
Abstract
Motion segmentation is a crucial step in video analysis and is associated with a number of computer vision applications. This paper introduces a new method for segmentation of moving object which is based on double change detection technique applied on Daubechies complex wavelet coefficients of three consecutive frames. Daubechies complex wavelet transform for segmentation of moving object has been chosen as it is approximate shift invariant and has a better directional selectivity as compared to real valued wavelet transform. Double change detection technique is used to obtain video object plane by inter-frame difference of three consecutive frames. Double change detection technique also provides automatic detection of appearance of new objects. The proposed method does not require any other parameter except Daubechies complex wavelet coefficients. Results of the proposed method for segmentation of moving objects are compared with results of other state-of-the-art methods in terms of visual performance and a number of quantitative performance metrics viz. Misclassification Penalty, Relative Foreground Area Measure, Pixel Classification Based Measure, Normalized Absolute Error, and Percentage of Correct Classification. The proposed method is found to have high degree of segmentation accuracy than the other state-of-the-art methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Moving object segmentation is an important step for development of any computer vision system [1]. Segmentation of moving object is a process of isolation of foreground object from background of a video sequence. Segmentation is a complicated task due to following reasons [2].
-
1.
Changing background.
-
2.
Presence of noise and blur in video.
-
3.
Shape and size of object may vary from frame to frame.
-
4.
Varying lighting conditions.
-
5.
Abrupt motion of object.
-
6.
Presence of occlusion.
In comparison with the literatures available on image segmentation [3], limited literatures are available on moving object segmentation. As per available literatures, moving object segmentation techniques can be broadly classified into following four groups [4, 5].
-
1.
Segmentation of moving object based on motion information [6–8].
-
2.
Segmentation of moving object based on motion and spatial information [9–12].
- 3.
-
4.
Segmentation of moving object based on change detection [15–20].
Motion information-based moving object segmentation algorithms are closely related with motion estimation. Kim et al. [6] have proposed a real-time foreground–background segmentation method using codebook. In this method, background values at each pixel are quantized into codebook, and the codebook represents a compressed form of background model for an image sequence. Xiaoyan et al. [7] have proposed a video object segmentation technique on the basis of adaptive change. This method is not able to remove noise from the video frames. Mahmoodi [8] has proposed a shape-based active contour method for video segmentation which is based on a piecewise constant approximation of the Mumford shah functional model. This method is slow as it is based on level set framework. Due to the lack of spatial information of object, these algorithms suffer from occlusion problem, and therefore, these algorithms are not able to detect accurate boundaries of segmented object.
Merging spatial information with motion information will provide more stable object boundary extraction. Javed et al. [9] have proposed a segmentation method that uses Gaussian mixture model (GMM) with color and gradient feature vectors to make the process of background subtraction more robust against illumination changes. GMM-based technique can be effectively used for scene modeling, but it suffers from the problems of slow convergence and false motion prediction. Reza et al. [10] have proposed a moving object segmentation technique, combining temporal and spatial features. This approach takes into account a current frame, ten preceding frames and ten next consecutive frames. All the twenty-one frames are processed to detect and remove the static part of motion window resulting in the segmented object. The method detects moving objects independent of their size and speed, but there is no provision for reduction in noise from frames, which may lead to inaccurate object segmentation. Ivanov et al. [11] have proposed an improvement over background subtraction method, which is faster than that proposed by Reza et al. [10] and is invariant to runtime change illuminations. Colombari et al. [12] have proposed a method for segmentation of multiple video objects by combining content-based representation with background modeling. This method uses projective transformation of objects from one frame to another.
Learning-based moving object segmentation algorithms require some predefined learning patterns. Kato et al. [13] have proposed a segmentation method for monitoring of traffic video based on hidden Markov model (HMM). In this method, each pixel or region is classified into three categories: shadow, foreground, and background. This method comprises of two phases: learning phase and segmentation phase. Stauffer et al. [14] have proposed a tracking method using learning patterns of observation. In this method, motion segmentation has been done by adaptive background subtraction that models each pixel as a mixture of Gaussians.
Strategy of change detection algorithm is based on computation of frame difference of two or more frames. The obtained frame difference is further processed to identify moving objects. Change detection method for segmentation gives feasible solutions because it enables automatic detection of new appearances [20]. Huang et al. [17] have proposed an algorithm for moving object segmentation using double change detection applied in wavelet domain. Baradarani [18, 19] have refined the work of Huang et al. [17] using 9/7–10/8 dual tree complex filter bank in wavelet domain algorithm. A robust scene change detection method for video object segmentation that combines the intensity and motion information has been proposed by Huang and Liao [16].
