
Abstract
Wireless Sensor Network (WSN) comprises several sensor nodes that are spatially distributed in a network environment. The sensor nodes are connected over a wireless medium for monitoring the physical data from the environment. As the nodes are considered battery-powered, the nodes lose their energy after a certain period, this degrades the lifespan of the network. To enhance the lifespan of the network by balancing the path reliability and energy efficiency results a challenging tasks in WSN. To solve these issues and to provide an efficient data communication process, an effective method named Tunicate Swarm Butterfly Optimization Algorithm (TSBOA) is developed for selecting CH to accomplish effective data transmission between the sensor nodes. The proposed TSBOA is derived by the incorporation of the Tunicate Swarm Algorithm and Butterfly Optimization Algorithm, respectively. Accordingly, the selection of CH is made by considering the objective factors, like inter-cluster distance, intra-cluster distance, and the energy consumption of nodes, predicted energy, link lifetime, and delay. The energy prediction is done using the Deep Long Short Term Memory classifier by considering the initial energy of nodes. The proposed TSBOA achieved higher performance using metrics, like residual energy and throughput of 0.1118J, and 82.101%, respectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
WSN signifies a major facilitating environment for pervasive computing and emergencies. The growth of WSN is gained by the fusion of communication and the data sensing model. However, it is widely deployed in different appliances, like threat detection, health monitoring [1, 2], environmental tracking, and object monitoring. In general, the WSN comprises several nodes such that the nodes are placed statically with limited energy [3, 4], less communication [5], and processing amid a limited range of radio links. As, the nodes contain less storage facility, multiple function sensors, and batteries are enable for reading humidity recordings, and the temperature values. In most of the scenarios, the nodes in this network are placed in an ad hoc manner such that the nodes are allowed to communicate with the neighboring nodes for generating the network [6]. Because of less communication range, single-hop transmission is employed for sending the data packets [7]. The nodes situated in the sensor network have the capability of data processing, capturing the unit, and communication. The nodes fetch the data, record it and forward the data through wireless channels [8, 9]. The WSN comprised number of nodes such that they are powered by the batteries such that they are specifically designed to capture, track and broadcast the data to sink. Energy management is a major serious concern in the WSN environment. The two different routing protocols are flat routing and hierarchical routing in the sensor network. The flat routing mechanism allows the nodes to perform direct communication of data packets to the base station (BS), whereas hierarchical routing divides the nodes into groups called clusters. According to the unique tasks, the nodes are categorized in the cluster. The low-level nodes in the structure forward the data from clusters to CH, while high-level nodes have the responsibility to send the captured data to BS [10,11,12,13].
Each cluster group in the network contains one header called CH that effectively contacts other members of CH in the network [14]. Since the nodes required a high amount of energy for transferring the data directly to BS, it is required to used routing protocol in clustered WSN for finding the best path among CH to BS to minimize the consumption of energy [15]. The features of the routing mechanism comprise reliability, scalability, information accumulation, and fault tolerance [16, 17]. During the process of clustering number of nodes are placed in the group termed cluster concerning a set of common attributes. The nodes with high quality are chosen as CH and its responsibility is to capture the information from the group members and forward it to the higher level nodes or BS based on the category of transmission, like single or multi-hop. In the single-hop data transmission, the CH directly transmits the information to BS, whereas in the multi-hop transmission, CH sends the data to higher-level CHs that send the information to BS. The multi-hop data transmission is commonly utilized in a large-scale network. The group members are partitioned into two different groups termed as CHs and common nodes [18]. The energy of the nodes is quickly exhausted due to direct interaction among nodes and BS [19]. Hence, optimal energy is needed in the sensor network for achieving improved lifetime and performance enhancement [16, 20]. Because of considering the energy efficiency, the researchers are concentrated on developing various cluster-based routing methods [21] for increasing scalability, load balancing, and lifespan of the network [22]. The hierarchical routing models offer multi-hop routing through the generation of several clusters by considering CH in the network. The single-hop routing mechanism reduced the utilization of energy for short distances, whereas it uses more energy for the longer distance that causes degradation in performance [23]. It is a complex task in WS for creating the energy-efficient routing protocol for optimizing lifetime and resource utilization [24, 25].
In [26], Gravitational Search Algorithm (GSA) is modeled to determine the best CH among several sensor nodes. However, the chosen CH is made by observing the energy of the nodes as an important factor. Accordingly, the objective function considered for the selection of CH includes intra-cluster distance and energy efficiency. Moreover, the cost function of the multi-hop mechanism [9] considered residual energy of further hop as well as the distance from BS. In [27], the Harmony search algorithm (HSA) is designed for grouping the nodes and to generate the path in the WSN. Accordingly, fitness factors employed in the process of clustering include energy, inter-cluster, and intra-cluster distance, and the degree of the node. However, energy inspired by the node is reduced through a selection of nodes with limited distance for the data communication process [16]. In [28], evolutionary methods, such as the strength Pareto evolutionary model, genetic algorithm is developed for optimizing performance [29], temperature, and energy. However, this model developed a precise Pareto optimal front with higher precision and higher quality [24]. In [30], a balanced and energy-efficient multi-hop algorithm (BEEMH) is modeled for the multi-hop routing process in the WSN based on the Dijkstra algorithm. In [31], a balanced multipath routing mechanism is modeled by employing the energy of nodes to find the optimal route. However, the performance of the method is based on the selection of optimal routes and a limited number of hops [32].
1.1 Problem definition and motivation
Clustering is an important process to prolong the network lifetime in WSN. Cluster head is a node, which collects data from the cluster sensors and passes it to the base station. Thus, it should be energy efficient. Many methods are in practice for cluster head selection however they limits due to various reasons like.
-
Selecting an appropriate cluster head
-
Complexity of forming clusters in multiple levels
-
Reliability in routing path
-
Better residual energy and throughput
-
Link breakage
This made a motivation to design a method, which is better and efficient when compared to the existing methods.
