
Abstract
To reach a practical landfill gas management system and to diminish the negative environmental impacts from landfills, accurate methane (CH4) prediction is essential. In this study, the preprocessing steps including minimizing multicollinearity, removal of outliers, and errors with missing data imputation are applied to enhance the data quality. This study is the first at employing periodic parameters in the two-stage non-linear auto-regressive model with exogenous inputs (NARX) with the aim of providing a convenient and precise approach to predict the daily CH4 collection rate from a municipal landfill in Regina, SK, Canada. Using a stepwise procedure, various volumes of training data were assessed, and concluded that employing the 3-year training data reduced the mean absolute percentage error (MAPE) of the CH4 prediction model by 26.97% at the testing stage. The favorable artificial neural network model performance was obtained using the day of the year (DOY) as a sole input of the time series model with MAPE of 2.12% showing its acceptable ability in CH4 prediction. Using an only DOY-based model is especially remarkable because of its simplicity and high accuracy showing a convenient and effective approach in time landfill gas modeling, particularly for the landfills with no reliable climatic data.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
North America’s solid waste generation and disposal rate is one of the highest in the world. Landfilling is a main solid waste management treatment in Saskatchewan, a Canadian province with a cold semi-arid climate with a disposal rate of about 86% higher than that of national (Statistics Canada 2010). Generation of greenhouse gas (GHG) and leachate are the major concerns with landfills. There are a number of studies on landfill gas (LFG) and leachate modeling due to the importance of GHG emission and groundwater pollution (Li et al. 2011; Abushammala et al. 2014; Mohsen et al. 2019; Fallah et al. 2019). In Canada, due to the high disposal rates, GHG emissions from the waste management systems increased by 15.2% from 1990 to 2006 and more than 90% of total Canadian GHG within the waste management sectors were generated from landfills (Environment Canada 2015).
Landfill gas modeling
Methane (CH4) (60%) and carbon dioxide (CO2) (40%) are the major landfill gases generated from the anerobic decomposition of the degradable solid waste. CH4 emission to the atmosphere with 25 times the potential damage imposed by CO2 has been a major concern in global warming over the past hundred-year period (IPCC 2007). LFG collection systems, as the most common method in North America, are applied to reduce global warming potentials to the environments as well as to mitigate gas emissions from landfills by utilizing CH4 for heating or electricity production through LFG flaring (Tolaymat et al. 2010; Rajaram et al. 2011; Sanchez 2016). Using flare systems, collected CH4 is converted to CO2 with less potential of global warming. Due to the contributions of GHG emissions and the explosive risk of methane gas, quantification of CH4 collection rate from landfills is of high importance (Perera et al. 2002). Accurate CH4 collection forecasts are needed for studying the feasibility of LFG management system design and operation and to warrant environmental assessment. An accurate prediction model helps the energy recovery to be done at the proper time, therefore helping to lower CH4 environmental impacts (Ozkaya et al. 2007). In LFG management, numerical models have been developed for LFG predictions since direct measurements at the surface of the landfills are more costly. Numerical studies on LFG prediction are commonly reported in the literature (Ozkaya et al. 2007; Scozzari 2008; Thompson et al. 2009; Li et al. 2011; Amini et al. 2013; Mohsen et al. 2019) due to their practical importance.
ANN modeling in in predicting methane
Recently, artificial neural network (ANN) models have been widely used in air pollution modeling to predict GHG concentrations in various atmospheric science studies (Gardner and Dorling 1999; Li et al. 2011; Abushammala et al. 2014; Arhami et al. 2013; Radojević et al. 2018). The main advantage of the neural networks is their ability to learn and identify the complex relationship between inputs and outputs directly from training data (Kukkonen et al. 2003; Jiang et al. 2004). Owing to ANN models’ generalization ability and computational efficiency, many GHG studies confirmed that ANN-based models provide more precise alternatives than the conventional statistical methods such as multilinear regression (Chelani et al. 2002; Sahin et al. 2005) especially, when the relationship of data is highly non-linear (Shi 2002; Karacan 2008).
Multilayer perceptron (MLP) neural network models have been adapted in various LFG studies. In predicting the CH4 fraction of LFG in a bioreactor landfill in Turkey, Ozkaya et al. (2007) applied a back propagation MLP neural network model with one hidden layer. Scozzari (2008) applied an ANN model with meteorological input parameters to identify the biogas flux generated from the municipal solid waste landfill. In southern California, USA, Li et al. (2011) presented a back propagation MLP neural network model to predict methane, carbon dioxide, oxygen concentrations, and temperature in a landfill. In a study by Abushammala et al. (2014), the feedforward back-propagation MLP neural network was proposed to predict CH4 oxidation fraction from the bottom of landfill cover soil in Malaysia. Air temperature was one of the effective input parameters in their prediction model. Possessing the ability to train time-variable relationships, time-series prediction is of special interest in GHG studies (Sergeev et al. 2018; Mohebbi et al. 2018). In a study by Mohebbi et al. (2018), the neural network auto-regressive model with exogenous inputs (NARX), a dynamic ANN model, was compared with MLP, a statistic neural network model, for predicting air carbon monoxide (CO) concentration in Shiraz, Iran. They concluded that the NARX model performed better than the MLP model. Sergeev et al. (2018) investigated the prediction ability of three neural network models of Elman neural network, MLP, and NARX to study the atmospheric CH4 content in Arctic regions and confirmed the higher accuracy of the NARX model in their study. The NARX model was also reported to outperform other neural network and autoregression techniques in prediction of CH4 concentrations in an atmospheric study in Russia (Buevich et al. 2020). In their study, Levenberg-Marquardt (LM) was applied for all types of ANNs as a training algorithm. In the year 2020, Fallah et al. studied the application of the multistage NARX model with LM algorithm using the climatic input parameters for CH4 rate prediction from an urban landfill, in Regina, Canada. They reported the effectiveness and precision of the proposed technique in CH4 gas modeling; however, the application of the periodic parameters was not assessed in their study.
Meteorological input parameters in methane prediction
Being a data-driven method, ANN performance strongly depends on input variables (Wang et al. 2015). Meteorological input parameters such as air temperature, relative humidity, air pressure, wind speed, and the effectiveness of their combination have been investigated in recent LFG modeling studies (Scozzari 2008; Li et al. 2011; Uyanik et al. 2012; Abushammala et al. 2014; Kumar et al. 2016; Xin et al. 2016). Having said that, none of these studies examined the impact of using periodic parameters and effective length of training dataset in ANN LFG prediction models.
