
Abstract
In the context of brain-computer interface (BCI) system, the common spatial patterns (CSP) method has been used to extract discriminative spatial filters for the classification of electroencephalogram (EEG) signals. However, the classification performance of CSP typically deteriorates when a few training samples are collected from a new BCI user. In this paper, we propose an approach that maintains or improves the recognition accuracy of the system with only a small size of training data set. The proposed approach is formulated by regularizing the classical CSP technique with the strategy of transfer learning. Specifically, we incorporate into the CSP analysis inter-subject information involving the same task, by minimizing the difference between the inter-subject features. Experimental results on two data sets from BCI competitions show that the proposed approach greatly improves the classification performance over that of the conventional CSP method; the transformed variant proved to be successful in almost every case, based on a small number of available training samples.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Noninvasive brain-computer interface (BCI) is a procedure for translating human intentions into control signals, potentially providing a direct communication channel between the brain and external devices by using brain activity recorded as electroencephalogram (EEG) signals (Wolpaw et al. 2002). Much of the impetus for developing BCI methods is derived from the need for assisting, augmenting, and repairing the cognitive or sensory-motor functions of disabled people (Wolpaw et al. 2002; Ebrahimi et al. 2003; Zhang et al. 2013). For every new user of an EEG-based BCI system, however, extensive tagged training samples are required due to the subject-specific features of the system. Obviously, tagging a large number of training samples represents a laborious and time-consuming task. This limitation of existing BCI system calls for improved procedures so that the preparation time could be shortened; in particular, the need for collection of training samples for each new user could be reduced, or even obviated (Krauledat et al. 2008).
The implementation of BCI system is frequently challenging due to the need for sufficient training samples, as is required to build a reliable classification model. In order to ensure the efficient operation of machine learning system, a novel strategy based on transfer learning has been proposed to alleviate the classification problem by sharing training samples between individuals (Shao et al. 2015). Unlike the classical strategy, in which both the training and testing EEG data for classification must be recorded from the same subject, the transfer learning-based strategy enables the transfer of the existing samples from other subjects (named as source domain) into target domain (the samples of the subject to be classified) (Pan and Yang 2010; Raina et al. 2007). The objective of transfer learning is to transfer useful information from a source group into the target training data set so as to overcome the problem of having small calibration data. As we know, the large inter-subject variability of EEG signals has been an impediment to the transfer learning. We thus would eliminate the variability typically existed in user-specific training sample data sets. Attainment of this goal would allow the routine use by new users of training samples collected previously in a data set from other subjects. The time required for new training sessions would substantially be shortened, which thus greatly improves the operating efficiency and general applicability of the BCI system.
In this paper, we develop a novel framework of spatial filter learning by introducing the transfer learning strategy into the classical common spatial patterns (CSP) technique (Blankertz et al. 2008b; Ramoser et al. 2000). The CSP method seeks spatial filters that maximize the discriminability of two classes of signals so as to extract discriminative features (Blankertz et al. 2006; Yue et al. 2012; Zhang et al. 2015). However, the conventional CSP method does not incorporate other subjects’ information engaged in the same task as the subject of interest. The performance of CSP would deteriorate when a given subject has very few training samples (Grosse-Wentrup et al. 2009).
