
Abstract
The variable step-size least-mean-square algorithm (VSSLMS) is an enhanced version of the least-mean-square algorithm (LMS) that aims at improving both convergence rate and mean-square error. The VSSLMS algorithm, just like other popular adaptive methods such as recursive least squares and Kalman filter, is not able to exploit the system sparsity. The zero-attracting variable step-size LMS (ZA-VSSLMS) algorithm was proposed to improve the performance of the variable step-size LMS (VSSLMS) algorithm for system identification when the system is sparse. It combines the \({\ell _1}\)-norm penalty function with the original cost function of the VSSLMS to exploit the sparsity of the system. In this paper, we present the convergence and stability analysis of the ZA-VSSLMS algorithm. The performance of the ZA-VSSLMS is compared to those of the standard LMS, VSSLMS, and ZA-LMS algorithms in a sparse system identification setting.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Adaptive filtering has received a great deal of interest in signal processing [1, 2]. Many adaptive algorithms have been developed for applications such as system identification [1]. The least-mean-square (LMS) [1] is one of the most popular adaptive methods, but suffers from low convergence rate and high power consumption when a long impulse response of an unknown system contains many near-zero coefficients and a few large ones; that is, the impulse response of the system is sparse [3]. The VSSLMS method [4] aims to improve the convergence speed of the LMS algorithm, but fails to exploit the sparsity of the system.
Motivated by the LASSO [6] and the recent developments in the field of compressive sensing [7, 8], the sparsity is addressed by combining \({\ell _0}\)-norm penalty function into the original cost function of the LMS algorithm [3]. Adding the \({\ell _0}\) norm to the cost function of the VSSLMS algorithm causes the optimization problem to be non-convex. In order to avoid this drawback, the \({\ell _1}\)-norm is used as an approximation to the \({\ell _0}\) norm [7–9]. This gives the adaption process the ability of attracting zero (or nearly zero) filter coefficients. This process is called the zero attraction [3]. The zero-attracting variable step-size LMS (ZA-VSSLMS) [10] is proposed which was shown to outperform the standard VSSLMS when the system is highly sparse. In this paper, the convergence properties of the ZA-VSSLMS are analyzed when the input to the system is white. The stability condition of the aforementioned method is derived, and the performance of the proposed algorithm is compared with those of the standard LMS, VSSLMS, and ZA-LMS [3, 5] algorithms.
The paper is organized as follows: In Sect. 2, the recently proposed ZA-VSSLMS algorithm is briefly reviewed. In Sect. 3, the convergence analysis of the ZA-VSSLMS algorithm is developed and its stability condition is derived. In Sect. 4, simulation results that compare the performance of the ZA-VSSLMS with those of the standard LMS, VSSLMS, and ZA-LMS algorithms are provided. Finally, conclusions are drawn in Sect. 5.
2 ZA-VSSLMS algorithm
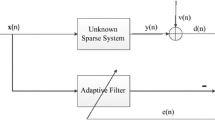
Consider the input–output relation of an linear time-invariant (LTI) system described by
where \(\mathbf{h}\) is the unknown tap weight vector of length \(N,\,T\) is the transposition operator, \(\mathbf{x}(k)\) is a white input signal, \(\ y(k)\) is the output, and \(v(k)\) is an additive noise process which is independent from \(x(k)\).
Modifying the cost function in [4] by adding the \(\ell _1\)-norm penalty of the coefficient vector to the square of the prediction error results in
where \(\mathbf{w}(k)\) corresponds to N-th order adaptive filter coefficients, and \(\lambda \) is a positive constant. The error signal in (2) is defined by
By the gradient method, the ZA-VSSLMS [10] update equation becomes
where \(\rho (k)=\lambda \mu (k),\,\hbox {sgn}(\cdot )\) is the pointwise sign function, and \(\mu (k)\) is a variable step-size [4] which is given by
\(\mu '(k+1)\) can be estimated in the following form
with \(0<\alpha <1\) and \(\gamma >0\).
3 Convergence analysis of the ZA-VSSLMS algorithm
In this section, we analyze the convergence of the ZA-VSSLMS algorithm when the input to the system is white. We start by defining the filter misalignment vector, and then, the mean and the covariance of misalignment vector can be computed. Once all these parameters are well-defined, we use them to estimate the updated value of covariance matrix and hence deriving the stability condition based on the trace of this matrix. Here, we present the stability condition in terms of the input variance \(\sigma ^2_x \) and filter length \(N\). The filter’s misalignment vector can be defined as
The mean and covariance matrices of \(\varvec{\delta }(k)\), respectively, as
where \(\mathbf{c}(k)\) is a zero mean vector defined as
We also define the instantaneous mean-square-deviation (MSD) in the following form
where \(\varLambda _i(k)\) represents the i-th tap MSD given by
In Eq. (12), \(S_{ii}(k)\) corresponds to the diagonal elements of the auto-covariance matrix \(\mathbf{S}(k)\).