Periodic parameter
Proper selection of input parameters with their effective combination is a major key point in ANN modeling (Arhami et al. 2013). However, applying a large number of input parameters in ANN models increases the size of the network (Maier and Dandy 2000), which lowers the processing speed and limits the network efficiency (Lachtermacher and Fuller 1994). Therefore, one can refer to the selection of the input parameters with the highest effect on model performance as the main step in ANN model development for GHG prediction studies. Using some meteorological data as inputs causes ANN models to be not much practicable for GHG forecasting since some of them are not predictable by conventional weather forecast models. In addition, climatic data are prone to stochastic fluctuations while periodic parameters are not prone to inherent variability and uncertainty (Arhami et al. 2013). Periodic parameters such as month of the year (MOY) and day of the year (DOY) have recently been used as inputs for some ANN models in atmospheric studies (Arhami et al. 2013; Khorasanizadeh et al. 2014; Gani et al. 2016; Radojević et al. 2019). Arhami et al. (2013) investigated the efficient length of training dataset and combination of climatic and periodic input variables in predicting hourly air pollutant (GHG) levels in Tehran, Iran. In their study, a stepwise procedure of eliminating the input parameter was performed to analyze the sensitivity of the prediction model to each input parameter. Khorasanizadeh et al. (2014) compared the climatic and DOY-based ANN models and reported a better performance by the DOY-based atmospheric prediction model in Birjand, Iran. In another atmospheric prediction study (global solar radiation) conducted by Gani et al. (2016), a higher accuracy of a DOY-based NARX model was reported compared to the adaptive neuro-fuzzy inference system (ANFIS) model. They also declared that using only the DOY as an input in the NARX model was a convenient approach to daily atmospheric predictions. However, in their study, finding the most efficient length of training data and forming a complete dataset was not conducted, and the interpolation method was only applied for the months with less than 5 days of missing or inaccurate values. Radojević et al. (2019) examined the usefulness of different forms of periodic parameters in combination with meteorological variables in daily ANN air pollutant prediction models in an urban area in Serbia. In their study, the significance of periodic input parameters was also evaluated using Analysis of variance (ANOVA). They reported the MOY-based ANN model proved superior to the models without MOY.
Objectives
In this study, after reducing the model uncertainty by removing the outliers and unreliable measurements and generating a complete dataset for time series ANN model, the efficient length of training input dataset was investigated to improve the LFG prediction model performance. The main goal is to provide a convenient and precise way for the daily CH4 collection prediction by using periodic parameters as the only input of the two-stage NARX neural network without applying climatic-based variables. Periodic parameters are not prone to inherent variability and uncertainty while climatic input parameters are prone to stochastic fluctuations (Arhami et al. 2013). This study is the first to employ the periodic parameters in the NARX neural network for CH4 prediction modeling and the objectives are as follows: (i) to assess the most efficient length of training dataset in the methane prediction model based on coefficient of determination (R2), mean square error (MSE), and mean absolute percentage error (MAPE); (ii) to examine and compare the accuracy of the two-stage NARX model using periodic parameters along with independent and significant selected climatic input variables; and (iii) to evaluate the accuracy of a single periodic input model in methane prediction from the landfill to check if the periodic parameter can be used as the sole input in NARX landfill gas modeling.
Material and methods
Landfill of Regina
Regina landfill is located in the province of Saskatchewan, Canada. The climate of Regina is categorized as “Dfb” based on the Koppen-Geiger classification system, representing a cold climate and a warm summer (Peel et al. 2007) with a mean temperature of 3.1°C (Canada Climate Normal 2016). The landfill started its operation in 1961 and is the only municipal landfill in the city of Regina (Conestoga-Rovers & Associates 2006) with Latitude and longitude coordinates of 50° 26′ N and 104° 37′ W, respectively (Fallah et al. 2020a). LFG collection with flaring system at the landfill was stablished in July 2008, consisting of 27 vertical gas wells, and the final cover with a 1-m compacted clay layer and a 0.15-m topsoil, which was constructed in 2007 at the LFG collection area (Conestoga-Rovers & Associates 2006).
Data description
Methane collection rate
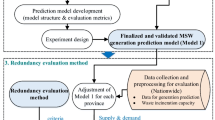
Real-time LFG data was collected at Regina landfill from August 2008 to December 2014 (Conestoga-Rovers & Associates 2008). Supervisory Control and Data Acquisition (SCADA) system measured per minute CH4 flow using Hitech sensors, which employed wavelength infrared techniques (Conestoga-Rovers & Associates 2008). The collected LFG was composed of 44% CH4, 37% CO2, and 19% residual gas with the average daily CH4 flow rate of 6100 m3/day (4.23 m3/min) during the period of study. A total of 1932 daily data points was measured, containing outliers and unreliable measurements among them. The methodology of the study is graphically represented in Fig. 1.

Methodology flowchart
Climatic variables
Twelve climatic variables including the maximum, average and minimum daily temperature (T), dew point (DP), maximum and minimum daily relative humidity (H), air pressure (P), and wind speed (W) were collected over the study period at the Regina station (elevation 0, 50.43° N, 104.67° W) from the Weather Underground (WU, 2018). These climatic parameters were also applied in the LFG prediction studies by Scozzari (2008), Li et al. (2011), Uyanik et al. (2012), Abushammala et al. (2014), Kumar et al. (2016), and Xin et al. (2016).
Periodic parameters
Prediction of daily CH4 data by applying the periodic input parameter as an only input would not only be appealing and beneficial due to its simplicity and fast application but also eliminates the need for any other climatic input data and pre-calculation analysis for the climatic input. Besides the climatic parameters, time variables such as the MOY and the DOY, that indicate various frequencies in the observed data, can be employed to optimize the model outcomes. Having said that, the periodic parameters are not liable to uncertainty and substantial variations unlike some climatic parameters (Arhami et al. 2013). In this study, since the prediction of daily CH4 collection data is the target in the ANN modeling, MOY and DOY are applied as periodic variables to represent the variation of CH4 through the years. These periodic parameters were smoothed by applying the MOY and DOY variables through using the following equations (Arhami et al. 2013; Gani et al. 2016):
where d is day of a year, ranging from 1 to 365, and m is month of a year, ranging from 1 to 12.
Applying such types of periodic variables prevent the sudden changes in the values of day and month as input parameters, and accordingly, reduces the sudden variations in the model results and improves the model performance (Arhami et al. 2013).
