
Abstract
In this study, the relationship between the sustainable development goals (SDGs) and snow avalanche susceptibility has been analyzed for the first time. Snow avalanche susceptibility of Uzungöl basin, which is a specially-protected area in Trabzon, Türkiye, was generated by a novel proposal of ensemble modeling of hesitant fuzzy sets and decision tree-based Machine Learning (ML) algorithms. The uncertainty effect of the snow avalanche conditioning factors was expressed regarding the Bel values at each class on snow avalanche susceptibility. Hesitant fuzzy ordered weighted averaging operator was used for aggregation of the ML classification of snow avalanche conditioning factors. The predicted avalanche susceptibility maps were validated by a receiver-operating-characteristics curve method and the areal-percentages of avalanche classes, and avalanche percentages at the classes. Area under curve and true skill statistics values for HFS-J48, HFS-RT and HFS-REPTree for the training process were calculated as 0.985, 0.966, 1.000, 0.989, 0.969, and 0.943, respectively. These values for testing process were calculated as 0.975, 0.947, 0.917, 0.840, 0.955, and 0.920, respectively. Although HFS-RT predicted the best for the training process, the HFS-J48 model was found to be performing the best predictions of snow avalanche susceptibility regarding the testing process and predicted classified areal and avalanche percentages. The findings of this study may contribute to further understanding achievement of many goals regarding environmental, ecological, and spatial, and landscape planning. The results of this study may be considered to achieve the goals of some SDGs such as tourism planning, developing economic activities, providing sustainable transportation, and land use control.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Cleaner Production (CP) is a fundamental concept that benefits improving production and service stages by prioritizing the human and environmental related risks without sacrificing economic concerns and the overall efficacy of the process (Giannetti et al. 2020). CP concentrates on developing environmental management strategies by reducing risks without denying economic activities. However, CP cannot achieve its goals without increasing the awareness of the communities since it requires some tasks to be modified in the production, maintenance, and service stages (Khalili et al. 2015). CP must not be also considered as a balance of conflicting goals, but it is a balance of long-term benefits regarding the environment and communities. CP aims to develop environmental sustainability by minimizing environmental and ecological risks considering the production and service constraints (Giannetti et al. 2020; Khalili et al. 2015).
Further endeavors were implemented by expanding the idea of the CP in the area of environmental, in 2015, to declare a concept of 17 Sustainable Development Goals (SDGs) attached with a set of targets and indicators by incorporation of the member states by the United Nations (UN) (UN 2015). UN aims by reaching goals to end poverty, protect the environment and habitat, and provide prosperity by the end of 2030. This is also a global call to foster support for developing environmental policies regarding the climate change challenges and quelling economic concerns by adapting green economic activities. Scholars attempted to develop models by analyzing the SDGs based on categorization, interconnection, and prioritization for guidance to policymakers.
Management of natural disasters and their resulting risks are very challenging tasks for policymakers (Šakić Trogrlić et al. 2022). Disaster risk reduction has a vital priority to get achievements regarding the integrated environmental management strategies to protect humans, and the environment (Cui et al. 2021). Kelman (2017) explained the interlinkage between climate change, disaster risk reduction, and sustainable development by introducing keypoints from the analysis of the Paris Agreement, ending artificial separations of international agreements. The vulnerability mitigation strategy actions and resilience improvement efforts are also convenient with the SDGs and are embedded in the targets to develop policies related to 2030 Agenda (Kelman 2017). In this context, natural hazards susceptibility maps are a preliminary attempt to understand the existing and temporal variation of disaster risks which are significant guides for disaster risk reduction that are the sub-set of sustainable development. Further emphasis on hydro-meteorological disasters was pointed out as the climate change impacts increase (Kumar et al. 2020). However, most of the studies were related to floods. Echendu (2020) analyzed the causes of flood incidences in Nigeria. The authors introduced the flood risk management and spatial planning and linked the flood impact with the challenges of SDG1 (no poverty), SDG2 (zero hunger), SDG3 (healthy lives), SDG4 (quality education), SDG6 (clean water and sanitation), SDG8 (decent work and economic growth), SDG11 (sustainable cities and communities), SDG14 (life below water), and SDG15 (life on land). Thacker et al. (2019) examined the influences of SDGs on water, energy, solid waste, transport, digital communication, and all infrastructures to guide the government and related sectors. Damages to infrastructures were found to have more influences on SDG3, SDG6, SDG7 (affordable and clean energy), SDG9 (industry), and SDG11. The study also revealed the current stocks and the infrastructure investment needs of the countries. Mansour et al. (2022) interlinked the SDGs, flash floods, and the morphometric behavior of the sub-watersheds. The authors linked their findings with achieving SDGs. Ezzeldin et al. (2022) and Aly et al. (2022) discussed the achievability of the SDGs by constructing solutions for flood management.
