
Abstract
For images with partial blur such as local defocus or local motion, deconvolution with just a single point spread function surely could not restore the images correctly. Thus, restoration relying on blur region segmentation is developed widely. In this paper, we propose an automatic approach for blur region extraction. Firstly, the image is divided into patches. Then, the patches are marked by three blur features: gradient histogram span, local mean square error map, and maximum saturation. The combination of three measures is employed as the initialization of iterative image matting algorithm. At last, we separate the blurred and non-blurred region through the binarization of alpha matting map. Experiments with a set of natural images prove the advantage of our algorithm.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Classical image restoration mainly focuses on the deconvolution under the assumptions of linear system transformation, stationary signal statistics, and stationary signal-independent noise [1, 2], with the usage of fast Fourier transform (FFT). Unfortunately, the assumptions are not always fit for real applications. For example, the degradations with SVPSF (space-variant point spread function), caused by optical aberration, medium perturbation, temperature variation, local defocus blur, local motion blur, etc., could not use FFT directly because of the added object-space coordinate. Usually, the image segmentation methods perform well in ordinary application [3, 4], but would fail in local blur segmentation. Therefore, sectioned approach [5, 6] is proposed to solve the problem.
Sectioned approach is based on subframe partition and traditional space-invariant point spread function (SIPSF) restoration. For applications with global SVPSF blur [7], the selection of isoplanatic region, in which the PSF does not vary significantly, usually depends on the regularity of PSF variation. While for partial blurred images, local defocus blurred images, and local motion blurred images, we need to extract the defocus region, or motion object. A single motion blurred image is deblurred using speed detection [8], which is a sectioned approach, while the results contain much ringing due to the error segmentation of blur region. It is not easy to perform the extraction, that is, to distinguish the blurred region from the non-blurred region.
Recently, researchers have made a great effort on this issue. It is apparent that highly blurred regions accommodate low spatial derivatives. So the sharpness of edge is an effective reflection of blur extent [9]. Rugna et al. [10] find that blurred regions are more invariant to low-pass filtering. Similarly, Bar et al. [11] smooth the partial blurred image by Laplacian function first, but the identification of blurred/non-blurred regions is different. It is based on the observation that the average gray level of the edges in the blurred region is lighter than in the sharp regions. The thickness of object contours after filtering with steerable Gaussian basis filter is utilized as a blur feature as well [12, 13]. Moreover, Chuang et al. [14] fit gradient magnitude along edge direction to a normal distribution and then combine the standard deviation of the distribution and gradient magnitude as the blur measure. The color, gradient, together with spectrum information of the partial blurred image, which is described in Liu’s [15] work, also provide additional useful knowledge for the discrimination.
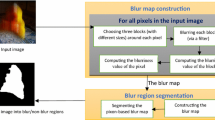
However, in most of existing research on blur detection, the accuracy rate is not satisfactory. To improve the reliability of blur region segmentation, we suggest to combine three blur features, gradient histogram span, local mean square error map, and maximum saturation, to discriminate blur patches and automatically create a ‘trimap’ (which means the image is divided into three partitions, the foreground marked with white, the background marked with black, and the unknown area), and then use image matting to extract the exactly blur region. Image matting [16–20] is a kind of soft segmentation which reserves the details, even as feather or hair, between different regions well. Nonetheless, in general, user interaction is needed to specify the foreground and background. In our investigation, there are no user strokes of foreground and background, instead of the marked regions detected automatically by the three blur features. The combination of automatic blur detection and image matting shows challenging results in our experiment presented in the following section.
2 Blur region detection
As shown in Fig. 1, there are two styles of partial blurred images. Figure 1a is a local defocus blurred image. The camera focuses on the forest backwards, and the rabbit in the front is out of focus, with obvious blur. The car in Fig. 1b is moving during the scene captured, which results in partial motion blur. Surely, deconvolution with a single blurring kernel for the entire image will lead to severe artifacts. Therefore, we need to distinguish the blurred region from the non-blurred region and restore them, respectively.

