
Abstract
Pattern classification algorithm is the crucial step in developing brain–computer interface (BCI) applications. In this paper, a hierarchical support vector machine (HSVM) algorithm is proposed to address an EEG-based four-class motor imagery classification task. Wavelet packet transform is employed to decompose raw EEG signals. Thereafter, EEG signals with effective frequency sub-bands are grouped and reconstructed. EEG feature vectors are extracted from the reconstructed EEG signals with one versus the rest common spatial patterns (OVR-CSP) and one versus one common spatial patterns (OVO-CSP). Then, a two-layer HSVM algorithm is designed for the classification of these EEG feature vectors, where “OVO” classifiers are used in the first layer and “OVR” in the second layer. A public dataset (BCI Competition IV-II-a)is employed to validate the proposed method. Fivefold cross-validation results demonstrate that the average accuracy of classification in the first layer and the second layer is 67.5 ± 17.7% and 60.3 ± 14.7%, respectively. The average accuracy of the classification is 64.4 ± 16.7% overall. These results show that the proposed method is effective for four-class motor imagery classification.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Some of the people with neurological disease suffer from troubles in walking, speaking, and writing because they lose fine motor control. People with these kinds of diseases such as amyotrophic lateral sclerosis (ALS), locked-in syndrome, Lou Gehrig’s disease, and high spinal cord injury lack control of their voluntary muscles. Thus, they are unable to do even simple tasks by themselves. Therefore, they cannot communicate with the environment and sometimes they are excluded from society because they are considered heavy burden [22, 24, 25]. Brain–computer interface (BCI) technology can be incorporated into medical treatments on those patients and enhance their quality of life. The mind intention of handicapped people can be detected when he performs actual or imagined movement by analyzing his/her brain signals only [9, 24] and converted into commands for sending messages or controlling home devices, which provides a higher quality of life for both disabled users and their family. Due to the safety concern of relevant techniques, noninvasive EEG-based BCI is widely used toward these assistive purposes, such as forward word spellers [16, 19], wheelchair control [7], and video games [21]. In addition, noninvasive BCIs may be useful for evaluating brain activity of severely paralyzed patients to predict the efficacy of invasive brain–machine interface [6].
EEG signals with several physiological mechanisms, such as motor imagery (MI) [2, 18], steady-state visual-evoked potential (SSVEP) [14, 26], and P300 [13], have been investigated by BCI researches. Compared with SSVEP- or P300-based BCIs, MI methods may have higher potentiality because they are independent to an external stimulus, which allows achieving asynchronous control and communication.
For MI EEG signal processing, the traditional common spatial pattern (CSP) method, which can be interpreted in both mathematics and physiology, was recognized as an effective method for feature extraction. However, the traditional CSP method is more suitable for two-class MI EEG data classification. Furthermore, it is sensitive to noise and not suitable for small training sets [8]. In order to handle the four-class classification, the traditional CSP method was extended by computing common spatial pattern for each class against all others [5]. In addition, several approaches to improve CSP methods were proposed to address the issue of selecting optimal time frequency bands for the CSP algorithm. For example, regularization terms were added as prior knowledge in regularized CSP (R-CSP) methods [11, 15]. By adding a probabilistic counterpart of CSP, the probabilistic CSP (P-CSP) infers spatial patterns by two linear Gaussian generative models which shared the basis matrix [10]. Filter bank common spatial pattern (FBCSP) method cutting a broad frequency band into small non-overlapping filters was proposed for an MI EEG-based BCI [1].However, FBCSP method is complex to compute subject-specific frequency bands.
This paper proposes a mathematical paradigm consisting of “one versus one” (OVO) and “one versus rest” (OVR) strategies to the traditional CSP for four-class motor imagery classification. Ten common spatial patterns are calculated, and their feature vectors are extracted. An HSVM algorithm is designed to coordinate with the feature vectors. The proposed algorithm is applied on real EEG data of nine human subjects to distinguish among four motor imagery tasks. The sensorimotor cortex is the region of the cerebral cortex involved in the planning, control, and execution of voluntary movements. This cortex is responsible on motor imagery tasks; therefore, it is a critical component of sending commands and receiving feedbacks to/from muscles. Figure 1 shows the different regions of the sensorimotor cortex which were considered in this study when placing electrodes.