Although the occurrence of snow avalanche incidents is not as common as floods, snow avalanches may be very destructive for snow-dominated basins in Türkiye (AFAD 2021). Snow avalanches may directly threaten the sustainability of human life, environment, landscape, socio-economic conditions of the region, tourism, etc. Therefore, snow avalanche susceptibility mapping is required to understand the spatial distribution of avalanche potentials and take actions accordingly to achieve SDGs in the basin. To the best knowledge of the author, snow avalanches have been linked with SDG 8, SDG 11 and SDG 15 in this study for the first time.
1.1 Literature Review of Snow Avalanche Susceptibility Mapping
Since the processes of snow mass movement are uncertain and very complicated, a limited number of snow avalanche susceptibility mapping studies, unlike floods and landslides, adopt statistical and machine learning models in some snow-dominated study areas worldwide exist. Akay (2021) presented a comprehensive review of the comparison of the performance of stand-alone machine learning models for the accurate estimation of snow avalanche susceptibility. Most of the researchers found Random Forest (RF) and Support Vector Machine (SVM) to be outperforming models (Rahmati et al. 2019; Choubin et al. 2019). Later, some statistical parameters were used for hybridization to get more reliable results. For instance, Yariyan et al. (2020) adopted the Belief (Bel) function, and Probability Density (PD) to hybridize Logistic Regression (LR) and Multi-Layer Perceptron (MLP) models to generate snow avalanche susceptibility map. The comparison results suggested that the PD-LR hybrid model achieved the best accuracy. Yariyan et al. (2022) performed a snow avalanche susceptibility map of Zarrinehroud and Darvan watersheds using four hybrid learning models fuzzy ART-MAP, MLP, self-organizing map (SOM) and Radial Basis Function (RBF), with weight of evidence, statistical index, K-means clustering method, and frequency ratio. Researchers introduced the K-means SOM model producing the best results. Later, researchers across the world endeavor to get more accurate predictions of highly susceptible areas prone to snow avalanches by using further ensemble machine learning models. Mosavi et al. (2020) executed susceptibility map performing Random Subspace (RS) ensemble model of Functional Tree (FT), in addition to the stand-alone models as LR, FT, Alternate Decision Tree (ADT), and Logistic Model Tree (LMT). Akay (2021) generated snow avalanche susceptibility map of Uzungöl Basin considering standalone models such as Random Tree (RT), J48, and ensemble models such as RF, AdaBoost M1, bagging, RealAdaBoost, and RS. The author concluded that some of the ensemble models improved the predictions. A recent study conducted by Chen et al. (2021) pointed out the performance of the Convolutional Neural Network (CNN), and two ensembles meta-heuristic algorithms of CNN, Imperialist Competitive Algorithm (ICA), and Grey Wolf Optimization (GWO) on snow avalanche susceptibility map of Darvan watershed. The authors stated that CNN-ICA model predictions gave the most efficient results.
There is still a gap in the adequacy of the applicability to predict the snow avalanche susceptibility mapping by ensemble modeling of machine learning and fuzzy models, as mentioned earlier. This may be also due to the complex structural mechanism of the snow avalanches. Hence, in this study, an ensemble proposal of Hesitant Fuzzy Set (HFS) theory combined with an aggregation operator, and classification of machine learning models was presented and used for the prediction of snow avalanche susceptibility of Uzungöl Basin. The theoretical background of the proposal which has not been conducted in any disaster susceptibility maps was clearly described in the manuscript.
2 Material and Method
2.1 Study Area
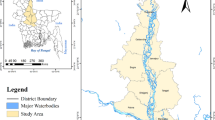
Uzungöl Basin is located in 4,487,447 – 4,504,821 Y, and 607,095 – 625,250 X coordinates and covers mostly Trabzon Province in Türkiye (Fig. 1). Uzungöl basin is surrounded by high mountains with forest cover and plateaus and is an attraction center for holiday lovers yearlong in terms of its wonderful and inspiring nature and landscape. However, serious snow avalanche incidents occurred in Uzungöl basin resulting in the loss of property in various years.