Partial blurred images, a local defocus blurred image, b local motion blurred image
In the following sections, we will quantify three blur features, denoted as \(q_{1}, q_{2}\), and \(q_{3}\), respectively, in Sect. 2. It is known that gradient of an image is the derivative of horizontal or vertical pixels, commonly denote where the sharp edge is. The gradient feature gradient histogram span (GHS) is determined by Eq. (2), as presented in Fig. 2a. Likewise, local mean square error (LMSE) describes the differences between neighbor pixels. The impulses near structure edges accommodate large values, while in blur region, the pixels are inclined to be similar with each other, which leads to small values. The LMSE feature is defined by Eq. (4), and Fig. 2b demonstrates the LMSE distribution map for Fig.1a. In addition, the blur process confuses the color information. With the concept that confused color means lower saturation, the observation motivates us to perform the blur detection by saturation of color. The maximum saturation (MS) feature is defined by Eq. (6). As shown in Fig. 2c, the blurred rabbit is expressed by low saturation. In the following sections, we will quantify the three blur features. And they are employed jointly to construct a pre-signed mask, that is, ‘trimap’ for the following matting. And Fig. 2d–f are corresponding to Fig. 1b. In Fig. 2f, the MS value of unblurred road is lower than the blur car. For different image content, one feather will make mistake, for that we prefer to combine three features together. The all three blur features map in Fig. 2 are only shown their intensity information.

2.1 Gradient histogram span
Comparing a blurred image with a non-blurred one, we could easily get the conclusion that the edge of blurred image is not as sharp as the latter. That means the gradient of blurred image is lower, as illustrated in Fig. 2a. Moreover, recent research in natural image modeling [15, 21, 22] suggests that the statistics of gradient response in natural images usually follow a mix-Gaussian distribution, and the gradient histogram span responds to the observed derivatives. As examples, we choose two pairs of blur/non-blur patches, which are marked with green/red rectangle in Fig. 3a, b, to demonstrate this distribution characteristic. The gradient maps of the patches are computed first, and then, the histograms of the maps are plotted. Figure 3c, d presents the log gradient distributions of blur patches, while Fig. 3e, f are for non-blur regions, which exhibit apparent heavy-tail compared with the former.

a One local defocus blurred image with a pair of blur/non-blur blocks marked by green/red rectangles. b One local motion blurred image with two blocks selected similarly. c, e present the gradient distributions of the blur/non-blur blocks in (a), respectively. The original log distributions are plotted in blue, whereas their approximations by mixture of Gaussian are displayed with magenta curves. d, f are gradient distributions of the two blocks in (b) (color figure online)
A mixture of two-component Gaussian model is used to approximate the distribution:
where mean value \(\mu _{1}= \mu _{2}=0\), and variance \(\sigma _{2}>\sigma _{1}\). \(a_{1}, a_{2}\) are constants. The components of the fitted Gaussian mixture models are illustrated as magenta curves in Fig. 3. The Gaussian component with larger variance \(\sigma _{2}\) is mainly responsible for causing the heavy-tail in the original distribution [15]. Hence, we set \(\sigma _{2}\) as a blur factor:
2.2 Local mean square error map
We define LMSE as the sum of all pixels’ mean square in the patch, expressed by:
It is a measure of the variance between the pixel and the mean value. There will be a large value near sharp edge, while blur region usually has small LMSE. Considering that different scenes contain different levels of edge sharpness, we take the relative local-to-global variance as our blur factor:
In which \(V_\mathrm{o}\) is the mean square error of the entire image.
2.3 Maximum saturation
Color information is also useful for blur detection. It is observed that blurred pixels tend to have less vivid colors than non-blurred pixels because of the smoothing effect of the blurring process [15]. Consequently, the saturation of color can be used as a measure of blur degree.
After computing the saturation \(S_p\) of each pixel in a patch, we find the maximum value max \((S_{p})\). It is compared with the maximum saturation value of the whole image max \((S_{o})\). Then, we get the third blur factor:
2.4 Blur/non-blur mask
Although the gradient histogram span, local mean square error, and maximum saturation are effective blur features, they could not work well lonely. To illustrate that, we apply the three blur measures to detect blur and non-blurred regions in the image shown in Fig. 1b individually. The image is partitioned to patches size of \(20 \times 20\) in advance. We set different thresholds \(T_{b},\,T_{d}\) for each blur measure. If the blur factor in a patch is smaller than \(T_{b}\), the patch is marked as blurred with white color. If the blur factor is larger than \(T_{d}\), the patch is marked as non-blurred region with black color. Note that since we use white and black as mark, the pixels with the color [0, 0, 0] and [255, 255, 255] must be removed from the pending image.
Figure 4a, c, e are the blur region detection results with above three approaches, respectively. No doubt that not all patches of car can be picked up. Simultaneously, there are some detection errors in the road patches, since the road has a unitary structure and color information which is similar with the blur region. The marked non-blur regions are shown in Fig. 4b, d, f. The road and grass are extracted correctly. However, the black patches containing different object structures are out of our expectation. These patches must be removed, or it will result errors in the following image matting. By the way, it is worth noting that the discrimination accuracy is related to the pattern of patches partition to some extent.