By combining (1), (3), (4), (7) and the independence assumption, we get
Taking the expectation of (13), we get
Due to the independence between \(x\) and \(v\), the expectation of the second term becomes zero. Thus, the expectation of (14) simplifies to
Subtracting \(E\{\varvec{\delta }(k+1)\}\) from both sides of Eq. (13)gives
Here
Adding \(\mu (k)\mathbf{x}(k)\mathbf{x}^{\mathrm{T}}(k)\epsilon (k)\) to both side of (16) and rearranging the terms we get
In the above equation,
Next, we estimate \(\mathbf{S}(k+1)\) based upon the independence among \(x(k),\,v(k)\), and \(\varvec{\delta }(k)\) as follows:
The estimate in (21) is obtained by calculating input’s fourth moment [11–13] as well as using the symmetric behavior of the covariance matrix \(\mathbf{S}(k)\). Finding the trace of (21)
In Eq. (22), \(\mathbf{p}(k),\,E\{\mathbf{w}(k)\},\,E\{\mathbf{w}(k)\mathbf{p}^{\mathrm{T}}(k)\}\), and \(\epsilon (k)\) are all bounded. Thus, the adaptive filter is stable if the following holds
This implies that as \(k\longrightarrow \infty ,\,E\{\mu ^2(k)\}=E\{\mu (k)\}^2=\mu ^2(k)\). Hence, the above equation simplifies to
This result shows that if \(\mu \) stratifies (24), the convergence of the ZA-VSSLMS is guaranteed.
4 Simulation results
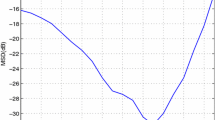
In this section, we evaluate the performance of the proposed adaptive filter for system identification problem. In our experiments, the input signal and the observed noise are both assumed to be white Gaussian random sequences with variances 1 and \(10^{-3}\), respectively, which results in a 30 dB signal-to-noise ratio (SNR). In the first experiment, the performance of the ZA-VSSLMS algorithm is tested and compared to those of the standard VSSLMS, LMS, and ZA-LMS algorithms. We set the filter length \(N=256\) with 10 % nonzero coefficients distributed randomly. In the first experiment, the following parameters were used : For the VSSLMS: \(\mu _{\mathrm{min}}=0.008,\,\mu _{\mathrm{max}}=0.012,\,\gamma =0.0048\) and \(\alpha =0.97\). For the ZA-VSSLMS: \(\mu _{\mathrm{min}}=0.008,\,\mu _{\mathrm{max}}=0.012,\,\rho =0.0001\). For the ZA-LMS : \(\mu =0.005\). The simulations are performed for 200 independent runs. Figure 1 shows the average MSD estimate of all algorithms. As shown, the ZA-VSSLMS algorithm converges to 2 and 9 dB lower MSDs compared to the VSSLMS, ZA-LMS algorithms respectively.

MSDs of the VSSLMS, ZA-VSSLMS, LMS and ZA-LMS algorithms in AWGN with 10 % nonzero coefficients
In the second experiment, we investigate the effect of parameter \(\rho \) on the performance of the ZA-VSSLMS algorithm. The parameter \(\rho \) in the ZA-VSSLMS algorithm that was defined in the Eq. (4) controls the strength of zero attraction to small adaptive taps and pulls them toward the origin, which consequently increases the convergence speed and decreases the MSD. Its value is changing within an interval \(0<\rho <1\). One can experimentally find the optimal value of \(\rho \) that results in the best performance in terms of MSD.
We implement both ZA-VSSLMS and the standard VSSLMS algorithms in the same setting and the parameters given in the first experiment. As we see in Fig. 2, the performance of the ZA-VSSLMS algorithm keeps improving compared to the VSSLMS algorithm by changing the \(\rho \) value until it reaches its minimum MSD at \(\rho =4\times 10^{-4}\). At this point, the ZA-VSSLMS algorithm shows 4 dB improvement over the standard VSSLMS algorithm. By choosing \(\rho \) value to be greater than its optimal value, the ZA-VSSLMS algorithm starts losing its ability of attracting the zero taps as it produces a higher MSD compared to the standard VSSLMS algorithm.