Location of snow avalanche affected cities and Uzungöl basin and elevation map of the study area
2.2 Dataset Used
The data used in this study can be categorized into two groups as inventory, and snow avalanche conditioning factors. It is the most prominent stage to prepare the snow avalanche inventory data for the prediction of the snow avalanche susceptible areas. Since the occurrence of snow avalanches are sensitive to the releasing zone of accumulated snow layers, the inventory data was generated using the characteristics of starting zone. Readily available releasing zone polygons generated by Geographic Information System (GIS) facilities and provided from General Directorate of Combating Desertification and Erosion (CEM) were obtained by experiences from past snow avalanches, satellite images, aerial photos, and comprehensive field surveys, etc. Each polygon without considering the dimensions was converted to a single inside representative releasing point. Two hundred and fifty out of a large number of potential snow avalanche releasing points were selected randomly and were coded as 1. Two hundred and fifty points were also selected randomly considering the expert opinions for non-occurrence snow avalanche points at very steep and mild slopes of the field, and were coded as 0. A hundred and seventy-five, and seventy-five points corresponded to 70% and 30% of all the points for occurrence and non-occurrence of the snow avalanches were used for training and testing processes, respectively. Thus, all the points were assumed that they have the same weights on snow avalanche occurrence. However, the estimation results proposed in this study enabled the classification of potential levels. Some points may be evaluated at a high potential level while some points may be at no potential level regarding starting of snow avalanches. Hence, the result of this study may be thought of as a checking process of the inventory data.
Snow avalanche conditioning factors are also as prominent as inventory data since snow avalanche susceptibility predictions require data acquisition by capturing information on snow avalanche occurrence and non-occurrence. The susceptibility study was analyzed by a combination of captured information based on the proposed methodology, and those values were extracted at training snow avalanche and non-avalanche points. The use of topographic, meteorological, lithological, and anthropogenic factors is recommended by many researchers to analyze the avalanche release movement of snow. Since the watershed is scarcely or poorly gauged and has too small drainage area to calculate the spatial variation of snow cover from a source point, the spatial variation of the predicted snow cover was assessed to be insignificant. Therefore, meteorological factors could not be considered as a triggering factor for analyzing snow avalanche susceptibility in Uzungöl basin. In this study, predominately topographic factors, but anthropogenic/natural such as Land Use (LU), and lithological factors were also considered. Elevation, curvature, aspect, slope, Length-Slope factor (LS), Relative Slope Position (RSP), Topographic Ruggedness Index (TRI), Topographic Position Index (TPI), Wind Exposition Index (WEI), and Vector Ruggedness Measure (VRM) are the factors that are found to contribute further understanding the mechanism of snow avalanche susceptibility of the studied area (Akay 2021). Those factors enable terrain classification varying between valley bottom to ridges which are the prominent geomorphic process of avalanches. Snow avalanche occurrence in a snow-dominated study area depends on precipitation type, snow drifting effect, deposition or accumulation of particles, initiation of snow avalanches, etc. Geospatial analysis requires analyzing not only the values of the cells themselves but also the values of the cells in a specified proximity. Potentially snow avalanche-affected cells for acting additional forces, zonation, and specification of snow mass sliding may also be analyzed by considering those geomorphic parameters. A Digital Elevation Model (DEM) with a finer resolution of 5 m cell size was used for processing the topographical conditioning factors by GIS softwares. Lithology data was downloaded and processed from the General Directorate of Mineral Research and Exploration (MTA) while CEM provided LU and DEM files. LU, lithology, aspect, and curvature were classified by supervision method while the rest of the factors were classified by the natural break method (Fig. 2, Table 1).


Training data, and maps of snow avalanche conditioning factors: a elevation, b wind exposition index, c aspect, d curvature, e land use, f lithology, g length-slope factor, h relative slope position, i slope, j topographic position index, k topographic ruggedness index, and l vector ruggedness measure
In the study, the Bel function value based on evidence theory was used for the representation of the class values of the factors. The Bel function, generalized Bayesian theory, was introduced as a lower probability to provide knowledge on the occurrence of a process (Roy and Datta 2019). Bel values were computed as the linear fuzzy membership of frequency ratio which was the ratio of the percentage of avalanche pixels in the class and the percentage of the class area in the domain.
2.3 Methodology
The proposed methodology is illustrated in Fig. 3. The methodology includes the following steps: (1) random selection of avalanche and non-avalanche points, (2) preparing the layers of conditioning factors, (3) classification of the factors and calculation of Bel function values of each class, (4) extraction of Bel values of each class and performing multicollinearity test, (5) setting hesitant fuzzy information and hesitant fuzzy elements, (6) aggregation of conditioning factors based on machine learning model classification and parameter importance (7) processing snow avalanche susceptibility maps, (8) extraction of values at testing and training points, and (9) validation of the proposed model.