Blur/non-blur regions detected by three blur features. a, b Blur/non-blur regions detected by gradient histogram span. c, d Blur/non-blur regions detected by local mean square error map. e, f Blur/non-blur regions detected by maximum saturation. g ‘Trimap’ created by the three features, blur regions are marked with white, and non-blurred regions are marked with black
Hence, we combine the three features to improve accuracy. That is, if all of the three features regard a patch blurred, the patch is blurred with higher probability. It is the same to the non-blurred patch.
If \(Q<T_{b}\), the patch is blurred, else if \(Q>T_{d}\), it is non-blurred. So we get the ‘trimap’ as shown in Fig. 4g.
3 Image matting
Image matting attempts to separate a foreground object from the background, which is guiding for our segmentation of blurred/non-blurred region. Matting algorithms typically assume that each pixel \(x=(i, j)\) in an input image \(I(x)\) is a linear combination of a foreground color \(F(x)\) and a background color \(B(x)\), by an alpha map \(\alpha _{x}\) [16]:
\(\alpha _{x}\) is opacity value for each pixel, ranged from 0 to 1. If the alpha map is constrained to be either 0 or 1, the matting problem degrades to be a segmentation problem. Wang [16] proposed an iterative optimization algorithm ground on belief propagation (BP) to determine \(F\), \(B\), and \(\alpha \), with the help of uncertainty \(u\). In the first stage, pixels in marked regions are initialized to have an uncertainty of 0, an \(\alpha \) of 0 (background) or 1 (foreground). \(u\) of the other pixels is set as 1, and \(\alpha =0.5\). In each iteration, the alpha map as well as uncertainty value is updated. Pixels with new estimated value \(u=0\) are removed from unknown region to foreground or background. While the certainty for the whole image cannot be reduced any further, we get the last matte. More details could be found in Wang [16].
We repeat the matting algorithm with a pre-signed mask as Fig. 4g and extract the alpha matte illustrated in Fig. 5a. Totally, the moving car is separated from the stationary plants very well. Though a part of car-roof is not sufficiently covered, mainly because of the erroneous black mark near the roof. This patch has a large gradient and LMSE, as it includes the edge of the car and rape with vivid color. We will take more attention on removing this kind of blocks in our future work.

a Alpha matte extracted by image matting. b The blur region segmentation with our algorithm (area within the red line) (color figure online)
4 Experiments and discussions
4.1 Typical experiments
Another group of experiment results are presented in Fig. 6. Figure 6a–c show the blurred regions picked up with three features, while Fig. 6d–f mark the focused forest. The composition of marks is presented in Fig. 6g. We get the alpha matting map in Fig. 6h and the blur region segmentation rounded by red line in Fig. 6i.
The [0, 0, 0] and [255, 255, 255] pixels are rejected in advance. Although black trunk of the tree in the \(20 \times 20\) patches which are nearly unitary regions incline to be mistreated as blurred region, we adjust the thresholds of three blur factors to eliminate the incorrect marks. Meanwhile, the marks of edge patches containing different object between two regions cancel each other, leaving only forest patches. Our algorithm successfully extracts the defocused rabbit. However, it is a pity that the triangle area within green line between the ear and the left boundary does not have a background mark, thus failure to be recognized. This situation could be improved by decreasing the size of image patch to match the small area. But too smaller patch will result in huge computational complexity, together with more difficulty in rejection of erroneous mark. A balance is required for each single application.

a–c Blurred regions detected by gradient histogram span, local mean square error map, and maximum saturation, respectively. d–f Non-blurred regions detected by three features. g ‘Trimap’ for matting. h Extracted matte. i Blurred region segmentation (color figure online)
More examples are shown in Fig. 7. Focused turtle and butterfly in Fig. 7a, b are successfully separated from the blurred background. Figure 7c is a challenging image with different kinds of blur and different extent of blur. The cat on the left side is focused and stationary, while the cat on the right is ‘flying’ with slight motion blur, and the defocused plant background is more blurred. By adjusting the thresholds of blur factors, we extract the two cats as illustrated in Fig. 7c, d.

Segmentation results. a Focused turtle and defocus background. b Focused butterfly together with flower, and defocused background. c Stationary non-blurred cat, ‘flying’ cat with a little blur and defocused background with more blur. d ‘Flying’ cat with a little blur and defocused background with more blur
We show a blur segmentation examples in Fig. 8, where (a) is a challenging image example for blur segmentation. Figure 8b is a result of [15], with unblurred regions in red, motion blurred region in yellow, and focal blurred regions in blue. Thus, the unblurred regions is in red and blur area is in other color. And Fig. 8c is extracted matte with our method, from which we can judge the blur and unblurred region. Our segmented result is shown in Fig. 8d. Our result is better than [15]’s in segmenting blur/non-blur regions, especially in “hand” area. Though the blur region and unblurred area are carefully separated, there are several mistakes in “leaf” area. We need to improve it in future work.