Data preprocessing and missing data estimation
The existence of LFG missing data can probably be attributed to the high possibility of the frozen well heads in Regina with semi-arid cold climate, equipment failure, sensor, or maintenance problems (Fallah et al. 2020b). The CH4 data preprocessing was performed by utilizing the collinearity analysis, filtering the outliers and missing data imputation. Pearson’s correlation analysis was adapted to select the independent and significant climatic input parameters to reduce the impact of multi-collinearity by excluding the input variables that have correlation coefficients higher than 0.8 (Hamilton 1991; Adamović et al. 2018a, b; Fallah et al. 2020b) with other inputs. Fallah et al. (2020b) concluded that selection of the input variables which have no or weak correlation coefficient with other inputs reduced the errors of the CH4 prediction models in the testing stage at the Regina landfill. Moreover, they reported that removing outliers could increase the ANN model performance at both testing and training stages. The outliers and missing data were possibly caused by system shutdowns, instruments’ malfunction, maintenance work, and frozen well heads at the Regina landfill (Fallah et al. 2020b). Inter-quartile range (IQR) filtering was adapted for removing the outliers from the dataset (Kannangara et al. 2018; Fallah et al. 2020b). The data located outside of upper level = Q3 + IQR × 1.5 and ower level = Q1 − IQR × 1.5 were considered outliers and were excluded from the dataset (Q1 and Q3are the first and third quartiles of the dataset, respectively).
In this study, missing daily CH4 collection data (m3/day) was estimated by using the feed forward back propagation MLP model (Fallah et al. 2020b) with LM as the most commonly used training algorithm in ANN prediction studies (Moghaddamnia et al. 2009; Taherdangkoo et al. 2020; Buevich et al. 2020; Fallah et al. 2020b) and a default of 10 number of neurons in the hidden layer (Ozcan et al. 2006). MLP with a single hidden layer was applied by Junninen et al. (2004) for missing data estimation in the air quality datasets. The MLP with a single hidden layer has been widely applied in the air pollutant prediction studies (Elangasinghe et al. 2014; Ozkaya et al. 2007; Feng et al. 2015) and missing data estimation (Junninen et al. 2004; Dastorani et al. 2010). In this study, ANN modeling is developed in MATLAB (version 2017b). A single hidden layer was utilized to avoid overfitting problems (Kannangara et al. 2018; Singh and Satija 2018) with a sigmoid transform function and an output layer with a linear transform function. An 85:15 train:test ratio was used on the available dataset (Feng et al. 2015; Abbasi and El Hanandeh 2016; Singh and Satija 2018; Fallah et al. 2020b). One indicator of overfitting is when the model is well-fitted during the training while poorly fitted in the testing stage. In the present study, early stopping is applied to reduce the overfitting problems (Sarle 1996). Therefore, the inputs were divided into training (70%), validation (15%), and testing (15%) in all trails. In addition, over 40 trails were conducted with selected climatic and periodic parameters to assess the model accuracy and to define the model with the minimum MSE. The result from this step is the complete time series dataset (2344 daily data) in the study period (August 2008–December 2014). More details on the missing daily CH4 data prediction is reported by Fallah et al. (2020b) and to avoid duplication has not been repeated here. Similar to Fallah et al.’s (2020) study, in this study, only the climatic input parameters have been applied for missing CH4 data estimation.
NARX model in daily methane prediction
In the present study, to predict the daily CH4 collection rate, a non-linear autoregressive neural network model with an external input (NARX) was employed by using the complete time series dataset produced from missing data estimation process. The standard NARX model is a two-layer network with sigmoidal and linear function in the hidden and output layers, respectively and the equations are as follows:
The complete dataset consists of 2344 time series data points for each input-output parameter during the study period (August 2008-December 2014). In NARX models, 1992 data points (85%) were used for training and 352 data points (15%) were applied at the testing stage (Feng et al. 2015; Abbasi and El Hanandeh 2016; Singh and Satija 2018; Fallah et al. 2020b) in the time series order. Similar to the MLP model for generating the complete dataset, in the NARX models, the daily methane collection rate (m3/day) is the target variable. In the NARX models, in addition to the climatic input parameters, the periodic parameters were also employed for model optimization assessment.
In this study, the LM training algorithm was applied in all NARX models as the most commonly used algorithm in GHG prediction studies (Fallah et al. 2020b; Buevich et al. 2020). The LM is a type of back propagation algorithm and has been applied in various ANN prediction models (Moghaddamnia et al. 2009; Taherdangkoo et al. 2020; Buevich et al. 2020; Fallah et al. 2020b) owing to the fast convergence speed (Marquardt 1963; Hagan and Menhaj 1994; Taherdangkoo et al. 2020). In LM algorithm, the weights and bias are updated based on the least-square technique (Buevich et al. 2020). The LM is a modification of the Gauss-Newton technique which consisted of consecutive approximation of the Hessian matrix to find the local optimum and optimizes the solution (Sahoo and Jha 2013; Taherdangkoo et al. 2020) using the following equation (Bishop 1995):
where w is the weight, J represents the Jacobian matrix, JT represents the transpose matrix of J, JTJ is the Hessian matrix, and I is the learning matrix. e is vector of network error and λ represents the step size and is automatically updated to secure the convergence according to the error at each iteration. To initiate the iteration for weight optimization in LM algorithm, the random value of λ was used in this study.
Prior to developing the ANN models, correlation analysis is usually applied to select the effective and independent inputs (Shahin et al. 2008; Fallah et al. 2020b). At this time, after calculating the periodic variables for the complete dataset, a correlation matrix was performed to identify the climatic and periodic input variables, which are statistically significant (P value < 0.05) and independent.
Stepwise procedure for the best training length
Generally, a model will be more accurate with a larger training dataset. However, the level and trend of the daily CH4 collection rate may change over the period of time. The changes in daily CH4 rate may be related to changes in decomposition speed of biodegradable buried waste, operational and climatic conditions in landfills. Therefore, more recent data may contribute to a better performance of the prediction model. In this study, after employing the correlation matrix, a stepwise procedure was applied to obtain the most effective length of input dataset for training the ANN models using R2 value, the MSE, and the MAPE, between the measured and predicted daily CH4 collection rate at the testing stage. Initially, the most recent one year of daily methane collection data were applied at the training stage and then, the temporal length of training dataset was increased gradually (6 months) until reaching the complete dataset (August 2008 to December 2014) with a training:test ratio of 85:15. Starting with the one-year-length data for training has the benefit of taking into account the full coverage of seasonal variations in CH4 levels and climatic variables in the trained model. After identifying the most efficient length of the training dataset, a new correlation matrix was provided for comparing the coefficients of inputs in the selected lengths of training and those from considering the full dataset.
ANN models development
All independent and significant climatic and periodic parameters were applied as inputs in a NARX neural network model (first and benchmark model as shown in Fig. 1). In the second NARX group, to evaluate the sensitivity of the NARX models to each input variable, a stepwise procedure of deleting the input parameter one-at-a-time was performed and the NARX models were generated using the remaining input parameters. Moreover, in the third NARX group, single-input-based models were developed by using the only one climatic and a periodic input parameter with the highest correlation coefficient with the target variable (daily CH4 rate). In the last NARX model, a combination of the two independent and significant climatic and periodic variables with the highest correlation coefficient with CH4 data was constructed. The main aim of the study is to provide a precise and convenient means for predicting the daily CH4 collection rate without applying any climatic inputs in the NARX model.
