
Abstract
The southern peninsular India is characterized by unique climatology with rainfall processes throughout the year from land–ocean contrasts. In addition, the complex terrain induces localized effects causing huge spatial and temporal variability in the observed precipitation. This study aims at evaluating the sensitivity of the high-resolution Weather Research and Forecasting (WRF) model (4 km) to multi-physics parameterizations, 3D variational data assimilation, and domain configuration, in the study domain covering southern peninsular India. Furthermore, the study focusses on the formulation of an ensemble method to improve the simulation of precipitation across seasons. A total of 120 experiments were set up across four crucial rainfall events, of varying spatial extent and duration, dominated by different rainfall generation mechanisms. The assessment of the experiments shows that the model’s cumulus and microphysics schemes have the highest impact on the location, intensity, and spread of the simulated 4-day long Quantitative Precipitation Forecasts (QPFs). Applying cumulus schemes at all domains represented the variability in the QPFs, across space and time, for the precipitation events dominated by convective activity. The cases without cumulus schemes at the convective scale domain (4 km), captured the higher intensity rains during organized cyclonic circulations in the north-east monsoon period. Hence, a 10-member multi-physics ensemble approach including members with and without cumulus parameterization at the fine resolution domain was adopted. The preliminary results demonstrate that the mean from the suggested ensemble approach (n-MPP) performed well in capturing the dynamics of QPFs across the rainfall events, as opposed to a single-member deterministic simulation and mean from larger member conventional multi-physics ensemble approach (c-MPP) without cumulus parameterization at the convective scale. The rank histogram, delta semi-variance plots, and outlier statistics at various lead times clearly showed that the suggested n-MPP was able to capture the high-intensity rainfall, increasing the spread of precipitation forecasts and consequently reducing the occurrence of outliers.
Highlights
-
Evaluated the sensitivity of a high-resolution Numerical Weather Prediction (NWP) model (4 km) with 120 experiments in generating short-term (4-day long) quantitative precipitation forecasts (QPFs).
-
The cumulus and microphysics schemes have the highest impact on the location, intensity, and spread of the simulated rainfall across events dominated by different rainfall generation mechanisms.
-
A 10-member multi-physics ensemble approach including members with and without cumulus parameterization at the fine resolution domain was able to capture the high-intensity rainfall, increasing the spread of precipitation forecasts and consequently reducing the occurrence of outliers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Impact studies in the field of agriculture and hydrology demand short-to-medium range weather forecasts at finer scales to address the spatiotemporal variabilities and associated risks in decision making. Particularly, reliable quantitative precipitation forecasts (QPFs) at fine scales are very critical for assessments of vulnerability, impact, and adaptation (VIA). However, the forecasting of precipitable structures at weather prediction time scales by the Numerical Weather Prediction (NWP) models is highly challenging and an active area of research. Global NWPs, commonly termed as Global Circulation Models (GCMs) have been providing near-to-future atmospheric circulations (10–15 days lead-time) by solving mathematical equations representing the dynamics and thermodynamics of the atmosphere. However, at coarser resolutions (~25–100 km), the mesoscale patterns induced by complex topographical interactions, coastlines, and convective processes have not been adequately resolved in the GCMs. With the nested domains, grid sizes that represent the local variability and the multiple sophisticated parameterization options to characterize the physical processes, the limited area models (LAMs) can add regional/local scale details and downscale the GCMs (extensively to spatial resolutions ranging between 1 and 50 km) (Feser et al. 2011). Due to the computational constraints, LAMs were commonly configured at parameterized convection scales (PCS) typically of resolution >10 km. The physical processes that are not explicitly resolved by the model grid need to be parameterized. The inherent assumptions in the formulations of the sub-grid cumulus parameterization were found to be the major source of uncertainty in the model output (Brockhaus et al. 2008). Consequently, the severe events like high-intensity rains, the diurnal cycles in convective events, and the terrain-induced local circulations are still under-represented by the LAMs at parameterized convection scales (PCS) (Clark et al. 2016).
Numerical weather models that explicitly resolve the convective processes with finer grid sizes (≤4 km, termed as Convective Permitting Scales (CPS)) have been showing promising performance in simulation of precipitation for rapidly developing systems extending from short to medium time scale (Clark et al. 2016). Predominantly, regions characterized by complex terrains, land-ocean contrasts, and extreme precipitation events from organized deep convective systems were well represented by convective scale models (Weisman et al. 1997; Mahoney 2016; Wagner et al. 2018; Woodhams et al. 2018). However, the exacerbation of the input and model-based uncertainties at finer spatial resolutions was found to be rapid and the value added by modelling at CPS was found to be strongly influenced by the region, time of the study, forecast time scale, spatial resolution, and the evaluation metrics (Prein et al. 2015). Some studies revealed no value addition or even deteriorated skill of the weather prediction model at CPS when compared to PCS (Johnson et al. 2013; Romine et al. 2013). In addition, few studies (Han and Hong 2018; On et al. 2018) have concluded that the requirement of convective parameterization at CPS is not very definite, as the validity of the inherent assumptions in the resolutions 3–5 km is uncertain. Despite the potential of numerical weather forecast model at CPS to predict extreme precipitation events (mainly convective in nature), the reliability of the CPS in seamless simulation of QPFs at weather prediction time scales is unclear. Further research is required to evaluate uncertainties in a systematic way through experiments and appropriate model verification techniques (Prein et al. 2017).
The prediction of precipitation is highly challenging and often huge risk is associated with wrong forecasts. Ensemble Prediction System (EPS) had been helpful to understand and quantify the uncertainty associated with the QPFs at weather prediction time scale. EPS at the convective scales, formulated by different methods including perturbation of initial conditions, lateral boundary conditions, and physics parameterizations has been suggested by researchers to better represent the input and model-based uncertainties (Tapiador et al. 2012; Romine et al. 2014; Zhu and Xue 2016; Tian et al. 2017). Some operational agencies are issuing medium-range weather forecasts (10 days lead time) from ensemble system set-up at convective scales (Schwartz et al. 2015; Hagelin et al. 2017; Frogner et al. 2019). However, the full potential is yet to be quantified as the ensemble at CPS was found to be biased and under-dispersive, showing limited predictability for the extreme precipitation events (Romine et al. 2014). Recent studies have addressed methods to increase the spread of LAM at CPS by improving forecast error growth and effective post-processing techniques in view of formulating cost-effective EPS at the convective scales (Clark et al. 2011; Tapiador et al. 2012; Romine et al. 2014; Schwartz et al. 2017).
Southern peninsular India has varied climatic conditions and is vulnerable to high impact rainfall events due to the complex terrain interactions and land–ocean contrasts. The objective of this study is to address various aspects of model and input-based sensitivities of the Weather Research and Forecasting (WRF) model in simulating 4-day long QPFs within the climatology of the southern peninsular India and formulate an ensemble method to improve the simulation of precipitation across seasons. A total of 120 experiments are designed to understand and quantify the sensitivity of CPS model to the physics parameterizations, 3D-variational (3DVAR) data assimilation techniques, and domain configuration, across four crucial rainfall events, dominated by different rainfall generation mechanisms. Grid-based statistics, spatial statistics, and object-based statistics are used to quantify the performance of the model simulations against the Global Precipitation Measurement (GPM) Integrated Multi-satellitE Retrievals for GPM (IMERG) data. The results from the extensive sensitivity study are used in designing a unique ensemble approach that improves reliability on the QPFs during different rainfall generation mechanisms. In addition, a preliminary investigation quantifies the performance of the suggested 10 member multi-physics ensemble approach in capturing the dynamics of QPFs as opposed to a single-member deterministic simulation and a larger member conventional multi-physics ensemble approach. The study is an early attempt to assess the performance of a distinctive multi-physics EPS at high-resolution convective scales over southern peninsular India. Furthermore, the study rigorously quantifies the performance of the WRF model in simulating QPFs across rainfall events of varying spatial extent and duration with a view to increase the practical usage in the application domains like agriculture and hydrology, primarily for water resources management.
Section 2 elucidates the model configuration, design of sensitivity experiments and ensemble approach, characteristics of the study area, and the selected events. Section 3 elaborates the verification strategy, while section 4 highlights the results and discussion thereof detailing the spatiotemporal pattern of the simulated QPFs, cluster-wise analysis, and an exploratory investigation on the performance of ensemble prediction system. Section 5 compiles the summary and critical conclusions from the study.
2 Methodology
2.1 Model configuration
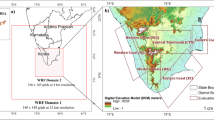
The Weather Research and Forecasting (WRF) model version 4.0 used in the study is a fully compressible, non-hydrostatic, and terrain-following model (Skamarock et al. 2019), extensively tested across the tropics (Das et al. 2008; Raju et al. 2014; Zhu and Xue 2016). The WRF is run in forecast mode with initial and boundary conditions from the Global Forecast System (GFS) (National Centers for Environmental Prediction/National Weather Service/NOAA/U.S. Department of Commerce 2015) at 0.25 degree resolution (40 vertical levels), lateral boundary conditions forced at every 3-hr. The model initial configuration (referred to as control run – CNT, alternatively as C0 for ease of usage) is set up at 1:3:3 downscaling ratio with three domains and two-nesting steps. The outermost domain (domain 1; termed as D1) has a resolution of 36 km (100 × 100 grid points), the nested domain (domain 2; termed as D2) is at 12 km resolution (148 × 148 grid points) and the innermost domain (domain 3; termed as D3) has a resolution of 4 km (166 × 169 grid points) (figure 1). Dynamic time integration is used with two-way feedback between the domains at every integration. A 6-hr spin-up time is given and the model top is set at 50 hPa with 32 vertical levels. The physics schemes used in the CNT run are listed in table 1 and are selected similar to the configuration used in Kumar et al. (2015).

Spatial map showing the WRF domains; domain 1 (D1) implemented at 36 km resolution, domain 2 (D2) at 12 km resolution and domain 3 (D3) at 4 km resolution. The inset map shows the detailed view of D3, the evaluation domain.
2.2 Design of sensitivity experiments
Based on the conclusions from earlier studies at CPS (Sikder and Hossain 2016; Zhu and Xue 2016; Prein et al. 2017; Jeworrek et al. 2019), some critical options are selected to test the vulnerability of the WRF model while generating quantitative precipitation forecasts (QPFs). A total of 120 experiments (30 experiments × 4 events) are designed, with each trial, run for a time-length of 102 forecast hours (table 1). The study uses the concept of Morris one-at-a-time (MOAT) sensitivity analysis to isolate the impact caused by a particular choice in the simulated QPFs (Di et al. 2015). Thus, one option-at-a-time is altered in the CNT set-up to generate the cases. Table 1 contains the description for each of the 30 sensitivity experiments.