Blur segmentation results for partially blurred images. a A challenging image example from Liu et al. [15]. b Liu et al. [15]’s result with unblurred regions in red, motion blurred region in yellow, and focal blurred regions in blue, c extracted matte with our method, d our segmentation result with separating blur and unblurred region (color figure online)
4.2 Effectiveness measures
We collect totally 200 partially blurred images to form our database, including local defocus or local motion. These images are from websites, such as Google and Flickr.com. And we manually select and segment them into square patches, generating blur patches and unblurred patches. The size of those images ranges from \(40 \times 40\) to \(200 \times 200\) pixels, which occupies about 5–20 % of the size of the original images. Figure 9 shows examples of images and patches. The first two rows are selected examples of images, and manually labeled patches (blur or unblurred) are shown in third row. Totally, we generated 400 blur patches and 400 unblurred patches.

Selected examples of images (first two rows) and manually labeled patches (third row) from our datasets
Using the accuracy metric, we can evaluate the ability of our classifier. Let \(N\) be the number of patches to classify, \(f_\mathrm{i}\) be the label for patch \(i\), and \(a_\mathrm{i}\) be the ground truth label for patch \(i\); the measurements are defined as [10, 15]
In our segmentation method, for an arbitrary image, we firstly do blur region segmentation like Fig. 5b, and then, the whole image is separated into blur region and unblurred region. Suppose patch \(i\) is a blur patch, \(a_\mathrm{i}\) is labeled as “blur”, if \(f_{i}\) belongs to the above blur region, then \(f_{i}= a_\mathrm{i}\). Suppose patch \(i\) is an unblurred patch, \(a_\mathrm{i}\) is labeled as “non-blur”, if \(f_{i}\) belongs to the above unblurred region, one can also conclude \(f_{i}= a_\mathrm{i}\).
According to the accuracy rate listed in Table 1, the accuracy rate of our method is 85.32 %. The excellent methods [10] and [15] are considered for comparison. Since we cannot get the original code, the results of Rugna and Konik [10] and Liu et al. [15] are the performance in their original papers. Because the similar definition and calculation of accuracy, the accuracy rate of Rugna and Konik [10] and Liu et al. [15] can be considered as reference results, which could still be used for comparison. In order to evaluate individual features in blur detection, we also calculate the accuracy with only \(q_{1}\) or \(q_2\) or \(q_3\), which is also listed in Table 1. In Table 1, \(Q_{2}\) means the result of \(Q_{2}=q_{1}+q_2+q_{3}\) replacing for Eq. (7). The accuracy of direct multiplication and direct summation is almost equal. The simple combination for three factors could do well in blur segmentation.
With the largest accuracy rate, our algorithm performs best. In Rugna and Konik [10] and Liu et al. [15], they need image data used for training. And in our algorithm, the threshold \(T_\mathrm{d}\) and \(T_\mathrm{b}\) for Eq. (7) should be slightly adjusted and changed for different images. This disadvantage should be improved in future.
4.3 Attempt for image restoration
To apply our algorithm in partial blur image, restoration is our final purpose. We try to restore Fig. 1 for further attempt. Actually, the most difficult in partial blur image restoration is how to well combine the restored blur region and original unblurred area together, reducing the artifacts between the two regions.
Estimating the PSF with image statistics [22], then we can restore the blur image. The extracted matte is used as weight matrix for blur region restoration, which could help reduce the effect from unblurred area. In order to further control the artifacts between the two regions, inpainting technique [24] is also used to reconstruct the deteriorated parts. The restored results for Fig. 1 are shown in Fig. 10. Though the restored images are promising, the deteriorated parts are still exists between blur and unblurred regions. How to well restore and reconstruct the border of two regions is the key point of future work.

