
Abstract
Location-based publish/subscribe plays a significant role in mobile information disseminations. In this light, we propose and study a novel problem of processing location-based top-k subscriptions over spatio-temporal data streams. We define a new type of approximate location-based top-k subscription, Approximate Temporal Spatial-Keyword Top-k (ATSK) Subscription, that continuously feeds users with relevant spatio-temporal messages by considering textual similarity, spatial proximity, and information freshness. Different from existing location-based top-k subscriptions, Approximate Temporal Spatial-Keyword Top-k (ATSK) Subscription can automatically adjust the triggering condition by taking the triggering score of other subscriptions into account. The group filtering efficacy can be substantially improved by sacrificing the publishing result quality with a bounded guarantee. We conduct extensive experiments on two real datasets to demonstrate the performance of the developed solutions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the development of Location-based services (LBS), user generated content on the Web has been increasingly associated with geo-locations. Massive amount of data that contain both text information and geographical location information are being generated at an unprecedented scale on the Web. For example, Tweets, each containing no more than characters, can be associated with locations as illustrated in Figure 1, and some social photo sharing websites (e.g., Instagram) contain photos with both textual description tags and location.

Tweet with location
We refer to such data with text, location, and timestamp as spatio-temporal messages. These spatio-temporal messages cover a wide range of topics. For example, Tweets often offer the quickest first-hand reports of news events [49], comments and reviews representing public idea, bursty events, etc. Users are interested in receiving up-to-date tweets such that their locations are close to a user specified location and their texts are interesting to users [7, 49]. For example, a user may want to be updated with tweets near her home on the topic “dengue spread,” or a user may be interested in tweets whose locations are close to her office and are related to “ice-cream sales” As another application example, a user may be interested in recent tweets whose locations are close to a POI and whose text is relevant to the description of the POI; furthermore, a POI service provider (e.g., Yelp) may want to annotate each POI with its up-to-date relevant tweets for providing users a better service. In these applications, users may not want to be overwhelmed by a large number of tweets. Instead, users would prefer to being updated with the top-k most relevant tweets in terms of distance, text relevance and recency, which is also one of the key indicators of relevance for tweets.
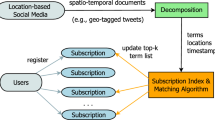
To solve this problem, some existing studies [7, 50] develop location-based top-k publish/subscribe systems that focus on processing a large number of location-based top-k subscriptions over geo-textual data streams. Specifically, such location-based top-k subscription is treated as a continuous query and tweets are treated as published spatio-temporal messages. The subscription takes into account the following three aspects in evaluating the relevance with a spatio-temporal message: (1) text similarity; (2) spatial proximity; and (3) freshness of spatio-temporal message. The location-based top-k subscription continuously maintains its up-to-date top-k results over a stream of spatio-temporal messages. A subscription is triggered by a new published message if and only if the new message scores higher than the current k-th top result message. As a result, when a new message arrives we need to evaluate each subscription and compute their relevance score to check if their relevance score is higher than the k-th result maintained by the subscription. Such one-by-one evaluation is very time-consuming especially when the number of subscriptions is very large (i.e., more than 1M). To enable the group evaluation, existing studies develop a grouping filtering technique [7] or hybrid indexing scheme [50] to accelerate the subscription matching process. Nevertheless, the improvement of performance of processing a large number of location-based top-k subscriptions is still limited. Consequently, we need to develop a more efficient way to process such large set of subscriptions with excellent scalability.
To address the challenge, we define a new type of approximate location-based top-k subscription, Approximate Temporal Spatial-Keyword Top-k (ATSK) Subscription. Instead of having a static triggering condition as the original location-based top-k subscription (i.e., the new message scores higher than the current k-th top result message), the triggering condition for ATSK is dynamic. In particular, it can automatically adjust the score of triggering condition by taking the score of other subscriptions into account. As a result, the group filtering efficacy can be substantially improved by sacrificing the publishing result quality. Note that the approximate location-based top-k subscription enables users to pre-define an approximation ratio to guarantee the publishing result quality.
For efficiently maintaining the up-to-date results of a large number of ATSK subscriptions over a stream of spatio-temporal messages, we define Approximate Conditional Influence Ring (ACIR) to represent each ATSK subscription. Based on the concept of ACIR, we develop hybrid indexing structure to group similar subscriptions and generate effective group filtering conditions to help filter out a group of subscriptions when a new message arrives. The proposed technique is featured by the following key technical components. 1) We propose a new concept to describe each ATSK subscription, namely the Approximate Conditional Influence Ring, based on which we develop an approach to determining whether a new spatio-temporal message is a result of a ATSK subscription. 2) We propose the Approximate Conditional Influence Ring based Quad-tree indexing structure for organizing the ATSK subscriptions based on the ACIRs of subscriptions. 3) We develop a spatial-aware inverted file technique to organize the ATSK subscriptions associated with a spatial cell in the CIQ-tree.
The rest of this paper is organized as follows. Section 1 introduces preliminaries and framework of processing ATSK subscriptions. Section 2 defines the ATSK subscription. Section 3 details our proposed solution. Section 4 presents the experimental studies. Section 5 reviews the related work, and Section 6 concludes the paper.
2 Problem statement
We introduce the spatio-temporal message, Exact Temporal Spatial-Keyword Top-k Subscription (ETSK), and Approximate Temporal Spatial-Keyword Top-k (ATSK) Subscription. In particular, spatio-temporal messages and ETSK subscriptions are defined based on existing work [7].
Definition 1
Spatio-temporal Message. A spatio-temporal message is represented with a triple m = 〈ψ, ρ, tc〉, where m.ψ is a set of terms, m.ρ is a geographical point location with latitude and longitude, and tc is the creation time of message m.
In this paper, we consider a stream of spatio-temporal messages. For instance, it can be geo-tagged tweets in Twitter, geo-tagged photos with tags in Instagram, check-ins with text descriptions in Foursquare, geo-tagged webpages, etc.
Intuitively, given a stream of spatio-temporal messages, an Exact Temporal Spatial-Keyword Top-k Subscription (ETSK) is to continuously retrieve k messages over time such that these messages are temporally most relevant to the subscription (i.e., their textual information is highly relevant to the subscription keywords, their locations are close to the subscription location, and they are fresh). Notice that apart from text similarity and spatial proximity, freshness is important for spatio-temporal data streams. For example, tweets are inclined to refer to some specific trending event and their relevance to a subscription declines as time elapses. Next, we define Approximate Temporal Spatial-Keyword Top-k Subscription (ATSK), which maintains an approximate result set of k most relevant messages over spatio-temporal data streams.
2.1 Exact temporal spatial-keyword top-k subscription
We present the concept of triggering condition, which is regarded as a preliminary of publish/subscribe systems, and the definition of ETSK subscription.
