
Abstract
Forecasting freshwater lake levels is vital information for water resource management, including water supply management, shoreline management, hydropower generation optimization, and flood management. This study presents a novel application of four advanced artificial intelligence models namely the Minimax Probability Machine Regression (MPMR), Relevance Vector Machine (RVM), Gaussian Process Regression (GPR) and Extreme Learning Machine (ELM) for forecasting lake level fluctuation in Lake Huron utilizing historical datasets. The MPMR is a probabilistic framework that employed Mercer Kernels to achieve nonlinear regression models. The GPR, which is a probabilistic technique used tractable Bayesian framework for generalization of multivariate distribution of input samples to vast dimensional space. The ELM is a capable algorithm-based model for the implementation of the single-layer feed-forward neural network. The RVM demonstrate depends on the specification of the Bayesian method on a linear model with proper preceding that results in demonstration of sparse. The recommended techniques were tested to evaluate the current lake water-level trend monthly from the historical datasets at four previous time steps. The Lake Huron levels from 1918 to 1993 was managed for the training phase, and the rest of data (from 1994 to 2013) was used for testing. Considering the monthly and annually previous time steps, six models were introduced and found that the best results are achieved for a model with (t-1, t-2, t-3, t-12) as input combinations. The results show that all models can forecast the lake levels precisely. The results of this research study exhibit that the MPMR model (R2 = 0.984; MAE = 0.035; RMSE = 0.044; ENS = 0.984; DRefined = 0.995; ELM = 0.874) found to be more precise in lake level forecasting. The MPMR can be utilized as a practical computational tool on current and future planning with sustainable management of water resource of Lake Michigan-Huron.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Global warming results in many significance changes in the analysis of climatological variables viz. flow, precipitation, evaporation, temperature and lake water-level (Burns et al. 2007; Hamed 2008; Qin et al. 2010; Shao and Li 2011; Bonakdari et al. 2019). These alterations result in considerable alters in the temporal and spatial distribution of water resources. Reservoirs are essential as far as water resources, and have various advantages consist of utility water demands, providing drinking water, agricultural land irrigation, making it accessible for tourism by inland conduits transport and making a promenade around it. In addition, due to the fluctuation of water level, it s adversely affects the road and rail transportation, settlements, shore-based recreational, plantations according to floods as well as educational facilities. Lakes intermittently supply vital water for numerous agricultural, industrial and domestic applications. Then, the lake level forecasting is a hot scientific subject in drainage canals, lake navigation, tidal irrigation management, and water resource planning.
Lake level is an intricate phenomenon influenced by the natural water swap among the distinguished lake and its catchments, hence, the water-level reflect climate change inside the area. Lake water level might cause damage on account of expanded water level in this way, to get most extreme advantages from them and convey cost down to the lowest level, the difference in lake water level ought to be known ahead of time and controlled, where vital. Alterations in water-level fluctuations are sequels of such parameters like evaporation from the lake surface, a variation of water and air temperature, entering runoffs from the adjacent catchments, precipitation over lake surface (or its watershed), groundwater change, humidity, and groundwater change. It would be an essential advance to build up the relationship between’s the hydrometeorological factors and lake-level variations (Kisi et al. 2012)
Sophisticated methods taking into account those previously stated parameters may on a fundamental level be developed, but the vulnerability of lake levels to these variables may be from one territory to another one. Also, the exact estimation of these parameters are frequently seriousness and with a remarkable measure of vagueness. Moreover, for numerous examinations and practical applications, it is productive to obtained a unitary model which is capable of simulating and foreseeing lake level alteration formed on exclusively historical datasets. In this manner, rather than utilizing conventional strategies with many sources of information, they are desirable that delicate artificial intelligence techniques (Ebtehaj et al. 2019).
Artificial intelligence techniques (AITs) are advantageous in clearing up the connection between a procedure yield and its information in any case. Recently, the utilization of AITs are generally utilized as an applicable instrument to solve complex nonlinear phenomena enveloping water resource management and hydrology (Yaseen et al. 2017a, b; Moeeni et al. 2017a, b; Ghorbani et al. 2017) and particularly prediction of lake water-level such as artificial neural network (Altunkaynak 2014; Güldal and Tongal 2010; Kakahaji et al. 2013; Khatibi et al. 2014; Kisi et al. 2012; Li et al. 2015; Vaheddoost et al. 2016); adaptive neuro fuzzy inference system (Altunkaynak 2014; Güldal and Tongal 2010; Kisi et al. 2012; Sanikhani et al. 2015; Shafaei and Kisi 2016); Wavelet transform (Altunkaynak 2014; Shafaei and Kisi 2016); Genetic programming (Aytek et al. 2014; Sanikhani et al. 2015; Zaji and Bonakdari 2018; Zaji et al. 2018 & 2019); Support vector machine (Shafaei and Kisi 2016); dynamic linear models (Kakahaji et al. 2013); Gene expression programming (Kisi et al. 2012; Khatibi et al. 2014); Firefly algorithm (Kisi et al. 2015) and Decision tree (Vaheddoost et al. 2016).