Different regions of the sensorimotor cortex. The brain area highlighted in pink in the figure controls different body parts. The navy blue circle (top of the head) limits the region controlling feet and legs. The pale blue circle (center of the head) limits the region controlling hands. Face and tongue are controlled by the small orange circled region near the bottom of the cortex (located just above ears) (color figure online)
The rest of the paper is organized as follows. In Sect. 2, experimental tests are described and all steps of the proposed algorithm are described in detail. In Sect. 3, results of motor imagery classification are presented. Advantages and disadvantages of the proposed algorithm in different scenarios are discussed in Sect. 4.
2 Method
2.1 EEG dataset
The dataset used in this study was taken from BCI competition IV-II-a [3]. It includes four motor imagery tasks: imagination of the left hand, right hand, both feet, and tongue movements of nine subjects. As shown in Fig. 2a, EEG signals were recorded from 22 Ag/AgCl electrodes and 3 monopolar electrooculogram (EOG) channels (with left mastoid serving as reference) with sampling frequency at 250 Hz, and band-pass filtered between 0.5 and 100 Hz. Power line interference was filtered by an additional 50-Hz notch filter. Timing scheme of the paradigm is shown in Fig. 2b. More detailed information about the EEG experiment can be found in [3].

Experimental paradigms. a Electrode positions; b timing scheme of the BCI paradigm
The EEG data are comprised of two sessions which were recorded on different days to take into consideration the non-stationary nature of EEG data. Each session has 6 runs separated by short breaks. There are 48 trials (12 per possible class) in each run. Thus, each session is composed of 288 trials in total. For data analysis, each trial was separated and extracted by its category of motor imagery task. Then, 72 valid trials for each task were achieved. Then, 72 available trials for each task were achieved. Fivefold cross-validation was applied to counteract over-fitting. In fivefold cross-validation, the original sample (72 trials) is randomly partitioned into five subsamples. Of the five subsamples, four subsamples are used as training data; the remaining single subsample (14 trials) is retained as the validation data for testing the model. For four imaginary tasks, 56 trials were included in test dataset. The cross-validation process is then repeated five times, with each of the five subsamples used exactly once as the validation data.
2.2 Preprocess
Motor imagery could cause event-related desynchronization (ERD) [5] and the ipsilateral hemisphere event-related synchronization (ERS) in the contra lateral hemisphere (see Fig. 1). Therefore, the μ rhythms (8–12 Hz) and β rhythms (14–30 Hz) of EEG signals in the related cortical are as would increase or decrease their amplitude and spectrum power. In addition, high-frequency component in EEG signals was usually nebulous, so the raw EEG signals were filtered by band-pass filter (3–34 Hz). Five-level wavelet package decomposition was applied to analyze the filtered EEG signals (3–34 Hz). The fifth level decomposed components \( \left\{ {U_{5}^{0} ,U_{5}^{1} ,U_{5}^{2} , \ldots ,U_{5}^{29} ,U_{5}^{30} ,U_{5}^{31} } \right\} \) correspond to specific frequency bands. For instance, when the filtered EEG signal was considered only in the band of [3, 34] Hz, the following frequency bands are considered \( \left\{ {\left[ {3,3 + \frac{{f_{\text{in}} }}{{2^{5} }}} \right],\left[ {3 + \frac{{f_{\text{in}} }}{{2^{5} }},3 + \frac{{2f_{\text{in}} }}{{2^{5} }}} \right], \cdots ,\left[ {3 + \frac{{\left( {2^{5} - 1} \right)f_{\text{in}} }}{{2^{5} }},3 + f_{\text{in}} } \right]} \right\} \), where f in is 32 Hz. As shown in Fig. 3, the amplitudes of average reconstructed EEG signals in the band of [25, 34] Hz were very low and almost no change was recorded during motor imagery. Thus, only the frequency bands falling in [3, 24] Hz were selected and used in feature selection.

Amplitudes (µV) of reconstructed EEG signals
2.3 Common spatial patterns with OVO and OVR strategies
Common spatial pattern (CSP) [12] was proposed, for two-class classification for EEG-based BCIs. For the four-class classification problem considered in this study, OVO and OVR strategies were applied to adjust CSP for feature selection.
