
Abstract
The identification and analysis of moderator relationships regularly confronts the empirical research with statistical and methodical challenges. Which misinterpretations and false conclusions result from different methodical procedures for the identification of moderator effects shall be demonstrated by means of the present contribution. Thereby, the moderated regression analysis represents the most popular procedure in this context.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Relevance of modelling with moderator effects
Does the effect of promotional activities on purchase intentions, to take an example, depend on specific variables such as the level of personal involvement in the customer segment, or does the organizational structure of the sales force influence sales performance depending on market growth? Is the relationship of the firms’ financial performance and R&D-effort influenced by the firms’ integration in an innovation network, or is the relationship of the firms’ financial performance and their capabilities influenced by the strategy type? These typical examples give a short glance at questions which were of growing importance during the last years in many fields of research, like marketing, management and organisation studies (Aguinis 2004; Landis and Dunlap 2000).
In this context, researchers are talking about the so called moderator effects. They can be defined as qualitative (e.g. gender, branch) or quantitative (e.g. age, income), as variables that are experimentally manipulable (e.g. company reputation) or naturally given (e.g. gender) (Baron and Kenny 1986; Aguinis 2004) and, most important, they influence the relationship between other variables.
An analysis of the literature shows, on the one hand (Aguinis 2004; Frazier et al. 2004) that only in the rarest cases within the modelling frame with interaction effects a distinction is made according to the kind of moderator, or the moderator is explicitly defined beforehand. On the other hand, the exact characterization of the kind of moderation is vital within the frame of modelling and involves different implications. If moderating effects are not taken into account within the analysis of relationships, the effect model is not displayed adequately and, therefore, can lead to false conclusions.
In general, we very often find a self-determined development of recommendations regarding the use of statistical tools concerning these procedural topics. A good example to illustrate this is Cronbach’s alpha. The common accepted standard of 0.7 was raised from 0.5 by Nunnally (1967, 1978) without any explanation (Peterson 1994). This is now widely accepted and sometimes misinterpreted (Cortina 1993) since Cronbach’s alpha should not be near one (or even near 0.9) at all in order to integrate most of the desirable and theoretically based facets of the—one-dimensional—construct, and therefore to leave a reasonable proportion of variance in the empirically measured construct, and finally to avoid a redundancy of the multi-item measurement.
There is a variety of procedures (techniques) for the identification and interpretation of moderator effects, whereby the moderated regression analysis represents the most popular method (Aguinis 1995). The identification of moderator effects does not often succeed because the moderated regression analysis is frequently afflicted with the problem of too low statistical power. This leads to the erroneous rejection of a model containing a moderator effect, so that the real moderator effect remains undiscovered (Aguinis 2004). Also methodical mistakes within the frame of the analysis of moderated effect relationships can lead to misinterpretations related to the moderator effect and, thus, to false conclusions (in detail also Carte and Russell 2003; Irwin and McClelland 2001).
From the above outlined problem areas it becomes obvious that the identification of moderator effects includes the overcoming of a number of hurdles. This concerns, on the one hand, the model specification. On the other hand, the usually used analytical procedures of research practice for the identification of moderator effects produce different results. Therefore, the present contribution
-
first of all gives an overview of typical ways to analyze moderating effects, which can be detected in the literature,
-
aims to deduce a kind of ‘best practice’, keeping all different aspects mentioned before in mind, and
-
finally illustrates the empirical consequences of the typical procedures that analyze moderating effects.
After a characterization of the moderation per se (Sect. 2), the procedure of the moderated regression analysis is introduced in detail, in which especially the methodical faults processing it are addressed. Following, the procedure of the subgroups analysis will be explained. Section 3 consists of a discussion and critical appraisal of alternative procedures for the identification of moderator effects. In Sect. 4 it will be demonstrated by means of four empirical examples which consequences and misinterpretations turn out from differences in the methodology used to identify moderator effects.
2 Defining and modelling moderation effects
The analysis and evaluation of moderator effects first of all demands a discussion of the various definitions of the moderator term. A review of the literature shows a variety of definitions with respect to the character of moderation. While Baron and Kenny (1986) describe a moderator as a factor that influences the direction and/or the strength of the relationship between an exogenous (predictor) and an endogenous (criterion) variable, James and Brett (1984) consider that “…a variable z is a moderator if the relationship between two (or more) other variables, say x and y, is a function of the level of z.”
Table 1 provides an overview of the literature with respect to the different definitions of the moderator term. Although the differences conceptualizing moderation turn out to be rather small, there is one important distinguishing feature. The definitions by Baron and Kenny (1986) and by Cohen et al. (2003) as well as by (Cortina 1993) explicitly determine a priori which variables are regarded as exogenous (predictor) and endogenous (criterion) variables, so that implicitly only the variable z can be a possible moderator of the relation between x → y. In contrast, there is no a priori determination concerning the exogenous (predictor) and the endogenous (criterion) variable in the definitions by James and Brett (1984), Schmitt and Klimoski (1991) and (Jaccard et al. 1990), (see Landis and Dunlap 2000).
It is common to all definitions above that the relationship between two quantitative variables x and y changes based on the value of a third variable z. For this reason the moderator effect is described frequently also as an interaction between x and z (Aguinis 2004).
Sharma et al. (1981) distinguish variables that influence the strength and the form of the relationship between an exogenous (predictor) and an endogenous (criterion) variable. Thereby, they differentiate three different types of moderator variables from other explaining variables. Homologizers are those variables that influence the strength of a relationship between two variables, but not their form. Homologizers neither show a statistically significant relation to the predictor and to the target variable (criterion), nor interact with other exogenous variables. The strength of the relationship between x and y is determined by the error term. Therefore, homologizers are interpreted as moderator variables, since they offer the possibility to set up homogeneous subgroups of a sample by means of the error term that differ with respect to their predictive validity (Sharma et al. 1981). The other two types of moderator variables that interact with the exogenous variable (predictor) change the form of the relationship between the exogenous and the endogenous variable. Additionally, these two moderator variables can be distinguished by whether they exert direct influence on the endogenous variable (criterion). There is a pure moderation if the moderator variable only interacts with the exogenous variable x, but itself does not exert any direct influence on the endogenous variable y. Besides, there is a quasi moderation if the moderator variable additionally exerts a direct influence on the endogenous variable y (Darrow and Kahl 1982; Sharma et al. 1981).