The neural network is proficient in solution-finding of complex nonlinear issues which might be troublesomely explained by classical parametric methodologies. There is numerous training algorithm for neural networks such as backpropagation, hidden Markov model, and support vector machine. The main shortcomings of classical neural network are deficient training time of gradient-based algorithm which is widely employed to train these networks, iteratively tuned of all parameters of neural networks using aforementioned algorithms, low generalization ability, overfitting of forecasting, local minima and also incapability to offer probabilistic forecasting (Azimi et al. 2017; Ebtehaj and Bonakdari 2016; El-Shafie et al., 2013). Accordingly, alternative AIT that addresses these circumscriptions is required for the lake water-level forecasting.
The innovation of this research study is to apply four nonlinear AITs, in particular, Minimax Probability Machine Regression (MPMR), Gaussian Process Regression (GPR), Extreme Learning Machine (ELM), and Relevance Vector Machine (RVM). Based on the authors’ knowledge, exception for the first one which is employed for Urmia lake in Iran (Shiri et al. 2016), the other AIT is not reported in lake level field and for the first time employed in this study. The ELM method (Huang et al. 2006a) is a training algorithm for the single-layer feed-forward neural network (SLFFNN) with fast training with high generalizability performance. This algorithm has three layers with some N neurons is a hidden layer. The input weights are handled randomly, while the outputsare estimated analytically.
It should be noted randomly tune of input weights in ELM not only don’t reduce the probability of the optimum solution but also results in high accurate results which are not effectively accomplished by utilizing convectional neural network models (Huang et al. 2006b; Huang and Chen 2008; Zeynoddin et al., 2018). The second technique, MPMR (Strohmann and Grudic, 2002), is a nonlinear probabilistic regression which is employed convex optimizations and linear discriminant. The MPMR was presented based on the maximization of the lowest feasibility of the target function to be inside the limits of actual regression. The MPMR approach is an enhanced adaptation of SVM. In this algorithm, a regression surface is defined and recognize probability bounds for misclassifying a point without providing distributional supposition (Deo and Samui 2017). The third techniques, GPR (Rasmussen and Williams 2006), is a non-parametric powerful probabilistic tool where observation happens in a continuous space or time.
In this model, varied input distribution of is generalized to absolute-dimensional space developing the controllable Bayesian system to determine the last distributions. The principal points of interest of this technique are the capacity of GPs from training the dataset to give uncertainty approximations and to learn the smoothness and noise variables. The fourth model, RVM (Tipping 2001) is a machine learning approach and an exceptional instance of a sparse kernel approach that utilizations Bayesian behavior of a generalized linear framework to acquire parsimonious solutions. The RVM advantage is that they permit sparse sets of training datasets and extremely relevant features. Given the common advantages and disadvantages of the ELM, MPMR, GPR, and RVM approach considered, and there is no earlier examinations have used these techniques for the forecasting water level variation in the Lake Huron, a comparison of their efficiency, in essence, utilizing AIT is an innovative part of this investigation.
In this research study, the exploration plans to apply four innovative AITs for the Lake Huron (45.814° N; 84.754° W). The state of the art of these AITs demonstrates display most recently, and advances in the development of execution, and investigators are enthusiastic to examine its ability in engineering applications. These AITs are employed for first one in forecasting of water-level of the Lake Huron. This study aims to assess the utilization of the minimax probability machine regression (MPMR), Gaussian process regression (GPR), extreme learning machine (ELM) and relevance vector machine (RVM) for lake water-level forecasting. Therefore, 76 years of historical datasets are employed to calibrate each model of AITs and the 20 years data are utilized to validate the performance of each one. To investigate the ability of all AITs in lake level prediction, five different models were proposed as a consequence of statistical studying of lagged effects of monthly and annually altering models in historical dataset of lake level.
2 Theoretical frameworks
2.1 Extreme Learning Machine (ELM)
Let us consider the following dataset (D).
For Q hidden nodes, the following equation can be written
where K(wi, bi, xj) is the activation function.
The eq. (2) is rewritten in the following way
\( \alpha ={\left[\begin{array}{c}{\alpha}_1^T\\ {}.\\ {}.\\ {}{\alpha}_Q^T\end{array}\right]}_{Q\mathrm{x}m} \)and\( Y={\left[\begin{array}{c}{y}_1^T\\ {}.\\ {}.\\ {}{y}_Q^T\end{array}\right]}_{N\mathrm{x}m} \).
where H is the hidden layer output matrix, wi is the weight connects the ith hidden node to the input nodes, \( {a}_i^m \) is the weight links the ith hidden node to the output nodes and bi is the threshold value.,.
The following relation is used for determination of α
where H+ is the Moore Penrose generalized inverse of matrix H.
2.2 Relevance Vector Machine (RVM)
In RVM, the basic equation is given below for estimation of output (y):
where N represents the samples number, wi is weight, x denotes input variable and K(xi,x) is kernel function.