First of all, we labeled imagination of the left hand, right hand, both feet, and tongue as classes 1, 2, 3, and 4, respectively. As shown in Fig. 4a, OVO strategy selects any two classes to form a pair to apply the traditional CSP method. By this way, a four-class classification problem is transformed into a six two-class classification problem.

Common spatial pattern strategies combined in this study: a OVO strategy; b OVR strategy
Let X i with i ∊ {1, 2} denote the reconstructed EEG signal of class i. The dimension of X i is T × N in each trial, where N and T denote the number of channels and the number of samples in time series for each channel, respectively. Note that the number of samples can be variable with respect to different subjects.
The covariance of one trial for class I is
where X T i denotes the transpose of X i and the trace is defined to be the sum of the elements on the main diagonal of a matrix. The spatial covariance C i should be calculated by averaging over all trials of each group.
The composite spatial covariance C is:
Then, C can be factored as
where U 0 is the matrix consisting of eigenvectors, and∧ is the diagonal matrix of eigenvalues. ∧ is defined so that the eigenvalues were sorted in descending order.
The whitening transformation is
Then, C 1 and C 2 are whitened as
S 1 and S 2 share common eigenvectors. Then, S 1 and S 2 can be factored as
Then, the sum of ∧1 and ∧2 would be identity matrix
which means the largest eigenvalue in S 1 corresponded to the smallest eigenvalue in S 2, because the sum of them keeps constant 1. The eigenvectors in B will be used for classification of the two classes. The optimal feature vectors would be given for discriminating two populations of EEG when whitened EEG signals are projected to the first and the last eigenvectors. The projection matrix is
The projection (mapping) of a trial is given as
The rows of W 12 can be considered as EEG source distribution vectors and the columns of W 12 are the common spatial patterns. By decomposing the whitened EEG signals according to Eq. (11), the features for classification could be achieved. In this way, for each class of the imagined movement, only the variances of a small set of signals are needed for the classifier training.
In OVR strategy (Fig. 4b), one class was defined as target class, and the other three classes were combined as the opposite class. The covariance of each trial and whitening transformation were calculated as the traditional CSP does. However, the common spatial pattern was computed differently as
Through whitening transformation, C 1r was transformed to S 1r and could be described as
In the phase of diagonalization, S 1r can be factored as
Then, the sum of ∧1 and ∧1r is
The projection matrix can be deduced as
The mapping of a trial is
The feature vectors f i could be computed as follows:
where VAR i denotes the variance matrix of the best projection of EEG signal Z 1, which is computed by common spatial filters. For OVO and OVR strategies, combined feature vectors are finally defined as
where f 12, f 13, f 14, f 23, f 24, f 34 denote the EEG feature vectors corresponding to OVO strategy, which are used to train OVO classifiers, while f 1, f 2, f 3, f 4 denote the EEG feature vectors for OVR classifiers corresponding to OVR strategy.
2.4 Hierarchical support vector machine
In this study, the traditional C-support vector machine (SVM) approach was used for supervisory classification [4, 23]. The basic idea of SVM is to map the input x onto a high-dimensional feature space (z = ϕ(x)) and look for the optimal decision hyperplane, which separates the data points into different classes with a maximum margin.
The decision hyperplane was defined as
where w is the normal vector and b is the bias of the separation hyperplane. The decision hyperplane can be found by solving the following optimizing problem.
where x i is the i-th input sample, y i is the class label value of x i , l is the number of input samples, ζ i is the slack variable that allows an example to be in the margin (0 ≤ ζ i ≤ 1,also called a margin error) or to be misclassified (ζ i > 1), and C is a penalty factor to be chosen by the user, a larger C corresponding to assigning a higher penalty to errors.
Eq. (21) can be solved by its dual problem using Lagrange optimization.
The solution can be calculated by
where α i is the Lagrange multiplier from the QP problem, Ns is the number of support vectors, and K(x i , x j ) is the kernel function.
