
Abstract
Clustering validity index (CVI) plays an important role in data partitioning and image segmentation. In this paper, a new CVI is proposed to perform the color image segmentation. The proposed CVI combines compactness, separation and overlap to assess the clustering quality effectively. The aggregation operators (t-norms and t-conorms) are used to build a new reliable and robust overlap measure. Moreover, a genetic algorithm is employed to dynamically optimize the clusters centroids and get the best possible data partition. The clustering of super-pixels is performed to reduce the computational cost and convergence time. The genetic algorithm with new clustering validity index is able to find the best data partitioning. The performance of the proposed algorithm is evaluated on the Berkeley image segmentation database. The extensive experimentation shows that the proposed algorithm performs better compared to other state-of-the-art methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In image processing and computer vision literature, segmentation refers to the process of dividing an image into multiple disjoint segments. It is a key preliminary vision task used by various high level image and videos analysis techniques such as: content-based image retrieval [1,2,3,4,5,6], image compression [7,8,9,10], object detection [11,12,13,14,15,16,17] and activity recognition [18,19,20,21,22,23]. There are two main types of image segmentation: interactive segmentation and automated segmentation. Interactive segmentation [24,25,26,27] extracts an object of interest with the help of human interaction, while automated segmentation partitions an image into a set of disjoint regions without any human interaction [28,29,30,31,32,33,34]. A large number of image segmentation algorithms have been reported in the literature. However, these can be divided into four categories: (1) image based, (2) feature-based, (3) physics-based and (4) hybrid approaches.
The physics-based approaches [35,36,37,38,39] utilize the reflectance property of the objects for segmentation. These methods can better handle the chromatic changes caused by shadows and highlights. However, in most cases, no prior information about the object’s reflectance is available. Therefore, physics-based methods are only useful for some specific cases, where the reflectance of objects is known.
The hybrid approaches [28, 29, 40,41,42,43,44,45] try to combine the strengths of each approach. However, how to combine the strengths of different approaches and avoid their weaknesses? Still remains an open question.
Feature-based approaches treat the segmentation process as a clustering problem [30,31,32, 46,47,48,49,50]. As in any clustering problem, determining the exact number of clusters is a principal shortcoming of these approaches.
The quality of data partitioning and clustering can be assessed by a clustering validity index (CVI) [51, 52]. Such an index quantify the extent to which the given clusters reflect the actual structure present in the data. In this paper, we propose a new clustering validity index which combines the compactness, separation and overlap to improve the accuracy of segmentation. The concept of aggregation (t-norms and t-conorms) is used to build a new measure of overlap. The optimal clusters centroids and the optimal number of clusters are estimated by using a genetic algorithm-based optimizer. Additionally, the super-pixels are used for reducing the computational complexity to get well-defined segments.
Section 2 presents the proposed method in detail, while Sect. 3 contains the experimental results followed by conclusion.
2 The proposed method
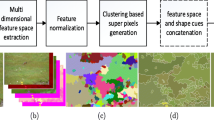
The proposed method has three key processes. The first is super-pixel segmentation to reduce the search space and computational cost of the clustering process. The second is a new clustering validity index (CVI) which is proposed to get the best possible arrangement of data partitioning. Finally, the genetic algorithm is used to optimize the cluster centroids and find the optimal number of clusters.
2.1 Super-pixels generation and features extraction
Perceptually uniform regions in image are called super-pixels. It exponentially reduces the image primitives regions and helps to extract rich spatial features [53,54,55,56]. In this work, the procedure of [56] is used for the super-pixel segmentation. Figure 1 shows the result of super-pixel segmentation [56].
Let \(\chi ^i\) represents the ith super-pixel, then its feature vector, \(\mathbf {x}^{i}\in \mathfrak {R}^{n\times 1}\), is computed as follows:
where the first, second and third components of the feature vector represent the means of super-pixel in RGB, HSV and Lab color spaces respectively, while \(\hbar \) represents the normalized histogram of oriented gradients (HoG) of \(8\times 8\) window centered on the super-pixel.

