
Abstract
In past few decades, there was a tremendous enhancement in natural disaster and their effects on economy and population. An adverse events like floods, wildfires, cyclones, earthquakes, tsunamis, etc., are regarded as a natural disaster once it strikes the vulnerable population areas. An early tracking of susceptibility areas and immediate tracking of affected areas might help in facilitating rescue and early warnings to the public. To achieve autonomous natural disaster prediction, this paper makes use of current developments in remote sensing, which speed up the availability of aerial/satellite data and are reinforced by progress in the computing sector. The aerial/satellite imageries are employed for acquiring the data from areas of Queensland-Australia that are more prone to natural disaster in an eagle-eye perspective. Since there were several techniques employed so far for the automatic prediction of natural disaster susceptibilities, there were some limitations like reduced rate of accuracy and so on. So as to overcome these limitations, deep learning based automated process is employed for predicting the natural disaster areas and probability of event occurrences. The main intention of the work is to detect the natural disaster occurrence from the sensed data which aids in providing warning to public and to safeguard them by taking necessary actions. Initially, remote sensing data is pre-processed and the features are extracted using Adaptive linear Internal embedding algorithm-based feature extraction (ALIE-FE). The extracted features are selected using Recursive Wrapper-based feature subset selection. To estimate best fitness function and to enhance the prediction accuracy, the optimization process is carried using Bio-Inspired Squirrel Search Optimization algorithm (BI-SSOA). Finally, the classification is carried by means of Deep learning based Multi-layer Alex Net classifier (DBMLA) approach. The simulation is carried and the outcomes attained are estimated for predicting flood susceptibility and wildfire susceptibility. The proposed BISSOA-DBMLA offers sensitivity of 98%, specificity of 99%, and TSS of 97%. The proposed system offers 98.99% classification accuracy. Accuracy, sensitivity, specificity, TSS, and area under the curve (AUC) are used to evaluate the efficacy of the suggested system in light of the achieved results from other approaches. To demonstrate the efficacy of the suggested mechanism, the achieved results are compared with those of current approaches.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Big data has made a huge difference and is now an integral part of almost all sectors. Multi-channel, intelligent healthcare, homeland security, log analysis, finance, manufacturing sectors, telecommunications, crime prediction and analysis, retail marketing, etc., are just a few of the many areas where big data analytics has been put to use. People's participation in social media review communities has grown (Raza et al. 2020). Since the social network produces such a large amount of data every second, sifting through it and analysing it for specific queries is a key challenge. Predictions based on such a large data set will benefit from the use of big data analytics. Despite its versatility, big data analytics have a long way to go before they can be effectively used for catastrophe prevention and mitigation. There has been little reliance on social media to seek immediate assistance during times of crisis (Quinn et al. 2018; Nugent et al. 2017). Since the crisis scenario is more chaotic, analysing the huge data created during the crisis will be the best alternative for successfully navigating such unpredictable situations (Resch et al. 2018; Razali et al. 2020). Making the right choices at this time is crucial to meeting the needs of those who have been impacted. Lack of direct contact during crisis management sometimes results in impacted persons receiving false or partial information. The rescue team will benefit from the use of computational intelligence and big data analytics in these scenarios so that they can extract meaningful insights from large data sets and respond appropriately in the moment (Yuan et al. 2019; Rahmati et al. 2019). Early warning and readiness; reaction and impact; and risk, mitigation, and vulnerability modelling are the three main aspects of disaster management. There are two types of data used throughout the process: user-generated material, which includes sites like Flickr, Twitter, and Facebook, and sensor data, which includes things like drone and satellite photographs. The impacts of the accident may be mitigated after careful analysis of this data.
The majority of large datasets come from remote sensing. This fast developing technology has the advantages of a large coverage area that can be reliably covered again and over, and it may also deliver a massive amount of data from otherwise inaccessible locations. The remote sensing information also represents the reaction of the integrated vegetation and the different aspects that impact their current position as a fuel basis for the catastrophe caused by the wildfire. The normalised difference vegetation index (NDVI) is the vegetation index that indicates the crop health status and may be used for assessing the changes ion spatiotemporal in green vegetation, and it will be extracted from remote sensing data along with other parameters related to wildfires and other natural disasters. The LST is a measure of how hot the ground really is, and it varies greatly depending on the amount of plant cover and the soil's moisture level. The incidence of natural disasters is a repeated issue in all parts of the world. The physical extent of the disaster leads humans to react immediately and encounter the problem. Since there were several techniques employed so far for the automatic prediction of natural disaster susceptibilities, there were some limitations like reduced rate of accuracy and so on. AI techniques have been applied in various fields of NDM because of their high-speed operation, accuracy, and easy use. AI is a computational means that act intelligently. Thus, to overcome existing limitations, deep learning based automated process is employed for predicting areas of natural disaster and event occurrences probability. The main intention of the proposed work is to detect the natural disaster occurrence from the sensed data which aids in providing warning to public and to safeguard them by taking necessary actions.