All the methods discussed so far, for segmentation of moving objects, are suffering from the problem of either inaccurate segmentation due to non-removal of noise or failure to detect new appearance automatically. Motivated by these facts and work of Baradarani [18, 19], we have proposed a new method for segmentation of moving object using double change detection method applied on Daubechies complex wavelet transform. The Daubechies complex wavelet transform is having advantages of shift invariance and better directional selectivity as compared to real valued discrete wavelet transform. The proposed method consists of the following six steps.
-
1.
Wavelet decomposition of three consecutive frames using Daubechies complex wavelet transform.
-
2.
Double change detection method applied in complex wavelet domain.
-
3.
Denoising of frames
-
4.
Canny edge detection applied on denoized frames
-
5.
Detection of moving edges
-
6.
Detection of moving object by using detected moving edges.
The proposed method has been compared with the following state-of-the-art methods.
-
1.
Method proposed by Kim et al. [6] that uses codebook for segmentation.
-
2.
Method proposed by Mahmoodi [8] that is based on active contour.
-
3.
Method proposed by Huang et al. [17] that is based on change detection in wavelet domain.
-
4.
Method proposed by Baradarani [18, 19] that is based on change detection in wavelet domain.
Performance of the proposed method is found better in terms of visual performance and a number of quantitative performance metrics viz. Misclassification Penalty (MP), Relative Foreground Area Measure (RFAM), Pixel Classification based Measure (PCM), Normalized Absolute Error (NAE), and Percentage of Correct Classification (PCC).
Rest of the paper is organized as follows: Sect. 2 describes basic introduction of Daubechies complex wavelet transform and its properties useful for motion segmentation. Section 3 explains the proposed method in detail. Experimental results and performance evaluation are given in Sects. 4 and 5, respectively. Finally, conclusions are given in Sect. 6.
2 Daubechies complex wavelet transform
In the proposed work, we have used Daubechies complex wavelet transform with its reduced shift sensitivity and edge information properties.
2.1 Construction of Daubechies complex wavelet
The basic equation of multiresolution theory is the scaling equation
where \(a_{i}\)’s are coefficients, and \(\phi (u)\) is the scaling function. The \(a_{i}\)’s can be real as well as complex valued and \(\sum {a_i =1}\). Daubechies’ wavelet bases \(\{\psi _{j,k} (t)\}\) in one-dimension are defined through the above-mentioned scaling function and multiresolution of \(L_2 (\mathfrak R )\) [21]. For formulation of general solution, Daubechies considered \(a_{i}\)’s to be real valued. If we relax the condition for \(a_{i}\)’s to be real valued, it leads to Daubechies complex valued scaling function. Construction of Daubechies complex wavelet transform is reported in [21, 22].
The generating wavelet \(\psi (t)\) is given by
Any function \(x(t)\) can be decomposed into complex scaling wavelet function as follows:
where, \(j_{0}\) is a given resolution level, \(\left\{ {c_k^{j_0 }} \right\} \) and \(\left\{ {d_k^j } \right\} \) are known as approximation and detailed coefficients, respectively.
Daubechies complex wavelets transform has following advantages, over real valued wavelet transform.
-
1.
Daubechies complex wavelet transform is approximate shift invariant [23, 24] in nature.
-
2.
Daubechies complex wavelet transform has perfect reconstruction property [22].
-
3.
Daubechies complex wavelet transform provides true phase information [24].
-
4.
Daubechies complex wavelet transform has no redundancy [22].
2.2 Properties of Daubechies complex wavelet transform
All general properties of real Daubechies wavelet bases are derived from amplitude only [21]. Therefore, these properties also hold for complex Daubechies wavelet. Daubechies complex wavelets have some other important properties that directly influence video object segmentation algorithm. A brief description of these properties is given in Subsects. 2.2.1 and 2.2.2.
2.2.1 Reduced shift sensitivity
Daubechies complex wavelet transform has reduced shift sensitivity. A transform is said to be shift sensitive if shift in input signal causes an unpredictable change in transform coefficients. In discrete wavelet transform (DWT), the shift sensitivity arises due to downsampler in its implementation. Figure 1 shows the reduced shift sensitivity of Daubechies complex wavelet transform. Figure 1a, b show an input signal and shifted form of the input signal by one sample, respectively. Figure 1c, d show magnitude of high-pass wavelet coefficients of the original and the shifted signal using DWT. Figure 1e, f show magnitude of high-pass wavelet coefficients of the original and the shifted signal using Daubechies complex wavelet transform. From the Fig. 1, it is clear that DWT is highly shift sensitive, whereas the Daubechies complex wavelet transform is approximate shift invariant.