Formally, moderation can be illustrated by the following regression equation:
The variables x and z represent the direct effects of the predictors and the product term xz provides information concerning the moderator effect. Transposing the right side of Eq. 1 it becomes apparent in Eq. 2
that the correlation between an exogenous variable x and an endogenous variable y varies depending on the value of the moderator z. It involves a linear interaction model. If at high values of the moderator the influence of the exogenous variable on the endogenous variable is stronger than at low moderator values, one talks about a positive moderator effect, and vice versa. Contrary to some recommendations in the literature (Sharma et al. 1981; Huber et al. 2006), the moderator variable z has to be integrated into the regression equation for the rating of the moderator effect independently from whether there is a quasi moderation (direct effect on z) or a pure moderation (no direct effect on z). An argumentation and a detailed description concerning the identification of the moderator effect will follow in Sect. 3.2.
Before introducing the procedures to analyze moderator effects in detail, a central problem in the context of the detection of moderator effects will be addressed—the dichotomisation of continuously spread variables.
This approach, which is often used in research practice, conflicts with diverse empirical findings showing that an artificial dichotomisation of variables (e.g. by median splitting) leads to false main or interaction effects (moderator effects) (MacCallum et al. 2002; Cohen et al. 2003; Jaccard and Turrisi 2003). Simulation studies prove that in moderated regression analyses that keep the original continuous character of the variables the type I (α) and the type II (β) error with respect to the identification of moderator effects turn out to be lower than at procedures that undertake a subsequent dichotomisation of the variables (see the simulation studies by Bissonnette et al. 1990; Mason et al. 1996; Stone-Romero and Anderson 1994). These empirical findings can be explained by the fact that artificially dichotomising the variables leads to a loss of information and, in consequence, to an increase of the error variance as the statistical power of the procedures decreases (Frazier et al. 2004); (Aguinis 2004); (Stone-Romero and Anderson 1994). It should be pointed out that an artificial dichotomisation of a continuous moderator variable can be quite reasonable when interpretation problems appear concerning the interaction term. Constellations of two interaction factors which result in equally high interaction terms are possible here, although they have to be interpreted differently regarding the content (in detail (Zedeck 1971)).
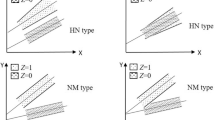
In the context of moderator effects, often mediator effects have also been considered (e.g. Baron and Kenny 1986; Frazier et al. 2004; Holmbeck 1997; James and Brett 1984; Judd et al. 2001; Shrout and Bolger 2002). This is caused by the similarity of both concepts that analyze the relationship between three variables x, y and z. Contrary to moderator effects, whose strength of the correlation between x and y varies depending on the value of the moderator variable z, a mediator effect indicates that the relationship between x and y is interrupted by the variable z (mediator), i.e. that the mediator explains the relationship between an exogenous (predictor) and an endogenous (criterion) variable within a causal chain (Baron and Kenny 1986). Figure 1 illustrates the difference between moderator and mediator effect.

Modelling of moderator vs. mediator effects
However, both effects can also occur in combination so that there is either a mediated moderation or a moderated mediation (in detail (Muller et al. 2005)).
When examining moderator effects, in many cases a clear theoretical basis for the analysis of these effects is missing. The reasons for this are, on the one hand, that the moderators that are examined are weak, or inconsistent effect relationships exist between the predictor and the criterion variable (Baron and Kenny 1986). On the other hand, moderator effects of variables, e.g. age in specific fields of research have been routinely considered (Einhorn and Bass 1971).
The previous considerations lead to the following intermediate result: the choice for a moderator should take place a priori and based on the theory in order to increase the chance of identifying moderator effects and to prevent misinterpretations in any case (Aguinis 2004; Frazier et al. 2004).
The focal points of this contribution are such situations in which researchers have specific theory-based predictions to test hypotheses about potential moderator variables. This means, there is an a priori rationale to investigate moderator effect. Hence, homologizers as moderator variables will not be considered any further in this paper since they cannot be specified a priori in the model.
3 Analyzing moderator effects
3.1 Systematisation of different procedures for the analysis of moderator effects
In the past decades numerous procedures have been developed to identify moderator variables and to describe their effects. Basically the following procedures—the application of which depends on the scales level of the predictor and moderator variables—can be distinguished:
-
The moderated regression analysis is a flexible procedure that can be employed both for continuous and also for categorical predictor and moderator variables, respectively.
-
In the case of a continuous predictor and a dichotomous moderator variable, the evidence of moderator effects can be provided by the help of a multi-group analysis (synonymic: group analysis or subgroup analysis). Hereby, the influence of the predictor on the criterion variable is observed separately for each characteristic of the moderator variable in order to subsequently analyze the groups concerning this correlation with regard to significant differences.
-
If both the predictor and the moderator variable feature a categorical scales level, the procedure of analysis of variance (ANOVA) is applied (Baron and Kenny 1986). The moderation is indicated by an interaction. This procedure will not be regarded any further here, since this method is very common for the analysis of experimental designs.
Table 2 contains the different procedures for the identification of moderator effects.
3.2 Moderated regression analysis
3.2.1 Options of regression model formulation
In the moderated regression analysis, the moderator variable z is connected to the exogenous variable x multiplicatively and is integrated into the analysis as interaction term xz, so that the moderator effect can be interpreted concerning its scope and significance. To test moderator effects the implementation of a hierarchical regression can be recommended, whereby the variables are taken in the regression equation in several successive steps (Aiken and West 1991; Cohen et al. 2003).
Assuming a quasi moderation in the first step (basic model–(3)), a regression model is formulated including both the predictor and the moderator variable. After that in a second step (interaction model–(4)), the product term is additionally taken into the regression equation (Aiken and West 1991; Cohen et al. 2003; Holmbeck 1997; McClelland and Judd 1993).
In contrast, assuming a pure moderation in a first step (basic model—(5)) a regression model is formulated including only the predictor variable. In a second step (interaction model—(6)), both the moderator variable and the product term are additionally taken into the regression equation.
It has to be noted that the moderator variable z needs to be included in the interaction model in both cases: in the quasi moderation and in the pure moderation. In a regression model with a product term as interaction variable, the product term displays the interaction (moderation) of two variables only if each of them is also taken in the regression model as elementary predictors. If the valuated regression model does not correspond with this specification, i.e. if the regression model includes only the product term without controlling the predictor and moderator variables, or a variable constituting the interaction term is missing, the interaction effect is distorted and the interaction term cannot be interpreted (Cohen et al. 2003; Cronbach 1987; Irwin and McClelland 2001).
