
Abstract
Twenty seven Iranian olive oil samples were collected from different provinces to evaluate fatty acids and sterol compositions. The samples were collected from different geographical locations that varied in altitude, temperature, humidity and rain fall. The sample collected from the northern part of Iran by the Caspian Sea had higher oleic acid [G2 sample (75.98%)] and lower linoleic acid [Go5 sample (6.5%)] and palmitic acid [G2 sample (10.78%)] concentrations than samples from the southern part of the country such as F1 whose contents of C16:0, C18:1 and C18:2 were 15.27, 62.73 and 16.09%, respectively, in the southern part, the climate is dry and the temperature variation is wider and the elevation is 1,488 m. The results indicated that oleic acid was the predominant fatty acid with 62.7% for F1 sample in the warmer climate at the south of Iran to 76.0% for G2 sample in the cooler climate in the north of Iran. According to the results, the highest content of β-sitosterol was 87% related to samples G9 and Z3 from the north of Iran and the lowest content was 69.95% related to sample F1–24 from the south of Iran. Clustering techniques such as principal component analysis and hierarchical cluster analysis were carried out on olive composition data to show similarities and discrimination between samples as a function of the cultivation zone. The two methods applied clearly showed the effect of growing regions on the distribution of the olive oil samples in the high dimensional space created by fatty acid and sterol compositions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Olive oil is distinguished by its composition, high monounsaturates, stability, the presence of alpha tocopherol, taste and aroma [1]. Olive fruit are harvested annually during November to March in Iran. The quality of the oil determines the price and is a function of weather during the growing season. Environmental effects on oil composition often complicate detection of various types of adulteration [2]. Due to a high demand for olive oil around the world, not only in the Mediterranean regions, the farmers in Iran have been encouraged to grow olive trees, therefore olive trees are widely distributed around the country particularly in the northern region.
Environmental effects on olive oil fatty acid composition may be associated with the zone of production, the latitude, the climate, the variety, and the stage of maturity of the fruit [3–8]. For example Greek, Italian, and Spanish olive oils are low in linoleic and palmitic acids and high in oleic acid. Tunisian olive oils are high in linoleic and palmitic acids and low in oleic acid.
Sterols are the major fraction of the nonsaponifiable components of the olive oils. Knowledge of the sterol and fatty acid composition is quite important in the evaluation of the nutritional value as well as identification of the olive oil.
The correct classification of the variety and cultivation zone of the olive oil, which also includes the tree and its different parts, is shown as a new problem in order to control the quality and the appellation of origin of the olive oils due to the fact that each combination of variety and cultivation zone has a different chemical composition [9].
The object of this research work was to obtain a clear understanding of the effect of environmental parameters on the composition of fatty acids and sterols in olive oil produced in Iran along with other performed research works [10].
Materials and Methods
In this research work 27 different olive oil samples from different regions of Iran were used to evaluate environmental effects on fatty acid and sterol composition. Olive oils were collected from Zanjan, Qazvin, Gilan, Golestan, Fars, and Kermanshah provinces during November to March 2007. The stratified sampling was used for the collection of the oil samples. Specification of climate regions for sampling Iranian olive oils is given in Table 1.
Fatty acid methyl ester, cholesterol, β-sitosterol, campesterol, stigmasterol standards were purchased from the Sigma Company. Isolated castor oil sterol, canola sterol and solvent extracted olive pomace oil sterol were employed to identify and quantify ∆5-avenasterol, brassicasterol and erythrodiol and uvaol, respectively. All reagents were of analytical grade and were purchased from the Sigma and Merck Companies.
Gas liquid chromatography was used for identification and quantification of the component fatty acids. Fatty acids were converted into their methyl esters according to the method COI/T.20/Doc. no. 24, 2001 [11]. A Hewlett Packard (model 684) gas chromatograph equipped with a flame ionization detector and an HP-5 capillary column (120 m, 0.25 mm I.D., particle size 0.25 μm) was employed to identify the fatty acids. The GC system was set up at an oven temperature of 165 °C. The oven temperature was isothermal at 165 °C for 10 min, then raised to 200 °C at 1.5 °C/min. The injector temperature was 220 °C and the detector temperature 250 °C. Hydrogen used as the carrier gas at a column head pressure of 130 kPa, approximately. The injection volume was 1 μL in split injection mode.