Definition 2
Triggering Condition. Let s be a subscription, m be a message from data streams, and B(m, s) be a Boolean expression. If m will be delivered to s if and only if B(m, s) is true, B(m, s) is considered to be the triggering condition of s.
Next, based on existing work [7] we define Exact Temporal Spatial-Keyword Top-k Subscription (ETSK) and its triggering condition.
Definition 3
Exact Temporal Spatial-Keyword Top-k Subscription (ETSK). An ETSK subscription s = 〈ψ, ρ, k〉, contains a set of subscription keywords/terms, s.ψ, a location s.ρ, and the number of messages to be maintained as results, s.k. The messages returned at time te are ranked according to the temporal spatial-keyword similarity score, which is defined by
where Ssk(m, s) computes the spatial-keyword similarity between subscription s and object m and St(m.tc, te) computes the message freshness.
When a new message mn arrives, an ETSKs will be triggered by mn if:
where me denotes the message with the k-th highest spatial-keyword similarity score in the result set of s.
Following previous work (e.g., [4]) we compute the spatial-keyword similarity Ssk(m, s) between s and m as follows.
where SD(m.ρ, s.ρ) is the proximity score between subscription s and message m, TR(m.ψ, s.ψ) indicates the text similarity between m and s, and α ∈ (0,1) denotes a preference parameter that balances the weight between spatial proximity and text similarity. The proximity score is computed by the normalized Euclidian distance: SD(m.ρ, s.ρ) = 1-\(\frac {\mathit {dist}(m.\rho , s.\rho )}{\mathit {dist_{max}}}\),where dist(m.ρ, s.ρ) is the Euclidian distance between m and s, and distmax can be the maximal possible distance in the spatial area. The text similarity is calculated by using an information retrieval model, such as language models [11], cosine similarity [33], or BM25 [10], and is normalized to a scale between 0 and 1. Here we use language models because it is originally defined for modeling the relevance between a keyword-based query and a textual document.
The freshness of message m is calculated by exponential decay function, which is defined as (4):
where D is base number that determines the rate of the freshness decay. The function is monotonically decrease with te − m.tc. It is introduced in [19] and is applied [1, 4, 22] as the measurement of recency for streaming data. Based on the experimental studies [12], the exponential decay function has been shown to be effective in blending the freshness and text similarity of textual documents.
2.2 Approximate temporal spatial-keyword top-k subscription
We proceed to define Approximate Temporal Spatial-Keyword Top-k Subscription (ATSK) and its triggering condition.
Definition 4
Approximate Temporal Spatial-Keyword Top-k Subscription (ATSK). An ATSK subscription s = 〈ψ, ρ, k〉, contains a set of terms, s.ψ, a location s.ρ, and the number of messages to be maintained as results, s.k. The messages returned at time te are ranked according to the temporal spatial-keyword similarity score, which is defined by
where Ssk(m, s) computes the spatial-keyword similarity between subscription s and message m and St(m.tc, te) computes the message freshness.
Let AStsk(m, s, tcur) be the approximate spatial-keyword similarity score computed by our approximate subscription matching algorithm. When a new message mn arrives, whether s will be triggered by mn is dependent by the spatial-keyword similarity score between s and mn, which is classified by the following scenarios:
-
(1)
If AStsk(m, s, tcur) ≥ (1 + 𝜖) × Stsk(m, s, tcur), m will be delivered to s;
-
(2)
If (1 − 𝜖) × Stsk(m, s, tcur) ≤ AStsk(m, s, tcur) < (1 + 𝜖) × Stsk(m, s, tcur), m will either be delivered to s or be filtered out by s;
-
(3)
If AStsk(m, s, tcur) ≤ (1 − 𝜖) × Stsk(m, s, tcur), m will be filtered out by s.
In our applications, the typical arrival rate of spatio-temporal messages (e.g., tweets) is in the scale of millions a day, while new ETSK or ATSK subscriptions are added at the rate of tens of thousands a day, and we may serve millions of ETSK or ATSK subscriptions at one time. We thus aim to develop a scalable solution to maintain the up-to-date results for a large number of ETSK or ATSK subscriptions over a data stream of spatio-temporal messages. It is possible for millions of subscriptions to be fitted into the available memory of modern servers. Hence, our solution is developed for in-memory setting. In the rare case that the ETSK or ATSK subscriptions cannot fit into memory, we can employ our proposed solution on multiple servers, each processing a subset of ETSK or ATSK subscriptions independently.
We would like to minimize the following costs: (1) CPU cost for subscription matching, which can be regarded as the runtime for finding the set of subscriptions that can include an incoming message as their top-k results; (2) CPU cost for result update, which is the time spent for updating the result of each subscription when a message arrives.
3 Framework for ATSK subscription processing
3.1 Preliminaries
We aim at the problem of continuous delivery of up-to-date top-k spatio-temporal messages for a large number of ATSK subscriptions over a stream of spatio-temporal messages. Before presenting our method to process ATSK subscriptions, we first introduce the baseline method and an advanced method to process ETSK subscriptions developed by Chen et al. [7].
3.1.1 Baseline of ETSK processing
A straightforward approach for processing ETSK works as follows: For each new spatio-temporal message m (i.e., arriving at timestamp tcur) compute its temporal spatial-keyword similarity score with each subscription s, Stsk(m, s, tcur); If the score is greater than the score with the temporal spatial-keyword similarity score of the k-th result of subscription s (at timestamp tcur), message m will be used to update the top-k results for s. Note that the temporal spatial-keyword similarity score of the k-th result of subscription s (at timestamp tcur) declines as time passes. As a consequence, for each new message we need to compute its score with respect to each subscription, and for each subscription we need to re-compute the temporal spatial-keyword score of its k-th result. Therefore, the straightforward approach is computationally prohibitive especially when the number of subscription is huge and the spatio-temporal messages arrive at a high rate.
3.1.2 Advanced method of ETSK processing
Chen et al. [7] develop a more efficient mechanism to process ETSK subscriptions over spatio-temporal message streams, where both new subscriptions and new messages arrive in a streaming manner. Figure 2 shows our proposed architecture for processing ETSK subscriptions. To index the spatial aspect of ETSK subscriptions, each subscription is represented by a set of Conditional Influence Regions (CIRs) based on the Quad-tree cells. The CIRs of all ETSK subscriptions are indexed by a CIQ-tree. Each ETSK subscription maintains the current top-k results over the stream of spatio-temporal messages. It is challenging to develop an index that can be used to efficiently maintain the up-to-date results for ETSK subscriptions over a stream of spatio-temporal messages because the indexing scheme is required to take spatial, textual, and temporal aspects into account while computing the similarity score of a spatio-temporal message for a subscription.

