
Abstract
We propose a weighting subgradient algorithm for solving multiobjective minimization problems on a nonempty closed convex subset of an Euclidean space. This method combines weighting technique and the classical projected subgradient method, using a divergent series steplength rule. Under the assumption of convexity, we show that the sequence generated by this method converges to a Pareto optimal point of the problem. Some numerical results are presented.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The multiobjective optimization, also known as multicriteria optimization, refers to the process of simultaneously optimizing two or more real-valued objective functions. The multiobjective optimization problem has applications in the economy, industry, agriculture, and others fields. For more details see, for example, Luc [11], Miettinen [13], and Pappalardo [14]. Among the strategies that can be used to find one solution of a smooth multiobjective optimization problem, we mention the weighting methods, steepest descent methods and Newton methods. On weighting methods, which are very simple and easy to implement, we refer the reader to Graña Drummond et al. [9], Burachik et al. [5] and references therein. See Fliege and Svaiter [7] and Fukuda and Graña Drummond [8] for more details on the steepest descent method, and to Fliege et al. [6] and references therein for more details on the Newton method. An interesting alternative for the nondifferentiable case is the use of subgradients. See, for example, Alber et al. [1] for the scalar case, Bello Cruz [2], Bento and Cruz Neto [3], and references therein. In the present work, we propose a combination of the weighting technique and the projected subgradient method for finding one solution of a nonsmooth constrained multicriteria optimization problem, where the multiobjective function is component-wise convex. Our aim is to provides an easily implementable scheme with a low-cost iteration. We emphasize that an essential difference between our approach and the projected subgradient method proposed in [2] is that, in [2] the author does not use scalarizations.
Our approach considers a scalarization process to obtain total convergence to a Pareto optimal point, even if the solution set is not a singleton. Furthermore, we present some numerical experiments in order to demonstrate the performance of our method. The rest of this paper is organized as follows. In Sect. 2, we recall some useful basic notions. In Sect. 3, we define the algorithm, and study its convergence properties. In Sect. 4, we present some computational experiments. In Sect. 5, we provide some concluding remarks.
2 Preliminaries
The following notation is used throughout our presentation. We denote by \(\langle \, \cdot \, , \cdot \, \rangle \) the usual inner product of \({\mathbb {R}}^n\), and by \(\Vert \cdot \Vert \) its corresponding norm. Furthermore, we use the Pareto order, that is, let \(I=\{1,\ldots , m\}\), \({{\mathbb {R}}}^{m}_{+} = \{x\in {{\mathbb {R}}}^m{:} x_{i}\ge 0, i \in I\}\) and \({{\mathbb {R}}}^{m}_{++}=\{x\in {{\mathbb {R}}}^m{:}x_{i}> 0, i \in I \}\). For \(x, \, y \in {{\mathbb {R}}}^{m}_{+}\), \(y\succeq x\) (or \(x \preceq y\)) means that \(y-x \in {{\mathbb {R}}}^{m}_{+}\) and \(y\succ x\) (or \(x \prec y\)) means that \(y-x \in {{\mathbb {R}}}^{m}_{++}\).
Consider the function \(F{:}{\mathbb {R}}^n \rightarrow {\mathbb {R}}^m\), given by \(F(x)=(F_1(x),\ldots ,F_m(x))\). We are interested in the multiobjective optimization problem
where \(C\subset {\mathbb {R}}^{n}\) is assumed to be a nonempty closed convex set.
Throughout this paper we assume that each component \(F_{i}\) of F is a convex function on an open subset \(\Omega \) containing C.
We recall some basic properties of convex functions, where \(\partial F_{i}\) denotes the Fenchel–Moreau subdifferential of \(F_{i}\).
Proposition 1
(See [17]) For each \(i \in \{1, \ldots ,m\}\), we have the following:
-
(i)
\(\partial F_{i}(x)\) is nonempty and compact, for all \(x \in C\);
-
(ii)
\(\partial F_{i}\) carries bounded on bounded sets.