The concept of transfer learning, originally developed in the field of machine learning (Pan and Yang 2010; Raina et al. 2007; Shao et al. 2015), was then adopted in the CSP community. Krauledat et al. (2008) used it for calibration transfer of different sessions. Afterwards, the transfer learning technique was employed for subject-to-subject transfer by linearly combining covariance matrices associated with subjects, named composite CSP (CCSP) (Kang et al. 2009). Likewise, the covariance matrix of the target subject was regularized with an identity matrix as well as covariance matrices of other subjects (Lu et al. 2009). Further, rather than using all source subjects available, Lotte and Guan (2010, 2011) used a subset of automatically selected subjects to formulate a weighted sum of covariance matrices, named regularized CSP with selected subjects (SSRCSP). Clearly, these methods aim to address the estimation of covariance matrix. With samples from multiple subjects, Devlaminck et al. (2011) optimized a spatial filter that is decomposed into a global filter and a subject-specific filter. However, their method has a very restrictive assumption that there exists similarity between spatial filters. Besides, the solving of the objective function is complex due to not a generalized eigenvalue problem. Samek et al. (2013) developed an approach that extracted nonstationary subspace across subjects and thus alleviated the gap between sessions of training and testing. Nevertheless, this method assumes that the principal nonstationarity is similar across subjects and can be transferred. Recently, the composite expression of the covariance matrix given in (Kang et al. 2009) was applied to local temporal correlation CSP, yielded composite local temporal correlation CSP (CLTCCSP) (Hatamikia and Nasrabadi 2015). Moreover, the transfer learning technique was extended to discriminative spatial pattern (DSP) based on empirical maximum mean discrepancy to reduce differences between subjects (Wang et al. 2015), and was generalized to transfer different domains of diseases (Cheng et al. 2015).
Unlike regularized covariance matrix and without restrictive assumption, we propose a variant of CSP that entails subject-to-subject transfer by directly comparing the difference of features between source and target subjects. Specifically, we regularize the spatial filters of CSP by requiring minimization of the feature difference. The regularization technique is commonly used to implement prior information into the CSP learning procedure (Lotte and Guan 2011). With a regularization term plugged in the formulation of CSP, the previous regularization addressed different situations, as for that reviewed in (Lotte and Guan 2011) as well as for small sample setting (Lu et al. 2010), semi-supervised learning (Wang and Xu 2012), stationary learning (Samek et al. 2012), robust learning (Kang et al. 2009; Samek et al. 2013; Wang and Li 2016), and nonlinear modeling (Zhao et al. 2010). The basic principle of the proposed regularized CSP is to extract filters that maximize the discriminability of the two classes of EEG signals and meanwhile minimize the feature difference between the target subject and the source subject (Samek et al. 2012). Since signals from the source subjects may differ from the target subject, we add weights in the penalty term of the regularized CSP, with formulation of the weights by using the Frobenius distance (Hatamikia and Nasrabadi 2015). We report the experimental results on two publicly available EEG data sets, which show the competitiveness of our proposed approach.
In short, the contribution of this paper is two-fold. Firstly, we propose a new framework of regularized CSP with the technique of transfer learning. That is, we introduce the feature difference-based transfer learning strategy into the procedure of spatial filtering with CSP so as to address the problem of small sample size of the target subject. Secondly, we apply different weights to the feature differences according to the similarities between the source subjects and the target subject.
The remainder of this paper is organized as follows. In “Methods” section, we propose the regularized CSP algorithm with transfer learning. The experiments are reported in “Experiments” section, followed by the results in “Results” section. Finally, we discuss the results and conclude the paper in “Discussion and conclusion” section.
Methods
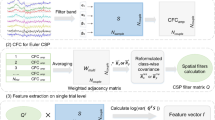
Common spatial patterns
The CSP algorithm aims at learning spatial filters, which maximize the variance of the EEG signals from one class while minimizing the variance of the EEG signals from the other class, thus achieving optimal discriminative features based on the variances. In this algorithm, the matrix \(X^{i} \in R^{D \times T}\) represents the EEG signals of a single trial i, where D denotes the number of channels, and T is the number of samples within a trial. We consider the task as a binary classification problem, the goal of which is to assign to testing trials the appropriate labels chosen from either class 1 or class 2. The CSP problem can be solved by maximizing (or conversely by minimizing) the Rayleigh quotient (Blankertz et al. 2008b), given by
where \(C_{1}\) and \(C_{2}\) are the average covariance matrices from classes 1 and 2, respectively. The spatial filters are solved by the generalized eigenvalue equation
where the leading generalized eigenvectors associated with the first few largest eigenvalues correspond to the spatial filter \(\omega\) that maximizes the variance of class 1 while minimizing the variance of class 2.