Varying the number of subscription keywords
The cost model for subscription insertion is used to decide how to index each subscription into the CIQ-tree. The cost model for subscription update is used to decide how to maintain the CIQ-tree in response to the update of the top-k results for a ETSK subscription.
The CIQ-tree and the corresponding cost models are the main components developed by Chen et al. [7]. The subscription table maintains the basic information of all subscriptions and their current results, including the subscription location, subscription keywords, subscription preference parameter α, and the minimum temporal spatial-keyword similarity score in the results of the subscription. Additionally, a complementary index for spatio-temporal messages is maintained for initializing the top-k result when a new subscription arrives. The problem of efficiently indexing spatio-temporal messages is beyond the scope of this work.
3.2 Overview of ATSK subscription processing
The difference between ETSK and ATSK subscriptions is that an ATSK subscription will be triggered by a new message whose temporal spatial-keyword similarity score is 𝜖-approximately greater than the k-th result of the subscription. While an ETSK subscription will be triggered by a new message whose temporal spatial-keyword similarity score is exactly greater than the k-th result of the subscription. The 𝜖-approximation property of the ATSK subscription allows us to develop a more effective group filtering technique by taking advantage of an approximate filtering condition generated by the 𝜖-approximation property. The major challenge here is to develop an effective way to represent each ATSK subscription and to propose corresponding group filtering condition with much more filtering power in comparison to that of an ETSK subscription.
Figure 3 illustrates the framework of processing ATSK subscriptions. We can see that the procedure of processing ATSK subscriptions is similar to the processing of ETSK subscriptions [7] but with the following differences:
-
(1)
Subscription representation. Because the triggering conditions of ATSK subscription and ETSK subscription are different, the conditional influence region defined by Chen et al. [7] is inapplicable. Consequently, we need to develop a new way to represent the spatial, textual, and temporal aspects of each ATSK subscription. Here we propose the approximate conditional influence ring to define each ATSK;
-
(2)
Group filtering technique. Because of the differences of triggering conditions, a new grouping mechanism is required to be developed for enabling the group filtering of a batch of ATSK subscriptions when a new message arrives. In addition, we need to generate ATSK based group filtering conditions accordingly.

Framework for Processing ETSK subscriptions
4 Representing ATSK subscriptions
In this section, we first present the concept of approximate conditional influence ring. Next we introduce how to represent an ATSK subscription by using a set of approximate conditional influence rings.
4.1 Approximate conditional influence rings
We propose the concept of Approximate Conditional Influence Ring (ACIR) to answer the ATSK subscription.
Our idea is inspired by the concept of influence region that is widely employed for processing continuous k nearest neighbor (Ck NN) queries. Each Ck NN is associated with a circular influence region that is centered at the query location, and whose radius is the distance from the query location to its k th nearest neighbor.
Based on the influence regions, they build different types of spatial index (e.g. grid, quad-tree, and etc.) to store those regions for matching an geographical object with the queries. For example, if we use the grid index to store the influence regions, when a message m arrives, we just need to search in the gird cell c where m is located and check the queries of which influence regions have overlapping areas with c. If a spatial object falls in the influence region of a subscription, the object becomes a result of the subscription; otherwise, it cannot be a result. The influence regions of Ck NN queries can be organized by a spatial indexing technique (e.g., grid cell), and we can easily find the queries for which a new object is a result.
Such method can avoid a great proportion of unnecessary subscription evaluations and is used by most of the techniques for processing Ck NN queries. For the textual part, inverted file is the most efficient indexing scheme for text information retrieval, which is widely used and optimized to solve various types of text-relevant problems.
However, the influence region cannot be directly used for representing ETSK and ATSK subscriptions. To represent an ETSK subscription, Chen et al. [7] use conditional influence region (CIR) for the propose. Specifically, each ETSK subscription is represented by a set of CIRs according a simple spatial-partitioning based indexing structure (i.e.,quad-tree). Each CIR denotes an influence region regarding a particular score of textual similarity and freshness. With the help of CIRs, irrelevant incoming messages can be filtered out in advance.
Recall that the triggering condition of ETSK is based on an exact temporal spatial-keyword similarity score (i.e., the score of the k-th message in the result set), while the triggering condition of ATSK is based on a temporal spatial-keyword similarity score range. Consequently, it is impossible to generate a set of CIRs for each ATSK subscription. To solve this problem, we propose approximate conditional influence ring (ACIR) to represent each ATSK subscription. The major difference between a CIR and an ACIR is that an ACIR has two boundary circles (i.e., an inner circle and an outer circle) while CIR just has one boundary circle.
Next, we formally define the approximate conditional influence ring, and then explain how it may help process the ATSK subscription.
Definition 5
Approximate Conditional Influence Ring. Let Rq be the list of up-to-date top-k spatio-temporal messages for an ATSK subscription s. The approximate conditional influence ring of s at time t and textual similarity score tr is denoted by a ring centered at the location of s. In particular, the radius of the inner circle of the ring is \(\mathsf {r}_{s}^{in}(tr, t)\) and the radius of the outer circle of the ring is \(\mathsf {r}_{s}^{out}(tr, t)\).
where Rq[k] is the k th result of subscription s.
The approximate conditional influence ring is denoted by ACIq(tr, tcur).
Like the influence region of Ck NN query, the approximate conditional influence ring is expected for narrowing the scope of subscription evaluation when organized by proposed indexing scheme.
Property
Consider a new spatio-temporal message m arriving at time t and suppose that its the text relevance to a ATSK subscription s is tr. Message m becomes a top-k result of s iff m falls in the approximate conditional influence ring ACIq(tr, tcur).
From (6) and (7), we can see that \(\mathsf {r}_{s}^{in}(tr,t)\) and \(\mathsf {r}_{s}^{out}(tr,t)\) increase as the time elapses, and a greater value of tr results in the greater values of \(\mathsf {r}_{s}^{in}(tr,t)\) and \(\mathsf {r}_{s}^{out}(tr,t)\). Example 1 demonstrates the approximate conditional influence ring.
Example 1
Let m0, m1 and m2 be three spatio-temporal messages such that tr0 = TR(m0.ψ, s.ψ), tr1 = TR(m1.ψ, s.ψ) = TR(m2.ψ, s.ψ), and tr0 < tr1. Assume that t0 and t1 are two timestamps and t0 < t1. Table 1 and Figure 4 illustrate the influence regions of subscription s under different timestamps and different values of text similarity. We observe that region radius becomes larger as time elapses and a greater value of tr corresponds to a greater radius (Table 2).

