GWL in Quebec, Canada assessed the performance of the wavelet-artificial neural network (W-ANN), ANN, and autoregressive integrated moving average (ARIMA) models. The results showed the high ability of the W-ANN model in GWL prediction. The wavelet-adaptive neuro-fuzzy inference system (W-ANFIS) and W-ANN models by Moosavi et al. (2014) optimized to predict the GWL in Mashhad, Iran. The results showed that W-ANFIS model works better than W-ANN model. Suryanarayana et al. (2014) compared a hybrid wavelet-support vector regression (W-SVR) with ANN, SVR, and ARIMA models to predict monthly GWL fluctuations in Vishakapatnam, India. They stated that the best performance belongs to the W-SVR model. Bahmani and Quarta (2020) presented GWL modeling by combining it with artificial intelligence (AI) techniques. For this study, the gene expression programming (GEP) and M5 models were combined with the WT and complementary ensemble empirical mode decomposition (CEEMD) techniques. The results showed that the model combined with GEP has a better performance. Bahmani et al. (2020) simulated the GWL with the GEP and the M5 tree model and their combination with WT (wavelet-gene expression programming (W-GEP) and wavelet-M5 (W-M5)). The results showed that the performance of the 2 hybrid models was similar and the hybrid models had better performance than the GEP and M5 models alone. Wu et al. (2021) were used to simulate groundwater levels, the long short-term memory (LSTM), and the combination of the wavelet transform (WT) with it (WT-LSTM) and combined WT-multivariate LSTM (WT-MLSTM). The results showed that the WT-MLSTM model was better than the LSTM, WT-LSTM, and MLSTM models. Shahbazi et al. (2023) utilized the W-ANN, W-SVR, CEEMD-ANN, and CEEMD-SVR models for modeling the GWL. The results of the models indicated that the ANN model outperformed the SVR model and showed that hybrid models performed best.
A review of references indicates that the use of intelligent models is increasing. In addition, the use of the GRACE Satellite, because data of the mentioned satellite is up to date, it can be an acceptable service for modeling and predicting GWL in different aquifers. Therefore, in this research, different methods are compared based on the observed values of GWL, and the best method is presented for similar tasks. The sharp drop in the GWL of the Aspas aquifer in the Tashk-Bakhtegan and Maharlu basins in the past years made it necessary to investigate the condition of the water level of this aquifer in this research. Also, by using satellite data and hybrid models, the water level of this aquifer will be checked in periods without statistics and in future periods, so that with sufficient and appropriate information, correct and practical decisions can be made in the field of exploitation. One of the novelties of this study is to provide a suitable approach for predicting the values of the groundwater level. In this new approach, the groundwater level has been estimated using the GRACE satellite data, the use of pre-processing tools, and AI models.
Materials and methods
Study area
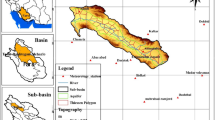
The study area of Aspas, covering an area of 1590.5km2, is located in the Northwestern part of the Tashk-Bakhtegan and Maharlu watersheds. The maximum height of the region is 3495 m at the peak of Bar Aftab mountain, while the minimum height is 2061 m related to the Oujan River. The location of the study area is illustrated, in the Tashk–Bakhtegan and Maharlu lakes basin in Fars Province of Iran in Fig. 1. This Fig., shows the location of 40 observation wells. It also shows the 16 meteorology stations used in the area. The average precipitation on the aquifer based on drawn maps is equal to 427 mm. The average annual temperature of the Aspas aquifer was 13 degrees Celsius and the average annual evaporation was 2273 mm.

Location of the study area in Iran [Shahbazi et al. (2023)]
Data preparation
The unit hydrograph shows the changes in the water level of the entire aquifer over a certain period. It is designed based on the Thiessen method for observation wells with an index period. The purpose of determining the hydrograph is to show the changes in the aquifer water level, to define the maximum and minimum periods, to determine the balance period, and to estimate the drop in the level in a certain period. Equation (1) is used to calculate the water level of the hydrograph.
where, H: the average water level above sea level in meters, ai: the area of each polygon (km2), A: the aquifer area (km2), and hi: the water level in the ith observation well.