The remainder of the paper is laid out as follows: "Related works" section is the analysis of various existing methods reviews employed so far. In "Proposed work" section is the detailed explanation of proposed system. The performance analysis of proposed system is estimated and the outcomes compared are projected in "Performance analysis" section. At last, the conclusion of work is made in "Conclusion" section.
Related works
Different current approaches were discussed in this section.
Using the Internet of Things (IoT), Big data (BD), and a convolutional deep neural network (CDNN), the author of Anbarasan et al. (2020) proposes a method for handling flood disasters. At first, BD flood data was used as input. HDFS map-reduce was then used to minimise the amount of duplicate data. Using a pre-processing strategy including missing value imputation and a normalisation function, we eliminated the duplicate data. After then, rules are generated by combining characteristics and methods. The resulting rule was then sent into the classifier CDNN, which assigned each piece of data to one of two categories: (a) data with a probability of being affected by a flood, and (b) data with no such risk. Parameters such as specificity, sensitivity, accuracy, recall, F-score, and precision were used to evaluate the results obtained using the suggested classifier CDNN approaches. In order to prove the efficacy of the suggested system, the achieved results were compared to those obtained using more conventional methods such as artificial neural networks (ANN) and deep neural networks (DNN). The inferred result demonstrates the superiority of the proposed technique over conventional methods.
In Yu et al. (2018), the authors published a literature analysis examining the significance of big data in disaster management, drawing attention to the state of the art in terms of technology and its potential for improving disaster response. This method has offered an evaluation of various studies from a wide variety of technical and scientific vantage points, all of which touch on the effectiveness of big data in easing the burden of disaster management. This approach reviews major sources of big data, the achievements associated at varied management of disaster phase, and the emerging technological topics that were associated with a leveraging new ecology for detecting and monitoring the natural hazards, effect mitigation, contributing recovery, assisting relief efforts and the process of reconstruction.
In (Fathi et al. 2021), the authors offered a review on existing methods for the analysis of big data techniques in forecasting weather published among 2014 and 2020. The taxonomy of feasible current reviewed approaches has been presented as a technology-dependent, technique-dependent, and the hybrid approaches. However, this approach suggests a comparative review of the aforementioned categorizations with respect to scalability, accuracy, execution time, and the other factors like Quality of service (QoS). The algorithm types, modelling tools, measurement environments, with their benefits and limitations were extracted. Also, the future trends and open issues were debated.
In (Li 2020), the authors introduced a scheme of GeoAI to be the emergent framework of spatial analysis intended for the GIscience data-intensive. This analyzed the recent outbreaks in the machine learning and advanced computation for attaining the scalable processing with the intelligent analysis in the geospatial big data. The view of three-pillar GeoAI along with their two technical threads like knowledge-driven and data-driven and the geospatial applications were highlighted. Thus, the discussion of the remaining difficulties and the future orientations of GeoAI is brought to a close.
Using techniques from the realm of machine learning such as bagging, decision trees, boosting, random forests, and bagging, the authors of Choi et al. (2018) propose a new method. Based on the overall model's prediction ability, the boosting model that included in the previous four days' worth of weather data was selected as the best option because to its higher AUC score of 95.87%.
On employing this model of prediction in this approach the study focuses on predicting the heavy rain damage occurrence for the entire administrative places which reduces the damage by the proactive management of disaster.
In Luechtefeld et al. (2018), the authors implemented the technique based on machine learning approach for predictions termed as REACH across attained unprecedented sensitivity higher than 70% for predicting six most usual topical and acute hazards for covering chemical universe about two thirds. Although this is expecting prescribed authentication, it reveals the new introduced superiority through modern data-mining and big data skills. A rapid enhancement in number of computational methods and diversity, along with data they were dependent on creating the opportunities and challenges for the computational methods usage.
