
Abstract
This paper presents a novel speech enhancement approach by combining Fourier series expansion and spectral subtraction. This approach is implemented in speaker identification systems where degraded speech could result in high false speaker identifications. A Fourier series is estimated for the noisy speech signals, and then spectral subtraction is used to reduce the amount of noise in order to enhance quality of the speech signals before the speaker identification process. Experimental results presented to compare between the proposed approach and the traditional methods demonstrate the ability of the proposed approach to both enhance speech quality and improve speaker recognition rates.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
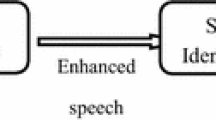
Noise is a random, undesirable signal that does not convey any useful information. If it is superimposed on the speech signal, it leads to some distortion in the signal. This may lead to poor intelligibility and poor hearing of the speech. Therefore, the ability to communicate between speaker and listener is reduced in noisy environments. Noise may originate from crosstalk speech, interference from other sources of sound, or mismatch between media utilized in the operation. Presence of noise has a severe impact on Speaker Identification (SI) system performance leading to a dramatical reduction in the recognition rate. Therefore, speech enhancement is crucial for such systems, and it is usually utilized as a pre-processing step in such systems for performance enhancement, as shown in Fig. 1.

Speaker identification system with a priori speech enhancement stage
Various speech enhancement methods have been adopted for noise reduction in speech signals. Spectral subtraction is among the popular and commonly used methods for speech enhancement [1]. It depends on subtracting the magnitude of the spectrum of the noise from that of the noisy signal, while keeping the phase [2]. However, this method suffers from the so-called musical noise, which is difficult to be omitted [3]. Wiener filtering is another speech enhancement method that depends on minimizing the Mean Square Error (MSE) between the source and estimated speech signals. However, the Wiener filter requires prior estimation of the noise level in the signal before filtering [4], for which it is not suitable for real-time operation.
This paper presents a combination of Fourier series decomposition and spectral subtraction to enhance the speech signals and improve the SI process.
2 Spectral Subtraction
An estimation of clean speech signal spectrum can be obtained by subtracting an estimate of noise spectrum from the noisy speech spectrum [5]. An estimation of the noise spectrum can be perceived during silence periods, which contain only background noise generally found at the beginning and end of recording.
Let,
where \(o(n)\) is the non-clean speech signal, which is a combination of the noise \(v(n)\) and the clean speech signal \(s(n).\)
Taking FFT,
Then \(S(\omega )\) can be written as
It is assumed that phase of the noise signal \(\theta_{v}\) equals the phase of the noisy speech signal \(\theta_{o}\).
where \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{S} (\omega )\) is the estimated spectrum of the clean signal and \(\mu (\omega )_{{}} =_{{}} mean_{{}} \left\{ {_{{}} \left| {V(\omega )} \right|_{{}} } \right\}\) is the average value taken during a non-speech period.
By taking inverse FFT, we get an estimation of the clean speech signal \(s(n)\).
The performance of the spectral subtraction is greatly dependent on the amount of estimated noise. If estimated noise is too low, residual noise can still be heard, and also if estimated noise is too high, some useful information might be lost.
The main drawback of spectral subtraction method is the presence of musical noise in the enhanced signal. Musical noise is difficult to be reduced since the musical noise spectrum is not stationary in short time frames [3].
3 Wiener Filter
Wiener filter is defined in the frequency domain. We can have [6]:
where \(S(\omega )\) is the Discrete Fourier Transform (DFT) of the clean signal, \(X(\omega )\) is the DFT of the noisy signal, and \(H(\omega )\) is the transfer function of the Wiener filter.
The Wiener filter is given by:
where \(P_{v} (\omega )\) is the power spectrum of the noise \(v(n)\), and \(P_{s} (\omega )\) is the power spectrum of the speech signal \(s(n).\)
The Signal-to-Noise Ratio (SNR) can be expressed as:
Then, the transfer function \(H(\omega )\) of the Wiener filter is obtained as:
The main drawbacks of the Wiener filter are that it has a fixed frequency response at all frequencies, and also it requires estimation of the noise prior to filtering [3], for which it is not suitable for real-time operation. Wiener filtering has superior enhancement results compared to those of the spectral subtraction method, resulting in more acceptable hearing of the utterance with less noticeable noise. However, the speech signal spectrum processed by spectral subtraction is more like the clean signal spectrum than the Wiener filter output spectrum. That is why the spectral subtraction method gives better performance in speaker recognition systems, which are frequency-dependent.
4 The Fourier Series
Fourier series decomposes the signal into a (possibly infinite) number of simple harmonic functions called sines and cosines [7]. These harmonics have amplitudes and frequencies covering a wide range (possibly whole) of the spectrum; the frequency of one harmonic is higher than the frequency of last one. Fortunately, only a finite number of these harmonics could describe (approximate) the signal with possibly some distortion. The higher the number of harmonics taken to describe the signal, the lower the amount of distortion that appears in the signal (Fig. 2). The number of harmonics taken to approximate the signal is called the order of the Fourier series.