To investigate the fluctuations of the GWL, it is necessary to evaluate the existing aquifers. In the studied area of Aspas, to investigate the trend and how the GWL fluctuates during a water year or long-term and to calculate the amount of water level drop or rise in a certain period, based on the water level measurement of the observation wells, unit hydrographs of alluvial aquifers are prepared.
The steps of drawing the unit hydrograph are done in the following order:
-
1-
Investigating the location, statistical period, and information of observation wells.
-
2-
Eliminating statistical deficiencies for the intended index period.
-
3-
Obtaining the area covered by each observation well in the GIS environment using Thiessen Polygon.
4- Using Eq. (1) and drawing the unit hydrograph of the aquifer.
In this research, precipitation, temperature and evaporation data from meteorological stations and data from observation wells were used. These data are taken from Fars Province Regional Water Company. Then, 40 observation wells were selected in the Aspas aquifer. The unit hydrograph of GWL changes was plotted for the water years 2002–03 to 2020–21. In Fig. 2, GWL changes are plotted on a monthly basis.

Unit Hydrograph of the GWL changes in the Aspas aquifer
The location of meteorological stations used in and around the Aspas aquifer is provided in Table 1. According to the information received from the GRACE Satellite, six different processing algorithms were used to check the status of changes in the GWL in the Aspas aquifer.
Precipitation data were analyzed and expanded by HEC-4 software. Then, box plot method was used to check outlier data. The GIS software and the kriging method were used to draw the maps. Monthly precipitation maps were drawn to the studied area. Then the monthly rainfall values were extracted on Aspas aquifer.
The Difference method was used to check the temperature data and their extension. After checking the outlier data, monthly iso-temperature maps were plotted for the Aspas studied area. Then, monthly temperature values were extracted on the Aspas aquifer. To analyze the evaporation of the aquifer, the statistics of eight stations inside and outside the studied area were used. The relationship between temperature and evaporation for each station was used to check evaporation data and their extension. After checking their outlier data, the monthly evaporation and transpiration map was plotted for the studied area. Then, the monthly evaporation values were extracted for the Aspas aquifer.
After specifying the monthly data of GWL, precipitation, temperature, and evaporation of the Aspas aquifer, the modeling process started. Before using the data, they were standardized (i.e., converting the data into a number between zero and one). For this purpose, according to Solgi (2014) suggestion, Eq. (2) was used.
where, x: desired data, x̄: average data, xmin: minimum data, xmax: maximum data, and y: standardized data.
Artificial intelligence models
After evaluating the AI models, two were used in this research, which had shown proper performance in previous research. These models are the ANN and the SVR. Then, two pre-processing tools, including the WT and CEEMD were utilized to enhance the performance of these models.
ANN model
The following general stages are pursued to build an ANN model: In the first step, effective parameters are determined. The purpose of this stage is to determine the number of neurons in the middle layer, the type of network, the optimal number of layers, and the transition and basic functions by trial and error to achieve a suitable solution. The second step is network training. The purpose of artificial neural network training is to modify the communication weights between layers as well as the network bias weights for multiple samples. The training of the network is complete when the model error or the difference between the output values of the network and the target values is minimized. To achieve this goal, training data related to the desired pattern are given to the network several times, so that the network corrects its weights each time using them. By doing this repeatedly, the weights are modified in a way that the network can provide acceptable output against non-training input data. The third step is network testing. After completing the process of training the network and correcting its weights, the network is evaluated using a set of data with known output. If the network testing is successful, it can be used to determine unknown values. To acquire more knowledge on this subject, study resources (Karamuz and Araghinezhad 2010).
SVR model
By using the concept of the inner product in Hilbert spaces and the Hilbert–Schmidt theorem, Vapnik showed that the input vector x can be first transferred to a high-dimensional space with a non-linear transformation and perform the inner product in that space. By this, it can be proved that if a symmetric kernel meets the conditions of Mercer's theorem, its application in a low-dimensional input space can be considered as an inner product in a high-dimensional Hilbert space and reduces the calculations significantly. (Cortes and Vapnik 1995).
In this study, used four common kernels (Eq. 3) of the polynomial (Poly), RBF, Sigmoid, and linear (Lin).