If it is not clear a priori whether a quasi or a pure moderation is involved, the following procedure is recommended: In a first step (basic model 1–(7)), a regression model is formulated including only one predictor variable. After that in a second step (basic model 2–(8)), the moderator variable z is taken into the regression equation. In a third step (interaction model–(9)), the product term is additionally integrated into the regression equation.
3.2.2 Determination and interpretation of moderator effects
Whether or not we find a moderating effect can be judged by the significance of the regression coefficient b 3 belonging to the interaction term (Aguinis 2004; Baltes-Götz 2006). Alternatively to the t-test for the regression parameter b 3, it can be examined with the F test whether the change of the coefficient of determination R 2 from the base model to the interaction model is significantly different from zero. The change of the coefficient of determination (∆R²) is also a measure for the effect size of the moderator effect (Aguinis 2004; Jaccard et al. 1990). The R²-increase indicates how much criterion variance is additionally explained by the product term and, therefore, can be ascribed to the moderator effect (Aguinis 2004). In view of the result, this is identical to the use of the t test.
The strength of the moderator effect is often displayed in form of the effect size index (f 2):
whereby \( R_{I}^{2} \) characterizes the coefficient of determination of the interaction model and \( R_{B}^{2} \) the coefficient of determination of the basic model.
Typically, the size of the interaction effect turns out to be rather low in many empirical studies. The cause for this is the low reliability of the product terms that were composed of factors afflicted with measurement errors (Cohen et al. 2003; Jaccard and Turrisi 2003). For the evaluation of the effect size, Cohen (1988) has proposed the following values of f 2 that are conventionally established: 0.02 = low; 0.15 medium; 0.35 = high (also (Cohen et al. 2003)). A literature review by Aguinis et al. (2005) over a time period of 30 years revealed that the average effect size f 2 is about 0.005, the median about 0.002. These values do not only deviate much from Cohen’s defined values of a low, medium and high effect size, but make clear, how difficult it is to prove moderator effects at all.
In case of a significant moderator effect (f > 1.98) it is necessary to do further analysis in more detail. First it is examined which kind of moderation is involved. This takes place by using a simple t test for the regression coefficient b 2 of the moderator variable z in model (3) or (8), respectively. In case of a quasi moderation, the regression parameter b 2 in either model (3) or (8) is statistically significant; otherwise, it is a pure moderation. Further analyses concerning the moderator effect are carried out in three steps.
The first step consists of an interpretation of the regression coefficient b 3 that belongs to the interaction term. This is interpreted as the difference of the regression parameters concerning the relationship between predictor and criterion variable if the moderator variable varies (takes different characteristics) (Jaccard et al. 1990).
In a second step, the relationship between the predictor and the criterion variable is checked in detail for different characteristics of the moderator variable. For this purpose we selected representative characteristics of the moderator variable, e.g. some statistical criteria such as the average value as well as the standard deviation above/below the average value (Baltes-Götz 2006; Cohen et al. 2003). After that, the relationship between the predictor and criterion variable for each selected characteristic of the moderator variable is graphically illustrated separately by means of the particular regression line, so that it is possible to identify the type of moderator effect.
Based on this, a subsequent third step is a statistical significance test of the regression increase of each particular regression line (Aiken and West 1991); (Cohen et al. 2003). Thus, it is necessary to check whether the conditional slope coefficients for selected values of the moderator variables (e.g. z low, z mean, z high) are different from zero (Baltes-Götz 2006). In order to do so, a regression estimation of y to x is made separately for each character of the moderator variable. Following we examined whether there is a statistically significant influence of x on y at the particular character of the moderator variable (with t-tests for each of the three conditional regression lines, e.g., z low, z mean, z high).
Baron and Kenny (1986) have noted that, against the background of a distinct interpretation of the moderator effect, it is principally desirable that the moderator variable does not correlate with the predictor or criterion variable. Hence, it can be reasoned that a pure moderation relationship can be interpreted more precisely compared to a quasi moderation.
3.2.3 Interpretation of first-order effects
The interpretation of the first-order effects of the predictor and moderator variable with respect to the target variable is generally afflicted with some problems as long as there are moderator effects. Initially considering the
it can be easily realized that the first-order effect of the predictor b 1 is identical for all characters of the moderator variable z, i.e. independent of the values of the moderator variable z. Because of the symmetryFootnote 1 these considerations also apply analogously to the first-order effect of the moderator variable b 2. Looking upon the interaction model by transposing Eqs. 4 or 1, respectively, one can ascertain that the effect of the predictor x with respect to the criterion variable y depends on the value of the moderator variable z Eqs. 4.1 or 2. Because the symmetry also affects the regression of y on z, it is obvious analogously that it depends on the characters of the predictor variable x Eq. 4.2.
By restating the interaction model Eqs. 4.1 or 4.2, respectively, it becomes apparent that for each value of the moderator z (of the predictor x) a conditional linear regression of the criterion on the predictor variable (moderator variable) can be built. Thereby, it applies to the conditional ordinate intercept \( b_{0}^{z} \):
and to the conditional slope coefficient or the conditional effect, respectively, \( b_{1}^{z} \) (\( b_{2}^{z} \))
If the moderator variable z (predictor variable x) has the value zero, the term \( b_{3} z \) is eliminated from the Eq. 4.1.2 or the term \( b_{3} x \) from the Eq. 4.2.2, and then it is true that:
The explanations above show that the first-order effect of b 1 (b 2) is interpreted as conditional effect at a value of zero for the moderator variable (predictor variable).Footnote 2
Whether the interpretation of the first-order effect of the predictor variable (moderator variable) makes sense, depends on the importance of the moderator variable (predictor variable) at the point of zero. If the measurement of the moderator variable (predictor variable) took place, for example, by a Likert-scale with scales descriptions, whose endpoints are not described by a verbal maximum or minimum (zero value: “totally disagree” or “I never do that”) and therefore are not encoded using zero, the value of zero for this scale is also not defined. Hence, also the regression coefficient of the predictor variable b 1 (moderator variable b 2) is not convincing. To enable sensible interpretations of the first-order effects, a convincing scales-zero point that can be created by the centring or standardisation of the predictor and moderator variable is necessary (Cohen et al. 2003). Given centred predictor and moderator variables, the first-order effect of the predictor variable (moderator variable) represents the influence of this variable on the criterion variable at an average level (average value) of the moderator variable (predictor variable). In other words, the regression coefficient b 1 (b 2) is interpreted as medium conditional effect (Baltes-Götz 2006).