Figure 2 shows the detailed classification of the clusters and the sub-clusters into which the experiments are grouped. The experiments are enlisted under four major clusters, viz., cluster-based on physics options (cases C1–C19, referred to as Physics cluster – PHY in the manuscript), domain configuration (cases C20–C25, referred to as Domain – DOM cluster), data assimilation (cases C26–C29, referred to as Data Assimilation cluster – DA cluster) and lateral boundary condition (case C30, referred to as Lateral Boundary Condition cluster – LBC cluster). The sub-clusters within the PHY cluster include the microphysics cluster (cases C1–C7, referred to as MPY), cumulus schemes based cluster (cases C8–C18, referred to as CUM), and cluster with an alternative planetary boundary layer scheme (case C19, referred to as PBL). Overall, eight different microphysics schemes and two planetary boundary layer schemes are evaluated. In addition, the impact of the four major cumulus parametrization schemes and three major trigger mechanisms in the Kain–Fritsch (KF) scheme are also elaborated. Previous studies (Lee et al. 2011; Mahoney 2016) have suggested the usage of cumulus parameterization at CPS, to characterize the rainfall structures realistically. Thus, the CUM cluster comprises CUM-D3 (cumulus scheme in D3) cases with cumulus schemes implemented in all the three domains (cases C8, C9, C11, C13, C15, and C17) and the widely recommended No-CUM (no cumulus scheme in D3) type cases (cases C0, C10, C12, C14, C16, and C18), where no cumulus scheme is applied in the high-resolution domain D3. The DOM cluster comprises DOM1 (no-nesting) and DOM2 (one-nesting step) sub-clusters. DOM1 cases address the effect of a single domain (cases C20–C22) and DOM2 sub-cluster includes the nested two domain-based model set-up (cases C23–C24). DOM cluster also includes case C25 with the same domain configurations as that of CNT, but with no-feedback mechanism between the domains. DA cluster comprises cases C26–C29. The 3DVAR data assimilation (3DVAR-DA) technique (Barker et al. 2004) is used in the DA cluster and the assimilated data were obtained from the globally collected upper-air and surface observations provided by the National Centers for Environmental Prediction (NCEP) (National Centers for Environmental Prediction/National Weather Service/NOAA/U.S. Department of Commerce 2008), satellite radiance data from AMSU-A, HIRS4 and MHS instruments in METOP and NOAA satellites (National Centers for Environmental Prediction/National Weather Service/NOAA/U.S. Department of Commerce 2009). Case C30 (termed as LBC) is driven by initial and lateral boundary conditions from the Fifth generation of ECMWF atmospheric reanalyzes of the global climate (ERA5) data (31 km resolution) (Copernicus Climate Change Service (C3S): ERA5 2017), the physics and domain configurations are similar to that of the CNT run. This case serves to address the model performance when quality of the input data is not limited (as reanalyzes data include real-time observations from global networks). However, the case is hypothetical, since such improved initial and lateral boundary data will not be available in real-time at the start of the model run in forecast mode (which is mainly addressed in the study).

Schematic diagram showing the classification of the sensitivity cases. The PHY and DOM clusters address the model uncertainity; while the DA and LBC clusters address the input uncertainity.
2.3 Design of ensemble prediction approaches
The ensemble approaches are investigated in the study to address the uncertainties exacerbated due to the finer grid sizes across the different rainfall events. Previous studies and the results from the sensitivity experiments conducted during this study are used to design the ensemble approaches which is elaborated in section 4.4.
2.4 Study area
The innermost high-resolution domain D3 is the evaluation domain (domain 3 in figure 1) and is designed to cover southern parts of peninsular India (figure 1). The southern edge of the Western Ghats has peaks reaching an elevation of about 2600 m above the mean sea level. Thus, the ranges clearly demarcate the area into windward (Kerala) and leeward (Tamil Nadu) regions. The region of interest receives rainfall throughout the year and intense showers occur during both the major monsoon seasons of India, the South-West Monsoon Season (SWMS) (June–September) and the North-East Monsoon Season (NEMS) (retreating monsoon) (October–December). The effect of NEMS is predominantly high across the whole region of interest, with very high rainfall in the eastern parts of the domain (the whole of Tamil Nadu). SWMS rainfall is consistently high in the western parts of D3 (the whole of Kerala and western parts of Tamil Nadu). Pre-monsoon rains (PM) which happen largely due to the convective activities before the onset of the SWMS also contribute to some intense showers in the region. With its complex terrain characteristics, varied climatic conditions, vulnerable coastlines, and mixed land-use types, this part of India serves as a practical and critical test-bed for high-resolution regional climate model simulations.
2.5 Synoptic view of the selected events
After an explorative study on the rainfall occurrences in the study region, four recent events of varying spatial extent and duration, dominated by different rainfall generation mechanisms have been selected for the study. Two events from NEMS, one event from SWMS, and one event from the PM period are chosen for the study. The rainfall characteristics of the event and the model simulation time period are listed in table 2.
2.5.1 Ochki event (OCH)
Ochki was a Very Severe Cyclonic Storm (VSCS) (force winds at speed 118–166 km/hr according to India Meteorological Department (IMD) definition) system that developed as the ninth depression during the NEM season (NEMS) in 2017. The storm initially formed as a low-pressure zone due to convergence of low-level circulations on 28th November 2017 in the southwest of Bay of Bengal (BOB), moved towards the landmass of South India, and dissipated in the Arabian Sea. The cyclone gained strength from the high moisture availability and warmer sea surface temperature between Kanyakumari and Sri Lanka. The main activity in the landmass occurred in the south of Tamil Nadu and Kerala during 30th November 2017 and 1st December 2017, causing extremely heavy rainfall (≥204.5 mm/day as per IMD definition).
2.5.2 Gaja event (GAJ)
Gaja was also a VSCS system formed during the NEMS during 2018. Developed as low pressure over the Gulf of Thailand during 8th November 2018, the cyclone made its landfall in Tamil Nadu, between Nagapattinam and Vedaranyam, with wind speeds in the range of 130–145 kmph on 16th November 2018. The major rainfall activity causing heavy rains (65–115 mm/day as per IMD definition) over the landmass of Tamil Nadu and Kerala from 16th November 2018 till 19th November 2019. Besides the Gaja event, another well-marked low pressure (WML) formed over the BOB region on 18th November 2018 and moved across Tamil Nadu and Kerala causing considerable rainfall activity until 24th November 2018.
2.5.3 South-west monsoon event (SWM)
The onset of the SWMS for the year 2018 was declared on 29th May 2018 over Kerala and further advanced to other parts of the country. With a backdrop of stationary monsoon trough during August 2018, low-pressure zones over the BOB region and off-shore trough along different parts of the west coast caused widespread rains across various parts of India. Massive rainfall events occurred during August 2018 causing a 164% departure from normal for the state of Kerala and thus resulted in severe floods. The extreme precipitation event during 14–16th August, 2018 (≥12 cm/day) has been considered for this study.
2.5.4 Pre-monsoon event (SUM)
A line of wind discontinuity prevailed due to the low-pressure zones on the landmass and high-pressure zones in the BOB region and Arabian ocean and favourable mesoscale conditions and local convective activities led to the development of dense cumulus clouds, causing isolated rainfall events with intensities of the order of 10 mm/day during 13–16 April, 2018.
3 Verification of WRF model forecasts
3.1 Evaluation data
Global precipitation measurement (GPM)-IMERG (Huffman et al. 2015) ‘final run’ precipitation product (0.1° resolution data available every 30 min), produced by merging satellite and gauge data, is used in the study to validate the simulated precipitation. For evaluation purposes, the simulated rainfall at 4 km is resampled using nearest neighbour method (~10 km), to match the resolution of GPM-IMERG data. ERA5 reanalysis based upper air and surface fields (12 hourly data at 31 km resolution) are used to understand the deviations in precipitation simulations by analyzing the driving variables, viz., temperature, U-V wind component and derived variables, viz., relative humidity, cloud cover, Convective Available Potential Energy (CAPE) and boundary layer height (BLH).
3.2 Evaluation metrics
Conventional grid-based metrics, including continuous, viz., Root Mean Squared Error (RMSE), Bias, Pearson’s correlation coefficient (r) (as detailed in Evans et al. 2011) and categorical, viz., Probability of Detection (POD), Critical Success Index (CSI), False Alarm Ratio (FAR), Frequency Bias Index (FBI) and Heidke Skill Score (HSS) (as mentioned in Tian et al. 2017) are calculated across the spatial and temporal dimensions to quantify the performance of the WRF simulations. However, the grid-based metrics are well-known for the double penalty problem, where the model is penalized twice for a slight shift in the simulated QPFs across the spatial and temporal dimensions. Particularly, when dealing with numerical weather prediction models at CPS, grid-based statistics are not effective in quantifying the model’s performance (Wernli et al. 2008). Thus, some studies (as for example, Evans et al. 2011) have used Fractional Skill Score (FSS) (originally suggested by Roberts and Lean 2008) to compare the simulated precipitation and the observed precipitation across a spatial neighbourhood (refer appendix 1 for detailed description). The size of the neighbourhood and the precipitation threshold are selected based on the spatial evenness of the event. In this study, a neighbourhood size of 5 × 5 pixels (50 km × 50 km coverage area) and four different threshold levels, viz., 1 mm/3 hr, 2.5 mm/3 hr, 5 mm/3 hr, and 10 mm/3 hr rainfall rates are used to derive the FSS.
Another feature-based evaluation metric – S–A–L (structure–amplitude–location) is also considered in the study (as suggested by Wernli et al. 2008). Rainfall objects are identified within the analysis domain, the structure and the location of individual objects are evaluated in the S–A–L methodology. The amplitude (A) values ranging from –2 to 2 are analogous to bias metrics (grid-based metrics), but normalized across the domain under investigation. Positive amplitude values denote over-estimation, and negative values represent under-estimation of the simulated rainfall. The location (L) values range from 0 to 2, with higher values indicating considerable shift (in any direction) in the simulated event from the actual location of the event. The structure (S) values have a range of –2 to 2, with negative values signifying that the event is simulated as a small spread and peaked event. Positive values, on the other hand, represent a much broader or flat event simulated by the model when compared to the actual event. In all the S–A–L metrics, zero denotes a perfect match in the properties of the simulated and actual structure of the rain object (refer appendix 1 for detailed description).