Data-driven scientific discovery, decision making, and process optimization have enormous promise, as shown by the work given in Sun and Scanlon (2019), which combines big data with ML approaches. Potentially, this technological development might help water management systems function more smoothly. EWM in particular because (1) many EWM applications, such as early flood warning, necessitate the ability to autonomously extract the useful information from the massive volume of information in real time, and (2) EWM researches become greatly multi-disciplinary on handling huge enhancing data types or volumes with the use of existing workflow, which was not a simple option. (3) The existing theoretical understanding of the EWM process was not comprehensive, but it might be supplemented by the finding of a data-driven model. Many ML and big data applications have previously been published in EWM's scholarly literature. In Anand Deva Durai (2021), the authors presented a big data model on climatic research which was potentially significant one. Initially, the huge volume of data on current climate were expected to enhance from increasing further at both complexity and volume in the upcoming years. Next, these approaches were employed typically that were associated with big data encountered climate research. Thirdly, the models on climatic research were rooted in the theory of science which was the significant cause of the security at their projections. This in turn makes the research on climate a significant test case for the presented shift process depending on the huge free modeling theory.
In Asencio-Cortés et al. (2018), the authors employed several regression algorithms usage integrated with the ensemble mechanism which was explored in the big data context at which 1 GB catalog was employed so as to detect the magnitude of earthquakes in the imminent days. The framework of Apache Spark, H2O library in the language R with the infrastructure of amazon cloud were employed which was considered as a promising outcome.
In (Obaid 2021), the authors suggested a technique with the use of ML approach intended for the Multimedia Surveillance at the time of fire emergencies. The suggested model has two major deep neural network approaches. Initially, hybrid model was employed that was made of Adaboost and several multi-layer perceptron techniques. The major intention of hybrid Adaboost-MLP technique was to detect the fire in an effective manner. This technique employs sensor data like heat, smoke, and the gas for training. Once the fire was predicted, CNN technique was employed for the detection of fire instantly. The outcome shows that the presented training model has the accuracy of 91% for fire detection. Also, the false positive rates were lower. Thus, the outcomes were enhanced on further training.
In Sayad et al. (2019), the authors introduced a technique which serves as a major purpose for constructing a sensing data depending on the remote sensing information associated with the state of crops (NDVI), LST (meteorological conditions), in addition to the indicator for fire. The outcomes attained were assessed with the use of various strategies on validation like regularization, cross validation, and classification metrics by comparing some early warning wildfire system.
In Ragini et al. (2018), the authors created a big data method to disaster response using sentiment analysis. The method described herein collects catastrophe data from social networks and organises it according to the requirements of those who have been impacted. Machine learning was used to analyse public mood in order to classify sensitive catastrophe data. Several aspects like lexicon, and parts of speech were analyzed for identifying best strategy of classification for disaster data. The outcomes show that the best strategy of classification of disaster data. The outcomes attained represent that the lexicon dependent approach was appropriate for the examination of people needs at the time of disaster. The analysis helps in emergency responders in rescuing the personnel's for developing strategies effectively for the efficient management of information that changes rapidly. Despite the use of many methods, it may be difficult to detect a disaster's onset and may result in inaccurate data due to the limitations of nature and technology. Data aggregation issues across numerous sources, as well as incomplete and missing data, provide regular challenges for researchers hoping to put AI into practise. Therefore, a novel approach is required for this objective.
Proposed work
A detailed narration of the presented technique is employed in this part. Initially, remote sensing data is pre-processed by means of z-score normalization technique so as to refine the input data by replacing missing values and removing redundant information. The features are extracted using Adaptive linear Internal embedding algorithm-based feature extraction (ALIE-FE). From the extracted features the most relevant ones are selected using Recursive Wrapper-based feature subset selection. To estimate best fitness function and to enhance the prediction accuracy, the optimization process is carried using Bio-Inspired Squirrel Search Optimization algorithm (BI-SSOA). Finally, the classification is carried by means of Deep learning based Multi-layer Alex Net classifier (DBMLA) approach. The entire workflow of proposed strategy is presented in Fig. 1.

Systematic progression of the proposed mechanism
Data pre-processing
The input data is preprocessed since it is unrefined and has duplicate and missing values. This is cleaned and preprocessed for removing the redundant and repeated samples along with missed data. In this, the data is normalized and z-score is estimated and is acquired in the initial normalization phase as:
Here, \(\alpha\) signifies the mean of the dataset, \(\omega\) means sample size, and Z is calculated by:
Here, \( \underline {U}\) signifies sample mean, and \(D\) refers to the standard deviation.
The random sample must follow a pattern of:
In this \(\varepsilon_{{\text{j}}}\) signifies errors and is relied on \(\omega^{2}\).
