
Abstract
Routing protocol plays a role of great importance in the performance of wireless sensor networks (WSNs). A centralized balance clustering routing protocol based on location is proposed for WSN with random distribution in this paper. In order to keep clustering balanced through the whole lifetime of the network and adapt to the non-uniform distribution of sensor nodes, we design a systemic algorithm for clustering. First, the algorithm determines the cluster number according to condition of the network, and adjusts the hexagonal clustering results to balance the number of nodes of each cluster. Second, it selects cluster heads in each cluster base on the energy and distribution of nodes, and optimizes the clustering results to minimize energy consumption. Finally, it allocates suitable time slots for transmission to avoid collision. Simulation results demonstrate that the proposed protocol can balance the energy consumption and improve the network throughput and lifetime significantly.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In wireless sensor networks (WSNs) [1], the energy of the sensor nodes is limited because of battery powered. It is required that the routing protocols in WSNs should not only transmit data correctly, but also reduce energy consumption to prolong the node lifetime. There are many routing protocols in WSNs, and one of them called hierarchical protocols or clustering protocols could reduce the energy consumption effectively [2].
LEACH (low-energy adaptive clustering hierarchy) protocol [3] is one of the first proposed clustering protocols, which is the basis of the most clustering protocols [2]. There are two ways on clustering, one based on cluster heads and the other based on location. Cluster heads play a key role in traffic and energy consumption. For protocols based on cluster heads, the member nodes join in the cluster whose cluster head is the nearest. DE_LEACH [4] uses the differential evolution to optimize the cluster heads selection of LEACH protocol. The new algorithm which combines genetic algorithm and Fuzzy C-Means clustering algorithm for energy balance is proposed in [5].Yu et al. [6] presented a competition radius for cluster head selection to make all clusters equal size. Heinzelman et al. [7] proposed a centralized clustering protocol, which reduces the nodes energy consumption because of the reduction on control information.
It is required that the energy consumption in different clusters should be balanced in order to prolong the lifetime of the network. Protocols based on cluster heads such as LEACH and DE_LEACH consume more energy in the clustering process and perform not very well in balancing energy consumption among different clusters. However, it is not easy to keep the energy consumption balanced by choosing cluster head first. Khalil and Attea [8] proved that clustering according to the global information is more reasonable. For protocols based on location, clustering is first carried out based on the area of the nodes in a fixed shape, and then cluster heads are chosen. Xiang et al. [9] proposed the clustering algorithm based on the best angle and the best single-hop distance, which can only be used in circle sensing area with base station in the center. Ferng et al. [10] made static clusters with dynamic structures by utilizing virtual points in a corona-based WSN, but the base station should also be in the center. In Geographic the Adaptive Fidelity (GAF) [11] protocol, the sensing area is divided into several fixed regions by virtual square grid. By the comparison of networks performance among cluster shapes, Salzmann et al. [12] found the use of virtual regular hexagon grid is the best one on network connectivity and energy consumption. When the nodes are distributed uniformly, it is not difficult to control the cluster size and balance the energy consumption, and the clustering algorithms are effective, such as the Energy-Efficient Clustering Technique (EECT) protocol [13]. EECT adopts hexagonal clustering, but a complete shape at the edge of sensing area could not be obtained by a fixed shape and the clusters could not be divided into the predetermined number. Although Arranging the Cluster sizes and Transmission (ACT ranges for the WSNs) protocol [14] can adjust cluster size, nodes should be distributed uniformly. Distance and Density Based Clustering (DDC) [15] can adjust cluster size but nodes should make up a mesh network. When sensor nodes are distributed non-uniformly, it is impossible to keep the balance of clusters by a fixed shape.
In this paper, we propose a centralized balance clustering (CBC) routing protocol based on location. Besides keeping energy consumption balance in each cluster, the protocol can be applied in WSNs with random distribution by adjusting the cluster size to adapt the sensing area and node distribution. We deduce the optimal value of the cluster number in theory, which is utilized to adapt the clustering result, and optimize the clustering result based on the selected cluster heads. Simulation results show that the proposed algorithm realize the balance on clustering and energy consumption in each cluster. The lifetime of the network can be prolonged with the throughput improvement.
The rest of this paper is organized as follows. Section 2 shows the network model in our protocol. Section 3 presents a description of the proposed routing protocol in detail. Simulation results and analysis are given in Sect. 4. Finally, Sect. 5 concludes this paper.