Regularized common spatial patterns based on transfer learning with weighted subjects
The regularization procedure of CSP (Lotte and Guan, 2011) is performed by adding a penalty term \(P(\omega )\) to the denominator of the objective function of CSP, as defined as the Rayleigh quotient in Eq. (1). Specifically, we maximize the Rayleigh quotients separately for each class, i.e.,
where \(C_{1}\) and \(C_{2}\) are calculated using the training trials of the source subjects and the training trials (any available) of the target subject, and the parameter \(\alpha\) is a user-defined positive constant which adjusts the influence of the regularization term. We incorporate inter-subject information into the penalty term \(P(\omega )\) by introducing a measure of inter-subject information, which is the absolute difference between the average filtered covariances of the source and the target subject samples. Mathematically, given a target subject, we seek to minimize the following quantity
where \(C^{s}\) is the average covariance matrix of the source subject and \(C^{t}\) the average covariance matrix of the target subject. Here, \(C^{t}\) is calculated by using all the trials (without labels) of the target subject. Note that there is no any class information involved, as suggested in (Wang et al. 2015). The basic idea of (5) is to measure the difference between the source subjects and the target subject. We then extract spatial filters that minimize the difference between the source subjects and the target subject during maximizing the variances between two classes.
For computational consideration, the penalty \(P(\omega )\) cannot be plugged directly into the Rayleigh quotient. We therefore apply an operator \(\varGamma\) that makes symmetric matrices positive and definite. More precisely, if a symmetric matrix \({\rm M}\) has the eigen-decomposition \({\rm M} = {\text{V}}{\text{diag}}(d_{i} )\,\;{\text{V}}^{T}\), then the operator returns \(\varGamma ({\rm M}) = {\text{V}}{\kern 1pt} \,{\text{diag}}(|d_{i} |)\,\;{\text{V}}^{T}\), i.e., the signs of all negative eigenvalues are inverted, thus insuring that the penalty term is always positive in magnitude. Clearly, if follows that
We thus minimize the upper bound of \(P(\omega )\) instead. Mathematically, we use the expression \(\sum\nolimits_{s \ne t} {\omega^{T} \varGamma (C^{s} - C^{t} )\omega }\) as penalty term and plug it into the objective function of CSP. By this means we maximize the regularized objective functions, as given by
In actual fact, the source subjects do not play equal roles in the classification of the target trials; we endeavor to emphasize the weighting of source subjects who are more similar to the target subject, based on objective measures of similarity. Specifically, the similarity between subjects is defined by using the Frobenius norm, given by (Hatamikia and Nasrabadi 2015)
where the notation tr denotes the trace operator. We assign larger weights to the source subjects who have more similarity with the target subject, with the weights determining the influence of the source subjects on the penalty term defined as
where \(N^{t} = \sum\nolimits_{s \ne t} {1/F_{{C^{s} ,C^{t} }} }\) is the normalization constant. Consequently, the Eqs. (7) and (8) are reformulated as
For resolving (11) and (12), the corresponding eigenvalue equation becomes
Experiments
EEG data sets
We evaluated the effectiveness of the proposed regularized CSP with the transfer learning (RCSPTL) using two EEG data sets of motor imagery (MI) derived from public BCI competitions. We compared the classification performance of this RCSPTL with that of the traditional CSP in order to verify the predicted advantages of our transfer learning-based method.
-
1.
Data set IVa-BCI competition III This public domain data set had been recorded from five subjects who were asked to perform cued motor imagery of two classes, i.e., motion of the right hand and the right foot. The EEG measurements were recorded using 118 electrodes, band-pass filtered between 0.05 and 200 Hz and sampled with 100 Hz. A total of 280 trials were available for each subject, among which, 60, 80, 30, 20 and 10% were fixed and labeled by the organizing committee of the contest as training samples for A1, A2, A3, A4 and A5, respectively. As such, the provided data was already divided into the training group and the testing group. The labels for the trials in the testing group were not revealed before the BCI competition III, in which the challenge was to make a good classification despite having only a small training set. Given this property, the data set was an ideal choice for interrogating a recognition method using information from other subjects with many labeled trials.
