
Abstract
Referring to current research on self-regulated learning, we analyse individual regulation in terms of a set of specific sequences of regulatory activities. Successful students perform regulatory activities such as analysing, planning, monitoring and evaluating cognitive and motivational aspects during learning not only with a higher frequency than less successful learners, but also in a different order—or so we hypothesize. Whereas most research has concentrated on frequency analysis, so far, little is known about how students’ regulatory activities unfold over time. Thus, the aim of our approach is to also analyse the temporal order of spontaneous individual regulation activities. In this paper, we demonstrate how various methods developed in process mining research can be applied to identify process patterns in self-regulated learning events as captured in verbal protocols. We also show how theoretical SRL process models can be tested with process mining methods. Thinking aloud data from a study with 38 participants learning in a self-regulated manner from a hypermedia are used to illustrate the methodological points.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In terms of theory and methodological development, some researchers in the field of self-regulated learning (SRL) have in recent years suggested that regulation should be seen in terms of events rather than in terms of traits and aptitudes. The phenomena worth explaining in this perspective are those relating to “the very actions that learners perform, rather than descriptions of those actions or of mental states that actions generate” (Winne 2010, p. 269). In need of explaining are regularities and patterns on the event level, rather than differences between learners in respect to their aptitudes (Winne and Perry 2000). Differences in learners’ (meta-/cognitive, motivational, emotional) dispositions are seen as less relevant than before for SRL research, with the possible exception of epistemic beliefs (Greene et al. 2010). Methodologically, this change in perspective has been progressing with an increasing focus on behavioral and verbal process data, and a decreasing interest in questionnaire methods (Azevedo 2009; Bannert 2009; Veenman et al. 2006). The interest in event data has been fueled by technical advances that make the recording of learning-related behavior on a level close to quantitative analysis almost effortless for the researcher, and largely un-obtrusive for the learners (e.g., Winne and Nesbit 2009).
Along with the conceptualization of SRL as an event and the availability of event data grew the interest in analysis methods that take into account the temporal nature of self-regulation processes, as evidenced by this special issue. The contribution we hope to make with this paper is to demonstrate how a specific class of analysis methods known as Process Mining (PM) can be applied to a type of data often found in SRL research—(coded) think aloud data. We argue that PM methods are appropriate in cases where, for theoretical reasons or qua instructional design, students’ regulative behavior can be seen as being driven by a holistic model of a process, akin to what Winne (2010, p. 270) calls a “patterned contingency”. We will provide more information on the assumptions of PM in the section ‘Process Mining: How is it done and how has it developed?’. To examine processes and events of self-regulated learning we analysed process data collected during hypermedia learning with process mining methods. Since these data have not been analysed in this form before, an additional contribution is made to increasing insights into students’ self-regulated learning.
The paper is structured as follows: We first sketch research on self-regulated learning that emphasizes the importance of different learning events and event patterns. At this point, we also explain our approach for the analysis of temporal patterns and our research aims. Then several of the foundations of PM are introduced. Next, we explain the design of a study which was conducted to investigate the spontaneous use of metacognitive skills during hypermedia learning. After that, we demonstrate how this data can be analysed using two kind of PM methods. At first, the application of an algorithm is described which can be used to identify process models in an inductive manner, that is, from coded think aloud data. Secondly, we demonstrate how theory-based or inductively identified process models can be tested against data. After presenting the application of PM methods and the results of our analysis, we discuss the pros and cons of this approach and the value PM can add to current research on self-regulated learning.
Components and processes of self-regulated learning
Self-regulated learning involves a complex interplay of cognitive, metacognitive, and motivational regulatory components (Boekaerts 1997). According to recent theoretical approaches, regulatory activities during learning include orientation in order to obtain an overview over the task and resources, planning the course of action, evaluating the learning product and monitoring and controlling all activities. Research has revealed that successful learning corresponds with all of these regulatory activities (e.g., Azevedo et al. 2004; Bannert 2009; Manlove et al. 2007; Moos and Azevedo 2009).
Most SRL models suggest a time-ordered sequence of regulatory activities, although there is no assumption of a strict order (Azevedo 2009). Commonly, cycles with the phases of forethought–performance–reflection (Zimmerman 2000) are distinguishable, even though more elaborated models exist (e.g., Winne 1996; Borkowski 1996). In this research, we are building on previous work on the temporal structure of self-regulated learning (e.g., Biswas et al. 2010; De Jong 1994; Hadwin et al. 2007; Kapur 2011; Schoor and Bannert 2012; Winne and Nesbit 1995).
In an exploratory case study Hadwin et al. (2007) showed differences in the ways eight selected students regulated their learning over time by means of activity transition graphs. The authors were able to distinguish between learners who used a high variety of activities and learners who adhered to a certain sequence. A higher degree of diversity was interpreted as experimenting with tactics and strategies due to more metacognitive monitoring. Although Hadwin et al. (2007) did not relate their transition graphs to a measure of learning success, we assume with reference to SRL research that, in general, more metacognitive activities and more active regulation should have resulted in a better learning outcome. Accordingly, De Jong (1994) was able to show differences in learning sequences between high and low performing students by means of concordance analysis. He analysed the frequencies and patterns of self-regulatory activities of successful and less successful students and found significant differences in respect to the kind and variability in learning patterns. That is, the manner in which successful students used regulation activities (especially testing and monitoring activities) in much more flexible ways than less successful students. He also found that different kinds of tasks were related to different sequences in self-regulatory activities. For example, regulation activities during expository text comprehension differed from regulation activities conducted to memorize vocabulary. Moreover, Biswas et al. (2012) also identified different learning patterns for high vs. low performers by means of an exploratory data mining method.
Kapur et al. (2008) found in a CSCL scenario that the type of interaction between students effects group learning differently depending on whether it is shown at the beginning or at the end of the learning session. Group performance was predicted by 30–40 % on learning activities that were shown at the beginning of learning. In a recent study using lag-sequential analysis, Kapur (2011) found that different temporal patterns of collaborative problem-based learning were significantly related to different group performance.
Although these studies show commonality in students’ patterns of learning activities corresponding significantly with students’ learning performance, comparisons between them are problematic. This is due to the fact that they use different types of data to investigate learning processes (e.g., verbal protocol vs. logfiles) with different levels of granularity (i.e. micro vs. macro level coding), as well as different learning settings (e.g., individual vs. collaborative learning settings), learning tasks and materials (e.g., learning with expository texts vs. vocabulary learning vs. group discussion). Also, different operationalization of learning performance (e.g., recall vs. comprehension vs. transfer) were employed. Nevertheless, all of these studies show that in addition to comparing frequencies of learning activities, process analysis can be valuable to further enhance the development of theoretical approaches in SRL and CSCL.
Moreover, we conclude from these studies that students display a very high degree of variation regarding the sequential organization of their learning and regulation activities. Therefore, we argue that it is not appropriate to aggregate across all learners, but to compare subgroups that probably share a similar regulation behavior. Furthermore, research on temporal patterns in SRL is at an early stage and largely explorative at the moment. In absence of prior research and knowledge about detailed expected effects, an analysis of extreme groups is a suitable approach (Preacher et al. 2005). Comparing extreme groups, e.g. the learning processes of the best and the lowest performance group, will help us to explore to what extent these groups deviate from ‘ideal’ regulation activity sequences that theoretical models suggest, and may shed more light onto practically relevant questions, for example, which sequences and patterns correspond to high and low performance. In this way, improvements can be made not only to assessment methodology but also to instructional support techniques such as adaptive scaffolding.