This research is designed to develop an effective CH selection method using the proposed TSBOA. The proposed TSBOA is derived by the incorporation of Tunicate Swarm Algorithm (TSA) and Butterfly Optimization Algorithm (BOA), which effectively generates the optimal solution by incorporating the swarming behavior of the optimization algorithm. The initial energy of the node is fed as input to the Deep LSTM classifier to compute the predicted energy. Accordingly, the process of selecting CH is done using the proposed TSBOA such that it depends on the fitness constraints, such as intra and inter-cluster distance, node initial energy, predicted energy, delay, and the LLT factor. Moreover, the energy consumption of nodes is computed by considering nodes transmitting energy and receiving energy. Finally, the route maintenance procedure is done by checking the reliability of the link.
The major contribution of the research is explained as follows:
-
The proposed Tunicate Swarm Butterfly Optimization Algorithm (TSBOA) is developed by combining Tunicate Swarm Algorithm (TSA) and Butterfly Optimization Algorithm (BOA) for CH selection.
-
The CH is selected by considering the objective factors, such as inter-cluster distance, intra-cluster distance, energy consumption of nodes, predicted energy, link lifetime (LLT), and delay.
The paper is organized as follows: Sect. 2 explains the review of different methods of selecting the CH in WSN, Sect. 3 explains the system model of WSN, and Sect. 4 presents the energy computation. Section 5 presents the proposed method, Sect. 6 discussed the results of the proposed method, and Sect. 6 concludes the research.
2 Motivation
In this section, different existing CH selection-based approaches are explained along with their merits and demerits that motivate the researchers to design a TSBOA model for selecting CH in WSN.
2.1 Literature survey
Various CH selection-based methods are explained in this section. Maheshwari et al. [16] developed a butterfly optimization algorithm (BOA) for choosing CH among the count of nodes in the network. The selection of CH was done with factors, like neighboring distance, the distance between nodes and BS, node centrality, node degree, and the energy of nodes. Here, ant colony optimization (ACO) was employed for transmitting the information among CH and BS. Accordingly, the routing procedure was done with the parameters, like degree of anode, distance, and energy. Here, the performance was measured with different parameters. It increased the network lifespan but failed to increase the performance in WSN. Doostali and Babamir [33] developed a clustering model based on the topology control mechanism in the sensor network. Here, the selection of CH was made by determining the near-optimal probability such that it reached higher efficiency in the consumption of energy. Here, the probability value was specified using the count of nodes as well as the distance among the neighboring nodes in the network. The clustering mechanism adopted here was based on the sleep awake and learning automata model for increasing performance. It showed better consumption in energy but failed to solve optimization issues in a distributed manner. Baradaran and Navi [18] developed a high-quality clustering algorithm (HQCA) to compute the clusters with high quality. This method used the criteria to measure the quality of the cluster that increased the intra-cluster and inter-cluster distances and reduced the error rate while clustering. However, the optimal CH was chosen using fuzzy logic depends on the parameters, like energy and distance. It increased the lifespan of the network but failed to analyze the performance. Vinitha and Rukmini [32] developed a Taylor-based cat salp swarm algorithm (C-SSA) for offering energy-efficient routing in the sensor network. At first, the CH was chosen with the LEACH model to make efficient data communication process. The nodes transmit the data to BS through CH. This method considered different trust factors, such as direct trust, integrity factor, indirect trust, and data forwarding rate. This method increased the performance concerning throughput and delay.
Nivedhitha et al. [7] developed an energy-efficient model for balancing energy consumption and the path reliability ratio. Initially, cluster creation was performed and then the route was determined for transmitting the data between the nodes. Here, a super CH was selected that was responsible to maintain all the records of the CH as well as cluster members. The path reliability factor was used for the packet routing. It reduced the overhead and does not provide a security mechanism. Soundaram and Arumugam [10] developed an energy-efficient genetic spider monkey-based routing protocol (EGSMRP) for improving the lifespan of the network. This method considered two phases, like the setup phase and the steady-state phase. The process of selecting CH was made at the setup phase, whereas the load balancing issues were solved at the steady-state phase. Here, the control overhead was reduced by employing energy-based broadcasting. Rambabu et al. [34] developed a hybrid artificial bee colony and the monarch butterfly optimization algorithm (HABC-MBOA) for selecting the CH. The process of data transmission was done after the selection of CH. The developed method increased the performance in terms of throughput but failed to stabilize energy in selecting the CH. Mehta and Saxena [24] developed an energy-aware optimized routing algorithm for effective routing in WSN. The process of selecting CH was done by the multi-objective function. It reduced the count of dead nodes and reduced the consumption of energy. Accordingly, the selection of optimal path was done using a sailfish optimizer (SFO) that in turn made effective data communication. It increased the energy efficiency but failed to consider the mobility factor.
2.2 Challenges
Some of the issues faced by the traditional CH selection methods are discussed as follows:
-
In [18], the HQCA method is designed to generate clusters of high quality. However, this approach failed to include the factors, like optimal cluster estimation and an energy model based on the peripheral density of nodes to increase the performance.
-
A major challenge lies in the clustering method is in resolving distributed convex optimization issues in computing optimal global sub-graph [33].
-
In [7], DMEERP model is developed to improve the performance of WSN. This method failed to incorporate a secure routing process with a data availability model for balancing the security constraint with the elliptic curve cryptography model.
-
The methods named EGSMRP developed in [10] increase the lifespan of the network but failed to optimize Quality-of-Service (QoS) factors to increase the routing performance.
-
In [34], the HABC-MBOA method is modeled to choose the CH in WSN. It failed to consider the bacterial foraging algorithm (BFA) for handling energy efficiency issues while selecting CH.
In the proposed work, CH is selected based on the objective constraints, like delay, distance, LLT, and energy thus the proposed method selects CH without any issues and the path between nodes are monitored for breakage thus routing is performed efficiently.
3 System model
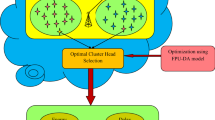
The system model of WSN is comprised of the energy model, mobility model, LLT model, and free space model. The energy loss while communicating the data between the nodes follows the free space model and is explained in the energy model. Let us assume the WSN with \(n\) number of nodes with a single sink node or BS as \(X\). The wireless links between the nodes specify direct communication within the transmission range. Accordingly, each node is distributed uniformly in the network environment. Each node contains its ID and the nodes are formed in a group called clusters. The sink node is placed at the near-optimal location for getting the data packets from the sensor nodes linked in the network. The data communication from a cluster member to BS is done through CH. The count of nodes availableat the network is represented as,
Here, \(L_{n}\) denotes a total number of sensor nodes. Figure 1 signifies the system model of WSN.