In RVM, a Gaussian prior is assumed on wi. The Gaussian prior has zero mean and hyperparameters (\( {\alpha}_i^{-1} \)) variance. RVM uses iterative formulae for hyperparameter estimation (MacKay 2001). In RVM, nonzero weights are called relevant vectors. The details of RVM have been obtained from Tipping (2000, 2001).
2.3 Gaussian Process Regression (GPR)
The operational relationship between input vector (x) and target (y) in GPR model is assumed by Eq. (6):
where f(xi) represents an arbitrary function, ε is the noise with an identical distributed Gaussian function based on the zero mean and variance σ2,which is εN(0, σ2).
To determine the f(x) where f is dependent variable and x is the independent variable and any unobserved pair (x*, f*) as (Andersson and Sotiropoulos 2015)
where K(X, X) is a n x n covariance matrix between all the simples in the training data, k(X, x∗)is an n × 1 vector of covariance between the point x* and training data. In the typical regression the mean (\( \overset{\_}{f} \)) from f and then it integrates tof∗:
The above eq. (8) expressed X and f by maximizing the joint probability of f∗ conditional on x∗ to determine the f∗.
For utilizing the noisy data, the model has to be accompanied by measurement error. Therefore the eq. (14) was converted into (Andersson and Sotiropoulos 2015):
where the conditional likelihood and the variance change to
and
where σ2 is the variance of the observed error and I is the identity matrix.
2.4 Minimax Probability Machine Regression (MPMR)
The principal of Minimax Probability Machine Classification (MPMC) is that probability of proper categorization of data points should reach to highest possible amount while a classification is constructed. For biased approaches, an alternative justification could be provided by the minimax technique.
To solve the regression problems, the concept of MPMC (Cheng and Liu 2006) was adopted, and it was extended as Minimax Probability Machine Regression (MPMR) (Strohmann and Grudic 2002). The accuracy of MPMR depends on the exactness of mean and covariance estimates. To crack the regression problem, the data were reduced to a binary classification problem by changing the reliant variable ±ε (Strohmann and Grudic 2002). The benefit of MPMR is that it can manage an input having any bounded distribution (Horata et al. 2013). For some unknown regression function (f∗ : Rd → R), the arbitrary vector is produced from some different bounded distribution which has mean (\( \overline{x} \)) and covariance (∑x) and let the training data to be generated accordingly as:
where x is the vector and ρ is the noise term with expected value 0 and finite variance∞. Let us consider the space Η of functionsRd → R; we want to determine a model\( \overset{\wedge }{f}\in H \), that increases the least probability of being ±ε accurate symbolized by Ωf
where ∑ = cov(y, x1, x2, .. …xd).
No other distributional assumptions were made except \( \overline{x},\overline{y},\sum \) are finite. For any function f which belongs to H the expected \( \overset{\wedge }{f} \) has to satisfy the following condition
For the linear models, Η holds all the functions that build by linear combinations of the training input vector as follows:
The general basis function formulation for the nonlinear model is as Eq. (16):
The hypothesis space comprises of linear combinations of kernel functions with the training inputs vectors as their first arguments, which is nothing but Φm(X) = K(Xm, X) (Smola and Scholkopf 1998).
where Xm ∈ Rd which depicts the mth input vector of the training set.
To obtain the minimax regression model, the expected points are to be predicted within the limit of±ε. So, every training data point (Xm, Ym) for m = 1,…., N converted into two-dimensional vectors which were stamped as u and v.
3 Materials
3.1 Case study area
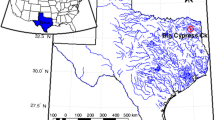
The lakes of Michigan, Huron, Superior, Ontario, and Erie are considered as great lakes basins (Fig. 1a). About 59% of the basins are located in the United States and 41% in Canada. The length of the basin is 1125 km from the north to the south, 1450 Km from west to east and its area is 2402 km2. The population of the area is about 33 million people, which economic activities are including agriculture, tourism, and the industrial manufacturing (Wilcox et al. 2007). This collection is one of the most significant freshwater sources in the United States. In this basin area, Michigan Lake is connected to the Lake Huron by a deep channel; therefore, all of the hydraulic conditions, including surface level, are similar.

Case study a) Geographical location of the Huron lakes. b) Michigan- Huron lake level time series
Hence, these two are known as the Lake Huron (45.814 ° N; 84.754 ° W) (Brinkmann 2000). Because of the size of the lakes, slight changes in their levels lead to dramatic changes in the amount of stored water. As the displacement of 0.3048 m from the lake leads to a volume reduction of about 75.0264 × 109 m3. Approximately the amount of water stored in the great lake is about 22.67 × 1012 m3 (Wilcox et al. 2007). Also, Change in Michigan- Huron lake level has a significant role in nearshore ecosystems and coastal processes, comprising maintained and development of wetlands, dunes and beaches and also human activities.
The data used is related to the monthly level of the lake level from 1918 to 2013. This data is measured at Harbor beach hydrometric station. To model and predict this series, its initial 76 years are utilized for the training period and the remaining 20 years of the forecast period. The Lake Huron lake level series is presented in Fig. 1b. Also, the statistical characteristics of the Lake Huron time series are presented in Table 1, where \( \overline{x} \), SD, CV, xmin, Q1, x50, Q3, and xmax are mean, standard deviation, the coefficient of variation, minimum, first quartile, median, third quartile and maximum.