The mistakes must therefore be independent of one another as illustrated below:
Here U denotes a random variable.
Then the standard deviation is employed for normalizing the variables and the moment scale deviation is estimated using:
Here, m denotes the moment scale.
In this \(\lambda\) signifies a random variable, and E refers to the expected value:
where \(y_{{\text{w}}}\) denotes the coefficient of the variance.
On changing entire variables to 0 or 1, the operation of feature scaling is thus terminated and is known as unison-based normalizing technique. It is shown as:
By this, the normalized data is attained and is further given as input for upcoming steps.
Feature extraction using (ALIE-FE) and feature subset selection
Adaptive linear internal embedding algorithm for feature extraction
The characteristics are being filtered out here for selection purposes. Common manifold learning algorithms include the Adaptive internal linear embedding method (ALIE-FE). On the concept that data on a nonlinear multiplying system may be perceived as linear in local regions, ALIE-FE is mainly designed to solve globally nonlinear issues with locally linear fitting. By calculating low-dimensional neighborhood-preserving input embeddings, ALIE-FE translates its inputs into a universal, lower dimensional co-ordinate scheme without resorting to local minimums. As a result of its ability to leverage local symmetries of linear reconstruction, ALIE-FE is able to acquire knowledge about the broader framework within which nonlinear divers function. Quarterly data is presented, and the local linear mounting is defined by the weight matrix, which is composed of linear coefficients that are descriptive of each data point from its surrounding regions. ALIE-FE looks for training data samples that are more distinguished by class importance (or discriminated against). The template specifically looks for a linear combination of input variables that maximises sample separation across classes (class average or means) and minimises sample separation within each class. Undergoing processing of the ALIE-FE. Samples from the ALIE-FE function space must be formed into a matrix as the initial stage of the linear analysis of discrimination. The ALIE-FE, which is of class C (C \(\ge\) 2), considers ka to be a set of dimensional space (DS) samples of type Sa. The Sbc group scatter matrix is retrieved for each class, and SNi c is computed using the formula below. The procedure typically consisted of three stages: selecting neighbours,
Afterward the matrix was constructed.
Generally, the matrix can be developed for the purpose of selecting the features. The pointed features are calculated by the calculation of the covariance matrix. Finally, the Map high-dimensional features can be mapped to the embedded coordinate.
Recursive wrapper-based feature subset selection
Feature selection methods are employed in several fields and is significant one for the modified extraction. Several methods for the selection of features have been used so far. The process of choosing relevant features from the extracted databases reduces training times and condensed model for facilitating better understanding. The eight functional attributes that corresponds to the criteria were extracted from the entire dataset. There are two significant features filtering strategies like filters, noisy, and wrapper data for picking correct functionality. In the process of data analysis, this technique enhances the performance speed and thereby enhances the accuracy of prediction. Depending on the combination of feature list, the method of recommendation computes the collection of features with the use of this approach. Minimal attributes set is intended for practical filtering so that the probability distribution that results in data groups for the initial distribution attained over the usage of entire attributes. This in decreases the tasks number and thus excludes irrelevant or redundant feature characteristics. This improves the statistical precision automatically and thus accelerates the presented algorithm. In spite of each element classification, wrapper is accountable for feature subsets identification with the output prediction of the classifier conferring to the projected subset. Wrappers were employed to scan any probable features subset and to discover comparable data among features, not as filters. By means of the proposed algorithm, the best and effective features can be picked and derived for more classification. Estimates of the vectors of the covariant matrices are constructed, and the data projected into the new subspace is found to be either lower than or equal to these estimates. In most cases, an automated matrix vector estimate is used to produce the covariance data matrix correlation. A subset of the variables in the massive dataset is selected on the basis of the actual variables and the highest degree of similarity in the principal components.
λ to represent the Eigen value; F to represent the updated collection of features; d to represent the baseline set of features. If we want our low-dimensional vector representation of the data records to seem accurate, we need to approximate mostly the neigen vectors that provide the biggest eigen values.
The covariance matrix has been provided to us, and its diagonal is defined by the matrix A:
The following criteria may be used to arrive at the total number of features:
where P is the total number of Eigen values. To do this, we first sort the indices in decreasing order and then choose the first set of attributes without making any changes to their original values.
Fitness evaluation using bio-inspired SSOA (bio-inspired squirrel search optimization algorithm)
The SSA is then used to pick out the best features using the combined features from the autoencoders. The SSA adjusts people's locations based on the time of year, the kind of people present, and the visibility of potential predators (Zhang et al. 2020).