In general, we expect that process patterns of high performers are similar to the ideal behavior described by SRL models (e.g., Zimmerman 2000) and that they show more active regulation, whereas the patterns of less successful students should be far from optimal regarding an ideal order. We see the analysis of successful versus less successful students as a first step in exploring the temporal patterns of SRL processes which should be continued based on the resulting patterns, e.g. by comparing less extreme groups and taking different learner characteristics explicitly into account. Moreover, the approach of exploratory data analysis has to be accompanied by theoretical development to allow a testing of fine-grained assumptions in process data. At the moment, it is only possible to compare results of process analysis with assumptions on the macro-level.
Process mining: how is it done and how has it developed?
There are numerous methods available for sequential and temporal analysis of SRL data (Sanderson and Fisher 1994; Langley 1999) so the question why it is necessary to introduce a new method needs to be answered. Firstly, as we have argued elsewhere in the case of collaborative learning research (Reimann 2009), methods for temporal analysis that are based on an event ontology rather than treating time as continuous variable deserve more attention in learning research. Secondly, while event-based methods are used in SRL research comparatively often (e.g., Biswas et al. 2010; Winne and Nesbit 1995), little attention has so far been given to taking the granularity level of process models into account when selecting a process analysis method.
With granularity, we are referring to the difference between treating a number of events that follow each other over time as (i) a sequence, as (ii) generated by a process, or as (iii) part of a narrative (Reimann 2009). Depending on theoretical assumptions of what brings the events about, they need to be analysed differently (Poole et al. 2000). Our motivation to suggest process mining as a method in SRL research is that it allows for the expression of the assumption that a sequence of events is generated by a particular process of self-regulation in a formal manner, and also, to test assumptions about such processes. Formally, this requires using an explicit modeling notation, such as Petri Nets, or Finite State Machines. We will come back to these.
Process mining (PM) refers to methods of data mining (Robero et al. 2010) that build on the notion of a process model. The purpose of engaging in PM is to identify, confirm or extend process models based on event data. PM is increasingly used in educational contexts, in particular in research on ICT-supported learning and teaching (Reimann and Yacef 2013; Trčka et al. 2010). Since PM has roots in computer science and business IT rather than in psychological research, it is important to point out that the notion of a process model in this tradition refers to a formal model, a parsimonious description of all possible events that are compatible with a model. A process model in this sense does not refer to a cognitive architecture, nor does it mean that the processes described have to be mental or cognitive in nature. The reason that we nevertheless suggest to employ PM methods in the context of SRL research is that in principle, these methods are compatible with conceptualizations of SRL measured by event logs (Azevedo et al. 2010; Winne and Perry 2000) rather than as changes in (continuous) variables over time (Mohr 1982; Reimann 2009).
The type of model used in much of PM research is a very abstract one, namely variants of Petri Nets (Reisig 1985). Petri Nets are preferred over other simpler formalisms such as Finite State Machines (Gill 1962) because Petri Nets can capture concurrency (‘parallelism’). Petri nets can be mathematically described as bipartite directed graph with a finite set of places P, a finite set of transitions T, both represented as nodes (round and rectangular, respectively), two sets of directed arcs, from places to transitions and from transitions to places, respectively and an initial markup of the nodes with tokens (usually representing resources). The Petri Net shown in Fig. 1 for instance, expresses a process starting with transition A and ending after transition D, with two transitions B and C in between which can be executed in parallel, or in any order. The black dot in the initial node represents a token, which enables the transition A to be ‘fired’. A transition can only be fired if all the predecessor nodes have at least one token. In the example, transition D cannot be fired until both B and C have been fired. This model could, for example, represent a script for a collaborative writing scenario where the final version of a paper (D) cannot be submitted before two peer reviews (B, C) have been solicited.

Example for a (very simple) Petri Net
PM representations that take the form of Petri Nets and similar formalisms have several interesting features. For instance, they may be used computationally to determine if a specific activity sequence is commensurate with a model or not; like a grammar, a model can ‘parse’ an activity sequence. For the same reason, one can use them to simulate potential (non-observed) model behavior computationally, and to compare different models with respect to certain formal parameters. That is to say, models of this kind can be used to generate event sequences (in principle all those that are commensurate with the model), a characteristic of which we will make use of when describing methods for model testing later in the paper.
As mentioned before, one purpose of PM techniques is to identify process models from data, such as is recorded in log files or coded from verbal protocols. The assumption is that the temporally ordered event sequence is governed by one or more processes, with each process corresponding to a process model. This is an important distinguishing feature of process mining compared to sequence mining, or sequential pattern analysis (Agrawal and Srikant 1995; Perera et al. 2009; Zhou et al. 2010); these methods, as well as stochastic methods such as lag-sequential analysis (Bakeman and Gottman 1997) do not contain the assumption of a (latent) process. (Hidden) Markov Models (e.g., Biswas et al. 2010) do allow expression of the ‘whole process’, and are in this sense comparable to process models as used in the PM literature. PM process models of the Petri Net kind are able to express event concurrency (‘parallelism’), but this is of little relevance in the context of SRL, at least as long as there are not theoretical models of SRL proposed that hypothesize parallel processing of some kind.
The process models of the sort used in PM enable us to express that the process as a whole matters; it is a more holistic view of a process than a process-as-sequence view affords (Reimann 2009). The PM view of process is hence particularly relevant when we have reasons—hopefully based on theory—to believe that the performance of the system that generates the event sequence is driven by something that resembles a plan for action. In the context of SRL, this ‘something’ can for instance, be a learning strategy (a mental structure), or can be a resource given to the learner from outside, such as prompts (Bannert 2009) or a worksheet. In group learning, the equivalent would be a collaboration script (Kollar et al. 2006).
Petri Nets and other formalisms to mathematically describe discreet event systems are deterministic in nature. They lack the means to state that a transition from one state to the next, or one event to the next, will take place (only) with some probability. This is the other side of the proverbial coin: One cannot have models with executable semantics and at the same time account for stochastic aspects. This has implications for process model identification in a variety of situations; where learners may have several degrees of freedom in how to go about a task and where the task environment varies from learner to learner and/or over time. Under such conditions one has to employ kinds of process models that have a weaker semantic and employ heuristics, such as the transition diagrams that will be described below in the context of analysing empirical data.
This is not to say that process models cannot be subjected to statistical testing. Statistical testing is rather straightforward in the case of theory based models; in such an instance, the match between a process model and an empirically observed event sequence can be employed using standard statistical methods, such as chi-square (Bakeman and Gottman 1997). We will go into more detail on model testing in the section ‘Illustrating model-testing approaches’ below.
As desirable as it might be to apply a specific analysis method, one would hesitate to recommend it if it would be overly time-consuming for an individual researcher. Fortunately, very comprehensive software support is readily available for process mining analysis in form of the ProM workbench (http://www.processmining.org/prom/). This software package, maintained at the University of Eindhoven, provides access to a large range of process mining and process analysis algorithms, under a unified framework for data import.
In the next section, a typical study on self-regulated learning is described; one that yields event data that are then analysed with process mining methods. A first analysis will be inductive, generating a process description in form of a transition graph from a sequence of coded thinking aloud data. A second line of analysis will employ model testing, starting from assumptions about’ideal’ regulation events, formulating these as a process model, and testing the model against the empirical data.
Empirical study
An empirical study was conducted in order to investigate students’ spontaneous use of self-regulated learning activities by taking into account their temporal order. According to SRL models (e.g., Zimmerman 2000) successful students perform different regulatory activities, in the order of analysis, monitoring their learning process and finally performing evaluation activities. As already explained at the end of the section ‘Components and processes of self-regulated learning’, we want to test these theoretical assumptions by analysing the temporal patterns in our empirical data and hereby illustrate the approach of Process Mining. As a first step, we try to identify differences in the process patterns of successful versus less successful students. We will show how Process Mining can be used in order to take the temporal order of cognitive and metacognitive learning activities into account and how a process model can be generated inductively by using event logs. Moreover, our empirical mined patterns will be compared to theoretical assumptions of SRL models.