The methods such as delta semi-variance (Marzban et al. 2009; Tapiador et al. 2012), rank histogram (Revelli et al. 2010), and outlier statistics (Buizza and Palmer 1998) are used to assess the performance of the ensemble approaches.
4 Results and discussion
4.1 Temporal pattern analysis
Figures 3–6 indicate the domain-averaged (land pixels only) temporal plots of rain rates across the four events. During the OCH event, the rainfall peak at 15 IST 30th November 2017 is predicted slightly early and the peak at 03 IST 1st December 2017 is highly underestimated across all the cases (figure 3). The CNT simulation, along with majority of the other cases, predicts an early initiation of the major cyclonic activity over the land. The timing and rainfall intensity of the peak event are well represented by most of the cases in the MPY cluster (figure 3a). The C11 from the CUM cluster is able to capture the precipitation dynamics better than the other cases with a reduced overall mean bias of –3.4 mm/3 hr (refer table 3). Cases C15, C20, and C22 simulate the OCH as a delayed event with dry bias, while case C10 predicts an early low-intensity cyclone (figure 3d). The larger deviations post 30th November 2017 (3rd-day forecast) indicate that the variability between the cases increases with the lead time.

Domain-averaged (land pixels only) temporal plots of rain rates for OCH event. The plots (a–c) show the temporal evolution of the event as captured in GPM (blue line) vs. various WRF simulation clusters. (a) PHY cluster, (b) cases from DA cluster and LBC cluster, and (c) DOM cluster. Plot (d) shows the bias plot (in mm/3 hr) across the time for each case. x-axis denotes the time of simulation as dd (date) hh (hour) in Indian Standard Time (IST) (local time); the yyyy (year) of simulation is 2017.
The 15 hrs duration of the major rainfall episode during the initial period of the GAJA event starting from 09 IST 16th November 2018 and extending till 00 IST 17th November 2018 (caused by the landfall of the cyclone Gaja) is well represented by the simulations (figure 4d). However, the rainfall intensity during the episode is highly underestimated across the cases (figure 4d). The formation of WML (12 IST 18th November 2018–03 IST 20th November 2018, termed as 2nd episode within the GAJ event) is well predicted by most of the cases. The WML was an upper-level circulation system with strong wind shear, and mainly a rain-bearing structure. The system triggered considerable convective activities as it evolved, and thus the cases within the CUM cluster induce the highest variability in the simulated rainfall (figure 4a). The cases in the DOM cluster simulate substantial wet bias during the WML event (figure 4c). Overall, case C17 of the CUM cluster gives the best performance for the GAJ event (table 3).

Same as figure 3, but for GAJ event; the yyyy (year) of simulation is 2018.
Figure 5 shows that the SWM event is not well captured by most of the WRF simulations. With close examination on the relative humidity profiles (not shown here for brevity), the substantial failure in simulating the peak event by most of the cases is due to an error induced by the cumulus scheme in the D1 and D2. The CNT set-up uses the KF scheme, which stabilizes the atmosphere by removing CAPE when the convective adjustment time is exceeded (time-scale closure method) (Kain 2004). In this study, the KF scheme in the outer domains (D1 and D2) have removed CAPE unrealistically during the SWM event and led to drier boundary conditions for the innermost domain (D3). Few simulations in the CUM (figure 5a) and DOM (figure 5c) clusters picked up the rainfall signals. Particularly, figure 5(d) highlights cases C13, C14, C15, C16, C17 and C18 which are non-KF schemes that give better estimates of the temporal distribution of rainfall. Case C22 slightly overestimates the rain rates at the beginning of the event and significant under-prediction is noticed during the peak event (figure 5d). The other cases in the DOM cluster (figure 5d), like C20, C21, C23, and C24 also capture the rainfall signals, but highly underestimate the intensity due to the implementation of the KF scheme in any one of the domains.

Same as figure 3, but for SWM event; the yyyy (year) of simulation is 2018.
The diurnal rainfall pattern, a characteristic of pre-monsoon rainfall during the SUM event is captured by most of the WRF simulations as shown in figure 6. Evidently, the CUM (figure 6a) and DOM (figure 6c) clusters cause the highest deviations from the CNT run. Figure 6(a) illustrates that the CUM-D3 from the CUM cluster clearly overestimate the events mainly during the peaks at 15 IST 14th April 2018 and 15 IST 15th April 2018. However, cases C11 and C17 still perform better in capturing the timing across the events (figure 6d), with overall mean bias of –0.24 mm/3 hr and –1.15 mm/3 hr, respectively (table 3).

Same as figure 3, but for SUM event; the yyyy (year) of simulation is 2018.
4.2 Analysis of spatial distribution
The spatial behaviour of the simulations can be better studied with the spatial metrics, viz., amplitude (figure 7b), structure (figure 7c), location (figure 7d), and FSS (figure 8). Figure 7(b) shows that the amplitude values display a widespread underprediction of the simulated rainfall across the events for most of the cases. Highest deviation in the predicted rainfall amount (amplitude value of –0.74) is noticed for the SWM case. Cases C13, C14, and C15 generate the forecasts with lowest amplitude bias. Object-based analysis of the WRF simulations shows that most of the cases predict small-spread and peaked occurrences (structure < 0) for the events GAJ, SWM and SUM (figure 7c). The highest peakedness is observed while simulating the SWM event. Cases C8, C9, C11, and C17 from the CUM-D3 cluster and cases C20, C21, C22, C23, and C24 from the DOM clusters show reduced structural bias across events. The highest bias in the structural component is noticed widely across the cases in the MPY and No-CUM clusters for the GAJ, SWM, and SUM events. The CUM and MPY clusters cause significant deviations in representing the location of the event as shown in figure 7(d). The DOM cluster also displays a considerable impact on the location of the maximum rainfall. The OCH and SWM events record the highest dispersion between the cases in capturing the spatial location of the precipitation occurrences. Overall from the S–A–L analysis, the cases record a high spatial skill for the OCH event and exhibit low spatial skill scores, while simulating the SWM event. Cases from CUM cluster and DOM cluster outperform the other cases in capturing the spatial variability. FSS plot (figure 8) shows the performance of the experiments across various thresholds. The event SUM does not have any pixels with mean rain rate in the threshold 10 mm/3 hr and thus these are not shown in figure 8(d). At large, the FSS score is higher for smaller rain-rate thresholds (1 mm/3 hr and 2.5 mm/3 hr) (figure 8a–b). However, during the OCH event, the cases display higher FSS across all the rainfall thresholds. Cases C11, C13, C15, C16, C17, C21, and C24 from CUM and DOM clusters give consistent FSS scores across the events and for various rain-rate thresholds.

Error statistics plots of predicted rainfall across the cases and events (a) bias (mm/3 hr), (b) amplitude, (c) structure, and (d) location.

FSS with 50 km radius of influence for the predicted rainfall. The plots denote different thresholds that are used to generate the FSS. (a) threshold: > 1 mm per 3 hr, (b) threshold: > 2.5 mm per 3 hr, (c) threshold: > 5 mm per 3 hr, and (d) threshold: > 10 mm per 3 hr.
4.3 Discussion on the model sensitivity across different clusters
From the spatial and temporal analysis, it is evident that the model is highly sensitive to certain clusters, while some experiments do not create considerable impact on the simulated QPFs. In addition, the sensitivity of the model tends to follow a pattern across the events considered in the study. Thus, detailed investigation on the behaviour of the model through the clusters and the events is done in this section.
4.3.1 Physics parameterizations (PHY)
Figure 9 gives the inter-quantile box plots of the rainfall intensities which clearly demonstrate that the highest sensitivity of the simulated rain intensities is caused by the PHY cluster. The variability amongst the sub-clusters, viz., MPY, CUM, and PBL are more during the SWM and SUM events. The cases with different cumulus schemes (CUM cluster) outperform the other physics-based clusters in capturing the rainfall variability for all the events (similar to results from Chandrasekar and Balaji 2012). In addition, the FSS plots (figure 8) clearly demonstrate that the cases from CUM cluster outperform the MPY and PBL clusters in capturing the rainfall of all intensity ranges across the rainfall events. Within the CUM cluster, cases with KF schemes, particularly KF2 scheme (cases C11 and C12) perform well in capturing the spatial (figures 7 and 8) and temporal (figures 3–6) dynamics of the precipitation across most of the events. KF2 accurately simulates the initiation time and location of the night-time peak rainfall occurrence during the OCH event as shown in figure 3(d) when compared to other cumulus schemes. The KF2 scheme explicitly uses an RH-based trigger and thus, enhances the performance of the KF scheme in high relative humidity environments with strong synoptic forcing (such as the OCH event). However, the afternoon rainfall during the GAJ (figure 4d) and SUM (figure 6d) events are triggered ~3–9 hrs before the occurrence of the actual event, by the KF and KF2 cases. The instantaneous response of the KF schemes to the convective instability by producing low-level disturbances leads to an early shift in the timing of the weakly forced synoptic events (2nd episode during the GAJ event and whole of the SUM event) (as reported by Choi et al. 2015). Interestingly, the KF1 variant (cases C9 and C10) reduces the aforesaid early prediction bias, as illustrated in figures 4(d) and 6(d). The moist advection based trigger used in KF1 realistically simulates the latent heat flux in weakly forced environments with high relative humidity (similar to results presented in Ma and Tan 2009). During the SWM event, all the KF scheme variants significantly underestimate the precipitation when compared to the other cumulus schemes. However, overall analysis shows that the KF scheme performs well in capturing all types of rainfall intensities across the events except SWM, when compared to other cumulus schemes (figures 8 and 9). The GF scheme (cases C13 and C14) simulates a northward shift in the Ochki (OCH) cyclone with early initiation of the rainfall activity, ~12 hrs before the event commenced in the GPM-IMERG derived data (figure 3d). Interestingly, the dissipation time of the cyclone in model forecast is similar to that captured by GPM-IMERG dataset, thus simulating a long sustained circulation with low-intensity rainfall. The GF scheme is a scale-aware, multi-closure, multi-parameter, ensemble scheme with each ensemble member having a different trigger function (Grell and Freitas 2014). Thus, early initiation and long duration could be the result of difference in the characteristics of the individual members in capturing precipitation. The other events are also simulated reasonably well and the GF scheme records a higher skill in capturing the rainfall during the SWM event (figure 5d). The GF scheme exhibits dry bias in simulating the weakly forced events especially in cold and moist environments (2nd, 3rd episode during the GAJ event and 4th episode during the SUM event). The BMJ scheme (cases C15 and C16) performs satisfactorily in capturing the temporal pattern of precipitation across events (figures 3d–6d). The early initiation errors in simulating the 2nd episode during the GAJ event (figure 4d) and whole of the SUM event (figure 6d) are reduced with the BMJ cases. The BMJ scheme is triggered by cloud depth and is mostly insensitive to the presence of CAPE (Janjic 1994). Thus, the scheme controls spurious development of grid-scale precipitation in conditionally unstable atmospheric conditions and reduces the temporal shift in the simulation of the events. In addition, the scheme performs better in capturing the spatial distribution of the total accumulated rainfall (as reported by Ardie et al. 2012). The location of peak rainfall occurrences is accurately reproduced by the BMJ scheme and the locational bias is highly reduced across the events (figure 7d). However, the temporal evolution of the organized cyclonic events, viz., OCH and GAJ is not well represented by the BMJ scheme. Previous studies have also shown that the performance of the BMJ scheme is below par, while simulating the north-east monsoon cyclones (Srinivas et al. 2012; Chandrasekar and Balaji 2015). The NT scheme is also a mass-flux scheme with a new trigger function based on moist air parcel and can resolve penetrative, shallow, and mid-level convection (Zhang and Wang 2017). A dry bias in the precipitation simulation is noticed across all the events spatially (figure 7) and temporally (figures 3–6) with the NT scheme (cases C17 and C18) when compared to the other cumulus schemes. Furthermore, the scheme does not perform well in capturing the moderately-high and high rainfall intensities across the events (figure 8).