Definition 1
A point \({\bar{x}} \in C \subset {\mathbb {R}}^{n}\) is called a weak Pareto optimal point for problem (1) if there exists no other \(x \in C\) such that \(F(x)\prec F({\bar{x}})\). In this case, we will employ the notation \({\bar{x}} \in WS(F,C)\). If there exists no other \(x \in C\) with \(F(x)\preceq F({\bar{x}})\) and \(F(x) \not = F({\bar{x}})\), then \({\bar{x}}\) is said to be a Pareto optimal point for problem (1), and we will denote this by \({\bar{x}} \in S(F,C)\).
Lemma 1
Assume that \({\bar{x}} \in C\) satisfies \(\max _{i} \left( F_{i}(x) - F_{i}({\bar{x}}) \right) \ge 0\) for all \(x \in C\). Then, \({\bar{x}} \in WS(F,C)\).
Proof
This is straightforward consequence of Definition 1. \(\square \)
Let \(x\in {\mathbb {R}}^{n}\), and let \(D\subset {\mathbb {R}}^{n}\) be a closed convex set. We recall that the orthogonal projection onto D, denoted by \(P_{D}(x)\), is the unique point in D such that \(\Vert P_{D}(x)-y\Vert \le \Vert x-y\Vert \) for all \(y \in D\). Moreover, \(P_{D}(x)\) satisfies
Finally, we conclude this section by presenting a well-known result that will be useful in our convergence analysis.
Lemma 2
(See [16]) Let \(\{\nu _{k}\}\) and \(\{\delta _{k}\}\) be nonnegative sequences of real numbers satisfying \(\nu _{k+1} \le \nu _{k} + \delta _{k}\) with \(\sum _{k=1}^{+\infty } \delta _{k} < +\infty \). Then, the sequence \(\{\nu _{k}\}\) is convergent.
3 The algorithm
In this section we define our proposed algorithm, and demonstrate that it is well defined.
Weighting Subgradient Algorithm (WSA)
Let \(\{\lambda _{i}^{k} \} \subset [0,1]\), \(\sum _{i=1}^{m}\lambda _{i}^{k}=1 \;\; \forall \; k \in {\mathbb {N}}\), \(\{\gamma _{k}\} \subset (0,1)\), and \(\{\alpha _{k}\} \subset {\mathbb {R}}_{+}\), with
Step 0: Choose \(x^{0} \in C\). Set \(k=0\).
Step 1: Take \(s_{i}^{k} \in \partial F_{i}(x^{k})\). If \(\min _{i=1,\ldots ,m} \Vert s_{i}^{k}\Vert = 0\), STOP.
Otherwise, obtain \(\eta _{k}=\displaystyle \max _{i=1,\ldots ,m} \{1,\Vert s_{i}^{k}\Vert \}\), define \(h_{x^{k}}(v) = \frac{\alpha _{k}}{\eta _{k}}\left\langle \sum _{i=1}^{m}\lambda _{i}^{k}s_{i}^{k}, v\right\rangle +\frac{\Vert v\Vert ^{2}}{2}\) and compute \(v^{k}\):
If \(v^{k} = 0\), STOP. Otherwise,
Step 2: Compute \(x^{k+1}\):
Remark 1
-
(i)
Let us note that WSA uses exogenous weights \(\lambda _{i}^{k}\) for the subgradients \(s_{i}^{k}\) in a manner reminiscent of a weighted-gradient method. See, for example, Graña Drummond et al. [9], Marler and Arora [12].
-
(ii)
Following [15], the use of weighted method is well acceptable in applications, and is favorable for mathematical analysis. Actually, the a priori selection of weights allows the resulting scalar objective function to be solved for a single Pareto optimal solution that represents the preference of the human decision maker.
In view of the strong convexity of \( h_{x^{k}}\), the direction \(v^{k}\) is well defined, and problem (4) has a quadratic (scalar-valued) objective function.
Now, we show that the stop criteria is well-defined.
Proposition 2
If the algorithm stops at iteration k, then \(x^{k} \in WS(F,C)\).