Method
Participants and procedure
Overall, 38 undergraduate German university students majoring in Psychology and Education (mean age = 23.89, SD = 4.54; female: 84 %) participated in our study. The study was conducted in individual learning sessions of approximately 1 1/2 h. In the introduction phase students were shown how to navigate in a hypermedia program (described below). Then they were introduced to the method of Thinking Aloud (Ericsson and Simon 1993) and were required to practice the method. Dependent on how quickly they adopted the thinking aloud methods, students were tasked with carrying out three to five search tasks using a program similar to the one employed in the learning session.
Immediately after the learning session started, the students’ task was to learn specific concepts and principles of operant conditioning in such a way that they would subsequently be able to teach and explain these concepts to other students. The learning time was limited to 30 min. Students were free in navigation, however they had to read and think aloud during their learning session. In case of silence, the participant was prompted by the experimenter to read and think aloud. Students’ verbalizations as well as actions on the screen, mouse and keyboard area were recorded using a video camera and a microphone.
In the testing session that was conducted immediately afterwards, learning was assessed by paper-pencil-tests described below.
Learning material and learning performance measures
The hypermedia learning environment was realized by HTML scripts and the use of a web browser. It consisted of 44 nodes (screen pages) with approximately 12,500 words, 19 pictures/diagrams, 4 tables and 234 links in total. The part to be learned involved 9 nodes including 2300 words, 2 pictures, 3 tables and 56 links. Navigation was made possible by using a hierarchical navigation menu, the forward-and backwards-buttons presented at the top and button on each page and the links embedded directly in the text.
Learning outcomes were measured on three different levels based on Bloom’s Taxonomy of the cognitive domain (Bloom 1956): Knowledge of basic terms and concepts (free recall method), comprehension of basic terms and principles (multiple-choice test) and application of basic concepts and principles in new situations (transfer test). Knowledge of basic terms was measured by counting the basic terms and concepts students wrote down on a blank piece of paper, e.g. reinforcement, Skinnerbox, Premack-Principle. For each correct concept one point was assigned. On average 14 points out of the 54 points maximum (~ 26 %) were reached. Comprehension of basic concepts attained was measured with a multiple-choice test consisting of 22 items about the basic concepts of operant conditioning, each with 1 correct and 3 false alternatives. Each correctly answered item was assigned 1 point, thus a maximum of 22 points could be achieved. On average 13 points (~60 %, α = 0.83) were attained. Transfer performance was measured using 8 items asking students to use the basic concepts and principles previously learned to solve prototypical problems in educational settings. For example, they had to answer the questions ‘Why and how should parents use the Premack-Principle?’ or ‘What could a teacher do when a student disturbs classroom interaction?’ Answers to the 8 transfer items were rated based on a self-developed rating scheme (max = 40 points; inter-rater agreement: Kappa = 0.84). On average 19 points (~60 %, α = 0.74) were achieved by students out of a maximum of 32 points.
Coding scheme for analysing the learning activities
Students’ verbal protocols were segmented and coded according to the coding scheme presented in Table 1. It is based on our theoretical framework of self-regulated hypermedia learning (Bannert 2007) and differentiates between the main categories metacognition, cognition, motivation, and others. Metacognition contains students’ utterances referring to orientation (ORIENT), goal specification (SETGOAL), planning (PLAN), searching information (SEARCH) and judgment of its relevance (EVALUATE), evaluation (EVAL), and finally, monitoring and regulation (MONITOR). Cognition contains the sub-categories reading (READ), repeating (REPEAT), and deeper processing, i.e., elaboration (ELABORATE) and organization (ORGANIZATION). The REPEAT event, when following a READ event, is best understood as ‘rehearsing’ the information read. The category motivation (MOT) includes all positiveand negative motivational utterances on task, situation or oneself. Finally others (REST) include task-irrelevant aspects such as questions to the experimenter about the overall procedure of the study or ambiguously utterances (‘not classifiable’) as well as phases of silence.
The coding procedure was based on the method suggested by Chi (1997). However, due to economic reasons segmenting and coding were completed in one step. Segmentation was based on meaning; multiple or nested codes were not allowed. Two trained raters coded the verbal protocols of all 38 students together. In cases of non-congruence, the final code was negotiated with the first author. Coding took about 6 h per student. Rater agreement was calculated by selecting 5 students’ protocols per chance and coding for all of them independently the segments between the 15th and the 20th minute. The inter-rater reliability was Kappa = 0.84 which is seen as sufficient grounds for the following analysis.
Results
Frequency analysis of coded learning events
Calculated descriptive statistics of coded events for all students are listed in Table 2. Besides the minimum and maximum occurrence of each category, the means and standard deviations of absolute frequencies are presented. As one can see in the last row, on average there are 143 events coded in 30 min of learning time, with nearly 65 metacognitive, 57 cognitive, 1.4 motivational utterances, and nearly 20 off-topic statements.
Research in SRL shows that students display a high variation in their learning and regulating activities (e.g., Hadwin et al. 2007 and therefore, an aggregation of the learning processes of all students would not be appropriate. Thus, we selected the coded events of two extreme groups for the purpose of further analysis which are assumed to share similar process structures. Referring to research and theoretical assumptions of SRL processes (e.g. Zimmerman 2000), successful students should show an ideal regulatory behavior, whereas the process patterns of less successful students should be far from optimal.
The most successful and the least successful students among our participants were selected with respect to post-test scores. The most important performance score in all of our experimental studies on SRL and metacognitive support was transfer performance (e.g., Bannert and Reimann 2011; Bannert and Mengelkamp 2013), which shows that students with a higher percentage of regulation activities during computer-based learning gained higher transfer scores. In this study, correlation coefficients between the sum of metacognitive activities listed in Table 2 and different performance scores was the highest for transfer (r = 0.44, p < 0.01, Fisher-Z = 0.47; comprehension: r = 0.24, ns, Fisher-Z = 0.24; basic terms: r = 0.23, ns, Fisher-Z = 0.23). Moreover, the correlation coefficients between the sum of cognitive activities (see also Table 2) and different performance score is lower; however, the highest coefficient was also reached for transfer (r = 0.27, ns, Fisher-Z = 0.28; comprehension: r = 0.08, ns, Fisher-Z = 0.08; basic term: r = 0.12, ns, Fisher-Z = 0.12). Although Fisher scores did not differ significantly in this data set, we used the transfer measure to operationalize successful learning, especially as the Fisher test is a very conservative test and depends strongly on sample size.
Operationalization of both extreme groups was carried out by calculating two empirical cutoff-values. All students with a transfer score of one standard deviation and more above the mean were classified as most successful (>23 points), whereas the students with a score of one standard deviation and less under the transfer mean were seen as least successful (< 14 points). This procedure resulted in the selection of 5 successful and 6 less successful students. Table 3 contains all scores of learning performance for both extreme groups, which differ significantly in respect to transfer, comprehension and knowledge of basic terms.
Table 4 contains the frequencies of coded events for all 5 successful and 6 less successful students. For successful students metacognitive learning activities with high frequencies are monitoring (MONITOR) and orientation (ORIENT). This is also the case for less successful students, although with a lower average frequency. Planning (PLAN) and goal specification (SETGOAL) were rarely executed by students, especially by less successful students.