The RBF kernel has one parameter g (Gamma). In the sigmoidal kernel, only the default values, including zero and 1/k Gamma, are used. The linear kernel doesn’t have any parameters. However, the polynomial kernel has two parameters d (the degree of the polynomial) and r (an accumulative fixed number). For more information on this topic, see references (Cortes and Vapnik 1995; Raghavendra and Deka 2014). To run the ANN and SVR models, six combinations of architecture, according to Table 2 were considered. From the data set, 75% of them were used for the training stage and 25% for the test stage. The input parameters are precipitation (Pt), temperature (Tt), evaporation (Et), and the groundwater level at time t (GWLt). The output parameter is the groundwater level at time t + 1 (GWLt+1).
Pre-processing tools
WT and CEEMD preprocessing tools were employed in this study.
Wavelet transform (WT)
Wavelet Transform, as a mathematical tool, has various applications in different branches of engineering. This is due to its unique capabilities, which is the ability to follow the changes of a signal in a wide time-scale spectrum (time–frequency) simultaneously.
Some of its applications are as follows: finding discontinuous points in the signal, removing noise from the signal, compressing the signal, and identifying the system. There are many types of wavelet functions with various accuracies depending on their applications. The most important and widely used ones include Haar, Morlet, Daubechies, Symlet, Gaussian, Meyr, Coif, Mexican Hat, Bior, etc. (MATLAB toolbox (2018)). According to Nourani et al. (2009), to determine the decomposition level in the WT method on a monthly time scale, Eq. (4) can be used as a preliminary estimate.
In this regard, L is the decomposition level, and N is the amount of data. To learn more about this topic, refer to (Mallat 1998 and Foufoula-Georgiou and Kumar 1994).
CEEMD method
The experimental mode analysis method is a technique for examining various signals. R software is used to implement the CEEMD method. First, the package "hht" must be installed in R software. Then, using coding in R software, sub-signals can be extracted. When the primary signal is analyzed using the CEEMD method and its sub-signals are entered as input to intelligent models, composite models are formed. The CEEMD method contains two parameters named maximum intrinsic mode function (IMF) and £. To learn more about this topic, refer to (Wu and Huang (2004); Amirat et al. 2018).
Combining models with the pre-processing tools
To obtain the W-ANN and W-SVR hybrid models, first, an initial signal is decomposed using WT and entered into the ANN and SVR models as input. If the original signal is decomposed using CEEMD and entered into ANN and SVR models, the CEEMD-ANN and CEEMD-SVR hybrid models are obtained. Figure 3 shows a schematic of how to create these models.

Schematic diagram of the W-ANN, W-SVR, CEEMD-ANN and CEEMD-SVR models
GRACE satellite
The GRACE Satellite is a project with cooperation between Germany and the USA, which consists of two similar and separate satellites. The satellites move at an altitude of 500km from the earth surface with a distance of 220 km from each other. By changing the local gravitational field through which the satellites pass, the distance between the satellite's changes. By analyzing these distance changes, the gravity field can be obtained (Swenson and Wahr 2002). These satellites were launched on March 17, 2002, from the Plesetsk space base in Russia. GRACE Satellite is the only remote sensing satellite that can monitor the changes in the level. The principal use of this satellite is to determine hydrological changes by measuring the continuous changes of water in water tables, soil, surface reservoirs, and snow with an accuracy of a few millimeters in terms of water height with a resolution of 400 km (Swenson et al. 2009). The mission of this satellite ended in 2017, but the GRACE-FO satellite, which started operating on May 22, 2018, is now recording data.
Gravitational data of GRACE Satellite are processed in different algorithms that include the geo forschungs zentrum (GFZ), jet propulsion laboratory (JPL), center for space research at the University of Texas (CSR) organizations, CNES, COST-G, AIUB, and TUGRAZ algorithms among other processing algorithms of the GRACE Satellite.
To learn more about this topic, refer to (Swenson and Wahr 2002; Swenson et al. 2009).
Evaluation criteria
Three evaluation criteria were employed in this research, including the coefficient of determination (R2), root mean square error (RMSE), and Akaike information criterion (AIC) (Bahmani et al. 2020). These evaluation criteria are presented in Eqs. (5, 6 and 7) (Bahmani et al. 2020).
where, n: number of data, i: counter variable, \({{{\text{G}}}_{{\text{i}}}}_{{\text{obs}}}\): observational data, \(\overline{{{{\text{G}} }_{{\text{i}}}}_{{\text{obs}}}}\): average of the observational.
data, \({{{\text{G}}}_{{\text{i}}}}_{{\text{pre}}}\): computational data, \(\overline{{{{\text{G}} }_{{\text{i}}}}_{{\text{pre}}}}\): average predicted data, m: number of the trained data, and \({\text{Npar}}\): number of the parameters of the model.