Approximate conditional influence rings of subscription s
From Figure 4 we can see that the approximate conditional influence rings are based on the text relevance of tr0 at time t and t′ respectively, and the corresponding radii of inner/outer radii of approximate conditional influence rings are shown in Table 1. We find that m0 falls outside the outer circle of ACI(tr0, t0) and ACI(tr0, t1). As a result, m0 cannot be a result of s at timestamps t0 or t1. We also find that m1 falls between in inner and outer circles of ACI(tr1, t0). Consequently, m1 may or may not be a result of s at timestamps t0. While if m1 arrives at timestamp t1, it will definitely be a result of s because m1 located inside the inner circle of ACI(tr1, t1).
4.2 Utilizing approximate conditional influence rings
According to Definition 5, the radii of ACIRs of a subscription s depend on not only the spatial-keyword similarity score between s and its k-th result (in Rs), but also the text similarity between s and an incoming spatio-temporal message m and the arrival time of m. This makes it inapplicable to generate an ACIR and then use the region to decide whether an incoming spatio-temporal message is a new result of s (in the similar way as the influence region is used for the Ck NN subscription).
To this end, we propose a novel way of generating conditional influence regions and utilizing them for processing ATSK subscriptions. Our high-level idea comprises three steps: 1) for an ATSK subscription s, and a spatial cell c, we generate two circle regions, whose radiuses are the minimum distance between s and cell c, and the maximum distance between s and c, respectively; 2) for each of the two circles, we generate a conditional influence region, and compute its corresponding text relevance score tr with respect to a past timestamp, e.g., the creation time (Rs[k].ct) of the k th result message in Rs; 3) for a new spatio-temporal message m that arrives at time t and falls in the cell c, we design an approach that is able to “map” the spatial-textual score between m and subscription s at time t to a backdated equivalent score at time Rs[k].ct; this enables us to compare the backdated equivalent score with the scores computed at step 2) to decide whether m is a result of s. We proceed to detail the three steps.
-
Step 1 Given a spatial cell c and an ATSK subscription s, we generate the following two circle regions: (1) minimum circle: its radius is the the minimum distance between s and cell c, and the radius is denoted by minD(s, c). When subscription s is located in cell c, minD(s, c) = 0; (2) maximum circle: its radius is the maximum distance between s and any location in cell c, and the radius is denoted by maxD(s, c). Figure 5a illustrates the two circles when s is located within c and Figure 5b illustrates the case when s is not located within c.
-
Step 2 Based on the two circles generated in Step 1, we generate two conditional influence regions. Recall that the text similarity tr and the time t are given and we compute the radius of the corresponding inner circle. In contrast, here we know the radius (minD(s, c) or maxD(s, c)) and the time is the creation time (Rs[k].ct) of the k-th result message in Rs, and we want to compute the corresponding text relevance score.
Definition 6
Minimum Approximate Conditional Text Similarity and Maximum Approximate Conditional Text Similarity. Given subscription s, cell c, time Rs[k].ct, and their minimum circle minD(s, c), based on (12), the corresponding text relevance score is computed by
The text similarity score is called minimum approximate conditional text similarity. Given subscription s, cell c, time Rs[k].ct, and their maximum inner circle maxD(s, c), based on (12), the corresponding text similarity score is computed by
The text similarity score is called maximum approximate conditional text similarity.
-
Step 3 This step is to utilize the minimum approximate conditional text similarity and maximum approximate conditional text similarity to check whether a new spatio-temporal message m is a result for subscription s if m falls in the spatial area of c. Recall that the two inner circles of approximate conditional influence rings correspond to the timestamp Rs[k].ct. However, the arrival time of m, denoted by tcur, is different from Rs[k].ct, and thus the spatial-keyword similarity score between m and s is not comparable with the score between m and its k-th results at time Rs[k].ct.
To make the two scores comparable, our idea is to design a method that can be used to “map” the spatial-textual score between m and subscription s at time tcur to a backdated equivalent score at time Rs[k].ct; and then we are able to compare the backdated equivalent score with the scores computed at step 2) to decide whether m is a result of s. The mapping is defined as follows.

Two inner circles for given s and c
Definition 7
Backdated Equivalent Text Relevance Score. Given an ATSK subscription s at time tcur, the backdated equivalent text relevance score at time tb is defined by
With the mapped score, we have the following lemma to determine whether m is a result.
Lemma 1
Letm be an incoming spatio-temporal messagelocated in the spatial cell c. We have (1)when \(\mathsf {TR}^{t_{b}}(m.\psi , s.\psi ) <\mathsf {minAT}(s,c)\), m is not be a result of s; (2) when \(\mathsf {TR}^{t_{b}}(m.\psi , s.\psi ) \geq \mathsf {maxAT}(s,c)\), m must be a new result ofs ; (3) when\(\mathsf {minAT}(s,c)\leq \mathsf {TR}^{t_{b}}(m.\psi , s.\psi ) <\mathsf {maxT}(s,c)\), m may be a result ofs.
Proof
We can easily proof this lemma based on Definitions 5 and 8. □
4.2.1 Mapping to backdated equivalent scores at a uniform time
Our three step idea and the mapping technique enable us to utilize the ACIR to check whether a message is a result of subscription s. Recall for each subscription we need to map its spatial-keyword similarity with a new message m back to the similarity value at the creation time of its k th result Rs[k].ct. However, we need to handle a large number of subscriptions, rather than a single subscription, and the k-th results of these subscriptions may have different timestamps. Hence, it is expensive to map the spatial-keyword similarity to each of different timestamps. To address the problem, our idea is to map Approximate Minimum Conditional Text Similarity and Approximate Maximum Conditional Text Similarity of all the subscriptions to their backdated equivalent scores at a single backdated time, denoted by tb. Different subscriptions may have different values of tu(s), which make it difficult to compute the text similarity required for updating each subscription (since we have to compute them one by one based on unique tu(s) for each subscription). So we convert minACIR(s, c, tu) and maxACIR(s, c, tu) of different subscriptions into minACIR(s, c, tb) and maxACIR(s, c, tb) respectively by using the backdated equivalent subscription update threshold, which is defined in Definition 8, instead of the subscription update threshold, where tb is a subscription-independent backdated time.
Definition 8
Backdated Equivalent Score. Let s be an ATSK subscription, the backdated equivalent subscription update threshold at time tb is defined as (11)
Based on (11), we map the update thresholds of all subscriptions to a previous predefined timestamp tb and use BUT(s, tb) to replace UT′(s), that is:
Since we have minACIR(s, c, tb) and maxACIR(s, c, tb) with a unified timestamp tb, we can derive their corresponding values of text relevance based on (12). Consequently, we have the following definition.