Furthermore, radial basis kernel function, which was applied to deal with the nonlinear characteristics of EEG signal, can be described as
where g is the kernel parameter which denotes the gamma distribution of the transformed data. The penalty factor C controls the degree of punishment for right or wrong classification. The kernel parameter g and penalty factor C are adjusted to search for optimal separation hyperplane. Therefore, g and C play an important role in improving the correct rate and classification efficiency of the SVM. In this study, the grid search method was used to optimize g and C. To avoid over-fitting, tenfold cross-validation is used for training classifiers.
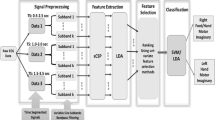
The hierarchical support vector machine paradigm is designed to optimize classification, as shown in Fig. 5. Four OVR and six OVO support vector machine classifiers are employed in the first layer and the second layer, respectively.

Flowchart of the classification process performed with the proposed HSVM algorithm
After preprocessing, EEG feature signals were given in input to the first-layer support vector machine which contains four OVR support vector machines. For OVR support vector machine, the classification result in OVR support vector machine maybe the “Class One” and the “Class Rest.” We defined the result “Class One” as a valid classification result because the result “Class Rest” means three possible classes. Note that the valid result here does not mean this result is a correct result.
In this manner, possible results can be achieved as shown in Table 1. The possible results can be categorized into three cases:
Case 1 Only one OVR support vector machine gets valid results and other three get invalid results (“class rest”).
Case 2 Any two OVR support vector machines get valid result, and the other two get invalid results.
Case 3 Any other situations which are different to Case 1 and Case 2.
For Case 1, the valid result is considered as the final classification result, and the trial would be labeled. The accuracy value in first layer was calculated among these labeled trials achieved in first layer. Otherwise, the unlabeled trials are sent to the second layer. The accuracy value in second layer was calculated among the unlabeled trials achieved in first layer.
For Case 2, the EEG feature signals are entered into only one corresponding classifier according to two valid results. For example, Class 1 and Class 2 are the possible classes in the first layer, this trial would be sent to the classifier only for Class 1 and Class 2. The classification result is the final result and the trial is labeled.
For Case 3, the EEG feature signals are entered into the six OVO support vector machine classifiers. The possible result is shown in Table 2. The vote rule was adopted. For situation 1, “Class one” appeared three times in OVO support vector machine classifiers. So this result was final result. Since in situation 2, “Class one” or others results just appear two times, the final result cannot be achieved. The classification of this trial was failed and counted as incorrect classification.
The final corrected rate (or fraction of correctly classified trials) was calculated as the proportion of the number of correctly labeled trials (after first- and second-layer SVM) divided by the total test number 280 (fivefold classification, 56 test trials per fold).
3 Experimental results
A test dataset containing 56 trials is considered for validating the proposed hierarchical support vector machine classifiers. The final classification results were 64.4 ± 16.7 and 69.16 ± 16.0% for sessions 1 and 2, respectively. The EEG data of sessions 1 and 2 were analyzed.
Classification results in the first layer are shown in Table 3, where the number of trials achieved valid results and correct results are 27.4 ± 7.8 and 19.4 ± 9.4 (mean ± standard deviation), respectively. The average accuracy of the first layer is 67.5 ± 17.7% in total. The largest number of valid results and correct results is 35.0 ± 5.3 for subject 2 and 30.2 ± 4.1 for subject 3, respectively. The best accuracy, 88.3%, was achieved for subject 3.
Table 4 shows the classification results in the second layer, where the “rest” results denote the trials being classified as “rest classes.” The average number of “rest” trials and correct trials is 27.4 ± 7.8 and 19.4 ± 9.4, respectively. The average accuracy is 67.5 ± 17.7%. In the second layer, subject 1 got 41.8 ± 1.3 “rest” trials, and 28.8 ± 1.6 correctly classified trials. The best accuracy is 75.4% for subject 7.
To calculate the total classification accuracy shown in Fig. 6, the numbers of correct results achieved in first layer (Table 3) and in second layer (Table 4) are added and divided by the total number of test dataset. The best accuracy is 82.1 ± 3.3% for subject 3. The average accuracy through the total 9 subjects is 64.4 ± 16.7%. A two-way ANOVA is then applied to analyze classification accuracy for the 9 subjects, and significant differences are observed (F 8,44 = 34.53, p = 1.30 × 10−13). It can be seen that accuracy for subjects 4, 5, and 6 is lower than for the other subjects. There is no significant difference between subject 2, subject 3, subject 7, subject 8, and subject 9.

