
Abstract
Epilepsy is a severe neurological disease which is diagnosed by analyzing Electroencephalogram. The epileptic seizure detection technique based on multiscale entropies and complete ensemble empirical mode decomposition (CEEMD) is proposed in this paper. CEEMD is used for the estimation of sub-bands and two multiscale entropies; multiscale dispersion entropy (MDE) and refined composite MDE are extracted from the sub-bands. The feature selection method, configured by hybridizing the filter based and wrapper based method, is used to select relevant multiscale entropies. The hybrid method has not only reduced features but also improved classification performance. An artificial neural network is trained with relevant features and performance is measured using classification accuracy, sensitivity and specificity. Five clinically relevant classification problems are used to assess the proposed technique. The performance is also compared with the state of the art techniques. The proposed technique has shown an improvement in detection of seizures and can be used to build the clinical system for epileptic seizure detection.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
One of the most common neurological diseases is epilepsy, which affects nearly 50 million people worldwide [1]. A person suffering from epilepsy experiences recurrent seizures due to the firing of the multiple neurons at a same time [2].This deeply affects the normal behavior and the cognitive process of a person [3]. Electroencephalogram (EEG) is one of the most effective techniques used for measuring the electrical activity of the brain for diagnosis of various neurological disorders like epilepsy, brain tumor, sleep disorders, encephalitis, and stroke [4]. EEG signals are recorded by placing electrodes either on the intracranial area or the scalp of the patients’ brain. Scalp-EEG measures the activities of the neurons which are nearer to the surface of the brain whereas intracranial EEG record activities of neurons which are deep inside of the brain [5]. In the case of epilepsy, long-term EEG monitoring is done, which results in the generation of a huge volume of EEG data. Manual analysis of such data is tedious and is much prone to errors due to its subjective nature which may lead to high medical expenditure and delay in treatment [6]. Thus, a computer-based diagnosis system for epilepsy not only reduces neurologists’ burden but also result in early diagnosis and medication of the patient.
Various techniques have been proposed for the diagnosis of epilepsy. Discrete Wavelet Transformation (DWT), which is widely used by researchers, decomposes a signal into sub-bands based on two parameters; mother wavelet function and level of decomposition. Seizure has been detected using spectral [7], statistics [8], entropy [9,10,11,12,13], line length [14] and spike [15] based features of wavelet coefficients. Recently, Subasi et al. [16] have used a combination of particle swarm optimization (PSO) and genetic algorithm (GA) to optimize support vector machine (SVM) along with the wavelet coefficients. Multiwavelet [17], Tunable-Q Wavelet Transform (TQWT) [18, 19] and Dual-Tree Complex Wavelet Transformation (DTCWT) [22] have also been employed to separate seizure free and seizure EEG signals. From the literature, it has been observed that the performance of wavelet based seizure detection techniques depends on the choice of mother wavelet function and the level of decomposition, and these are chosen through experimentations.
Empirical Mode Decomposition (EMD) is a data driven method that estimates sub-bands of a signal in the form of Intrinsic Mode Functions (IMFs) and these are highly localized in the time–frequency domain [20]. Numerous techniques have been developed for detection of an epileptic EEG signal, where different types of parameters have been extracted from IMFs. These include analytical and area representation [21, 22], mean frequency [23], amplitude and frequency based parameters [24, 25], higher order statics [26], second order difference plot [27], statistical parameters [28]. The major disadvantage of EMD is that it suffers from a mode mixing problem where oscillations belonging to the same mode get dispersed, and oscillations belonging to different modes get merged [29]. Ensemble Empirical Mode Decomposition (EEMD) overcomes the disadvantages of EMD by averaging the results of multiple EMD [29]. It has been employed for epilepsy detection where an average of marginal spectrums of IMFs is used for the classification of seizure free and seizure EEG signals [30]. The presence of residual noise in estimated IMFs and requirement of many iterations affects EEMD based epileptic seizure detection technique. To overcome this limitation, Complete Ensemble Empirical Mode Decomposition (CEEMD) is proposed by Colominas et al. [31].
Seizure detection techniques have also been developed without the usage of any decomposition techniques on EEG signals where entropy measures [32, 33], recurrence quantification analysis parameters [34], random sampling techniques [35], Discrete Probability Distribution Function (DPDF) [36], fractional linear prediction [37], Difference of Gaussian (DoG) [38] also have been used for separation of normal and abnormal EEG signals.
Entropy has been widely extracted from the estimated sub-bands of EEG signals for the diagnosis of epilepsy. Sample entropy (SaEn), permutation entropy (PEn), Rényi entropy (REn) and Shanon entropy (ShEn) have been widely used for the analysis of an epileptic EEG signal, where an epileptic EEG signal has shown more regular behavior than a normal EEG signal [9,10,11,12,13, 32, 36, 39]. These entropy measures quantify an EEG signal on the single scale [40], which are not able to represent dynamics of EEG signals completely. Multiscale entropy (MSE) overcomes the shortcomings of single scale entropies by measuring the dynamics of signals in different temporal scales [41]. In [42], multiscale PrEn (MPE) was proposed for the analysis of the pathological signal. Later, it was found that MSE and MPE do not fulfill the complexity criteria and they proposed a refined composite multiscale entropy (RCMSE) [43]. The RCMSE also overcomes the disadvantage of MSE where it was less sensitive to short pathological signals [44]. In [45], authors have analyzed that MSE and RSMSE were still resulting in undefined entropy values, high complexity and unstable nature for a short time series which was overcome with the development of multiscale dispersion entropy (MDE) and Refined Composite MDE (RCMDE).