-
2.
Data set IIa-BCI competition IV This data set was constructed by EEG recording from nine subjects who carried out left hand, right hand, foot and tongue MI tasks. The signals were recorded using 22 EEG channels, sampled with 250 Hz and bandpass filtered between 0.5 and 100 Hz with Notch filter on. Only the data of left and right hands MI were used for the present study. Each subject participated training and testing sessions, both of which containing 72 trials for each class. The given data were also divided into training and testing parts by the competition organizers.
Data processing
The same preprocessing was applied for all the data sets. The EEG signals were band-pass filtered with a fifth order Butterworth filter in the range 8–30 Hz, which contained the main frequencies involved in MI (Ramoser et al. 2000), and time interval ranging from 0.5 to 2.5 s were applied used after the visual cue instructing the subjects to perform the assigned motor imaginary tasks (Lotte and Guan 2011).
We used RCSPTL to extract features from the data sets. In order to investigate the impact of the weights as defined in (10), we chose two ways to implement the RCSPTL method: (a) Introduced the weights \(b_{st}\) into the penalty term, which we called RCSP based on transfer learning with weighted sources (RCSPTLw), and (b) considered that all the source subjects had an equal role in the weighting. Furthermore, we considered a transient transform version of CSP (tvCSP), which was formed by dropping out the penalty term in RCSPTL. In order to show the effect of the subject-to-subject transfer, we performed the classification by using the original CSP method, which had been trained only on the target subject’s own training data. In addition, three existing CSP-based transfer learning methods (i.e., CCSP, SSRCSP, CLTCCSP) were applied to give more comparisons with the results of the proposed algorithm. The relevant settings of the methods mentioned above were summarized in Table 1. For example, in the experiment for subject A1, all 168 training trials of subject A1 were used as the training data when performing the traditional CSP. In contrast, while performing the RCSPTLw for subject A1, the training data consisted of his/her own training data as well as the 392 (i.e., 224 + 84 + 56 + 28) training trials from the other four source subjects. To investigate further the role of the transfer strategy, we varied the size of the training trials of the target subject from zero to the complete set of all training trials.
The parameter \(\alpha\) in the RCSPTL method was selected by using the technique of ten-fold cross-validation on the training trials. Then, the spatial filters were learnt on the training trials, which contained the training trials of the source subjects and the trials from the training part of the target subject. In our experiments, the first three pairs of spatial filters (Lotte and Guan 2011) were used for extracting features. Finally, the log-variances of the spatially filtered EEG signals were used as input features for linear discriminant analysis (LDA) so as to classify the remaining trials of the target subject.
Results
Classification performances on data set one
The classification accuracies on data set one were reported in Table 2. In this experiment, the number of training trials associated with each subject was set as in the description of the “EEG data sets” subsection. Although all three methods (i.e., tvCSP, CSPTL, and CSPTLw) borrowed data from the other subjects, the classification results obtained by RCSPTLw were significantly higher than that of tvCSP (p < .05) for every target subject, and also greater than that of RCSPTL. Notably, the RCSPTLw gained a respectable recognition rate (74.68 ± 9.24), while tvCSP and RCSPTL had performance merely around the chance level when only using the training data from the source subjects. The classification rate of RCSPTLw (78.99 ± 10.61) was much greater than that of the traditional CSP (67.07 ± 14.05) when the training trials of the target subject were added. Besides, compared with the results of the previous regularized algorithm (i.e., CCSP, SSRCSP, CLTCCSP), the classification accuracies of RCSPTLw showed superiority. Especially, in the condition without the targets’ own training data, the result of RCSPTLw was statistically higher than that of CCSP, SSRCSP, and CLTCCSP (p < .05), such as, RCSPTLw (74.68 ± 9.24) versus CCSP (61.01 ± 3.56). Moreover, the classification rate of RCSPTLw (78.99 ± 10.61) was significantly higher than that of SSRCSP (74.57 ± 10.32) (p < .05), when the training trials of the target subject were added.