In this investigation, to forecast the lake level data using four different methods (MPMR, GPR, RVM, ELM), different time delays of historical lake level are considered as input combinations. The number of variables is from 1 to 4 due to statistically lagged effects of monthly and annually altering patterns in historical lake level dataset. The considering models are as follows:
-
Model 1: h(t) = f(h(t − 1))
-
Model 2: h(t) = f(h(t − 1), h(t − 2))
-
Model 3: h(t) = f(h(t − 1), h(t − 2), h(t − 3))
-
Model 4: h(t) = f(h(t − 1), h(t − 12))
-
Model 5: h(t) = f(h(t − 1), h(t − 2), h(t − 12))
-
Model 6: h(t) = f(h(t − 1), h(t − 2), h(t − 3), h(t − 12))
3.2 Performance Evaluation Criteria
The proficiency of the intruduced methodology in monthly lake level forecasting at Michigan- Huron lake should be evaluated. Recognizing the stochastic essence of the hydrological variable, the use of an individual metric to evaluate the statistical model performance is not logical (Dawson et al. 2007). Hence, the results of effectiveness evaluation of the MPMR, GPR, RVM, and ELM techniques regarding the mean absolute error (MAE), root mean square error (RMSE) and coefficient of determination (R2) as 1st-order statistics is an assessment as follows:
where P is the forecasted records, A is the actual records, \( \overline{A} \) and \( \overline{P} \) are the mean values of actual and forecasted records and N is the number of samples in training nad testing stages.
It should be noted that the MAE and RMSE construe the goodness-of-fit of each model irrespective of the sign of the difference between actual and forecasted lake level. The RMSE criterion is suitable for a set of forecasting errors with a normal distribution (Chai and Draxler 2014). In fact, the measuring index may not be fulfilled by all anticipating models. Thus, the MAE has employed to assessment all deflections of anticipated samples from the actual values in an equivalent way irrespective of the sign (Krause et al. 2005). The value of R2 designates the variance in the actual lake level samples that can be described by the anticipating model. However, this index comes form linear presumptions (Deo et al. 2016). Also, these criteria may be not sensitive to outliers and proportional, and accretive difference between actual nad predicted samples (Legates and Mccabe 1999; Willmott and Matsuura 2005). If the model is appraised exclusively based on one of these indices, a shift in predicted samples can result in fallacious conclusions.
Supplementary information about the four proposed models’ accurateness was gathered from the Legates and McCabes Index (ELM), refined Willmott’s Index (Drefined) and Nash-Sutcliffe coefficient (ENS) as normalised goodness-of-fit as (Nash and Sutcliffe 1970; Legates and Mccabe 1999):
3.3 The architecture of AIT models
The optimum parameters of the AIT frameworks hired in the current study are given in Table 2. In this Table, the NHN, AF, WRBF, NRV, and EP are the Number of hidden neurons, radial basis function, Width of radial basis function, number of relevance vector and error parameter, respectively.
4 Results and discussion
In this part, the outcomes of the Lake Huron water level modeling are presented using four methods ELM, MPMR, GPR, and RVM in testing stage dataset. The predicted results for the lake level are recorded based on monthly observations on this lake.
The proposed models in this study have been calibrated using historical data for 76 different years. Using the data for the next 20 years, the prediction accuracy of each model has been investigated using different statistical indices. To achieve modeling results with appropriate accuracy, in addition to using the proper method, the input components of the model can also have a significant effect on the results. The incorrect selection of compounds may have a negative effect on the results of a method.
Therefore, in this study, for each of four presented methods, the modeling results related to six different models that have effects of one to three months ago along with the amount of lake level in the desired month of the prior year (t-12), is considered as inputs. Table 3 shows the values of different statistical indices (R2, MAE, RMSE, ENS, defined, ELM) for each of the methods for six input combinations. The maximum value of the coefficient of determination for model 1, to estimate the lake level which is used only the amount of prior month (t-1), R2 = 0.96, is related to the MPMR model.
The results of this index for other models show that the least difference with MPMR model is related to the ELM model (R2 = 0.959). However, the value of this index relative to the other two methods (i.e., RVM & GPR) also shows no significant difference with the MPMR. The values of the MAE and RMSE index, which examine the mean squared of modeling error, show that the superior performance in this index is also related to the MPMR model (MAE = 0.056 & RMSE = 0.069). The RMSE index for ELM, RVM and GPR models was about 4%, 11%, and 7%, respectively, and the MAE index values were about 3%, 7%, and 10% respectively more than the index value of MPMR.
The superiority of the MPMR model in comparison with other models in all of the indices presented in Table 3, except the defined (defined(ELM) = 0.998), represents a higher performance of this model than other models. In addition to quantitative comparisons of the models presented, the qualitative study of these models can present significant perception into the performance of each of the models. Figure 2 illustrated the boxplot for actual data and estimated lake level values for test data. The best performance among the four MPMR, GPR, ELM, and RVM models is related to the MPMR method.