Definition 9
Minimum and Maximum Border Score. The minimum border score of subscription s under cell c at time tb, denoted by BSmin(s, c, tb), is the corresponding text relevance w.r.t. minACIR(s, c, tb). And denoted by BSmax(s, c, tb) the maximum border score of s under c is the corresponding text relevance w.r.t. maxACIR(s, c, tb). Equation (13) and (14) compute BSmin(s, c, tb) and BSmax(s, c, tb) respectively.
where RminACIR(s, c, tb) and RmaxACIR(s, c, tb) denote the radius of minACIR(q, c, tb) and maxCIR(s, c, tb) respectively.
For each subscription s, we select a set of cells, which may from different layers of the quad-tree, to generate corresponding BSmin(s, c, tb) and BSmax(s, c, tb) respectively on each selected cell c. Now we proceed to discuss how to store a subscription on a selected cell.
Based on (13) (resp. (14)), BSmin(q, c, tb) (resp.BSmax(q, c, tb)) can be regarded as the sum of the following two parts, namely \(BUT(q,t_{b})\cdot D^{t_{b}-t_{cur}}/(1+\alpha )\) and α ⋅ RminCIR(s, c, tb)/(1 + α), where \(BUT(s,t_{b})\cdot D^{t_{b}-t_{cur}}/(1+\alpha )\) is dependent on the current time tcur and α ⋅ RminCIR(s, c, tb)/(1 + α) (resp. α ⋅ RmaxCIR(s, c, tb)/(1 + α)) is time-independent.
We separately store the following values for each subscription s on each relevant cell c and then organize them together with hierarchical based inverted file: (1) BUT(s, tb)/(1 + α); (2) α ⋅ RminCIR(s, c, tb)/(1 + α); (3) α ⋅ RmaxCIR(s, c, tb)/(1 + α). Notice that we do not maintain the real-time values of the border scores, instead, we store the border scores at a pre-defined backdated time tb, just as (1), and calculate the current border scores as soon as a new message arrives. The reason is that it is impractical to maintain the real-time values of BSmin(s, c, tb) and BSmax(s, c, tb).
4.3 IQ*-tree
We proceed to describe the structure of the IQ*-tree, which is a hybrid spatial keyword indexing structure and basically consists of the quad-tree and hierarchical inverted file. It is used for indexing conditional influence regions of the ATSK subscription.
After having BSmin(s, c, tb) and BSmax(s, c, tb) for the subscription s under cell c, we notice that incoming spatio-temporal messages may fall in any cells in the spatial index, and each subscription s may have different values of BSmin(s, c, tb) and BSmax(s, c, tb) for different c. If we use the grid index to store each subscription, then all the cells in the grid will be associated by the subscription. It is hard to determine an optimal granularity of grid index because different subscriptions may have their unique values of optimal granularity based on their locations, keywords, and preference parameters. Consequently, we use the quad-tree to index the subscriptions, which is a space partitioning based hierarchical index structure.
The reasons for using quad-tree to organize the spatial information of the ATSK subscription are summarized as follows. First, quad-tree has a space based partitioning scheme that allows ATSK subscription to be indexed in mutually-exclusive cells. In contrast, the bounding rectangles of the R-tree are dependent on the location distribution of messages, and they may overlap with each other. As a result, it is difficult to use the R-tree to index the conditional influence regions. Second, we can use diverse indexing granularity for different ATSK subscription by considering the spatial distribution, text distribution, and different values of the subscription performance parameter α. This is important to the performance of both stream message assignment and subscription result update. Note that different from many applications that only keep the leaf level quad-tree cells, we need to keep all the cells including both leaf cells and internal cells.
The next problem is how to organize the subscriptions in each cell c. According to our problem definition, the messages that do not contain any subscription keyword will never be considered as subscription result. So we just need to evaluate the subscriptions containing at least one common keyword with the incoming message. In order to filter the subscriptions without common keyword with the message in advance, we organize the subscriptions in hierarchical inverted lists for each cell.
4.4 Multi-level inverted file
Each node of the IQ*-tree corresponds to a multi-level inverted file for indexing the text information of the ATSK subscriptions associated at the node. Each inverted file consists of the hierarchical inverted lists for each subscription keyword.
Figure 6 illustrates the structure of the hierarchical inverted lists and the postings. We can see that the hierarchical inverted list is basically a binary tree where each leaf node points to a posting list, which contains at most pmax postings. Each posting stores the subscription id and the pointers to corresponding subscriptions in the subscription list. Note that each subscription may have different subscription ids under different quad-tree cells. This is because the subscription id is assigned based on the value of α ⋅ RminACIR(s, c, tb)/(1 + α) and each subscription bears unique value under different cells.

Structure of the hierarchical inverted list
In order to help prune the queries in the subtree rooted at the nodes of the inverted list that cannot make the incoming spatio-temporal message be the subscription results, each node c is augmented with the following values: (1) minID and maxID, which respectively indicate the minimum and maximum ids of the subscriptions in the subtree rooted at node c; (2) minNBUT and maxNBUT, which are the minimum and maximum values of BUT(s, tb)/(1 − s.α) where s ∈ Sc and Sc represents the subscriptions that belong to the subtree rooted at node n; (3) minminNR, which is the minimum value of α ⋅ RminACIR(s, c, tb)/(1 + α) for all s ∈ Sc; (4) maxmaxNR, which is the maximum value of α ⋅ RmaxACIR(s, c, tb)/(1 + α) for all q ∈ Sc.
Since the text relevance between a subscription and an spatio-temporal message is related to both the number of subscription keywords and the number of message keywords, storing the subscriptions according to the number of subscription keywords in the first place can help estimate the bound of text relevance between a subscription and a message. Consequently, we make ATSK subscriptions firstly classified according to their numbers of subscription keywords. As Figure 7, we build separate IQ*-trees for the subscriptions with a particular number of subscription keywords.

Subscription Classification based on # subscription keywords
5 Experimental study
5.1 Baselines
We discuss how to exploit existing techniques for maintaining the real-time results for ATSK subscriptions over a stream of spatio-temporal messages. No structure and algorithm exist for solving the problem. Hence we develop some baselines utilizing existing structures for spatial and text retrieval.
A straightforward baseline is to use the inverted file to index the ATSK subscriptions. The posting of each subscription contains the corresponding subscription id. We also maintain a global subscription table. For each subscription s, the table stores the subscription id, Sbsk(s, Rs[k], tb), s.ρ, s.α, and the current subscription results of s. When a spatio-temporal message m arrives, we traverse the postings lists associated with the terms in the message in the Document-at-a-Time (DAAT) manner. For each posting, we get the subscription information from the subscription table based on its subscription id for computing the temporal spatial-keyword similarity score between m and the subscription (Stsk(m, s, tcur)). Then we compare Stsk(m, s, tcur) with Stsk(s, Rs[k], tcur), which is computed from Sbsk(s, Rs[k], tb), and we determine whether m is a result of s. If so, we update the result set of s with m in the subscription table.
