
Abstract
TCP Vegas performance can be improved since its rate-based congestion control mechanism could proactively avoid possible congestion and packet losses in multi-hop ad hoc networks. Nevertheless, Vegas cannot make full advantage of available bandwidth to transmit packets since incorrect bandwidth estimates may occur due to frequent topology changes caused by node mobility. This paper proposes an improved TCP Vegas based on the grey prediction theory, named TCP-Gvegas, for multi-hop ad hoc networks, which has the capability of prediction and self-adaption, as well as three enhanced aspects in the phase of congestion avoidance. The lower layers’ parameters are considered in the throughput model to improve the accuracy of theoretical throughput. The prediction of future throughput based on grey prediction is used to promote the online control. The optimal exploration method based on Q-Learning and Round Trip Time quantizer are applied to search for the more reasonable changing size of congestion window. Besides, the convergence analysis of grey prediction by using the Lyapunov’s second method proves that a shorter input data length of prediction implies a faster convergence rate. The simulation results show that the TCP-Gvegas achieves a substantially higher throughput and lower delay than Vegas in multi-hop ad hoc networks.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Transmission control protocol (TCP) in multi-hop ad hoc networks has recently attracted substantial research attentions [1–3]. TCP-Vegas is a typical enhanced TCP that uses a rate-based congestion control mechanism [4]. Generally speaking, TCP-Vegas has good performance in ad hoc networks for three reasons. First, the transmission rate is adjusted carefully by comparing with the estimated rate. Secondly, Vegas halves the congestion window (cwnd) size by identifying whether the retransmission packets belong to the current stage of congestion control. Thirdly, it emphasizes packet delay rather than packet loss as the criterion to determine the transmission rate. However, it only calculates the expected throughput using the round-trip time (RTT), which may not characterize the real throughput of the whole network due to the overlook of lower layer parameters. Besides, Vegas changes its current cwnd value based on the previous network situation, which means that this mechanism incurs latency to the computation and thus leads to the loss of accuracies and adaptations in rapidly changing environments.
Due to the potential improvements in performance, multiple studies have been made to cope with the problems of Vegas in wireless networks. An improved mechanism Vegas-W was proposed in [5], in which the cwnd is extended by a fraction with a rate control timer in the sending process, and the probing schemes have been changed to increase the window upon receiving more than one acknowledgment (ACK). However, the interaction analysis between TCP and lower protocols is needed for further improvement. Cheng etc. presented a threshold control mechanism with cross-layer response approach in [6] for improving TCP Vegas performance in IEEE 802.11 wireless networks. A model [7] based bandwidth estimation algorithm for 802.11 TCP data transmissions was developed by using feedback information from receivers.
Although these methods attained some improvements, all of them still have the inherent weaknesses of conventional TCP that stems from deferred calculations. Specifically, the calculations only reflect the past network conditions rather than the present and future ones, which makes them unsuitable for rapid changing environments. In this paper, we are inspired from the prediction algorithm [8], where the available duration of links is predicted to construct an efficient topology.
In this paper, we propose an improved TCP version based on TCP Vegas and Grey prediction named Gvegas, to deal with the problem of real throughput prediction and online congestion control. In addition, unlike other typical TCP variants, our scheme only needs revisions at the sender without involving intermediate nodes. To our best knowledge, this is the first work to consider both prediction and decision in congestion avoidance (CA) stage by predicting network condition before collision. Specifically, our contributions are summarized as follows:
In order to make the basis of congestion control more precisely for online congestion control in multihop ad hoc networks, we improve the theoretical and actual throughput model with cross-layer information sharing and grey prediction, respectively.
We model the congestion control decision as a MDP to choose the congestion window changing factor more effectively and adaptively. In addition, the action is quantified according to network state with round trip time.
We provide the performance analytic models of the improved congestion control over TCP Vegas, and utilize simulations and theoretical analysis to demonstrate the improved scheme can significantly promote the TCP performance in terms of both throughput and delay.
The remainder of this paper is organized as follows. We briefly describe some related works in Sect. 2. The main idea of the improved mechanism is introduced in Sect. 3. Section 4 formulates the cross layer model of expected throughput. Section 5 introduces the actual throughput prediction based on grey theory. Section 6 describes the RTT quantification and the exploration of cwnd changes based on Q-learning, in addition, the detailed algorithm and corresponding complexity analysis of space and time are also discussed. Section 7 numerically examines the Gvegas’s performance along with the Vegas and Newreno. Finally, Sect. 8 provides the conclusions of this paper.