A further point for discussion concerning the interpretation of first-order effects in interaction models refers to the point of time the interpretation should be made. In some cases first-order effects are interpreted within the basic model, in other cases within the interaction model (Jaccard et al. 1990; Frazier et al. 2004). Some authors advocate interpreting first-order effects only in the case that the moderator effect is statistically insignificant (Carte and Russell 2003). If there is, by contrast, a significance of the moderator effect or a significant interaction, first-order effects should be interpreted within the interaction model. Cohen et al. (2003) point out that an interpretation of first-order effects within the basic model only makes sense if there is a strong theoretical basis to do so. Nevertheless, it shall be explicitly remarked that the interpretation of first-order effects in case an interaction/moderation exists is not always reasonable, because within the effects only one part of the available information is included (Baltes-Götz 2006; Hays 1983). Against this background the contingent effects should always be documented, both graphically and numerically (Baltes-Götz 2006).
3.2.4 Error specification in the model: non-distinctive causality and curvilinearity
Within moderated regression analysis, non-distinctive causal relationships between the variables can lead to misinterpretations and false conclusions with respect to the existence of moderator effects. According to the specification of the correlation x → y or y → x significant moderator effects can occur or not. If a clear theoretical basis for the direction of the correlation of two variables is missing, or if the causal relationship between two variables is ambiguous under certain circumstances, the use of two alternative models serves as a legitimate possibility for the identification of moderator effects. In this case, within a first model variable y is treated as criterion and x as predictor variable, within a second model the variable x as criterion and y as predictor variable as well as z as moderator variable each time. It is explicitly pointed out that this procedure is only advisable in situations described above, as an explorative mode of practice (Landis and Dunlap 2000).
There is a further form of error specification if moderator effects are confused with curvilinear main effects. Assuming that, for example, the following square model is true:
and that the variable z correlates with x, selecting the wrong model
can lead to a significant moderator effect b 3 because the square predictor x 2 is imitated by the product term xz (Baltes-Götz 2006; MacCallum and Mar 1995). Lubinski and Humphreys (1990) showed that this especially occurs at relatively high multicollinearity for this phenomenon. For this reason both the moderator regression model and the square regression model should be considered. The most appropriate model is the one showing the biggest change in R 2 or the highest effect size, respectively, whereby it should also be considered that the lacking reliability of the predictor and moderator variables affects the validity of the effect size (MacCallum and Mar 1995).
3.3 Multi-group analysis
Moderator effects can also be examined by a multi-group analysis. With this approach the whole sample is divided into subgroups by means of the moderator variable, whereby the number of groups corresponds to the number of characteristics of the moderator variable. Typically, having a continuous moderator variable the whole sample is divided into two subgroups on the basis of a median split. Following, regression analyses are conducted separately for each partial sample examining the relationship between the predictor and the criterion variable. The difference of the regression slope of the estimated regression equations between the partial samples expresses the influence of the moderator variable. Thereby, the proof of moderator effects is based on the following consideration:
If a moderator z can influence the effect between the predictor variable x and the criterion variable y, then, analyzing the effect separately in each particular moderator group, there should be a disparity with respect to the strength of influence, the direction of influence or the significance of this effect. This disparity is expressed by the partial regression coefficients of the estimated regression equations. Thus, the moderator effect can be identified by a comparison of the partial regression coefficients (non-standard) of the particular regression equations (Jaccard et al. 1990; Zedeck 1971).
Within the approach of multi-group analysis another method—which in principal is similar to the procedure described above—is found in the literature. In contrast instead of partial regression coefficients, correlation coefficients are checked following otherwise the above procedure (Arnold 1982; Baron and Kenny 1986; Hunter and Schmidt 1978; Stone-Romero and Anderson 1994).
According to the verification of the moderator type, it can be registered that without further analysis it is not possible to detect whether a pure or a quasi moderation is involved (Sharma et al. 1981). Insofar, the question arises whether the multi-group analysis is an appropriate method in case of a quasi moderation, because only the correlation between x and y is regarded within the analysis, separately for the moderator based subgroups. The direct and therefore relevant effect of z on y remains unconsidered.
3.4 Alternative methods in the literature and critical appraisal of the discussed procedures
Both the moderated regression analysis and subgroup analysis are procedures that offer the principal possibility to identify moderator effects. Both procedures provide insights concerning strength and direction of a relationship between two variables, which may vary depending on a third variable, the moderator. However, independent of the fact that these procedures are statistically correct they have some—already discussed—deficits when providing an answer for the particular research question. These issues have to be taken into consideration when choosing an appropriate procedure in view of the particular research background.
In the literature numerous alternative methods have been proposed in order to increase the chance to identify moderator effects (Anderson et al. 1996; Arnold 1982, 1984; Darrow and Kahl 1982; Kahl and Darrow 1984). Darrow and Kahl (1982), for example, proposed the technique of the so-called backward regression within the moderated regression analysis, for which in a first step the product term, and in a second step the predictor and moderator variable are taken in. The central critique concerning this procedure is based on the argumentation that this methodology breaks with the basic principle of multiple regression analysis, in which first-order effects and subsequently (or simultaneously) the product/interaction term are taken into account (Stone 1988; Stone and Hollenbeck 1984, 1989).
Within the subgroup analysis the use of the correlation coefficient, recommended by Hunter and Schmidt (1978), instead of the regression coefficient has to be regarded critically because the correlations are influenceable by the variance heterogeneity of the subgroups (Baron and Kenny 1986). Furthermore, correlation coefficient (r) and regression coefficient (b) are related with each other as follows: b = r (sy/sx). Only if the relation of the standard deviation of y (sy) and x (sx) has the value of one, are the regression and the correlation coefficients commensurate. In this case, the differences of the correlation coefficients between the subgroups point to a moderator effect. If the relation of the standard deviation does not have the value of one, the regression and the correlation coefficients are not commensurate, and the differences in the correlations between the subgroups are not a reliable indication of a moderator effect (Aguinis 2004). Correlations between predictor and criterion variable are also influenced by the subgroups specific measurement errors of the depending variable, which have to be checked before. Against the background of these deficits, the subgroup analysis should always be based on the regression coefficient (Baron and Kenny 1986).