5.2 Experimental settings
Our experiments are conducted on two real datasets: FSQ and TWE. FSQ is a real-life dataset collected from Foursquare, which contains 4 million worldwide check-ins with both location and text description. The dataset TWE is a larger real-life dataset that comprises 40 million tweets with geo-locations.
The ATSK subscriptions are generated as follows. For each check-in (resp. tweet with geo-location), we randomly select a number of keywords from the check-in (resp. tweet) keywords, and the subscription location is the same as the corresponding check-in (resp. tweet with geo-location) location. Note that both the check-ins description and the tweets posted by the user may reveal the interests of the user and their locations are likely to represent the active spots of the user, and thus the subscription generated in this way would be close to real subscriptions. In addition, each check-in description together with its location is considered to be a spatio-temporal message on FSQ, and each tweet with geo-location is regarded as a spatio-temporal message on TWE.
Default value for each parameter involved in the experiments are presented in Table 3.
5.3 Experimental result
A1 the time effect
In this set of experiments, each index runs for 4,000 seconds on both FSQ and TWE. At the beginning, each algorithm is initialized with 2,000,000 and 10,000,000 subscriptions respectively for FSQ and TWE. During each second 5 spatio-temporal messages are issued and 5 subscriptions are issued and expired respectively. We report the average runtime for processing a message and the average runtime for inserting a subscription during each period of 500 seconds. Note that the decaying scale is set to 0.5. The value of decaying scale is related to the exponential decay function, which has been presented in (4). If we set the decaying scale to ds, then \(D^{-{\Delta } t_{sim}}=d_{s}\), where Δtsim is the duration of the simulation. In our experimental setting, Δtsim = 4000.
From Figure 8, we notice that both CIR and ACIR outperform the two baselines significantly in message processing, and ACIR exhibits the best performance. The reasons could be explained as follows.

Effect of time for message processing
For IFL, we need to check each postings in the postings lists the contain the keyword of the incoming spatio-temporal message. Its pruning technique is not able to consider the spatial proximity between the subscriptions and incoming messages. So the performance is the worst. In addition, ACIR performs moderately better than CIR. Such performance improvement is contributed by the grouping technique that takes advantage of the Approximate Conditional Influence Rings. Furthermore, we notice that the runtime of message processing for all structures exhibits an increasing trend as the time elapses. This is because that based on the exponential decaying function the values of Rs[k] for the subscriptions whose results are not updated will decrease as the time goes by, which may increase the number of subscriptions that can regard an incoming message as their results.
Figure 9 demonstrates the time cost of subscription insertion for each method. Because CIR and ACIR store subscriptions in the postings list maintained by each associating cell, the time costs of subscription insertion for CIR and ACIR are higher than IFL. However, according to the real-world publish/subscribe scenario, the frequency of subscription insertion is much lower than that of new messages. Consequently, the overall performance for CIR and ACIR still substantially outperforms the baseline.

Effect of time for subscription insert
A2 the number of subscription keywords
This set of experiments investigates the effect of the number of keywords on each method. Figure 10 demonstrates that all of the methods exhibit an increasing trend for the runtime of message processing as we increase the number of subscription keywords. The reason is that increasing the number of subscription keywords results in the increasing of the number of postings for indexing the subscription, which will extend posting lists.

Varying the number of subscription keywords
A3 effect of α
This set of experiments evaluates the effect of the subscription preference parameter α. A greater value of α denotes the greater weight on the spatial proximity. While a smaller value of α indicates more emphasis on the text similarity. We observe the similar trends on both datasets. More weight put on the spatial aspect will lower the textual pruning effectiveness and vice-versa (Fig. 11).

Effect of α
A4 effect of k
This experiment evaluates the performance w.r.t. the number of results maintained by each subscription. From Figure 12 we can find that the runtime for message processing slightly increases as we increase k. It can be explained by the fact that higher value of k is likely to induce the lower temporal spatial-keyword similarity score of the k-th message.

Varying the number of results for each subscription
6 Related work
Top-k spatial keyword search
Top-k spatial keyword query returns k most spatial-textual relevant geo-textual objects that are ranked by both spatial proximity and text relevancy between them and the query. A number of geo-textual indices have been developed to efficiently answer top-k spatial keyword queries [11, 18, 33, 61, 62]. There exits no sensible way to adopt these indexes to handle a stream of ATSK subscriptions. Moreover, Wu et al. [54] consider the problem of continuously answering moving top-k spatial keyword queries over a set of static geo-textual objects. The solution is to compute the safe zone based on a variant of Voronoi cells. The problem and solution are very different from ours.
Content based top-k publish/subscribe
Existing work on top-k publish/subscribe systems [2, 5, 14, 15, 32, 49] make published items trigger a subscription if it ranks among the top-k published items. The top-k publish/subscribe system [49] is similar to our setting, where the published items are tweets and the subscriptions are news. The published items do not have a fixed expiration time. Instead, time is a part of the relevance score, which decays as time passes. Older items retire from the top-k only when new items that score higher arrive and take their places. The inverted files are used as the indexes and the classic information retrieval methods are adapted for the filtering.
Some proposals on publish/subscribe [3, 20] in the literature consider spatio-temporal documents. The subscription contains a spatial circle and a set of keywords, and the published items are spatio-temporal documents. Published items trigger a subscription when they match both the keywords and spatial region of the subscription. In the setting, each subscription has a region and a set of keywords, and the problem is to maintain an index on the subscriptions such that the subscriptions matching an incoming spatio-temporal document can be efficiently retrieved. To do this, Chen et al. [3] present a hybrid index based on Quad-tree and Inverted files, and Li et al. [20] present a hybrid index based on R-tree and Inverted files. The problem is much easier than that for the top-k publish/subscribe, and the indexing methods and subscription matching algorithms cannot be employed to handle our subscriptions.
A different type of ranked publish/subscribe systems is introduced [31], which produces a ranked list of subscriptions for a published item, while we produce a ranked set of published items for each subscription. The subscriptions [31] are defined as interval ranges, and published items are points that match the intervals. The setting is very different from that in our work.
In the future, it is of interest to integrate text data with multiple spatial queries. First, it is of interest to integrate spatial trajectory data [23,24,25,26, 28, 29, 38, 45, 46, 48, 63, 64] with text data and to conduct novel spatio-textual trajectory search, recommendation, and analysis studies. Second, it is of interest to use POI data and geo-tagged social media data to discover significant locations/regions [13, 34, 35, 40, 44, 47, 51, 59]. Third, it is of interest to study integrate text data to routing problem [36, 37, 39, 41,42,43, 55, 58, 65] and to study spatio-textual routing problem. Fourth, it is of interest to consider streaming data sampling and analysis, and other query types [6, 8, 9, 16, 17, 21, 27, 30, 52, 53, 56, 57, 60].