2 Related works
TCP is the most widely applied transport layer protocol for reliable data transmission. Although there are many TCP versions with various congestion control schemes for different environments, such as TCP Newreno, TCP Vegas etc., some researchers have demonstrated that TCP Vegas can achieve higher throughput, fewer retransmissions and less delay than Newreno [9], because Vegas implements a more precise congestion avoidance mechanism based on packet delay rather than the packet loss. However, Vegas fails to make full use of available bandwidth to transmit packets since incorrect bandwidth estimates may occur due to unstable conditions in multi-hop wireless networks.
To detect congestion more reliably, several TCP throughput models have been proposed [10–12]. Samios et al. [10] developed a model to estimate the throughput of a Vegas flow as a function of packet loss rate, RTT, and protocol parameters. Similarly, a steady-state throughput of TCP Newreno was transferred as a function of RTT and loss behavior in [11]. The simulation results in [10, 11] show that TCP throughput model combining both packet loss and delay can achieve higher throughput. Furthermore, the throughput model of Vegas in [10] was extended by [12], which combined with the TCP segment information and TCP acknowledgement (ACK) to maximize the TCP throughput. Although these researches achieve the TCP performance improvements, they don’t fully concern the performance improvement from congestion control in wireless ad hoc environments.
Congestion control is another most significant way to improve TCP performance in wireless ad hoc networks [13]. An intelligent congestion control technique was proposed in [14] by using a neural network (NN) to regulate reliable data traffic in ad hoc wireless mesh networks. Badarla et al. [15] mainly concentrated on adapting to the changing network conditions and appropriately updating the congestion window by learning algorithm without relying on any network feedbacks. The above congestion control methods obtain some enhancements to some degree, however, they seldom explicitly consider the cross-layer network information to improve TCP performance.
Cross-layer designs allow information sharing among different layers in order to improve the functionality [13], in which some lower parameters could be considered when performing the cross layer design. Cheng et al. [6] proposed a congestion control scheme with dynamic threshold and cross layer response, in which the network performance was improved by the adaptation of congestion window size in accordance with the estimated buffer length. In [16], some typical cross layer factors were analyzed and modeled, and the TCP optimization was formulated as a Markov Decision Process (MDP). Furthermore, Xie et al. [17] presented a TCP pacing protocol by cross-layer measurement and analysis on the lower bound of the contention window to reduce packet burstiness in wireless networks.
In addition to the above schemes, TCP performance could be improved by status prediction through probabilistic approaches. For example, prediction strategies such as increasing the hold time of the topology for static scenario or increasing the HELLO generation rate for mobile scenario were proposed to promote the TCP efficiency [18]. Different from [18], congestion window was adjusted based on the estimation of network state by using the feedback information from the receiver [19].
Although, there are various cross-layer improved researches to improve the performance of multi-hop wireless networks, most of them always try to solve the basis of congestion and its control decision separately and make congestion control decision corresponding to past congestion control status which cannot really reflect the environmental conditions on time. In order to achieve overall and online optimization, this paper will promote the TCP performance towards the direction of prediction and joint cross-layer optimization.
3 Gvegas formulation
The Vegas mechanism uses the difference presented by (1) [4] between the expected (v_expect_) and actual (v_actual_) throughput to decide how to change cwnd:
Specifically, the cwnd is either changed by adding or subtracting one packet or remains unchanged according to diff as follows:
where \(v\_\alpha\) and \(v\_\beta\) are corresponding threshold values [4].
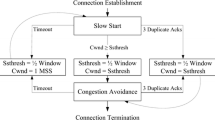
Gvegas has two parts as shown in Fig. 1. The first one, which contains expected throughput, grey prediction and residual modification model, makes the congestion control more accurate. The other one, which comprises quantification and reinforcement learning model, makes the cwnd adaptive to network changes. In the first part, v_expect_ and v_actual_ in (1) are replaced with expected and predicted values, respectively. The expected model uses cross-layer parameters to obtain throughput, and the prediction uses grey theory to predict the future throughput. In the second part, we quantify RTT into cwnd changing size, and a Q-learning algorithm is used to explore the optimal changing size for different cwnd phases.

