
Abstract
Generally, traditional convolutional neural networks (CNN) models require a long training time and output high-dimensional features for content-based remote sensing image retrieval (CBRSIR). This paper aims to examine the retrieval performance of the MobileNets model and fine-tune it by changing the dimensions of the final fully connected layer to learn low dimensional representations for CBRSIR. Experimental results show that the MobileNets model achieves the best retrieval performance in term of retrieval accuracy and training speed, and the improvement of mean average precision is between 11.2% and 44.39% compared with the next best model ResNet152. Besides, 32-dimensional features of the fine-tuning MobileNet reach better retrieval performance than the original MobileNets and the principal component analysis method, and the maximum improvement of mean average precision is 11.56% and 9.8%, respectively. Overall, the MobileNets and the proposed fine-tuning models are simple, but they can indeed greatly improve retrieval performance compared with the commonly used CNN models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
With the development of Earth observation technology, the number of high-resolution remote sensing (RS) images has grown rapidly(Bapu and Florinabel 2020; Shao et al. 2018). This has led to the challenge of efficiently retrieving objects or scenes of interest to users from the increased RS image database (Li and Ren 2017; Shao et al. 2020). Therefore, content-based remote sensing image retrieval (CBRSIR), which can rapidly acquire similar images from a large-scale dataset by using RS image features, has become research hotspots in the RS domain(Ge et al. 2018; Napoletano 2018).
Currently, a considerable literature has grown up around the theme of image feature extraction for CBRSIR. Initially, the mid/low level features are often directly extracted from RS images to represent their contents, such as HSV (hue, saturation, value) color space, bag of visual words, Gabor texture features and others (Du et al. 2016; Zhou et al. 2018; Zhou et al. 2015). Subsequently, various high-level deep learning features are becoming popular due to their high efficiency and effectiveness (Hou et al. 2019; Zhou et al. 2017). For example, Zhou et al. (2018) and Hou et al. (2019) employed various convolutional neural networks (CNN, i.e. AlexNet, VGG16, VGG19 and ResNet) to evaluate the performance of their CBRISR datasets, respectively. As described in the literature(Sudha and Aji 2019; Tong et al. 2019), scholars mainly use AlexNet, CaffeNet, VGG-M, VGG16, VGG19, GoogLeNet, ResNet, DenseNet and their variants or combination to carry out research on CBRSIR. Surprisingly, the effects of MobileNets networks, which is nearly as accurate as VGG16 in image classification while having less compute intensive(Howard et al. 2017), have not been closely examined in CBRSIR. In fact, experiments in literature(Qi et al. 2017) demonstrate that retrieval performance for natural images is improved by adding a hash layer to MobileNets compared to other hashing methods.
In general, the above high-level features directly extracted from deep learning methods are high dimensional with thousands of codes, which can lead to low retrieval efficiency, especially in a large image database(Ge et al. 2017; Tong et al. 2019). Therefore, several studies have attempted to compress high-level features as low dimensional features for better retrieval performance(Wang et al. 2020). For instance, Ge et al. (2017) used principal component analysis (PCA) method to compress CNN features to different dimensions and indicated that high-level features with 32 dimensions perform better. Tong et al. (2019) also demonstrated that the PCA method is effective for compressing CNN features and the optimized dimensions for CBRSIR are in the range of 8–32.
Unlike the above methods using the PCA compression, Xiao et al. (2017) treated the fully connected layers of CNN methods as ordinary neural networks and set 4096, 1024, 256, 64 dimensions of the second fully connected layer of Alexnet and VGG-16 to evaluate the retrieval performance. They concluded that the 64-dimensional features achieve the best retrieval results compared with other dimensional features and PCA-based features. Similarly, Cao et al. (2020) added a fully connected layer with a lower dimension in their proposed triplet network to condense the final features and also used PCA dimension reduction. Experimental results show that the PCA method has better performance than the fully connected-based method and the 32-dimensional features achieve the best retrieval results. Overall, there seems to be some evidence to indicate that the final fully connected layers can be treated as an ordinary neural network and directly modifying its dimension can achieve a similar dimensionality reduction effect as PCA methods(Cao et al. 2020; Hinton and Salakhutdinov 2006; Xiao et al. 2017). However, far too little attention has been paid to dimensionality reduction by modifying the dimension of the final fully connected layers in other deep learning methods.
Inspired by this and the efficient learning ability of the MobileNets, this paper investigates the retrieval performance of the MobileNets and exploits low dimensional features from the fine-tuning MobileNets for CBRSIR by changing the dimensions of the final fully connected layer. Our main contributions are as follows.