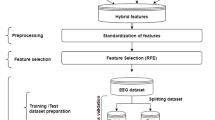
An epileptic seizure detection technique is proposed and tested on widely used open access EEG dataset (Sect. 2). An EEG signal is analyzed after decomposing it into sub-bands because information derived from EEG signal does not magnify its relevant properties [46]. CEEMD is employed on EEG signals to decompose them into a set of sub-bands, namely IMFs, because it is a data driven technique and does not suffer from a mode mixing problem (Sect. 3). Moreover, the resultant IMFs from CEEMD does not have residual noise. The effects on the dynamics of an EEG signal, due to the presence of seizures, are measured by extracting MDE and RCDME from IMFs (Sect. 4). In MDE and RCMDE, dispersion entropy is measured on a multiple scale, and it requires less computational cost than other entropy measures. Dispersion entropy is a fast entropy measure because it neither calculate distance between two composite delay vector and embedding dimension, nor it sorts the values of amplitude of each embedding vector [47]. The hybrid feature selection procedure is used to discard irrelevant entropy measures because it uses the advantage of both filter and wrapper method (Sect. 5). The artificial neural network is trained with selected relevant entropy measures for epileptic seizure detection (Sect. 6). The experimentation and results is discussed in Sects. 7, and 8 concludes results of the proposed technique.
2 Dataset
The well-known EEG dataset by Bonn University, Germany is used in study [48]. It comprised of five sets, namely A, B, C, D and E where each set contains 100 EEG signals of 23.6 s duration. The set A and set B were recorded, according to 10–20 international system, by placing the electrodes on the scalp of patients during relaxed state of healthy volunteers with eyes opened and closed. EEG recordings of other three sets belong to five patients for whom seizures were under control. Recordings of set C belong to the hippocampal formation of an opposite hemisphere, the set D belong to an epileptogenic zone during a normal stage of epileptic patients and set E belong to seizure activity. These EEG samples were segmented out from a continuous multichannel recordings after removal of artifacts due to eye and muscle movement (A and B) and electrodes containing pathological activity (C, D and E). The 128-channel system was used to record EEG signals, and each signal was digitized at a sampling frequency of 173.61 Hz by 12-bit analog to digital converter. The performance of the proposed technique has been evaluated using five classification problems (CPs) of the dataset. The brief descriptions and clinical relevance of the CPs are given below:
-
(a)
CP1 (AB vs. E): The EEG signals belonging to healthy volunteers (A and B) are separated from seizure EEG signals (E). This helps to discriminate normal and epileptic patients.
-
(b)
CP2 (CD vs. E): The seizure free EEG signals (C and D) belonging to patients are separated from seizure EEG signals (E). This CP helps to separate seizure free EEG signals and seizure EEG signals of epileptic patients.
-
(c)
CP3 (AB vs. CD): The EEG signals belonging to healthy volunteers (A and B) are separated from seizure free EEG signals of patients (C and D). This CP helps to separate an EEG signal of healthy people from seizure free EEG signals of epileptic patients.
-
(d)
CP4 (ABCD vs. E): The EEG signals belonging to healthy volunteers (A and B) and seizure EEG signals belonging to patients (C and D) are separated from seizure EEG signals of patients (E). In clinical practice, this CP helps to identify seizure EEG signals of epileptic patients.
-
(e)
CP5 (AB vs. CD vs. E): The EEG signals belonging to healthy volunteers (A and B), seizure free EEG signals from patients (C and D) and seizure EEG signals from patients (E) are separated from each other. This CP helps to discriminate healthy EEG signals, seizure free EEG signals of epileptic patients and seizure EEG signals of epileptic patients.
3 Complete Ensemble Empirical Mode Decomposition (CEEMD)
Empirical mode decomposition (EMD) is a data driven method which decomposes a signal into numbers of amplitude and frequency modulated patterns known as intrinsic mode functions (IMFs) and residual [20]. Each IMF satisfies two essential conditions where first the condition states that number of extreme points and number of zero crossing can be same or differ by one at most. The second condition states that the average value of local maxima and local minima define by envelope must be zero [20]. EMD suffers from mode mixing problem due to intermittency signals and noises, which makes it unstable. To overcome the problem of EMD, the EEMD was proposed by Wu and Huangin [29], where each IMF consists of the additional noise of finite amplitude. The addition of white noise to original signal largely eliminates mode mixing problem caused in EMD, but it results in different realizations of signal and noise which produces a different number of modes. In CEEMD, the final white noise residue is decreased by adding positive and negative noise in the original signal, and final \(IMF\)s are the accumulation of IMFs with positive and negative noise [49]. Let \(x\left( n \right)\) and \(v^{i} \left( n \right)\) denotes the signal (\(x\)) with \(n\) number of samples and white Gaussian noise with unit variance and zero mean. The \(i\) ranges from 1 to \(I\) represents different realization of white noise. The computation of IMFs with CEEMD comprises of following steps:
-
(a)
Calculate \(x\left( n \right) + \varepsilon_{0} v^{i} \left( n \right)\), where \(\varepsilon_{0}\) denotes the standard deviation of the white Gaussian noise.
-
(b)
The \(I\) signals are decomposed using EMD method and first \(IMF\) is obtained [Eq. (1)]
$$IMF_{1} = \frac{1}{I}\mathop \sum \limits_{j = 1}^{I} imf_{1}^{j} \left( n \right)$$(1) -
(c)
The first residual (\(r\)) is calculated by using Eq. (2)
$$r_{1} \left( n \right) = x\left( n \right) - IMF_{1} \left( n \right)$$(2) -
(d)
Decompose \(r_{1} \left( n \right) + \varepsilon_{1} E_{1} \left( {v^{i} \left( n \right)} \right)\) for \(i = 1, \ldots ,I\) up to its first EMD mode, where \(E_{k} \left( . \right)\) represent the extraction of kth EMD mode and \(\varepsilon_{k}\) is standard deviation of kth stage white gaussian noise. The \(IMF_{2} \left( n \right)\) is calculated as shown in Eq. (3).
$$IMF_{2} \left( n \right) = \frac{1}{I}\mathop \sum \limits_{j = 1}^{I} E_{1} (r_{1} \left( n \right) + \varepsilon_{1} E_{1} \left( {v^{i} \left( n \right)} \right)$$(3) -
(e)
The Eq. (4) shows the kth residue.