Concerning cognitive learning activities, reading (READ) and elaboration (ELABORATE) are the main events for the successful students, whereas for less successful students reading (READ) and repeating (REPEAT) were the most frequently coded events. These findings correspond to theoretical approaches to learning (e.g., Marton and Säljö 1976; Biggs 1988) which postulate a surface-level approach for less successful students (rehearsal and repeating) and a deep-level approach for successful students with deeper information processing by means of elaboration. Motivational events (MOT) also seldom occurred, however, were 7 times more often in the successful students group.
Process analysis of coded events
In a further step we analysed the coded verbal protocols by taking the temporal order of regulatory activities into account, using the ProM-software V 5.0 (2008). In order to analyse the process patterns of the successful and less successful students we used the Fuzzy Miner (Günther and van der Aalst 2007; Reimann et al. 2009) and generated a model for each of these two groups. The Fuzzy Miner algorithm, when applied to an event sequence, yields a transition diagram that is in essence quite comparable to the graphs suggested first in Winne and Nesbit (1995). Certain heuristics ared used, as further explained below, to create a process model that can be visualized so as to be readily understandable. And while being based on an adjacency frequency matrix, like the graphs described in Winne and Nesbit (1995), the Fuzzy Miner offers many more options to remove or increase detail of the graphical model, based on information metrics and the user’s information needs.
We should mention that PM methods in SRL research are of course not restricted to coded verbal data. Indeed, they will rather more frequently be used directly on log files with ‘action’ traces. We use coded protocols of thinking aloud data in this paper as this data level corresponds more directly to the level of theory formulation in SRL research. The general message is that process modeling methods as developed in PM research are not particular to any level of event aggregation; hence decisions on the level at which to work have to be based on theoretical considerations.
Parameters and metrics of the Fuzzy Miner
First of all, it is important to note that the ‘Fuzzy Miner’ algorithm got its name not because it is ‘fuzzy’ as in ‘not precise’, but because it can be used to cluster events flexibly into larger units, dependent on the level of detail needed by the process analyst. Fuzzy Mining is an approach to find underlying processes in data which are unstructured in appearance, for example in our case coded events of self-regulated learning behavior. It makes it possible to distinguish between important and less important details of a sequence of events and thus to generate an interpretable abstraction. More precisely, an algorithm is applied on a data set in order to transform an event chain to a process model that consists of nodes (event classes) and edges (relations between two event classes) as visualized below in Fig. 2. In the following paragraphs we explain how the algorithm of the Fuzzy Miner works, as well as its basic principles and the steps involved in the generation of a process model.

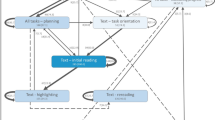
Process Model of successful students (n = 5, left) and less successful students (n = 6, right). Metacognitive Activities: ORIENT = Orientation; PLAN = Planning; EVALUATE = Judgment; EVAL = Evaluation; MONITOR = Monitoring. Cognitive Activities: READ = Reading; REPEAT = Repeating; ELABORATE = Elaborating
The data input consists of several cases (e.g., our 5 cases of successful students) with every case including a sequence of events, ordered by a time stamp. The Fuzzy Miner Algorithm uses this data to generate a complete model which consists of nodes (event classes) and edges (relations between event classes) by taking the relative importance and the temporal order of all events into account. The algorithm uses two fundamental metrics, significance and correlation, for computing a process model for the given data set. Although these two metrics are labeled identical to the well-known statistical measures, one has to be aware, that they do not directly correspond. Significance measures the relative importance of the occurrence of event classes and of relations between events. For example, events which occur more frequently are assessed as more significant (Günther and van der Aalst 2007). Correlation is only calculated for edges and it indicates “how closely related two events following one another are” (Günther and van der Aalst 2007, p. 333). The basic concepts of significance and correlation are embedded in a metrics framework which calculates three primary types of metrics: unary significance (of nodes/event classes), binary significance (of edges/relation of two event classes) and binary correlation (of edges). These metrics are described in detail by Günther and van der Aalst (2007) and summarized in Schoor and Bannert (2012). As a final step, the model is simplified by making decisions regarding the inclusion of nodes and edges in the process model by the following rules: Events that are highly significant are preserved, events that are less significant, but highly correlated are aggregated and events that are less significant and lowly correlated are abstracted (Günther and van der Aalst 2007).
It is possible to influence the process of model simplification by parameter setting, e.g. the specification of cutoff values. We will provide a short overview of these parameters. In order to bring structure to the model, the algorithm uses edge filtering and thereby tries to focus only on the most important relations between nodes. The utility of edges, a weighted sum of significance and correlation of an edge, is calculated and this weighting is configured by the utility ratio. Moreover, by setting the parameter edge cutoff, an absolute threshold value for filtering edges can be determined. The higher the value of the edged cutoff is set, the more likely the Fuzzy Miner removes edges. Finally, there is another important mean to simplify the model: node aggregation and abstraction. Nodes are removed based on a parameter called node cutoff. If the unary significance of a node is below this cutoff, it will be excluded from the resulting model or aggregated. The latter happens if less-significant nodes can be preserved by merging them to a cluster of highly correlated nodes (Günther and van der Aalst 2007).
Our analysis was conducted by using the following parameter settings: edge filtering was set with the edge cutoff = 0.2 and the utility ratio = 0.75; the significance cutoff of node filter was set to 0.25.
Mining process models of successful and less successful students
To focus on self-regulated learning activities we excluded the category REST from process mining analysis. For the most successful students a total number of 783 events and for the least successful students 518 events were analysed. Figure 2 shows the resulting models with the main event categories and their process relationships. Events are represented by the square nodes which include the event name and its significance (a value between 0 and 1). Arcs between categories indicate successive events (the upper number displays significance, i.e. their relative importance, and the lower number shows correlation, i.e. a measure which indicates how closely related two events are) while arcs pointing towards the category itself indicate repeated occurrence of this category. Less significant and lowly correlated events were discarded from the process model, i.e. nodes and arcs that fall into this category were not included in the graph.
In Fig. 2 the model of successful students (left part) contains 8 event categories and the model of less successful students (right part) contains 5 categories with 2 clusters. Both models do not include the categories goal specification (SETGOAL), searching information (SEARCH), organization of information (ORGANIZATION) and motivation (MOT) which means that these events did not reached the significance cutoff = 0.25. Here the main idea of the Fuzzy Miner is realized by abstracting from information seen as too fuzzy, i.e. not all event classes will be included in the resulting process model but only those that occurred more frequently and that play a significant role in the process as a whole.
As theoretical SRL models postulate, one can see in Fig. 2 that successful students show a variety of metacognitive activities (ORIENT, EVALUATE, PLAN, EVAL, MONITOR). For successful students reading (READ) is mainly connected with monitoring (MONITOR) and elaboration (ELABORATE), however repeating (REPEAT) is also listed in their process model. There is a double loop of monitoring (MONITOR), reading (READ) and elaboration (ELBORATE).
Less successful students (Fig. 2, right part) do not only show less events (as already listed in Table 4), but they also display less event types in their process model. For them, reading (READ) is mainly connected with repeating (REPEAT). Reading is also strongly connected with monitoring (MONITOR), and repeating (REPEAT) is also connected with elaboration (ELABORATE).
Since current models of SRL operate mainly with the three phases of forethought–performance–reflection (i.e., Zimmerman 2000), we aggregated several of the coded categories in a further step as follows: The metacognitive activities orientation (ORIENT), planning (PLAN) and goal specification (SETGOAL) were combined into the new category analysis (ANALYSIS), and the cognitive activities elaboration and organization of information into the new category deeper processing (PROCESS). In addition, motivation (MOT) was excluded from further analysis due to low frequencies. The process models with these aggregated categories (altogether 7 codes: ANALYSIS, SEARCH, MONITOR, READ, REPEAT, PROCESS, EVAL) were again calculated separately for the most successful students and the less successful students and are listed in Fig. 3. The same parameter settings as in our first analysis were used.