In view of the above results, we varied the training samples of the target subjects and looked for more convincing results. The classification performances with varying numbers of training trials of the target subjects, as used in (Wang and Xu 2012), were plotted in Fig. 1, where the means and standard deviations over ten repetitions were depicted. Note that all the training trials of the source subjects were used in this figure. We point it out that, when none training trials of the target subject are used, the covariance matrices \(C_{1}\) and \(C_{2}\) are calculated using the training trials of the source subjects, \(C^{s}\) is calculated as the average covariance matrix of the training trials of the source subject and \(C^{t}\) the average covariance matrix of the testing trials of the target subject.

Average classification rates (%), as well as standard deviations, with varying numbers of training trials of the target subject for the five subjects on data set IVa of BCI competition III. a subject A1, b subject A2, c subject A3, d subject A4, e subject A5. In each panel, the first column denotes the case that none training trials of the target subject were used while the last column is the accuracy in the case of using all the training trial of the target subject in the training process. Each point represents the mean (±SD) of multiple determinations
Classification performances on data set two
We proceeded to investigate the performances of all seven methods mentioned above (CSP, CCSP, SSRCSP, CLTCCSP, tvCSP, RCSPTL, and RCSPTLw) on data set two. For each target subject, we evaluated the cases that none or all of the training trials of the target subject were used in the training procedure. Furthermore, we considered the case of random selection of one-third of the training trials. The average results of the four methods over ten repetitions for each target subject were recorded. All the classification results were reported in Table 3. The classification rate of RCSPTLw (75.81 ± 13.86) was significantly higher than that of the traditional CSP (67.36 ± 15.54) (p < .05) and that of RCSPTL (68.52 ± 13.41) (p < .05) in the cases of random selection of one-third of the training trials.
Discussion and conclusion
According to the size of the training trials of the target subject used, our experiments were broadly performed in three conditions: the target subject without own training trials, with a few own training trials, and with mild size of own training trials. For the case of data set one, the number of training samples was not held constant. When the training trials of the target subject were contained in the training procedure, the results showed roughly that the promotion of classification accuracies by RCSPTLw was more apparent in the cases with fewer training trials, as shown in Table 2. Specifically, in the situation of the least own training samples (A5), RCSPTLw led to dramatic increase in performance, attaining a score as high as 35%, while the subject’s performance by CSP was close to the chance level. Compared with the three CSP-based transfer learning methods (i.e., CCSP, SSRCSP, CLTCCSP), the relatively higher accuracies of the proposed RCSPTLw approach were also shown in this case. On the other hand, the encouraging results achieved in the cases without training data from the target subject demonstrated the effectiveness of our strategy of transfer learning. Generally, the transfer learning imparted more benefits for correct classification in case of subjects with few or no training samples. This improvement in the efficiency of the BCI system through the use of existing data allowed reduction of the required recording time, sometimes to zero.
The effect of the weights in RCSPTLw stood out prominently in almost all cases, regardless of the variety of the size of the training trials of the target subject, as shown in Fig. 1. In particular, the recognition rate gained by RCSPTLw remained relatively stable across a varying number of training trials. The results showed that the novel RCSPTLw approach was better than tvCSP and the traditional CSP methods in almost all cases. By comparing RCSPTLw with the traditional CSP, the best improvement (up to 40%) was evident for the particular case of the minimum number of training trials of the target subject. This substantial improvement confirmed that combining all the source subjects with different weights did substantially improve the quality of transfer information from the other subjects. Exception occurred in the cases that subject A1 and A2 had relatively many own training trials. There, the CLTCCSP method produced the highest classification accuracies. Nevertheless, the RCSPTLw approach demonstrated its advantage when the target’s own training data reduced to few.