a Original input signal, b input signal shifted by one sample, c magnitude of high-pass wavelet coefficient of original input signal using real db4 wavelet, d magnitude of high-pass wavelet coefficient of shifted input signal using real db4 wavelet, e magnitude of complex wavelet coefficient of original input signal using SDW6 wavelet, f magnitude of complex wavelet coefficient of shifted input signal using SDW6 wavelet
This property helps in segmentation of object with shifting orientation in different frames of video.
2.2.2 Edge detection property of Daubechies complex wavelet transform
Let \(\phi (t)=l(t)+iv(t)\) be a scaling function and \(\psi (t)=k(t)+iu(t)\) be a wavelet function. Let \(\hat{{v}}(w)\) and \(\hat{{l}}(w)\) are Fourier transforms of \(v(t)\) and \(l(t)\). Consider the ratio
Clonda et al. [22] observed that \(\alpha (w)\) is strictly real valued and behaves as \(w^{2}\) for \({\vert }w{\vert }<\pi \). This experiment relates the imaginary and real components of scaling function as \(v(t)\) accurately approximate another derivatives \(l(t)\) up to some constant factor.
As a result, it can be derived from Eq. (4) that \(v(t)\approx \alpha \Delta l(t)\), where \(\Delta \) represents second-order derivative. This gives multiscale projection as
From Eq. (5), it can be concluded that the real component of complex scaling function carries averaging information and the imaginary component carries edge information. Daubechies complex wavelet transform acts as local edge detector because imaginary components of complex scaling coefficient represent strong edges. This helps in preserving the edges and implementation of edge sensitive video object segmentation method.
3 The proposed method
This paper presents a new method for automatic segmentation of moving object. The proposed algorithm uses double change detection scheme in Daubechies complex wavelet transform domain.
Change detection is a method used for obtaining video object plane using frame difference. It is easy to implement for real-time systems [15–19]. In case of change detection method, difference of two consecutive frames, which also gives the changed pixel value from frame \(n-1\) to \(n\), can be obtained using following algorithm:
Here, \(P_{n}(i,j)\) is the value of \((i,j)\)th pixel of frame \(n\) and \(P_{n-1}(i,j)\) is the value of \((i,j)\)th pixel of frame \(n-1,\,V_\mathrm{thr}\) is a threshold value and \(\text{ FD }_{n}(i,j)\) is the frames difference of two consecutive frames.
There are two types of change detection methods—single change detection (SCD) method and double change detection (DCD) method. Double change detection method is advantageous over SCD method as it uses three consecutive frames for obtaining frame difference.
The proposed method consists of the following six steps:
-
1.
Wavelet decomposition of sequence of frames.
-
2.
Application of double change detection method on wavelet coefficients.
-
3.
Application of soft thresholding to remove noise.
-
4.
Application of canny edge detector to detect strong edges in wavelet domain.
-
5.
Detection of moving edges.
-
6.
Detection of moving object.
Details of all these steps are described below:
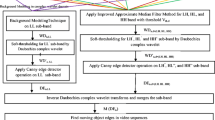
Block Diagram of the proposed method is shown in Fig. 2.

Block diagram of the proposed method
3.1 Step 1: Wavelet decomposition of image frames
Wavelet transform converts an image into four subbands: LH, HL, HH, and LL. LH contains the high-frequency horizontal information, HL contains the high-frequency vertical information, HH contains the high-frequency diagonal information, and LL contains-low frequency diagonal information. In the proposed approach, we have computed wavelet transform of three consecutive frames—current frame, previous frame, and next frame.
3.2 Step 2: Double change detection method
After wavelet decomposition of three consecutive frames—current frame, previous frame, and next frame—we apply the double change detection method in wavelet domain. For extraction of moving objects with double change detection method, three consecutive frames \(F_{n-1},\,F_{n }\), and \(F_{n+1}\) are used. Moving objects in frame \(n\) can be obtained by detection of common regions of \((F_{n-1}, F_{n})\), and \((F_{n}, F_{n+1})\), where \((F_{n-1}, F_{n})\) represents frame difference between frame \(n-1\) and frame \(n\), and \((F_{n}, F_{n+1})\) represents frame difference between frame \(n\) and frame \(n+1\).