In the past years numerous authors have been dealing with the relative profitability of the moderated regression analysis and the subgroup analysis (Cohen et al. 2003; Stone 1988; Stone and Hollenbeck 1984, 1989; Stone-Romero and Anderson 1994; Zedeck 1971). Compared to the subgroup analysis the moderated regression analysis has a better performance in the case of an original continuous moderator variable that has been subsequently transformed into a categorical scales system (e.g. dichotomisation) in order to carry out a subgroup analysis (Stone-Romero and Anderson 1994). The loss of statistical power results from the loss of information connected to the dichotomising. This problem has already been pointed out. In the case of a naturally given categorical moderator variable the use of the moderated regression analysis instead of the subgroup analysis is recommended by many authors (Aguinis 2004; Chaplin 1991; Stone 1988). Finally also against the background of an a priori often indistinct moderator relationship, the moderated regression analysis seems to be more advantageous than the subgroup analysis because, for example, direct effects of the moderator variable remain undetected by the execution of a subgroup analysis.
The moderated regression analysis shows some deficits, too (Jaccard et al. 1990). Especially with models of latent constructs the moderated regression analysis does not provide the possibility to integrate the existing measurement errors into the model. This can lead to misjudgements concerning the importance or existence of moderator effects. Lacking reliability caused by measurement errors leads to a low correlation of the criterion variable with the predictor variable, which leads to a decreasing model fit (R²) and therefore also to a loss of statistical power (Aguinis 1995).
A possible solution is the use of structural equation models (Aguinis 1995; Baron and Kenny 1986); related with the problem of bigger sample sizes etc. (see further literature about moderator effects in structural equation models: (Huber et al. 2006; Jaccard and Wan 1996; Schermelleh-Engel et al. 1998).
The last category of factors influencing the statistical power refers to the characteristic of the predictor variables. Some authors argue that existing multicollinearity leads to an attenuation of the statistical power (Morris et al. 1986; Smith and Sasaki 1979). The multicollinearity results, on the one hand, from the correlation of the predictor variable x and the moderator variable z, and on the other hand, from the particular correlation of the interaction term xz with the variables x and z. Some part of this multicollinearity problem can be solved by centring the predictor/moderator variable (Aguinis 2004; Baltes-Götz 2006). Cronbach (1987) could prove that the correlations between predictor and moderator variable have no negative influence on the statistical power. Concerning the correlation between the predictor variable x and the criterion variable y it can be noted that moderator effects are most likely detected if there is a strong relationship between the predictor and the criterion variable, i.e. if there are strong first-order effects (Nunnally 1967). In this context Jaccard and Wan (1995) propose to increase the explanatory power of the model (R²) by the integration of additional significant predictors and, thus, also the statistical power.
A further proposal has been advanced by Anderson et al. (1996) using the technique of errors-in-variables-regression (EIVR) instead of the moderated regression analysis. This method takes into account the error variances of the regressors within the frame of the parameter estimation so that the influence of a lacking reliability of the predictors and, thus, also of the product term is weakened. The results of the simulation showed that the parameter estimation values of the EIVR were especially better than the parameter estimation values of the moderated regression analysis as long as the sample size was n ≥ 250 and the reliability of the predictors r ii ≥ 0.65 was high (Anderson et al. 1996). Taking into consideration that in many social science studies both the sample size and the reliabilities turn out to be rather low, the moderated regression analysis has to be favoured over the EIVR (Aguinis 2004).
The findings up to now suggest the following conclusions:
-
Independent of the type of the actual moderation relationship within the interaction model, the interaction term as well as the predictor and the moderator variable have to be integrated.
-
In case of a continuous predictor and moderator variable and in case of a naturally given categorical moderator variable the moderated regression analysis is preferred.
-
A hierarchical regression is preferred.
-
The interpretation of the first-order effects is made within the interaction model.
-
Finally, it should be abstained from an artificial dichotomising of the moderator variable.
4 Empirical consequences for the identification of moderator effects using different regression models
In the following it shall be demonstrated with the help of an adapted data set (empirical data record with typical distribution of variables) which consequences and misinterpretations can occur (or can be found in empirical studies in the literature) when ignoring the above-presented proposals. For illustration purposes, we apply these case studies to the example in Sect. 1, where we already mentioned the influence of the firms’ R&D-effort on financial performance, and the question whether this relationship is influenced by the firms’ integration in an innovation network. This example will demonstrate again the importance of selecting the model of analysis on the basis of theoretical considerations. Otherwise, depending on the researchers’ choice of model different implications will result due to different analysis results. It is imperative to formulate a sound model concerning the connections between the variables of our example, and formulate the corresponding regression equations.
All OLS-regressions executed in the following case studies were examined for violation of premises concerning the non-normal distribution of the residuals, nonlinearity between independent and dependent variables, multicollinearity, auto-correlation and heteroscedasticity. Thereby, no violations of the application premises were found. It should be noted that, whether the analysis method is modified does not concern the goodness of the results, but rather a change of the results.
In Case I (Table 3) based on theoretical considerations a pure moderation is insinuated. The predictor variable x (R&D-effort) features a continuous scales level, the moderator variable (member of an innovation network) a categorical scales level (yes or no). This constellation corresponds to the ideal case for the identification of a moderator relationship. Firstly, a hierarchical regression analysis is executed estimating Basic Model I and subsequently Interaction Model I. The moderated regression with categorical moderator variable presupposes the homogeneity of the residual variances. A violation of the assumption, which often remains disregarded within the research practices, can influence the results of the moderated regression (Judd et al. 1995). The executed homogeneity test, F = 0.971, p < 0.01, confirmed no violation of this assumption. The regression results prove the presence of a pure moderation.
In Basic Model I the predictor variable x (R&D-effort) shows, on the one hand, a significant influence with p < 0.01 while, on the other hand, no significant direct influence of the moderator variable z (member of an innovation network) on the dependent variable y (financial performance) can be attested. The integration of the product term xz (the combined effect of the membership in an innovation network and the R&D-effort) leads to an increase of R² with 0.019, F (1.142) = 5.940, p < 0.05 within Interaction Model I. The effect size (f 2) of the moderating effect is 0.042 and has to be characterized as too low according to the classification by Cohen et al. (2003).