MSDs of the ZA-VSSLMS and VSSLMS algorithms with \(\rho \) varying

MSDs of the VSSLMS, ZA-VSSLMS, LMS, and ZA-LMS algorithms in AWGN
Finally, to investigate the tacking ability and steady performance of the ZA-VSSLMS algorithm in a different scenario, we design a filter of 50 coefficients with abrupt changes at certain periods of time. Initially, a random tap of the unknown system is set to 1, and the rest are zeros. After each 1,500 iterations, 4 and 14 coefficients are set to ones and others to zeros, respectively. The performance of the ZA-VSSLMS algorithm is compared to those of the standard VSSLMS, LMS, and ZA-LMS algorithms. All the experiments are implemented with 200 independent runs.
The following parameters were used during this experiment: For the VSSLMS: \(\mu _{\mathrm{min}}=0.009,\,\mu _{\mathrm{max}}=0.013,\,\gamma =0.0048\) and \(\alpha =0.97\). For the ZA-VSSLMS: \(\mu _{\mathrm{min}}=0.008,\, \mu _{\mathrm{max}}=0.012,\, \gamma =0.0048,\, \alpha =0.97\) and \(\rho =0.0001\). For the LMS: \(\mu =0.001\). For the ZA-LMS: \(\mu =0.001\) and \(\rho =0.0001\).
As it can be seen from Fig. 3, when the system is highly sparse (before 1,500th iteration), the ZA-VSSLMS algorithm has 5.5 dB lower MSD than over the LMS and VSSLMS algorithms and about 3.5 dB lower than ZA-LMS algorithm. After 1,500th iterations, as the number of nonzero taps increases, the performance difference between ZA-VSSLMS and the other three algorithms becomes smaller. In the last 1,500 iterations where the system is non-sparse, the ZA-VSSLMS reduces to the standard VSSLMS. However, it still performs comparably better than the VSSLMS.
5 Conclusions
In this paper, we presented the convergence analysis of the recently proposed ZA-VSSLMS algorithm, and we derived its stability condition. The stability result is consistent with the standard VSSLMS algorithm. The performance of the ZA-VSSLMS were studied when the parameter \(\rho \) is changing. It is observed that when \(\rho < 10^{-3}\), the ZA-VSSLMS outperforms the standard VSSLMS algorithm for sparse impulse response. We also investigated the MSD of ZA-VSSLMS algorithm for different sparsity orders. The results shows superiority of ZA-VSSLMS over the standard VSSLMS algorithm when the system is highly sparse.
References
Widrow, B., Stearns, S.D.: Adaptive Signal Processing. Prentice Hall, Eaglewood Cliffs, NJ (1985)
Haykin, S.: Adaptive Filter Theory. Prentice Hall, Upper Saddle River, NJ (2002)
Gu, Y., Jin, J., Mei, S.: \(\ell _0\) norm constraint LMS algorithm for sparse system identification. IEEE Signal Process. Lett. 16, 774–777 (2009)
Kwong, R., Johnston, E.W.: A variable step size LMS algorithm. IEEE Trans. Signal Process. 40, 1633–1642 (1992)
Shi, K., Shi, P.: Convergence analysis of sparse LMS algorithms with l1-norm penalty based on white input signal. Signal Process. 90, 3289–3293 (2010)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 58, 267–288 (1996)
Donoho, D.: Compressive sensing. IEEE Trans. Inf. Theory 52, 1289–1306 (2006)
Bajwa, W.U., Haupt, J., Raz, G. Nowak, R.: Compressed channel sensing. In: Proceedings of the 42nd Annual Conference on Information Sciences and Systems, pp. 5–10 (2008)
Chen, Y., Gu, Y., Hero, A.O.: Sparse LMS for system identification. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 3125–3128, Taipei, Taiwan (2009)
Salman, M.S., Jahromi, M.N., Hocanin, A., Kukrer, O.: A zero-attracting variable step-size LMS algorithm for sparse system identification. In: IX International Symposium on Telecommunications, pp. 25–27 (2012)
Kenney, J.F., Keeping, E.S.: Kurtosis. In: Mathematics of Statistics, Pt. 1, 3rd edn., pp. 102–103. Van Nostrand, Princeton, NJ (1962)
Hoyer, P.O.: Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 5, 1457–1469 (2004)
Gu, Y., Jin, J., Mei, S.: A stochastic gradient approach on compressive sensing signal reconstruction based on adaptive filtering framework. IEEE J. Sel. Top. Signal Process. 4, 409–420 (2010)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Jahromi, M.N.S., Salman, M.S., Hocanin, A. et al. Convergence analysis of the zero-attracting variable step-size LMS algorithm for sparse system identification. SIViP 9, 1353–1356 (2015). https://doi.org/10.1007/s11760-013-0580-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-013-0580-9