Let \(\text{ WI }_n (i,j),\,\text{ WI }_{n-1} (i,j)\) and \(\text{ WI }_{n+1} (i,j)\) are the wavelet coefficients of the current frame, previous frame and next frame, respectively. Wavelet domain change detection masks \(\{\text{ FD }_n (i,j)\}\) and \(\{\text{ FD }_{n+1} (i,j)\}\) can be calculated as
3.3 Step 3: Soft thresholding
Change detection masks obtained after applying double change detection method may have noise. In the presence of noise, Eq. (6) is expressed as:
where \(\text{ FD }_n^{\prime } (i,j)\) and \(\text{ FD }_{n+1}^{\prime } (i,j)\) are frame difference without noise, \(\eta _1\) and \(\eta _2\) represent corresponding noise components. We have applied wavelet domain soft thresholding technique [23, 25] for estimation of frame difference \(\text{ FD }_n^{\prime } (i,j)\) and \(\text{ FD }_{n+1}^{\prime } (i,j)\) without noise.
3.4 Step 4: Canny edge detection
Canny edge detection method [26] is one of the most useful and popular edge detection methods, because of its low error rate, well-localized edge points, and single edge point response.
Therefore, we applied Canny edge detection operator on \(\{\text{ FD }_n^{\prime } (i,j)\}\) and \(\{\text{ FD }_{n+1}^{\prime } (i,j)\}\) to detect the edges of significant difference pixels in all subbands., i.e.,
3.5 Step 5: Moving edge detection
Moving object edge map for frame \(n (\text{ ME }_n )\) is derived as intersection of \(D_n \) and \(D_{n+1} \), where \(D_n \) and \(D_{n+1}\) are inverse wavelet transform of \(\text{ DE }_n\) and \(\text{ DE }_{n+1}\), respectively, to get the robust interframe difference edges \(D_n \) and \(D_{n+1}\). The points corresponding to the moving object edge map \((\text{ ME }_n )\) are not necessarily restricted to be on the boundary of the moving object. Instead, these points may be part of interior of the boundary of the moving object.
3.6 Step 6: Moving object detection
Moving objects for frame \(n\) can be formed by the detected moving edges. Due to non-ideal segmentation of moving object edges, disconnected edges are found. Extractions of moving object using these disconnected edges are lead to inaccurate moving object segmentation. Therefore, some morphological operation is needed for post-processing of object edge map to generate connected edges. Here, we have used binary closing morphological operation as described in Gonzalez and Woods [27]. The structuring element of binary closing morphological operation is shown in Fig. 2.
4 Experiments and result
The proposed method for segmentation of moving object as described in Sect. 3 has been applied on a number of video clips. Results are being presented here for four representative video sequences viz. One Step video sequence, Hall Monitor video sequence, Campus video sequence, and Taichi video sequence. Hall Monitor video sequence is a low-quality video sequence. Campus video sequence is a low contrast video sequence. Shadows of different objects are also present in this video sequence. In Taichi video sequence, background is non-stationary.
To start with frames 1, 2, and 3 have been taken into account for segmentation of the moving object as the first frame for which a just previous frame and next frame are available is frame-2. The same is repeated for the frames following frame-2. The results obtained for all representative video clips have been compared with those obtained using methods used by Kim et al. [6] and Mahmoodi [8] falling under category of spatial domain segmentation methods; and methods used by Huang et al. [17] and Baradarani [18, 19] falling under category of wavelet domain segmentation methods. Implementation regarding method used by Kim et al. [6] is taken from book entitled “Learning Open CV” authored by Gary Bradski and Adrian Kaehler [28]. Implementation regarding method used by Mahmoodi [8] is available on author’s own website. Method used by Huang et al. [17] and Baradarani [18, 19] has been implemented by the authors of this work.
4.1 Experiment-1
Figure 3 shows results for One Step video sequence which is downloaded from http://homepages.inf.ed.ac.uk/rbf/CAVIARDATA1/. One Step video sequence contains 458 frames of frame size \(384 \times 288\). Results for frame numbers 2, 100, 200, 300, and 400 are given in Fig. 3.