The structure diagram of Gvegas
3.1 Overview of grey prediction
Grey theory is a system that focuses on the uncertainty problems of small samples and poor information [20] which consists of two parts: grey prediction and grey decision. A grey system represents the cognitive degree for environment data and is widely used due to its simple and information imperfect characteristics. Typically, there are five categories of grey prediction including: (1) time series forecasting, (2) calamity forecasting, (3) seasonal calamity forecasting, (4) topological forecasting and (5) systematic forecasting [21].
GM(1,1) model [22, 23], which is one of the most widely used grey prediction models, can weaken the stochastic fluctuation in original series by accumulated generating operation (AGO), so as to dig out its inherent law, and build a one order different equation model to describe the law. The model gets the undecided coefficients of the one order grey differential equation by using least squares estimation and obtains the final prediction value by using inverse accumulated generating operation.
3.2 Overview of Q-learning
Reinforcement learning (RL) [24] is a learning system aiming to maximize a long-term performance measure with typical scenario shown in Fig. 2. In RL model, one agent can interact with its environment autonomously: it observes environment state in S, chooses one available action from A, and receives one reward in R from environment. The state-action pair in \(S \to A\) is a policy \(\pi^{ * }\) which aims to maximize the total reward \(V^{\pi } \left( {s_{t} } \right) = \sum\limits_{t = 0}^{\infty } {\gamma^{t} r_{t} }\), where the \(r_{t}\) is a received reward.

The reinforcement learning scenario
Q-learning is a widely used RL algorithm [25]. In real applications, due to existence of uncertainty, agent cannot forecast the reward and next state when an action is performed. This will result in that the agent cannot obtain perfect \(\pi^{ * }\) by solving \(V^{\pi } \left( {s_{t} } \right)\). Therefore, Q-learning uses \(Q^{\pi } \left( {s,a} \right)\) to get the best policy: \(V^{{\pi^{ * } }} \left( s \right) = \mathop {\hbox{max} }\limits_{a \in A} Q^{{\pi^{ * } }} \left( {s,a} \right)\) and the renewal of Q value is as follows:
where \(\alpha\) is the learning rate denoted as \(\alpha = \frac{1}{1 + visit(s,a)}\), visit(s,a) is the times of one station-action pair has been visited. s′ and a′ are the next state and action which belong to the set of S and A, respectively. Q-learning typically selects the “greedy” action a which has the highest Q(s,a) value with a probability \(\varepsilon\) (approximating 1) and selects a random action with probability 1−\(\varepsilon\).
4 Cross-layer model of TCP expected throughput
For simplicity of analysis, we assume that the main consideration of the throughput model involves the Transport Layer (TL) and Media Access Control (MAC) sub-layer.
4.1 TCP Vegas throughput model
A typical stochastic model for the steady-state throughput of TCP Vegas has been modeled by [10], as shown in (4), where Th Vegas is the throughput received, n is the expected number of consecutive Loss Free Periods (LFP) that occurs between one slow start (SS) and another slow start period, p denotes the loss event rate, W 0 is the average of cwnd during stable backlog state, T TO is the average duration of first timeout in a series of timeouts, and RTT is the average RTT.
where N SS2TO and D TO are represented by Eqs. (5) and (6), respectively
In order to predict the maximum achievable expected throughput for TCP-based data transmissions over IEEE 802.11 WLANs in multi-hop ad hoc networks. We extend TCP throughput model in (4) to include the characteristics of IEEE 802.11 Distributed Coordination Function (DCF) and queue management model in the subsequent subsections.
4.2 IEEE 802.11 DCF model
IEEE 802.11 DCF can be executed in either ad hoc or infrastructure-based networks and, indeed, is the typical access method implemented in most commercial wireless cards [26]. DCF contains three-times handshake as shown in Fig. 3. A sender sends a Request to Send (RTS) to a receiver after a DIFS time. Upon receiving the RTS, the receiver waits for one SIFS delay to send Clear to Send (CTS) to the sender. Then, the sender and receiver establish a link, during which the sender detects whether there is a collision before transmitting. If the answer is yes, a random back-off time will be selected by sender to build next transmission request. When the retransmission times reach the retry attempt limit, the packet will be dropped. The process time, successful delivery probability and loss probability of a packet from node to node are denoted by pt DCF , dp DCF and lp DCF , respectively.
The value of dp DCF is given by [7]
where \(ncdf\) indicates the number of competition channel data flow. \(D\_\tau\) denotes the probability of a request to send data. BER, dl, dh and CW I are the bit error rate, packet size, length of packet header and initial size of cwnd, respectively, i.e.