Results and discussion
In this part, first, intelligent models were implemented and their results were presented. In the next stage, preprocessing tools were used and the results of hybrid models were presented. Finally, the results of the models were compared based on statistical criteria.
Results of the AI models
Results of the ANN & SVR models
To run the ANN and SVR models, used MATLAB software. For this work, were analyzed in each combination, several structures. The ANN model obtained the best structure with R2 = 0.927 and RMSE = 0.0158 m. This best combination had a "trainlm" training rule and a "tansig" transfer function. In this combination, 3 neurons in the middle layer and 8 neurons in the input layer are used. The results of the SVR model showed that the best structure had R2 = 0.918 and RMSE = 0.0168 m. In this case, the best performance was related to Line Kernel. By the criteria, the results showed the ANN model did better than the SVR model. In Fig. 4, a comparison has been made between the performance of these models and the observed values. This Fig. shows that the ANN model has performed better at minimum points than at peak points. Also, this Fig. shows that the performance of the ANN model is better than the SVR.

The results of the ANN and SVR models -testing stage
Results of the W-ANN & W-SVR models
To run the W-ANN and W-SVR models, first, the WT was used. Then sub-signals obtained from it were entered as input to the models. Based on the number of data which is 222, the level of analysis was calculated as 2, according to Eq. (4). To increase the accuracy, decomposition levels 1 to 4 are considered.
The results of the W-ANN model showed that the Sym3 wavelet function had the best performance at decomposition level 1. This best combination had 8 input neurons and 4 hidden layers. This combination used the “Trainbr” training rule and the “Purelin” transfer function. In this superior combination, R2 = 0.938 and RMSE = 0.0149 m were obtained.
In the W-SVR model, the Coif1 wavelet function has performed best at the level of decomposition 2. In this combination, the best performance was related to the RBF kernel. The best combination had R2 = 0.949 and RMSE = 0.0164 m.
In Fig. 5, a comparison has been made between the performance of these models and the observed values. This Fig. shows that the W-SVR model has performed better at peak points. But at minimum points the W-ANN model has performed better. Also, this Fig. shows that the performance of the W-SVR model is better than the W-ANN.

The results of the W-ANN and W-SVR models -testing stage
Results of the CEEMD-ANN & CEEMD-SVR models
The program was executed for the maximum IMF number of 10, and the outcomes indicated that the maximum number of sub-signals could be 6. Therefore, the program code was run for the number of IMFs from 1 to 6. The results of the CEEMD-ANN model showed that the best performance was obtained in IMF of 1 and ε value of 0.2. The best performance in this combination was related to the “Trainbr” training rule and the “Tansig” transfer function. This superior structure had an R2 and error value of 0.998 and 0.0035, respectively. Based on CEEMD-SVR model, the best performance was obtained in IMF and ε value of 2 and 0.1, respectively. The best performance had been related to the Lin kernel. In this case, the R2 and error value were 0.948 and 0.0154 m, respectively. In Fig. 6, a comparison has been made between the performance of these models and the observed values. This Fig. shows that the CEEMD-ANN model has performed better at minimum points than at peak points. Also, this Fig. shows that the performance of the CEEMD-ANN model is better than the CEEMD-SVR.

The results of the CEEMD-ANN and CEEMD-SVR models -testing stage
Comparison between the outputs of the models
In this section, the outputs of the models in their various states were compared. The measurement of the differences between various methods was carried out from March 2014 to March 2019 in accordance with the statistical period used for the data testing stage. According to Table 3, using pre-processing tools has enhanced the performance of ANN and SVR models. Utilizing the WT has improved the ANN model by 1.18%. Moreover, using of the WT has improved the SVR model by 3.26%.
According to the results, using other preprocessing tools (i.e., the CEEMD) has enhanced the performance of the ANN and the SVR models. So that the performance of the ANN model got better by 7.65% and the SVR model by 3.15%. Based on outcomes, it can be viewed that the CEEMD-ANN hybrid model has the best performance. So that the CEEMD-ANN model had R2 = 0.998, RMSE = 0.0035 m. The CEEMD-ANN hybrid model had the lowest Akaike coefficient (the AIC = 85.35).