Segmentation results for One Step video sequence corresponding to a Frame 2, b frame 100, c frame 200, d frame 300, e frame 400 (i Frame no. n, ii ground truth segmented frame, iii segmented frame obtained by use of the proposed method, iv segmented frame obtained by the method used by Kim et al. [6], v segmented frame obtained by the method used by Mahmoodi [8], vi segmented frame obtained by the method used by Huang et al. [17] and vii segmented frame obtained by the method used by Baradarani [18, 19])
4.2 Experiment-2
Figure 4 shows results for Hall Monitor video sequence which is downloaded from http://trace.eas.asu.edu/yuv/. Hall monitor video sequence contains 287 frames of frame size \(352 \times 240\). Results for frame numbers 25, 75, 125, 175, 225, and 275 are given in Fig. 4.

Segmentation results for Hall Monitor video sequence corresponding to a Frame 25, b frame 75, c frame 125, d frame 175, e frame 225, f frame 275 (i Frame no. n, ii ground-truth segmented frame, iii segmented frame obtained by use of the proposed method, iv segmented frame obtained by the method used by Kim et al. [6], v segmented frame obtained by the method used by Mahmoodi [8], vi segmented frame obtained by the method used by Huang et al. [17] and vii segmented frame obtained by the method used by Baradarani [18, 19])
From Figs. 3 and 4, it is observed that better shape of moving object with least noise in segmented frame is obtained by using the proposed method as compared to all other methods [6, 8, 17–19] taken into consideration for comparison. Method used by Baradarani [18, 19] results in comparable shape structure as compared to the proposed method but is poor in noise removal. Method used by Mahmoodi [8] also gives satisfactory shape information but have poor noise removal capability in comparison with the proposed method, and the method used by Baradarani [18, 19]. Method used by Kim et al. [6] is poor in shape information than the proposed method, but is better in noise removal as compared to the method used by Baradarani [18, 19] and Mahmoodi [8]. Method used by Huang et al. [17] is inferior in shape information of moving object as well as in noise removal as compared to the proposed method and method used by Kim et al. [6], Mahmoodi [8], and Baradarani [18, 19].
4.3 Experiment-3
Figure 5 shows results for Campus video sequence which is downloaded from http://itee.uq.edu.au/~uqasanin/. Campus video sequence is of low-quality video with poor contrast. Shadows of different objects are also present in this video. It contains 410 frames of frame size \(352 \times 288\). Results for frame numbers 100, 150, 200, 250, 300, and 350 are given in Fig. 5.

Segmentation results for Campus video sequence corresponding to a Frame 100, b frame 150, c frame 200, d frame 250, e frame 300, f frame 350 (i Frame no. n, ii ground-truth segmented frame, iii segmented frame obtained by use of the proposed method, iv segmented frame obtained by the method used by Kim et al. [6], v segmented frame obtained by the method used by Mahmoodi [8], vi segmented frame obtained by the method used by Huang et al. [17] and vii segmented frame obtained by the method used by Baradarani [18, 19])
From Fig. 5, one can observe that the segmentation result obtained by the proposed method has better shape of object as compared to all other methods [6, 8, 17–19] for low contrast video as well as for video with shadow of moving objects.
4.4 Experiment-4
Figure 6 shows segmentation results for Taichi video sequence which is downloaded from http://crcv.ucf.edu/data/UCF101.php. This video sequence has non-stationary background. Taichi video sequence contains 335 frames of frame size \(320 \times 240\). Results for frame numbers 50, 100, 150, 200, 250, and 300 are given in Fig. 6.

Segmentation results for Taichi video sequence corresponding to a Frame 50, b frame 100, c frame 150, d frame 200, e frame 250, f frame 300 (i Frame no. n, ii ground-truth segmented frame, iii segmented frame obtained by use of the proposed method, iv segmented frame obtained by the method used by Kim et al. [6], v segmented frame obtained by the method used by Mahmoodi [8], vi segmented frame obtained by the method used by Huang et al. [17] and vii segmented frame obtained by the method used by Baradarani [18, 19])
Double change detection method is suitable for video with stationary background. In case of non-stationary background, results of this method would not satisfactory because difference between three consecutive frames with moving object and non-stationary background would not be necessarily same as difference corresponding to stationary background. From Fig. 6, one can observe that segmentation results for a video with non-stationary background are poor using the proposed method as well as method used by Kim et al. [6], Mahmoodi [8], Huang et al. [17], and Baradarani [18, 19]. However, it is worth mentioning here that the proposed method results in better segmentation of moving object with slowly varying background as compared to the other methods [6, 8, 17–19] as evidenced by Fig. 6f.
The proposed method has been compared with other mentioned methods in terms of computation time required. Computation has been done on a machine with Intel 1.73 GHz Dual core processor with 2 GB RAM using MATLAB 2012a software. In Table 1, we have shown total computation time (in second) for different methods for a video of frame size \(384 \times 288\) with 500 frames.