$$r_{k} \left( n \right) = r_{k - 1} \left( n \right) - IMF_{k} \left( n \right)$$(4) -
(f)
The \(\left( {k + 1} \right)th\) EMD mode is shown in Eq. (5), which is obtained after decomposition of \(r_{1} \left( n \right) + \varepsilon_{1} E_{1} \left( {v^{i} \left( n \right)} \right)\) for \(i = 1, \ldots ,I\) is shown in Eq. (5)
$$IMF_{k + 1} \left( n \right) = \frac{1}{I}\mathop \sum \limits_{j = 1}^{I} E_{1} (r_{k} \left( n \right) + \varepsilon_{k} E_{k} \left( {v^{i} \left( n \right)} \right)$$(5) -
(g)
Go to step e for next \(k\). The steps e to g are repeated until \(r\) become monotonic in nature and original can be written as shown in Eq. (6), where \(T\) is the total number of EMD modes and \(r_{k} \left( n \right)\) is final residue.
$$x\left( n \right) = \mathop \sum \limits_{k = 1}^{T} IMF_{k} \left( n \right) + r_{k} \left( n \right)$$(6)
4 Feature Extraction
Entropies are used to measure the uncertain and irregular nature of a signal. Its higher values depict the higher uncertainty and irregularity whereas lower values depict lower uncertainty and irregularity of a signal [47, 50, 51]. Most of the entropies measure an uncertainty on a single scale and fail to represent the signal. Azmi et al. [45] have proposed MDE which measures the Dispersion Entropy (DisEn) of a univariate signal on multiple scales by dividing it into a non-overlapping segment of size τ, where τ is known as a scale factor. Initially, coarse grain of a signal (\(s\)) is obtained by calculating the average of each segment [52] [Eq. (7), where \(s_{i}\) is ith sample of \(s\) and \(L\) is its sample size].
The DisEn of each coarse grain is calculated, where each sample of \(s\) is mapped to the range of 1 and \(c\) (number of classes) using Normal Cumulative Distribution Function (NCDF) and linear algorithm. After that times series are made with embedding dimension (\(m\)) and time delay (\(d\)). Each time series is assigned a dispersion pattern where possible number of dispersion patterns are equal to \(c^{m}\) [47]. Finally, DisEn of \(s\) are obtained using the concept of ShEn, as shown in (8). The \(p\left( {\pi_{{v_{0} \ldots v_{m - 1} }} } \right)\) denotes the number of dispersion patterns of \(\pi_{{v_{0} \ldots v_{m - 1} }}\). The detail mathematical explanation of MDE can be found in [45].
RCMDE is the value of ShEn of the mean of a sequence of dispersion patterns. For each scale factor (τ), a different time series corresponds to the different initial point of a coarse grain process is created where \(ith\) coarse grained series (\(s_{i}^{\left( \tau \right)} = \left\{ {s_{i,1}^{\left( \tau \right)} , s_{i,2}^{\left( \tau \right)} ,s_{i,3}^{\left( \tau \right)} \ldots } \right\}\)) of \({\text{s}}\) is (9) and RCMDE for each scale factor is calculated as (10). The relative frequency of a dispersion patterns is π in a series \(s_{i}^{\left( \tau \right)} \left( {1 \le i \le \tau } \right)\) and \(\bar{p}\left( {\pi_{{v_{0} \ldots v_{m - 1} }} } \right) = \frac{1}{\tau }\mathop \sum \nolimits_{1}^{\tau } p_{i}^{\left( \tau \right)}\)
5 Feature Selection
The presence of relevant and non-redundant features in data helps in the correct classification of test samples, the reduction of training time, data understanding and storage requirement [53, 54]. The redundant features append more noise to data than relevant information and irrelevant features increase classification time [55]. The feature selection methods mainly fall into three categories; filter, wrapper, and hybrid method. If a feature selection method works independently of a classifier, then it is known as filter based methods; otherwise wrapper method. The combination of filter and wrapper method, known as a hybrid method, is also used by exploiting their respective strengths [56]. The ReliefF and Sequential Backward Search (SBS) are combined to form the hybrid feature selection method. ReliefF algorithm is an extended version of Relief algorithm, where only one nearest hit/miss is chosen and limited to two class problems [57, 58]. The ReliefF algorithm selects an instance in a random fashion and then select k number of a neighbor from the same class (nearest hits) and k number of a neighbors from different classes (nearest misses) [59]. If the value of an attribute of nearest hits and a randomly selected sample is making fine discrimination among them, the weight of the respective attribute is decreased. On the other hand, if the value of an attribute of nearest misses and the randomly selected sample is making fine discrimination among them, the weight of the respective attribute is increased. The selection of nearest neighbor value is a crucial step in ReliefF, as it is deeply affected by the presence of irrelevant features and the noise [59]. The SBS is a wrapper method which selects the relevant and non-redundant features by considering the correlation dependencies of features, where two highly correlated features are considered redundant [60]. The pseudo code of proposed procedure used for feature selection is shown below:

ReliefF is applied to Data (\(D\)) by a set of nearest neighbor values, i.e. from one to \(k^{\prime}\) (line 1), to sort the features in descending order of their relevance (line 2 and 3). The ANN is used to measure the performance of sorted features (discussed in Sect. 6) and stored in \(M\) (line 4–6), wherein each iteration next relevant feature is added to the feature set. The best value of nearest neighbor (\(k_{b}\)) and its corresponding optimum feature set (\(f_{b}\)), which has provided the best performance, are chosen by extracting the index of a maximum of \(M\) (\(max_{index} \left( M \right) = \left\{ {\left( {p,q} \right): x_{p,q} = max\left( M \right)} \right\}\)). The \(p\) and \(q\) represent nearest neighbor value and feature set (line 8). In line 9, the best feature set (\(f_{b}^{'}\)) is chosen by applying SBS on \(D\) with \(f_{b}\) feature set (obtained using Relief with \(k_{b}\) nearest neighbors). If there are more than one value of \(k_{b}\) which show maximum performance, then the one with minimum \(f_{b}\) is chosen and if \(f_{b}\) will be the same then the minimum \(k_{b}\) is chosen.