2 Network Model
We have the following assumptions for the proposed protocol. The WSN is consist of a base station and \(N\) randomly distributes sensor nodes with fixed location and square sensing area. The base station can be set either inside or outside of the sensing area and it must be not too far from the sensing area if it is outside of the sensing area. The base station has infinite energy while every sensor node has equal and finite energy. In addition, each sensor node has its specific ID.
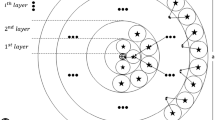
As shown in Fig. 1, a certain period of time is defined as a round [3]. There are two phases in each round: one is set-up phase, and the other is steady-state phase. Cluster heads selection and clustering are done in set-up phase, and then data are transmitted in steady-state phase. Code division multiple access (CDMA) is employed in inter-cluster communication by direct sequence spread spectrum (DSSS), while time division multiple access (TDMA) is employed in intra-cluster communication where each node is assigned a time slot. The steady-state operation is composed of frames, where all the member nodes in a cluster transmit data to its cluster head and the cluster head transmits data to base station once in a frame.

Working cycle of LEACH protocol
Energy is consumed on data transmitting /receiving for a member node based on the network model [7], which is shown as follows:
(1) expresses the transmit energy consumption \(E_{Tx}\) of transmitting \(l\) bits the data through the distance \(d\). The distance threshold \(d_{0}\) is defined in (2), where \(\varepsilon _{fs}\) and \(\varepsilon _{mp}\) represent the amplifier parameter in free space or multi-path fading channel model, respectively. In (3), \(E_{Rx}\) is the energy consumption on receiving data.
In general, when the distance between a member node and its cluster head \(d_{toCH}\) is less than \(d_{0}\), the free space channel model is adopted. The energy consumption of the \(i\)th member node \(E_{\mathrm{m}-\text{ node}}^\mathrm{i} \) is:
For a cluster head, it consumes energy on data aggregating and data transmitting/receiving. Energy consumption on \(l\) bits data aggregating \(E_{Aggr}\) is shown in (5), where \(E_{DA}\) is the data aggregation parameter.
Supposing that there are \(n-1\) nodes are member nodes and a cluster head in one cluster, the energy consumption of the cluster head \(E_{CH}\) is:
Thus, the total energy consumption of a cluster \(E_{cluster}\) is:
Since \( E_{elec }\) is much larger than \(\varepsilon _{fs}\) and \(d_{toCH}\) is very small, the energy consumption \(E_{m-node}\) is almost the same for every member node. As both \(\varepsilon _{fs}\) and \(\varepsilon _{mp}\) are very small, the distance from the cluster head to base station \(d_{toBS}\) has little impact on the energy consumption. The energy consumption of a cluster can be approximated by (8).
3 Centralized Balance Clustering Routing Protocol
At set-up phase, all nodes send their own positions and energy information to base station in order of their ID. Base station make clustering and chose cluster heads in each cluster according to the received information. At last, base station broadcast the clustering results.
The proposed protocol improves the clustering balance. First, we decide the optimal cluster parameters and use hexagonal clustering as the initial criterion. Second, the sensing area is divided by the optimal number of clusters, where the number of nodes in each cluster is the same. Finally, we select the cluster head and optimize clustering in order to minimize the total energy consumption.
3.1 Optimal Cluster Parameters
Based on (2), the energy consumption is mainly related to the nodes number. Hence, the number of nodes in each cluster should be equal to keep energy consumption balance.
Suppose that the nodes are randomly distributed and the area of each cluster is equal. If the cluster number is \(m\) and the side length of the square sensing area is \(a\), the number of nodes in a cluster will be \(n=N/m\) and the average area of each cluster will be \(S=a^{2}/m\). For simplicity, it is supposed that the shape of a cluster approximates to a circle with the radius of \(\frac{a}{\sqrt{m\pi }}\) and the cluster head is located at the center of the circle. Then, the mean square of the distance from a member node to its cluster head \(d_{toCH}\) can be obtained:
\(\rho \) is the parameter representing the nodes distribution probability. If nodes are distributed uniformly in the area, \(\rho =m/ a ^{2}\), (9) can be simplified as:
The total energy consumption \(E_{total}\) can be expressed as:
Since cluster heads are chosen in turn among all nodes, the average distance for a cluster head to the base station is represented by \(d_{toBS}\). With the minimum \(E_{total}\), we can get the optimal cluster number \(m_{opt}\) and the optimal nodes number \(n\) in each cluster, \(n=N/m_{opt}\).