2.2 Clustering validity index (CVI)
Let \(\mathbf {v}^{1}\), \(\mathbf {v}^{2}, \ldots , \mathbf {v}^{K}\in \mathfrak {R}^{n\times 1}\) represent the clusters centroids and \(X=\{\mathbf {x}^{1}, \mathbf {x}^{2}, \mathbf {x}^{3}, \ldots \mathbf {x}^{N}\}\) denote the data points. Then, the membership values \({{u}^{ij}}\), \(i = 1, 2,\ldots , K\) and \(j = 1, 2,\ldots , N\) can be determined as [57]:
where m is a parameter used to control the fuzziness of the membership values. The membership \(u^{ij}\) demonstrates the relationship of a point \(\mathbf {x}^{j}\) to a centroid \(\mathbf {v}^i\). The t-conorm is normally used to assign a data point \(\mathbf {x}^{j}\) to the most matching element of the membership vector \(\mathbf {u}^{j} =[u^{1j}; \ldots ;u^{K j}]^T\). However, a data point \(\mathbf {x}^{j}\) may be a member of multiple centroids with different degree of similarity. Thus, the aggregate value of \(\mathbf {u}^{j}\) is better to evaluate the overlap of a particular data point, \(\mathbf {x}^{j}\). The fuzzy OR operator \((\hbox {fOR}-l)\) [58] uses the combination of t-norms with a given order (l) to estimate the extent of similarity. Suppose a \(\rho \) represents the power set of \(C= {1,2, \ldots ,K}\) and \(\rho _{l} =\{S \in \rho :|S|=l \}\), where |S| represents the cardinality of the subset S. Then \((\hbox {fOR}-l)\) maps \(u^{j}\) to a scalar value .i.e., \(\overset{l}{\bot }(\mathbf {u}^{j})\in [0; 1]\),
The above equation demonstrates that the standard t-norms, \(\overset{l}{\bot }(\mathbf {u}^{j})\) give us the lth highest value of \(\mathbf {u}^{j}\).
Then, for a particular point \(\mathbf {x}^{j}\in X\), the degree of overlap among l fuzzy clusters can be determined by its membership vector \(\mathbf {u}^{j}\), as given in Eq. (3). For a point \(\mathbf {x}^{j}\) the total degree of overlap is determined by the order which induces minimum overlap. The K-order overlap measure is adopted to explore the most probable order(s) that induces minimum overlap. Thus, for a given point \(\mathbf {x}^{j}\) the overall overlap can be given by Eq. (4).
Thus, the commutative overlap for K-order is given by:
Illustration of Overlap\(O_{\bot }(K)\) Consider the following fuzzy membership matrix U:
where \(K=5\) and number of data points are six. In this case the \(\overset{\lceil K/2\rceil }{\bot }\mathbf {u}^{j} \) and \(\overset{K}{\bot }\mathbf {u}^{j}\) give us the third and fifth maximum values in each column, respectively, where \(j=1,2, \ldots ,6\).
Thus, \(\frac{\overset{3}{\bot }\mathbf {u}^{j}+\overset{5}{\bot }\mathbf {u}^{j}}{2}\) becomes: \(\big [ 0.080 \; 0.098 \; 0.478 \; 0.095 \; 0.093 \; 0.108 \big ]\). So the total overlap \(O_{\bot }(5)\) becomes 0.1587.
The commutative normalized fuzzy deviation of data points [59] is used as a compactness measure,
The separation is defined in term of clusters centroids diversity. Let \(V=[\mathbf {v}^1,\mathbf {v}^2,\ldots \mathbf {v}^K]^\mathrm{T}\) represent the K clusters centroids then a symmetric matrix \(A\in \mathfrak {R}^{K\times K}\) is constructed:
The clusters separation \(\Psi \) can be computed by the following equation:
where \(\lambda \) represent the eigenvalues of A. The compactness ‘\(\Omega \)’ needs to be minimized in order to maximize the intra-cluster similarities. Similarly, we need smaller overlap \(O_{\bot }(\cdot )\) to ensure the maximum disjointness. To increase inter-clusters deviation, we need to maximize the fuzzy separation \(\Psi \). So, the final clustering validity index (CVI) is given by:
The smaller CVI represents the best clustering and vice versa.