6 Artificial Neural Network (ANN)
ANN is inspired by the biological neural network which deals with nonlinear data [61]. It consists of interconnected layers of neurons, which is used to perform computation in pattern recognition. It is one of the widely used classifiers for the classification of seizure in EEG signals [25, 26, 62]. The feedforward ANN is used in the proposed technique which comprises of three layers; input, hidden and an output layer. The size of an input layer depends on the number of input features and size of output layer depends on number classes present in CPs. The number of hidden neurons are fixed to 10 through experimentation. The scale conjugate gradient function is used to train ANN. The hyperbolic tangent sigmoid and soft max functions are used as the transfer function of a hidden and an output layer.
7 Results and Discussion
To test the proposed technique, five clinically significant CPs are formulated using well-known Bonn University EEG dataset. One EEG sample from each set is shown in Fig. 1. The CEEMD is used to estimate sub-bands of EEG signals in the form of IMFs and the first ten IMFs are used in this study. The estimated IMFs of one sample EEG from the set A and set E are shown in Figs. 2 and 3. The MDE and RCDME are extracted from each of the ten IMFs signals. While extracting entropies (MDE and RCDME), four parameters namely time delay \(d\), scale factor \(\tau\), embedding dimensions \(m\) and a number of classes \(c\) are required. The value of \(c\) can be a number between 3 and 9, because the number of dispersion patterns (\(c^{m}\)) should be less than the length of the signal [45]. It is chosen empirically for the proposed methodology. The value of \(d\) is recommended to be 1, because a greater value leads to aliasing, where some frequency information are discarded [47]. The larger value of \(m\) makes entropies algorithm unable to measure small changes whereas too small \(m\) leads entropies algorithm to a stage where they fail to measure dynamic changes of a signal [47]. The τ is fixed to 30 as suggested by Azami et al. in [45] for short signals. The significant entropies are chosen by using the feature selection method explained in Sect. 5. The chosen relevant features are fed to ANN, and performance is measure using classification accuracy (CA), sensitivity (SEN), and Specificity (SPEC) [25]. The Hold-out method is used to protect the ANN model from over-fitting where 60% dataset is used for training and 40% dataset is used for testing. The Hold-out method is repeated 20 times for better estimation of results. In each run, 60% and 40% of the dataset is randomly chosen for training and testing of the proposed technique. The results are compiled by averaging the results of 20 independent runs (mean ± standard deviation). Initially, the performance of MDE and RCMDE are analyzed individually for each CP5, therefore from each EEG sample, 300 values of the respective entropy measure are extracted which comprise of 30 entropies from each of the ten IMFs because the value of τ is set to 30.

An EEG sample from each set

IMFs of an EEG signal from set A

IMFs of an EEG signal from set E
The significance of features is assessed by one-way-analysis of variance (ANOVA) where features with p < 0.01 are considered relevant. Further, the feature selection method presented in the section is used to discard irrelevant and redundant features. The value of \(k^{\prime}\) is set to 50 because the value the nearest neighbor in ReliefF cannot set too high and near to a number of samples present in class, as it reduces the effect of the ReliefF algorithm [59]. Table 1 presents the performance of the proposed technique on CP5 when both entropy measures are extracted with the permissible values of \(c\). The reason for choosing CP5 is because it is the most crucial clinical problem as it separates EEG signals of all three classes namely; normal, seizure free and seizure. In Table 1, the entropy (\(c\)) represents the name of entropy measure, and the corresponding value of \(c\) used for calculation, ANOVA (dim) represents the number of features after applying one-way-ANOVA test, kb (CA,\(f_{b}\)) depicts the performance in the term of CA when the first \(f_{b}\) ranked features (obtained using kb nearest neighbor with ReliefF) are fed to ANN. The SBS (\(f_{b}^{'}\)) and CA shows the number of features obtained with SBS and its corresponding performance in the classification of EEG signals present in CP5. The bold values indicate the best accuracy which is obtained with RCDME entropy measure using parametric value c = 6.
Therefore, RCDME with \(c\) = 6 is considered for the evaluation of CP1 to CP4. More importantly, it has been observed that the feature selection method reduces the features by 83.67% as compared to the extracted features. The performance of the ReliefF used for the feature selection method on CP5 is shown in Fig. 4 where the best result (98% CA) is shown by first the 185 ranked features when 43 nearest neighbors (kb) are chosen. These 185 ranked features (\(f_{b}\)) are fed to SBS and 49 features (\(f_{b}^{'}\)) are chosen. The 49 selected features are used to train ANN and CA of 98.97% is observed. The performance of the proposed technique on CP1-CP4 is shown in Table 2, where for every CP, the proposed technique achieved very good results. It has also been noted that there is a reduction in features by more than 90% in CP1–CP4.

The performance of ReliefF in hybrid feature selection method on CP5
The presence of noise and dependent features in data demands a higher value of the nearest neighbor in the ReliefF algorithm [59]. For CP3, the feature selection method has found the value of kb equal to 1 (Table 2), whereas in other CPs its value is larger than 1. The CP3 is the only classification problem which does not classify ictal EEG signals. This shows that entropy measures of ictal EEG signals contain more noise and dependency in features.
The performance of the proposed technique has also been measured with EEG samples of different lengths which helps to identify the minimum length of EEG signal for acceptable performance [38]. First \(L\) numbers of samples are chosen from EEG signals for this experimentation. The robustness of proposed technique against the length of EEG sample is presented in Table 3. The 1500 samples (8.64 s) are considered as minimum sample length because an EEG signal is confirmed as abnormal if the abnormality persists for 6–10 s [63]. It has been observed from Table 3 that the proposed technique is able to detect seizure even with small segments of the EEG signals.