Signal approximation with Fourier series with different orders
4.1 Fourier Series Expansion
The Fourier series of a discrete signal \(y(k)\) is given by:
where \(M\) is the order of the Fourier series, \(1 \le M < \infty\), \(L\) is the length of the signal, and
The term \(a_{m} \cos \left( {\frac{2\pi m}{L}y} \right) + b_{m} \sin \left( {\frac{2\pi m}{L}y} \right)\) in Eq. (11) is called the mth harmonic of the Fourier series, thus the term
-
\(a_{{1_{{}} }} \cos \left( {\frac{2\pi (1)}{L}y} \right) + b_{{1_{{}} }} \sin \left( {\frac{2\pi (1)}{L}y} \right)\) is called the 1st harmonic,
-
\(a_{{2_{{}} }} \cos \left( {\frac{2\pi (2)}{L}y} \right) + b_{{2_{{}} }} \sin \left( {\frac{2\pi (2)}{L}y} \right)\) is called the 2nd harmonic, and so on.
4.2 Fourier Series for Noise Reduction
Fourier series decomposes the signal into simple harmonics (sines and cosines), each with a single frequency, covering all signal bandwidth. Each harmonic is weighted by amplitudes (\(a_{n}\) and \(b_{n}\)) to shape the waveform of the signal. Signals with low frequencies can be expressed by the first fewer harmonics, and the number of harmonics increases by increasing the frequency components within the signals. For a clean signal contaminated by an Additive Whaite Gaussian Noise (AWGN), the spectrum of the compound is extended to cover the high-frequency components contained within the noise signal such that most of the clean signal power occupies the lower part of the spectrum while the noise power spans over whole spectrum. When applying Fourier series expansion to such compound, we can obtain an approximation for the clean signal by taking the first few harmonics only which can express most of the signal with some low frequency noise components. Higher harmonics representing most of the noise and some high frequency signal components are ignored. Figures 3 and 4 show a clean signal, the generated noisy signal after adding AWGN with SNR = 10 dB, and the Fourier approximation for the noisy signal with N = 10 and N = 60, respectively. These figures clarify that the much higher the order of the Fourier approximation for a noisy signal, the more the noise in the resultant waveform.

Fourier approximation for a noisy signal (N = 10)

Fourier approximation for a noisy signal (N = 60)
5 The Proposed Algorithm
The proposed algorithm for speech enhancement comprises both Fourier series expansion and spectral subtraction. The complete form of the proposed speech enhancement algorithm is shown in Fig. 5. Firstly, the noisy speech signal is segmented into small frames. Then, each frame is decomposed into N harmonics using Fourier series. Then, the frame is reconstructed again by summing up these harmonics to get an approximated frame which often has lower noise than the original one. This process continues till all frames are processed. After that, the spectral subtraction is applied to the reconstructed signal to obtain an enhanced speech signal.

Proposed speech enhancement approach
The reason for framing of speech signals before Fourier expansion is to obtain approximated signals with more details as the smaller the scale of a signal, the more the details we get from the Fourier expansion. Figure 6 shows the enhanced speech signal with the proposed approach and a noisy speech signal with SNR = 0 dB for comparison.

Noisy and enhanced speech signal with the proposed approach
6 Speaker Identification
The speaker identification system comprises two phases: feature extraction and feature matching [8]. Figure 7 illustrates the two phases of the speaker identification system. In feature extraction phase, unique features (voice print) are extracted from the speaker utterance. The feature set extracted from authorized persons is stored for later use for discriminating between persons. Feature matching phase involves identification of a claiming speaker by comparing his voice print with pre-stored voice prints of authorized persons. If the speaker’s voice print matches one of those of the authorized persons, the speaker is accepted, else the speaker is rejected.

Speaker verification system
There are various techniques to extract features form user utterance such as Mel Frequency Cepstral Coefficients (MFCCs), Dynamic Time Warping (DTW), Linear Predictive Coding (LPC), and Zero Crossings with Peak Amplitudes (ZCPA). Moreover, feature matching techniques include Vector Quantization (VQ), Hidden Markov Models (HMMs), Gaussian Mixture Models (GMMs), and Artificial Neural Networks (ANNs). In this paper, we will consider MFCCs as features with VQ for feature matching.
6.1 Feature Extraction
Human hearing organ can distinguish different speakers through extracting high-level perceptual features from utterance like dialect, speaking style, tone, and emotional state [3]. These features can discriminate between speakers effectively; however they are very complex to implement in a software or hardware system. Instead, low-level features of speech such as frequency, loudness, energy, and spectrum can discriminate between speakers with a recognition rate depending on the feature extraction technique and the amount of features extracted from the utterance. The MFCCs is an example of such low-level features.
The MFCCs are commonly used as features in speaker identification systems, because the basic principles of their extraction resemble the operation of the actual human auditory system [9].
The MFCCs work analogue to the human auditory perception system, which cannot perceive frequencies higher than 1 kHz, linearly. Thus, extraction of MFCCs requires two types of filters spaced linearly at low frequencies below 1 kHz and logarithmically beyond 1 kHz. The outputs of these filters are aligned with the Mel scale which can be described by Eq. (15).
where Mel is the Mel frequency and f is the linear frequency in Hz.
A block diagram of the structure of an MFCC extraction processor is given in Fig. 8. The operation of the MFCC extraction processor starts with capturing the input speech signal through a microphone with sampling frequency \(F_{s} \ge 8\,{\text{KHz}}\). This ensures that most of the energy contained in the baseband signal with frequency \(300 \le F_{m} \le 3400\,{\text{Hz}}\) is captured. Then sampled signal is passed through seven computational steps till we get the MFCCs (voice print) from the last step.