Box plots showing the distribution of data values under each cluster. (a) OCH event, (b) GAJ event, (c) SWM event, and (d) SUM event. The upper x-axis denotes the major clusters and the lower x-axis denotes each of the sub-clusters for which the data values are plotted. The box plots contain the median (black line within the box), 25–75th percentile (the box) and the spread (whiskers). The dashed blue lines are included to segregate between the major clusters.
The No-CUM and the CUM-D3 cases within the CUM cluster, records varied impact on the precipitation simulations (figure 9). No-CUM cases, viz., C0, C10, C12, C16, and C18 simulate weak precipitation distribution over the ocean. Furthermore, the land precipitation is highly skewed towards the Western Ghats region than in the coasts. The change of the cumulus schemes in the outer domains (D1 and D2) influences the precipitation simulations through the impact on the quality of the boundary conditions provided to the innermost domain (D3). However, the highest impact is noticed with the CUM-D3 experiments (C8, C9, C11, C13, and C15) which give consistently higher skill scores for various rainfall intensities (figures 8 and 9). A major portion of the study region is characterized by complex terrain features, due to the presence of the Western Ghats. Additionally, most of the rainfall events in the study region have significant influence from the convective processes (Rajeevan et al. 2012; Konwar et al. 2014). Thus, the CUM-D3 cases show a positive impact in capturing the spatiotemporal pattern and give consistent performances across all the events. In addition, the differences between the CUM-D3 and the No-CUM clusters are amplified with an increase in the forecast lead-time (figures 3–6). The variability between the CUM-D3 and No-CUM clusters is significantly high for SWM and SUM events (events with significant contribution from convective activities), when compared to the OCH and GAJ events (figure 9). The cases with the GF scheme (C13 and C14) behave very similarly in capturing the spatial and temporal patterns due to their scale-aware nature. In so far as the BMJ scheme is considered, the CUM-D3 variant (C15) and the No-CUM case (C16) give varied performances across the events and thus, inference on the best performing variant is equivocal.
All the eight microphysics options used within the MPY cluster belong to bulk microphysics schemes with the Lin (C0), WSM3 (C1), WSM5 (C2), WSM6 (C3), Goddard (C4) and Kessler schemes (C6) being single moment schemes having the ability to model the mixing ratios of hydrometeors. However, they differ by the number of hydrometeor types, they can simulate. The WDM6 (C7) and Morrison (C5) schemes belong to the double-moment category, which can predict the number concentration of various hydrometeors along with the mixing ratios. Morrison is a sophisticated double moment scheme predicting the mixing ratios and number concentrations of rain, cloud water, cloud ice, graupel, and snow (Morrison et al. 2009). The temporal plots (figures 3–6) and box plots (figure 9) show that cases from the MPY cluster give better performance skills during OCH and GAJ events (NEMS period). The MPY cases are found to be considerably impact the timing (figures 3–6) and intensity (figures 7b and 8) of the rainfall. However, the location of the major event (figure 7d) and the spatial spread (figure 7c) are not significantly altered by the different MPY schemes except for the OCH event. The SWM event records negligible impact of the microphysics schemes on the predicted rainfall, owing to the error induced by the cumulus scheme used in the outer domains. The MPY cases display higher skill score for 2.5 mm/3 hr (figure 8b) and 5 mm/3 hr (figure 8c) thresholds for the GAJ, SWM and SUM events, while during OCH event the MPY, cluster gives reasonable skill while simulating higher intensity rainfall (10 mm/3 hr) (figure 8d). Largely, the double moment microphysics schemes (cases C5 and C7) perform better in capturing the timing (figures 3d–6d) and spatial distribution of high-intensity precipitation (figure 8) for most of the events. In particular, the Morrison’s double moment scheme (C5) captures the characteristics of the events and spatial distribution of various intensity rainfall occurrences better than the other schemes. The timing and the intensity of the OCH event are realistically represented by C5 compared to the other cases in the PHY cluster (figure 3d). The default Lin scheme (C0) gives substantially better performance when compared to the other microphysics schemes. Goddard scheme (C4) also gives consistent performance across all the events and the timing of the simulated event matches closely with the Lin scheme.
The PBL schemes influence the temperature and moisture tendencies, thus affecting the development of precipitable structures through vertical transport of energy (Srinivas et al. 2012). In the present study, two different classes of the PBL schemes, i.e., local (MYJ) closure and non-local (YSU) closure schemes are considered. The two classes differ in the way they parameterize the transport of turbulence in the vertical extent. The MYJ scheme simulates the precipitation with a dry bias when compared to YSU scheme for most of the events. The relative humidity and temperature profiles show that the local scheme MYJ predicts slightly cold and moist low-level layers when compared to YSU scheme. The mixing conditions are well represented by the YSU scheme, leading to better simulation of the intensity of the event (figure 8). However, the time of occurrence of the events (figures 3a–6a) is not different across the PBL schemes.
4.3.2 Domain configuration (DOM)
The box plots show that the changes in the domain configurations cause higher deviations in the simulated variables next to the cumulus schemes (figure 9). The simulated intensity (figure 8), the timing of the rainfall (figures 3d–6d), and the spatial characteristics (figure 7) of the simulated precipitation, are strongly impacted by the domain set-up. The structure of the simulated rainfall clearly shows that the control run C0 set-up with three domains (D1 and D2 in PCS and Lin scheme in D3) has reduced the development of precipitable structures in the D3, subsequently simulating narrow and peaked rainfall totals for GAJ, SWM and SUM events (figure 7c). The model errors lead to the imperfect realization of the simulated variables in the outer domains, which is forced as input to the high-resolution domain. The wide underestimation in the case C30 (LBC), which is forced with better quality initial/lateral boundary conditions from the ERA5 data reflects that the current model set-up induces high errors in the simulated QPFs across the events. When the domains (nesting-steps) are reduced from three (two-nesting steps) to one (no-nesting; DOM1) or to two (one-nesting step; DOM2), the skill scores improve over the control simulation especially for the SWM event (table 3).
The precipitation forecasts by single domain cases with no nesting in DOM1 cluster, viz., C20 (36 km), C21 (12 km), and C22 (4 km) are significantly different from one another. The simulated precipitation by C22 shows substantial diurnal variation with the simulated rainfall peaks occurring in the evenings (figures 3d–6d). Besides, the spatial distribution of the accumulated rainfall is skewed towards the Western Ghats in the simulation by C22 (not shown here). Particularly, the case with single high-resolution domain performs poorly in capturing the low-intensity rains (figure 8a). An interesting pattern is noticed with case C22, where the lowest locational error is recorded for OCH event, while the highest errors are observed during the simulation of GAJ, SWM, and SUM events (figure 7d) amongst the DOM1 cases. Even though, the overall performance metrics are better for C22, the experiment displays lack of reliability (temporal and spatial shifts) due to the large resolution jumps (25 km GFS forced directly to 4 km WRF domain) and the requirement of spatial spin-up grids between the strong lateral inflow and the domain of interest. Studies (Brisson et al. 2016; Matte et al. 2016) have shown that enough spatial spin-up distance and optimal resolution jump between the lateral boundary inflow and the regional domain is required to enable full development of small-scale features. The overall performance is high for case C21 (only D2) within all the single domain cases for OCH, GAJ, and SUM events. Diurnal rainfall features, the terrain and the coastline impact are represented and also widely controlled by the lateral boundary forcing (figures 3d–6d). However, the case does not perform well for highly intense (>10 mm/3 hr) precipitation events across the events studied here (figure 8d). Particularly, the case C21 performs below par for higher rain intensities during the SWM and SUM events dominated by mesoscale to fine-scale convective processes, respectively. The unresolved convective activities at the given resolution (12 km) have led to the underprediction of the rainfall events.
The DOM2 cases (C23 and C24) with the two domains and one-nesting step perform better than the single domain (no-nesting; DOM1) and the three-domain (two-nesting steps; CNT, C25) cases. Experiment C24 uses an intermediate resolution domain, D2 (12 km in PCS) as the outer domain with D3 (4 km in CPS) as the inner domain which is expected to reduce the errors caused by the requirement of large spatial spin-up grids (as in C22), appropriate spatial resolution to resolve convective structures (as in C20, C21 and C23) and restricted rainfall development (as in three domain cases C0 and C25). However, the skill scores in spatial and temporal domain do not show considerable difference between C23 and C24, except for the SWM event. The uncertainty induced by domain D1 with coarser resolution (36 km) is high during the SWM event simulated by cases C23 and C0 which is significantly reduced in the C24 simulation (figures 7–8 and table 3). Feedback mechanism between the nests (C0 and C25) does not create any significant difference in the simulated precipitation.