In Fig. 7, used models were compared in the testing stage, based on the unit hydrographs of the aquifer (Observed). As seen, the hybrid models have more performance that is suitable. Among them, the CEEMD-ANN values are closer to the observational values. Based on this fig., the CEEMD-ANN model has a better estimate of points peak and least. Therefore, the mentioned model can be used for forecasting the GWL of the Aspas aquifer.

Comparison of the results of the models used-testing stage
Comparing the results of the different algorithms of the GRACE satellite
This satellite had monthly information on changes in the GWL from April 2002 to the present time for the Aspas aquifer, which was used for this study from October 2002 to July 2022.
Based on the information received from the GRACE Satellite, 6 different processing algorithms were used to check the status of variations in the GWL of the Aspas aquifer. Comparing the data of these algorithms with the observational data obtained from the unit hydrograph of the Aspas aquifer, the changes in the GWL of the aquifer must first be calculated.
As mentioned, the GRACE Satellite has had no data for several months due to the end of its operation and being replaced by the GRACE-FO Satellite, and this is shown in the Fig that is compared with the observational data of the GWL resulted from the unit hydrograph.
By comparing the results of various algorithms in train and test periods, it can be observed that GFZ and TUGRAZ have better performance than other algorithms in the changes of the observational values of the GWL based on the evaluation criteria presented in Table 4. To calculate these criteria, the months with statistics were included. According to the Table 4, in the test stage (from March 2014 to March 2019), the GFZ processing algorithm with R2 = 0.706, RMSE = 39.15, and Akaike’s criterion of 91.67 had the best performance and was chosen as the best algorithm. It can be the reason that the Akaike criterion for the train period in JPL and CNES is lower than other algorithms in Table 4, which is related to their fewer data than other algorithms.
Figures 8, 9 illustrate the comparison between the performance of different algorithms along with the observational values in the train and test stages, respectively. As can be seen in Fig. 8, the data of the GRACE satellite has a longer statistical length. In Fig. 9, which is related to the test period, some data are not available due to the completion of the satellite mission.

Comparison between different processing algorithms of GRACE Satellite with observational values—training stage

Comparison between different processing algorithms of GRACE Satellite with observational values—testing stage
Comparison between the results of intelligent models with the processing algorithms of the GRACE satellite
In this section, considering the statistical criteria and based on the observed values obtained from the unit hydrograph, the performance of the best intelligent model employed in this research has been compared with the best GRACE Satellite processing algorithm. As explained in the previous sections, the CEEMD-ANN model outperformed all the intelligent models. Because the GRACE Satellite data provide changes in the GWL on a monthly basis, the changes in the GWL were calculated using CEEMD-ANN hybrid model to compare the results. Among the processing algorithms of the GRACE Satellite, the GFZ performed the best. A comparison was made between the results of the best structures to calculate the GWL changes during the training and testing periods. The results of this comparison are presented in Table 5. According to what can be observed in Table 5, it is clear that intelligent models have better performance than the data of the GRACE Satellite.
Figures 10, 11 provided a comparison between the performance of the best intelligent model and the best algorithm of the GRACE satellite with the observational values in the train and test stages. Based on these Figs, the intelligent model has the best performance. Thus, it is more appropriate to use the CEEMD-ANN intelligent model to predict the GWL.

The best performance of the structures used-training stage

Comparison of the best performance of the structures used- testing stage
Predicting the GWL changes
As cited in the previous section, the CEEMD-ANN model was identified as the best model in this research. Now, to use this model to predict the GWL, it is necessary to have input parameters, which are not available. Here the aim is to obtain these values from satellite data, while they are different from the observational data of observation wells. First, these values should be corrected and then calculated for the future period and used in the CEEMD-ANN model. Also, as intelligent models must be implemented step by step and each step is used as input for the next step, they will have good results in the short term. However, as the time step increases, the accumulated errors in each step will cause irrational estimates. For this purpose, in this study, a new and suitable approach was presented to predict changes in the GWL in the Aspas aquifer.