5 Conclusions
The restoration of partial images is inherently a limited SVPSF restored problem, absent from classical FFT deconvolution. Therefore, blur region segmentation algorithm is used to recover different area separately. In this paper, gradient histogram span, local mean square error map, together with saturation information of pixels are utilized for automatic segmentation. Iterative image matting is also introduced to extract the blurred region more accurately, without the drawback of user interaction. Our algorithm provides results as well as, if not outperform, the state-of-the-art segmentation. The limitations on unitary region discrimination and edge block erroneous mark will be our emphasis for the future work. How to perfectly restore and reconstruct the border of blur and unblurred region is also a challenging job.
References
Gonzalez, C., Woods, E.: Digital Image Processing, 2nd edn. Electronic Industry Press, Beijing (2002)
Zou, Y.: Deconvolution and Signal Recovery. National defence industry press, Beijing (2001)
Xu, T., Gondra, I.: A simple and effective texture characterization for image segmentation. Signal Image Video Process. 6(2), 231–245 (2010)
Freedman, D.: An improved image graph for semi-automatic segmentation. Signal Image Video Process. (2010). doi:10.1007/s11760-010-0181-9
Trussell, H., Hunt, B.: Image restoration of space variant blurs by sectioned methods. IEEE International Conference on Acoustics, Speech, and Signal Processing, Apr. 10–12, pp. 196–198 (1978)
Trussell, H., Hunt, B.: Sectioned methods for image restoration. IEEE Trans. Acoust. Speech Signal Process. 26(2), 157–164 (1978)
Costello, T., Mikhael, W.: Efficient restoration of space-variant blurs from physical optics by sectioning with modified Wiener filtering. Digit. Signal Process. 13(1), 1–22 (2003)
Lin, H., Li, K., Chang, H.: Vehicle speed detection from a single motion blurred image. Image Vis. Comput. 26(10), 1327–1337 (2008)
Marziliano, P., Dufaux, F., Winkler, S., Ebrahimi, T.: A no-reference perceptual blur metric. Proc. International Conference on Image Processing, Jun. 24–28, pp. 57–60 (2002)
Rugna, J., Konik, H.: Automatic blur detection for metadata extraction in content-based retrieval context. Proc. SPIE 5304, 285–294 (2003)
Bar, L., Sochen, N., Kiryati, N.: Restoration of images with piecewise space-variant blur. Scale Space Var. Methods Comput. Vis. 4485, 533–544 (2007)
Freeman, W., Adelson, E.: The design and use of steerable filters. IEEE Trans. Pattern Anal. Mach. Intell. 13(9), 891–906 (1991)
Zhang, W., Bergholm, F.: Multi-Scale Blur estimation and edge type classification for scene analysis. Int. J. Comput. Vis. 24(3), 219–250 (1997)
Chung, Y., Wang, J., Bailey, R., Chen, S., Chang, S.: A nonparametric blur measure based on edge analysis for image processing applications. IEEE Conference on Cybernetics and Intelligent Systems, Dec. 1–3, pp. 356–360 (2004)
Liu, R., Li, Z., Jia, J.: Image partial blur detection and classification. IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, USA, Jun. 23–28, pp. 954–961 (2008)
Wang, J., Cohen, M.: An iterative optimization approach for unified image segmentation and matting. Proceedings of tenth International Computer Vision, Oct. 17–21, pp. 936–943 (2005)
Levin, A., Lischinski, D., Weiss, Y.: A closed form solution to natural image matting. IEEE Trans. Pattern Anal. Mach. Intell. 30(2), 228–242 (2008)
Levin, A., Acha, A., Lischinski, D.: Spectral matting. IEEE Conference on Computer Vision and Pattern Recognition, Jun. 17–22, pp. 1–8 (2007)
Li, Y., Sun, J., Tang, C., Shum, H.: Lazy snapping. ACM Trans. Graph. 23(3), 303–308 (2004)
Rother, C., Kolmogorov, V., Blake, A.: Grab cut: interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 23(3), 309–314 (2005)
Roth, S., Black, M.: Fields of experts: A framework for learning image priors. IEEE Conference on Computer Vision and Pattern Recognition, Jun. 20–25, pp. 860–867 (2005)
Levin, A.: Blind motion deblurring using image statistics. Adv. Neural Inf. Process. Syst. 19, 841–848 (2007)
Fergus, R., Singh, B., Hertzmann, A., Roweis, S.T., Freeman, W.T.: Removing camera shake from a single photograph. ACM Trans. Graph. 25(3), 787–794 (2006)
Oliveira, M., Bowen, B., Mckenna, R., Chang, Y.: Fast digital image inpainting. Proceedings International Conference on Visualization, Imaging and Image Processing (VIIP 2001): Marbella, Spain, pp. 261–266, (2001)
Acknowledgments
We wish to thank the reviewers for their comments and suggestions which have helped improve the content of the paper. And we thank Dr. Li for checking the text. This research is supported by the National Basic Research Program (973) of China (Grant No. 2009CB724006) and the National Hi-Tech Research and Development Program (863) of China (2009AA12Z108).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Zhao, J., Feng, H., Xu, Z. et al. Automatic blur region segmentation approach using image matting. SIViP 7, 1173–1181 (2013). https://doi.org/10.1007/s11760-012-0381-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-012-0381-6