2.3 Genetic algorithm-based super-pixels clustering
We consider the clustering of super-pixels as a maximization case of optimization problem. The main purpose of genetic algorithm is to decide the optimal number of clusters, K, and estimate optimal centroids.
Let \(\mathbf {v^i\in \mathfrak {R}^{n\times 1}},i=1\dots K\) represent the clusters centroids then a chromosome is represented by string of real numbers, \([(\mathbf {v}^1)^\mathrm{T},(\mathbf {v}^2)^\mathrm{T},\dots (\mathbf {v}^K)^\mathrm{T}]\in \mathfrak {R}^{1\times nK}\), where n is the dimension of centroid and K denote the number of centroids.
In case of genetic algorithm, one need to have a fitness function to evaluate the quality of chromosome (solution). Here, we consider clustering as a maximization optimization problem and define a fitness function by incorporating the new clustering validity index (CVI),
The given fitness function is the reciprocal of the clustering validity index (CVI), as given in Eq. 9. Note that the highest fitness value means the best chromosome and low fitness value means the bad chromosome.

Algorithm 1 demonstrates the genetic algorithm in detail. A container \(B_\mathrm{s}\) is used to store the best solution found so far. An initial population is selected form \(\{ \bar{P}\cup P\}\), where P is randomly generated from the set of super-pixels X and \(\bar{P}\) represents its opposition [60]. For each individual, i, its opposition is computed,
where \(P_{i,j}\) and \(\bar{P}_{i,j}\) represent the jth component of the ith individual of the current population and its opposition respectively. The details of parameters setting of GA are given in Table 1. The binary tournament selection is used to select the candidates for reproduction. Subsequently, the chromosomes that are being selected are put into the mating pool for reproduction. New offsprings are produced on the basis of single point crossover with random cut point. The crossover rate \(\rho _\mathrm{c}\) is set to 0.8. Initially, the mutation rate \(\rho _\mathrm{m}\) is kept high for the sake of better exploration and decreased with time to ensure exploitation. The initial mutation probability \(\rho _\mathrm{m}\) is set to 0.18 (as given in line 3). In the successive iterations, the mutation rate is decreased by factor of \(\hbox {e}^{-g/\eta }\), where \(\eta =20\) (line 13). The lines 14–15, set the lower bound of the mutation rate \(\rho _\mathrm{m}\). To ensure elitism the best individuals among the parent population and newly generated offspring are retained in the new population. The stopping criteria, (\(g\le G \Vert \delta \ne \hbox {true}\)) is used to terminate the execution. Note that G represents the maximum epochs while \(\delta \), \(f_{g,\mathrm{best}}\), and \(f_{g-1,\mathrm{best}}\) represent the flag, best solutions in the current generation and previous generation respectively. Lines 18 and 19 of the Algorithm 1 demonstrate that the old best solution, which is stored in container \(B_\mathrm{s}\), is replaced by the new best solution if \(f(P_k)>f(B_\mathrm{s})\), where \(f(\cdot )\) represent the fitness of a chromosome. We run the algorithm for different number of clusters, K, with \(K\in \{2,3,\dots , K_{\max }\}\). Thus, the algorithm returns the best possible number of clusters, K, with optimized centroids.
3 Experimental results
The experimentation is performed on Berkeley image segmentation database (BSD) [61]. The results of proposed algorithm are compared with six well-known image segmentation methods: Segmentation via Lossy Data Compression (LDC) [62], Efficient Graph-based Image Segmentation (EG) [63], Describing Reflectance’s for Color Segmentation Robust to Shadows, Highlights, and Textures (also called Ridge-based Analysis of Distributions physics-based) (RADp) [35], Statistical Region Merging (SRM) [64], A Level Set Method for Image Segmentation in the Presence of Intensity Inhomogeneities with Application to MRI (LS) [65] and Multi-region Image Segmentation by Parametric Kernel Graph Cuts (KGC) [66].