When the retransmission times reach the retry attempt limit rl, a packet is dropped with probability given by

The access mechanism of DCF with RTS/CTS
4.3 Queue management model
In this paper, we assume that Random Early Discard (RED) is used as the mechanism of queue management. The loss probability and the processing time of successfully transmitted packet at the RED stage are denoted by lp queue and pt queue , respectively. pt queue is available in real time via the feedbacks of RED protocol. lp queue is given by
where \(queue_{t - 1}^{\hbox{min} }\) and \(queue_{t - 1}^{\hbox{max} }\) are the minimal and maximal size of queue at time t−1. \(queue_{t}^{avg}\) indicates the average queue length at time t.
4.4 The expected throughput model
We formulate the expected throughput model by joint consideration of the term Th Vegas in (4) and the limitation of the maximum cwnd in a multihop ad hoc network. The throughput model is given by:
where N SS2TO and D TO are defined by (5) and (6), respectively. Besides, p * and RTT * are defined by
and
where hs represents the sum of hops of a network connection, the p in \(N_{SS2TO}\) and \(D_{TO}\) is replaced by p *. The lp TCPdrop and pt TCP_ACK are the drop probability and processing time of TCP ACK which could be detected in real time via feedbacks of TCP protocol. The value of pt DCF , lp DCF and lp queue can be calculated by (7, 10) and (11).
5 Prediction of actual throughput based on grey model
Chapter 4 discusses the expected throughput in cross-layer model, however, the existing TCP variants also use the actual throughput of last stage in the Eq. (1) as the basis to control the congestion at next stage. This mechanism cannot cope with the real-time control and unpredictable dynamics of ad hoc networks. Thus, we propose a future actual throughput prediction scheme based on the GM(1,1) grey model [22, 23].
5.1 The grey prediction of throughput
We focus on predicting the actual throughput of the next stage by grey prediction GM(1,1) model [23] shown in Fig. 4. For simplicity, we assume that grey model predicts at discrete time interval called “stage”. The mode predicts the future network throughput at stage t + 1 to determine the cwnd changing size. In our model, the actual network throughputs of the last t stages are regarded as the input column ag o = {ag o(1), ag o(2),…,ag o(t)}, where t represents the length of input data and its minimum length is 4 for the purpose of prediction precision [23]. Accumulated Generating Operation (AGO), which will output the sequence of ag 1, aims to eliminate the randomness of ag o. In addition, ag z(t), created by Adjacent Average Generation Operation (AAGO), is the intermediate sequence to calculate the parameters of aga and agb as follows:
where aga and agb are evolution parameter and grey action, respectively:
The throughput prediction for next stage is denoted by

Definition model of GM(1,1)
5.2 Residual modification model
Residual modification model is used to correct the prediction error, which is given by
The original sequence of prediction error is set to be the input of grey prediction model. Therefore, the prediction of error, which is defined as \(a\hat{r}^{0} \left( {t + 1} \right)\), will reduce the error between the predicted and actual throughputs. Finally, the throughput prediction with residual modification is given by
5.3 Stability analysis of grey prediction
5.3.1 The condition of convergence
We analyze the stability of the grey prediction system according to Lyapunov’s second method. The definition of differential function of grey prediction is given by
We define the positive definite function of Lyapunov as
The time derivative of V is given by
Equation (23) can be rewritten as follows by combining with (21).
According to Lyapunov’s second method [27], if aga is larger than zero, then \(V(x^{(1)} )^{{\prime }}\) is negative semi-definite, which means that the Eq. (21) has asymptotic stability about zero solutions. At the same time, the value of aga should belong to the range [−2/(t + 1),2/(t + 1)] for the sake of ensuring prediction accuracy in grey model [22]. Thus, we let the value of aga lie in the range (0, 2/(t + 1)].
5.3.2 Convergence rate of grey prediction
The solution of (21) is given by [22]
with prediction sequence \(\hat{x}^{(1)} (t + 1)\). The next stage prediction of \(x^{(0)} (t)\) can be calculated by
under the relationship of \(x^{(0)} \left( {t + 1} \right) = x^{\left( 1 \right)} \left( {t + 1} \right) - x^{\left( 1 \right)} \left( t \right)\).