Population initialization
Assuming N people, with SSU and SSL as the upper and lower search space boundaries, respectively. The formula below is used to generate the random formula by which the persons are created.
\(SS_{{\text{I}}}\) represents the ith individual \(\left( {i = 1, \ldots ,N} \right)\), The variable R is the random integer between 0 and 1, and the variable D is the size of the issue.
Population classification
For the minimization issue to be solved using SSA, one squirrel is sufficient for each tree, with N being the total number of squirrels. Thus, there are N trees in the forest, only some of which are edible (the hickory and acorn trees). Squirrels prioritise hickory tree tops and acorn trees as food sources. The population fitness ranking is based on increasing values. The squirrels may be broken down into three distinct groups: animals living on hickory trees are squirrels \( S_{{\text{H}}}\), animals in acorn trees squirrels \(S_{{\text{A}}}\) and typical squirrels in trees \(S_{{\text{N}}}\). In order to secure the most reliable supply of food, the travel of \(S_{{\text{A}}}\) is \(S_{{\text{H}}}\) and final destination of \(S_{{\text{N}}}\) arbitrarily chosen to be either \(S_{{\text{H}}}\) or \(S_{{\text{A}}}\).
Position updation
The squirrels' locations are refreshed whenever they glide to either the hickory or acorn trees.
The iteration number 't' is always there, and R is always the random integer. There is a 10% chance of a predator appearing, denoted by PAP. The squirrel glides across the forest in quest of food if R > PAP, meaning there is no danger from any predators. If \(R > P_{{{\text{AP}}}}\), the predators will show up, and the squirrels will have to cut down on their food-gathering activities. After then, the squirrels' locations are shuffled about at random. The constant (C) has a value of 1.9, and the gliding distance (G) is represented by the letter "g". The squirrel identified as \(S_{{{\text{AI}}}}^{{\text{t}}}\) was selected at random from SA. An equation for determining glide distance is as follows:
\(G_{{\text{H}}}\) is equal to 8, and S equals 18; both are constants, \(\tan \left( \theta \right)\) signifies the angle at which the glider will travel.
The conventional SSA starts with the assumption that all individuals are in winter at the beginning of each cycle. The yearly adjustments are decided upon once everyone has been brought up to date. When summer arrives, the squirrels no longer migrate to the old hickory tree; instead, they all remain in the new one. Squirrels soaring to the acorn tree are not ambushed by predators, therefore they don't have to move. The individuals' motion is halted if the number of iterations is greater than the maximum number of iterations. Otherwise, the preceding procedures are repeated.
Classification using deep learning based multi-layer Alex net classifier (DBMLA)
The chosen input is thus utilized for the classification of data and is thus employed for the estimation of proposed DBMLA approach. This is the distributed system for the estimation the unexpected values and technique is based on random variables. This aims mainly at identifying the background and thus monitoring the suitable information over random way. For attaining the objective, there is a need of daily interval. The user likelihood and the value that are secured might be observed specifically. If the proposed model is capable of computing the vector's probability distribution, it is identified by the determination of dispersed probability multiplication and thus dividing the outcome through the standard constant.
Here, \( P \left( \emptyset \right) {\text{ refers to the function of probability distribution}}\).
\(P\left( {\frac{y}{\emptyset }} \right)\) signifies the likelihood function that are determined.
Pdf(\(\emptyset /G)\) denotes the function of evidence.
Thus, the posterior probability is proportional to the likelihood and is the prior probability multiple.
In this, F(G) signifies the function of prior density.
f(y) L(G/x = x(G) refers to the likelihood function.
Basically, the equation of probability was employed for plotting the abnormality of function. The values that are abnormal was estimated once the prior likelihood was determined. On following this, the abnormal value is computed as shown:
Once the abnormal value was estimated, the data affected with disaster will be classified. This proposed model includes major layer as a convolutional layer for training input data and is responsible for eradicating the lower-level features that is kernels. A large data governs the classifier pre-trained systems for executing the task of classification. The classifier intensity has an important influence on accuracy of classification with suitable detection efficacy as the classifier depth increases, the error rate of classifier decreases. According to probabilities, the target is thus graded. The presented DBML Alex net CNN model technique offers discrepancy among the single and one or more varied variables that were computed.
Here, F denotes the feature, N refers to pointed feature, \( \mu_{1} \mu_{2}\) refers to classified features.