3.1 Qualitative comparisons
Here, the results of the proposed algorithm are visually compared with six algorithms: SRM, LDC, RADp, KGC, LS, and EG. For qualitative analysis, 11 images are selected from Berkeley Segmentation Database (BSD) [61] which include Coastal (321 \(\times \) 481), Night (481 \(\times \) 321), Building (481 \(\times \) 321), Bear (321 \(\times \) 481), Flower (321 \(\times \) 481), Cow (321 \(\times \) 481), Men (321 \(\times \) 481), Boat (4811 \(\times \) 321), Bird (481 \(\times \) 321), Lady (481 \(\times \) 321) and Ship (481 \(\times \) 321).
Figure 2 visually presents the results of the above-mentioned algorithms for 11 BSD images. The first row demonstrate the results of the mentioned algorithms for Coastal image. The Coastal image contain rocks, water, sky and a small boat. For Coastal image, the proposed method performs best and accurately segment out the water, sky, rock and the boat. Similarly, SRM also performs better for the Coastal image and generate results near to human perception. The LDC over-segments the water and rock regions, while the RADp is unable to perform any segmentation. The KGC, LS, EG and NC perform poor and tend to produce over-segmentation. The second row of Fig. 2 shows the results for Night image. It is clear that the proposed method outperforms the other methods and achieve results near to the corresponding human subject. For the same image, SRM and RADp perform better and segment forest region but fail to detect the moon area. Although KGC detects the moon but divides the sky region into undesirable segments. The LS, EG and NC fail to detect the actual boundaries of the objects and lead to undesirable results. Note that the proposed method also outperform the other techniques in case of Building (third row), Bear (fourth row), Flower (fifth row) and Cow (sixth row) and produce results which nearly matching corresponding human segmentations. Seventh row demonstrates the results for Men image. It can be observed that the proposed method performs better than other stated methods. For the Men image, the SRM, RADp, and KGC perform comparatively good but LDC and LS makes over-segmentation. In case of Boat (eight row), the proposed method performs best, while the rest of methods perform over-segmentation of water, sky and boat regions. For Boat, the RADp is unable to perform any segmentation. It is clear form Fig. 2 that the proposed algorithm perform better compared to other stated methods in case of Bird (ninth row), Lady (tenth row) and Ship (eleventh row).
The proposed algorithm uses the RGB, HSV and Lab color spaces to encode the color information and histogram of oriented gradients (HoG) to encode the texture information. Thus, the proposed algorithm fails when two different segments have nearly the same textures and colors. It can be noted from Fig. 3 that the spider and rock region (non-fungus region) have nearly the same colors and textures and hence the proposed algorithm fails to separate them out.
Generally, the SRM faces the problem of under segmentation, while the LDC is unable to achieve the actual contours and hence produce over-segmented results. Normally, RADp fails to get the segments boundaries and tends to under segmentation, while in some cases it over-segment the uniform regions and makes noisy segmentation. The KGC generally leads to over-segmentation but for some instances, it performs better comparatively. The LS perform poorly to detect the segments boundaries. For many images, the performance of EG is good enough but generally leads to over-segmentation. The results show that the proposed method comparatively performs better than other stated methods.
3.2 Quantitative comparison
We have used the variation of information (VoI) [67] and probabilistic rand index (PRI) [68] to quantitatively evaluate the performance of the proposed method.
Variation of information (VoI) relates two segmentation in term of information contents and returns a score in the range \([0, \infty )\). The smaller value of VoI denotes the high degree of similarity between the different setup of segmentations and vice versa.
The Probabilistic Rand Index (PRI) matches the given segmentation with underlying ground truth segmented images. It assigns variable weights to pixels pairs to incorporate the human-induced variability among ground truths. PRI generates a score in the range of [0, 1]. The larger PRI score means the better segmentation and vice versa.

Qualitative comparison of the proposed method with other algorithms. The first column contains the ground truth human segmented images, while second to seventh column present the results of proposed method, SRM, LDC, RADp, KGC, LS, and EG respectively
Table 2 shows the PRI score of each algorithm for the 11 selected BSD images. The last column of the Table 2 contains the average PRI score of each algorithm for the 11 images. It is clear from the given table that the proposed algorithm outperforms the rest of the algorithms in term of PRI score. Similarly, Table 3 presents the VoI score of each algorithm for the given 11 BSD images. It can be noted from Table 3 that the proposed algorithm perform better than the other algorithms in term of VoI score. Table 4 show the mean PRI and VoI scores of the seven algorithms for 500 BSD images. It is clear from Table 4 that the proposed method perform better compared to other stated methods in term of VoI and PRI scores.