According to the definition, (26) can be rewritten as \(\hat{x}^{(0)} (t + 1) = \exp (aga) \cdot \hat{x}^{(0)} (t)\), which can be replaced with \(x_{t + 1} = g(x_{t} ) = \exp ( - aga) \cdot x_{t}\). We assume that the initial value of system is perturbed by \(\zeta_{0}\). Then, according to the Lyapunov exponential spectrum [27], the distance between original and interrupted values is by the following equation after N iterations
where t s represents continuous-time variable and \(\lambda\) is defined by
where N is the times of iterations, x i is the prediction value of the ith iteration.
Finally, the evaluation of the Lyapunov exponential spectrum of (28) is given by
From (29), (27) can be rewritten as \(\zeta_{t} \cong \zeta_{0} \cdot \exp ( - aga \cdot t_{s} )\). When aga∈(0,2/(t + 1)], the Lyapunov exponential spectrum \(\lambda \in [ - 2/(t + 1),0) < 0\). It means that the phase volume of system is contracted in this direction, and the movement is stable in this direction. Specifically, the distance between original and interrupted values decreases exponentially as \(\left| \lambda \right|\) increases. In other words, the convergence rate is exponential in the length of input data.
6 Mechanism of congestion control
In the process of transmission, we try to make a full use of available network capacity and follow the conditions and principles of Vegas simultaneously by combining quantification with Q-learning. From formulation (1, 12) and (20), the final diff is calculated by
6.1 RTT quantization
In order to take more proper actions according to the circumstances, we combine the throughput and the RTT quantization to control the cwnd change sizes, instead of only using the criterion of throughput. At the same time, the RTT is quantified to different degrees as the size of cwnd changes, which is described by
In order to overcome the conservation of cwnd changes in traditional Vegas mechanism, minRTT and maxRTT in Eq. (31) are the minimal and maximal RTTs at each congestion control stage, respectively.
The random parameter bl is uniformly chosen in the interval \(\left[ {m_{sf} \cdot \gamma ,n_{sf} \cdot \gamma } \right]\), where γ value is −1, 0 or 1 according to throughput state,m sf and n sf are span factor which could determine the width of the range. Besides, we formulate the phase of CA as a MDP to explore the optimal value of bl for cwnd changing phases for the purpose of improving the accuracy of congestion control.
6.2 Q-learning exploration model
In the Q-learning model, we let the state S t be the different stages of cwnd changes. The action associated with a state is the value selection for bl. The return of R i (s,a i ) is set to be the value of the actual throughput. The purpose of the Q-learning is to choose the optimal action that maximizes the following Q function [28].
where \(q\gamma \in \left( {0,1} \right]\) is a discount factor that denotes the relative importance of present and future rewards. Q converges to Q * with probability 1 [28] when the learning rate \(\alpha_{n}\) meets the condition \(\sum\nolimits_{i = 1}^{\infty } {\alpha_{{t\left( {i,s,a} \right)}} } = \infty ,\sum\nolimits_{i = 1}^{\infty } {\left( {\alpha_{{t\left( {i,s,a} \right)}} } \right)}^{2} < \infty\), where t(i,s,a) means that the action a is selected in state s in the ith iteration. The optimal strategy of s t is defined by \(\pi^{ *} \left( {s_{t} } \right){ = }\mathop {\text{argmax}}\limits_{{s_{t} }} Q^{*} \left( {s_{t} ,a} \right)\).
For a tradeoff between exploration and exploitation, we utilize the \(\varepsilon - greedy\) [29] action selection strategy, in which the optimal action is selected with probability of \(\varepsilon\).
6.3 Algorithm and complexity analysis
The algorithm of improved congestion avoidance control with prediction and self-adaption are summarized in Algorithm 1.

From Algorithm 1, the space and time complexities of Gvegas mainly rely on the ones of the grey model and Q-learning model. The space and time complexities of the grey prediction can be denoted by \(O_{sg} \left( t \right)\) and \(O_{tg} \left( {t - 1} \right)\), respectively. Similarly, the space and time complexity of Q-learning can be denoted by \(O_{qg} \left( {\left| S \right| \cdot \left| A \right|} \right)\) and \(O_{qg} \left( {\left| A \right|} \right)\) [29]. Therefore, the overall space complexity of Gvegas is \(O\left( {\left| S \right| \cdot \left| A \right|} \right)\), and the time complexity is \(O\left( {\hbox{max} \left( {\left| A \right|,\left( {t - 1} \right)} \right)} \right)\). In addition, there is no deployment difficulty for Gvegas which is realized only on the sender without any changes at routers and receivers.