If now falsely the moderator variable z (member of an innovation network), which is part of the interaction term xz but exerts no significant influence on the criterion variable, is not considered for the assessment of the regression models, this leads to a falsification of the interaction effect, as the results of Interaction Model II show. At first, Basic Model II is estimated without the moderator variable z (member of an innovation network), and the predictor x (R&D-effort) shows with p < 0.01 a significant influence. In view of the estimation of Interaction Model II it is evident that the integration of the interaction term does not lead to a significant increase of R². This means that within Interaction Model II no significant moderator effect (i.e. the combined effect of the membership in an innovation network and the R&D-effort) can be proved. The consideration of the effect sizes (f 2) shows that in Interaction Model II, where the moderator variable z (member of an innovation network) remains disregarded, the effect size is weakened and is only f 2 = 0.011 compared to an effect size of f 2 = 0.042 in Interaction Model I. Thus, the regression coefficient b 3 belonging to the interaction term cannot be interpreted either. Hence, it can be registered that the absence of the moderator variable z in the regression estimation causes an undetected but actual existing moderator effect, i.e. researchers would not detect the reinforcing effect of the membership in an innovation network on the relationship between the R&D-effort and the financial performance although this does exist in the empirical data.
In analogy to Case I, in Case II (Table 4) also a pure moderation is insinuated based on theoretical considerations. Both the predictor (R&D-effort) and moderator variables (member of an innovation network looking at the cooperation intensity) show a continuous scales level. Firstly, a hierarchical regression analysis is executed estimating Basic Model I and subsequently Interaction Model I. All regression coefficients both in Basic Model I and in Interaction Model I are statistically significant with p < 0.01. But contrary to the original assumption, it turns out that the moderator variable z (member of an innovation network) exerts a direct influence on the criterion variable (financial performance). The integration of the product term leads to an increase of R² with 0.037, F (1.178) = 11.581, p < 0.01, so that the results attest the existence of a quasi moderation. The effect size (f 2) of the moderating effect is 0.065 and has to be characterized as low.
First of all it should be mentioned that executing a hierarchical regression with consideration of all relevant regression parameters, i.e. of both the predictor variable x (R&D-effort) and also the moderator variable z (member of an innovation network), leads to an unexpected quasi moderation. This situation might be typical for social and behavioural science studies.
If at this point—in contrast to the procedure described above and supposing a pure moderation—either the moderator variable z (Model II) or the predictor variable x (Model IIIFootnote 3) are falsely not integrated when assessing the regression analysis, the interaction effect (i.e. the combined effect of the membership in an innovation network and the R&D-effort) is falsified. The results of Basic Models II and III attest each a significant direct influence of the variables x (R&D-effort) and z (member of an innovation network), respectively, with p < 0.01. The integration of the product term leads to an increase of R² with 0.019, F (1.179) = 5.590, p < 0.05 within Interaction Model II and within Interaction Model III to an increase of R² with 0.074, F (1.179) = 15.860, p < 0.01. The results confirm a statistically relevant interaction effect of the membership in an innovation network and the R&D-effort in each of the two models (II and III) and, hence, a (positive) moderator relationship. However, by ignoring a variable that builds the interaction term in each case, the interaction effect is falsified. This is evident in view of the effect size of the moderator effect (f 2), which leads to an attenuation of the moderator effect (f 2 = 0.031) in case of omission of the moderator variable z (member of an innovation network) in Model II, and to an intensification of the moderator effect (f 2 = 0.089) in case of the missing predictor variable x (R&D-effort) in Model III. Thus, the regression coefficient b 3 belonging to the interaction term (combined effect of the membership in an innovation network and the R&D-effort) cannot be interpreted either. Hence, it is obvious that ignoring a variable that forms a part of the interaction term leads to a distortion of the actual size of the moderator effect. The combined effect of the firm’s membership in an innovation network and the R&D-effort on financial performance does not result in a valid parameter, with the consequence that the research implications vary according to the chosen model.
In the literature the execution of a subgroup analysis is often done in case of a naturally given categorical moderator variable (member of an innovation network: yes or no). As mentioned above, a big disadvantage is that possible direct effects of the moderator variable remain undetected. In light of this, in Case III (Table 5) a quasi moderation with continuous predictor (R&D-effort) and naturally given categorical moderator variable (member of an innovation network) is detected. Firstly, a hierarchical regression analysis is executed estimating the Basic Model and subsequently the Interaction Model. All regression coefficients both in the Basic Model and in the Interaction Model are statistically significant with p < 0.01 and p < 0.05, respectively, with regards to the interaction term. The integration of the product term (combined effect of the membership in an innovation network and the R&D-effort) leads to an increase of R² with 0.030, F (1.180) = 9.675, p < 0.05. The results confirm the existence of a quasi moderation and, based on the negative interaction term, the presence of a negative moderator effect, i.e. a negative effect of the interaction between the membership in an innovation network and the R&D-effort on financial performance. The effect size (f 2) of the moderating effect is 0.053 and has to be characterized as low.
Subsequently for both characteristics of the moderator variable (subgroup 1: firm is a member of an innovation network; and subgroup 2: firm is not a member of an innovation network) a separate regression of x (R&D-effort) on y (financial performance) is estimated and a check-up of the regression coefficients b 1 is carried out concerning a significant difference. Thus, we have to test whether −0.671 is a statistically higher result than −1.262. The premise of homogeneity of the residual variances of the two universes has to be complied for both the moderated regression with categorical variable and the subgroup analysis. The executed homogeneity test, F = 1.163 with p < 0.01 confirmed no violation of this assumption. The parameter comparison of the two regression coefficients revealed a significant difference with p < 0.01. This means that the correlation between the predictor (R&D-effort) and the criterion variable (financial performance) turns out to be lower at a high characteristic of the moderator variable (firm is a member of an innovation network) than at a low characteristic of the moderator variable (firm is not a member of an innovation network). Hence, there is a negative moderator effect. This result is consistent with the result of the moderated regression analysis that attests a significantly negative interaction effect, b 3 = −0.590 with p < 0.05. It can be noted that a significant moderator effect can also be identified by the subgroup analysis, but the direct effect of the moderator variable (the direct effect of the membership in an innovation network on financial performance) remains undetected using this approach. Insofar as having a naturally given categorical moderator variable, a moderated regression analysis should be preferred to the subgroup analysis.