Fail case
Running time analysis It is difficult to compute the running time complexity of Genetic Algorithm (GA) analytically, in term of Big Oh notation, due to its stochastic and randomized nature. Therefore, the running time of the proposed algorithm is measured and compared with other algorithms in terms of CPU time. The simulations are performed in MATLAB R2014a with Windows 7 operating system on a Laptop machine having the processor, Intel(R) Core(TM) i3-2350M CPU@ 2.30 GHz, and installed memory of 8 GB. The detail of the running time (in seconds) of different algorithms is given in Table 5.
4 Conclusion
In this paper, a new clustering validity index (CVI) is proposed. The proposed CVI combines the clusters overlap, global compactness and fuzzy separation. The clusters overlap determines that how much a particular data point belongs to the other clusters centroids. The global compactness determines that how much the points in a particular cluster are similar while the fuzzy separation looks for the difference among different clusters centroids. The better clustering/segmentation needs minimum overlap and minimum compactness while maximum separation. Furthermore, a genetic algorithm is applied to optimize the clusters/segments centroids. The clustering of super-pixels is performed in order to reduce the computational complexity. The proposed dynamic genetic algorithm automatically converges to the optimal number of clusters/segments, which have minimum overlap and compactness, and maximum separation. The algorithm runs for a different number of clusters K in the range [\(K_{\min }\), \(K_{\max }\)]. The number of clusters K, which best maximize the objective function is considered the optimal segmentation. For initialization, the opposition-based strategy is used in order to have a better start. Performance of the proposed algorithm is compared with six state-of-the-art image segmentation algorithms. The qualitative and quantitative results demonstrate that the proposed algorithm performs better compared to other state-of-the-art image segmentation methods. In future work, the image segmentation may be extended to semantic segmentation by incorporating saliency and attention networks [69, 70].
References
Zhang, X., Su, H., Yang, L., Zhang, S.: Fine-grained histopathological image analysis via robust segmentation and large-scale retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5361–5368 (2015)
Belloulata, K., Belallouche, L., Belalia, A., Kpalma, K.: Region based image retrieval using shape-adaptive dct. In: 2014 IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), pp. 470–474. IEEE (2014)
Ahmad, J., Sajjad, M., Mehmood, I., Rho, S., Baik, S.W.: Saliency-weighted graphs for efficient visual content description and their applications in real-time image retrieval systems. J. Real Time Image Process. 13(3), 431–447 (2017)
Tsochatzidis, L., Zagoris, K., Arikidis, N., Karahaliou, A., Costaridou, L., Pratikakis, I.: Computer-aided diagnosis of mammographic masses based on a supervised content-based image retrieval approach. Pattern Recognit. 71, 106–117 (2017)
Ghosh, N., Agrawal, S., Motwani, M.: A survey of feature extraction for content-based image retrieval system. In: Proceedings of International Conference on Recent Advancement on Computer and Communication, pp. 305–313. Springer (2018)
Irtaza, A., Adnan, S.M., Ahmed, K.T., Jaffar, A., Khan, A., Javed, A., Mahmood, M.T.: An ensemble based evolutionary approach to the class imbalance problem with applications in CBIR. Appl. Sci. 8(4), 495 (2018)
Hsu, W.-Y.: Segmentation-based compression: new frontiers of telemedicine in telecommunication. Telemat. Inform. 32(3), 475–485 (2015)