Proposed methodology for the study area
2.4 Multicollinearity Test
The Bel values enabled simplification for the extracted values at training points to be utilized in the multicollinearity test. The multicollinearity test helped check the conditioning factors as independent variables without causing a linear dependency or a repetitive factor in the study. Tolerance (TOL) and Variance Inflation Factor (VIF) were used to detect the multicollinearity problem as a function of the correlation coefficient of two or more factors considered. VIF values of more than 10 were assessed as a limit value to achieve this problem by leaving the factor out using SPSS v22 (Mosavi et al. 2020).
2.5 Hesitant Fuzzy Sets and Aggregation of Factors
In this study, some factors influencing snow avalanche susceptibility were used to estimate pixel-wise snow avalanche occurrence and its potential levels. The contributions of parameters to cause snow avalanches may vary considering each class of the parameters. For instance, the contribution of elevation parameter may differ as the classification of the layer increases. Parameters as in different classes of the snow avalanche conditioning factors may incorporate a more comprehensive description of snow avalanche occurrence than a crisp number. Hence, in this study, the uncertainty issue of the effect of factors was eliminated by the hesitancy approach by the representation of consideration of the class of each conditioning factor, for the first time. Thus, the Hesitant Fuzzy Sets (HFS) theory introduced by Torra (2010) was adopted to estimate the snow avalanche susceptibility maps.
Thus, the ultimate estimation of the snow avalanche occurrence index is a function of a combination of conditioning factors whose values are not constant about a value, but it has a hesitancy between several class values of conditioning factors (Akay and Baduna Koçyiğit 2021).
All the factors may be represented considering all the classes of the factors in terms of hesitant fuzzy elements (HFEs) that can be approximated by belief function values of each class to avoid hesitancy in expressing the randomness and complexity of data and variation of snow avalanche susceptibility (Torra 2010).
Set of A represents the snow avalanche susceptibility and can be expressed mathematically as in Eq. (1) (Xia and Xu 2011).
where hA(x) is a set of values in [0, 1], indicating the possible membership degrees of the element x of set the of X to the set of snow avalanche susceptibility, A. X = {x1, x2, x3, …, xn} is a fixed set of snow avalanche conditioning factors. For convenience, h = hA(x) indicates a hesitant fuzzy element (HFE) of each snow avalanche conditioning factor, and H is the set of HFEs (Eq. (2)).
where h(γi) is a set of some elements, γi indicates the hesitant fuzzy information of a snow avalanche conditioning factor in [0, 1], and i = 1, 2, 3, …, #h in which #h is the number of possible number of classes.
Aggregation operators were handled for combination of the classified factors so that the susceptibility output as a single fuzzy set could be represented by using aggregation operation functions. Xia and Xu (2011) defined hi (i = 1, 2, 3, …, n) as a collection of HFEs, hσ(i) as i th largest of them, w = (w1, w2, …, wn)T as the aggregation associated vector in [0, 1], and the summation of this vector is unity. The authors also introduced a hesitant fuzzy ordered weighted averaging (HFOWA) operator to aggregate the HFEs (Eq. (3)).
2.6 Application of Machine Learning Models
In the study, class label values of snow avalanche non-occurrence and occurrence adapting 10 folds cross-validation in Weka 3.9 software were classified by using various tree algorithms such as random tree (RT), J48, and Reduced Error Pruning Tree (REPTree). The adapted models are tree-based classifiers that have internal nodes representing alternatives to the test (Pham et al. 2017). They are quite powerful classifiers using training information without needing feature scaling, easy to interpret and understand. Hence, snow avalanche susceptibility from root to leaf nodes of trees was computed using the aforementioned models since they are easy to adapt to classification. However, it was replaced as 0 for the places where it was classified as snow avalanche non-occurrence. The most important aspect of the study was the fusion of decision trees based on classified factors by hesitant fuzzy sets theory.
2.6.1 J48
Snow avalanche non-occurrence and occurrence using the J48 algorithm were classified based on splitting the snow avalanche conditioning factors starting from root the node and then creating branches by using the normalized gained information at each node of the unpruned or pruned decision tree (Quinlan 1993). In this study, 0.95 for the confidence factor was set, so that the decision trees were subjected to less and less pruning (Akay 2021).
2.6.2 Random Tree (RT)
A specified number of snow avalanche conditioning factors are selected randomly at each node of RT without pruning. The best class of a factor is then picked to split a tree node (Breiman 2001).
2.6.3 Reduced Error Pruning Tree (REPTree)
REPTree model enables the fast building of the tree using the information on the effects of the factors on snow avalanche susceptibility. It also prunes with reduced error, the learning tree of classified snow avalanche conditioning factors.