7 Conclusions
We consider the problem of maintaining up-to-date most relevant spatio-temporal messages for a large number of location-based top-k subscriptions with a guaranteed approximation ratio of temporal spatial-keyword similarity sores between subscription and new messages. We define a brand new type of location-based top-k subscription, the ATSK subscription, that can automatically adjust the score of triggering condition by taking the scores of other subscriptions into account. As a result, the group filtering efficacy can be substantially improved at the cost of sacrificing the publishing result quality in a controlled range. We propose an efficient approach to processing a large number of ATSK subscriptions. The experimental results on two real-world datasets show that our solution is able to achieve a reduction of the processing time by 20%–70% compared with two baselines.
References
Amati, G., Amodeo, G., Gaibisso, C.: Survival analysis for freshness in microblogging search. In: CIKM, pp. 2483–2486. ACM (2012)
Chen, L., Cong, G.: Diversity-aware top-k publish/subscribe for text stream. In: SIGMOD, pp. 347–362 (2015)
Chen, L., Cong, G., Cao, X.: An efficient query indexing mechanism for filtering geo-textual data. In: SIGMOD, pp. 749–760 (2013)
Chen, L., Cong, G., Jensen, C.S., Wu, D.: Spatial keyword query processing: an experimental evaluation. In: PVLDB, pp. 217–228 (2013)
Chen, L., Cui, Y., Cong, G., Cao, X.: SOPS: A system for efficient processing of spatial-keyword publish/subscribe, vol. 7 (2014)
Chen, Z., Cafarella, M.J.: Integrating spreadsheet data via accurate and low-effort extraction. In: KDD, pp. 1126–1135 (2014)
Chen, L., Cong, G., Cao, X., Tan, K.: Temporal spatial-keyword top-k publish/subscribe. In: ICDE, pp. 255–266 (2015)
Chen, Z., Cafarella, M.J., Jagadish, H.V.: Long-tail vocabulary dictionary extraction from the Web. In: WSDM, pp. 625–634 (2016)
Chen, Z., Dadiomov, S., Wesley, R., Xiao, G., Cory, D., Cafarella, M.J., Mackinlay, J.: Spreadsheet property detection with rule-assisted active learning. In: CIKM, pp. 999–1008 (2017)
Christoforaki, M., He, J., Dimopoulos, C., Markowetz, A., Suel, T.: Text vs. space: Efficient geo-search query processing. In: CIKM, pp. 423–432 (2011)
Cong, G., Jensen, C.S., Wu, D.: Efficient retrieval of the top-k most relevant spatial Web objects. In: PVLDB, pp. 337–348 (2009)
Efron, M., Golovchinsky, G.: Estimation methods for ranking recent information. In: SIGIR, pp. 495–504. ACM (2011)
Guo, D., Zhu, Y., Xu, W., Shang, S., Ding, Z.: How to find appropriate automobile exhibition halls: Towards a personalized recommendation service for auto show. Neurocomputing 213, 95–101 (2016)
Haghani, P., Michel, S., Aberer, K.: Evaluating top-k queries over incomplete data streams. In: CIKM, pp. 877–886 (2009)
Haghani, P., Michel, S., Aberer, K.: The gist of everything new: Personalized top-k processing over Web 2.0 streams. In: CIKM, pp. 489–498 (2010)
Han, J., Zheng, K., Sun, A., Shang, S., Wen, J.: Discovering neighborhood pattern queries by sample answers in knowledge base. In: ICDE, pp. 1014–1025 (2016)
Hu, S., Wen, J., Dou, Z., Shang, S.: Following the dynamic block on the Web. World Wide Web 19(6), 1077–1101 (2016)
Felipe, I.D., Hristidis, V, Rishe, N.: Keyword search on spatial databases. In: ICDE, pp. 656–665 (2008)
Li, X., Croft, W.B.: Time-based language models. In: CIKM, pp. 469–475. ACM (2003)
Li, G., Wang, Y., Wang, T., Feng, J.: Location-aware publish/subscribe. In: KDD, pp. 802–810 (2013)
Li, Z., Shang, S., Xie, Q., Zhang, X.: Cost reduction for Web-based data imputation. In: DASFAA, pp. 438–452 (2014)
Liang, H., Xu, Y., Tjondronegoro, D., Christen, P.: Time-aware topic recommendation based on micro-blogs. In: CIKM, pp. 1657–1661 (2012)
Liu, K., Yang, B., Shang, S., Li, Y., Ding, Z: MOIR/UOTS: Trip recommendation with user oriented trajectory search. In: MDM, pp. 335–337 (2013)
Liu, K., Li, Y., Dai, J., Shang, S., Zheng, K.: Compressing large scale urban trajectory data. In: CloudDP@EuroSys, pp. 3:1–3:6 (2014)
Liu, K., Li, Y., Ding, Z., Shang, S., Zheng, K.: Benchmarking big data for trip recommendation. In: ICCCN, pp. 1–6 (2014)
Liu, J., Zhao, K., Sommer, P., Shang, S., Kusy, B., Jurdak, R.: Bounded quadrant system: Error-bounded trajectory compression on the go. In: ICDE, pp. 987–998 (2015)
Liu, J., Shang, S., Zheng, K., Wen, J.: Multi-view ensemble learning for dementia diagnosis from neuroimaging: An artificial neural network approach. Neurocomputing 195, 112–116 (2016)
Liu, J., Zhao, K., Sommer, P., Shang, S., Kusy, B., Lee, J., Jurdak, R.: A novel framework for online amnesic trajectory compression in resource-constrained environments. IEEE Trans. Knowl Data Eng. 28(11), 2827–2841 (2016)
Liu, A., Wang, W., Shang, S., Li, Q., Zhang, X.: Efficient task assignment in spatial crowdsourcing with worker and task privacy protection. GeoInformatica, online first, 1–28 (2017)
Liu, A., Shen, X., Li, Z., Xu, J., Zhao, L., Zheng, K., Shang, S.: Differential private collaborative Web services qos prediction. World Wide Web, online first, 1–25 (2018)
Machanavajjhala, A., Vee, E., Garofalakis, M., Shanmugasundaram, J.: Scalable ranked publish/subscribe. PVLDB 1(1), 451–462 (2008)
Pripužić, K., žarko, I.P., Aberer, K.: Top-k/w publish/subscribe: finding k most relevant publications in sliding time window w. In: DEBS, pp. 127–138 (2008)