7 Simulation results and discussions
We implement Gvegas in NS2 and verify its performance along with TCP Vegas and Newreno under different length of input data (t = 4, 5, 6, 7, 8) in three simulation scenarios: “chain”, “Reference Point Group Mobility Model (RPGM)” and “Wireless Mobile Ad Hoc Network (WMAHN)” scenarios, and each performance metric of scenario is computed by averaging results of 500 simulation runs. We assume that the Internet layer, MAC layer and queue manager use IP, IEEE 802.11 and RED protocols, respectively. All scenarios have the same MAC layer parameters given in Table 1. We set the span factor m sf = 1, and n sf = 3. The learning factor \(q\gamma\) and learning rate \(\alpha_{t}\) are equal to 0.95 and 0.3 [30], respectively. In addition,\(\varepsilon\) is set to be 0.8. One TCP flow in Gvegas, Vegas or Newreno is always transmitted from sender nodes 4 to receiver node 5 throughout the simulation in each scenario, and the end-to-end throughput and delay between node 4 and node 5 are collected to be the performance analysis parameters by gathering the simulation information from those two nodes. Each chain scenario simulation has a duration of 240 and 600 s for each RPGM and WMAHN scenario. For the purpose of better display, each four seconds is denoted as a timestamp in multi-hop chain scenario, and ten seconds for both RPGM and WMAHN scenario.
7.1 Multi-hop chain wireless network scenario
We assume that there are six nodes that have the identical transmission range of 150 meters and initial positions of those nodes are indicated in Fig. 5. In this simulation, a linear multi-hop chain is kept by all nodes with random velocities in a range [5, 8] m/s. The average throughput and delay of 500 runs among Gvegas, Vegas and Newreno are displayed by Fig. 6. In addition, the expectations of throughput and delay of 500 runs each with 240 s simulation of different prediction length of t = {4, 5, 6, 7, 8} are shown by Fig. 7.

Positions information of nodes

The average simulation results of multi-hop chain network. a t = 4, b t = 5, c t = 6, d t = 7, e t = 8

The expectation of throughput and delay of chain of different prediction length
From Fig. 6, we compare the performance in terms of throughput and delay of Gvegas with those of Vegas and Newreno for different t = {4, 5, 6, 7, 8}. We can see that both the average throughput and delay of Gvegas are significantly improved compared with Vegas and Newreno, irrespective of the values of t in Fig. 6. From Fig. 7, we can further see that the throughput of Gvegas is improved more than doubled and fivefold in Vegas and Newreno, respectively. In addition, the delay of Gvegas is shorter by 42 and 90 % on average than Vegas and Newreno, respectively.
7.2 RPGM scenario
RPGM is a typical rescue type of ad hoc mobile group mode, in which each group has a logic center, and other nodes are equally distributed around the center. The group movement is represented by change of the center, including the position, velocity, direction and accelerated speed, etc.
Let a group have six nodes, each having the same transmission range of 80 m in a 800 × 600 m area. We assume that the group is formed by these six nodes randomly distributed in a sub-area of 200 × 200 m. The group’s velocity is uniformly randomly chosen in [1, 3] m/s with a random pause time when reaching a destination. The average throughput and delay of 500 simulation runs among Gvegas, Vegas and Newreno in RPGM are displayed by Fig. 8. In addition, the expectations of throughput and delay of 500 runs each with 600 s simulation of different prediction length of t = {4, 5, 6, 7, 8} are shown by Fig. 9.

The average simulation results of group ad hoc network. a t = 4, b t = 5, c t = 6, d t = 7, e t = 8

The expectation of throughput and delay of RPGM of different prediction length
From Fig. 8, we can see that the performance of Gvegas is greatly better than that of Vegas and Newreno in terms of both average throughput and transmission delay in RPGM. In more detail, Fig. 9 shows that Gvegas attains more throughputs than Vegas and Newreno by about 22 and 52 % on average for each t = {4, 6, 5, 7, 8}, and shorter delay by about 60 and 82 %, respectively. Because Gvegas has the capability to foresee the environment conditions in the near future, Gvegas can take reasonable actions before collision or congestion based on the prediction. As demonstrated in Sect. 5.3, the shorter the input data length of prediction is, the faster the convergence rate is. The simulation results in RPGM scenario further confirm that the curves of both throughput and delay in forecast sequence of t = 4 are more smoothly than other prediction length.