It is expressed as:
The Residual connection-based Alex net CNN model classification was concluded as:
The value K denotes an observed or measured value.

To demonstrate the efficacy of the proposed approach, the performance of the classifier is assessed using database testing.
Performance analysis
The performance analysis of proposed strategy is estimated and the attained outcomes are illustrated in this section.
Performance analysis of flood susceptibility
Two types of data sets were taken into account in order to map flood susceptibility and modelling: an inventory map of past flood occurrences and the elements that determine risks (Kalantar et al. 2021).
We estimate sensitivity, specificity, OA, and TSS for performance evaluation. This is how the numbers are crunched:
Here, TSS is the true skill statistic.
Queensland, Australia, is the location of the research, namely a section of the Brisbane River watershed region. As reported by the Queensland government, two big flood occurrences occurred in February 1893 and January 1974 due to tropical cyclones. Parameters such as (a) altitude, (b) slope, (c) aspect, (d) curvature, (e) distance to river, (f) distance to road, (g) SPI, (h) TWI, (i) 0STI, (j) annual total rainfall, (k) soil, (l) lithology, and (m) land-use are taken into account to evaluate performance.
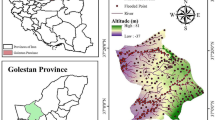
Devastating flood risks occurred along the river in 2010, 2011, and again in January 2013. As a result, this area is thought of as a floodplain and is constantly monitored by the government along with other sectors. The 1,474,617 square metres that make up this research area are located between the latitudes of 27.450S and 27.250S, and the longitudes of 152.500E and 153.050E. The majority of this area is marked by dense urbanisation, and its height spans from 0 to 548 m. It has subtropical humid climate conditions, with an average annual temperature of 20.3 °C and 1168 mm of annual rainfall. The research region and a broad map of Australia are shown in Fig. 2. Slope, curvature, height, aspect, distance to road, distance to river, SPI, STI, TWI, total annual rainfall, soil, lithology, and land use are the thirteen explanatory elements shown in Fig. 3.

Overall location of the research area: (a) map of Australia, a location map for the research region, (b) study area with both non-flood and flood inventory points, and (c) study area that includes non-flood and flood inventory points

The thirteen explanatory variables included in this analysis's model formulation: (a) Altitude, (b) Slope, (c) Aspect, (d) Curvature, (e) Distance to River, (f) Distance to Road, (g) SPI, (h) TWI, (i) STI, (j) Annual Total Precipitation, (k) Soil, (l) Lithology and (m) Land Use
Based on area and percentage research, Table 1 contrasts the categories of people that are vulnerable to flooding. The analysis is carried out using both proposed and existing approaches, and the results are shown below.
The suggested model's predicted map of susceptibility is contrasted with three other models in five categories of susceptibility. Each class's area and percentage are calculated separately. Figure 4 compares flooded zones according to hazard maps and displays the simulated ranking of flood susceptibility for each class according to the suggested strategy.

Flooded zone comparison using hazard maps and simulated evaluation of each class's flood susceptibility using the BISSOA-DBMLA technique
Where geologically Middle to Late Triassic volcanic units, Neranleigh-Fernvale layers, lacustrine deposits, and the Bunya phyllite are present, the Bundamba and Landsborough sandstone are less prone to flooding. These regions are typically those with altitudes lower than 20 m. The natural conservation and environment zones with thick forest are the least vulnerable to flooding from a land-use standpoint. Additionally, there were locations with significant susceptibility among the dense residential and areas with intense usage. Tb64 (red mottled soils and hard acidic yellow), Sj12 (yellow mottled soils and hard acidic yellow), and MM9 (grey and brown crumbling clays) classes are the most likely types of soil for the flood event. For such a dynamic hazard to be more accurately predicted and predicted with more precision, high spatial accuracy and resolution data must be accessible and available at the time of the flood and after it has occurred. The achieved result demonstrates how information from big data and effective identification of dangerous areas may improve land use planning and economic output.
The ability of current and new strategies to anticipate is compared in Table 2. In terms of sensitivity, specificity, TSS, and AUC, the estimated analysis is contrasted with current approaches like ANN, DLNN, PSO-DLNN, and BISSOA-DBMLA (proposed). The result demonstrates that the suggested procedure is superior than current methods.
The visual representation of a comparison investigation of the propensity for prediction of both current and suggested methodologies is shown in Fig. 5. In terms of sensitivity, specificity, TSS, and AUC, the estimated analysis is contrasted with current approaches like ANN, DLNN, PSO-DLNN, and BISSOA-DBMLA (proposed). The result demonstrates that the suggested procedure is superior than current methods.