A system model of WSN
3.1 Energy model
Each node in the network has initial energy of \(G_{0}\) such that the energy of the node is not rechargeable [35]. The energy loss while traversing the packets from \(a^{th}\) normal node to \(b^{th}\) CH follows the multipath fading as well as free space mechanism based on the distance between the sender as well as the receiver. However, the transmitter contains a power amplifier as well as the radio electronics for dissipating the energy, while the receiver contains only the radio electronics for dissipation of energy. When a node sends \(q\) byte of data, the energy dissipation of the nodes is represented as,
where \(G_{elec}\) denotes electronic energy that depends on the factors, such as modulation, spreading, filtering, amplifier, and digital coding.
where \(G_{trans}\) indicates transmitter energy, \(G_{agg}\) specifies energy of data aggregation, \(G_{amp}\) signifies the energy of power amplifier, and \(\left\| {{\text{L}}_{{\text{a}}} - V_{b} } \right\|\) indicates the distance between \(a^{th}\) node and \(b^{th}\) CH. However, the energy dissipation by the receiver while receiving \(q\) bytes of data by CH is represented as,
After sending or receiving \(q\) bytes of data, energy value of each node gets updated.
The above process of data transmission is repeated until all the node becomes dead nodes. A node becomes dead only when its energy goes to less than zero.
3.2 Mobility model
The mobility model [36] is used to define the movement of sensor nodes and to specify their acceleration, location, and velocity changes concerning time. The mobility pattern is more important in determining network performance. Let us consider the initial location of the node \(a\) and \(k\) as \(\left( {u_{1} ,v_{1} } \right)\) and \(\left( {u_{2} ,v_{2} } \right)\). However, the nodes \(a\) and \(k\) moves with the varying velocity at a unique direction using the angle \(\theta_{1}\) and \(\theta_{2}\), respectively. The Euclidean distance between the node \(a\) and \(k\) is represented as,
Here, \(D\) denotes the Euclidean distance among the nodes.
3.3 LLT model
Due to the dynamic topology of network structure, it is needed to dynamically find route reliability [37]. Let us consider the two sensor nodes \(a\) and \(k\) are lie in the transmission range. The LLT is computed at each hop during the traversing of the route request packet. However, an individual node calculates the lifetime of the link between the current and previous hop. Let us consider the coordinate of the node \(a\) as \(\left( {{\rm M}_{a} ,{\rm N}_{a} } \right)\) and the coordinate of the node \(k\) as \(\left( {{\rm M}_{k} ,{\rm N}_{k} } \right)\), respectively. The mobility speed of node \(a\) and node \(k\) is represented as, \(S_{a}\) and \(S_{k}\). However, the distance of movement of sensor node \(a\) and node \(k\) is given as, \(\theta_{a}\) and \(\theta_{k}\). The LLT is computed as,
4 Energy prediction based on deep long short term memory classifier
The Deep LSTM is employed to compute the predicted energy by considering the initial energy of the node \(G_{0}\) as input. Deep LSTM [38, 39] is considered to compute the predicted energy based on the initial energy \(G_{0}\) of sensor nodes in a network environment. The Deep LSTM classifier gained the merits from both the deep network structure and LSTM model for solving the vanishing gradient issues by considering the memory cells. It comprises contextual state cells that work as long-term and short-term memory cells. Here, the predicted energy depends on the state of memory cells. The input node \(Y_{m}\) associated with the classifier receives the initial energy value from the input layer of the deep network as well as the previous hidden states \(x_{m - 1}\). The data prediction process performed is non-linear. The method used for predicting the output has a non-linear element. The function employed in the computation process includes a non-linear function as it increases the prediction accuracy. The initial energy and the result of \(x_{m - 1}\) fed to \(\tanh\) function is represented as,
where \(g_{{YG_{0} }}\) denotes weight matrix among input layer and the input node of the memory cell, \(x_{m - 1}\) indicates the input of hidden state at the time \(m - 1\), specifies weight matrix among the hidden states at a diverse time interval, and \(I_{in}\) signifies bias to the input node.
The input gate \(\left( {IG_{m} } \right)\) is the same as that of the input node as it gets the same input as that of the input node. This unit considers the sigmoidal activation function and it blocks the flow of input from other nodes to current nodes and so it is specified as input gate. The operation of the input gate is represented as,
where \(IG_{m}\) specifies the input gate at a time \(m\), \(\alpha\) denotes sigmoidal activation function, and \(I_{ig}\) indicates bias to the input gate. Accordingly, the internal state \(w\) is a node with the self-loop recurrent edge of the unit weight and the linear activation function such that it is computed as,
where \(w_{m}\) specifies internal state at the time \(m\), and \(w_{m - 1}\) indicates the internal state at the time \(m - 1\). Accordingly, the forget gate \(FG\) is utilized to reinitiate the internal state of the memory cell such that it is computed as,
where \(FG\) indicates forget state at the time \(m\), \(\Theta\) signifies the pointwise linear operator, \(g_{{FG.G_{0} }}\) signifies weight matrix of forgetting gate and input layer, \(g_{FGx}\) denotes weight matrix of forgetting gate and the hidden state, and \(I_{fg}\) signifies bias of forgetting gate.
Accordingly, the output gate \(T_{m}\) is computed as,
where \(g_{{xG_{0} }}\) indicates weight matrix among output gate and input layer, \(g_{Tx}\) portrays weight matrix among output gate and hidden state and \(I_{og}\) signifies bias for output gate. Moreover, the final output of the memory cell is represented as,
where \(w_{m} = Y_{m} \Theta IG_{m} + w_{m - 1} \Theta FG_{m}\). The energy predicted by the Deep LSTM classifier is represented as \(G^{p}\), respectively. Figure 2 portrays the structure of the Deep LSTM classifier.