4.3.3 Data assimilation (DA)
Data assimilation (DA) is a sequential (or the variational) process which uses model’s previous forecast as the first guess along with current observations to update the model state known as analysis. The analysis reflects the observational conditions, thus improving the initial and lateral boundary conditions (Pan et al. 2015). In the study, the effect of a simple DA approach 3DVAR is tested using globally available surface and upper-air observations and radiance data. The background error statistics are built for the study area with differences between 24 and 48-hr GFS forecasts generated across one month. Different variations of DA methods, viz., warm start with no cycle (C26) and varying cycles (C27, C28 and C29) of assimilation are analyzed under the DA cluster. The warm start uses the initial-boundary conditions from the GFS data, i.e., the analysis as first guess and performs the DA. The cycling approach performs DA using the WRF forecast as the first guess. The DA for C27 (one cycle), C28 (four cycles), and C29 (eight cycles) are performed at 6-hr interval between the cycles. Large deviations between the DA clusters are noticed during the OCH and SUM events. The DA clusters reduce the early prediction error in the control run during the OCH event (figure 3b). Yet, the intensity estimates from the DA clusters show dry bias across the simulations. Even though the initial values of relative humidity, temperature, and wind profiles are better represented using the DA cases, the solution from the WRF model set-up dominates the results for longer duration simulations. Thus, the DA clusters do not give a clear advantage over the control run, and the impact of the DA is not pronounced for longer simulations beyond 48 hrs (as noticed by Subramani et al. 2013; Chandrasekar and Balaji 2015).
4.4 Investigation on the ensemble prediction approaches
The WRF model in the current set-up shows the highest sensitivity to the physics cluster (from section 4.1 to 4.3) and there is undoubtedly no single best physics combination that outperforms in capturing the variability through space and time and across the rainfall events with different driving processes. Thus, an attempt is made towards formulating EPS at the convective scales (CPS) for the study region from the physics clusters. Prior studies (Tapiador et al. 2012; Zhu and Xue 2016; Tian et al. 2017) have suggested the use of multi-physics ensemble approach at CPS to capture the model-based uncertainty better. Thus, the members from the PHY cluster are chosen as the initial set of ensemble members. The cases from the CUM-D3 cluster (cases C8, C9, C11, C13, C15, and C17) are not included in the first ensemble approach (termed as conventional multi-physics parameterization (c-MPP) ensemble) since the 4-km resolution is widely considered as convection-allowing scale and earlier ensemble prediction studies have traditionally not used cumulus schemes in the innermost, high-resolution domain (Zhu and Xue 2016; Jeworrek et al. 2019). Therefore, the c-MPP ensemble consists of 14 members from microphysics, cumulus (No-CUM cases), and PBL scheme variants, viz., C0, C1, C2, C3, C4, C5, C6, C7, C10, C12, C14, C16, C18, and C19. The sensitivity experiments clearly demonstrate that the CUM-D3 cases realistically capture the spread of moderate (figure 9c) to heavy (figure 9d) rainfall intensities during SWM and SUM events which are dominated by convective processes. While some cases in the No-CUM cluster particularly with the double moment microphysics schemes (cases C5, C7) capture the location (figure 7d) and intensity (figures 3 and 4) of the peak event during the NEMS events (viz., OCH and GAJ events). Thus, with the understanding developed, another distinctive ensemble method (termed as newly suggested multi-physics parameterization (n-MPP) ensemble), consisting of 10 members is adopted. The list includes three cases from the MPY cluster, viz., C0, C5, C7, six CUM-D3 cases from CUM cluster, viz., C8, C9, C11, C13, C15, C17 and one No-CUM case from CUM cluster, viz., C16. In basic terms, the n-MPP contains cases with simple microphysics scheme and varying cumulus schemes applied in all the domains (CUM-D3 cases) (6 members – C8, C9, C11, C13, C15, and C17) along with cases without cumulus scheme in D3 but with complex microphysics schemes (4 members – C0, C5, C7, and C16).
The two ensemble approaches (c-MPP and n-MPP) are evaluated with rank histograms, outlier statistics, and delta semi-variance. The shape of the rank histogram should be flat to denote the equal probability of all the ensemble members to predict the rainfall occurrences. In case of the c-MPP ensemble (figure 10a), the rank histogram is U-shaped and is shifted towards the right, reaffirming that the ensemble members have weak dispersion and highly underestimate the rainfall values when compared to the GPM-IMERG data. The n-MPP (figure 10b) also produces an asymmetric rank histogram. However, the right tail frequency is highly reduced and gets re-distributed across other ranks of a lesser order. Thus, it is evident that the simulated rainfall values by the n-MPP members are able to capture the high-intensity rainfall occurrences better than the c-MPP ensemble members. The delta semi-variance plot (figure 11) shows the difference between the simulated semi-variance values vs. the GPM-IMERG derived semi-variance values at various spatial lags. The n-MPP set is able to capture the variances in the GPM-IMERG data, as indicated by the median values of delta variance close to the y=0 line for the OCH (figure 11a) and SUM (figure 11d) events. The spread (represented from the box plots of delta semi-variance) in case of n-MPP is also broad for these events highlighting the difference in spatial structure between the cases. However, members in both the ensemble strategies (c-MPP and n-MPP) uniformly display huge differences in the spatial structure due to simulation of narrow rainfall-band during GAJ (figure 11b) and SWM (figure 11c) events, as compared to the GPM. The inherent problem with the domain configuration and physics member selection in the control run is creating the background deviation across the ensemble members indicating a biased model (as elaborated in sections 4.1–4.3). Furthermore, to quantify the performance of the ensemble approaches in capturing the extremes, the outlier statistics is calculated at various lead-times across the events (table 4). For an ensemble with N members, there are (N+1) intervals in which the verification can fall at every data point (spatially and temporally). When the ensemble is statistically consistent, none of the intervals should be preferred and all the intervals should be equally likely which is denoted as the base rate (expressed in percentage), represented as (1/(N+1))×100. The two intervals in the tails (right and left) correspond to the outliers and thus, the outlier base rate (expressed in percentage) is expected to be closer (neither large nor small) to (2/(N+1))×100. For c-MPP, the expected outlier base rate (mentioned under Reference column in table 4) is 13%, while for n-MPP the expected rate is 18%. It is very evident from table 4 that the n-MPP reduces the distance between the actual and expected outlier base rate, thereby reducing the probability of outlier occurrences across the lead-times when compared to c-MPP. Overall, the evaluation of the ensemble approaches shows that the newly suggested n-MPP ensemble method with lesser members performs better or at worse, comparably with the traditionally used c-MPP ensemble method. Thus, a combination of switching on and off (with complex microphysics scheme) the presence of cumulus schemes in the high-resolution domain (n-MPP), introduced realistic variability in the simulated rainfall across the spatial and temporal dimensions during the events under study (similar results were reported by Han and Hong 2018).

Rank histogram plots. (a) c-MPP ensemble and (b) n-MPP ensemble. The dotted lines denote the optimal value of relative frequency to get a flat rank histogram calculated with respect to the number of ensemble members.

Delta semi-variance plots. (a) OCH event, (b) GAJ event, (c) SWM event, and (d) SUM event. The x-axis denotes the delta semi variance values in mm2. The y-axis denotes the spatial lag in km. The red (c-MPP) and green (n-MPP) are the inter-quantile box plots denoting the median (line within the box), 25–75th percentile (the box) and the spread (whiskers).
A simple mean of the n-MPP ensemble members is derived to understand the performance of the ensemble-based deterministic forecast on the spatial (figure 12) and temporal (figure 13) domain. The overall RMSE (Mean Bias) of the simulated rainfall from the ensemble mean approach is 14.2 mm/3 hr (–2.7 mm/3 hr) with a Pearson’s correlation coefficient of 0.38. Figure 12 shows a comparison plot between the GPM-IMERG (left), C0 (middle) and n-MPP (right) based mean precipitation fields for OCH (figure 12-1st row), GAJ (figure 12-2nd row), SWM (figure 12-3rd row) and SUM (figure 12-4th row) events. The spatial maps of mean rainfall rate from the c-MPP ensemble are not shown in the figure, since they are not significantly different from the maps created from n-MPP ensemble approach. The spatial distribution of the rainfall intensities is considerably improved with n-MPP mean precipitation fields when compared to the individual member-based deterministic forecasts. The ocean precipitation in the south-west quadrant of the domain during the OCH event is well represented by the n-MPP based ensemble. However, the shift of the mean precipitation field towards the Indian landmass is still present during the simulation of the OCH event. The track and spread during the GAJ event are reasonably reproduced in the n-MPP based results. The improvement in the simulation of the SWM event is evidently noticed in the n-MPP based mean precipitation field (figure 12-3rd row). The temporal plots (figure 13) show that the ensemble mean gives a better prediction over the deterministic forecast and c-MPP for most of the time of simulation during the SWM and SUM events. However, for the OCH and GAJ events, the improvement offered by the n-MPP is not very significant. The box plots (plotted as inset over the n-MPP line in figure 13) visibly show the widespread across the ensemble members captured by the n-MPP method during the SWM and SUM events. The usage of statistical techniques like probability matching method to calculate the deterministic value can help in improving the performance of the suggested EPS (as reported by On et al. 2018).

Mean rain rate map in mm/3 hr. 1st row: OCH event, 2nd row: GAJ event, 3rd row: SWM event and 4th row: SUM event. Left: GPM-IMERG data; middle: C0 (CNT) simulation; right: n-MPP ensemble mean.

Temporal rain rate plots. (a) OCH event, (b) GAJ event, (c) SWM event, and (d) SUM event. x-axis denotes the time of simulation as dd (date) hh (hour) in Indian Standard Time (IST) (local time). Suffix yyyy should be added, 2017 for OCH event and 2018 for other three events. The y-axis denotes the rainfall rates in mm/3 hr. The box plots denote the spread of the n-MPP ensemble for each time of simulation. The box plot contains the median (line within the box), 25–75th percentile (the box) and the spread (whiskers).
5 Summary and conclusions
This study aimed at evaluating the WRF model at convective scales (4 km), to understand the model sensitivities in simulating the quantitative precipitation forecasts (QPFs) at 4-day lead-time and thereby design an ensemble approach for dependable performance of WRF across the seasons. A total of 120 experiments across four events were designed to understand and quantify the model sensitivity at convective-permitting scales (CPS) to the physics parameterizations, 3DVAR data assimilation techniques, and domain configuration over the southern regions of peninsular India with complex topography. A distinctive ensemble approach was formulated from the results and was evaluated for performance in capturing the dynamics of QPFs as opposed to a single-member deterministic simulation and a larger member conventional multi-physics ensemble approach. The key findings are stated below:
-
The highest variability among the cases is noticed during the SWM and SUM events. The events during the NEMS (OCH and GAJ) were driven mainly by large scale conditions and thus, the perturbations to the convective scale model created lesser variability among the simulated QPFs when compared to the other events (SWM and SUM).