Comparison of prediction accuracy
Performance analysis of wildfire susceptibility
The Australian mainland is the research region used in this methodology since it had a wildfire occurrence during the fire season of 2019–2020. Five states, including New South Wales, Victoria, Queensland, Western Australia, the Northern Territory, and the Australian Capital Territory, are included in Australia's mainland. The map of the area of interest (AOI) is shown in Fig. 6. One of the world's most prone to fires is Australia's eastern area (Fig. 6).

Australian mainland limits specify the AOI
The dataset from GEE's Fire information for management of resource system (FIRMS) is used to estimate the frequency of fires. Within three hours of the satellite's observation, the dataset FIRMS disseminates near-real-time data. It provides data from the Moderate Resolution Imaging Spectroradiometer (MODIS), Terra and Aqua EOS, and VIIRS (visible infrared imaging radiometer suite), and is a component of NASA's land, atmosphere near real-time capability (LANCE) for the EOS.
Figure 7 is a graphical representation of the average yearly temperature in Australia from 1979 to 2019. Figure 8 illustrates the topological elements of height, aspect, and slope.

Australia's average yearly temperature from 1979 to 2019

Topological factors: (a) elevation, (b) aspect, and (c) slope
The topological divisions made up of aspect, elevation, and slope. Elevation was determined using a digital elevation model with a spatial resolution of 30 m. The information used to create the model was obtained from NASA's shuttle radar topography mission (SRTM). The direction that the slope faces and the gradient or slope of the land are generated from DEM. The gradient or slope of the land is also denoted by an aspect and angle.
The outcomes attained show the fire and no-fire point distribution and are represented in Fig. 9. These entire locations are the portion of the model training of the dataset, that comprise of 10,800 points of training over Australian mainland.

Output attained from proposed automation process (distributed no-fire and fire points)
Figure 10 signifies the probability map at which the greenery areas signify the probability of lower wildfire event as divergent to red areas representing higher probability of wildfire. The classes of fire risk are categorized as five classes. It was evident that the area with high risk is more concentrated at some coastlines in the southeastern, southwestern, and northern Australia regions mainly.

Fire susceptibility map result and categorized map based on proposed method
Table 3 is the comparative analysis of overall accuracy of prediction in terms of both existing techniques and proposed method. The existing techniques like Naïve Bayes, SVM, CART, MARS, and random forest are compared with proposed method. The attained outcomes represent that the proposed strategy offers better outcome than existing techniques. The proposed system offers 98.99% accuracy.
Figure 11 is the comparative analysis of overall accuracy of prediction in terms of both existing techniques and proposed method. The existing techniques like Naïve Bayes, SVM, CART, MARS, and random forest are compared with proposed method. The attained outcomes represent that the proposed strategy offers better outcome than existing techniques.

Comparative analysis of accuracy
The findings of this work show that the most important aspect of wildfire is soil moisture which is followed by drought index and air temperature, whereas the least significant one is electric network. Since land cover is an important aspect, this has no higher importance values. The attained outcome signifies that the proposed system offers better susceptibility of wildfire, and flood. Thus, the presented technique is better on comparing traditional techniques.
Conclusion
This method proposed an automated methodology based on deep learning for the susceptibility of natural calamities like wildfire and flood. Data from remote sensing was initially pre-processed, then ALIE-FE was used to extract the features. Recursive Wrapper-based feature subset selection was used to choose the retrieved features. The optimization procedure was carried out utilising BI-SSOA in order to determine the optimal fitness function and improve prediction accuracy. Final step: Deep learning-based Multi-layer Alex Net classifier (DBMLA) approach was used to carry out the classification. For forecasting flood susceptibility and wildfire susceptibility, the simulation was run, and the results were estimated. The suggested BISSOA-DBMLA has 98% sensitivity, 99% specificity, and 97% TSS. The suggested approach provides 98.99% accuracy in classifying objects. The achieved results were contrasted with those obtained using current techniques, and the effectiveness of the suggested approach was evaluated in terms of accuracy, sensitivity, specificity, TSS, and AUC. The recommended method performed better when evaluating conventional mechanisms. Future development on this project will include using an automated alerting system to get notifications when a crisis occurs.