The architecture of the Deep LSTM classifier
5 Proposed tunicate swarm butterfly optimization algorithm for CH selection
It is more significant in the WSN environment for the selection of CH to make an efficient data transmission process. To reduce the communication delay and to enhance the routing performance, it is required to choose CH among the number of sensor nodes. By selecting CH, the cluster members cannot directly communicate with BS instead of that, the nodes can directly interact with CH, which sends the data packets to BS. The selection of CH is made by considering the objective factors, such as intra-cluster and inter-cluster distance, the energy consumption of nodes, delay, predicted energy, and LLT such that the minimum objective function is assumed as the best solution. Here, the process of selecting CH is done using the proposed TSBOA, which is derived by the integration of TSA [40], and BOA [41]. TSA is bio-inspired algorithm that mimics swarm behavior and the jet propulsion of tunicates. It considers two processes, namely foraging and the navigation process. The tunicate is the swarm that generates blue-green light. This swarm is cylindrical that is open at one end and is closed at another end. Each tunicate contains a gelatinous tunic that helps to group all the individuals. The tunicate draws water from neighboring and generates jet propulsion at the open end by the atrial siphons. The jet-like propulsion is more powerful for migrating tunicates at the vertical direction in the ocean. The swarming behavior of tunicates helps them to successfully survive in the ocean. BOA is the nature-inspired algorithm that considers the mating and the food searching behavior of butterflies. The foraging mechanism of butterflies uses the sense of smell for finding the location of mating or nectar partner. Figure 3 portrays the schematic view of the proposed TSBOA for CH selection.

Schematic view of proposed TSBOA for CH selection
Solution encoding: It is the representation of the solution vector that determines the optimal nodeas CH by considering the objective parameters. The node with maximal distance, energy and minimum delay is selected as the CH. Figure 4 portrays solution encoding.

Solution encoding
Fitness function: The fitness value is computed by employing parameters, like intra-cluster distance, inter-cluster distance, delay, energy of the nodes, LLT, and the predicted energy as the objective factors. The fitness function is computed as,
where \(D^{{{\text{int}} ra}}\) denotes intra-cluster distance, \(D^{{{\text{int}} er}}\) signifies inter-cluster distance, \(G_{cons}\) specifies energy consumption of the nodes, \(B\) denotes delay, \(LLT\) denotes link lifetime, and Gp specifies predicted energy of nodes computed by Deep LSTM classifier. The intra-cluster distance is specified as,
Here, \(D_{ab}\) denotes the distance between \(a^{th}\) node and \(b^{th}\) CH, \(n\) specifies the number of nodes, \(\vartheta\) represents the number of CHs, and \(K\) indicates normalizing factor. The inter-cluster distance is computed as,
where \(K_{2}\) denotes normalizing factor, and \(D_{bi}\) signifies distance between \(b^{th}\) CH and \(i^{th}\) CH. The energy consumption of nodes is represented as,
where \(G^{trans}\) indicates transmitter energy, \(G^{rcvr}\) indicates receiver energy and \(K\) denotes normalizing factor. The delay is represented as,
Here, \(L_{b}\) denotes the number of nodes in \(b^{th}\) CH.
5.1 Algorithmic procedure of proposed TSBOA
The algorithmic steps involved in the proposed TSBOA are explained as follows:
-
i)
Initialization: Let us initialize the population of \(z\) butterflies in the solution space as, \(A_{j} \left( {j = 1,2,...,z} \right)\). The sensory is used to measure the energy form, whereas modality represents raw input utilized by sensors. The stimulus is correlated with the fitness of the solution.
-
ii)
Compute objective function: The fitness measure is computed to select the node as CH by considering the objective factors, such as inter-cluster distance, intra-cluster distance, delay, LLT, the energy consumption of nodes, and predicted energy. The fitness function computed for selecting CH is specified in Eq. (16).
-
iii)
Update solution: The sensing concept, as well as the modality processing, is based on factors, like sensory modality \(\left( M \right)\), stimulus intensity \(\left( W \right)\), and the power exponent \(\left( C \right)\), respectively.
The standard equation of BOA is expressed as,
where \(A_{j}^{r}\) denotes the solution of \(j^{th}\) butterfly at \(r^{th}\) iteration, \(s^{*}\) indicates current best solution, \(y_{j}\) indicates fragrance of \(j^{th}\) butterfly and \(h\) specifies random number with the range of \(\left[ {0,1} \right]\).The standard equation of TSA that satisfies the condition \(\left( {rand \ge 0.5} \right)\) is expressed as,
where \(\vec{J}\) indicates the best search agent, and \(\vec{Q}\) specifies prey density. As, \(\vec{J}\) is best search agent in TSA, \(\vec{J} = s^{*}\). By substituting the Eq. (23) in Eq. (21) is represented as,
where \(A_{j}^{r}\) denotes the solution of \(j^{th}\) butterfly at \(r^{th}\) iteration, \(h\) specifies random number with the range of \(\left[ {0,1} \right]\), and \(y_{j}\) indicates fragrance of \(j^{th}\) butterfly. Here,
Here, \(\vec{R}\) specifies the vector, \(h_{1}\), \(h_{2}\), and \(h_{3}\) represents the random number with the range of \(\left[ {0,1} \right]\).
-
iv)
Evaluating feasibility: The optimal solution is computed by determining the best fitness value such that a node with minimum fitness value is accepted as CH.
-
v)
Termination: The above steps are repeated until the best solution is obtained. Algorithm 1 portrays the pseudo-code of the proposed TSBOA.

5.2 Route maintenance
The route maintenance phase examines the path and reports the failure of a link to the source node. The path between the cluster member and CH is required to be more optimal to make efficient data transmission. Moreover, it is necessary to find the link breakage in the network based on the rate of link failure [42]. Accordingly, link reliability is represented as,
where \(\mu\) denotes average link failure rate that is computed as \(\left( \frac{1}{LLT} \right)\), and \(l\) indicates the time at which the link is active. If link reliability is greater than the threshold value, then the routing process can be effectively accomplished between the nodes in the network.
6 Results and discussion
This section describes the results and discussion of the proposed TSBOA for the performance measures.
6.1 Experimental setup
The implementation of the proposed method is carried out in the MATLAB tool with windows 10 OS, Intel processor, and 4 GB RAM. The simulation parameter used for the experimentation is shown in Table 1.