-
(1)
We provide comprehensive comparisons between MobileNets and other commonly used deep learning methods on the six benchmark datasets, by giving a summary of retrieval performance and training time. Experimental results show that MobileNets achieves better retrieval performance than other CNN models while having shorter training time.
-
(2)
We fine-tune the MobileNets to learn low dimensional representations by directly changing the dimensions of the final fully connection layer, and give the optimal dimensions of the fine-tuning model by experimental comparison. Experimental results indicate that 32-dimensional features achieve the best result, compared with the original MobileNets and PCA compression method.
The remainder of this paper is organized as follows. Section II outlines the methodological framework of the fine-tuning MobileNets, followed by extensive experiments and analysis in Section III. Section IV provides conclusions and future work.
Fine-tuning MobileNets networks for CBRSIR
MobileNets is a recent efficient CNN model, which is designed for various recognition tasks on mobile devices or under limited hardware conditions (Howard et al. 2017). It requires less computation than VGG16 model with only a small reduction in classification accuracy on the imagenet dataset (Howard et al. 2017). The reduction in classification accuracy may be the reason why no scholars have used the MobileNets in CBRSIR, whose main goal is to improve retrieval accuracy.
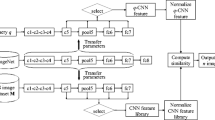
Figure 1 shows the architecture of the original and fine-tuning MobileNets for CBRSIR. Compared with other CNN models, it contains 13 depthwise separable convolutional layers and 13 pointwise convolutional layers, each of which is followed by each depthwise separable convolutional layer and is omitted in Fig. 1. Besides, each convolutional layers is followed by a batchnorm and ReLU nonlinearity. In the original MobileNets, the final fully connected layer is 1024 dimensions. In this paper, the final fully connected layer of the MobileNets is treated as output layer of ordinary neural networks and is fine-tuned to 512, 256, 128, 64, 32, 16, 8 and 4 dimensions, respectively, for learning low dimensional features. To evaluate the retrieval performance of the fine-tuning MobileNets, the PCA method is also adopted to compress the high dimensional features from the original MobileNets.

Architecture of the original and fine-tuning MobileNets for CBRSIR
Experiments and analysis
The experiments are implemented by using the Keras library with TensorFlow backend in Python language, and performed on the same desktop with Intel Core 3.70 GHz i7-8700K processor and 2 NVIDIA GeForce GTX1080Ti GPUs.
Datasets and experimental setup
Six benchmark datasets of NWPU (Cheng et al. 2017), AID(Xia et al. 2017), PatternNet(Zhou et al. 2018), VArcGIS, VBing and VGoogle(Hou et al. 2019) are selected as the experimental data to demonstrate the retrieval accuracy of the MobileNets. Table 1 reports the details of these public datasets. As shown in Table 1, there are both datasets with the same source and different classification systems, as well as datasets with different sources and the same classification systems in the six datasets. This diversity can promote the credibility of evaluation results.
In total, six kinds of current state-of-the-art CNN models, which have been widely used for RSIR, are selected as comparison standard. In detail, our selections include VGG16, VGG19, ResNet50, ResNet101, ResNet152 and DenseNet201. In particular, the first and second fully-connected layers of VGG16 and VGG19 are both selected as features for comparisons, which are named as VGG16_f1, VGG16_f2, VGG19_f1 and VGG19_f2, respectively. For the ResNet and DenseNet201, the last global average pooling layer is selected as features.
In our experiments, the batch size is 32, the initial learning rate is 0.00001 and epoch number is set to 20 as described in literature (Tong et al. 2019). Besides, the most commonly used categorical cross entropy is selected as loss function to measure difference between actual output (probability) and the desired output (probability). 50 images from each class in the six datasets are randomly selected as query images and the remaining images are randomly split into a training set and a validation set, respectively. In particular, 50 images from each class are separated for validation set and the rest images are served as training set. Taking VGoogle dataset as an example, a total of 1900,1900 and 55,604 images are selected query images, validation set and training set, respectively.
Euclidean distance is used to measure similarity in our experiments. The nearer the distance between visual features of query image and other images is, the more similar these images are, and vice versa.
Average Normalized modified retrieval rank (ANMRR), mean average precision (mAP), precision at k (Pk, the percentage of the number of ground truth images within the top k position of the retrieval results), which are three kinds of standard retrieval measures, are adopted to evaluate the results(Cao et al. 2020). The k value is set as 5,10,20,50,100 and 1000 in this paper. Especially, lower values of the ANMRR indicate better retrieval performance, while for mAP and Pk, higher is better(Hou et al. 2019; Zhou et al. 2018).