The proposed technique is also compared with the state of the art techniques for epileptic seizure detection (Table 4). Only those techniques are considered for comparisons that have used the same EEG dataset. From Table 4, it is evident that the proposed seizure detection technique performs better than all other techniques in terms of CA. In [12], authors have employed DWT for the estimation of sub-bands, and ApEn of sub-band were used to train ANN and SVM. A CA of 94% was reported in the separation of EEG signals in CP4, and 95% was reported for the separation of the interictal (set D) and the ictal (set E) stage. A CA of 100% was reported in [27] when a combination of EMD and SODP with ANN was used for the separation of EEG signals in CP3. Samiee et al. [64] proposed a Fourier based technique for the seizure detection which was evaluated on five two class CPs where CA of 99.80%, 99.30%, 98.50%, 94.90% and 98.10% was reported. Extreme machine learning (ELM) was trained with SaEn of wavelet coefficients in [65], where CA of 100% was reported for the separation of normal EEG (set A) and seizure EEG (set E). A CA of 99.25% was also reported for the separation of EEG signals in CP4. In [66], wavelet coefficients obtained using DTCWT was reduced by extracting their respective SP and ANN was trained for the classification of epileptic EEG signals. A CA of 99.33% was observed while classifying EEG signals in CP4, whereas CA of 98.28% was noted for CP5. The ANN trained with SP of IMFs have reported CA of 100% and 97.70% for the classification of normal (set A) and abnormal (set E) epileptic EEG samples, and interictal (set D) and ictal (set E) EEG signals, respectively [28]. In other work [35], LS–SVM was trained with SP of EEG signals and classified the EEG samples into normal (set A) and abnormal (set E) with 100% CA. In [38], authors performed a classification with a combination of DoG and SVM in four CPs where CA of 100%, 99.45%, 99.31% and 98.80% was reported for CP1, CP2, CP4, and CP5, respectively. Goa et al. [33] presented a technique for epileptic seizure detection based on visibility graphs with CA of 100% and 98% for CP1 and CP2. The combination DWT and Fourier transformation with k-NN classifier reported 100% CA in CP1, CP2 and CP4 [67] but the results were presented without cross-validation. A CA of 96.75% for CP3 was reported by Redelico et al. [36] with PEn based seizure detection technique. The k-NN entropy from wavelet coefficients was obtained to train SVM, and CA of 99% and 98.60% was reported for CP4 and CP5. The normal (set A and B) and interictal (set C and D) EEG signals were separated from ictal EEG signals with 100%, 99.5% and 98% CA [18]. In [16], a combination of PSO and GA was used to optimize SVM when it was fed with wavelet coefficients, and CA of 99.38% was reported while separating normal (set A) and ictal (set E) EEG signals. The sum of time variance and frequency variance and Wavelet Filter Bank (WFB) is used for separation non-seizure and seizure EEG signals in CP3 [68]. In [69], an epileptic seizure detection algorithm based on log-normal distribution (LND) model and maximal overlap discrete wavelet transform (MODWT) was proposed, and CAs of 99.10% and 98.10% were reported for CP4 and CP5. Sharma et al. [70] have presented a seizure detection method based on MMSFL-OWFB (minimally mean squared frequency localized-optimal orthogonal wavelet filter banks) where CA of 99.00% and 99.20% in CP2 and CP4 were reported, respectively. In [71], the combination of Wavelet Packet Decomposition (WPD) and fuzzy distribution entropy (fDistEn) was used for seizure classification, and proposed method performed better in most of the cases except CP4, where it is marginally less.
Most of these methods are based on EMD and wavelet based transformation, used for the estimation of sub-bands which suffers from a mode mixing problem, dependence on mother wavelet function and level of decomposition. Single scale entropies are also widely used with the combination EMD and wavelet transformation which does not measure the dynamics of EEG signal completely. The following are highlights of the proposed seizure detection technique:
-
The proposed seizure detection technique performs better than all state of the art seizure detection technique for all clinically relevant classification problems. The final performance is compiled by averaging results of the twenty independent runs.
-
In proposed technique, CEEMD is used for signal decomposition and multiscale entropies are extracted from decomposed signals. CEEMD overcomes the disadvantages of EMD and wavelet transformation, where these techniques suffer from mode mixing problem, dependence on mother wavelet and decomposition level. The usage of multiscale entropy measures also overcomes the signal scale entropies as these are unable to measure the dynamics of EEG signal completely.
-
The robustness of the proposed technique is also measured using an EEG signal of different length where it shows good performance with small EEG signals. The comparison with the state of the art seizure detection technique also validates the results of proposed techniques.
-
A hybrid feature selection method is presented, which not only decreases features but also improve the classification performance. In the future, this technique could be used for the other classification problems in the future.
8 Conclusion
The epileptic seizure detection technique based on multiscale entropy and CEEMD is presented in this paper. The performance is measured on the five clinically relevant cases: separating of normal and seizure prone EEG signals; separating seizure free and seizure EEG signals of epileptic patients; separating EEG signals of normal people and seizure free EEG signals of epileptic patients; separating normal and seizure free EEG signals from epileptic EEG signals; and separating normal seizure free and epileptic EEG signals. EEG signals are decomposed into set of IMFs using CEEMD to overcome the disadvantages of EMD, EEMD and DWT. Multiscale entropies, namely MDE and RCDME, are extracted from IMFs to measure dispersion entropy of a signal on multiple scale, and moreover, it is also faster than other multiscale entropies. Multiscale entropies also measure the complexity and dynamics of signals where single scale entropy measures fail. The hybrid feature selection method, used in proposed technique, reduced the features by more than 90% in four clinical cases and by 83.67% in the fifth case. The feature selection method not only helped to remove redundant, irrelevant features and improve classification performance, but also helped to reduce the classification time eventually. The robustness of proposed technique is also tested on the EEG signals of different sample lengths. The results are also compared with the state of the art seizure detection techniques, where the proposed technique has outperformed. The better performance of proposed technique concludes that multiscale entropies measure the dynamic behavior of epileptic EEG signals better than single scale entropies. The less sensitive nature of the proposed technique to EEG sample length and high accuracy makes the proposed technique more desirable for clinical applications for seizure detection. In the future, the proposed technique can also be tested on other physiological signals for diagnosis of other diseases, and it can be tested on long term epileptic dataset.