6.2 Evaluation metrics
The performance of developed TSBOA is progressedby employing parameters, like alive nodes, residual energy, and throughput.
Throughput: It is termed as the measure that shows the number of packets transmitted from source to destination at unit second. It is represented as,
where, \(\delta\) specifies successfully transmitted packets, and \(t\) represents time.
Alive nodes: It defined the number of nodes that are alive in network with higher energy for routing the data packets.
Residual energy: It is the energy that remained in nodes that is the summation of the remaining energy of all the nodes.
6.3 Experimental results
Figure 5 portrays the samples simulated result by considering 50 and 100 nodes. Figure 5a represents the simulated result with 50 nodes, and the simulated result with 100 nodes is shown in Fig. 5b.

Simulated result, a with 50 nodes, b with 100 nodes
6.4 Performance analysis
This section elaborates the performance analysis of the developed TSBOA model based on the number of rounds.
6.4.1 Analysis based on 50 nodes
Figure 6 shows an analysis based on 50 nodes. The analysis made to show the number of nodes alive with 50 nodes is represented in Fig. 6a. By considering 500 rounds, the nodes alive by considering the proposed TSBOA with epoch 20 is 41, epoch 40 is 40, epoch 60 is 45, epoch 80 is 47.5, and epoch 100 is 50, respectively. When rounds = 1000, the nodes that are considered as alive by the proposed TSBOA with epoch 20 is 40.59, epoch 40 is 39.6, epoch 60 is 44.55, epoch 80 is 47.025, and epoch 100 is 49.5. For 1500 rounds, nodes alive in the proposed TSBOA with epoch 20 are 26.24, epoch 40 is 25.6, epoch 60 is 28.8, epoch 80 is 30.4, and epoch 100 is 32. By increasing the rounds to 2000, the number of nodes alive by proposed TSBOA with epoch 20 is 2.05, epoch 40 is 2, epoch 60 is 2.25, epoch 80 is 2.375, and epoch 100 is 2.5.Thus, from the analysis, when number of round increases the number of alive nodes in proposed TSBOA with different epoch values is minimized.

Analysis based on 50 nodes, a alive nodes, b residual energy, c throughput
Figure 6b depicts the analysis based on the residual energy. At 500 rounds, the energy remained by the nodes using the proposed TSBOA with epoch 20 is 0.2358J, epoch 40 is 0.2489J, epoch 60 is 0.4072J, epoch 80 is 0.2620J, and epoch 100 is 0.4286J, respectively. For 1000 rounds, the residual energy obtained using proposed TSBOA with epoch 20 is 0.0742J, epoch 40 is 0.0783J, epoch 60 is 0.2062J, epoch 80 is 0.0824J, and epoch 100 is 0.2171J. When considering 1500 rounds, residual energy computed using the proposed TSBOA with epoch 20 are 0.0056J, epoch 40 is 0.0059J, epoch 60 is 0.0516J, epoch 80 is 0.0062J, and epoch 100 is 0.0543J. When the number of rounds is considered as 2000 rounds, the energy remained in the nodes using proposed TSBOA with epoch 20 is 0.0026J, epoch 40 is 0.0028J, epoch 60 is 0.0030J, epoch 80 is 0.0029J, and epoch 100 is 0.0031J.
The analysis made by the throughput measure is illustrated in Fig. 6c. When the number of rounds is considered as 500 rounds, the throughput achieved by the proposed TSBOA with epoch 20 is 68.879%, with epoch 40 is 71.310%, epoch 60 is 72.931%, epoch 80 is 76.172%, and with epoch 100 is 81.034%, respectively. By considering 1000 rounds, the throughput obtained using proposed TSBOA with epoch 20 is 66.328%, epoch 40 is 68.669%, epoch 60 is 70.230%, epoch 80 is 73.351%, and epoch 100 is 78.033%. The throughput measured by the proposed TSBOA at 1500 rounds epoch 20 is 48.139%, epoch 40 is 49.838%, epoch 60 is 50.970%, epoch 80 is 53.236%, and epoch 100 is 56.634%. For 2000 rounds, throughput of proposed TSBOA with epoch 20 is 13.331%, epoch 40 is 13.802%, epoch 60 is 14.115%, epoch 80 is 14.743%, and epoch 100 is 15.684%.
6.4.2 Analysis with 100 nodes
Figure 7 portrays the performance analysis made by considering 100 nodes. Figure 7a portrays the analysis by considering alive nodes. When it is considered 500 rounds, the nodes alive by the proposed TSBOA with epoch 20 are 82, epoch 40 is 80, epoch 60 is 90, epoch 80 is 95, and epoch 100 is 100, respectively. When increasing the rounds to 1000, the nodes that are considered as alive nodes using proposed TSBOA with epoch 20 is 81.18, epoch 40 is 79.2, epoch 60 is 89.1, epoch 80 is 94.05, and epoch 100 is 99. For 1500 rounds, nodes alive using the proposed TSBOA with epoch 20 are 52.48, epoch 40 is 51.2, epoch 60 is 57.6, epoch 80 is 60.8, and epoch 100 is 64. When increasing the rounds to 2000 rounds, the total number of nodes alive in the network using proposed TSBOA with epoch 20 is 4.1, epoch 40 is 4, epoch 60 is 4.5, epoch 80 is 4.75, and epoch 100 is 5.

Analysis based on 100 nodes, a alive nodes, b residual energy, c throughput
The analysis showed by considering the residual energy of nodes is depicted in Fig. 7b. When considering 500 rounds, the residual energy computed by the proposed TSBOA with epoch 20 is 0.2344J, epoch 40 is 0.2474J, epoch 60 is 0.4048J, epoch 80 is 0.2604J, and epoch 100 is 0.4261J, respectively. At 1000 rounds, energy remained in nodes with proposed TSBOA with epoch 20 is 0.0737J, epoch 40 is 0.0778J, epoch 60 is 0.2050J, epoch 80 is 0.0819J, and epoch 100 is 0.2158J. When increasing the rounds to 1500 rounds, residual energy computed using the proposed TSBOA with epoch 20 are 0.0055J, epoch 40 is 0.0059J, epoch 60 is 0.0512J, epoch 80 is 0.0062J, and epoch 100 is 0.0539J. By considering 1800 rounds, the remaining energy of the nodes using proposed TSBOA with epoch 20 is 0.0035J, epoch 40 is 0.0037J, epoch 60 is 0.0136J, epoch 80 is 0.0039J, and epoch 100 is 0.0144J.