Process model with aggregated categories for successful (n = 5, left) and less successful students (n = 6, right). Metacognitive Activities: ANALYSIS = ORIENT + PLAN + SETGOAL; EVAL = Evaluation; MONITOR = Monitoring. Cognitive Activities: READ = Reading; REPEAT = Repeating; PROCESS = ELABORATE + ORGANIZATION
In both models the coded category searching information (SEARCH) did not reach the significance cutoff = 0.25 and thus do not appear in the graphs.
Successful students (left part of Fig. 3) show high frequencies of preparing activities (ANALYSIS) which are monitored (MONITOR). Reading (READ) is highly connected with monitoring (MONITOR) and deep processing (PROCESS). There are also evaluation activities (EVAL) which are connected to preparing activities (ANALYSIS). Moreover, there is a triple loop with analyzing (ANALYSE), monitoring (MONITOR), reading (READ) and deep processing (PROCESS). This model comes close to Zimmerman’s model of ideal SRL (2000).
For less successful students the process model with aggregated categories (right part of Fig. 3) also includes 5 categories. However, their type, occurrence and relationships are quite different. Here we can see less preparing activities (ANALYSIS) which are connected to reading (READ). Reading (READ) is followed by repeating (REPEAT) and monitoring (MONITOR). Whereas successful students show deep processing activities when reading, the less successful students show mainly surface processing by repeating (REPEAT). There is a double loop between analysis (ANALYIS), reading (READ) and repeating (REPEAT). Their process model does not include evaluation (EVAL) which is different from successful students.
So far, we have used PM methods to mine think aloud data during self-regulated hypermedia learning. The resulting models for successful and less successful students show differences, but one has to keep in mind that these models are only descriptions; the graphical models as such do not tell us if the differences between them are statistically significant, for instance. In the following we will go a step further by applying model testing methods to our data.
Illustrating model-testing approaches
While in this paper the focus has so far been on generating process models inductively and data-driven, even a short introduction to PM would not be complete without illustrating model testing. Testing process models can take a number of forms, dependent on the information available:
-
1.
The process model is theory-based and can be expressed as a Petri Net, or any modeling language equipped with executable semantics. The model can alternatively be prescriptive, such as a script for individual or collaborative learning. In both cases, methods for conformance checking (Rozinat and van der Aalst 2008) can be employed.
-
2.
The process model is inductively created (i.e., mined from data, as described above) and can be expressed in a language with executable semantics (e.g., Finite State Machine, Petri Net). In this case, methods of conformance checking can be used as well, but one has to keep an eye on over-fitting, by using jackknife or similar methods for re-sampling (Glymour et al. 1996).
-
3.
The model is either theory-based or developed inductively, but cannot be expressed in a formal manner; model testing is then possible with conventional statistical approaches, that is, they are based on frequencies of events, and/or with methods developed specifically for sequence data (e.g., Abbott and Hrycak 1990).
-
4.
No ‘holistic’ model is at hand (neither from theory nor from data), but a researcher may wish to see if certain sequence patterns appear in the event trace. These patterns can come from theory, or from pedagogy, or from sequence mining. Methods are available in the PM field to identify instances of event sequences that match these patterns.
Space does not permit a demonstration of all these cases with the data presented. In the following we will constrain ourselves to case (1) as it shows the strengths of model testing with PM methods, and to (4) as this will be a rather more frequent case for SRL research, with no theoretically motivated holistic process models available at this stage. Case (2) is also relevant for SRL research, but requires a significant amount of additional technical apparatus, and case (3) is largely identical with statistical model testing, which is not the subject of this paper.
Testing a full model
At first, we will describe how a full model can be formalized in order to test its assumptions on empirical data. The input to full model testing is a process model ‘translated’ into a formal language with executable semantics, and an event sequence (a log). The output can take various forms, depending on the capabilities of the analysis algorithm, but will in general consist of one or more measures of fit, and optionally of visualizations of (mis-)fit. For our illustrative analysis of model testing, we use again the data from the 6 least successful and from the 5 most successful students which have been described in the previous section.
First, a process model was constructed in form of a Petri Net (Fig. 4), using WOPED (http://www.woped.org/) as the editor. WOPED saves Petri Nets in a format that can be imported into ProM. This model is not theory-based in any strict sense (see discussion section for further thoughts on the kind of theory that would be required to afford model testing on the event level). It is a somewhat ‘ideal’ sequence of steps one would like to see learners engage in: (1) ANALYSE the learning task, (2) then perform any of the actions SEARCH, READ, PROCESS or REPEAT, (3) MONITOR your progress, (4) EVALuate if you are done, and stop or perhaps continue with a similar cycle. This is obviously a simple model, but it includes a number of constraints. A completely unconstrained model would allow any action in any sequence; a more constrained model would increase the number of sequence constraints—for instance, allow for PROCESS only after SEARCH or READ—and/or would reduce the number of elements allowed—for instance, do not allow a REPEAT.

An ‘exemplary’ SRL process expressed as a Petri Net
In order to compare this model against the empirical trace data, we used the ProM module Conformance Checker; the methods that this software module implements, and the metrics it is able to calculate are described by Rozinat and van der Aalst (2008). The only metric used for our analysis is model fit. Model fit for Petri Nets is defined for the Conformance Checker as follows (Rozinat and van der Aalst 2008, p. 10):
Metric 3 (Fitness) Let k be the number of different traces from the aggregated log. For each log trace i (1 ≤ i ≤ k), n i is the number of process instances combined into the current trace, m i is the number of missing tokens, r i is the number of remaining tokens, c i is the number of consumed tokens, and p i is the number of produced tokens during log replay of the current trace. The token-based fitness metric f is defined as follows:
$$ f=\frac{1}{2}\left(1-\frac{{\displaystyle \sum {}_{i=1}^k{n}_i{m}_i}}{{\displaystyle \sum {}_{i=1}^k{n}_i{c}_i}}\right)+\frac{1}{2}\left(1-\frac{{\displaystyle \sum {}_{i=1}^k{n}_i{r}_i}}{{\displaystyle \sum {}_{i=1}^k{n}_i{p}_i}}\right) $$
Note that for all i, m i < = c i and r i < = p i , hence 0 < = f < = 1. The notion of a token has been introduced with the definition of Petri Nets above; informally speaking, one can think of tokens as ‘units’ being pushed through a Petri Net model in order to simulate the performance of that model. For instance, if we modeled case handling in an insurance company as a Petri Net, we could use tokens to simulate how a specific case file might be routed through the company. In our case, a token refers to something more abstract, a kind of ‘cognitive unit’ that can be in one of various states (READ, SEARCH etc.). Note that a token does not refer to the information attended to by the learner in any of these states; this would require so-called Coloured Petri Nets, which add a dimension of complexity (Kristensen et al. 1998). In order to understand the fitness metric, it is further relevant to know that ‘missing tokens’ and’remaining tokens’ means that there were steps taken in the process not commensurate with the model, or that a process enactment was not completed, respectively.
Firstly, we applied the Conformance Checker to our data of the less successful students in order to compare the full model (Fig. 4) with our empirical data (sequences of coded think aloud data from 6 cases). This comparison yields a fitness value of f = 0.41, which can be interpreted as the model accounting for approximately 40 % of the observed event sequences. The ProM Conformance Checker also produces a number of interactive visualizations, which can shed further light on where the (mis-)matches occurred. One visualization is trace-based: Fig. 5 shows the first process steps for all 6 less successful participants, highlighting mismatches with the model. A ‘technical’ source of mismatch is due to the fact that our coding scheme allows for repeated adjacent codes (e.g., Orientation can be followed by Orientation), which is awkward to express in Petri Nets as it yields significantly unconstrained models.