Akbari, M., Liang, J., Han, J.: Dsslic: deep semantic segmentation-based layered image compression. arXiv:1806.03348 (2018)
Song, X., Huang, Q., Chang, S., He, J., Wang, H.: Lossless medical image compression using geometry-adaptive partitioning and least square-based prediction. Med. Biol. Eng. Comput. 56(6), 957–966 (2018)
Li, S., Wang, J., Zhu, Q.: Adaptive bit plane quadtree-based block truncation coding for image compression. In: Ninth International Conference on Graphic and Image Processing (ICGIP 2017), vol 10615, p. 106151K. International Society for Optics and Photonics (2018)
Borji, A., Cheng, M.-M., Jiang, H., Li, J.: Salient object detection: a benchmark. IEEE Trans. Image Process. 24(12), 5706–5722 (2015)
Schwarz, M., Milan, A., Periyasamy, A.S., Behnke, S.: RGB-D object detection and semantic segmentation for autonomous manipulation in clutter. Int. J. Robot. Res. 37(4–5), 437–451 (2018)
Wei, Y., Shen, Z., Cheng, B., Shi, H., Xiong, J., Feng, J, Huang, T.: Ts2c: tight box mining with surrounding segmentation context for weakly supervised object detection. In: European Conference on Computer Vision, pp. 454–470. Springer, Cham (2018)
Wang, W., Shen, J., Shao, L.: Video salient object detection via fully convolutional networks. IEEE Trans. Image Process. 27(1), 38–49 (2018)
Wang, W., Shen, J., Yang, R., Porikli, F.: Saliency-aware video object segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 1, 20–33 (2018)
Wang, W., Shen, J., Porikli, F., Yang, R.: Semi-supervised video object segmentation with super-trajectories. IEEE Trans. Pattern Anal. Mach. Intell. (2018). https://doi.org/10.1109/TPAMI.2018.2819173
Ullah, J., Khan, A., Jaffar, M.A.: Motion cues and saliency based unconstrained video segmentation. Multimed. Tools Appl. 77(6), 7429–7446 (2018)
Weinzaepfel, P., Harchaoui, Z., Schmid, C.: Learning to track for spatio-temporal action localization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3164–3172 (2015)
Mosabbeb, E.A., Cabral, R., De la Torre, F., Fathy, M.: Multi-label discriminative weakly-supervised human activity recognition and localization. In: Asian Conference on Computer Vision, pp. 241–258. Springer (2014)
Gu, F., Khoshelham, K., Valaee, S., Shang, J., Zhang, R.: Locomotion activity recognition using stacked denoising autoencoders. IEEE Internet Things J. 5(3), 2085–2093 (2018)
Noor, M.H.M., Salcic, Z., Kevin, I., Wang, K.: Adaptive sliding window segmentation for physical activity recognition using a single tri-axial accelerometer. Pervasive Mob. Comput. 38, 41–59 (2017)
Triboan, D., Chen, L., Chen, F., Wang, Z.: Semantic segmentation of real-time sensor data stream for complex activity recognition. Personal Ubiquitous Comput. 21(3), 411–425 (2017)
Jalal, A., Kim, Y.-H., Kim, Y.-J., Kamal, S., Kim, D.: Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 61, 295–308 (2017)
Shen, J., Du, Y., Li, X., et al.: Interactive segmentation using constrained Laplacian optimization. IEEE Trans. Circuits Syst. Video Technol. 24(7), 1088–1100 (2014)
Shen, J., Peng, J., Dong, X., Shao, L., Porikli, F.: Higher order energies for image segmentation. IEEE Trans. Image Process. 26(10), 4911–4922 (2017)
Dong, X., Shen, J., Shao, L., Van Gool, L.: Sub-markov random walk for image segmentation. IEEE Trans. Image Process. 25(2), 516–527 (2016)
Peng, J., Shen, J., Li, X.: High-order energies for stereo segmentation. IEEE Trans. Cybern. 46(7), 1616–1627 (2016)
Ciesielski, K.C., Miranda, P.A.A., Falcão, A.X., Udupa, J.K.: Joint graph cut and relative fuzzy connectedness image segmentation algorithm. Med. Image Anal. 17(8), 1046–1057 (2013)