2.7 Significance of Snow Avalanche Influential Factors
In the study, the Information Gain Ratio (IGR) method was employed adapting the 10-folds cross-validation technique (Quinlan 1986). IGR enabled the order of the factors on the occurrence of snow avalanches and to measure the sensitivity of snow avalanche susceptibility. IGR is capable to decide the convenience of the parameters by measuring the information gained concerning the class (Mosavi et al. 2020; Akay 2021). IGR values, herein, also stand for the aggregation associated vector of the snow avalanche conditioning factor, when they are linearly normalized.
2.8 Validation of the Predicted Results
Snow avalanche susceptibility for each model was processed, and those values at training and testing points were extracted employing GIS to validate the prediction results. A receiver operating characteristics (ROC) analysis was conducted to assess the accuracy of the predicted results based on some metrics. One-specificity on x versus sensitivity on y directions were plotted by the ROC curve. The area under the ROC curve (AUC) was calculated, and the efficacy of the estimations was evaluated accordingly. Yesilnacar and Topal (2005) appraised these AUC values as: very good (0.8–0.9) and excellent (0.9–1). The other accuracy metric is the True Skill Statistics (TSS) proposed by Allouche et al. (2006). TSS is an alternative for co-evaluation of specificity, and sensitivity, and is expressed in terms of the components of the confusion matrix that are computed from the number of trueness or falseness of the snow avalanche occurrence and non-occurrence points (Eq. (4)).
where TP and TN are the numbers of true classified snow avalanche occurrence and non-occurrence points while FP and FN are the numbers of misclassified points.
The susceptibility maps were categorized based on the natural break method in five potential groups, such as Very High (VH), High (H), Moderate (M), Low (L), and Very Low (VL). The number of snow avalanche and non-avalanche points were also extracted from the corresponding groups to assess the compatibility of the prediction results.
3 Results
Bel values of all the classes of each snow avalanche influential factor were computed from the randomly selected snow avalanche training points, separately (Table 1). The Bel values corresponding to classes were assumed constant throughout these classes. For the pixels whose slope are < 16.63º, LS < 5.62 and LS > 26.70, TPI > 12.93, TRI < 1.41 and TRI > 6.15, VRM > 0.30, aspect = flat, LU = wet land and special land, and lithology = rhyolite, were found to be non-occurrence of snow avalanches. However, snow avalanche susceptibility may be found at internal nodes of the classifications depending on the success of the machine learning algorithms. Bel values provided hybridization concentrating on the same classified label.
VIF values vary between 1.048 for curvature and 2.447 for slope. Hence, all the factors satisfied the allowable TOL and VIF values and were found to be utilized to express susceptibility assessment of the study area.
Values of 0.653, 0.569, 0.392, 0.282, 0.244, 0.175, 0.167, 0.108, 0.075, 0.041, 0.031 and 0.012 were found for IGR of slope, LU, elevation, TRI, LS, TPI, lithology, WEI, VRM, RSP, aspect and curvature, respectively. Slope and land use were the most effective parameters while curvature was the least effective parameter. Hence, this study highlighted the forested landscape dynamics of avalanche susceptibility. The other important aspect of average merit values was linear normalization that satisfies the summation of the factors’ unity to be used as an aggregation-associated vector.
Snow avalanche conditioning factors as a hesitant fuzzy element were introduced regarding the Bel values at each class regarding hesitant fuzzy information. For example, the elevation was expressed as helevation = (0.048, 0.137, 0.290, 0.243, 0.283) which indicates the hesitancy of that factor in snow avalanche susceptibility. All these hesitant fuzzy elements were the sub-set of the snow avalanche susceptibility set. Later, subsets of snow avalanche susceptibility set with a different number of element combinations based on the machine learning algorithms were calculated by the Hesitant Fuzzy Ordered Weighted Averaging (HFOWA) operator. Thus, the corresponding elements of the snow avalanche susceptibility values to the intersections of the polygons of decision tree-based classification were assigned from the subsets of snow avalanche susceptibility and were processed in GIS.
When the non-occurrence and occurrence of snow avalanches were classified, the sizes of the trees were 170, 70, and 22 for RT, J48, and REPTree, respectively. After processing the snow avalanche susceptibility for each model, the maps were categorized into five groups based on the natural break method (Fig. 4). HFS-J48, HFS-RT, and HFS-REPTree predicted approximately 60%, 70%, and 55% of the drainage area for VL and L classes, while the models predicted 29%, 23%, and 20% for H and VH classes. HFS-J48, HFS-RT, and HFS-REPTree models predicted the percentages of the snow avalanche pixels in H, and VH classes as 71%, 44%, and 57% respectively.