References
Epilepsy. (2017). http://www.who.int/mediacentre/factsheets/fs999/en/. Accessed October 25, 2017.
Dastidar, S. G., Adeli, H., & Dadmehr, N. (2007). Mixed band wavelet chaos neural network methodology for epilepsy and epileptic seizure detection. IEEE Transactions on Biomedical Engineering, 54, 1545–1551. https://doi.org/10.1109/TBME.2007.891945.
Motamedi, G., & Meador, K. (2003). Epilepsy and cognition. Epilepsy & Behavior, 4, 25–38. https://doi.org/10.1016/j.yebeh.2003.07.004.
Electroencephalogram. (2018). https://www.healthline.com/health/eeg. Accessed January 2, 2018.
Shoeb, A. H. (2009). Application of machine learning to epileptic seizure onset detection and treatment. Cambridge: Massachusetts Institute of Technology.
Patnaik, L. M., & Manyam, O. K. (2008). Epileptic EEG detection using neural networks and post-classification. Computer Methods and Programs in Biomedicine, 91, 100–109. https://doi.org/10.1016/j.cmpb.2008.02.005.
Güler, I., & Ubeyli, E. D. (2005). Adaptive neuro-fuzzy inference system for classification of EEG signals using wavelet coefficients. Journal of Neuroscience Methods, 148, 113–121. https://doi.org/10.1016/j.jneumeth.2005.04.013.
Übeyli, E. D. (2008). Wavelet/mixture of experts network structure for EEG signals classification. Expert Systems with Applications, 34, 1954–1962. https://doi.org/10.1016/j.eswa.2007.02.006.
Ocak, H. (2008). Optimal classification of epileptic seizures in EEG using wavelet analysis and genetic algorithm. Signal Processing, 88, 1858–1867. https://doi.org/10.1016/j.sigpro.2008.01.026.
Ocak, H. (2009). Automatic detection of epileptic seizures in EEG using discrete wavelet transform and approximate entropy. Expert Systems with Applications, 36, 2027–2036. https://doi.org/10.1016/j.eswa.2007.12.065.
Song, Y., & Zhang, J. (2013). Automatic recognition of epileptic EEG patterns via extreme learning machine and multiresolution feature extraction. Expert Systems with Applications, 40, 5477–5489. https://doi.org/10.1016/j.eswa.2013.04.025.
Kumar, Y., Dewal, M. L., & Anand, R. S. (2014). Epileptic seizures detection in EEG using DWT-based ApEn and artificial neural network. Signal, Image Video Process, 8, 1323–1334. https://doi.org/10.1007/s11760-012-0362-9.
Kumar, Y., Dewal, M. L., & Anand, R. S. (2014). Epileptic seizure detection using DWT based fuzzy approximate entropy and support vector machine. Neurocomputing, 133, 271–279. https://doi.org/10.1016/j.neucom.2013.11.009.
Guo, L., Rivero, D., Dorado, J., Rabunal, J. R., & Pazos, A. (2010). Automatic epileptic seizure detection in EEGs based on line length feature and artificial neural networks. Journal of Neuroscience Methods, 191, 101–109. https://doi.org/10.1016/j.jneumeth.2010.05.020.
Singh, G., Kaur, M., & Singh, D. (2016). Detection of epileptic seizure using wavelet transformation and spike based features. In 2015 2nd international conference on recent advances in engineering computing science RAECS 2015, pp. 1–4. https://doi.org/10.1109/raecs.2015.7453376.
Subasi, A., Kevric, J., & Abdullah, Canbaz M. (2017). Epileptic seizure detection using hybrid machine learning methods. Neural Computing and Applications. https://doi.org/10.1007/s00521-017-3003-y.
Guo, L., Rivero, D., & Pazos, A. (2010). Epileptic seizure detection using multiwavelet transform based approximate entropy and artificial neural networks. Journal of Neuroscience Methods, 193, 156–163. https://doi.org/10.1016/j.jneumeth.2010.08.030.
Bhattacharyya, A., Pachori, R., Upadhyay, A., & Acharya, U. (2017). Tunable-Q wavelet transform based multiscale entropy measure for automated classification of epileptic EEG signals. Applied Science, 7, 385. https://doi.org/10.3390/app7040385.
Sharma, M., & Pachori, R. B. (2017). A novel approach to detect epileptic seizures using a combination of tunable-Q wavelet transform and fractal dimension. Journal of Mechanics in Medicine and Biology, 17, 1740003. https://doi.org/10.1142/S0219519417400036.
Huang, N. E., Shen, Z., Long, S. R., Wu, M. C., Shih, H. H., Zheng, Q., et al. (1998). The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proceeding of Royal Society of London, 454, 903–995. https://doi.org/10.1098/rspa.1998.0193.
Pachori, R. B., & Varun, B. (2011). Analysis of normal and epileptic seizure EEG signals using empirical mode decomposition. Computer Methods and Programs in Biomedicine, 104, 373–381. https://doi.org/10.1016/j.cmpb.2011.03.009
Sharma, R., & Pachori, R. B. (2015). Classification of epileptic seizures in EEG signals based on phase space representation of intrinsic mode functions. Expert Systems with Applications, 42, 1106–1117. https://doi.org/10.1016/j.eswa.2014.08.030.
Pachori, R. B. (2008). Discrimination between ictal and seizure-free EEG signals using empirical mode decomposition. Research Letters in Signal Processing, 2008, 1–5. https://doi.org/10.1155/2008/293056.
Bajaj, V., & Pachori, R. B. (2012). Classification of seizure and nonseizure EEG signals using empirical mode decomposition. IEEE Transactions on Information Technology in Biomedicine, 16, 1135–1142. https://doi.org/10.1109/TITB.2011.2181403.
Kaur, M., & Singh, G. (2017). Classification of seizure prone EEG signal using amplitude and frequency based parameters of intrinsic mode functions. Journal of Medical and Biological Engineering, 37, 540–553. https://doi.org/10.1007/s40846-017-0275-8.