-
The CPS model is highly sensitive to the cumulus schemes than to the other physics schemes. Large differences in the location, extent, timing, and intensity of the simulated QPFs are observed, when the cumulus schemes are perturbed. Relative humidity-dependent additional perturbation for the KF scheme (KF2) scheme performs well in capturing the spatial and temporal patterns of the rainfall especially during the OCH and the GAJ events. The BMJ scheme performs well during the SWM and the SUM events.
-
The CUM-D3 cluster with cumulus schemes in the innermost high-resolution domain causes considerable difference in the simulations, when compared to the No-CUM cases without cumulus schemes in the innermost domain of 4 km resolution. The variability is high during the events with considerable convective activity like the SWM and SUM events and in addition, increases with forecast lead-time. The CUM-D3 cluster is able to capture the spread of the low-intensity rains better than the No-CUM cases for all the simulated events (as reported by Han and Hong 2018). KF and BMJ schemes show the highest dispersion between their own CUM-D3 and No-CUM versions.
-
The NEMS events show better performance between the MPY cases, especially during the peak rainfall occurrences. The double moment Morrison scheme performs better in capturing the high rainfall intensities, when cumulus schemes are not implemented in the innermost domain.
-
Domain configuration, viz., the different nesting steps, and downscaling ratio create considerable impact on the simulated rainfall. A two-domain with one-nesting step as in case C29 with a nominal downscaling ratio and spatial-spin up is able to capture the patterns of QPF better at a lower computational cost than the control run. Simulation of precipitation with feedback between the nests does not deviate much from the simulation produced without feedback between nests for the events studied.
-
The EPS with conventional multi-physics parameterization (c-MPP) members is biased with less dispersion for this study. Though the n-MPP with members having cumulus schemes ON and OFF in the high-resolution domain has a dry bias, it is able to slightly improve the spatial and temporal dispersions in the precipitation simulations. The n-MPP provided highly substantial spread across space and time for SWM and SUM events, dominated by convective processes than the events during NEMS. In addition, the occurrence of outliers is significantly reduced with n-MPP across all the lead times.
The study is an early attempt in investigating the performance of a regional weather forecast model (WRF) at convective scales over the southern parts of peninsular India with a unique climatology. The results from sensitivity analysis match well with the conclusions from the earlier studies across different climatic conditions (Lee et al. 2011; Tapiador et al. 2012; Chandrasekar and Balaji 2015; Prein et al. 2015; Mahoney 2016; Matte et al. 2016; Sikder and Hossain 2016; Tian et al. 2017; Coppola et al. 2018; Han and Hong 2018; Jeworrek et al. 2019; Liang et al. 2019) thereby increasing the validity of the results in improving the spatial and temporal resolutions of short–medium range weather forecasts. The reliability of the suggested ensemble approach must be evaluated for numerous rainfall events to understand the systematic bias in the ensemble design and efficiency in capturing the spatial and temporal variability of the QPFs. A simplistic approach has been adopted to address uncertainties in initial and boundary conditions in this study. Advanced procedures to perturb the driving boundary conditions can be attempted and tested for the value-added to the ensemble prediction system at the CPS.
Abbreviations
- 3DVAR–DA:
-
Three-Dimensional Variational Data Assimilation
- BMJ:
-
Betts–Miller–Janjic cumulus scheme
- c-MPP:
-
Conventional type Multi-Physics Parameterization (MPP) ensemble consisting of 14 members from different physics schemes viz., C0, C1, C2, C3, C4, C5, C6, C7, C10, C12, C14, C16, C18 and C19
- CNT:
-
Control Run, alternatively referred as C0 for ease of usage and use in figures
- CPS:
-
Convective Permitting Scales
- CUM:
-
Sub-cluster including sensitivity cases with changes in cumulus schemes
- CUM-D3:
-
Sub-cluster including sensitivity cases with cumulus schemes implemented in Domain 3
- D1:
-
Domain 1 as given in figure 1
- D2:
-
Domain 2 as given in figure 1
- D3:
-
Domain 3 as given in figure 1
- DA:
-
Main sensitivity cluster including cases with changes in data assimilation approach
- DOM:
-
Main sensitivity cluster including cases with changes in domain configuration
- DOM1:
-
Sub-cluster including sensitivity cases with any single domain (no nesting) selected form the CNT run
- DOM2:
-
Sub-cluster including sensitivity cases with any two domains (one nesting step) selected form the CNT run
- EPS:
-
Ensemble prediction system
- ERA5:
-
ECMWF atmospheric reanalyzes of the global climate data
- FSS:
-
Fractional Skill Score
- GAJ:
-
Gaja cyclone associated extreme rain event
- GF:
-
Grell-Freitas cumulus scheme
- GFS:
-
Global Forecast System generated initial and boundary data
- GPM–IMERG:
-
Global Precipitation Measurement (GPM) Integrated Multi-satellitE Retrievals data
- IST:
-
Indian Standard Time
- KF:
-
Kain–Fritsch cumulus scheme
- KF1:
-
Moisture advection based trigger for KF cumulus scheme
- KF2:
-
Relative Humidity dependent additional perturbation for the KF cumulus scheme
- LAM:
-
Limited Area Model
- MPY:
-
Sub-cluster including sensitivity cases with changes in microphysics schemes
- MYJ:
-
Mellor–Yamada–Janjic (MYJ) PBL Scheme
- NEMS:
-
North-East Monsoon Season
- n-MPP:
-
Newly suggested Multi-Physics Parameterization (MPP) consisting of 10 members viz., C0, C5, C7, C8, C9, C11, C13, C15, C17 and C16
- No-CUM:
-
Sub-cluster including sensitivity cases without cumulus schemes in Domain 3
- NT:
-
New Tiedtke cumulus scheme
- OCH:
-
Ockhi cyclone associated extreme rain event
- PBL:
-
Sub-cluster including sensitivity cases with changes in planetary boundary layer schemes
- PCS:
-
Parameterized Convection Scales
- PHY:
-
Main sensitivity cluster including cases with changes in physics schemes
- PM:
-
Pre-monsson season
- QPF:
-
Quantitative Precipitation Forecast
- S-A-L:
-
Structure-Amplitude-Location
- SUM:
-
Pre-monsoon season extreme rain event
- SWM:
-
South-West Monsoon Season extreme rain event
- SWMS:
-
South-West Monsoon Season
- WRF:
-
Weather Research and Forecasting model
- YSU:
-
Yonsei University Scheme for PBL
References
Ardie W A, Sow K S, Tangang F T, Hussin A G, Mahmud M and Juneng L 2012 The performance of different cumulus parameterization schemes in simulating the 2006/2007 southern peninsular Malaysia heavy rainfall episodes; J. Earth Syst. Sci. 121 317–327, https://doi.org/10.1007/s12040-012-0167-9.
Barker D M, Huang W, Guo Y, Bourgeois A J and Xiao Q N 2004 A three-dimensional variational data assimilation system for MM5: Implementation and initial results; Mon. Weather Rev. 132 897–914, https://doi.org/10.1175/1520-0493(2004)132%3c0897:ATVDAS%3e2.0.CO;2.
Brisson E, Demuzere M and van Lipzig N P M 2016 Modelling strategies for performing convection-permitting climate simulations; Meteorologische Zeitschrift 25(2) 149–163, https://doi.org/10.1007/10.1127/metz/2015/0598.
Brockhaus P, Lüthi D and Schär C 2008 Aspects of the diurnal cycle in a regional climate model; Meteorologische Zeitschrift 17(4) 433–443, https://doi.org/10.1127/0941-2948/2008/0316.
Buizza R and Palmer T N 1998 Impact of ensemble size on ensemble prediction; Mon. Weather Rev. 126(9) 2503–2518, https://doi.org/10.1175/1520-0493(1998)126%3c2503:ioesoe%3e2.0.co;2.
Chandrasekar R and Balaji C 2012 Sensitivity of tropical cyclone Jal simulations to physics parameterizations; J. Earth Syst. Sci. 121 923–946, https://doi.org/10.1007/s12040-012-0212-8.
Chandrasekar R and Balaji C 2015 Impact of physics parameterization and 3DVAR data assimilation on prediction of tropical cyclones in the Bay of Bengal region; Nat. Hazards 80(1) 223–247, https://doi.org/10.1007/s11069-015-1966-5.
Chen S-H and Sun W-Y 2002 A one-dimensional time dependent cloud model; J. Meteorol. Soc. Japan 80(1) 99–118, https://doi.org/10.2151/jmsj.80.99.
Choi I-J, Jin E K, Han J-Y, Kim S-Y and Kwon Y 2015 Sensitivity of diurnal variation in simulated precipitation during East Asian summer monsoon to cumulus parameterization schemes; J. Geophys. Res. 120(23) 11,971–11,987, https://doi.org/10.1002/2015jd023810.
Clark A J, Kain J S, Stensrud D J, Xue M, Kong F, Coniglio M C, Thomas K W, Wang Y, Brewster K, Gao J, Wang X, Weiss S J and Du J 2011 Probabilistic precipitation forecast skill as a function of ensemble size and spatial scale in a convection-allowing ensemble; Mon. Weather Rev. 139(5) 1410–1418, https://doi.org/10.1175/2010mwr3624.1.
Clark P, Roberts N, Lean H, Ballard S P and Charlton-Perez C 2016 Convection-permitting models: A step-change in rainfall forecasting; Meteorol. Appl. 23 165–181, https://doi.org/10.1002/met.1538.
Copernicus Climate Change Service (C3S) 2017 ERA5: Fifth generation of ECMWF atmospheric reanalyses of the global climate; Copernicus Climate Change Service Climate Data Store (CDS), https://cds.climate.copernicus.eu/cdsapp#!/home.
Coppola E, Sobolowski S, Pichelli E, Raffaele F, Ahrens B and Anders I et al. 2018 A first-of-its-kind multi-model convection permitting ensemble for investigating convective phenomena over Europe and the Mediterranean; Clim. Dyn. 55 3–34, https://doi.org/10.1007/s00382-018-4521-8.
Das S, Ashrit R, Iyengar G R, Mohandas S, Gupta D, George J P, Rajagopal E N and Dutta S K 2008 Skills of different mesoscale models over Indian region during monsoon season: Forecast errors; J. Earth Syst. Sci. 117 603–620, https://doi.org/10.1007/s12040-008-0056-4.