An appropriate approach for predicting the GWL using the data of the GRACE satellite
The use of the GRACE Satellite data has advantages such as up-to-dateness, high speed, lower cost, and obtaining results in a short time. Therefore, these data should be corrected by correcting their values to use these capabilities for current and future periods. Considering the up-to-dateness of the GRACE Satellite data and the results obtained from the data in the previous sections, a suitable approach was adopted to use them. For this purpose, first by using the standardization relationship (Eq. 2), the data values of the GRACE Satellite (the values of the GFZ processing algorithm) were standardized, and then the filtration capability of the CEEMD and CEEMD-ANN models were used. According to the appropriateness of the IMF = 1 and the ε value of 0.2, the data of the GFZ algorithm was decomposed. The obtained values were then entered as input to the ANN model so that the modeling is based on the observed data of GWL changes. Considering the results of the CEEMD-ANN hybrid model, the “trainbr” training rule and the “tansig” transfer function (In the best intelligent model structure) were utilized. Results of this study are presented in Table 6, according to which the model with R2 = 0.78 for the test stage and an error value of 0.0696 has performed well. This model can be used for the predicting stage. Results reveal that the R2 of the new approach has improved the performance of the GFZ processing algorithm by 2.70% and 7.53% in the training and testing phases, respectively. Then, the data of the GFZ in the period of April 2021 to June 2022 was given as input to the model. The model estimated the changes in the GWL of the Aspas aquifer in this time span. The results of the train stage provided in Fig. 12. The predicted values (from April 2021 to Jul 2022) and the data of the test stage of the new approach are illustrated in Fig. 13. The results of this approach can be used for the coming months as well, considering the updating of the GFZ algorithm data.

The results of applying the CEEMD-ANN model using the data of the GRACE Satellite-training stage

The results of applying the CEEMD-ANN model using the data of the GRACE Satellite-testing and prediction stage
It can be said that the results of this study in terms of the more satisfactory performance of hybrid models with WT and CEEMD are agreeing with the results of Bahmani et al. 2020; Bahmani and Ouarda 2020. Also, this study's results agree with those of Adamowski and Chan (2011). They found the artificial neural network model performed better.
By conducting this study, suggestions are provided to improve similar studies.
-
1-
Using the approach presented in this study, it is possible to use the data values of the GRACE Satellite for the current and future periods for other aquifers as well.
-
2-
Other methods and approaches can be used to correct the values of the GRACE satellite and compare with the results of this study.
Conclusions
In this study, AI models, including ANN and SVR, were used to model the GWL of the Aspas aquifer. Then, the tools consisting of data analysis, including WT and CEEMD, were used to form hybrid models. The outputs of intelligent models were compared with each other based on observational data. In the next stage, different processing algorithms of the GRACE Satellite were used. Performance comparison of different processing algorithms was done based on observational data. The results showed that the intelligent ANN model performed better than the SVR model. The W-SVR hybrid model has outperformed the W-ANN. In addition, the results showed that the CEEMD-ANN model has outperformed the CEEMD-SVR model. Based on the results of intelligent models proved that the best performance is related to the CEEMD-ANN hybrid model. Also, the results showed that the GFZ algorithm had the best performance compared to other processing algorithms of GRACE Satellite in the train and test stages. Comparing the results between the best intelligent model (CEEMD-ANN) and the best GRACE Satellite processing algorithm (GFZ) for calculating changes in the GWL showed that the hybrid model performs better. A new approach was utilized to forecast the GWL shifts. In this approach, data of the GRACE Satellite (GFZ processing algorithm) were decomposed using CEEMD and entered as input to the CEEMD-ANN model. Then, modeling was done and the values of changes in the GWL were estimated for the current and future periods. The results show that the coefficient of determination of the new approach, 2.70% and 7.53% in train and test stages, respectively, has improved the performance of the GFZ processing algorithm. Using the approach presented in this study, the values of changes in the GWL of the Aspas aquifer from April 2021 to Jul 2022 (the time of writing this article) were presented. The approach presented in this study has the capacity to estimate the changes in the GWL in the coming months by updating the data of the GFZ processing algorithm.
Data availability
The authors declare that the data supporting the findings of this study are available. Should raw data files be needed, they become available from the corresponding author upon reasonable request.