Rocha-Junior, J.B., Gkorgkas, O., Jonassen, S., Nørvåg, K.: Efficient processing of top-k spatial keyword queries. In: SSTD, pp. 205–222 (2011)
Shang, S., Yuan, B., Deng, K., Xie, K., Zhou, X.: Finding the most accessible locations: Reverse path nearest neighbor query in road networks. In: ACM SIGSPATIAL, pp. 181–190 (2011)
Shang, S., Yuan, B., Deng, K., Xie, K., Zheng, K., Zhou, X: PNN query processing on compressed trajectories. GeoInformatica 16(3), 467–496 (2012)
Shang, S., Lu, H., Pedersen, T.B., Xie, X.: Finding traffic-aware fastest paths in spatial networks. In: SSTD, pp. 128–145 (2013)
Shang, S., Lu, H., Pedersen, T.B., Xie, X.: Modeling of traffic-aware travel time in spatial networks. In: MDM, pp. 247–250 (2013)
Shang, S., Ding, R., Zheng, K., Jensen, C.S., Kalnis, P., Zhou, X.: Personalized trajectory matching in spatial networks. VLDB J. 23(3), 449–468 (2014)
Shang, S., Liu, J., Zheng, K., Lu, H., Pedersen, T.B., Wen, J.: Planning unobstructed paths in traffic-aware spatial networks. GeoInformatica 19(4), 723–746 (2015)
Shang, S., Zheng, K., Jensen, C.S., Yang, B., Kalnis, P., Li, G., Wen, J.: Discovery of path nearby clusters in spatial networks. IEEE Trans Knowl Data Eng 27(6), 1505–1518 (2015)
Shang, S., Chen, L., Wei, Z., Guo, D., Wen, J.: Dynamic shortest path monitoring in spatial networks. J Comput Sci Technol 31(4), 637–648 (2016)
Shang, S., Chen, L., Wei, Z., Jensen, C.S., Wen, J., Kalnis, P: Collective travel planning in spatial networks. IEEE Trans. Knowl Data Eng 28(5), 1132–1146 (2016)
Shang, S., Guo, D., Liu, J., Wen, J.: Prediction-based unobstructed route planning. Neurocomputing 213, 147–154 (2016)
Shang, S., Guo, D., Liu, J., Zheng, K., Wen, J.: Finding regions of interest using location based social media. Neurocomputing 173, 118–123 (2016)
Shang, S., Chen, L., Wei, Z., Jensen, C.S., Zheng, K., Kalnis, P.: Trajectory similarity join in spatial networks. PVLDB 10(11), 1178–1189 (2017)
Shang, S., Chen, L., Jensen, C.S., Wen, J., Kalnis, P.: Searching trajectories by regions of interest. IEEE Trans. Knowl Data Eng. 29(7), 1549–1562 (2017)
Shang, S., Zhu, S., Guo, D., Lu, M.: Discovery of probabilistic nearest neighbors in traffic-aware spatial networks. World Wide Web 20(5), 1135–1151 (2017)
Shang, S, Chen, L, Wei, Z, Jensen, CS, Zheng, K., Kalnis, P: Parallel trajectory similarity joins in spatial networks. VLDB J, online first, 1–25 (2018)
Shraer, A., Gurevich, M., Fontoura, M., Josifovski, V.: Top-k publish-subscribe for social annotation of news. PVLDB 6(6), 385–396 (2013)
Wang, X., Zhang, Y., Zhang, W., Lin, X., Wang, W.: Ap-tree: Efficiently support continuous spatial-keyword queries over stream. In: ICDE, pp. 1107–1118 (2015)
Wang, Y., Li, J., Zhong, Y., Zhu, S., Guo, D., Shang, S.: Discovery of accessible locations using region-based geo-social data. WWW J, online first, pp. 1–18 (2018)
Wei, Z., Liu, X., Li, F., Shang, S., Du, X., Wen, J.: Matrix sketching over sliding windows. In: SIGMOD, pp. 1465–1480 (2016)
Wei, Z., He, X., Xiao, X., Wang, S., Shang, S., J. W. e. n.: Topppr: top-k personalized pagerank queries with precision guarantees on large graphs. In: SIGMOD, pp. 1–16 (2018)
Wu, D., Yiu, M.L., Jensen, C.S., Cong, G.: Efficient continuously moving top-k spatial keyword query processing. In: ICDE, pp. 541–552 (2011)
Xie, K., Deng, K., Shang, S., Zhou, X., Zheng, K.: Finding alternative shortest paths in spatial networks. ACM Trans. Database Syst. 37(4), 29:1–29:31 (2012)
Xie, Q., Shang, S., Yuan, B., Pang, C., Zhang, X.: Local correlation detection with linearity enhancement in streaming data. In: CIKM, pp. 309–318 (2013)
Xie, X., Lu, H., Chen, J., Shang, S.: Top-k neighborhood dominating query. In: DASFAA, pp. 131–145 (2013)
Yang, B., Guo, C., Jensen, C.S., Kaul, M., Shang, S.: Stochastic skyline route planning under time-varying uncertainty. In: ICDE, pp. 136–147 (2014)
Yao, B., Chen, Z., Gao, X., Shang, S., Ma, S., Guo, M.: Flexible aggregate nearest neighbor queries in road networks. In: ICDE, pp. 1–12 (2018)
Yao, B., Zheng, W., Wang, Z., Chen, Z., Shang, S., Zheng, K., Guo, M.: Distributed in-memory analytics for big temporal data. In: DASFAA, pp. 1–16 (2018)
Zhang, C., Zhang, Y., Zhang, W., Lin, X.: Inverted linear quadtree: Efficient top k spatial keyword search. In: ICDE, pp. 901–912 (2013)
Zhang, D., Tan, K. -L., Tung, A.K.H.: Scalable top-k spatial keyword search. In: EDBT, pp. 359–370 (2013)
Zheng, K., Zheng, Y., Yuan, N.J., Shang, S.: On discovery of gathering patterns from trajectories. In: ICDE, pp. 242–253 (2013)
Zheng, B., Wang, H., Zheng, K., Su, H., Liu, K., Shang, S.: Sharkdb: An in-memory column-oriented storage for trajectory analysis. World Wide Web 21(2), 455–485 (2018)
Zhu, S., Wang, Y., Shang, S., Zhao, G., Wang, J.: Probabilistic routing using multimodal data. Neurocomputing 253, 49–55 (2017)
Author information
Authors and Affiliations
Corresponding author
Additional information
This article belongs to the Topical Collection: Special Issue on Big Data Management and Intelligent Analytics
Guest Editors: Junping Du, Panos Kalnis, Wenling Li, and Shuo Shang
Rights and permissions
About this article

Cite this article
Chen, L., Shang, S. Approximate spatio-temporal top-k publish/subscribe. World Wide Web 22, 2153–2175 (2019). https://doi.org/10.1007/s11280-018-0564-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11280-018-0564-3