3.2 Centralized Balance Clustering Algorithm
In the proposed algorithm, there are some key steps to optimize the clustering. First, the number of clusters is set to the optimal value \(m_{opt}\) by cluster adapting, where the number of nodes in each cluster is the same. Then, we optimize the selection of cluster heads. The last step of the algorithm is allocating the time slots.
3.2.1 Clustering Adapting
In order to reduce energy consumption, base station divides the sensing area into regular hexagon clusters with the same shape from center to the edge [12], and each cluster is assigned an ID. Supposing that the best number of clusters is \(m_{opt}\), the area of each cluster is \(S=a^{2}/m_{opt}\). Here the hexagon is regarded as a circle for approximation, and the hexagon side length \(R\) can be determined. The area of a hexagon is \(S=\frac{3\sqrt{3}}{2}R^{2}\) with the side length \(R=\sqrt{\frac{2S}{3\sqrt{3}}}=\sqrt{\frac{2a^{2}}{3\sqrt{3}m_{opt} }}\).
Because of the edge area, the real number of clusters based on hexagon is bigger than \(m_{opt}\). Clustering adapting is applied to divide the sensing area into \(m_{opt}\) clusters with approximated equal number of nodes. The objective for the same size of a cluster is to keep the number of clusters unchanged. Once some nodes die, the number of clusters remains unchanged through adjusting the node number of each cluster. Since the nodes energy is limited, the less number of nodes in a cluster can reduce the burden of cluster heads and extend their lifetime. Suppose the number of total alive nodes is \(N_{alive}\) now, the number of upper limit is \(n_{\mathrm{max}} =\left\lceil {\frac{N_{alive} }{m_{opt} }} \right\rceil \), and the lower limit is \(n_{\mathrm{min}} =\left\lfloor {\frac{N_{alive} }{m_{opt} }} \right\rfloor \). The algorithm is shown as follows:
Algorithm 1
Clustering adapting algorithm
-
Step 1: Initialize the two parameters isdelete and isjoin for each cluster according to their nodes number. isdelete stands for whether to delete this cluster, 1—delete, 0 —keep. And isjoin stands for whether to accept this node, 1 —accept, 0—refuse. Rank all clusters in the decreasing order of nodes number and preserve the first \(m_{opt}\) clusters. For the preserved clusters, isdelete=0, others isdelete=1. If the nodes number \(n \ge \quad n_{max }\) in the cluster, set isjoin =0; otherwise, set isjoin =1. In addition, each cluster has a parameter isfixed, whose initial value is 0, representing the nodes in the cluster is not fixed yet.
-
Step 2: Delete clusters whose isdelete = 1 and merge their nodes to clusters whose isdelete = 0, so that the number of clusters is \(m_{opt}\). The merging is proceeded from edge to centre. For a cluster whose isdelete = 1, set \(n\) =0 and isjoin = 0, meaning the cluster does not exist. Every node in this cluster joins the nearest cluster with isdelete = 0.
-
Step 3: Find a cluster whose isfixed = 0 in the order from edge to center. if n \(_{min}\le n \le n_{max }\)Set the clusterisfixed = 1. If isfixed =1 in all clusters, the algorithm ends. Quit from the procedure. else if \(n> n_{max}\) For each member node \(i _{th}\), find the adjacent cluster \(j _{th}\) with \({ isjoin} \!=\! 1\) whose hexagon center is the nearest. Record distance \(d _{ij}\) from the \(i_{th}\) node to the \(j_{th}\) cluster center. Choose the smallest distance and let the \(i_{th}\) node join the \(j_{th}\) cluster. If adjacent cluster whose isjoin=1 cannot be found, find the nearest adjacent cluster with isfixed = 0. Record distance from the \(i_{th}\) node to the cluster center. Choose the smallest distance and let the \(i_{th}\) node join the cluster. Then update the number of nodes and isjoin in both clusters. Repeat the procedure until \(n=n_{max }\)in the cluster, and set isfixed = 1. Then, repeat step 3. else Find the nearest node \(i_{th}\) in the adjacent cluster whose isfixed=0. Let \(i_{th}\) node join the cluster. Update \(n\) and isjoin in both clusters. If there is no adjacent cluster with isfixed=0, find the nearest node in the adjacent clusters whose isfixed=1 and \(n= n_{max}\). Repeat the procedure until \(n= n_{min}\), and set this cluster isfixed=1. Then, repeat step 3.