Di Z, Duan Q, Wei G, Chen W, Gan Y J, Quan J, Li J, Miao C, Ye A and Tong C 2015 Assessing WRF model parameter sensitivity: A case study with 5-day summer precipitation forecasting in the Greater Beijing Area; Geophys. Res. Lett. 42 579–587, https://doi.org/10.1002/2014GL061623.
Dudhia J 1989 Numerical study of convection observed during the winter monsoon experiment using a mesoscale two-dimensional model; J. Atmos. Sci. 46(20) 3077–3107, https://doi.org/10.1175/1520-0469(1989)046%3c3077:nsocod%3e2.0.co;2.
Evans J P, Ekström M and Ji F 2011 Evaluating the performance of a WRF physics ensemble over south-east Australia; Clim. Dyn. 39 1241–1258, https://doi.org/10.1007/s00382-011-1244-5.
Feser F, Rockel B, von Storch H, Winterfeldt J and Zahn M 2011 Regional climate models add value to global model data: A review and selected examples; Bull. Am. Meteorol. Soc. 92(9) 1181–1192, https://doi.org/10.1175/2011bams3061.1.
Frogner I, Singleton A T, Køltzow M Ø and Andrae U 2019 Convection-permitting ensembles: Challenges related to their design and use; Quart. J. Roy. Meteorol. Soc. 145(Suppl. 1) 90–106, https://doi.org/10.1002/qj.3525.
Grell G A and Freitas S 2014 A scale and aerosol aware stochastic convective parameterization for weather and air quality modeling; Atmos. Chem. Phys. 14 5233–5250, https://doi.org/10.5194/acp-14-5233-2014.
Hagelin S, Son J, Swinbank R, McCabe A, Roberts N and Tennant W 2017 The Met Office convective-scale ensemble MOGREPS-UK; Quart. J. Roy. Meteorol. Soc. 143(708) 2846–2861, https://doi.org/10.1002/qj.3135.
Han J and Hong S 2018 Precipitation forecast experiments using the weather research and forecasting (WRF) model at gray-zone resolutions; Weather Forecast. 33 1605–1616, https://doi.org/10.1175/waf-d-18-0026.1.
Hong S Y and Lim J-O 2006 The WRF single-moment 6-class microphysics scheme (WSM6); J. Korean Meteorol. Soc. 42 129–151.
Hong S-Y, Dudhia J and Chen S-H 2004 A revised approach to ice microphysical processes for the bulk parameterization of clouds and precipitation; Mon. Weather Rev. 132(1) 103–120, https://doi.org/10.1175/1520-0493(2004)132%3c0103:aratim%3e2.0.co;2.
Hong S-Y, Noh Y and Dudhia J 2006 A new vertical diffusion package with an explicit treatment of entrainment processes; Mon. Weather Rev. 134(9) 2318–2341, https://doi.org/10.1175/mwr3199.1.
Huffman G, Bolvin D, Braithwaite D, Hsu K, Joyce R and Xie P 2015 Integrated Multi-satellitE Retrievals for GPM (IMERG), version 4.4; NASA's Precipitation Processing Center, ftp://arthurhou.pps.eosdis.nasa.gov/gpmdata/.
Janjic Z I 1994 The step-mountain eta coordinate model: Further developments of the convection, viscous sublayer, and turbulence closure schemes; Mon. Weather Rev. 122(5) 927–945, https://doi.org/10.1175/1520-0493(1994)122%3c0927:tsmecm%3e2.0.co;2.
Jeworrek J, West G and Stull R 2019 Evaluation of cumulus and microphysics parameterizations in WRF across the convective gray zone; Weather Forecast. 34 1097–1115, https://doi.org/10.1175/WAF-D-18-0178.1.
Jimenez P A and Dudhia J 2012 Improving the representation of resolved and unresolved topographic effects on surface wind in the WRF Model; J. Appl. Meteorol. Climatol. 51(2) 300–316, https://doi.org/10.1175/jamc-d-11-084.1.
Johnson A, Wang X, Kong F and Xue M 2013 Object-based evaluation of the impact of horizontal grid spacing on convection-allowing forecasts; Mon. Weather Rev. 141(10) 3413–3425, https://doi.org/10.1175/mwr-d-13-00027.1.
Kain J S 2004 The Kain-Fritsch convective parameterization: An update; J. Appl. Meteorol. 43(1) 170–181, https://doi.org/10.1175/1520-0450(2004)043%3c0170:tkcpau%3e2.0.co;2.
Kessler E 1969 On the distribution and continuity of water substance in atmospheric circulations; Meteorol. Monogr. Am. Meteorol. Soc. 10 1–84, https://doi.org/10.1007/978-1-935704-36-2_1.
Konwar M, Das S K, Deshpande S M, Chakravarty K and Goswami B N 2014 Microphysics of clouds and rain over the Western Ghat; J. Geophys. Res.: Atmos. 119(10) 6140–6159, https://doi.org/10.1002/2014jd021606.
Kumar P, Bhattacharya B K and Pal P K 2015 Evaluation of weather research and forecasting model predictions using micrometeorological tower observations; Bound.-Layer Meteorol. 157(2) 293–308, https://doi.org/10.1007/s10546-015-0061-5.
Lee S, Lee D and Chang D 2011 Impact of horizontal resolution and cumulus parameterization scheme on the simulation of heavy rainfall events over the Korean peninsula; Adv. Atmos. Sci. 28(1) 1–15, https://doi.org/10.1007/s00376-010-9217-x.
Liang X-Z, Li Q, Mei H and Zeng M 2019 Multi-grid nesting ability to represent convections across the gray zone; J. Adv. Modeling Earth Syst. 11 4352–4376, https://doi.org/10.1029/2019MS001741.
Lim K-S S and Hong S-Y 2010 Development of an effective double-moment cloud microphysics scheme with prognostic cloud condensation nuclei (CCN) for Weather and climate models; Mon. Weather Rev. 138(5) 1587–1612, https://doi.org/10.1175/2009mwr2968.1.
Ma L-M and Tan Z-M 2009 Improving the behavior of the cumulus parameterization for tropical cyclone prediction: Convection trigger; Atmos. Res. 92(2) 190–211, https://doi.org/10.1016/j.atmosres.2008.09.022.
Mahoney K M 2016 The representation of cumulus convection in high-resolution simulations of the 2013 Colorado Front Range Flood; Mon. Weather Rev. 144(11) 4265–4278, https://doi.org/10.1175/mwr-d-16-0211.1.
Marzban C, Sandgathe S, Lyons H and Lederer N 2009 Three spatial verification techniques: Cluster analysis, variogram, and optical flow; Weather Forecast. 24(6) 1457–1471, https://doi.org/10.1175/2009waf2222261.1.
Matte D, Laprise R and Theriault J M 2016 Comparison between high-resolution climate simulations using single- and double-nesting approaches within the Big-Brother experimental protocol; Clim. Dyn. 47(12) 3613–3626, https://doi.org/10.1007/s00382-016-3031-9.
Mlawer E J, Taubman S J, Brown P D, Iacono M J and Clough S A 1997 Radiative transfer for inhomogeneous atmospheres: RRTM, a validated correlated-k model for the longwave; J. Geophys. Res.: Atmos. 102(D14) 16663–16682, https://doi.org/10.1029/97jd00237.
Morrison H, Thompson G and Tatarskii V 2009 Impact of cloud microphysics on the development of trailing stratiform precipitation in a simulated squall line: Comparison of one- and two-moment schemes; Mon. Weather Rev. 137(3) 991–1007, https://doi.org/10.1175/2008mwr2556.1.
National Centers for Environmental Prediction/National Weather Service/NOAA/U.S. Department of Commerce 2008 updated daily NCEP ADP Global Upper Air and Surface Weather Observations (PREPBUFR format); Research Data Archive at the National Center for Atmospheric Research, Computational and Information Systems Laboratory, https://doi.org/10.5065/Z83F-N512.
National Centers for Environmental Prediction/National Weather Service/NOAA/U.S. Department of Commerce 2009 updated daily NCEP GDAS Satellite Data 2004-continuing; Research Data Archive at the National Center for Atmospheric Research, Computational and Information Systems Laboratory, https://doi.org/10.5065/DWYZ-Q852.
National Centers for Environmental Prediction/National Weather Service/NOAA/U.S. Department of Commerce 2015 updated daily NCEP GFS 0.25 Degree Global Forecast Grids Historical Archive; Research Data Archive at the National Center for Atmospheric Research, Computational and Information Systems Laboratory, https://doi.org/10.5065/D65D8PWK.
On N, Kim H M and Kim S 2018 Effects of resolution, cumulus parameterization scheme, and probability forecasting on precipitation forecasts in a high-resolution limited-area ensemble prediction system; Asia-Pacific J. Atmos. Sci. 54 623–637, https://doi.org/10.1007/s13143-018-0081-4.
Pan L, Liu Y, Liu Y, Li L, Jiang Y, Cheng W and Roux G 2015 Impact of four-dimensional data assimilation (FDDA) on urban climate analysis; J. Adv. Model. Earth Syst. 7(4) 1997–2011, https://doi.org/10.1002/2015ms000487.
Prein A F, Langhans W, Fosser G, Ferrone A, Ban N, Goergen K, Keller M, Tölle M, Gutjahr O, Feser F, Brisson E, Kollet S, Schmidli J, van Lipzig N P M and Leung R 2015 A review on regional convection-permitting climate modeling: Demonstrations, prospects, and challenges; Rev. Geophys. 53(2) 323–361, https://doi.org/10.1002/2014rg000475.
Prein A F, Rasmussen R and Stephens G 2017 Challenges and advances in convection-permitting climate modeling; Bull. Am. Meteorol. Soc. 98 1027–1030, https://doi.org/10.1175/BAMS-D-16-0263.1.
Rajeevan M, Unnikrishnan C K, Bhate J, Niranjan Kumar K and Sreekala P P 2012 Northeast monsoon over India: Variability and prediction; Meteorol. Appl. 19(2) 226–236, https://doi.org/10.1002/met.1322.
Raju A, Parekh A, Chowdary J S and Gnanaseelan C 2014 Assessment of the Indian summer monsoon in the WRF regional climate model; Clim. Dyn. 44(11–12) 3077–3100, https://doi.org/10.1007/s00382-014-2295-1.
Revelli J A, Rodríguez M A and Wio H S 2010 The use of Rank Histograms and MVL diagrams to characterize ensemble evolution in weather forecasting; Adv. Atmos. Sci. 27(6) 1425–1437, https://doi.org/10.1007/s00376-009-9153-6.