Trace-based view of model-fit: all events not conforming to the model are highlighted
Another type of visualization is model-based (Fig. 6): the results of the analysis are over-laid on the model (see Fig. 4). The numbers on the edges of the graph correspond to numbers of traversals. The (red) numbers in the place representations (the circles) indicate how often the constraint at that place was not obeyed. For instance, the number ‘-232’ in the first place indicates that in 232 (of the 515) instances, any one of the actions of SEARCH, READ, PROCESS or REPEAT was performed without a preceding ANALYSIS step. The same interpretation applies to the negative number in the next place, for the event MONITORING; the positive number ‘+166’ indicates that in 166 instances the MONITORING action has not been performed.

Model-based view of the model fit for the less successful students: all non-matching nodes are highlighted
The fitness metric usually makes more sense when set in comparison to alternative models, or other trace data. Therefore, we will compare the model testing of our two extreme groups, the successful and less successful students. Figure 7 shows the model view for the data from the 5 successful students (762 events). The fitness metric here takes a value of 0.48. Hence, it is only marginally better than the value for the less successful group. We can interpret this finding as saying that the differences between the successful and the less successful group, as far as they are due to differences in the temporal structure of their performance, are not expressed in the model. The successful group does not adhere (overall) more to the model than the less successful group. Only further analysis could tell if this is due to the same kind of (mis-) matches. The ProM Conformance Checker supports such kinds of analyses, but they rely on interactive features of the software, which in this case have not been used for analysis, because its focus has been model testing.

Model-based view of model fit for the 5 successful students
Besides the comparisons of two groups of students, it is also possibility to execute a comparison with alternative models. Again, ideally these would be theory-based, but in the absence of such we illustrate the case here with a second ad-hoc model for the group of less successful students, as displayed in Fig. 8. The fit of this model is 0.41, not much worse than the original model (Fig. 4), which was somewhat less constrained. Note that increasing the number of constraints in the model does not necessarily mean that the fit will be reduced. If the constraint model is a ‘good’ model for the data, its fitness value will of course, be higher. For the lengthy traces analysed here, the model would need to express that the same kind of process is repeated multiple times. This is not possible with the basic Petri Net variant employed. As a consequence, it is necessary to use the description of one process instance to describe multiple instances, with the likelihood of small variations increasing with each process instantiation. Again, this is the price one pays for using a modeling formalism with executable semantics.

An alternative to the model displayed in Fig. 4 with fit calculated against less successful group (N = 6, number of events = 515)
Testing a partial model (a sequence pattern)
As mentioned in the introduction to PM, the approach is particularly relevant in situations where we have reasons to assume that the learner behavior is driven by a holistic model representation; either an internal (schema) or an external model (such as a worksheet, a collaboration script). In such cases, model testing should commence with the full model, as illustrated in the above section. If that test fails (according to a criterion, for instance, a value of the fitness metric to be set before testing commences), or if no model representation is available that can form the basis for calculating a fitness value, the need arises to test ‘partial’ models, sequence patterns in effect.
The input to partial model testing is a description of an event pattern and an event sequence (a log). The output is a list of all instances of sequences in the log where the pattern is matched, if it is matched at all. ProM offers an analysis module called LTL checker that allows execution of this kind of analysis. As before, we can only provide an example for this kind of analysis, and it is unfortunately one that barely scratches the surface.
In order to perform partial model checking, that is, in order to check for the existence of sequences of events, one needs a language for sequence patterns. ProM provides such a language, namely LTL (Language for Temporal Logic). In this language, one can formulate logical formulae akin to first-order predicate logic, such as: Always_when_A_then_B, or Eventually_A_next_B.
The LTL language as well as the LTL checker software is described in de Beer and van den Brand (2007). It is very powerful indeed, but due to its formal nature, not easy to put to use for the non-expert. Fortunately, the LTL Checker module of ProM provides a library of formula templates, which can be easily instantiated and tested against trace data (Fig. 9).

Choosing a pattern template in the LTL graphical query interface
While one can use this sequence pattern language with any event sequence trace that can be imported into ProM, a particularly interesting application comprises the comparison between groups of learners, such as our successful and less successful performers. Table 5 shows the results for a number of patterns in these two extreme groups. Again, the queries are more illustrative in nature than being informed by theory. They illustrate, that more constraint sequence patterns occur with the same or less frequency than a less constrained pattern, and that what one might see as ‘good patterns’ are proportionally less frequent in the less successfully performing group.
Discussion
In addition to introducing selected methods of process mining, the aim of this paper was to analyse students’ processes of self-regulated learning. Besides detecting differences in frequencies of SRL events, we wanted to gain insight into the temporal patterns in students’ self-regulated learning. Our analysis contrasted the processes of the most successful and least successful students and considered whether these extreme groups differed in their SRL activities during hypermedia learning.
We found that successful and less successful students differ in as much as successful students show more learning and regulation events. Furthermore, by using process mining techniques (i.e., Fuzzy Miner, ProM V 5.0, 2008) we found differences in the temporal pattern of students’ spontaneous learning steps. Successful students also show more regulation event types in their process model: Preparing (i.e., forethought) activities (orientation and planning) before they process the information to be learned. During reading they elaborate the information more deeply. Further, they also constantly monitor different learning events and perform evaluation activities. The process model with aggregated codes of successful students corresponds well to current theories of self-regulated learning and metacognition (Boekaerts et al. 2000; Efklides 2008; Pintrich 2000; Zimmerman 2000). Moreover, temporal patterns of less successful students mainly resemble a surface approach to learning, which is also in line with findings in other studies. Preparing and evaluation activities are partly missing and repeating is more important than deeper processing in their model.
Furthermore, we demonstrated how theoretical models and assumptions can be tested by methods of Process Mining. For this purpose, we used our empirical data set again and tested some ad-hoc models and possible sequence patterns. This analysis is rather illustrative than informative for SRL research because theoretical assumptions on the micro-level would be needed for a proper analysis which are not provided by SRL models at the moment.
From a methodological point of view we have only shown the tip of the iceberg: Process Mining comprises many other algorithms for sequence data and temporal data than those applied here, and also many more methods for model analysis and comparison. Also, we have focused only on process logic; we have not taken into account data that capture aspects of the process environment (such as what it read in the hypertext), nor have we taken into account quantitative temporal aspects (duration of events). For both aspects, specific analysis and data mining methods are available in the ProM-Framework (e.g., Rozinat and van der Aalst 2006).
One of the disadvantages of process mining models as introduced here is that they are not directly related to statistical testing, such as significance testing. This is in particular the case of the descriptive models that are produced with algorithms such as the Fuzzy Miner. Methods such as these have been developed to be useful for practical purposes, such as optimizing business processes, not for testing theories. Their use in learning research is correspondingly to be sought as a tool for model and theory development rather than statistical testing. The relation to statistical testing is more direct for the case of generative (rather than descriptive) models. As our short overview of process model testing has demonstrated, when a type of process model formalism is chosen that generates ‘behavior’, such as a Petri Net, a Finite State Machine, or a Hidden Markov Model, then the goodness of fit of the model data can be tested against empirical data with established statistical methods, such as Chi Square. One can also see the relationship between any two adjacent events in a temporal sequence as a conditional probability, and perform statistical tests accordingly at the level of two-step, or multi-step sequences. We are not discussing these methods of lag-sequential analysis further at this juncture as they are already described in the psychological method literature (see Bakeman and Gottman 1997, for an excellent introduction) and also as they work with a sequence view of events, rather than a process view. In principle, lag-sequential analysis can be applied to longer chains of events; however, the demands on the size of the data points increase at such a rate that statistical testing is usually not possible on any sequences longer than two to three events, at least not with the data available from experimental studies.