3.2.2 Clustering Optimization
Though the size of clusters is the same by cluster adapting, the total energy consumption may be not the minimum due to the non-uniform distribution of nodes. Therefore, an optimization of clustering is necessary.
Cluster heads selection in each cluster is important on energy consumption. The energy consumption for a member node changes with the square of the distance from this member node to its cluster head. In order to reduce the total energy consumption, it is necessary to reduce the quadratic sum of distance from member nodes to their cluster heads, which is the criterion for the selection of cluster heads. Since a cluster head consumes much more energy than a member node does, it is necessary to avoid energy exhausted and ensure the stability of data transmission. Besides, the times of being cluster head should also be balanced. If the highest energy of all nodes is \(E_{max}\) and the lowest is \(E_{min}\), a threshold \(E_{th1}=E_{max}-E_{min}\) can be used to decide whether the energy of the node is enough. A threshold \(E_{th2}=(E_{max}+E_{min})\)/2 is applied to evaluate whether the times of being cluster head are balanced for all nodes. The higher value between \(E_{th1}\) and \(E_{th2}\) is the final threshold \(E_{th}\) of being cluster head. Following is the optimization algorithm:
Algorithm 2
Algorithm on cluster head selection
-
Step 1: Record the current nodes number \(n_{orig}\) in each cluster. If there are nodes with energy above \(E_{th}\), choose the one with minimum quadratic sum of distance as cluster head; otherwise, choose the node with maximum energy as cluster head.
-
Step 2: Let each member nodes join the nearest cluster and record the distance to its current cluster head \(d_{cur}\). Record the current node number \(n_{cur}\) for each cluster. Set all clusters isfixed=0.
-
Step 3: Find a cluster denoted by \(i_{th}\) whose isfixed = 0 in the order from edge to center. Compare the original number of nodes \(n_{orig}\), and the current number of nodes \(n_{cur}\). if n \(_{cur}= n_{orig}\) Set isfixed = 1 and repeat step 3. If all clusters isfixed = 1, the algorithm ends. else if \(n_{cur} > n_{orig}\) Find node with the smallest \(d_{inc}=d^{2}_{new}-d^{2}_{cur}\), where \(d_{new}\) is the distance that the node to the nearest cluster head in the adjacent cluster whose \(n_{cur} < n_{orig}\). If no cluster satisfies the condition, find the nearest cluster whose isfixed=0. Let the node join the cluster, then update \(d_{cur}\) of the node and\( n_{cur}\) in both clusters. Repeat this process until \(n_{cur}= n_{orig}\) and set isfixed = 1. Then, repeat Step 3. else From adjacent clusters whose isfixed=0 and \(n_{cur} \quad > n_{orig}\), find the member node with the smallest \(d_{inc}=d^{2}_{new}-d^{2}_{cur}\) where \(d_{new}\) is the distance from this node to the cluster head. If no node satisfies the condition, find such member nodes in adjacent cluster whose isfixed=0. Let it join cluster and update \(d_{cur}\) and\( n_{cur}\). Then, Repeat step 3.
3.2.3 Time Slot Allocation
In the centralized algorithm, base station allocates time slots to each node uniformly in order to avoid transmission collision, keeping the data transmitting with the same speed and balancing the nodes energy consumption in different clusters.
A frame includes at least \(n_{max}+ m_{opt}\) -1 slots. Since the nodes number of each cluster is \(n_{max }\)at most and the number of member nodes is no more than \(n_{max}\)-1, the first \(n_{max}\)-1 time slots are allocated to each member node for data transmission. The residual time slots are allocated to the cluster heads to transmit data after member nodes transmitting.
After all, the time slots are allocated, and base station broadcasts the message during time slot allocation so that the sensor nodes know when to transmit data. Then in steady-state phase, nodes transmit data in the allocated time slot. In general, the sensor nodes are in sleep mode unless they transmit or receive data.