Investigating retrieval performance of the MobileNets
We perform several experiments to investigate retrieval performance of the MobileNets. Table 2 shows the performance of the seven deep learning models on the six datasets. The best performance of these models is achieved by the MobileNets on the six datasets. Except for the MobileNets, the ResNet152 performs best. However, the mAP values of the MobileNets improve by 11.2% to 44.39% than the ResNet152, which indicates that the retrieval performance of the MobileNets is much higher than other CNN models.
Figure 2 shows the results of precisions at top 5,10,20,50,100 and 1000 on the six datasets. We can see that the MobileNets still performs much better than other models when only the top 5,10,20,50,100 and 1000 results are returned. The top 100 precisions of the MobileNets on the PatternNet, VGoogle, VArcGIS and VBing datasets all achieve between 97.71% and 99.07%, the other two datasets reach between 83.92% and 86.81%, while the top 100 precisions of other CNN models are between 21.28% and 95.02%.

Results of precisions at top 5,10,20,50,100 and 1000 on the six datasets
To test the efficiency of the various models, we directly select training time under the same conditions as an evaluation indicator rather than floating-point operations (FLOPs). This is because that the actual training time of models with similar FLOPs can vary by at least one order of magnitude(Almeida et al. 2019). Table 3 represents the training time of the seven deep learning models on the six datasets. It can be seen that the MobileNets spends less training time than other models with a maximum difference of 4 times, especially for the larger-scale datasets of VGoogle, VArcGIS and VBing.
Overall, the above comprehensive comparisons further illustrate that the MobileNets achieves better retrieval performance than other deep learning models while being smaller training time.
Exploiting low dimensional features from the fine-tuning MobileNets
To exploit low dimensional representations from the fine-tuning MobileNets, we conduct several experiments with different dimensions. Table 4 shows the results of different dimensions of the fine-tuning MobileNets. It can be seen that the best low dimensions of the fine-tuning MobileNets are 32. Specifically, the maximum improvement of the mAP value is 11.56% compared with the mAP of the original MobileNets. Besides, the result of 16, 64 and 128 dimensions are very close to the results of 32 dimensions.
To prove that the precision of the top retrieval results was not sacrificed in the fine-tuning MobileNets, we take VGoogle dataset for example and give its different dimensions’ results of precisions at top 5,10,20,50,100 and 1000 in Table 5. We can see that 32 dimensions of the fine-tuning MobileNets also achieve the best performance at top 5,10,20,50,100 and 1000 results, while it only takes around 2 min longer than the original MobileNets (as shown in Fig. 3).

Training time of different dimensions of the fine-tuning MobileNets on VGoogle dataset
Besides, we also adopt the PCA method to compress the high dimensional features from the original MobileNets into 32 dimensions for comparisons. Table 6 shows the results of 32 dimensions of the fine-tuning MobileNets and PCA-based method. It can be seen that the fine-tuning MobileNets offers a slightly better performance than PCA-based method and the maximum improvement of the mAP value is 9.8%.
Conclusions
In this paper, we examine the retrieval performance of the MobileNets model and fine-tune it by changing the dimensions of the final fully connected layer to learn low dimensional representations for CBRSIR. Experimental results indicate that the MobileNets outperforms other commonly used CNN models in term of retrieval accuracy and training speed. It also can be concluded that 32-dimensional features of the fine-tuning MobileNets achieves better retrieval performance compared with the original MobileNets and PCA compression method. Our future work will concentrate on exploiting low dimensional features from other MobileNets models and exploring their applications in multilabel remote sensing image retrieval.