Proof
Take \(k\in {\mathbb {N}}\), and let us suppose that there exists \(i_{0}\in \{1,\ldots , m\}\) such that \(s_{i_{0}}^{k} = 0\). Hence, taking into account that \(F_{i_{0}}\) is a convex function on C, from subgradient’s inequality we get that
Then, it follows that \(x^{k} \in WS(F,C)\). Now, assume that \(v^{k} = 0\). From (4), combined with the definition of \(h_{x^{k}}\), we have
Using (2) together with \(D = C - x^{k}=\{x - x^{k} {:} x \in C\}\) and \(x=- \frac{\alpha _{k}}{\eta _{k}} \displaystyle \sum _{i=1}^{m}\lambda _{i}^{k}s_{i}^{k}\), and taking into account that \(v^{k}=0\), last equality implies that
That is,
Now, from the above inequality, there exists \(j \in \{1,\ldots ,m\}\) such that
Using that \(F_{i}\) is convex on C for each i, we get that
By combining this with Lemma 1, it follows that \(x^{k} \in WS(F,C)\). \(\square \)
From now on, we assume that \(\{x^{k}\}\) is infinite.
4 Convergence analysis
We begin this section by showing that our method is feasible.
Lemma 3
\(x^{k}\in C\), for all \(k\in {\mathbb {N}}\).
Proof
The proof is constructed by induction on k. Note that \(x^{0}\in C\), by the initialization of the algorithm (WSA). Take a fixed \(k\in {\mathbb {N}}\), and let us suppose that \(x^{k}\in C\). Then, \(x^{k+1}=x^{k}+\gamma _{k}v^{k}\), which can be rewritten as
Since \(v^{k}\in C-x^{k}\), we have in particular that \(x^{k}+v^{k} \in C\). Hence, from the last equality combined with the convexity of C, we conclude the induction process, and the desired result is proved. \(\square \)
Now, we present three preliminary results that will be useful for our convergence analysis.
Lemma 4
For all \(k\in {\mathbb {N}}\), the following statements hold:
-
(i)
\(\Vert v^{k} \Vert \le 2\alpha _{k}\);
-
(ii)
\(\Vert x^{k+1}-x^{k}\Vert \le 2\alpha _{k}\).
Proof
-
(i)
From Lemma 3, we have \(0 \in C-x^{k}\). Using (4), for a fixed \(k \in {\mathbb {N}}\) we obtain that
$$\begin{aligned} h_{x^{k}}\left( v^{k}\right) \le h_{x^{k}}(0)=0. \end{aligned}$$That is,
$$\begin{aligned} \frac{\alpha _{k}}{\eta _{k}}\left\langle \sum _{i=1}^{m}\lambda _{i}^{k}s_{i}^{k}, v^{k}\right\rangle +\frac{\Vert v^{k}\Vert ^{2}}{2} \le 0. \end{aligned}$$Therefore, by using the Cauchy–Schwarz inequality in the second inequality, and by recalling that \(\Vert s^{k}_{i}\Vert \le \eta _{k}\) in the third, we have
$$\begin{aligned} \begin{array}{lll} \Vert v^{k}\Vert ^{2} &{} \le &{} -2\frac{\alpha _{k}}{\eta _{k}}\left\langle \sum _{i=1}^{m}\lambda _{i}^{k}s_{i}^{k}, v^{k}\right\rangle \le 2\frac{\alpha _{k}}{\eta _{k}} \displaystyle \sum _{i=1}^{m}\lambda _{i}^{k}\Vert s_{i}^{k}\Vert \Vert v^{k}\Vert \\ &{} \le &{} 2\frac{\alpha _{k}}{\eta _{k}} \displaystyle \sum _{i=1}^{m}\lambda _{i}^{k}\eta _{k}\Vert v^{k}\Vert = 2\alpha _{k}\Vert v^{k}\Vert \end{array} \end{aligned}$$since \(\sum _{i=1}^{m}\lambda _{i}^{k} = 1\) for each \(k \in {\mathbb {N}}\).