Final classification accuracy achieved by the proposed approach
The classification results obtained in this study are compared with the literature [4, 10]. The final accuracy 64.4 ± 16.7% obtained in this paper for the worst session (session 1) is however higher than 61.9 ± 17.7% (standard OVR-CSP method) and 62.6 ± 18.7% (filter bank method).
4 Discussion and conclusions
In this paper, two common spatial pattern strategies and hierarchical support vector machine method were proposed to process four-class motor imagery data. EEG signals were preprocessed, and the features were extracted through 10 common spatial patterns (four OVR-CSPs and six OVO-CSPs). Then, these EEG features were given in input to the hierarchical support vector machines.
Table 5 compares the performance of the proposed method with the directed acyclic graph (DAG) SVM method. Computations were carried out on a Lenovo computer (CPU 3.3 GHz). It can be seen that processing time in training phase and test phase is longer than for DAG SVM. However, processing time of test phase remains short enough for real-time applications. Furthermore, the proposed method is more accurate than DAG SVM.
Classification results demonstrated that the average classification accuracy 67.5 ± 17.7% in the first layer was higher than the 60.3 ± 14.7% accuracy achieved in the second layer. The classification process implemented in the proposed method is divided into two layers. One trial can be labeled in the first layer or in the second layer. The number of labeled results in the first OVR SVM layer reveals larger differences between one class and the other three classes in EEG signals. The number of labeled results in the first layer also correlated with the average accuracy in the first layer (correlation coefficient 0.73) and final results (correlation coefficient 0.67). Higher classification accuracy in first layer is the reason why proposed method is better than traditional SVM methods, like DAG SVM method.
The average achieved for the 9 subjects was 64.4 ± 16.7%, better than its counterpart for the traditional OVR-CSP method and filter bank method. These results prove that the proposed method is effective for four-class EEG imagery classification problems.
Testing performance of paralyzed patients in noninvasive BCIs might be useful for evaluating their brain activity to predict the efficacy of invasive clinical brain–machine interface such as for the five subjects who in this study got an average classification accuracy higher than 70%, hence satisfying the requirement criterion for real-time binary BCI [17, 20]. In addition, the final classification result (Fig. 6) showed that classification accuracy of six subjects was about and above 70% with chance level of 25% (since there are 4 classes motor imagery, the expected agreement of each class is 1/4, i.e., 25%), which suggested the proposed method is suitable for clinical and non-clinical applications.
In the near future, we are going to use our proposed algorithm in real-time motor imagery-based BCI to demonstrate its robustness and efficiency.
References
Ang KK, Chin ZY, Zhang H, Guan C (2008) Filter bank common spatial pattern (FBCSP) in brain–computer interface. In: IEEE international joint conference on neural networks, Hong Kong, China, pp 2390–2397
Brunner C, Naeem M, Leeb R, Graimann B, Pfurtscheller G (2007) Spatial filtering and selection of optimized components in four class motor imagery data using independent components analysis. Pattern Recogn Lett 28(8):957–964
Brunner C, Leeb R, Muller-Putz GR, Schlogl A, Pfurtscheller G (2008) BCI competition 2008-graz data set A, Institute for Knowledge Discovery (Laboratory of Brain–Computer Interfaces), Graz University of Technology
Chang C-C, Lin C-J (2011) LIBSVM: a library for support vector machines. Proc IEEE Int Conf Neural Netw 2(3):1–27
Dornhege G, Blankertz B, Curio G, Muller K-R (2004) Boosting bit rates in noninvasive EEG single-trial classifications by feature combination and multiclass paradigms. IEEE Trans Biomed Eng 51(6):993–1002