Abbreviations
- GWL:
-
Groundwater level
- GRACE:
-
Gravity recovery and climate experiment
- SVR:
-
Support Vector Regression
- ANN:
-
Artificial Neural Network
- WT:
-
Wavelet Transform
- EMD:
-
Empirical mode decomposition
- W-ANN:
-
Wavelet Artificial Neural Network
- ARIMA:
-
Autoregressive integrated moving average
- CEEMD:
-
Complementary ensemble empirical mode decomposition
- W-ANFIS:
-
Wavelet-adaptive neuro fuzzy inference system
- W-SVR:
-
Wavelet-support vector regression
- AI:
-
Artificial intelligence
- GEP:
-
Gene expression programming
- W-GEP:
-
Wavelet-gene expression programming
- W-M5:
-
Wavelet- M5
- Poly:
-
Polynomial
- Lin:
-
Linear
- IMF:
-
Intrinsic mode function
- CEEMD-ANN:
-
Complementary ensemble empirical mode decomposition-ANN
- CEEMD-SVR:
-
Complementary ensemble empirical mode decomposition-SVR
- GPS:
-
Global positioning system
- GFZ:
-
Geo forschungs zentrum
- JPL:
-
Jet propulsion laboratory
- CSR:
-
Center for space research at the university of Texas
- R2 :
-
Coefficient of determination
- RMSE:
-
Root mean square error
- AIC:
-
Akaike information criterion
References
Adamowski J, Chan FH (2011) A wavelet neural network conjunction model for groundwater level forecasting. J Hydrol 407(1–4):28–40. https://doi.org/10.1016/j.jhydrol.2011.06.013
Aderemi BA, Olwal TO, Ndambuki JM, Rwanga SS (2023) Groundwater levels forecasting using machine learning models: a case study of the groundwater region 10 at Karst Belt. South Africa System Soft Comput 5(200049):1–15. https://doi.org/10.1016/j.sasc.2023.200049
Amirat Y, Benbouzidb M, Wang T, Bacha K, Feld G (2018) EEMD-based notch filter for induction machine bearing faults detection. Appl Acoust 133:202–209. https://doi.org/10.1016/j.apacoust.2017.12.030
Bahmani R, Ouarda TBMJ (2020) Groundwater level modeling with hybrid artificial intelligence techniques. J Hydrol 595:1–12. https://doi.org/10.1016/j.jhydrol.2020.125659
Bahmani R, Solgi A, Ouarda TBMJ (2020) Groundwater level simulation using gene expression programming and M5 model tree combined with wavelet transform. Hydrol Sci J 65(8):1430–1442. https://doi.org/10.1080/02626667.2020.1749762
Behzadi Sheikh Rabat R (2017) Estimation of groundwater level and mass changes due to geodynamic effects using GRACE satellite data. Master’s thesis, department of earth sciences, Shahrood university of technology
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–295
Faraji Z, Kaviani A, Ashrafzadeh A (2016) Evaluation of GRACE satellite data in the estimation of groundwater level changes in Qazvin province. Iran J Ecohydrol 4(2):476–463. https://doi.org/10.22059/IJE.2017.61482
Foufoula-Georgiou E, Kumar P (1994) Wavelet in geophysics: an introduction. Academic Press, San Diego New. https://doi.org/10.1016/B978-0-08-052087-2.50007-4
Frappart F, Ramillien G (2018) Monitoring groundwater storage changes using the gravity recovery and climate experiment (GRACE) satellite mission: a review. Remote Sensing 10(6):829–854. https://doi.org/10.3390/rs10060829
Ghosh A, Bera B (2023) Estimation of groundwater level and storage changes using innovative trend analysis (ITA), GRACE data, and google earth engine (GEE). Groundw Sustain Dev 23(101003):1–15. https://doi.org/10.1016/j.gsd.2023.101003
Karamooz M, Araghi Nejad SH (2010) Advanced hydrology, 2nd edn. Amirkabir University of Technology Press, Tehran, p 464
Liu D, Mishra AK, Yu Z, Lü H, Li Y (2021) Support vector machine and data assimilation framework for groundwater level forecasting using GRACE satellite data. J Hydrol 603(126929):1–18. https://doi.org/10.1016/j.jhydrol.2021.126929
Mallat S (1998) A wavelet tour of signal processing. Academic Press is an imprint of Elsevier, San Diego
MATLAB software toolbox version R2018a.