-
(ii)
The result follows from (5) and (i):
$$\begin{aligned} \Vert x^{k+1}-x^{k}\Vert =\gamma _{k}\Vert v^{k}\Vert \le \Vert v^{k}\Vert \le 2\alpha _{k}. \;\;\;\;\; \square \end{aligned}$$
\(\square \)
Lemma 5
Let \(y \in C\). It holds that
Proof
From (6), we have
Therefore, by using (2) with \(x=-\frac{\alpha _{k}}{\eta _{k}} \sum _{i=1}^{m}\lambda _{i}^{k}s_{i}^{k}\) and \(D=C-x^{k}\), it is easy to see that
Note that for each \(k\in {\mathbb {N}}\), we have \(w=y-x^{k}\in C-x^{k}\). Thus, for this particular choice of w and for \(k=0,1,\ldots \), the last inequality implies that
where the last inequality follows from that fact that \(\sum _{i=1}^{m}\lambda _{i}^{k} \Vert s_{i}^{k} \Vert \le \eta _{k}\). Therefore, by combining (7) with item (i) of Lemma 4, we obtain the desired result. \(\square \)
Lemma 6
For all \(y \in C\), the following inequality holds:
Proof
Let \(k \in {\mathbb {N}}\), by using Lemmas 4 and 5, and (5), it follows that
From \(\gamma _{k} \in (0,1)\), last inequality becomes
Now, taking into account that F is convex, we have
Thus, by applying last inequality, (9) yields
and the desired result is proved. \(\square \)
We attain stronger convergence results, by assuming the following property.
R1. The set \(T:=\{z \in C :F(z) \preceq F(x^{k}), \quad k \in \quad {\mathbb {N}}\}\) is nonempty.
Remark 2
This assumption it appeared in scalar case in Alber et al. [1] and which has been assumed in Bello Cruz [2] on vector optimization setting. Condition R1 extends \({\mathbb {R}}_+^m\)-completeness for the constrained case. When \(C = {\mathbb {R}}^{n}\), it is a standard assumption of ensuring the existence of Pareto optimal points for vector optimization problems. See, for example, [11]. Furthermore, we know that if \(\{ F(x^{k}) \}\) is a decreasing sequence, then \(\{x^{k}\}\subset C{\setminus }S(F,C)\), which is a standard result from the extension of classical methods to vector optimization. For more details see, for example, [6]. Finally, R1 holds if S(F, C) is nonempty, for scalar case.
Theorem 1
Assume R1, and let \(z \in T\). Then, \(\{\Vert x^{k} - z\Vert \}\) is a convergent sequence. Moreover, \(\{x^{k}\}\) is bounded.
Proof
Since \(z \in T\), it holds that
Using this inequality and (8), we obtain that
From (3) and Lemma 2, we conclude the proof. \(\square \)
A natural choice for the parameters \(\{\lambda _{i}^{k}\}\) is given by \(\lambda _{i}^{k} = 1/m\), for \(i \in \{1,\ldots ,m\}\). More generally, we obtain the convergence of the whole sequence by assuming the following requirement.
R2. There exists a vector \({\underline{\lambda }} \in {\mathbb {R}}^{m}\) such that \(0 \prec {\underline{\lambda }} \preceq \lambda ^{k}\) for all \(k \in {\mathbb {N}}\).
Theorem 2
Assume that R1 and R2 hold. Then, the whole sequence \(\{x^{k}\}\) converges to \(x^{*} \in S(F,C)\).
Proof
Firstly, we show that \(\{x^{k}\}\) converges to \(x^{*} \in T\).
Let us consider \(z \in T\), from Theorem 1, it follows that \(\{x^{k}\}\) is a bounded sequence. Therefore, by using (8), we can write
Applying the sum from \(k=0\) to \(k=l\) in (10), we obtain
Moreover, there exists an \(L > 0\) such that \(\eta _{k} \le L\), then
By letting l go to \(+\infty \), it holds that
From (3), (11) and last inequality, we obtain
Therefore, owing to the fact that \(z \in T\), we get
By taking a subsequence \(\{x^{k_{j}}\} \subset \{x^{k}\}\) that satisfies the limit above, we obtain
Hence, we have
Without loss of generality, there exists an \(x^{*} \in C\) such that \(x^{k_{j}}\rightarrow x^{*}\). Because \(F_{p}\) is continuous, we have that \(F_{p}(x^{k_{j}}) \rightarrow F_{p}(x^{*})\). Then, it follows that \(x^{*} \in T\). By using Theorem 1, with \(z = x^{*}\), we conclude that \(\lim _{j \rightarrow +\infty }\Vert x^{k_j} - x^{*}\Vert = 0\). From Theorem 1, we achieve our desired result.