Models performance assessment
To examine the accuracy of the developed models for daily methane predictions, three statistical metrics were defined as: R2 value, the MSE, and the MAPE. These metrics were calculated by applying the model predictions of the daily CH4 rate and the corresponding measured data. The equations for these statistical parameters are as follows (Hastie et al. 2009):
where Oi and Pi are the observed and predicted daily CH4 collection values, respectively. In i = 1, 2, ..., n days, Ō is the mean of the observed times series daily CH4 collection rate (m3/day), and n is the total number of observations.
Result and discussion
Data analysis and screening
Before any preprocessing is done, 1932 time-series data points on the daily CH4 collection rate were available (August 2008–December 2014). The fluctuations in the CH4 collection rates and the characteristics of the daily dataset are observed in Fig. 2a and Table 1, respectively. The average daily CH4 collection rate was 6286.87 m3/day and close to the median (6235.77 m3/day), which represents the normal distribution of target dataset. However, the median is higher than the average for some climatic parameters (T, DP, and H), which indicates the data to be skewed. The most fluctuated parameters are T and DP (Max, Avg, and Min) with coefficients of variation higher than 1 (1.43, 3.21, −6.76, 4.41, −11.80, and −2.70). This may be related to the extreme cold winters in the study area. A close-to-one coefficient of variation (0.94) for the minimum wind speed shows the considerable variations of this input parameter. The coefficient of variation of the air pressure is close to zero (0.01) in the study period.

Missing data estimation using MLP neural network; a measured CH4 data in the study period; b constructed missing data to form a complete daily CH4 dataset
Preprocessing for missing data imputation
Collinearity analysis
The preprocessing and missing data estimation procedure is similar to the study conducted by Fallah et al. (2020b), this time for CH4 collection rate prediction at the Regina landfill. In this study, the correlation analysis indicates that Tavg has the greatest correlation coefficient (R = 0.29) with the daily CH4 collection rate. High correlation coefficients, ranging from 0.92 to 0.99, are observed between T (Max, Avg, and Min) and DP (Max, Avg and Min). WMax and WMin; PMax and PMin are also correlated to each other with R values of 0.85 and 0.83, respectively, which are above the 0.8 cut-off value (Hamilton 1991; Adamović et al. 2018a, b). Therefore, to avoid multicollinearity that may result in confusion in ANN modeling, and to increase the accuracy of the MLP missing data estimation model (Fallah et al. 2020b), the combination of the average air temperature (Tavg), maximum pressure (PMax), minimum humidity (HMin), maximum wind speed (WMax), and maximum humidity (HMax) with correlation coefficients of 0.29, −0.15, −0.11, −0.06, and −0.05, respectively, have been applied as independent and significant (P value < 0.05) input variables in the ANN modeling.
Removal of outliers
Among 1932 CH4 observed data points, errors, and outliers are removed using the inter-quartile range (IQR = 1007 m3/day, Q1 = 5760 m3/day, and Q3 = 6768 m3/day). The CH4 collection rate data smaller than lower level = 4250 and higher than upper level = 8278 were excluded from the dataset. In the dataset, 2.5 % of CH4 data were below the lower level while no data was higher than the upper level. After performing correlation analysis and the removal of outliers, the remaining 1883 data points were applied in the MLP neural network model described in section 2.3 to estimate the missing daily CH4 collection rate.
Missing data estimation
To form a complete time series dataset, 2344 daily CH4 data points are expected in the study period (from August 2008 to December 2014) while only 1883 data points are available after the outlier removal. Therefore, 19.7% of CH4 collection data are missing, and are predicted through the back propagation MLP neural network model. In this model, the available data points (1883) were divided into two groups of 85% and 15%, in which the 85% were used at the training and the remaining 15% were employed at the testing stage to predict the missing data. Therefore, a train: test ratio of 65:35 was applied to the incomplete dataset (85:15 to the available dataset) and the missing daily CH4 rate data were predicted in the testing stage using the MLP model. The model shows an acceptable performance with the average MAPE of 7.97% and 9.15% at the training and testing stages, respectively. The 461 daily CH4 rate predicted data were generated from the testing stage of the MLP model led to obtaining a complete dataset (as illustrated in Fig. 2b) consisting of 2344 data points in the study period (from August 2008 to December 2014). In construction of the complete dataset, to minimize the effect of the MLP prediction model errors, only the missing data were replaced by the testing stage outcomes (constructed data) while the observed data were not replaced by the predicted ones. The complete dataset was employed in the NARX neural network model developments in which, 1992 data points (85%) were used at training whereas 352 data points (15%) were applied at the testing stage in time series order.
Preprocessing for NARX models developments
Correlation analysis for complete dataset
Effective selection of input variables, reducing the uncertainty of model inputs, and improving the prediction model performance are essential to the practical use of prediction models (Arhami et al. 2013). As described in the methodology, in developing the NARX neural network models, periodic variables are also applied in addition to the climatic parameters. The results from the correlation analysis to find the most effective and independent input parameters in the NARX prediction models are tabulated in Table 2.
Similar to the correlation analysis for the missing data estimation, in a complete dataset, TAvg showed the highest correlation (0.312) with the daily CH4 collection rate. The input parameters with correlation coefficients less than |0.099| were not used as input in ANN modeling due to their minimal impacts on daily CH4 rate. Multicollinearity is observed between T and DP (Max, Avg, and Min) with high correlation coefficients ranging from 0.928 to 0.987. PMin is correlated with PMax with the R value of 0.827 higher than the cut off value (0.8) (Hamilton 1991; Adamović et al. 2018a, b). As discussed in the methodology section, the periodic input parameters including MOY and DOY were considered in the analysis to evaluate the effectiveness of the periodic parameters on CH4 rate prediction models. Based on the correlation matrix, MOY and DOY variables are highly correlated to each other (R = 0.954) and collinearity is also observed between DOY and T (Max, Avg, and Min) with the absolute R value ranging from 0.837 to 0.853. Therefore, to decrease the collinearity problems that may cause confusion in the ANN modeling, the combination of the average air temperature (TAvg), maximum pressure (PMax), minimum humidity (HMin), and only MOY was employed as the independent and significant (P value < 0.05) input variables in ANN model developments. However, DOY was applied in a single-input-variable ANN model, to check the effectiveness of the periodic parameters on the accuracy of CH4 prediction models. Information on different ANN CH4 prediction models is provided in the Result and discussion section.