Alam, S. M. S., & Bhuiyan, M. I. H. (2013). Detection of seizure and epilepsy using higher order statistics in the EMD domain. IEEE Journal of Biomedical Health Informatics, 17, 312–318. https://doi.org/10.1109/JBHI.2012.2237409.
Pachori, R. B., & Patidar, S. (2014). Epileptic seizure classification in EEG signals using second-order difference plot of intrinsic mode functions. Computer Methods and Programs in Biomedicine, 113, 494–502. https://doi.org/10.1016/j.cmpb.2013.11.014.
Djemili, R., Bourouba, H., & Amara Korba, M. C. (2016). Application of empirical mode decomposition and artificial neural network for the classification of normal and epileptic EEG signals. Biocybernetics and Biomedical Engineering, 36, 285–291. https://doi.org/10.1016/j.bbe.2015.10.006.
Wu, Z., & Huang, N. E. (2005). Ensemble empirical mode decomposition: a noise-assisted data analysis method. Advances in Adaptive Data Analysis, 1, 1–41. https://doi.org/10.1142/S1793536909000047.
Bizopoulos, P. A., Tsalikakis, D. G., Tzallas, A. T., Koutsouris, D. D., & Fotiadis, D. I. (2013). EEG epileptic seizure detection using k-means clustering and marginal spectrum based on ensemble empirical mode decomposition. In 13th IEEE international conference on bioinformatics and bioengineering, pp. 1–4. https://doi.org/10.1109/bibe.2013.6701528.
Colominas, M. A., Schlotthauer, G., & Torres, M. E. (2014). Improved complete ensemble EMD: a suitable tool for biomedical signal processing. Biomedical Signal Processing and Control, 14, 19–29. https://doi.org/10.1016/j.bspc.2014.06.009.
Sree, S. V., Ang, P. C. A., Yanti, R., & Suri, J. S. (2012). Application of non-linear and wavelet based features for the automated identification of epileptic EEG signals. International Journal of Neural Systems. https://doi.org/10.1142/s0129065712500025.
Gao, Z.-K., Cai, Q., Yang, Y.-X., Dong, N., & Zhang, S.-S. (2017). Visibility graph from adaptive optimal kernel time-frequency representation for classification of epileptiform EEG. International Journal of Neural Systems, 27, 1750005. https://doi.org/10.1142/S0129065717500058.
Acharya, U. R., Sree, S. V., Chattopadhyay, S., Yu, W., & Ang, P. C. A. (2011). Application of recurrence quantification analysis for the automated identification of epileptic EEG signals. International Journal of Neural Systems, 21, 199–211. https://doi.org/10.1142/S0129065711002808.
Al Ghayab, H. R., Li, Y., Abdulla, S., Diykh, M., & Wan, X. (2016). Classification of epileptic EEG signals based on simple random sampling and sequential feature selection. Brain Informatics, 3, 85–91. https://doi.org/10.1007/s40708-016-0039-1.
Redelico, F. O., Traversaro, F., García M del, C., Silva, W., Rosso, O. A., & Risk, M. (2017). Classification of normal and pre-ictal EEG signals using permutation entropies and a generalized linear model as a classifier. Entropy, 1, 1. https://doi.org/10.3390/e19020072.
Joshi, V., Pachori, R. B., & Vijesh, A. (2014). Classification of ictal and seizure-free EEG signals using fractional linear prediction. Biomedical Signal Processing and Control, 9, 1–5. https://doi.org/10.1016/j.bspc.2013.08.006.
Tiwari, A. K., Pachori, R. B., Kanhangad, V., & Panigrahi, B. K. (2017). Automated diagnosis of epilepsy using key-point based local binary pattern of EEG signals. IEEE Journal of Biomedical and Health Informatics, 21, 888–896. https://doi.org/10.1109/JBHI.2016.2589971.
Sharma, R., Pachori, R. B., & Rajendra, Acharya U. (2015). An integrated index for the identification of focal electroencephalogram signals using discrete wavelet transform and entropy measures. Entropy, 17, 5218–5240. https://doi.org/10.3390/e17085218.
Shannon, C. E. (2001). A mathematical theory of communication. ACM SIGMOBILE Mobile Computing and Communications, 5, 3–55. https://doi.org/10.1145/584091.584093.
Costa, M., Goldberger, A. L., & Peng, C. (2002). Multiscale entropy analysis of complex physiologic time series. Physical Review Letters, 89, 068102. https://doi.org/10.1103/PhysRevLett.89.068102.
Morabito, F. C., Labate, D., La Foresta, F., Bramanti, A., Morabito, G., & Palamara, I. (2012). Multivariate multi-scale permutation entropy for complexity analysis of Alzheimer’s disease EEG. Entropy, 14, 1186–1202. https://doi.org/10.3390/e14071186.
De, Wu S, Wu, C. W., & Humeau-Heurtier, A. (2016). Refined scale-dependent permutation entropy to analyze systems complexity. Physica A: Statistical Mechanics and its Applications, 450, 454–461. https://doi.org/10.1016/j.physa.2016.01.044.
De, Wu S, Wu, C. W., Lin, S. G., Lee, K. Y., & Peng, C. K. (2014). Analysis of complex time series using refined composite multiscale entropy. Physics Letters, Section A: General, Atomic and Solid State Physics, 378, 1369–1374. https://doi.org/10.1016/j.physleta.2014.03.034.
Azami, H., Rostaghi, M., Abasolo, D., & Escudero, J. (2017). Refined composite multiscale dispersion entropy and its application to biomedical signals. IEEE Transactions on Biomedical Engineering, 64, 2872–2879. https://doi.org/10.1109/TBME.2017.2679136.
Mainardi, L. T., Bianchi, L. M., & Cerutti, S. (2012). Digital biomedical signal acquisition and processing. In H. Liang, J. D. Bronzino, & D. R. Peterson (Eds.), Biosignal processing principles and practice. Boca Raton: CRC Press.
Rostaghi, M., & Azami, H. (2016). Dispersion entropy: A measure for time series analysis. IEEE Signal Processing Letters, 23, 610–614. https://doi.org/10.1109/LSP.2016.2542881.