Roberts N M and Lean H W 2008 Scale-selective verification of rainfall accumulations from high-resolution forecasts of convective events; Mon. Weather Rev. 136(1) 78–97, https://doi.org/10.1175/2007mwr2123.1.
Romine G S, Schwartz C S, Berner J, Fossell K R, Snyder C, Anderson J L and Weisman M L 2014 Representing forecast error in a convection-permitting ensemble system; Mon. Weather Rev. 142(12) 4519–4541, https://doi.org/10.1175/mwr-d-14-00100.1.
Romine G S, Schwartz C S, Snyder C, Anderson J L and Weisman M L 2013 Model bias in a continuously cycled assimilation system and its influence on convection-permitting forecasts; Mon. Weather Rev. 141(4) 1263–1284, https://doi.org/10.1175/mwr-d-12-00112.1.
Schwartz C S, Romine G S, Fossell K R, Sobash R A and Weisman M L 2017 Toward 1-km ensemble forecasts over large domains; Mon. Weather Rev. 145(8) 2943–2969, https://doi.org/10.1175/mwr-d-16-0410.1.
Schwartz C S, Romine G S, Sobash R A, Fossell K R and Weisman M L 2015 NCAR’s experimental real-time convection-allowing ensemble prediction system; Weather Forecast. 30(6) 1645–1654, https://doi.org/10.1175/waf-d-15-0103.1.
Sikder S and Hossain F 2016 Assessment of the weather research and forecasting model generalized parameterization schemes for advancement of precipitation forecasting in monsoon-driven river basins; J. Adv. Model. Earth Syst. 8(3) 1210–1228, https://doi.org/10.1002/2016ms000678.
Skamarock W C, Klemp J B, Dudhia J, Gill D O, Liu Z, Berner J, Wang W, Powers J G, Duda M G, Barker D M and Huang X-Y 2019 A description of the advanced research WRF Model Version 4 (No. NCAR/TN-556+STR), https://doi.org/10.5065/1dfh-6p97.
Srinivas C V, Bhaskar Rao D V, Yesubabu V, Baskaran R and Venkatraman B 2012 Tropical cyclone predictions over the Bay of Bengal using the high-resolution Advanced Research Weather Research and Forecasting (ARW) model; Quart. J. Roy. Meteorol. Soc. 139(676) 1810–1825, https://doi.org/10.1002/qj.2064.
Subramani D, Chandrasekar R, Ramanujam K S and Balaji C 2013 A new ensemble-based data assimilation algorithm to improve track prediction of tropical cyclones; Nat. Hazards 71(1) 659–682, https://doi.org/10.1007/s11069-013-0942-1.
Tao W-K, Wu D, Lang S, Chern J-D, Peters-Lidard C, Fridlind A and Matsui T 2016 High-resolution NU-WRF simulations of a deep convective-precipitation system during MC3E: Further improvements and comparisons between Goddard microphysics schemes and observations; J. Geophys. Res.: Atmos. 121(3) 1278–1305, https://doi.org/10.1002/2015jd023986.
Tapiador F J, Tao W, Shi J J, Angelis C F, Martinez M A, Marcos C, Rodriguez A and Hou A 2012 A comparison of perturbed initial conditions and multiphysics ensembles in a severe weather episode in Spain; J. Appl. Meteorol. Climatol. 51(3) 489–504, https://doi.org/10.1175/jamc-d-11-041.1.
Tewari M, Chen F, Wang W, Dudhia J, LeMone M A, Mitchell K, Ek M, Gayno G, Wegiel J and Cuenca R H 2004 Implementation and verification of the unified NOAH land surface model in the WRF model; 20th conference on weather analysis and forecasting/16th conference on numerical weather prediction, pp. 11–15.
Tian J, Liu J, Yan D, Li C and Yu F 2017 Numerical rainfall simulation with different spatial and temporal evenness by using a WRF multiphysics ensemble; Nat. Hazards Earth Syst. Sci. 17 563–579, https://doi.org/10.5194/nhess-17-563-2017.
Wagner A, Heinzeller D, Wagner S, Rummler T and Kunstmann H 2018 Explicit convection and scale-aware cumulus parameterizations: High-resolution simulations over areas of different topography in Germany; Mon. Weather Rev. 146(6) 1925–1944, https://doi.org/10.1175/mwr-d-17-0238.1.
Weisman M L, Skamarock W C and Klemp J B 1997 The resolution dependence of explicitly modeled convective systems; Mon. Weather Rev. 125(4) 527–548, https://doi.org/10.1175/1520-0493(1997)125%3c0527:trdoem%3e2.0.co;2.
Wernli H, Paulat M, Hagen M and Frei C 2008 SAL: A novel quality measure for the verification of quantitative precipitation forecasts; Mon. Weather Rev. 136(11) 4470–4487, https://doi.org/10.1175/2008mwr2415.
Woodhams B J, Birch C E, Marsham J H, Bain C L, Roberts N M and Boyd D F A 2018 What is the added value of a convection-permitting model for forecasting extreme rainfall over Tropical East Africa? Mon. Weather Rev. 146(9) 2757–2780, https://doi.org/10.1175/mwr-d-17-0396.1.
Zhang C and Wang Y 2017 Projected future changes of tropical cyclone activity over the western north and south Pacific in a 20-km Mesh Regional Climate Model; J. Clim. 30(15) 5923–5941, https://doi.org/10.1175/jcli-d-16-0597.1.
Zhu K and Xue M 2016 Evaluation of WRF-based convection-permitting multi-physics ensemble forecasts over China for an extreme rainfall event on 21 July 2012 in Beijing; Adv. Atmos. Sci. 33(11) 1240–1258, https://doi.org/10.1007/s00376-016-6202-z.
Acknowledgement
We would like to acknowledge the funding support from the Ministry of Water Resources, RD&GR, Govt. of India under Indian National Committee on Climate Change (INCCC) Grant no: 16/22/2016-R&D.
Author information
Authors and Affiliations
Contributions
S M Kirthiga: Conception and design of the study, data download and processing, analysis and interpretation of data, drafting of the manuscript, and approval of the final version. B Narasimhan: Conception of the study, providing resources, revising the manuscript critically for important intellectual content and approval of the final version of the manuscript and C Balaji: Conception of the study, providing resources, revising the manuscript critically for important intellectual content, and approval of the final version of the manuscript.
Corresponding author
Additional information
Communicated by Kavirajan Rajendran
Appendices
Appendix
A.1 Formulation of FSS
Fractional skill score is helpful in determining the usefulness of a forecast for a given rainfall threshold and neighbourhood size. The higher the neighbourhood size, the FSS for same rainfall threshold will be high, since it averages spatially a larger areal extent, thus removing the errors due to spatial shift. The measure is subjective in the sense the score will depend on the selection of neighbourhood size and the rainfall threshold. In general, the FSS is derived for different rainfall thresholds and neighbourhood sizes. In this study, as mentioned in section 3.2, 5 × 5 pixels were selected as neighbourhood size (neighbourhood scale of 50 km) after testing neighbourhood scales of 20, 30, 50, and 70 km. Four different threshold levels, viz., 1 mm/3 hr, 2.5 mm/3hr, 5 mm/3hr, and 10 mm/3hr rainfall rates were selected based on the intensities of the selected events. The binary map (if the value of a pixel in the raster is above the selected threshold, the value 1 will be assigned to the pixel and vice versa) for four rainfall thresholds was derived for both observed and simulated average rainfall rate raster for every event. Later a non-overlapping 5×5 size window (50 km neighbourhood scale) was moved across the raster and the fractions within the window were calculated. The FSS for every sensitivity experiment was computed using equation (A1).
where \(P_{f}\) is forecast fraction, \(P_{o}\) is observed fraction, and N is the number of spatial windows in the evaluation domain.
A.2 Formulation of S–A–L
The quality measure S–A–L (as suggested by Wernli et al. 2008) has been designed to effectively assess the NWP performance of simulating single-type precipitation within a defined domain like a river basin. Furthermore, the metric does not require subjective decisions on the threshold or the size of the neighbourhood like FSS. The components of S–A–L, i.e., structure, amplitude, and location are derived based on the order of complexity which goes from A to L and then finally to S. The implementation of S–A–L involved the following steps:
-
(1) Define domain: In the study, the evaluation domain 3 was selected as the domain for the derivation of S–A–L.
-
(2) Identifying rain objects: As S–A–L is an object-based metric, the precipitation objects need to be defined. The threshold value (R*) to select the object was defined by \( R{*} = \frac{1}{15}R^{95}\), where \(R^{95} \) is the 95th percentile of all the values within the domain, calculated separately for each precipitation field considered. Binary map with 1 representing the values beyond \(R{*} \) was derived. An algorithm was formulated to identify spatially connected cells with value 1 in the binary map and was declared as rain object.
-
(3) Amplitude: A was calculated as the normalized difference of domain averaged precipitation between simulated and observed precipitation field. The values range from –2 to 2 are analogous to bias metrics (grid-based metrics). Positive amplitude values denote over-estimation, and negative values represent under-estimation of the simulated rainfall. Value 0 represents perfect prediction.
-
(4) Location: The L component comprises two additional parts. The first part (L1) accounted for the distance between the center of mass of the simulated and observed precipitation fields. L1 ranges from 0 to 1 with 0 representing no deviation of the center of mass in the simulated precipitation field from the observed. Second part (L2) was calculated as averaged distance between the center of mass of the total rainfall and the individual rain objects as computed in step 2. L2 will become 0, if both the simulated and observed precipitation fields have single rain object. In other scenarios, the range of L2 will be between 0 and 1. Thus, the value of L ranges between 0 and 2 with 0 denoting no shift from the observed field, while higher values indicating a spatial shift from actual rainfall occurrences.
-
(5) Structure: The structure component (S) compared the volume of rain objects, quantifying the size and shape of the objects. The values range between –2 and 2, with negative values signifying that the event is simulated as a small spread and peaked event. Positive values on the other hand represent a much broader or flat event simulated by the model when compared to the actual event. Values close to 0 represent closely simulated rain structures as compared to the observed.
Rights and permissions
About this article

Cite this article
Kirthiga, S.M., Narasimhan, B. & Balaji, C. A multi-physics ensemble approach for short-term precipitation forecasts at convective permitting scales based on sensitivity experiments over southern parts of peninsular India. J Earth Syst Sci 130, 68 (2021). https://doi.org/10.1007/s12040-021-01556-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12040-021-01556-8