Block diagram of MFCC extraction processor
6.2 Feature Matching
Vector Quantization (VQ) is a lossy data compression approach based on mapping vectors from a large vector space to a finite number of regions in that space. It works using the principle of the LBG algorithm which was originally proposed by Linde et al. [10]. In the VQ-based speaker identification algorithm, the speaker model is formed by clustering the speakers' feature vectors in K non-overlapping clusters. Each cluster is expressed by its center called a codeword, which is the centroid. The collection of all codewords is called a codebook. In the identification phase, the constructed codebook of the speaker is compared against stored codebooks of all speakers, and the distance is measured. The codebook with the least average distance is identified as that of the speaker of the input speech.
7 Experimental Results
The experiments were conducted on 50 speakers from ITU-T speech database [11]. ITU-T database is a collection of speech sentences with duration ranges from 4 to 12 s spoken by different males and females in different languages. Theses speech signals are contaminated by AWGN with different SNRs to test the speaker identification system when using the proposed speech enhancement approach as a pre-processing step as shown in Fig. 1. Different enhancement methods are adopted in the pre-processing step in the testing phase to evaluate the effect of each one on the speaker identification system performance. Two evaluation metrics are used: recognition rate and output SNR (SNRoutput). The recognition rate is the ratio of the number of correcct identifications to the total number of identification trials. The output SNR is computed as [12]:
where \(y(i)\) is the enhanced signal and \(s(i)\) is the original speech signal.
Table 1 shows the output SNRs for different speech enhancement methods versus input SNRs for noisy speech signals when enhanced by different enhancement methods. Table 2 and Fig. 9 show the results of recognition rates for the speaker identification system when using different speech enhancement methods, versus different input SNRs.

Comparison of recognition rates for different enhancement methods
8 Conclusion
This paper presented and evaluated a proposed speech enhancement algorithm using Fourier series expansion and spectral subtraction. This algorithm is to be used prior to the speaker identification process for noise reduction. The results showed that the proposed algorithm provides better results for noise reduction in speech signals than those obtained with the baseline speech enhancement algorithms. Furthermore, if it is used prior to the speaker identification process, the proposed method provides a robust speaker identification system from degraded speech.
References
Mavaddaty, S., Ahadi, S. M., & Seyedin, S. (2016). A novel speech enhancement method by learnable sparse and low-rank decomposition and domain adaptation. Speech Communication, 76, 42–60.
Kamath, S., & Loizou, P. (2002). A multi-band spectral subtraction method for enhancing speech corrupted by colored noise. In IEEE international conference on acoustics, speech and signal processing, p. 4164.
El-Samie, F. E. A. (2011). Information security for automatic speaker identification. New York: Springer.
Scalart, P., & Filho, J. (1996). Speech enhancement based on a priori signal to noise estimation. In IEEE international conference on acoustics, speech and signal processing, pp. 629–632.
Lu, Y., & Loizou, P. (2008). A geometric approach to spectral subtraction. Speech Communication, 50, 453–466.
El-Fattah, M. A. A., Dessouky, M. I., Diab, S. M., & El-Samie, F. E. A. (2008). Speech enhancement using an adaptive wiener filtering approach. Progress in Electromagnetics Research, 4, 167–184.
Osgood, B. (2013). Lecture notes for EE 261: The Fourier transform and its applications. Stanford University.
Reynolds, D., & Rose, R. (1995). Robust text-independent speaker identification using Gaussian mixture speaker models. IEEE Transactions on Speech and Audio Processing, 3, 72–83.
Kurzekar, P., Deshmukh, R., Waghmare, V., & Shrishrimal, P. (2014). A comparative study of feature extraction techniques for speech recognition system. IJIRSET, 3, 18006–18016.
Linde, Y., Buzo, A., & Gray, R. M. (1980). An algorithm for vector quantizer design. IEEE Transactions on Communications, 28, 84–96.
ITU-T Test Signals for Telecommunication Systems. http://www.itu.int/net/itu-t/sigdb/genaudio/Pseries.htm.
Kondo, K. (2012). “Subjective quality measurement of speech”, signals and communication technology (pp. 7–20). Berlin, Heidelberg: Springer. https://doi.org/10.1007/978-3-642-27506-7_2.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Siam, A.I., El-khobby, H.A., Elnaby, M.M.A. et al. A Novel Speech Enhancement Method Using Fourier Series Decomposition and Spectral Subtraction for Robust Speaker Identification. Wireless Pers Commun 108, 1055–1068 (2019). https://doi.org/10.1007/s11277-019-06453-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-019-06453-4