On data set two, the recognition was also successful for the nine subjects when using only the training trials of the source subjects. Further, the results for the less demanding task indicated that when the training trials of the target subject were cut to one-third, the RCSPTLw approach still outperformed some other methods (i.e., the traditional CSP, RCSPTL) in nearly all cases, which was consistent with the results of experiment one. In other words, the fewer training samples there were for the target subject, the better the improvement that was obtained by RCSPTLw. Compared with the existing three CSP-based transfer learning methods (i.e., CCSP, SSRCSP, CLTCCSP), RCSPTLw gained competitive classification accuracies. Ultimately, these four methods were all regularized CSP based on transfer learning strategy but with different improvement ideas.
In order to obtain satisfied BCI performance, it is prescriptively required to collect approximately 40 training trials per class, as suggested in (Blankertz et al. 2008a). In our study, RCSPTLw obtained satisfactory performance in data sets I and II with only 20 or so training trials, and even in the absence of any samples per class. The task of developing an effective BCI system for analysis of EEG signals has long been a matter of research interest. Generally speaking, a large number of labeled EEG trials are needed to train the filters of the ordinary CSP approach. This is an onerous requirement, requiring considerable investment of time. In order to shorten the preparation time of a BCI system, and aiming to maintain or even increase the recognition rate of the system, we investigated in this paper the performance of a novel RCSPTLw approach by using existing trials available on two public data sets. Comparing with the traditional CSP and tvCSP, the novel RCSPTLw approach depended on the regularization of CSP by means of transfer learning with weighted sources. This procedure substantially increased the recognition accuracy, especially when few or no training samples were available from a given new BCI user. We find that implementation of the, RCSPTLw approach enables reduction (even complete omission) of the training sample collection for a new subject, and thus greatly improve the efficiency of BCI system.
References
Blankertz B, Müller KR, Krusienski DJ, Schalk G, Wolpaw JR, Schlögl A, Pfurtscheller G, Millán Jdel R, Schröder M, Birbaumer N (2006) The BCI competition III: validating alternative approaches to actual BCI problems. IEEE Trans Neural Syst Rehabil Eng 14:153–159
Blankertz B, Losch F, Krauledat M, Dornhege G, Curio G, Müller KR (2008a) The Berlin brain-computer interface: accurate performance from first-session in BCI-naive subjects. IEEE Trans Biomed Eng 55:2452–2462
Blankertz B, Tomioka R, Lemm S, KawanabeM Muller KR (2008b) Optimizing spatial filters for robust EEG single-trial analysis. IEEE Signal Process Mag 25:41–56
Cheng B, Liu M, Zhang D, Munsell BC, Shen D (2015) Domain transfer learning for MCI conversion prediction. IEEE Trans Biomed Eng 62:1805–1817
Devlaminck D, Wyns B, Grosse-Wentrup M, Otte G, Santens P (2011) Multi-subject learning for common spatial patterns in motor-imagery BCI. Comput Intell Neurosci 217987:1–9
Ebrahimi T, Vesin JF, Garcia G (2003) Brain-computer interface in multimedia communication. IEEE Signal Process Mag 20:14–24
Grosse-Wentrup M, Liefhold C, Gramann K, Buss M (2009) Beamforming in noninvasive brain computer interfaces. IEEE Trans Biomed Eng 56:1209–1219
Hatamikia S, Nasrabadi AM (2015) Subject transfer BCI based on composite local temporal correlation common spatial pattern. Comput Biol Med 64:1–11
Kang H, Nam Y, Choi S (2009) Composite common spatial pattern for subject-to-subject transfer. IEEE Signal Process Lett 16(8):683–686
Krauledat M, Tangermann M, Blankertz B, Müller KR (2008) Towards zero training for brain-computer interfacing. PLoS ONE 3:e2967