Classification of snow avalanche susceptibility using a HFS-J48, b HFS-RT, and c HFS-REPTree models
The model results were validated by ROC analysis (Fig. 5). The AUC values of HFS-J48, HFS- RT, and HFS-REPTree models for the training process were 0.985, 1.000, and 0.969, while AUCs for testing were 0.975, 0.917, and 0.955, respectively. TSS values for training were 0.966, 0.878, and 0.943, while TSSs for testing were 0.947, 0.840, and 0.920, respectively. The models exhibited an excellent performance on snow avalanche susceptibility estimation of Uzungöl basin considering AUC values.

Validation of the predicted results of training and testing processes, respectively
4 Discussion
4.1 Proposed Modelling of Snow Avalanche Susceptibility Mapping
In this study, hybridization by Bel function values of classes of snow avalanche influential factors was adapted to consider the same features in terms of snow avalanche occurrence at all classes. Multicollinearity test and Hesitant Fuzzy Set (HFS) theory were implemented using Bel values. On the other hand, HFS was adapted as an ensemble model to provide robust results of snow avalanche susceptibility.
Bel values of factors at the considered number of classes were utilized as hesitation fuzzy information of the hesitant fuzzy elements and hesitant fuzzy ordered weighted averaging (HFOWA) operator led to computation of label values at leaf nodes. The superiority of the elements was also prominent in the assessment of snow avalanche susceptibility. Curvature has the most superiority while aspect has the least superiority in snow avalanche susceptibility. Since Bel values were considered, the mean values were the same in the same number of classes. Deviation degrees were then considered, and the superiority of the factors was determined (Liao et al. 2014). Among factors that have five classes, RSP has the most superiority while TRI has the least superiority.
This study was proposed as an integration of HFS, machine learning models such as J48, RT, and REPTree, and aggregation operator, HFOWA to employ the uncertainty effect of influential factors by a learning system and computation the label values under uncertainty. To the best knowledge of the author this is the first attempt to consider the vagueness of the factors and the ensemble of HFS and machine learning algorithms in the assessment of disaster-prone zones. This study also gained a new insight on ensemble modeling of disaster susceptibility. It can be concluded considering the results that the ensemble modelling of HFS, machine learning algorithms, and HFOWA aggregating operator computed the spatial variation of snow avalanche occurrence in the study area, very well. Moreover, the prediction results may be developed by increasing the class numbers of factors, implementing various robust aggregating operators, and being enriched by conducting sensitivity analysis for weights of the factors as a result of linear normalization of average merit values.
HFS-REPTree enabled fast classification, but HFS-RT required the most computational effort to understand the snow avalanche dynamics. The HFS-RT model predicted the most accurate results of snow avalanche occurrence and non-occurrence for the training process, while the HFS-J48 model predicted the most accurate results for the testing process. However, the performance metrics for the testing process exhibited less accuracy than those for the training process. Similar problems as data selection, generalization errors, memorizing problems, etc. may lead to misclassifying the snow avalanche conditioning factors by insufficient training. Variation in performance measures between training and testing processes were the highest in the predictions of HFS-RT. Hence, the HFS-RT model was assessed to be apt to memorizing tendencies.
Reasonably accurate predicted maps also require reasonable snow avalanche potential classification. For example, higher percentage values of the basin area are expected to predict the Very Low (VL) and Low (L) susceptibility classes while lower percentages of that should correspond to Very High (VH) and High (H) susceptibility classes. Furthermore, snow avalanche pixels should concentrate on the VH and H classes for a reasonably accurate predicted map. Therefore, when the prediction results are evaluated, not only performance metrics but also the percentage of areal variation of potential classes, and snow avalanche pixel percentage in a class should be assessed. These are vital criteria for better-predicted susceptibility maps. Hence, HFS-J48 among the others was assessed to be the best performing model to catch susceptible zones in Uzungöl basin considering AUC, TSS, and areal percentages of the classes.
4.2 Significant Evaluation by Linking Snow Avalanche Susceptibility and SDGs
Snow avalanches disturb the environment and ecology, threaten human lives seriously, and are a crucial milestone to combat the sustainable development of the region. The proposed model results and environmental management strategies may be coupled to link with SDGs. Very high and high susceptible zones as a result of the proposed study may be a vital guide for decision-makers regarding social, economic, and environmental issues such as risk awareness, land use control, and economic and social activities. Moreover, low and very low susceptible zones may be considered for installing both new residential, scientific, and touristic facilities.
Living on a mountainous and upland landscape, especially, Uzungöl basin which is protected by legislation has some challenges for people in fighting and surviving. If human security and needs are hung on by a thread by the prediction of the study, protective and preventive measures as aimed by SDG 11 with targets of disaster risk reduction and sustainable transportation should be provided. This is an action to sustain human settlement and prevent migration aimed by SDG 8 providing social protection.