7.3 WMAHN scenario
WMAHN is a self-configuring, dynamic network in which nodes are free to move. We assume that ten nodes are randomly distributed in a square area of 300 × 300 m area and each node has the same transmission range of 80 m. In addition, we let the node’s velocity be uniformly randomly chosen in [1, 5] m/s with a random pause time in [0,5]s when arriving at a destination. The average throughput and delay of 500 simulation runs among Gvegas, Vegas and Newreno in WMAHN are displayed by Fig. 10. Furthermore, the expectations of throughput and delay of 500 runs each with 600 s simulation of different prediction length of t = {4, 5, 6, 7, 8} are shown by Fig. 11.

The average simulation results of mobile ad hoc network. a t = 4, b t = 5, c t = 6, d t = 7, e t = 8

The expectation of throughput and delay in WMAHM of different prediction length
From Fig. 10, we can see that the performance of Gvegas is obviously better than that of Vegas and Newreno after a few simulation times. At the beginning of simulation, Gvegas is not stable since the perception of dynamic environment is not enough for Q-learning and Grey predictor. But, the throughput and delay of Gvegas become better than Vegas and Newreno through exploration about 100 s. This is further explained in Fig. 11, which shows that the expectation of throughput of Gvegas is better than that of Vegas and Newreno by about 60 % and five times for each t = {4, 6, 5, 7, 8}, and delay shorter by about 60 and 80 %, respectively. Besides, the simulation results confirm that the curves of both throughput and delay in forecast sequence of t = 4 are more smoothly than other prediction length.
8 Conclusions
This paper uses the cross-layer throughput model to calculate the achievable throughput and predict the throughput of the next time stage based on grey theory for real-time congestion control. In addition, the quantization of RTT is performed by the optimal action exploration of Q-learning. The convergence condition and rate of grey model based on Lyapunov’s second method have shown the effectiveness of the improved method. Simulation results show that the performance of our proposed scheme greatly outperforms the Vegas and Newreno in terms of both average throughput and delay in multi-hop ad hoc networks. From simulation results and convergence analysis, we suggest that the prediction length t = 4 is a reasonable choice for typical scenarios.
References
Cai, Y., Jiang, S., Guan, Q., et al. (2013). Decoupling congestion control from TCP (semi-TCP) for multi-hop wireless networks. EURASIP Journal on Wireless Communications and Networking, 1, 1–14.
Al-Jubari, A. M., Othman, M., Ali, B. M., et al. (2013). An adaptive delayed acknowledgment strategy to improve TCP performance in multi-hop wireless networks. Wireless Personal Communications, 69(1), 307–333.
Majeed, A., Abu-Ghazaleh, N. B., Razak, S., et al. (2012). Analysis of TCP performance on multi-hop wireless networks: A cross layer approach. Ad Hoc Networks, 10(3), 586–603.
Brakmo, L. S., O’Malley, S. W., & Peterson, L. L. (1994). TCP Vegas: New techniques for congestion detection and avoidance. In Proceedings of the conference on communications architectures, protocols and applications (ACM SIGCOMM) (pp. 24–35).
Ding, L., Wang, X., Xn, Y., et al. (2008). Improve throughput of TCP-Vegas in multi-hop ad hoc networks. Computer Communications, 31(10), 2581–2588.
Cheng, R. S., Deng, D. J., Chao, H. (2011). Congestion control with dynamic threshold adaptation and cross-layer response for TCP over IEEE 802.11 wireless networks. In Proceedings of the international conference on wireless information networks and systems (WINSYS) (pp. 95–100).
Yuan, Z., Venkataraman, H. M., Muntean, G. M. (2012). A novel bandwidth estimation algorithm for IEEE 802.11 TCP data transmissions. 2012 Wireless Vehicular Communications and Networks (WCNC) (pp. 377–382).
Guan, Q., Yu, F. R., Jiang, S., et al. (2010). Prediction-based topology control and routing in cognitive radio mobile ad hoc networks. IEEE Transactions on Vehicular Technology, 59(9), 4443–4452.
Ghaffari, A. (2015). Congestion control mechanisms in wireless sensor networks: A survey. Journal of Network and Computer Applications, 52, 101–115.
Samios, C. B., & Vernon, M. K. (2003). Modeling the throughput of TCP Vegas. ACM SIGMETRICS Performance Evaluation Review, 31(1), 71–81.
Parvez, N., Mahanti, A., & Williamson, C. (2010). An analytic throughput model of TCP Newreno. IEEE/ACM Transactions on Networking, 18(2), 448–461.