Stepwise procedure for the best training length
As described in the methodology section, initially, the most recent 1 year of measured data was utilized for training. Then, the temporal length of training data was gradually increased by 6 months at each step until reaching the complete dataset in which the daily CH4 rate data from 01 Aug 2008 to 13 Jan 2014 and from 14 Jan 2014 to 30 Dec 2014 were applied at the training and testing stages, respectively. Performance metrics (R2 value, MSE, and MAPE) for predicted and available CH4 levels with various volumes of training data are illustrated in Fig. 3. The best fit with the highest average R2 value of 0.8 and the lowest average MSE and MAPE of 47,698.30 m3/day and 2.26% at the testing stage, respectively, was achieved by applying the most recent 3 years of available data (from 10 Jul 2011 to 23 Jun 2014) for training (data from 24 Jun 2014 to 31 Dec 2014 were used for testing). In comparison to the full-length dataset, the average R2 value increased from 0.72 to 0.80 and MSE and MAPE decreased from 97,918.39 to 47,698.30 and from 3.10 to 2.26%, respectively, during the testing stage. This result may possibly be attributed to the fluctuations of daily CH4 rate data over the past years and the date 22 Jun 2011 with the peak CH4 rate of 7852.945 m3/day.

Performance metrics (R2 value, MSE, and MAPE) for predicted and measured CH4 levels, with various volume of training dataset
As previously described, after identifying the most efficient length of training dataset, a comparative analysis was performed to see the changes in the coefficients of the effective inputs between 3-year length training dataset and those of in the trained model with the full dataset. The coefficients of inputs for 3-year length data and the full dataset is tabulated in Table 3. The result shows that by applying the 3-year length data in training, the coefficients of TAvg and PMax and HMin increased by 10.56%, 18.24%, and 2.83%, respectively, and TAvg is still the highest correlated (R = 0.345) input among other input parameters.
NARX models performance assessment
A total of nine time series ANN prediction models were developed using the most recent 3 years of data for training. The first ANN model was constructed with the combination of 4 inputs (T-P-H-MOY), and four ANN models were developed through sensitivity analysis using the stepwise procedure of omitting one input at the time (without T, without P, without H, without MOY). Moreover, single-input models were generated by using T (with highest correlation coefficient with target variable), MOY, DOY (the two periodic parameters), and the last model (T-MOY) performed by a combination of the climatic and periodic inputs with highest coefficient with target variable. The comparative evaluation of these nine time-series ANN model performances is presented in Fig. 4.

Comparative evaluation of the nine-time series daily CH4 prediction models using performance indices
MSE is scale dependent; therefore, the R2 value and MAPE at the testing step are used to compare the relative performance of the time series ANN models. The MAPE of the nine CH4 prediction models compared favorably to other solid waste energy recovery ANN models, in which MAPE ranged from 0.3 to 12.6% (Ogwueleka and Ogwueleka 2010; Nabavi-Pelesaraei et al. 2017; Adamović et al. 2018a, b; Fallah et al. 2020b) as shown in Appendix Table 4.
The model with all four independent and significant inputs performed well with an average R2 value of 0.829 and the average MSE and MAPE of 40,839.68 m3/day and 2.05%, respectively, at the testing stage. Among the ANN groups generated by sensitivity analysis, the model with three inputs (without H) showed the lowest average MSE of 38,171.21 m3/day and MAPE of 2.06% with the R2 value of 0.793. The results, however, highlight the importance of periodic parameters on the accuracy of CH4 collection prediction models. Of these four models with three inputs as shown in Fig. 4, Without MOY model had the poorest estimates with a MSE of 47,698.30 m3/day and a MAPE of 2.26%. It also implies that MOY is an acceptable indicator for CH4 rate prediction models. The second poorest model was without T model with a MSE of 47,037.12 m3/day and MAPE of 2.21% but with lower R2 value of 0.775 than that of the without MOY model (0.803). Among all the three single-input variable models, the DOY-based model had the highest R2 value of 0.801 and the lowest MSE of 38,579.24 m3/day. The MAPE in T and DOY models are both 2.12%, and negligibly lower than that of the MOY-based model (2.19%). The last model (T-MOY) did not show a high performance in comparison to the other eight ANN models, with the highest MSE and MAPE of 48,033.75 and 2.34%, respectively. Therefore, the combination of these two climatic and periodic parameters is not recommended in this study. Comparison of the two single periodic input variable models shows the higher performance of DOY than that of the MOY model with respect to all three performance indices: R2, MSE, and MAPE of the DOY model are 2.37%, 8.69%, and 3.17% better than those in the MOY model, respectively. The DOY model even performed better than the T model with 7.95% lower MSE, which represents the benefit of considering DOY as the only input in CH4 rate prediction models from the landfill.
The R2 value and MAPE of the DOY model (0.80 and 2.12%, respectively) at the testing stage are compared favorably to other published ANN models (Ozcan et al. 2006; Ozkaya et al. 2007; Karacan 2008; Ogwueleka and Ogwueleka 2010; Nabavi-Pelesaraei et al. 2017; Adamović et al. 2018a, b), in which the R2 value and MAPE ranged from 0.66 to 0.0.99 and 0.3 to 12.6%, respectively (Appendix Table 4). It is observed that the performance of the DOY-based model with MAPE of 2.12% is obviously higher than those reported in Ogwueleka and Ogwueleka (2010) and Adamović et al. (2018a, b) studies in which the MAPE ranged from 9.05 to 12.6%. The results from the present study suggest that applying DOY as a single input of time-series ANN models can be a convenient and rapid approach for daily CH4 rate prediction from landfills, particularly for the landfills with no reliable climatic data.
Using the DOY model, the measured and predicted daily CH4 collection data are graphically compared in Fig. 5 at both training and testing stages. Figure 5a shows the DOY model in training period from 10 Jul 2011 to 23 Jun 2014. The DOY model well captured the daily CH4 collection data particularly the day with average and peak values. Figure 5b represents the DOY model in the testing stage from 24 Jun 2014 to 31 Dec 2014. This model again accurately captured the real CH4 collection data at the testing period. The model, however, is less useful in the prediction of the CH4 data with values lower than the daily average CH4 collection rate.

Performance of the day of the year (DOY)-based CH4 prediction model; a training stage from 10 Jul 2011 to 23 Jun 2014; b testing stage from 24 Jun 2014 to 31 Dec 2014
Conclusion
Accurate and precise LFG prediction models are not only essential for mitigating the GHG environmental impacts but also helpful in the efficient LFG management systems in landfills. The preprocessing steps, including minimizing multicollinearity problems, filtering the outliers and erroneousness, and constructing missing data to form a complete dataset, were employed on the raw daily CH4 collection data. Missing data estimation using the MLP neural network model represented an acceptable performance at both training (MAPE = 7.97%) and testing (MAPE = 9.15%) stages. In this study, the CH4 rate prediction model performance was improved by selecting the most recent 3-year length dataset for training through the stepwise procedure. It is found that using the most recent 3-year length training dataset, the R2 value increased by 10.86% while the MSE and MAPE decreased by 51.29% and 26.97%, respectively, at testing stages.