Spina, T.V., de Miranda, P.A.V., Falcao, A.X.: Hybrid approaches for interactive image segmentation using the live markers paradigm. IEEE Trans. Image Process. 23(12), 5756–5769 (2014)
Kumar, S.N., Fred, A.L., Varghese, P.S.: Suspicious lesion segmentation on brain, mammograms and breast MR images using new optimized spatial feature based super-pixel fuzzy c-means clustering. J. Digit. Imaging (2018). https://doi.org/10.1007/s10278-018-0149-9
Zhao, F., Liu, H., Fan, J., Chen, C.W., Lan, R., Li, N.: Intuitionistic fuzzy set approach to multi-objective evolutionary clustering with multiple spatial information for image segmentation. Neurocomputing 312(27), 296–309 (2018)
Khan, A., Ullah, J., Jaffar, M.A., Choi, T.S.: Color image segmentation: a novel spatial fuzzy genetic algorithm. Signal Image Video Process. 8(7), 1233–1243 (2014)
Khan, A., Jaffar, M.A., Shao, L.: A modified adaptive differential evolution algorithm for color image segmentation. Knowl. Inf. Syst. 43(3), 583–597 (2015)
Khan, A., Jaffar, M.A., Choi, T.S.: Som and fuzzy based color image segmentation. Multimed. Tools Appl. 64(2), 331–344 (2013)
Vazquez, E., Baldrich, R., Van De Weijer, J., Vanrell, M.: Describing reflectances for color segmentation robust to shadows, highlights, and textures. IEEE Trans. Pattern Anal. Mach. Intell. 33(5), 917–930 (2011)
Lee, S., Kim, J., Lim, H., Ahn, S.C.: Surface reflectance estimation and segmentation from single depth image of ToF camera. Signal Process. Image Commun. 47, 452–462 (2016)
Pérez-Carrasco, J.A., Acha-Piñero, B., Serrano-Gotarredona, C., Gevers, T.:. Reflectance-based segmentation using photometric and illumination invariants. In: International Conference Image Analysis and Recognition, pp. 179–186. Springer (2014)
Bruls, T., Maddern, W., Morye, A.A., Newman, P.: Mark yourself: road marking segmentation via weakly-supervised annotations from multimodal data. In: 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 1863–1870. IEEE (2018)
Garces, E., Reinhard, E.: Light-field surface color segmentation with an application to intrinsic decomposition. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 1480–1488. IEEE (2018)
Qin, A.K., Clausi, D.A.: Multivariate image segmentation using semantic region growing with adaptive edge penalty. IEEE Trans. Image Process. 19(8), 2157–2170 (2010)
Plath, N., Toussaint, M., Nakajima, S.: Multi-class image segmentation using conditional random fields and global classification. In: Proceedings of the 26th Annual International Conference on Machine Learning, pp. 817–824 (2009)
Bejar, H.H.C., Miranda, P.A.V.: Oriented relative fuzzy connectedness: theory, algorithms, and its applications in hybrid image segmentation methods. EURASIP J. Image Video Process. 2015(1), 21 (2015)
Kumar, M.J., Raj Kumar, G.V.S.: Hybrid image segmentation model based on active contour and graph cut with fuzzy entropy maximization. Int. J. Appl. Eng. Res. 12(23), 13623–13637 (2017)
Wang, F., Yan, W., Li, M., Zhang, P., Zhang, Q.: Adaptive hybrid conditional random field model for sar image segmentation. IEEE Trans. Geosci. Remote Sens. 55(1), 537–550 (2017)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2018)
Nascimento, M.C.V., De Carvalho, A.C.P.L.F.: Spectral methods for graph clustering a survey. Eur. J. Oper. Res. 211(2), 221–231 (2011)
Rajkumar, G.V., Rao, K.S., Rao, P.S.: Image segmentation method based on finite doubly truncated bivariate gaussian mixture model with hierarchical clustering. Int. J. Comput. Sci. 8(4), 151–110 (2011)
Yanga, H.Y., Wanga, X.Y., Wanga, Q.Y., Zhanga, X.J.: LS-SVM based image segmentation using color and texture information. J. Vis. Commun. Image Represent. 23(7), 1095–1112 (2012)