Non saponifiable matter was extracted by alcoholic potassium hydroxide saponification followed by extraction with diethylether according to IOOC method COI/T.20/Doc. no. 10/Rev. 1, 2001 [12]. The sterols were isolated by thin layer chromatography (TLC) on plates coated with 0.5 mm silica gel G type 60 along a line with the standard and developed in hexane:ether (4:1). The plates were sprayed with 0.01% Rhodamine 6G in ethanol and observed under a UV lamp. The band related to sterols was removed and the sterols were extracted by diethyl ether and were transformed into trimethylsilyl ethers (TMSE). A Hewlett Packard (model 684) gas chromatograph equipped with flame ionization detector and BPX70 capillary column (30 m, 0.25 mm, 0.25 μm) was used to identify and quantify the sterols. Each sample was replicated at least three times. Conditions of the GC system were as follows:
-
Column temperature: 260 ± 5 °C
-
Injector temperature: 280 °C
-
Detector temperature: 290 °C
-
Linear velocity of the carrier gas: hydrogen 30–50 cm/s
-
Splitting ratio: from 1:50
-
Amount of substance injected: 0.5–1 μL of TMSE solution
Principal Component Analysis
Principal component analysis (PCA) is a linear and unsupervised pattern recognition technique used for analysis, classification, and reduction of the dimensionality of numerical datasets in a multivariate problem [13]. PCA groups correlated variables, into principal components. PCA decompose the data matrix X into the product of two orthogonal matrices, namely the T score matrix and P loading matrix. The columns of the T matrix are principal components, PCs;
where, superscript T refer to the transpose of the matrix. These PCs are completely uncorrelated and are built as a simple linear combination of the original variables. It is important to point out here that the PCs contain most of the variability in the data set, albeit in a much lower-dimensional space. The first principal component, PC1, is defined in the direction of maximum variance of the whole data set. PC2 is the direction that describes the maximum variance in the orthogonal subspace to PC1. The subsequent components are taken orthogonally to those previously chosen, and describe the maximum of the remaining variance. Once the redundancy is removed, only the first few principal components are required to describe most of the information contained in the original data set. If a multivariate data set is visualized as a set of coordinates in a high-dimensional data space (1 axis per variable), PCA supplies the user with a lower-dimensional picture, a “shadow” of this object when viewed from its (in some sense) most informative viewpoint. The results of a PCA are usually discussed in terms of component scores and loadings. The PCA was done using PLS_Toolbox version 4 (Eigenvector company, http://www.eigenvector.com).
Hierarchical Cluster Analysis
Clustering is known as the classification of objects into different groups, or more precisely, the partitioning of a data set into subsets (clusters), so that the data in each subset (ideally) share some common trait—often proximity according to some defined distance measure. Data clustering is a common technique for statistical data analysis, which is used in many fields, including machine learning, data mining, pattern recognition, image analysis and bioinformatics. Hierarchical cluster analysis (HCA) is an unsupervised technique that examines the interpoint distances between all of the samples and represents that information in the form of a two dimensional plot called a dendrogram [14]. These dendrograms present the data from high dimensional row spaces in a form that facilitates the use of human vision abilities [14]. In order to generate the dendrogram, HCA methods form clusters of samples based on their nearness in row space. Initially every sample is considered as a cluster and join closest clusters together. This process is repeated until only one cluster remains. Variation of HCA use different approaches to measure distances between clusters (e.g., single, Euclidean and Mahalanobis distances). The linkage rules iteratively link nearby points (similar samples) by using the similarity (distance) matrix. The initial cluster is formed by linkage of the two samples with the greatest similarity. Ward’s method is distinct from all other methods because it uses an analysis of variance (ANOVA) approach to evaluate the distances between clusters and forms smaller distinct clusters than those formed by other methods. The Euclidian distance was selected as the similarity measurement, which is a straight line distance between two points in c-dimensional space defined by c number of variables. The HCA was done in PLS_Toolbox ver. 4 (Eigenvector company, http://www.eigenvector.com).
Results and Discussion
Table 2 shows the fatty acid composition of the examined Iranian olive oils. Fatty acid composition of all the samples examined is within the range indicated by the olive oil codex standard [15] and IOOC regulations [16]. The fatty acid composition of the samples collected from the northern region; Gilan, Qazvin, Zanjan and Golestan provinces indicated that the oils are among the high oleic, low linoleic–palmitic group, while others might be related to high linoleic–palmitic, low oleic group. For example, the lowest value of palmitic acid (10.78%) related to G2 and the highest value of oleic acid (75.98%) related to this sample as well. The minimum value of linoleic acid (6.5%) belong to Go5 that both of them (G2 and Go5) are located in north of Iran. The results obtained indicate that the plants cultivated might have originated from Mediterranean regions due to the agreements in fatty acid composition. The northern part of Iran where the majority of the samples were collected has a similar climate to the Mediterranean region. According to our results, the maximum amounts of palmitic and linoleic acids are 15.6 and 16.09% for F3 and F1 samples respectively. F1, F2 and F3 are the samples collected from the southern region. The result verifies that the percentage of fatty acids followed Ivanov’s rule: “the amount of linoleic acid rises when the temperature decreases, contrary to oleic acid” [17]. Fatty acid composition of the olive oil samples collected from the south where the climate is hot and dry with low humidity and temperature variations indicated that the oils had low oleic, high linoleic–palmitic acid content and is similar to Tunisian olive oil where palmitic acid is the major saturated fatty acid [1, 12]. Due to the fact that olive tree plantations have been encouraged in the southern states of the country since three decades ago, it might be concluded that the trees which were imported and planted originally were of the type resistant to mentioned climatical conditions. The findings in this research are in agreement with the work done by Lotti et al. [18] who showed that the climate has a great influence on ripeness and hence on the chemical composition of the oils. Di Bella et al. [5] suggested that although the effect of the cultivar is significant in the olive oil classification based on the fatty acid composition, a predominant and well-defined geographic condition might also have quite an effect.