Boxplots demonstration of MPMR, GPR, RVM, and ELM for the investigated six models at testing stage
Hence, the distribution of observed and predicted values with MPMR for the model according to the indices minimum, maximum, median, lower, and upper quartiles are the same. Figure 3 presents the relative error distribution (RE) of the intended samples for the testing of 4 different models that the highest RE value has a normal distribution and the predicted samples have a similar distribution to the measured lake level. Comparison of relative values of MAE (%) (Fig. 4) shows that all four models of MPMR, GPR, ELM and RVM have good accuracy for lake level prediction, that the lowest is related to the MPMR method (Relative MAE = 0.02%).


Relative error distribution histogram for MPMR, GPR, RVM, and ELM for six models at testing stage

Relative mean absolute error (MAE %) for the MPMR, GPR, RVM and ELM models for all six models in testing stage
The results presented in Fig. 4 and 5 show that the proposed models have a high ability to estimate the lake level. The results of the scatter plot for these four models show a high correlation between the observed and predicted samples, as for all the range of samples considered for model testing, the predicted values have a small difference with actual values. Also, these models also have acceptable performance in peak values.


Scatter plots of the observed and forecasted lake level (m/month) for MPMR, GPR, RVM and ELM models at the test stage
Although prediction of the lake level is of great accuracy with the models presented for the average observational samples, as previously stated, a change of about 0.3 m from the lake level leads to a significant change in the volume of the lake about 75 × 109 m3 (Wilcox et al. 2007). For the MPMR method, with the input combination given for Model 1, the maximum difference between the meausred and estimated values is about 0.18 m.
Therefore, it is necessary to provide other input combinations to increase the accuracy of modeling. Models 2 and 3, in addition to considering the amount of lake level from the previous month in the estimation of lake level of the current month, also use the lake level values for two months and three months before (respectively). The values of the statistical indices given in Table 3 show that the use of h(t-2) and h(t-3) along with h(t-1) leads to an increment in the accuracy of modeling. Comparison of these two models with model 1 shows the rise of R2 index and reduction of other indices for these two models.
According to the boxplot (Fig. 2), the distribution of predicted values in the GPR method differs from other methods and data. This model at minimum lake level values shows lower accuracy than the other models. In the lake level, this happens to the RVM model, which is less accurate than other methods. The RE distribution (Fig. 3) for both models 2 and 3 compared to model 1 has less elongation, which its variations for model 2 compared to model 1 is significant. Increasing the number of inputs in models 2 and three has led to a decrease in Relative MAE (%) in (Fig. 4) in both models 2 and three compared to model 1. The value of this index in MPMR, GPR, RVM and ELM methods has been decreased 32%, 22%, 32%, and 35% respectively for Model 2, and about 20%, 22%, 12% and 23 respectively for Model 3.
In addition to the three models presented, models 4 to 6, in addition to considering input combinations in these models, also examined the effect of annual variations (t-12) in these models. The results of the scatter plot (Fig. 5) regarding the four methods of MPMR, ELM, GPR, and RVM in model 4 show that in general, this model predicts the lake level with accurate accuracy. The quantitative comparison of model 4 with model 1 (Table 3) shows that the use of the parameter h(t-1) not only has not significantly changed the accuracy of predictions but also in some of the indices like as defined index related to the ELM method, using this input, also had a negative effect. Indeed, the reason for this is the effectiveness of changes in the second and third previous months compared to the first month, while comparing models 2 and 3 with model 1, it was also shown that in order to achieve a good model, in addition to using lake level value in just one month before (h(t-1)), it is necessary to consider the effect of the second and third prior months (h(t-1) and h(t-2)).
The scattering of the estimated values using four different methods by boxplots (Fig. 2) shows that the ELM and GPR methods estimates small amounts related to the lake level and the RVM method, which estimates both small values and the peak values with less accuracy than the actual values. Despite these three methods, the MPMR method has good accuracy, and the value distribution in this method is approximately the same as the values measured at the Harbor Beach Station. Similarly, the RE distribution (Fig. 3) and the relative MAE value (%) (Fig. 4) for all models are relatively similar to model 1. Comparing model 5 with model 2, it also has almost the same results compared to model 4 with 1.
As different methods have various functions regarding each index, and in all cases, using the input combination presented in model 5, showed no significant increase in the performance of each method in all indices. Therefore, to achieve a suitable model, in addition to using an appropriate method, it is required to assess different input compounds that take into account the physics of the problem.
The MPMR method, using the model 6, shows superior performance than the model 3, which the only difference with model 6 is the use of h(t-12) as input combination. Comparison of the statistical indices presented in Table 3 shows that this model has higher accuracy than the model 3 for most of the proposed parameters. In the case of indices that the value for model 6 compared to model 3 is less, there is generally no significant difference between the two indices. The qualitative study of this model (Fig. 4 and 5) also shows that this model has a good ability to evaluate the water-level of Lake Huron.