A sustainable transport network aimed by SDG 11 is required for arriving destinations safely. Since tourism is an important income for both government and local people, snow avalanches should not delay economic activities. The transportation network may sometimes coincide with the runout zone of snow avalanches and may result in damage. Time, maintenance, and service losses are important risk components that urgent actions or mitigation measures should be considered accordingly to reduce disaster risks. The proposed study results can enable us to consider the risks of the current and future potential roadways.
Land-use control should be enabled to manage forests and combat deforestation. It is aimed by SDG 15 to protect mountains, and biodiversity and not to cause land degradation. It is clear from Table 1, forest soil and deteriorated forests are the most susceptible land covers. Thus, excessive logging activities can induce deforestation which is a triggering factor for snow avalanches. In this case, SDG 8 and 15 are not conflicting goals since they point out to develop by protecting the environment.
5 Conclusion
Disaster risk reduction is one of the most important common issues for policymakers to provide the continuity of sustainable development. It is also a crucial problem pointed out to achieve the SDGs. Previous studies examined the linkages of floods and the sustainable development goals mostly. However, this study analyzed the relationship between snow avalanche susceptibility and sustainable development goals using proposed novel ensemble modelling for the first time.
Accurate estimation of snow avalanche susceptibility of an area enables us to develop environmental management strategies and take suitable actions considering human, ecological, and environmental constraints. In this study, snow avalanche susceptibility maps of Uzungöl basin were predicted by proposing a novel method of ensemble modeling of HFS and machine learning algorithms. In snow avalanche susceptibility of the study area, topographical factors were more significant factors, but the land cover was also found the second most important attribute due to the canopy characteristics of the forested landscape. Based on the results concluded in the study, very high and high potential levels of snow avalanche susceptibility may lead to assure the awareness of risks. The awareness of risks appraises for mitigating vulnerability and developing an efficient environmental management strategy by prioritization avalanche corridors based on full consideration of snow avalanche susceptibility classes, human needs, and socioeconomic activities. The finding of this study may contribute to identifying the problem and further understanding the achievement of many goals regarding environmental, ecological, spatial and landscape planning and structural design. It may be useful to consider the results of this study in achieving the targets of some SDGs such as tourism planning, developing economic activities, providing sustainable transportation, and making people stay homeland.
Availability of Data and Materials
Limited data is available upon request.
References
AFAD (2021) 2020 Yılı Doğa Kaynaklı Olay İstatistikleri. AFAD, Ankara (in Turkish)
Akay H (2021) Spatial modeling of snow avalanche susceptibility using hybrid and ensemble machine learning techniques. CATENA 206:105524. https://doi.org/10.1016/j.catena.2021.105524
Akay H, Baduna Koçyiğit M (2021) An approach for determination of the drainage network effect on GIUH using hesitant probabilistic fuzzy linguistic sets. Water Resour Manag 35(11):3873–3902. https://doi.org/10.1007/s11269-021-02935-y
Allouche O, Tsoar A, Kadmon R (2006) Assessing the accuracy of species distribution models: Prevalence, kappa and the true skill statistic (TSS). J Appl Ecol 43:1223–1232. https://doi.org/10.1111/j.1365-2664.2006.01214.x
Aly MM et al (2022) Ecohydrology and flood risk management under climate vulnerability in relation to the sustainable development goals (SDGs): A case study in Nagaa Mobarak Village. Egypt Nat Hazards 112:1107–1135. https://doi.org/10.1007/s11069-022-05220-2
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Chen Y et al (2021) Toward the development of deep learning analyses for snow avalanche releases in mountain regions. Geocarto Int 1–26. https://doi.org/10.1080/10106049.2021.1986578
Choubin B et al (2019) Snow avalanche hazard prediction using machine learning methods. J Hydrol 577:123929. https://doi.org/10.1016/j.jhydrol.2019.123929
Cui P et al (2021) Scientific challenges of research on natural hazards and disaster risk. Geography and Sustainability 2:216–223. https://doi.org/10.1016/j.geosus.2021.09.001
Echendu AJ (2020) The impact of flooding on Nigeria’s sustainable development goals (SDGs). Ecosystem Health and Sustainability 6:1791735. https://doi.org/10.1080/20964129.2020.1791735