Patel, J., Doshi, K.: A study of segmentation methods for detection of tumor in brain MRI. Adv. Electron. Electr. Eng. 4(3), 279–284 (2014)
Guo, Y., Xia, R., Şengür, A., Polat, K.: A novel image segmentation approach based on neutrosophic c-means clustering and indeterminacy filtering. Neural Comput. Appl. 28(10), 3009–3019 (2017)
Vendramin, L., Campello, R.J., Hruschka, E.R.: Relative clustering validity criteria: a comparative overview. Stat. Anal. Data Min. 3(4), 209–235 (2010)
Starczewski, A.: A new validity index for crisp clusters. Pattern Anal. Appl. 20(3), 687–700 (2017)
Shen, J., Du, Y., Wang, W., Li, X.: Lazy random walks for superpixel segmentation. IEEE Trans. Image Process. 23(4), 1451–1462 (2014)
Shen, J., Hao, X., Liang, Z., Liu, Y., Wang, W., Shao, L.: Real-time superpixel segmentation by dbscan clustering algorithm. IEEE Trans. Image Process. 25(12), 5933–5942 (2016)
Dong, X., Shen, J., Shao, L.: Hierarchical superpixel-to-pixel dense matching. IEEE Trans. Circuits Syst. Video Technol. 27(12), 2518–2526 (2017)
Liu, M.Y., Tuzel, O., Ramalingam, S., Chellappa, R.: Entropy rate superpixel segmentation. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 2097–2104 (2011)
Bezdek, J.C.: Cluster validity with fuzzy sets. J. Cybern. 3(3), 58–73 (1973)
Mascarilla, L., Berthier, M., Frélicot, C.: A k-order fuzzy or operator for pattern classification with k-order ambiguity rejection. Fuzzy Sets Syst. 159(15), 2011–2029 (2008)
Khan, A., Jaffar, M.A.: Genetic algorithm and self organizing map based fuzzy hybrid intelligent method for color image segmentation. Appl. Soft Comput. 32, 300–310 (2015)
Rahnamayan, S., Tizhoosh, H.R., Salama, M.M.: Opposition-based differential evolution. IEEE Trans. Evol. Comput. 12(1), 64–79 (2008)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceeding of the IEEE International Conference on Computer Vision, vol 2, pp. 416–423 (2001)
Yang, A.Y., Wright, J., Ma, Y., Sastry, S.S.: Unsupervised segmentation of natural images via lossy data compression. In: Computer Vision and Image Understanding, pp. 212–225 (2008)
Felzenszwalb, P.F., Huttenlocher, D.P.: Efficient graph-based image segmentation. Int. J. Comput. Vis. 59(02), 167–181 (2004)
Nock, R., Nielsen, F.: Statistical region merging. IEEE Trans. Pattern Anal. Mach. Intell. 26(11), 1452–1458 (2004)
Li, C., Huang, R., Ding, Z., Gatenby, J.C., Metaxas, D.N., Gore, J.C.: A level set method for image segmentation in the presence of intensity inhomogeneities with application to MRI. IEEE Trans. Image Process. 20(7), 2007–2016 (2011)
Salah, M.B., Mitiche, A., Ayed, I.B.: Multiregion image segmentation by parametric kernel graph cuts. IEEE Trans. Image Process. 20(2), 545–557 (2011)
Meila, M.: Comparing clusterings by the variation of information. In: Schölkopf, B., Warmuth, M.K. (eds.) Learning theory and kernel machines, Lecture Note in Computer Science, vol. 2777, pp. 173–187. Springer, Berlin, Heidelberg (2003)
Unnikrishnan, R., Hebert, M.: Measures of similarity. In: Proceedings of the IEEE Workshop on Computer Vision Applications, vol 1, pp. 394–401 (2005)
Wang, W., Shen, J.: Deep visual attention prediction. IEEE Trans. Image Process. 27(5), 2368–2378 (2018)
Wang, W., Shen, J., Ling, H.: A deep network solution for attention and aesthetics aware photo cropping. IEEE Trans. Pattern Anal. Mach. Intell. (2018). https://doi.org/10.1109/TPAMI.2018.2840724
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Khan, A., ur Rehman, Z., Jaffar, M.A. et al. Color image segmentation using genetic algorithm with aggregation-based clustering validity index (CVI). SIViP 13, 833–841 (2019). https://doi.org/10.1007/s11760-019-01419-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-019-01419-2