The Relative MAE (%) value also shows that the lowest value of this index among the 24 models presented (six different models calibrated using four methods) is related to model 6, which is calibrated by MPMR method. The relative error distribution (Fig. 3) and the presented boxplot associated with the MPMR method with the input combinations presented in model 6 show that the good accuracy of this model in the prediction of the lake level.
5 Concluding Remarks
Application of advanced artificial intelligence forecast models is needed to achieve a higher dergree of accuracy due to the chaotic feature of lake water level fluctuation patterns. The primary aim of this study was to introduce a novel method for the forecasting of monthly lake water-level one month ahead using historical datasets for the Lake Huron (45.814° N; 84.754° W). The projecting variables considered were lake level at different lags (t-1, t-2, t-3, t-12) for the period (1918-2013). All datasets were categorized into 76 years for calibration and the 20 years for validating. The numbers of six models are proposed considering one to four models. The inputs of each model are include monthly and annually delays. The result indicates the best results for input combination with only monthly delays are achieved at Model 3 (t-1, t-2, t-3). Also, the use of annually lag (t-12) results in a boost in model accuracy especially in MPMR techniques which is the best Model is gained for Model 6 (t-1, t-2, t-3, t-12) validating using MPMR. All four AIT yielded encouraging general execution, in spite of the fact that the execution of the MPMR model was moderately superior to the ELM, RVM, and GPR models. This was shown by the lower MAE, RMSE, ENS, defined, ELM, and higher correlation coefficients and rarer outliers in the predicted values of lake level. It is important to note that the overall accuracy of the MPMR and ELM models was not significantly different. Given the present discoveries, it is interpreted AITs developed for forecasting of the lake level must incorporate circumstance of monthly and annually time delays in their indicator datasets, as these factors gave the most important highlights in the forecast of lake level, particularly in the present investigation district.
This novel model offers a fascinating prospect for the estimating of lake level, which underscore to examine the methodology on annually or seasonally time scale. In its feasible implementation, the dependability of the MPMR, ELM, GPR and RVM models can be assessed advance for a scope of hydrological destinations, consisting of the further hydro-meteorological information (e.g., vaporization, inflow, and precipitation) that could be utilized to examine the stochastic impact of such attributes on lake level estimating. Moreover, the model could be connected to other hydrological procedures, for example, groundwater level, evaporation, rainfall, and streamflow.
References
Altunkaynak A (2014) Predicting water level fluctuations in Lake Michigan-Huron using wavelet-expert system methods. Water Resour Manag 28:2293–2314. https://doi.org/10.1007/s11269-014-0616-0
Andersson JL, Sotiropoulos SN (2015) Non-parametric representation and prediction of single-and multi-shell diffusion-weighted MRI data using Gaussian processes. Neuroimage 122:166–176. https://doi.org/10.1016/j.neuroimage.2015.07.067
Aytek A, Kisi O, Guven A (2014) A genetic programming technique for lake level modeling. Hydrol Res 45:529–539. https://doi.org/10.2166/nh.2013.069
Azimi H, Bonakdari H, Ebtehaj I (2017) Sensitivity analysis of the factors affecting the discharge capacity of side weirs in trapezoidal channels using extreme learning machines. Flow Meas Instrum 54:216–223. https://doi.org/10.1016/j.flowmeasinst.2017.02.005
Bonakdari H, Zaji AH, Binns AD, Gharabaghi B (2019) Integrated Markov chains and uncertainty analysis techniques to more accurately forecast floods using satellite signals. J Hydrol 572:75–95. https://doi.org/10.1016/j.jhydrol.2019.02.027
Brinkmann WA (2000) Causes of variability in monthly Great Lakes water supplies and lake levels. Clim Res 15:151–160. https://doi.org/10.3354/cr015151
Burns DA, Klaus J, McHale MR (2007) Recent climate trends and implications for water resources in the Catskill Mountain region, New York, USA. J Hydrol 336:155–170. https://doi.org/10.1016/j.jhydrol.2006.12.019
Chai T, Draxler RR (2014) Root mean square error (RMSE) or mean absolute error (MAE)? -Arguments against avoiding RMSE in the literature. Geosci Model Dev 7:1247–1250. https://doi.org/10.5194/gmd-7-1247-2014
Cheng QH, Liu ZX (2006) Chaotic load series forecasting based on MPMR. In: Machine Learning and Cybernetics, 2006 International Conference on. IEEE. Dalian, 13-16 August 2006, pp. 2868-2871. https://doi.org/10.1109/ICMLC.2006.259071