Proper selection of input parameters and model architecture is a key item in ANN model developments. In the present study, a fast and convenient approach for the methane rate prediction model was investigated based on periodic parameters as a sole input. In all nine NARX daily CH4 models developed in this study, the R2 value, MSE, and MAPE of the models are in ranges of 0.775–0.829, 38,171.21–48,033.75 m3/day, and 2.05–2.34%, respectively. Among all nine ANN models, the T-P-H-MOY model with all independent and significant climatic and periodic inputs represented the highest performance with R2 value and MAPE of 0.829 and 2.05%, respectively, with an MSE of 40,839.68 m3/day at the testing stage. The sensitivity analysis showed that MOY plays an important role in daily CH4 rate prediction models since by eliminating MOY, the model’s accuracy R2, MSE, and MAPE dropped by 3.07%, 16.79%, and 10.25%, respectively (at testing stage). A favorable precision is achieved by the DOY model with an R2 value of 0.80, MSE of 38,579.24 m3/day, and MAPE of 2.12%, respectively. The results suggest that the highest accuracy is achieved by the model with all four independent and significant climatic and periodic inputs. However, application of the DOY as the only input in the NARX CH4 prediction models has minimum impacts on the prediction accuracy of the model with four climatic and periodic inputs by reducing the R2 value by 3.41% and increasing MAPE by 3.07%.
The results illustrate utilizing both MOY and DOY as sole inputs in the daily CH4 rate prediction models would be highly practical owing to the precise performance of the time series ANN models. In this study, the DOY-based model outperforms the MOY-based model, probably due to the greater absolute coefficient of DOY (|R| = 0.185) than that of MOY (|R| = 0.099) with the daily CH4 collection rate data in the correlation matrix. The main advantage of the DOY-based NARX model application is its simplicity and no need for meteorological input elements. The results suggest that the DOY-based model can be applied as proper substitutes for climatic-based NARX CH4 prediction models owing to their close and precise prediction. Therefore, the proposed method can be applied as an effective and convenient LFG modeling tool, particularly in landfills with no climatic data.
Data availability
The data that support the findings of this study are available from City of Regina Solid Waste Department but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of City of Regina Solid Waste Department.
Abbreviations
- ANN:
-
Artificial neural network
- CH4:
-
Methane
- CO2 :
-
Carbon dioxide
- DOY:
-
Day of the year
- DPMax:
-
Maximum dew point
- DPMean:
-
Mean dew point
- DPMin:
-
Minimum dew point
- GHG:
-
Greenhouse gas
- H Max :
-
Maximum relative humidity
- H Min :
-
Minimum relative humidity
- IA:
-
Index of agreement
- IQR:
-
Inter-quartile range
- LFG:
-
Landfill gas
- LM:
-
Levenberg-Marquardt
- MAPE:
-
Mean absolute percentage error
- MLP:
-
Multilayer perceptrons
- MOY:
-
Month of the year
- MSE:
-
Mean square error
- NARX:
-
Non-linear auto-regressive model with exogenous inputs
- P Max :
-
Maximum air pressure
- P Min :
-
Minimum air pressure
- Q1:
-
First quartiles
- Q3:
-
Third quartiles
- R :
-
Correlation coefficient
- R 2 :
-
Coefficient of determination
- RMSE:
-
Root mean square error
- SCADA:
-
Supervisory Control and Data Acquisition
- T Max :
-
Maximum temperature
- T Mean :
-
Mean temperature
- T Min :
-
Minimum temperature
- W Max :
-
Maximum wind speed
- W Min :
-
Minimum wind speed
References
Abbasi M, El Hanandeh A (2016) Forecasting municipal solid waste generation using artificial intelligence modelling approaches. Waste Manag 56:13–22. https://doi.org/10.1016/j.wasman.2016.05.018
Abushammala MF, Basri NEA, Elfithri R, Younes MK, Irwan D (2014) Modeling of methane oxidation in landfill cover soil using an artificial neural network. J Air Waste Manage Assoc 64(2):150–159. https://doi.org/10.1080/10962247.2013.842510
Adamović VM, Antanasijević DZ, Ćosović AR, Ristić MĐ, Pocajt VV (2018a) An artificial neural network approach for the estimation of the primary production of energy from municipal solid waste and its application to the Balkan countries. Waste Manag 78:955–968. https://doi.org/10.1016/j.wasman.2018.07.012
Adamović VM, Antanasijević DZ, Ristić MĐ, Perić-Grujić AA, Pocajt VV (2018b) An optimized artificial neural network model for the prediction of rate of hazardous chemical and healthcare waste generation at the national level. J Mater Cycles Waste Manag 20:1736–1750. https://doi.org/10.1007/s10163-018-0741-6
Amini HR, Reinhart DR, Niskanen A (2013) Comparison of first-order-decay modeled and actual field measured municipal solid waste landfill methane data. Waste Manag 33:2720–2728. https://doi.org/10.1016/j.wasman.2013.07.025
Arhami M, Kamali N, Rajabi MM (2013) Predicting hourly air pollutant levels using artificial neural networks coupled with uncertainty analysis by Monte Carlo simulations. Environ Sci Pollut Res 20(7):4777–4789. https://doi.org/10.1007/s11356-012-1451-6
Bishop CM (1995) Neural networks for pattern recognition. Oxford University Press
Buevich A, Sergeev A, Shichkin A, Baglaeva E (2020) A two-step combined algorithm based on NARX neural network and the subsequent prediction of the residues improves prediction accuracy of the greenhouse gases concentrations. Neural Comput & Applic. https://doi.org/10.1007/s00521-020-04995-4
Canada Climate Normals (2016) http://climate.weather.gc.ca/climate_normals/results_1981_2010_e.html?searchType=stName&txtStationName=Regina&searchMethod=contains&txtCentralLatMin=0&txtCentralLatSec=0&txtCentralLongMin=0&txtCentralLongSec=0&stnID=3002&dispBack=0. Accessed 15 Oct 2019
Chelani AB, Rao CC, Phadke KM, Hasan MZ (2002) Prediction of sulphur dioxide concentration using artificial neural networks. Environ Model Softw 17(2):159–166. https://doi.org/10.1016/S1364-8152(01)00061-5
Conestoga-Rovers & Associates, 2006. Landfill gas collection system – pre-design brief.