Case IV (Table 6) deals with the problem of unreal interaction effects based on a median split of the moderator variable. On the basis of theoretical considerations a quasi moderation is assumed, predictor (R&D-effort) and moderator variable (member of an innovation network looking at the cooperation intensity) show a metrical scales level. Firstly, a hierarchical regression analysis is executed estimating Basic Model I and subsequently Interaction Model I. The regression coefficients with respect to the predictor and the moderator variables are statistically significant both in Basic Model I and in Interaction Model I with p < 0.01. However, the integration of the product term (combined effect of the membership in an innovation network and the R&D-effort) only leads to an increase of R² with 0.006, F (1.181) = 2.564, p > 0.1. That means that in Interaction Model I no significant moderator effect can be confirmed. The effect size (f 2) is only 0.014.
Now, once again a hierarchical regression is executed after the moderator variable was transformed into a categorical scales level by median splitting (intensive cooperation within the innovation network versus low cooperation within the innovation network). Both the predictor (R&D-effort) and the moderator variable attest with p < 0.01 a significant influence on the criterion variable (financial performance) in Basic Model II. But the integration of the product term (combined effect of the “degree” of cooperation in an innovation network and the R&D-effort) in Interaction Model II leads to a significant increase of R² with 0.012, F (1.181) = 5.186, p < 0.05. The results of the model assessment II attest the existence of a moderator effect, whose effect size of f 2 = 0.027 turns out to be higher than in model assessment I. Despite of the significant moderator effect in Interaction Model II the result should be critically observed, because a median split is always connected to a loss of information (the metric scale of the variable “cooperation intensity in an innovation network” is transferred to “high/low”) and thus, the significant moderator effect seems to be doubtful.
5 Summary
The moderated regression analysis represents the most popular procedure for the identification of moderator effects. The advantage of this procedure is also emphasised in relation to an a priori and often indistinct moderator relationship. The purpose of this paper is to show in which way moderator effects can be systematically identified by means of a multiple hierarchical regression.
Thereby, special attention was directed to possible misinterpretations and false conclusions that result from different methodical procedures for the identification of moderator effects that cannot be found yet in the literature. This was illustrated by means of four empirical case studies, in which a typical question often rising in business research and practice studies, in which a typical question often rising in business research and practice (the influence of the firms’ R&D-effort on financial performance and the question whether this relationship is positively or negatively influenced by the firms’ integration in an innovation network) appears. The case studies were interpreted based on a common data record, whereby the chosen methods corresponded to current research practices in the literature. Looking at the various results and implications when applying these methods to the case studies or to the other examples mentioned at the beginning of the paper, it is obvious that depending on the four methodological cases different implications for (further) management research and practice are derived. This follows from the fact that either certain moderating effects (in our example the combined effect of R&D-effort and the membership in an innovation network) remain unconsidered (Case 1) or were falsely categorised (Case 4). Beyond that, it is possible that the impact of certain determining factors is over-/underestimated (Case 2/3). Specifically in our case, the effect size or even the significance of an effect depends only on the way the model has been formulated.
It is obvious that the different results from the analysis of an empirical data set lead the management to false or inefficient activities, e.g. whether to integrate the own R&D activities into an innovation network or not. Bearing in mind the enormous resources which have to be allocated and the dangers of loosing strategic competencies following a recommendation like this, it is highly relevant to analyse this type of research question adequately. This is even more important as the models per se are quite simple, and many researchers obviously think that they can easily do the analysis. In the research example we were looking at only one predictor and one moderator variable, so that the structure of the research question remained somewhat comprehensible, but the execution of these moderated regression analyses is empirically in line with Aguinis (2004) and resembles “…walking in a minefield”.
Furthermore it became clear that besides the statistical-methodical problems, the theoretical considerations of moderator relationships play a central role. Both the selection of the moderator and the hypothesised effect relation of the moderator should be the basis for theoretical considerations (Jaccard et al. 1990). The procedure described in this paper as well as the case studies are supposed to give assistance analyzing moderator relationships and evaluating already published research results concerning moderator effects.
Notes
Implying an interaction effect of the independent variables x and z on the dependent variable y, on the one hand, one can assume that the effect of x on y is moderated by z; on the other hand, the correlation can also be interpreted in a way that the effect of z on y is moderated by x. Insofar the variables x and z act symmetrically. Which variable is defined as moderator variable is an issue for theoretical consideration.
On the supposition that x and y act symmetrically for reasons of completeness, also Model III is displayed; see also the annotations in footnote 2. Model III implies that z serves as predictor and x as moderator variable.
References
Aguinis H (1995) Statistical power problems with moderated multiple regression in management research. J Manag 21:1141–1158
Aguinis H (2004) Regression analysis for categorical moderators. Guilford Press, New York
Aguinis H, Beaty JC, Boik RJ, Pierce CA (2005) Effect size and power in assessing moderating effects of categorical variables using multiple regression: a 30- year review. J Appl Psychol 90(1):94–107
Aiken LS, West SG (1991) Multiple regression: testing and interpreting interactions. Sage, Newbury Park, CA
Anderson LE, Stone-Romero EF, Tisak JA (1996) A comparison of bias and mean squared error in parameter estimates of interaction effects: moderated multiple regression versus errors-in-variables regression. Multivar Behav Res 31:69–94
Arnold HJ (1982) Moderator variables: a clarification of conceptual, analytic, and psychometric issues. Organ Behav Hum Perform 29:143–174