Ezzeldin M, Konstantinovich SE, Igorevich GI (2022) Determining the suitability of rainwater harvesting for the achievement of sustainable development goals in Wadi Watir, Egypt using GIS techniques. J Environ Manag 313:114990. https://doi.org/10.1016/j.jenvman.2022.114990
Giannetti BF et al (2020) Cleaner production for achieving the sustainable development goals. J Clean Prod 271:122127. https://doi.org/10.1016/j.jclepro.2020.122127
Khalili NR, Duecker S, Ashton W, Chavez F (2015) From cleaner production to sustainable development: the role of academia. J Clean Prod 96:30–43. https://doi.org/10.1016/j.jclepro.2014.01.099
Kelman I (2017) Linking disaster risk reduction, climate change, and the sustainable development goals. Disaster Prev Manag 26:254–258. https://doi.org/10.1108/DPM-02-2017-0043
Kumar P et al (2020) Towards an operationalisation of nature-based solutions for natural hazards. Sci Total Environ 731:138855. https://doi.org/10.1016/j.scitotenv.2020.138855
Liao HC, Xu ZS, Xia MM (2014) Multiplicative consistency on hesitant fuzzy preference relation and the application on group decision making. Int J Inf Tech Decis 13:47–76. https://doi.org/10.1142/S0219622014500035
Mansour MM, Ibrahim MG, Fujii M, Nasr M (2022) Sustainable development goals (SDGs) associated with flash flood hazard mapping and management measures through morphometric evaluation. Geocarto Int 1–18. https://doi.org/10.1080/10106049.2022.2046868
Mosavi A et al (2020) Towards an ensemble machine learning model of random subspace based functional tree classifier for snow avalanche susceptibility mapping. IEEE Access 8:145968–145983. https://doi.org/10.1109/ACCESS.2020.3014816
Quinlan JR (1986) Induction of decision trees. Mach Learn 1:81–106. https://doi.org/10.1007/BF00116251
Quinlan JR (1993) C4.5: Programs for Machine Learning. San Mateo, CA
Pham BT, Khosravi K, Prakash I (2017) Application and comparison of decision tree-based machine learning methods in landside susceptibility assessment at Pauri Garhwal Area, Uttarakhand, India. Environ Process 4:711–730. https://doi.org/10.1007/s40710-017-0248-5
Rahmati O et al (2019) Multi-hazard exposure mapping using machine learning techniques: A case study from Iran. Remote Sens-Basel 11:1943. https://doi.org/10.3390/rs11161943
Roy DK, Datta B (2019) An Ensemble Meta-Modelling Approach Using the Dempster-Shafer Theory of Evidence for Developing Saltwater Intrusion Management Strategies in Coastal Aquifers. Water Resour Manag 33:775–795. https://doi.org/10.1007/s11269-018-2142-y
Šakić Trogrlić R, Donovan A, Malamud BD (2022) Invited perspectives: A community perspective on natural hazards key challenges and the Sustainable Development Goals. Nat Hazards Earth Syst Sci 22:2771–2790. https://doi.org/10.5194/nhess-22-2771-2022
Thacker S et al (2019) Infrastructure for sustainable development nature sustainability 2:324–331. https://doi.org/10.1038/s41893-019-0256-8
Torra V (2010) Hesitant fuzzy sets. Int J Intell Syst 25:529–539. https://doi.org/10.1002/int.20418
UN (2015) Transforming our world: the 2030 agenda for sustainable development. Department of Economic and Social Affairs Website. https://sdgs.un.org/2030agenda. Accessed 28 Jun 2022
Xia MM, Xu ZS (2011) Hesitant fuzzy information aggregation in decision making. Int J Approx Reason 52:395–407. https://doi.org/10.1016/j.ijar.2010.09.002
Yariyan P et al (2020) GIS-based spatial modeling of snow avalanches using four novel ensemble models. Sci Total Environ 745:141008. https://doi.org/10.1016/j.scitotenv.2020.141008
Yariyan P et al (2022) An optimization on machine learning algorithms for mapping snow avalanche susceptibility. Nat Hazards 111:79–114. https://doi.org/10.1007/s11069-021-05045-5
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng Geol 79:251–266. https://doi.org/10.1016/j.enggeo.2005.02.002
Acknowledgements
The authors would like to thank Gazi University Academic Writing Application and Research Center for proofreading the article and CEM for data and technical support.
Funding
This research is not funded, but the author gives many thanks to CEM for data and technical support.
Author information
Authors and Affiliations
Contributions
All steps in the manuscript were implemented by Hüseyin Akay.
Corresponding author
Ethics declarations
Ethical Approval
Compliance with ethical standards.
Consent to Participate
Author consent to participate in this research/publication.
Consent to Publish
This research does not have any consent to publish.
Conflict of Interest
The author declares that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Akay, H. Towards Linking the Sustainable Development Goals and a Novel-Proposed Snow Avalanche Susceptibility Mapping. Water Resour Manage 36, 6205–6222 (2022). https://doi.org/10.1007/s11269-022-03350-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-022-03350-7