As regards limitations and further research, clearly, because of the small sample sizes of our two extreme groups, replication studies are needed. Furthermore, although process mining analysis can provide researchers with useful insights into the temporal sequences of self-regulated learning, we urgently require further standardizations and routines. For one, the impact of parameter settings (i.e., cutoffs and thresholds) on mining outcomes needs to be better understood for the kind of data used in SRL research. Currently it is left to the individual researcher to select reasonable values. This is fine for exploratory purposes, but makes it difficult to compare findings across data sets and studies. Applying different analysis methods to one fixed data set while carefully varying the parameters will likely be a productive way forward in order to develop further educational data mining.
The kind of process measures considered is also of importance. Commonly, students’ navigation behavior is mined (Biswas et al. 2010; Winne and Perry 2000; Wirth 2004). In addition, chats and products in group cooperation (Kapur 2011; Lajoie and Lu 2012; Schoor and Bannert 2012), verbal protocols (as in our study), eye registration or even single item measures (such as JOLs: Judgments of Learning or FOKs: Feeling of Knowledge) serve as process data in SRL research, all of which could be easily mined from a technical point of view. However, there are limits to the value of a purely inductive, data-driven approach. If there exists no theory that can guide mining on a given data level, this fact should channel initial efforts into the direction of conducting conceptual work, rather than to start looking for regularities and patterns without a guiding conceptual framework. But not any theory will do; it must be expressed on the level of granularity that matches the data available. It’s probably fair to say that at this stage no such theory/model in SRL research is fully elaborated. Good candidates are information processing models of SRL, in particular Winne and Hadwin (2008), but even this model is far from the degree of elaboration needed to correspond directly to data on the granularity level of log files; and it is has never been implemented as a computational model.
We hesitate to recommend using the results of process mining or other event-based temporal analysis methods directly for instructional purposes. A strategy often suggested in educational data mining and learning analytics research is to use patterns in performance that have been found to discriminate between more and less successful learners directly for instruction. That is, in the sense that patterns found in more successful students are used as recommendations for future learners. This strategy is not only limited in scope—recommendations so derived can only work in the same environment and context in which they have been identified—but also raises ethical concerns; we know that inductively identified regularities can be spurious and brittle, and should critically reflect if we want to ground instructional advice on such a basis alone.
To conclude, for explanation-oriented research in SRL, process models of the kind introduced here are an ‘accommodation’: They are better than no model, but they have strong limitations as explanatory accounts. Eventually, what is needed are process models of the symbolic information processing type (Winne and Hadwin 2008), but implemented, and models which include sub-symbolic processing (Sun et al. 2005). For practical purposes, however, the process model type introduced here is highly valuable ‘as is’, for monitoring student learning, providing graphical mirroring and feedback information (e.g., deviations from optimal/expert model).
References
Abbott, A., & Hrycak, A. (1990). Measuring resemblance in sequence data: an optimal matching analysis of musicians’ careers. American Journal of Sociology, 96, 144–185.
Agrawal, R., & Srikant, R. (1995). Mining sequential patterns. Paper presented at the Proceedings of the International Conference on Data Engineering (ICDE95).
Azevedo, R. (2009). Theoretical, conceptual, methodological, and instructional issues in research on metacognition and self-regulated learning: a discussion. Metacognition and Learning, 4(1), 87–95.
Azevedo, R., Guthrie, J., & Seibert, D. (2004). The role of self-regulated learning in fostering students’ conceptual understanding of complex systems with hypermedia. Journal of Educational Computing Research, 30(1–2), 87–111.
Azevedo, R., Moos, D. C., Johnson, A. M., & Chauncey, A. D. (2010). Measuring cognitive and metacognitive regulatory proceses during hypermedia learning: issues and challenges. Educational Psychologist, 45(4), 210–223.
Bakeman, R., & Gottman, J. M. (1997). Observing interaction: an introduction to sequential analysis (2nd ed.). Cambridge: Cambridge Univ. Press.
Bannert, M. (2007). Metakognition beim lernen mit hypermedien. Münster: Waxmann Verlag.
Bannert, M. (2009). Promoting self-regulated learning through prompts: a discussion. Zeitschrift für Pädagogische Psychologie, 22(2), 139–145.
Bannert, M., & Mengelkamp, C. (2013). Scaffolding Hypermedia Learning through Metacognitive Prompts. In R. Azevedo & V. Aleven (Eds.), International Handbook of Metacognition and Learning Technologies. Springer Science.
Bannert, M., & Reimann, P. (2011). Supporting self-regulated hypermedia learning through prompts. Instructional Science, 1, 193–211.
Biggs, J. B. (1988). Approaches to learning and to essay writing. In R. R. Schmeck (Ed.), Learning strategies and learning styles (pp. 185–228). New York: Plenum Press.
Biswas, G., Jeong, H., Kinnebrew, J., Sulcer, B., & Roscoe, R. (2010). Measuring self-regulated learning skills through social interactions in a teachable agent environment. Research and Practice in Technology-Enhanced Learning (RPTEL), 5(2), 123–152.
Biswas, G., Kinnebrew, J. S., & Segedy, J. R. (2012). Analyzing Student Learning and Metacognitive Processes in a Choice-Rich Science Learning Environment. Paper presented at the 5th Biennial Meeting of the EARLI Special Interest Group on Metacognition. Milano, Italy.
Bloom, B. S. (1956). Taxonomy of educational objectives. Boston: Allyn and Bacon.
Boekaerts, M. (1997). Self-regulated learning: a new concept embraced by researchers, policy makers, educators, teachers, and students. Learning and Instruction, 7(2), 161–186.
Boekaerts, M., Pintrich, P. R., & Zeidner, M. (Eds.). (2000). Handbook of self-regulation. San Diego: Academic.
Borkowski, J. G. (1996). Metacognition: theory or chapter heading? Learning and Individual Differences, 8, 391–402.
Chi, M. T. H. (1997). Quantifying qualitative analyses of verbal data: a practical guide. The Journal of the Learning Sciences, 6, 271–315.
De Beer, H. T., & van den Brand, P. C. W. (2007). The LTL checker plugins. A (reference) manual. Eindhoven: University of Eindhoven.
De Jong, F. (1994). Task and student dependency in using self-regulation activities: consequences for process-oriented instruction. In F. de Jong & B. van Hout-Wolters (Eds.), Process-oriented instruction: Verbal and pictorial aid and comprehension strategies (pp. 87–99). Amsterdam: VU University Press.
Efklides, A. (2008). Metacognition. Defining its facets and levels of functioning in relation to self-regulation and co-regulation. European Psychologist, 13(4), 277–287.
Ericsson, K. A., & Simon, H. A. (1993). Protocol analysis: verbal reports as data. Cambridge: MIT Press.
Gill, A. (1962). Introduction to the theory of finite-state machines. New York: McGraw-Hill.
Glymour, C., Madigan, D., Predibon, D., & Smyth, P. (1996). Statistical inference and data mining. Communication of the ACM, 39, 35–41.
Greene, J. A., Muis, K. R., & Pieschl, S. (2010). The role of epistemic beliefs in students’ self-regulated learning with computer-based learning environments: conceptual and methodological issues. Educational Psychologist, 45(4), 245–257.
Günther, C., & van der Aalst, W. (2007). Fuzzy Mining: Adaptive process simplification based on multi-perspective metrics. In G. Alonso, P. Dadam, & M. Rosemann (Eds.), International conference on business process management (BPM 2007) (pp. 328–343). Berlin: Springer.