Dawson CW, Abrahart RJ, See LM (2007) HydroTest: A web-based toolbox of evaluation metrics for the standardised assessment of hydrological forecasts. Environ Model Softw 22:1034–1052. https://doi.org/10.1016/j.envsoft.2006.06.008
Deo RC, Samui P (2017) Forecasting evaporative loss by least-square support-vector regression and evaluation with genetic programming, Gaussian process, and minimax probability machine regression: case study of Brisbane City. J Hydrol Eng 22:05017003. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001506
Deo RC, Tiwari MK, Adamowski JF, Quilty JM (2016) Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model. Stoch Env Res Risk A 31:1211–1240. https://doi.org/10.1007/s00477-016-1265-z
Ebtehaj I, Bonakdari H (2016) A Comparative Study of Extreme Learning Machines and Support Vector Machines in Prediction of Sediment Transport in Open Channels. Int J Eng T B Appl 29:1499–1506 http://www.ije.ir/Vol29/No11/B/3.pdf
Ebtehaj I, Bonakdari H, Gharabaghi B (2019) Closure to “An integrated framework of Extreme Learning Machines for predicting scour at pile groups in clear water condition by Ebtehaj, I., Bonakdari, H., Moradi, F., Gharabaghi, B., Khozani, Z.S”. Coast Eng 147:135–137. https://doi.org/10.1016/j.coastaleng.2019.02.011
El-Shafie A, Alsulami HM, Jahanbani H, Najah A (2013) Multi-lead ahead prediction model of reference evapotranspiration utilizing ANN with ensemble procedure. Stoch Env Res Risk A 27:1423–1440. https://doi.org/10.1007/s00477-012-0678-6
Ghorbani MA, Shamshirband S, Haghi DZ, Azani A, Bonakdari H, Ebtehaj I (2017) Application of firefly algorithm-based support vector machines for prediction of field capacity and permanent wilting point. Soil Tillage Res 172:32–38. https://doi.org/10.1016/j.still.2017.04.009
Güldal V, Tongal H (2010) Comparison of recurrent neural network, adaptive neuro-fuzzy inference system and stochastic models in Eğirdir Lake level forecasting. Water Resour Manag 24:105–128. https://doi.org/10.1007/s11269-009-9439-9
Hamed KH (2008) Trend detection in hydrologic data: theMann-Kendall trend test under the scaling hypothesis. J Hydrol 349:350–363. https://doi.org/10.1016/j.jhydrol.2007.11.009
Horata P, Chiewchanwattana S, Sunat K (2013) Robust extreme learning machine. Neurocomputing 102:31–44. https://doi.org/10.1016/j.neucom.2011.12.045
Huang GB, Zhu QY, Siew CK (2006a) Extreme learning machine: theory and applications. Neurocomputing 70:489–501. https://doi.org/10.1016/j.neucom.2005.12.126
Huang GB, Chen L, Siew CK (2006b) Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Netw 17:879–892. https://doi.org/10.1109/TNN.2006.875977
Huang GB, Chen L (2008) Enhanced random search based incremental extreme learning machine. Neurocomputing 71:3460–3468. https://doi.org/10.1016/j.neucom.2007.10.008
Kakahaji H, Banadaki HD, Kakahaji A, Kakahaji A (2013) Prediction of Urmia Lake water-level fluctuations by using analytical, linear statistic and intelligent methods. Water Resour Manag 27:4469–4492. https://doi.org/10.1007/s11269-013-0420-2
Khatibi R, Ghorbani MA, Naghipour L, Jothiprakash V, Fathima TA, Fazelifard MH (2014) Inter-comparison of time series models of lake levels predicted by several modeling strategies. J Hydrol 511:530–545. https://doi.org/10.1016/j.jhydrol.2014.01.009
Kisi O, Shiri J, Nikoofar B (2012) Forecasting daily lake levels using artificial intelligence approaches. Comput Geosci 41:169–180. https://doi.org/10.1016/j.cageo.2011.08.027
Kisi O, Shiri J, Karimi S, Shamshirband S, Motamedi S, Petković D, Hashim R (2015) A survey of water level fluctuation predicting in Urmia Lake using support vector machine with firefly algorithm. Appl Math Comput 270:731–743. https://doi.org/10.1016/j.amc.2015.08.085
Krause P, Boyle DP, Base F (2005) Comparison of different efficiency criteria for hydrological model assessment. Adv Geosci 5:89–97. https://doi.org/10.5194/adgeo-5-89-2005
Legates DR, Mccabe GJ (1999) Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour Res 35:233–241. https://doi.org/10.1029/1998WR900018
Li YL, Zhang Q, Werner AD, Yao (2015) Investigating a complex lake-catchment-river system using artificial neural networks: Poyang Lake (China). Hydrol Res 46:912–928. https://doi.org/10.2166/nh.2015.150
MacKay DJ (2001) Bayesian methods for adaptive models. Dissertation Department of Computer and Neural Sysyt., California institure of technology., Pasadena, California institure of technology
Moeeni H, Bonakdari H, Ebtehaj I (2017a) Integrated SARIMA with Neuro-Fuzzy Systems and Neural Networks for Monthly Inflow Prediction. Water Resour Manag 31:2141–2156. https://doi.org/10.1007/s11269-017-1632-7