4 Simulation Results and Discussion
The proposed protocol is simulated by NS2. The results are compared with LEACH [3] and the improved DE_LEACH [6]. As the hexagonal clustering is applied in the proposed protocol, simulation results are also compared with the fixed hexagon clustering [13].

Clustering results
The parameters shown in Table 1 for computer simulation are the same with [7]. The best number for clustering is 5 based on the conclusion in Sect. 4.1 and the side length of hexagonal is 27.7 m.
4.1 Clustering Results
The clustering results at t = 0 s, t = 300 s, t = 600 s are shown in Fig. 2. Since there is no energy consumption at t = 0 s, the cluster number is 5 with 20 nodes in each cluster. There are no nodes dying at t = 300 s and the nodes number of each cluster is 20. At t = 600 s, some nodes died. The number of nodes in each cluster reduces, but nodes number in different cluster is same or similar.
4.2 Simulation Performance
We use three parameters to evaluate the network lifetime [4]. One is used to represent the optimal working time from the deployment of the network to the first node death (First Node Dies, FND). Another is the time to represent the total working time when all the nodes died in the network (Last Node Dies, LND). The last is the time when a certain percent of nodes is alive (Percentage Nodes Alive, PNA). Here the percent is 80% (Table 2).
4.2.1 Network Lifetime
The comparison of the alive nodes among different proposals is shown in Fig. 3. It can be seen that FND is 350 s, PNA is 440 s and LND is 530 s for LEACH. The performance is improved for DE_LEACH, where FND is 520 s, PNA is 580 s and LND is 710 s, where the network lifetime is prolonged obviously compared with LEACH. For fixed hexagon clustering, FND is 650 s, PNA is 720 s and LND is 900 s, whose lifetime is the longest. For CBC, FND is 540 seconds and PNA is 620 s, which is a little longer than that of DE_LEACH, and LND is 830 s which is much longer than that of DE_LEACH, the increase is about 57 and 17% compared with LEACH and DE_LEACH.

Comparison on the alive nodes
4.2.2 Network Throughput
Network lifetime is just one of the representations of the performance. Furthermore, the number of the transmitted data packets or the throughput is also of great importance. Figure 4 is the comparison of the received data on base station. It shows that DE_LEACH has a higher transmitting speed than that of LEACH. The transmitting speed of CBC is almost the same with DE_LEACH, while the fixed hexagon clustering has a much slower transmitting speed than that of LEACH. Both LEACH and DE_LEACH are distributed protocols, without a general time slot allocation. Therefore, there are some ripples on the number of received data packets because the number of time slots is different in different rounds, which affects the respective transmitting speed. In CBC, based on the centralized algorithm and unified time slots allocation, the speed of data transmitting is constant in each round and the number of received data packs on base station is stable.

Comparison on the received data by base station

Comparison of alive nodes and received data
The number of alive nodes and the received data in different protocols is compared in Fig. 5. The number of received data packets in LEACH is the minimum; about 38,000 during FND, 46,000 during PNA and 53,000 during LND. The number of received data packs in DE_LEACH is about 58,000 during FND, 60,000 during PNA and 62,000 during LND. And more than LEACH, but less than DE_LEACH, the data packets received in fixed hexagon clustering is about 40,000 during FND, 52,000 during PNA and 55,000 during LND. Compared with LEACH and DE_LEACH, the received data packets in CBC is about 62,000 during FND, 70,000 during PNA and 79,700 during LND, with an increase of 35.8 and 16.1%.
4.3 Discussion
It can be seen from Fig. 2 that the edge clusters of fixed hexagonal clustering are not complete hexagons. There is a big difference in the cluster size and the number of nodes in different clusters which may destroy the balance in energy consumption. The real number of clusters is more than 5. Distinguishing clusters by DSSS, more clusters need longer codes. The coded data length increases with the longer time slot and the smaller number of transmitting data in every round. And the energy consumption in transmitting increases, which leads to the decrease of the total number of the transmitted data packets. Therefore, fixed hexagonal clustering is unreasonable and deteriorates the network performance.
CBC makes optimization based on the hexagonal clustering. Compared with other clustering protocols, the performance of CBC is better than that of LEACH in general. DE_LEACH focuses on the distribution of cluster heads and may have a better distribution than CBC, but its energy consumption is higher. CBC considers the distribution of clustering and makes a better energy consumption balance which results in the decrease of the average energy consumption. The network working time is longer, i.e., LND is bigger. Besides, CBC can make better use of alive nodes after some nodes died, thus the effective working time, almost equaling to LND, is much longer than that of DE_LEACH. It verifies that the performance of CBC is the best among these proposals.