5 Performance evaluation
It can be observed from the results that none of the segmentation algorithm gives accurate segmentation result as compared to ground-truth frames. It is also very difficult to compare the segmentation results visually because human visual system can identify and understand scenes with different connected objects effortlessly. Therefore, quantitative performance metrics together with visual results are more appropriate. We have compared quantitative performance metrics of the proposed method with those of other state-of-the-art methods viz. the methods used by Kim et al. [6], Mahmoodi [8], Huang et al. [17], and Baradarani [18, 19]. For quantitative comparisons, we have considered five different performance metrics: MP, RFAM, PCM, NAE, and PCC.
5.1 Misclassification penalty
The misclassified pixels in the segmentation results which are farther from the actual object boundary (ground-truth image) are penalized more than the misclassified pixels which are closer to the actual object boundary [29]. MP value lies in the range [0,1] and can be computed using following formula [29]:
where \(\text{ Chem }_\mathrm{GT}\) denotes the Chamfer distance transform of the boundary of ground-truth object. Indicator function \(I\) can be computed as
where \(I_\mathrm{GT} (m,n)\) and \(I_\mathrm{Seg} (m,n)\) are ground-truth frame and segmented frame, respectively, with dimension \((m \times n)\). Zero value of MP represents perfect segmentation.
Table 2 shows the values of MP for the proposed method and other methods [6, 8, 17–19] for four video sequences: One Step video sequence, Hall Monitor video sequence, Campus video sequence, and Taichi video sequence.
From Table 2, it is obvious that the proposed method has less value of MP as compared to other methods [6, 8, 17–19].
5.2 Relative foreground area measure
Relative foreground area measure (RFAM) is calculated between ground-truth frame and segmented frame using following formula [30]:
where \(\text{ Area }(I_\mathrm{GT})\) and \(\text{ Area }(I_\mathrm{Seg})\) are area of objects in ground-truth frame and segmented frame, respectively. Value of RFAM will be in the range [0,1]. RFAM with value 1 represents perfect segmentation.
Table 3 shows the values of RFAM for the proposed method and other methods [6, 8, 17–19] for four video sequences: One Step video sequence, Hall Monitor video sequence, Campus video sequence, and Taichi video sequence.
From Table 3, one can conclude that the proposed method has better relative foreground area as compared to other methods [6, 8, 17–19].
5.3 Pixel classification based measure
Pixel classification based measure (PCM) reflects the percentage of background pixels misclassified as foreground pixels and conversely foregrounds pixels misclassified as background pixels [30]. Value of PCM will be in the range [0,1]. PCM with value 1 represents perfect segmentation. PCM can be computed as follows: [30]:
where \(B_\mathrm{GT}\) and \(F_\mathrm{GT}\) denote the background and foreground of the ground-truth frame, whereas \(B_\mathrm{Seg} \) and \(F_\mathrm{Seg} \) denote the background and foreground pixels of the achieved segmented frame. ‘\(\cap \)’ is the logical AND operation. \(\text{ Cardi }(\cdot )\) is the cardinality operator.
Table 4 shows the values of PCM for the proposed method and other methods [6, 8, 17–19] for four video sequences: One Step video sequence, Hall Monitor video sequence, Campus video sequence, and Taichi video sequence.
From Table 4, it is obvious that the proposed method has better values of PCM as compared to other methods [6, 8, 17–19].
5.4 Normalized absolute error
Normalized absolute error (NAE) is calculated between ground-truth frame and segmented frame using following formula [3, 31]:
where \(I_\mathrm{GT}\) and \(I_\mathrm{Seg}\) are ground-truth frame and segmented frame, respectively, with dimension \((m\times n)\). Lower value of NAE means good segmentation while high value of NAE indicates poor segmentation.
Table 5 shows the values of NAE for the proposed method and other methods [6, 8, 17–19] for four video sequences: One Step video sequence, Hall Monitor video sequence, Campus video sequence, and Taichi video sequence.
From Table 5, it can be inferred that the proposed method has lower values of NAE as compared to other method [6, 8, 17–19].
5.5 Percentage of correct classification
Percentage of corrected classification is defined as [32]:
where TP is True Positives, i.e., the number of pixels, with change, detected correctly as pixels with change, FP is False Positives, i.e., the number of pixels, with change, detected incorrectly as pixels without change. TN is True Negatives, i.e., the number of pixels, without change, detected correctly as pixels without change and FN is False Negative, i.e., the number of pixels, without change, detected incorrectly as pixel without change. Higher value of PCC means good segmentation.