Table 3 presents the sterol composition of different Iranian olive oils. According to many researches the composition of the steroidal fraction of the olive oil is considered a useful parameter for detecting adulteration or verifying authenticity, it might therefore be used as a distinct fingerprint for identification [7, 8, 14, 19–21].
The sterol compositions of the olive oil samples are almost in agreement with olive oil codex standard, however, there is a slight variation between the composition of the oil samples collected from the northern part of Iran by the Caspian Sea and those obtained from the Fars province. Fars samples had lower β-sitosterol (69.95%) and higher ∆-5-avenasterol (13.75%) contents while the northern samples had higher β-sitosterol (87%) and lower ∆-5-avenasterol (5.6%). This agrees with the Lotti et al. findings that the concentration of β-sitosterol increased and those of campesterol and stigmasterol decreased as the climate became colder [18]. The apparent β-sitosterol in all samples examined with the exception of one Fars samples (F1) agreed with the standard and was higher than 93%. During the isolation of the nonsaponifiable matter prior to its fractionation into different classes of chemical compounds, observations were made on the isolated nonsaponifiable matter at ambient temperature. Some isolated nonsaponifiable matter appeared as a dark colored liquid fraction while others were semi-solid or solid with a lighter color. Such behavior, such as being liquid or solid at this point, is a matter of further investigation and might be due to the composition of the nonsaponifiable matter which consist of other groups of chemical compounds namely 4-methyl sterol, triterpene alcohol, triterpene diols, aliphatic alcohols, dimers, hydrocarbons and pigments.
The results of the analytical determinations were organized into a matrix of 27 samples × 20 variables. PCA was applied on the variables and seven principal components (PC) were extracted, covering 87% of the variance.
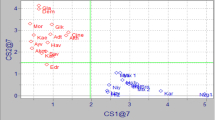
Since a seven dimensional display is practically not possible, then the first two PC were used for the plot Fig. 1 which obviously shows the differentiation between samples with the different geographical origin and different variety. The means of each class has significant differences at 95% confidence level when comparing the other classes using a t test.

Score plot for the 27 varieties Iranian olive oil samples, the numbers are according to Table 1 sample numbers entry
An examination of the loadings associated with each PC allows the most important variables to be singled out, Fig. 2. According to these results the samples collected from the northern part of Iran by the Caspian Sea were correlated with their content of oleic acid, whereas samples from southern part of the country, where the climate is dry and temperature variation is wider, had a high content of linoleic and palmitic acids. These variables contain information useful for distinguishing the Iranian olive oil samples that were collected from different geographical positions concerning altitudes, temperature, humidity and rain fall, and cultivars.

Also HCA (single-linkage method, with the Euclidean distance as the similarity measurement), was used in this case. The results obtained were confirmed by performing an HCA on the first seven PCs, applying a Ward linkage procedure on Manhattan distances. The dendrogram in Fig. 3 shows that it is possible to obtain clusters composed mostly of samples of the same climate. The classes distinguished by HCS dendrogram is according to t test and PCA results. The results obtained with HCA are analogous to those from PCA. It is useful to mention that these two techniques can successfully applied for the classification and evaluation of the regional growing effects on the specification of the olive oils.

HCA dendrograms for the 27 varieties of Iranian olive oil samples, numbers in the left side correspond to the row numbers of Table 1
Conclusion
Chemical analysis of the investigated oils indicated that all the samples were of olive oil origin. Fatty acid and sterol composition of the oils corresponds with the olive oil codex standard, however, variations in the individual samples might exist which are due to the geographical conditions. The findings in this work agree with several researchers who have tried to correlate the chemical composition of olive oil to fruit variety, geographic origin, denomination of origin, year of harvest or different qualities. As some scientists have used the fatty acid composition and different fractions of the non-saponifiable matter as a means to verify and identify olive oils, one might conclude that the identification of fatty acids and sterols has proved to be the most practical and least time-consuming procedure to achieve this aim. The multivariate statistical analysis methods like PCA and HCA clearly show the effect of the geographical effects on the specification of the olive oils. The growing region factors make olive oil samples form clear classes in multidimensional space.