Figure 7c represents the analysis made with the throughput metric by 100 nodes. For 500 rounds, the throughput computed by the proposed TSBOA with epoch 20 is 68.879%, epoch 40 is 71.310%, epoch 60 is 72.931%, epoch 80 is 76.172%, and epoch 100 is 81.034%, respectively. At rounds = 1000, throughput measured by the proposed TSBOA with epoch 20 is 66.328%, epoch 40 is 68.669%, epoch 60 is 70.230%, epoch 80 is 73.351%, and epoch 100 is 78.033%. When considering the rounds as 1500 rounds, throughput achieved using the proposed TSBOA with epoch 20 are 48.139%, epoch 40 is 49.838%, epoch 60 is 50.970%, epoch 80 is 53.236%, and epoch 100 is 56.634%. When the rounds are improved to 1800 rounds, the throughput achieved using proposed TSBOA with epoch 20 is 13.331%, epoch 40 is 13.802%, epoch 60 is 14.115%, epoch 80 is 14.743%, and epoch 100 is 15.684%.
6.5 Comparative methods
The performance of the proposed method is analyzed by considering the traditional method, such as Butterfly Optimization Algorithm (BOA) + Ant Colony Optimization (ACO) [16], Taylor based Cat Salp Swarm Algorithm (Taylor C-SSA) [32], Genetic Spider Monkey Optimization (GSMO) [10], and Hybrid Artificial Bee Colony and Monarchy Butterfly Optimization Algorithm (HABC-MBOA) [34].
6.6 Comparative analysis
This section explains the comparative analysis of the developed TSMOA based on the rounds with the variation of nodes.
6.6.1 Analysis with 50 nodes
Figure 8 illustrates the comparative analysis of the TSMOA scheme by varying the rounds with 50 nodes. Figure 8a portrays analysis based on the number of alive nodes. For 100 rounds, the number of nodes alive in the network using BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, proposed TSBOA is 39.6, 35.1,36, 41.4, and 45, respectively. Here, the performance of the proposed algorithm is 12% better than BOA + ACO, 8% better than Taylor C-SSA, 20% better than GSMO, and 22% better than HABC-MBOA. When increasing the rounds to 200, the alive nodes measured by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, proposed TSBOA is 38.808, 34.398, 35.28, 40.572, and 44.1, respectively. The number of alive nodes is more for HABC-MBOA next to the proposed method and next to HABC-MBOA, BOA + ACO has more alive nodes and BOA + ACO has minimum alive nodes.

Analysis with 50 nodes, a alive nodes, b residual energy, c throughput
The analysis made by the residual energy metric is shown in Fig. 8b. At 80 rounds, the residual energy of existing BOA + ACO, Taylor C-SSA, GSMO, and HABC-MBOA is 0.4727J, 0.4521J, 0.4778J, and 0.5035J, whereas the proposed TSBOA has acquired higher energy of 0.5293J such that the developed method shows the performance improvement of 11%, 15%, 10%, and 5% with traditional BOA + ACO, Taylor C-SSA, GSMO, and HABC-MBOA, respectively. When considering the rounds of 100, residual energy of BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 0.4569J, 0.4371J, 0.4619J, 0.4867J, and 0.5116J, respectively. The performance improvement of the proposed algorithm with BOA + ACO is 11%, Taylor C-SSA is 15%, GSMO is 10%, and HABC-MBOA is 5%. When increasing the rounds to 130, residual energy computed by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 0.4421J, 0.4229J, 0.4469J, 0.4709J, and 0.4949J, respectively. Here, the performance enhancement of the proposed algorithm while comparing with that of traditional BOA + ACO is 11%, Taylor C-SSA is 15%, GSMO is 10%, and HABC-MBOA is 5%.
Figure 8c represents the analysis of throughput using 50 nodes. At 300 rounds, throughput computed by existing methods, like BOA + ACO, Taylor C-SSA, GSMO, and HABC-MBOA is 58.593%, 71.705%, 74.266%, and 78.534%, whereas proposed TSBOA achieved higher throughput of 85.363% that results in the performance improvement while comparing with the existing BOA + ACO is 31%, Taylor C-SSA is 16%, GSMO is 13%, and HABC-MBOA is 8%. When increasing to 400 rounds, throughput measured by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 58.593%, 71.705%, 74.266%, 78.534%, and 85.363%, respectively. Here, the proposed algorithm has the performance improvement with that of BOA + ACO is 31%, Taylor C-SSA is 16%, GSMO is 13%, and HABC-MBOA is 8%. For 500 rounds, throughput obtained by the traditional techniques, like BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 58.593%, 71.705%, 74.266%, 78.534%, and 85.363%, respectively.
6.6.2 Analysis with 100 nodes
Figure 9 portrays the comparative analysis of the proposed TSMOA method with varying the rounds with 100 nodes. Figure 9a illustrates the analysis by considering the number of alive nodes. For 100 rounds, nodes alive in the network using BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, proposed TSBOA is 44, 39, 40, 46, and 50, respectively. Here, the performance of the proposed algorithm is 12% better than BOA + ACO, 22% better than Taylor C-SSA, 20% better than GSMO, 8% better than HABC-MBOA. When increasing the rounds to 200, the alive nodes measured by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, proposed TSBOA is 43.12, 38.22, 39.2, 45.08, and 49, respectively.

Analysis with 100 nodes, a alive nodes, b residual energy, c throughput
The analysis made with the residual energy measure is portrayed in Fig. 9b. When considering 800 rounds, the residual energy of existing BOA + ACO, Taylor C-SSA, GSMO, and HABC-MBOA is 0.1493J, 0.1433J, 0.1508J, and 0.1584J, while the proposed TSBOA has higher energy of 0.1659J. At 900 rounds, residual energy of BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 0.1258J, 0.1208J, 0.1271J, 0.1333J, and 0.1395J, respectively. By increasing the rounds to 1000, residual energy acquired by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 0.1016J, 0.0977J, 0.1026J, 0.1074J, and 0.1123J, respectively.