Table 6 shows the values of PCC for the proposed method and other methods [6, 8, 17–19] for four video sequences: One Step video sequence, Hall Monitor video sequence, Campus video sequence, and Taichi video sequence.
From Table 6, one can observe that the proposed method has higher value of PCC as compared to other methods [6, 8, 17–19].
6 Conclusions
In the present work, we have proposed a new method for segmentation of moving object using double change detection together with Daubechies complex wavelet transform. Reduced shift sensitivity and better edge detection properties of Daubechies complex wavelet transform make the proposed method more suitable for segmentation of moving object as compared to methods using real valued wavelet transform. Double change detection method has been chosen as it provides automatic detection of appearance of new objects. The proposed method has been evaluated for a number of video sequences, and results for four representative video sequences viz. One Step video sequence, Hall Monitor video sequence, Campus video sequence, and Taichi video sequence have been presented and analyzed. The results after segmentation of moving object using the proposed method have been compared qualitatively and quantitatively with those methods used by Kim et al. [6], Mahmoodi [8], Huang et al. [17], and Baradarani [18, 19]. The proposed method exhibits better noise removal and better shape preservation of segmented moving object as compared to other methods [6, 8, 17–19]. The shape information obtained by the proposed method as well as other methods [6, 8, 17–19] are not satisfactory for video sequence with non-stationary background. The reason behind non-satisfactory shape information from the proposed method is that the change detection method being used by the proposed method assumes stationary background. However, the shape information from the proposed method is better than those from other methods [6, 8, 17–19] for video sequence with comparatively slowly varying non-stationary background. We have used five performance metrics viz. MP, RFAM, NAE, PCM, and PCC for quantitative comparison. The proposed method is found better in terms of all these performance metrics as compared to other methods [6, 8, 17–19].
Contribution of the proposed method can be summarized as follows:
-
1.
A new method for moving object segmentation which is based on Daubechies complex wavelet transform and double change detection method is developed.
-
2.
This method needs only values of Daubechies complex wavelet transform coefficients.
-
3.
This method needs no manual intervention.
-
4.
The method has been tested on several video sequences and is found to have better performance in terms of a number of performance metrics as compared to representative state-of-the-art methods.
References
Sonka, M., Hlavac, V., Boyle, R.: Image Processing Analysis and Machine Vision, 3rd edn. Thomson Asia Pvt. Ltd., Singapore (2008)
Hu, W., Tan, T.: A survey on visual surveillance of object motion and behaviors. IEEE Trans. Syst. Man Cybern. Part C 34(3), 334–352 (2006)
Khare, M., Srivastava, R.K.: Level set method for segmentation of medical images without reinitialization. J. Med. Imaging Health Inform. 2(2), 158–167 (2012)
Meier, T.: Segmentation for Video Object Plane Extraction and Reduction of Coding Artifacts, PhD Thesis. Department of Electrical and Electronics Engineering, University of Western, Australia (1988)
Kim, C., Hwang, J.N.: Fast and automatic video object segmentation and tracking for content based applications. IEEE Trans. Circuits Syst. Video Technol. 12(2), 122–129 (2002)
Kim, K., Chalidabhongse, T.H., Harwood, D., Davis, L.: Real time forground background segmentation using codebook model. Real Time Imaging 11(3), 172–185 (2005)
Xiaoyan, Z., Lingxia, L., Xuchun, Z.: An automatic video segmentation scheme. In: proceeding of IEEE International Symposium on Intelligent Signal Processing and Communication Systems, pp. 272–275. Xieman, China, Nov. 28-Dec. 1 (2007)
Mahmoodi, S.: Shape based active contour for fast video segmentation. IEEE Signal Process. Lett. 16(10), 857–860 (2009)
Javed, O., Shafique, K., Shah, M.: A hierarchical approach to robust background subtraction using color and gradient information. In: Proceeding of International Workshop on Motion and Video Computing, pp. 22–27. Orlando, Florida, USA, Dec. 5–6 (2002)