References
Boskou D (2006) Olive oil, chemistry and technology. AOCS Press, Champaign
Bucci R, Magrí AL, Marini D, Marini F (2002) Chemical authentication of extra virgin olive oil varieties by supervised chemometric procedures. J Agric Food Chem 50:413–418
Ballabio D, Mauri A, Todeschini R, Buratti S (2006) Geographical classification of wine and olive oil by means of classification and influence matrix analysis (CAIMAN). Anal Chim Acta 570:249–258
Lopez-Feria S, Cardenas S, Garcıa-Mesa JA, Valcarcel M (2008) Classification of extra virgin olive oils according to the protected designation of origin, olive variety and geographical origin. Talanta 75:937–943
Di bella G, Maisano R, La pera L, Lo turco V, Salvo F, Dugo G (2007) Statistical characterization of sicilian olive oils from the Peloritana and Maghrebian zones according to the fatty acid profile. J Agric Food Chem 55:6568–6574
Galtier O, Dupuy N, Le Dr′eau Y, Ollivier D, Pinatel C, Kister J, Artaud J (2007) Geographic origins and compositions of virgin olive oils determinated by chemometric analysis of NIR spectra. Anal Chim Acta 595:136–144
Rui Alves M, Cunha SC, Amaral JS, Pereira JA, Beatriz Oliveira M (2005) Important classification of PDO olive oils on the basis of their sterol composition by multivariate analysis. Anal Chim Acta 549:166–178
Haddada FM, Manaï H, Oueslati I, Daoud D, Sánchez J, Osorio E, Zarrouk M (2007) Fatty acid, triacylglycerol, and phytosterol composition in six Tunisian olive varieties. J Agric Food Chem 55:10941–10946
Ranalli A, De Mattia G, Ferrante ML, Giansante L (1997) Incidence of olive cultivation area on the analytical characteristics of the oil. Note 1 RiV Ital Sostanze Grasse 74:501–508
Piravi-Vanak Z, Ghavami M, Ezzatpanah H, Arab J, Safafar H, Ghasemi JB (2009) Evaluation of authenticity of Iranian olive oil by fatty acid and triacylglycerol profiles. J Am Oil Chem Soc 86:827–833
IOOC, Preparation of the fatty acid methyl esters from olive oil and olive pomace olive oil, COI/T.20/Doc. no. 24, 2001
IOOC, Determination of the composition and content of sterols by capillary-column gas chromatography, COI/T.20/Doc. no. 10/Rev. 1, 2001
Massart DL, Vadeginste BGM, Buydens LMC, de Jong S, Lewi PJ, Smeyers-Verbeke J (1997) Handbook of chemometrics and qualimetrics, Parts A and B. Elsevier, Amsterdam
Pirouette, MultiVariate Data Analysis for Windows 95/98 and NT, version 2.6, Infometrix, Inc
Codex standard for olive oils and olive pomace oils. Codex Stan 33-1981 (Rev. 2, 2003)
IOOC: Trade standard applying to olive oils and olive pomace oils. COI/T.15/NC no. 3/Rev. 3, 2008
Aparicio R, Ferreiro L, Alonso V (1994) Effect of climate on the chemical composition of virgin olive oil. Anal Chim Acta 292:235–241
Lotti G, Izzo R, Riu R (1992) Influence of climate on the fatty acids and sterol composition of olive oil. Riv. Sci. Alimentazione 11:115–121
D’Imperio M, Dugo G, Alfa M, Mannina L, Segre AL (2007) Segre, statistical analysis on sicilian olive oils. Food Chem 102:956–965
Galeano Diaz T, Duran Meras I, Sanchez Casas J, Alexandre Franco MF (2005) Characterization of virgin olive oils according to its triglycerides and sterols composition by chemometric methods. Food Control 16:339–347
Araghipour N, Colineau J, Koot A, Akkermans W, Rojas JMM, Beauchamp J, Wisthaler A, Tilmann DM, Downey G, Guillou C, Mannina L, Ruth SV (2008) Geographical origin classification of olive oils by PTR-MS. Food Chem 108:374–383
Author information
Authors and Affiliations
Corresponding authors
About this article
Cite this article
Piravi-Vanak, Z., Ghasemi, J.B., Ghavami, M. et al. The Influence of Growing Region on Fatty Acids and Sterol Composition of Iranian Olive Oils by Unsupervised Clustering Methods. J Am Oil Chem Soc 89, 371–378 (2012). https://doi.org/10.1007/s11746-011-1922-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11746-011-1922-9