Conestoga-Rovers & Associates (2008) Site plan and LFG collection system layout. In: Regina. Canada. Unpublished report, Saskatchewan
Elangasinghe MA, Singhal N, Dirks KN, Salmond JA (2014) Development of an ANN–based air pollution forecasting system with explicit knowledge through sensitivity analysis. Atmospheric Pollut Res 5(4):696–708. https://doi.org/10.5094/APR.2014.079
Environment Canada, 2015. National Inventory Report: 1990–2013. From United Nations, Publications(2015):http://unfccc.int/national_reports/annex_i_ghg_inventories/national_inventories_submissions/items/8812.php. Accessed 10 Oct 2019.
Fallah, B., Ng, K. T. W., Richter, A., Vu, H. L., Peng, W., Torabi, F. (2020a) Spatial-temporal analysis of dissolved metal pollutants near an unlined municipal landfill in a semi-arid climate. Journal of Environmental Science and Natural Rescores. 2020; 26(2): 556181. DOI: 10.19080/IJESNR.2020.26.556181.
Fallah B, Ng KTW, Vu HL, Torabi F (2020b) Application of a multi-stage neural network approach for time-series landfill gas modeling with missing data imputation. Waste Manag 116:66–78. https://doi.org/10.1016/j.wasman.2020.07.034
Fallah B, Richter A, Ng KTW, Salama A (2019) Effects of groundwater metal contaminant spatial distribution on overlaying Kriged maps. Environ Sci Pollut Res 26(22):22945–22957. https://doi.org/10.1007/s11356-019-05541-z
Feng X, Li Q, Zhu Y, Hou J, Jin L, Wang J (2015) Artificial neural networks forecasting of PM2. 5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos Environ 107:118–128. https://doi.org/10.1016/j.atmosenv.2015.02.030
Gardner MW, Dorling SR (1999) Neural network modelling and prediction of hourly NOx and NO2 concentrations in urban air in London. Atmos Environ 33(5):709–719. https://doi.org/10.1016/S1352-2310(98)00230-1
Gani A, Mohammadi K, Shamshirband S, Khorasanizadeh H, Danesh AS, Piri J, Zamani M (2016) Day of the year-based prediction of horizontal global solar radiation by a neural network auto-regressive model. Theor Appl Climatol 125(3–4):679–689. https://doi.org/10.1007/s00704-015-1533-8
Hagan MT, Menhaj MB (1994) Training feedforward networks with the Marquardt algorithm. IEEE Trans Neural Netw 5(6):989–993. https://doi.org/10.1109/72.329697
Hamilton LC (1991) Modern data analysis: a first course in applied statistics. Technometrics. Brooks/Cole Pub, Co, Pacific Grove, CA, USA
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: data mining, inference, and prediction, Springer Series in Statistics https://doi.org/10.1007/BF02985802
Intergovernmental Panel on Climate Change (IPCC) (2007) Climate change 2007. The physical science basis. Contribution of Working Group I to the Fourth Assessment Report of the IPCC, New York, Cambridge http://ipcc-wg1.ucar.edu/wg1/wg1-report.html
Jiang D, Zhang Y, Hu X, Zeng Y, Tan J, Shao D (2004) Progress in developing an ANN model for air pollution index forecast. Atmos Environ 38(40):7055–7064. https://doi.org/10.1016/j.atmosenv.2003.10.066
Kannangara M, Dua R, Ahmadi L, Bensebaa F (2018) Modeling and prediction of regional municipal solid waste generation and diversion in Canada using machine learning approaches. Waste Manag 74:3–15. https://doi.org/10.1016/j.wasman.2017.11.057
Karacan CÖ (2008) Modeling and prediction of ventilation methane emissions of U.S. longwall mines using supervised artificial neural networks. Int J Coal Geol 73(3-4):371–387. https://doi.org/10.1016/j.coal.2007.09.003
Khorasanizadeh H, Mohammadi K, JalilvandM (2014) A statistical comparative study to demonstrate the merit of day of the year-based models for estimation of horizontal global solar radiation. Energy Convers Manag 87:37–47. https://doi.org/10.1016/j.enconman.2014.06.086
Kukkonen J, Partanen L, Karppinen A, Ruuskanen J, Junninen H, Kolehmainen M, Cawley G (2003) Extensive evaluation of neural network models for the prediction of NO2 and PM10 concentrations, compared with a deterministic modelling system and measurements in central Helsinki. Atmos Environ 37(32):4539–4550. https://doi.org/10.1016/S1352-2310(03)00583-1
Kumar S, Nimchuk N, Kumar R, Zietsman J, Ramani T, Spiegelman C, Kenney M (2016) Specific model for the estimation of methane emission from municipal solid waste landfills in India. Bioresour Technol 216:981–987. https://doi.org/10.1016/j.biortech.2016.06.050
Lachtermacher G, Fuller JD (1994) Stochastic and statistical methods in hydrology and environmental engineering. In: Hipel KW, McLeod AI, Panu US, Singh VP (eds) Back propagation in hydrological time series forecasting. Kluwer, Dordrecht
Li H, Sanchez R, Joe Qin S, Kavak HI, Webster IA, Tsotsis TT, Sahimi M (2011) Computer simulation of gas generation and transport in landfills. V: Use of artificial neural network and the genetic algorithm for short- and long-term forecasting and planning. Chem Eng Sci 66(12):2646–2659. https://doi.org/10.1016/j.ces.2011.03.013
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modeling issues and applications. Environ Model Softw 15:101–124. https://doi.org/10.1016/S1364-8152(99)00007-9
Marquardt DW (1963) An algorithm for least-squares estimation of nonlinear parameters. J Soc Ind Appl Math 11(2):431–441. https://doi.org/10.1137/0111030
Moghaddamnia A, Remesan R, Kashani MH, Mohammadi M, Han D, Piri J (2009) Comparison of LLR, MLP, Elman, NNARX and ANFIS Models—with a case study in solar radiation estimation. J Atmos Sol Terr Phys 71(8-9):975–982. https://doi.org/10.1016/j.jastp.2009.04.009
Mohebbi MR, Jashni AK, Dehghani M, Hadad K (2018) Short-term prediction of carbon monoxide concentration using artificial neural network (NARX) without traffic data: case study: Shiraz City. Iranian Journal of Science and Technology, Transactions of Civil Engineering, pp 1–8. https://doi.org/10.1007/s40996-018-0210-4
Mohsen RA, Abbassi B, Dutta A (2019) Assessment of greenhouse gas emissions from Ontario’s solid waste landfills: assessment of improvement scenarios. J Environ Eng 145(8):05019004. https://doi.org/10.1061/(ASCE)EE.1943-7870.0001557
Nabavi-Pelesaraei, A., Bayat, R., Hosseinzadeh-Bandbafha, H., Afrasyabi, H., & Chau, K. W. (2017). Modeling of energy consumption and environmental life cycle assessment for incineration and landfill systems of municipal solid waste management-a case study in Tehran Metropolis of Iran. J Clean Prod, 148, 427-440. https://doi.org/10.1016/j.jclepro.2017.01.172