Xie, H., Boukerche, A., De Grande, R., et al. (2015). Towards a distributed TCP improvement through individual contention control in wireless networks. IEEE International Conference on Communications (ICC), 2015, 5602–5607.
Fu, B., Xiao, Y., Deng, H., et al. (2014). A survey of cross-layer designs in wireless networks. IEEE Communications Surveys and Tutorials, 16(1), 110–126.
Al Islam, A. B. M. A., & Raghunathan, V. (2015). ITCP: An intelligent TCP with neural network based end-to-end congestion control for ad-hoc multi-hop wireless mesh networks. Wireless Networks, 21(2), 581–610.
Badarla, V., & Murthy, C. S. R. (2011). Learning-TCP: A stochastic approach for efficient update in TCP congestion window in ad hoc wireless networks. Journal of Parallel and Distributed Computing, 71(6), 863–878.
Xie, H., Pazzi, R. W., & Boukerche, A. (2012). A novel cross layer TCP optimization protocol over wireless networks by Markov Decision Process. IEEE Global Communications Conference (GLOBECOM), 2012, 5723–5728.
Xie, H., & Boukerche, A. (2015). TCP-CC: Cross-layer TCP pacing protocol by contention control on wireless networks. Wireless Networks, 21(4), 1061–1078.
Mezzavilla, M., Quer, G., & Zorzi, M. (2014). On the effects of cognitive mobility prediction in wireless multi-hop ad hoc networks. IEEE International Conference on Communications (ICC), 2014, 1638–1644.
Wang, J., Dong, P., Chen, J., et al. (2013). Adaptive explicit congestion control based on bandwidth estimation for high bandwidth-delay product networks. Computer Communications, 36(10), 1235–1244.
Liu, S., Forrest, J., & Yang, Y. (2012). A brief introduction to grey systems theory. Grey Systems: Theory and Application, 2(2), 89–104.
Xie, N., & Liu, S. (2009). Discrete grey forecasting model and its optimization. Applied Mathematical Modelling, 33(2), 1173–1186.
Kayacan, E., Ulutas, B., & Kaynak, O. (2010). Grey system theory-based models in time series prediction. Expert Systems with Applications, 37(2), 1784–1789.
Chen, C. I., & Huang, S. J. (2013). The necessary and sufficient condition for GM(1,1) grey prediction model. Applied Mathematics and Computation, 219(11), 6152–6162.
Kaelbling, L. P., Littman, M. L., & Moore, A. W. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
Marco, M., Lorenza, G., Michele, R., et al. (2015). Distributed Q-learning for energy harvesting heterogeneous networks. IEEE International Conference on Communications (ICC), 2015, 2006–2011.
Alonso-Zárate, J., Crespo, C., Skianis, C., et al. (2012). Distributed point coordination function for IEEE 802.11 wireless ad hoc networks. Ad Hoc Networks, 10(3), 536–551.
Paunonen, L., & Zwart, H. (2013). A Lyapunov approach to strong stability of semigroups. System and Control Letters, 62(8), 673–678.
Yau, K. L. A., Komisarczuk, P., & Teal, P. D. (2012). Reinforcement learning for context awareness and intelligence in wireless networks: Review, new features and open issues. Journal of Network and Computer Applications, 35(1), 253–267.
Shiang, H. P., & Van der Schaar, M. (2010). Online learning in autonomic multi-hop wireless networks for transmitting mission-critical applications. IEEE Journal on Selected Areas in Communications, 28(5), 728–741.
Xu, X., Liu, C., & Hu, D. (2011). Continuous-action reinforcement learning with fast policy search and adaptive basis function selection. Soft Computing, 15(6), 1055–1070.
Acknowledgments
This work was supported in part by National Nature Science Foundation of China under Grant 61379005, State Administration of Science, Technology and Industry for National Defence under Grant B3120133002, China Academy of Engineering Physics(CAEP) project under Grant 2015A0403002, and the Robot Technology Used for Special Environment Key Laboratory of Sichuan Province under Grant 13zxtk07. The authors would like to thank the editor and anonymous reviewers for their thorough review and valuable comments and suggestions to improve the quality of the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Jiang, H., Luo, Y., Zhang, Q. et al. TCP-Gvegas with prediction and adaptation in multi-hop ad hoc networks. Wireless Netw 23, 1535–1548 (2017). https://doi.org/10.1007/s11276-016-1242-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-016-1242-y