Lotte F, Guan C (2010) Learning from other subjects helps reducing Brain-Computer interface calibration time. In: IEEE international Conference on acoustics, speech, and signal processing (ICASSP), pp 614–617
Lotte F, Guan C (2011) Regularizing common spatial patterns to improve BCI designs: unified theory and new algorithms. IEEE Trans Biomed Eng 58:355–362
Lu H, Plataniotis KN, Venetsanopoulos AN (2009) Regularized common spatial patterns with generic learning for EEG signal classification. In: Proceedings EMBC, pp 6599–6602
Lu H, Eng H-L, Guan C, Plataniotis KN, Venetsanopoulos AN (2010) Regularized common spatial pattern with aggregation for EEG classification in small-sample setting. IEEE Trans Biomed Eng 57(12):2936–2946
Pan SJ, Yang Q (2010) A survey on transfer learning. IEEE Trans Knowl Data Eng 22:1345–1359
Raina R, Battle A, Lee H, Packer B, Ng AY (2007) Self-taught learning: transfer learning from unlabeled data. In: Proceedings 24th international conference machine learning doi:10.1145/1273496.1273592
Ramoser H, Muller-Gerking J, Pfurtscheller G (2000) Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans Rehabil Eng 8:441–446
Samek W, Vidaurre C, Müller KR, Kawanabe M (2012) Stationary common spatial patterns for brain-computer interfacing. J Neural Eng 9(2):026013
Samek W, Meinecke FC, Müller KR (2013) Transferring subspaces between subjects in brain-computer interfacing. IEEE Trans Biomed Eng 60(8):2289–2298
Shao L, Zhu F, Li X (2015) Transfer learning for visual categorization: a survey. IEEE Trans Neural Netw Learn Syst 26(5):1019–1034
Wang H, Li X (2016) Regularized filters for L1-norm-based common spatial patterns. IEEE Trans Neural Syst Rehabil Eng 24(2):201–211
Wang H, Xu D (2012) Comprehensive common spatial patterns with temporal structure information of EEG data: minimizing nontask related EEG component. IEEE Trans Biomed Eng 59(9):2496–2505
Wang P, Lu J, Lu C, Tang Z (2015) An algorithm for movement related potentials feature extraction based on transfer learning. In: IEEE international conference on information science and technology, pp 309–314
Wolpaw JR, Birbaumer N, McFarland DJ, Pfurtscheller G, Vaughan TM (2002) Brain-computer interfaces for communication and control. Clin Neurophysiol 113:767–791
Yue J, Zhou Z, Jiang J, Liu Y, Hu D (2012) Balancing a simulated inverted pendulum through motor imagery: an EEG-based real-time control paradigm. Neurosci Lett 524:95–100
Zhang JH, Peng XD, Liu H, Raisch J, Wang RB (2013) Classifying human operator functional state based on electrophysiological and performance measures and fuzzy clustering method. Cogn Neurodyn 7(6):477–494
Zhang L, Gan JQ, Wang H (2015) Localization of neural efficiency of the mathematically gifted brain through a feature subset selection method. Cogn Neurodyn 9(5):495–508
Zhao Q, Rutkowski TM, Zhang L, Cichocki A (2010) Generalized optimal spatial filtering using a kernel approach with application to EEG classification. Cogn Neurodyn 4(4):355–358
Acknowledgements
The authors would like to thank the anonymous reviewers for their thoughtful comments and suggestions. This work was supported in part by the National Basic Research Program of China under Grant 2015CB351704 and the National Natural Science Foundation of China under Grant 61375118.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animal rights
All procedures followed were in accordance with the ethical standards of the responsible committee on human experimentation (institutional and national) and with the Helsinki Declaration of 1975, as revised in 2008 (5).
Informed consent
Informed consent was obtained from all patients for being included in the study.
Rights and permissions
About this article

Cite this article
Cheng, M., Lu, Z. & Wang, H. Regularized common spatial patterns with subject-to-subject transfer of EEG signals. Cogn Neurodyn 11, 173–181 (2017). https://doi.org/10.1007/s11571-016-9417-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11571-016-9417-x