Figure 9c shows the analysis of throughput measures using 100 nodes. At 300 rounds, throughput computed by existing methods, like BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA is 68.741%, 71.167%, 72.785%, and 76.020%, while the proposed TSBOA achieved better throughput of 80.872% that reports the performance of improvement of 15%, 12%, 10%, and 5% while comparing with the existing BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, respectively. By considering the number of rounds as 400, throughput achieved by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, proposed TSBOA is 68.741%, 71.167%, 72.785%, 76.020%, and 80.872% such that the developed model shows the percentage of improvement as 15%, 12%, 10%, and 5% with BOA + ACO, Taylor C-SSA, GSMO, and HABC-MBOA. By considering 500 rounds, throughput computed by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 68.741%, 71.167%, 72.785%, 76.020%, and 80.872%, respectively.
6.7 Comparative discussion
Table 2 represents the comparative discussion of the proposed TSMOA model. The below table shows the performance measured by the proposed TSMOA model with that of the conventional methods by analyzing the values computed at rounds 1000 for each evaluation metrics. The residual energy computed by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 0.1012J, 0.0973J, 0.1022J, 0.1070J, and 0.1118 for 50 nodes. The throughput computed at 1000 rounds by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 56.354%, 68.965%, 71.428%, 75.533%, and 82.101% with 50 nodes. Similarly, for 1000 rounds, the residual energy measured by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 0.1016J, 0.0977J, 0.1026J, 0.1074J, and 0.1123J with 100 nodes. Moreover, the throughput computed by BOA + ACO, Taylor C-SSA, GSMO, HABC-MBOA, and proposed TSBOA is 66.195%, 68.532%, 70.089%, 73.204%, and 77.877% with 100 nodes, respectively.
7 Conclusion
In this research, an effective method is developed for selecting the CH in the WSN environment using the proposed TSBOA, which is the incorporation of TSA and BOA, respectively. The proposed method selects the CH optimally by considering the fitness constraints, such as inter-cluster distance, intra-cluster distance, delay, LLT, energy consumption of the nodes, and predicted energy. The prediction energy is computed using a Deep LSTM classifier based on the initial energy value. The transmission energy, receiver energy, and the normalizing factors are used for computing the energy consumption among the nodes. The reliability of the routing path is measure using the route maintenance phase by monitoring the link breakage. The link reliability factor is compared with the threshold value to route the data packets between the source and destination. The proposed method achieved higher performance using metrics, like residual energy and throughput of 0.1118J, and 82.101%, respectively. The future dimension of research will be the consideration of the routing process using the optimization algorithm and thereby the performance can be improved.
References
Digennaro, M., Sambiasi, D., Tommasi, S., Pilato, B., Diotaiuti, S., Kardhashi, A., Trojano, G., Tufaro, A., & Paradiso, A. V. (2017). Hereditary and non-hereditary branches of family eligible for BRCA test: Cancers in other sites. Hereditary Cancer in Clinical Practice, 15(1), 1–5.
Caponio, M. A., Addati, T., Popescu, O., Petroni, S., Rubini, V., Centrone, M., Trojano, G., & Simone, G. (2014). P16 INK4a protein expression in endocervical, endometrial and metastatic adenocarcinomas of extra-uterine origin: Diagnostic and clinical considerations. Cancer Biomarkers, 14(2–3), 169–175.
Gayathri Devi, K. S. (2019). Hybrid genetic algorithm and particle swarm optimization algorithm for optimal power flow in power system. Journal of Computational Mechanics, Power System and Control, 2(2), 31–37.
Brajula, W., & Praveena, S. (2018). Energy efficient genetic algorithm based clustering technique for prolonging the life time of wireless sensor network. Journal of Networking and Communication Systems, 1(1), 1–9.
Vidyadhari, C., Sandhya, N., & Premchand, P. (2019). A semantic word processing using enhanced cat swarm optimization algorithm for automatic text clustering. Multimedia Research, 2(4), 23–32.
Chauhan, S., Singh, M., & Aggarwal, A. K. (2021). Cluster head selection in heterogeneous wireless sensor network using a new evolutionary algorithm. Wireless Personal Communications, 119, 585–616.
Nivedhitha, V., Saminathan, A. G., & Thirumurugan, P. (2020). DMEERP: A dynamic multi-hop energy efficient routing protocol for WSN. Microprocessors and Microsystems, 79, 103291.
Marappan, P., & Rodrigues, P. (2016). An energy efficient routing protocol for correlated data using CL-LEACH in WSN. Wireless Networks, 22(4), 1415–1423.
Tejashwini, N., Shashi Kumar, D. R., & Satyanarayana Reddy, K. (2020). Multi-stage secure clusterhead selection using discrete rule-set against unknown attacks in wireless sensor network. International Journal of Electrical and Computer Engineering, 10(4), 4296–4304.
Soundaram, J., & Arumugam, C. (2020). Genetic spider monkey-based routing protocol to increase the lifetime of the network and energy management in WSN. International Journal of Communication Systems, 33(14), e4525.
Elsmany, E. F., Omar, M. A., Wan, T. C., & Altahir, A. A. (2019). EESRA: Energy efficient scalable routing algorithm for wireless sensor networks. IEEE Access, 7, 96974–96983.
Kelotra, A., & Pandey, P. (2019). Energy-aware cluster head selection in WSN using HPSOCS algorithm. Journal of Networking and Communication Systems, 2(1), 24–33.
AlBalushi, F. M. (2019). Chaotic based hybrid artificial sheep algorithm—particle swarm optimization for energy and secure aware in WSN. Journal of Networking and Communication Systems, 2(2), 37–48.
Mann, P. S., & Singh, S. (2017). Improved metaheuristic based energy-efficient clustering protocol for wireless sensor networks. Engineering Applications of Artificial Intelligence, 57, 142–152.
Kaur, S., & Mahajan, R. (2018). Hybrid meta-heuristic optimization based energy efficient protocol for wireless sensor networks. Egyptian Informatics Journal, 19(3), 145–150.