References
Anand Deva Durai c, (2021) Global Ocean monitoring through remote sensing methods and big data analysis. Int J Innov Sci Eng Res 8 1 10–19
Anbarasan M et al (2020) Detection of flood disaster system based on IoT, big data and convolutional deep neural network. Comput Commun 150:150–157
Asencio-Cortés G, Morales-Esteban A, Shang X, Martínez-Álvarez FJC (2018) Earthquake prediction in California using regression algorithms and cloud-based big data infrastructure. Comput Geosci 115:198–210
Choi C, Kim J, Kim J, Kim D, Bae Y, and. Kim HSJAIM, (2018) Development of heavy rain damage prediction model using machine learning based on big data. Adv Meteorol. 2018 1 11
Choubin B, Mosavi A, Alamdarloo EH, Hosseini FS, Shamshirband S, Dashtekian K, Ghamisi P (2019) Earth fissure hazard prediction using machine learning models. Environ Res 179:108770
Fathi M, Haghi Kashani M, Jameii SM, and. Mahdipour EEJAOCMI, (2021) Big data analytics in weather forecasting: a systematic review. Arch Comput Methods Eng 29 1
Kalantar B et al (2021) Deep Neural network utilizing remote sensing datasets for flood hazard susceptibility mapping in Brisbane, Australia. Remote Sens 13(13):2638
Li W (2020) GeoAI: Where machine learning and big data converge in GIScience. J Spatial Inf Sci 20:71–77
Luechtefeld T, Rowlands C, r Hartung TJT (2018) Big-data and machine learning to revamp computational toxicology and its use in risk assessment. Toxicol Res 7(5):732–744
Nugent T, Petroni F, Raman N, Carstens L, Leidner JL, A comparison of classification models for natural disaster and critical event detection from news. In 2017 IEEE International Conference on Big Data (Big Data) pp. 3750–3759: IEEE. (2017).
Obaid AJ (2021) Multiple objective effect analysis to monitor the sustainability for the refurbishment of ecosystem. Int J Innov Sci Eng Res 8(3):81–88
Quinn JA et al (2018) Humanitarian applications of machine learning with remote-sensing data: review and case study in refugee settlement mapping. Phil Trans R Soc A 376(2128):20170363
Ragini JR, Anand PR, and. Bhaskar VJIJOIM, (2018) Big data analytics for disaster response and recovery through sentiment analysis. Int J Inf Manag 42, 13–24
Rahmati O et al (2019) Multi-hazard exposure mapping using machine learning techniques: a case study from Iran. Remote Sens 11(16):1943
Raza M et al (2020) Establishing effective communications in disaster affected areas and artificial intelligence based detection using social media platform. Arch Comput Method Eng 112:1057–1069
Razali N, Ismail S, Mustapha A (2020) Machine learning approach for flood risks prediction. Int J Artif Intell 9(1):73
Resch B, Usländer F, Havas CJC, Science GI (2018) Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr Geogr Inf Sci 45(4):362–376
Sayad YO, Mousannif H, sj Al Moatassime HJF (2019) Predictive modeling of wildfires: a new dataset and machine learning approach. Fire Saf J 104:130–146
Sulova a, and. Jokar Arsanjani JJRS, (2021) Exploratory analysis of driving force of wildfires in Australia: an application of machine learning within Google Earth engine. Remote Sens 13 1 10
Sun AY, Scanlon BRJERL (2019) How can big data and machine learning benefit environment and water management: a survey of methods, applications, and future directions. Environ Res Lett 14(7):073001
Yu M, Yang C, Li YJG (2018) Big data in natural disaster management: a review. Geosciences 8(5):165
Yuan F,and Liu R, (2019) Identifying damage-related social media data during Hurricane Matthew: a machine learning approach. In Computing in Civil Engineering 2019: visualization information modeling, and simulation: American Society of Civil Engineers Reston VA 207 214
Zhang X, Zhao K, Wang L, Wang Y, Niu Y (2020) An improved squirrel search algorithm with reproductive behavior. IEEE Access 8:101118–101132
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Ethical approval
The authors declare that this paper has not submitted to anywhere and published anywhere. The submitted work is original and not published elsewhere in any form or language.
Additional information
Edited by Dr. V. Vinoth Kumar (GUEST EDITOR) / Dr. Michael Nones (CO-EDITOR-IN-CHIEF).
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sankaran, K.S., Lim, SJ. & Bhaskar, S.C.V. An automated prediction of remote sensing data of Queensland-Australia for flood and wildfire susceptibility using BISSOA-DBMLA scheme. Acta Geophys. 70, 3005–3021 (2022). https://doi.org/10.1007/s11600-022-00925-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11600-022-00925-1