Reza, H., Broojeni, S., Charkari, N.M.: A new background subtraction method in video sequences based on temporal motion windows. In: Proceeding of International Conference on IT to Celebrate S. Charmonman’s 72 Birthday, pp. 25.1–25.7, March 2009 (2009)
Ivanov, Y., Bobick, A., Li, J.: Fast lighting independent background subtraction. In: Proceeding of IEEE Workshop on Visual Surveillance, pp. 49–55. Bombay, India, Jan. 2, 1998 (1998)
Colombari, A., Fusiello, A., Murino, V.: Segmentation and tracking of multiple video objects. Pattern Recognit. 40(4), 1307–1317 (2007)
Kato, J., Watanabe, T., Joga, S., Rittscher, J., Blake, A.: An HMM based segmentation method for traffic monitoring movies. IEEE Trans. Pattern Recognit. Mach. Intell. 24(9), 1291–1296 (2002)
Stauffer, C., Eric, W., Grimson, L.: Learning patterns of activity using real-time tracking. IEEE Trans. Pattern Recognit. Mach. Intell. 22(8), 747–757 (2000)
Hunag, J.C., Hsieh, W.S.: Wavelet based moving object segmentation. Electron. Lett. 39(19), 1380–1382 (2003)
Huang, C.L., Liao, B.Y.: A robust scene-change detection method for video segmentation. IEEE Trans. Circuits Syst. Video Technol. 11(12), 1281–1288 (2001)
Huang, J.C., Su, T.S., Wang, L.J., Hsieh, W.S.: Double change detection method for wavelet based moving object segmentation. Electron. Lett. 40(13), 798–799 (2004)
Baradarani, A., Wu, Q.M.J.: Wavelet based moving object segmentation: from scalar wavelets to dual-tree complex filter banks. In: Herout, A. (ed.) Pattern Recognition Recent Advances, ISBN 978-953-7619-90-9, InTech Publication (2010)
Baradarani, A.: Moving object segmentation using 9/7-10/8 dual tree complex filter bank. In: Proceeding of IEEE 19th International Conference on Pattern Recognition (ICPR), pp. 1–4. Tampa, Florida, USA, Dec. 8–11, 2008 (2008)
Radke, R.J., Andra, S., Al-Kofahi, O., Roysam, B.: Image change detection algorithms: a systematic survey. IEEE Trans. Image Process. 14(3), 294–307 (2005)
Daubechies, I.: Ten Lectures on Wavelets. SIAM (1992)
Clonda, D., Lina, J.M., Goulard, B.: Complex Daubechies wavelets: properties and statistical image modeling. Signal Process. 84(1), 1–23 (2004)
Khare, A., Tiwary, U.S., Pedrycz, W., Jeon, M.: Multilevel adaptive thresholding and shrinkage technique for denoising using Daubechies complex wavelet transform. Imaging Sci. J. 58(6), 340–358 (2010)
Khare, A., Khare, M., Jeong, Y.Y., Kim, H., Jeon, M.: Despeckling of medical ultrasound images using Daubechies complex wavelet transform. Signal Process. 90(2), 428–439 (2010)
Khare, A., Tiwary, U.S.: Soft thresholding for denoising of medical images—a multiresolution analysis. Int. J. Wavelets Multiresolut. Inf. Process. 3(4), 477–496 (2005)
Canny, J.F.: A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI) 6(8), 679–698 (1986)
Gonzalez, R.C., Woods, R.E.: Digital Image Processing Ch. 9, 3rd edn, pp. 519–566. Pearson Education Asia Publication, India (2008)
Bradski, G., Kaehler, A.: Learning OpenCV: Computer Vision with OpenCv Library, 1st edn. Oreilly, Sharoff Publication, India (2008)
Erdem, C.E., Sankur, B., Tekalp, A.M.: Performance measures for video object segmentation and tracking. IEEE Trans. Image Process. 13(7), 937–951 (2004)
Gao-bo, Y., Zhao-yang, Z.: Objective performance evaluation of video segmentation algorithms with ground-truth. J. Shanghai Univ. (English Edition) 8(1):70–74 (2002)
Avcibas, I., Sankur, B., Sayood, K.: Statistical evaluation of image quality measures. J. Electron. Imaging 11(2), 206–223 (2002)
Rosin, P., Ioannidis, E.: Evaluation of global image thresholding for change detection. Pattern Recognit. Lett. 24(14), 2345–2356 (2003)
Acknowledgments
This work was supported in part by the Department of Science and Technology, New Delhi, India, under Grant No. SR/FTP/ETA-023/2009 and the University Grants Commission, New Delhi, India, under Grant No. 36- 246/2008(SR).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Khare, M., Srivastava, R.K. & Khare, A. Moving object segmentation in Daubechies complex wavelet domain. SIViP 9, 635–650 (2015). https://doi.org/10.1007/s11760-013-0496-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-013-0496-4