Andrzejak, R. G., Lehnertz, K., Mormann, F., Rieke, C., David, P., & Elger, C. E. (2001). Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Physical Review E, 64, 061907. https://doi.org/10.1103/PhysRevE.64.061907.
Torres, M. E., Colominas, M., Schlotthauer, G., & Flandrin, P. (2011). A complete ensemble empirical mode decomposition with adaptive noise. In IEEE international conference on acoustics, speech, and signal processing, pp. 4144–4147. https://doi.org/10.1109/ICASSP.2011.5947265.
Richman, J., & Moorman, J. (2000). Physiological time-series analysis using approximate entropy and sample entropy. American Journal of Physiology-Heart and Circulatory, 278, H2039–H2049. https://doi.org/10.1152/ajpheart.2000.278.6.H2039.
Sanei, S., & Chambers, J. (2007). EEG signal processing. Hoboken: Wiley.
Costa, M., Goldberger, A. L., & Peng, C.-K. (2005). Multiscale entropy analysis of biological signals. Physical Review E: Statistical, Nonlinear, and Soft Matter Physics, 71, 21906. https://doi.org/10.1103/PhysRevE.71.021906.
Jain, A., & Zongker, D. (1997). Feature selection: Evaluation, application, and small sample performance. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19, 153–158. https://doi.org/10.1109/34.574797.
Peng, Y., Wu, Z., & Jiang, J. (2010). A novel feature selection approach for biomedical data classification. Journal of Biomedical Informatics, 43, 15–23. https://doi.org/10.1016/j.jbi.2009.07.008.
Tiwari, S., Singh, B., & Kaur, M. (2017). An approach for feature selection using local searching and global optimization techniques. Neural Computing and Applications, 28, 2915–2930. https://doi.org/10.1007/s00521-017-2959-y.
Sebban, M., & Nock, R. (2013). A hybrid filter/wrapper approach of feature selection using information theory. Journal of Chemical Information and Modeling, 53, 1689–1699. https://doi.org/10.1017/CBO9781107415324.004.
Kira, K., & Rendell, L. (1992). A practical approach to feature selection. In Proceedings of ninth international workshop on machine learning, pp. 249–56. https://doi.org/10.1016/B978-1-55860-247-2.50037-1.
Kira, K., & Rendell, L. (1992). The feature selection problem: Traditional methods and a new algorithm. In Proceedings of tenth national conference on artificial intelligence, pp. 129–34.
Kononenko, I. (1994). Estimating attributes: Analysis and extensions of RELIEF. In Proceedings of 7th European conference of machine learning, pp. 171–182. https://doi.org/10.1007/3-540-57868-4_57.
Hall, M. (1999). Correlation-based feature selection for machine learning. Hamilton: University of Waikato.
Guo, P. T., Wu, W., Sheng, Q. K., Li, M. F., Liu, H. B., & Wang, Z. Y. (2013). Prediction of soil organic matter using artificial neural network and topographic indicators in hilly areas. Nutrient Cycling in Agroecosystems, 95, 333–344. https://doi.org/10.1007/s10705-013-9566-9.
Singh, G., Kaur, M., & Singh, D. (2015). Detection of epileptic seizure using wavelet transformation and spike based features. In 2015 2nd international conference on recent advances engineering and computer science, pp. 1–4. https://doi.org/10.1109/raecs.2015.7453376.
Shoeb, A. H., & Guttag, J. V. (2010). Application of machine learning to epileptic seizure detection. In Proceedings of 27th international conference on machine learning, pp. 975–82.
Samiee, K., Kovács, P., & Gabbouj, M. (2015). Epileptic seizure classification of EEG time-series using rational discrete short-time fourier transform. IEEE Transactions on Biomedical Engineering, 62, 541–552. https://doi.org/10.1109/TBME.2014.2360101.
Zheng, Y., Yuting, Z., Wang, J., & Zheng, X. (2015). Comparison of classification methods on EEG signals based on wavelet packet decomposition. Neural Computing and Applications, 26, 1217–1225. https://doi.org/10.1007/s00521-014-1786-7.
Peker, M., Sen, B., & Delen, D. (2016). A novel method for automated diagnosis of epilepsy using complex-valued classifiers. IEEE Journal of Biomedical and Health Informatics, 20, 108–118. https://doi.org/10.1109/JBHI.2014.2387795.
Chen, G., Xie, W., Bui, T. D., & Krzyżak, A. (2017). Automatic epileptic seizure detection in EEG using nonsubsampled wavelet-Fourier features. Journal of Medical and Biological Engineering, 37, 123–131. https://doi.org/10.1007/s40846-016-0214-0.
Bhati, D., Pachori, R. B., & Gadre, V. M. (2017). A novel approach for time–frequency localization of scaling functions and design of three-band biorthogonal linear phase wavelet filter banks. Digital Signal Processing A Review Journal, 69, 309–322. https://doi.org/10.1016/j.dsp.2017.07.008.
Li, M., Chen, W., & Zhang, T. (2017). Application of MODWT and log-normal distribution model for automatic epilepsy identification. Biocybernetics and Biomedical Engineering, 37, 679–689. https://doi.org/10.1016/j.bbe.2017.08.003.
Sharma, M., Bhurane, A. A., & Acharya, U. R. (2018). MMSFL-OWFB: A novel class of orthogonal wavelet filters for epileptic seizure detection. Knowledge-Based Systems, 160, 265–277. https://doi.org/10.1016/j.knosys.2018.07.019.
Zhang, T., Chen, W., & Li, M. (2018). Fuzzy distribution entropy and its application in automated seizure detection technique. Biomedical Signal Process Control, 39, 360–377. https://doi.org/10.1016/j.bspc.2017.08.013.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Singh, G., Kaur, M. & Singh, B. Detection of Epileptic Seizure EEG Signal Using Multiscale Entropies and Complete Ensemble Empirical Mode Decomposition. Wireless Pers Commun 116, 845–864 (2021). https://doi.org/10.1007/s11277-020-07742-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-020-07742-z