References
Almeida M, Laskaridis S, Leontiadis I, Venieris SI, Lane ND (2019) EmBench: quantifying performance variations of deep neural networks across modern commodity devices. In: the 3rd international workshop on deep learning for Mobile systems and applications. Association for Computing Machinery, New York, pp 1–6. https://doi.org/10.1145/3325413.3329793
Bapu JJ, Florinabel DJ (2020) Automatic annotation of satellite images with multi class support vector machine. Earth Sci Inf. https://doi.org/10.1007/s12145-020-00471-8
Cao R, Zhang Q, Zhu J, Li Q, Li Q, Liu B, Qiu G (2020) Enhancing remote sensing image retrieval using a triplet deep metric learning network. Int J Remote Sens 41(2):740–751. https://doi.org/10.1080/2150704x.2019.1647368
Cheng G, Han J, Lu X (2017) Remote sensing image scene classification: benchmark and state of the art. Proc IEEE 105(10):1865–1883. https://doi.org/10.1109/jproc.2017.2675998
Du Z, Li X, Lu X (2016) Local structure learning in high resolution remote sensing image retrieval. Neurocomputing 207:813–822. https://doi.org/10.1016/j.neucom.2016.05.061
Ge Y, Jiang S, Xu Q, Jiang C, Ye F (2017) Exploiting representations from pre-trained convolutional neural networks for high-resolution remote sensing image retrieval. Multimed Tools Appl 77(13):17489–17515. https://doi.org/10.1007/s11042-017-5314-5
Ge Y, Tang Y, Jiang S, Leng L, Xu S, Ye F (2018) Region-based cascade pooling of convolutional features for HRRS image retrieval. Remote Sens Lett 9(10):1002–1010. https://doi.org/10.1080/2150704X.2018.1504334
Hinton GE, Salakhutdinov RR (2006) Reducing the dimensionality of data with neural networks. Science 313:504–507. https://doi.org/10.1126/science.1127647
Hou D, Miao Z, Xing H, Wu H (2019) V-RSIR: an open access web-based image annotation tool for remote sensing image retrieval. IEEE Access 7:83852–83862. https://doi.org/10.1109/access.2019.2924933
Howard AG et al. (2017) Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:170404861
Li P, Ren P (2017) Partial randomness hashing for large-scale remote sensing image retrieval. IEEE Geosci Remote Sens Lett 14(3):464–468. https://doi.org/10.1109/lgrs.2017.2651056
Napoletano P (2018) Visual descriptors for content-based retrieval of remote-sensing images. Int J Remote Sens 39(5):1343–1376. https://doi.org/10.1080/01431161.2017.1399472
Qi H, Liu W, Liu L (2017) An efficient deep learning hashing neural network for mobile visual search. In: 2017 IEEE global conference on signal and information processing (GlobalSIP), IEEE, Montreal, pp 701–704. https://doi.org/10.1109/GlobalSIP.2017.8309050
Shao Z, Yang K, Zhou W (2018) Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset. Remote Sens 10(6):964. https://doi.org/10.3390/rs10060964
Shao Z, Zhou W, Deng X, Zhang M, Cheng Q (2020) Multilabel remote sensing image retrieval based on fully convolutional network. IEEE J Sel Top Appl Earth Obs Remote Sens 13:318–328. https://doi.org/10.1109/JSTARS.2019.2961634
Sudha S, Aji S (2019) A review on recent advances in remote sensing image retrieval techniques. J Indian Soc Remote Sens 47:2129–2139. https://doi.org/10.1007/s12524-019-01049-8
Tong XY, Xia GS, Hu F, Zhong Y, Datcu M, Zhang L (2019) Exploiting deep features for remote sensing image retrieval: a systematic investigation. IEEE Trans Big Data. https://doi.org/10.1109/TBDATA.2019.2948924
Wang Y, Ji S, Lu M, Zhang Y (2020) Attention boosted bilinear pooling for remote sensing image retrieval. Int J Remote Sens 41(7):2704–2724. https://doi.org/10.1080/01431161.2019.1697010
Xia G et al (2017) AID: a benchmark data set for performance evaluation of aerial scene classification. IEEE Trans Geosci Remote Sens 55(7):3965–3981. https://doi.org/10.1109/tgrs.2017.2685945
Xiao Z, Long Y, Li D, Wei C, Tang G, Liu J (2017) High-resolution remote sensing image retrieval based on CNNs from a dimensional perspective. Remote Sens 9(7):725. https://doi.org/10.3390/rs9070725
Zhou W, Shao Z, Diao C, Cheng Q (2015) High-resolution remote-sensing imagery retrieval using sparse features by auto-encoder. Remote Sens Lett 6(10):775–783. https://doi.org/10.1080/2150704X.2015.1074756
Zhou W, Newsam S, Li C, Shao Z (2017) Learning low dimensional convolutional neural networks for high-resolution remote sensing image retrieval. Remote Sens 9(5):489. https://doi.org/10.3390/rs9050489
Zhou W, Newsam S, Li C, Shao Z (2018) PatternNet: a benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J Photogramm Remote Sens 145:197–209. https://doi.org/10.1016/j.isprsjprs.2018.01.004
Acknowledgments
The authors would like to thank the PatternNet, NWPU and AID datasets for their open access. The authors also would like to thank the editors and the anonymous reviewers for their constructive comments and suggestions.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 41,701,443 and Grant 41,801,308, and in part by the National Key Research and Development Program of China under Grant 2018YFB0505002.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
No potential conflict of interest was reported by the authors.
Additional information
Communicated by: H. Babaie
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Communicated by: H. Babaie
Rights and permissions
About this article

Cite this article
Hou, D., Miao, Z., Xing, H. et al. Exploiting low dimensional features from the MobileNets for remote sensing image retrieval. Earth Sci Inform 13, 1437–1443 (2020). https://doi.org/10.1007/s12145-020-00484-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-020-00484-3