Finally, we show that \(x^{*} \in S(F,C)\).
In fact, take \(y \in C\) such that \(F(y) \preceq F(x^{*})\). So, \(y \in T\). Hence, by using (12), we have \(F(y)=F(x^{*})\). The proof is completed. \(\square \)
5 Numerical results
In this section, two numerical tests are used for the purpose of illustrating the algorithm performance. The algorithm was coded in SCILAB 5.5.2 on a 8 GB RAM 1.60 GHz i5 notebook. For these tests, we adopt the stop condition \(\Vert v^{k}\Vert < 10^{(-8)}\) or number of iterations equals to 200. We show a comparison among WSA and two other subgradient-type algorithms. The subgradient method for Vector optimization (SMVO), given by [2], does not use scalarizations and at each iteration, solves a non quadratic problem on C. The relaxed projection method for multiobjective optimization (RPM), given in [4] at each iteration, performs a finite number of projections on suitable halfspaces that contain C.
To apply WSA, the scalarized problem is defined by
where \(\lambda _{j} \in (0,1)\), \(j=1, \ldots , m\).
Example 1
In this example, we present the results obtained by WSA, RPM and SMVO for three known problems given at [10]. We solved the problem using 100 starting points from a uniform random distribution over the interval (L, U) and \(\lambda _{1} = \lambda _{2} = 1/2\). Average number of iterations and CPU time are reported in Table 1.
In this example, the stepsize sequence was defined using \(\alpha _{k} = 9/(k+1),13/(k+1), 12/(k+1)\), respectively, with \(\gamma _{k} = 0.95, \) for all \(k \in {\mathbb {N}}\). By using the same notation of each bibliographical reference, SMVO, given by [2], uses the stepsize \(\beta _{k} = 19/(k+1)\), for all three problems, and RPM considers the stepsize \(\beta _{k} = 14/(k+1),14/(k+1), 0.1/(k+1)\), respectively.
In this test, note that WSA has shown the better behavior in terms of computational time.
Example 2
Consider a nondifferentiable multiobjective problem defined by \(C = \{ x \in {\mathbb {R}}^{n} :-10 \le x_j \le 10, \; j=1,\ldots ,n \}\) and
We solved the problem using 100 starting points from a uniform random distribution in \((-10,10)\). Weight value \(\lambda \), average number of iterations, CPU time, average of \(\Vert v^{k}\Vert \) and \(F(x^{k})\), which is the last iteration, are reported in Table 2.
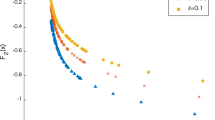
In this example, the stepsize sequence was defined using \(\alpha _{k} = 20/(k+1)\) with \(\gamma _{k} = 0.9\) for all \(k \in {\mathbb {N}}\). By using the same notation of each bibliographical reference, SMVO, given by [2], uses the stepsize \(\beta _{k} = 20/(k+1)\) and RPM consider the stepsize \(\beta _{k} = 35 / (k+1)\). In Fig. 1, we plot the objective function space and the Pareto optimal front set to confirm our results.

A comparison among subgradient-type algorithms, with \(n=2\)
Observe that, as intended, WSA finds a subset of the Pareto frontier.