Mirarabi A, Nassery HR, Nakhaei M, Adamowski J, Akbarzadeh AH, Alijani F (2019) Evaluation of data-driven models (SVR and ANN) for groundwater-level prediction in confined and unconfined systems. Environ Earth Sci 78(15):478–489. https://doi.org/10.1007/s12665-019-8474-y
Moosavi V, Vafakhah M, Shirmohammadi B, Ranjbar M (2014) Optimization of wavelet-ANFIS and wavelet-ANN hybrid models by taguchi method for groundwater level forecasting. Arabian J Sci Eng 39(3):1785–1796. https://doi.org/10.1007/s13369-013-0762-3
Nourani V, Komasi M, Mano A (2009) A multivariate ANN-wavelet approach for rainfall–runoff modeling. Water Res Manag 23:2877–2894. https://doi.org/10.1007/s11269-009-9414-5
Raghavendra NS, Deka PC (2014) Support vector machine applications in the field of hydrology: a review. Appl Soft Comput 19:372–386. https://doi.org/10.1016/j.asoc.2014.02.002
Sattari MT, Mirabbasi R, Shamsi Sushab R, Abraham J (2017) Prediction of groundwater level in ardebil plain using support vector regression and M5 tree model. Nat’l Ground Water Assoc 56(4):636–646. https://doi.org/10.1111/gwat.12620
Shahbazi M, Zarei H, Solgi A (2023) De-noising groundwater level modeling using data decomposition techniques in combination with artificial intelligence (case study Aspas aquifer). Appl Water Sci 13(88):1–18. https://doi.org/10.1007/s13201-023-01885-7
Soleimani Sardoo F, Rafiiei Sardooi E, Nateghi S, Azareh A (2021) Evaluation of groundwater level fluctuations in Jiroft plain using GRACE satellite images. Environ Erosion Res J 10(4):58–73
Solgi A (2014) Stream flow forecasting using combined neural network wavelet model and comparsion with adaptive neuro fuzzy inference system and artificial neural network methods (case study: Gamasyab river, Nahavand). M.Sc. Thesis, department of hydrology and water resource, Shahid Chamran University of Ahvaz (Persian)
Suryanarayana CH, Sudheer CH, Mahammood V, Panigrahi BK (2014) An integrated wavelet-support vector machine for groundwater level prediction in Visakhapatnam India. Neurocomputing 145:324–335. https://doi.org/10.1016/j.neucom.2014.05.026
Swenson S, Wahr J (2002) Methods for inferring regional surface mass anomalies from GRACE measurements of time-variable gravity. J Geophysical Res. https://doi.org/10.1029/2001JB000576
Swenson SC, Wahr J (2009) Monitoring the water balance of Lake Victoria, East Africa, from space. J Hydrol 370(1–4):163–176. https://doi.org/10.1016/j.jhydrol.2009.03.008
Wu C, Zhang X, Wang W, Lu C, Zhang Y, Qin W, Tick GR, Liu B, Shu L (2021) Groundwater level modeling framework by combining the wavelet transform with a long short-term memory data-driven model. Sci Total Environ 783(146948):1–18. https://doi.org/10.1016/j.scitotenv.2021.146948
Wu Z, Huang NF (2004) A study of the characteristics of white noise using the empirical mode decomposition method. Proc RS Lond 460A:1597–1611
Acknowledgements
The authors are grateful to the Research Council of the Shahid Chamran University of Ahvaz for financial support. In addition, great thanks of the Regional Water Company of Fars and Iran Water Resources Management Company for sharing the required data.
Funding
The authors received funding from Shahid Chamran University of Ahvaz (GN: SCU.WH99.589).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study's conception and design. Dr. Heidar Zarei, Dr. Abazar Solgi and Maryam Shahbazi performed material preparation, data collection, and analysis. Maryam Shahbazi wrote the first draft of the manuscript and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose. The authors declare that they have no known competing personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shahbazi, M., Zarei, H. & Solgi, A. A new approach in using the GRACE satellite data and artificial intelligence models for modeling and predicting the groundwater level (case study: Aspas aquifer in Southern Iran). Environ Earth Sci 83, 240 (2024). https://doi.org/10.1007/s12665-024-11538-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-024-11538-w