Arnold HJ (1984) Testing moderator variable hypotheses: a reply to Stone and Hollenbeck. Organ Behav Hum Perform 34:214–224
Baltes-Götz B (2006) Moderatoranalyse per multipler Regression mit SPSS, Online-Dokument: http://www.uni-trier.de/urt/urthome.shtml, abgerufen am 15 July 2006
Baron RM, Kenny DA (1986) The moderator-mediator variable distinction in social psychological research: conceptual, strategic, and statistical considerations. J Pers Soc Psychol 51(6):1173–1182
Bissonnette V, Ickes W, Bernstein I, Knowles E (1990) Personality moderating variables: a warning about statistical artifact and a comparison of analytic techniques. J Pers 58:567–587
Carte TA, Russell CJ (2003) In pursuit of moderation: nine common errors and their solutions. MIS Q 27(3):479–501
Chaplin WF (1991) The next generation in moderation research in personality psychology. J Pers 59:143–178
Cohen J (1988) Statistical power analysis for the behavioral sciences, 2nd edn. Erlbaum, Hillsdale, NJ
Cohen J, Cohen P, West SG, Aiken LS (2003) Applied multiple regression/correlation analyses for the behavioral sciences, 3rd edn. Lawrence Erlbaum, Mahwah, NJ
Cortina JM (1993a) Interaction, nonlinearity, and multicollinearity: implications for multiple regression. J Manag 19:915–922
Cortina JM (1993b) What is coefficient alpha? an examination of theory and applications. J Appl Psychol 78:98–104
Cronbach LJ (1987) Statistical tests for moderator variables: flaws in analyses recently proposed. Psychol Bull 102:414–417
Darrow AL, Kahl DR (1982) A comparison of moderated regression techniques considering strength of effect. J Manag 8(2):35–47
Einhorn HJ, Bass AR (1971) Methodological considerations relevant to discrimination in employment testing. Psychol Bull 75:261–269
Frazier PA, Tix AP, Barron KE (2004) Testing moderator and mediator effects in counseling psychology research. J Couns Psychol 51(1):115–134
Hays WL (1983) Statistics. Holt Rinehart & Winston, New York
Holmbeck GN (1997) Toward terminological, conceptual, and statistical clarity in the study of mediators and moderators: examples from the child-clinical and pediatric psychology literatures. J Consult Clin Psychol 65:599–610
Huber F, Heitmann M, Herrmann A (2006) Ansätze zur Kausalmodellierung mit Interaktionseffekten. Die Betriebswirtschaft 66(6):696–710
Hunter JE, Schmidt FL (1978) Differential and single-group validity of employment tests by race: a critical analysis of three recent studies. J Appl Psychol 63:1–11
Irwin JR, McClelland GH (2001) Misleading heuristics and moderated multiple regression models. J Mark Res 38:100–109
Jaccard J, Turrisi R (2003) Interaction effects in multiple regression, 2nd edn. Sage, Newbury Park, CA
Jaccard J, Wan CK (1995) Measurement error in the analysis of interaction effects between continuous predictors using multiple regression: multiple indicator and structural equation approaches. Psychol Bull 117:348–357
Jaccard J, Wan CK (1996) LISREL approaches to interaction effects in multiple regression. Thousand Oaks, London, New Delhi
Jaccard J, Turrisi R, Wan CK (1990) Interaction effects in multiple regression, Sage University paper series on quantitative applications in the social sciences 07–072. Sage, Newbury Park, CA
James LR, Brett JM (1984) Mediators, moderators, and tests for mediation. J Appl Psychol 69:307–321
Judd CM, McClelland GH, Culhane SE (1995) Data analysis: continuing issues in the everyday analysis of psychological data. Annu Rev Psychol 46:433–465
Judd CM, Kenny DA, McClelland GH (2001) Estimating and testing mediation and moderation in within-subjects designs. Psychol Methods 6:115–134
Kahl DR, Darrow AL (1984) Model determination in moderated regression. J Manag 10:234–236
Landis RS, Dunlap WP (2000) Moderated multiple regression–tests are criterion specific. Organ Res Methods 3:254–266
Lubinski D, Humphreys LG (1990) Assessing spurious “moderator effects”: illustrated substantively with the hypothesized (“synergistic”) relation between spatial and mathematical ability. Psychol Bull 107:385–393
MacCallum RC, Mar CM (1995) Distinguishing between moderator and quadratic effects in multiple regression. Psychol Bull 118:405–421
MacCallum RC, Zhang S, Preacher KJ, Rucker DD (2002) On the practice of dichotomization of quantitative variables. Psychol Methods 7:19–40
Mason CA, Tu S, Cauce AM (1996) Assessing moderator variables: two computer simulation studies. Educ Psychol Measur 56:45–62
McClelland GH, Judd CM (1993) Statistical difficulties of detecting interactions and moderator effects. Psychol Bull 114:376–390
Morris JH, Mansfield ER, Sherman JD (1986) Failures to detect moderating effects with ordinary least squares-moderated multiple regression: some reasons and a remedy. Psychol Bull 99:282–288
Muller D, Judd CM, Yzerbyt VY (2005) When moderation is mediated and mediation is moderated. J Pers Soc Psychol 89(6):852–863
Nunnally JC (1967) Psychometric theory. McGraw-Hill, New York
Nunnally JC (1978) Psychometric theory, 2nd edn. McGraw-Hill, New York
Peterson RA (1994) A meta-analysis of cronbach’s coefficient alpha. J Consum Res 21:381–391
Schermelleh-Engel K, Moosbrugger H, Klein A (1998) Structural equation models with latent interaction effects: comparing the efficiency of LMS, LISREL-ML and LISREL-WLSA. In: Hox JJ, de Leeuw ED (eds) Assumptions, robustness, and estimation methods in multivariate modeling. TT-Publikaties, Amsterdam, pp 87–109
Schmitt NW, Klimoski RJ (1991) Research methods in human resource management. South-Western, Cincinnati, OH
Sharma S, Durand RM, Gur-Arie O (1981) Identification and analysis of moderator variables. J Mark Res 18:291–300
Shrout PE, Bolger N (2002) Mediation in experimental and nonexperimental studies: new procedures and recommendations. Psychol Methods 7:422–445
Smith KW, Sasaki MS (1979) Decreasing multicollinearity: a method for models with multiplicative functions. Sociol Methods Res 8:35–56
Stone EF (1988) Moderator variables in research: a review and analysis of conceptual and methodological issues. In: Ferris GR, Rowland KM (eds) Research in personnel and human resources management, vol 6. JAI Press, Greenwich, pp 191–229
Stone EF, Hollenbeck JR (1984) Some issues associated with the use of moderated regression. Organ Behav Hum Perform 34:195–213
Stone EF, Hollenbeck JR (1989) Clarifying some controversial issues surrounding statistical procedures for detecting moderator variables: empirical evidence and related matters. J Appl Psychol 74:3–10
Stone-Romero EF, Anderson LE (1994) Relative power of moderated multiple regression and the comparison of subgroup correlation coefficients for detecting moderating effects. J Appl Psychol 79(3):354–359
Zedeck S (1971) Problems with the use of “moderator” variables. Psychol Bull 76:295–310
Acknowledgments
The authors would like to thank two anonymous reviewers and Wolfgang Kuersten for helpful comments on earlier versions of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Helm, R., Mark, A. Analysis and evaluation of moderator effects in regression models: state of art, alternatives and empirical example. Rev Manag Sci 6, 307–332 (2012). https://doi.org/10.1007/s11846-010-0057-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11846-010-0057-y