6 Conclusion
In this work we have presented an implementable algorithm for solving constrained multiobjective optimization problems, which requires only one projection at each iteration. In the convergence analysis, we relaxed the standard hypotheses, and established several results according to the requirements imposed on F and C. First, we found that \(\{x^{k}\}\) is bounded. Second, we considered the boundedness of exogenous parameters in order to prove the convergence of the whole sequence \(\{x^{k}\}\) to a solution of the problem, without requiring a uniqueness assumption (see [2]). We illustrated the numerical behavior of the algorithm by considering four problems. An interesting future direction would be to consider a more detailed computational experiment.
References
Alber, Y.I., Iusem, A.N., Solodov, M.V.: On the projected subgradient method for nonsmooth convex optimization in a Hilbert space. Math. Program. 81, 23–35 (1998)
Bello Cruz, J.Y.: A subgradient method for vector optimization problems. SIAM J. Optim. 23(4), 2169–2182 (2013)
Bento, G.C., Cruz Neto, J.X.: A subgradient method for multiobjective optimization on Riemannian manifolds. J. Optim. Theory Appl. 159, 125–137 (2013)
Brito, A.S., Cruz Neto, J.X., Santos, P.S.M., Souza, S.S.: A relaxed projection method for solving multiobjective optimization problems. Eur. J. Oper. Res. 256, 17–23 (2016). doi:10.1016/j.ejor.2016.05.026
Burachik, R.S., Kaya, C.Y., Rizvi, M.M.: A new scalarization technique to approximate Pareto fronts of problems with disconnected feasible sets. J. Optim. Theory Appl. 162, 428–446 (2014)
Fliege, J., Graña Drummond, L.M., Svaiter, B.F.: Newton’s method for multiobjective optimization. SIAM J. Optim. 20(2), 602–626 (2009)
Fliege, J., Svaiter, B.F.: Steepest descent methods for multicriteria optimization. Math. Methods Oper. Res. 51, 479–494 (2000)
Fukuda, E.H., Graña Drummond, L.M.: Inexact projected gradient method for vector optimization. Comput. Optim. Appl. 54(3), 473–493 (2012)
Graña Drummond, L.M., Maculan, N., Svaiter, B.F.: On the choice of parameters for the weighting method in vector optimization. Math. Program. 111, 201–216 (2008)
Huband, S., Hingston, P., Barone, L., While, L.: A review of multiobjective test problems and a scalable test problem toolkit. IEEE Trans. Evol. Comput. 10(5), 477–506 (2006)
Luc, D.T.: Theory of Vector Optimization. Lecture Notes in Economics and Mathematical Systems, vol. 319. Springer, Berlin (1989)
Marler, R.T., Arora, S.J.: The weighted sum method for multiobjective optimization: new insights. Struct. Multidiscip. Optim. 41(6), 853–862 (2009)
Miettinen, K.M.: Nonlinear Multiobjective Optimization. Kluwer Academic, Norwell (1999)
Pappalardo, M.: Multiobjective optimization: a brief overview. In: Chinchuluun, A., Pardalos, P.M., Migdalas, A., Pitsoulis, L. (eds.) Pareto Optimality, Game Theory and Equilibria. Springer Optimization and Its Applications, vol. 17, pp. 517–528. Springer, New York (2008)
Pardalos, P.M., Steponaviče, I., Žilinskas, A.: Pareto set approximation by the method of adjustable weights and successive lexicographic goal programming. Optim. lett. 6, 665–678 (2012)
Polyak, B.T.: Introduction to Optimization. Translations Series in Mathematics and Engineering. Optimization Software, Inc., New York (1987)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (1970)
Acknowledgements
First author was supported in part by CAPES-MES-CUBA 226/2012, FAPEG 201210267000909-05/2012 and CNPq Grants 458479/2014-4, 471815/2012-8, 303732/2011-3, 312077/2014-9. The second was partially supported by CNPq Grant 305462/2014-8 and PRONEX Optimization(FAPERJ/CNPq). The third was supported in part by CNPq Grant 485205/2013-0 and PROPESQ/UFPI.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Bento, G.C., Neto, J.X.C., Santos, P.S.M. et al. A weighting subgradient algorithm for multiobjective optimization. Optim Lett 12, 399–410 (2018). https://doi.org/10.1007/s11590-017-1133-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-017-1133-x