Ogwueleka T, Ogwueleka F (2010) Modelling energy content of municipal solid waste using artificial neural network. J Environ Health Sci Eng 7(3):259–266
Ozcan HK, Ucan ON, Sahin U, Borat M, Bayat C (2006) Artificial neural network modeling of methane emissions at Istanbul Kemerburgaz-Odayeri landfill site. J Sci Ind Res 65:128–134
Ozkaya B, Demir A, Bilgili MS (2007) Neural network prediction model for the methane fraction in biogas from field-scale landfill bioreactors. Environ Model Softw 22(6):815–822. https://doi.org/10.1016/j.envsoft.2006.03.004
Peel MC, Finlayson BL, McMahon TA (2007) Updated world map of the Köppen-Geiger climate classification. Hydrol Earth Syst Sci Discuss 4(2):439–473
Perera LAK, Achari G, Hettiaratchi JPA (2002) Determination of source strength of landfill gas: a numerical modeling approach. J Environ Eng 128(5):461–471. https://doi.org/10.1061/(ASCE)0733-9372(2002)128:5(461)
Radojević D, Antanasijević D, Perić-Grujić A, Ristić M, Pocajt V (2018) The significance of periodic parameters for ANN modeling of daily SO2 and sssNOx concentrations: a case study of Belgrade, Serbia. Atmos Pollut Res. https://doi.org/10.1016/j.apr.2018.11.004
Rajaram V, Siddiqui FZ, Khan ME (2011) Chapter 2: Planning and design of LFG recovery system. From landfill gas to energy-technologies and challenges (p. 27). CRC Press, Boca Raton
Sahin U, Ucan ON, Bayat C, Oztorun N (2005) Modeling of SO2 distribution in Istanbul using artificial neural networks. Environ Model Assess 10(2):135–142. https://doi.org/10.1007/s10666-004-7262-5
Sahoo S, Jha MK (2013) Groundwater-level prediction using multiple linear regression and artificial neural network techniques: a comparative assessment. Hydrogeol J 21(8):1865–1887. https://doi.org/10.1007/s10040-013-1029-5
Sanchez, J.G. (2016). Development of alternative medium to sustain methanotrophs in methane biofilters (Master’s thesis). University of Calgary, Calgary.
Sarle WS (1996) Stopped training and other remedies for overfitting. Comput Sci Stat:352–360
Scozzari A (2008) Non-invasive methods applied to the case of Municipal Solid Waste landfills (MSW): analysis of long-term data. Adv Geosci 19:33–38. https://doi.org/10.5194/adgeo-19-33-2008
Sergeev, A., Shichkin, A., & Buevich, A. (2018). Time series forecasting of methane concentrations in the surface layer of atmospheric air in Arctic region. In AIP Conference Proceedings (Vol. 2048, No. 1, p. 060005). AIP Publishing. https://doi.org/10.1063/1.5082120
Shahin MA, Jaksa MB, Maier HR (2008) State of the art of artificial neural networks in geotechnical engineering. Electron J Geotech Eng 8(1):1–26
Shi JJ (2002) Clustering technique for evaluating and validating neural network performance. J Comput Civ Eng 16(2):152–155. https://doi.org/10.1061/(ASCE)0887-3801(2002)16:2(152)
Singh D, Satija A (2018) Prediction of municipal solid waste generation for optimum planning and management with artificial neural network—case study: Faridabad City in Haryana State (India). Int J Syst Assur Eng Manag 9(1):91–97. https://doi.org/10.1007/s13198-016-0484-5
Statistics Canada, (2010). Waste Management Industry Survey: Business and Government Sectors. Ottawa: Statistics Canada 2013, Catalogue no.16F0023X.From Statistics Canada, Publications (2013): http://www.statcan.gc.ca/pub/16f0023x/16f0023x2013001-eng.pdf (accessed 2.10.2019).
Taherdangkoo R, Tatomir A, Taherdangkoo M, Qiu P, Sauter M (2020) Nonlinear autoregressive neural networks to predict hydraulic fracturing fluid leakage into shallow groundwater. Water 12(3):841. https://doi.org/10.3390/w12030841
Thompson S, Sawyer J, Bonam R, Valdivia JE (2009) Building a better methane generation model: validating models with methane recovery rates from 35 Canadian landfills. Waste Manag 29:2085–2091. https://doi.org/10.1016/j.wasman.2009.02.004
Tolaymat TM, Green RB, Hater GR, Barlaz MA, Black P, Bronson D, Powell J (2010) Evaluation of landfill gas decay constant for municipal solid waste landfills operated as bioreactors. J Air Waste Manage Assoc 60(1):91–97. https://doi.org/10.3155/10473289.60.1.91
Uyanik I, Ozkaya B, Demir S, Cakmakci M (2012) Meteorological parameters as an important factor on the energy recovery of landfill gas in landfills. J Renew Sustain Energy 4:1–9. https://doi.org/10.1063/1.4769202
Wang P, Liu Y, Qin Z, Zhang G (2015) A novel hybrid forecasting model for PM10 and SO2 daily concentrations. Sci Total Environ 505:1202–1212. https://doi.org/10.1016/j.scitotenv.2014.10.078
Xin D, Hao Y, Shimaoka T, Nakayama H, Chai X (2016) Site specific diel methane emission mechanisms in landfills: a field validated process based on vegetation and climate factors. Environ Pollut 218:673–680. https://doi.org/10.1016/j.envpol.2016.07.060
Acknowledgments
Acknowledgment goes to the team at the City of Regina Solid Waste Department, who supported the data collection and Dr. Kelvin Ng’s research team for data collection. The views expressed herein are those of the writers and not necessarily those of our research and funding partners. The financial support to the first author of this manuscript in the form of graduate research scholarship and PhD award is greatly acknowledged.
Funding
The financial support to the first author of this manuscript in the form of graduate research scholarship and PhD award is greatly acknowledged.
Author information
Authors and Affiliations
Contributions
Bahareh Fallah: Conceptualization, Formal analysis, Writing and Original draft preparation. Farshid Torabi: Supervision, Review & Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable
Additional information
Responsible Editor: Marcus Schulz
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix 1
Appendix 1
Rights and permissions
About this article

Cite this article
Fallah, B., Torabi, F. Application of periodic parameters and their effects on the ANN landfill gas modeling. Environ Sci Pollut Res 28, 28490–28506 (2021). https://doi.org/10.1007/s11356-021-12498-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-021-12498-5