Moeeni H, Bonakdari H, Ebtehaj I (2017b) Monthly reservoir inflow forecasting using a new hybrid SARIMA genetic programming approach. J Earth Syst Sci 126:18–30. https://doi.org/10.1007/s12040-017-0798-y
Nash JE, Sutcliffe JV (1970) River flow forecasting through conceptual models part I - A discussion of principles. J Hydrol 10:282–290. https://doi.org/10.1016/0022-1694(70)90255-6
Qin N, Chen X, Fu G, Zhai J, Xue X (2010) Precipitation and temperature trends fort the Southwest China: 1960–2007. Hydrol Process 24:3733–3744. https://doi.org/10.1002/hyp.7792
Rasmussen CE, Williams CK (2006) Gaussian processes for machine learning, vol 1. MIT press, Cambridge
Sanikhani H, Kisi O, Kiafar H, Ghavidel SZZ (2015) Comparison of Different Data-Driven Approaches for Modeling Lake Level Fluctuations: The Case of Manyas and Tuz Lakes (Turkey). Water Resour Manag 29:1557–1574. https://doi.org/10.1007/s11269-014-0894-6
Shafaei M, Kisi O (2016) Lake level forecasting using wavelet-SVR, wavelet-ANFIS and wavelet-ARMA conjunction models. Water Resour Manag 30(1):79–97. https://doi.org/10.1007/s11269-015-1147-z
Shao Q, Li M (2011) A new trend analysis for seasonal time series with consideration of data dependence. J Hydrol 396:104–112. https://doi.org/10.1016/j.jhydrol.2010.10.040
Shiri J, Shamshirband S, Kisi O, Karimi S, Bateni SM, Nezhad SHH, Hashemi A (2016) Prediction of water-level in the Urmia Lake using the extreme learning machine approach. Water Resour Manag 30:5217–5229. https://doi.org/10.1007/s11269-016-1480-x
Smola A, Scholkopf BA (1998) Tutorial on support vector regression. Technical Report NC2-TR-1998-030, Royal Holloway College, London, UK
Strohmann TR, Grudic GZ (2002) A Formulation for minimax probability machine regression. In: Dietterich TG, Becker S, Ghahramani Z (eds) Advances in Neural Information Processing Systems (NIPS) 14. MIT Press, Cambridge, MA
Tipping ME (2000) The relevance vector machine. Adv. Neural Inf Proc Syst 12:625–658
Tipping ME (2001) Sparse Bayesian learning and the relevance vector machine. J Mach Learn Res 1:211–244
Vaheddoost B, Aksoy H, Abghari H (2016) Prediction of Water Level using Monthly Lagged Data in Lake Urmia, Iran. Water Resour Manag 30:4951–4967. https://doi.org/10.1007/s11269-016-1463-y
Wilcox DA, Thompson TA, Booth RK, Nicholas JR (2007) Lake-level variability and water availability in the Great Lakes. U.S. Geological Survey Circular 1311. Reston, VA, USA
Willmott CJ, Matsuura K (2005) Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim Res 30:79–82. https://doi.org/10.3354/cr030079
Yaseen ZM, Ghareb MI, Ebtehaj I, Bonakdari H, Siddique R, Heddam S, Yusif A, Deo R (2017a) Rainfall pattern forecasting using novel hybrid intelligent model based ANFIS-FFA. Water Resour Manag. https://doi.org/10.1007/s11269-017-1797-0
Yaseen ZM, Ebtehaj I, Bonakdari H, Deo RC, Mehr AD, Mohtar WHMW, Diop L, El-Shafie A, Singh VP (2017b) Novel approach for streamflow forecasting using a hybrid ANFIS-FFA model. J Hydrol 554C:263–276. https://doi.org/10.1016/j.jhydrol.2017.09.007
Zaji AH, Bonakdari H (2018) Robustness lake water level prediction using the search heuristic-based artificial intelligence methods. ISH J Hydraul Eng 25(3):316–324. https://doi.org/10.1080/09715010.2018.1424568
Zaji AH, Bonakdari H, Gharabaghi B (2018) Reservoir water level forecasting using group method of data handling. Acta Geophys 66(4):717–730. https://doi.org/10.1007/s11600-018-0168-4
Zaji AH, Bonakdari H, Gharabaghi B (2019) Developing an AI-based method for river discharge forecasting using satellite signals. Theor Appl Climatol:1–16. https://doi.org/10.1007/s00704-019-02833-9
Zeynoddin M, Bonakdari H, Azari A, Ebtehaj I, Gharabaghi B, Madavar HR (2018) Novel hybrid linear stochastic with non-linear extreme learning machine methods for forecasting monthly rainfall a tropical climate. J Environ Manag 222:190–206. https://doi.org/10.1016/j.jenvman.2018.05.072
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that there is no conflict of interests regarding publishing this paper.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic Supplementary Materials
The following are available at the supplementary material: Fig. S1: Ideology of MPMR algorithm, Fig. S2: Time-series plot of the observed and forecasted monthly lake level (m/month) using MPMR, GPR, RVM, and ELM models at the test stage.
ESM 1
(DOCX 1075 kb)
Rights and permissions
About this article

Cite this article
Bonakdari, H., Ebtehaj, I., Samui, P. et al. Lake Water-Level fluctuations forecasting using Minimax Probability Machine Regression, Relevance Vector Machine, Gaussian Process Regression, and Extreme Learning Machine. Water Resour Manage 33, 3965–3984 (2019). https://doi.org/10.1007/s11269-019-02346-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-019-02346-0