Fukuma R, Yanagisawa T, Yorifuji S, Kato R, Yokoi H (2015) Closed-loop control of a neuroprosthetic hand by magnetoencephalographic signals. PLoS ONE 10(7):e0131547
Galan F, Nuttin M, Lew E, Ferrez PW, Vanacker G, Philips J, Millan JDR (2008) A brain-actuated wheelchair: asynchronous and non-invasive brain–computer interfaces for continuous control of robots. Clin Neurophysiol 119(9):2159–2169
Grosse-Wentrup M, Liefhold C, Gramann K, Buss M (2009) Beamforming in non-invasive brain–computer interfaces. IEEE Trans Biomed Eng 56(4):1209–1219
Hadjidimitriou SK, Hadjileontiadis LJ (2012) Toward an EEG-based recognition of music liking using time-frequency analysis. IEEE Trans Biomed Eng 59(12):3498–3510
Kang H, Choi S (2014) Bayesian common spatial patterns for multi-subject EEG classification. Neural Netw 57(9):39–50
Kang H, Nam Y, Choi S (2009) Composite common spatial pattern for subject to subject transfer. IEEE Signal Process Lett 16(8):683–686
Koles ZJ (1991) The quantitative extraction and topographic mapping of the abnormal components in the clinical EEG. Electroencephalogr Clin Neurophysiol 79(6):440–447
Krusienski DJ, Sellers EW, McFarland DJ, Vaughan TM, Wolpaw JR (2008) Towardenhanced p300 speller performance. J Neurosci Methods 167(1):15–21
Lin Z, Zhang C, Wu W, Gao X (2007) Frequency recognition based on canonical correlation analysis for SSVEP-based BCIs. IEEE Trans Biomed Eng 54(6):1172–1176
Lotte F, Guan C (2011) Regularizing common spatial patterns to improve BCI designs: unified theory and new algorithms. IEEE Trans Biomed Eng 58(2):355–362
Martens S, Leiva J (2010) A generative model approach for decoding in the visual event-related potential-based brain–computer interface speller. J Neural Eng 7(2):1393–1402
Pfurtscheller G, Neuper C, Birbaumer N (2005) Human brain-computer interface. In: Vaadia E, Riehle A (eds) Motor cortex in voluntary movements: a distributed system for distributed functions, Methods and New Frontiers in Neuroscience. CRC Press, Boca Raton, pp 367–401
Ramoser H, Muller-Gerking J, Pfurtscheller G (2010) Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans Rehabil Eng 8(4):441–446
Salvaris M, Sepulveda F (2009) Visual modifications on the p300 speller BCI paradigm. J Neural Eng 6(4):046011
Suk HI, Lee SW (2011) Subject and class specific frequency bands selection for multiclass motor imagery classification. Int J Imaging Syst Technol 21(2):123–130
Tangermann M, Krauledat M, Grzeska K, Sagebaum M, Vidaurre C, Blankertz B (2008) Playing pinball with non-invasive BCI. Adv Neural Inf Process Syst 21:1641–1648
Thulasidas M, Guan C, Wu J (2006) Robust classification of EEG signal for brain–computer interface. IEEE Trans Neural Syst Rehabil Eng 14(1):24–29
Vapnik VN (2000) The nature of statistical learning theory. Springer, Berlin
Wolpaw JR, McFarland DJ (2004) Control of a two-dimensional movement signal by a noninvasive brain-computer interface in humans. Proc Natl Acad Sci USA 101(51):17849–17854
Wolpaw JR, Mcfarland DJ, Neat GW, Forneris CA (1991) An EEG-based brain-computer interface for cursor control. Electroencephalogr Clin Neurophysiol 78(3):252–259
Zhang D, Huang B, Li S, Wu W (2015) An idle-state detection algorithm for SSVEP-based brain-computer interfaces using a maximum evoked response spatial filter. Int J Neural Syst 25(7):1550030
Acknowledgements
This work was financially supported by the National Natural Science Foundation of China (61502340, 61172185), Natural Science Foundation of Tianjin City (15JCYBJC51800), and Higher School Science and Technology Development Fund Planning Project of Tianjin City (20120829).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Rights and permissions
About this article

Cite this article
Dong, E., Li, C., Li, L. et al. Classification of multi-class motor imagery with a novel hierarchical SVM algorithm for brain–computer interfaces. Med Biol Eng Comput 55, 1809–1818 (2017). https://doi.org/10.1007/s11517-017-1611-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-017-1611-4