5 Conclusion
The proposed centralized balance clustering protocol in this paper can be applied to the WSNs with random distribution. In order to reduce the energy consumption, the key is to make the energy consumption balanced. There are three steps in the algorithm: they are the hexagonal clustering, cluster results optimization and cluster head selection. It is shown by computer simulation that this protocol can make better use of alive nodes, prolong the network working time and transmit the data effectively, which improves the performance obviously compared with LEACH and DE_LEACH protocol.
References
Akyildiz, I., Su, W., Sankarasubramaniam, Y., & Cayirci, E. (2002). A survey on sensor networks. IEEE Communications Magazine, 40(8), 102–114.
Akkaya, K., & Younis, M. (2005). A survey on routing protocols for wireless sensor networks. Ad Hoc Network, 3(3), 325–349.
Heinzelman, W., Chandrakasan, A., & Balakrishnan, H. (2000). Energy-efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd Hawaii international conference on system sciences (pp. 3005–3014). Maui.
Li, X. F., Xu, L. Z., & Wang, H. B. (2010). A differential evolution-based routing algorithm for environmental monitoring wireless sensor networks. Sensors, 10(6), 5425–5442.
He, S. J., Dai, Y. Y., Zhou, R. Y., & Zhao, S. T. (2012). A Clustering Routing Protocol for Energy Balance of WSN based on Genetic Clustering Algorithm. IERI Procedia, 2, 788–793.
Yu, J., Qi, Y. Y., Wang, G. H., & Gu, X. (2012). A cluster-based routing protocol for wireless sensor networks with nonuniform node distribution. International Journal of Electronics and Communications (AEÜ), 66(1), 54–61.
Heinzelman, W. B., Chandrakasan, A., & Balakrishnan, H. (2002). An application-specific protocol architecture for wireless microsensor networks. IEEE Transactions on Wireless Communications, 1(4), 660–670.
Khalil, E. A., & Attea, B. A. (2011). Energy-aware evolutionary routing protocol for dynamic clustering of wireless sensor networks. Swarmand Evolutionary Computation, 1(4), 195–203.
Xiang, M., Shi, W. R., Jiang, C. J., & Zhang, Y. (2010). Energy efficient clustering algorithm for maximizing lifetime of wireless sensor networks. International Journal of Electronics and Communications (AEÜ), 64(4), 289–298.
Ferng, H. W., Tendean, R., & Kurniawan, A. (2012). Energy-efficient routing protocol for wireless sensor networks with static clustering and dynamic structure. Wireless Personal Communications, 65(2), 347–367.
Xu, Y., Heidemann, J., & Estrin, D. (2001). Geography-informed Energy Conservation for Ad Hoc Routing. In Proceedings of the Seventh Annual ACM/IEEE International Conference on Mobile Computing and Networking (pp. 70–84). Rome.
Salzmann, J., Behnke, R., & Timmermann, D. (2010). Tessellating Cell Shapes for Geographical Clustering. In 2010 10th IEEE International Conference on Computer and Information Technology (pp. 2891–2896). Bradford.
Guan, X., Wang, Y. X., & Liu, F. (2008). An energy-efficient clustering technique for wireless sensor networks. In International Conference on Networking, Architecture, and Storage (pp. 248–252). Chongqing.
Lai, W. K., Fan, C. S., & Lin, L. Y. (2012). Arranging cluster sizes and transmission ranges for wireless sensor networks. Information Sciences, 183(1), 117–131.
Long H., Liu Y., Fan X., Dick R. P., & Yang H. (2009). Energy-efficient spatially-adaptive clustering and routing in wireless sensor networks. In Design, Automation Test in Europe Conference Exhibition (pp. 1267–1272). Leuven.
Acknowledgments
This work was supported by National Science Foundation China under Grant 60972072 and the 111 Project of China (B08038).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Chen, J., Li, Z. & Kuo, YH. A Centralized Balance Clustering Routing Protocol for Wireless Sensor Network. Wireless Pers Commun 72, 623–634 (2013). https://doi.org/10.1007/s11277-013-1033-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-013-1033-z