Maheshwari, P., Sharma, A. K., & Verma, K. (2020). Energy efficient cluster based routing protocol for WSN using butterfly optimization algorithm and ant colony optimization. Ad Hoc Networks, 110, 102317.
Khabiri, M., & Ghaffari, A. (2018). Energy-aware clustering-based routing in wireless sensor networks using cuckoo optimization algorithm. Wireless Personal Communications, 98(3), 2473–2495.
Baradaran, A. A., & Navi, K. (2020). HQCA-WSN: High-quality clustering algorithm and optimal cluster head selection using fuzzy logic in wireless sensor networks. Fuzzy Sets and Systems, 389, 114–144.
Mittal, N., Singh, U., & Sohi, B. S. (2019). An energy-aware cluster-based stable protocol for wireless sensor networks. Neural Computing and Applications, 31(11), 7269–7286.
Moh’d Alia, O. (2018). A dynamic harmony search-based fuzzy clustering protocol for energyefficient wireless sensor networks. Annals of Telecommunications, 73(5–6), 353–365.
Nagarajan, L., & Thangavelu, S. (2020). Hybrid grey wolf sunflower optimisation algorithm forenergy-efficient cluster head selection in wireless sensor networksfor lifetime enhancement. The Institute of Engineering and Technology. https://doi.org/10.1049/cmu2.12072
Sabet, M., & Naji, H. R. (2015). A decentralized energy efficient hierarchical cluster-based routing algorithm for wireless sensor networks. AEU-International Journal of Electronics and Communications, 69(5), 790–799.
Arioua, M., El Assari, Y., Ez-Zazi, I., & El Oualkadi, A. (2016). Multi-hop cluster based routing approach for wireless sensor networks. Procedia Computer Science, 83, 584–591.
Mehta, D., & Saxena, S. (2020). |MCH-EOR: Multi-objective cluster head based energy-aware optimized routing algorithm in wireless sensor networks. Sustainable Computing: Informatics and Systems, 28, 100406.
Jabri, M., Moussaoui, O., Moussaoui, M., & El Moussati, A. (2018). Combination of a successive surface experiment design and a hierarchical routing protocol to the optimization of the system energy in wireless sensor networks. In: Proceedings of International Symposium on Advanced Electrical and Communication Technologies (ISAECT), IEEE, pp. 1–5.
Morsy, N. A., AbdelHay, E. H., & Kishk, S. S. (2018). Proposed energy efficient algorithm for clustering and routing in WSN. Wireless Personal Communications, 103(3), 2575–2598.
Lalwani, P., Das, S., Banka, H., & Kumar, C. (2018). CRHS: Clustering and routing in wireless sensor networks using harmony search algorithm. Neural Computing and Applications, 30(2), 639–659.
Sheikh, H. F., Ahmad, I., & Arshad, S. A. (2019). Performance, energy, and temperature enabled task scheduling using evolutionary techniques. Sustainable Computing: Informatics and Systems, 22, 272–286.
Alghamdi, T. A. (2020). Energy efficient protocol in wireless sensor network: optimized cluster head selection model. Telecommunication Systems, 74, 331–345.
Fawzy, A. E., Shokair, M., & Saad, W. (2018). Balanced and energy-efficient multi-hop techniques for routing in wireless sensor networks. IET Networks, 7, 33–43.
Laouid, A., Dahmani, A., Bounceur, A., Euler, R., Lalem, F., & Tari, A. (2017). A distributed multi-path routing algorithm to balance energy consumption in wireless sensor networks. Ad Hoc Networks. https://doi.org/10.1016/j.adhoc.2017.06.006
Vinitha, A., & Rukmini, M. S. S. (2019). Secure and energy aware multi-hop routing protocol in WSN using Taylor-based hybrid optimization algorithm. Journal of King Saud University-Computer and Information Sciences. https://doi.org/10.1016/j.jksuci.2019.11.009
Doostali, S., & Babamir, S. M. (2020). An energy efficient cluster head selection approach for performance improvement in network-coding-based wireless sensor networks with multiple sinks. Computer Communications, 164, 188–200.
Rambabu, B., Reddy, A. V., & Janakiraman, S. (2019). Hybrid artificial bee colony and monarchy butterfly optimization algorithm (HABC-MBOA)-based cluster head selection for WSNs. Journal of King Saud University-Computer and Information Sciences. https://doi.org/10.1016/j.jksuci.2019.12.006
Kumar, R., & Kumar, D. (2016). Multi-objective fractional artificial bee colony algorithm to energy aware routing protocol in wireless sensor network. Wireless Networks, 22(5), 1461–1474.
Yadav, A. K., & Tripathi, S. (2017). QMRPRNS: Design of QoS multicast routing protocol using reliable node selection scheme for MANETs. Peer-to-Peer Networking and Applications, 10(4), 897–909.
Balachandra, M., Prema, K. V., & Makkithaya, K. (2014). Multiconstrained and multipath QoS aware routing protocol for MANETs. Wireless Networks, 20(8), 2395–2408.
Zhu, W., Lan, C., Xing, J., Zeng, W., Li, Y., Shen, L., Xie, X. (2016). Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, February 2016, (pp. 3697–3703)
Majhi, B., Naidu, D., Mishra, A. P., & Satapathy, S. C. (2020). Improved prediction of daily pan evaporation using deep-LSTM model. Neural Computing and Applications, 32(12), 7823–7838.
Kaur, S., Awasthi, L. K., Sangal, A. L., & Dhiman, G. (2020). Tunicate swarm algorithm: A new bio-inspired based metaheuristic paradigm for global optimization. Engineering Applications of Artificial Intelligence, 90, 103541.
Arora, S., & Singh, S. (2019). Butterfly optimization algorithm: A novel approach for global optimization. Soft Computing, 23(3), 715–734.
Palaniappan, S., & Chellan, K. (2015). Energy-efficient stable routing using QoS monitoring agents in MANET. EURASIP Journal on Wireless Communications and Networking, 1, 1–11.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Daniel, J., Francis, S.F.V. & Velliangiri, S. Cluster head selection in wireless sensor network using tunicate swarm butterfly optimization algorithm. Wireless Netw 27, 5245–5262 (2021). https://doi.org/10.1007/s11276-021-02812-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-021-02812-x