Hadwin, A. F., Nesbit, J. C., Jamieson-Noel, D., Code, J., & Winne, P. H. (2007). Examining trace data to explore self-regulated learning. Metacognition and Learning, 2(2), 107–124.
Kapur, M. (2011). Temporality matters: advancing a method for analyzing problem-solving processes in a computer-supported collaborative environment. International Journal of Computer-Supported Collaborative Learning (ijCSCL), 6(1), 39–56.
Kapur, M., Voiklis, J., & Kinzer, C. (2008). Sensitivities to early exchange in synchronous computer-supported collaborative learning (CSCL) groups. Computers and Education, 51, 54–66.
Kollar, I., Fischer, F., & Hesse, F. W. (2006). Collaboration scripts—a conceptual analysis. Educational Psychological Review, 18, 159–185.
Kristensen, L. M., Christensen, S., & Jensen, K. (1998). The practitioner’s guide to coloured Petri nets. International Journal on Software Tools for Technology Transfer (STTT), 2, 98–132.
Lajoie, S. P., & Lu, J. (2012). Supporting collaboration with technology: does shared cognition lead to co-regulation in medicine? Metacognition and Learning, 7, 45–62.
Langley, A. (1999). Strategies for theorizing from process data. Academy of Management Review, 24(4), 691–710.
Manlove, S., Lazonder, A., & De Jong, T. (2007). Software scaffolds to promote regulation during scientific inquiry learning. Metacognition and Learning, 2(2), 141–155.
Marton, F., & Säljö, R. (1976). On qualitative differences in learning: I—outcome and process. British Journal of Educational Psychology, 46, 4–11.
Mohr, L. (1982). Explaining organizational behavior. San Francisco: Jossey-Bass.
Moos, D. C., & Azevedo, R. (2009). Self-efficacy and prior domain knowledge: to what extent does monitoring mediate their relationship with hypermedia learning? Metacognition and Learning, 4(3), 197–216.
Perera, D., Kay, J., Koprinska, I., Yacef, K., & Zaiane, O. (2009). Clustering and sequential pattern mining of online collaborative learning data. IEEE Transactions on Knowledge and Data Engineering, 21(6), 759–772.
Pintrich, P. R. (2000). The role of goal orientation in self-regulated learning. In M. Boekaerts, P. R. Pintrich, & M. Zeidner (Eds.), Handbook of self-regulation (pp. 452–502). San Diego: Academic.
Poole, M. S., van de Ven, A., Dooley, K., & Holmes, M. E. (2000). Organizational change and innovation processes. Theories and methods for research. New Oxford: Oxford University Press.
Preacher, K. J., Rucker, D. D., MacCallum, R. C., & Nicewander, W. A. (2005). Use of the extreme groups approach: a critical reexamination and new recommendations. Psychological Methods, 10(2), 178.
ProM (Version 5.0) [Computer Software]. (2008). Retrieved from http://www.processmining.org.
Reimann, P. (2009). Time is precious: variable-and event-centred approaches to process analysis in CSCL research. International Journal of Computer-Supported Collaborative Learning, 4, 239–257.
Reimann, P., & Yacef, K. (2013). Using process mining for understanding learning. In R. Luckin, S. Puntambekar, P. Goodyear, B. Grabowski, J. D. M. Underwood, & N. Winters (Eds.), Handbook of design in educational technology. New York: Routledge.
Reimann, P., Frerejean, J., & Thompson, K. (2009). Using process mining to identify models of group decision making processes in chat data. In C. O’Malley, D. Suthers, P. Reimann, & A. Dimitracopoulou (Eds.), Computer-supported collaborative learning practives: CSCL2009 conference proceedings (pp. 98–107). Rhodes: International Society for the Learning Sciences.
Reisig, W. (1985). Petri nets. An introduction. Berlin: Springer.
Robero, C., Ventura, S., Pechenizkiy, M., & Baker, R. (Eds.). (2010). Handbook of educational data mining. Boca Raton: Chapman&Hall/CRC.
Rozinat, A., & van der Aalst, W. M. P. (2006). Decision mining in ProM. In S. Dustdar, J. L. Fiadeiro, & A. Sheth (Eds.), BPM 2006, volume 4102 of lecture notes in computer science (pp. 420–425). Berlin: Springer.
Rozinat, A., & van der Aalst, W. M. P. (2008). Conformance checking of processes based on monitoring real behavior. Eindhoven University.
Sanderson, P. M., & Fisher, C. (1994). Exploratory sequential data analysis: foundations. Human-Computer Interaction, 9, 251–317.
Schoor, C., & Bannert, M. (2012). Exploring regulatory processes during a computer-supported collaborative learning task using process mining. Computers in Human Behavior, 28(4), 1321–1331.
Sun, R., Coward, L. A., & Zenzen, M. J. (2005). On levels of cognitive modeling. Philosphical Psychology, 18(5), 613–637.
Trčka, N., Pechenizkiy, M., & van der Aalst, W. M. P. (2010). Process mining from educational data. In C. Robero, S. Ventura, M. Pechenizkiy, & R. Baker (Eds.), Handbook of educational data mining (pp. 123–142). Boca Raton: Chapman&Hall/CRC.
Veenman, M. V. J., van Hout-Wolters, B. H. A. M., & Afflerbach, P. (2006). Metacognition and learning: conceptual and methodological considerations. Metacognition and Learning, 1, 3–14.
Winne, P. H. (1996). A metacognitive view of individual differences in self-regulated learning. Learning and Individual Differences, 8, 327–353.
Winne, P. H. (2010). Improving measurements of self-regulated learning. Educational Psychologist, 45, 267–276.
Winne, P. H., & Hadwin, A. F. (2008). The weave of motivation and self-regulated learning. In D. Schunk & B. Zimmerman (Eds.), Motivation and self-regulated learning: theory, research, and applications (pp. 297–314). Mahwah: Erlbaum.
Winne, P. H., & Nesbit, J. C. (1995). Graph theoretic techniques for examining patterns and strategies in students’ studying: An application of LogMill. Paper presented at the American Educational Research Association, San Francisco.
Winne, P. H., & Nesbit, J. C. (2009). Supporting self-regulated learning with cognitive tools. In D. J. Hacker, J. Dunlosky, & A. C. Graesser (Eds.), Handbook of metacognition in education. New York: Routledge.
Winne, P. H., & Perry, N. E. (2000). Measuring self-regulated learning. In M. Boekaerts, P. R. Pintrich, & M. Zeidner (Eds.), Handbook of self-regulation (pp. 531–566). San Diego: Academic.
Wirth, J. (2004). Selbstregulation von Lernprozessen. Münster: Waxmann.
Zhou, M., Xu, Y. X., Nesbit, J. C., & Winne, P. H. (2010). Sequential pattern analysis of learning logs: Methodology and applications. In C. Robero, S. Ventura, M. Pechenizkiy, & R. Baker (Eds.), Handbook of educational data mining (pp. 107–121). Boca Raton: Chapman&Hall/CRC.
Zimmerman, B. J. (2000). Attaining self-regulation: a social cognitiv perspective. In M. Boekaerts, P. R. Pintrich, & M. Zeidner (Eds.), Handbook of self-regulation (pp. 13–39). San Diego: Academic.
Acknowledgments
We thank the German Research Foundation for funding (DFG: BA 2044/5-1).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Bannert, M., Reimann, P. & Sonnenberg, C. Process mining techniques for analysing patterns and strategies in students’ self-regulated learning. Metacognition Learning 9, 161–185 (2014). https://doi.org/10.1007/s11409-013-9107-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11409-013-9107-6